Abstract
Underwater images frequently suffer from severe quality degradation due to light attenuation and scattering effects, manifesting as color distortion, low contrast, and detail blurring. These issues significantly impair the performance of downstream tasks. Therefore, underwater image enhancement (UIE) becomes a key technology to solve underwater image degradation. However, existing data-driven UIE methods typically rely on difficult-to-acquire paired data for training, severely limiting their practical applicability. To overcome this limitation, this study proposes MambaRA-GAN, a novel unpaired UIE framework built upon a CycleGAN architecture, which introduces a novel integration of Mamba and intra-domain reconstruction autoencoders. The key innovations of our work are twofold: (1) We design a generator architecture based on a Triple-Gated Mamba (TG-Mamba) block. This design dynamically allocates feature channels to three parallel branches via learnable weights, achieving optimal fusion of CNN’s local feature extraction capabilities and Mamba’s global modeling capabilities. (2) We construct an intra-domain reconstruction autoencoder, isomorphic to the generator, to quantitatively assess the quality of reconstructed images within the cycle consistency loss. This introduces more effective structural information constraints during training. The experimental results demonstrate that the proposed method achieves significant improvements across five objective performance metrics. Visually, it effectively restores natural colors, enhances contrast, and preserves rich detail information, robustly validating its efficacy for the UIE task.
1. Introduction
With the continuous expansion of ocean exploration and exploitation, the quality of underwater imagery has become increasingly important for subsea operations [1,2,3,4]. Its application scope is extensive, encompassing multiple critical fields such as marine biological research, underwater archaeological excavation, subsea engineering operations, and marine resource exploration. These images provide intuitive and detailed underwater visual information that is crucial for revealing characteristics of seafloor topography, monitoring the structure of biological communities and ecosystem dynamics, assessing the occurrence state of mineral resources, and diagnosing the operational status of underwater infrastructure. However, the acquisition and transmission of underwater images are frequently plagued by severe quality degradation problems [5]. This degradation primarily stems from selective light absorption and intense scattering by water: water exhibits strong selective absorption and scattering of light (particularly within the red wavelength spectrum), resulting in significant reductions in image contrast and pronounced color casts. Concurrently, the abundance of suspended particulate matter in water (e.g., plankton, sediment) further obstructs and scatters light, exacerbating image blurring and turbidity. Therefore, investigating effective underwater image enhancement (UIE) methods to eliminate degradation effects caused by seawater is of considerable significance.
To improve the visibility of underwater images for better practical use, various UIE methods have been proposed, but existing methods still have obvious limitations in complex underwater environments: Traditional nonphysical model-based approaches typically ignore underwater image degradation mechanisms, directly manipulating pixel values for adjustment while lacking a theoretical foundation. Physical model-based methods employ mathematical modeling to describe degradation processes, estimate imaging parameters, and invert degradation mechanisms to enhance visual quality. However, they exhibit heavy reliance on model assumptions and face adaptability issues in parameter estimation, resulting in constrained performance in complex underwater environments. Data-driven methods establish end-to-end mappings from degraded to high-quality images through neural networks’ powerful feature extraction capabilities. Compared to traditional approaches, these methods mitigate complex environmental interference via large-scale sample learning yet suffer from strong training data dependency and limited robustness in complex scenarios. To address the limitations of existing methods, this paper proposes a Triple-Gated Mamba (TG-Mamba) extraction unit capable of multi-scale feature extraction and long-range dependency modeling and constructs a novel generator network based on this unit. Subsequently, a structural consistency loss (SC Loss) based on reconstruction autoencoders is designed to ensure structural similarity between input and reconstructed images through multi-channel feature constraints. Finally, by integrating TG-Mamba and SC Loss within the CycleGAN framework, we propose the MambaRA-GAN model to achieve efficient and accurate domain translation from low-quality to high-quality underwater images. The core contributions of this study are as follows:
- A Triple-Path Gated Mamba (TG-Mamba) module is proposed to fully leverage the local feature extraction capabilities of CNNs and the long-range dependency modeling abilities of Mamba.
- An intra-domain reconstruction autoencoder is constructed that generates structured supervision signals to guide model training by quantifying the reconstruction quality differences within the cycle consistency loss.
- The proposed method generates images with significantly enhanced visual quality, demonstrating superior color cast correction and detail enhancement. It outperforms all comparative methods across five performance metrics, validating its overall excellence.
2. Related Work
We now review the existing work related to this study. Existing UIE methods can be broadly categorized into three classes: nonphysical model-based methods, physical model-based methods, and data-driven methods. In addition, this work leverages the strengths of Mamba in long-range dependency modeling, introducing it into the field of UIE to explore its adaptability and performance in underwater degradation scenarios.
2.1. Nonphysical Model-Based Methods
Nonphysical model-based UIE methods commonly enhance underwater images by directly adjusting pixel values. These methods primarily include histogram equalization [6] and white balance algorithms [7,8]. Histogram equalization addresses the characteristics of underwater images with limited dynamic range and concentrated histogram distribution by expanding the histogram distribution range through gray-level mapping transformations to enhance contrast. In contrast, contrast-limited adaptive histogram equalization (CLAHE) [9] overcomes the local over-/under-enhancement issues of traditional methods. It divides the image into subregions and employs region-adaptive gray-level mapping functions to achieve refined contrast enhancement. For example, Garg et al. [10] developed a technique for UIE based on contrast-limited adaptive histogram equalization and quantization; Iqbal et al. [11] proposed an unsupervised color correction method (UCM). Based on the characteristics of the underwater environment, they implemented differentiated histogram stretching strategies for the red and blue channels and finally adjusted the contrast in the HSI color model. Additionally, white balance methods such as the Gray World Assumption [7] and Grey Edge Assumption [8] are frequently employed for underwater image enhancement. While these color-temperature-driven correction techniques can partially improve image color and contrast, they fail to account for underwater degradation mechanisms, often resulting in insufficient or excessive correction.
