A Collaborative Pilot Platform for Data Annotation and Enrichment in Viticulture




Abstract
1. Introduction
- lack of structured and rich descriptive metadata;
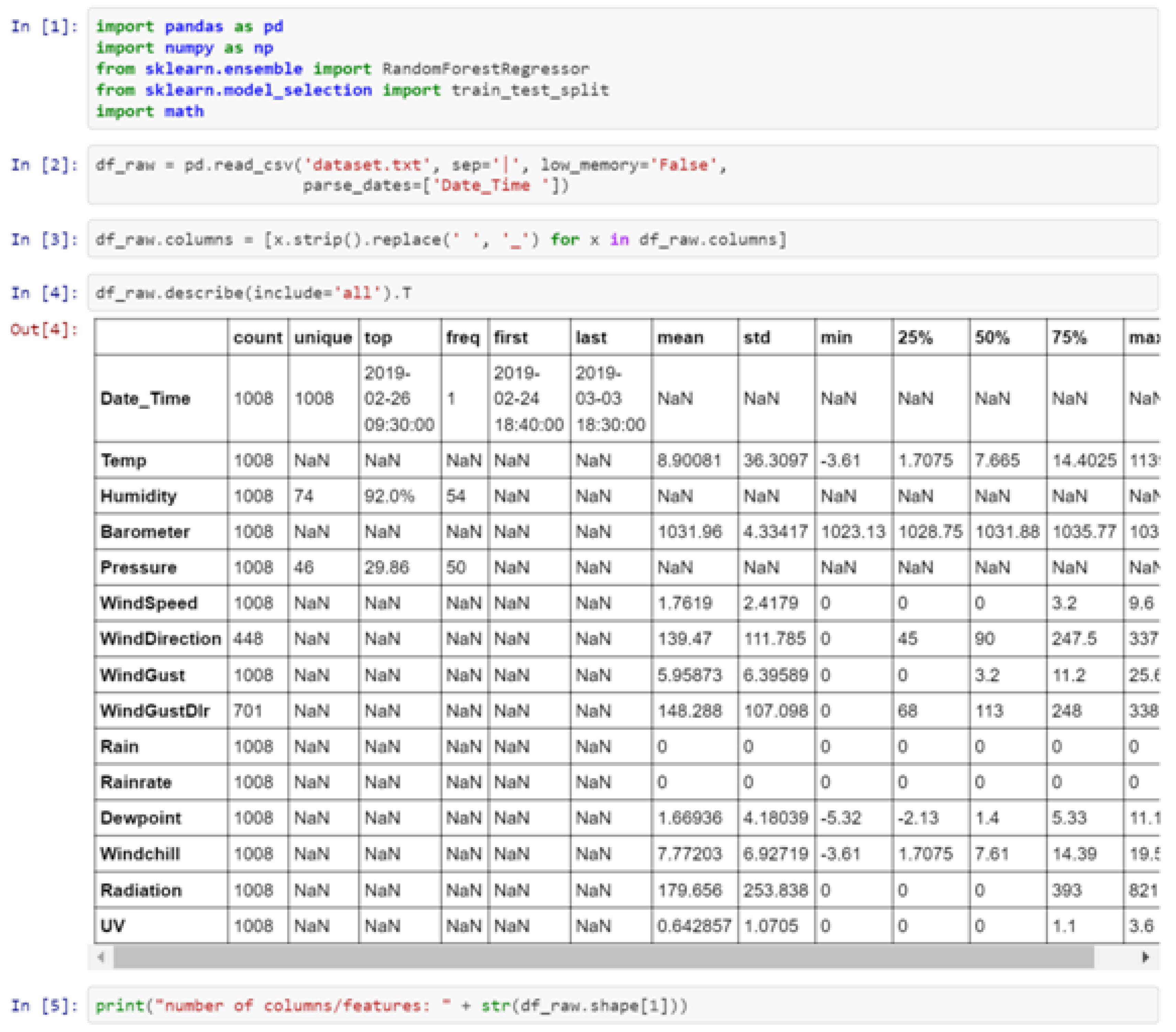
- complex, heterogeneous, and multi-channel aggregation workflows;
- possible shortcomings in the data providing process (surpassing manual quality control of automatic metadata generation in digital repositories);
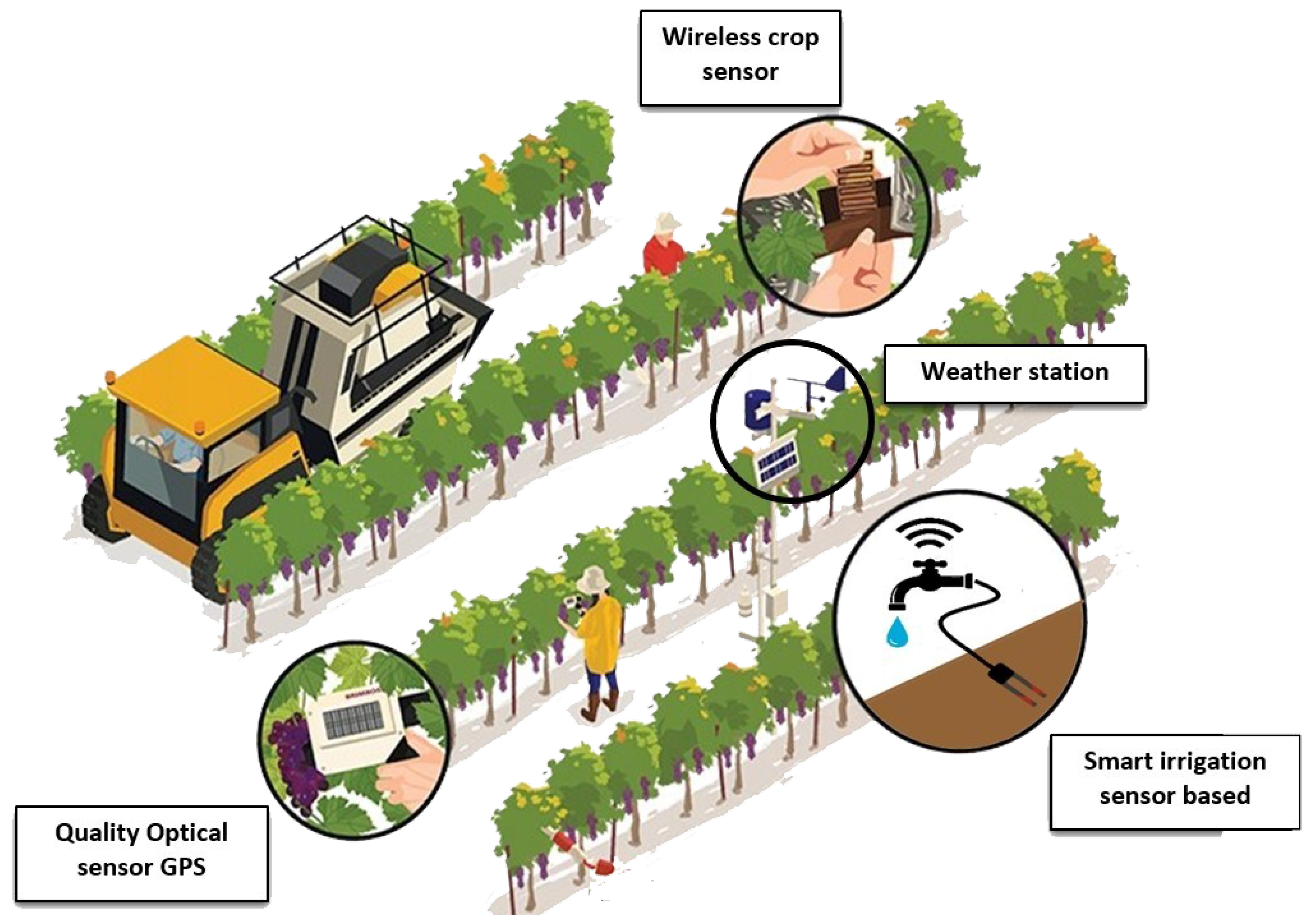
2. Smart Agriculture Overview
2.1. Pioneer Works on Smart Agriculture/Viticulture
2.2. Precision Viticulture
2.3. Utilization of Artificial Intelligence
3. Agricultural Data Aggregation—An Interconnected System
- Viticulture data are aggregated from multiple repositories and published;
- Viticulture data are translated into usable information consumable for decision-making purposes;
- Heterogeneous data are translated into the same form using a common data model;
- The data model is able to actually evolve, so as to include additional requirements, data sources and other models;
- Data can be made more accessible to a wide range of users, such as data scientists, business analysts, etc., by granting a unified access to knowledge from multiple sources, thus promoting the viti-cultural content;
- Data can be queried and queries may be asked in multiple ways that haven’t been anticipated while modeling the data;
- Back-end processing can be initiated to extract useful information from translated data;
- Viticulture-related information is retrieved, stored, extracted and sustained for future use;
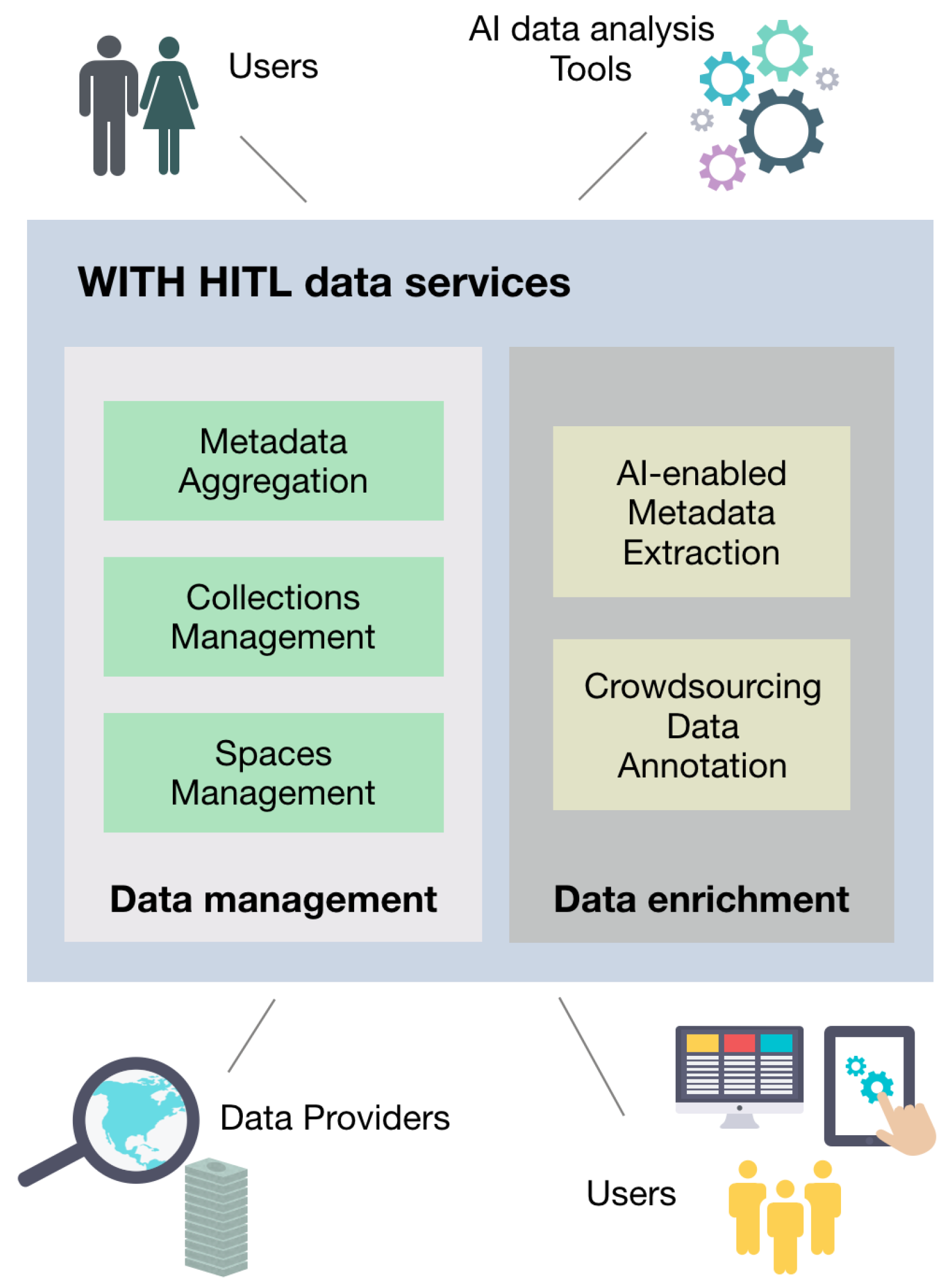
- For end users: wine lovers, viticulture, enthusiasts, winemakers and producers etc., the platform serves as an outlet for the breakthrough of content and interfaces bonded to propagated repositories. Users can potentially create customizable multi-source content (e.g., searched through multiple viticulture repositories), on the scope of