Improving Intrusion Detection Model Prediction by Threshold Adaptation


Abstract
:1. Introduction
2. Problem Statement
3. Related Work
3.1. Batch Learning
3.2. Real-Time Learning
3.3. Data Stream Learning
3.4. Research Gaps
4. Threshold Adaptation
5. Experimental Settings
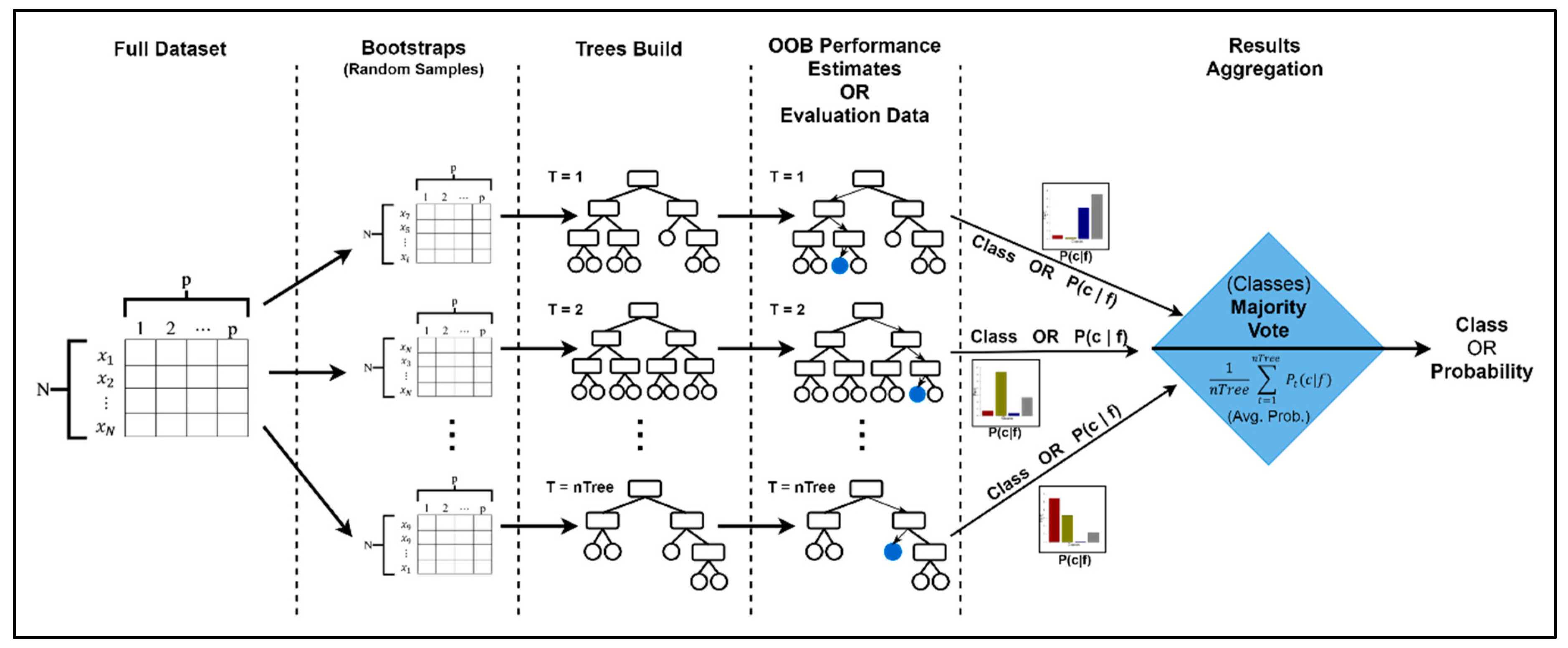
5.1. Overview of Classification/Machine Learning Algorithms
5.1.1. Decision Trees (C5.0)
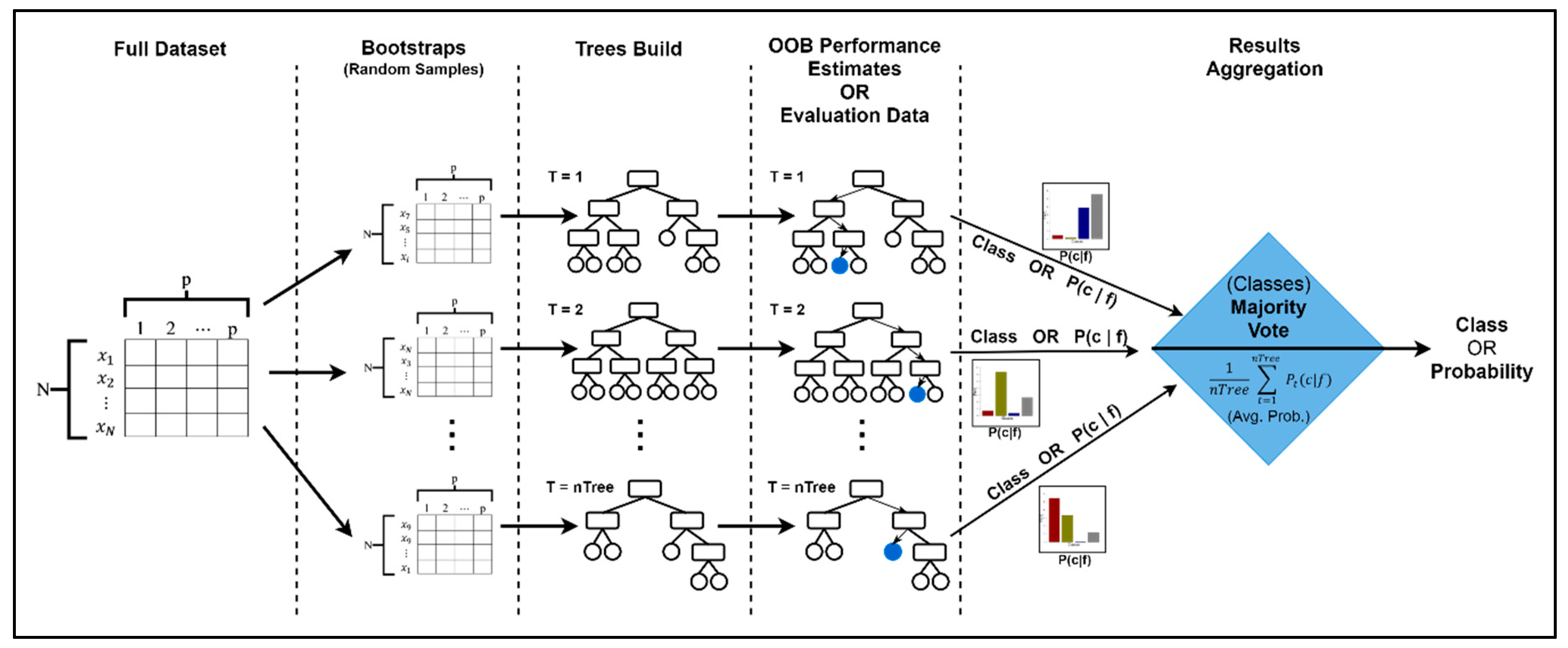
5.1.2. Random Forest (RF)
5.1.3. Support Vector Machine (SVM)
5.2. Parameter Setting for the ML Algorithms
5.2.1. C5.0 Algorithm
5.2.2. Random Forest
5.2.3. Support Vector Machine (SVM)
5.3. Performance Assessment Techniques
5.4. Datasets Description
5.4.1. SEA
5.4.2. AGR
| Function 1: |
|
| Function 2: |
|
5.4.3. gureKDDcup
5.4.4. STA2018
5.6. Hardware Specifications
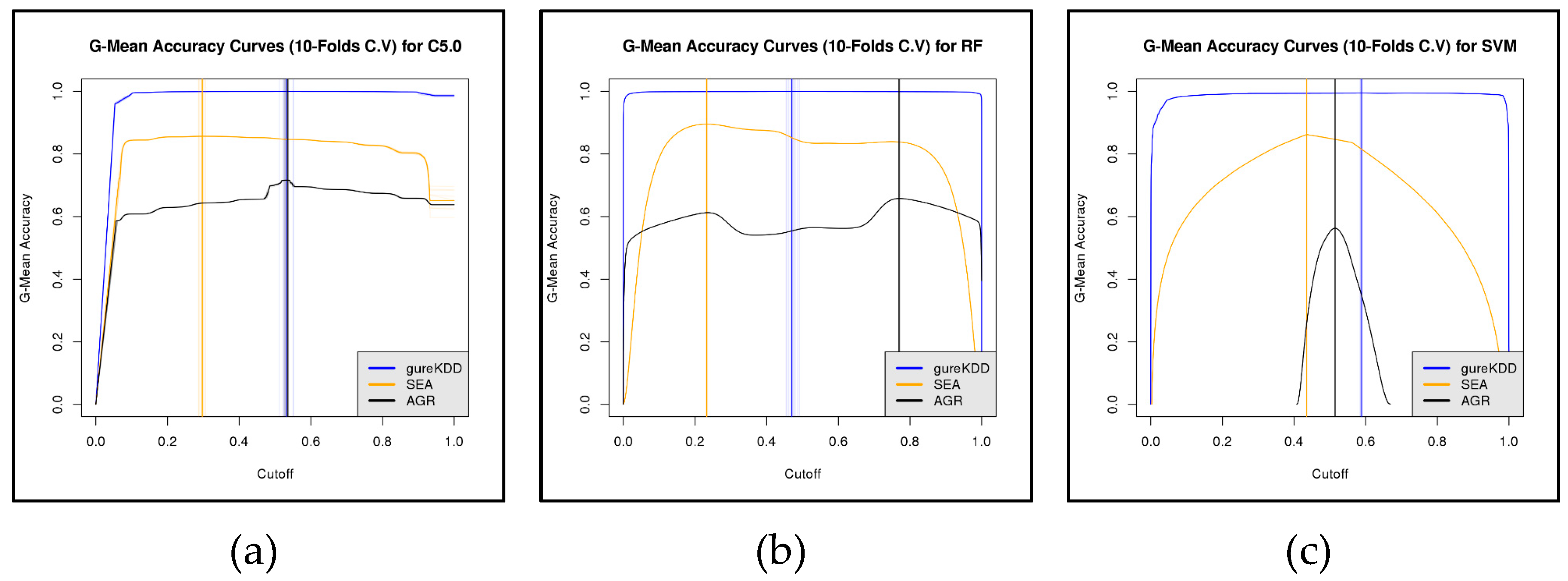
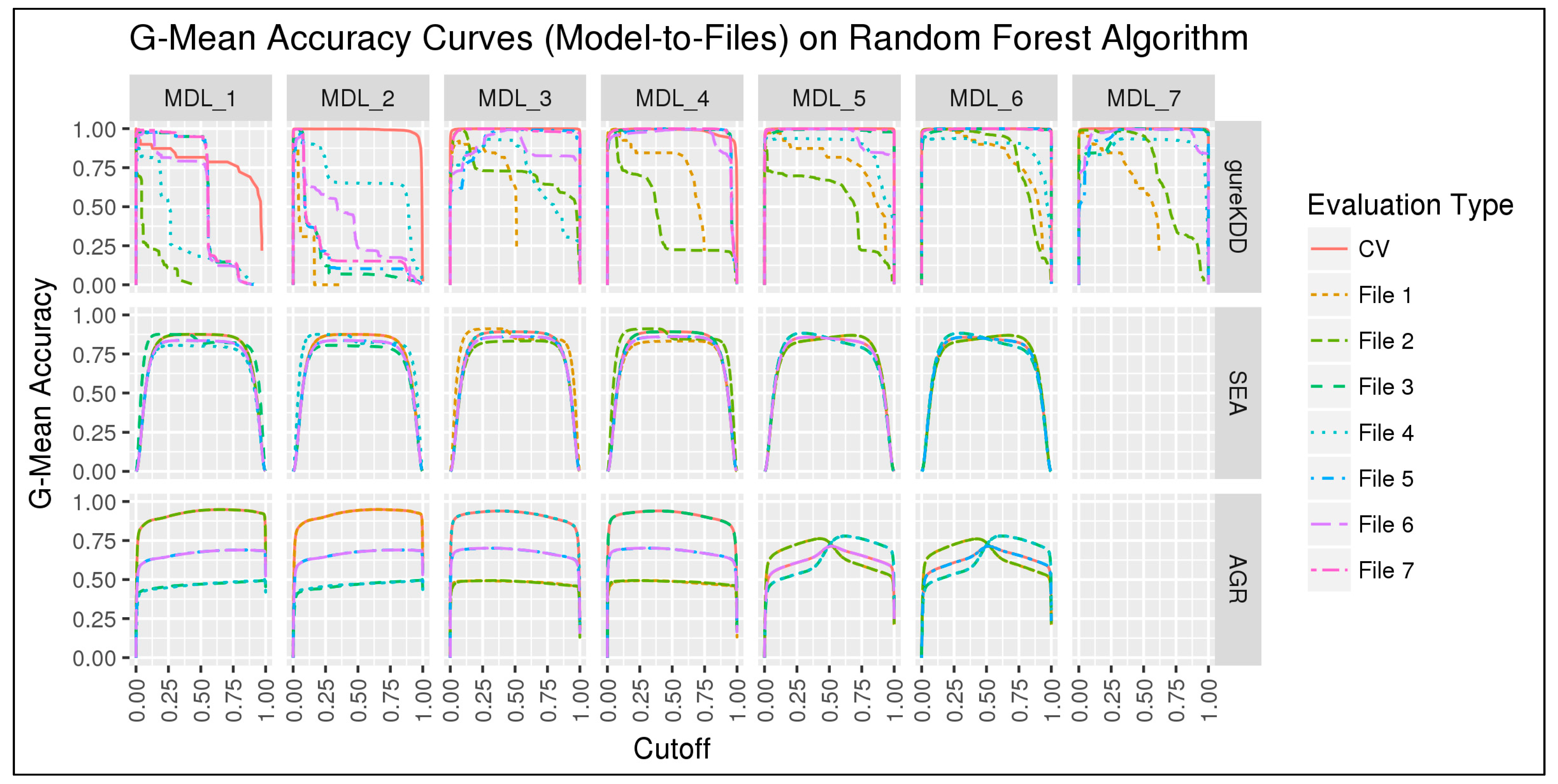
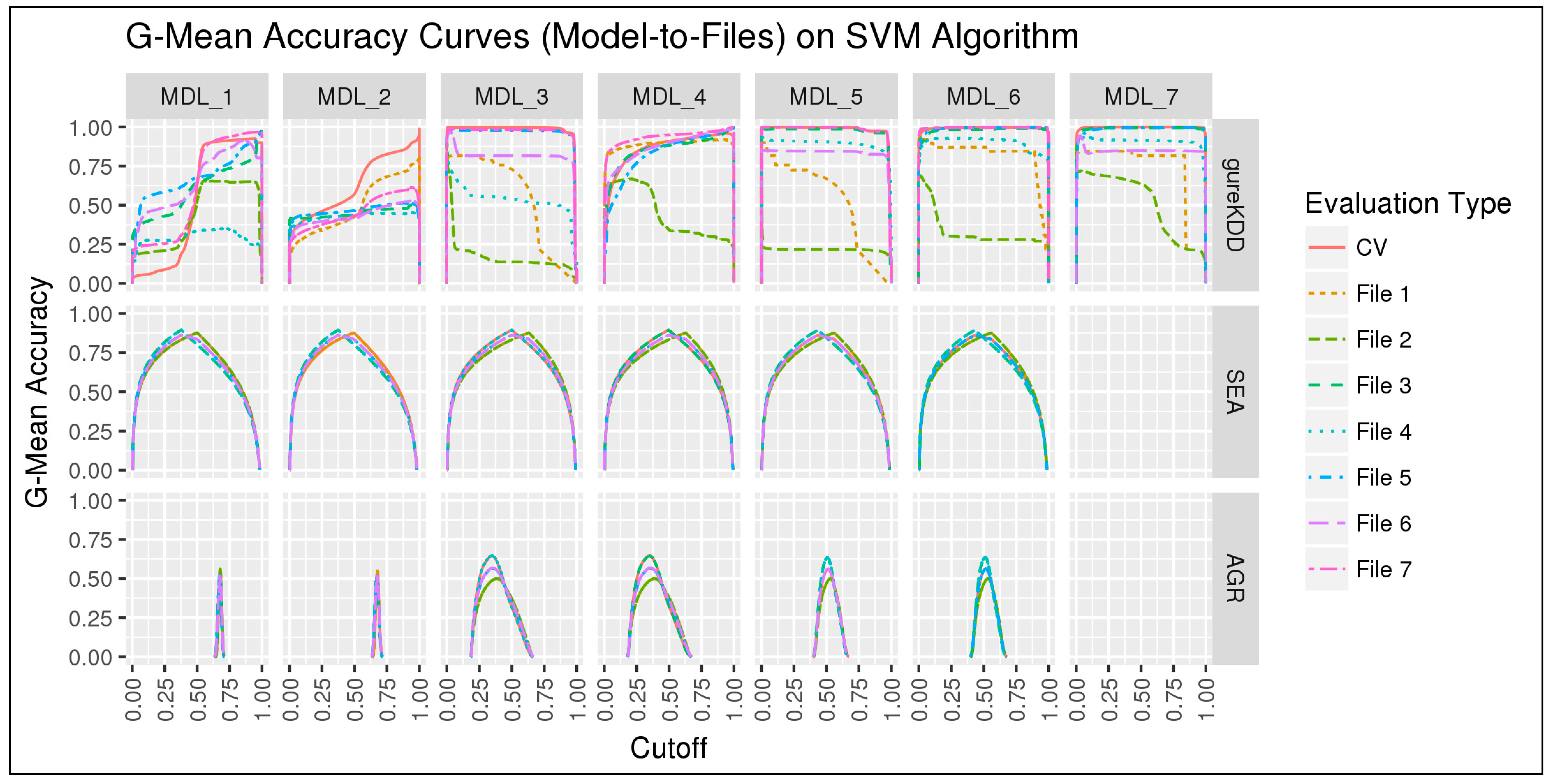
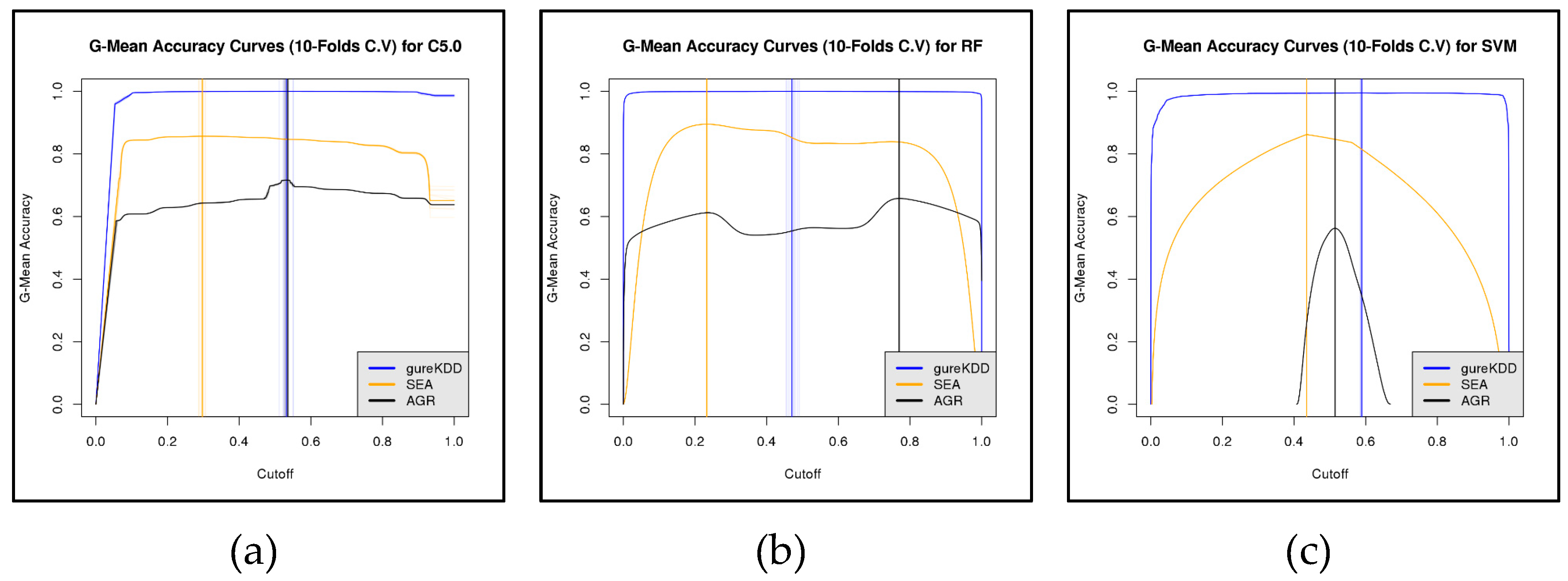
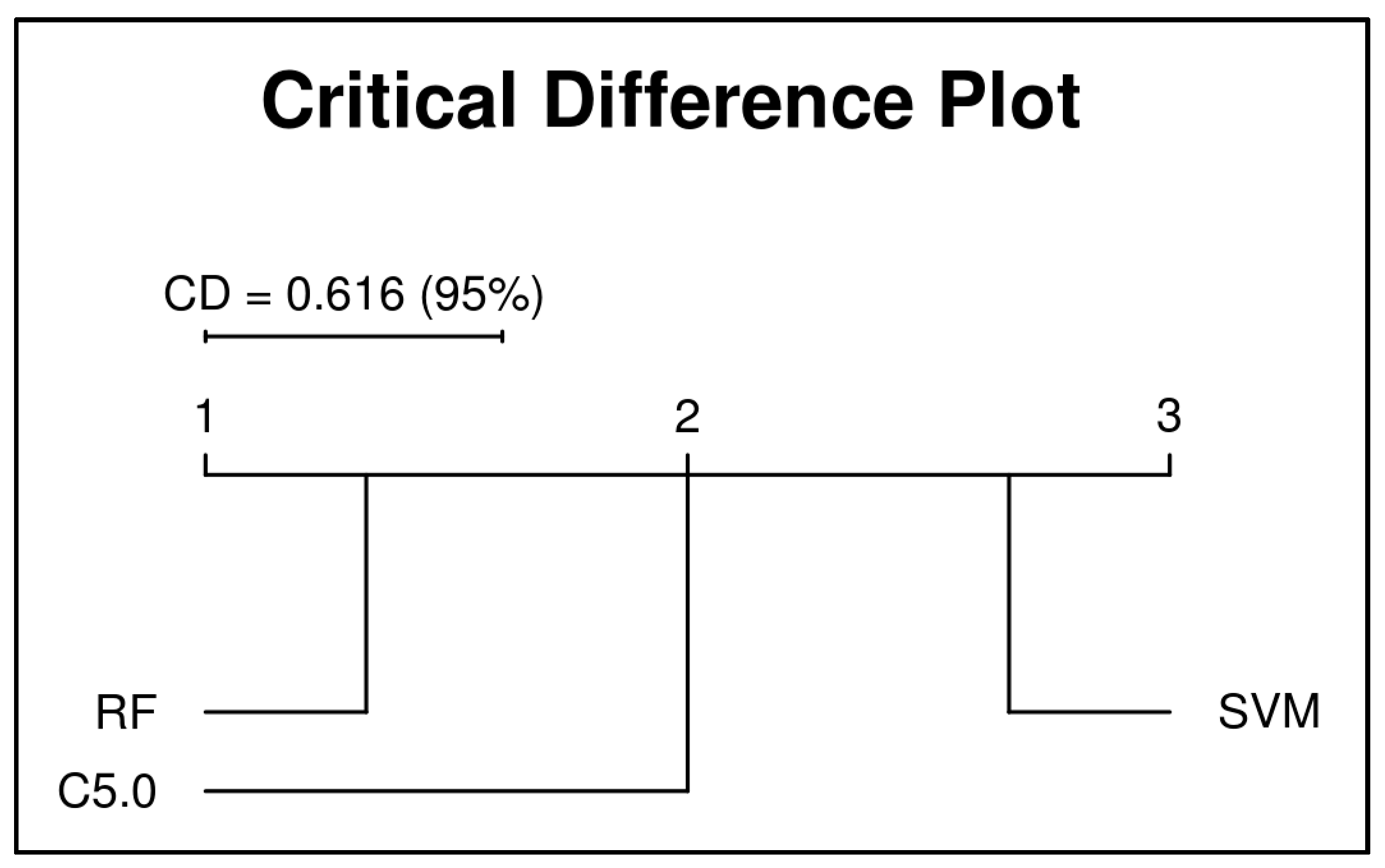
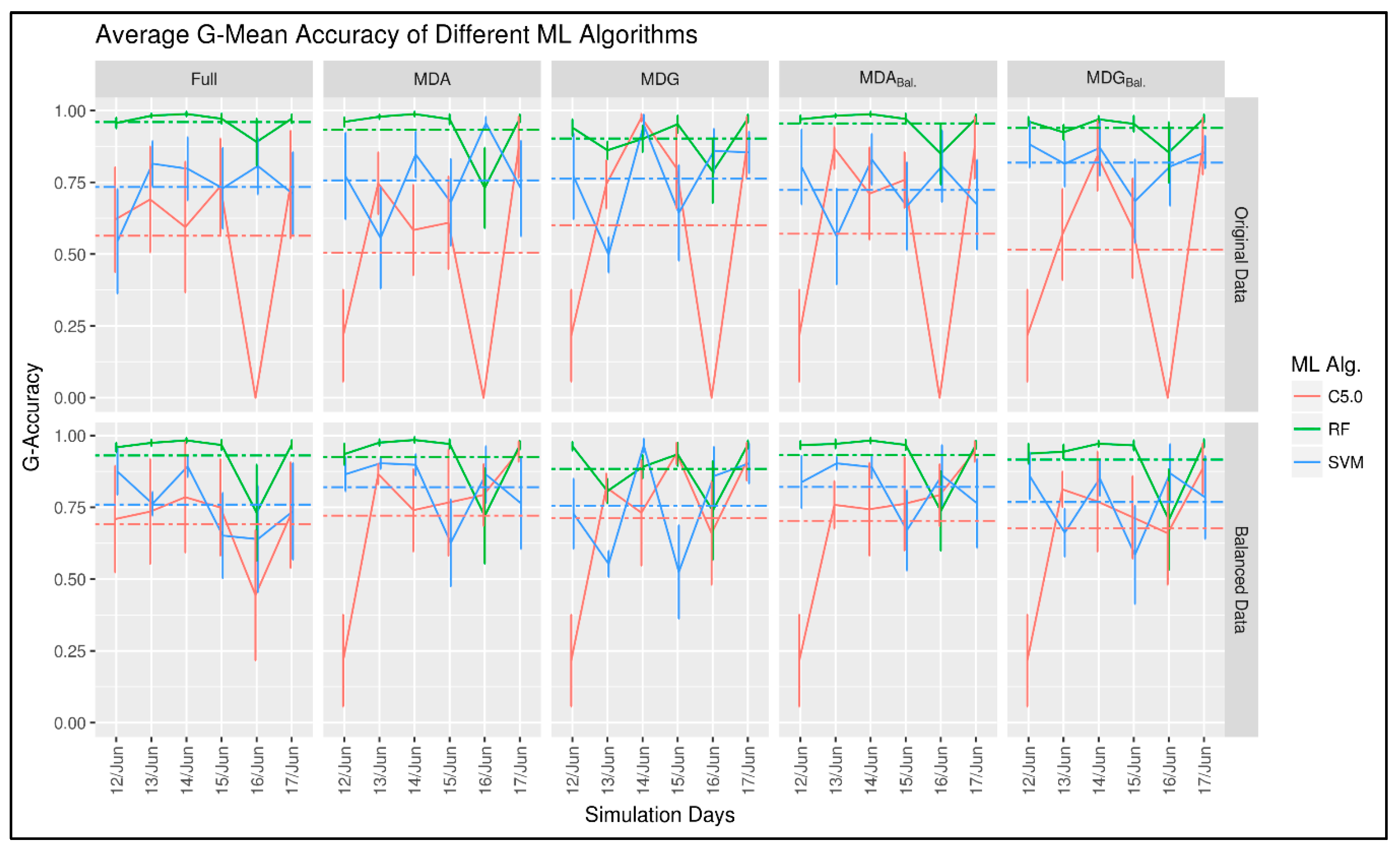
6. First Experiment
6.1. Results and Discussion
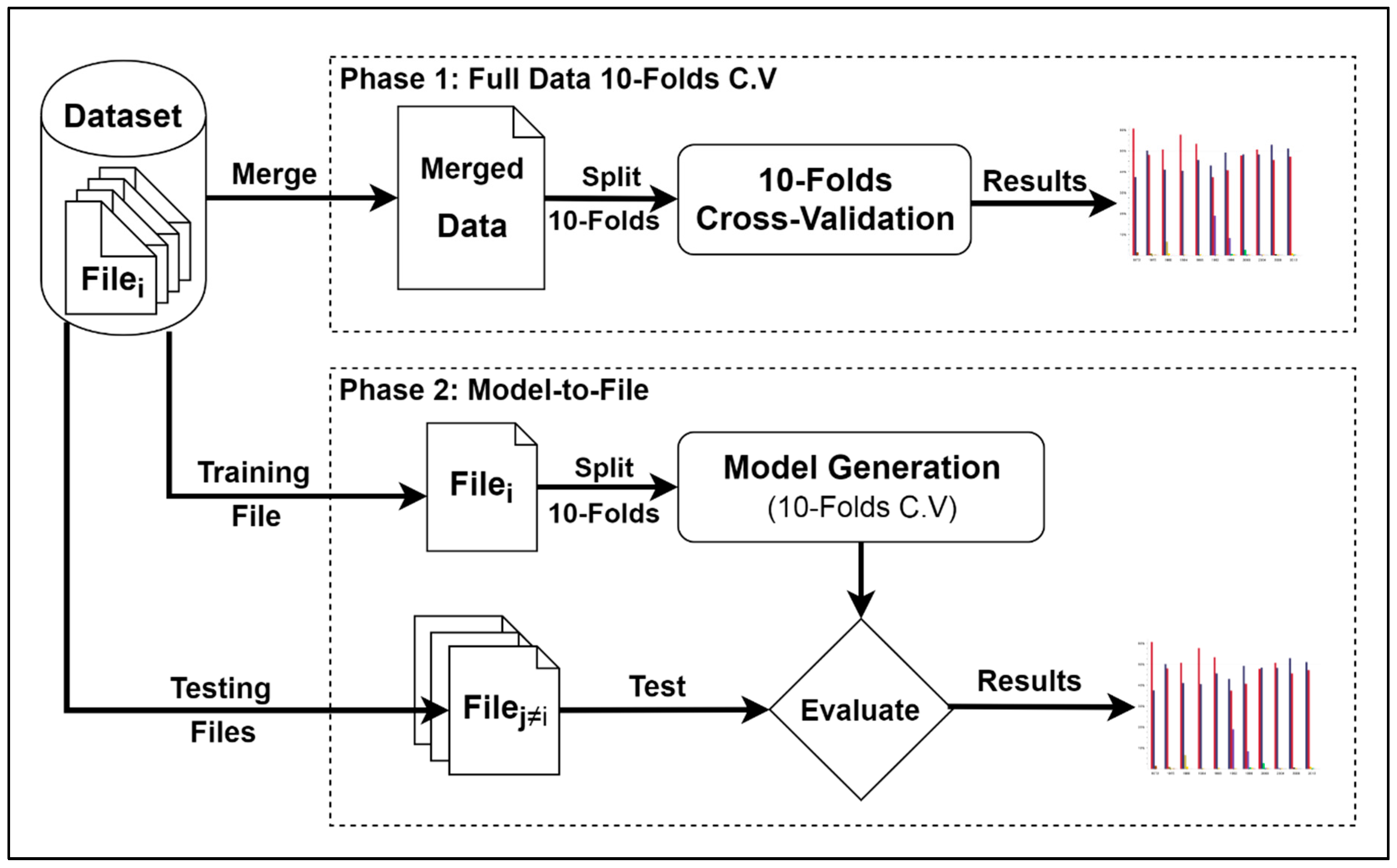
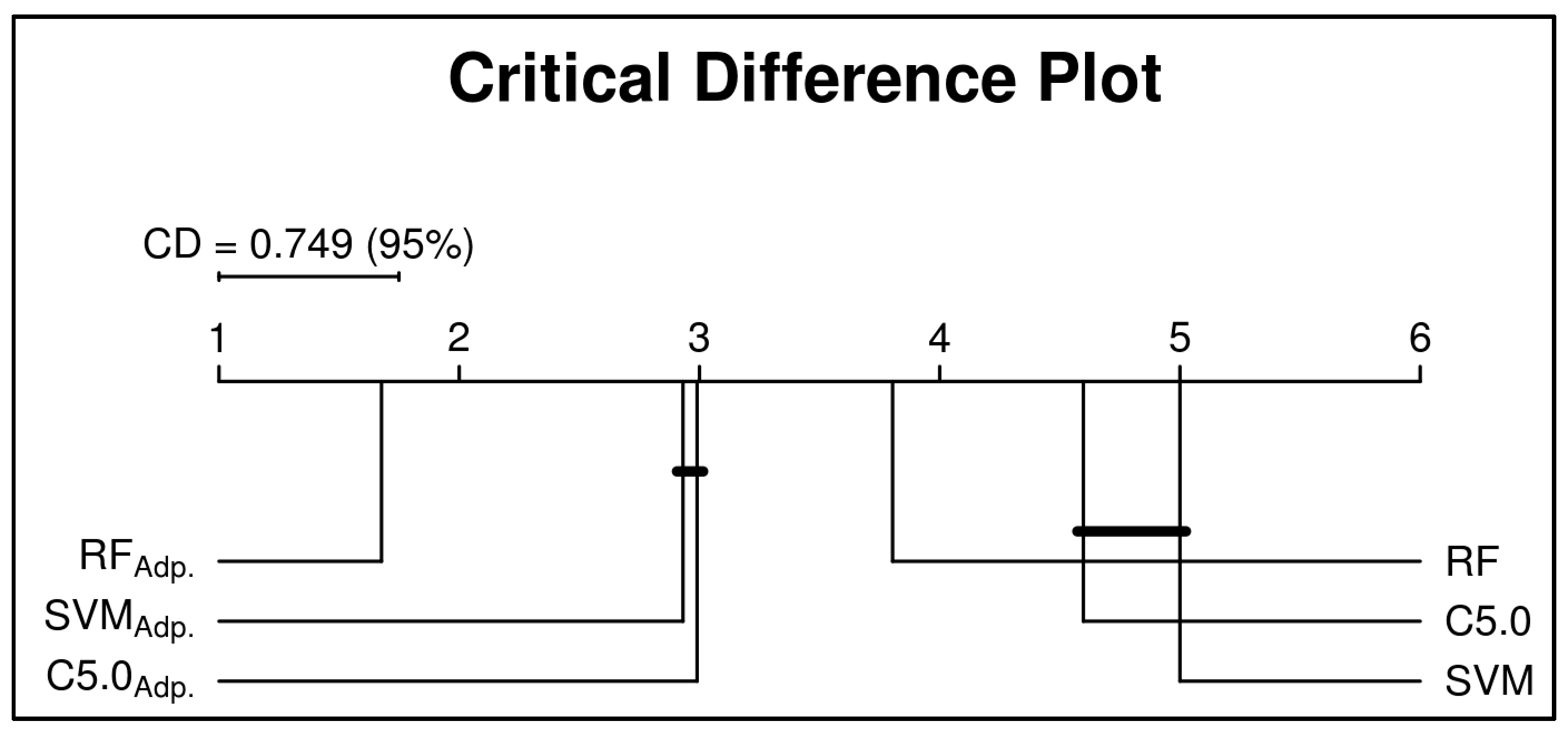
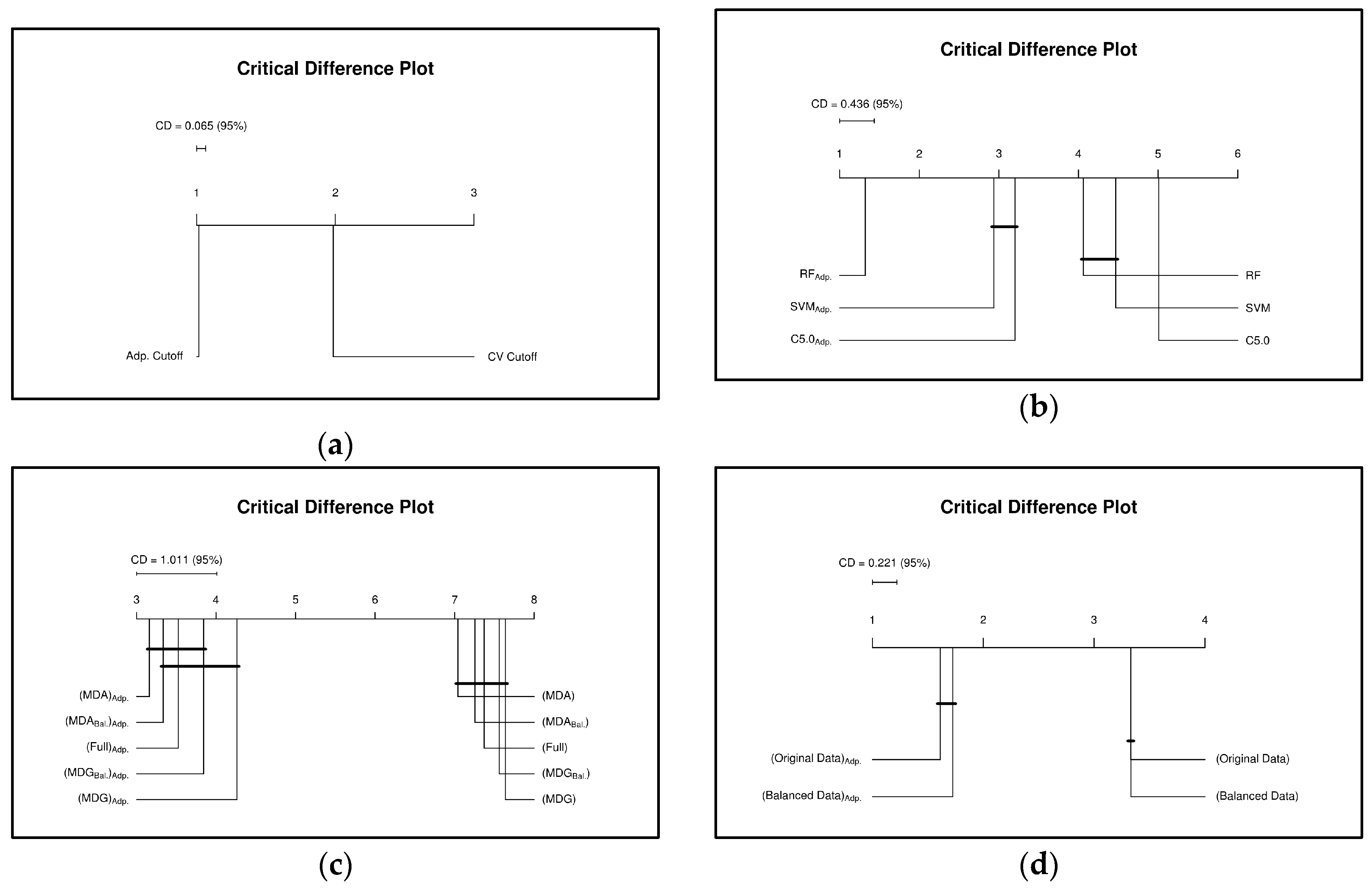
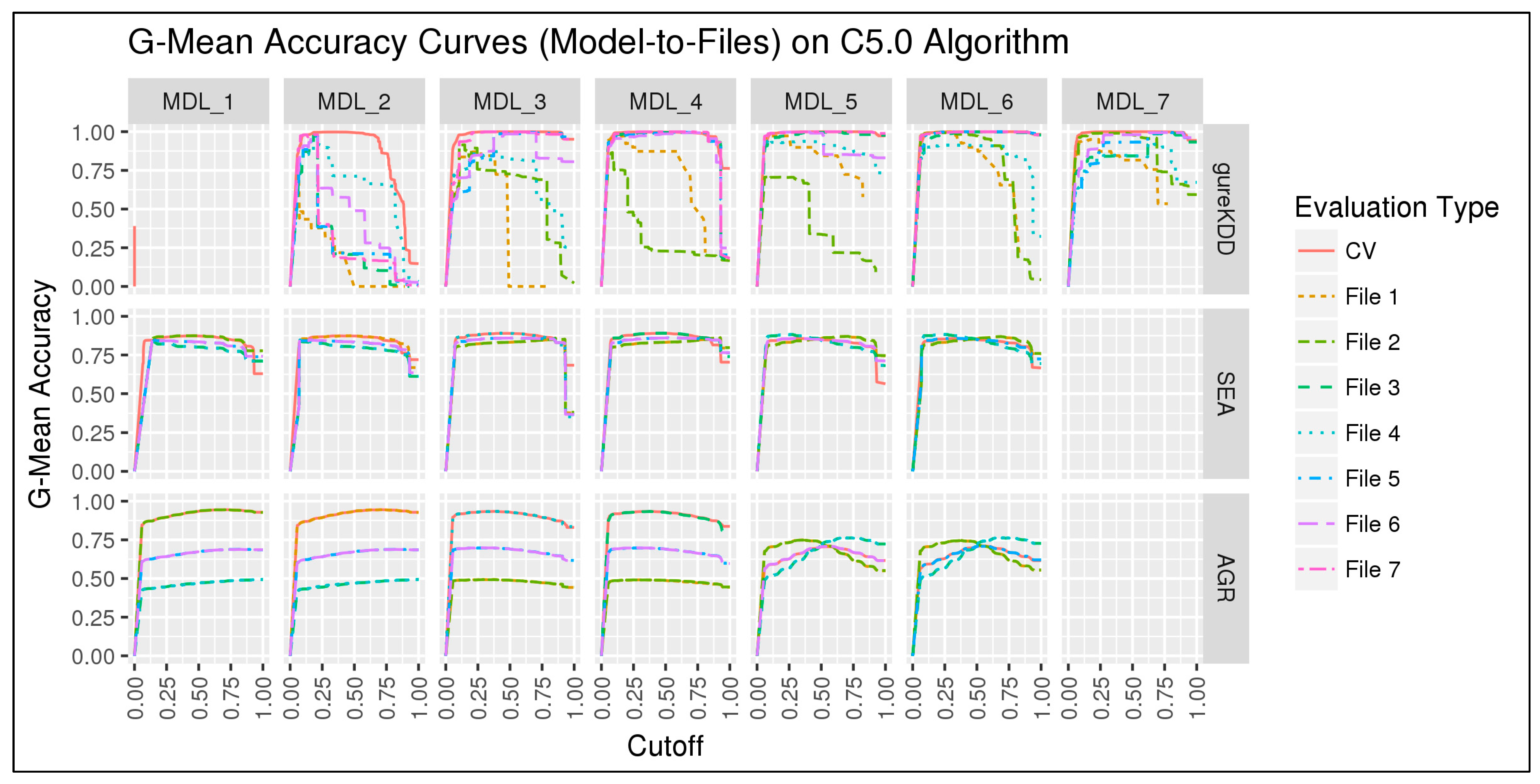
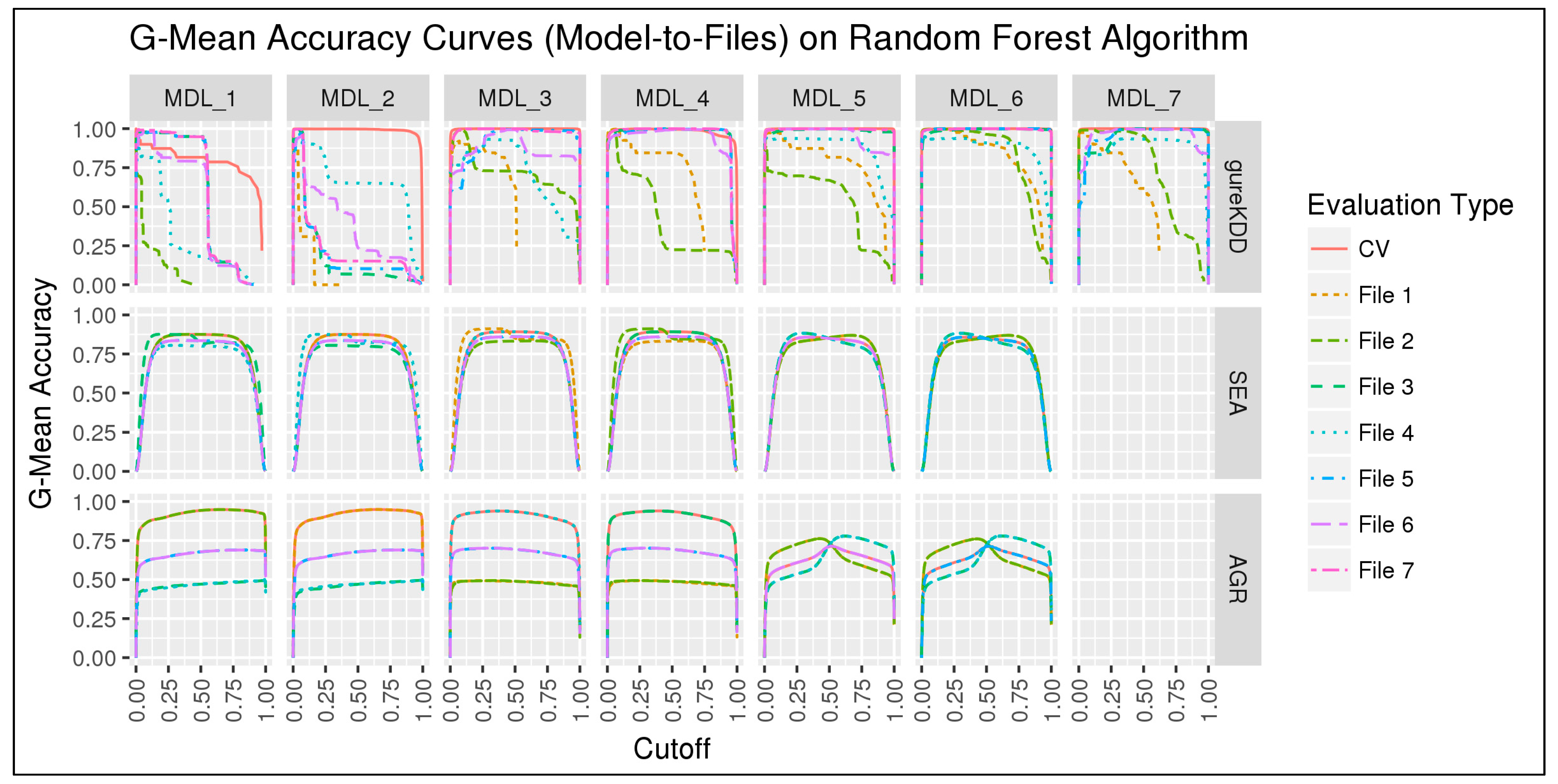
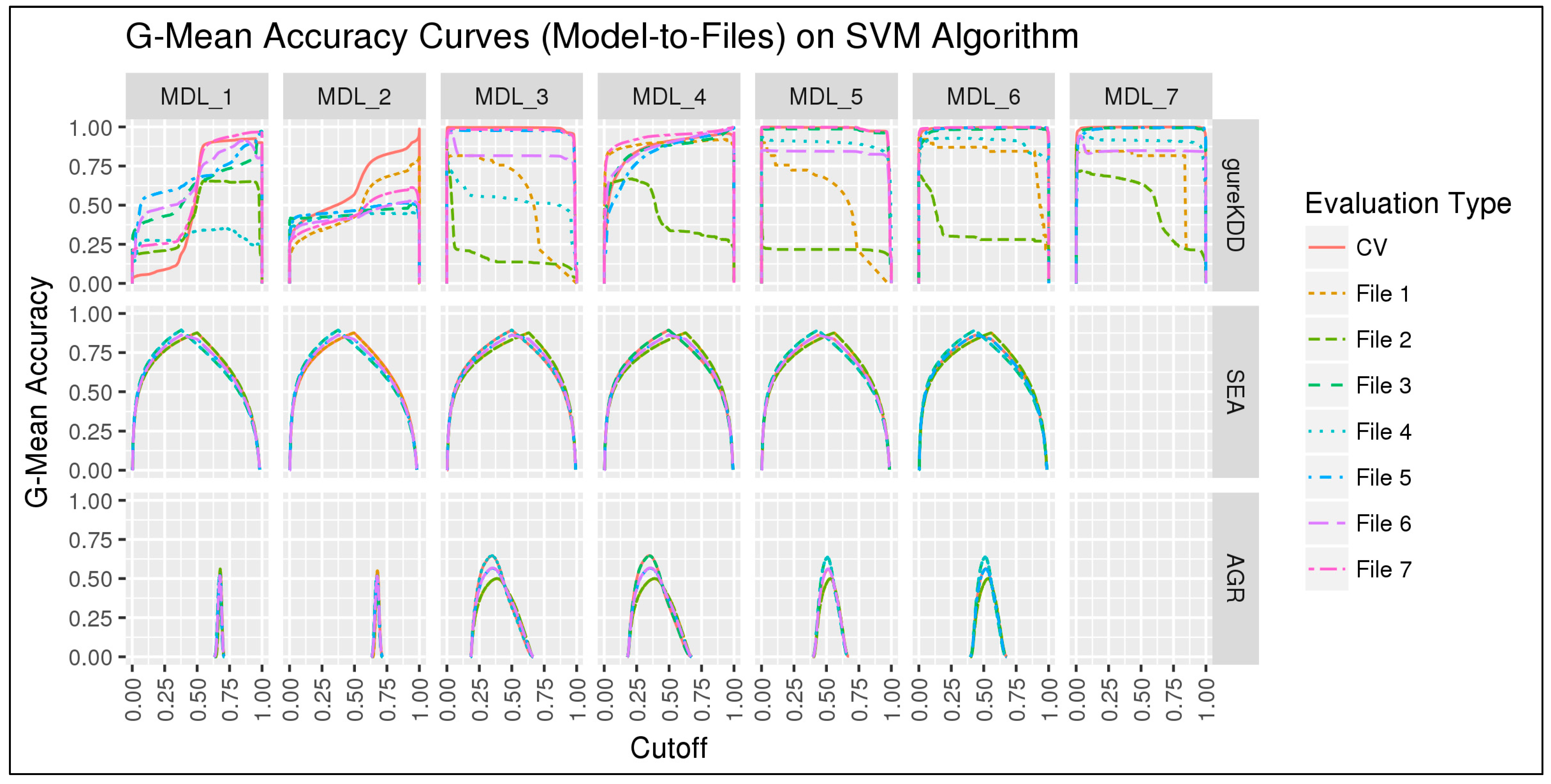
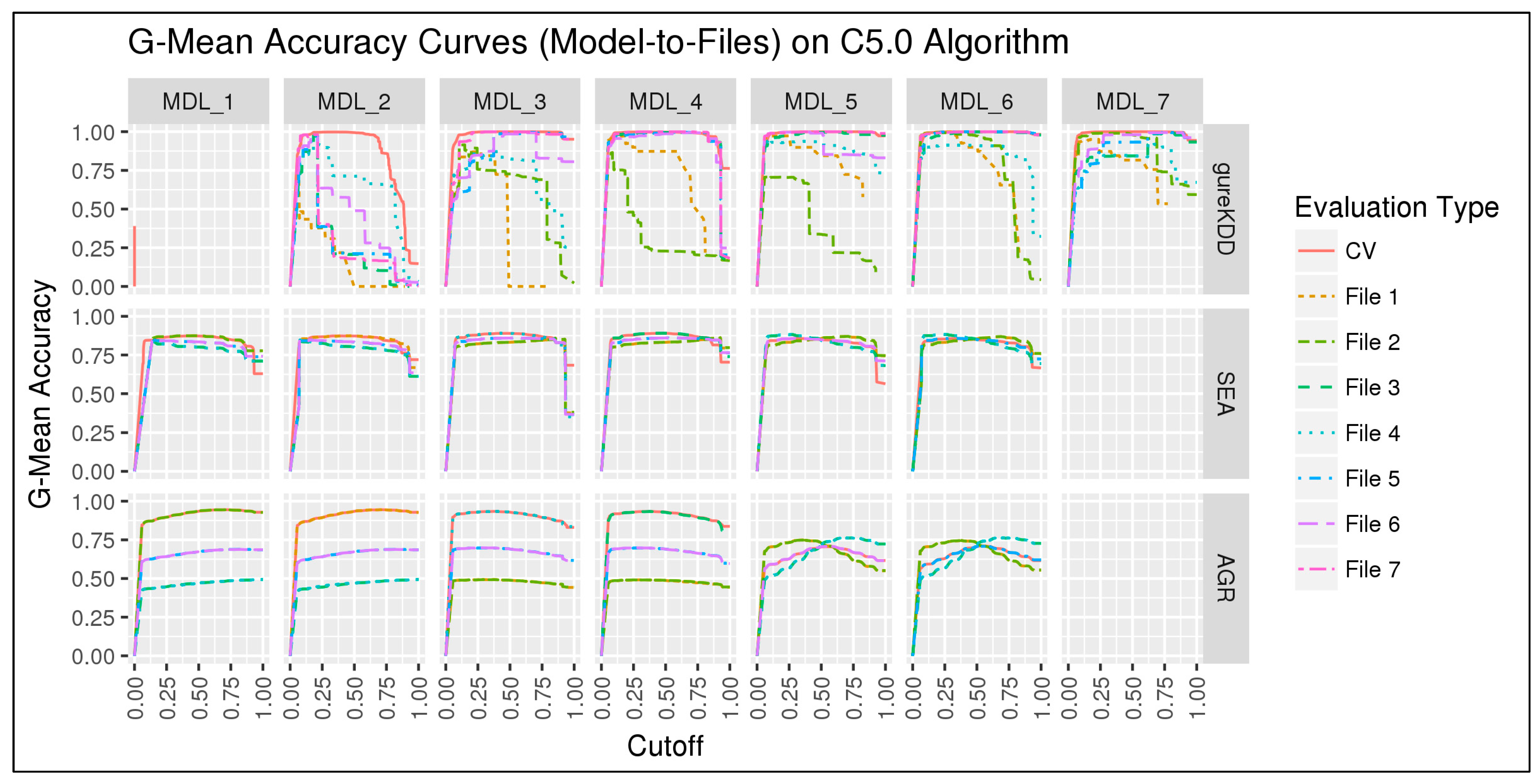
6.1.1. 10-folds Cross-Validation on Full Data
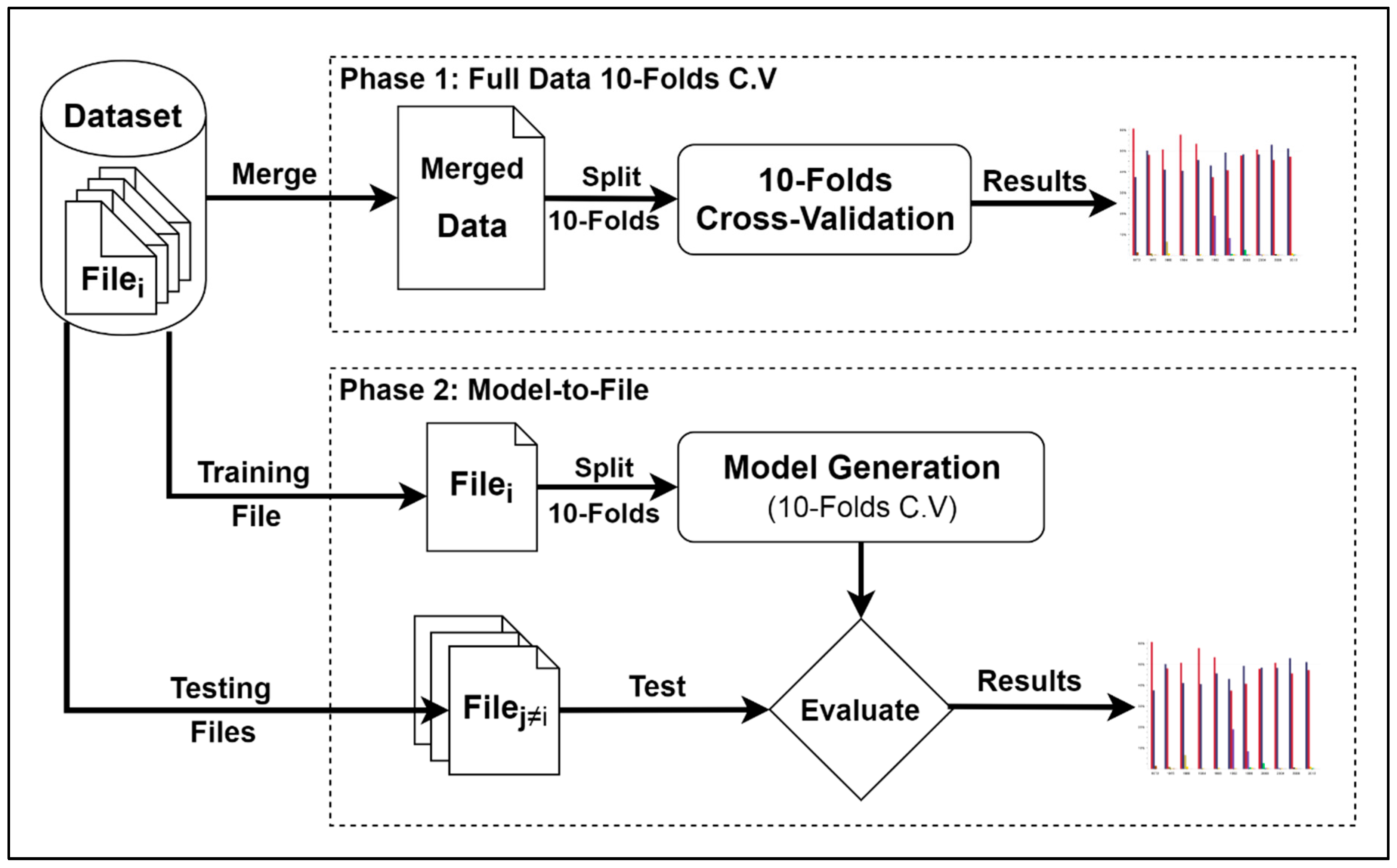
6.1.2. Subset-to-Subset (File-to-File)
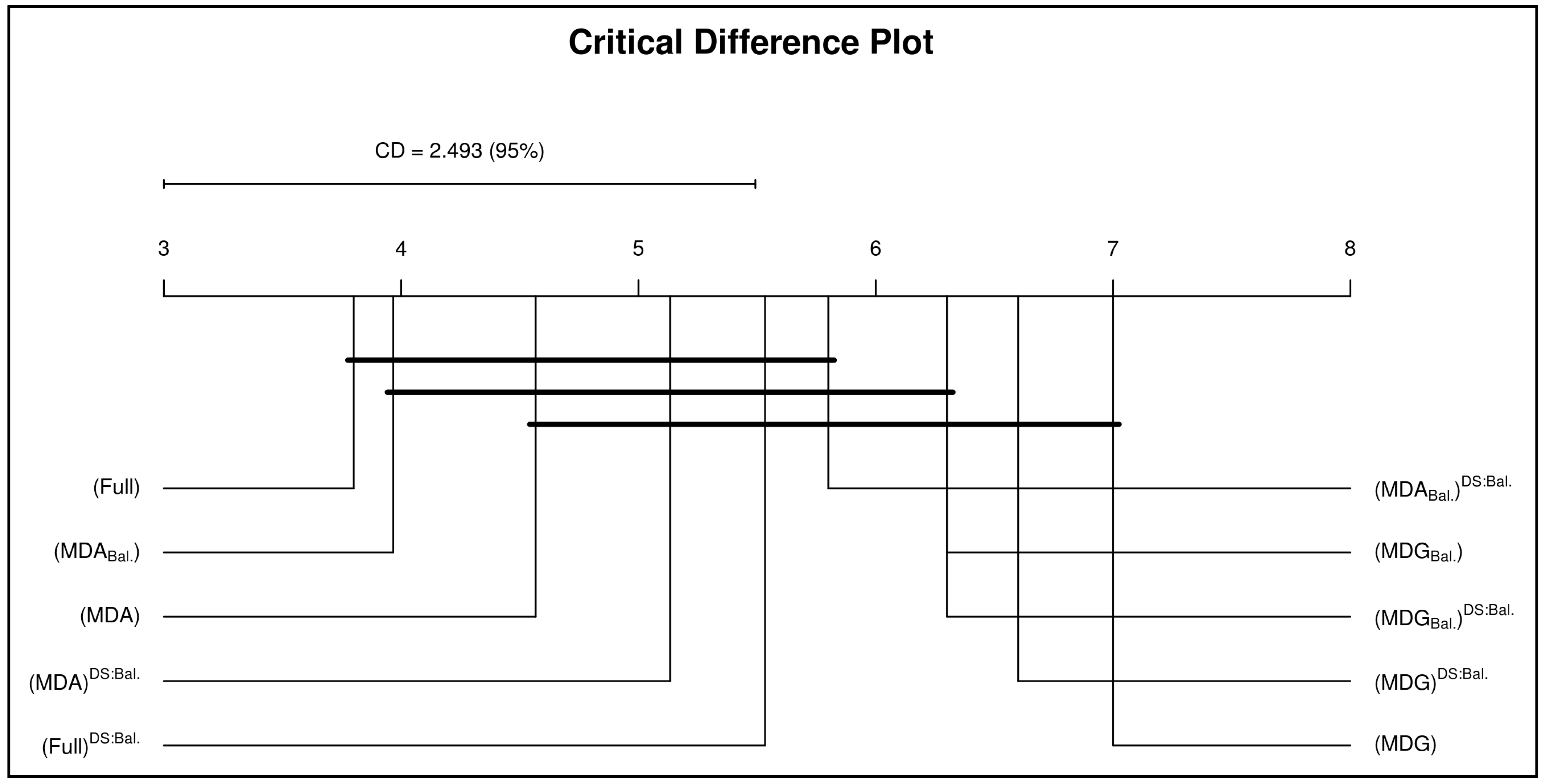
6.2. Discussion
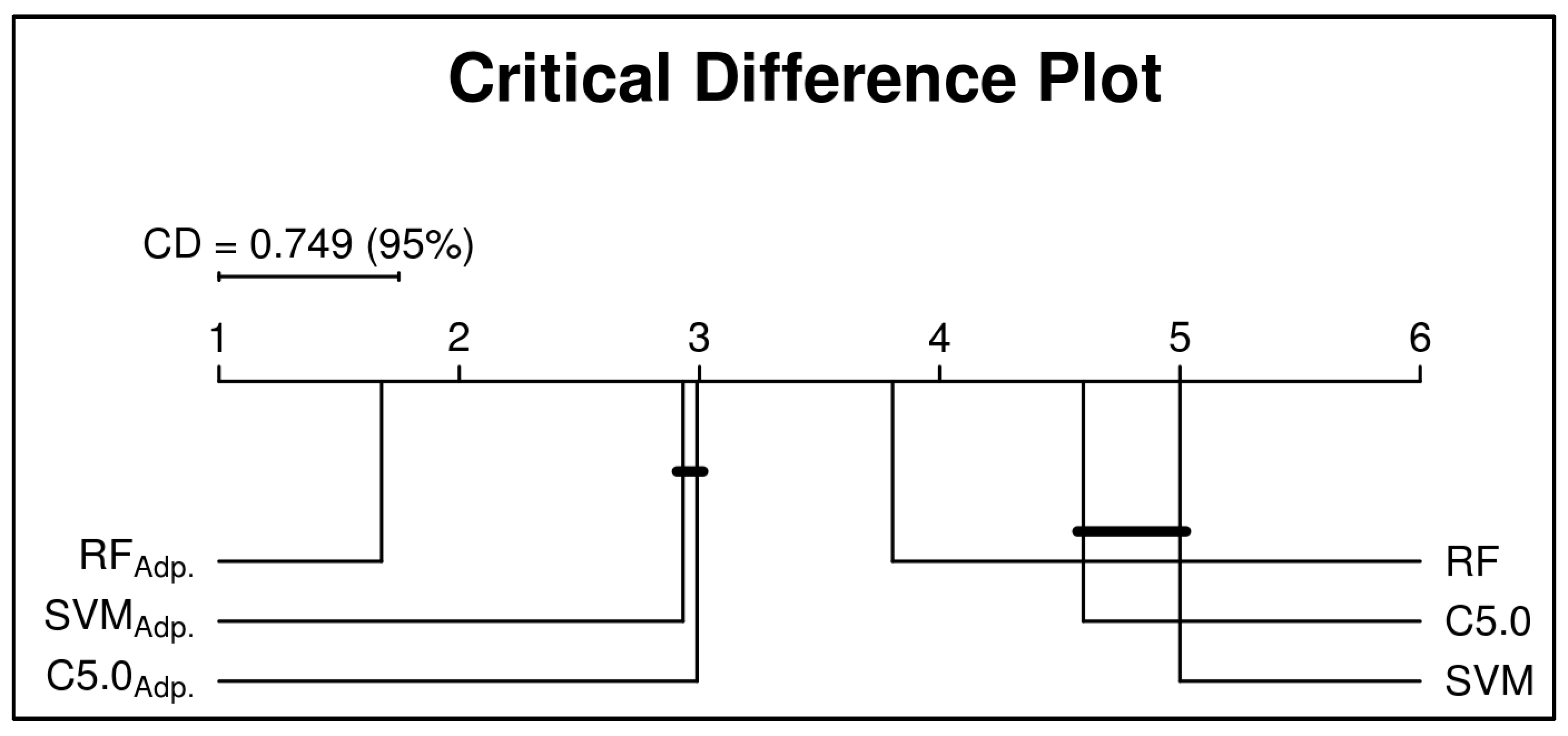
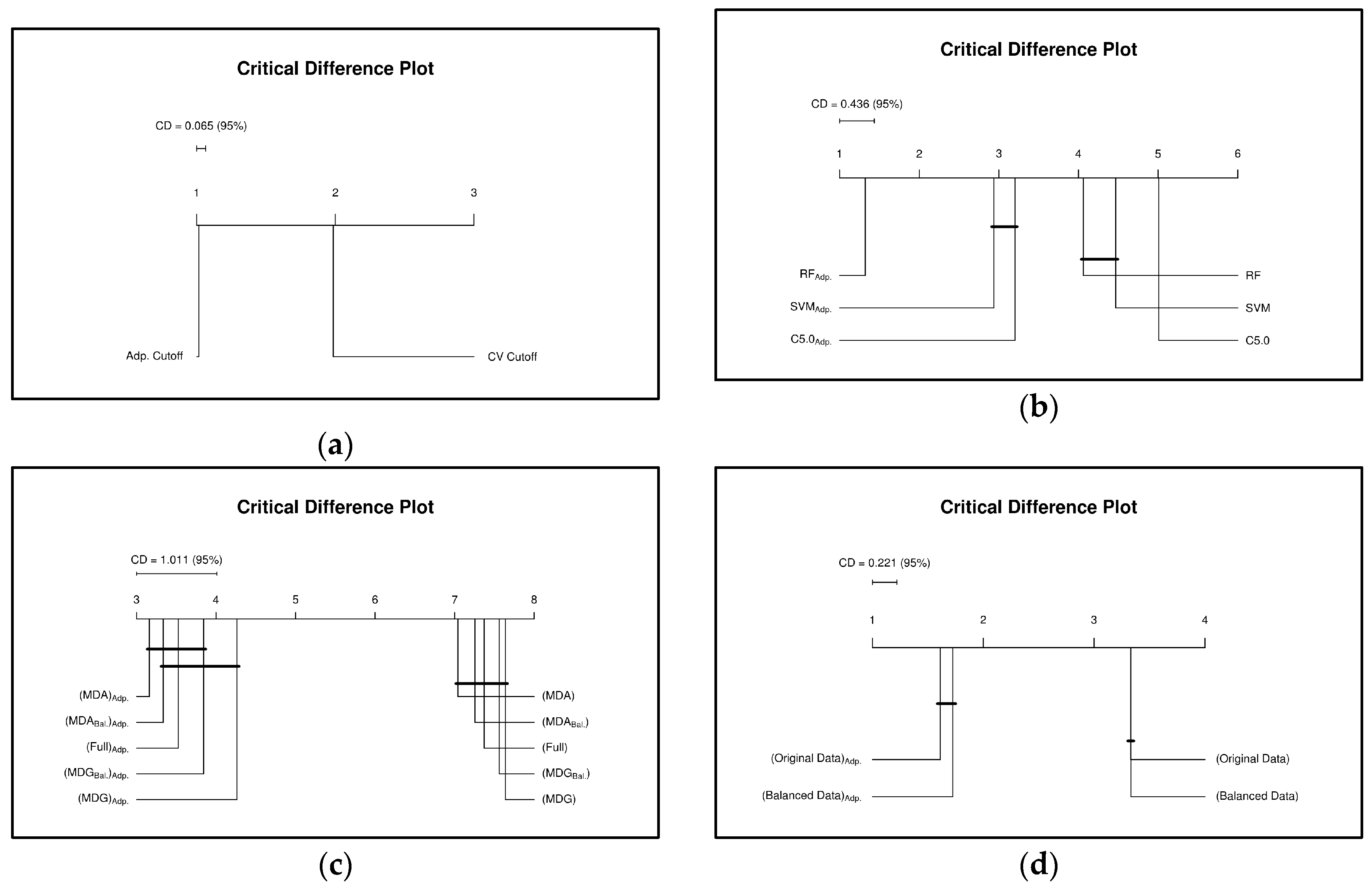
7. Second Experiment
| Algorithm 1: Feature Selection with Fake Features (pseudo code) | |
| Input: dataFile, ftrType | |
| Result: Selected Important Features | |
| 1 | dataFile <- filename, // Name of the data file to be processed |
| 2 | ftrType <- ftrMsr, // Features importance measure {MDA or MDG} |
| 3 | |
| 4 | ftrImprtance <- {}, // Initialize list to contain the computed |
| 5 | // importance value of every feature |
| 6 | ftrSelected <- {}, // Initialize list to contain the selected features |
| 7 | |
| 8 | DS <- load file (fileName), // Load the content of the data file |
| 9 | ftrSet <- getDataFeatures(DS), // Get the list of features in the data file |
| 10 | N <- num_rows(DS), // Get number of records in the training data |
| 11 | |
| 12 | <- rand(sample=N, mean=0, sd=1), // Generate 3 lists of random variables where |
| 13 | <- rand(sample=N, mean=0, sd=1), // each list contains N random numbers with |
| 14 | <- rand(sample=N, mean=0, sd=1), // mean=0 and standard deviation=1 |
| 15 | |
| 16 | |
| 17 | newDS <- [ ], // Append the fake features to the original data |
| 18 | partsDS <- create K partitions of newDS, // Create K partitions to calculate features |
| 19 | // importance measures using K-folds Cross-Validation |
| 20 | |
| 21 | // Compute the importance of every feature using K-folds |
| 22 | // Cross-Validation and save them in ftrImprtance |
| 23 | For fold in K-folds, do |
| 24 | trainRcrds <- partsDS[-c(fold)] |
| 25 | ftrImprtance[fold, ] <- featre_importance(data=newDS[trainRcrds, ], measure=ftrMsr) |
| 26 | done |
| 27 | |
| 28 | // Evaluate every feature in the data file by comparing its performance |
| 29 | // to the performances of the 3 fake features. If the mean importance of |
| 30 | // that feature is statistically higher than the mean importance of the |
| 31 | // fake features, then add that feature to the selection set. |
| 32 | For Fi in ftrSet, do |
| 33 | if( ftrImprtance[,Fi] > ftrImprtance[,c(, , )] with t.test probability > 0.05 ){ |
| 34 | ftrSelected <- ftrSelected ∪ {Fi}, |
| 35 | } |
| 36 | |
| 37 | done |
| 38 | |
| 39 | return( ftrSelected ), // Return the list of selected features |
| Algorithm 2: Experiment Phases (pseudo code) | |
| Input: Dataset | |
| Result: Performance results | |
| 1 | For Fi in Dataset, do // Process every file Fi in the STA2018 dataset |
| 2 | Ftrs.Set[Full] <- {Full.Ftrs} // 544 features |
| 3 | Mdls.Set <- {} |
| 4 | Rslt.Set <- {} |
| 5 | |
| 6 | Fi.bal <- Balance(Fi) // Generate/get a balanced version of data file Fi with balanced |
| 7 | // instances’ classes by generating synthetic instances of |
| 8 | // minority class using SMOTE algorithm. |
| 9 | |
| 10 | // Phase 1: features selection... |
| 11 | Ftrs.Set[MDA] <- getImportantFtrs(data=Fi, ftrType=MDA) , |
| 12 | Ftrs.Set[MDG] <- getImportantFtrs(data=Fi, ftrType=MDG) , |
| 13 | Ftrs.Set[MDABal.] <- getImportantFtrs(data=Fi.bal, ftrType=MDA) , |
| 14 | Ftrs.Set[MDGBal.] <- getImportantFtrs(data=Fi.bal, ftrType=MDG) , |
| 15 | |
| 16 | // Phase 2: models generation... |
| 17 | // Generate five predictive models using original data with five different sets of features. |
| 18 | For ftrsa in Ftrs.Set, do |
| 19 | Mdls.Set[Fi, ftrsa] <- generate.Model(data=Fi, features= ftrsa) |
| 20 | done |
| 21 | |
| 22 | // Generate five predictive models using balanced data with five different sets of features. |
| 23 | For ftrsa in Ftrs.Set, do |
| 24 | Mdls.Set[Fi.bal, ftrsa] <- generate.Model(data=Fi.bal, features= ftrsa) |
| 25 | done |
| 26 | |
| 27 | // Phase 3: models evaluation... |
| 28 | // Perform total of 50 evaluations (5 testing files X 10 predictive models) |
| 29 | For Fj≠Fi in Dataset, do |
| 30 | // Test every file other than Fi on every one of the 10 prediction models |
| 31 | // trained on Fi or Fi.bal |
| 32 | For Mdlb in Mdls.Set, do |
| 33 | // Get the following results: |
| 34 | // 1) G-Mean Accuracy using model’s cutoff (threshold) value, |
| 35 | // 2) G-Mean Accuracy using adapted cutoff (threshold) value, |
| 36 | Rslt.Set[Fj, Mdlb] <- evaluate(data=Fj, model=Mdlb) |
| 37 | done |
| 38 | done |
| 39 | |
| 40 | done |
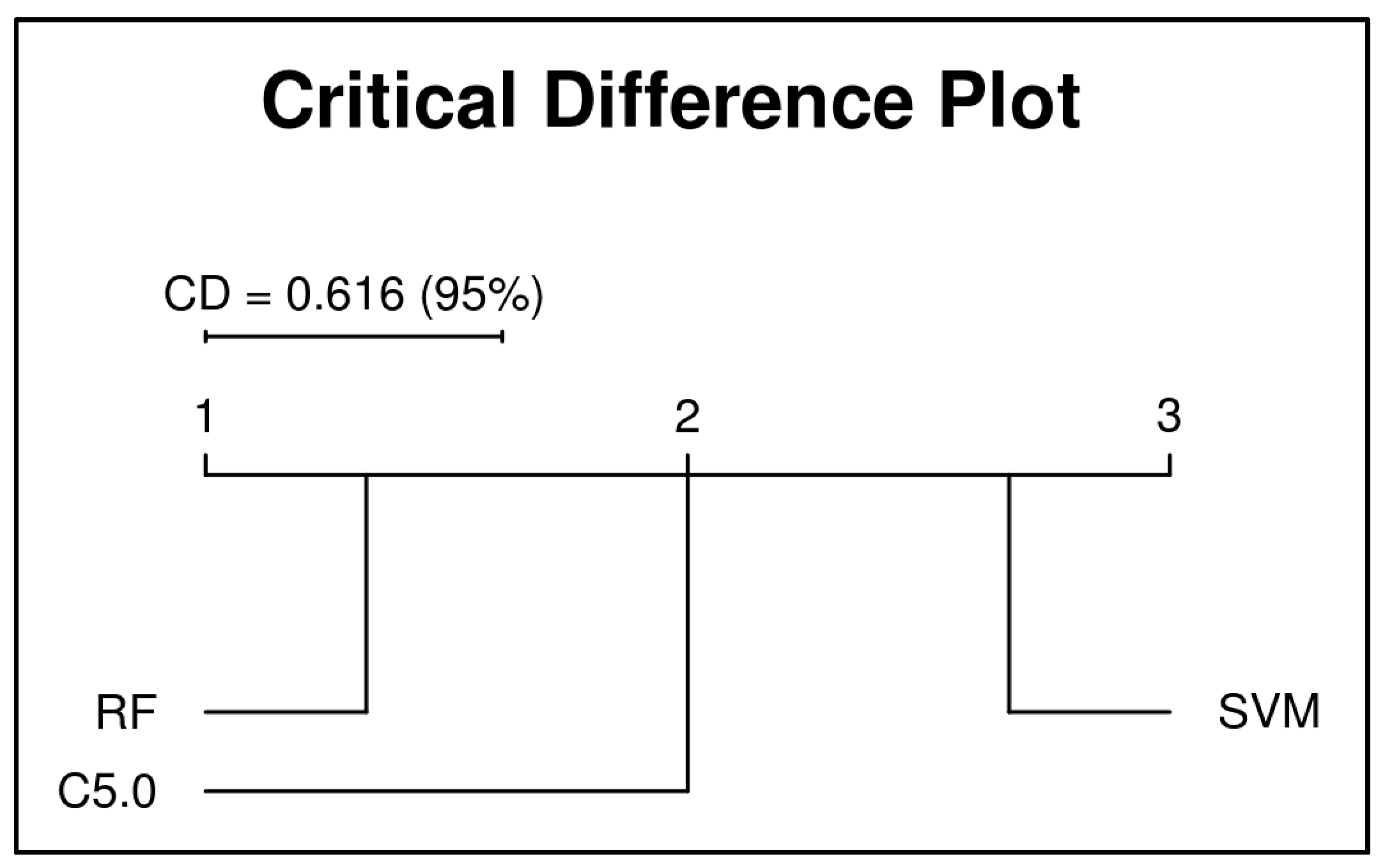
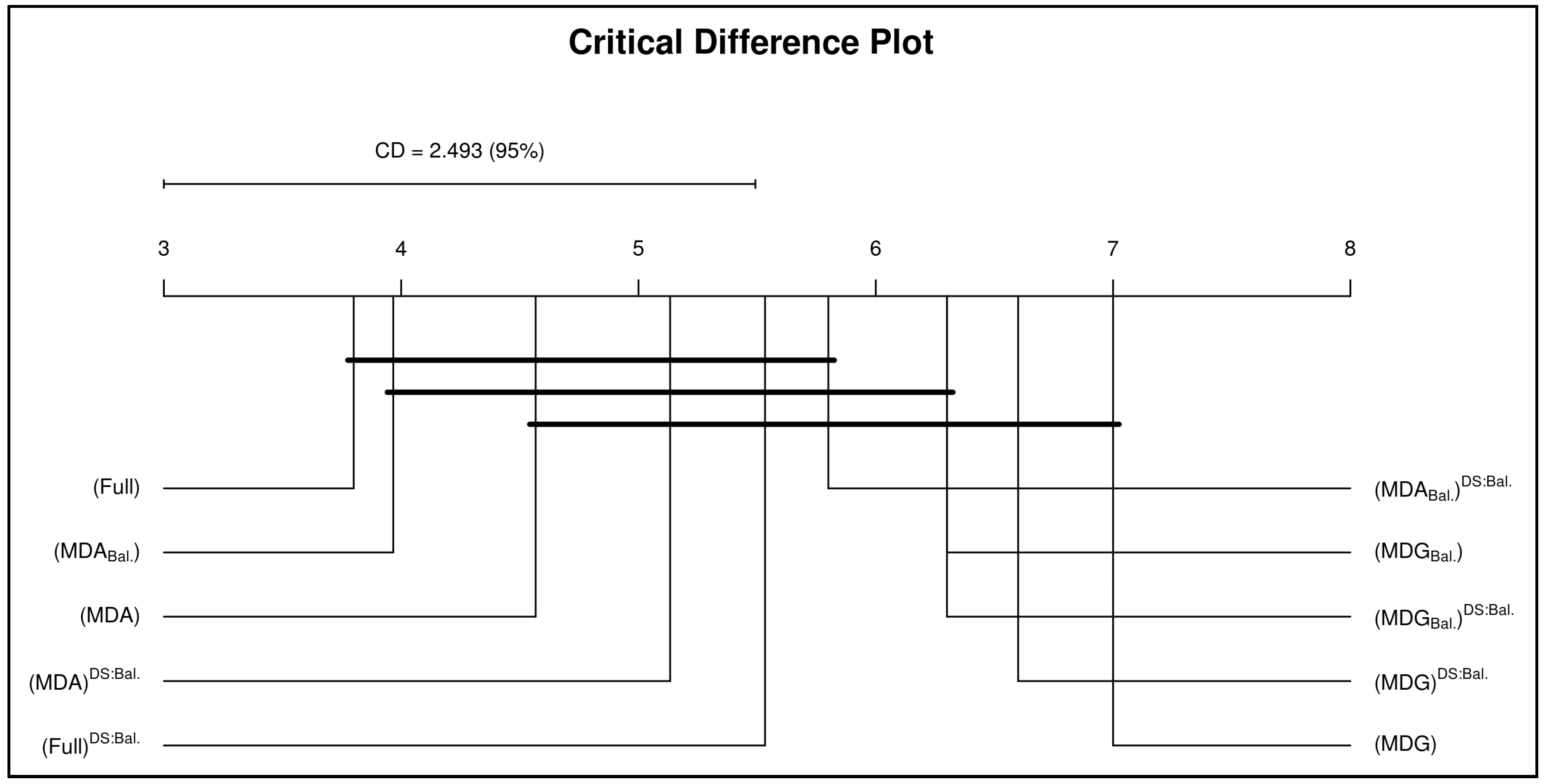
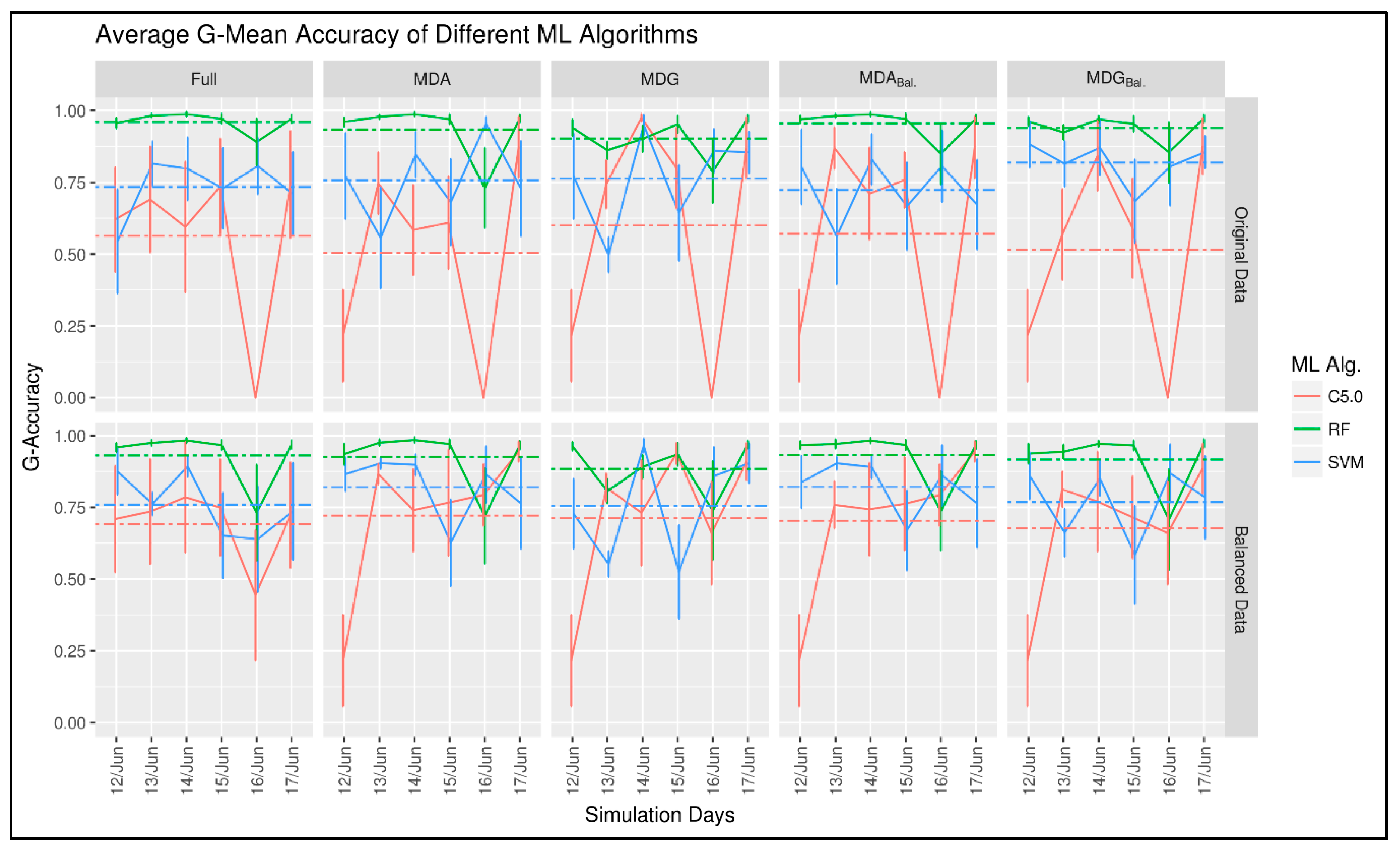
7.1. Results and Discussion
8. Conclusions
- An adaptive cut-off (threshold) approach results in better classification performance than a fixed threshold.
- Using a single cut-off (threshold) will lead to misleading results, which could result in a decision to terminate a good prediction model that merely required some tuning.
