1. Introduction
Dialog act recognition is an important task in the context of a dialog system, since dialog acts are the minimal units of linguistic communication that reveal the intention behind the uttered words [
1]. Identifying the intention behind the utterances of its conversational partners allows a dialog system to apply specialized interpretation strategies, accordingly. Thus, automatic dialog act recognition is a task that has been widely explored over the years on multiple corpora and using multiple classical machine learning approaches [
2]. However, recently, most approaches on the task focus on applying different Deep Neural Network (DNN) architectures to generate segment representations from word embeddings and combine them with context information from the surrounding segments [
3,
4,
5,
6]. All of these approaches look at the segment at the word level. That is, they consider that a segment is a sequence of words and that its intention is revealed by the combination of those words. However, there are also cues for intention at the sub-word level. These cues are mostly related to the morphology of words. For instance, there are cases, such as adverbs of manner and negatives, in which the function, and hence the intention, of a word is related to its affixes. On the other hand, there are cases in which considering multiple forms of the same lexeme independently does not provide additional information concerning intention and the lemma suffices. This information is provided by different groups of characters that constitute relevant morphological aspects. Thus, it is hard to capture using word-level approaches.
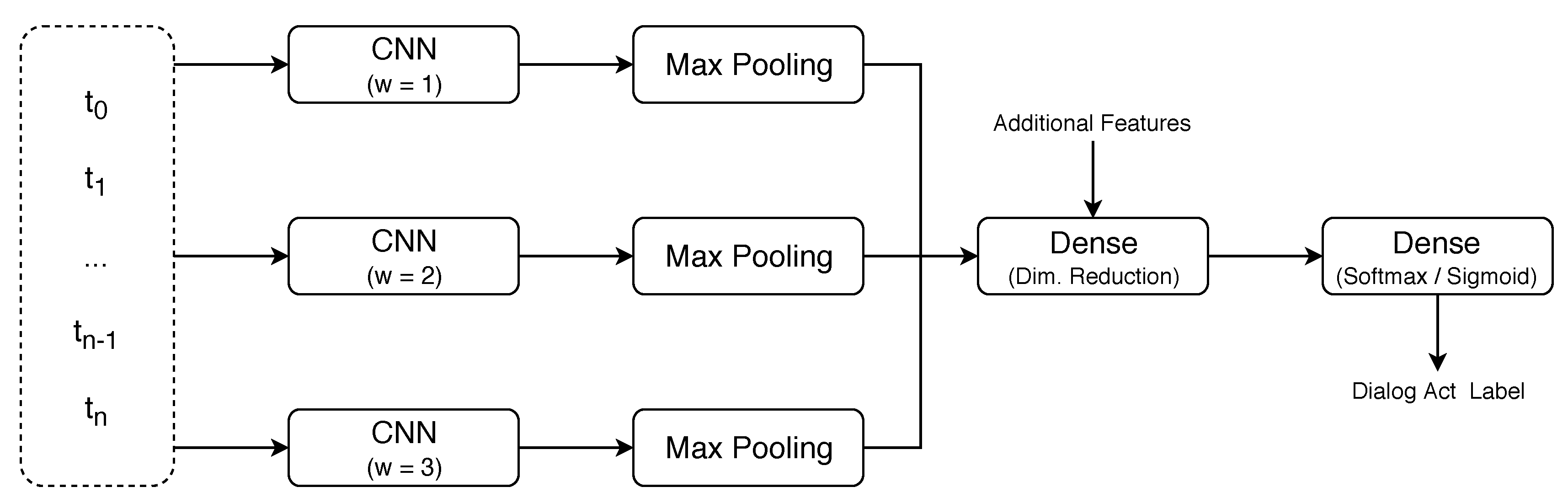
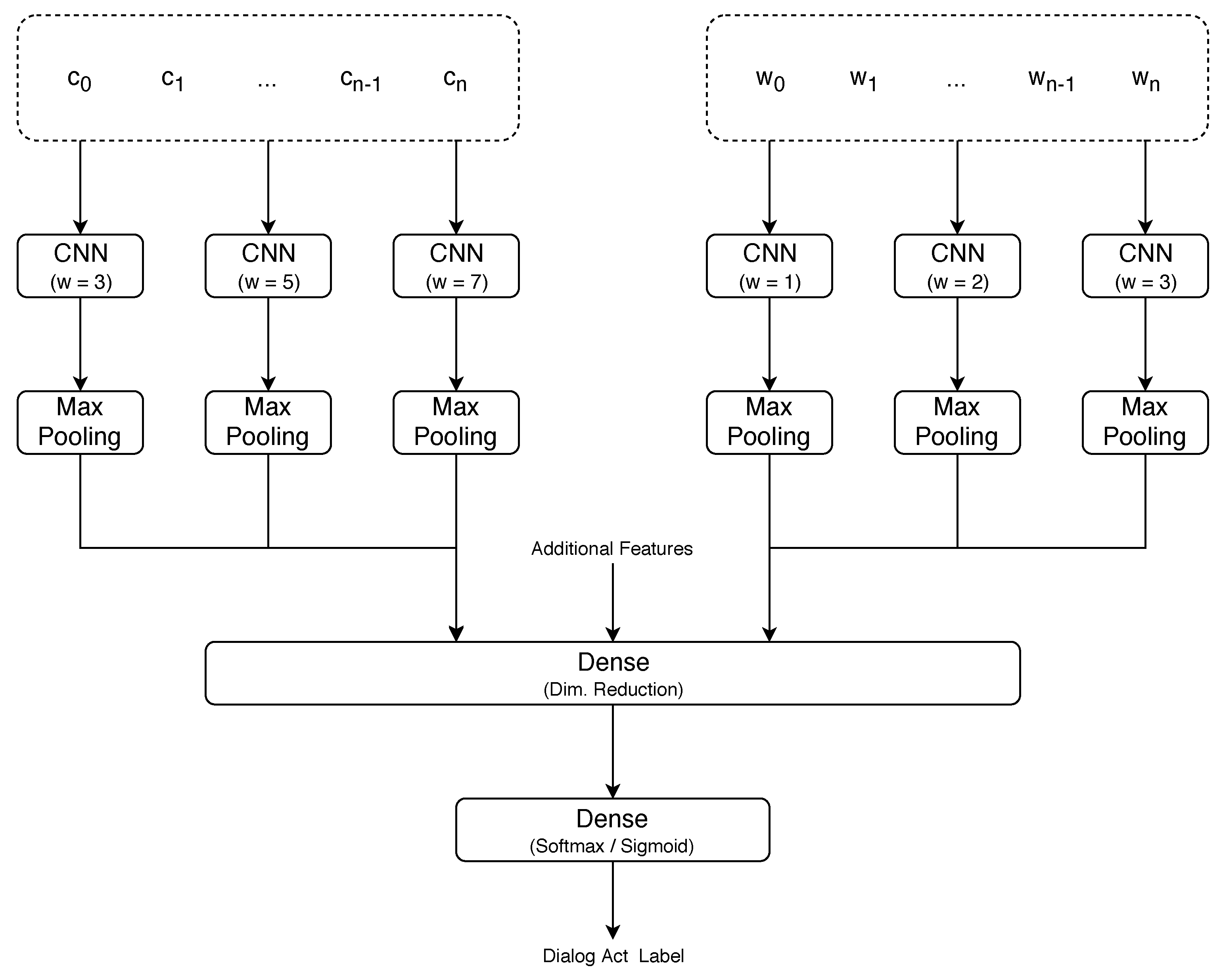
We aimed at capturing sub-word information and, consequently, improving the state-of-the-art on dialog act recognition by performing character-level tokenization and exploring the use of multiple context windows surrounding each token to capture different morphological aspects. Although character-level approaches are typically used for word-level classification tasks, such as Part-of-Speech (POS) tagging [
7], their use for dialog act recognition is supported by the interesting results achieved on other short-text classification tasks, such as language identification [
8] and review rating [
9]. In addition to the aspects concerning morphological information, using character-level tokenization allows assessing the importance of aspects such as capitalization and punctuation for the task. Furthermore, we assessed whether the character-level approach is able to capture all the relevant word-level information or if there are some aspects that can only be captured using a word-level approach. That is, we assessed whether the word- and character-level approaches are complementary and can be combined to improve the performance on the task.