further enrichment of dissemination for viticulture. Customized collections will create a virtual aggregation of data related to viticulture allowing a straightforward method of presenting popular narratives in a web-based environment. Furthermore, the platform offers collaborative content creation and modification within registered groups of users.
- For specialized professionals (from viticulture, agriculture domain, etc.), the platform offers the tools to synthesize and construct eclectic collections, for the enrichment, optimization, and development of specialized semantic knowledge.
- For viticulture content holders, i.e., winemakers and producers, it offers an easy to use content & metadata repository and management system, that can ensure interoperability with standards, best practices, and guidelines. Winemakers are able to upload their historic data from a specific vineyard, like for instance soil data, management data, meteorological information, and actual yields per season. Data can be stored in the platform’s repository and then plugged into the system’s machine learning models to predict the yield from the coming season, even from the early stages of growth.
- For organizations, the platform offers the notion of spaces, i.e., a novel way to organize and promote content and improve its metadata, as well as engage with users through campaigns.
- For aggregators, it provides the MINT (Metadata INTeroperabillity, http://mint.image.ece.ntua.gr/redmine/) [28,29], open source, web-based platform. It offers full implementation of workflows on the scope of ingestion, formal mapping, transformation, and aggregation of metadata records.
- For developers, it provides a back-end toolset for digital content re-usability, employing a fully functional API (api.withculture.eu/assets/developers-lite.html) that disseminates the total of the available data and services to anyone willing to utilize for further exploitation.
