Detecting Emotions in English and Arabic Tweets


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
- There were more emotions than tweets in each dataset; this was to be expected since tweets can, and often do, contain multiple emotions.
- There were approximately the same number of average emotions per tweet across all four datasets; it is not clear whether this is by design or naturally occurring.
- The distributions of emotions across datasets from the same language were similar and, in some cases, (e.g., anger) were the same across all the datasets.
- Table 1 shows the breakdown of tweets by emotion. The table also shows that anger was the most popular emotion. Anger is an emotion that manifests itself by hostility towards someone or something. According to psychologists, anger can be a “substitute” emotion, meaning that people can make themselves angry so that they do not have to experience an even worse emotion such as pain. Fan et al. [25] collected 70 million tweets from Sina Weibo (a Chinese microblogging website) to examine how tweets that channelled specific emotions (joy, sadness, anger and disgust) influenced other people across the site. They found that “the most observable pattern was in the spread of angry tweets”. This means that if a user sent an angry tweet, that anger emotion is likely to leak into the tweets of not only the followers who saw the tweet, but also their followers, and their followers’ followers. They concluded that anger spreads faster than any other emotions on Twitter, and this could help explain why anger is the most popular emotion in the SemEval 2018 datasets. The next most popular emotion was sadness, followed closely by joy, possibly for similar reasons. At the opposite end of the scale are surprise and trust. This is likely because aside from the emotion words themselves, there are not many other words that convey these emotions. Furthermore, these are hardly emotions that one would see being shared amongst social media users.
2.2. The Task
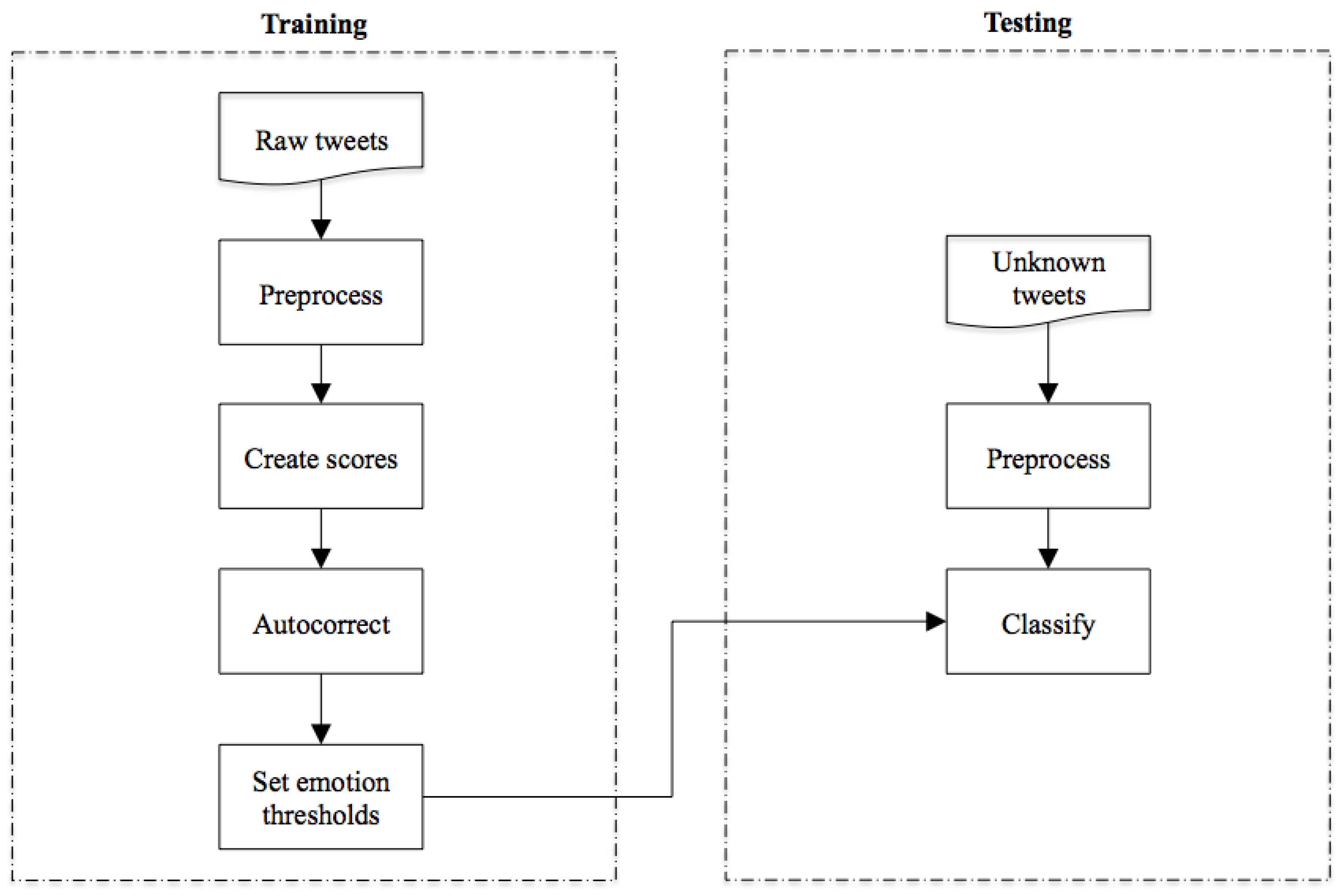
2.3. Algorithm
- Using the tweets in the annotated training dataset to create word vectors.