In the conference paper that this article extends [
10], we performed experiments on two corpora, Switchboard Dialog Act Corpus (SwDA) [
11] and DIHANA [
12], which vary in terms of domain, the nature of the participants, and language—English and Spanish, respectively. However, in both cases, we focused on assessing the performance of character-level approaches to predict generic domain-independent dialog act labels. Here, we extended that study by assessing the performance when predicting the domain-dependent dialog act labels of the LEGO corpus [
13] (an annotated subset of the Let’s Go Corpus) and the Levels 2 and 3 of the dialog act annotations of the DIHANA corpus, which are both domain-dependent and multilabel. Additionally, we assessed the performance on the German dialogs of the VERBMOBIL corpus [
14]. The latter is interesting since the German language features morphological aspects that are not predominant in English or Spanish.
In the remainder of the article, we start by providing an overview of previous approaches on dialog act recognition, in
Section 2. Then, in
Section 3, we discuss why using character-level tokenization is relevant for the task and define the aspects that we want to explore.
Section 4 describes our experimental setup, including the used datasets in
Section 4.1, our classification approach in
Section 4.2, and the evaluation method and word-level baselines in
Section 4.3. The results of our experiments are presented and discussed in
Section 5. Finally,
Section 6 states the most important conclusions of this study and provides pointers for future work.
2. Related Work
Automatic dialog act recognition is a task that has been widely explored over the years, using multiple classical machine learning approaches, from Hidden Markov Model (HMMs) [
15] to Support Vector Machine (SVMs) [
16,
17]. The article by Král and Cerisara [
2] provides an interesting overview on many of those approaches on the task. However, recently, similar to many other Natural Language Processing (NLP) tasks [
18,
19], most studies on dialog act recognition take advantage of different Neural Network (NN) architectures.
To our knowledge, the first of those studies was that by Kalchbrenner and Blunsom [
3]. The described approach uses a Convolutional Neural Network (CNN)-based approach to generate segment representations from randomly initialized word embeddings. Then, it uses a Recurrent Neural Network (RNN)-based discourse model that combines the sequence of segment representations with speaker information and outputs the corresponding sequence of dialog acts. By limiting the discourse model to consider information from the two preceding segments only, this approach achieved 73.9% accuracy on the SwDA corpus.
Lee and Dernoncourt [
4] compared the performance of a Long Short-Term Memory (LSTM) unit against that of a CNN to generate segment representations from pre-trained embeddings of its words. To generate the corresponding dialog act classifications, the segment representations were then fed to a two-layer feed-forward network, in which the first layer normalizes the representations and the second selects the class with highest probability. In their experiments, the CNN-based approach consistently led to similar or better results than the LSTM-based one. The architecture was also used to provide context information from up to two preceding segments at two levels. The first level refers to the concatenation of the representations of the preceding segments with that of the current segment before providing it to the feed-forward network. The second refers to the concatenation of the normalized representations before providing them to the output layer. This approach achieved 65.8%, 84.6%, and 71.4% accuracy on the Dialog State Tracking Challenge 4 (DSTC4) [
20], ICSI Meeting Recorder Dialog Act Corpus (MRDA) [
21], and SwDA corpora, respectively. However, the influence of context information varied across corpora.
