Abstract
Parametric granular computing classification algorithms lead to difficulties in terms of parameter selection, the multiple performance times of algorithms, and increased algorithm complexity in comparison with nonparametric algorithms. We present nonparametric hyperbox granular computing classification algorithms (NPHBGrCs). Firstly, the granule has a hyperbox form, with the beginning point and the endpoint induced by any two vectors in N-dimensional (N-D) space. Secondly, the novel distance between the atomic hyperbox and the hyperbox granule is defined to determine the joining process between the atomic hyperbox and the hyperbox. Thirdly, classification problems are used to verify the designed NPHBGrC. The feasibility and superiority of NPHBGrC are demonstrated by the benchmark datasets compared with parametric algorithms such as HBGrC.
1. Introduction
The classification algorithm is a traditional data analysis method that is widely applied in many fields, including computer vision [1], DNA analysis [2], and physical chemistry [3]. For classification problems, the main method is the parameter-based learning method, whereby the relation between the input and the output is found to predict the class label of an input with unknown class label. The parameter-based learning method includes the analytic function method and the discrete inclusion relation method. The analytic function method establishes the mapping relationship between the input and output of the training datasets. The trained mapping is used to predict the class label of inputs with unknown class labels. Support Vector Machine (SVM) and multilayer perceptron (MLP) are kinds of methods by which linear or nonlinear mapping relationships are formed to predict the class label of inputs without class labels. The discrete inclusion relation method estimates the class labels of inputs based on the discrete inclusion relation between an input with a determined class label and an input without a class label and includes techniques such as random forest (RF) and granular computing (GrC). In this paper, we mainly study the classification algorithm using GrC, especially GrC with the form of hyperbox granule, the superiority and feasibility of which are shown in references [4,5,6,7,8,9,10,11].
As a classification and clustering method, GrC involves a computationally intelligent theory and method, and jumps back-and-forth between different granularity spaces [12,13,14]. Being fundamentally a data analysis method, GrC is commonly studied from the perspectives of theory and application, the latter of which includes pattern recognition, image processing, and industrial applications [12,13,14,15,16,17,18,19]. The main research issues of GrC include shape, operation, relation, granularity, etc.
A granule is a set of objects in which the elements are regarded to be objects with similar properties [17]. Binary granular computing proposes a conventional binary relation between two sets. Correspondingly, the operations between two sets are converted into the operation between two granules, such as the intersection operation and the union operation between two sets (granules). Another research issue in GrC is how to define the distance between two granules. Chen and his colleague introduced Hamming distance to understand distance measurements with respect to binary granules for a rough set. Moreover, granule swarm distance is used to measure the uncertainty between two granules [20].
Operations between two granules are expressed as the equivalent form of membership grades, which are produced by the two triangular norms [15]. Kaburlasos defined the join operation and the meet operation as inducing granules with different granularity in terms of the theory of lattice computing [5,6]. Kaburlasos defined the fuzzy inclusion measure between two granules on the basis of the defined join operation and meet operation, and the fuzzy lattice reasoning classification algorithm was designed based on the distance between the beginning point and the endpoint of the hyperbox granule [7].
The relation between two granules is mainly used to generate the rules of association between inputs and outputs for classification problems and regression problems. A specialized version of this general framework is proposed by GrC theory in order to mine the potential relations behind data [21]. Kaburlasos and his colleague embed the lattice computing, including GrC, into a fuzzy inference system (FIS), and preliminary industrial applications have demonstrated the advantages of their proposed GrC methods [4].
Granularity is the index of measurement for the size of a granule and the means by which the granularity of a granule can be measured is one of the foundational issues in GrC. Yao regarded a granule as a set and defined the granularity as the cardinality of the set by a strictly monotonic function [14]. As a classification algorithm, GrC is concerned with human information processing procedures: the procedure includes both the data abstraction and the derivation of knowledge from information. To induce and deduce knowledge from the data, parameters are introduced to achieve suitable prior knowledge from the given data, such as the granularity threshold, the λ of positive valuation function used for the construction of fuzzy inclusion measure between two granules, and the maximal number of data belonging the granule, thus resulting in some redundant granules during the training process. On one hand, these parameters improve the performance of GrC classification algorithms and GrC clustering algorithms. On the other hand, these parameters also have negative impacts, such as the higher time consumption required by parametric GrC compared with nonparametric GrC algorithms.
