Es-Tacotron2: Multi-Task Tacotron 2 with Pre-Trained Estimated Network for Reducing the Over-Smoothness Problem

Abstract
:
1. Introduction
- We propose the Es-Network, which is an unsupervised network that learns the general speech features from some target speech. Then, we describe the importance of learning individual features in speech synthesis.
- We propose a model called Es-Tacotron2, which combines the Es-Network with Tacotron 2, and set the learning of the estimated residual of the mel spectrogram as the third task of Tacotron 2. Compared with original Tacotron 2, the synthesized speech of Es-Tacotron2 contains more details, and it achieved 67.5% preference in a mean opinion score (MOS) test.
2. Related Work
2.1. End-to-End Speech Synthesis
2.2. Multi-Task Learning
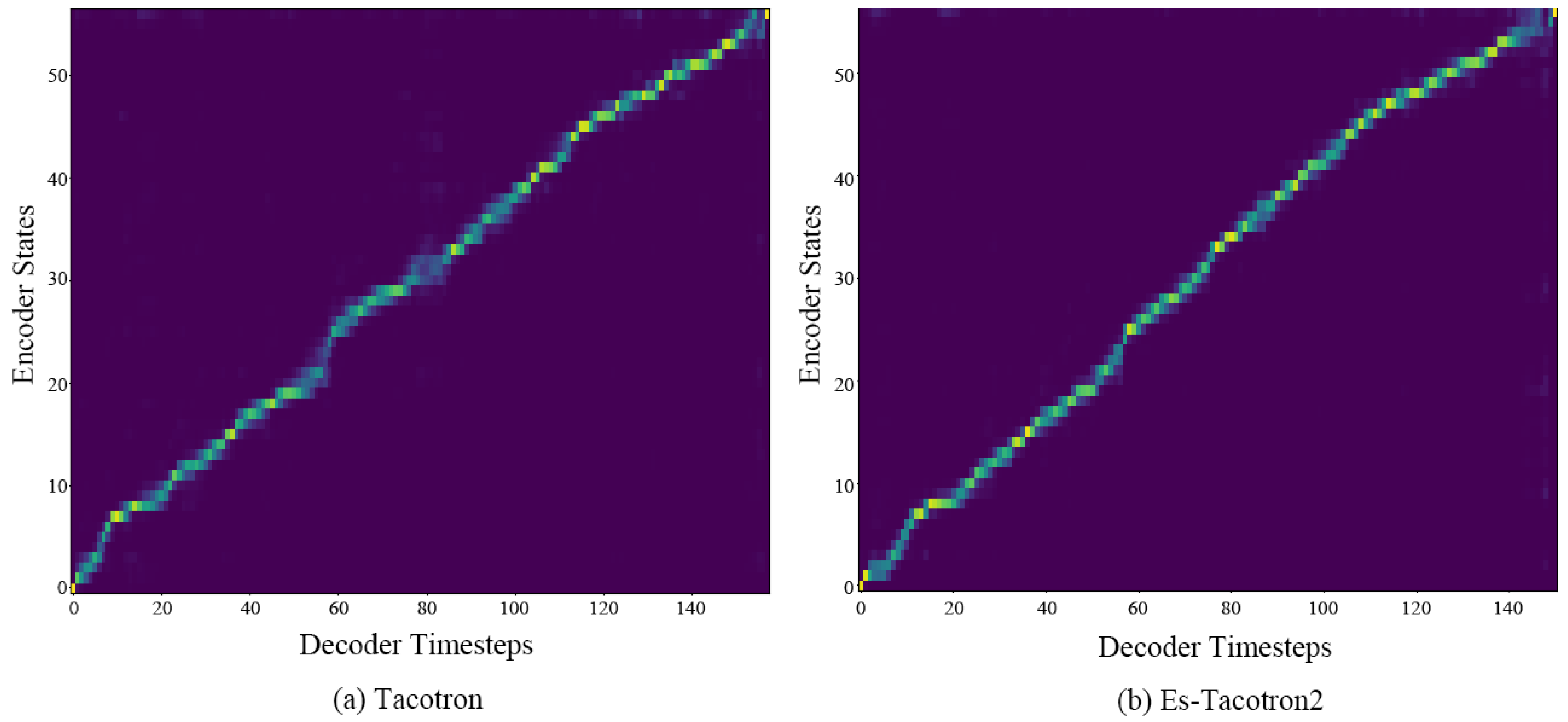