Ji et al. [
5] explored the combination of positive aspects of NN architectures and probabilistic graphical models. They used a Discourse Relation Language Model (DRLM) that combined a Recurrent Neural Network Language Model (RNNLM) [
22] to model the sequence of words in the dialog with a latent variable model over shallow discourse structure to model the relations between adjacent segments which, in this context, are the dialog acts. This way, the model can perform word prediction using discriminatively-trained vector representations while maintaining a probabilistic representation of a targeted linguistic element, such as the dialog act. To function as a dialog act classifier, the model was trained to maximize the conditional probability of a sequence of dialog acts given a sequence of segments, achieving 77.0% accuracy on the SwDA corpus.
The previous studies explored the use of a single recurrent or convolutional layer to generate the segment representation from those of its words. However, the top performing approaches use multiple of those layers. On the one hand, Khanpour et al. [
23] achieved their best results using a segment representation generated by concatenating the outputs of a stack of 10 LSTM units at the last time step. This way, the model is able to capture long distance relations between tokens. On the convolutional side, Liu et al. [
6] generated the segment representation by combining the outputs of three parallel CNNs with different context window sizes to capture different functional patterns. In both cases, pre-trained word embeddings were used as input to the network. Overall, from the reported results, it is not possible to state which is the top performing segment representation approach since the evaluation was performed on different subsets of the SwDA corpus. However, Khanpour et al. [
23] reported 73.9% accuracy on the validation set and 80.1% on the test set, while Liu et al. [
6] reported 74.5% and 76.9% accuracy on the two sets used to evaluate their experiments. Additionally, Khanpour et al. [
23] reported 86.8% accuracy on the MRDA corpus.
Liu et al. [
6] also explored the use of context information concerning speaker changes and from the surrounding segments. The first was provided as a flag and concatenated to the segment representation. Concerning the latter, they explored the use of discourse models, as well as of approaches that concatenated the context information directly to the segment representation. The discourse models transform the model into a hierarchical one by generating a sequence of dialog act classifications from the sequence of segment representations. Thus, when predicting the classification of a segment, the surrounding ones are also taken into account. However, when the discourse model is based on a CNN or a bidirectional LSTM unit, it considers information from future segments, which is not available to a dialog system. However, even when relying on future information, the approaches based on discourse models performed worse than those that concatenated the context information directly to the segment representation. In this sense, providing that information in the form of the classification of the surrounding segments led to better results than using their words, even when those classifications were obtained automatically. This conclusion is in line with what we had shown in our previous study using SVMs [
17]. Furthermore, both studies have shown that, as expected, the first preceding segment is the most important and that the influence decays with the distance. Using the setup with gold standard labels from three preceding segments, the results on the two sets used to evaluate the approach improved to 79.6% and 81.8%, respectively.
Finally, considering the focus of this study, it is important to make some remarks concerning tokenization and token representation. In all the previously described studies, tokenization was performed at the word level. Furthermore, with the exception of the first study [
3], which used randomly initialized embeddings, the representation of those words was given by pre-trained embeddings. Khanpour et al. [
23] compared the performance when using Word2Vec [
24] and Global Vectors for Word Representation (GloVe) [
25] embeddings trained on multiple corpora. Although both embedding approaches capture information concerning words that commonly appear together, the best results were achieved using Word2Vec embeddings. In terms of dimensionality, that study compared embedding spaces with 75, 150, and 300 dimensions. The best results were achieved when using 150-dimensional embeddings. However, 200-dimensional embeddings were used in other studies [
4,
6], which was not one of the compared values.
3. The Character Level
It is interesting to explore character-level tokenization because it allows us to capture morphological information that is at the sub-word level and, thus, cannot be directly captured using word-level tokenization. Considering the task at hand, that information is relevant since it may provide cues for identifying the intention behind the words. When someone selects a set of words to form a segment that transmits a certain intention, each of those words is typically selected because it has a function that contributes to that transmission. In this sense, affixes are tightly related to word function, especially in fusional languages. Thus, the presence of certain affixes is a cue for intention, independently of the lemma. However, there are also cases, such as when affixes are used for subject–verb agreement, in which the cue for intention is in the lemmas and, thus, considering multiple forms of the same lexeme does not provide additional information.
