1. Introduction
Big data is regarded as a huge data set costing time beyond what we can tolerate to capture, manage, and process by normal methods [
1]. In general, big data possesses 3V characteristics (Volume/Variety/Velocity) [
2]. Volume refers to the large amount of data. Variety indicates that the types and source of data are quite different. Velocity emphasizes the speed requirements of data processing. To solve the problem, big data technique is proposed to deal with large amounts of data from various sources [
3]. Storage formats are diversified, semantic expressions vary from person to person, and numerical values are diverse, which lead to data inconsistency in big data.
From the perspective of database development, data consistency is mainly reflected in distributed systems and relational databases [
4]. Data consistency in distributed systems is different from the data consistency described in this paper. It refers to the correct and complete logical relationship between related data in relational databases [
5]. When users access the same database at the same time and operate on the same data, four things can happen: lost update, undetermined correlations, inconsistent analysis, and read fantasy [
6]. Consistency in distributed systems indicates that each copy of data is consistent after concurrent operations [
7,
8]. When one data in one node is changed, the system needs to change all the corresponding data in other nodes synchronously [
9,
10]. Since inconsistent data can lead to inconsistencies, we need to ensure that the data is consistent. For example, the creep performance of the same type material may be different because of testing errors or materials’ microdifference. The inconsistent data may cause lots of problems, especially for scientific big data. However, more research is now being done on the consistency of shared data.
From the perspective of computing strategy, data consistency is mainly reflected in the consistent hashing algorithm. The consistent hashing algorithm was proposed by Karger et al. in solving distributed cache in 1997 [
11]. The design goal of the consistent hashing algorithm is to solve the hot spot problem on the internet, which is similar to CARP (Common Access Redundancy Protocol). The consistent hashing algorithm fixes the problems that can be caused by the simple hashing algorithm used in the CARP [
12]. Therefore, DHT (Distributed Hash Table) can be applied in the P2P environment. The consistency hashing algorithm proposes four adaptive conditions that hashing algorithm should meet in the dynamic cache environment: Balance, Monotonicity, Spread, and Load [
13]. The consistent hashing algorithm basically solves the most critical problem in the P2P environment, that is, how to distribute storage and routing in the dynamic network topology [
14]. Each node only needs to maintain a small amount of information about its neighbors, and only a small number of nodes participate in the maintenance of the topology when the nodes join or exit the system. All this makes consistent hashing the first practical DHT algorithm.
From the perspective of data science, data consistency is mainly reflected in data integration. Since big data comes from various sources, its contents probably have a large difference in the format, representation, and value [
15]. More important, scientific big data contains more conflicts because of the errors from the tests. Although data integration technology provides some methods to integrate the contents from different sources into one uniform format [
16], it only solves the problem of data heterogeneity, including semantic or format heterogeneity. Data value conflict cannot be solved by data integration methods. Some researchers gave some rules for data collection to improve observer accuracy and decrease the value conflicts [
17]. Therefore, data conflict in science big data is inevitable and should be solved by other ways.
To solve the problem above, data consistency theory and a case study are proposed in the paper. The contributions of this paper can be summarized as follows.
- (1)
Data consistency theory for scientific big data is proposed.
- (2)
Consistency degree and its quantization method are proposed to measure the quality of data.
- (3)
A case study on material creep performance is operated to guide the application for other domains.
This paper is organized as follows:
Section 2 first analyzes the causes of data inconstancy and then proposes the basic theory of data consistency and its evaluation method.
Section 3 gives the results of the case study of data consistency theory on material creep testing data. The theory and application are described and discussed in
Section 4. And last,
Section 5 summarizes the paper and points out the future work.
3. Results of Case Study
Based on the data consistency theory above, the evaluation of data consistency can be implemented in different domains. Here, we take material creep testing as a case to show the application of data consistency theory.
Table 5 shows the creep testing data of T91 at 650 °C, collected from different sources.
The consistency degree of the data in the table can be calculated as follows. Firstly, deviation between two data units is calculated. Here, data unit 1 and 2 in
Table 5 are taken as an example. The calculation of the deviation between data unit 1 and 2 is shown in Equation (4).
Secondly, the consistency vector
C = (Cv, Cs, Cf) can be quantified as the defined rules (cf.