2.3. Attention Mechanism
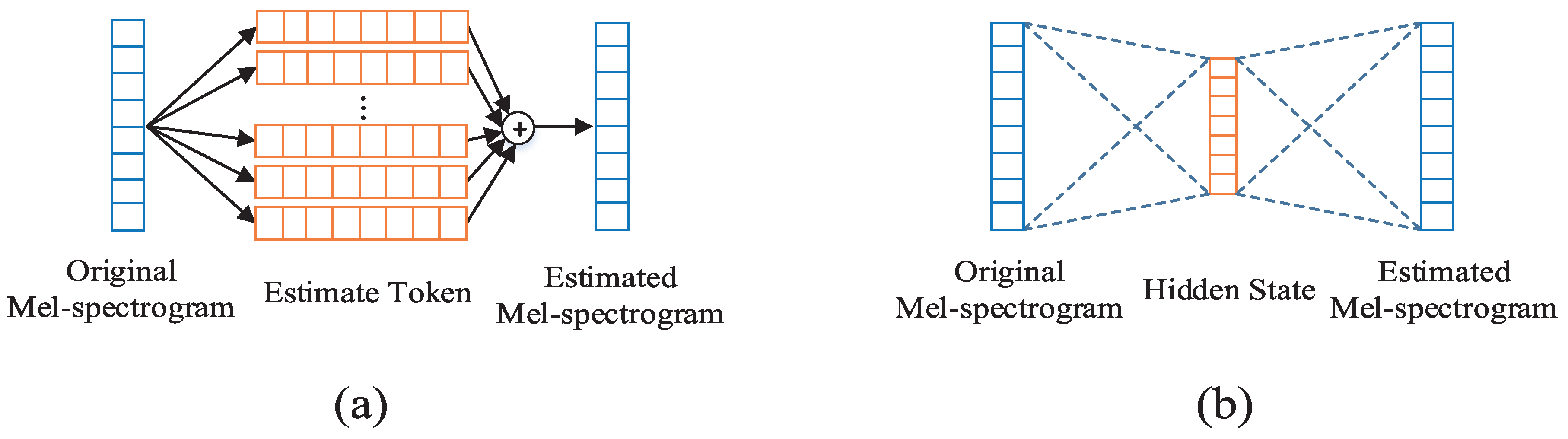
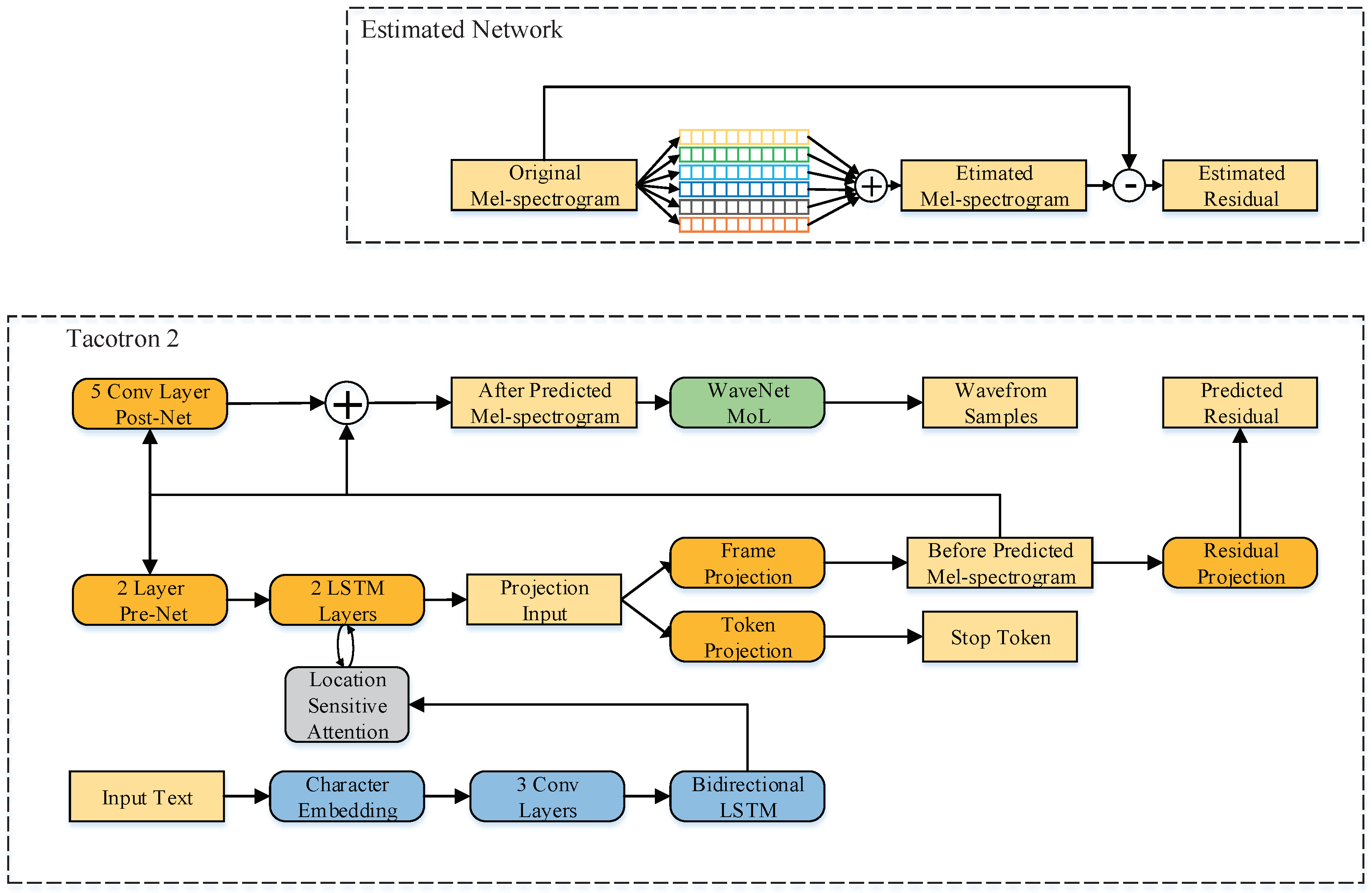
3. Proposed Method
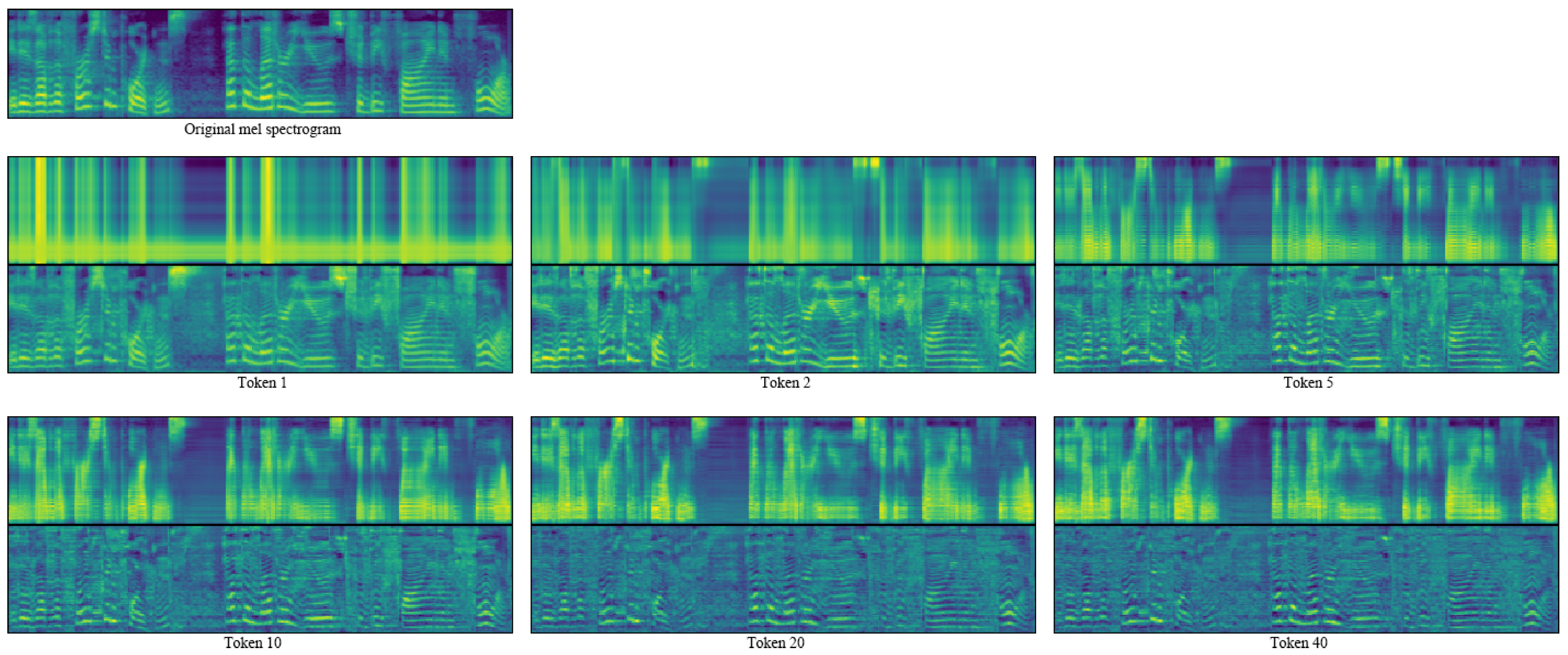
3.1. Estimated Network
3.2. Multi-Task Tacotron 2 with Pre-Trained Estimated Network
4. Experience
4.1. Initialization
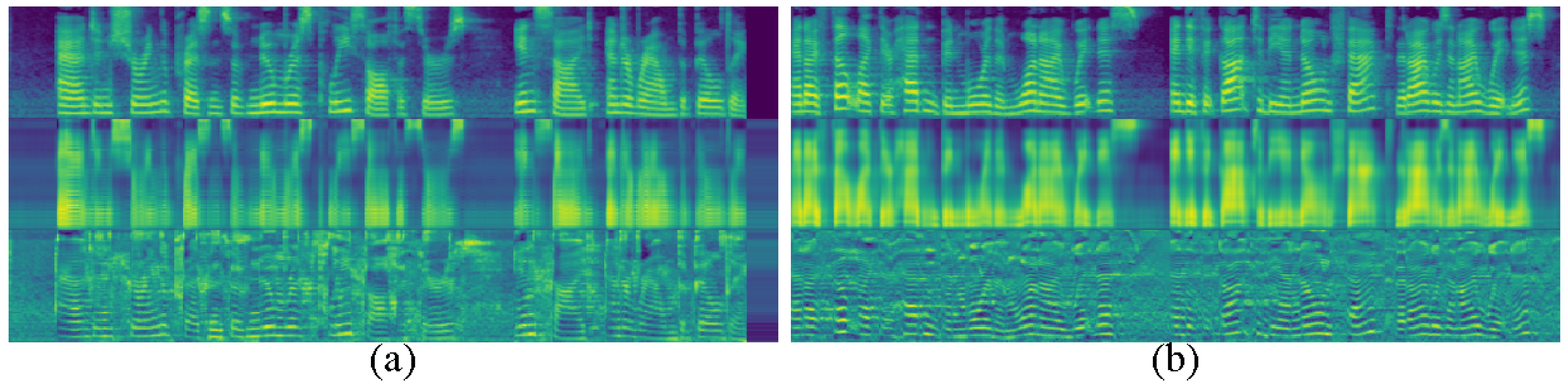
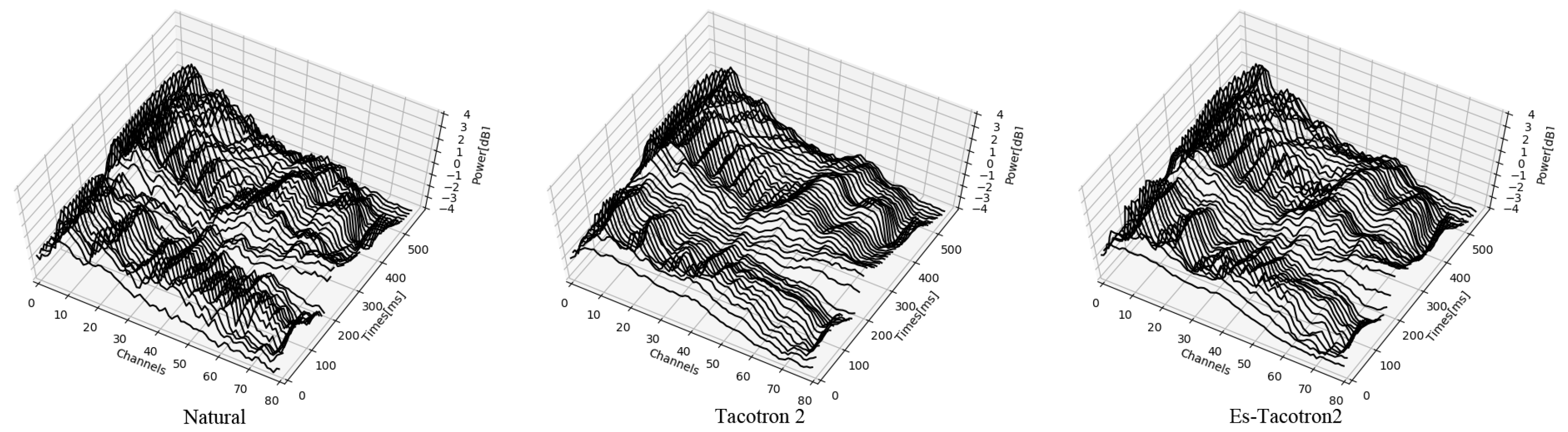
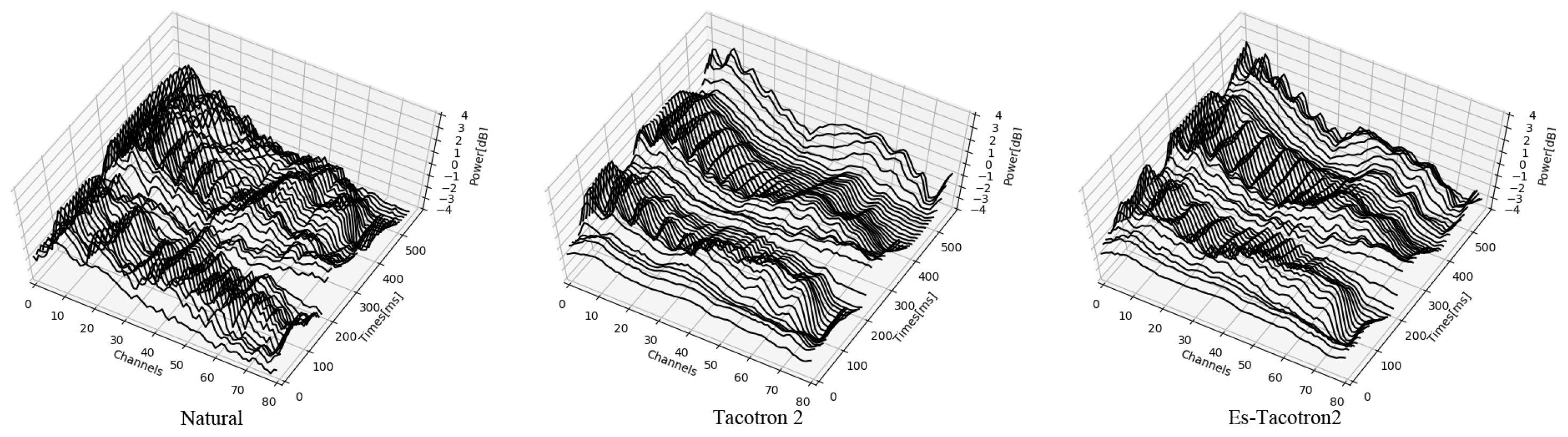
4.2. Objective Evaluation
4.3. Subjective Evaluation
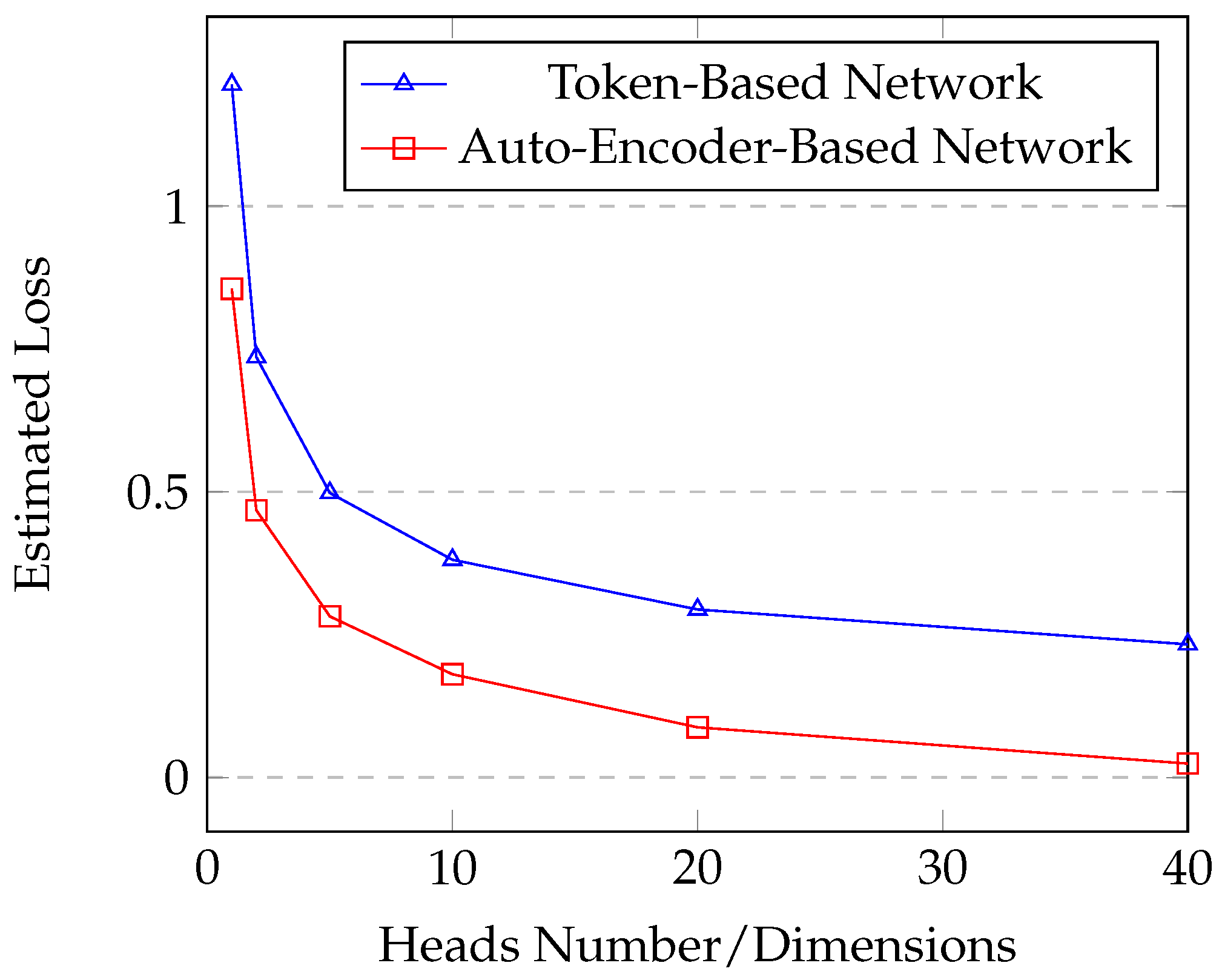
4.4. Effect of Heads Number n of the Es-Network
5. Conclusion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Skerry-Ryan, R.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. Proc. Interspeech 2017. [Google Scholar] [CrossRef]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 12–17 May 2018; pp. 4779–4783. [Google Scholar] [CrossRef]