- Threshold adaptation approach may not show significant improvement to a model’s accuracy when the testing data exhibits the same statistical properties as the training data.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File 1 | File 2 | File 3 | File 4 | File 5 | File 6 | File 7 | ||
|---|---|---|---|---|---|---|---|---|
| gureKDD | Model 1 | 0.3904 | 0.0000 0.0000 | 0.0000 0.0000 | 0.0000 0.0000 | 0.0000 0.0000 | 0.0000 0.0000 | 0.0000 0.0000 |
| Model 2 | 0.2181 0.8125 | 0.9981 | 0.2108 0.9740 | 0.7154 0.9248 | 0.2162 0.9715 | 0.5786 0.9646 | 0.1850 0.9805 | |
| Model 3 | 0.0000 0.8884 | 0.7127 0.9150 | 0.9995 | 0.8198 0.8997 | 0.9874 0.9956 | 0.9849 0.9928 | 0.9981 0.9994 | |
| Model 4 | 0.8727 0.9770 | 0.4109 0.8656 | 0.9948 0.9949 | 0.9981 | 0.9862 0.9965 | 0.9740 0.9944 | 0.9988 0.9995 | |
| Model 5 | 0.8448 0.9740 | 0.3315 0.7145 | 0.9963 0.9965 | 0.9107 0.9453 | 0.9998 | 0.8525 0.9977 | 0.9995 0.9995 | |
| Model 6 | 0.8451 0.9997 | 0.9610 0.9948 | 0.9986 0.9989 | 0.9093 0.9128 | 0.9996 0.9997 | 0.9998 | 0.9994 0.9994 | |
| Model 7 | 0.8161 0.9504 | 0.9894 0.9903 | 0.8435 0.9908 | 0.8454 0.9308 | 0.9321 0.9959 | 0.9802 0.9939 | 0.9998 | |
| SEA | Model 1 | 0.8731 | 0.8740 0.8744 | 0.8046 0.8517 | 0.8052 0.8522 | 0.8361 0.8502 | 0.8362 0.8503 | No results as there were only 6 files. |
| Model 2 | 0.8726 0.8736 | 0.8731 | 0.8086 0.8486 | 0.8074 0.8493 | 0.8373 0.8471 | 0.8372 0.8468 | ||
| Model 3 | 0.8320 0.8574 | 0.8319 0.8586 | 0.8898 | 0.8896 0.8901 | 0.8592 0.8599 | 0.8593 0.8600 | ||
| Model 4 | 0.8317 0.8612 | 0.8319 0.8617 | 0.8906 0.8906 | 0.8902 | 0.8599 0.8603 | 0.8599 0.8603 | ||
| Model 5 | 0.8387 0.8700 | 0.8394 0.8704 | 0.8781 0.8821 | 0.8775 0.8821 | 0.2959 0.8567 | 0.8568 0.8569 | ||
| Model 6 | 0.8391 0.8686 | 0.8395 0.8691 | 0.8762 0.8819 | 0.8759 0.8821 | 0.8563 0.8570 | 0.8559 | ||
| AGR | Model 1 | 0.9449 | 0.9443 0.9445 | 0.4844 0.4932 | 0.4850 0.4930 | 0.6873 0.6888 | 0.6873 0.6885 | No results as there were only 6 files. |
| Model 2 | 0.9447 0.9448 | 0.9448 | 0.4835 0.4938 | 0.4829 0.4934 | 0.6871 0.6882 | 0.6867 0.6882 | ||
| Model 3 | 0.4925 0.4932 | 0.4925 0.4929 | 0.9341 | 0.9341 0.9341 | 0.6968 0.6984 | 0.6976 0.6990 | ||
| Model 4 | 0.4907 0.4916 | 0.4900 0.4911 | 0.9328 0.9334 | 0.9339 | 0.6956 0.6977 | 0.6964 0.6985 | ||
| Model 5 | 0.7114 0.7492 | 0.7114 0.7484 | 0.7382 0.7623 | 0.7386 0.7624 | 0.7059 | 0.7079 0.7081 | ||
| Model 6 | 0.7147 0.7463 | 0.7140 0.7459 | 0.7360 0.7626 | 0.7376 0.7628 | 0.7082 0.7085 | 0.7101 | ||
| File 1 | File 2 | File 3 | File 4 | File 5 | File 6 | File 7 | ||
|---|---|---|---|---|---|---|---|---|
| gureKDD | Model 1 | 0.9987 | 0.9752 0.9777 | 0.8538 0.9914 | 0.7948 0.9423 | 0.6733 0.9937 | 0.7410 0.9929 | 0.9673 0.9952 |
| Model 2 | 0.3085 0.9930 | 0.9984 | 0.9807 0.9851 | 0.9103 0.9359 | 0.9657 0.9699 | 0.9531 0.9563 | 0.9859 0.9963 | |
| Model 3 | 0.2182 0.9205 | 0.6430 0.9902 | 0.9996 | 0.5304 0.9324 | 0.9898 0.9951 | 0.8262 0.9930 | 0.9815 0.9994 | |
| Model 4 | 0.8448 0.9970 | 0.7060 0.9894 | 0.9953 0.9966 | 0.9983 | 0.9862 0.9990 | 0.9747 0.9947 | 0.9987 0.9995 | |
| Model 5 | 0.8165 0.9736 | 0.6326 0.8836 | 0.9968 0.9969 | 0.9311 0.9418 | 0.9999 | 0.9980 0.9981 | 0.9996 0.9996 | |
| Model 6 | 0.8863 0.9981 | 0.9542 0.9965 | 0.9989 0.9991 | 0.9082 0.9486 | 0.9998 0.9998 | 0.9999 | 0.9994 0.9996 | |
| Model 7 | 0.8448 0.9754 | 0.9841 0.9908 | 0.9884 0.9986 | 0.9300 0.9352 | 0.9914 0.9970 | 0.9961 0.9974 | 0.9999 | |
| SEA | Model 1 | 0.8750 | 0.8758 0.8758 | 0.8696 0.8764 | 0.8027 0.8053 | 0.8358 0.8364 | 0.8358 0.8364 | No results as there were only 6 files. |
| Model 2 | 0.8752 0.8752 | 0.8757 | 0.8026 0.8053 | 0.8680 0.8759 | 0.8357 0.8363 | 0.8357 0.8363 | ||
| Model 3 | 0.8536 0.9113 | 0.8323 0.8338 | 0.8920 | 0.8924 0.8926 | 0.8609 0.8610 | 0.8604 0.8607 | ||
| Model 4 | 0.8319 0.8333 | 0.8636 0.9113 | 0.8921 0.8921 | 0.8925 | 0.8609 0.8612 | 0.8606 0.8609 | ||
| Model 5 | 0.8389 0.8685 | 0.8393 0.8695 | 0.8782 0.8832 | 0.8786 0.8839 | 0.8576 | 0.8572 0.8576 | ||
| Model 6 | 0.8369 0.8691 | 0.8368 0.8695 | 0.8806 0.8829 | 0.8815 0.8835 | 0.8579 0.8579 | 0.8574 | ||
| AGR | Model 1 | 0.9483 | 0.9482 0.9484 | 0.4774 0.5042 | 0.4812 0.5040 | 0.6869 0.6895 | 0.6871 0.6893 | No results as there were only 6 files. |
| Model 2 | 0.9488 0.9490 | 0.9486 | 0.4788 0.5059 | 0.4762 0.5054 | 0.6858 0.6894 | 0.6856 0.6895 | ||
| Model 3 | 0.4900 0.4939 | 0.4933 0.4940 | 0.9387 | 0.9387 0.9395 | 0.6989 0.7007 | 0.6995 0.7019 | ||
| Model 4 | 0.4928 0.4939 | 0.4902 0.4942 | 0.9390 0.9391 | 0.9398 | 0.6995 0.7011 | 0.6997 0.7016 | ||
| Model 5 | 0.7208 0.7620 | 0.7212 0.7620 | 0.7401 0.7785 | 0.7402 0.7779 | 0.7127 | 0.7144 0.7149 | ||
| Model 6 | 0.7248 0.7607 | 0.7243 0.7608 | 0.7351 0.7788 | 0.7367 0.7805 | 0.7139 0.7140 | 0.7129 | ||
| File 1 | File 2 | File 3 | File 4 | File 5 | File 6 | File 7 | ||
|---|---|---|---|---|---|---|---|---|
| gureKDD | Model 1 | 0.9250 | 0.6471 0.6545 | 0.8171 0.9727 | 0.2401 0.3504 | 0.8974 0.9695 | 0.8250 0.9123 | 0.9665 0.9715 |
| Model 2 | 0.0000 0.8253 | 0.9869 | 0.1701 0.5024 | 0.3076 0.4525 | 0.1176 0.5163 | 0.3457 0.5285 | 0.1116 0.6131 | |
| Model 3 | 0.8092 0.8303 | 0.7206 0.9022 | 0.9977 | 0.7544 0.9028 | 0.9699 0.9793 | 0.9583 0.9636 | 0.9791 0.9878 | |
| Model 4 | 0.9195 0.9196 | 0.2794 0.6683 | 0.9678 0.9941 | 0.9591 | 0.9766 0.9958 | 0.9783 0.9840 | 0.9867 0.9986 | |
| Model 5 | 0.8724 0.9757 | 0.2233 0.6778 | 0.9865 0.9922 | 0.9172 0.9339 | 0.9992 | 0.8503 0.8507 | 0.9983 0.9985 | |
| Model 6 | 0.8443 0.9531 | 0.2804 0.6929 | 0.9894 0.9907 | 0.9145 0.9270 | 0.9976 0.9979 | 0.9970 | 0.9986 0.9986 | |
| Model 7 | 0.8165 0.8518 | 0.3163 0.8853 | 0.9944 0.9944 | 0.9107 0.9366 | 0.9960 0.9962 | 0.8476 0.9434 | 0.9994 | |
| SEA | Model 1 | 0.8763 | 0.8771 0.8771 | 0.8018 0.8936 | 0.8016 0.8941 | 0.8358 0.8617 | 0.8360 0.8615 | No results as there were only 6 files. |
| Model 2 | 0.8759 0.8760 | 0.8765 | 0.8021 0.8928 | 0.8018 0.8933 | 0.8356 0.8613 | 0.8359 0.8610 | ||
| Model 3 | 0.8319 0.8763 | 0.8320 0.8770 | 0.8933 | 0.8939 0.8940 | 0.8615 0.8617 | 0.8613 0.8615 | ||
