
Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV


Abstract
:1. Introduction
2. The Backbone Network and Feature Fusion Network of YOLO v4
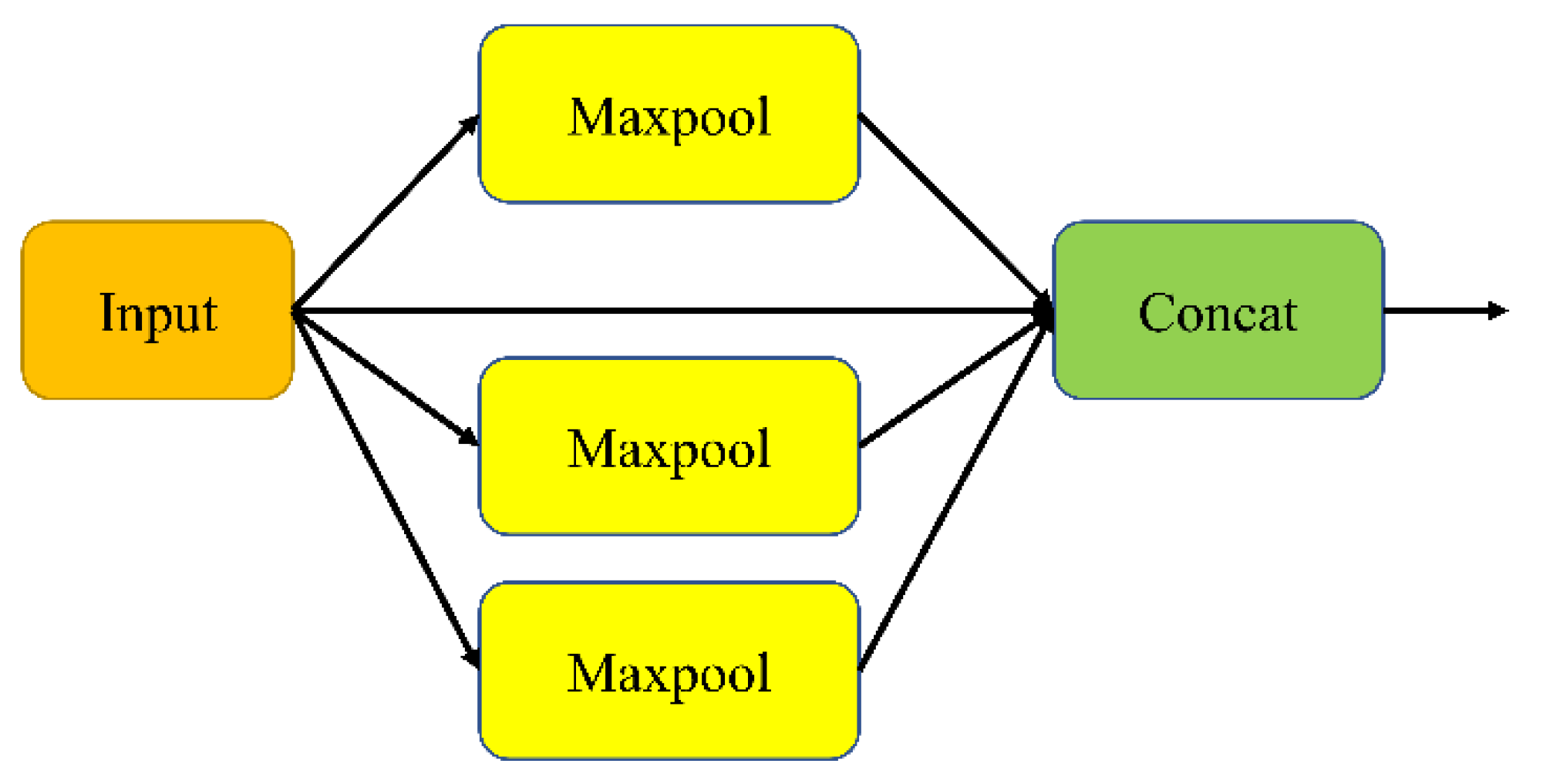
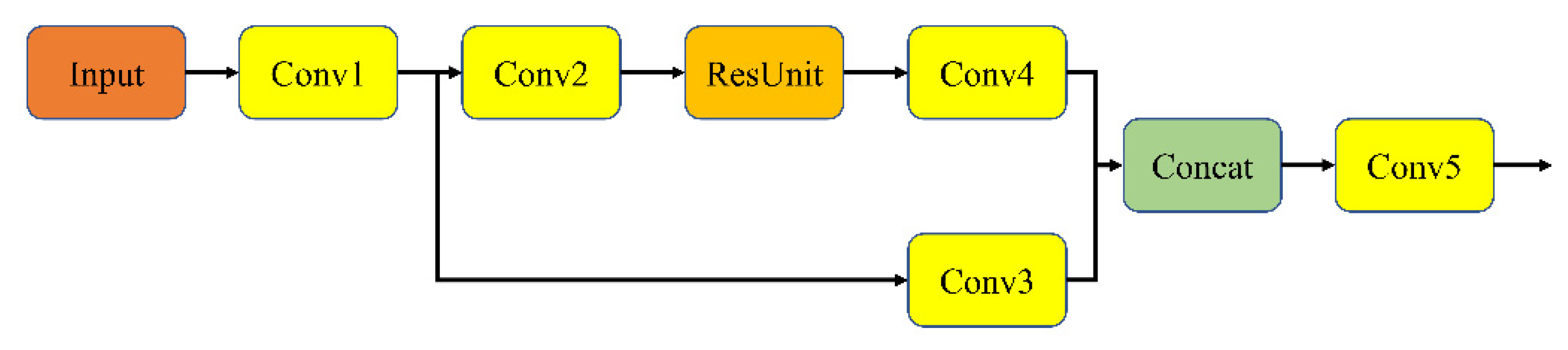
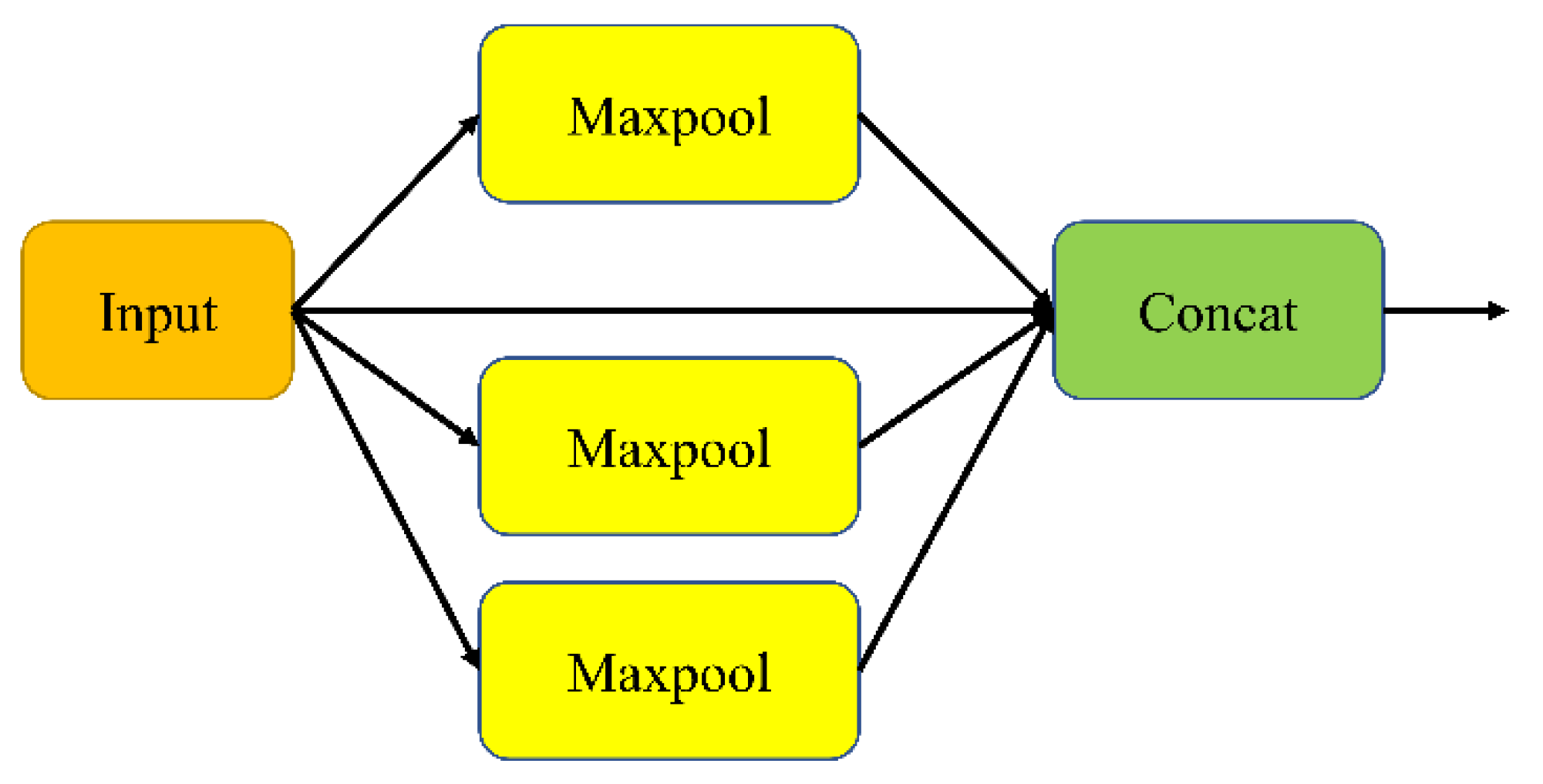
2.1. Backbone Network
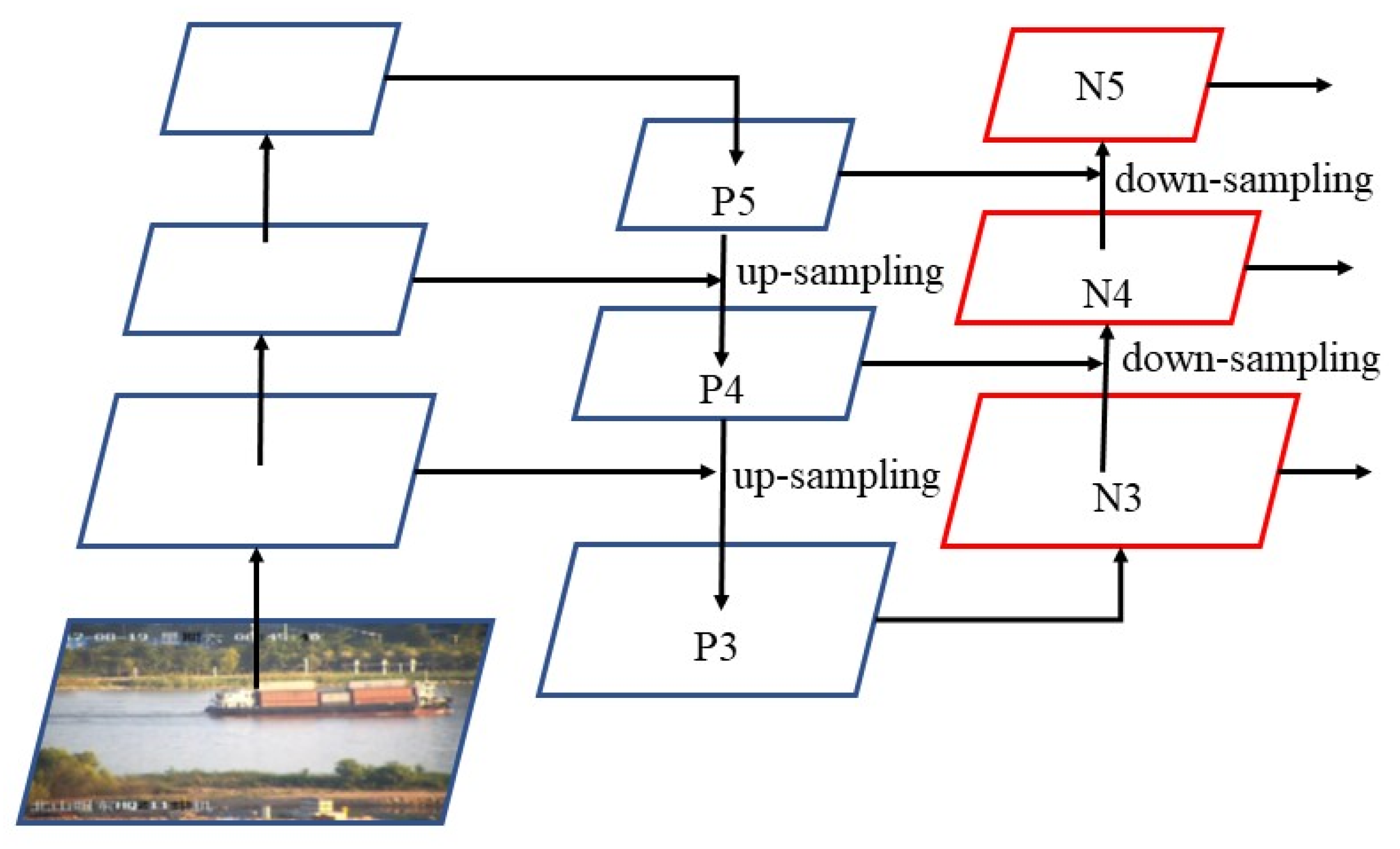
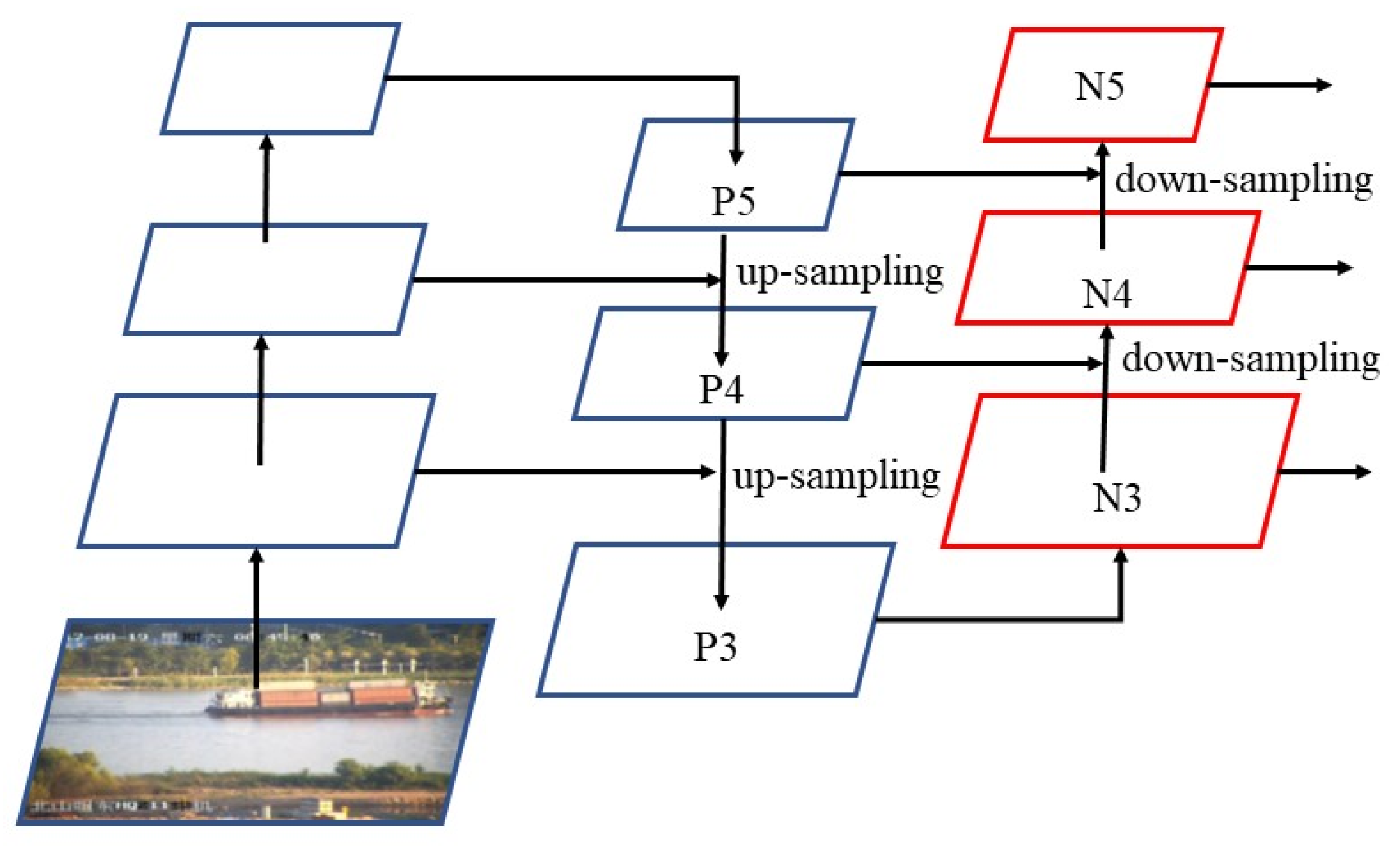
2.2. Feature Fusion Network
3. Methods
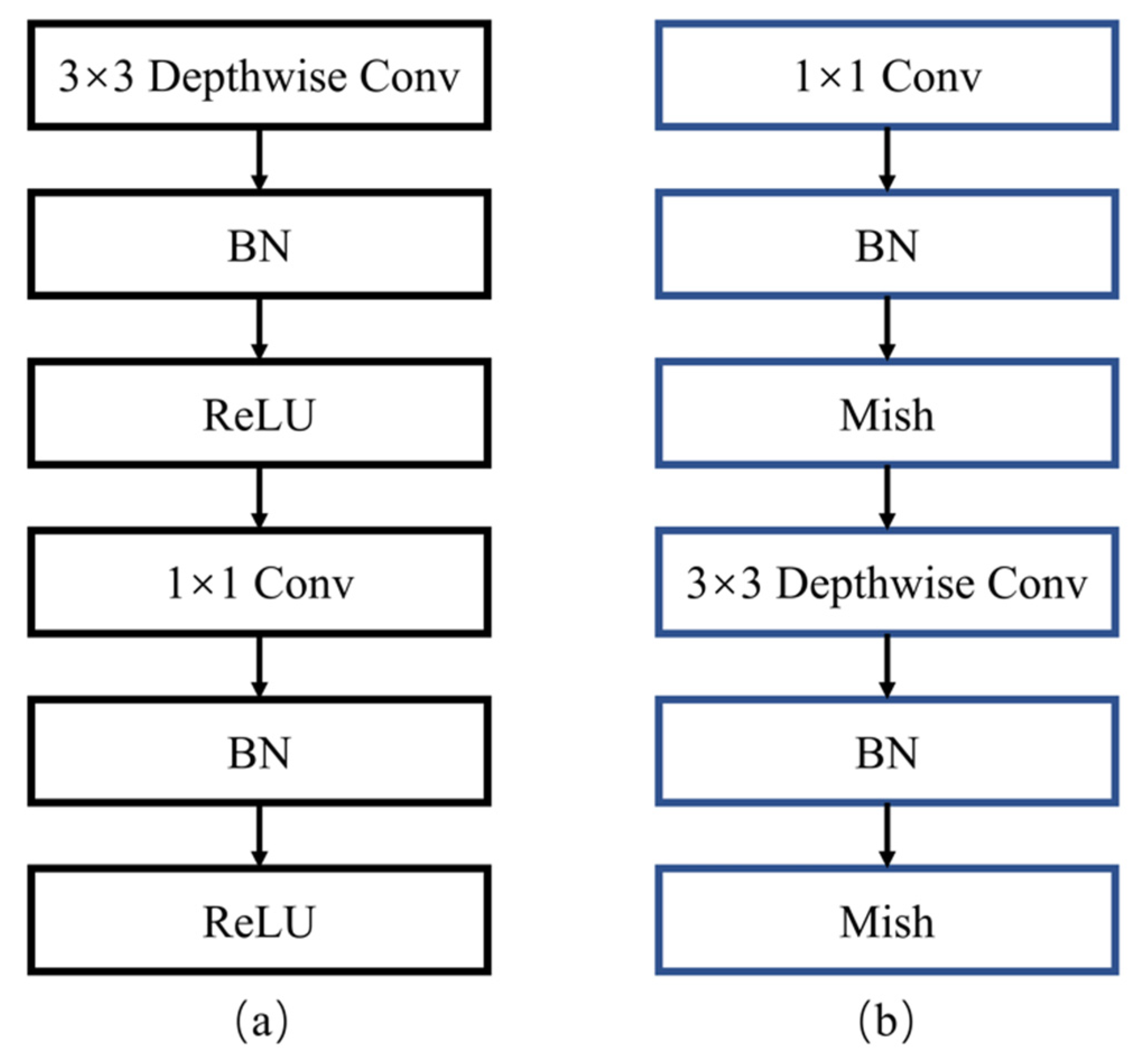
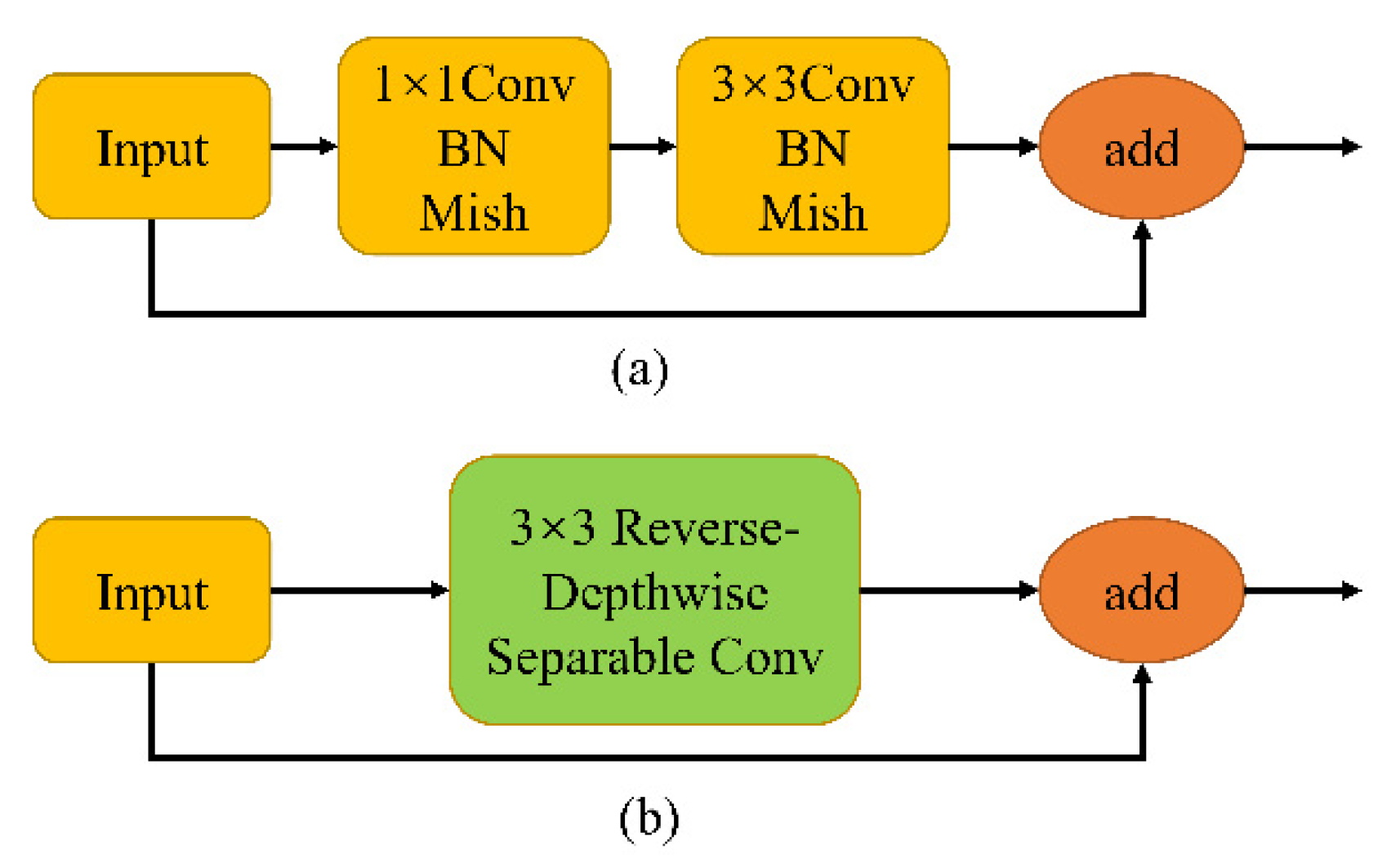
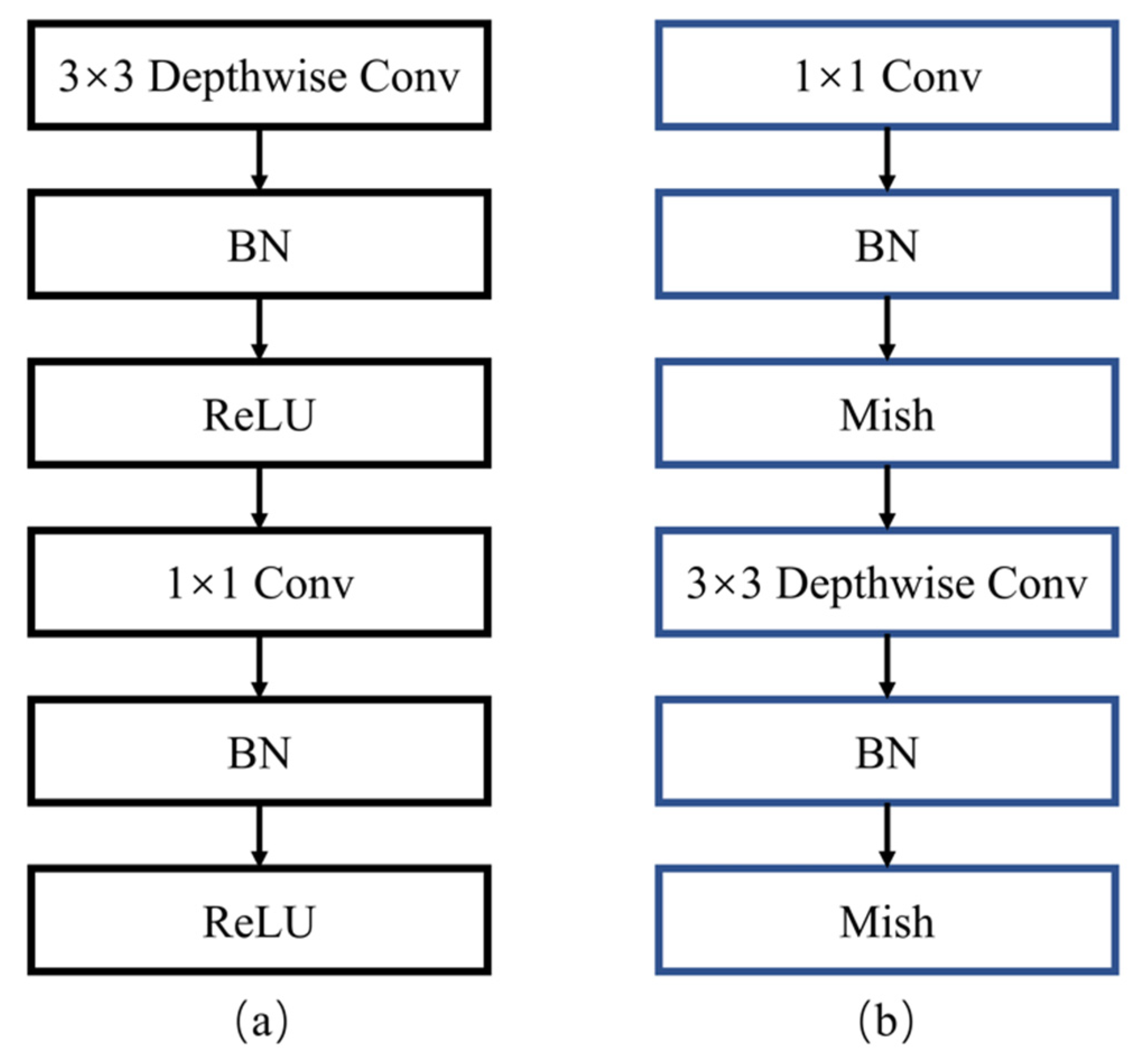
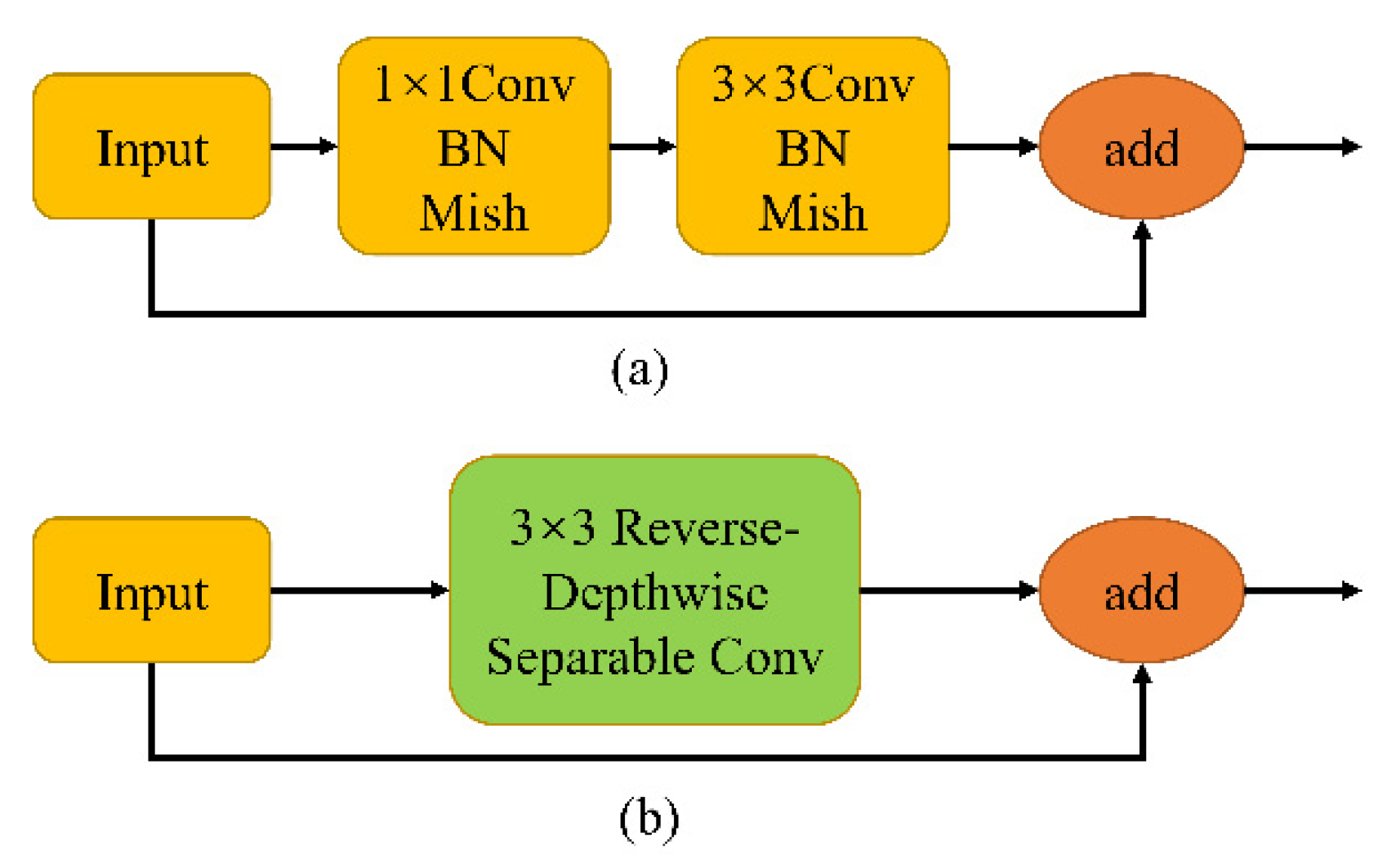
3.1. RDSC in the Backbone Network
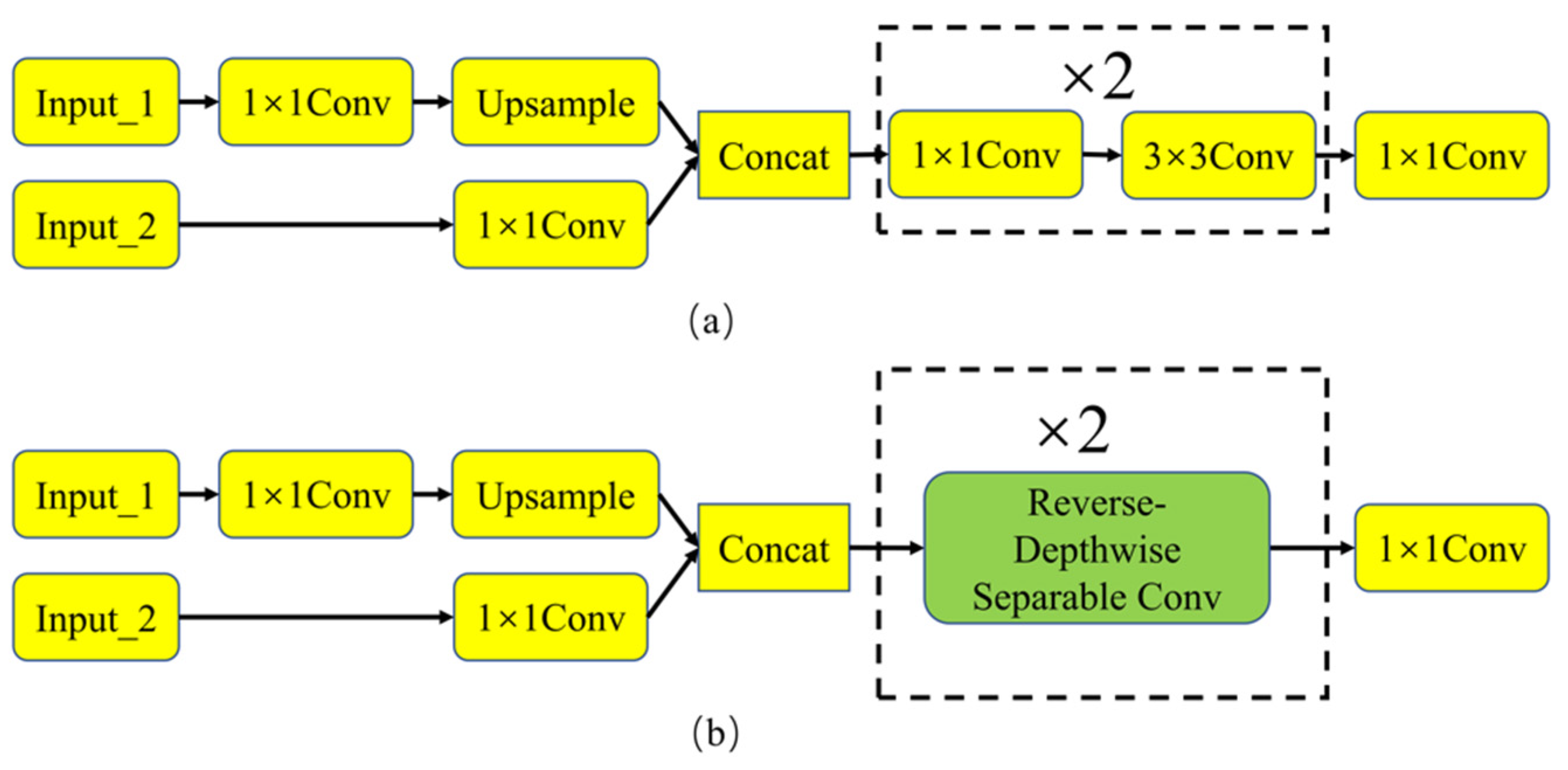
3.2. RDSC in Feature Fusion Network
4. Results and Discussion
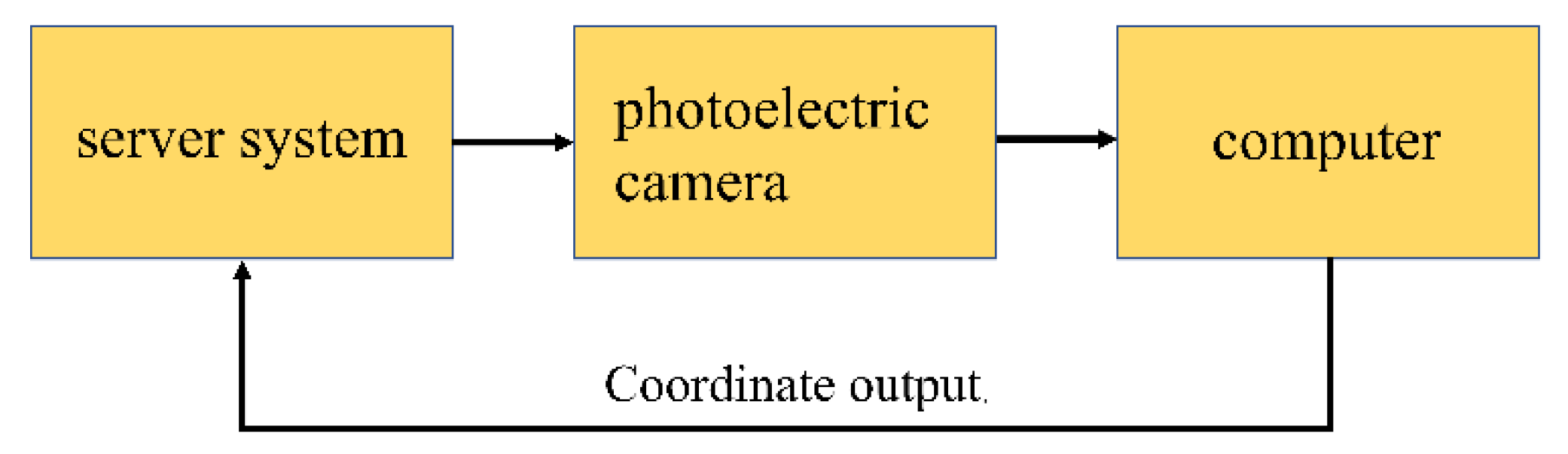
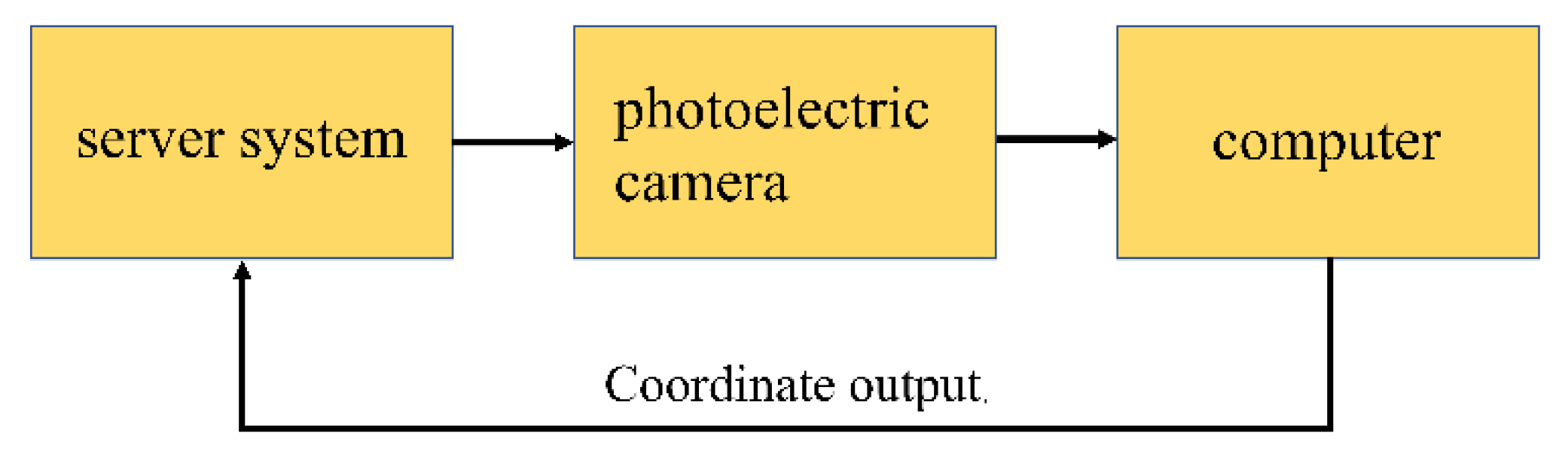
4.1. Introduction to USV and Datasets
