A Feature Selection and Classification Method for Activity Recognition Based on an Inertial Sensing Unit


Abstract
:1. Introduction
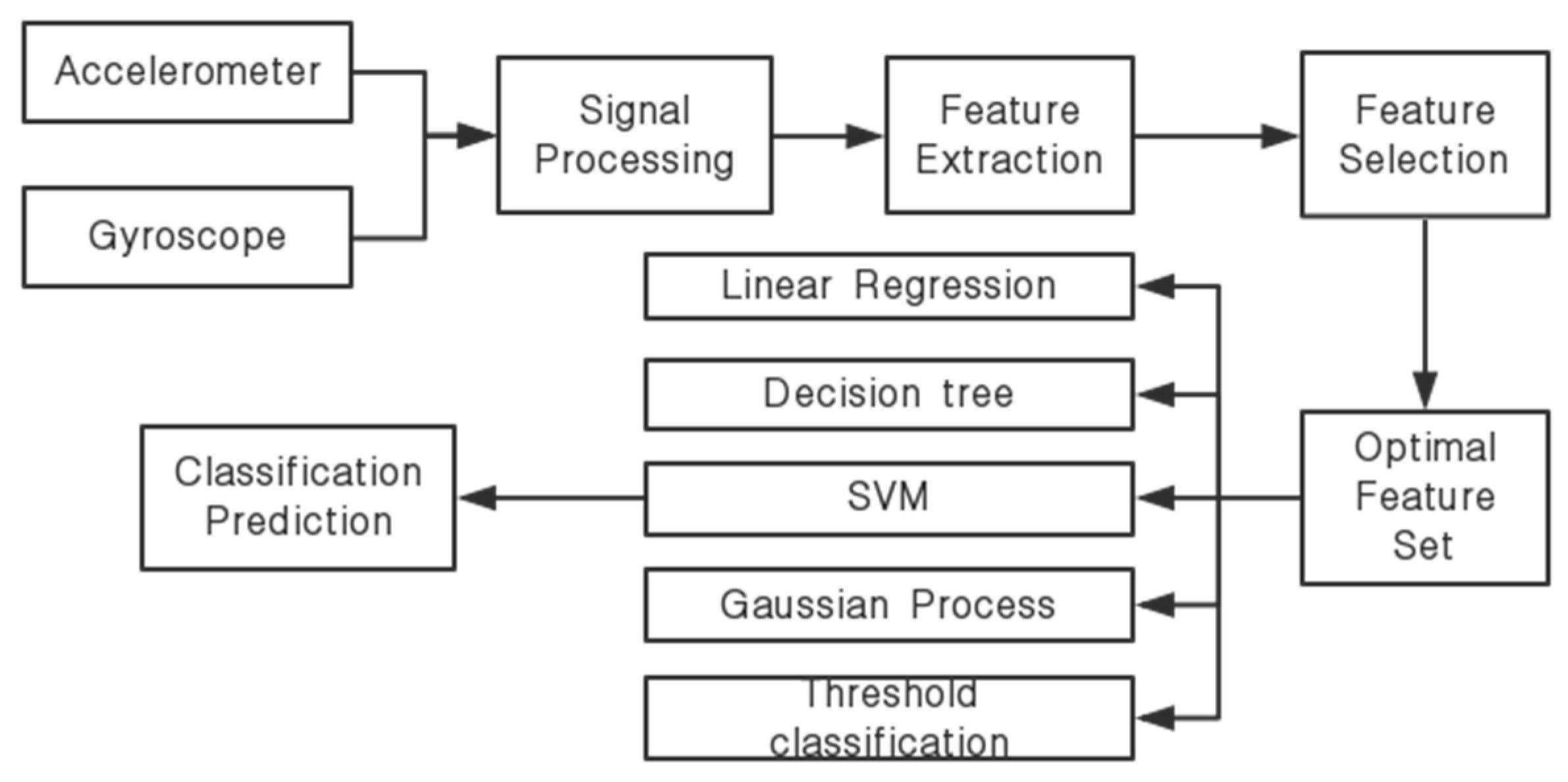
2. System Frameworks
3. Signal Processing, Feature Extraction, and Feature Selection
3.1. Signal Processing and Feature Extraction
3.2. Feature Selection
3.2.1. Fisher_score
3.2.2. ReliefF
3.2.3. Chi_square
3.3. Classification Methods
3.3.1. Support Vector Machine
3.3.2. Threshold Classification
3.3.3. Other Classification Methods
4. Experimental Results and Analysis
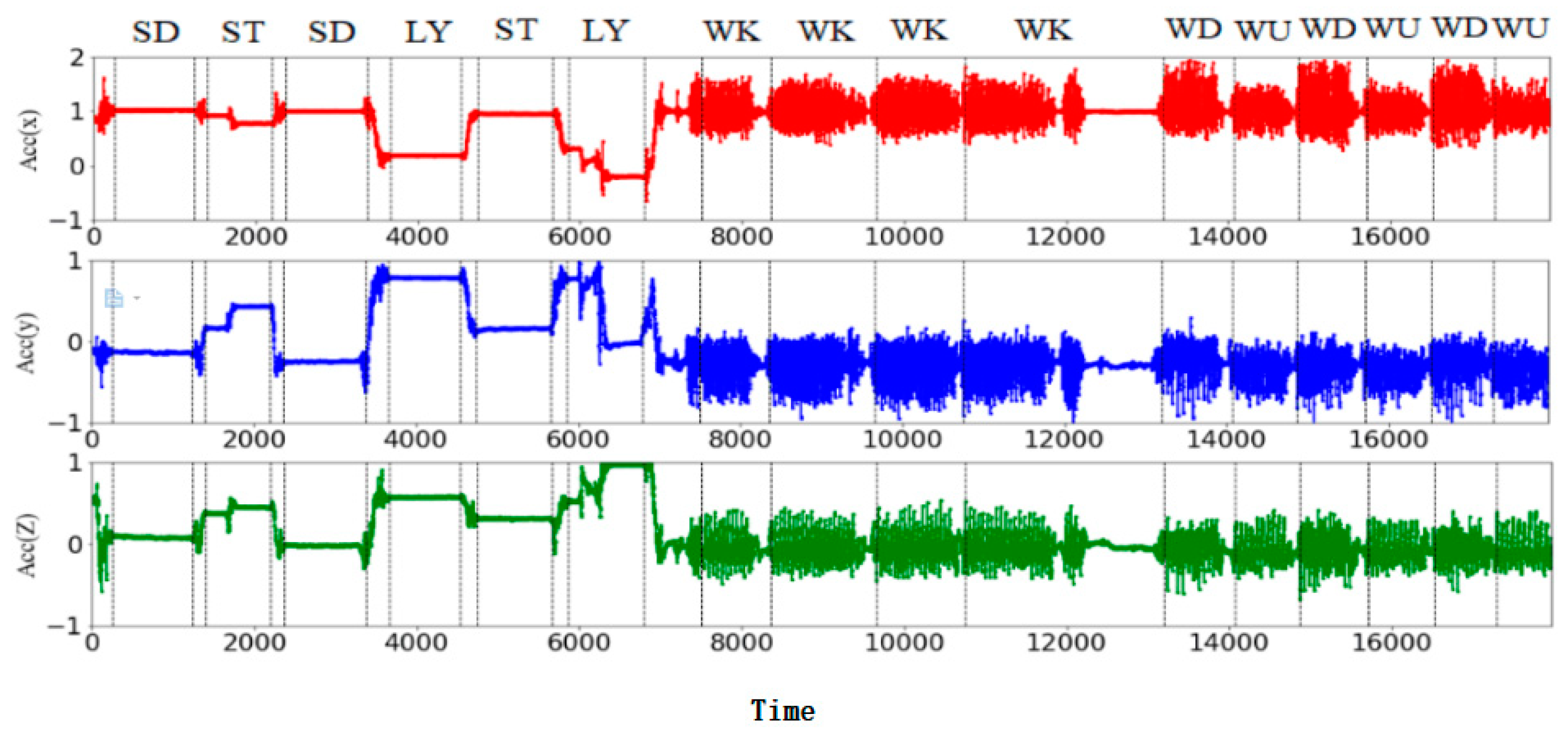
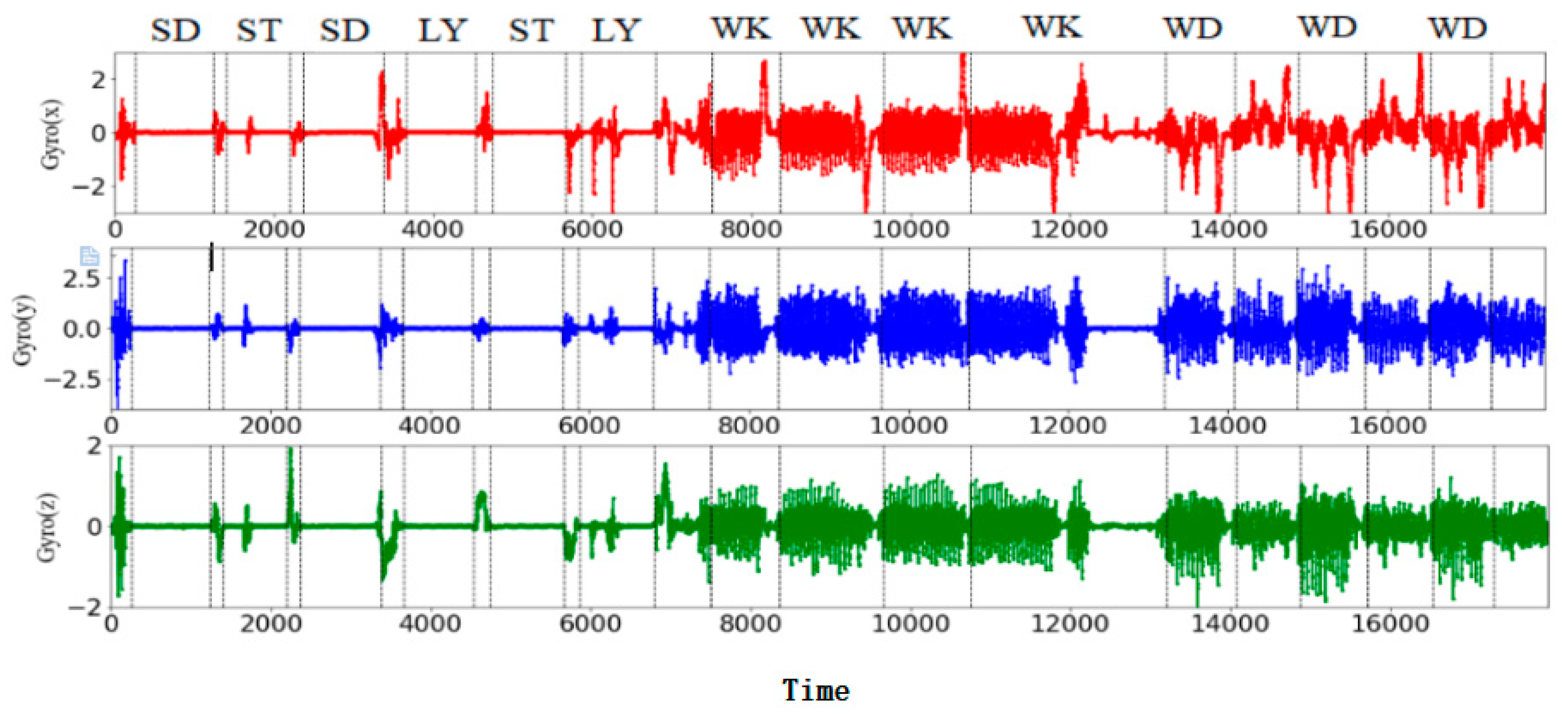
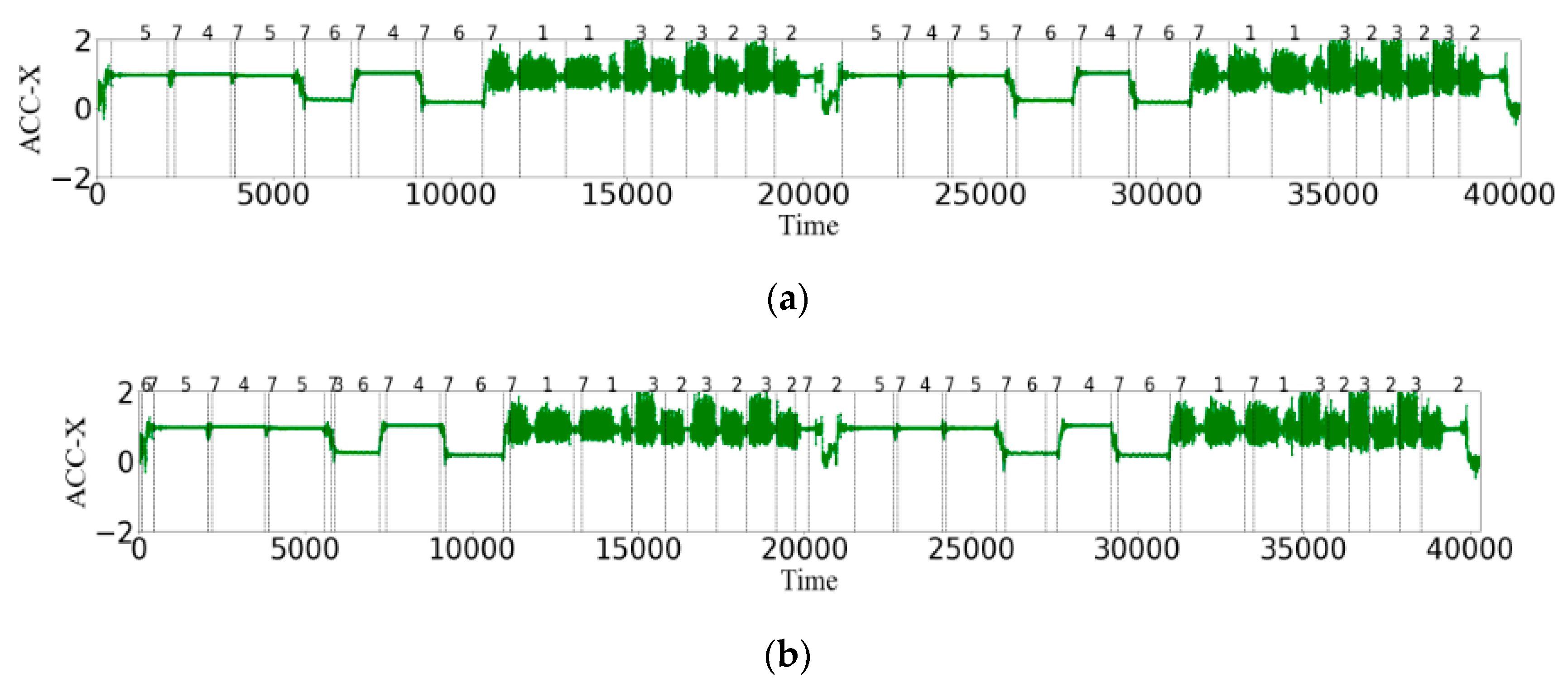
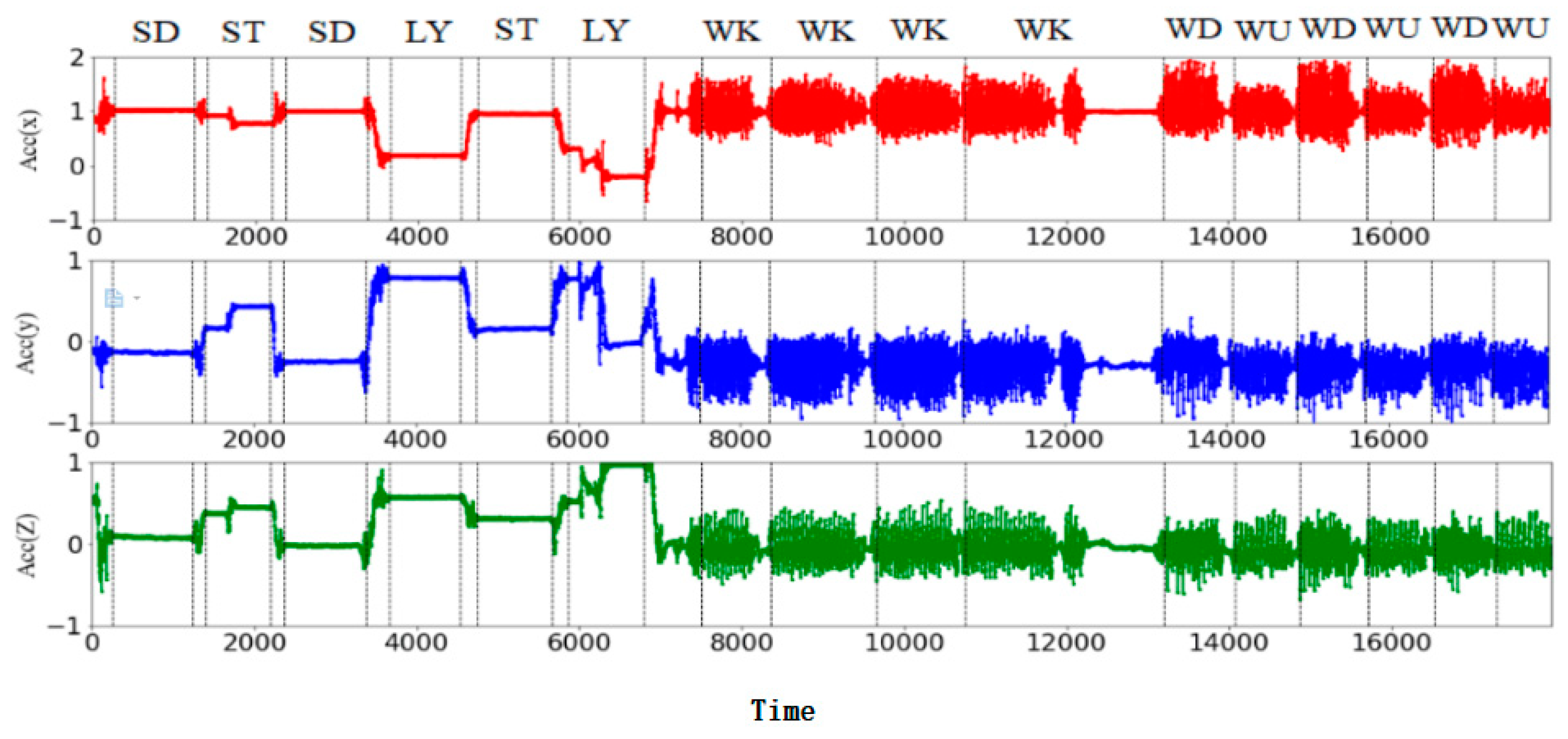
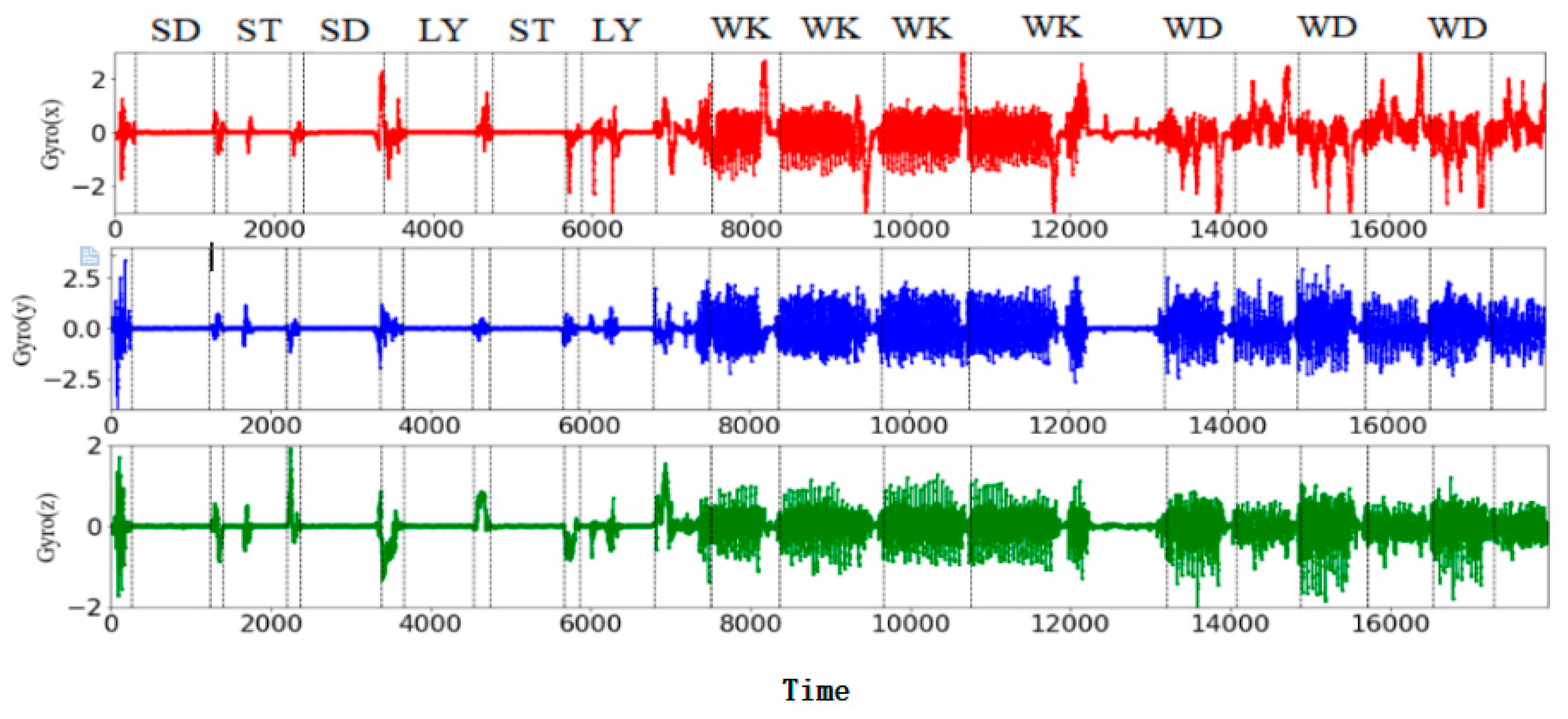
4.1. Selection of Data Sets
4.2. Experimental Results
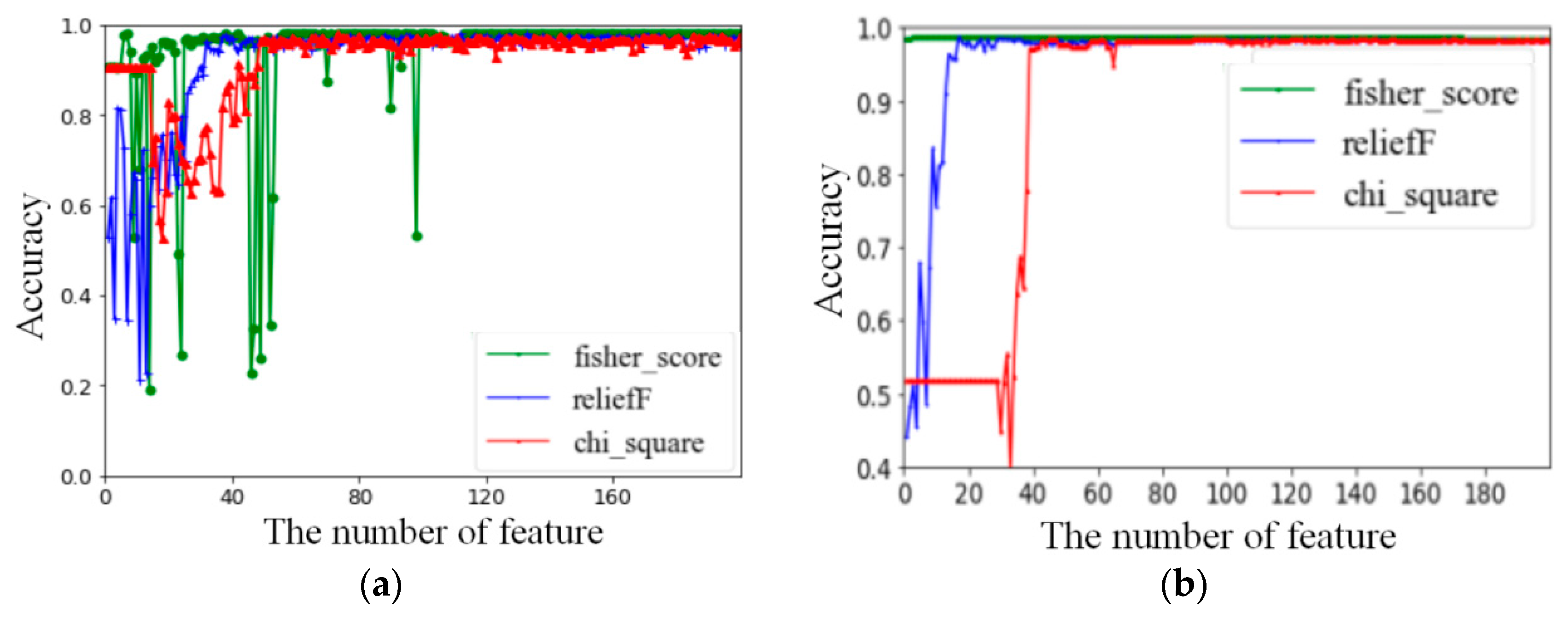
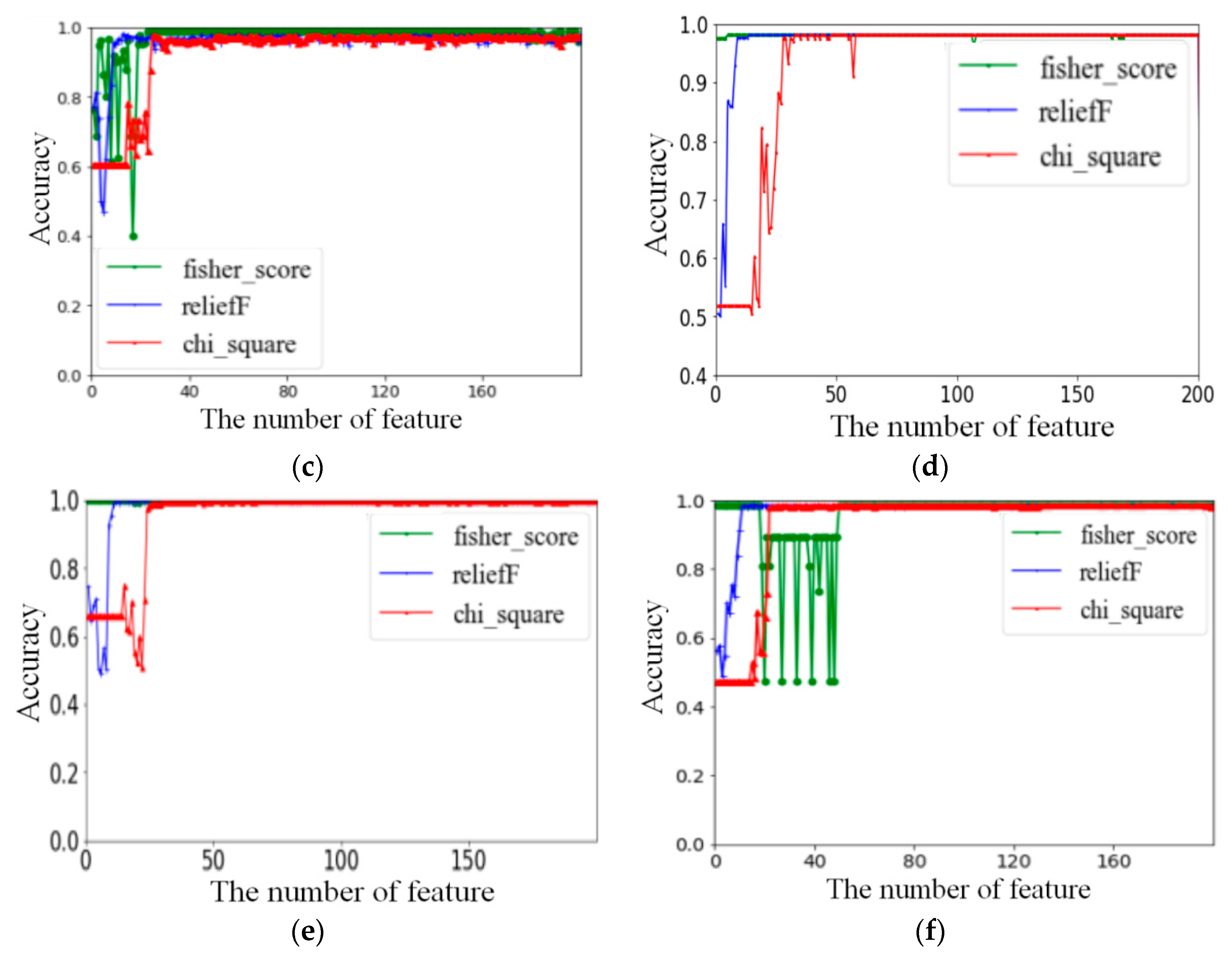
4.2.1. Results of Feature Selection
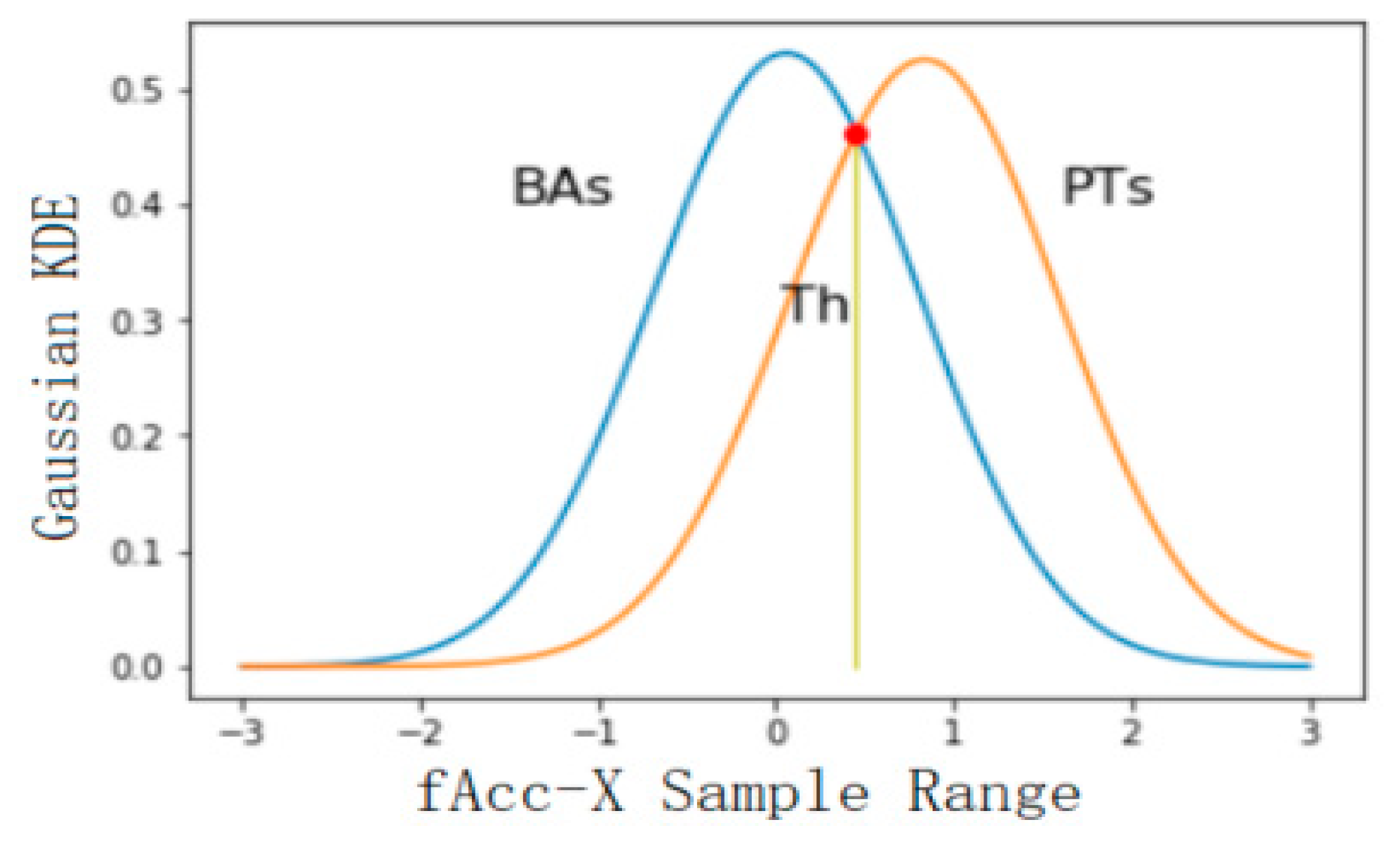
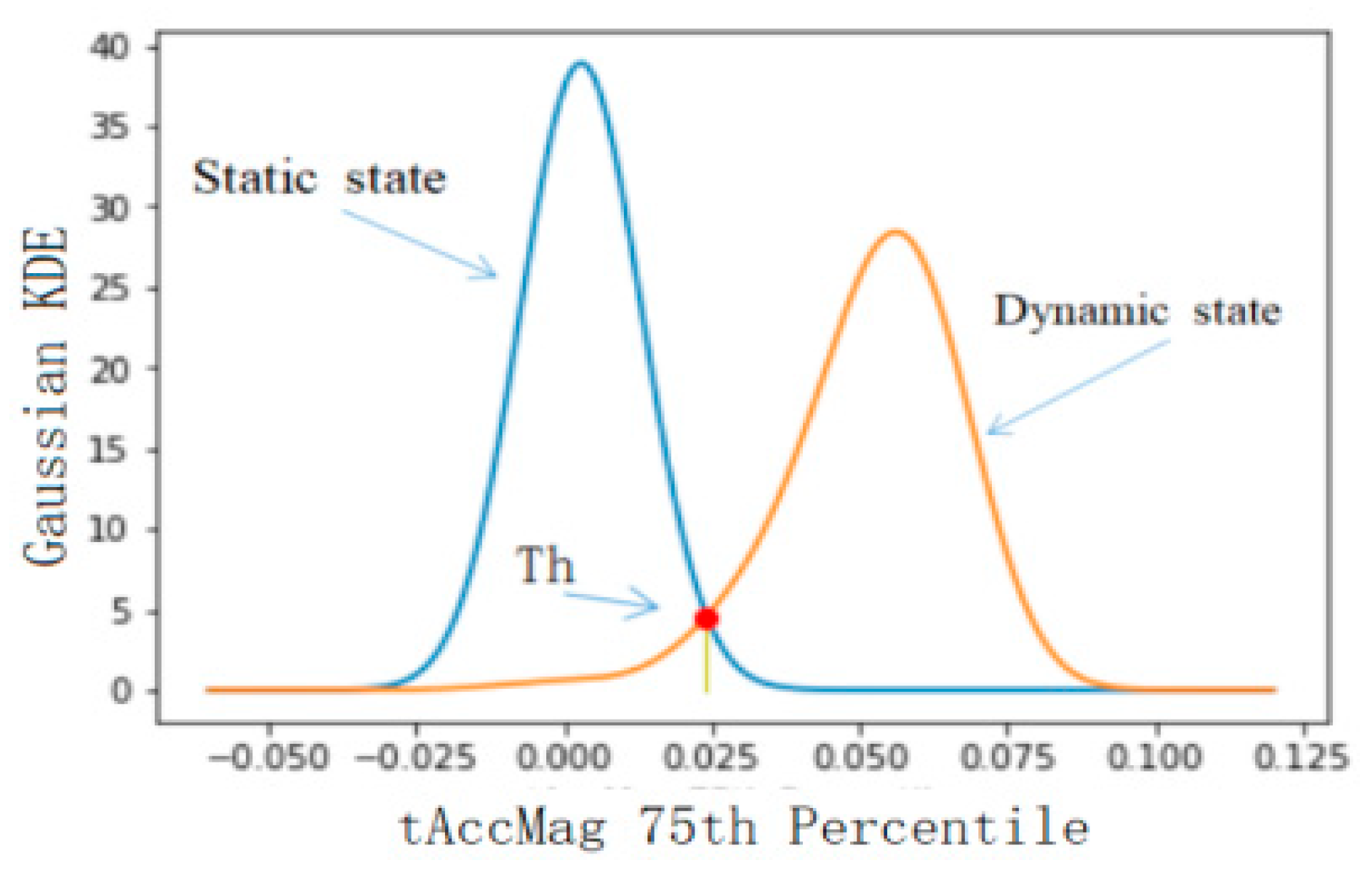
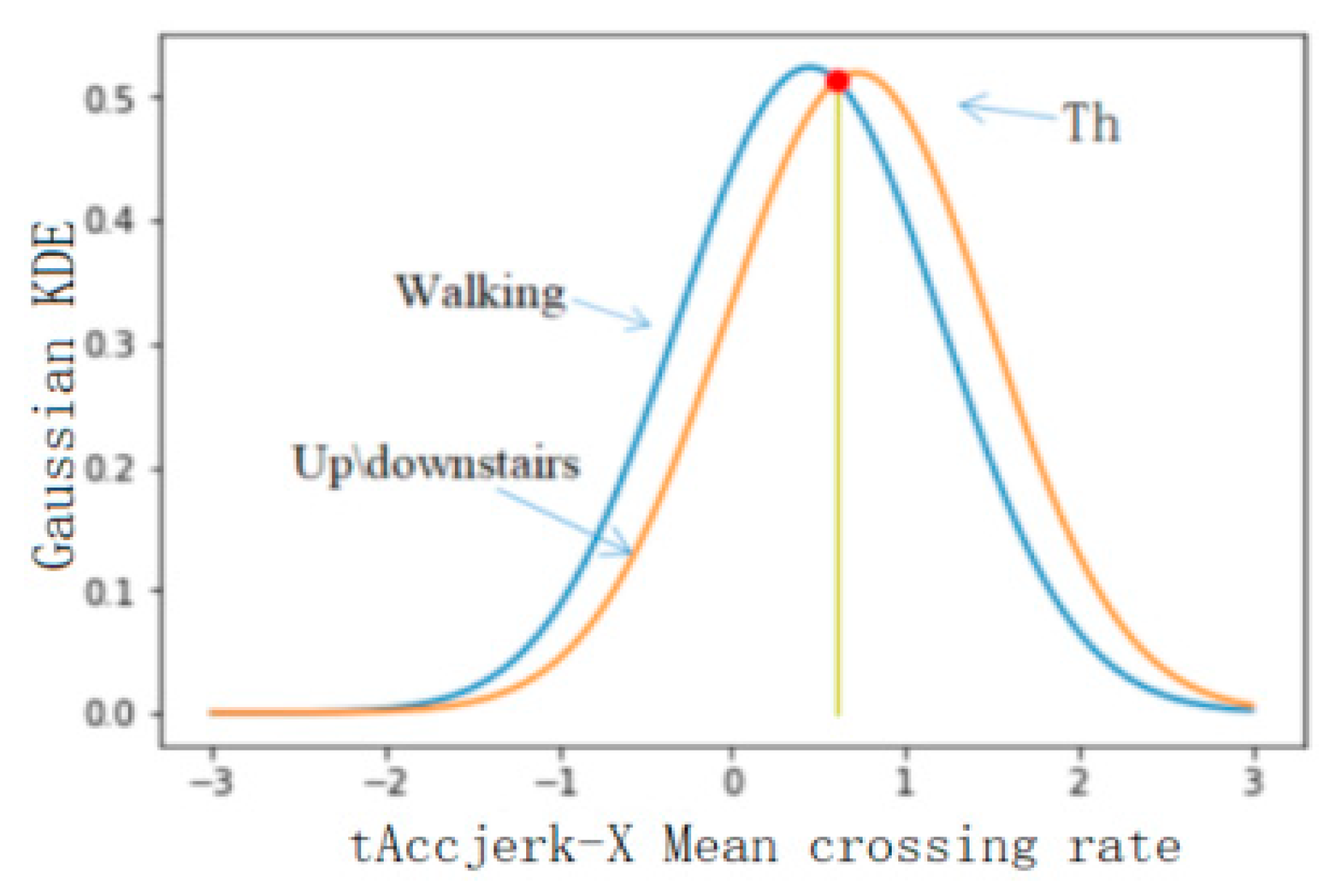
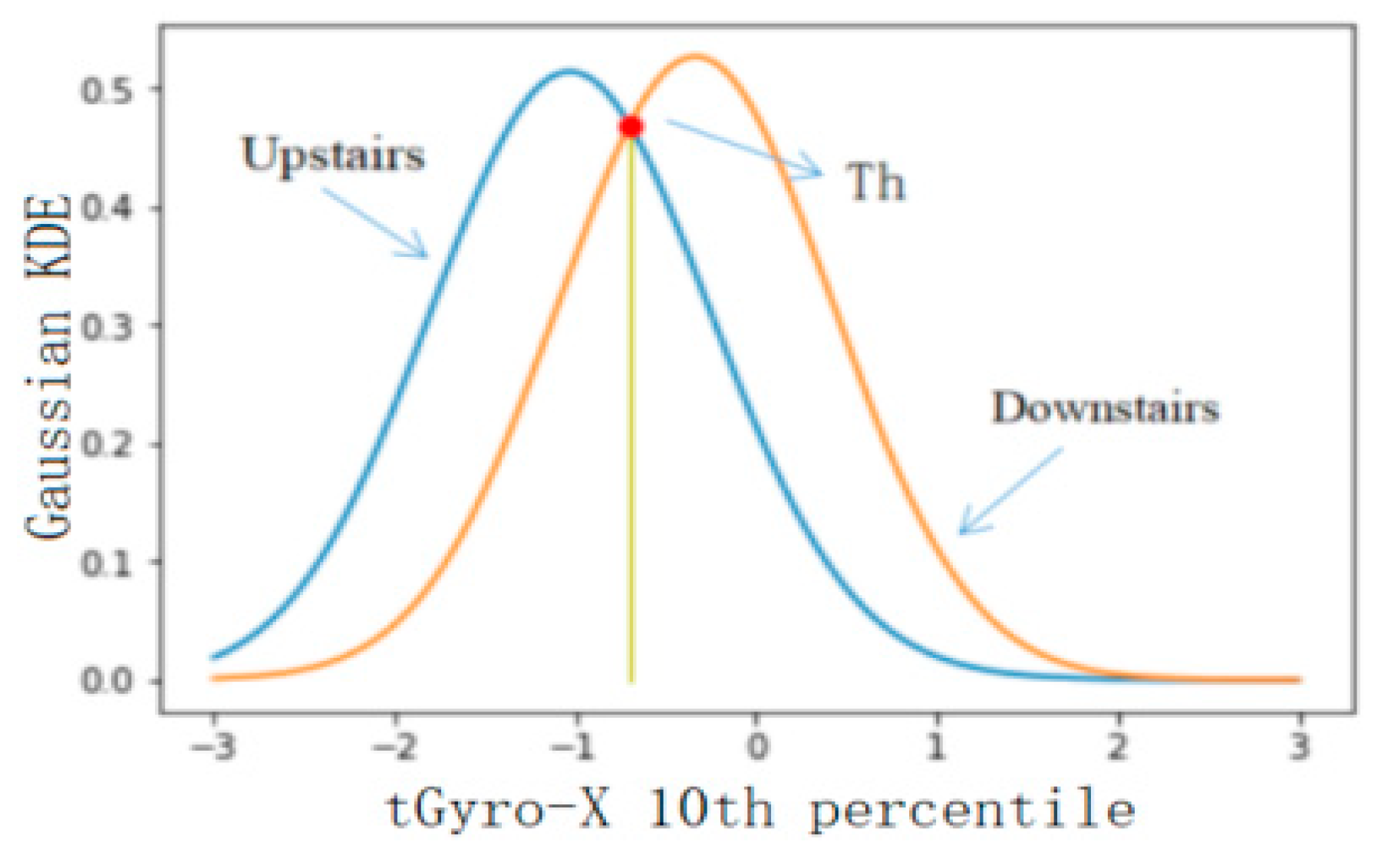
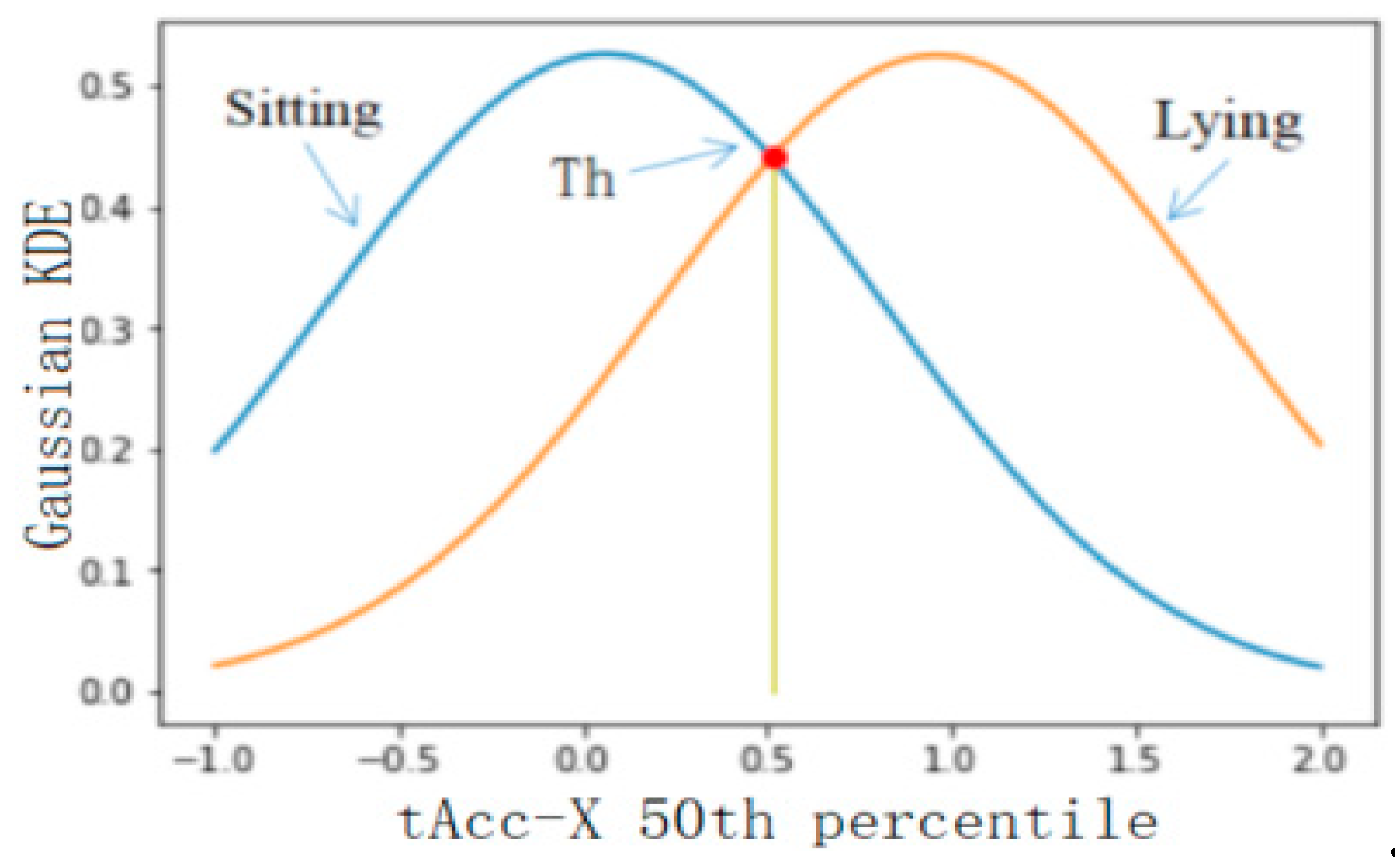
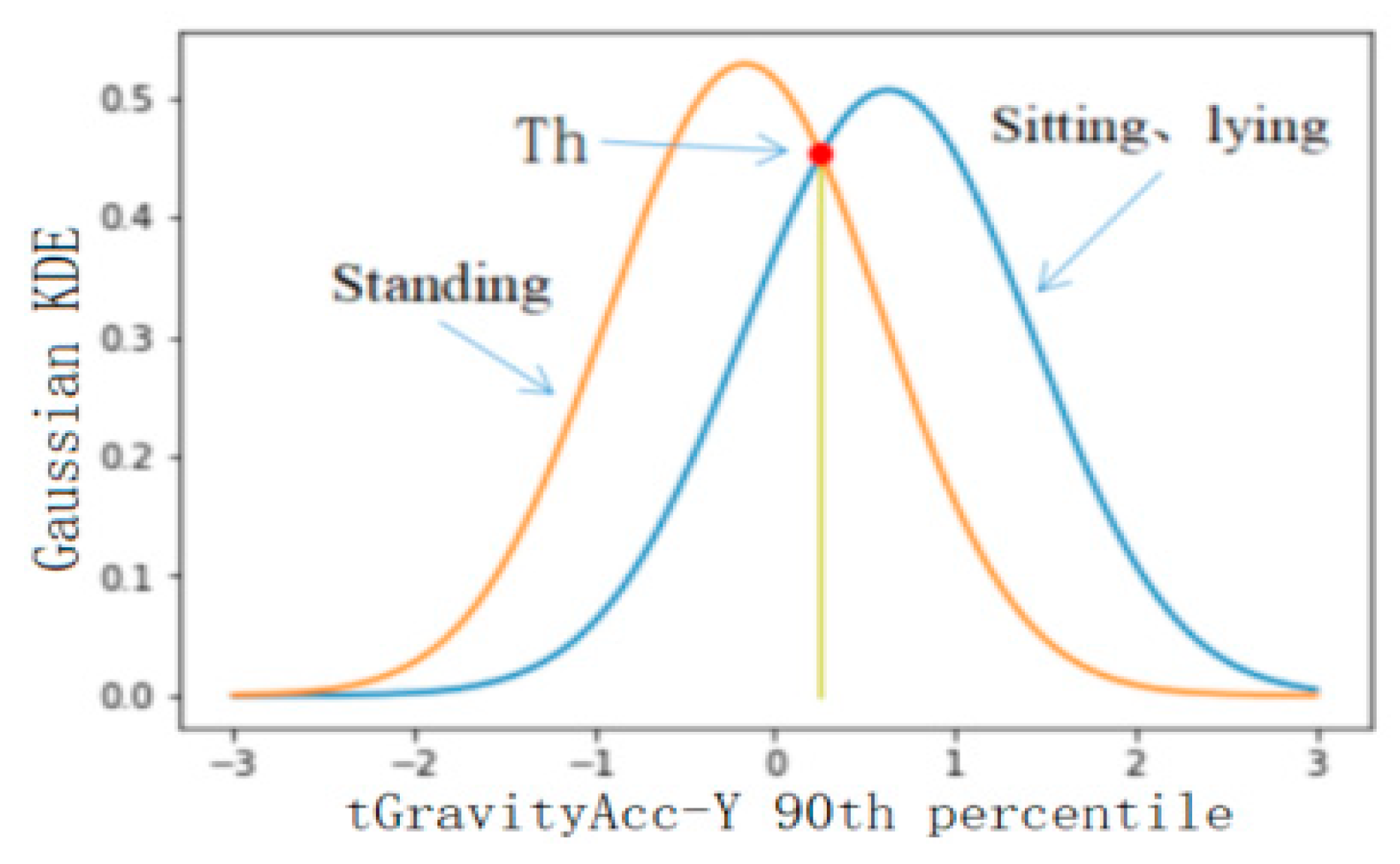
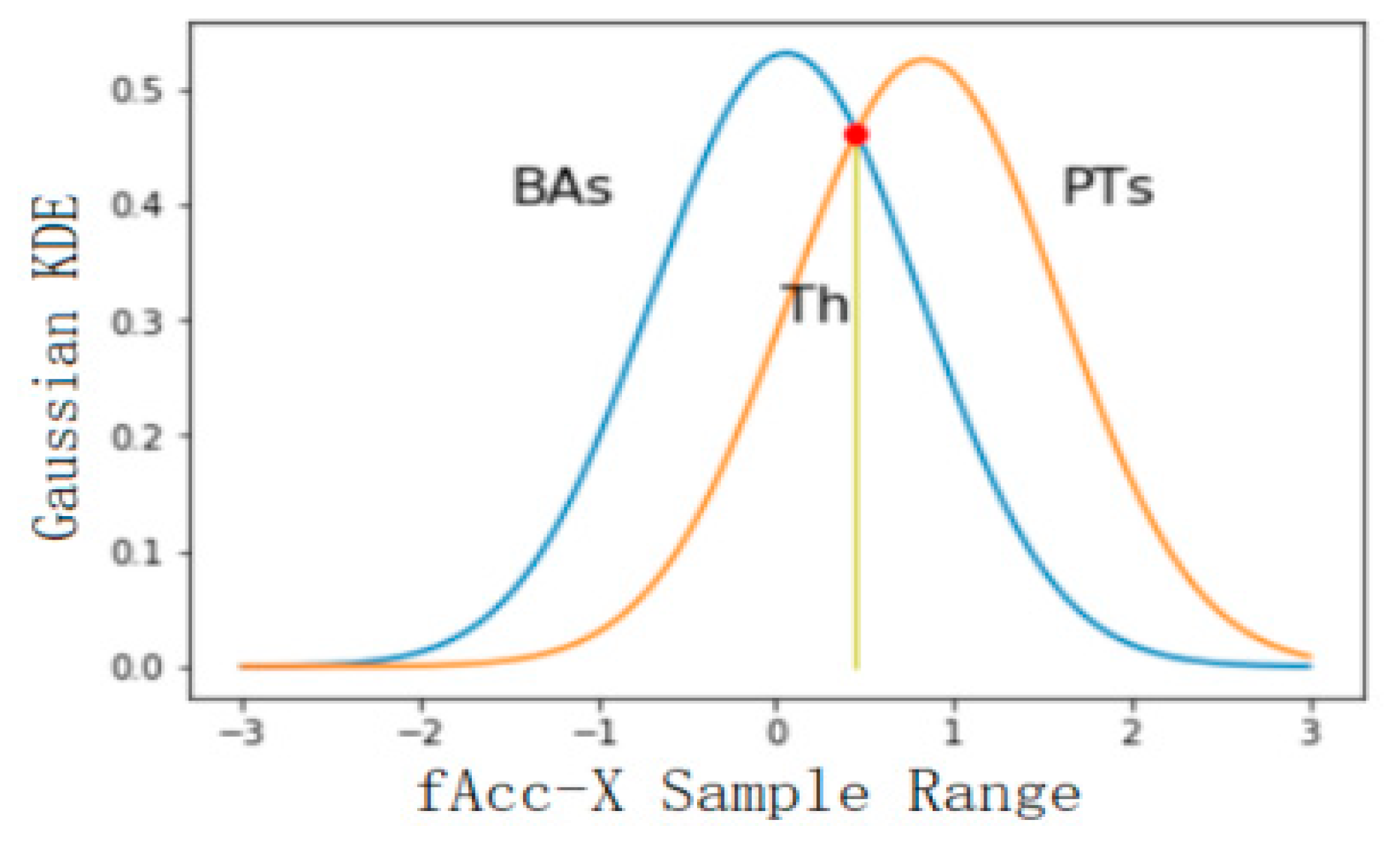
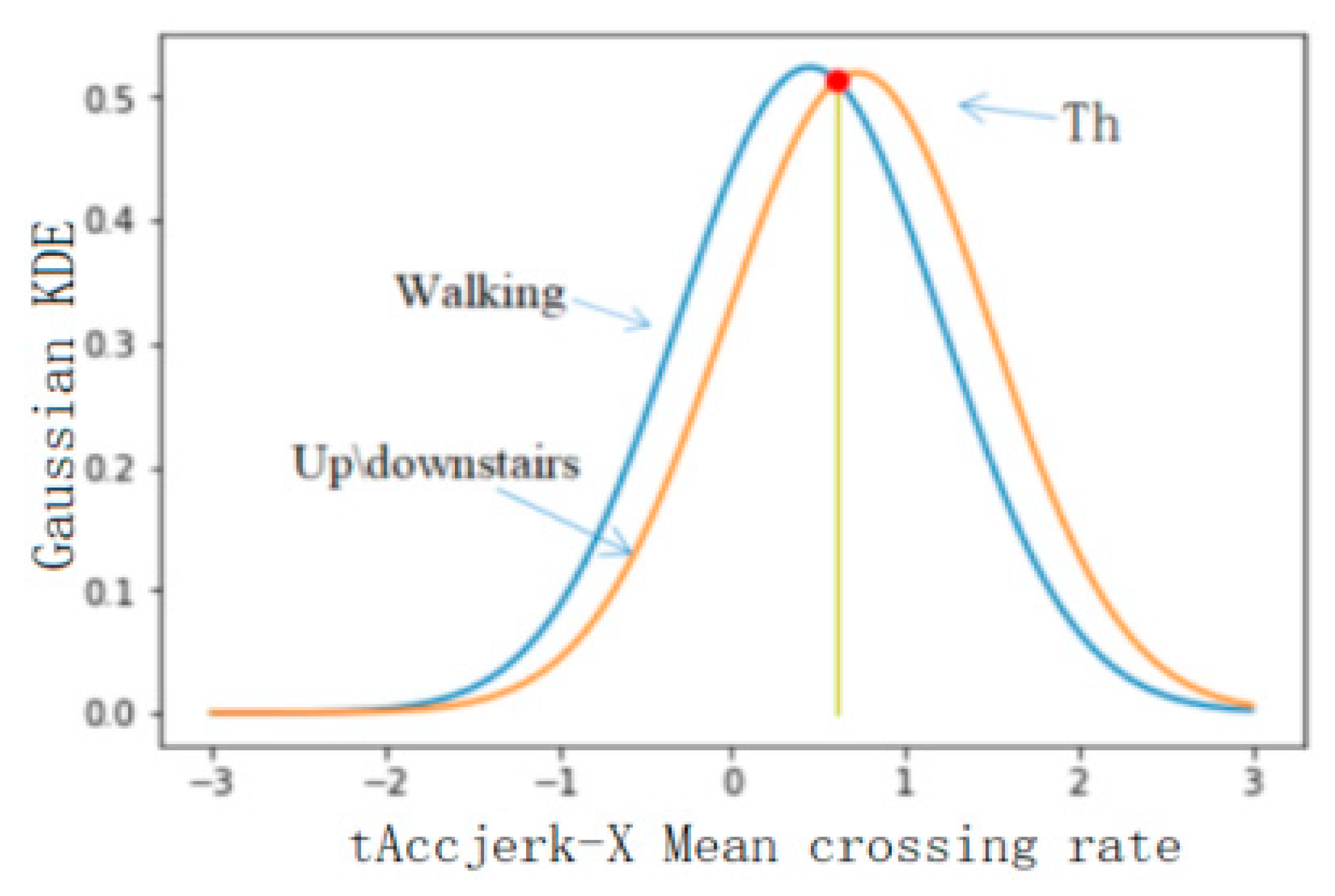
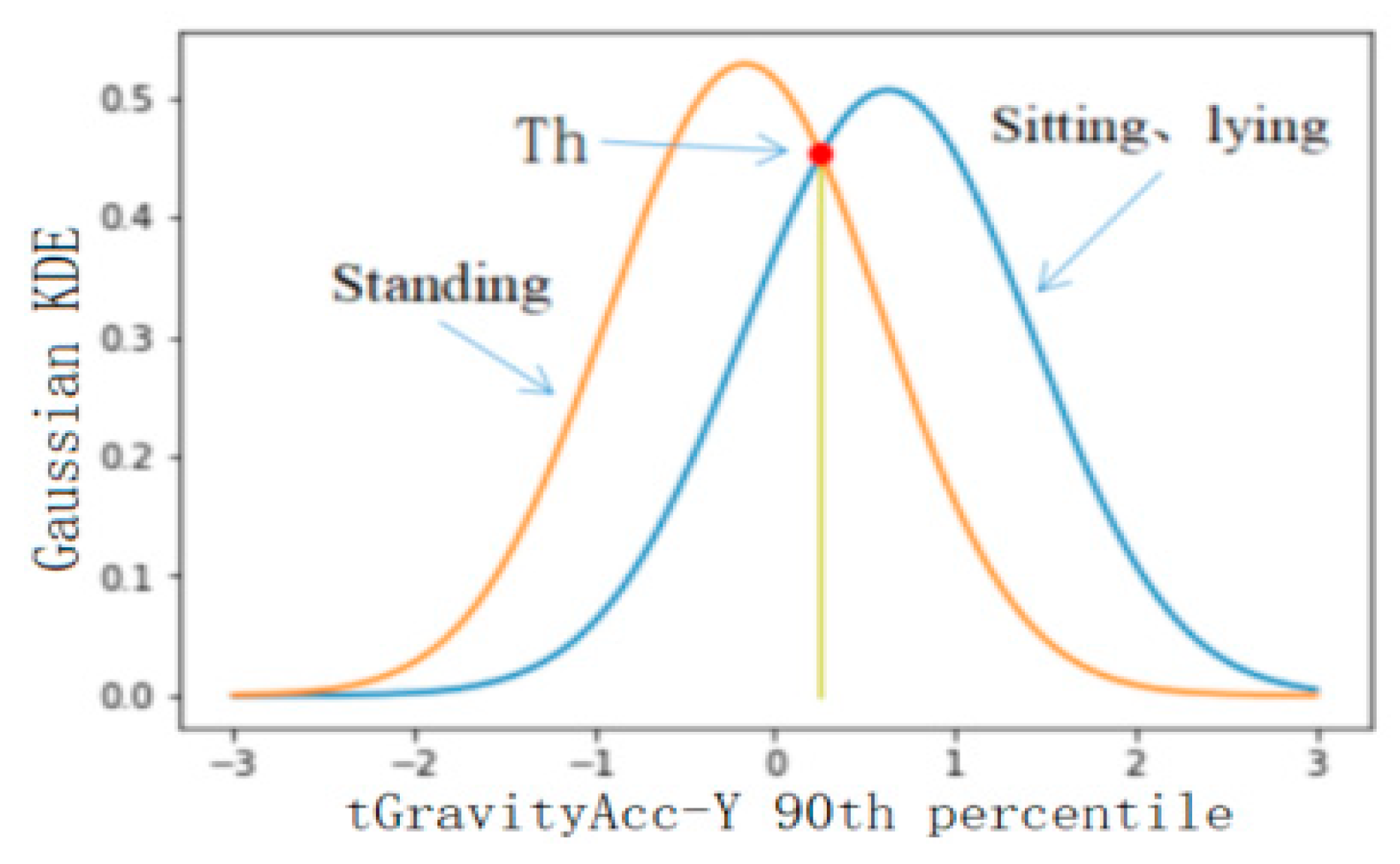
4.2.2. Threshold Selection of Classification Results
5. Discussions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lee, J.; Kim, J. Energy-Efficient Real-Time Human Activity Recognition on Smart Mobile Devices. Mob. Inf. Syst. 2016, 2016, 2316757. [Google Scholar] [CrossRef]
- Yang, R.; Wang, B. PACP: A Position-Independent Activity Recognition Method Using Smartphone Sensors. Information 2016, 7, 72. [Google Scholar] [CrossRef]
- He, Y.; Li, Y. Physical activity recognition utilizing the built-in Kinematic sensors of a smartphone. Int. J. Distrib. Sens. Netw. 2013, 9, 481580. [Google Scholar] [CrossRef]
- Qifan, Z.; Hai, Z.; Zahra, L.; Liu, Z.B.; Naser, E.S. Design and Implementation of Foot-Mounted Inertial Sensor Based Wearable Electronic Device for Game Play Application. J. Sens. 2016, 16, 1752. [Google Scholar]
- Robertas, D.; Mindaugas, V.; Justas, Š.; Marcin, W. Human Activity Recognition in AAL Environments Using Random Projections. Comput. Math. Methods Med. 2016, 2016, 4073584. [Google Scholar]
- Sorkun, M.C.; Danişman, A.E.; İncel, Ö.D. Human activity recognition with mobile phone sensors: Impact of sensors and window size. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar]
- Nurhazarifah, C.H.; Nazatul, A.A.M.; Haslina, A.; Waqas, K.O. User Satisfaction for an Augmented Reality Application to Support Productive Vocabulary Using Speech Recognition. Adv. Multimed. 2018, 2018, 9753979. [Google Scholar]
- Zheng, Y.H. Human Activity Recognition Based on the Hierarchical Feature Selection and Classification Framework. J. Electr. Comput. Eng. 2015, 2015, 140820. [Google Scholar] [CrossRef]
- Leonardis, G.D.; Rosati, S.; Balestra, G.; Agostini, V.; Panero, E.; Gastaldi, L.; Knaflitz, M. Human Activity Recognition by Wearable Sensors: Comparison of different classifiers for real-time applications. In Proceedings of the 2018 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Rome, Italy, 11–13 June 2018; pp. 1–6. [Google Scholar]
