Deep Image Similarity Measurement Based on the Improved Triplet Network with Spatial Pyramid Pooling


Abstract
:1. Introduction
2. Related Work
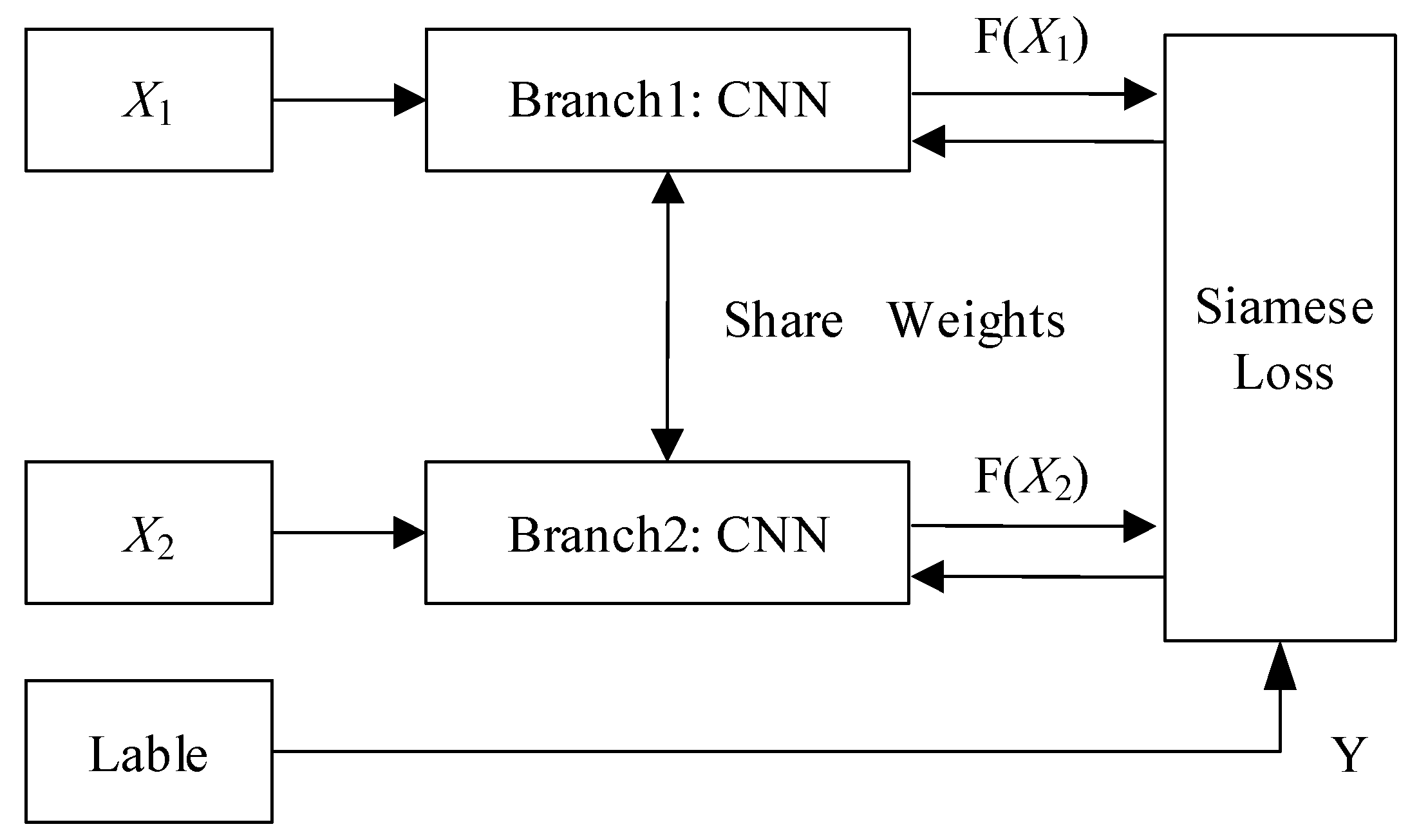
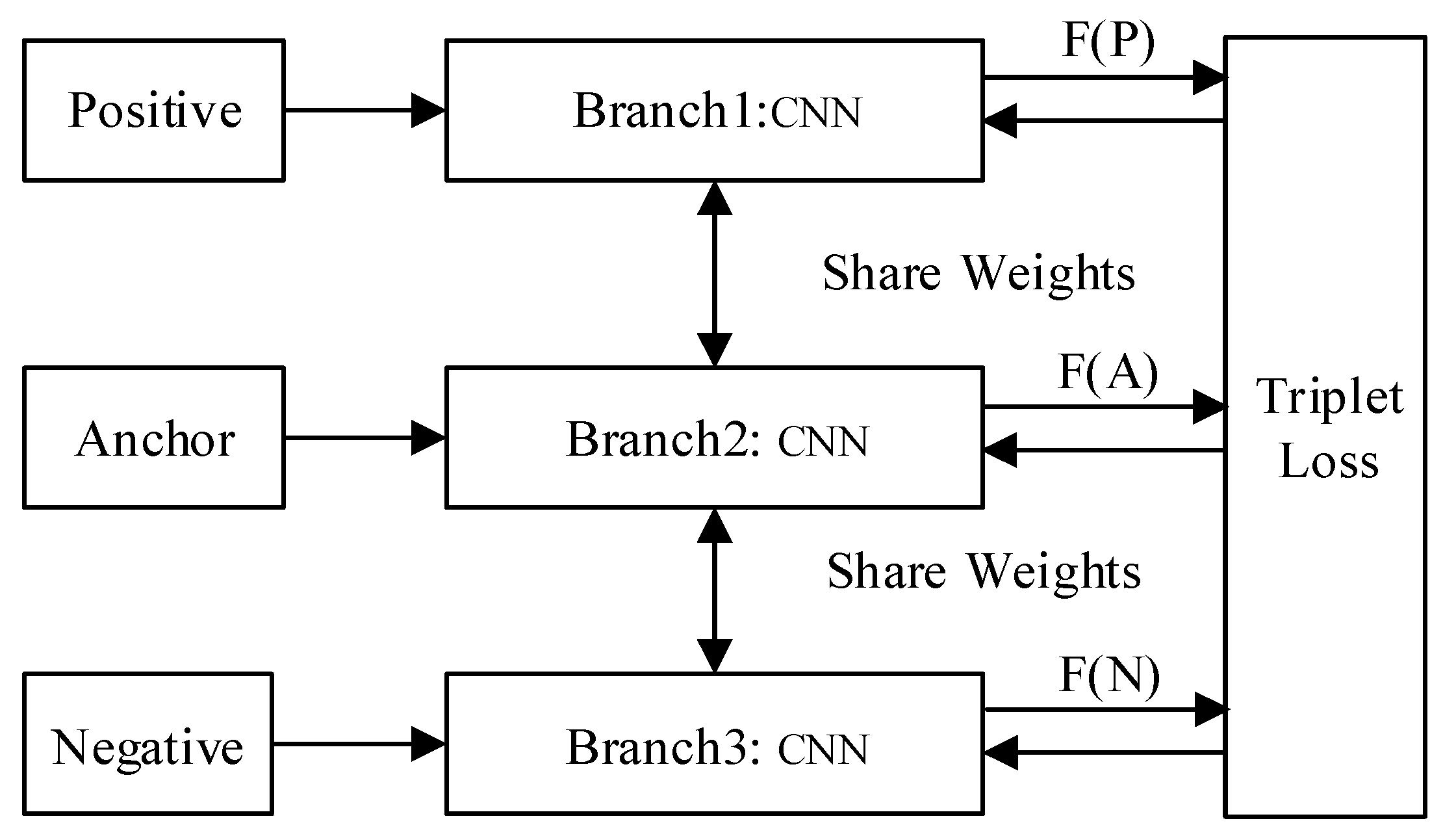
2.1. Siamese Network and Triplet Network
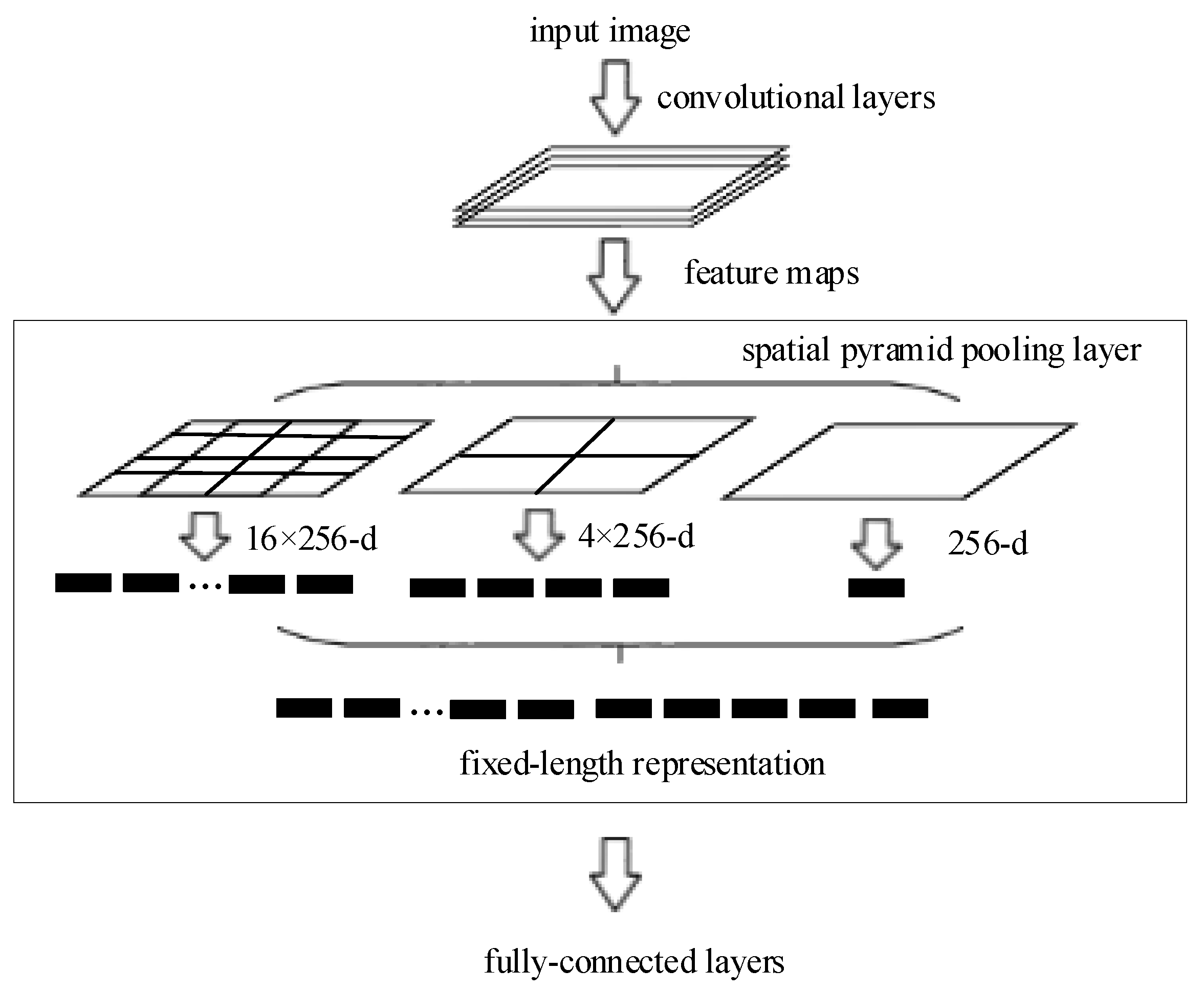
2.2. Spatial Pyramid Pooling
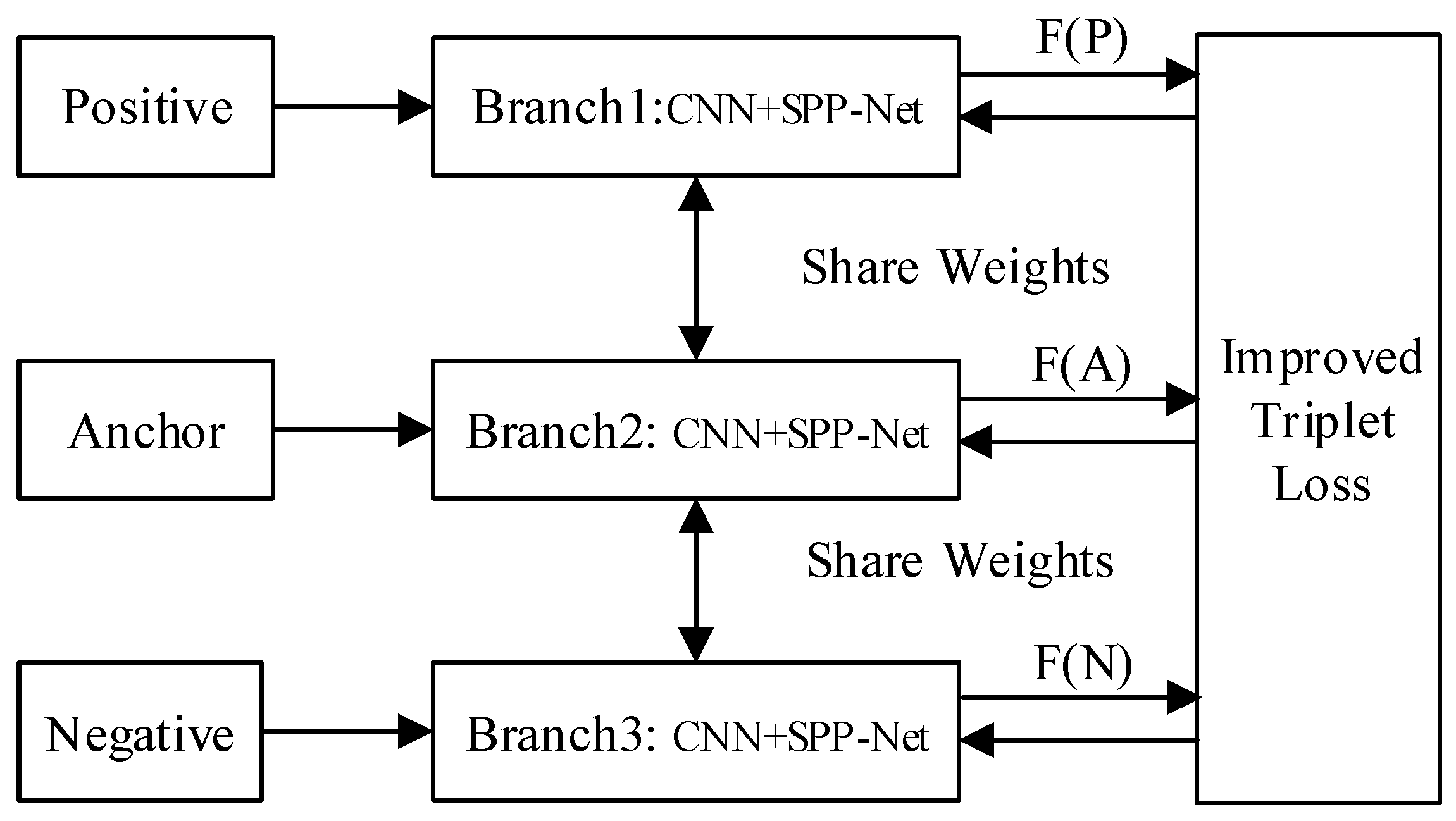
3. The Improved Triplet Network with Spatial Pyramid Pooling
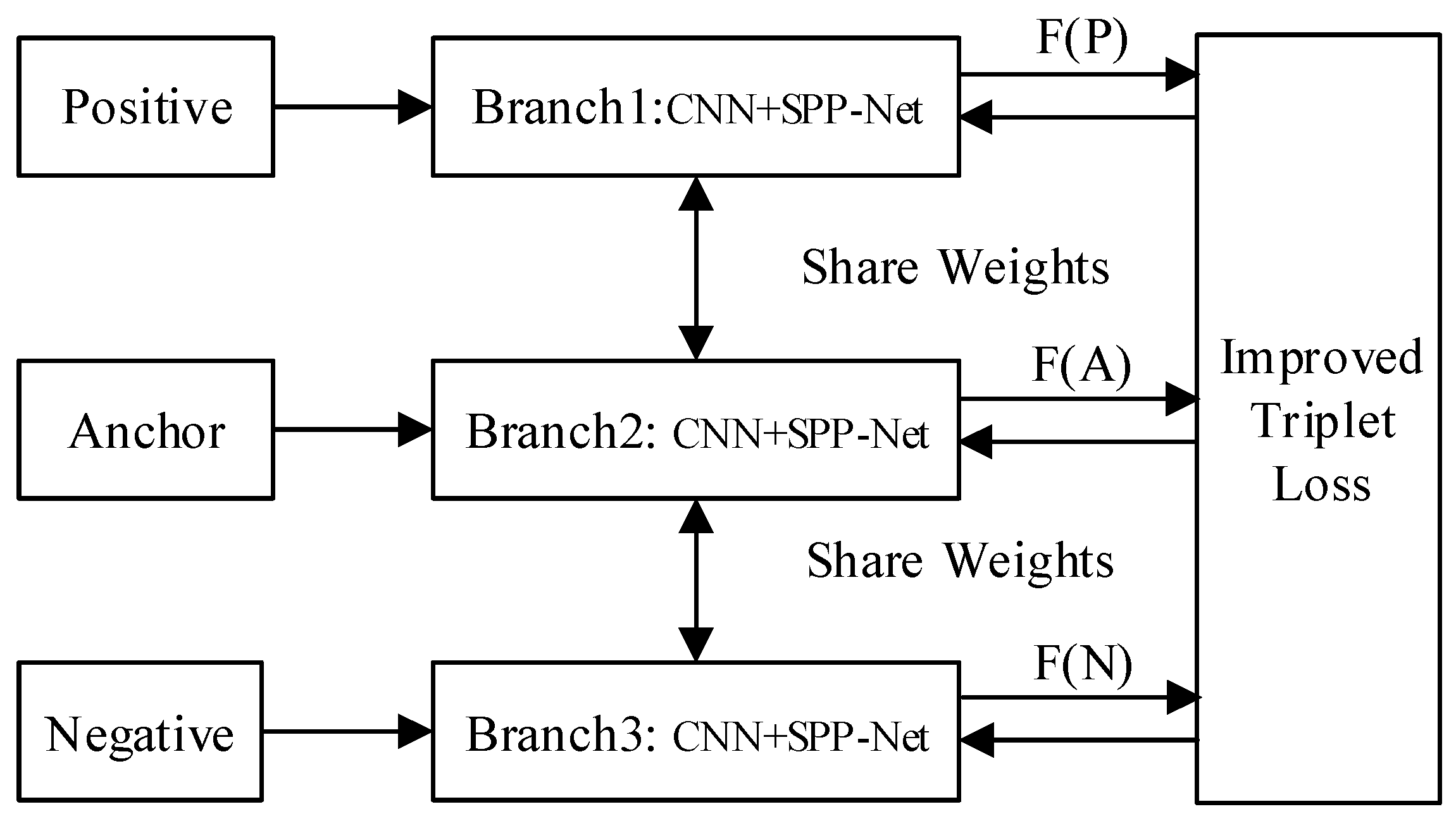
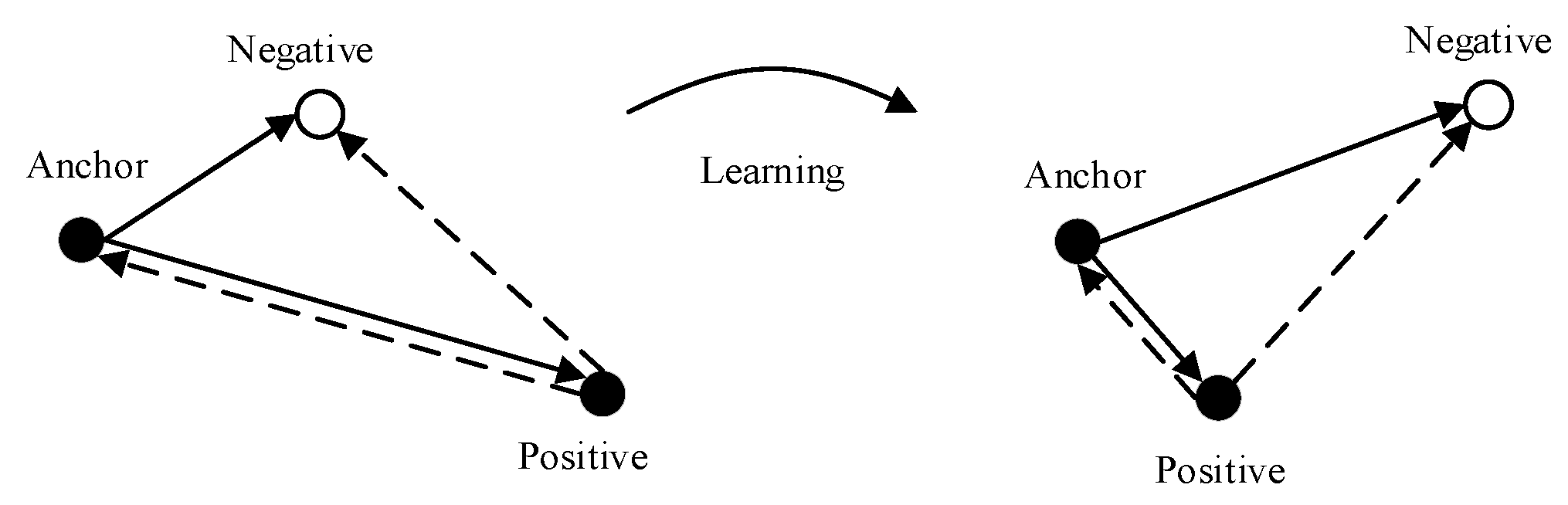
3.1. The Improved Triplet Network
3.2. Image Similarity Measurement Algorithm
| Algorithm 1: Training the TSPP-Net Model | |
| Input: | |
| Training image dataset: I = {I} Epoch number: T Mini-Bath size: m Learning rate: η | |
| Output: | |
| Network parameters: W = {W}, b = {b} | |
| 1: | while e < E do |
| 2: | e = e + 1; |
| 3: | Randomly generate the triplet samples: X = , ,…, through the image dataset I; |
| 4: | Divide the triplet samples X into the min-batch samples M= {M1, M2, …} and each of Mi contains m triplet samples, where Mi = {,,…,}; |