- Nguyen, G.N.; Phung, T.N. Reducing over-smoothness in HMM-based speech synthesis using exemplar-based voice conversion. EURASIP J. Audio Speech Music Proc. 2017, 2017, 14. [Google Scholar] [CrossRef]
- Toda, T.; Black, A.W.; Tokuda, K. Spectral conversion based on maximum likelihood estimation considering global variance of converted parameter. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’05), Philadelphia, PA, USA, 23–23 March 2005; Volume 1, pp. I-9–I-12. [Google Scholar]
- Toda, T.; Tokuda, K. A speech parameter generation algorithm considering global variance for HMM-based speech synthesis. IEICE Trans. Inf. Syst. 2007, 90, 816–824. [Google Scholar] [CrossRef]
- Nghia, P.T.; Van Tao, N.; Huong, P.T.M.; Diep, N.T.B.; Hien, P.T.T. A Measure of Smoothness in Synthesized Speech. REV J. Electr. Commun. 2016, 6. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Michelsanti, D.; Tan, Z.H. Conditional Generative Adversarial Networks for Speech Enhancement and Noise-Robust Speaker Verification. arXiv 2017, arXiv:1709.01703. [Google Scholar]
- Sheng, L.; Pavlovskiy, E.N. Reducing over-smoothness in speech synthesis using Generative Adversarial Networks. arXiv 2018, arXiv:1810.10989. [Google Scholar]
- Donahue, C.; McAuley, J.; Puckette, M. Adversarial Audio Synthesis. arXiv 2018, arXiv:1802.04208. [Google Scholar]
- Van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Arik, S.O.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Ng, A.; Raiman, J.; et al. Deep Voice: Real-time Neural Text-to-Speech. arXiv 2017, arXiv:1702.07825. [Google Scholar]