- Jarraya, A.; Arour, K.; Bouzeghoub, A.; Borgi, A. Feature selection based on Choquet integral for human activity recognition. In Proceedings of the 2017 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Naples, Italy, 9–12 July 2017; pp. 1–6. [Google Scholar]
- Doewes, A.; Swasono, S.E.; Harjito, B. Feature selection on Human Activity Recognition dataset using Minimum Redundancy Maximum Relevance. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics—Taiwan (ICCE-TW), Taipei, Taiwan, 12–14 June 2017; pp. 171–172. [Google Scholar]
- Li, J. A Feature Subset Selection Algorithm Based on Feature Activity and Improved GA. In Proceedings of the 2015 11th International Conference on Computational Intelligence and Security (CIS), Shenzhen, China, 19–20 December 2015; pp. 206–210. [Google Scholar]
- Ridok, A.; Mahmudy, W.F.; Rifai, M. An improved artificial immune recognition system with fast correlation based filter (FCBF) for feature selection. In Proceedings of the 2017 Fourth International Conference on Image Information Processing (ICIIP), Shimla, India, 21–23 December 2017; pp. 1–6. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Xavier, P.; Davide, A. Transition-aware human activity recognition using smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, Y.; Cai, J.; Kot, A.C. Efficient object feature selection for action recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2707–2711. [Google Scholar]
- San-Segundo, R.; Montero, J.M.; Barra-Chicote, R.; Fernando, F.; José, M.P. Feature extraction from smartphone inertial signals for human activity segmentation. Signal Process. 2016, 120, 359–372. [Google Scholar] [CrossRef]
- Gao, L.; Bourke, A.K.; Nelson, J. A comparison of classifiers for activity recognition using multiple accelerometer-based sensors. In Proceedings of the 2012 IEEE 11th International Conference on Cybernetic Intelligent Systems (CIS), Limerick, Ireland, 23–24 August 2012; pp. 149–153. [Google Scholar]
- Xie, L.; Tian, J.; Ding, G.; Zhao, Q. Human activity recognition method based on inertial sensor and barometer. In Proceedings of the 2018 IEEE International Symposium on Inertial Sensors and Systems (INERTIAL), Moltrasio, Italy, 26–19 March 2018; pp. 1–4. [Google Scholar]
- Rajesh, K.; Sugumaran, V.; Vijayaram, T.; Karthikeyan, C. Activities of daily life (ADL) recognition using wrist-worn accelerometer. Int. J. Eng. Technol. 2016, 8, 1406–1413. [Google Scholar]
- Nhan, D.N.; Duong, T.B.; Phuc, H.T.; Gu-Min, J. Position-Based Feature Selection for Body Sensors regarding Daily Living Activity Recognition. J. Sens. 2018, 2018, 9762098. [Google Scholar]
- Karantonis, M.D.; Narayanan, M.R.; Mathie, M.; Lovell, N.H.; Celler, B.G. Implementation of a realtime human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 156–167. [Google Scholar] [CrossRef] [PubMed]
- Mobark, M.; Chuprat, S.; Mantoro, T. Improving the accuracy of complex activities recognition using accelerometer-embedded mobile phone classifiers. In Proceedings of the 2017 Second International Conference on Informatics and Computing (ICIC), Jayapura, Indonesia, 1–3 November 2017; pp. 1–5. [Google Scholar]