2.2. Physical Model-Based Methods
Physical model-based UIE methods establish imaging models of degradation processes, computationally solve model parameters, and invert degradation mechanisms, thereby enhancing visual quality. Existing enhancement approaches predominantly rely on the Jaffe–McGlamery underwater imaging model [12] and the dark channel prior (DCP) algorithm [13]. In 2009, He et al. proposed the DCP algorithm based on the statistical observation of haze-free and hazy images: in non-sky regions of haze-free images, at least one color channel exhibits pixel values approaching zero. This prior has been widely adopted in image dehazing. Given the physical similarity between underwater scattering effects and atmospheric scattering, researchers have extended the dark channel prior to the UIE domain [14,15,16]. For example, Chiang et al. [14] utilize scene depth maps to segment foreground and background regions, combining artificial light source compensation to achieve image enhancement; Galdran et al. [15] leverage an underwater optical imaging model to reconstruct pre-degradation scenes by solving critical parameters (background light and transmission maps); Drews et al. [16] proposed the Underwater dark channel prior (UDCP), which specifically adapts the dark channel prior concept to underwater environments by leveraging the characteristic richness of underwater visual information in blue–green channels, thereby significantly enhancing transmission estimation. However, the complexity of underwater environments requires model-based methods to rely on diverse prior knowledge for parameter estimation, while the difficulty of parameter estimation further constrains the performance of such methods. Given these limitations, data-driven adaptive learning frameworks are imperative to overcome bottlenecks in conventional UIE approaches.
2.3. Data-Driven Methods
Data-driven methods enable automated enhancement by directly establishing end-to-end mappings from low-quality underwater images to high-quality images. According to differences in network architectures, such methods can be broadly divided into two categories: underwater image enhancement approaches based on Convolutional Neural Networks (CNNs) and those utilizing Generative Adversarial Networks (GANs) [17]. In CNN-based image enhancement applications, Li et al. [18] developed a physics-driven framework to synthesize ten categories of low-quality underwater images. Building upon this synthesis mechanism, they trained ten specialized UWCNN models, each specifically designed for enhancing a corresponding type of synthetic underwater image. Li et al. [19] proposed the WaterNet framework, which enhances low-quality underwater images by fusing the original input with predicted confidence maps. Among GAN-based UIE methods, Li et al. [20] introduced the SSIM-CycleGAN architecture with Structural Similarity Index (SSIM) integration in adversarial optimization, boosting perceptual quality in outputs. Similarly, Li et al. [21] proposed SESS-CycleGAN, introducing an edge structure similarity constraint (computed via the OTSU algorithm [22]) into the loss function of Cycle-Consistent Generative Adversarial Networks (CycleGANs) [23], effectively achieving color correction and visual enhancement for underwater images. Another model, MuLA-GAN [24], incorporates multi-level attention mechanisms to effectively address color distortion and contrast degradation. Cong et al. [25] combined physical models of underwater imaging, proposed PUGAN, and introduced a dual-content-style discriminator to ensure the visual quality of generated images. Additionally, Guan et al. [26] proposed an UIE approach called DiffWater. This method is based on a conditional denoising diffusion model (DDPM) and addresses quality degradation and color deviation issues in underwater images through a color channel compensation technique.
2.4. Mamba and Its Variants
Transformer [27] has become a foundational model in visual tasks such as object detection, semantic segmentation, and video understanding. However, the quadratic complexity of its attention mechanism limits scalability and imposes significant computational burdens. In response, researchers continue to explore more efficient sequence modeling methods to better capture long-range dependencies while reducing resource consumption in practical applications. Against this backdrop, approaches based on state space models (SSMs) have gained increasing attention, with the structured state space sequence model (S4) [28] being particularly notable. Mamba [29] builds upon S4 by introducing a selective scan mechanism, which dynamically selects information, simplifies structural design, and employs parallel scanning strategies. This enables effective modeling of long-range dependencies while significantly improving training and inference efficiency. Subsequently, several vision-specific variants of Mamba have been proposed. Zhu et al. introduced Vision Mamba (ViM) [30], which establishes a general-purpose vision backbone network. This model encodes image sequences via positional embeddings and leverages bidirectional state space models to efficiently extract and integrate image features. VMamba [31] further proposes a Cross-Scan Module (CSM), which traverses feature maps from four directions, allowing each location to aggregate global contextual information. This achieves a global receptive field without increasing linear computational complexity. Mamba2 [32] further introduces Structured State Space Duality (SSD) and designs a new algorithm based on block decomposition matrix multiplication for SSM computation, markedly enhancing computational efficiency and model expressiveness. To overcome the causal constraint—i.e., the inability to utilize future context information, relying only on current and past information—researchers have proposed non-causal state space models (NC-SSDs) [33]. This approach removes the unidirectional constraint inherent to traditional sequence modeling, enabling the model to leverage global information simultaneously and enhancing its ability to comprehend overall image structure and semantic context. The Efficient Vision Mamba (EfficientViM) [34] model adopted in this work is further optimized based on the NC-SSD architecture. It reduces linear computational complexity while maintaining the ability to model global dependencies in images.