- Gibiansky, A.; Arik, S.; Diamos, G.; Miller, J.; Peng, K.; Ping, W.; Raiman, J.; Zhou, Y. Deep Voice 2: Multi-Speaker Neural Text-to-Speech. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 2962–2970. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning. arXiv 2017, arXiv:1710.07654. [Google Scholar]
- Bradbury, J.; Merity, S.; Xiong, C.; Socher, R. Quasi-Recurrent Neural Networks. arXiv 2016, arXiv:1611.01576. [Google Scholar]
- Sotelo, J.; Mehri, S.; Kumar, K.; Santos, J.F.; Kastner, K.; Courville, A.; Bengio, Y. Char2wav: End-to-end speech synthesis. In Proceedings of the ICLR 2017 Workshop, Toulon, France, 24–26 April 2017. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Gu, Y.; Kang, Y. Multi-task WaveNet: A Multi-task Generative Model for Statistical Parametric Speech Synthesis without Fundamental Frequency Conditions. arXiv 2018, arXiv:1806.08619. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3104–3112. [Google Scholar]
- Gray, R. Vector quantization. IEEE ASSP Mag. 1984, 1, 4–29. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vocoder | Tacotron 2 | Es-Tacotron2 | N/P |
|---|---|---|---|
| Griffin-Lim | 14.0 | 67.5 | 18.5 |
| WaveNet | 18.5 | 33.5 | 48.0 |
| Heads Number | aCE | aCos | aVar | ||
|---|---|---|---|---|---|
| Es-Spec | Es-Res | Es-Spec | Es-Res | ||
| 1 | 28.76 | 8.78 | 0.7341 | 0.3741 | |
| 2 | 25.79 | 9.95 | 0.8519 | 0.2441 | |
| 5 | 24.41 | 10.68 | 0.8916 | 0.1769 | |
| 10 | 23.46 | 11.15 | 0.9109 | 0.1477 | |
| 20 | 22.85 | 11.50 | 0.9212 | 0.1250 | |
| 40 | 22.50 | 11.91 | 0.9345 | 0.0997 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zheng, J. Es-Tacotron2: Multi-Task Tacotron 2 with Pre-Trained Estimated Network for Reducing the Over-Smoothness Problem. Information 2019, 10, 131. https://doi.org/10.3390/info10040131
Liu Y, Zheng J. Es-Tacotron2: Multi-Task Tacotron 2 with Pre-Trained Estimated Network for Reducing the Over-Smoothness Problem. Information. 2019; 10(4):131. https://doi.org/10.3390/info10040131
Chicago/Turabian StyleLiu, Yifan, and Jin Zheng. 2019. "Es-Tacotron2: Multi-Task Tacotron 2 with Pre-Trained Estimated Network for Reducing the Over-Smoothness Problem" Information 10, no. 4: 131. https://doi.org/10.3390/info10040131
APA StyleLiu, Y., & Zheng, J. (2019). Es-Tacotron2: Multi-Task Tacotron 2 with Pre-Trained Estimated Network for Reducing the Over-Smoothness Problem. Information, 10(4), 131. https://doi.org/10.3390/info10040131