- Albert, S.; Angulo, C.; Pardo, D.; Andreu, C.; Cabestany, J. Analyzing human gait and posture by combining feature selection and kernel methods. Neurocomputing 2011, 74, 2665–2674. [Google Scholar] [Green Version]
- Kaytaran, T.; Bayindir, L. Activity recognition with wrist found in photon development board and accelerometer. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar]
- Ho, J. Interruptions: Using activity transitions to trigger proactive messages. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2004. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A real-time human action recognition system using depth and inertial sensor fusion. IEEE Sens. J. 2016, 16, 773–781. [Google Scholar] [CrossRef]
- Tao, D.; Jin, L.; Yuan, Y.; Xue, Y. Ensemble manifold rank preserving for acceleration-based human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2014, 27, 1392–1404. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Jin, L. Activity recognition from acceleration data based on discrete consine transform and SVM. In Proceedings of the IEEE Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 5041–5044. [Google Scholar]
- Wang, Z.; Wu, D.; Chen, J.; Ghoneim, A.; Hossain, M.A. A Triaxial Accelerometer-Based Human Activity Recognition via EEMD-Based Features and Game-Theory-Based Feature Selection. IEEE Sens. J. 2016, 16, 3198–3207. [Google Scholar] [CrossRef]
- Pourpanah, F.; Zhang, B.; Ma, R.; Hao, Q. Non-Intrusive Human Motion Recognition Using Distributed Sparse Sensors and the Genetic Algorithm Based Neural Network. In Proceedings of the 2018 IEEE SENSORS, New Delhi, India, 28–31 October 2018; pp. 1–4. [Google Scholar]
- Wang, L.; Gu, T.; Tao, X.P.; Chen, H.H.; Lu, J. Recognizing multi-user activities using wearable sensors in a smart home. Pervasive Mob. Comput. 2011, 7, 287–298. [Google Scholar] [CrossRef]
- Zhou, S.L.; Fei, F.; Zhang, G.L.; John, D.M.; Liu, Y.H.; Liou, J.Y.J.; Li, W.J. 2D Human Gesture Tracking and Recognition by the Fusion of MEMS Inertial and Vision Sensors. IEEE Sens. J. 2014, 14, 1160–1170. [Google Scholar] [CrossRef]
- Yang, M.; Chen, Y.; Ji, G. Semi_Fisher Score: A semi-supervised method for feature selection. In Proceedings of the 2010 International Conference on Machine Learning and Cybernetics, Qingdao, China, 11–14 July 2010; pp. 527–532. [Google Scholar]
- Liu, X.; Wang, X.L.; Su, Q. Feature selection of medical data sets based on RS-RELIEFF. In Proceedings of the 2015 12th International Conference on Service Systems and Service Management (ICSSSM), Guangzhou, China, 22–24 June 2015; pp. 1–5. [Google Scholar]
- Haryanto, A.W.; Mawardi, E.K.; Muljono. Influence of Word Normalization and Chi-Squared Feature Selection on Support Vector Machine (SVM) Text Classification. In Proceedings of the 2018 International Seminar on Application for Technology of Information and Communication, Semarang, Indonesia, 21–22 September 2018; pp. 229–233. [Google Scholar]