- Using the word vectors to create a lexicon of tokens and conditional probabilities.
- Transforming the probabilities into “scores”.
- Autocorrecting the lexicon by iteratively using a range of thresholds to remove unhelpful words.
- Using the modified lexicon to calculate the threshold that achieved the best results for each emotion.
- Classifying the test data using the modified lexicon and the best set of thresholds.
2.3.1. Preprocessing
2.3.2. Arabic Tagging and Stemming
2.3.3. English Tagging and Stemming
2.3.4. From Probabilities to Scores
Lexicon
Raw Conditional Probabilities
Normalisation
Skew
2.3.5. Autocorrection
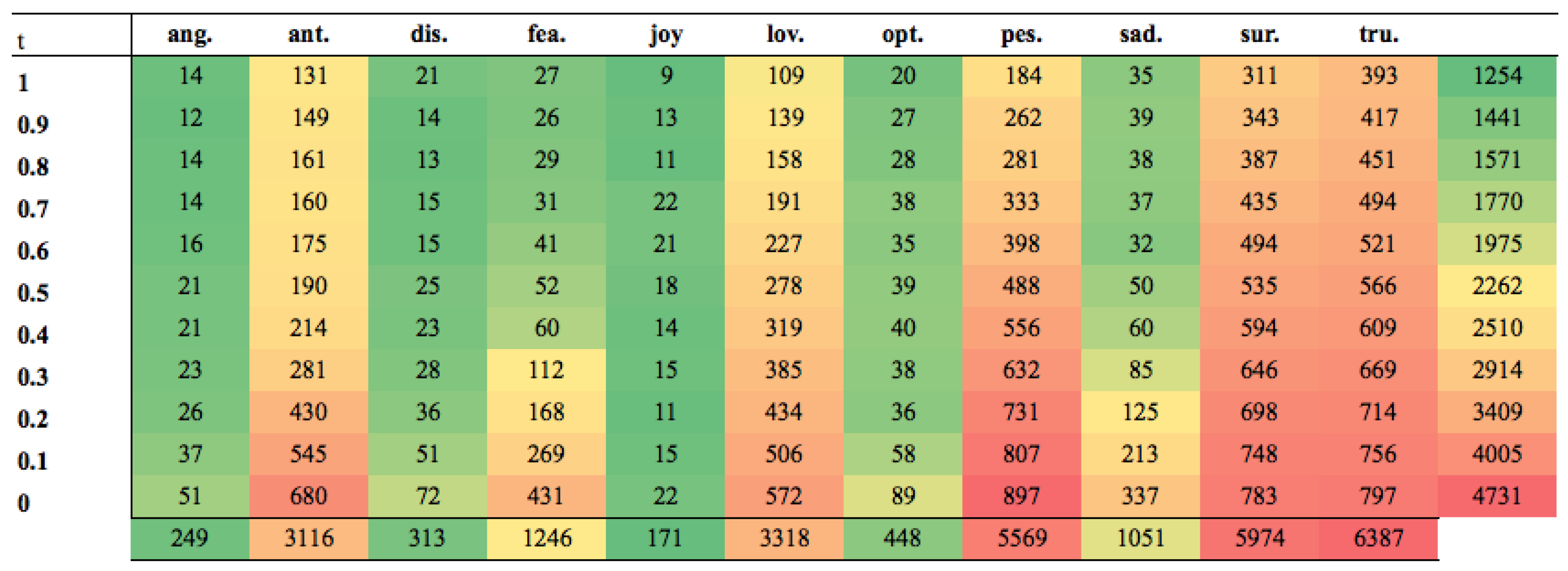
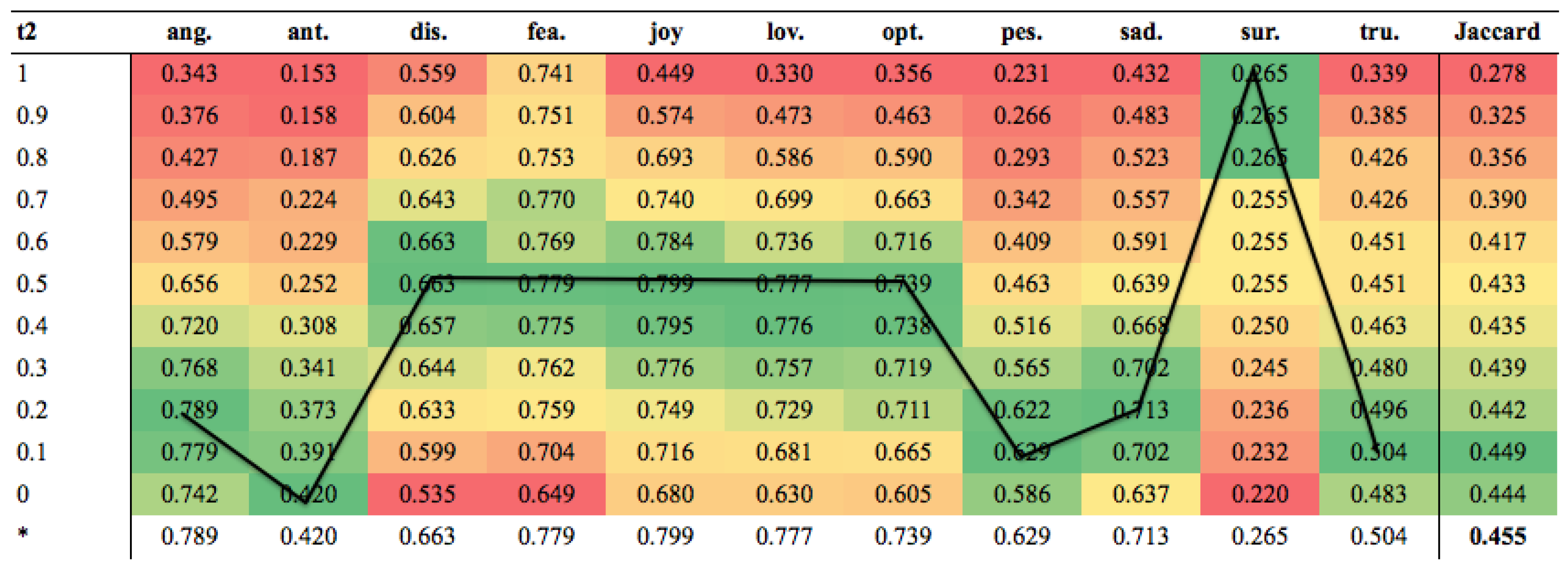
2.3.6. Thresholds
2.3.7. Classification
2.4. Other Methods
2.4.1. Support Vector Machines
2.4.2. Deep Neural Nets
2.5. Computing Resources
3. Results
“If you build up resentment in silence are you really doing anyone any favors”,
4. Discussion
- The effects of combining preprocessing steps such as lowercasing, removing punctuation and tokenising emojis were positive for the Arabic and the English datasets.