| 5: | T = size(M); |
| 6: | while t < T do |
| 7: | t = t + 1; |
| 8: | Obtain the min-batch samples Mt from M; |
| 9: | for all the min-batch samples Mt: |
| 10: | According to the Equation (10), calculate the gradient by back propagation algorithm; |
| 11: | According to the Equation (14), calculate the gradient by back propagation algorithm; |
| 12: | end for |
| 13: | According to the Equation (18) and the Equation (19), update the parameters; |
| 14: | end while |
| 15: | end while |
4. The Experiment and Analysis
4.1. Experimental Settings
4.2. Experimental Results
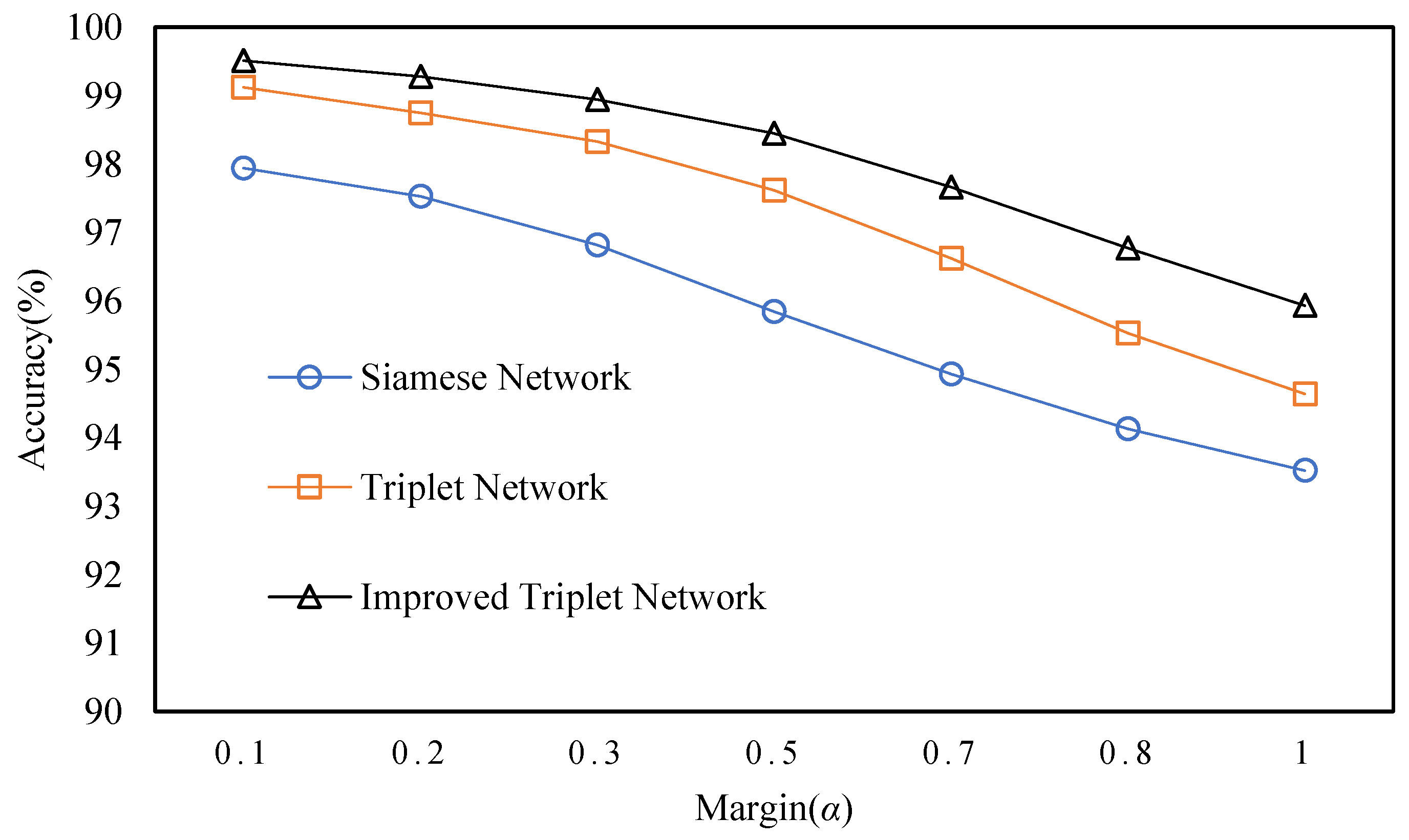
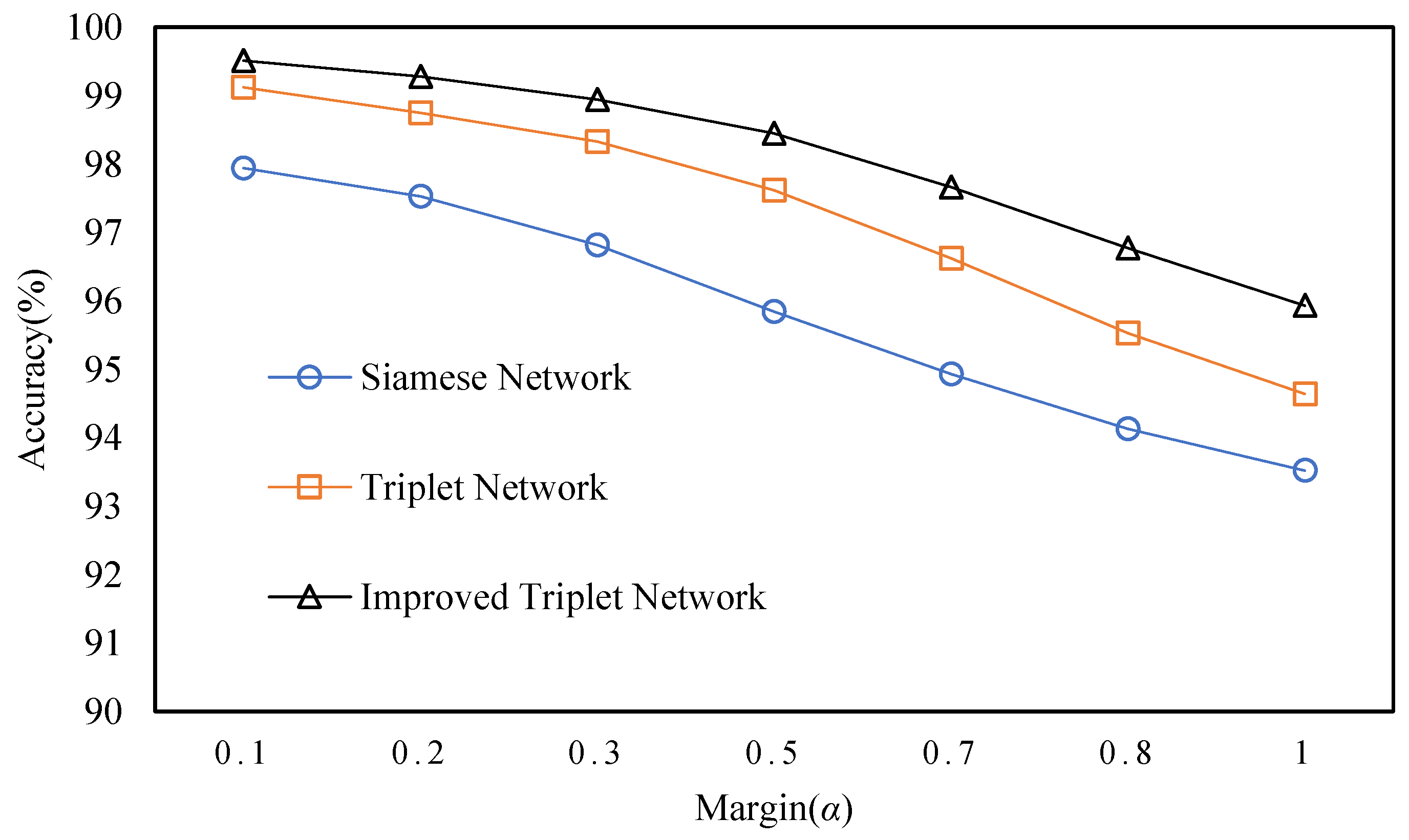
4.2.1. Verifying the Improved Triple Loss Function
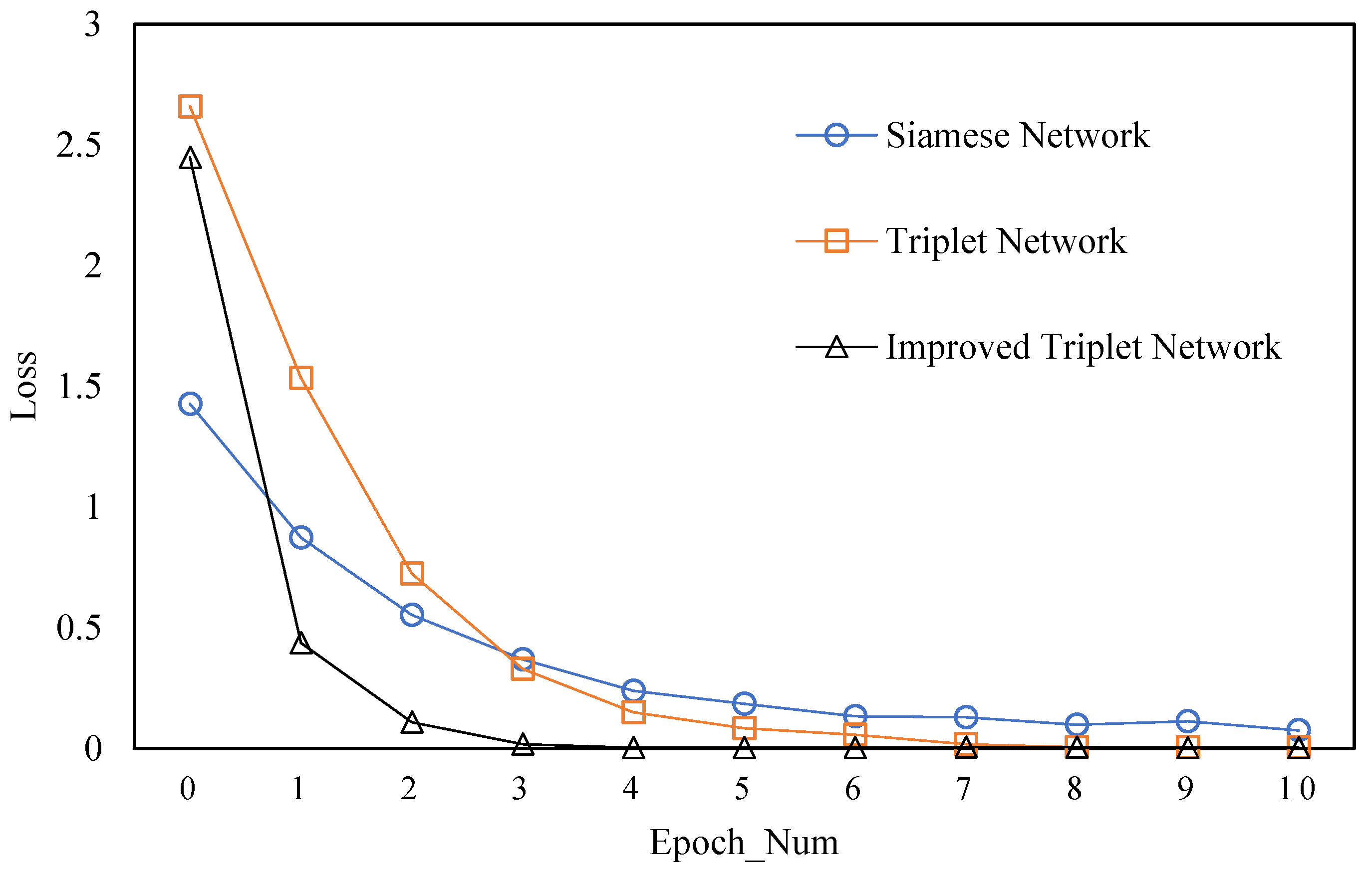
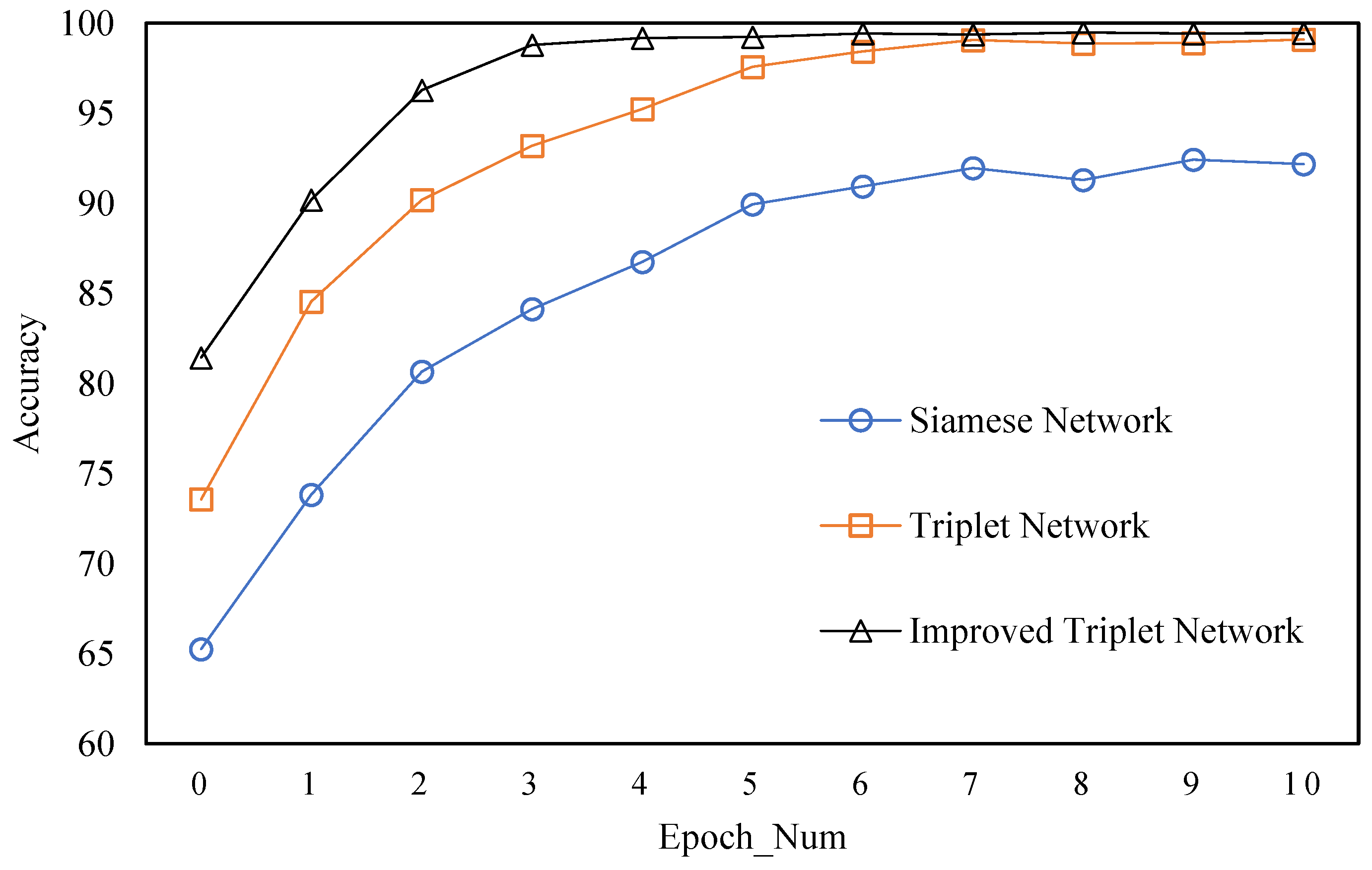
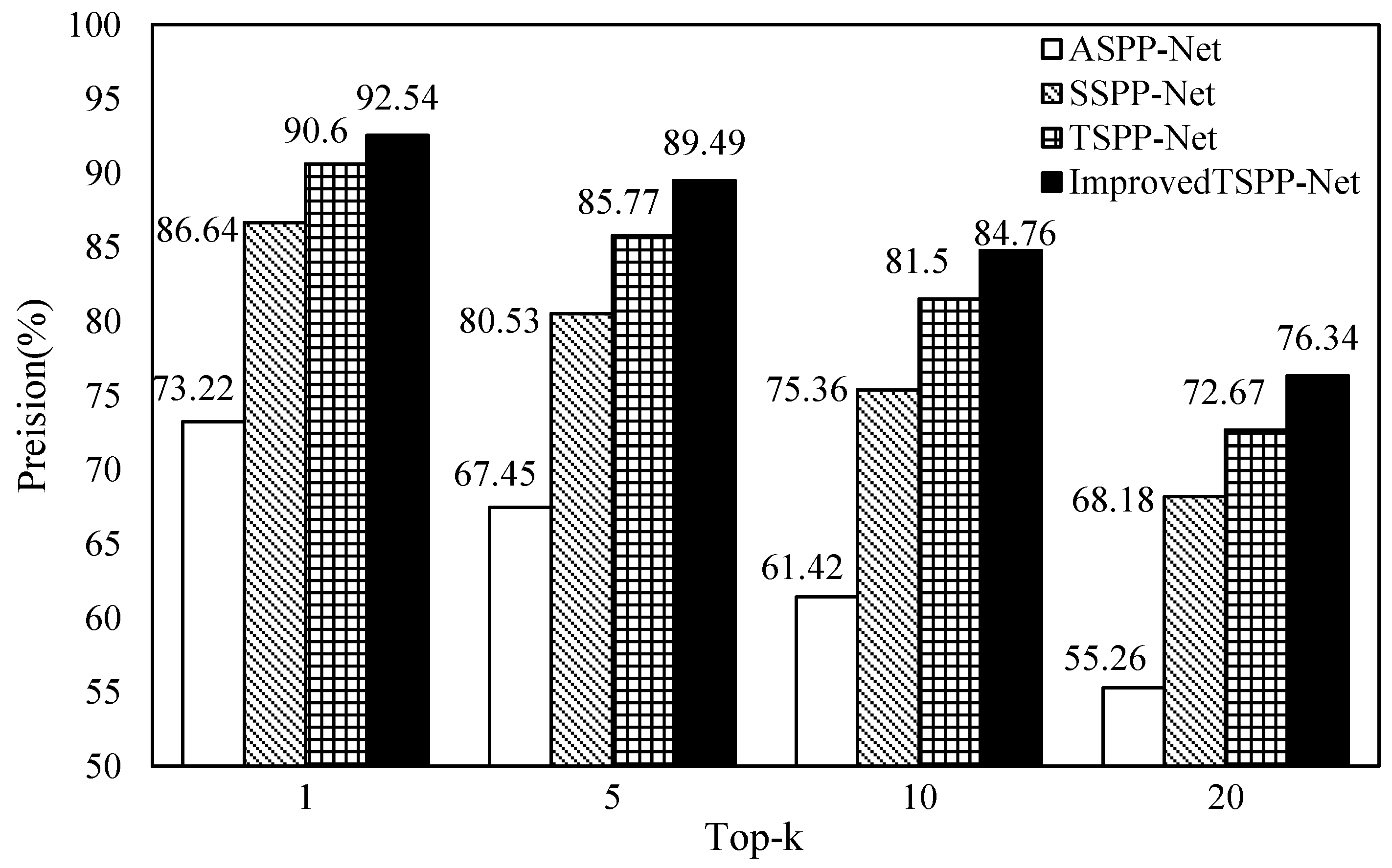
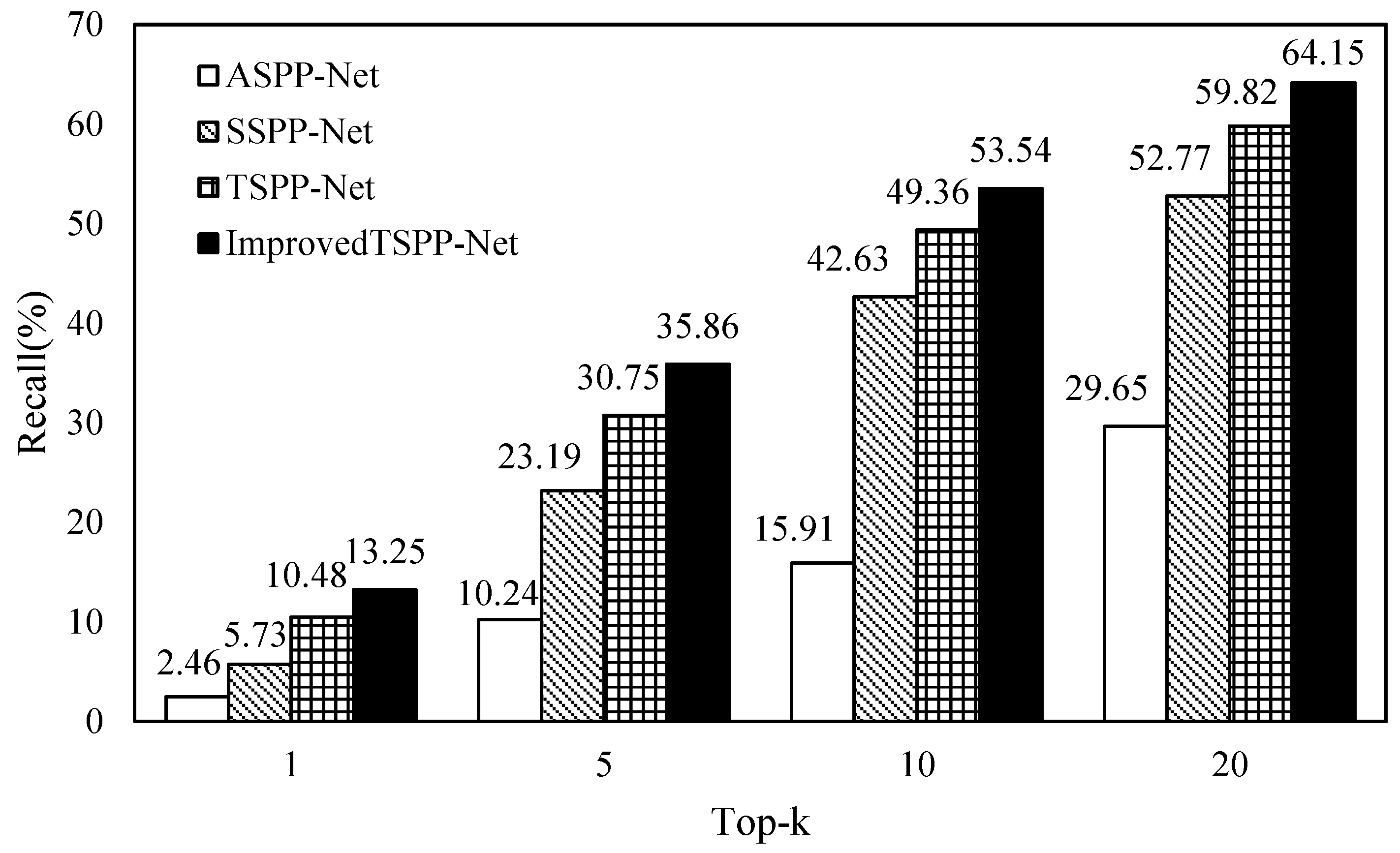
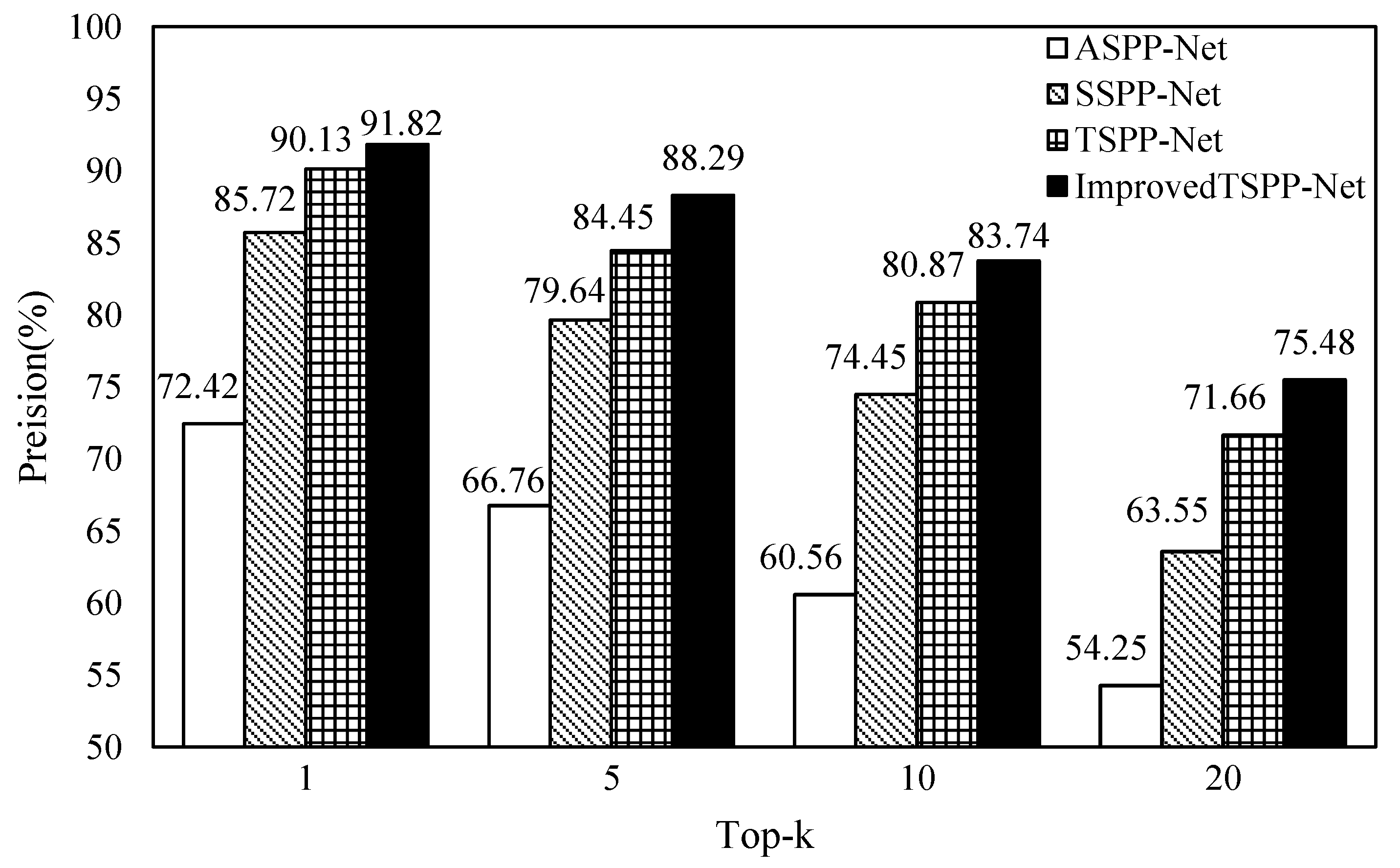
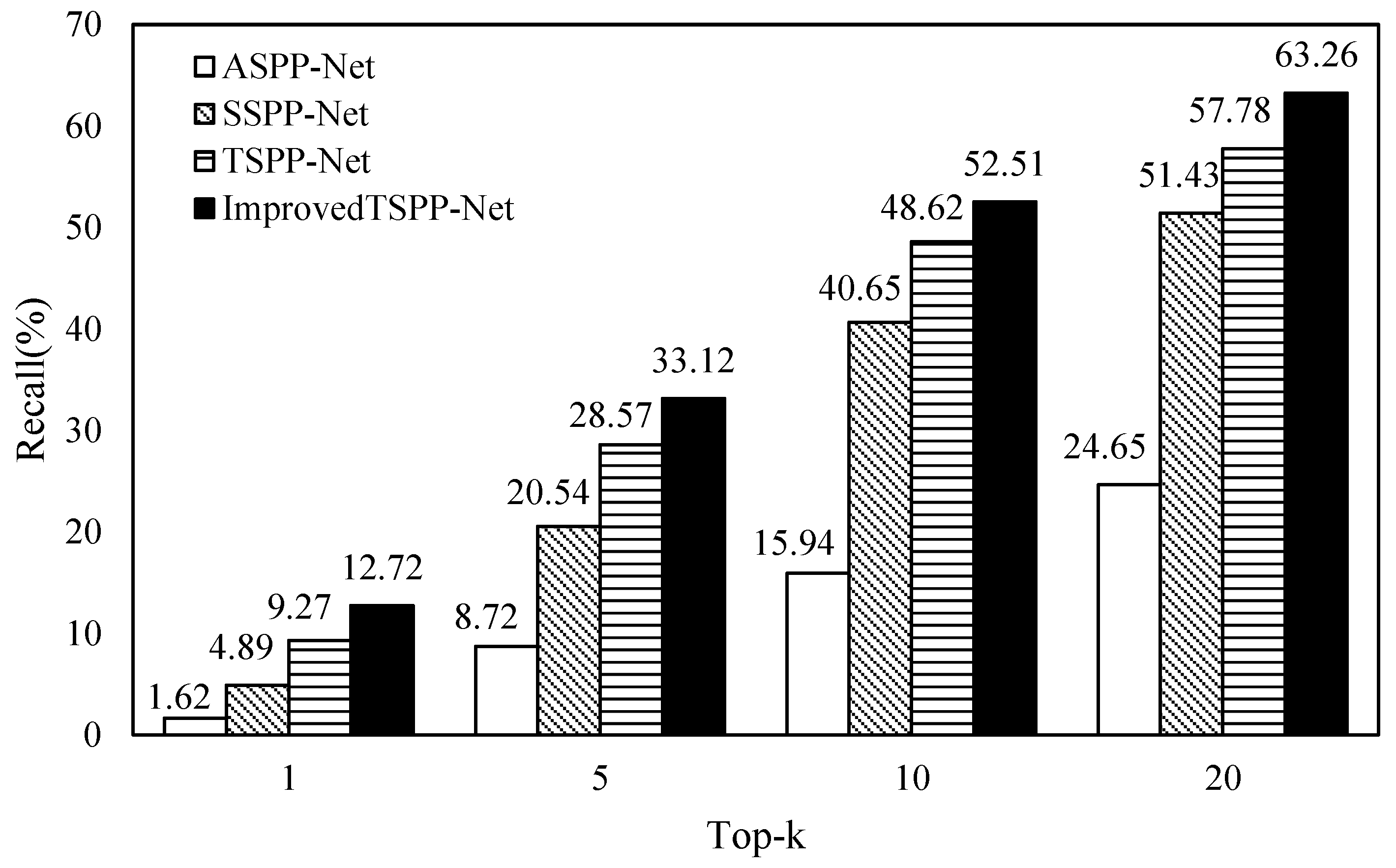
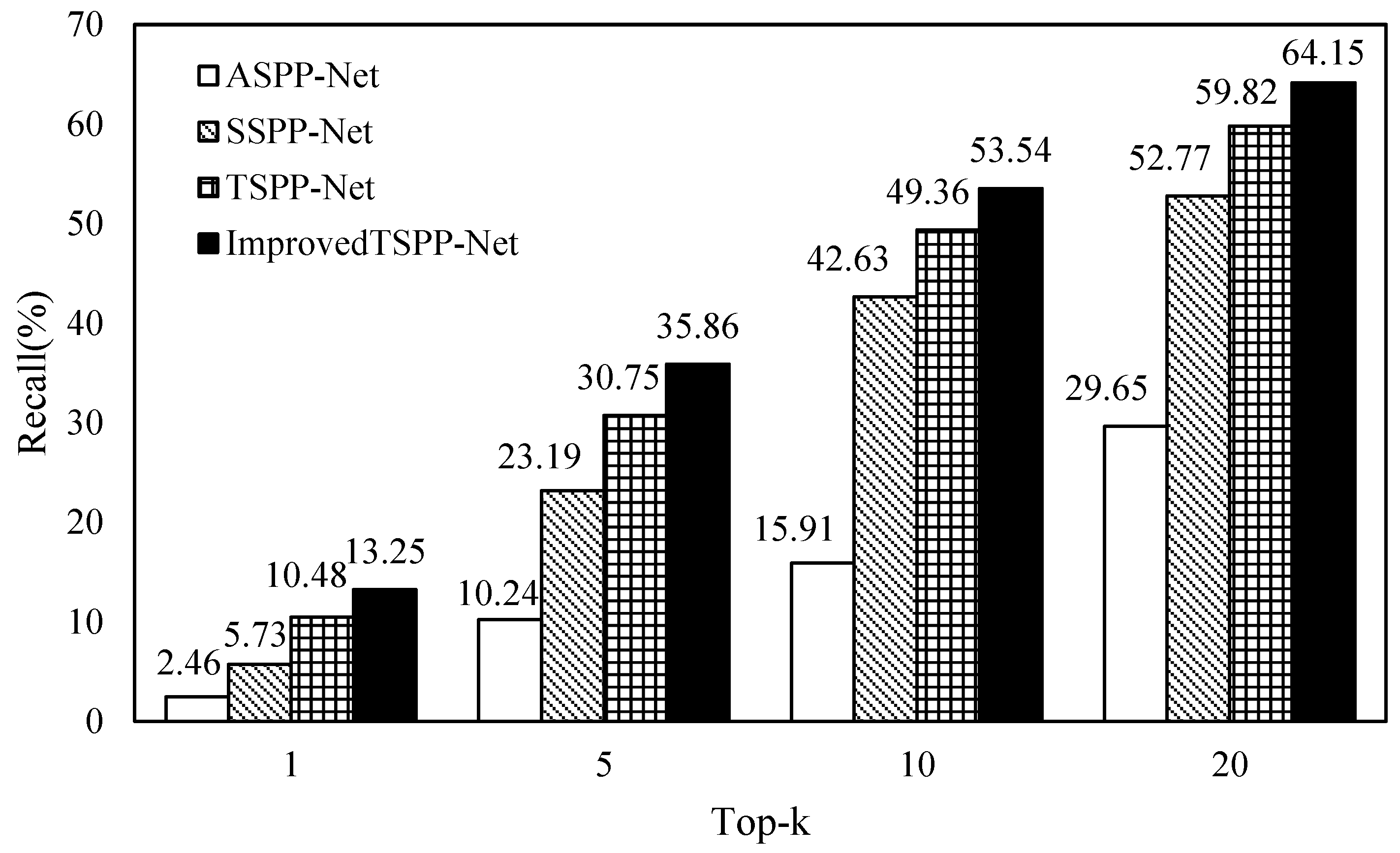
