Nonparametric Hyperbox Granular Computing Classification Algorithms

Abstract
:1. Introduction
2. Nonparametric Granular Computing
2.1. Representation of Hyperbox Granule
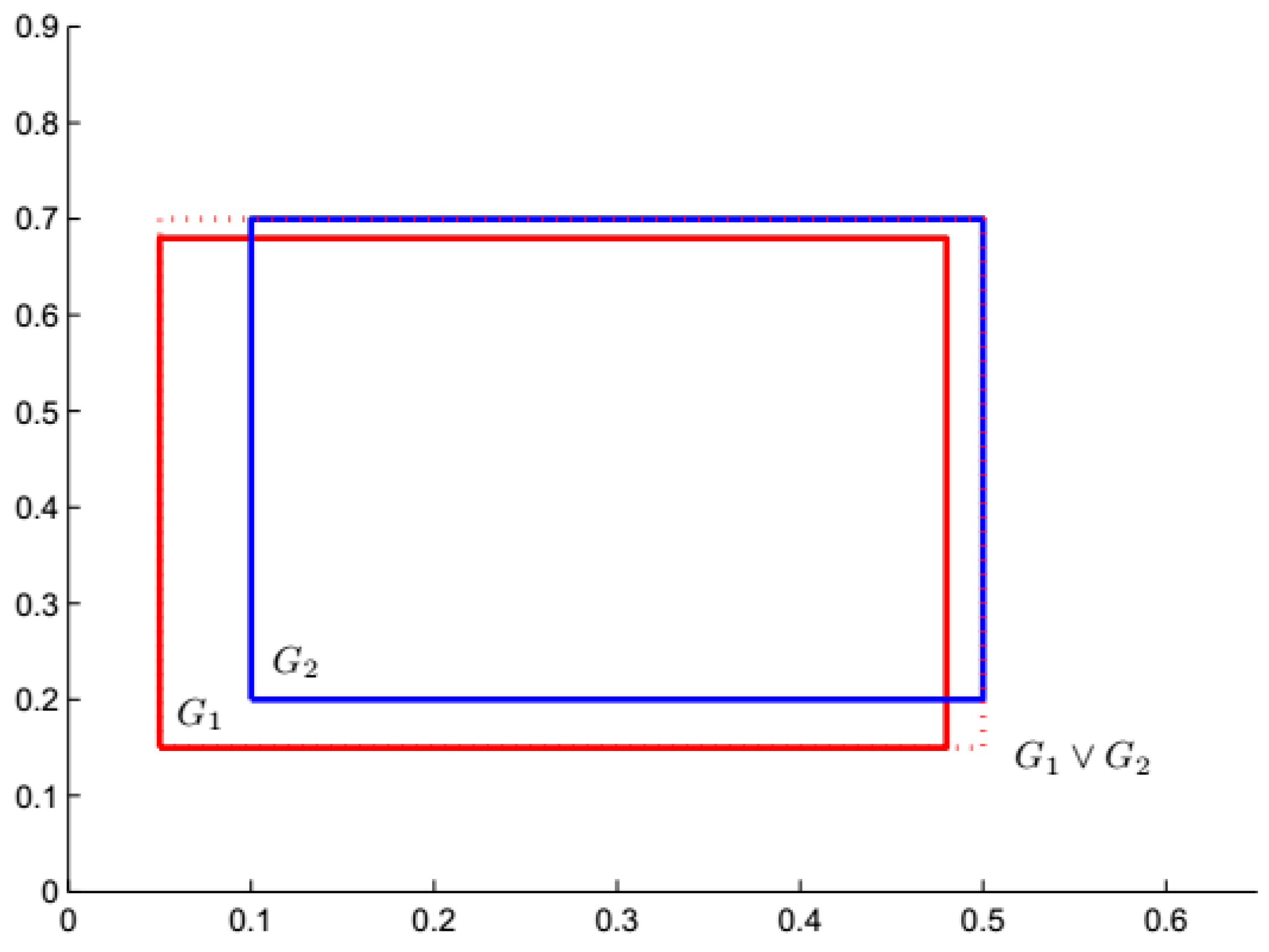
2.2. Operations between Two Hyperbox Granules
2.3. Novel Distance between Two Hyperbox Granules
2.4. Nonparametric Granular Computing Classification Algorithms
| Algorithm 1: Training process |
| Input: Training set Output: Hyperbox granule set , the class label corresponding to S1. Initialize the hyperbox granule set , ; S2. ; S3. Select the samples with class labels , and generate set ; S4. Initialize the hyperbox granule set ; S5. If , the sample in is selected to construct the corresponding atomic hyperbox granule , is removed from , otherwise ; S6. The sample is selected from and forms the hyperbox granule ; S7. If the join hyperbox granule between and does not include the other class sample, the is replaced by the join hyperbox granule and the samples included in with the class labels i are removed from X, namely, , otherwise and are updated, , ; S8. ; S9. If , output and class label , otherwise . |
| Algorithm 2: Testing process |
| Input: inputs of unknown datum , the trained hyperbox granule set and class label Output: class label of S1. For ; S2. Compute the distance between and in ; S3. Find the minimal distance ; S4. Find the corresponding class label of the as the label of . |
3. Experiments
3.1. Classification Problems in 2-D Space
3.2. Classification Problems in N-dimensional (N-D) Space
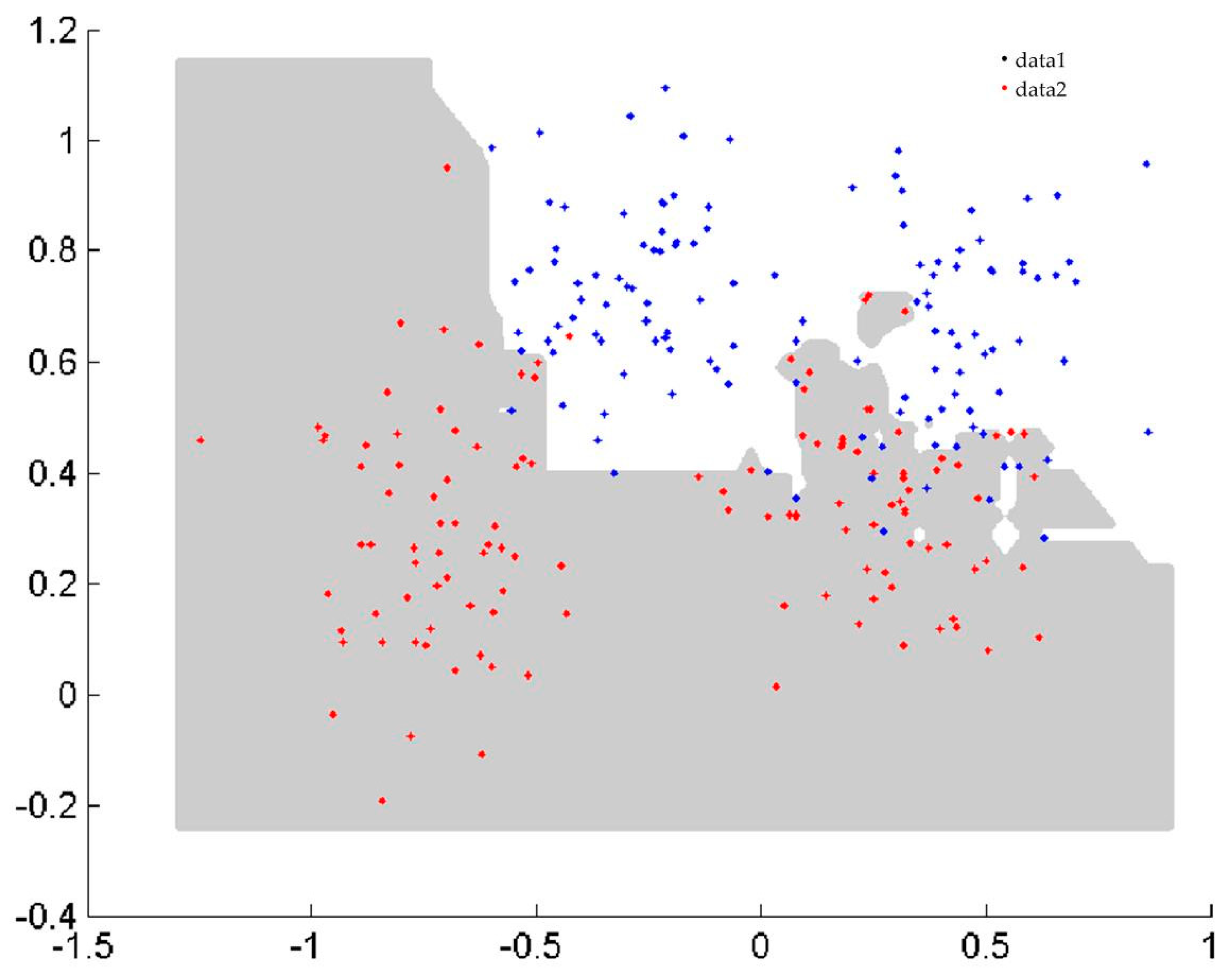
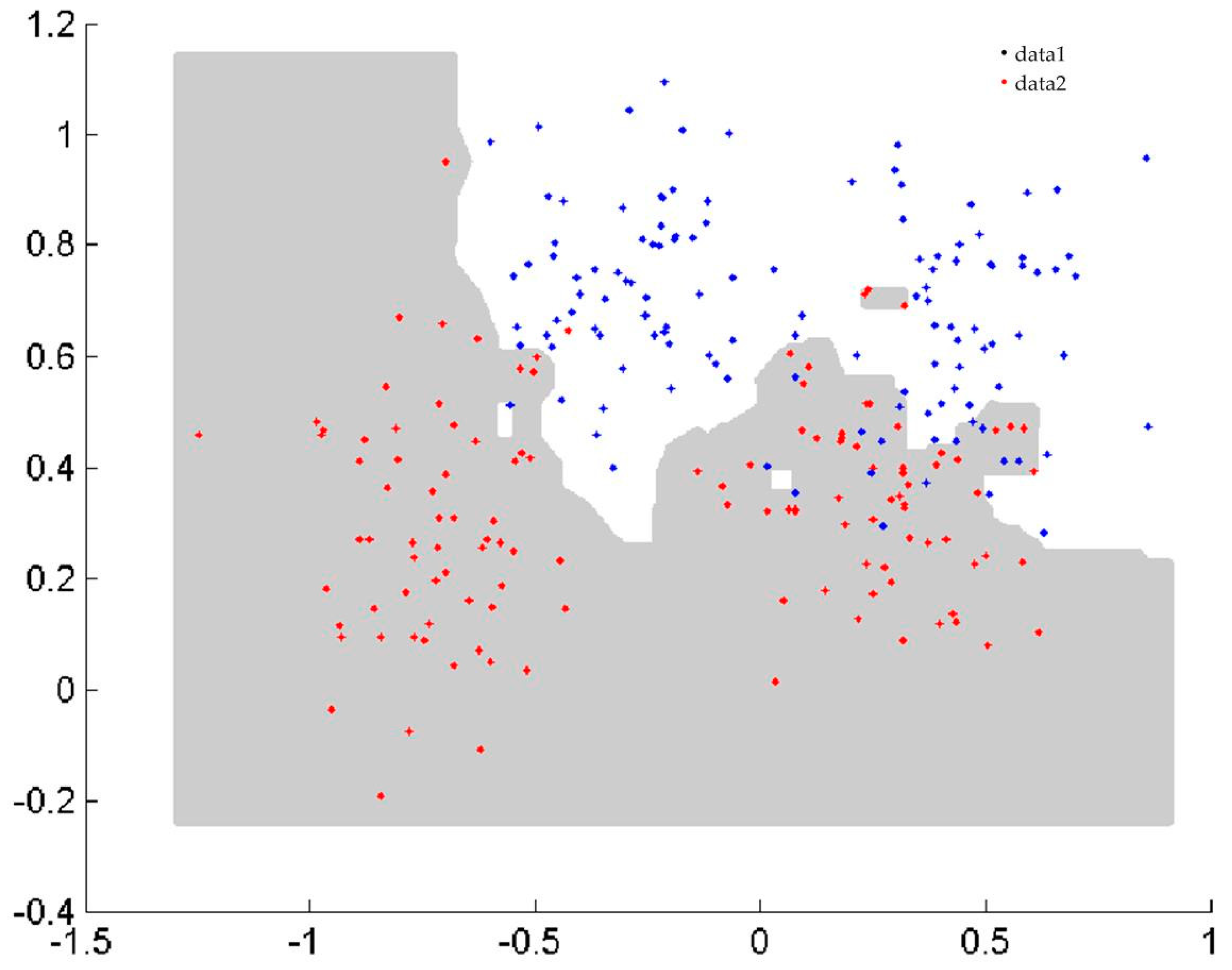
3.3. Classification for Imbalanced Datasets