- Expanding hashtags was a beneficial step for the English dataset, but detrimental in the Arabic dataset. This was because out of the 5448 distinct hashtags in the dataset, only 1168 (21%) appeared five or more times. Consequently, this reduced their ability to have any meaningful impact on the classifier.
- Stemming using the tags from Albogamy and Ramsay’s tagger almost always decreased classifier performance.
- There were emotions (e.g., trust) that WCP found difficult to classify.
- The sizes of the training and test datasets and the proportions of tweets for each emotion were significant factors in classifier performance. Increasing the training dataset size only had a positive effect if the new data were from a similar domain and were annotated in a similar fashion.
- Decreased the likelihood that tweets containing autocorrected tokens would be incorrectly classified.
- Increased the likelihood that genuine tweets containing autocorrected tokens would be correctly classified.
“Experience killed mercenaries of Taiz with a weapon and I killed the mercenaries of Twitter. Praise be to God for these victories. Hehe”“The feeling of victory”“Some fans were surprised about the amount of frustration inside them, trust your team and let the predestination does as it please. Hala Madrid! after defeat comes victory”
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Quintana, D.S.; Guastella, A.J.; Outhred, T.; Hickie, I.B.; Kemp, A.H. Heart rate variability is associated with emotion recognition: Direct evidence for a relationship between the autonomic nervous system and social cognition. Int. J. Psychophysiol. 2012, 86, 168–172. [Google Scholar] [CrossRef] [PubMed]
- Nakasone, A.; Prendinger, H.; Ishizuka, M. Emotion recognition from electromyography and skin conductance. In Proceedings of the 5th International Workshop on Biosignal Interpretation, Tokyo, Japan, 6–8 September 2005; pp. 219–222. [Google Scholar]
- Busso, C.; Deng, Z.; Yildirim, S.; Bulut, M.; Lee, C.M.; Kazemzadeh, A.; Lee, S.; Neumann, U.; Narayanan, S. Analysis of emotion recognition using facial expressions, speech and multimodal information. In Proceedings of the 6th international conference on Multimodal Interfaces, State College, PA, USA, 13–15 October 2004; ACM: New York, NY, USA, 2004; pp. 205–211. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Bravo-Marquez, F.; Salameh, M.; Kiritchenko, S. SemEval-2018 Task 1: Affect in Tweets. In Proceedings of the International Workshop on Semantic Evaluation (SemEval-2018), New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Baziotis, C.; Athanasiou, N.; Chronopoulou, A.; Kolovou, A.; Paraskevopoulos, G.; Ellinas, N.; Narayanan, S.; Potamianos, A. NTUA-SLP at SemEval-2018 Task 1: Predicting Affective Content in Tweets with Deep Attentive RNNs and Transfer Learning. arXiv, 2018; arXiv:1804.06658. [Google Scholar]
- Kim, Y.; Lee, H.; Jung, K. AttnConvnet at SemEval-2018 Task 1: Attention-based Convolutional Neural Networks for Multi-label Emotion Classification. arXiv, 2018; arXiv:1804.00831. [Google Scholar]
- Gee, G.; Wang, E. psyML at SemEval-2018 Task 1: Transfer Learning for Sentiment and Emotion Analysis. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 369–376. [Google Scholar]
- Zhang, Y.; Wang, J.; Zhang, X. YNU-HPCC at SemEval-2018 Task 1: BiLSTM with Attention based Sentiment Analysis for Affect in Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 273–278. [Google Scholar]