Section 2.3). Because data unit 1 and 2 come from the same source, their storage formats and semantics are the same. So, the value of
Cs and
Cf are both 9 and the value of
Cv can be obtained according to
Table 2. Then, the grade of consistency can be obtained according to
Table 4. Since 199 belongs to [0,900), the two data units meet the requirement of weak consistency. Weak consistency in scientific testing data is common. Testing data is influenced by various factors and data collected from different sources has different parameters, so the trend of similar data can be compared through collecting the same kind of material and the same performance data.
Only when stress, temperature, and rupture time are exactly the same together, two data units meet the requirement of complete consistency. The completely consistent data probably come from the same database because the test result is highly affected by a certain specimen and external environment.
When stress and temperature are the same, the deviation between data point
i and
j, that is,
dij, can be calculated. Data is inconsistent when the deviation between two data is greater than 10%, according to the rule in
Section 2.3.2.
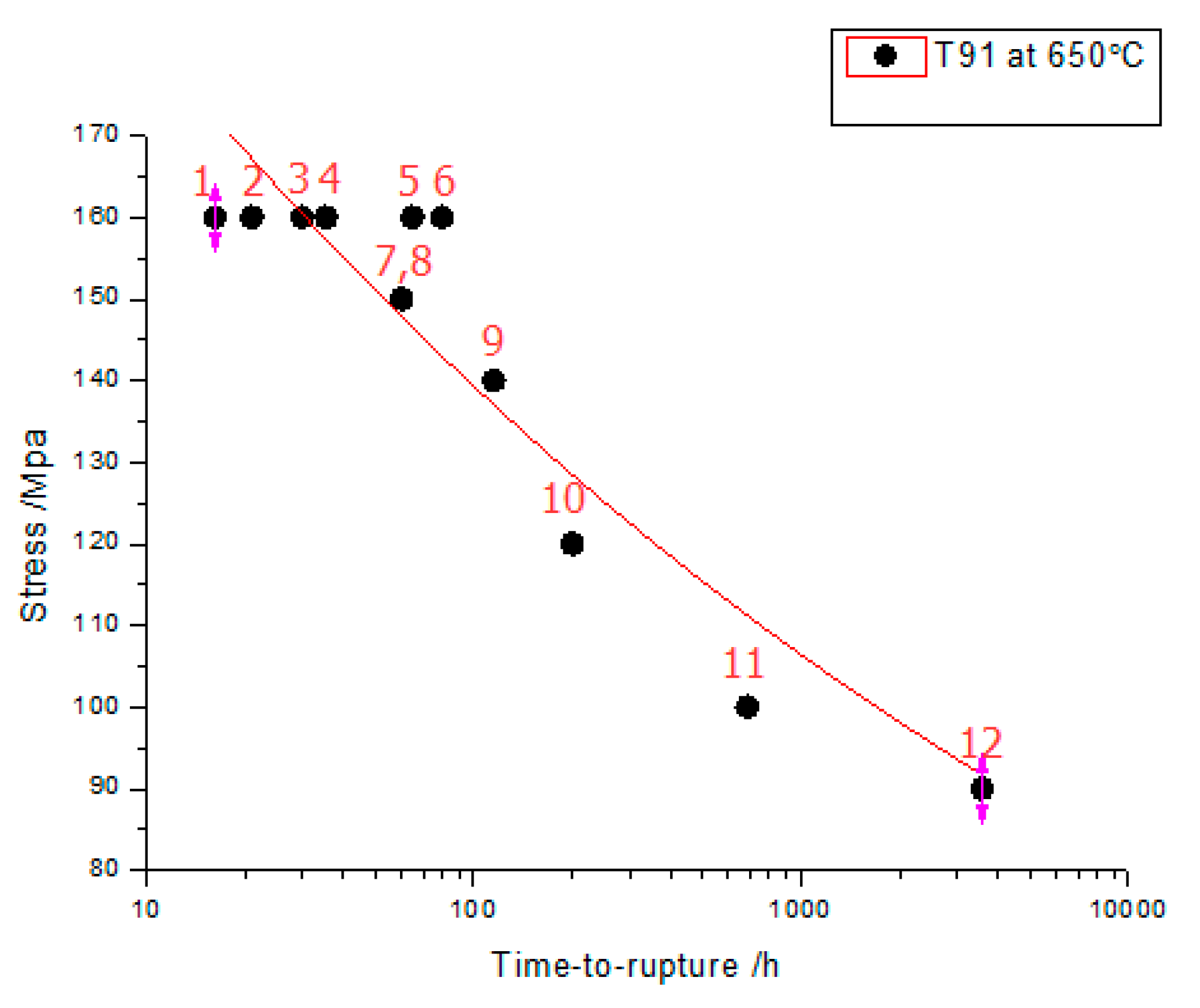
Conditional consistency refers to those which conform to the trend of creep data. Here, creep curve can be seen as the condition. The creep curve in
Figure 2 can be more intuitive to analyze data consistency.