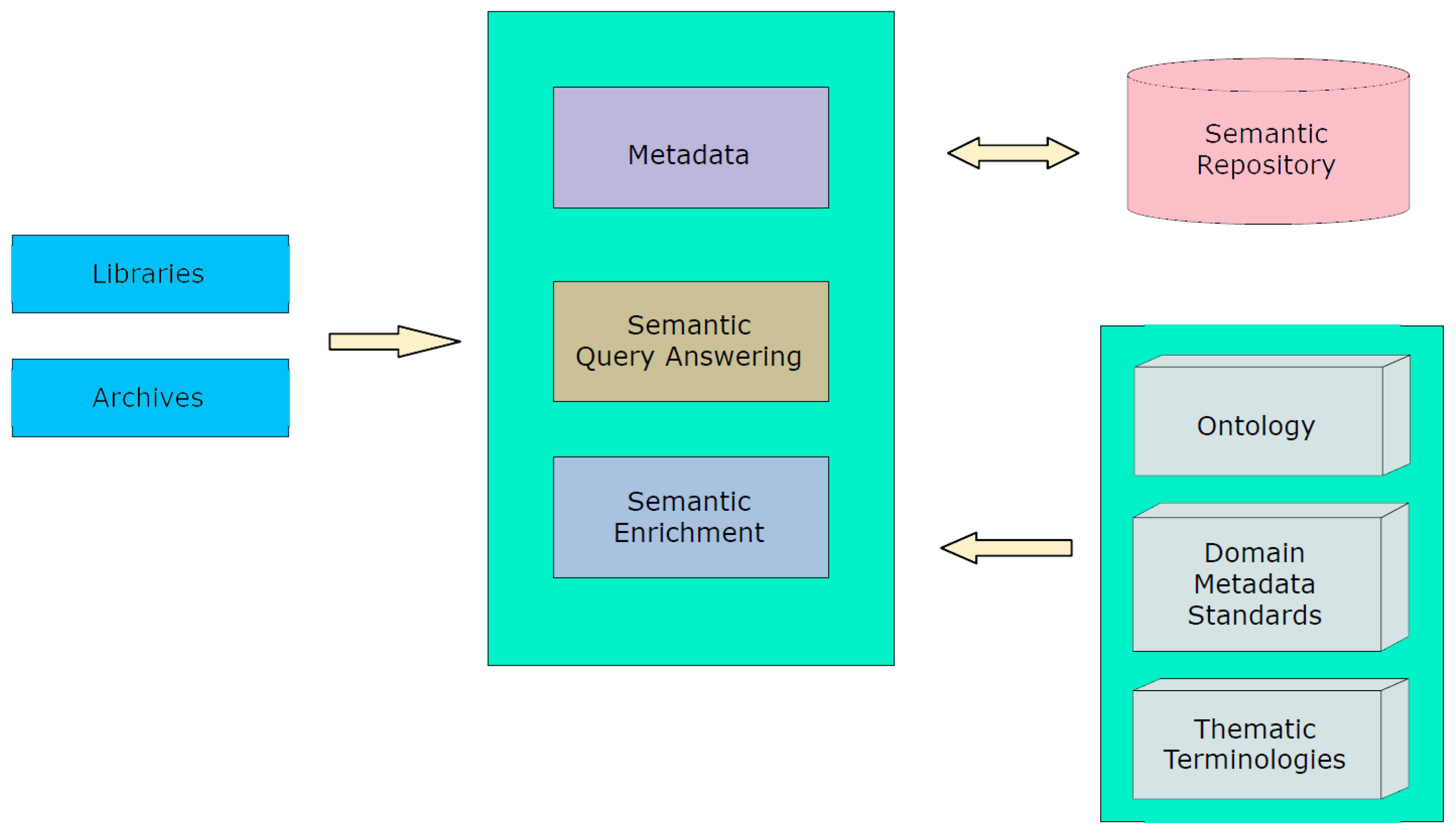
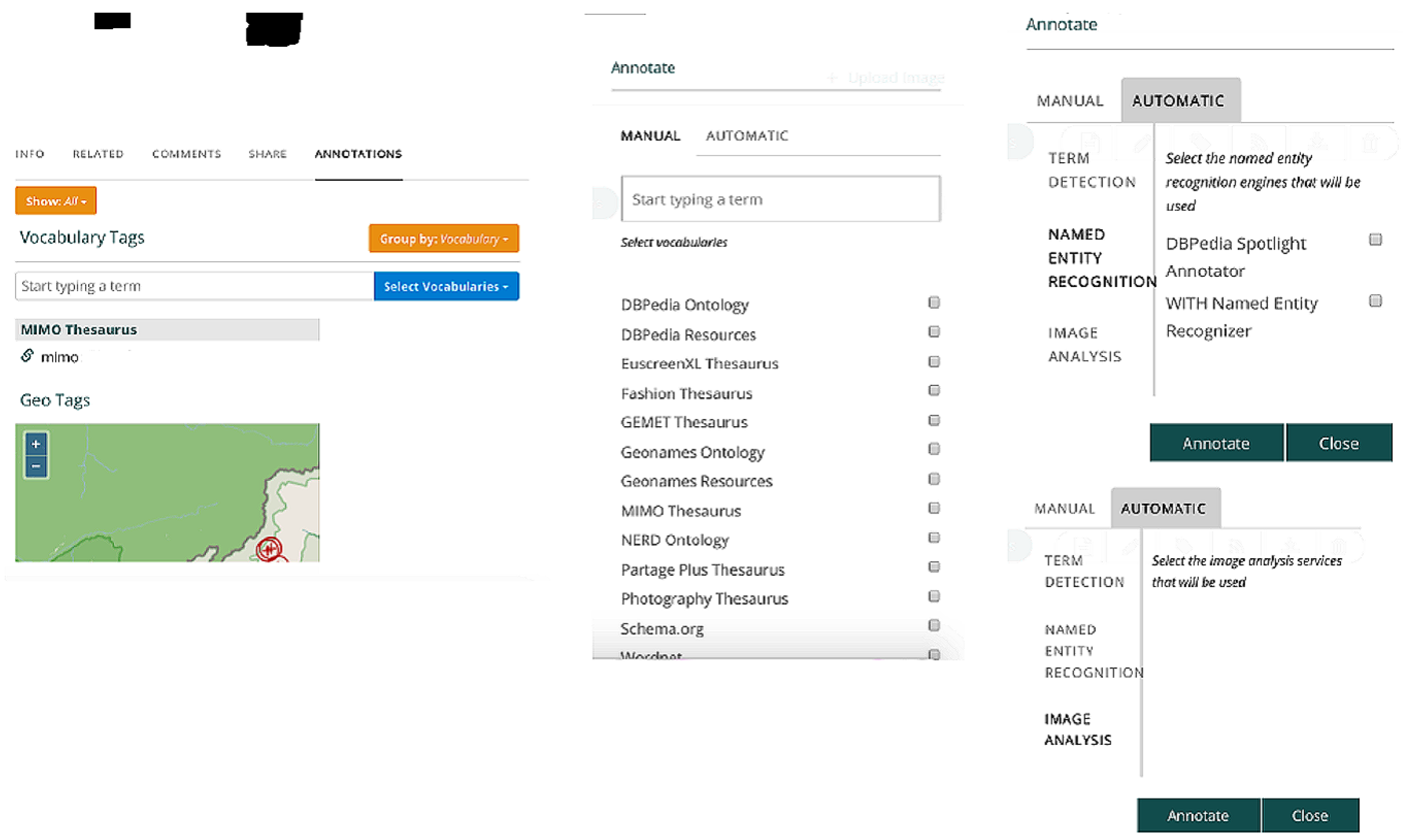
3.1. Handling of Metadata Semantic Heterogeneity
- harvesting and aggregating metadata inputs, created under shared community standards or proprietary metadata schemata,
- migrating from providers’standard or local models to a reference model,
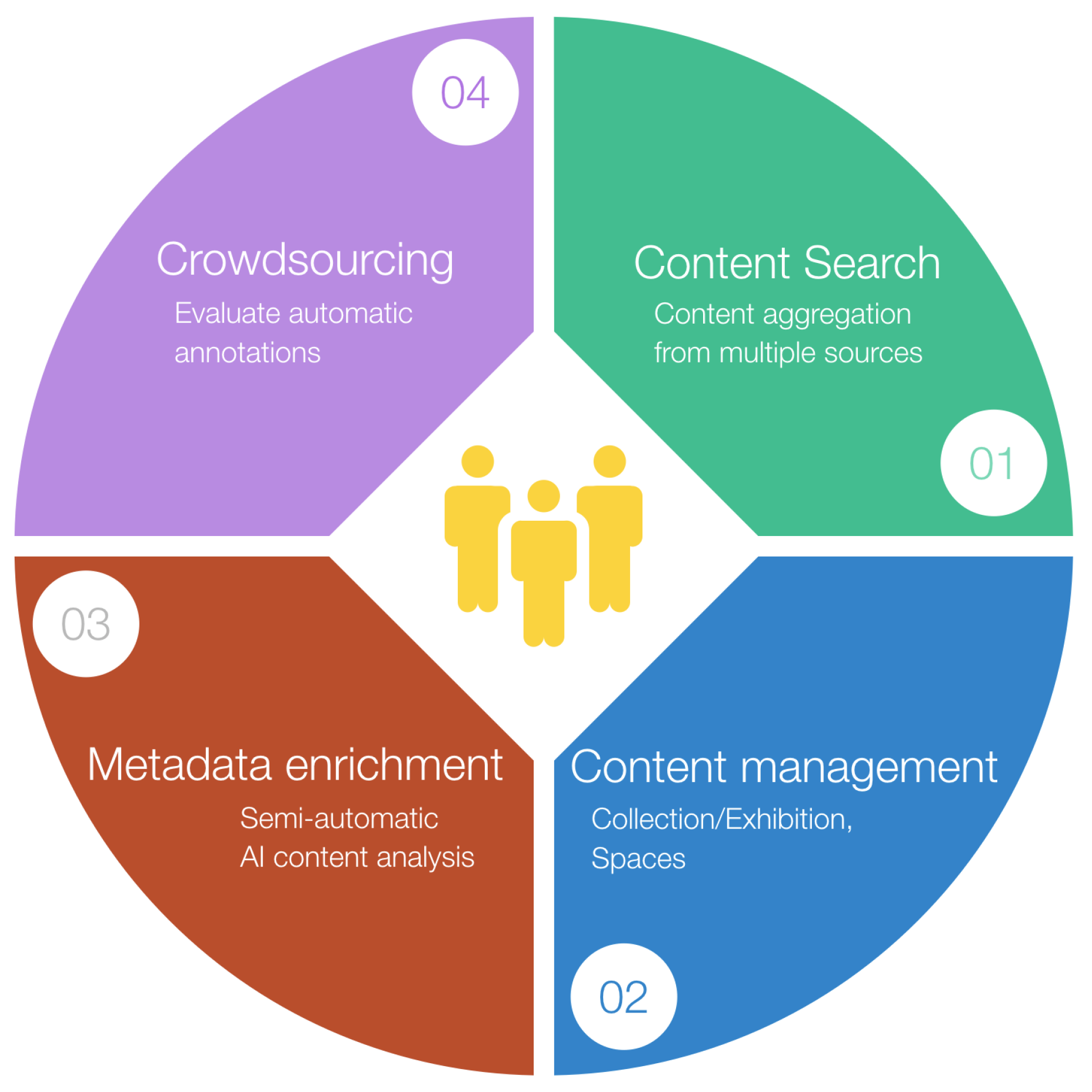
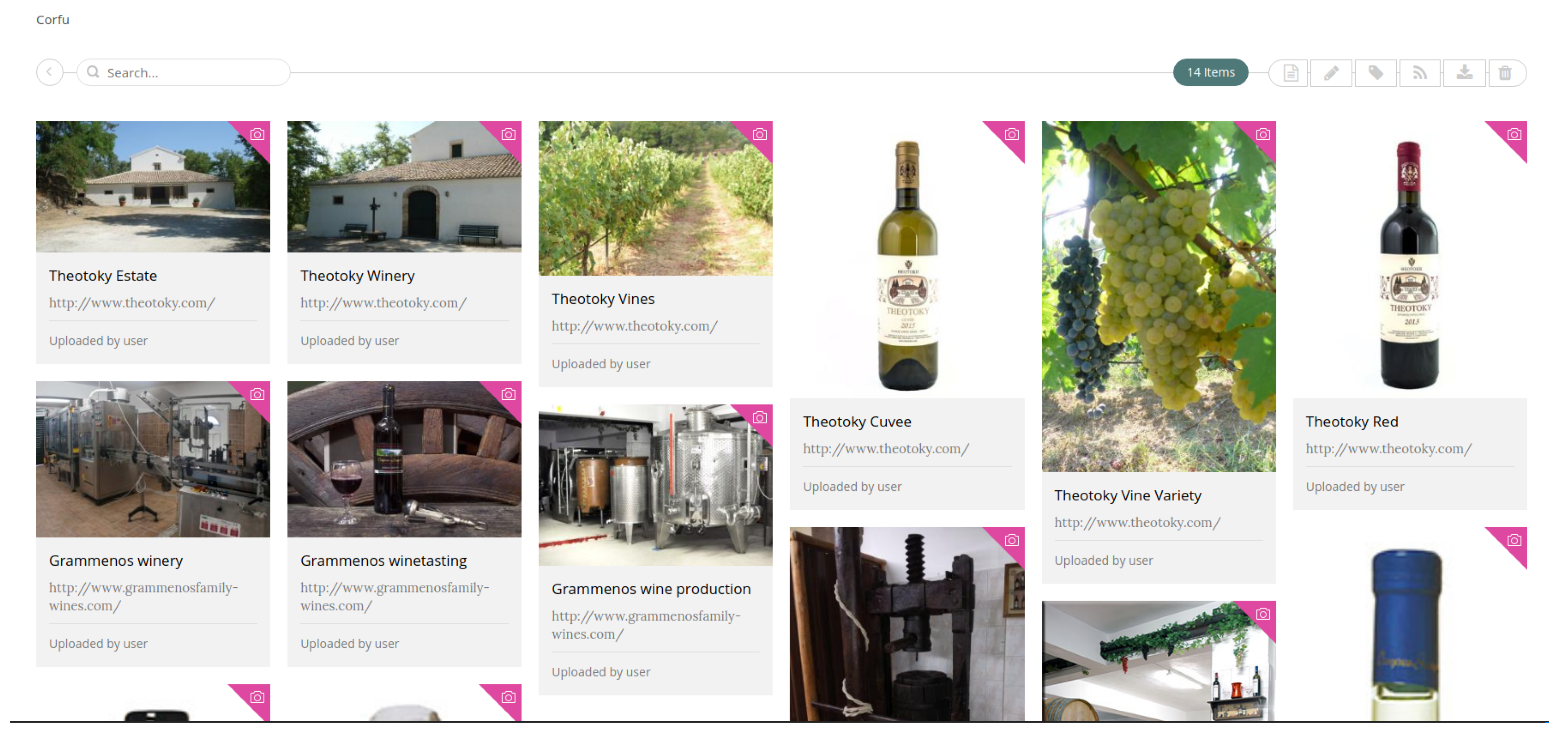
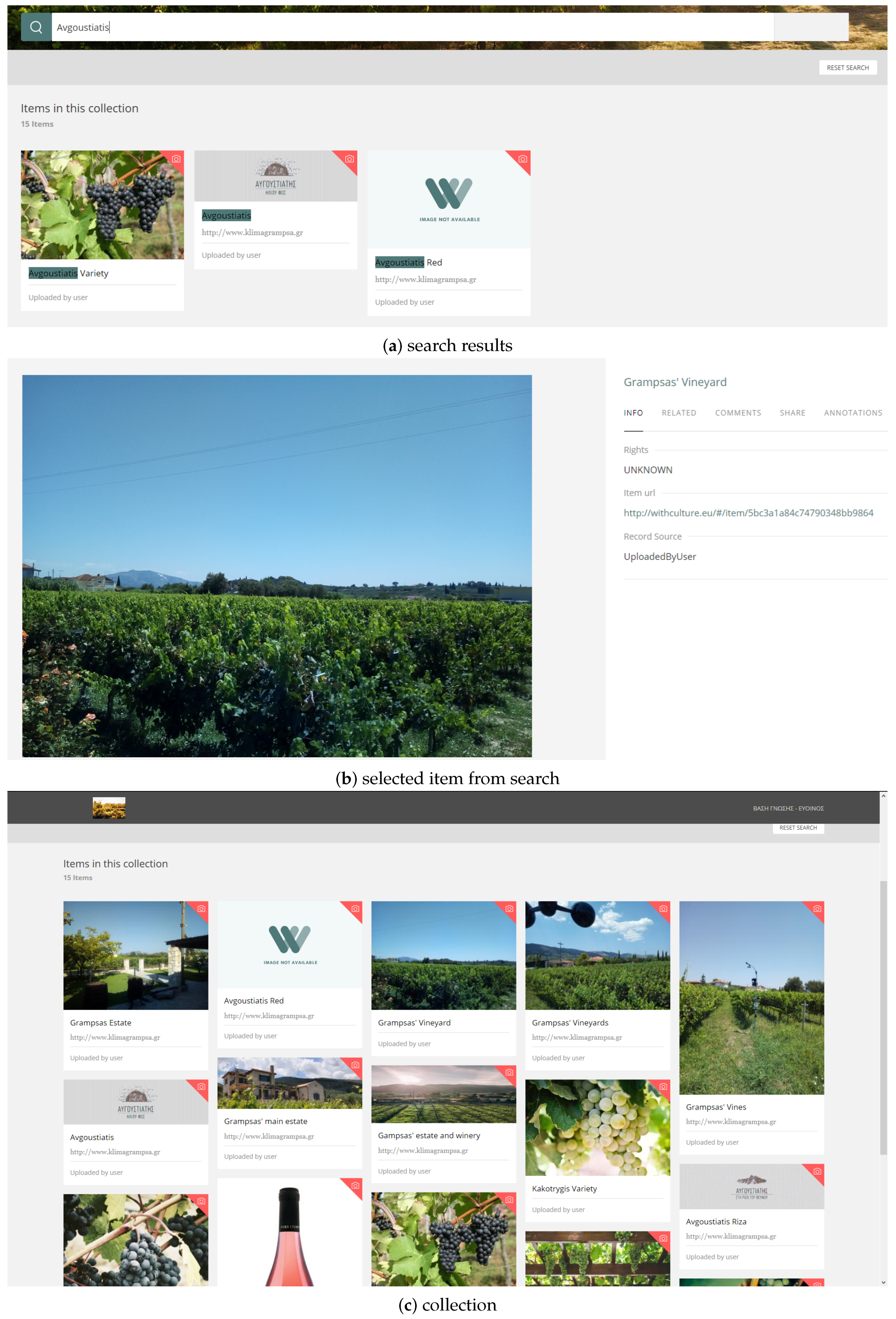
3.2. Content Search and Management
3.2.1. Content Aggregation
3.2.2. Collections and Spaces Management
| Algorithm 1 Platform’s datamodel. |
| "descriptiveData": { |
| "label": "Greek wine type", |
| "description": "This image depicts a Greek wine type |
| from the Ionian Islands geographical region", |
| "keywords": [ |
| "Greek", |
| "wine", |
| "avgoustiatis", |
| "winery" |
| ], |
| "isShownAt": "http://www.europeana.eu/api/ANgfDzTpW", |
| "isShownBy": "https://www.uvinum.co.uk/zakynthos-wine/avgoustiatis-in-the-mountains-root-2015", |
| "rdfType": "http://www.europeana.eu/schemas/edm/ProvidedCHO", |
| "country": "Greece", |
| "dclanguage": "English", |
| "dctype": "scanned image", |
| "dcrights": "Public Domain", |
| "dctermsspatial": "Zakynthos, 1999", |
| "dcformat": "jpg" |
| } |
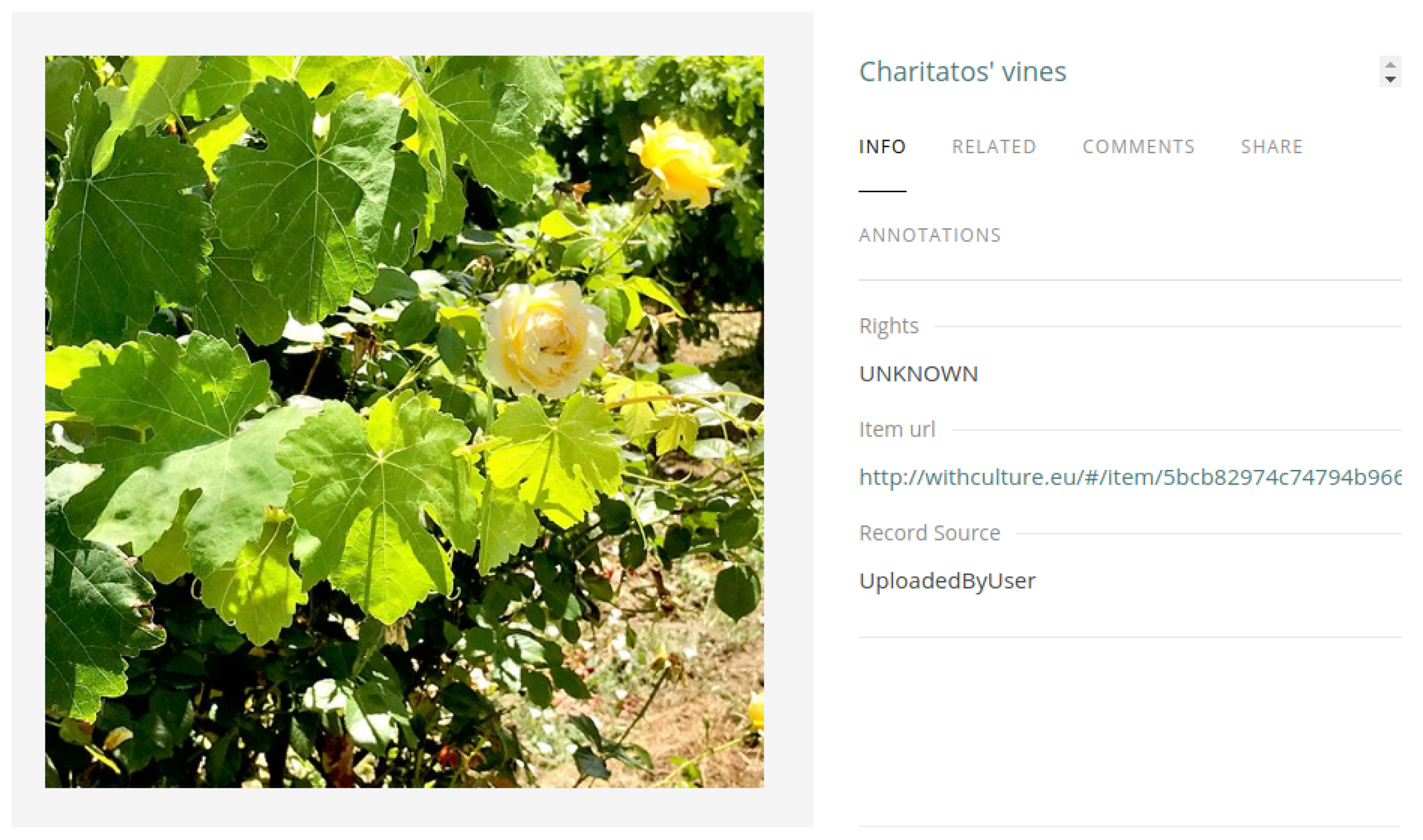
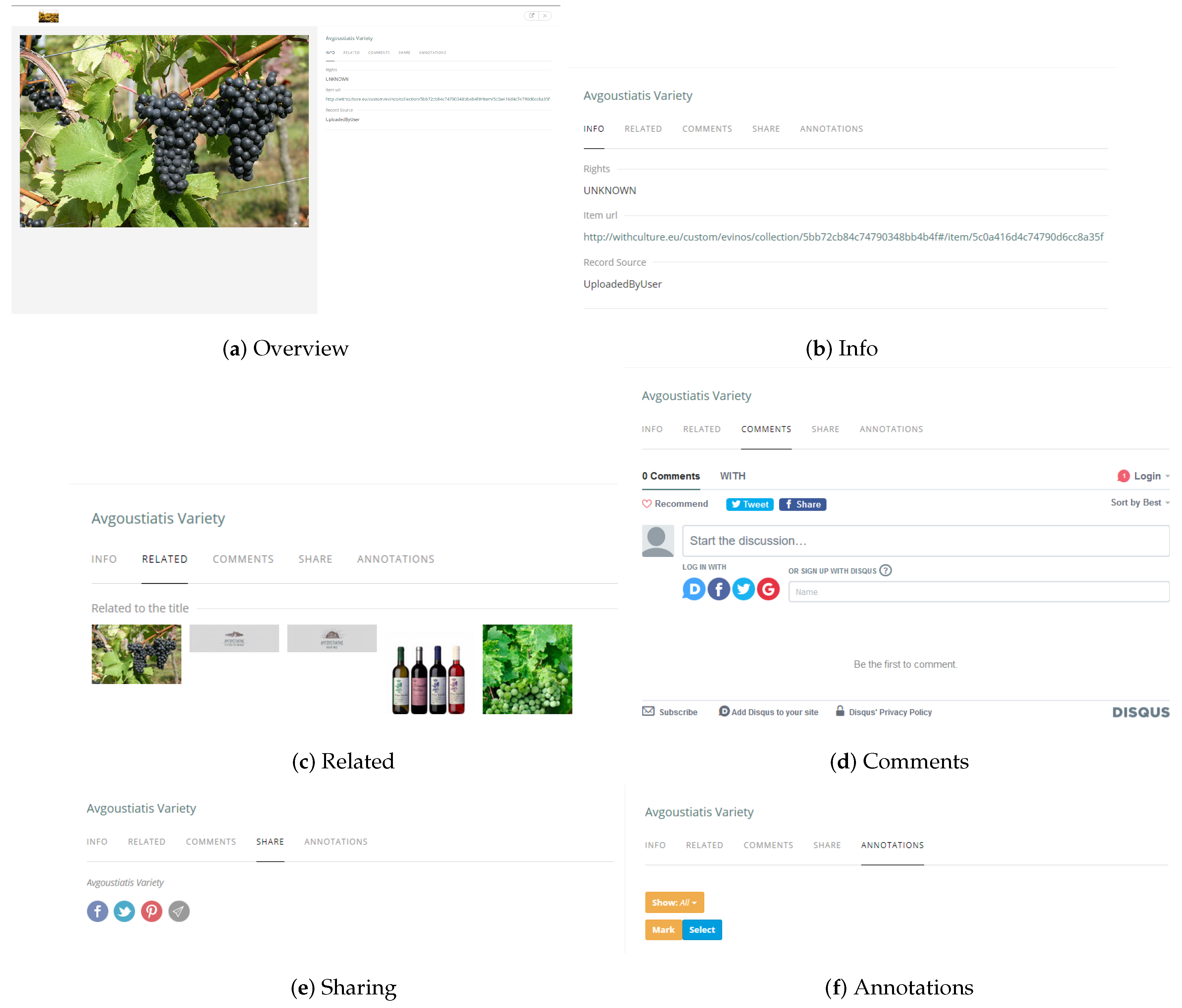
3.3. Metadata Generation and Enrichment
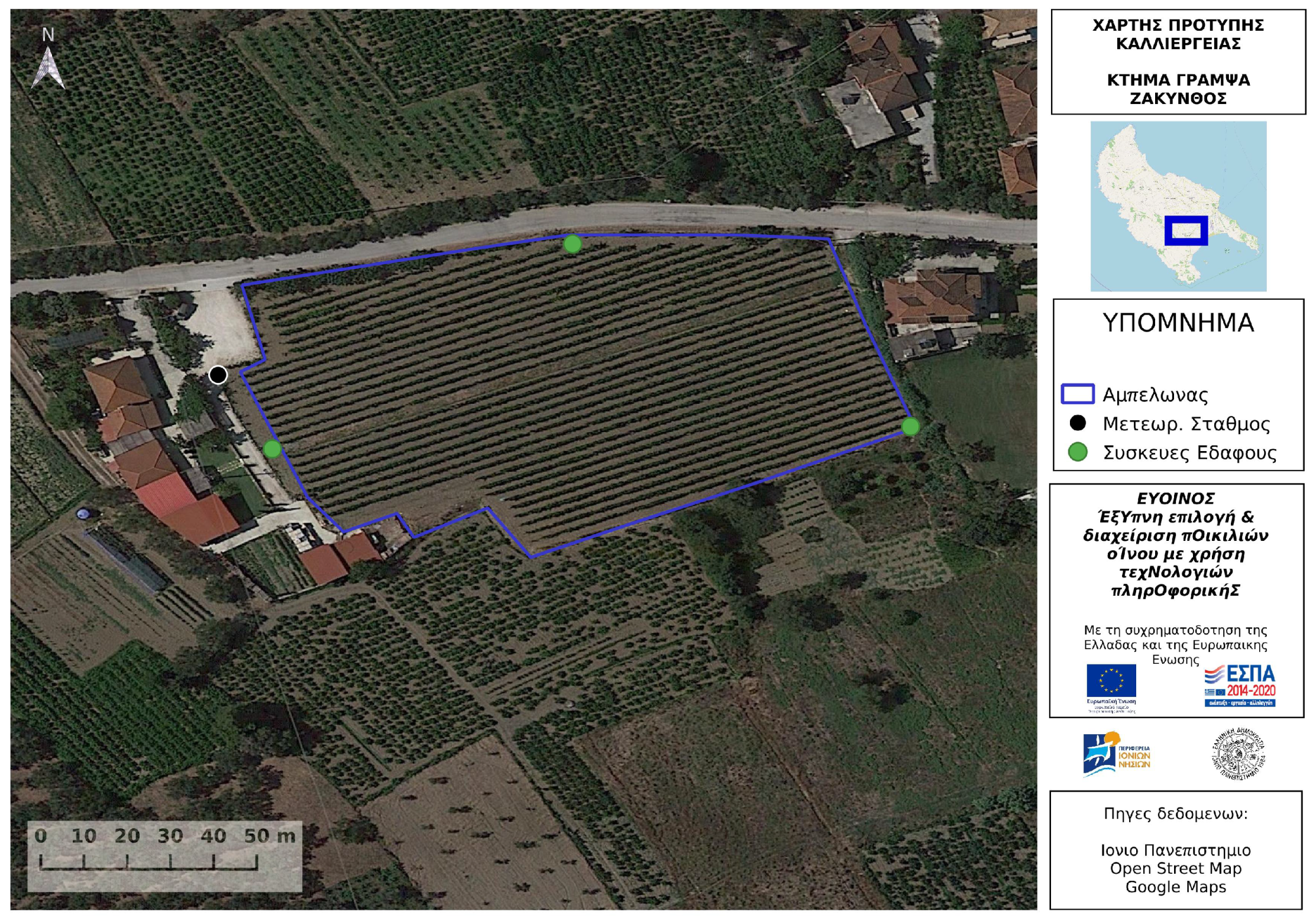
3.4. Case Study: The Zakytnhian Variety Selection
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A




References
- Liakos, K.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed]
