Combined Recommendation Algorithm Based on Improved Similarity and Forgetting Curve


Abstract
1. Introduction
2. Materials and Methods
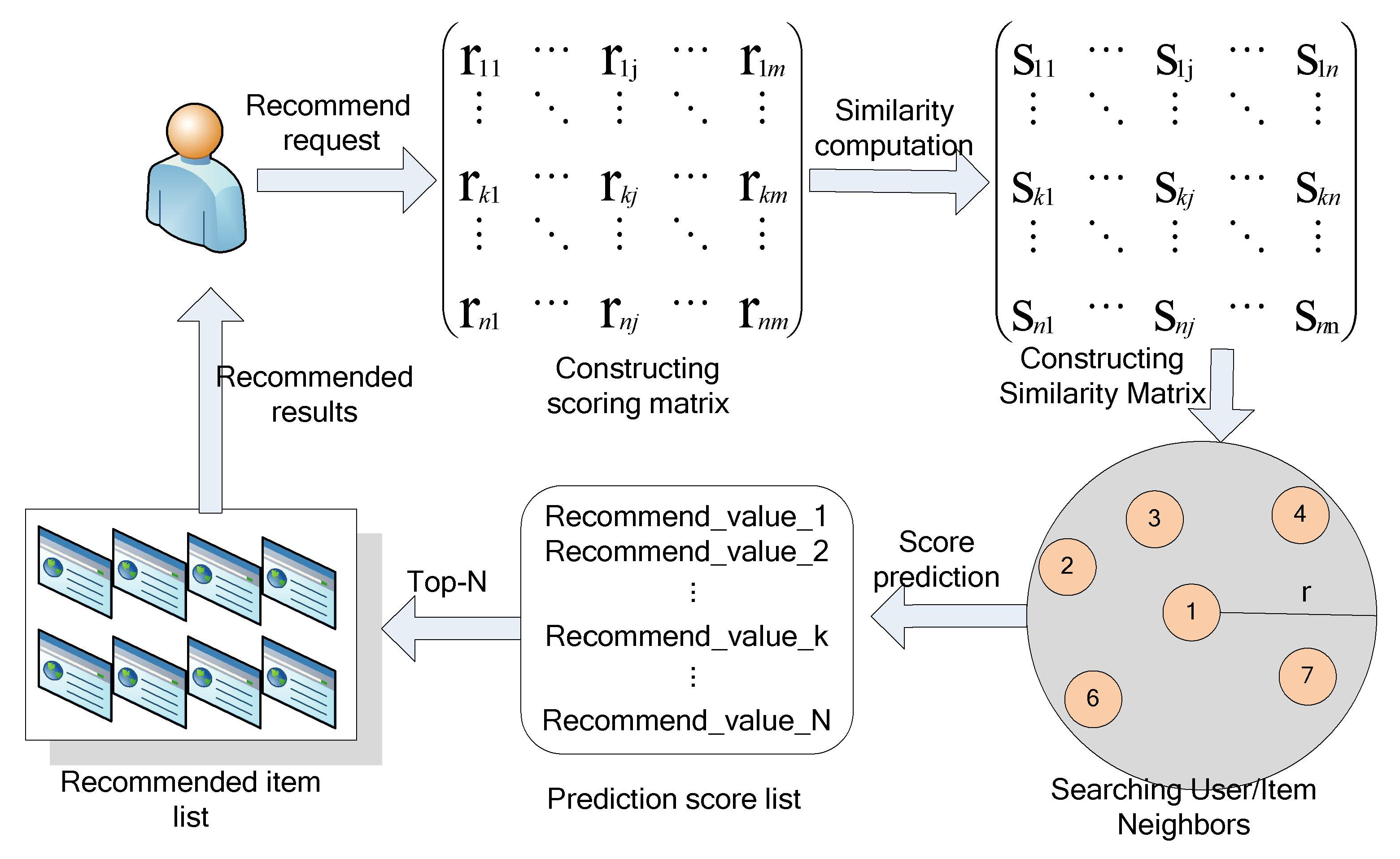
2.1. Collaborative Filtering Algorithm Based on Pearson
2.2. Recommendation Algorithm Based on Improved Ebbinghaus Forgetting Curve
2.2.1. Recommendation Considering Time
2.2.2. Correction of Ebbinghaus Forgetting Curve
2.2.3. Improved Recommendation Algorithm
2.3. Combined Recommendations of Improved Similarity and Forgetting Curve
- (1)
- The similarity calculation is enhanced by two methods respectively, and the recommendation results based on the improved similarity of the user are more accurate than the effect based on the time effect. Therefore, under the condition of sparse data, the improved similarity can more accurately match the correlation among users, so it is more appropriate to use improved user similarity in similarity calculations.