- Meisheri, H.; Dey, L. TCS Research at SemEval-2018 Task 1: Learning Robust Representations using Multi-Attention Architecture. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 291–299. [Google Scholar]
- Karasalo, M.; Nilsson, M.; Rosell, M.; Bolin, U.W. FOI DSS at SemEval-2018 Task 1: Combining LSTM States, Embeddings, and Lexical Features for Affect Analysis. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 109–115. [Google Scholar]
- Rozental, A.; Fleischer, D. Amobee at SemEval-2018 Task 1: GRU Neural Network with a CNN Attention Mechanism for Sentiment Classification. arXiv, 2018; arXiv:1804.04380. [Google Scholar]
- González, J.Á.; Hurtado, L.F.; Pla, F. ELiRF-UPV at SemEval-2018 Tasks 1 and 3: Affect and Irony Detection in Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 565–569. [Google Scholar]
- Wang, W.; Chen, L.; Thirunarayan, K.; Sheth, A.P. Harnessing twitter “big data” for automatic emotion identification. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2012 International Conference on Social Computing (SocialCom), Amsterdam, The Netherlands, 3–5 September 2012; pp. 587–592. [Google Scholar]
- Pak, A.; Paroubek, P. Twitter as a Corpus for Sentiment Analysis and Opinion Mining. In Proceedings of the LREC 2010, Valletta, Malta, 17–23 May 2010; Volume 10, pp. 1320–1326. [Google Scholar]
- Nam, J.; Mencía, E.L.; Kim, H.J.; Fürnkranz, J. Maximizing Subset Accuracy with Recurrent Neural Networks in Multi-label Classification. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5419–5429. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Emotions evoked by common words and phrases: Using Mechanical Turk to create an emotion lexicon. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; pp. 26–34. [Google Scholar]
- Mohammad, S.M.; Kiritchenko, S. Understanding Emotions: A Dataset of Tweets to Study Interactions between Affect Categories. In Proceedings of the 11th Edition of the Language Resources and Evaluation Conference, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Purver, M.; Battersby, S. Experimenting with distant supervision for emotion classification. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; pp. 482–491. [Google Scholar]
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384. [Google Scholar] [CrossRef] [PubMed]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word—Emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Al-Kabi, M.N.; Al-Qwaqenah, A.A.; Gigieh, A.H.; Alsmearat, K.; Al-Ayyoub, M.; Alsmadi, I.M. Building a standard dataset for Arabie sentiment analysis: Identifying potential annotation pitfalls. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–6. [Google Scholar]
- Roberts, K.; Roach, M.A.; Johnson, J.; Guthrie, J.; Harabagiu, S.M. EmpaTweet: Annotating and Detecting Emotions on Twitter. In Proceedings of the LREC, Istanbul, Turkey, 21–27 May 2012; Volume 12, pp. 3806–3813. [Google Scholar]
- Fan, R.; Zhao, J.; Chen, Y.; Xu, K. Anger is more influential than joy: Sentiment correlation in Weibo. PLoS ONE 2014, 9, e110184. [Google Scholar] [CrossRef] [PubMed]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Albogamy, F.; Ramsay, A. Unsupervised Stemmer for Arabic Tweets. In Proceedings of the 2nd Workshop on Noisy User-Generated Text (WNUT), Osaka, Japan, 11 December 2016; pp. 78–84. [Google Scholar]
- Albogamy, F.; Ramsay, A.; Ahmed, H. Arabic Tweets Treebanking and Parsing: A Bootstrapping Approach. In Proceedings of the Third Arabic Natural Language Processing Workshop, Valencia, Spain, 3–4 April 2017; pp. 94–99. [Google Scholar]