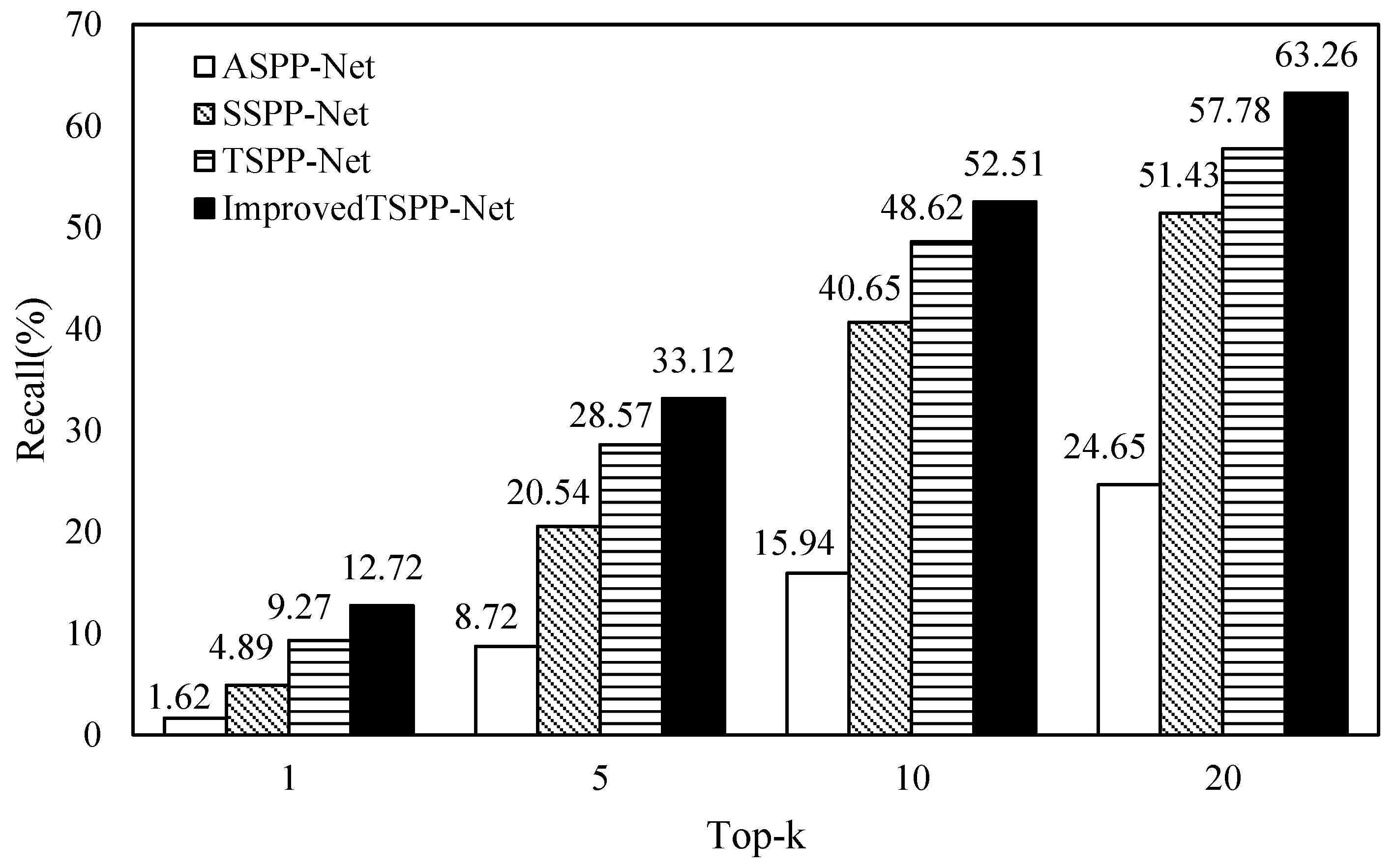
4.2.2. Verifying the TSPP-Net Model
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, L.; Wang, S.; Liu, Z.; Tian, Q. Packing and padding: Coupled multi-index for accurate image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1947–1954. [Google Scholar]
- Zheng, L.; Wang, S.; Liu, Z.; Tian, Q. Fast image retrieval: Query pruning and early termination. IEEE Trans. Multimed. 2015, 17, 648–659. [Google Scholar] [CrossRef]
- Jiang, W.; Yi, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A Unified Framework for Multi-label Image Classification. In Proceedings of the 2016 Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, Z.; Ding, R.; Chin, T.W.; Marculescu, D. Understanding the Impact of Label Granularity on CNN-based Image Classification. arXiv, 2019; arXiv:1901.07012. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Conference on Neural Information Processing Systems, Montreal, ON, Canada, 7–12 December 2015. [Google Scholar]