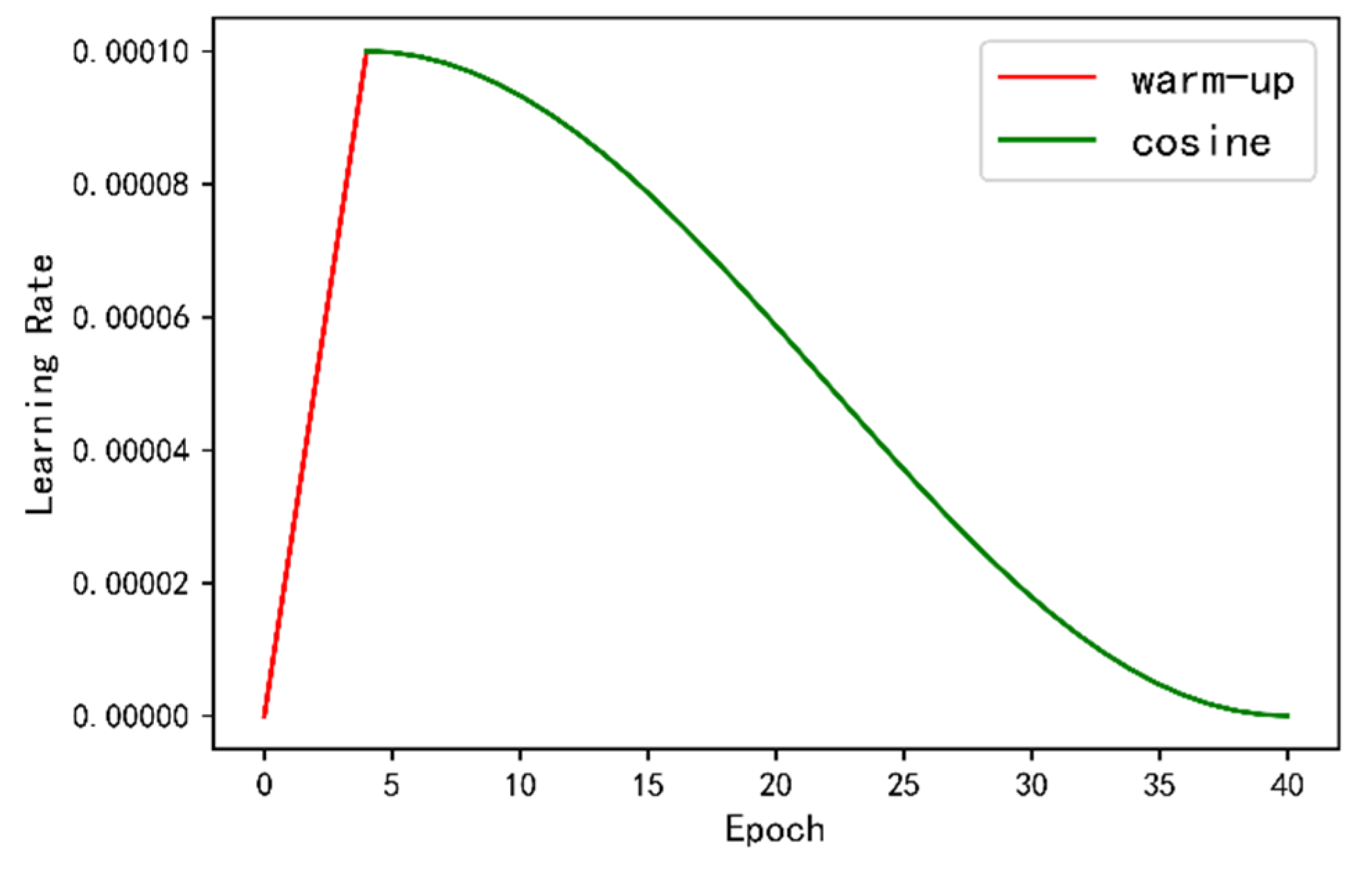
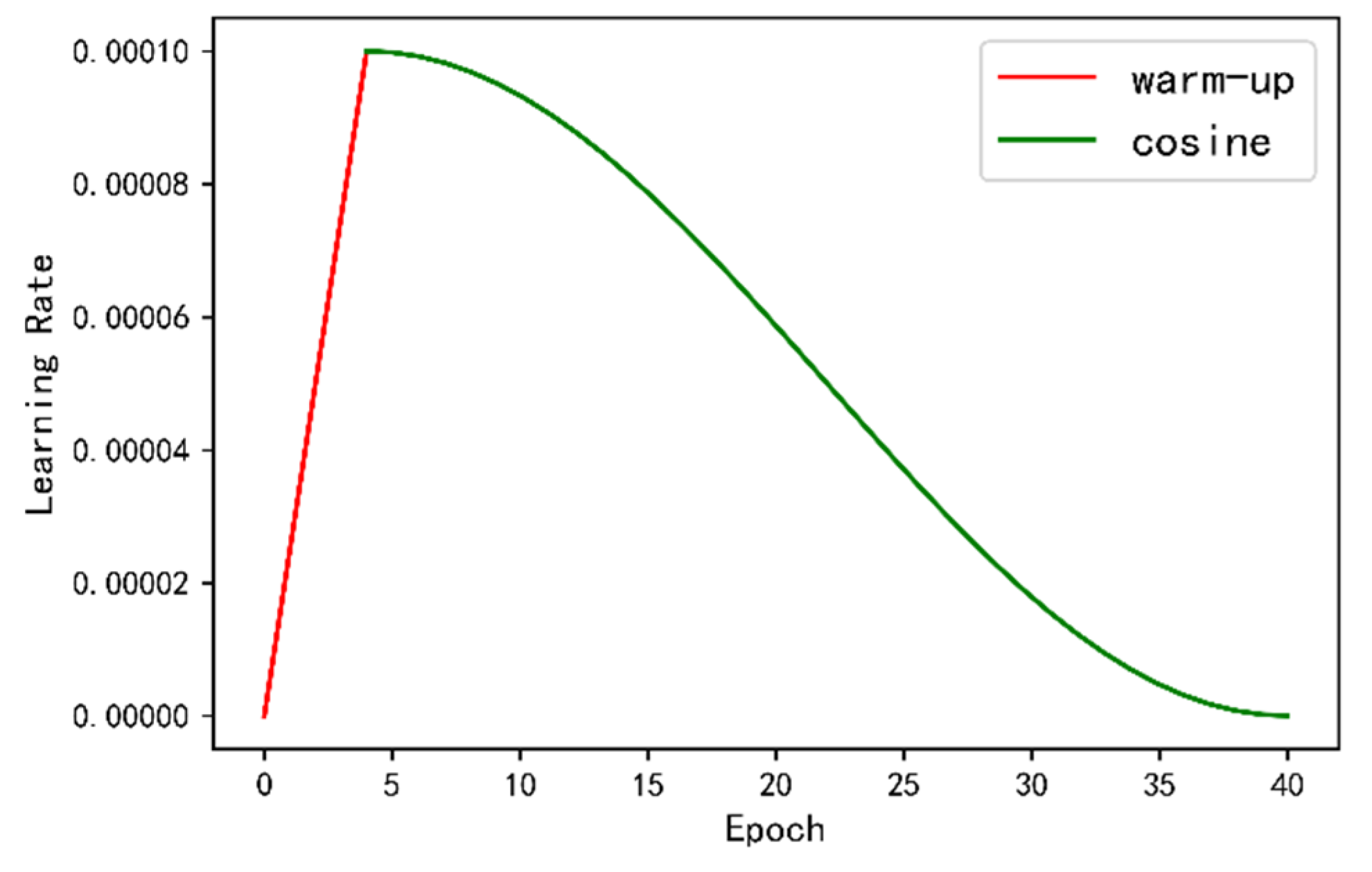
4.2. Experimental Details
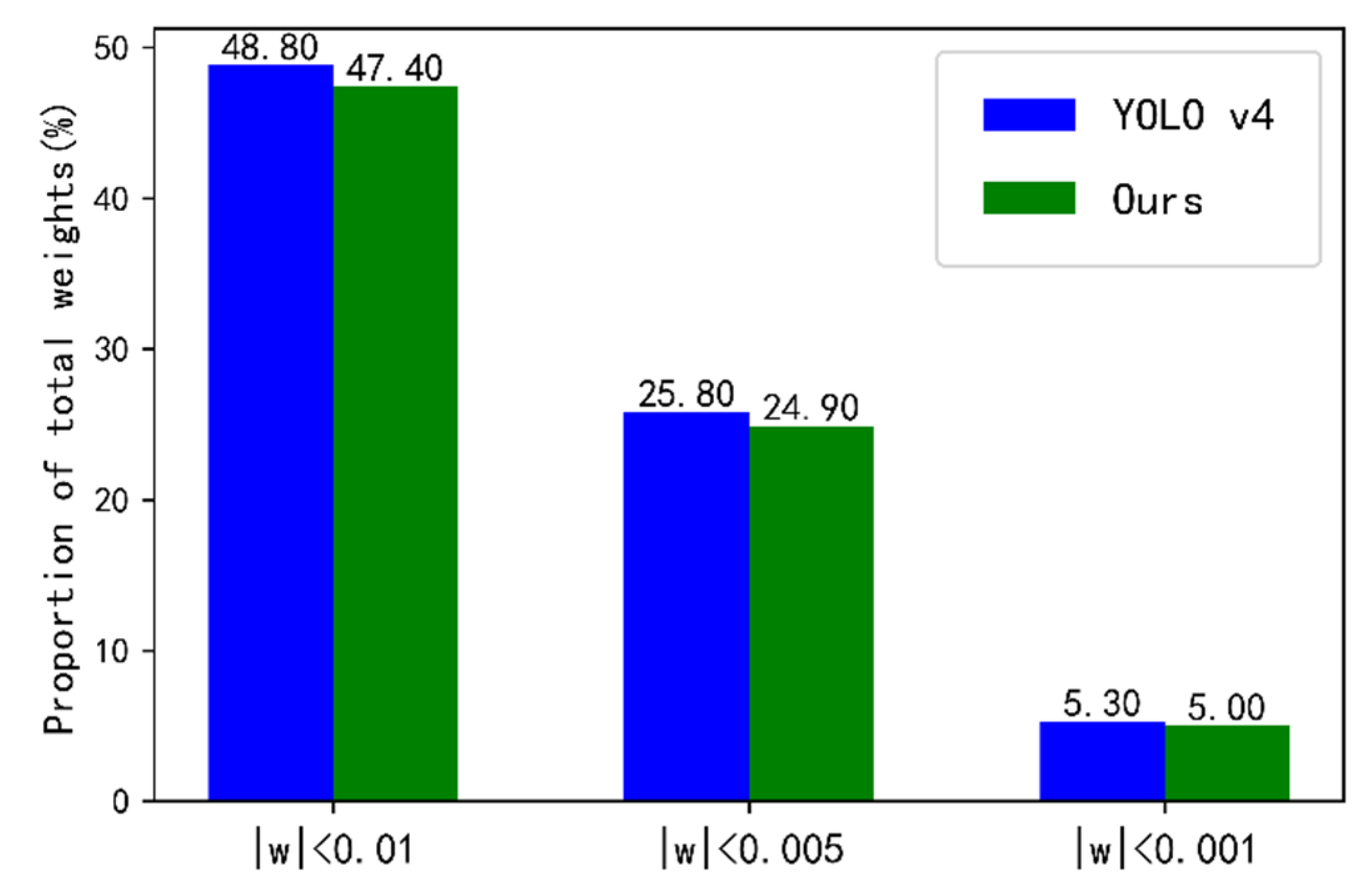
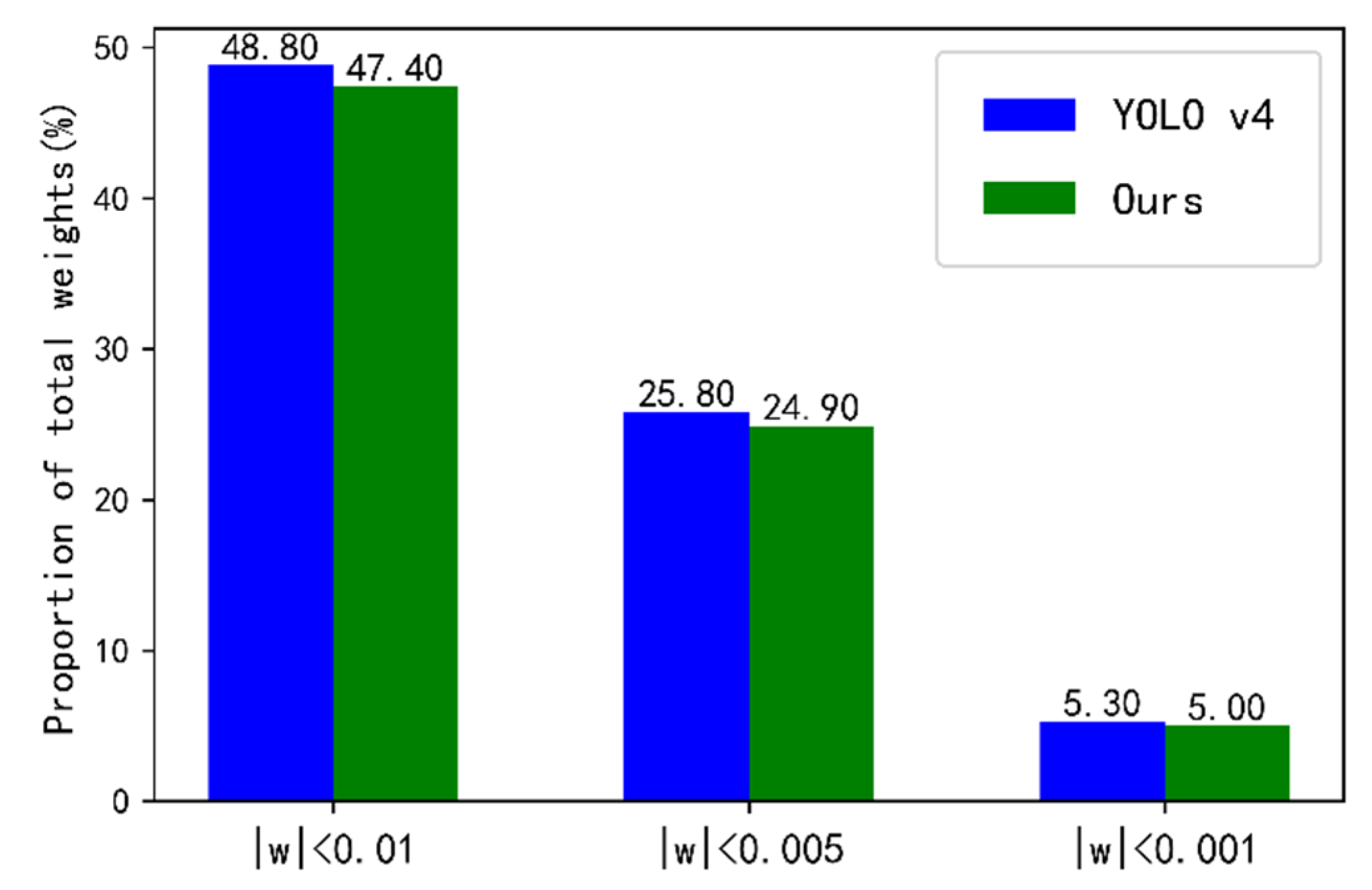
4.3. Ablation Experiment in SeaShips
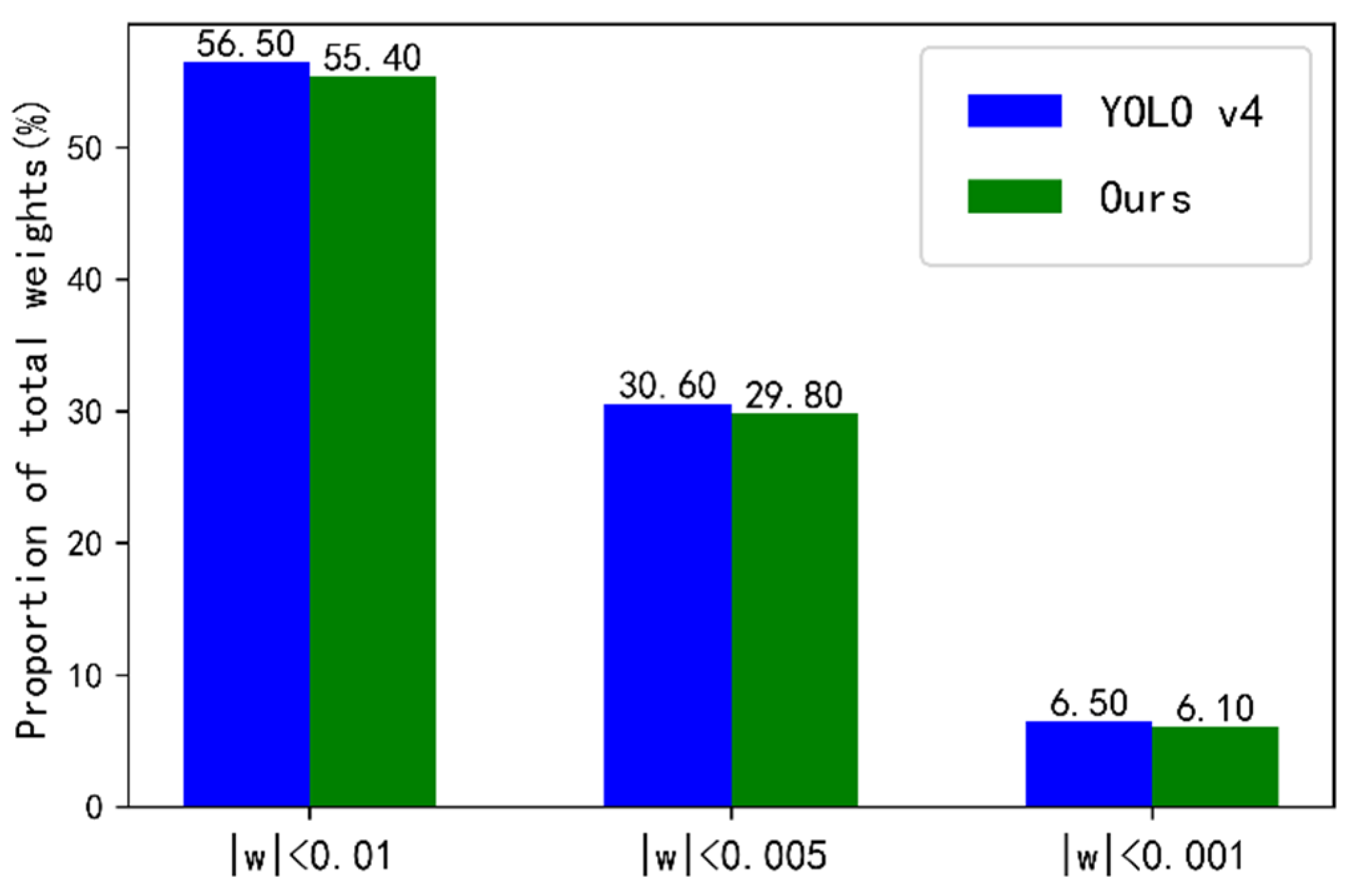
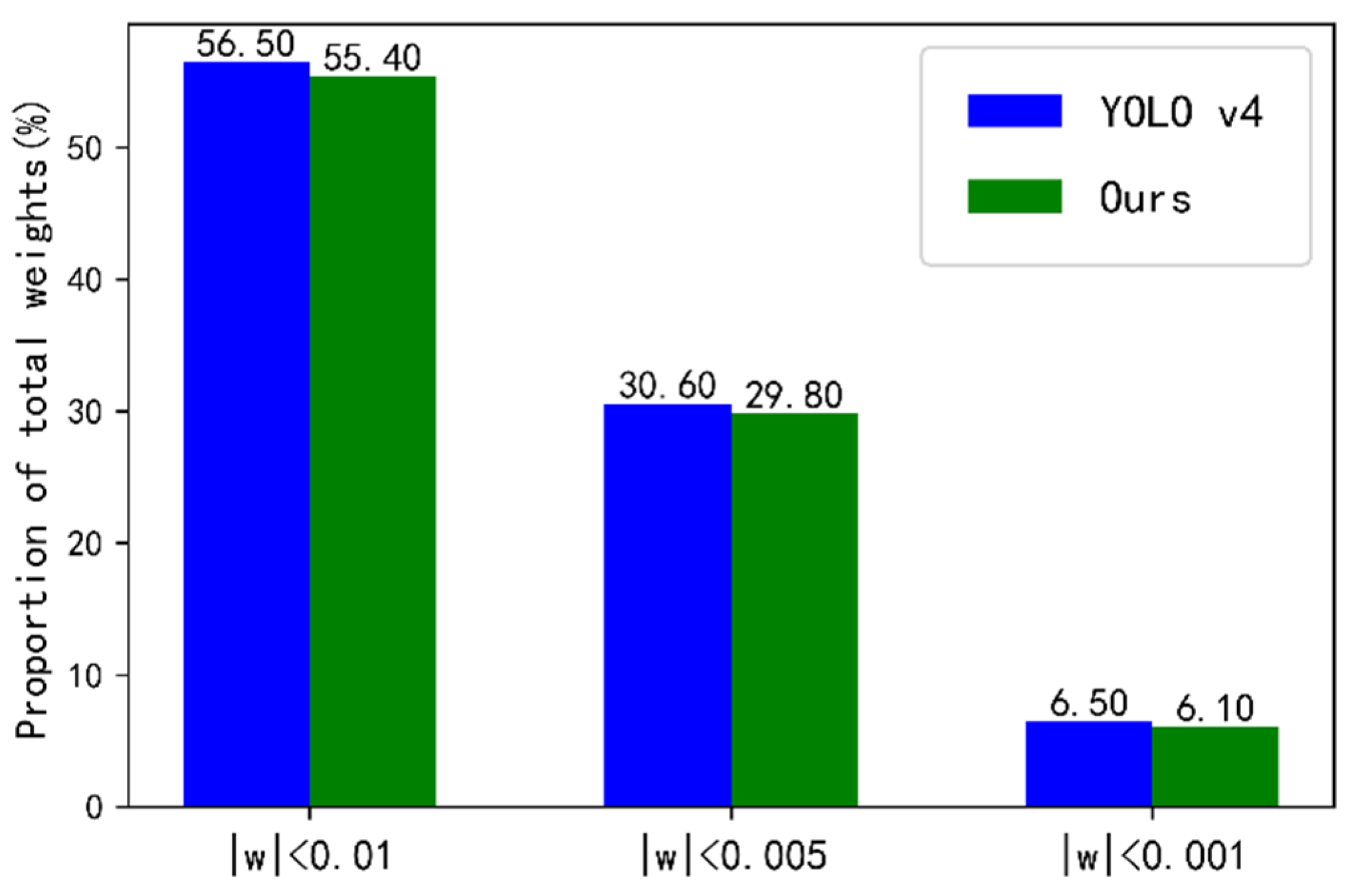
4.4. Ablation Experiment in SeaBuoys
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, W.; Gao, X.-Z.; Yang, C.-F.; Jiang, F.; Chen, Z.-Y. A object detection and tracking method for security in intelligence of unmanned surface vehicles. J. Ambient. Intell. Humaniz. Comput. 2020, 2020, 1–13. [Google Scholar] [CrossRef]
- Glowacz, A. Ventilation diagnosis of angle grinder using thermal imaging. Sensors 2021, 21, 2853. [Google Scholar] [CrossRef]