3. Materials and Methods
3.1. MambaRA-GAN
As illustrated in Figure 1, MambaRA-GAN introduces two key improvements upon the classic CycleGAN framework: the TG-Mamba module and a structural consistency loss (SC Loss) based on an intra-domain reconstruction autoencoder. The model employs a weakly supervised training paradigm using unpaired data to achieve cross-domain color transfer from the underwater low-quality image domain () to the underwater high-quality image domain (). Its core architecture retains CycleGAN’s cyclic design, comprising two mirror–symmetric generators (: , : ) and their corresponding discriminators (, ). In the forward path (), the SC Loss and Cycle Loss jointly quantify the discrepancy between the underwater degraded image, , and its reconstructed counterpart, , generated by generator . Critically, the SC Loss addresses the limitations of the traditional CycleGAN L1 loss by incorporating crucial structural information into the training process. The GAN Loss is computed by feeding the generated image, , and a randomly sampled real image from domain into the discriminator, , for authenticity discrimination. Based on the discriminator’s output, the GAN Loss is formulated to quantify the distribution divergence between synthetic and real samples, thereby enabling both the generator, , and the discriminator, , to learn effectively from the adversarial process. The losses for the backward path () are defined analogously. The core objective of this architecture is to train generators and to learn bidirectional mappings between the domains. For generator , must ensure that its output, , distribution closely matches that of the real domain, . Conversely, the reverse transformation, : , must make the reconstructed sample, , as close as possible to . This cycle consistency constraint (i.e., and ) is crucial for preventing mode collapse [25] (e.g., mapping all images in to a single image in ). Concurrently, discriminator distinguishes between generated images, , and randomly chosen real images from domain ; discriminator functions analogously for the reverse mapping. The model is trained by alternately optimizing the generators (, ) and the discriminators (, ). The goal is to reach a Nash equilibrium state (where the discriminator’s output for generated samples approaches 0.5, indicating maximum uncertainty), thereby learning the high-quality mappings.
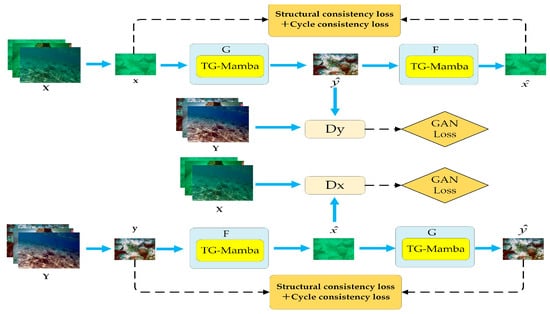
Figure 1.
Network structure of MambaRA-GAN.
3.2. TG-Mamba Generator Network Structure
As illustrated in Figure 2, the generator adopts an encoder–decoder architecture comprising an input mapping layer, two upsampling layers, two downsampling layers, an output layer, six feature fusion residual blocks, and four TG-Mamba modules. The TG-Mamba operation consists of three parts: Part 1 utilizes an EfficientViM [34] module to efficiently capture long-range dependencies; Part 2 employs multi-scale dilated convolutions to acquire rich multi-scale features; Part 3 performs identity mapping to achieve redundancy reduction in high-dimensional channel information. Its core innovation lies in the introduction of three learnable weight parameters, , , and (satisfying , , , ), which dynamically partition the input feature map along the channel dimension and assign it proportionally to the three aforementioned processing branches. The design motivation for this three-branch architecture stems from the characteristic differences between CNN and Mamba at different resolutions: while CNNs possess strong local feature extraction capabilities, they struggle to capture long-range dependencies effectively when processing high-resolution inputs; on the other hand, although Mamba excels at global modeling, its computation on low-resolution features tends to be redundant. The proposed three-branch structure effectively addresses these issues by dynamically allocating computational resources based on the input features: it emphasizes the Mamba branch at high-resolution stages to enhance global perception while focusing on the CNN path at low-resolution phases to maintain efficient local feature modeling. EfficientViM offers multiple state dimension options (including 64, 49, 32, 25, 16, and 9). Experimental results from the original EfficientViM paper show that a state dimension of 64 achieves optimal quality and accuracy while maintaining high efficiency. Although larger state dimensions typically lead to computational redundancy in high-dimensional spaces corresponding to low-resolution features, the TG-Mamba module adopted in our work effectively mitigates this issue. Therefore, we set the state space dimension, , in EfficientViM to 64 to fully leverage its strength in modeling long-range dependencies. Consequently, regardless of input dimension or scale, the model optimally leverages the superior local feature extraction capability of CNNs and the powerful long-range dependency modeling capabilities of Mamba, ensuring stable and efficient feature fusion.
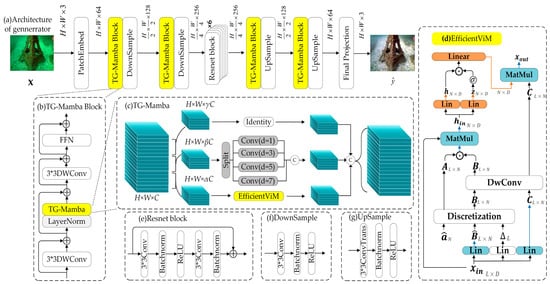
Figure 2.
The generator network architecture of MambaRA-GAN. “⊕” denotes element-wise addition, “©” denotes the concatenation operation, “⊙” denotes the Hadamard product, and “” denotes SiLU activation function.
EfficientViM is an efficient Mamba mechanism. The core of the Mamba mechanism is the state space model (SSM), which is represented by the following linear differential equation:
where is the hidden state, and , , and are projection matrices ( is the state space dimension). To adapt to discrete sequential data, Mamba generates the following parameters for the input ( is the sequence length, ): , , , where , , and are learnable weight matrices. Subsequently, the continuous SSM is discretized using the zero-order hold (ZOH) method:
where denotes the output sequence, and represents the hidden state. Discretization is achieved via the zero-order hold method: , . Through the coordinated action of the time-varying parameters , , and , Mamba dynamically selects the input, , and hidden state, , at timestep t.