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ristin, M.; Guillaumin, M.; Gall, J.; Van Gool, L. Incremental Learning of Random Forests for Large-Scale Image Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 490–503. [Google Scholar] [CrossRef] [PubMed]
- Garro, B.A.; Rodríguez, K.; Vázquez, R.A. Classification of DNA microarrays using artificial neural networks and ABC algorithm. Appl. Soft Comput. 2016, 38, 548–560. [Google Scholar] [CrossRef]
- Yousef, A.; Charkari, N.M. A novel method based on physicochemical properties of amino acids and one class classification algorithm for disease gene identification. J. Biomed. Inform. 2015, 56, 300–306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaburlasos, V.G.; Kehagias, A. Fuzzy Inference System (FIS) Extensions Based on the Lattice Theory. IEEE Trans. Fuzzy Syst. 2014, 22, 531–546. [Google Scholar] [CrossRef]
- Kaburlasos, V.G.; Pachidis, T.P. A Lattice—Computing ensemble for reasoning based on formal fusion of disparate data types, and an industrial dispensing application. Inform. Fusion 2014, 16, 68–83. [Google Scholar] [CrossRef]
- Kaburlasos, V.G.; Papadakis, S.E.; Papakostas, G.A. Lattice Computing Extension of the FAM Neural Classifier for Human Facial Expression Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1526–1538. [Google Scholar] [CrossRef] [PubMed]
- Kaburlasos, V.G.; Papakostas, G.A. Learning Distributions of Image Features by Interactive Fuzzy Lattice Reasoning in Pattern Recognition Applications. IEEE Comput. Intell. Mag. 2015, 10, 42–51. [Google Scholar] [CrossRef]
- Liu, H.; Li, J.; Guo, H.; Liu, C. Interval analysis-based hyperbox granular computing classification algorithms. Iranian J. Fuzzy Sys. 2017, 14, 139–156. [Google Scholar]
