Conceptual Encoding and Advanced Management of Leonardo da Vinci’s Mona Lisa: Preliminary Results


Abstract
1. Introduction
2. The General Background
2.1. Short Discussion about the Cultural Heritage Digitization Procedures
2.2. Using NKRL in the Context of the Cultural Heritage Domain
3. The Experiment
3.1. A First (Quite Simple) Result
3.2. A More Advanced Result: Isabella d’Aragona’s Hypothesis
3.3. Approximating Some Erudite Theories about Mona Lisa’s “Meaning”
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- European Commission: Horizon 2020, Work Programme 2018-2020 - 13. Europe in a changing world – Inclusive, innovative and reflective societies, 2019. Available online: https://ec.europa.eu/research/ participants/data/ref/h2020/wp/2018-2020/main/h2020-wp1820-societies_en.pdf (accessed on 25 July 2019).
- Grieves, M. Origins of the Digital Twin Concept—Working Paper; Florida Institute of Technology: Melbourne, FL, USA, 2016; Available online: https://www.researchgate.net/publication/307509727 (accessed on 30 July 2019).
- Amelio, A. Exploring Leonardo Da Vinci’s Mona Lisa by Visual Computing: A Review. In Proceedings of the 1st International Workshop on Visual Pattern Extraction and Recognition for Cultural Heritage Understanding (VIPERC). CEUR-WS, Pisa, Italy, 30 January 2019; pp. 25–38. [Google Scholar]
- Zarri, G.P. Representation and Management of Narrative Information—Theoretical Principles and Implementation; Springer: London, UK, 2009. [Google Scholar]
- Lagoze, C.; Hunter, J. The ABC Ontology and Model. In Proceedings of the International Conference on Dublin Core and Metadata Applications, Tokyo, Japan, 24–26 October 2001; pp. 160–176. [Google Scholar]
- Nilsson, M.; Powell, A.; Johnston, P.; Naeve, A. Expressing Dublin Core Metadata Using the Resource Description Framework, RDF (DCMI Recommendation 2008-01-04); Dublin Core Metadata Initiative: Silver Spring, MD, USA, 2008; Available online: https://www.dublincore.org/specifications/dublin-core/dc-rdf/ (accessed on 5 August 2019).
- Le Boeuf, P.; Doerr, M.; Ore, C.E.; Stead, S. (Eds.) Definition of the CIDOC Conceptual Reference Model (version 6.2.6, June 2019); ICOM/CIDOC Documentation Standard Group: Heraklion, Greece, 2019. [Google Scholar]
- Troncy, R.; van Ossenbruggen, J.; Pan, J.Z.; Stamou, G. (Eds.) Image Annotation on the Semantic Web, W3C Incubator Group Report 14 August 2007; W3C: Cambridge, MA, USA, 2007; Available online: https://www.w3.org/2005/Incubator/mmsem/XGR-image-annotation/ (accessed on 10 August 2019).
- Isaac, A.; Clayphan, R. (Eds.) Europeana Data Model Primer; Europeana Foundation: The Hague, The Netherlands, 2011; Available online: https://pro.europeana.eu/files/Europeana_Professional/Share_your_data/Technical_requirements/EDM_Documentation/EDM_Primer_130714.pdf (accessed on 10 August 2019).
- D’Andrea, A.; Ferrandino, G. Shared Iconographical Representations with Ontological Models. In Proceedings of the 35th International Conference on Computer Applications and Quantitative Methods in Archaeology (CAA), Budapest, Hungary, 2–6 April 2008; pp. 194–199. [Google Scholar]
- Carboni, N.; de Luca, L. An Ontological Approach to the Description of Visual and Iconographical Representations. Heritage 2019, 2, 1191–1210. [Google Scholar] [CrossRef]
- Lodi, G.; Asprino, L.; Nuzzolese, A.G.; Presutti, V.; Gangemi, A.; Reforgiato Recupero, D.; Veninata, C.; Orsini, A. Semantic Web for Cultural Heritage Valorisation. In Data Analytics in Digital Humanities Valorisation; Hai-Jew, S., Ed.; Springer International Publishing AG: New York, NY, USA, 2017; pp. 3–37. [Google Scholar]
- Zarri, G.P. Functional and Semantic Roles in a High-Level Knowledge Representation Language. Artif. Intell. Rev. 2019, 51, 537–575. [Google Scholar] [CrossRef]
- Zarri, G.P. Modelling and Exploiting the Temporal Information Associated with Complex ‘Narrative’ Documents. Int. J. Knowl. Eng. Data Min. 2019, 6, 135–167. [Google Scholar] [CrossRef]
- Zarri, G.P. Advanced Computational Reasoning Based on the NKRL Conceptual Model. Expert Syst. Appl. 2013, 40, 2872–2888. [Google Scholar] [CrossRef]
- Schwartz, L.F.F. The Mona Lisa Identification: Evidence from a Computer Analysis. Vis. Comput. 1988, 4, 40–48. [Google Scholar] [CrossRef]
- Asmus, J.F. Mona Lisa Symbolism Uncovered by Computer Processing. Mater. Charact. 1992, 29, 119–128. [Google Scholar] [CrossRef]
- Mao, J.; Gan, C.; Kohli, P.; Tenenbaum, J.B.; Wu, J. The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences from Natural Supervision. In Proceedings of the Seventh International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; Available online: https://openreview.net/pdf?id=rJgMlhRctm (accessed on 1 September 2019).