- Hashmi, M.F.; Pal, R.; Saxena, R.; Keskar, A.G. A new approach for real time object detection and tracking on high resolution and multi-camera surveillance videos using GPU. J. Central South Univ. 2016, 23, 130–144. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 60. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S.-C. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks; IEEE Computer Society Press: Piscataway, NJ, USA, 2016. [Google Scholar]
- Wang, C.; Liao, H.; Yeh, I.; Wu, Y.; Chen, P.; Hsieh, J.W. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN; IEEE Computer Society Press: Piscataway, NJ, USA, 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2008, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-J.M. YOLOv4 Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Transactions on Petri Nets and Other Models of Concurrency XV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection; IEEE Computer Society Press: Piscataway, NJ, USA, 2017. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, Q.; Shen, F.; Cheng, L.; Jiang, J.; He, G.; Sheng, W.; Jing, N.; Mao, Z. Ship detection based on fused features and rebuilt YOLOv3 networks in optical remote-sensing images. Int. J. Remote Sens. 2021, 42, 520–536. [Google Scholar] [CrossRef]
- Cui, H.; Yang, Y.; Liu, M.; Shi, T.; Qi, Q. Ship Detection: An Improved YOLOv3 Method. In Proceedings of the OCEANS 2019, Marseille, France, 17–20 June 2019. [Google Scholar]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Xiao, Q.; Cheng, Y.; Xiao, M.; Zhang, J.; Shi, H.; Niu, L.; Ge, C.; Lang, H. Improved region convolutional neural network for ship detection in multiresolution synthetic aperture radar images. Concurr. Comput. Pract. Exp. 2020, 32, e5820. [Google Scholar] [CrossRef]