The proposed nonparametric hyperbox GrC has two main advantages for classification tasks. First, the nonparametric hyperbox GrC achieved better performance when compared with the parametric hyperbox GrC. Second, compared with the nonparametric hyperbox GrC, the parametric hyperbox GrC classification algorithms perform the algorithm multiple times, which is time-consuming for the selection of parameters, such as the parameter for positive valuation function and the threshold of granularity. The nonparametric hyperbox granular computing classification algorithm (NPHBGrC) includes the following steps. First, the granule has a regular hyperbox shape, with the beginning point and the endpoint that are induced by two vectors in N-dimensional (N-D) space; second, the distance between two hyperbox granules is introduced to determine their join process; and third, the NPHBGrC is designed and verified by the benchmark dataset compared with hyperbox granular computing classification algorithms (HBGrCs).
2. Nonparametric Granular Computing
In this section, we discuss the nonparametric granular computing, including the representation of granules, the operation between two granules, and the distance between two granules.
2.1. Representation of Hyperbox Granule
For granular computing in N-D space, we suppose a granule as a regular shape, such as a hyperbox with the beginning point and the endpoint which satisfy the partial order relation . The beginning point and the endpoint are vectors in N-D space, and the hyperbox granule has the form , where is the beginning point and is the endpoint. For any two vectors and , if the two vectors and satisfy the partial order relation , then and , otherwise and . The partial order relation between two vectors in N-D space is defined as follows
The operation and operation between two vectors are defined as follows
where the operation and operation between two scalars are and .
Obviously, for two vectors and in N-D space, we form the hyperbox granule with the form of vector , where is the beginning point and is the endpoint of the granule. In the following sections, we represent hyperbox granule by for N-D space. In 2-D space, the granule is box, and in N-D space, the granule is a hyperbox.
2.2. Operations between Two Hyperbox Granules
For two hyperbox granules and , the join hyperbox granule is the following form by the join operation
where and are vectors, , .
The join hyperbox granule has greater granularity than the original hyperbox granules. The original hyperbox granules and the join hyperbox granule have the following relations.
The meet hyperbox granule has the following form by the meet operation
The meet hyperbox granule has less granularity than the original hyperbox granules. The meet hyperbox granule and the original hyperbox granules have the following relations.
For example, in 2-D space, and are two hyperbox granules, and their join hyperbox granule is , which is induced by the aforementioned join operation. These three hyperboxes are shown in Figure 1.
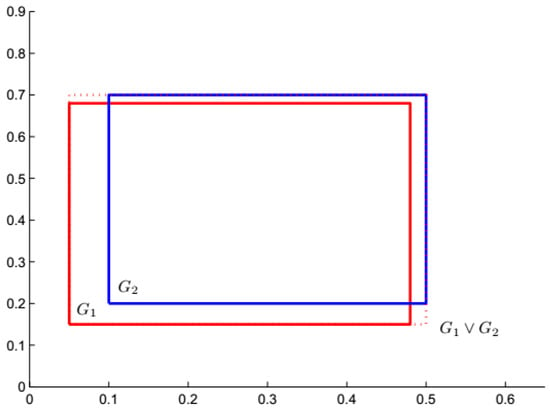
Figure 1.
Join process of two hyperbox granules in 2-D space.
2.3. Novel Distance between Two Hyperbox Granules
The atomic hyperbox granule is a point in N-D space and is represented as the hyperbox with a beginning point and an endpoint which are identical. We can measure the distance relation between the point and the hyperbox granule.
For N-D space, the distance function is the mapping between N-D vector space and 1-D real space. From a visual point of view, distance is a numerical description of how far two objects are from one another. The distance function between two hyperbox granules is the mapping between hyperbox granule space and 1-D space, and a larger distance means that there is a smaller overlap area between the two hyperbox granules. The distance function between two hyperbox granules in granule space S is a function:
where R denotes the set of real numbers. We define the distance between two hyperbox granules and as follows.
Definition 1.
The distance between pointand hyperbox granuleis defined as
whereis the beginning point and is denoted as, is the endpoint and is denoted as, andis the Manhattan distance between two points:
Suppose is a point in N-D space, is a hyperbox granule in granule space, the distance between and is the mapping between the granule space and the real space which satisfies the following non-negativity property.