- (2)
- For predicting user scores, on the basis of traditional similarity, the historical score data of the nearest neighbor of the target user is processed based on time influence, so the score is more in correspondence with the interest of the user’s score, and effectively enhances the recommendation effect.
3. Results and Discussion
3.1. Resutls of the Improved Similarity Recommendation Algorithm
3.2. Results of the Improved Ebbinghaus Forgetting Curves
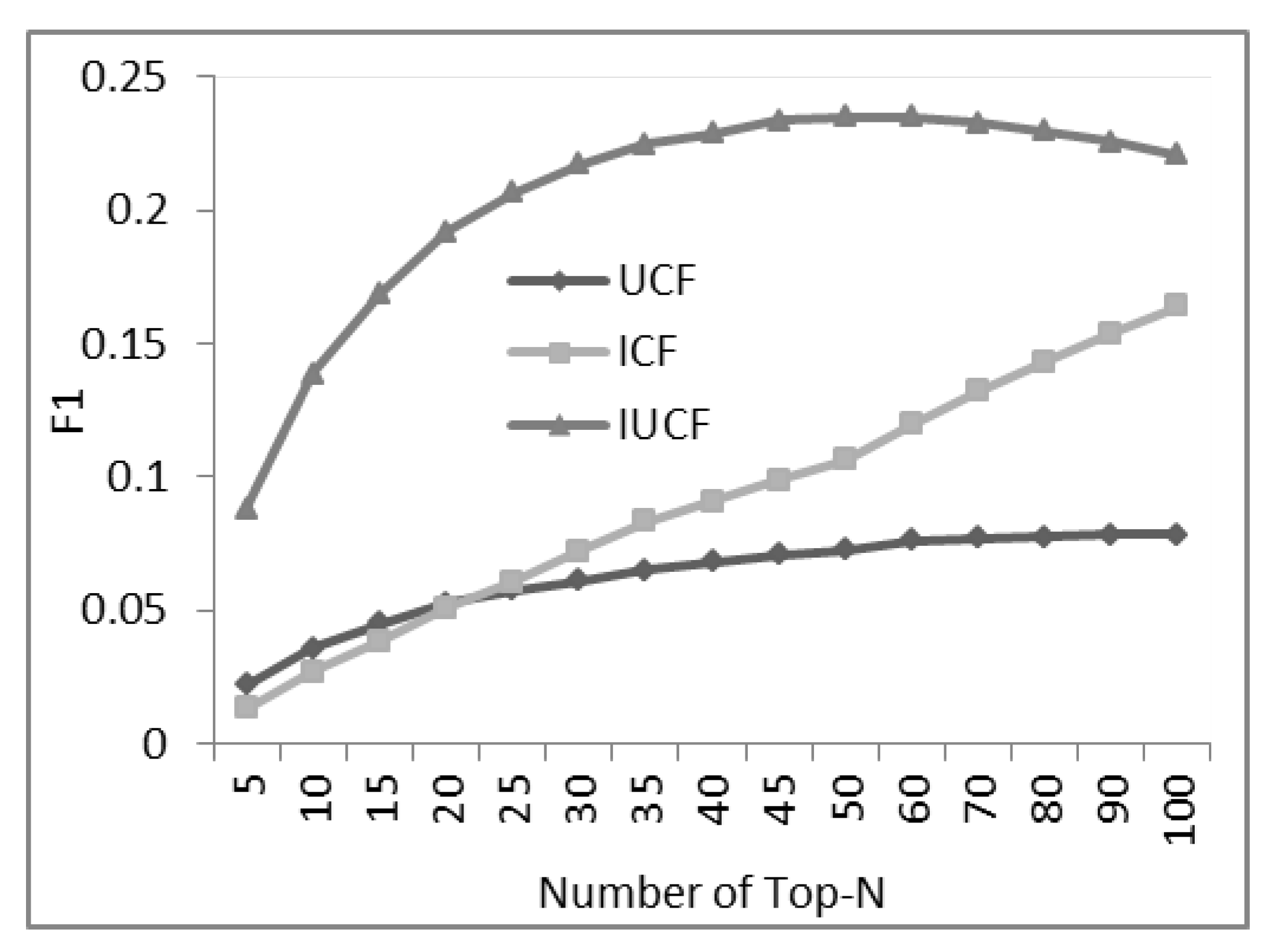
3.3. Results of the Combined Recommendation Algorithm
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kitts, B.; Freed, D.; Vrieze, M. A fast promotion tunable customer-item recommendation method based on conditionally independent probabilities. In Proceedings of the Second Annual International Conference on Knowledge Discovery in Data, KDD ’00, Boston, MA, USA, 20–23 August 2000; pp. 437–446. [Google Scholar]
- Jing, N.; Wang, J.; Xu, H.; Bian, Y. Friend Recommendation Algorithm based on User Relations in Social Networks. Chin. J. Manag. Sci. 2017, 25, 164–171. [Google Scholar]
- Huang, Z.; Zhang, J.; Tian, C.; Sun, S.; Xiang, Y. Survey on Learning-to-Rank Based Recommendation Algorithms. J. Softw. 2016, 27, 691–713. [Google Scholar]
- Su, Y.; Liu, J.; Guo, Q. Personalized Recommendation Algorithm by Considering the Negative Scores. Oper. Res. Manag. Sci. 2012, 21, 17–22. [Google Scholar]
- Wang, W.; Wang, H.; Meng, Y. The collaborative filtering recommendation based on sentiment analysis of online reviews. Syst. Eng. Theory Pract. 2014, 34, 3238–3249. [Google Scholar]
- Hu, R.; Yang, D.; Qi, R. Recommended Trust Evaluation Model in Mobile Commerce Based on Combination Evaluation Model. Oper. Res. Manag. Sci. 2010, 19, 85–93. [Google Scholar]
- Li, C.; Liang, C.; Yang, S. Sparsity Problem in Collaborative Filtering: A Classification. J. Ind. Eng. Eng. Manag. 2011, 25, 94–101. [Google Scholar]
- Deng, X.; Jin, C.; Han, J.C.; Higuchi, Y. Improved collaborative filtering model based on context clustering and user ranking. Syst. Eng. Theory Pract. 2013, 33, 2945–2953. [Google Scholar]
- Ren, X.; Song, M.; Song, J. Point-of-Interest Recommendation Based on the User Check-in Behavior. Chin. J. Comput. 2016, 39, 1–25. [Google Scholar]