| Model 4 | 0.8319 0.8763 | 0.8321 0.8769 | 0.8933 0.8933 | 0.8938 | 0.8615 0.8616 | 0.8612 0.8613 | ||
| Model 5 | 0.8325 0.8759 | 0.8326 0.8765 | 0.8924 0.8928 | 0.8929 0.8932 | 0.8614 | 0.8610 0.8611 | ||
| Model 6 | 0.8331 0.8756 | 0.8332 0.8760 | 0.8914 0.8923 | 0.8918 0.8927 | 0.8612 0.8612 | 0.8609 | ||
| AGR | Model 1 | 0.5529 | 0.5614 0.5615 | 0.4695 0.5106 | 0.4676 0.5079 | 0.5148 0.5211 | 0.5112 0.5178 | No results as there were only 6 files. |
| Model 2 | 0.5494 0.5498 | 0.5479 | 0.4829 0.5045 | 0.4813 0.5032 | 0.5148 0.5174 | 0.5125 0.5161 | ||
| Model 3 | 0.4879 0.4995 | 0.4877 0.5004 | 0.6440 | 0.6460 0.6462 | 0.5656 0.5659 | 0.5676 0.5685 | ||
| Model 4 | 0.4862 0.4991 | 0.4861 0.5005 | 0.6450 0.6453 | 0.6467 | 0.5652 0.5664 | 0.5673 0.5688 | ||
| Model 5 | 0.4867 0.4990 | 0.4862 0.5003 | 0.6338 0.6348 | 0.6352 0.6365 | 0.5598 | 0.5620 0.5623 | ||
| Model 6 | 0.4892 0.4996 | 0.4889 0.5006 | 0.6357 0.6374 | 0.6362 0.6384 | 0.5615 0.5617 | 0.5632 | ||
| Original | Balance | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Day 7 | Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Day 7 | ||
| Full | MDL 2 | 0.9996 | 0.0099 | 0.0176 | 0.0053 | 0.8062 | 0.0568 | 0.9999 | 0.0100 | 0.0241 | 0.0053 | 0.8995 | 0.0562 |
| 0.5882 | 0.5045 | 0.0148 | 0.9999 | 0.9934 | 0.9044 | 0.6387 | 0.0144 | 1.0000 | 0.9879 | ||||
| MDL 3 | 0.5967 | 0.9834 | 0.8106 | 0.0105 | 0.0000 | 0.9477 | 0.9014 | 0.9823 | 0.8661 | 0.0130 | 0.6304 | 0.7753 | |
| 0.9745 | 0.9137 | 0.0211 | 0.5650 | 0.9776 | 0.9487 | 0.9043 | 0.0134 | 0.9652 | 0.8440 | ||||
| MDL 4 | 0.0375 | 0.9373 | 0.9813 | 0.0000 | 0.0000 | 0.0316 | 0.9916 | 0.9249 | 0.9815 | 0.0129 | 0.9985 | 0.7109 | |
| 0.9937 | 0.9507 | 0.0130 | 0.9514 | 0.0616 | 0.9931 | 0.9271 | 0.0176 | 0.9989 | 0.9900 | ||||
| MDL 5 | 0.9982 | 0.0000 | 0.0216 | 0.9977 | 0.9045 | 0.0875 | 0.8820 | 0.0100 | 0.3610 | 0.9975 | 0.8523 | 0.7759 | |
| 0.9993 | 0.1950 | 0.4956 | 0.9999 | 0.9895 | 0.9934 | 0.1419 | 0.6242 | 0.9966 | 0.9907 | ||||
| MDL 6 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.4606 | 0.0000 | 0.9910 | 0.0200 | 0.0250 | 0.0479 | 1.0000 | 0.7458 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.9988 | 0.1485 | 0.0278 | 0.0480 | 0.9980 | ||||
| MDL 7 | 0.9901 | 0.9151 | 0.4357 | 0.0043 | 0.9998 | 0.9999 | 0.9956 | 0.3826 | 0.3916 | 0.0092 | 0.9999 | 1.0000 | |
| 0.9945 | 0.9413 | 0.7629 | 0.0132 | 0.9998 | 0.9962 | 0.9210 | 0.6703 | 0.0258 | 1.0000 | ||||
| MDA | MDL 2 | 0.9998 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 1.0000 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 |
| 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | ||||
| MDL 3 | 0.9814 | 0.9838 | 0.5062 | 0.2146 | 0.7327 | 0.1403 | 0.5278 | 0.9826 | 0.8504 | 0.8807 | 0.8344 | 0.8673 | |
| 0.9845 | 0.5720 | 0.7332 | 0.9890 | 0.4531 | 0.7520 | 0.8558 | 0.9420 | 0.8395 | 0.9405 | ||||
| MDL 4 | 0.1127 | 0.8999 | 0.9802 | 0.0402 | 0.3013 | 0.0283 | 0.7905 | 0.9193 | 0.9800 | 0.0790 | 0.9985 | 0.0647 | |
| 0.6653 | 0.9476 | 0.3447 | 0.8502 | 0.1108 | 0.9882 | 0.9299 | 0.3659 | 0.9992 | 0.4175 | ||||
| MDL 5 | 0.9902 | 0.0100 | 0.0983 | 0.9977 | 0.8528 | 0.0550 | 0.9087 | 0.0100 | 0.6697 | 0.9974 | 0.9478 | 0.8538 | |
| 0.9990 | 0.4568 | 0.4944 | 0.9504 | 0.1438 | 0.9857 | 0.0378 | 0.8277 | 0.9896 | 0.9923 | ||||
| MDL 6 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.4606 | 0.0000 | 0.9808 | 0.0141 | 0.0128 | 0.0473 | 1.0000 | 0.0532 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.8035 | 0.4143 | 0.7486 | 0.9999 | ||||
| MDL 7 | 0.9923 | 0.8980 | 0.4348 | 0.0485 | 0.9998 | 0.9998 | 0.9469 | 0.1264 | 0.0249 | 0.7837 | 1.0000 | 0.9998 | |
| 0.9976 | 0.9286 | 0.4498 | 0.9837 | 1.0000 | 0.9940 | 0.9236 | 0.8137 | 0.9907 | 1.0000 | ||||
| MDG | MDL 2 | 0.9998 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 1.0000 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 |
| 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | ||||
| MDL 3 | 0.1309 | 0.9702 | 0.8138 | 0.5949 | 0.0000 | 0.6922 | 0.4031 | 0.9656 | 0.8976 | 0.5522 | 0.5120 | 0.7539 | |
| 0.8279 | 0.8979 | 0.7917 | 0.4171 | 0.7796 | 0.8978 | 0.9092 | 0.6895 | 0.7127 | 0.8859 | ||||
| MDL 4 | 0.6496 | 0.9160 | 0.9431 | 0.9906 | 0.0000 | 0.9976 | 0.5688 | 0.8835 | 0.9165 | 0.9049 | 0.0000 | 0.9666 | |
| 0.9799 | 0.9246 | 0.9912 | 0.9815 | 0.9977 | 0.8639 | 0.9026 | 0.9100 | 0.0000 | 0.9792 | ||||
| MDL 5 | 0.9208 | 0.0200 | 0.0176 | 0.9969 | 0.0000 | 0.9611 | 0.9927 | 0.0141 | 0.3249 | 0.9972 | 0.8519 | 0.9978 | |
| 0.9896 | 0.2523 | 0.8186 | 0.9529 | 0.9836 | 0.9961 | 0.8160 | 0.8821 | 0.9965 | 0.9982 | ||||
| MDL 6 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.4606 | 0.0000 | 0.0614 | 0.0100 | 0.0000 | 0.0092 | 1.0000 | 0.0142 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.9935 | 0.8094 | 0.4154 | 0.0822 | 0.9993 | ||||
| MDL 7 | 0.9943 | 0.8910 | 0.4342 | 0.0485 | 0.9999 | 0.9999 | 0.9867 | 0.9068 | 0.4390 | 0.5440 | 0.9525 | 0.9997 | |
| 0.9976 | 0.9253 | 0.4423 | 0.9837 | 1.0000 | 0.9944 | 0.9142 | 0.6559 | 0.9853 | 0.9962 | ||||
| MDABal. | MDL 2 | 0.9998 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 1.0000 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 |
| 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | ||||
| MDL 3 | 0.9849 | 0.9833 | 0.5069 | 0.8782 | 0.5156 | 0.4736 | 0.7077 | 0.9821 | 0.6074 | 0.5015 | 0.7124 | 0.0816 | |
| 0.9876 | 0.5967 | 0.9296 | 0.9843 | 0.8484 | 0.8853 | 0.8378 | 0.8607 | 0.7731 | 0.4364 | ||||
| MDL 4 | 0.1337 | 0.9435 | 0.9802 | 0.0580 | 0.3013 | 0.0245 | 0.9852 | 0.6290 | 0.9805 | 0.0627 | 0.9958 | 0.4256 | |
| 0.6646 | 0.9492 | 0.9824 | 0.8496 | 0.1062 | 0.9906 | 0.9232 | 0.1455 | 0.9971 | 0.6606 | ||||
| MDL 5 | 0.9984 | 0.1142 | 0.0993 | 0.9977 | 0.7977 | 0.0568 | 0.8156 | 0.0100 | 0.0278 | 0.9974 | 0.7368 | 0.3558 | |
| 0.9995 | 0.4586 | 0.7236 | 0.9367 | 0.6729 | 0.9888 | 0.1569 | 0.6789 | 0.9954 | 0.9915 | ||||
| MDL 6 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.4606 | 0.0000 | 0.0614 | 0.0100 | 0.0125 | 0.0092 | 1.0000 | 0.0142 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.9985 | 0.8062 | 0.4115 | 0.7465 | 0.9996 | ||||
| MDL 7 | 0.9923 | 0.8952 | 0.4348 | 0.0485 | 0.9998 | 0.9998 | 0.9873 | 0.1978 | 0.0892 | 0.7895 | 0.9999 | 0.9998 | |