The distance between the point and hyperbox granule is explained in 2-D space. For and the point , , , , . The location of and is shown in Figure 2. As shown in Figure 2, the point is outside the hyperbox granule .
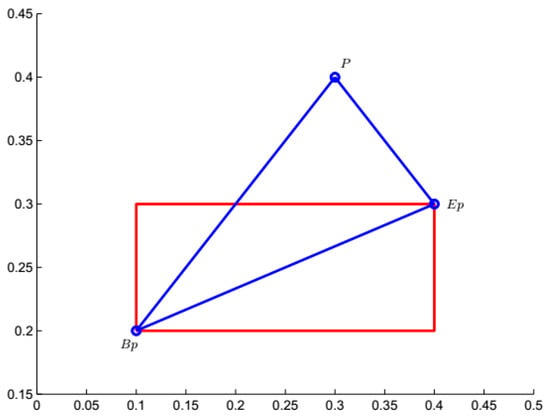
Figure 2.
Distance between a point and a hyperbox granule in 2-D space.
Theorem 1.
In N-D space, the point is inside the hyperbox granule if and only if .
Proof:
Suppose, , and .
If the point is inside the hyperbox granule , then and , and :
Namely,
If , then
Because and , . We discuss the relation between and and the relation between and in two situations.
When , owing to ,
Namely, . This is obviously not in agreement with , namely .
When , owing to ,
Namely, . This is obviously not in agreement with , namely .
Therefore, and , namely, P is included in G. □
Definition 2.
The distance between two hyperbox granulesandis defined as
Obviously,and the distance between two hyperbox granules have the following properties.
Theorem 2.
if.
Proof:
Because and ,
, according to Theorem 1, is inside the hyperbox granule and is inside the hyperbox granule , namely and . So .
If , both and are inside the hyperbox granule . According to Theorem 1, and , the maximum of and is zero, namely,
□
Theorem 3.
.
Proof:
Owing to , . □
2.4. Nonparametric Granular Computing Classification Algorithms
For classification problem, the training set is the set and the NPHBGrC are proposed by the following steps to form the granule set , which is composed of hyperbox granules. First, the sample is selected to form the atomic hyperbox granule randomly. Second, the other sample with the same class label as the hyperbox granule in GS is selected to form the join hyperbox by join operation. Third, the hyperbox granule is updated if the join hyperbox granule does not include the sample with the other class label. The NPHBGrC algorithms include training process and testing process, which are listed as Algorithms 1 and 2.
| Algorithm 1: Training process |
| Input: Training set Output: Hyperbox granule set , the class label corresponding to S1. Initialize the hyperbox granule set , ; S2. ; S3. Select the samples with class labels , and generate set ; S4. Initialize the hyperbox granule set ; S5. If , the sample in is selected to construct the corresponding atomic hyperbox granule , is removed from , otherwise ; S6. The sample is selected from and forms the hyperbox granule ; S7. If the join hyperbox granule between and does not include the other class sample, the is replaced by the join hyperbox granule and the samples included in with the class labels i are removed from X, namely, , otherwise and are updated, , ; S8. ; S9. If , output and class label , otherwise . |
| Algorithm 2: Testing process |
| Input: inputs of unknown datum , the trained hyperbox granule set and class label Output: class label of S1. For ; S2. Compute the distance between and in ; S3. Find the minimal distance ; S4. Find the corresponding class label of the as the label of . |
We take the training set including 10 training data for example to explain the training algorithm. Suppose the training set is
where the inputs of data are
The corresponding class label is
We explain the generation of by Algorithm 1. The is selected to form the atomic hyperbox granule with the granularity 0 and the class label 1 shown in Figure 3a. The second datum with the same class label as is selected to generate the atomic hyperbox granule [7 6 7 6] which is joined with and forms the join hyperbox granule . Since there are no data with the other class label lying in the join hyperbox granule , the is replaced by the join hyperbox granule, namely , as shown in Figure 3b. The third datum x6 with the same class label with is selected to generate atomic hyperbox granule , which is joined with and forms the join hyperbox granule . As there are no data with the other class label lying in the join hyperbox granule , is replaced by , namely , as shown in Figure 3c. During the join process, the datum with the class label with the hyperbox granule lies in the hyperbox granule is not considered the join process, such as datum x8 with the class label 1. In this way, the hyperbox granule with the blue lines is generated for the data with the class label 1. The same strategy is adopted for the data with the class label 2; two hyperbox granules and are generated and are shown in Figure 3d. For the training set S, the achieved granule set is and the corresponding class label is . The granules in GS are shown in Figure 3d; the granule marked with the blue lines is the granule with class label 1, and the granules with the red lines are the granules with class label 2.