{kind=link}
| gio1.c1) | (COORD gio1.c2 gio1.c3 gio1.c4) | ||
| The formalization of the gio1.c1 narrative is represented by three predicative and binding (see below) occurrences. | |||
| gio1.c2) | EXIST | SUBJ | PAINTING_1: (LOUVRE_MUSEUM) |
| TOPIC | (SPECIF portrait_ WOMAN_52) | ||
| date-1: | 1/1/1797, 31/12/1797 | ||
| date-2: | 29/1/2020 | ||
| Exist:EntityBePresent (2.11) | |||
| A painting concerning (TOPIC) the portrait of a woman (conventionally: WOMAN_52) is located at the Louvre Museum from | |||
| an (unknown) date in 1797. | |||
| gio1.c3) | (COORD gio1.c5 gio1.c6) | ||
| The component gio1.c3 of the narrative is formed of two coordinated predicative occurrences. | |||
| gio1.c5) | EXPERIENCE | SUBJ | WOMAN_52 |
| OBJ | (SPECIF identified_with LISA_GHERARDINI) | ||
| SOURCE | (SPECIF art_historian (SPECIF cardinality_ several_)) | ||
| { mult } | |||
| date-2: | 29/1/2020 | ||
| Experience:GenericSituation (3.1) | |||
| The woman of the Mona Lisa portrait has been often (modal modulator mult) identified with Lisa Gherardini. | |||
| gio1.c6) | BEHAVE | SUBJ | LISA_GHERARDINI: (FLORENCE_) |
| MODAL | wife_ | ||
| TOPIC | (SPECIF FRANCESCO_DEL_GIOCONDO florentine_merchant) | ||
| { poss } | |||
| date-1: | 1/1/1495, 31/12/1495 | ||
| date-2: | 15/7/1542 | ||
| Behave:Kinship (1.113) | |||
| Lisa Gherardini has been the wife of the Florentine merchant Francesco del Giocondo from an unknown date in 1495 to July | |||
| 15, 1542 (date of death). | |||
| gio1.c4) | OWN | SUBJ | PAINTING_1: (LOUVRE_MUSEUM) |
| OBJ | property_ | ||
| TOPIC | (SPECIF painted_on (SPECIF POPLAR_PLANK_1 (SPECIF length_ (SPECIF | ||
| centimetre_ 53)) (SPECIF height_ (SPECIF centimetre_ 77)))) | |||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| The painting has been realized on a poplar plank; its dimensions are: length 53 cm, height 77 cm. | |||
| name: Behave:Kinship | ||
| father: Behave:Role | ||
| position: 1.113 | ||
| natural language description: “An Individual Has a Given Kinship Relationship with a Human Being Filling the TOPIC Role” | ||
| BEHAVE | SUBJ | var1: [(var2)] |
| *(OBJ) | ||
| [SOURCE | var3: [var4]] | |
| (BENF) | ||
| MODAL | var5 | |
| TOPIC | var6 | |
| [CONTEXT | var7] | |
| { [modulators] } | ||
| var1 = | human_being | |
| var1 = | individual_ | |
| var3 = | human_being_or_social_body | |
| var4 = | human_being_or_social_body | |
| var5 = | extended_family_role | |
| var6 = | human_being_or_social_body | |
| var7 = | situation_, symbolic_label | |
| var2, var4 = | location_ | |
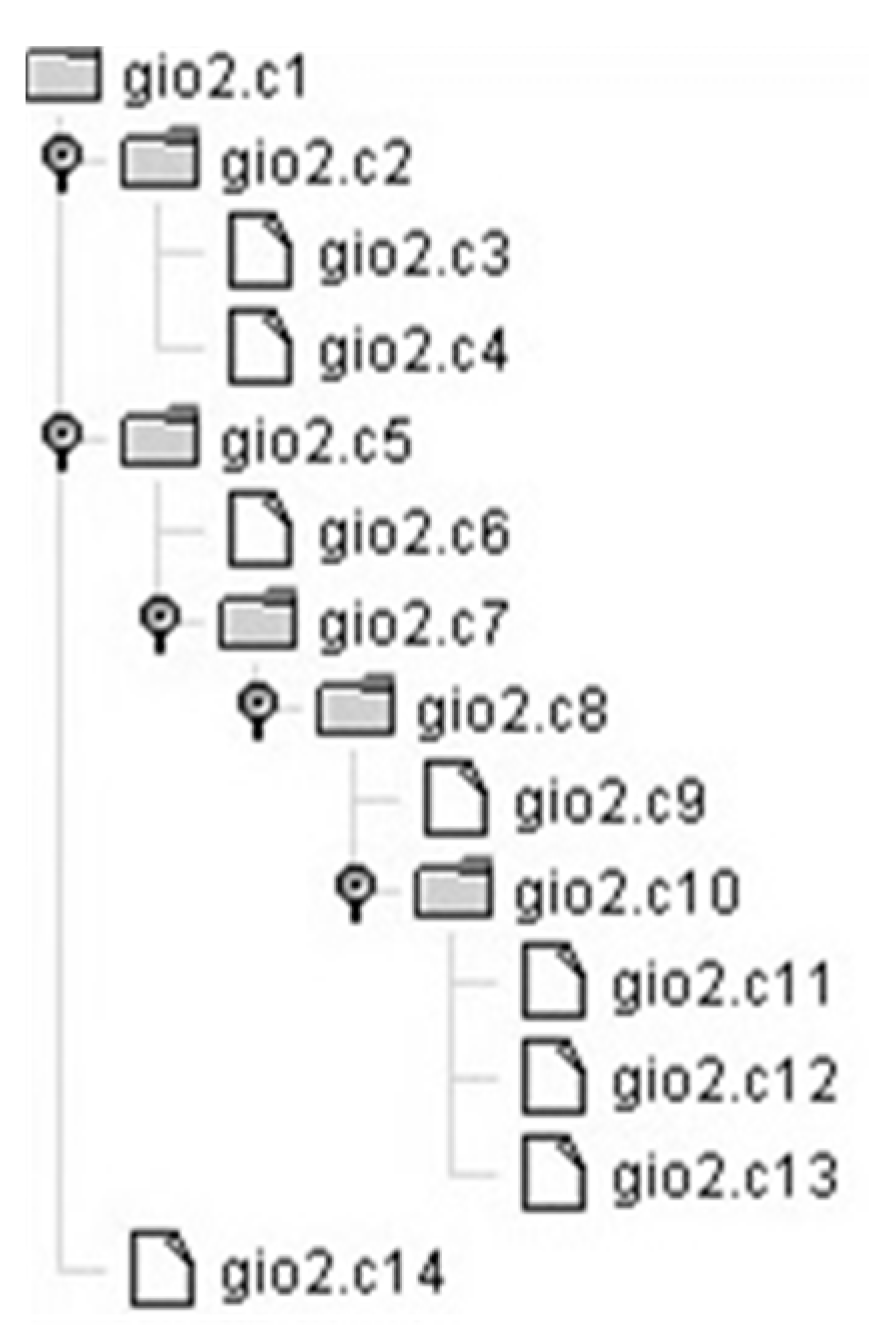
| gio2.c1) | (COORD gio2.c2 gio2.c5 gio2.c14) | ||
| The top level of the gio2 narrative is represented by three occurrences, two binding occurrences and a predicative one. | |||
| gio2.c2) | (COORD gio2.c3 gio2.c4) | ||