- Qian, X.; Feng, H.; Zhao, G.; Mei, T. Personalized recommendation combining user interest and social circle. IEEE Trans. Knowl. Data Eng. 2014, 26, 1763–1777. [Google Scholar] [CrossRef]
- Lian, D.; Zhao, C.; Xie, X.; et al. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA, 24–27 August 2014; pp. 831–840. [Google Scholar]
- Zhu, G.; Zhou, L. Hybrid recommendation based on forgetting curve and domain nearest neighbor. J. Manag. Sci. China 2012, 15, 55–64. [Google Scholar]
- Cui, X. Hybrid recommendation based on functional network. Syst. Eng. Theory Pract. 2014, 34, 1034–1042. [Google Scholar]
- Xu, H.; Wu, X.; Li, X.; Yan, B. Comparison Study of Internet Recommendation System. J. Softw. 2009, 20, 350–362. [Google Scholar] [CrossRef]
- Yu, H.; Li, Z. A Collaborative Filtering Method Based on the Forgetting Curve. In Proceedings of the International Conference on Web Information Systems and Mining, WISM 2010, Sanya, China, 23–24 October 2010; pp. 183–187. [Google Scholar]
- Yin, G.; Cui, X.; Ma, Z. Forgetting curve-based collaborative filtering recommendation model. J. Harbin Eng. Univ. 2012, 33, 85–90. [Google Scholar]
- Wang, G.; Liu, H. Survey of personalized recommendation system. Comput. Eng. Appl. 2012, 7, 66–76. [Google Scholar]
- Resnick, P.; Varian, H.R. Recommender Systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Deshpande, M.; Karypis, G. Item-Based Top-N Recommendation Algorithms. ACM Trans. Inf. Syst. 2004, 22, 143–177. [Google Scholar] [CrossRef]
- Sawar, B.; Kkarypis, G.; Konsan, J.A.; Riedl, J. Item-Based Collaborative Filtering Recommendation algorithms. In Proceedings of the Hypermedia Track of the 10th International World Wide Web Conference, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Zhang, Y.; Liu, Y. A Collaborative Filtering Algorithm Based on Time Period Partition. In Proceedings of the Third International Symposium on Intelligent Information Technology and Security Informatics, Jinggangshan, China, 2–4 April 2010; pp. 777–780. [Google Scholar]
- Ding, Y.; Li, X. Time weight collaborative filtering. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October–5 November 2005; pp. 485–492. [Google Scholar]
- Töscher, A.; Jahrer, M.; Bell, R.M. The big chaos solution to the Netflix prize. 2009. Available online: https://www.netflixprize.com/assets/GrandPrize2009_BPC_BigChaos.pdf (accessed on 6 April 2019).