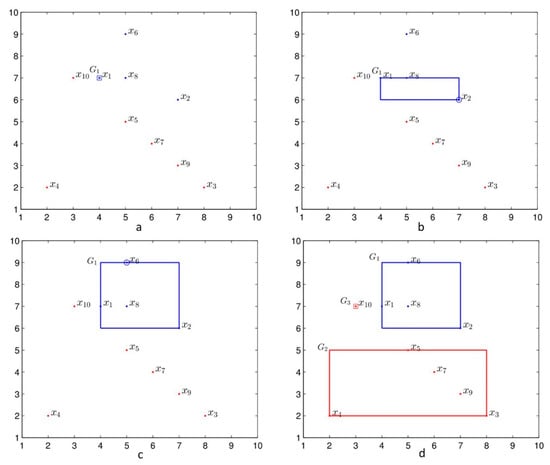
Figure 3.
The example of Algorithm 1. (a) The hyperbox granule by ., (b) the join hyperbox granule between the granule and the atomic hyperbox granule [7 6 7 6], (c) the join hyperbox granule between and the atomic hyperbox granule [5 9 5 9], and (d) the granule set including three hyperbox granules with class label 1 (blue) and class label 2 (red).
3. Experiments
The effectiveness of the NPHBGrC is evaluated with a series of empirical studies including the classification problems in 2-D space and classification problems in N-D space. We compare NPHBGrC with GrC with parameters, such as the HBGrC [22], and evaluate the performance of classification algorithms by the threshold of granularity of HBGrC(Par.), the number of hyperbox granules (Ng), time cost (T(s)) including the training and testing processes, training accuracy (TAC), and testing accuracy (AC).
3.1. Classification Problems in 2-D Space
In the first benchmark study, the two spiral curve classification problem [23], Ripley classification problem [24], and sensor2 classification problem (wall—following robot navigation data) from the websites http://archive.ics.uci.edu/ml/datasets.html, which were created in two dimensions, were used to assess the efficacy of classification algorithms and to visualize the boundary of classification. The details of the datasets and classification performance are summarized in Table 1. The number of training data (#Tr), the number of testing data (#Ts), and the performances of NPHBGrC and HBGrC are shown in Table 1. From Table 1, it can be seen that NPHBGrC has greater or equal testing accuracies and less time cost compared with HBGrC. NPHBGrC has less time cost than HBGrC due to the fact that HBGrC produces some redundant hyperbox granules. Figure 4 and Figure 5 show the boundaries of NPHBGrC and HBGrC for the Ripley dataset.

Table 1.
The classification problems and their performances in 2-D space.
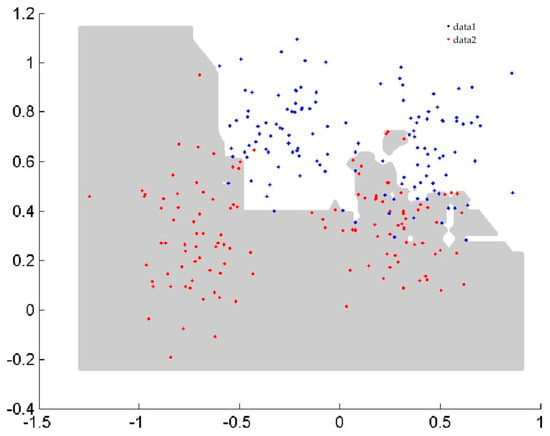
Figure 4.
Boundary performed by nonparametric hyperbox granular computing classification algorithm (NPHBGrC) for the Ripley dataset.
