1. Introduction
An increasing number of individual investors have recently become involved with equity markets. Mutual funds are also becoming popular, especially in Japan. A mutual fund is a financial derivative and built by companies, such as mutual fund companies and insurance companies, and contains equities in its portfolio.
Although exchange traded funds (ETF), which are also a financial derivatives, are fixed regarding their constituents, fund managers can change a mutual fund based on its constituents. This means a mutual fund is controlled by fund managers who also determine the equities that are bought or sold in the portfolio.
Themed mutual funds are popular among Japanese individual investors. A themed mutual fund is a mutual fund having one specific theme such as health, robotics, or artificial intelligence (AI). Such a fund is aimed at obtaining high returns from the theme’s prosperity. For example, an AI fund should include assets related to AI such as stocks in NVIDIA, and if AI technologies further develop and AI becomes more widespread, these assets’ prices will increase.
To attract many customers, mutual fund companies have to develop, launch, and manage various types of themed mutual funds. However, building such funds is burdensome for fund managers.
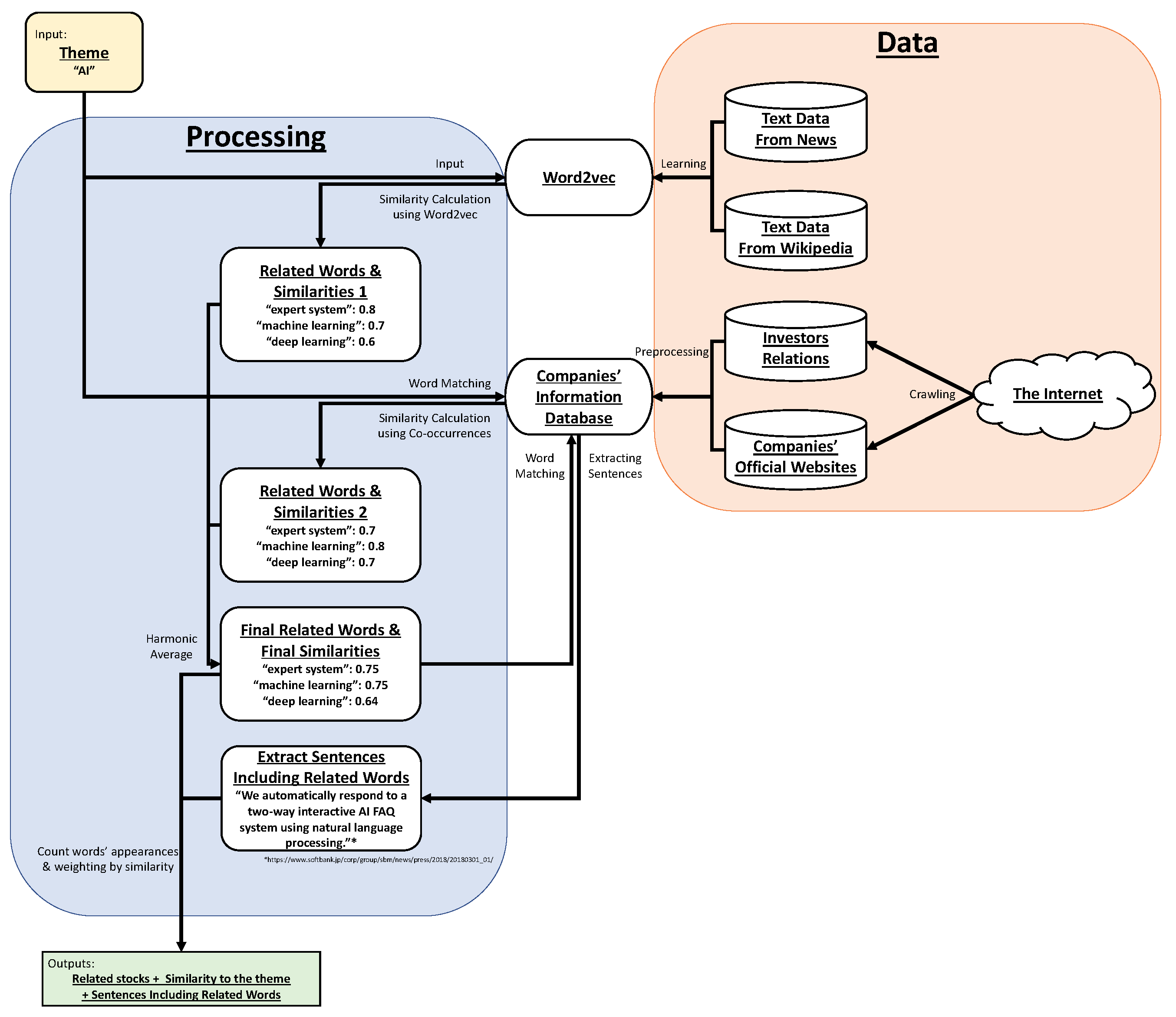
The following is the procedure fund managers use to build themed funds: (a) selecting a theme for the fund; (b) selecting stocks related to the fund’s theme; (c) using some of the selected stocks to build a portfolio for asset management.