| The first component of the narrative consists of two predicative occurrences. | |||
| gio2.c3) | PRODUCE | SUBJ | LEONARDO_DA_VINCI |
| OBJ | PAINTING_2 | ||
| TOPIC | (SPECIF portrait_ WOMAN_53) | ||
| date-1: | 1/1/1497, 31/12/1503 | ||
| date-2: | |||
| Produce:Entity (6.2) | |||
| The portrait of a woman (conventionally: WOMAN_52) has been produced by Leonardo in the temporal interval 1497–1503. | |||
| gio2.c4) | OWN | SUBJ | PAINTING_2 |
| OBJ | property_ | ||
| TOPIC | (COORD1 (SPECIF painted_on POPLAR_PLANK_1 (SPECIF under_ | ||
| PAINTING_1)) (SPECIF labelled_as HIDDEN_PAINTING)) | |||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| PAINTING_2 has been painted under the plank of PAINTING_1, and is known as the HIDDEN_PAINTING. | |||
| gio2.c5) | (CAUSE gio2.c6 gio2.c7 #gio2.c8) | ||
| The elementary event modelized by the predicative occurrence gio2.c6 has been caused by what is collectively described in the | |||
| completive construction involving occurrences gio2.c7 and gio2.c8. | |||
| gio2.c6) | BEHAVE | SUBJ | (SPECIF WOMAN_53 (SPECIF identified_with WOMAN_52)) |
| { obs, negv } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| The elementary event represented by gio2.c7 is a “negated event” (modulator negv), i.e., WOMAN_53 is not WOMAN_52. | |||
| gio2.c7) | MOVE | SUBJ | LILLIAN_FELDMANN_SCHWARTZ |
| OBJ | #gio2.c8 | ||
| MODAL | (SPECIF SCIENTIFIC_PAPER_2 (SPECIF published_on | ||
| THE_VISUAL_COMPUTER_JOURNAL)) | |||
| date-1: | 1/1/1988, 31/1/1988 | ||
| date-2: | |||
| Lillian Feldmann Schwartz has spread what described in gio2.c8 by means of a paper in “The Visual Computer” Journal. | |||
| gio2.c8) | (COORD gio2.c9 gio2.c10) | ||
| The message transmitted by L.F. Schwartz through her paper is formed of two coordinated components. | |||
| gio2.c9) | OWN | SUBJ | (COORD1 (SPECIF eye_ (SPECIF cardinality_ 2) WOMAN_53)) |
| OBJ | property_ | ||
| TOPIC | (SPECIF different_from (SPECIF eye_ (SPECIF cardinality_ 2) WOMAN_52)) | ||
| MODAL | x_ray_analysis | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| For the sake of simplification, only the dissimilarity between the eyes of WOMAN_52 and WOMAN_53 has been taken into | |||
| account here. In reality, also the mouth, nose, chin and hairline of the two women are incompatible. | |||
| gio2.c10) | (COORD gio2.c11 gio2.c12 gio2.c13) | ||
| The second component of L.F. Schwartz’s message is formed of three predicative occurrences. | |||
| gio2.c11) | PRODUCE | SUBJ | LEONARDO_DA_VINCI |
| OBJ | CARTOON_DRAWING_1 | ||
| TOPIC | (SPECIF portrait_ ISABELLA_D_ARAGONA) | ||
| date-1: | 1/1/1490, 31/12/1495 | ||
| date-2: | |||
| Produce:Entity (6.2) | |||
| In the period 1490–1495, Leonardo da Vinci realized, as a cartoon drawing, the portrait of Isabella d’Aragona. | |||