- Wolfert, S.; Verdouw, L.G.C.; Bogaardt, M.J. Big Data in Smart Farming—A review. Agric. Syst. 2017, 153, 69–80. [Google Scholar] [CrossRef]
- Proffitt, T.; Bramley, R.; Lamb, D.; Winter, E. Precision Viticulture: A New Era in Vineyard Management and Wine Production; Winetitles: Ashford, UK, 2006. [Google Scholar]
- Bramley, R.G.V.; Hamilton, R.P. Understanding variability in winegrape production systems: 1. Within vineyard variation in yield over several vintages. Aust. J. Grape Wine Res. 2004, 10, 32–45. [Google Scholar] [CrossRef]
- Bramley, R.G.V. Understanding variability in winegrape production systems 2. Within vineyard variation in quality over several vintages. Aust. J. Grape Wine Res. 2005, 11, 33–42. [Google Scholar] [CrossRef]
- Morais, R.; Peres, E.; Boaventura-Cunha, J.; Mendes, J.; Cosme, F.; Nunes, F.M. Distributed monitoring system for precision enology of the Tawny Port wine aging process. Comput. Electron. Agric. 2018, 145, 92–104. [Google Scholar] [CrossRef]
- Canete, E.; Chen, J.; Martin, C.; Rubio, B. Smart Winery: A Real-Time Monitoring System for Structural Health and Ullage in Fino Style Wine Casks. Sensors 2018, 18, 803. [Google Scholar] [CrossRef]
- Naumowicz, T.; Freeman, R.; Kirk, H.; Dean, B.; Calsyn, M.; Liers, A.; Braendle, A.; Guilford, T.; Schiller, J. Wireless Sensor Network for habitat monitoring on Skomer Island. In Proceedings of the 35th Annual IEEE Conference on Local Computer Networks, LCN 2010, Denver, CO, USA, 10–14 october 2010; pp. 2882–2888. [Google Scholar]