| 0.9976 | 0.9285 | 0.4445 | 0.9829 | 1.0000 | 0.9940 | 0.9236 | 0.8137 | 0.9907 | 1.0000 | ||||
| MDGBal. | MDL 2 | 0.9998 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 1.0000 | 0.0000 | 0.0279 | 0.0479 | 0.8528 | 0.0568 |
| 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | 0.0940 | 0.0279 | 0.0479 | 0.8528 | 0.0568 | ||||
| MDL 3 | 0.2910 | 0.9827 | 0.6145 | 0.1415 | 0.0000 | 0.4229 | 0.8819 | 0.9820 | 0.8189 | 0.9222 | 0.5312 | 0.6688 | |
| 0.4477 | 0.8308 | 0.7589 | 0.0000 | 0.8031 | 0.8896 | 0.8388 | 0.9300 | 0.5783 | 0.8254 | ||||
| MDL 4 | 0.6499 | 0.9485 | 0.9811 | 0.9764 | 0.3011 | 0.0567 | 0.9824 | 0.9265 | 0.9803 | 0.7625 | 0.8510 | 0.0615 | |
| 0.9342 | 0.9497 | 0.9799 | 0.9918 | 0.3565 | 0.9826 | 0.9265 | 0.9326 | 0.9341 | 0.0756 | ||||
| MDL 5 | 0.9673 | 0.0158 | 0.1048 | 0.9976 | 0.7977 | 0.0531 | 0.8201 | 0.0000 | 0.0736 | 0.9973 | 0.8510 | 0.4139 | |
| 0.9985 | 0.4339 | 0.4977 | 0.9522 | 0.0680 | 0.9485 | 0.1562 | 0.7646 | 0.9005 | 0.8068 | ||||
| MDL 6 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.4606 | 0.0000 | 0.0614 | 0.0100 | 0.0000 | 0.0092 | 1.0000 | 0.0142 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.9935 | 0.8094 | 0.4154 | 0.0822 | 0.9993 | ||||
| MDL 7 | 0.9929 | 0.1801 | 0.0729 | 0.7814 | 0.9997 | 0.9998 | 0.9883 | 0.0064 | 0.0139 | 0.0533 | 0.9998 | 0.9999 | |
| 0.9954 | 0.9267 | 0.4813 | 0.9778 | 1.0000 | 0.9900 | 0.9054 | 0.5412 | 0.9913 | 1.0000 | ||||
| Original | Balance | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Day 7 | Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Day 7 | ||
| Full | MDL 2 | 1.0000 | 0.0042 | 0.0279 | 0.0482 | 1.0000 | 0.0602 | 1.0000 | 0.0100 | 0.0216 | 0.0476 | 0.9535 | 0.0559 |
| 0.9272 | 0.9478 | 0.9094 | 1.0000 | 0.9987 | 0.9293 | 0.9413 | 0.9257 | 1.0000 | 0.9987 | ||||
| MDL 3 | 0.9521 | 0.9849 | 0.9213 | 0.6884 | 0.8560 | 0.9411 | 0.9663 | 0.9848 | 0.9191 | 0.7498 | 0.9530 | 0.9758 | |
| 0.9932 | 0.9739 | 0.9577 | 0.9870 | 0.9976 | 0.9925 | 0.9688 | 0.9340 | 0.9793 | 0.9987 | ||||
| MDL 4 | 0.9428 | 0.9301 | 0.9827 | 0.8425 | 0.8832 | 0.9404 | 0.9762 | 0.9237 | 0.9829 | 0.8991 | 0.9268 | 0.9688 | |
| 0.9945 | 0.9560 | 0.9920 | 0.9998 | 0.9978 | 0.9948 | 0.9471 | 0.9858 | 0.9997 | 0.9882 | ||||
| MDL 5 | 0.9997 | 0.0133 | 0.0648 | 0.9978 | 0.9535 | 0.0585 | 0.9888 | 0.2259 | 0.6808 | 0.9981 | 0.9934 | 0.9925 | |
| 0.9999 | 0.9205 | 0.9395 | 1.0000 | 0.9976 | 0.9971 | 0.9156 | 0.9302 | 0.9998 | 0.9926 | ||||
| MDL 6 | 0.9912 | 0.0000 | 0.0250 | 0.0479 | 1.0000 | 0.0568 | 0.0217 | 0.0100 | 0.0125 | 0.0053 | 1.0000 | 0.0142 | |
| 1.0000 | 0.9120 | 0.5737 | 0.9671 | 0.9998 | 0.9999 | 0.8685 | 0.6837 | 0.1048 | 0.9998 | ||||
| MDL 7 | 0.9964 | 0.9140 | 0.4314 | 0.7864 | 1.0000 | 1.0000 | 0.0217 | 0.0100 | 0.0125 | 0.0341 | 0.5279 | 1.0000 | |
| 0.9979 | 0.9351 | 0.9340 | 0.9911 | 1.0000 | 0.9998 | 0.9381 | 0.9319 | 0.9755 | 1.0000 | ||||
| MDA | MDL 2 | 1.0000 | 0.0463 | 0.0279 | 0.0482 | 1.0000 | 0.0585 | 1.0000 | 0.0100 | 0.0216 | 0.0476 | 0.8528 | 0.0564 |
| 0.9308 | 0.9417 | 0.9322 | 1.0000 | 0.9983 | 0.9281 | 0.9504 | 0.7999 | 1.0000 | 0.9984 | ||||
| MDL 3 | 0.9790 | 0.9848 | 0.9636 | 0.9089 | 0.9570 | 0.9890 | 0.9683 | 0.9848 | 0.9197 | 0.8158 | 0.8781 | 0.9282 | |
| 0.9895 | 0.9738 | 0.9490 | 0.9844 | 0.9963 | 0.9927 | 0.9690 | 0.9336 | 0.9839 | 0.9983 | ||||
| MDL 4 | 0.9493 | 0.9374 | 0.9826 | 0.8913 | 0.8956 | 0.9448 | 0.9463 | 0.9269 | 0.9827 | 0.8882 | 0.9024 | 0.9467 | |
| 0.9947 | 0.9557 | 0.9917 | 0.9971 | 0.9984 | 0.9948 | 0.9449 | 0.9889 | 0.9993 | 0.9942 | ||||
| MDL 5 | 0.9997 | 0.0141 | 0.0872 | 0.9978 | 0.9535 | 0.0619 | 0.9891 | 0.2439 | 0.6620 | 0.9981 | 0.9935 | 0.9933 | |
| 0.9999 | 0.9162 | 0.9388 | 1.0000 | 0.9951 | 0.9996 | 0.9218 | 0.9411 | 0.9981 | 0.9935 | ||||
| MDL 6 | 0.9983 | 0.0100 | 0.0250 | 0.0479 | 1.0000 | 0.0568 | 0.0217 | 0.0100 | 0.0176 | 0.0053 | 1.0000 | 0.0142 | |
| 1.0000 | 0.8553 | 0.4649 | 0.3326 | 0.9999 | 1.0000 | 0.9320 | 0.4956 | 0.1731 | 1.0000 | ||||
| MDL 7 | 0.9933 | 0.9309 | 0.4459 | 0.9875 | 1.0000 | 1.0000 | 0.0217 | 0.0100 | 0.0125 | 0.0367 | 0.4053 | 1.0000 | |
| 0.9971 | 0.9360 | 0.9370 | 0.9911 | 1.0000 | 0.9998 | 0.9355 | 0.9280 | 0.9699 | 1.0000 | ||||
| MDG | MDL 2 | 1.0000 | 0.0452 | 0.0279 | 0.0482 | 1.0000 | 0.0585 | 1.0000 | 0.0100 | 0.0216 | 0.0473 | 0.8528 | 0.0561 |
| 0.9296 | 0.9317 | 0.8425 | 1.0000 | 0.9982 | 0.9287 | 0.9457 | 0.9430 | 1.0000 | 0.9984 | ||||
| MDL 3 | 0.5035 | 0.9780 | 0.9171 | 0.6307 | 0.0000 | 0.7868 | 0.5308 | 0.9698 | 0.9051 | 0.5622 | 0.0000 | 0.6543 | |
| 0.8340 | 0.9185 | 0.8195 | 0.7887 | 0.9471 | 0.8000 | 0.9112 | 0.7204 | 0.7087 | 0.8924 | ||||
| MDL 4 | 0.7032 | 0.9160 | 0.9432 | 0.9856 | 0.0000 | 0.9884 | 0.6800 | 0.8996 | 0.8906 | 0.9829 | 0.0000 | 0.9531 | |
| 0.7703 | 0.9242 | 0.9913 | 0.8236 | 0.9974 | 0.8676 | 0.9000 | 0.9829 | 0.7499 | 0.9538 | ||||
| MDL 5 | 0.1390 | 0.0100 | 0.0254 | 0.9978 | 0.6742 | 0.0375 | 0.9897 | 0.0223 | 0.5450 | 0.9981 | 0.9999 | 0.3540 | |
| 0.9992 | 0.8518 | 0.9138 | 0.9996 | 0.9976 | 0.9926 | 0.8016 | 0.8817 | 1.0000 | 0.9982 | ||||
| MDL 6 | 0.9982 | 0.0000 | 0.0250 | 0.0479 | 1.0000 | 0.0568 | 0.0217 | 0.0100 | 0.0125 | 0.0053 | 1.0000 | 0.0142 | |
| 1.0000 | 0.8573 | 0.4349 | 0.6449 | 0.9998 | 1.0000 | 0.8710 | 0.7446 | 0.0767 | 1.0000 | ||||
| MDL 7 | 0.9926 | 0.9353 | 0.4493 | 0.9911 | 0.9999 | 1.0000 | 0.0217 | 0.0100 | 0.0125 | 0.0136 | 0.4116 | 1.0000 | |
| 0.9972 | 0.9357 | 0.9354 | 0.9912 | 1.0000 | 1.0000 | 0.9376 | 0.9377 | 0.9700 | 1.0000 | ||||
| MDABal. | MDL 2 | 1.0000 | 0.0418 | 0.0279 | 0.0482 | 1.0000 | 0.0586 | 1.0000 | 0.0100 | 0.0216 | 0.0473 | 0.8528 | 0.0559 |
| 0.9331 | 0.9434 | 0.9739 | 1.0000 | 0.9985 | 0.9277 | 0.9460 | 0.9603 | 1.0000 | 0.9985 | ||||
| MDL 3 | 0.9758 | 0.9848 | 0.9558 | 0.8755 | 0.8884 | 0.9777 | 0.9742 | 0.9849 | 0.9122 | 0.8515 | 0.8980 | 0.9522 | |
| 0.9933 | 0.9747 | 0.9604 | 0.9826 | 0.9965 | 0.9919 | 0.9715 | 0.9103 | 0.9833 | 0.9983 | ||||
| MDL 4 | 0.9505 | 0.9349 | 0.9824 | 0.8801 | 0.8903 | 0.9464 | 0.9508 | 0.9275 | 0.9827 | 0.8870 | 0.8912 | 0.9422 | |
| 0.9947 | 0.9560 | 0.9913 | 0.9960 | 0.9982 | 0.9945 | 0.9442 | 0.9897 | 0.9991 | 0.9864 | ||||