| gio2.c12) | OWN | SUBJ | (SPECIF eye_ (SPECIF cardinality_ 2) ISABELLA_D_ARAGONA): |
| (CARTOON_DRAWING_1) | |||
| OBJ | property_ | ||
| TOPIC | (SPECIF coincident_with (SPECIF eye_ (SPECIF cardinality_ 2) | ||
| WOMAN_53)) | |||
| MODAL | x_ray_analysis | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| There is a correspondence between the eyes of Isabella d’Aragona and those of WOMAN_53. | |||
| gio2.c13) | OWN | SUBJ | (SPECIF hairline_ ISABELLA_D_ARAGONA): |
| (CARTOON_DRAWING_1) | |||
| OBJ | property_ | ||
| TOPIC | (SPECIF coincident_with (SPECIF hairline_ WOMAN_53)) | ||
| MODAL | x_ray_analysis | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| There is a correspondence between the hairline of WOMAN_53 and the hairline of WOMAN_54. | |||
| gio2.c14) | BEHAVE | SUBJ | (SPECIF individual_person art_historian (SPECIF cardinality_ |
| several_)) | |||
| OBJ | LILLIAN_FELDMANN_SCHWARTZ | ||
| MODAL | endorsement_ | ||
| TOPIC | (SPECIF ISABELLA_D_ARAGONA_HYPOTHESIS | ||
| LILLIAN_FELDMANN_SCHWARTZ) | |||
| { for, obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Behave:FavourableAttitude (1.311) | |||
| Several art historians agree with Lillian Feldmann Schwartz about her Isabella d’Aragona hypothesis. | |||
| gio3.c1) | (COORD gio3.c2 gio3.c3 gio3.c4 gio3.c5) | ||
| The top level of the gio3 narrative is represented by four occurrences, a predicative occurrence and three binding ones. | |||
| gio3.c2) | OWN | SUBJ | (SPECIF LANDSCAPE_1 (SPECIF right_hand_part landscape_)) |
| OBJ | property_ | ||
| TOPIC | (SPECIF different_from greatly_ (SPECIF LANDSCAPE_2 (SPECIF left_hand_part | ||
| landscape_))) | |||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| The two parts of the landscape are very different. | |||
| gio3.c3) | (CAUSE gio3.c6 gio3.c7) | ||
| The reason of what is described in occurrence gio3.c6 is provided in occurrence gio3.c7. | |||
| gio3.c6) | PRODUCE | SUBJ | (SPECIF physical_aspect LANDSCAPE_2) |
| OBJ | neutral_feeling | ||
| BENF | (SPECIF individual_person (SPECIF visitor_ LOUVRE_MUSEUM)) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Produce:CreateCondition/Result (6.4) | |||
| The left part of the landscape generates no particular feelings in the Louvre Museum’s visitors. | |||
| gio3.c7) | OWN | SUBJ | LANDSCAPE_2 |
| OBJ | property | ||
| TOPIC | (SPECIF regular_ greatly_) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| The left part of the landscape appears as perfectly regular. | |||
| gio3.c4) | (CAUSE gio3.c8 gio3.c9) | ||
| The reason of what is described in occurrence gio3.c8 is provided in occurrence gio3.c9. | |||
| gio3.c8 ) | PRODUCE | SUBJ | (SPECIF physical_aspect LANDSCAPE_1) |
| OBJ | anomaly_feeling | ||