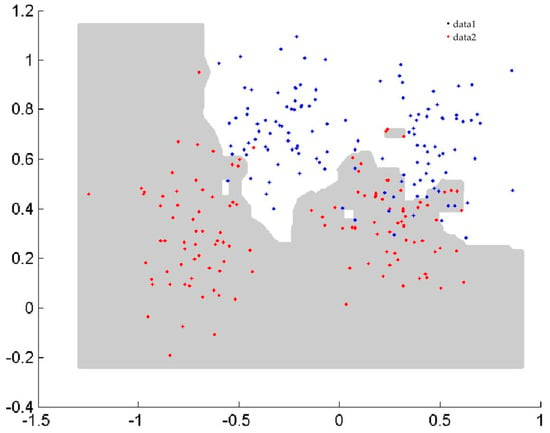
Figure 5.
Boundary performed by hyperbox granular computing classification algorithm (HBGrC) for the Ripley dataset.
3.2. Classification Problems in N-dimensional (N-D) Space
In this section, we verify the performance of the proposed classification algorithms which are extended to N-D space compared with the HBGrC by the selected benchmark datasets from the website, http://archive.ics.uci.edu/ml/. These datasets are the most popular datasets since 2007, and the characteristics and the performance of the datasets are listed in Table 2 and Table 3.
Table 2.
The classification problems in N-dimensional (N-D) space.
Table 3.
The performances in N-D space.
For the parametric algorithm, in order to facilitate the selection of parameters of thresholds of granularities, the RN space is normalized into the [0,1]N space, the granularity parameters are set to between 0 and 0.5 with steps of 0.01 for the n-class classification problems performed by HBGrC.
A 10-fold cross-validation is used to evaluate the parametric and nonparametric classification algorithms. For each dataset, the nonparametric and parametric algorithms are performed for each fold, and the parametric algorithms are performed 51 times for each fold due to the selection of granularity threshold parameters.
The performances of classification algorithms include the maximal testing accuracies, the mean testing accuracies, the minimal testing accuracies, and the standard deviation of testing accuracies. The superiority of algorithms is evaluated by the mean testing accuracies and the stability of algorithms is verified by the standard deviation of testing accuracies, which are shown in Table 3. From the Table 3, it can be seen that NPHBGrC algorithms are superior to HBGrC algorithms regardless of the maximum testing accuracy (max), the mean testing accuracy (mean), or the minimum testing accuracy (min). On the other hand, it can also be seen from Table 3 that the standard deviations of 10-fold cross-validation by NPHBGrC are less than those of HBGrC, which shows that NPHBGrC algorithms are more stable than HBGrC algorithms.
The testing accuracies are the main evaluation indices for the classification algorithms. A t-test was used to verify the testing accuracies by nonparametric algorithms and parametric algorithms statistically. If h = 0, then the testing accuracies achieved by NPHBGrC and HBGrC have no significant difference statistically, although h = 0, but p is relatively small, close to 0.05, we regard the achieved testing accuracies have significant difference. If h = 1, then the testing accuracies achieved by NPHBGrC and HBGrC are significantly different, and we can illustrate the superiority of the algorithm by the mean testing accuracy, especially, although h = 1, but p is relatively small, close to 0.05, we regard the achieved testing accuracies as having no significant difference.
For the datasets Iris, Wine, Cancer1, Sensor4, and Cancer2, h = 0, as shown in Table 4. Statistically, the testing accuracies obtained by NPHBGrC and HBGrC have no significant difference from the h values of t-test listed in Table 3, and the testing accuracies of NPHBGrC are slightly higher than those of HBGrC in terms of maximal testing accuracies, mean testing accuracies, and the minimal testing accuracies listed in Table 3.
Table 4.
The t-test values of comparison of NPHBGrC and HBGrC.
For the datasets Phoneme, Car, and Semeion, h = 1, as shown in Table 4. Statistically, the testing accuracies by NPHBGrC and HBGrC are significantly different, and we determine which is the better classification algorithm for NPHBGrC and HBGrC from the mean testing accuracies in Table 3. NPHBGrC algorithms are better than HBGrC algorithms, since the mean testing accuracies obtained by NPHBGrC are greater than those obtained by HBGrC, as shown in Table 3.
The computational complexities are evaluated by the time cost, including the training and testing time cost. Obviously, NPHBGrC algorithms have lower computational complexities compared with HBGrC due to the redundant hyperbox granules and the parameter selection for HBGrC.