| MDL 5 | 0.9996 | 0.0141 | 0.0671 | 0.9978 | 0.9535 | 0.0619 | 0.9868 | 0.2331 | 0.6778 | 0.9981 | 0.9933 | 0.9934 | |
| 0.9999 | 0.9163 | 0.9402 | 0.9999 | 0.9984 | 0.9973 | 0.9141 | 0.9344 | 0.9969 | 0.9941 | ||||
| MDL 6 | 0.9947 | 0.0000 | 0.0250 | 0.0479 | 1.0000 | 0.0568 | 0.0217 | 0.0100 | 0.0125 | 0.0053 | 1.0000 | 0.0142 | |
| 1.0000 | 0.8610 | 0.4367 | 0.9482 | 0.9998 | 1.0000 | 0.8753 | 0.4526 | 0.3582 | 1.0000 | ||||
| MDL 7 | 0.9955 | 0.9148 | 0.4329 | 0.9083 | 1.0000 | 1.0000 | 0.0217 | 0.0100 | 0.0125 | 0.0465 | 0.9535 | 1.0000 | |
| 0.9976 | 0.9366 | 0.9349 | 0.9907 | 1.0000 | 0.9997 | 0.9335 | 0.9364 | 0.9680 | 1.0000 | ||||
| MDGBal. | MDL 2 | 1.0000 | 0.0457 | 0.0279 | 0.0482 | 1.0000 | 0.0585 | 1.0000 | 0.0100 | 0.0216 | 0.0473 | 0.8528 | 0.0560 |
| 0.9257 | 0.9409 | 0.9439 | 1.0000 | 0.9983 | 0.9272 | 0.9512 | 0.8091 | 1.0000 | 0.9984 | ||||
| MDL 3 | 0.9795 | 0.9850 | 0.9346 | 0.8227 | 0.8250 | 0.8990 | 0.9710 | 0.9850 | 0.8950 | 0.7824 | 0.7985 | 0.8641 | |
| 0.9849 | 0.9556 | 0.8257 | 0.9309 | 0.9231 | 0.9892 | 0.9517 | 0.8583 | 0.9215 | 0.9974 | ||||
| MDL 4 | 0.9571 | 0.9339 | 0.9827 | 0.8879 | 0.8889 | 0.9422 | 0.9438 | 0.9313 | 0.9826 | 0.8991 | 0.9096 | 0.9547 | |
| 0.9923 | 0.9540 | 0.9696 | 0.9346 | 0.9962 | 0.9947 | 0.9411 | 0.9752 | 0.9521 | 0.9949 | ||||
| MDL 5 | 0.9975 | 0.0141 | 0.0330 | 0.9978 | 0.9535 | 0.0531 | 0.9881 | 0.0903 | 0.6163 | 0.9981 | 0.9931 | 0.9366 | |
| 0.9993 | 0.8693 | 0.9049 | 0.9995 | 0.9954 | 0.9941 | 0.9133 | 0.9340 | 0.9951 | 0.9927 | ||||
| MDL 6 | 0.9952 | 0.0141 | 0.0250 | 0.0479 | 1.0000 | 0.0568 | 0.0217 | 0.0100 | 0.0125 | 0.0053 | 1.0000 | 0.0142 | |
| 1.0000 | 0.8642 | 0.4449 | 0.9611 | 0.9999 | 1.0000 | 0.8675 | 0.5907 | 0.0747 | 1.0000 | ||||
| MDL 7 | 0.9970 | 0.9036 | 0.4303 | 0.0505 | 1.0000 | 1.0000 | 0.0217 | 0.0100 | 0.0125 | 0.0053 | 0.4273 | 1.0000 | |
| 0.9974 | 0.9391 | 0.9365 | 0.9908 | 1.0000 | 1.0000 | 0.9339 | 0.9412 | 0.9893 | 1.0000 | ||||
| Original | Balance | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Day 7 | Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Day 7 | ||
| Full | MDL 2 | 1.0000 | 0.1630 | 0.3695 | 0.0573 | 0.9857 | 0.9681 | 0.9996 | 0.9076 | 0.5294 | 0.6040 | 0.9997 | 0.8786 |
| 0.1756 | 0.3977 | 0.1891 | 0.9875 | 0.9703 | 0.9137 | 0.5622 | 0.9011 | 0.9999 | 0.9966 | ||||
| MDL 3 | 0.5133 | 0.9809 | 0.5184 | 0.3624 | 0.7800 | 0.8279 | 0.4939 | 0.9754 | 0.4641 | 0.4042 | 0.4023 | 0.4473 | |
| 0.9312 | 0.5200 | 0.8053 | 0.9517 | 0.8661 | 0.8235 | 0.6112 | 0.7456 | 0.8289 | 0.8026 | ||||
| MDL 4 | 0.3545 | 0.9161 | 0.9814 | 0.0538 | 0.9182 | 0.4942 | 0.1242 | 0.7312 | 0.9800 | 0.0160 | 0.0000 | 0.0200 | |
| 0.9397 | 0.9457 | 0.3852 | 0.9589 | 0.7560 | 0.9154 | 0.9405 | 0.7563 | 0.9677 | 0.8836 | ||||
| MDL 5 | 0.0000 | 0.1026 | 0.7030 | 0.9961 | 0.0000 | 0.7385 | 0.0000 | 0.1387 | 0.5176 | 0.9913 | 0.4249 | 0.7042 | |
| 0.8674 | 0.1761 | 0.8065 | 0.9531 | 0.8429 | 0.9490 | 0.1474 | 0.5208 | 0.9242 | 0.7166 | ||||
| MDL 6 | 0.9806 | 0.8750 | 0.6296 | 0.0575 | 0.9994 | 0.9985 | 0.3346 | 0.0282 | 0.0216 | 0.1027 | 1.0000 | 0.5148 | |
| 0.9913 | 0.8931 | 0.6411 | 0.5101 | 0.9990 | 0.9978 | 0.1468 | 0.2367 | 0.9575 | 0.8563 | ||||
| MDL 7 | 0.9820 | 0.1070 | 0.4882 | 0.0599 | 0.9532 | 0.9999 | 0.9860 | 0.0489 | 0.1797 | 0.9667 | 0.9995 | 0.9999 | |
| 0.9906 | 0.2143 | 0.6021 | 0.7417 | 0.9997 | 0.9931 | 0.1611 | 0.5437 | 0.9843 | 0.9995 | ||||
| MDA | MDL 2 | 1.0000 | 0.9206 | 0.4812 | 0.0542 | 0.9534 | 0.0585 | 0.9997 | 0.6143 | 0.4374 | 0.2112 | 0.9534 | 0.0568 |
| 0.9224 | 0.7470 | 0.1977 | 0.9999 | 0.9911 | 0.6945 | 0.7889 | 0.8507 | 1.0000 | 0.9921 | ||||
| MDL 3 | 0.0000 | 0.9809 | 0.8553 | 0.0237 | 0.8381 | 0.1051 | 0.9330 | 0.9765 | 0.8737 | 0.4306 | 0.7185 | 0.8755 | |
| 0.2443 | 0.8658 | 0.0382 | 0.9337 | 0.6997 | 0.9621 | 0.8743 | 0.8487 | 0.9143 | 0.9184 | ||||
| MDL 4 | 0.6177 | 0.9447 | 0.9810 | 0.4665 | 0.9038 | 0.0722 | 0.1466 | 0.9397 | 0.9792 | 0.9226 | 0.0000 | 0.0317 | |
| 0.9725 | 0.9454 | 0.5871 | 0.9978 | 0.7330 | 0.8707 | 0.9413 | 0.9360 | 0.9749 | 0.7675 | ||||
| MDL 5 | 0.0000 | 0.0307 | 0.5224 | 0.9957 | 0.0000 | 0.0000 | 0.9178 | 0.1268 | 0.5203 | 0.9914 | 0.0000 | 0.0000 | |
| 0.9743 | 0.1444 | 0.6106 | 0.9529 | 0.7213 | 0.9865 | 0.1812 | 0.5285 | 0.9433 | 0.4924 | ||||
| MDL 6 | 0.9953 | 0.8535 | 0.7474 | 0.9685 | 0.9998 | 0.0568 | 0.9992 | 0.8966 | 0.3735 | 0.9686 | 1.0000 | 0.0568 | |
| 0.9993 | 0.9134 | 0.8951 | 0.9806 | 0.9908 | 0.9992 | 0.9242 | 0.4774 | 0.9821 | 0.9402 | ||||
| MDL 7 | 0.2622 | 0.0691 | 0.5673 | 0.8781 | 0.9515 | 0.9999 | 0.9795 | 0.1287 | 0.2820 | 0.9669 | 0.9526 | 0.9995 | |
| 0.9931 | 0.1308 | 0.6090 | 0.9117 | 0.9971 | 0.9922 | 0.1891 | 0.6485 | 0.9902 | 0.9989 | ||||
| MDG | MDL 2 | 1.0000 | 0.7706 | 0.6099 | 0.0429 | 0.9998 | 0.0602 | 0.9997 | 0.6713 | 0.4638 | 0.0480 | 0.9534 | 0.0568 |
| 0.7912 | 0.8736 | 0.1953 | 0.9999 | 0.9962 | 0.7400 | 0.4888 | 0.4182 | 1.0000 | 0.9905 | ||||
| MDL 3 | 0.0000 | 0.9391 | 0.6141 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.9357 | 0.6555 | 0.0000 | 0.0000 | 0.0000 | |
| 0.5136 | 0.6847 | 0.5639 | 0.3726 | 0.3531 | 0.5481 | 0.6685 | 0.5900 | 0.3930 | 0.5643 | ||||
| MDL 4 | 0.8259 | 0.7480 | 0.8851 | 0.9870 | 0.9831 | 0.9910 | 0.9773 | 0.8656 | 0.9092 | 0.9834 | 0.9888 | 0.9888 | |
| 0.9675 | 0.8062 | 0.9879 | 0.9927 | 0.9956 | 0.9833 | 0.8665 | 0.9884 | 0.9928 | 0.9958 | ||||
| MDL 5 | 0.0000 | 0.0331 | 0.7649 | 0.9950 | 0.9528 | 0.0000 | 0.0803 | 0.0695 | 0.4730 | 0.9849 | 0.9479 | 0.0647 | |
| 0.9378 | 0.1450 | 0.7727 | 0.9967 | 0.3657 | 0.7791 | 0.1176 | 0.4839 | 0.9935 | 0.2488 | ||||
| MDL 6 | 0.9994 | 0.0895 | 0.0250 | 0.8181 | 0.9999 | 0.0585 | 0.9916 | 0.0000 | 0.0210 | 0.7853 | 1.0000 | 0.0550 | |
| 0.9996 | 0.8718 | 0.5703 | 0.9710 | 0.8849 | 0.9992 | 0.8828 | 0.4595 | 0.9673 | 0.9852 | ||||
| MDL 7 | 0.0000 | 0.9120 | 0.4510 | 0.6801 | 0.9519 | 0.9998 | 0.8579 | 0.9096 | 0.5099 | 0.9655 | 0.9517 | 0.9995 | |
| 0.9742 | 0.9201 | 0.6205 | 0.7580 | 0.9974 | 0.9903 | 0.9100 | 0.6328 | 0.9849 | 0.9982 | ||||
| MDABal. | MDL 2 | 1.0000 | 0.8373 | 0.6823 | 0.0727 | 0.9999 | 0.0585 | 0.9994 | 0.9202 | 0.4744 | 0.0480 | 0.9999 | 0.0778 |
| 0.8590 | 0.8670 | 0.2976 | 0.9999 | 0.9943 | 0.9307 | 0.5384 | 0.7213 | 1.0000 | 0.9972 | ||||