- Muangprathub, J.; Boonnam, N.; Kajornkasirat, S.; Lekbangpong, N.; Wanichsombat, A.; Nillaor, P. IoT and agriculture data analysis for smart farm. Comput. Electron. Agric. 2019, 156, 467–474. [Google Scholar] [CrossRef]
- Voutos, Y.; Mylonas, P. A semantic data model for sensory spatio-temporal environmental concepts. In Proceedings of the 22nd Panhellenic Conference on Informatics, Athens, Greece, 29 November–1 December 2018. [Google Scholar]
- Borgogno-Mondino, E.; Lessio, A.; Tarricone, L.; Novello, V.; de Palma, L. A comparison between multispectral aerial and satellite imagery in precision viticulture. Precis. Agric. 2018, 19, 195–217. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Behmanesh, J.; Khalili, K. Using MARS, SVM, GEP and empirical equations for estimation of monthly mean reference evapotranspiration. Comput. Electron. Agric. 2017, 139, 103–114. [Google Scholar] [CrossRef]
- Feng, Y.; Peng, Y.; Cui, N.; Gong, D.; Zhang, K. Modeling reference evapotranspiration using extreme learning machine and generalized regression neural network only with temperature data. Comput. Electron. Agric. 2017, 136, 71–78. [Google Scholar] [CrossRef]
- Patil, A.P.; Deka, P.C. An extreme learning machine approach for modeling evapotranspiration using extrinsic inputs. Comput. Electron. Agric. 2016, 121, 385–392. [Google Scholar] [CrossRef]
- Mohammadi, K.; Shamshirband, S.; Motamedi, S.; Petkovic, D.; Hashim, R.; Gocic, M. Extreme learning machine based prediction of daily dew point temperature. Comput. Electron. Agric. 2015, 117, 214–225. [Google Scholar] [CrossRef]