- Guo, H.; Wang, W. Granular support vector machine: A review. Artif. Intell. Rev. 2017, 51, 19–32. [Google Scholar] [CrossRef]
- Wang, Q.; Nguyen, T.-T.; Huang, J.Z.; Nguyen, T.T. An efficient random forests algorithm for high dimensional data classification. Adv. Data Anal. Classif. 2018, 12, 953–972. [Google Scholar] [CrossRef]
- Kordos, M.; Rusiecki, A. Reducing noise impact on MLP training—Techniques and algorithms to provide noise-robustness in MLP network training. Soft Comput. 2016, 20, 49–65. [Google Scholar] [CrossRef]
- Zadeh, L.A. Some reflections on soft computing, granular computing and their roles in the conception, design and utilization of information/intelligent systems. Soft Comput. 1998, 2, 23–25. [Google Scholar] [CrossRef]
- Yao, Y.; She, Y. Rough set models in multigranulation spaces. Inform. Sci. 2016, 327, 40–56. [Google Scholar] [CrossRef]
- Yao, Y.; Zhao, L. A measurement theory view on the granularity of partitions. Inform. Sci. 2012, 213, 1–13. [Google Scholar] [CrossRef]
- Savchenko, A.V. Fast multi-class recognition of piecewise regular objects based on sequential three-way decisions and granular computing. Knowl. Based Syst. 2016, 91, 252–262. [Google Scholar] [CrossRef]
- Kerr-Wilson, J.; Pedrycz, W. Design of rule-based models through information granulation. Exp. Syst. Appl. 2016, 46, 274–285. [Google Scholar] [CrossRef]
- Bortolan, G.; Pedrycz, W. Hyperbox classifiers for arrhythmia classification. Kybernetes 2007, 36, 531–547. [Google Scholar] [CrossRef]
- Hu, X.; Pedrycz, W.; Wang, X. Comparative analysis of logic operators: A perspective of statistical testing and granular computing. Int. J. Approx. Reason. 2015, 66, 73–90. [Google Scholar] [CrossRef]