| MDL 3 | 0.0000 | 0.9807 | 0.7562 | 0.0237 | 0.8247 | 0.2069 | 0.9366 | 0.9761 | 0.8781 | 0.4806 | 0.7460 | 0.8900 | |
| 0.3185 | 0.7765 | 0.0382 | 0.9415 | 0.7326 | 0.9593 | 0.8804 | 0.8301 | 0.9235 | 0.9226 | ||||
| MDL 4 | 0.8749 | 0.9298 | 0.9810 | 0.4613 | 0.9512 | 0.0837 | 0.1365 | 0.9384 | 0.9791 | 0.9123 | 0.0000 | 0.0245 | |
| 0.9727 | 0.9416 | 0.5578 | 0.9957 | 0.6791 | 0.8578 | 0.9399 | 0.9160 | 0.9818 | 0.7552 | ||||
| MDL 5 | 0.0000 | 0.0223 | 0.4724 | 0.9957 | 0.0000 | 0.0000 | 0.9151 | 0.1754 | 0.5767 | 0.9924 | 0.0000 | 0.0000 | |
| 0.9745 | 0.1443 | 0.5477 | 0.9531 | 0.7137 | 0.9868 | 0.2139 | 0.6023 | 0.9410 | 0.6056 | ||||
| MDL 6 | 0.9789 | 0.0479 | 0.5601 | 0.9336 | 1.0000 | 0.1291 | 0.5956 | 0.7399 | 0.2373 | 0.1566 | 1.0000 | 0.0492 | |
| 0.9940 | 0.3377 | 0.7603 | 0.9640 | 0.9749 | 0.9984 | 0.9135 | 0.4465 | 0.9562 | 0.9925 | ||||
| MDL 7 | 0.0795 | 0.0582 | 0.6014 | 0.3942 | 0.9982 | 0.9999 | 0.6721 | 0.1356 | 0.4007 | 0.9694 | 0.9529 | 0.9996 | |
| 0.9902 | 0.1513 | 0.6418 | 0.5782 | 0.9986 | 0.9925 | 0.2104 | 0.6328 | 0.9849 | 0.9992 | ||||
| MDGBal. | MDL 2 | 1.0000 | 0.9263 | 0.7197 | 0.0474 | 0.9534 | 0.0585 | 0.9995 | 0.8279 | 0.4580 | 0.0484 | 0.9998 | 0.0776 |
| 0.9311 | 0.9164 | 0.5652 | 0.9999 | 0.9974 | 0.9140 | 0.5588 | 0.8278 | 0.9999 | 0.9976 | ||||
| MDL 3 | 0.8727 | 0.9780 | 0.6410 | 0.3583 | 0.7586 | 0.8608 | 0.5333 | 0.9695 | 0.4830 | 0.4616 | 0.6226 | 0.7089 | |
| 0.9800 | 0.7587 | 0.5333 | 0.9002 | 0.8995 | 0.8954 | 0.4834 | 0.4654 | 0.6894 | 0.7755 | ||||
| MDL 4 | 0.1225 | 0.9035 | 0.9801 | 0.7684 | 0.0000 | 0.0316 | 0.1238 | 0.9446 | 0.9781 | 0.8969 | 0.0000 | 0.0245 | |
| 0.9823 | 0.9435 | 0.9535 | 0.9851 | 0.4872 | 0.8983 | 0.9449 | 0.8983 | 0.8981 | 0.6145 | ||||
| MDL 5 | 0.0307 | 0.0141 | 0.6289 | 0.9958 | 0.7384 | 0.0000 | 0.8877 | 0.0518 | 0.0889 | 0.9900 | 0.0000 | 0.0000 | |
| 0.9694 | 0.1687 | 0.6689 | 0.9521 | 0.6616 | 0.9827 | 0.1426 | 0.3074 | 0.9714 | 0.5188 | ||||
| MDL 6 | 0.9978 | 0.0100 | 0.7001 | 0.5854 | 1.0000 | 0.1670 | 0.7335 | 0.8746 | 0.3746 | 0.9650 | 1.0000 | 0.0531 | |
| 0.9996 | 0.2816 | 0.7927 | 0.9595 | 0.9908 | 0.9961 | 0.9199 | 0.4683 | 0.9665 | 0.9930 | ||||
| MDL 7 | 0.0000 | 0.6830 | 0.8442 | 0.5596 | 0.9527 | 0.9998 | 0.8509 | 0.1288 | 0.2795 | 0.9692 | 0.9990 | 0.9996 | |
| 0.9320 | 0.7189 | 0.8991 | 0.7260 | 0.9978 | 0.9921 | 0.2576 | 0.6870 | 0.9873 | 0.9994 | ||||
References
- Cherdantseva, Y.; Hilton, J. A Reference Model of Information Assurance & Security. In Proceedings of the 2013 International Conference on Availability, Reliability and Security, Regensburg, Germany, 2–6 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 546–555. [Google Scholar]
- Das, S.; Datta, S.; Chaudhuri, B.B. Handling data irregularities in classification: Foundations, trends, and future challenges. Pattern Recognit. 2018, 81, 674–693. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Burlutskiy, N.; Petridis, M.; Fish, A.; Chernov, A.; Ali, N. An Investigation on Online Versus Batch Learning in Predicting User Behaviour. In Research and Development in Intelligent Systems XXXIII; Springer International Publishing: Cham, Switzerland, 2016; pp. 135–149. [Google Scholar]
- Chen, J.J.; Tsai, C.-A.; Moon, H.; Ahn, H.; Young, J.J.; Chen, C.-H. Decision threshold adjustment in class prediction. SAR QSAR Environ. Res. 2006, 17, 337–352. [Google Scholar] [CrossRef]
- Catania, C.A.; Garino, C.G. Automatic network intrusion detection: Current techniques and open issues. Comput. Electr. Eng. 2012, 38, 1062–1072. [Google Scholar] [CrossRef]
- Freeman, E.A.; Moisen, G.G. A comparison of the performance of threshold criteria for binary classification in terms of predicted prevalence and kappa. Ecol. Modell. 2008, 217, 48–58. [Google Scholar] [CrossRef]
- Buczak, A.L.; Guven, E. A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection. IEEE Commun. Surv. Tutor. 2016, 18, 1153–1176. [Google Scholar] [CrossRef]
- Beguería, S. Validation and Evaluation of Predictive Models in Hazard Assessment and Risk Management. Nat. Hazards 2006, 37, 315–329. [Google Scholar] [CrossRef]
- Yang, Y. A study of thresholding strategies for text categorization. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 01), New Orleans, LA, USA, 9–13 September 2001; ACM Press: New York, NY, USA, 2001; pp. 137–145. [Google Scholar]
- Lakhina, A.; Crovella, M.; Diot, C. Diagnosing network-wide traffic anomalies. In Proceedings of the 2004 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications (SIGCOMM ’04), Portland, OR, USA, 30 August–3 September 2004; ACM Press: New York, NY, USA, 2004; Volume 34, pp. 219–230. [Google Scholar]
- Fan, R.-E.; Lin, C.-J. A Study on Threshold Selection for Multi-Label Classification; Technical Report; National Taiwan University: Taipei, Taiwan, 2007. [Google Scholar]
- Pillai, I.; Fumera, G.; Roli, F. Threshold optimisation for multi-label classifiers. Pattern Recognit. 2013, 46, 2055–2065. [Google Scholar] [CrossRef]
- Koyejo, O.O.; Natarajan, N.; Ravikumar, P.K.; Dhillon, I.S. Consistent Binary Classification with Generalized Performance Metrics. In Proceedings of the Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2744–2752. [Google Scholar]
- Yan, B.; Koyejo, O.; Zhong, K.; Ravikumar, P. Binary Classification with Karmic, Threshold-Quasi-Concave Metrics. arXiv 2018, arXiv:1806.00640. [Google Scholar]
- Eskin, E.; Miller, M.; Zhong, Z.-D.; Yi, G.; Lee, W.-A.; Stolfo, S. Adaptive Model Generation for Intrusion Detection Systems. In Proceedings of the ACMCCS Workshop on Intrusion Detection and Prevention, Athens, Greece, 1 November 2000; pp. 1–14. [Google Scholar]
- Honig, A.; Howard, A.; Eskin, E.; Stolfo, S. Adaptive Model Generation: An Architecture for Deployment of Data Mining-based Intrusion Detection Systems. In Applications of Data Mining in Computer Security; Springer: Boston, MA, USA, 2002; pp. 153–193. [Google Scholar]
- Hossain, M.; Bridges, S.M. A Framework for an Adaptive Intrusion Detection System with Data Mining. In Proceedings of the 13th Annual Canadian Information Technology Security Symposium, Ottawa, ON, Canada, 11–15 June 2001; pp. 1–8. [Google Scholar]