Mamba2 proposes State Space Duality (SSD), simplifying the evolution matrix, , in continuous SSMs to a scalar , which is expanded into a vector, , after discretization. This represents the discrete SSM as a matrix transformation, (“” is the Hadamard product), significantly enhancing computational efficiency.
Non-causal SSD (NC-SSD) resolves the causal constraint limitation of SSD by introducing a row-constant mask, , making it better suited for image tasks. Building upon the NC-SSD framework, EfficientViM further optimizes matrix operations and computational principles: First, it compresses the original high-dimensional features (dimension , where is the sequence length, and is the number of channels) into a low-dimensional hidden state, , via linear projection. This reduces computational complexity from to . Second, it performs gating operations and output projection directly on the compressed low-dimensional state, . When the state size, , is sufficiently small, the overhead for global context modeling becomes negligible. This design fundamentally achieves an efficient balance between lightweight implementation and performance through the tripartite synergy of dimensionality compression, operation simplification, and structural optimization.
3.3. Discriminator Network Structure
As shown in Figure 3, the discriminator of MambaRA-GAN is designed based on the PatchGAN [35] structure, whose core is a fully convolutional network. Compared to traditional GAN discriminators that output a single real/fake probability for the entire image, the PatchGAN discriminator operates with a more refined mechanism: it evaluates the input at the level of local image patches. This convolutional architecture transforms the input into an N×N feature map where each spatial element corresponds to a local image patch, and its value represents the probability that the content of that region is judged as “real”. By scoring the authenticity of the image locally on a patch-by-patch basis and considering the results collectively, this design allows the discriminator to guide the discrimination process with greater precision.
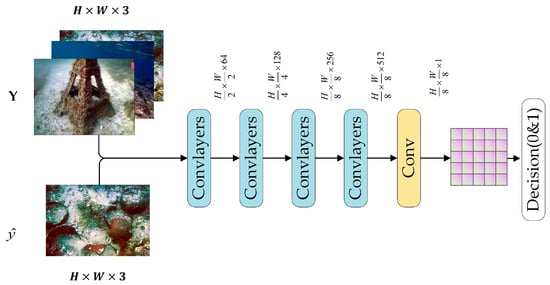
Figure 3.
The discriminator network architecture of MambaRA-GAN.
3.4. Loss Function
The loss function of MambaRA-GAN comprises three components: an adversarial loss (GAN Loss), a cycle consistency loss (Cycle Loss), and a structural consistency loss (SC Loss).
- (1)
- GAN Loss
The adversarial loss aims to train the generator to create images statistically matching the target domain’s distribution while training the discriminator to reliably identify synthetic outputs versus authentic ones. Since MambaRA-GAN involves bidirectional image translation (, ), the adversarial loss is correspondingly divided into forward and backward adversarial losses.
Forward Adversarial Loss: This loss operates on the translation from source domain to target domain . Its mathematical expression is
In Equation (3), represents the probability that discriminator correctly identifies real target domain image as “real”. represents the probability that discriminator falsely identifies the counterfeit target domain image, (generated by generator ), as “real”. Therefore, generator seeks to maximize Equation (3), whereas discriminator optimizes toward minimizing it.
Backward Adversarial Loss: This loss operates on the translation from target domain to source domain . It has an analogous meaning to the forward loss: the objective of generator is to maximize Equation (4), while the objective of discriminator is to minimize Equation (4). Its mathematical expression is
The total adversarial loss is the sum of the forward and backward losses. Its mathematical expression is
- (2)
- Cycle Loss
Since the training data for MambaRA-GAN is unpaired, relying solely on adversarial loss may lead the generator to learn mappings that are visually plausible in the target domain but semantically irrelevant to the input content (mode collapse). The cycle consistency loss enforces a strong constraint to guarantee content preservation and bidirectional invertibility. Its core idea is as follows: an image from one domain translated to the other domain and then translated back to the original domain should closely match the original input image. The loss function for this component is expressed as
where denotes the L1 norm.
- (3)
- Structural Consistency Loss (SC Loss)
The L1 loss in CycleGAN’s cycle consistency loss fundamentally performs pixel-wise error computation, consequently lacking modeling capability for image spatial structural consistency. To overcome this limitation, SSIM-CycleGAN [20] calculates SSIM loss between underwater degraded images and generated high-quality counterparts to enforce luminance, contrast, and structural consistency, while SESS-CycleGAN [21] minimizes the L1 distance between edge maps extracted from original and generated images. Although these strategies successfully incorporate structural information into CycleGAN’s loss, inherent luminance/contrast discrepancies between degraded and enhanced images in SSIM-CycleGAN may interfere with color restoration, causing distortion. Furthermore, SESS-CycleGAN’s Otsu algorithm exhibits noise sensitivity and suboptimal thresholding performance with significant scale variations or multiple objects. To comprehensively resolve these issues, this study innovatively designs a structural constraint mechanism based on deep feature consistency. The specific implementation is as follows:
1. Pre-training of Isomorphic Autoencoders
First, two autoencoders ( and ), structurally identical to the generator, were constructed and pre-trained from scratch prior to the main CycleGAN training. Both autoencoders were initialized with random weights using Kaiming initialization. was trained on underwater degraded images and optimized by minimizing the L1 distance between its reconstructed output and the original input. It was trained for 150 epochs on 800 degraded images from the UIEB dataset with a batch size of 8, using the Adam optimizer () with an initial learning rate of 0.0002, which was reduced by half every 20 epochs. Similarly, was trained under the same architectural and hyperparameter settings, but using 800 high-quality reference images from the UIEB dataset to support the reverse reconstruction process. Note that both autoencoders were trained independently. This pre-training strategy enables both autoencoders to learn domain-specific image reconstruction capabilities.