- Qi, L.; Li, B.; Chen, L.; Wang, D.; Dong, L.; Jia, X.; Huang, J.; Ge, C.; Xue, G. Ship target detection algorithm based on improved faster R-CNN. Electronics 2019, 8, 959. [Google Scholar] [CrossRef] [Green Version]
- Fan, W.; Zhou, F.; Bai, X.; Tao, M.; Tian, T. Ship detection using deep convolutional neural networks for PolSar images. Remote Sens. 2019, 11, 2862. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Zhan, J.; Tan, L.; Gao, Y.; Župan, R. Comparison of two deep learning methods for ship target recognition with optical remotely sensed data. Neural Comput. Appl. 2021, 33, 4639–4649. [Google Scholar] [CrossRef]
- Li, Y.; Guo, J.; Guo, X.; Liu, K.; Zhao, W.; Luo, Y.; Wang, Z. A novel target detection method of the unmanned surface vehicle under all-weather conditions with an improved YOLOV3. Sensors 2020, 20, 4885. [Google Scholar] [CrossRef]
- Jie, Y.; Leonidas, L.; Mumtaz, F.; Ali, M. Ship detection and tracking in Inland waterways using improved YOLOv3 and deep SORT. Symmetry 2021, 13, 308. [Google Scholar] [CrossRef]
- Wang, J.; Lin, Y.; Guo, J.; Zhuang, L. SSS-YOLO: Towards more accurate detection for small ships in SAR image. Remote Sens. Lett. 2021, 12, 93–102. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Ai, S.; Sun, X. Study on visual detection algorithm of sea surface targets based on improved YOLOv3. Sensors 2020, 20, 7263. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. SeaShips: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimedia 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline | Method | mAP (%) | FPS | Number of Weights |
|---|---|---|---|---|