- Clingeleffer, P.; Petrie, P.; Dunn, G.; Martin, S.; Krstic, M.; Welsh, M. Final Report to Grape and Wine Research & Development Corporation: Crop Control for Consistent Supply of Quality Winegrapes; CSIRO Division of Horticulture: Canberra, Australia, 2005. [Google Scholar]
- Diago, M.; Correa, C.; Millan, B.; Barreiro, P.; Valero, C.; Tardaguila, J. Grapevine Yield and Leaf Area Estimation Using Supervised Classification Methodology on RGB Images Taken under Field Conditions. Sensors 2012, 12, 16988–17006. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Pulido, F.; Gomez-Robledo, L.; Melgosa, M.; Gordillo, B.; Gonzalez-Mireta, M.; Heredia, F. Ripeness estimation of grape berries and seed by image analysis. Comput. Electron. Agric. 2012, 82, 128–133. [Google Scholar] [CrossRef]
- Usha, K.; Singh, B. Potential applications of remote sensing in horticulture—A review. Sci. Hortic. 2013, 153, 71–83. [Google Scholar] [CrossRef]
- Zhang, B.; Huang, W.; Li, J.; Zhao, C.; Fan, S.; Wu, J.; Liu, C. Principles, developments and applications of computer vision for external quality inspection of fruits and vegetables: A review. Food Res. Int. 2014, 62, 326–343. [Google Scholar] [CrossRef]
- Diago, M.; Fernandes, A.; Millan, B.; Tardaguila, J.; Melo-Pinto, P. Identification of grapevine varieties using leaf spectroscopy and partial least squares. Comput. Electron. Agric. 2013, 99, 7–13. [Google Scholar] [CrossRef]
- Ramos, P.; Prieto, F.; Montoya, E.; Oliveros, C. Automatic fruit count on coffee branches using computer vision. Comput. Electron. Agric. 2017, 137, 9–22. [Google Scholar] [CrossRef]
- Amatya, S.; Karkee, M.; Zhang, Q.; Whiting, M.D. Automated Detection of Branch Shaking Locations for Robotic Cherry Harvesting Using Machine Vision. Robotics 2017, 6, 31. [Google Scholar] [CrossRef]