| DEST | (SPECIF individual_person (SPECIF visitor_ LOUVRE_MUSEUM)) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Produce:CreateCondition/Result (6.4) | |||
| The vision of the right part of the landscape engenders a feeling of strangeness in the Louvre Museum’s visitors. | |||
| gio3.c9) | OWN | SUBJ | LANDSCAPE_1 |
| OBJ | property_ | ||
| TOPIC | (COORD1 (SPECIF characterized_by (SPECIF mountain_ (SPECIF cardinality_ | ||
| several_) wild_uninhabited_)) (SPECIF characterized_by (SPECIF | |||
| bridge_ (SPECIF flooded_by (SPECIF river_ turbulent _))))) | |||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| The right part is characterized by the presence of wild and inhabited mountains and by a bridge flooded by a | |||
| tumultuous river. | |||
| gio3.c5) | (CAUSE gio3.c10 gio3.c11) | ||
| The reason of what is described in occurrence gio3.c10 is provided in occurrence gio3.c11. | |||
| gio3.c10 ) | PRODUCE | SUBJ | (SPECIF part_of (SPECIF physical_aspect WOMAN_52)) |
| OBJ | anomaly_feeling | ||
| DEST | (SPECIF individual_person (SPECIF visitor_ LOUVRE_MUSEUM)) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Produce:CreateCondition/Result (6.4) | |||
| Some elements of the physical appearance of WOMAN_52 engender a feeling of strangeness in the Louvre Museum’s visitors. | |||
| gio3.c11) | (COORD gio3.c12 #gio3.c13 gio3.c14 gio3.c15) | ||
| Three aspects of this physical appearance are noticed here; gio3.c12 + #gio3.c13 = completive construction. | |||
| gio1.c12) | EXPERIENCE | SUBJ | WOMAN_52 |
| OBJ | (SPECIF need_for instinctive_) | ||
| MODAL | #gio.c13 | ||
| TOPIC | (SPECIF reinforcement_ (SPECIF self_protection WOMAN_52)) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Experience:NegativeSituation (3.21) | |||
| The woman manifests an instinctive demand for the reinforcement of her own protection making use (MODAL) of what is specified | |||
| in the gio.c13 binding occurrence. | |||
| gio.c13) | (COORD gio3.c16 gio3.c17) | ||
| The modalities of auto-protection of WOMAN_52 are detailed in two predicative occurrences. | |||
| gio3.c16) | OWN | SUBJ | (SPECIF right_arm WOMAN_52)) |
| OBJ | property_ | ||
| TOPIC | (SPECIF crossing_ foreground_ (SPECIF chest_ WOMAN_52)) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| The right arm of the woman crosses in the foreground her chest. | |||
| gio3.c17) | OWN | SUBJ | (SPECIF hand_ (SPECIF right_arm WOMAN_52)) |
| OBJ | property_ | ||
| TOPIC | (SPECIF grabbing_ strong_ (SPECIF left_arm WOMAN_52)) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| The left arm of the woman is clasped by the hand of the right arm. | |||
| gio3.c14) | OWN | SUBJ | (SPECIF hand_ (SPECIF cardinality_ 2) WOMAN_52) |
| OBJ | property_ | ||