- Fellbaum, C. WordNet; Wiley Online Library: Hoboken, NJ, USA, 1998. [Google Scholar]
- Brill, E. Transformation-based error-driven learning and natural language processing: A case study in part-of-speech tagging. Comput. Linguist. 1995, 21, 543–565. [Google Scholar]
- Badaro, G.; El Jundi, O.; Khaddaj, A.; Maarouf, A.; Kain, R.; Hajj, H.; El-Hajj, W. EMA at SemEval-2018 Task 1: Emotion Mining for Arabic. In Proceedings of the 12th International Workshop on Semantic Evaluation (SemEval-2018), New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP. Linguistics 2017, 1877, 0509. [Google Scholar] [CrossRef]
- Park, J.H.; Xu, P.; Fung, P. PlusEmo2Vec at SemEval-2018 Task 1: Exploiting emotion knowledge from emoji and# hashtags. arXiv, 2018; arXiv:1804.08280. [Google Scholar]
- De Bruyne, L.; De Clercq, O.; Hoste, V. LT3 at SemEval-2018 Task 1: A classifier chain to detect emotions in tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation (SemEval-2018), New Orleans, LA, USA, 5–6 June 2018; pp. 123–127. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ang. | ant. | dis. | fea. | joy | lov. | opt. | pes. | sad. | sur. | tru. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Arabic training | 17 | 4 | 8 | 6 | 12 | 12 | 12 | 10 | 16 | 1 | 2 |
| Arabic test | 16 | 4 | 8 | 7 | 12 | 12 | 12 | 9 | 16 | 1 | 3 |
| English training | 16 | 6 | 16 | 8 | 16 | 4 | 12 | 5 | 13 | 2 | 2 |
| English test | 15 | 6 | 15 | 6 | 18 | 5 | 14 | 5 | 12 | 2 | 2 |
| Token | ang. | ant. | dis. | fea. | joy | lov. | opt. | pes. | sad. | sur. | tru. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| admire | −0.457 | 0.438 | −0.516 | 2.640 | −0.287 | 2.133 | −1.533 | −3.402 | −3.402 | 7.787 | −3.402 |
| adorable | −6.112 | −6.112 | −6.112 | −6.112 | 7.245 | 41.354 | 0.299 | −6.112 | −6.112 | −6.112 | −6.112 |
| … | |||||||||||
| con | 24.690 | −5.457 | 19.868 | −5.457 | −0.902 | −5.457 | −5.457 | −5.457 | −5.457 | −5.457 | −5.457 |
| inflame | 20.181 | −5.029 | 14.737 | 5.315 | −5.029 | −5.029 | −5.029 | −5.029 | −5.029 | −5.029 | −5.029 |
| outrage | 9.200 | −1.710 | 7.008 | −0.602 | −2.336 | −2.713 | −1.448 | −2.029 | −1.729 | −1.765 | −1.876 |
| … | |||||||||||
| sick | 1.623 | −2.167 | 1.526 | 1.748 | 0.195 | −3.219 | 0.365 | 0.734 | 5.634 | −3.219 | −3.219 |
| … | |||||||||||
| the | 0.018 | 0.074 | 0.004 | −0.006 | 0.001 | −0.368 | 0.104 | 0.189 | −0.082 | 0.023 | 0.043 |
| Arabic | English | |||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F | Jaccard | Precision | Recall | F | Jaccard | |
| WCP | 0.620 | 0.632 | 0.626 | 0.455 | 0.589 | 0.658 | 0.622 | 0.451 |
| single DNN | 0.601 | 0.537 | 0.567 | 0.396 | 0.624 | 0.488 | 0.587 | 0.416 |
| multi-DNNs | 0.611 | 0.528 | 0.567 | 0.395 | 0.624 | 0.546 | 0.582 | 0.411 |
| (WCP | 0.484 | 0.508) | ||||||
| (SVM-unigrams | 0.380 | 0.442) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, T.; Ramsay, A.; Ahmed, H. Detecting Emotions in English and Arabic Tweets. Information 2019, 10, 98. https://doi.org/10.3390/info10030098
Ahmad T, Ramsay A, Ahmed H. Detecting Emotions in English and Arabic Tweets. Information. 2019; 10(3):98. https://doi.org/10.3390/info10030098
Chicago/Turabian StyleAhmad, Tariq, Allan Ramsay, and Hanady Ahmed. 2019. "Detecting Emotions in English and Arabic Tweets" Information 10, no. 3: 98. https://doi.org/10.3390/info10030098
APA StyleAhmad, T., Ramsay, A., & Ahmed, H. (2019). Detecting Emotions in English and Arabic Tweets. Information, 10(3), 98. https://doi.org/10.3390/info10030098