- Pedrycz, W. Granular fuzzy rule-based architectures: Pursuing analysis and design in the framework of granular computing. Intell. Decis. Tech. 2015, 9, 321–330. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, Q.; Wu, K.; Zhu, S.; Zeng, Z. A binary granule representation for uncertainty measures in rough set theory. J. Intell. Fuzzy Syst. 2015, 28, 867–878. [Google Scholar]
- Hońko, P. Association discovery from relational data via granular computing. Inform. Sci. 2013, 234, 136–149. [Google Scholar] [CrossRef]
- Eastwood, M.; Jayne, C. Evaluation of hyperbox neural network learning for classification. Neurocomputing 2014, 133, 249–257. [Google Scholar] [CrossRef]
- Sossa, H.; Guevara, E. Efficient training for dendrite morphological neural networks. Neurocomputing 2014, 131, 132–142. [Google Scholar] [CrossRef] [Green Version]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Fernández, A.; Garcia, S.; Del Jesus, M.J.; Herrera, F. A study of the behaviour of linguistic fuzzy rule-based classification systems in the framework of imbalanced data-sets. Fuzzy Sets Syst. 2008, 159, 2378–2398. [Google Scholar] [CrossRef]
- Akbulut, Y.; Şengür, A.; Guo, Y.; Smarandache, F. A Novel Neutrosophic Weighted Extreme Learning Machine for Imbalanced Data Set. Symmetry 2017, 9, 142. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Tr | #Ts | Algorithms | Par. | Ng | TAC | AC | T(s) |
|---|---|---|---|---|---|---|---|---|
| Spiral | 970 | 194 | NPHBGrC HBGrC | – 0.08 | 58 161 | 100 100 | 99.48 99.48 | 0.6864 1.6380 |