- Dai, H. Research on SVM improved algorithm for large data classification. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA), Shanghai, China, 9–12 March 2018; pp. 181–185. [Google Scholar]
- Alam, S.; Moonsoo, K.; Jae-Young, P.; Kwon, G. Performance of classification based on PCA, linear SVM, and Multi-kernel SVM. In Proceedings of the 2016 Eighth International Conference on Ubiquitous and Future Networks (ICUFN), Vienna, Austria, 5–8 July 2016; pp. 987–989. [Google Scholar]
- Zhou, Y.; Cheng, Z.; Jing, L. Threshold selection and adjustment for online segmentation of one-stroke finger gestures using single tri-axial accelerometer. Multimed. Tools Appl. 2015, 74, 9387–9406. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. Acm Comput. Surv. 2013, 46, 33. [Google Scholar] [CrossRef]
- Hoai, M.; Torre, F.D.L. Maximum margin temporal clustering. In Proceedings of the 25th IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 18–20 June 2012. [Google Scholar]
- Kavitha, S.; Varuna, S.; Ramya, R. A comparative analysis on linear regression and support vector regression. In Proceedings of the 2016 Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 19 November 2016; pp. 1–5. [Google Scholar]
- Liu, X.; Zhang, J. Active learning for human action recognition with Gaussian Processes. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 3253–3256. [Google Scholar]
- Oh, J.; Kim, T.; Hong, H. Using Binary Decision Tree and Multiclass SVM for Human Gesture Recognition. In Proceedings of the 2013 International Conference on Information Science and Applications (ICISA), Suwon, Korea, 24–26 June 2013; pp. 1–4. [Google Scholar]
- Yazdansepas, D.; Niazi, A.H.; Gay, J.L.; Maier, F.W.; Ramaswamy, L.; Rasheed, K.; Buman, M.P. A Multi-featured Approach for Wearable Sensor-Based Human Activity Recognition. In Proceedings of the 2016 IEEE International Conference on Healthcare Informatics (ICHI), Chicago, IL, USA, 4–7 October 2016; pp. 423–431. [Google Scholar]
- Capela, N.; Lemaire, E.; Baddour, N. Feature Selection for Wearable Smartphone-Based Human Activity Recognition with Able bodied, Elderly, and Stroke Patients. PLoS ONE 2015, 10. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type Description | Definitions |
|---|---|
| Arithmetic mean tAcc-X | |
| Sample Standard deviation tAcc-X | |
| Sample Variance tAcc-X | |
| Median tAcc-X | |
| Median absolute deviation tAcc-X | |
| Largest values tAcc-X | |
| Smallest value tAcc-X | |
| Sample Range tAcc-X | |
| Inter-quartile range tAcc-X | |
| Mean crossing rate tAcc-X | |
| Skewness tAcc-X | |
| Kurtosis tAcc-X | |
| Curve Length tAcc-X | |
| Slope tAcc-X | |
| Power tAcc-X | |
| Root Mean Square tAcc-X | |
| Mean Euclidean distance tAcc-X | |
| 10th percentile tAcc-X | |
| 25th Percentile tAcc-X | |
| 50th Percentile tAcc-X | |
| 75th Percentile tAcc-X | |
| 90th Percentile tAcc-X |
| Type Description | Definitions |
|---|---|
| Covariance tAcc-XY | |
| Correlation coefficient tAcc-XY |
| Feature | Feature Description | Feature | Feature Description | Feature | Feature Description |
|---|---|---|---|---|---|
| 0 | Mean tAcc-X | 10 | Mean tAccJerk-Y | 20 | Mean fAcc-X |
| 1 | Mean tAcc-Y | 11 | Mean tAccJerk-Z | 21 | Mean fAcc-Y |