Information concerning lemmas and affixes cannot be captured from single independent characters. Thus, it is necessary to consider the context surrounding each token and look at groups of characters. The size of the context window plays an important part in what information can be captured. For instance, English affixes are typically short (e.g., un-, -ly, and a-), but in other languages, such as Spanish, there are longer commonly used affixes (e.g., -mente, which is used to transform adjectives into adverbs in the same manner as -ly in English). Furthermore, to capture the lemmas of long words, the agglutinative aspects of German, and even inter-word relations, wider context window sizes must be considered. However, using wide context windows impairs the ability to capture information from short groups of characters, as additional irrelevant characters are considered. This suggests that, to capture all the relevant information, multiple context windows should be used.
Using character-level tokenization also allows us to consider punctuation, which is able to provide both direct and indirect cues for dialog act recognition. For instance, an interrogation mark provides a direct cue that the intention is related to knowledge seeking. On the other hand, commas structure the segment, indirectly contributing to the transmission of an intention.
Additionally, character-level tokenization allows us to consider capitalization information. However, in the beginning of a segment, capitalization only signals that beginning and, thus, considering it only introduces entropy. In both English and Spanish, capitalization in the middle of a segment is typically only used to distinguish proper nouns, which are not related to intention. In German, all nouns are capitalized, which simplifies their distinction from words of other classes, such as adjectives. However, while some nouns may be related to intention, others are not. Thus, capitalization information is not expected to contribute to the task.
Finally, previous studies have shown that word-level information is relevant for the task and that word-level approaches are able to identify intention with acceptable performance. Although we expect character-level approaches to be able to capture most of the information that is captured at the word level, exploring the character level highly increases the number of tokens in a segment, which introduces a large amount of entropy. Thus, it is possible that some specific aspects can only be captured at the word level. In this case, it is important to assess whether both approaches are complementary.
6. Conclusions
In this article, we have assessed the importance of information at a sub-word level, which cannot be captured by word-level approaches, for automatic dialog act recognition in three different languages—English, Spanish, and German—on dialogs covering multiple domains, and using both domain-independent and domain-dependent tag sets.
We used character-level tokenization together with multiple character windows with different sizes to capture relevant morphological elements, such as affixes and lemmas, as well as long words and inter-word information. Furthermore, we have shown that, as expected, punctuation is important for the task since it is able to provide both direct and indirect cues regarding intention. On the other hand, capitalization is irrelevant under normal conditions.
Our character-level approach achieved results that are in line or surpass those achieved using state-of-the-art word-based approaches. The only exception was when predicting the domain-specific labels of Level 3 of the DIHANA corpus. However, this level refers to information that is explicitly referred to in the segment. Thus, it is highly keyword oriented and using character information introduces unnecessary entropy. In the remaining cases, the character-level approach was always able to capture relevant information, independently of the domain of the dialog, the domain-dependence of the dialog act labels, and the language. Concerning the latter, it was interesting to observe that the highest performance gain in comparison with the word-level approaches occurred in German data, while the lowest occurred in English data. This suggests that the amount of relevant information at the sub-word level increases with the level of inflection of the language.
Furthermore, our experiments revealed that in most cases the character- and word-level approaches capture complementary information and, consequently, their combination leads to improved performance on the task. In this sense, by combining both approaches with context information, we achieved state-of-the-art results on SwDA corpus, which is the most explored corpus for dialog act recognition. Additionally, given appropriate context information, our approach also achieved results that surpass the previous state-of-the-art on the DIHANA and LEGO corpora. On the VERBMOBIL corpus, we were not able to compare our results with those of previous studies, since they use different label sets.
In terms of morphological typology, although English has a more analytic structure than Spanish, and German has some agglutinative aspects, the three are fusional languages. Thus, as future work, it would be interesting to assess the performance of the character-level approach when dealing with data in analytic languages, such as Chinese, and agglutinative languages, such as Turkish. However, it is hard to obtain annotated corpora with such characteristics and it is hard to draw conclusions without knowledge of those languages.





{kind=link}
{kind=link}