| Ripley | 250 | 1000 | NPHBGrC HBGrC | – 0.27 | 32 67 | 100 96 | 90.2 90.1 | 0.0625 0.1159 |
| Sensor2 | 4487 | 569 | NPHBGrC HBGrC | – 4 | 4 8 | 100 100 | 99.47 99.47 | 1.0764 1.365 |
| Datasets | N | Classes | Samples |
|---|---|---|---|
| Iris | 4 | 3 | 150 |
| Wine | 13 | 3 | 178 |
| Phoneme | 5 | 2 | 5404 |
| Sensor4 | 4 | 4 | 5456 |
| Car | 6 | 5 | 1728 |
| Cancer2 | 30 | 2 | 532 |
| Semeion | 256 | 10 | 1593 |
| Dataset | Algorithms | Testing Accuracy | T(s) | |||
|---|---|---|---|---|---|---|
| max | mean | min | std | |||
| Iris | NPHBGrC | 100 | 98.6667 | 93.3333 | 3.4427 | 0.0265 |
| HBGrC | 100 | 97.3333 | 93.3333 | 2.8109 | 1.1560 | |
| Wine | NPHBGrC | 100 | 96.8750 | 93.7500 | 3.2940 | 0.0406 |
| HBGrC | 100 | 96.2500 | 87.5000 | 4.3700 | 1.0140 | |
| Phoneme | NPHBGrC | 91.6512 | 89.8236 | 88.3117 | 1.1098 | 22.4844 |
| HBGrC | 87.5696 | 85.9350 | 83.1169 | 1.3704 | 422.3009 | |
| Cancer1 | NPHBGrC | 100 | 98.5075 | 95.5224 | 1.7234 | 0.9064 |
| HBGrC | 100 | 97.6362 | 92.5373 | 2.6615 | 69.8214 | |
| Sensor4 | NPHBGrC | 100 | 99.4551 | 97.4217 | 0.8621 | 1.0670 |
| HBGrC | 100 | 99.2157 | 96.6851 | 0.9944 | 71.8509 | |
| Car | NPHBGrC | 97.6608 | 91.1445 | 81.8713 | 5.3834 | 8.7532 |
| HBGrC | 94.7368 | 85.9593 | 77.7778 | 5.5027 | 1166.5 | |
| Cancer2 | NPHBGrC | 100 | 98.0769 | 92.3077 | 2.3985 | 0.4602 |
| HBGrC | 100 | 97.4159 | 94.2308 | 1.9107 | 7.5676 | |
| Semeion | NPHBGrC | 100 | 98.7512 | 97.4026 | 0.7177 | 6.7127 |
| HBGrC | 97.4026 | 94.9881 | 92.2078 | 1.4397 | 533.2691 | |
| Algorithms | Iris | Wine | Phoneme | Cancer1 | ||||
| h-value | p-value | h-value | p-value | h-value | p-value | h-value | p-value | |
| NPHBGrC-HBGrC | 0 | 0.3553 | 0 | 0.7222 | 1 | 0 | 0 | 0.3963 |