| 2 | Mean tAcc-Z | 12 | Mean tGyroJerk-X | 22 | Mean fAcc-Z |
| 3 | Mean tGyro-X | 13 | Mean tGyroJerk-Y | 23 | Mean fGyro-X |
| 4 | Mean tGyro-Y | 14 | Mean tGyroJerk-Z | 24 | Mean fGyro-Y |
| 5 | Mean tGyro-Z | 15 | Mean tAccMag | 25 | Mean fGyro-Z |
| 6 | Mean tGravityAcc-X | 16 | Mean tGyroMag | 26 | Mean fAccJerk-X |
| 7 | Mean tGravityAcc-Y | 17 | Mean tGravityAccMag | 27 | Mean fAccJerk-Y |
| 8 | Mean tGravityAcc-Z | 18 | Mean tAccAng | 28 | Mean fAccJerk-Z |
| 9 | Mean tAccJerk-X | 19 | Mean tGyroAng |
| Feature | Name |
|---|---|
| 0–28 | Arithmetic-mean (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 29–57 | Median (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 58–86 | Largest-values (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 87–115 | Smallest-value (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 116–144 | Sample-Variance (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 145–173 | Skewness (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 174–202 | Kurtosis (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 203–231 | Sample-Range (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 232–260 | Inter-quartile-range (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 261–289 | 10th-percentile (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 290–318 | 25th-Percentile (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 319–347 | 50th-Percentile (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 348–376 | 75th-Percentile (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 377–405 | 90th-Percentile (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng, fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 406–425 | Mean-crossing-rate (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng) |
| 426–445 | Root-Mean-Square (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng) |
| 446–465 | Power (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng) |
| 466–485 | Slope (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng) |
| 486–505 | Information-entropy (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng) |
| 506–525 | Mean-Euclidean-distance (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng) |
| 526–545 | Median-Absolute-deviation (tAcc-X,Y,Z, tGyro-X,Y,Z, tGravityAcc-X,Y,Z, tAccJerk-X,Y,Z, tGyroJerk-X,Y,Z, tAccMag, tGyroMag, tGravityAccMag, tAccAng, tGyroAng) |
| 546–551 | Covariance (tAcc-XY,YZ,XZ, tGyro-XY,YZ,XZ) |
| 552–557 | Correlation coefficient (tAcc-XY,YZ,XZ, tGyro-XY,YZ,XZ) |
| 558–566 | f_maxInds (fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 567–575 | f_meanFreq (fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| 576–584 | f_bandsEnergy (fAcc-X,Y,Z, fGyro-X,Y,Z, fAccJerk-X,Y,Z) |
| Levels | Category 1 | Category 2 |
|---|---|---|
| Level 1 | ST, SD, LY, WK, GU, and GD | SD-to-ST, ST-to-SD, SD-to-LY, LY-to-SD, ST-to-LY, and LY-to-ST |
| Level 2 | Immobile: ST, SD, and LY | Mobile: WK, GU, and GD |
| Level 3 | WK | GU and GD |
| Level 4 | GU | GD |
| Level 5 | SD | ST and LY |
| Level 6 | ST | LY |
| Level | Activities | Number of Windows |