3.3. Classification for Imbalanced Datasets
For the imbalanced datasets, an imbalanced dataset called yeast, including 1484 data, was used to verify the performance of the proposed algorithm, where the positive data belong to class NUC (class label 1 in the paper) and the negative data belong to the rest (class label 2 in the paper). The dataset can be downloaded from the website http://keel.es/. Five-fold cross-validation was used to evaluate the performance of NPHBGrC and HBGrC, such as the testing accuracy and class-based testing accuracy. The accuracies are listed in Table 5, and the histogram of accuracies is shown in Figure 6. For the testing set, AC is the total accuracy, C1AC is the accuracy of data with class label 1, and C2AC is the accuracy of data with class label 2. For the five tests, named Test 1, Test 2, Test 3, Test 4, and Test 5, NPHBGrC achieved better total accuracies (AC) than HBGrC for the imbalanced class problem yeast. The geometric mean (GM) of the true rates is defined in [22] and attempts to maximize the accuracy of each of the two classes with a good balance. From Table 5, it can be seen that the GM of NPHBGrC is 74.2023, which is superior to the GM of HBGrC (64.8344), and to the fuzzy rule-based classification systems (69.66) by Fernández [25] and the weighted extreme learning machine (73.19) by Akbulut [26].
Table 5.
Performance of NPHBGrC and HBGrC for the imbalanced dataset “yeast”.
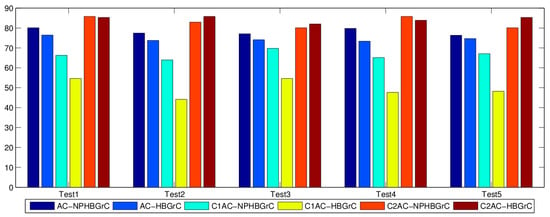
Figure 6.
The histogram of performance by nonparametric hyperbox granular computing classification algorithm (NPHBGrC) and HBGrC for the yeast dataset.
4. Conclusions
According to the computational complexity produced the redundant hyperbox granules, we presented the NPHBGrC. The novel distance was introduced to measure the distance between two hyperbox granules and to determine the join process between two hyperbox granules. The feasibility and superiority of NPHBGrC were demonstrated by the benchmark datasets compared with HBGrC. There are some improvements in the NPHBGrC, for example, relating to the overfitting problem and the effect of the data order on the classification accuracy. The purpose of using distance in this paper was to determine the positional relationship between points (such as the points inside and outside the hyperbox) and the hyperbox. For the interval set and the fuzzy set, the operations between two granules were designed based on the fuzzy relation between two granules. For the fuzzy set, further research is needed in the future to determine how to use the proposed distance between two granules to design classification algorithms. For the classification of imbalanced datasets, the superiority of NPHBGrC was verified by the yeast dataset. In the future, the superiority and feasibility of GrC need to be verified using more metrics—such as the receiver operating curve (ROC), usually known as area under curve (AUC)—by more imbalanced datasets, and the computing theory of GrC needs further study for imbalanced datasets to achieve a better performance.
Author Contributions
Conceptualization, H.L.; Methodology, H.L. and X.D.; Validation, H.L., X.D., and H.G.; Data Curation, X.D.; Writing—Original Draft Preparation, H.L.