Selecting stocks related to the fund’s theme is quite difficult for fund managers because there is a huge number of stocks. Even in the Tokyo Stock Exchange alone there are over 3600 stocks. For themed mutual funds focusing only on Japanese stocks, fund managers need to search only Japanese stocks and their information (company information) to build funds. However, focusing on stocks from around the world is practically impossible. Even focusing only on Japanese stocks, selecting all related stocks is difficult for fund managers who are not familiar with a fund’s theme. In addition, there is a good chance of missing related stocks because of human errors or fund managers’ lack of knowledge for companies. So, to reduce the burden of fund managers and avoid missing promising stocks, a method selecting related stocks automatically is needed.
As the method, we propose a scheme extended from our previous scheme [
1]. We developed the previous scheme to handle this task mainly using natural language processing (NLP). Details of this and the extended scheme are given in
Section 2. The main contributions in this article are as follows: (a) extending our previous scheme, (b) creating ground truth data through collaboration with experienced fund managers and evaluating our scheme, (c) assessing the task difficulty from preliminary experiments, (d) hyperparameter tuning for our scheme, and (e) deeper analysis for data collaboration.
Author Contributions
Conceptualization, M.H., H.S., S.K., K.I., H.M., S.N., and A.K.; methodology, M.H.; software, M.H.; validation, M.H.; formal analysis, M.H.; investigation, M.H.; resources, M.H., S.K., S.N., and A.K.; data curation, M.H., S.K., S.N., and A.K.; writing-original draft preparation, M.H.; writing-review and editing, M.H., H.S., and K.I.; visualization, M.H.; supervision, M.H., H.S., and K.I.; project administration, H.S., and K.I.; funding acquisition, H.S., K.I., and H.M.
Funding
This research was funded by Daiwa Securities Group.
Acknowledgments
We thank Uno, G.; Shiina, R.; Suda, H.; Ishizuka, T. and Ono, Y. from Daiwa Asset Management Co. Ltd. for participating in our interviews. In the process to make our scheme, we referred to a fund candidates list provided by Suda, H. We thank Takebayashi, M.; Kounishi, T.; Suda, H. and Shiina, R. for making evaluation data. We also thank Tsubone, N. from Daiwa Institute of Research Ltd. for supporting our meeting, Morioka, T. from Daiwa Institute of Research Ltd. for providing our communication tool, and Yamamoto, Y. from the School of Engineering, The University of Tokyo for assisting in our clerical tasks including scheduling.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Hirano, M.; Sakaji, H.; Kimura, S.; Izumi, K.; Matsushima, H.; Nagao, S.; Kato, A. Selection of related stocks using financial text mining. In Proceedings of the 18th IEEE International Conference on Data Mining Workshops (ICDMW 2018), Singapore, 17–20 November 2018; pp. 191–198. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations (ICLR 2013), Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Nagata, R.; Nishite, S.; Ototake, H. A method for detecting overgeneralized be-verb based on subject-compliment identification. In Proceedings of the 32nd Annual Conference of the Japanese Society for Artificial Intelligence (JSAI 2018), Kagoshima, Japan, 5–8 June 2018. (In Japanese). [Google Scholar]
- Neubig, G.; Nakata, Y.; Mori, S. Pointwise prediction for robust, adaptable Japanese morphological analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL HLT 2011); Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 529–533. [Google Scholar]
- Morita, H.; Kawahara, D.; Kurohashi, S. Morphological analysis for unsegmented languages using recurrent neural network language model. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015), Lisbon, Portugal, 17–21 September 2015; pp. 2292–2297. [Google Scholar]
- Kudo, T.; Yamamoto, K.; Matsumoto, Y. Applying conditional random fields to Japanese morphological analysis. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP 2004), Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Toshinori, S. Neologism Dictionary Based on the Language Resources on the Web for Mecab. 2015. Available online: https://github.com/neologd/mecab-ipadic-neologd (accessed on 6 March 2019).