- Hui, Z.; Wang, K.; Tian, Y.; Gou, C.; Wang, F.-Y. MFR-CNN: Incorporating Multi-Scale Features and Global Information for Traffic Object Detection. IEEE Trans. Veh. Technol. 2018, 67, 8019–8030. [Google Scholar]
- Fu, R.; Li, B.; Gao, Y.; Wang, P. Content-based image retrieval based on CNN and SVM. In Proceedings of the IEEE International Conference on Computer and Communications, Chengdu, China, 14–17 October 2016; pp. 638–642. [Google Scholar]
- Seddati, O.; Dupont, S.; Mahmoudi, S.; Parian, M. Towards Good Practices for Image Retrieval Based on CNN Features. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.C.; Tang, X. Deep Learning Markov Random Field for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1814–1828. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Chopra, S.; Hadsell, R.; Lecun, Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–06 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Melekhov, I.; Kannala, J.; Rahtu, E. Siamese network features for image matching. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Appalaraju, S.; Chaoji, V. Image similarity using Deep CNN and Curriculum Learning. arXiv, 2017; arXiv:1709.08761. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C. Learning Fine-Grained Image Similarity with Deep Ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. In Proceedings of the International Workshop on Similarity-based Pattern Recognition, Copenhagen, Denmark, 12–14 October 2015. [Google Scholar]
- Bui, T.; Ribeiro, L.; Ponti, M.; Collomosse, J. Compact Descriptors for Sketch-based Image Retrieval using a Triplet loss Convolutional Neural Network. Comput. Vis. Image Underst. 2017, 164, 27–37. [Google Scholar] [CrossRef]
- Huang, C.Q.; Yang, S.M.; Pan, Y.; Lai, H.J. Object-Location-Aware Hashing for Multi-Label Image Retrieval via Automatic Mask Learning. IEEE Trans. Image Process. 2018, 27, 4490. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Lu, J.; Tan, Y.P. Discriminative Deep Metric Learning for Face Verification in the Wild. In Proceedings of the Computer Vision & Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. arXiv, 2015; arXiv:1503.03832. [Google Scholar]