Funding
This work was supported in part by the Henan Natural Science Foundation Project (182300410145, 182102210132).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ristin, M.; Guillaumin, M.; Gall, J.; Van Gool, L. Incremental Learning of Random Forests for Large-Scale Image Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 490–503. [Google Scholar] [CrossRef] [PubMed]
- Garro, B.A.; Rodríguez, K.; Vázquez, R.A. Classification of DNA microarrays using artificial neural networks and ABC algorithm. Appl. Soft Comput. 2016, 38, 548–560. [Google Scholar] [CrossRef]
- Yousef, A.; Charkari, N.M. A novel method based on physicochemical properties of amino acids and one class classification algorithm for disease gene identification. J. Biomed. Inform. 2015, 56, 300–306. [Google Scholar] [CrossRef] [PubMed]
- Kaburlasos, V.G.; Kehagias, A. Fuzzy Inference System (FIS) Extensions Based on the Lattice Theory. IEEE Trans. Fuzzy Syst. 2014, 22, 531–546. [Google Scholar] [CrossRef]
- Kaburlasos, V.G.; Pachidis, T.P. A Lattice—Computing ensemble for reasoning based on formal fusion of disparate data types, and an industrial dispensing application. Inform. Fusion 2014, 16, 68–83. [Google Scholar] [CrossRef]
- Kaburlasos, V.G.; Papadakis, S.E.; Papakostas, G.A. Lattice Computing Extension of the FAM Neural Classifier for Human Facial Expression Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1526–1538. [Google Scholar] [CrossRef] [PubMed]
- Kaburlasos, V.G.; Papakostas, G.A. Learning Distributions of Image Features by Interactive Fuzzy Lattice Reasoning in Pattern Recognition Applications. IEEE Comput. Intell. Mag. 2015, 10, 42–51. [Google Scholar] [CrossRef]
- Liu, H.; Li, J.; Guo, H.; Liu, C. Interval analysis-based hyperbox granular computing classification algorithms. Iranian J. Fuzzy Sys. 2017, 14, 139–156. [Google Scholar]
- Guo, H.; Wang, W. Granular support vector machine: A review. Artif. Intell. Rev. 2017, 51, 19–32. [Google Scholar] [CrossRef]
- Wang, Q.; Nguyen, T.-T.; Huang, J.Z.; Nguyen, T.T. An efficient random forests algorithm for high dimensional data classification. Adv. Data Anal. Classif. 2018, 12, 953–972. [Google Scholar] [CrossRef]
- Kordos, M.; Rusiecki, A. Reducing noise impact on MLP training—Techniques and algorithms to provide noise-robustness in MLP network training. Soft Comput. 2016, 20, 49–65. [Google Scholar] [CrossRef]
- Zadeh, L.A. Some reflections on soft computing, granular computing and their roles in the conception, design and utilization of information/intelligent systems. Soft Comput. 1998, 2, 23–25. [Google Scholar] [CrossRef]
- Yao, Y.; She, Y. Rough set models in multigranulation spaces. Inform. Sci. 2016, 327, 40–56. [Google Scholar] [CrossRef]
- Yao, Y.; Zhao, L. A measurement theory view on the granularity of partitions. Inform. Sci. 2012, 213, 1–13. [Google Scholar] [CrossRef]
- Savchenko, A.V. Fast multi-class recognition of piecewise regular objects based on sequential three-way decisions and granular computing. Knowl. Based Syst. 2016, 91, 252–262. [Google Scholar] [CrossRef]
- Kerr-Wilson, J.; Pedrycz, W. Design of rule-based models through information granulation. Exp. Syst. Appl. 2016, 46, 274–285. [Google Scholar] [CrossRef]
- Bortolan, G.; Pedrycz, W. Hyperbox classifiers for arrhythmia classification. Kybernetes 2007, 36, 531–547. [Google Scholar] [CrossRef]
- Hu, X.; Pedrycz, W.; Wang, X. Comparative analysis of logic operators: A perspective of statistical testing and granular computing. Int. J. Approx. Reason. 2015, 66, 73–90. [Google Scholar] [CrossRef]
- Pedrycz, W. Granular fuzzy rule-based architectures: Pursuing analysis and design in the framework of granular computing. Intell. Decis. Tech. 2015, 9, 321–330. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, Q.; Wu, K.; Zhu, S.; Zeng, Z. A binary granule representation for uncertainty measures in rough set theory. J. Intell. Fuzzy Syst. 2015, 28, 867–878. [Google Scholar]
- Hońko, P. Association discovery from relational data via granular computing. Inform. Sci. 2013, 234, 136–149. [Google Scholar] [CrossRef]
- Eastwood, M.; Jayne, C. Evaluation of hyperbox neural network learning for classification. Neurocomputing 2014, 133, 249–257. [Google Scholar] [CrossRef]
- Sossa, H.; Guevara, E. Efficient training for dendrite morphological neural networks. Neurocomputing 2014, 131, 132–142. [Google Scholar] [CrossRef]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Fernández, A.; Garcia, S.; Del Jesus, M.J.; Herrera, F. A study of the behaviour of linguistic fuzzy rule-based classification systems in the framework of imbalanced data-sets. Fuzzy Sets Syst. 2008, 159, 2378–2398. [Google Scholar] [CrossRef]
- Akbulut, Y.; Şengür, A.; Guo, Y.; Smarandache, F. A Novel Neutrosophic Weighted Extreme Learning Machine for Imbalanced Data Set. Symmetry 2017, 9, 142. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).