- Radhika, Y.; Shashi, M. Atmospheric Temperature Prediction using Support Vector Machines. Int. J. Comput. Theory Eng. 2009, 1, 55–58. [Google Scholar] [CrossRef]
- Gill, M.K.; Asefa, T.; Kemblowski, M.W.; McKee, M. Soil moisture prediction using Support Vector Machines. JAWRA J. Am. Water Resour. Assoc. 2006, 42, 1033–1046. [Google Scholar] [CrossRef]
- Huuskonen, J.; Oksanen, T. Soil sampling with drones and augmented reality in precision agriculture. Comput. Electron. Agric. 2018, 154, 25–35. [Google Scholar] [CrossRef]
- Fuentes, S.; Hernandez-Montes, E.; Escalona, J.; Bota, J.; Viejo, C.G.; Poblete-Echeverria, C.; Tongson, E.; Medrano, H. Automated grapevine cultivar classification based on machine learning using leaf morpho-colorimetry, fractal dimension and near-infrared spectroscopy parameters. Comput. Electron. Agric. 2018, 151, 311–318. [Google Scholar] [CrossRef]
- Drosopoulos, N.; Tzouvaras, V.; Simou, N.; Christaki, A.; Stabenau, A.; Pardalis, K.; Xenikoudakis, F.; Kollias, S. A Metadata Interoperability Platform. In Museums and the Web 2012 (MW2012); Museums and the Web: San Diego, CA, USA, 2012. [Google Scholar]
- Kollia, I.; Tzouvaras, V.; Drosopoulos, N.; Stamou, G. A systemic approach for effective semantic access to cultural content. Semant. Web 2012, 3, 65–80. [Google Scholar]
- Isaac, A.; Clayphan, R. Europeana Data Primer. 2010. Available online: https://pro.europeana.eu/files/Europeana_Professional/Share_your_data/Technical_requirements/EDM_Documentation/EDM_Primer_130714.pdf (accessed on 21 April 2019).