|---|---|---|
| 1 | BAs: ST, SD, LY, WK, GU and GD | 345,441 |
| PTs: SD-to-ST, ST-to-SD, SD-to-LY, LY-to-SD, ST-to-LY and LY-to-ST | 72,518 | |
| 2 | Immobile: ST, SD and LY | 173,473 |
| Mobile: WK, GU and GD | 171,968 | |
| 3 | WK | 62,017 |
| GU and GD | 109,951 | |
| 4 | GU | 57,731 |
| GD | 52,220 | |
| 5 | SD | 54,701 |
| ST and LY | 118,772 | |
| 6 | ST | 59,438 |
| LY | 59,334 |
| Level | Fisher_score | ReliefF | Chi_square |
|---|---|---|---|
| 1 | 402, 256, 286, 255, 257, 451, 242, 223, 78, 417, 281, 239, 397, 245, 372, 431, 238, 117, 313, 406, 128, 398, 457, 449, 233, 418, 271, 244, 422, 420, 408, 407, 129, 123, 421, 314, 424, 425, 473, 423 | 197, 199, 196, 136, 198, 194, 223, 78, 201, 195, 200, 224, 139, 137, 140, 108, 79, 225, 226, 80, 202, 138, 81, 227, 110, 141, 109, 168, 82, 107, 111, 228, 170, 166, 167, 112, 83, 171, 169, 192 | 499, 491, 498, 486, 487, 488, 490, 489, 492, 493, 494, 495, 496, 497, 199, 197, 196, 198, 136, 194, 202, 195, 223, 78, 201, 139, 137, 224, 140, 108, 225, 226, 138, 79, 80, 200, 141, 81, 227, 110 |
| 2 | 235, 363, 276, 301, 247, 86, 392, 362, 365, 249, 305, 272, 40, 330, 275, 307, 394, 231, 11, 246, 359, 278, 391, 241, 266, 237, 388, 364, 280, 309, 251, 248, 304, 396, 382, 367, 441, 507, 527, 353 | 199, 197, 196, 198, 194, 195, 139, 223, 78, 201, 200, 140, 137, 79, 224, 564, 136, 226, 80, 565, 566, 108, 225, 110, 227, 202, 141, 81, 109, 138, 168, 559, 82, 111, 228, 107, 563, 192, 167, 170 | 584, 491, 501, 486, 487, 488, 489, 490, 492, 500, 493, 494, 495, 496, 497, 498, 502, 503, 499, 578, 582, 583, 581, 504, 580, 579, 505, 576, 577, 199, 200, 202, 196, 201, 139, 140, 194, 136, 79, 137 |
| 3 | 114, 85, 160, 161, 230, 45, 335, 44, 334, 415, 125, 86, 429, 449, 406, 78, 116, 212, 223, 261, 239, 96, 226, 270, 81, 170, 182, 193, 190, 295, 451, 203, 278, 245, 231, 382, 324, 34, 149, 119 | 197, 196, 198, 195, 199, 201, 78, 223, 226, 194, 200, 140, 139, 110, 224, 108, 81, 227, 202, 111, 82, 141, 225, 109, 168, 107, 137, 228, 80, 112, 83, 167, 169, 138, 79, 170, 184, 172, 229, 230 | 499, 491, 498, 487, 488, 489, 490, 486, 492, 497, 494, 495, 496, 493, 197, 201, 198, 199, 168, 136, 140, 78, 194, 223, 226, 81, 196, 202, 109, 138, 110, 169, 195, 200, 111, 79, 80, 82, 230, 227 |
| 4 | 114, 275, 276, 392, 235, 391, 264, 441, 363, 278, 247, 40, 330, 11, 394, 246, 305, 365, 388, 249, 301, 293, 359, 304, 266, 295, 396, 307, 463, 237, 362, 443, 280, 130, 212, 241, 231, 382, 440, 467 | 199, 196, 197, 139, 195, 198, 200, 226, 136, 140, 110, 201, 194, 78, 223, 141, 80, 224, 81, 227, 108, 225, 192, 107, 109, 202, 170, 167, 82, 191, 228, 137, 111, 188, 142, 112, 193, 183, 229, 138 | 499, 498, 497, 496, 495, 494, 493, 492, 491, 490, 489, 488, 487, 486, 199, 198, 196, 139, 197, 200, 140, 226, 110, 170, 141, 202, 201, 192, 191, 107, 227, 81, 80, 82, 109, 142, 190, 188, 183, 229 |
| 5 | 166, 65, 384, 378, 349, 355, 59, 114, 7, 1, 320, 30, 326, 36, 83, 84, 108, 480, 78, 291, 297, 470, 484, 79, 85, 223, 466, 477, 483, 93, 230, 475, 113, 460, 444, 228, 440, 66, 267, 482 | 197, 199, 198, 194, 196, 201, 195, 137, 79, 78, 224, 223, 136, 225, 200, 80, 108, 170, 138, 202, 107, 191, 169, 192, 226, 228, 166, 139, 189, 112, 168, 109, 81, 110, 141, 188, 190, 83, 193, 165 | 499, 491, 498, 486, 487, 488, 489, 490, 492, 493, 494, 495, 496, 497, 197, 196, 201, 198, 199, 200, 136, 194, 137, 79, 78, 223, 202, 138, 224, 225, 80, 108, 192, 107, 191, 170, 169, 189, 171, 168 |