2. Main training phase of MambaRA-GAN
During the main training phase of CycleGAN, SC Loss is incorporated into both the forward and reverse cycles. Taking the forward cycle as an example, the original input, , and its cyclically reconstructed output, , are fed into the pre-trained autoencoder, , to extract multi-scale feature maps corresponding to two downsampling and two upsampling operations (as indicated by the red arrows in Figure 4). This yields four pairs of corresponding feature maps—eight in total—from the two images. Each pair of feature maps is then normalized along the channel dimension, producing normalized representations for and . Subsequently, the Frobenius norm of the difference between each corresponding pair of normalized feature maps is computed layer-wise. These values are spatially averaged and summed across all layers to form the final SC Loss. A lower SC Loss indicates greater structural consistency between the original and regenerated images.
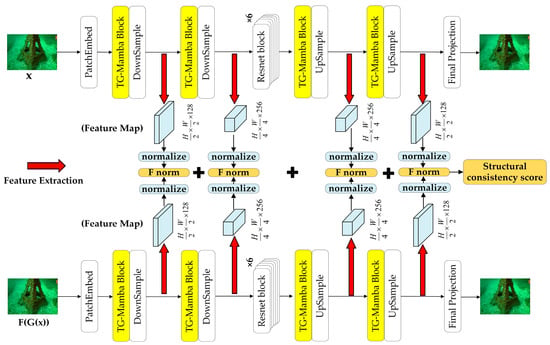
Figure 4.
Computational flowchart of SC Loss.
The complete computational workflow of SC Loss is illustrated in Figure 4, providing explicit visualization of the feature extraction, normalization, and norm-calculation processes. This mechanism ensures cyclic consistency at multiple feature representation levels while avoiding explicit reliance on pixel–space comparisons.
The mathematical expression of this process is
Here, “” denotes Frobenius norm, while and represent the width and height of the feature map at the i-th layer. For a matrix, , its is defined as the square root of the sum of the squares of its entries, i.e.,
During MambaRA-GAN’s forward pass, the original image, , and reconstructed image, , are processed by the pre-trained autoencoder to produce structural similarity-based supervision signals. Generators and jointly minimize Equation (7), with this structural constraint strategy improving image structure preservation. The backward process follows an analogous procedure to the forward pass. The complete SC Loss definition is as follows:
- (4)
- Total loss function
In summary, the total loss function of MambaRA-GAN is expressed as
where and represent the weight coefficients for Cycle Loss and SC Loss, respectively.
4. Experiments
To comprehensively evaluate the performance of the proposed image enhancement model, this study conducts systematic comparative experiments in Section 4.3 and Section 4.4, benchmarking MambaRA-GAN against multiple categories of underwater image enhancement algorithms. The comparison encompasses two methodological frameworks: (1) traditional image processing algorithms, including CLAHE [10], UCM [11], and UDCP [16], and (2) deep learning approaches involving UWCNN [18], CycleGAN [23], SSIM-CycleGAN [20], SESS-CycleGAN [21], MuLA-GAN [24], DiffWater [26], and PUGAN [25]. Additionally, Section 4.5 validates the effectiveness of model components through ablation studies, while Section 4.6 discusses the model’s performance and parameter volume.
4.1. Dataset Description and Experimental Setup
As shown in Figure 5, This study employs three benchmark datasets—UIEB [19], EUVP [36], and RUIE [37]—for model evaluation. All models are uniformly trained on UIEB’s training dataset and evaluated across all three test sets to ensure fairness and comparability. Specific configurations are as follows:

Figure 5.
(a,b) UIEB degraded images and paired reference; (c,d) EUVP degraded images and paired reference; (e) RUIE unpaired degraded images.
Experimental Platform:
Experiments were conducted on a Windows 11 system powered by VirtAITech (Shanghai, China) servers, featuring an NVIDIA® GeForce RTX 3090 GPU (24GB VRAM). The software stack utilized PyTorch 2.1.2 with Python 3.9, VS Code IDE, and CUDA 11.7.
Training configurations:
To ensure thorough training of each model in the comparative experiments, all input images were resized to 256 × 256 pixels. Each model was trained for 300 epochs with a batch size of 1, using the Adam optimizer. For the diffusion-based model DiffWater, the training was conducted with 1,000,000 iterations and a total diffusion step T of 2000. Other hyperparameters (e.g., learning rate, optimizer momentum, etc.) were set following the recommendations of the original repository (i.e., default values).
Datasets configurations:
- (1)
- UIEB: 890 paired samples (800 training/90 testing);
- (2)
- EUVP: 100 paired images randomly selected from the EUVP-515 dataset were used as the test set;
- (3)
- RUIE: 90 unreferenced images with significant blue–green color bias served as the test set.
4.2. Evaluation Indicators
This study employs five standard metrics for comprehensive evaluation: the Structural Similarity Index (SSIM) evaluates structural/textural preservation between enhanced results and references; the Peak Signal-to-Noise Ratio (PSNR) measures pixel-level numerical fidelity; underwater image quality measure (UIQM) [38] integrates chromaticity, sharpness, and contrast to quantify perceptual enhancement; underwater color image quality evaluation (UCIQE) [39] combines color saturation, contrast, and luminance for underwater-specific assessment; and average gradient (AG) computes spatial gradients to indicate edge sharpness and detail richness. SSIM and PSNR function as full-reference (FR) metrics requiring pairwise comparison with ground truth, whereas UIQM, UCIQE, and AG constitute no-reference (NR) schemes that autonomously analyze single-image features. Formal definitions are provided in Equations (11)–(15).
and represent the mean pixel values of the two images, and represent the standard deviations of the pixel values of the two images, denotes the covariance matrix of the pixel values between the two images, and and are constant values to prevent division by zero.
represents the maximum possible pixel value of the image, and denotes the mean squared error.