- Hossain, M.; Bridges, S.M.; Vaughn, R.B. Adaptive intrusion detection with data mining. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Washington, DC, USA, 8 October 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 4, pp. 3097–3103. [Google Scholar]
- Jung, J.; Paxson, V.; Berger, A.W.; Balakrishnan, H. Fast portscan detection using sequential hypothesis testing. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 12 May 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 211–225. [Google Scholar]
- Ali, M.Q.; Al-Shaer, E.; Khan, H.; Khayam, S.A. Automated Anomaly Detector Adaptation using Adaptive Threshold Tuning. ACM Trans. Inf. Syst. Secur. 2013, 15, 1–30. [Google Scholar] [CrossRef]
- Idé, T.; Kashima, H. Eigenspace-based anomaly detection in computer systems. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; ACM Press: New York, NY, USA, 2004; pp. 440–449. [Google Scholar]
- Yu, Z.; Tsai, J.J.P.; Weigert, T. An Automatically Tuning Intrusion Detection System. IEEE Trans. Syst. Man Cybern. Part B 2007, 37, 373–384. [Google Scholar] [CrossRef]
- Yu, Z.; Tsai, J.J.P.; Weigert, T. An adaptive automatically tuning intrusion detection system. ACM Trans. Auton. Adapt. Syst. 2008, 3, 10:1–10:25. [Google Scholar] [CrossRef]
- Chou, H.-H.; Wang, S.-D. An adaptive network intrusion detection approach for the cloud environment. In Proceedings of the International Carnahan Conference on Security Technology (ICCST), Taipei, Taiwan, 21–24 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Agosta, J.M.; Diuk-Wasser, C.; Chandrashekar, J.; Livadas, C. An Adaptive Anomaly Detector for Worm Detection. In Proceedings of the 2nd USENIX Workshop on Tackling Computer Systems Problems with Machine Learning Techniques (SYSML’07), Cambridge, MA, USA, 10 April 2007; USENIX Association: Berkeley, CA, USA, 2007; pp. 3:1–3:6. [Google Scholar]
- Gu, G.; Fogla, P.; Dagon, D.; Lee, W.; Skoric, B. Towards an Information-Theoretic Framework for Analyzing Intrusion Detection Systems. In Proceedings of the European Symposium on Research in Computer Security (ESORICS 2006), Hamburg, Germany, 18–20 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 527–546. [Google Scholar]
- Strasburg, C.; Basu, S.; Wong, J.S. S-MAIDS: A Semantic Model for Automated Tuning, Correlation, and Response Selection in Intrusion Detection Systems. In Proceedings of the the IEEE 37th Annual Computer Software and Applications Conference (COMPSAC), Kyoto, Japan, 22–26 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 319–328. [Google Scholar]
- Jyothsna, V.; Rama Prasad, V.V. Assessing degree of intrusion scope (DIS): a statistical strategy for anomaly based intrusion detection. CSI Trans. ICT 2018, 6, 99–127. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Pfahringer, B.; Kirkby, R.; Gavaldà, R. New ensemble methods for evolving data streams. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; ACM Press: New York, NY, USA, 2009; pp. 139–148. [Google Scholar]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Masud, M.; Gao, J.; Khan, L.; Han, J.; Thuraisingham, B.M. Classification and Novel Class Detection in Concept-Drifting Data Streams under Time Constraints. IEEE Trans. Knowl. Data Eng. 2011, 23, 859–874. [Google Scholar] [CrossRef]
- Farid, D.M.; Zhang, L.; Hossain, A.; Rahman, C.M.; Strachan, R.; Sexton, G.; Dahal, K. An adaptive ensemble classifier for mining concept drifting data streams. Expert Syst. Appl. 2013, 40, 5895–5906. [Google Scholar] [CrossRef]
- Masud, M.M.; Chen, Q.; Khan, L.; Aggarwal, C.; Gao, J.; Han, J.; Thuraisingham, B. Addressing Concept-Evolution in Concept-Drifting Data Streams. In Proceedings of the the IEEE International Conference on Data Mining (ICDM), Sydney, NSW, Australia, 13–17 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 929–934. [Google Scholar]
- Masud, M.M.; Chen, Q.; Khan, L.; Aggarwal, C.C.; Gao, J.; Han, J.; Srivastava, A.; Oza, N.C. Classification and Adaptive Novel Class Detection of Feature-Evolving Data Streams. IEEE Trans. Knowl. Data Eng. 2013, 25, 1484–1497. [Google Scholar] [CrossRef]
- Cretu-Ciocarlie, G.F.; Stavrou, A.; Locasto, M.E.; Stolfo, S.J. Adaptive Anomaly Detection via Self-calibration and Dynamic Updating. In Recent Advances in Intrusion Detection (RAID 2009); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5758, pp. 41–60. [Google Scholar]
- Chen, S.; Wang, H.; Zhou, S.; Yu, P.S. Stop Chasing Trends: Discovering High Order Models in Evolving Data. In Proceedings of the IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 923–932. [Google Scholar]
- Gomes, H.M.; Bifet, A.; Read, J.; Barddal, J.P.; Enembreck, F.; Pfharinger, B.; Holmes, G.; Abdessalem, T. Adaptive random forests for evolving data stream classification. Mach. Learn. 2017, 106, 1469–1495. [Google Scholar] [CrossRef]
- Kotłowski, W.; Dembczyński, K. Surrogate regret bounds for generalized classification performance metrics. Mach. Learn. 2017, 106, 549–572. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the Curse of Imbalanced Training Sets: One-Sided Selection. In Proceedings of the 14th International Conference on Machine Learning (ICML97), Nashville, TN, USA, 8–12 July 1997; pp. 179–186. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Kuncheva, L.I.; Arnaiz-González, Á.; Díez-Pastor, J.-F.; Gunn, I.A.D. Instance selection improves geometric mean accuracy: a study on imbalanced data classification. Prog. Artif. Intell. 2019, 1–14. [Google Scholar] [CrossRef]
- Rao, C.M.; Naidu, M.M. A Model for Generating Synthetic Network Flows and Accuracy Index for Evaluation of Anomaly Network Intrusion Detection Systems. Indian J. Sci. Technol. 2017, 10, 1–16. [Google Scholar] [CrossRef]
- Rao, C.M.; Naidu, M.M. Acceptance Sampling for Network Intrusion Detection. J. Theor. Appl. Inf. Technol. 2017, 95, 6707–6718. [Google Scholar]
- Bujlow, T.; Riaz, T.; Pedersen, J.M. A method for classification of network traffic based on C5.0 Machine Learning Algorithm. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; pp. 237–241. [Google Scholar]
- Raghav Aggiwal Introduction to Random Forest. Available online: https://dimensionless.in/tag/random-forest/ (accessed on 21 February 2019).