- Isaac, A.; Charles, V. Europeana Data Model Definition. 2017. Available online: https://pro.europeana.eu/files/Europeana_Professional/Share_your_data/Technical_requirements/EDM_Documentation/EDM_Definition_v5.2.7_042016.pdf (accessed on 21 April 2019).
- Sanderson, R.; Ciccarese, P.; Young, B. Web Annotation Data Model. 2017. Available online: https://www.w3.org/TR/annotation-model/ (accessed on 21 April 2019).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Task(s) | Method(s) | Pros | Cons | Dataset(s) |
|---|---|---|---|---|---|
| [4] | Study of spatial variability in winegrape yield | Assessment of the yield growth probability through k-means | Introduction of a system of zonal vineyard management | They didn’t address the physiology of the grape | Field data from two areas in South Australia |
| [5] | Demonstrate temporal stability within-vineyard variation and winegrape quality | Geo-statistical assessment (k-means) clustering and | Justify the use of zonation on yield monitoring | Requirements for large scale sampling and analysis | Field data from two areas in South Australia |
| [6] | Investigation of behaviour models on wine aging | Deployment of a distributed monitoring system (hardware and software | Detect differences between type of wood barrels and the different storage conditions on wine aging quality | Their model produced variations due to oxidation in aging process | Measurements of environmental parameters from two wineries along with barrel dimensions |
| [11] | Investigate satellite data potential to evaluate changes in vegetation characteristics on occasional acquisitions | Investigation of spatial resolution role in radiometric features of data | Concrete correlations between grapevine physiological, reproductive and qualitative indices | Weak quantitative interpretation of mapped vigour | Aerial and mid-resolution satellite multispectral images from two growing seasons (2013 and 2014) |
| [7] | Real time monitoring system with IoT prototyping to maintain the balance between ullage and wine | Prototype embedded system to detect possible damages to barrels and to track the level of wine inside the cask | Provide a plan for tracking and assessing the suitability of the delicate wine elaboration process | Low distinctive capability | Recordings of physical and natural characteristics from IoT devices |
| [10] | Preliminary ontological scheme for environmental monitoring | Spatio-temporal ontological development | Relation between environmental factors and spatio-temporal distribution | Not deployed with field data | - |
| [8] | Automated Insular environmental monitoring | Deployment of a WSN for wildlife monitoring | Remote deployment | Not widely applicable | - |
| [9] | Optimized water supply system for crops | IoT network of sensors and software infrastructure | Automatic deployment of a monitoring system | The system is not scalable | Climatic variables gathered by a WSN |
| Work | Task(s) | Method(s) | Pros | Cons | Dataset(s) |
|---|---|---|---|---|---|
| [1] | Review of applied Machine Learning in agriculture | Presentation of a number of relevant papers with emphasis on key and unique features of popular Machine Learning models | Categorization of Machine Learning methodologies | Not related to decision making processes | forty (40) related articles |
| [12] | Equation performance of monthly mean reference evapotranspiration | Comparative analysis between empirical equations and soft computing approaches | - | - | Meteorological dataset from southwest of Asia |
| [13] | Modeling reference ET0 through ML and techniques | Implementation of temperature based ELM and GRNN models for the estimation of daily ET0 | Emphasize on the capabilities of ELM and GRNN models | Experimental data were not used | A dataset of daily meteorological variables from 6 stations of the National Climatic Centre of the China Meteorological Administration |
| [14] | Evaluation of capabilities of Extreme ML to model the process of evapotranspiration | Implementation of ANN1, LS-SVM1, ELM1 and Hargreaves equations in climatic data | Comparability between models | - | Weekly climatic data from two weather stations in India |
| [15] | Daily Dew point prediction methodology | Extreme Machine Learning | Reliable prediction techniques deployed in varied climatic conditions | Decrease of model’s performance between training and testing | 2555 days of measurements from two meteorological stations |
| [17] | Automatic yield estimation | Leaf spectroscopy and partial least squares | The model has many classification efficiencies | Data obtained from a limited number of samples | Hyperspectral images of vine leaves |
| [18] | Complete characterization of grape seed quality | Detection of morphological differences through image analysis | They produced an efficient evaluation tool | They employed a small distinctive sample | Images from one hundred berries from a specific cultivation |
| [21] | Grapevine variety identification | Automatic leaf spectroscopy classification of grapevine varieties | Their word produced robust results | Limited samples for required laboratory testing | Images from grapevines of Vitis vinifera L. |
| [22] | Automatic identification of harvestable and not harvestable fruits on a coffee branch | Object based classification based on a Machine Vision System & an Image Processing Algorithm | Appropriate tool for assessing harvest potential | Labour intensive procedure | Acquired and adjusted grape images from 1018 coffee branches |
| [23] | Branch shaking localization for automated cherry harvesting | Machine vision system for automatic cherry recognition and counting | High success rate | Time consuming procedure | Color RGB images of cherry trees from Washington, USA |
| [27] | Accurate& automated ampelographic measurements | Two types of ANN models | High accuracy rate | Requires complex processes | Morpho-colorimetric data obtained from vine leaves |
| [26] | Remote soil sampling | Drone imaging and segmentation | Novel integrated agricultural monitoring approach | Not tested in large scale | Soil data from the study area |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mylonas, P.; Voutos, Y.; Sofou, A. A Collaborative Pilot Platform for Data Annotation and Enrichment in Viticulture. Information 2019, 10, 149. https://doi.org/10.3390/info10040149
Mylonas P, Voutos Y, Sofou A. A Collaborative Pilot Platform for Data Annotation and Enrichment in Viticulture. Information. 2019; 10(4):149. https://doi.org/10.3390/info10040149
Chicago/Turabian StyleMylonas, Phivos, Yorghos Voutos, and Anastasia Sofou. 2019. "A Collaborative Pilot Platform for Data Annotation and Enrichment in Viticulture" Information 10, no. 4: 149. https://doi.org/10.3390/info10040149
APA StyleMylonas, P., Voutos, Y., & Sofou, A. (2019). A Collaborative Pilot Platform for Data Annotation and Enrichment in Viticulture. Information, 10(4), 149. https://doi.org/10.3390/info10040149