| YOLO v4 | - | 92.80 | 55 | 63,963,584 |
| Ours | 94.58 | 68 | 35,524,224 | |
| DSC in ResUnit | 93.53 | 68 | 35,524,224 | |
| DSC in all layers | 87.41 | 58 | 14,814,724 | |
| RDSC in all layers | 90.00 | 53 | 14,814,724 |
| Baseline | Method | mAP (%) | FPS | Number of Weights |
|---|---|---|---|---|
| YOLO v4 | - | 98.12 | 55 | 63,963,584 |
| Ours | 99.07 | 68 | 35,524,224 | |
| DSC in ResUnit | 97.53 | 68 | 35,524,224 | |
| DSC in all layers | 91.41 | 58 | 14,814,724 | |
| RDSC in all layers | 93.23 | 53 | 14,814,724 |
| Model | FPS | mAP in SeaShips (%) | mAP in SeaBuoys (%) |
|---|---|---|---|
| Faster RCNN + ResNet50 | 7 | 88.25 | 94.28 |
| EfficientDet-D1 | 22 | 84.09 | 89.89 |
| EfficientDet-D0 | 29 | 78.02 | 84.47 |
| YOLO v4 | 55 | 92.80 | 98.12 |
| Cross YOLO v3 [40] | 45 | 92.85 | 98.25 |
| Ours | 68 | 94.58 | 99.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Pang, B.; Zhang, L.; Yang, W.; Sun, X. Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV. J. Mar. Sci. Eng. 2021, 9, 753. https://doi.org/10.3390/jmse9070753
Liu T, Pang B, Zhang L, Yang W, Sun X. Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV. Journal of Marine Science and Engineering. 2021; 9(7):753. https://doi.org/10.3390/jmse9070753
Chicago/Turabian StyleLiu, Tao, Bo Pang, Lei Zhang, Wei Yang, and Xiaoqiang Sun. 2021. "Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV" Journal of Marine Science and Engineering 9, no. 7: 753. https://doi.org/10.3390/jmse9070753
APA StyleLiu, T., Pang, B., Zhang, L., Yang, W., & Sun, X. (2021). Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV. Journal of Marine Science and Engineering, 9(7), 753. https://doi.org/10.3390/jmse9070753