| 6 | 432, 426, 452, 446, 29, 319, 325, 35, 0, 6, 296, 290, 458, 459, 261, 354, 267, 348, 78, 223, 447, 453, 427, 433, 36, 326, 30, 320, 42, 332, 41, 331, 438, 439, 12, 13, 303, 7, 1, 302 | 199, 197, 198, 201, 194, 196, 136, 195, 223, 78, 137, 224, 200, 79, 225, 80, 202, 138, 108, 170, 169, 107, 228, 109, 168, 226, 189, 139, 188, 112, 83, 165, 81, 110, 141, 227, 172, 167, 140, 166 | 499, 491, 498, 486, 487, 488, 490, 489, 492, 493, 494, 495, 496, 497, 199, 197, 201, 200, 198, 194, 136, 137, 78, 223, 79, 224, 138, 196, 225, 80, 169, 172, 139, 170, 171, 202, 226, 165, 110, 109 |
| Feature | 201 | 78 | 286 | 255 | 257 | 197 | 199 | 223 | 196 | 198 |
|---|---|---|---|---|---|---|---|---|---|---|
| 201 | 0.76 | |||||||||
| 78 | 0.95 | 0.98 | ||||||||
| 286 | 0.98 | 0.98 | 0.98 | |||||||
| 255 | 0.98 | 0.98 | 0.97 | 0.98 | ||||||
| 257 | 0.89 | 0.87 | 0.87 | 0.87 | 0.87 | |||||
| 197 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | ||||
| 199 | 0.94 | 0.96 | 0.96 | 0.98 | 0.98 | 0.98 | 0.98 | |||
| 223 | 0.91 | 0.99 | 0.98 | 0.95 | 0.97 | 0.97 | 0.97 | 0.97 | ||
| 196 | 0.97 | 0.97 | 0.97 | 0.97 | 0.98 | 0.90 | 0.90 | 0.84 | 0.85 | |
| 198 | 0.94 | 0.94 | 0.94 | 0.92 | 0.94 | 0.89 | 0.91 | 0.91 | 0.88 | 0.84 |
| Feature | 235 | 276 | 363 | 301 | 199 | 197 | 196 | 198 | 247 | 194 |
|---|---|---|---|---|---|---|---|---|---|---|
| 235 | 0.62 | |||||||||
| 276 | 0.84 | 0.84 | ||||||||
| 363 | 0.71 | 0.74 | 0.59 | |||||||
| 301 | 0.59 | 0.86 | 0.65 | 0.65 | ||||||
| 199 | 0.76 | 0.76 | 0.79 | 0.80 | 0.76 | |||||
| 197 | 0.78 | 0.86 | 0.78 | 0.78 | 0.78 | 0.78 | ||||
| 196 | 0.59 | 0.87 | 0.59 | 0.59 | 0.59 | 0.78 | 0.59 | |||
| 198 | 0.75 | 0.89 | 0.75 | 0.75 | 0.75 | 0.85 | 0.74 | 0.74 | ||
| 247 | 0.81 | 0.97 | 0.81 | 0.81 | 0.81 | 0.91 | 0.81 | 0.84 | 0.82 | |
| 194 | 0.79 | 0.79 | 0.75 | 0.75 | 0.67 | 0.60 | 0.80 | 0.80 | 0.80 | 0.80 |
| Feature | 114 | 275 | 392 | 235 | 199 | 196 | 276 | 278 | 139 | 195 |
|---|---|---|---|---|---|---|---|---|---|---|
| 114 | 0.69 | |||||||||
| 275 | 0.56 | 0.78 | ||||||||
| 392 | 0.67 | 0.35 | 0.67 | |||||||
| 235 | 0.94 | 0.89 | 0.94 | 0.93 | ||||||
| 199 | 0.95 | 0.97 | 0.97 | 0.98 | 0.97 | |||||
| 196 | 0.69 | 0.68 | 0.78 | 0.93 | 0.98 | 0.78 | ||||
| 276 | 0.96 | 0.97 | 0.97 | 0.99 | 0.97 | 0.96 | 0.97 | |||
| 278 | 0.88 | 0.90 | 0.89 | 0.96 | 0.97 | 0.89 | 0.98 | 0.89 | ||
| 139 | 0.83 | 0.85 | 0.76 | 0.94 | 0.98 | 0.49 | 0.89 | 0.89 | 0.62 | |
| 195 | 0.56 | 0.56 | 0.56 | 0.61 | 0.69 | 0.60 | 0.60 | 0.65 | 0.59 | 0.60 |
| Feature | 432 | 319 | 452 | 426 | 446 | 199 | 197 | 296 | 201 | 194 |
|---|---|---|---|---|---|---|---|---|---|---|
| 432 | 0.86 | |||||||||
| 319 | 0.80 | 0.87 | ||||||||
| 452 | 0.86 | 0.79 | 0.70 | |||||||
| 426 | 0.59 | 0.87 | 0.79 | 0.62 | ||||||
| 446 | 0.89 | 0.89 | 0.79 | 0.80 | 0.84 | |||||
| 199 | 0.89 | 0.89 | 0.83 | 0.83 | 0.85 | 0.86 | ||||