As shown in
Figure 2, data point 3 is very close to data point 4, so they are consistent. Data point 4 is far from data point 5, so they are inconsistent. Data point 7 and data point 8 overlap and they meet the requirement of strong consistency. If the creep curve is used as a condition, the data points 9, 10, 11, and 12 distributed around the fitted curve are conditionally consistent. Conditional consistency requires that the values of two data meet predefined conditional requirements. It is associated with a particular application, and there needs to be clear knowledge on the logical relationships between data. The conditional consistency here indicates that the points 9, 10, 11, and 12 are probably four different values of the same material performance curve.
Table 6 shows the deviations between two units in
Table 5. Each pair of data units with the same testing condition is treated by Equation (2). In
Table 6, 0.10 in the first row and second column is the calculation result of Formula (4). It can be seen that the data in the table is symmetric, which is caused by the symmetric property of data consistency. Larger deviation means larger error between two data units.
Table 7 shows the consistency degree and relationships of the data in
Table 5. There are the relationships of complete consistency, strong consistency, weak consistency, and inconsistency.
The judgment of conditional consistency depends on the domain knowledge and the conditions set ahead. It reflects the degree to which the data obeys the rules.
Author Contributions
Conceptualization, P.S..; methodology, M.Z.; software, Y.C.; validation, Y.C.; formal analysis, L.D.; investigation, L.D.; resources, K.X.; data curation, K.X.; writing—original draft preparation, Y.C.; writing—review and editing, P.S. and L.D.; visualization, M.Z.; supervision, L.D.; project administration, P.S.; funding acquisition, P.S. and L.D.
Funding
This research was funded by National Key R&D Program of China, grant number 2017YFB0203703and Science and Technology Plan General Program of Beijing Municipal Education Commission, grant number KM201910037186.
Acknowledgments
Thanks to Meiling Wang at University of Science and Technology Beijing for providing abundant testing data on materials for the verification of the method.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, S.; Dragicevic, S.; Anton, F.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A.; et al. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef]
- Ishwarappa; Anuradha, J. A Brief Introduction on Big Data 5Vs Characteristics and Hadoop Technology. Procedia Comput. Sci. 2015, 48, 319–324. [Google Scholar] [CrossRef]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Fortier, P.J.; Michel, H.E. Database Systems Performance Analysis. In Computer Systems Performance Evaluation and Prediction; Digital Press; Elsevier Science: Amsterdam, The Netherlands, 2003; pp. 409–444. [Google Scholar]
- Tosun Umut. Distributed Database Design: A Case Study. Procedia Comp. Sci. 2014, 37, 447–450. [Google Scholar] [CrossRef][Green Version]
- Gao, H.; Duan, Y.; Miao, H.; Yin, Y. An Approach to Data Consistency Checking for the Dynamic Replacement of Service Process. IEEE Access 2017, 5, 11700–11711. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, J. Client-centric consistency formalization and verification for system with large-scale distributed data storage. Future Gener. Comput. Syst. 2010, 26, 1180–1188. [Google Scholar] [CrossRef]
- Chihoub, H.E. Managing Consistency for Big Data Applications: Tradeoffs and Self-Adaptiveness; Databases [cs.DB]; École Normale Supérieure de Cachan-ENS Cachan: Paris, France, 2013. (In English) [Google Scholar]
- Liu, J.; Li, J.; Li, W.; Wu, J. Rethinking big data: A review on the data quality and usage issues. ISPRS J. Photogramm. Remote Sens. 2016, 115, 134–142. [Google Scholar] [CrossRef]
- Gorton, I.; Klein, J. Distribution, data, deployment: Software architecture convergence in big data systems. IEEE Softw. 2015, 32, 78–85. [Google Scholar] [CrossRef]