- Toshinori, S.; Taiichi, H.; Manabu, O. Operation of a word segmentation dictionary generation system called NEologd. In Information Processing Society of Japan, Special Interest Group on Natural Language Processing (IPSJ SIGNL 2016); Information Processing Society of Japan: Tokyo, Japan, 2016; p. NL-229-15. (In Japanese) [Google Scholar]
- Toshinori, S.; Taiichi, H.; Manabu, O. Implementation of a word segmentation dictionary called mecab-ipadic-NEologd and study on how to use it effectively for information retrieval. In Proceedings of the Twenty-three Annual Meeting of the Association for Natural Language Processing (NLP 2017); The Association for Natural Language Processing: Tokyo, Japan, 2017; p. NLP2017-B6-1. (In Japanese) [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Cohen, J. Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit. Psychol. Bull. 1968, 70, 213–220. [Google Scholar] [CrossRef] [PubMed]
- Jarvelin, K.; Kekalainen, J. IR evaluation methods for retrieving highly relevant documents. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’00); ACM Press: New York, NY, USA, 2000; pp. 41–48. [Google Scholar] [CrossRef]
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- Koppel, M.; Shtrimberg, I. Good news or bad news? Let the market decide. In Computing Attitude and Affect in Text: Theory and Applications; Springer: Dordrecht, The Netherlands, 2006; pp. 297–301. [Google Scholar]
- Fellbaum, C. WordNet: An Electronic Lexical Database; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Low, B.T.; Chan, K.; Choi, L.L.; Chin, M.Y.; Lay, S.L. Semantic expectation-based causation knowledge extraction: A study on Hong Kong stock movement analysis. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2001), Hong Kong, China, 16–18 April 2001; pp. 114–123. [Google Scholar]
- Schumaker, R.P.; Chen, H. Textual analysis of stock market prediction using breaking financial news: The AZFin text system. ACM Trans. Inf. Syst. 2009, 27, 12. [Google Scholar] [CrossRef]
- Ito, T.; Sakaji, H.; Tsubouchi, K.; Izumi, K.; Yamashita, T. Text-visualizing neural network model: Understanding online financial. In Proceedings of the 22nd Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2018), Melbourne, Australia, 3–6 June 2018; pp. 247–259. [Google Scholar] [CrossRef]
- Ito, T.; Sakaji, H.; Izumi, K.; Tsubouchi, K.; Yamashita, T. GINN: Gradient interpretable neural networks for visualizing financial texts. Int. J. Data Sci. Anal. 2018, 1–15. [Google Scholar] [CrossRef]
- Milea, V.; Sharef, N.M.; Almeida, R.J.; Kaymak, U.; Frasincar, F. Prediction of the MSCI EURO index based on fuzzy grammar fragments extracted from European Central Bank statements. In Proceedings of the 2010 International Conference of Soft Computing and Pattern Recognition, Paris, France, 7–10 December 2010; pp. 231–236. [Google Scholar] [CrossRef]
- Xing, F.; Cambria, E.; Welsch, R.E. Growing semantic vines for robust asset allocation. Knowl. Based Syst. 2018, 165, 297–305. [Google Scholar] [CrossRef]
- Sakai, H.; Masuyama, S. Extraction of cause information from newspaper articles concerning business performance. In Proceedings of the 4th IFIP Conference on Artificial Intelligence Applications & Innovations (AIAI 2007), Athens, Greece, 19–21 September 2007; pp. 205–212. [Google Scholar] [CrossRef]
- Sakaji, H.; Sakai, H.; Masuyama, S. Automatic extraction of basis expressions that indicate economic trends. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2008), Osaka, Japan, 20–23 May 2008; pp. 977–984. [Google Scholar] [CrossRef]
- Sakaji, H.; Murono, R.; Sakai, H.; Bennett, J.; Izumi, K. Discovery of rare causal knowledge from financial statement summaries. In Proceedings of the 2017 IEEE Symposium on Computational Intelligence for Financial Engineering and Economics (CIFEr 2017), Honolulu, HI, USA, 27 November–1 December 2017; pp. 602–608. [Google Scholar] [CrossRef]
- Kitamori, S.; Sakai, H.; Sakaji, H. Extraction of sentences concerning business performance forecast and economic forecast from summaries of financial statements by deep learning. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (IEEE SSCI 2017), Honolulu, HI, USA, 27 November–1 December 2017; pp. 67–73. [Google Scholar] [CrossRef]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work (CSCW ’94); ACM Press: New York, NY, USA, 1994; pp. 175–186. [Google Scholar] [CrossRef]
- Shardanand, U.; Maes, P. Social information filtering: Algorithms for automating “Word of Mouth”. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’95); ACM Press: New York, NY, USA, 1995; pp. 210–217. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web; ACM Press: New York, NY, USA, 2001; pp. 285–295. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Int. Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).

 ,
, 



{kind=link}
{kind=link}