| 197 | 0.89 | 0.89 | 0.83 | 0.83 | 0.85 | 0.86 | 0.85 | |||
| 296 | 0.89 | 0.90 | 0.78 | 0.79 | 0.86 | 0.87 | 0.85 | 0.76 | ||
| 201 | 0.82 | 0.82 | 0.68 | 0.68 | 0.77 | 0.83 | 0.84 | 0.74 | 0.68 | |
| 194 | 0.80 | 0.80 | 0.79 | 0.75 | 0.81 | 0.81 | 0.85 | 0.75 | 0.70 | 0.78 |
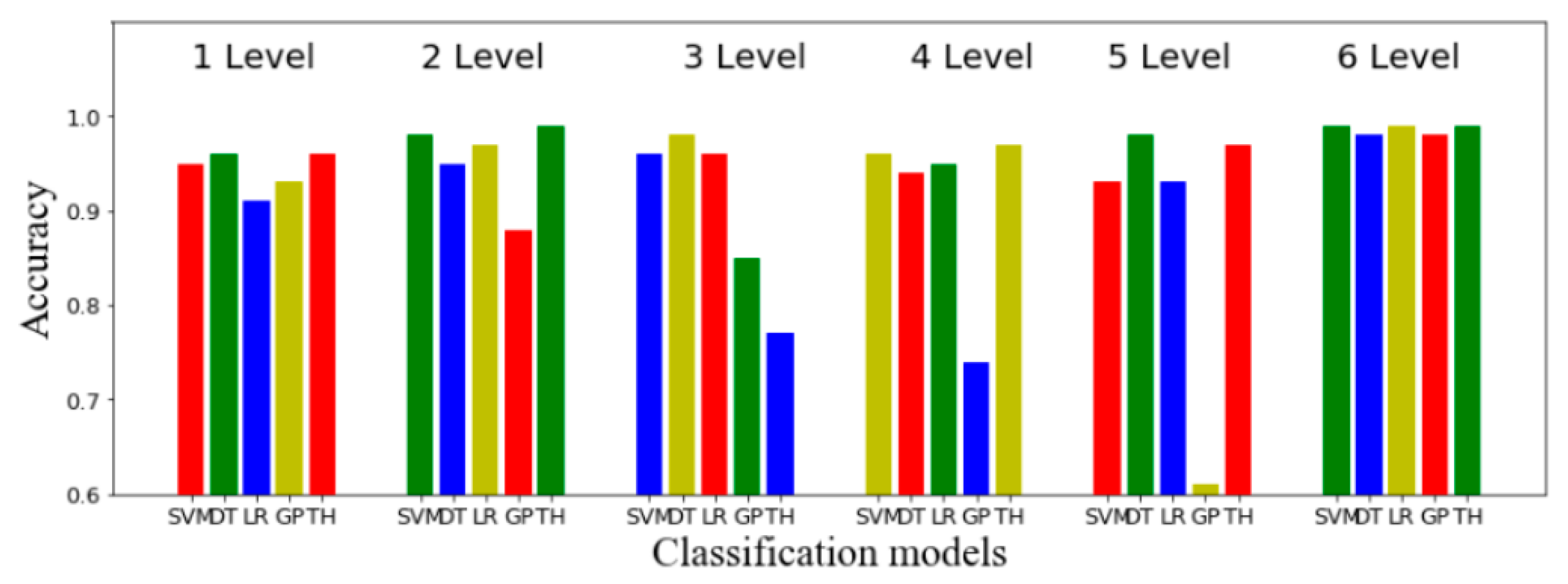
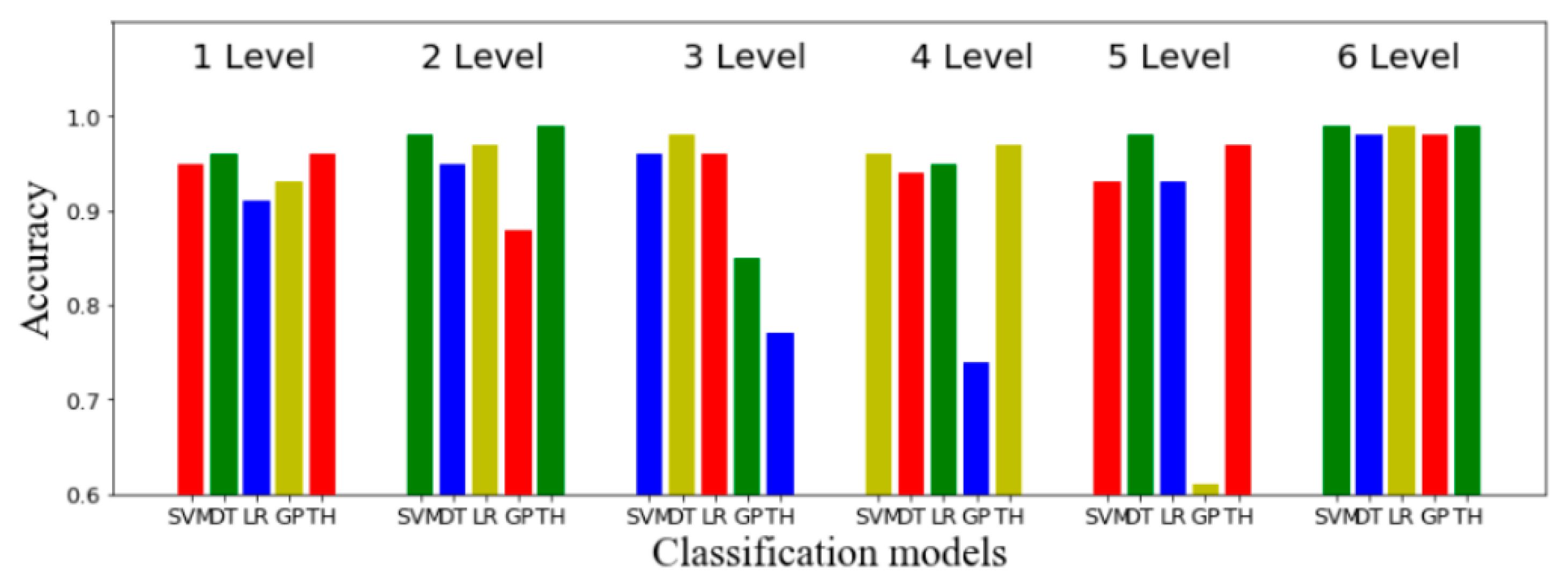
| Level | SVM | DT | LR | GP | TH |
|---|---|---|---|---|---|
| One | 0.98 | 0.96 | 0.97 | 0.89 | 0.91 |
| Two | 0.97 | 0.98 | 0.97 | 0.85 | 0.99 |
| Three | 0.97 | 0.94 | 0.96 | 0.74 | 0.77 |
| Four | 0.94 | 0.99 | 0.94 | 0.61 | 0.97 |
| Five | 0.94 | 0.99 | 0.93 | 0.68 | 0.97 |
| Six | 0.98 | 0.94 | 0.94 | 0.99 | 0.99 |
| Class | WK | GU | GD | ST | SD | LY | PTs |
|---|---|---|---|---|---|---|---|
| WK | 181 | 0 | 0 | 0 | 1 | 0 | 4 |
| GU | 5 | 174 | 7 | 0 | 0 | 0 | 1 |
| GD | 5 | 2 | 153 | 0 | 0 | 0 | 1 |
| ST | 5 | 0 | 0 | 186 | 3 | 0 | 5 |
| SD | 5 | 0 | 0 | 9 | 192 | 0 | 1 |
| LY | 6 | 0 | 0 | 0 | 0 | 207 | 1 |
| PTs | 6 | 1 | 5 | 4 | 1 | 0 | 38 |
| Level | The Features Selected | Classifier |
|---|---|---|
| 1 | fAcc-X-Sample Range, fAcc Largest Values | SVM |
| 2 | tAccMag-75th-Percentile | TH |
| 3 | tGyroJerk-Z-Sample-Variance, tAccMag-50th-Percentile, tGyro-X-50th-Percentile, tGyro-Y-Mean, tGyro-X-25th-Percentile, tGyro-X-Mean, tGyro-X-Median, tGyro-X-75th-Percentile, tGyro-X-10th-percentile, fGyro-X-Largest-values, tGyro-X-90th-Percentile, tAccMag-Skewness, tGyro-Y-Median, tGyro-X- 50th-Percentile, fAccJerk-Y-Smallest-value, tGyroMag-Skewness, tAccJerk-X-Samlpe-Variance, tGyroJerk-Z-Median, tGyroJerk-Z-50th-Percentile, tAccMag-Median, tAcc-X-Samlpe-Variance, tGyroJerk-Z-Skewness, tGyro-X-Skewness, fGyro-X-Smallest-value, tGyroJerk-Z-Power, Median-tGyroMag, tGyroMag-50th-percentile, fAccJerk-Y-Sample-Range, fAccJerk-Y-Largest-value, tGyroAng-Slope, tGyroAng-Kurtosis, tGyroJerk-Z-Root-Mean-Square, tAccJerk-X-Sample-Range, tGyroMag-Largest-values, tGyroMag-Power, tGyroAng-Power | SVM |
| 4 | tAccMag-10th-percentile, tGravityAccMag-10th-percentile | DT |
| 5 | tGravityAccMag-50th-Percentile, tGravityAcc-Y-Median, fAcc-Y-Smallest-value, fAcc-XLargest-values, fGyro-Z-Largest-values, fAccJerk-X-Largest-values | DT |
| 6 | tAcc-50th-Percentile | TH |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, S.; Jia, Y.; Jia, C. A Feature Selection and Classification Method for Activity Recognition Based on an Inertial Sensing Unit. Information 2019, 10, 290. https://doi.org/10.3390/info10100290
Fan S, Jia Y, Jia C. A Feature Selection and Classification Method for Activity Recognition Based on an Inertial Sensing Unit. Information. 2019; 10(10):290. https://doi.org/10.3390/info10100290
Chicago/Turabian StyleFan, Shurui, Yating Jia, and Congyue Jia. 2019. "A Feature Selection and Classification Method for Activity Recognition Based on an Inertial Sensing Unit" Information 10, no. 10: 290. https://doi.org/10.3390/info10100290
APA StyleFan, S., Jia, Y., & Jia, C. (2019). A Feature Selection and Classification Method for Activity Recognition Based on an Inertial Sensing Unit. Information, 10(10), 290. https://doi.org/10.3390/info10100290