- Yeung, H.W.F.; Li, J.; Chung, Y.Y. Improved performance of face recognition using CNN with constrained triplet loss layer. In Proceedings of the International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Marin-Reyes, P.A.; Bergamini, L.; Lorenzo-Navarro, J.; Palazzi, A.; Calderara, S.; Cucchiara, R. Unsupervised Vehicle Re-identification Using Triplet Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Taha, A.; Chen, Y.T.; Misu, T.; Davis, L. In Defense of the Triplet Loss for Visual Recognition. arXiv, 2019; arXiv:1901.08616. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. arXiv, 2014; arXiv:1901.08616. [Google Scholar]
- Yue, J.; Mao, S.; Mei, L. A deep learning framework for hyperspectral image classification using spatial pyramid pooling. Remote Sens. Lett. 2016, 7, 875–884. [Google Scholar] [CrossRef]
- Heravi, E.J.; Aghdam, H.H.; Puig, D. An optimized convolutional neural network with bottleneck and spatial pyramid pooling layers for classification of foods. Pattern Recognit. Lett. 2017, 105, 50–58. [Google Scholar] [CrossRef]
- Tao, Q.; Zhang, Q.; Sun, S. Vehicle detection from high-resolution aerial images using spatial pyramid pooling-based deep convolutional neural networks. Multimed. Tools Appl. 2017, 76, 21651–21663. [Google Scholar]
- Peng, L.; Liu, X.; Liu, M.; Dong, L.; Hui, M.; Zhao, Y. SAR target recognition and posture estimation using spatial pyramid pooling within CNN. In Proceedings of the 2017 International Conference on Optical Instruments and Technology: Optoelectronic Imaging/Spectroscopy and Signal Processing Technology; SPIE: Bellingham, WA, USA, 2018. [Google Scholar]
- Cao, Y.; Lu, C.; Lu, X.; Xia, X. A Spatial Pyramid Pooling Convolutional Neural Network for Smoky Vehicle Detection. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9170–9175. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Network Model | mAP (%) | |
|---|---|---|---|
| Single-Size | Multi-Size | ||
| 1 | ASPP-Net | 58.56 | 57.42 |
| 2 | SSPP-Net | 72.18 | 70.69 |
| 3 | TSPP-Net | 78.33 | 76.65 |
| 4 | Improved TSPP-Net | 81.24 | 79.35 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, X.; Liu, Q.; Long, J.; Hu, L.; Wang, Y. Deep Image Similarity Measurement Based on the Improved Triplet Network with Spatial Pyramid Pooling. Information 2019, 10, 129. https://doi.org/10.3390/info10040129
Yuan X, Liu Q, Long J, Hu L, Wang Y. Deep Image Similarity Measurement Based on the Improved Triplet Network with Spatial Pyramid Pooling. Information. 2019; 10(4):129. https://doi.org/10.3390/info10040129
Chicago/Turabian StyleYuan, Xinpan, Qunfeng Liu, Jun Long, Lei Hu, and Yulou Wang. 2019. "Deep Image Similarity Measurement Based on the Improved Triplet Network with Spatial Pyramid Pooling" Information 10, no. 4: 129. https://doi.org/10.3390/info10040129
APA StyleYuan, X., Liu, Q., Long, J., Hu, L., & Wang, Y. (2019). Deep Image Similarity Measurement Based on the Improved Triplet Network with Spatial Pyramid Pooling. Information, 10(4), 129. https://doi.org/10.3390/info10040129