, , and represent the colorfulness measure, sharpness measure, and contrast measure, respectively, while , , and are weighting coefficients.
is the standard deviation of chroma; represents the contrast of luminance, denotes the mean value of saturation; and , , and are weighting coefficients.
represents the generated image, while and denote the height and width of the image, respectively.
4.3. Visual Comparison with Other Methods
Visual comparisons in Figure 6, Figure 7 and Figure 8 demonstrate the proposed approach’s superior performance in color cast correction and detail richness.

Figure 6.
Comparative reconstruction results of 11 methods using the UIEB benchmark, where the red boxs highlight local enhancement areas to show the contrast clearly.

Figure 7.
Comparative reconstruction results of 11 methods using the EUVP benchmark, where the red boxs highlight local enhancement areas to show the contrast clearly.

Figure 8.
Comparative reconstruction results of 11 methods using the RUIE benchmark, where the red boxs highlight local enhancement areas to show the contrast clearly.
- (1)
- Color cast corrections
Due to the complexity of underwater environments, traditional methods struggle to obtain accurate priors, resulting in systematic color casts: UDCP introduces blue–green casts with insufficient brightness; CLAHE fails to effectively remove haze and lacks color correction capabilities for severely color-biased images; UCM exhibits red-channel oversaturation. Among deep learning methods, UWCNN’s loss function neglects luminance priority, generating images with dark red tones; CycleGAN, SSIM-CycleGAN, and SESS-CycleGAN improve fundamental color bias but retain residual shifts in deep blue–green water scenes; Mula-GAN only partially corrects colors, with limited generalizability and local over-/underexposure; DiffWater introduces blue artifacts during restoration while appearing visually darker; and PUGAN performs local correction on green–blue channel deviations, yet fails to eliminate background color casts and enhance overall contrast. In contrast, the proposed method more effectively corrects blue–green casts, demonstrating superior contrast, color fidelity, and generalizability.
- (2)
- Detail richness
Traditional methods directly perform color correction based on prior knowledge, yet struggle to overcome edge blurring in original degraded underwater images. Deep learning-based approaches establish low-quality to high-quality image mappings, which can improve texture clarity but exhibit inherent limitations due to their reconstruction-based nature: CycleGAN, SSIM-CycleGAN, and SESS-CycleGAN produce red checkerboard artifacts, while UWCNN and PUGAN suffer from local blurring and noise points. Crucially, only DiffWater and the proposed method achieve satisfactory texture detail restoration, whereas all others fail to attain optimal results.
4.4. Objective Comparison with Other Methods
Table 1, Table 2 and Table 3 display quantitative metrics for UIE methods across three datasets, with optimal values bolded and suboptimal results underlined.

Table 1.
UIEB Benchmark: Quantitative assessment of enhancement methods (↑ indicates better).
Table 2.
EUVP Benchmark: Quantitative assessment of enhancement methods (↑ indicates better).
Table 3.
RUIE Benchmark: Quantitative assessment of enhancement methods (↑ indicates better).
As shown in Table 1, Table 2 and Table 3, the proposed method outperforms all comparative methods in SSIM, PSNR, and AG. While it does not surpass some traditional methods in UIQM and UCIQE, it achieves the highest scores on these two metrics among data-driven methods. The advantage across SSIM, PSNR, and AG demonstrates the model’s breakthrough improvements in structural fidelity, luminance accuracy, and detail richness. However, on the UIQM and UCIQE metrics, our method falls behind some traditional approaches. This is because these no-reference metrics rely solely on basic image features such as color and brightness for linear computation, while neglecting critical aspects such as human visual perception. This observation is consistent with findings in [37,40]. Visual experiments in Section 4.3 further confirm that traditional methods yield color-distorted and detail-blurred results despite high UCIQE/UIQM scores (e.g., color casts in UDCP and block artifacts in CLAHE). Although UIQM and UCIQE may not fully align with human perception and can sometimes yield misleadingly high scores, they still offer valuable references for low-level attributes such as luminance, contrast, and color saturation. Therefore, the fact that our method achieves the highest scores on these two metrics among deep learning-based approaches indicates that it also has significant advantages in enhancing low-level visual attributes.
4.5. Ablation Experiment
To validate the effectiveness of each component of MambaRA-GAN, we designed ablation experiments using CycleGAN as the baseline, sequentially evaluating the performance gains of the TG-Mamba module (Mamba), structural consistency loss (SC), and their combined implementation (MambaRA-GAN), with both qualitative and quantitative analysis of module contributions. Table 4 presents the performance comparison of different components on the UIEB dataset, while Figure 9 displays the visual results of the ablation experiments.
Table 4.
Ablation study results on UIEB dataset (↑ indicates better, best results are shown in bold).

Figure 9.
Comparative effectiveness of enhancement strategies on UIEB dataset, where the red boxs highlight local enhancement areas to show the contrast clearly.
As shown in Table 4, compared to the control group (T1), both the T2 and T3 groups achieve significant improvements across all five performance metrics, demonstrating the effectiveness of TG-Mamba and SC Loss, respectively. Simultaneously, the T4 group, combining both strategies, outperforms other ablation models in all five metrics, proving the effectiveness of their integration. Observing the visual comparison results in Figure 9 reveals that CycleGAN-generated images exhibit noticeable red checkerboard artifacts. After processing with the Mamba block, these artifacts are significantly reduced, though still require further improvement, while images processed with SC Loss eliminate checkerboard artifacts, resulting in smoother images with finer texture details, though their brightness and contrast could be enhanced. In contrast, the fused model MambaRA-GAN demonstrates superior performance in color restoration, contrast representation, and texture details, coming closer to authentic high-quality underwater images.