| TOPIC | (SPECIF appear_as (SPECIF extraneous_ (SPECIF body_ WOMAN_52))) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Own:CompoundProperty (5.42) | |||
| The hands of WOMAN_52 seem to be extraneous to her body. | |||
| gio1.c15) | BEHAVE | SUBJ | WOMAN_52 |
| MODAL | (SPECIF half_smiling slight_ ambiguous_) | ||
| { obs } | |||
| date-1: | 29/1/2020 | ||
| date-2: | |||
| Behave:HumanProperty (1.1) | |||
| The woman produces an imperceptible and mysterious half-smile. | |||
| EXIST | |
| SUBJ: relationship_ | |
| TOPIC: (COORD1 (SPECIF feeling_ (SPECIF related_to (physical_appearance LANDSCAPE_1))) (SPECIF feeling_ | |
| (SPECIF related_to (physical_appearance WOMAN_52)))) | |
| { obs } | |
| date1: 29/1/2020 | |
| date2: | |
| T54: “identical reaction of specific people in front of different visions” transformation. | |||
| antecedent: | |||
| EXIST | SUBJ | relationship_ | |
| TOPIC | (COORD1 (SPECIF feeling_ (SPECIF related_to (SPECIF physical_appearance var1))) (SPECIF feeling_ (SPECIF related_to (SPECIF physical_appearance var2))) | ||
| var1 | = | location_ | |
| var2 | = | individual_person | |
| first consequent schema (conseq1): | |||
| PRODUCE | SUBJ | (SPECIF physical_appearance var1) | |
| OBJ | var3 | ||
| BENF | var4 | ||
| var3 = | emotionally_charged_feeling | ||
| var4 = | individual_person | ||
| var4 ≠ | var2 | ||
| second consequent schema (conseq2): | |||
| PRODUCE | SUBJ | (SPECIF physical_appearance var2) | |
| OBJ | var5 | ||
| BENF | var6 | ||
| var5 = | emotionally_charged_feeling | ||
| var6 = | individual_person | ||
| var5 = | var3 | ||
| var6 ≠ | var2 | ||
| var6 = | var4 | ||
| If the same person (see the equality constraint between var4 and var6 in conseq2) feels the same emotion (see the equality constraint between var3 and var5 in the same conseq2) in front of two different entities—here a location, LANDSCAPE_1 and an individual, Mona Lisa—it is possible that some type of relationship exists between these two entities. | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amelio, A.; Zarri, G.P. Conceptual Encoding and Advanced Management of Leonardo da Vinci’s Mona Lisa: Preliminary Results. Information 2019, 10, 321. https://doi.org/10.3390/info10100321
Amelio A, Zarri GP. Conceptual Encoding and Advanced Management of Leonardo da Vinci’s Mona Lisa: Preliminary Results. Information. 2019; 10(10):321. https://doi.org/10.3390/info10100321
Chicago/Turabian StyleAmelio, Alessia, and Gian Piero Zarri. 2019. "Conceptual Encoding and Advanced Management of Leonardo da Vinci’s Mona Lisa: Preliminary Results" Information 10, no. 10: 321. https://doi.org/10.3390/info10100321
APA StyleAmelio, A., & Zarri, G. P. (2019). Conceptual Encoding and Advanced Management of Leonardo da Vinci’s Mona Lisa: Preliminary Results. Information, 10(10), 321. https://doi.org/10.3390/info10100321