| Algorithms | Sensor4 | Car | Cancer2 | Semeion | ||||
| h-value | p-value | h-value | p-value | h-value | p-value | h-value | p-value | |
| NPHBGrC-HBGrC | 0 | 0.5722 | 1 | 0.0472 | 0 | 0.5041 | 1 | 0 |
| Tests | AC (%) | C1AC (%) | C2AC (%) | G (%) | ||||
|---|---|---|---|---|---|---|---|---|
| NPHBGrC | HBGrC | NPHBGrC | HBGrC | NPHBGrC | HBGrC | NPHBGrC | HBGrC | |
| Test 1 | 78.7879 | 76.4310 | 58.1395 | 54.6512 | 87.2038 | 85.3081 | 75.4026 | 68.2802 |
| Test 2 | 74.0741 | 73.7374 | 48.8372 | 44.1860 | 84.3602 | 85.7820 | 72.8299 | 61.5659 |
| Test 3 | 76.7677 | 74.0741 | 55.8140 | 54.6512 | 85.3081 | 81.9905 | 74.7530 | 66.9394 |
| Test 4 | 74.0741 | 73.4007 | 51.1628 | 47.6744 | 83.4123 | 83.8863 | 74.7382 | 63.2395 |
| Test 5 | 76.0135 | 74.6622 | 57.6471 | 48.2353 | 83.4123 | 85.3081 | 73.2875 | 64.1472 |
| mean | 75.9435 | 74.4611 | 54.3201 | 49.8796 | 84.7393 | 84.4550 | 74.2023 | 64.8344 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Diao, X.; Guo, H. Nonparametric Hyperbox Granular Computing Classification Algorithms. Information 2019, 10, 76. https://doi.org/10.3390/info10020076
Liu H, Diao X, Guo H. Nonparametric Hyperbox Granular Computing Classification Algorithms. Information. 2019; 10(2):76. https://doi.org/10.3390/info10020076
Chicago/Turabian StyleLiu, Hongbing, Xiaoyu Diao, and Huaping Guo. 2019. "Nonparametric Hyperbox Granular Computing Classification Algorithms" Information 10, no. 2: 76. https://doi.org/10.3390/info10020076
APA StyleLiu, H., Diao, X., & Guo, H. (2019). Nonparametric Hyperbox Granular Computing Classification Algorithms. Information, 10(2), 76. https://doi.org/10.3390/info10020076