4.6. Real-Time Analysis and Discussion
Table 5 benchmarks architectural efficiency across three dimensions: (1) Parameters: Total learnable weights in the model. (2) FLOPs (Floating-Point Operations Per Second): Computational workload measures. (3) FPS (Frames Per Second): Real-time processing speed.
Table 5.
Real-time performance analysis (↑ indicates better, ↓ denotes worse).
Analysis of Table 5 demonstrates that conventional UIE methods attain superior frame rates (FPS) owing to their non-data-driven nature and closed-form computations. Among deep learning models, diffusion-based DiffWater shows inherent latency due to iterative sampling and large-scale data dependency. UWCNN achieves optimal FPS via its ultra-lightweight parameters, minimal FLOPs, and streamlined end-to-end architecture. Though not the fastest, our method’s 96.5 FPS readily satisfies real-time constraints in subsea applications. Meanwhile, GAN-based methods excel in inference speed over diffusion models due to their generative mechanisms: GANs produce an image in one forward pass, ensuring high efficiency, while diffusion models require iterative denoising steps, each needing a full network pass, leading to linear computational growth with sampling steps, T, which is slower and requires more computation. However, this iterative process often yields higher-quality results. As shown in Table 1, Table 2 and Table 3, DiffWater outperforms early GAN-based methods such as CycleGAN, SSIM-CycleGAN, and SESS-CycleGAN. However, the performance gap has been closed by recent models like MULA-GAN (which incorporates a multi-level attention mechanism) and PUGAN (which employs physics-guided learning and a dual-discriminator structure). This demonstrates that with architectural advancements, GANs remain highly competitive in terms of output quality. Our method incorporates a lightweight Mamba module and a reconstruction autoencoder constraint, retaining GANs’ fast inference while enhancing global dependency modeling and reconstruction consistency, outperforming DiffWater overall. Thus, we achieve a superior balance between speed, quality, and efficiency, demonstrating strong practical potential.
4.7. Application
To validate the practical effectiveness of our method in UIE, we evaluated its performance with several downstream vision tasks, including object detection (YOLOv5s), keypoint detection (SIFT) [41], color image segmentation (SFFCM) [42], and edge detection (Canny) [43]. As shown in Figure 10, when trained with the default configuration provided in the official repository, the enhanced images significantly improved detection accuracy on the UTTS dataset [37] (with 270 training images and 30 testing images), compared to the degraded results from the originals. In keypoint detection, the number of SIFT features increased dramatically—from 42 and 190 to 1103 and 1441 after enhancement. In SFFCM and Canny tasks, significantly improved segmentation of targets such as sea urchins and richer edge details were observed. These results demonstrate the method’s strong applicability in improving underwater imagery for diverse vision tasks.

Figure 10.
Application examples of object detection, keypoint detection, color image segmentation, and Canny detection.
4.8. Failure Cases
When dealing with severely blue–green-biased underwater images, the generalization capability of the proposed method remains insufficient, with specific failure cases illustrated in Figure 11. Combined with the performance of various methods shown in Table 1, Table 2 and Table 3, it is evident that all methods experience significant performance degradation on the RUIE dataset. Although the proposed method still outperforms other comparable approaches, its metrics also notably decline, indicating limited adaptability to out-of-distribution data. This phenomenon may be attributed to two main factors: first, the insufficient representation of severely color-biased samples in the training data—the UIEB dataset used in this study contains a relatively low proportion of deep blue–green-biased images, resulting in inadequate model learning for such scenarios; second, the model lacks guidance from physical imaging principles, which limits its interpretability and adaptability to unfamiliar environmental conditions. Future work will focus on constructing more diverse and representative underwater image datasets and introducing physical model-guided learning strategies to enhance the model’s enhancement capability, interpretability, and robustness under complex color bias conditions.

Figure 11.
Examples of failure cases on the RUIE dataset. Subfigures (a–c) show enhanced results that still exhibit a blue cast and over-correction.
5. Conclusions
This paper proposes an efficient underwater image enhancement (UIE) solution—MambaRA-GAN. The main innovations of our work can be summarized as follows: (1) We design a novel generator architecture based on a Triple-Gated Mamba mechanism that significantly enhances the model’s capability for multi-scale feature extraction and long-range dependency modeling. (2) We construct intra-domain reconstruction autoencoders, strengthening the structural constraints in the reconstruction process by introducing a structural consistency loss, thereby significantly enhancing the detail restoration accuracy for complex underwater scenes. Experiments demonstrate that the proposed method achieves significant improvements across five quantitative metrics and produces subjectively superior results in color correction and texture detail enhancement, closer to real high-quality underwater images. Furthermore, results from both the real-time performance analysis and application experiments demonstrate the significant practical potential of the proposed method. Future work will focus on constructing more diverse and representative datasets and exploring physics-guided training strategies to further improve robustness and adaptation capability.
Author Contributions
Conceptualization, J.W. and Y.F.; methodology, J.W.; software, J.W.; validation, J.W. and G.Z.; formal analysis, J.W.; investigation, J.W.; resources, Y.F.; data curation, J.W.; writing—original draft preparation, J.W.; writing—review and editing, Y.F.; visualization, J.W. and G.Z.; supervision, G.Z. and Y.F.; project administration, Y.F.; funding acquisition, Y.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Yunnan Provincial Major Science and Technology Project (research on the blockchain-based agricultural product traceability system and demonstration of platform construction; Project No. 202102AD080002).