- Aporras. What Is the Difference between Bagging and Boosting? Available online: https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/ (accessed on 21 February 2019).
- Rulequest Research Is C5.0 Better Than C4.5? Available online: https://rulequest.com/see5-comparison.html (accessed on 21 February 2019).
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kauffmann Publishers, Inc.: Burlington, MA, USA, 1993. [Google Scholar]
- Rulequest Research C5.0: An Informal Tutorial. Available online: https://www.rulequest.com/see5-unix.html (accessed on 21 February 2019).
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman & Hall, Inc.: Boca Raton, FL, USA, 1993. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar]
- Li, C. Probability Estimation in Random Forests. Master’s Thesis, Department of Mathematics and Statistics, Utah State University, Logan, UT, USA, 2013. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016; ISBN 9780128043578. [Google Scholar]
- Resende, P.A.A.; Drummond, A.C. A Survey of Random Forest Based Methods for Intrusion Detection Systems. ACM Comput. Surv. 2018, 51, 48:1–48:36. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Golawala, M.; Hulse, J. Van An Empirical Study of Learning from Imbalanced Data Using Random Forest. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, 29–31 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 310–317. [Google Scholar]
- Lin, S.-W.; Ying, K.-C.; Lee, C.-Y.; Lee, Z.-J. An intelligent algorithm with feature selection and decision rules applied to anomaly intrusion detection. Appl. Soft Comput. 2012, 12, 3285–3290. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory; John Wiley and Sons, Inc.: New York, NY, USA, 1998. [Google Scholar]
- Golmah, V. An Efficient Hybrid Intrusion Detection System based on C5.0 and SVM. Int. J. Database Theory Appl. 2014, 7, 59–70. [Google Scholar] [CrossRef]
- Kelsey, T. Lecture Notes—ID5059: Knowledge Discovery and Data Mining, Lecture 21—Support Vector Machines (SVMs). 2015. Available online: https://tom.host.cs.st-andrews.ac.uk/ID5059/L21-slides.pdf (accessed on 28 April 2019).
- Marsupial, D. SVM, Overfitting, Curse of Dimensionality. Available online: https://stats.stackexchange.com/questions/35276/svm-overfitting-curse-of-dimensionality (accessed on 21 February 2019).
- Lin, C.-J. Chih-Jen Lin’s Home Page. Available online: https://www.csie.ntu.edu.tw/~cjlin/ (accessed on 21 February 2019).
- Kelsey, T. Lecture Notes—ID5059: Knowledge Discovery and Data Mining, Lecture 22—Support Vector Machines (SVMs) (2). 2015. Available online: https://tom.host.cs.st-andrews.ac.uk/ID5059/L22-slides.pdf (accessed on 28 April 2019).
- Schölkopf, B.; Tsuda, K.; Vert, J.-P. Kernel Methods in Computational Biology, Chapter 2: A Primer on Kernel Methods; MIT Press: Cambridge, MA, USA, 2004; ISBN 9780262195096. [Google Scholar]
- Gwardys, G. Why Is Kernelized SVM Much Slower Than Linear SVM? Available online: https://www.quora.com/Why-is-kernelized-SVM-much-slower-than-linear-SVM (accessed on 21 February 2019).
- Team, R.D.C. R: A Language and Environment for Statistical Computing.; R Foundation for Statistical Computing: Vienna, Austria, 2008; ISBN 3-900051-07-0. Available online: https://www.r-project.org/ (accessed on 21 February 2019).
- Kuhn, M.; Weston, S.; Coulter, N.; Culp, M.; C code for C5.0 by R. Quinlan C50: C5.0 Decision Trees and Rule-Based Models. Available online: https://cran.r-project.org/package=C50 (accessed on 21 May 2018).
- Wright, M.N.; Ziegler, A. ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Wright, M.N.; Wager, S.; Probst, P. CRAN—Package Ranger: A Fast Implementation of Random Forests. Available online: https://cran.r-project.org/package=ranger (accessed on 21 May 2018).
- Helleputte, T.; Gramme, P.; Paul, J. Linear Predictive Models Based on the LIBLINEAR C/C++ Library. Available online: https://cran.r-project.org/package=LiblineaR (accessed on 21 May 2018).
- Fan, R.-E.; Chang, K.-W.; Hsieh, C.-J.; Wang, X.-R.; Lin, C.-J. LIBLINEAR: A Library for Large Linear Classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Al Tobi, A.M. Anomaly-Based Network Intrusion Detection Enhancement by Prediction Threshold Adaptation of Binary Classification Models. Ph.D. Thesis, School of Computer Science, University of St Andrews, St Andrews, UK, 2018. [Google Scholar]
- Garavaglia, S.; Sharma, A. A Smart Guide to Dummy Variables: Four Applications and a Macro. In Proceedings of the Northeast SAS Users Group Conference, Pittsburgh, PA, USA, 4–6 October 1998; pp. 46–55. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar] [CrossRef]
- Geisser, S. Predictive Inference; Chapman and Hall: New York, NY, USA, 1993; ISBN 9780203742310. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1145. [Google Scholar]
- Devijver, P.A.; Kittler, J. Pattern Recognition: A Statistical Approach; Prentice Hall: London, UK, 1982. [Google Scholar]
- Seni, G.; Elder, J.F. Ensemble Methods in Data Mining: Improving Accuracy Through Combining Predictions. Synth. Lect. Data Min. Knowl. Discov. 2010, 2, 1–126. [Google Scholar] [CrossRef]
- Gupta, P. Cross-Validation in Machine Learning. Available online: https://towardsdatascience.com/cross-validation-in-machine-learning-72924a69872f (accessed on 21 February 2019).
- Ambroise, C.; McLachlan, G.J. Selection bias in gene extraction on the basis of microarray gene-expression data. Proc. Natl. Acad. Sci. USA 2002, 99, 6562–6566. [Google Scholar] [CrossRef]
- Fielding, A.H.; Bell, J.F. A review of methods for the assessment of prediction errors in conservation presence/absence models. Environ. Conserv. 1997, 24, 38–49. [Google Scholar] [CrossRef]
- Street, W.N.; Kim, Y. A streaming ensemble algorithm (SEA) for large-scale classification. In Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; ACM Press: New York, NY, USA, 2001; pp. 377–382. [Google Scholar]
- Bifet, A. SEAGenerator.java. Available online: https://github.com/Waikato/moa/blob/master/moa/src/main/java/moa/streams/generators/SEAGenerator.java (accessed on 28 April 2019).
- Agrawal, R.; Imielinski, T.; Swami, A. Database Mining: A Performance Perspective. IEEE Trans. Knowl. Data Eng. 1993, 5, 914–925. [Google Scholar] [CrossRef]
- Kirkby, R. AgrawalGenerator.java. Available online: https://github.com/Waikato/moa/blob/master/moa/src/main/java/moa/streams/generators/AgrawalGenerator.java (accessed on 28 April 2019).
- Perona, I.; Gurrutxaga, I.; Arbelaitz, O.; Martín, J.I.; Muguerza, J.; Pérez, J.M. gureKddcup Database. Available online: http://www.sc.ehu.es/acwaldap/gureKddcup/galdetegia_jaso.php (accessed on 21 February 2019).
- Perona, I.; Gurrutxaga, I.; Arbelaitz, O.; Martín, J.I.; Muguerza, J.; Pérez, J.M. Service-independent payload analysis to improve intrusion detection in network traffic. In Proceedings of the 7th Australasian Data Mining Conference, Glenelg, Australia, 27–28 November 2008; Volume 87, pp. 171–178. [Google Scholar]
- Perona, I.; Arbelaiz Gallego, O.; Gurrutxaga, I.; Martín, J.I.; Muguerza Rivero, J.F.; Pérez, J.M. Generation of the Database Gurekddcup. Universidad del País Vasco. 2008. Available online: http://hdl.handle.net/10810/20608 (accessed on 28 April 2019).
- Lincoln Laboratory, Massachusetts Institute of Technology. 1998 DARPA Intrusion Detection Evaluation Data Set. Available online: http://www.ll.mit.edu/ideval/data/1998data.html (accessed on 24 May 2015).
- UCI KDD Archive KDD Cup 1999 Data. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 21 February 2019).
- Al Tobi, A.M.; Duncan, I. KDD 1999 generation faults: A review and analysis. J. Cyber Secur. Technol. 2018, 2, 164–200. [Google Scholar] [CrossRef]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Onut, I.-V.; Ghorbani, A.A. A Feature Classification Scheme for Network Intrusion Detection. Int. J. Netw. Secur. 2007, 5, 1–15. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Friedman, M. The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Friedman, M. A Comparison of Alternative Tests of Significance for the Problem of m Rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Hollander, M.; Wolfe, D.A.; Chicken, E. Nonparametric Statistical Methods, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013; ISBN 9780470387375. [Google Scholar]
- Bi, J.; Bennett, K.; Embrechts, M.; Breneman, C.; Song, M. Dimensionality Reduction via Sparse Support Vector Machines. J. Mach. Learn. Res. 2003, 3, 1229–1243. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Rudnicki, W.R.; Wrzesień, M.; Paja, W. All Relevant Feature Selection Methods and Applications. In Feature Selection for Data and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2015; Volume 584, pp. 11–28. [Google Scholar]
- Welch, B.L. The Generalization of ‘Student’s’ Problem when Several Different Population Variances are Involved. Biometrika 1947, 34, 28–35. [Google Scholar] [CrossRef] [PubMed]
- Ruxton, G.D. The unequal variance t-test is an underused alternative to Student’s t-test and the Mann–Whitney U test. Behav. Ecol. 2006, 17, 688–690. [Google Scholar] [CrossRef]
- Liaw, A. randomForest: Breiman and Cutler’s Random Forests for Classification and Regression. Available online: https://cran.r-project.org/package=randomForest (accessed on 21 May 2018).
- Shapiro, S.S.; Wilk, M.B. An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Nemenyi, P.B. Distribution-free multiple comparisons. Biometrics 1962, 18, 263. [Google Scholar]
- Nemenyi, P.B. Distribution-Free Multiple Comparisons. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 1963. [Google Scholar]
- Hollander, M.; Wolfe, D.A. Nonparametric Statistical Methods, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 1999; ISBN 0471190454. [Google Scholar]



| Actual | |||||
|---|---|---|---|---|---|
| Prediction | |||||
| File 1 | File 2 | File 3 | File 4 | File 5 | File 6 | Total | |
|---|---|---|---|---|---|---|---|
| groupA | 71,609 | 71,298 | 85,190 | 84,965 | 78,295 | 77,913 | 469,270 |
| groupB | 128,391 | 128,702 | 114,810 | 115,035 | 121,705 | 122,087 | 730,730 |
| File 1 | File 2 | File 3 | File 4 | File 5 | File 6 | Total | |
|---|---|---|---|---|---|---|---|
| groupA | 134,572 | 134,457 | 76,577 | 76,947 | 105,301 | 105,785 | 633,639 |
| groupB | 65,428 | 65,543 | 123,423 | 123,053 | 94,699 | 94,215 | 566,361 |
| Week 1 | Week 2 | Week 3 | Week 4 | Week 5 | Week 6 | Week 7 | Total | |
|---|---|---|---|---|---|---|---|---|
| Normal | 177,889 | 186,706 | 72,676 | 98,627 | 128,516 | 247,699 | 217,743 | 1,129,856 |
| Attack | 21 | 2,084 | 215,693 | 15,319 | 475,787 | 703,662 | 217,072 | 1,629,638 |
| DOS | 16 | 1,002 | 207,896 | 1,171 | 465,825 | 684,741 | 207,035 | 1,567,686 |
| PROBE | 0 | 1,027 | 7,757 | 12,366 | 9,941 | 18,017 | 10,031 | 59,139 |
| R2L | 1 | 55 | 39 | 1,752 | 0 | 881 | 2 | 2,730 |
| U2R | 4 | 0 | 1 | 30 | 21 | 14 | 4 | 74 |
| Anomaly | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 9 |
| Total | 177,910 | 188,790 | 288,369 | 113,946 | 604,303 | 951,361 | 434,815 | 2,759,494 |
| Day 1 11/Jun | Day 2 12/Jun | Day 3 13/Jun | Day 4 14/Jun | Day 5 15/Jun | Day 6 16/Jun | Day 7 17/Jun | Total | |
|---|---|---|---|---|---|---|---|---|
| Normal | 442,705 | 164,545 | 168,947 | 213,798 | 633,388 | 600,017 | 409,090 | 2,632,490 |
| Attack | 0 | 2,123 | 10,037 | 6,422 | 35,260 | 11 | 4,959 | 58,812 |
| Total (Original) | 442,705 | 166,668 | 178,984 | 220,220 | 668,648 | 600,028 | 414,049 | 2,691,302 |
| Synthetic | 0 | 162,422 | 158,910 | 207,376 | 598,128 | 600,006 | 404,131 | 2,130,973 |
| Total (Balanced) | 442,705 | 329,090 | 337,894 | 427,596 | 1,266,776 | 1,200,034 | 818,180 | 4,822,275 |
| C5.0 | RF | SVM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| G-Mean Accuracy | Optimal Cutoff | G-Mean Accuracy | Optimal Cutoff | G-Mean Accuracy | Optimal Cutoff | |||||||
| gureKDD | 0.9998 | ±0.0000 | 0.5322 | ±0.0122 | 0.9998 | ±0.0000 | 0.4714 | ±0.0126 | 0.9947 | ±0.0000 | 0.5879 | ±0.0022 |
| SEA | 0.8568 | ±0.0002 | 0.2959 | ±0.0070 | 0.8951 | ±0.0002 | 0.2329 | ±0.0011 | 0.8621 | ±0.0000 | 0.4354 | ±0.0001 |
| AGR | 0.7162 | ±0.0003 | 0.5322 | ±0.0044 | 0.6580 | ±0.0001 | 0.7700 | ±0.0011 | 0.5627 | ±0.0000 | 0.5144 | ±0.0002 |
| No. | Feature |
|---|---|
| 2 | src_ip |
| 3 | src_zone |
| 5 | dst_ip |
| 6 | dst_zone |
| 9 | ipVersion |
| 10 | Protocol |
| 11 | conn_state |
| 23 | bro_conn_state |
| 24 | bro_service |
| 31 | conn_start |
| 32 | conn_partial_start |
| 33 | conn_close |
| 34 | conn_partial_close |
| 43 | conn_stats_orig_endian_type |
| 50 | conn_stats_resp_endian_type |
| Day2 | Day3 | Day4 | Day5 | Day6 | Day7 | |
|---|---|---|---|---|---|---|
| MDA | 130 | 518 | 364 | 368 | 60 | 355 |
| MDABalanced | 166 | 507 | 378 | 388 | 170 | 322 |
| MDG | 124 | 27 | 11 | 113 | 70 | 137 |
| MDGBalanced | 119 | 137 | 117 | 168 | 84 | 134 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Tobi, A.M.; Duncan, I. Improving Intrusion Detection Model Prediction by Threshold Adaptation. Information 2019, 10, 159. https://doi.org/10.3390/info10050159
Al Tobi AM, Duncan I. Improving Intrusion Detection Model Prediction by Threshold Adaptation. Information. 2019; 10(5):159. https://doi.org/10.3390/info10050159
Chicago/Turabian StyleAl Tobi, Amjad M., and Ishbel Duncan. 2019. "Improving Intrusion Detection Model Prediction by Threshold Adaptation" Information 10, no. 5: 159. https://doi.org/10.3390/info10050159
APA StyleAl Tobi, A. M., & Duncan, I. (2019). Improving Intrusion Detection Model Prediction by Threshold Adaptation. Information, 10(5), 159. https://doi.org/10.3390/info10050159