- Karger, D. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web. ACM Symp. Theory Comput. 1997, 97, 654–663. [Google Scholar]
- Albanese, M.; Erbacher, R.F.; Jajodia, S.; Molinaro, C.; Persia, F.; Picariello, A.; Sperlì, G.; Subrahmanian, V.S. Recognizing unexplained behavior in network traffic. Netw. Sci. Cybersecur. 2014, 55, 39–62. [Google Scholar]
- Schutt, T.; Schintke, F.; Reinefeld, A. Structured Overlay without Consistent Hashing: Empirical Results. In Proceedings of the IEEE International Symposium on Cluster Computing and the Grid, Singapore, 16–19 May 2006. [Google Scholar]
- Flora, A.; Vincenzo, M.; Antonio, P.; Giancarl, S. Diffusion Algorithms in Multimedia Social Networks: A preliminary model. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 31 July–3 August 2017; pp. 844–851. [Google Scholar]
- Liu, D.; Xu, W.; Du, W.; Wang, F. How to Choose Appropriate Experts for Peer Review: An Intelligent Recommendation Method in a Big Data Context. Data Sci. J. 2015, 14, 16. [Google Scholar] [CrossRef]
- Pang, L.Y.; Zhong, R.Y.; Fang, J.; Huang, G.Q. Data-source interoperability service for heterogeneous information integration in ubiquitous enterprises. Adv. Eng. Inform. 2015, 29, 549–561. [Google Scholar] [CrossRef]
- Hinz, K.L.; Mcgee, H.M.; Huitema, B.E.; Dickinson, A.M.; Van Enk, R.A. Observer accuracy and behavior analysis: Data collection procedures on hand hygiene compliance in a neurovascular unit. Am. J. Infect. Control 2014, 42, 1067–1073. [Google Scholar] [CrossRef]
- Laure, E.; Vitlacil, D. Data storage and management for global research data infrastructures—Status and perspectives. Data Sci. J. 2013, 12, GRDI37–GRDI42. [Google Scholar] [CrossRef]
- Jiang, D. The electronic data and retrieval of the secret history of the mongols. Data Sci. J. 2007, 6, S393–S399. [Google Scholar] [CrossRef]
- Aswathy, R.K.; Mathew, S. On different forms of self similarity. Chaos Solitons Fractals 2016, 87, 102–108. [Google Scholar] [CrossRef]
- Finney, K. Managing antarctic data-a practical use case. Data Sci. J. 2015, 13, PDA8–PDA14. [Google Scholar] [CrossRef]
- Martínez-Rocamora, A.; Solís-Guzmán, J.; Marrero, M. LCA databases focused on construction materials: A review. Renew. Sustain. Energy Rev. 2016, 58, 565–573. [Google Scholar] [CrossRef]
- Yao, T.; Kong, X.; Fu, H.; Tian, Q. Semantic consistency hashing for cross-modal retrieval. Neurocomputing 2014, 193, 250–259. [Google Scholar] [CrossRef]
- Thorsen, H.V. Computer-Implemented Control of Access to Atomic Data Items. U.S. Patent 6052688A, 18 April 2000. [Google Scholar]
- Yang, S.; Ling, X.; Zheng, Y.; Ma, R. Creep life analysis by an energy model of small punch creep test. Mater. Des. 2016, 91, 98–103. [Google Scholar] [CrossRef]
- Beliakov, G.; Pagola, M.; Wilkin, T. Vector valued similarity measures for Atanassov’s intuitionistic fuzzy sets. Inf. Sci. 2016, 280, 352–367. [Google Scholar] [CrossRef]
- He, Y.; Xu, M.; Chen, X. Distance-based relative orbital elements determination for formation flying system. Acta Astronaut. 2016, 118, 109–122. [Google Scholar] [CrossRef]
- Li, P.F.; Zhu, Q.M.; Zhou, G.D. Using compositional semantics and discourse consistency to improve Chinese trigger identification. Inf. Process. Manag. 2014, 50, 399–415. [Google Scholar] [CrossRef]
- WordNet. Available online: https://wordnet.princeton.edu (accessed on 8 April 2019).
- Tongyici Cilin (Extended). Available online: http://www.bigcilin.com/browser/ (accessed on 8 April 2019).
- Vera-Baquero, A.; Colomo-Palacios, R.; Molloy, O. Real-time business activity monitoring and analysis of process performance on big-data domains. Telemat. Inf. 2016, 33, 793–807. [Google Scholar] [CrossRef]
- Yurechko, M.; Schroer, C.; Wedemeyer, O.; Skrypnik, A.; Konys, J. Creep-to-rupture of 9% Cr steel T91 in air and oxygen-controlled lead at 650 °C. In Proceedings of the NuMat 2010 Conference, Karlsruhe, Germany, 4–7 October 2010. [Google Scholar]
- NIMS Database. Available online: https://smds.nims.go.jp/creep/index_en.html (accessed on 8 April 2019).
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}