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, J.; Xu, W.; Deng, L.; Xiao, Y.; Han, Z.; Zheng, H. Deep learning for visual recognition and detection of aquatic animals: A review. Rev. Aquac. 2023, 15, 409–433. [Google Scholar] [CrossRef]
- Li, X.; Zhuang, Y.; You, B.; Wang, Z.; Zhao, J.; Gao, Y.; Xiao, D. LDNet: High Accuracy Fish Counting Framework using Limited training samples with Density map generation Network. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 102143. [Google Scholar] [CrossRef]
- Rahman, M.A.; Barooah, A.; Khan, M.S.; Hassan, R.; Hassan, I.; Sleiti, A.K.; Hamilton, M.; Gomari, S.R. Single and Multiphase Flow Leak Detection in Onshore/Offshore Pipelines and Subsurface Sequestration Sites: An Overview. J. Loss Prev. Process Ind. 2024, 90, 105327. [Google Scholar] [CrossRef]
- Bell, K.L.; Chow, J.S.; Hope, A.; Quinzin, M.C.; Cantner, K.A.; Amon, D.J.; Cramp, J.E.; Rotjan, R.D.; Kamalu, L.; de Vos, A.; et al. Low-cost, deep-sea imaging and analysis tools for deep-sea exploration: A collaborative design study. Front. Mar. Sci. 2022, 9, 873700. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, T.; Zhang, W. Underwater vision enhancement technologies: A comprehensive review, challenges, and recent trends. Appl. Intell. 2023, 53, 3594–3621. [Google Scholar] [CrossRef]
- Hummel, R. Image enhancement by histogram transformation. Comput. Graph. Image Process. 1977, 6, 184–195. [Google Scholar] [CrossRef]
- Buchsbaum, G. A spatial processor model for object colour perception. J. Frankl. Inst. 1980, 310, 1–26. [Google Scholar] [CrossRef]
- Liu, Y.-C.; Chan, W.-H.; Chen, Y.-Q. Automatic white balance for digital still camera. IEEE Trans. Consum. Electron. 1995, 41, 460–466. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphics Gems IV; Academic Press: Cambridge, MA, USA, 1994; pp. 474–485. [Google Scholar]
- Garg, D.; Garg, N.K.; Kumar, M. Underwater image enhancement using blending of CLAHE and percentile methodologies. Multimed. Tools Appl. 2018, 77, 26545–26561. [Google Scholar] [CrossRef]
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using unsupervised colour correction method. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Jaffe, J.S. Computer modeling and the design of optimal underwater imaging systems. IEEE J. Ocean. Eng. 1990, 15, 101–111. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [CrossRef]
- Chiang, J.Y.; Chen, Y.C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2011, 21, 1756–1769. [Google Scholar] [CrossRef]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 1–8 December 2013; pp. 825–830. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; p. 27. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Guo, C. Emerging from water: Underwater image color correction based on weakly supervised color transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Li, Q.Z.; Bai, W.X.; Niu, J. Underwater image color correction and enhancement based on improved cycle-consistent generative adversarial networks. Acta Autom. Sin. 2020, 46, 1–11. [Google Scholar]
- Chen, B.; Zhang, X.; Wang, R.; Li, Z.; Deng, W. Detect concrete cracks based on OTSU algorithm with differential image. J. Eng. 2019, 23, 9088–9091. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Bakht, A.B.; Jia, Z.; Din, M.U.; Akram, W.; Saoud, L.S.; Seneviratne, L.; Lin, D.; He, S.; Hussain, I. MuLA-GAN: Multi-Level Attention GAN for Enhanced Underwater Visibility. Ecol. Inform. 2024, 81, 102631. [Google Scholar] [CrossRef]
- Cong, R.; Yang, W.; Zhang, W.; Li, C.; Guo, C.-L.; Huang, Q.; Kwong, S. Pugan: Physical model-guided underwater image enhancement using gan with dual-discriminators. IEEE Trans. Image Process. 2023, 32, 4472–4485. [Google Scholar] [CrossRef] [PubMed]
- Guan, M.; Xu, H.; Jiang, G.; Yu, M.; Chen, Y.; Luo, T.; Zhang, X. DiffWater: Underwater image enhancement based on conditional denoising diffusion probabilistic model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 2319–2335. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems; NIPS: La Jolla, CA, USA, 2017. [Google Scholar]
- Gu, A.; Goel, K.; Re, C. Efficiently Modeling Long Sequences with Structured State Spaces. arXiv 2022, arXiv:2111.00396. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. Vmamba: Visual state space model. Adv. Neural Inf. Process. Syst. 2024, 37, 103031–103063. [Google Scholar]
- Dao, T.; Gu, A. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. arXiv 2024, arXiv:2405.21060. [Google Scholar] [CrossRef]
- Liu, S.H.; Yu, W.H.; Tan, Z.X.; Wang, X.C. Linfusion: 1 gpu, 1 minute, 16k image. arXiv 2024, arXiv:2409.02097. [Google Scholar] [CrossRef]
- Lee, S.; Choi, J.; Kim, H.J. Efficientvim: Efficient vision mamba with hidden state mixer based state space duality. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 10–17 June 2025; pp. 14923–14933. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, J.; He, W.; Gao, H.; Yue, H.; Zhang, Z.; Li, C. Is underwater image enhancement all object detectors need? IEEE J. Ocean. Eng. 2024, 49, 606–621. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Lei, T.; Jia, X.; Zhang, Y.; Liu, S.; Meng, H.; Nandi, A.K. Superpixel-based fast fuzzy C-means clustering for color image segmentation. IEEE Trans. Fuzzy Syst. 2018, 27, 1753–1766. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).