- Lu, Z.; Agarwal, D.; Dhillon, I.S. A spatio-temporal approach to collaborative filtering. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 13–20. [Google Scholar]
- Lee, T.Q.; Park, Y.; Park, Y.T. A time-based approach to effective recommender systems using implicit feedback. Expert Syst. Appl. 2008, 34, 3055–3062. [Google Scholar] [CrossRef]
- Ren, L. A Collaborative Recommendation Algorithm in Combination with Score Time Characteristic. Comput. Appl. Softw. 2015, 32, 112–115. [Google Scholar]
- Yu, H.; Li, Z. A collaborative filtering recommendation algorithm based on forgetting curve. J. Nanjing Univ. Nat. Sci. 2010, 46, 520–527. [Google Scholar]
- Ebbinghaus, H. Memory: A Contribution to Experimental Psychology. Ann. Neurosci. 2013, 20, 155–156. [Google Scholar] [CrossRef]
- Margaris, D.; Vassilakis, C. Pruning and aging for user histories in collaborative filtering. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016. [Google Scholar]
- Vaz, P.C.; Ribeiro, R.; Matos, D.M. Understanding temporal dynamics of ratings in the book recommendation scenario. In Proceedings of the ISDOC 2013 International Conference on Information Systems and Design of Communication, Lisbon, Portugal, 11–12 July 2013; pp. 11–15. [Google Scholar]
- Cheng, W.; Yin, G.; Dong, Y.; Dong, H.; Zhang, W. Collaborative filtering recommendation on users’ interest sequences. PLoS ONE 2016, 11, e0155739. [Google Scholar] [CrossRef] [PubMed]
- Lo, Y.-Y.; Liao, W.; Chang, C.-S.; Lee, Y.-C. Temporal matrix factorization for tracking concept drift in individual user preferences. IEEE Trans. Comput. Soc. Syst. 2018, 5, 156–168. [Google Scholar] [CrossRef]
- Vinagre, J.; Jorge, A.M. Forgetting mechanisms for scalable collaborative filtering. J. Braz. Comput. Soc. 2012, 18, 271–282. [Google Scholar] [CrossRef][Green Version]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Time (Day) | Mnemic Residues (%) |
|---|---|---|
| 1 | 0 | 100 |
| 2 | 0.0139 | 58 |
| 3 | 0.0417 | 44 |
| 4 | 0.375 | 36 |
| 5 | 1 | 33 |
| 6 | 2 | 28 |
| 7 | 6 | 25 |
| 8 | 31 | 21 |
| Functions | Formula |
|---|---|
| Linear function | |
| Gaussian function | |
| Rational function | |
| Exponential function |
| SSE | R-Square | Adjusted R-Square | RMSE | |
|---|---|---|---|---|
| Multiform approximation | 0.2606 | 0.4383 | 0.3447 | 0.2084 |
| Gaussian approximation | 0.3079 | 0.3364 | 0.07102 | 0.2481 |
| Rational approximation | 0.2364 | 0.4905 | 0.4056 | 0.1985 |
| Exponential approximation | 0.01087 | 0.9766 | 0.959 | 0.05213 |
| User1 | …… | Userm | |
|---|---|---|---|
| item1 | T11 | …… | T1m |
| …… | …… | Tij | …… |
| itemn | Tn1 | …… | Tnm |
| Maximum Value | Minimum Value | Average Value | |
|---|---|---|---|
| UCF | 1.13306 | 1.0134 | 1.0719 |
| ICF | 1.0936 | 1.0265 | 1.0488 |
| IUCF | 0.9959 | 0.9589 | 0.9695 |
| Min MAE | Avg MAE | Max Precision | Avg Precision | Max Recall | Avg Recall | |
|---|---|---|---|---|---|---|
| UCF | 0.7642 | 0.8167 | 0.1335 | 0.0759 | 0.3064 | 0.1734 |
| TCF1 | 0.7694 | 0.7751 | 0.1266 | 0.1154 | 0.2905 | 0.2647 |
| TCF2 | 0.7254 | 0.7376 | 0.1353 | 0.1285 | 0.3104 | 0.2949 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Jin, L.; Wu, Z.; Chen, Y. Combined Recommendation Algorithm Based on Improved Similarity and Forgetting Curve. Information 2019, 10, 130. https://doi.org/10.3390/info10040130
Li T, Jin L, Wu Z, Chen Y. Combined Recommendation Algorithm Based on Improved Similarity and Forgetting Curve. Information. 2019; 10(4):130. https://doi.org/10.3390/info10040130
Chicago/Turabian StyleLi, Taoying, Linlin Jin, Zebin Wu, and Yan Chen. 2019. "Combined Recommendation Algorithm Based on Improved Similarity and Forgetting Curve" Information 10, no. 4: 130. https://doi.org/10.3390/info10040130
APA StyleLi, T., Jin, L., Wu, Z., & Chen, Y. (2019). Combined Recommendation Algorithm Based on Improved Similarity and Forgetting Curve. Information, 10(4), 130. https://doi.org/10.3390/info10040130