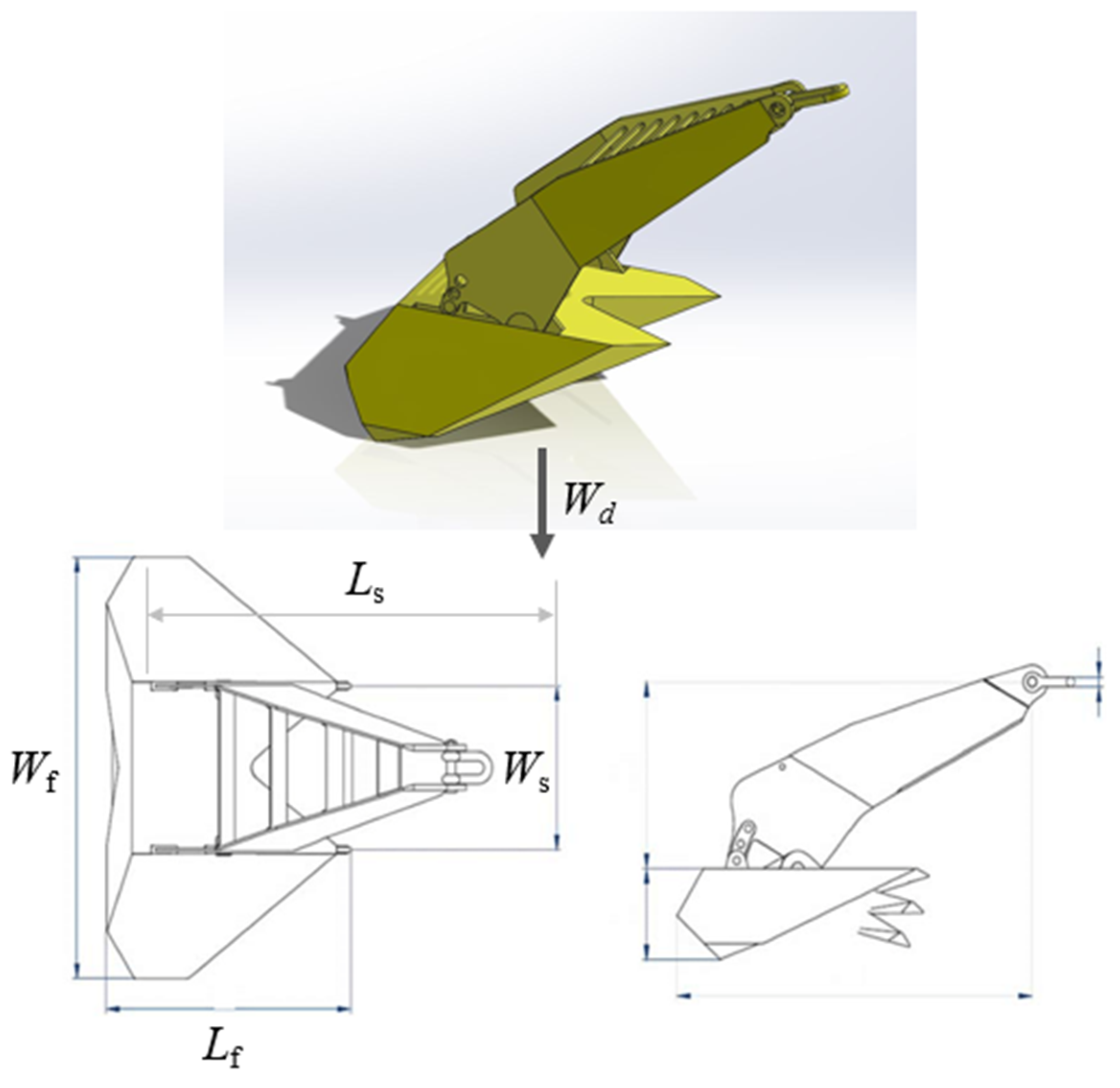
3.1. Clay Seabed
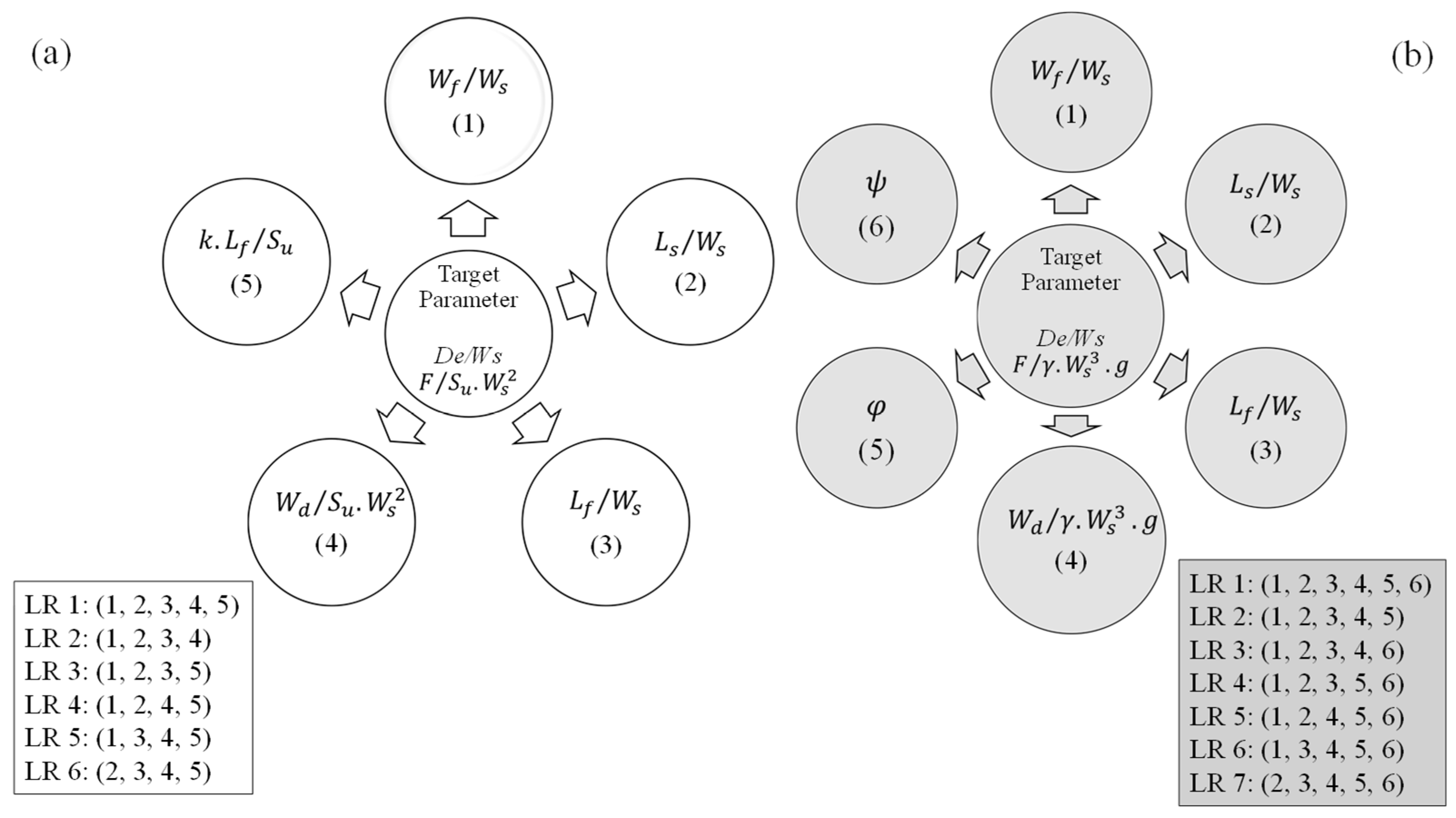
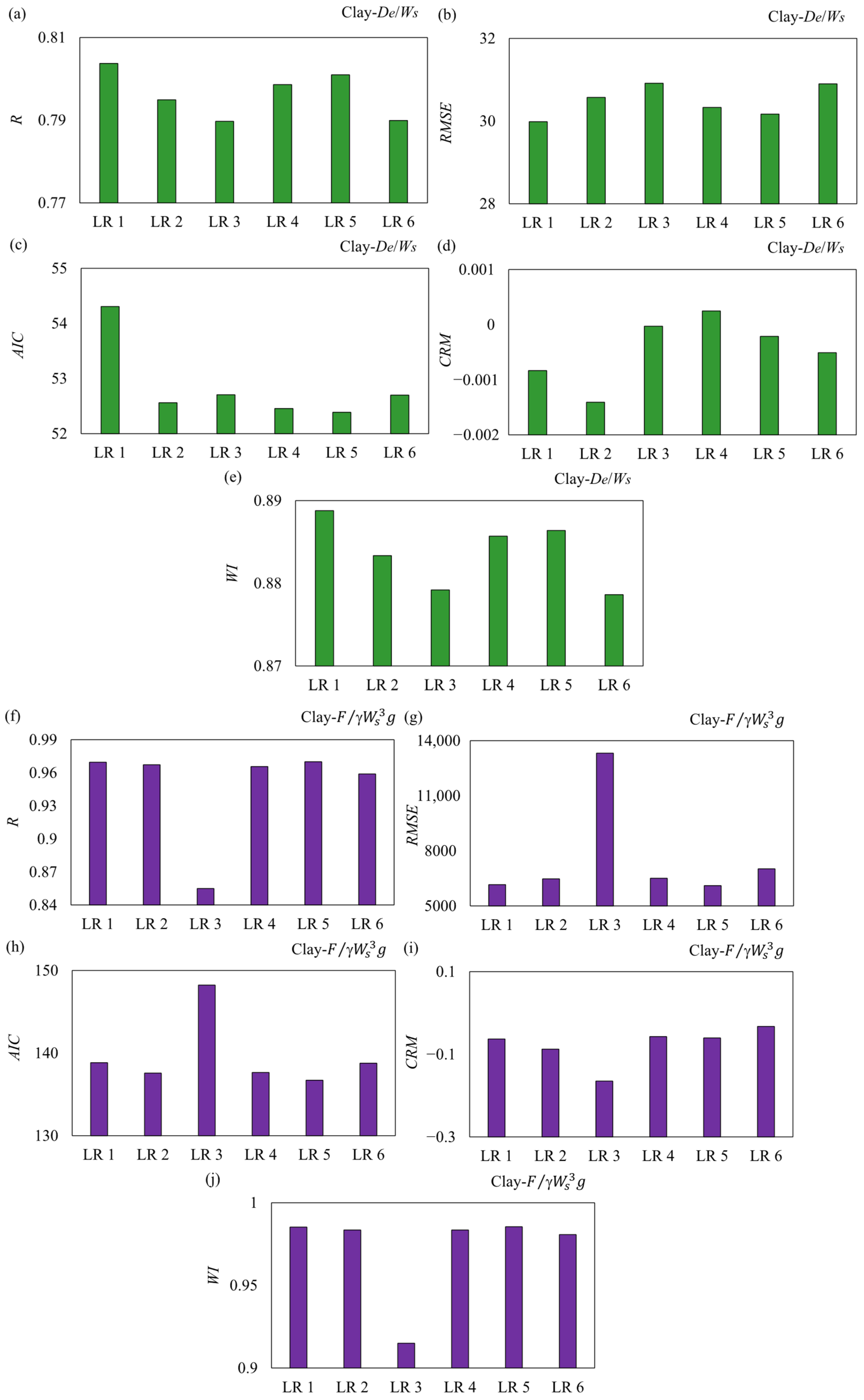
Figure 4 depicts the results of statistical metrics of the LR models for predicting the penetration depth and the holding capacity of the drag embedment anchor in the clay seabed. The six linear regression (LR) models (LR 1 to LR 6) are systematically developed by varying the selection of five key dimensionless groups that define anchor and soil interactions in clay seabed. LR 1 serves as the most comprehensive model, incorporating all five input parameters
. Moving to LR 2, one input
is removed, simplifying the model while still capturing the primary influences on penetration depth and holding capacity. Similarly, LR 3 excludes
, refining the analysis further. This stepwise elimination process continues, with each subsequent LR model omitting a different input to assess its contribution. By LR 6, the model retains only four inputs
, removing
(see
Figure 3). The coefficient of determination indicated that all models have moderate predictive capabilities, with values ranging between 0.77 and 0.81. Among them, LR 1 exhibited the highest R index, confirming its superior ability to capture the relationship between the predictors and penetration depth. In contrast, the LR 3 model demonstrated the lowest value of the R index. The LR3 model exhibited the highest
RMSE and
AIC values, indicating the weakest predictive accuracy and least efficient model structure among the evaluated regression models. This inferior performance can be attributed to the lack of critical parameters that capture essential geotechnical mechanisms in LR3, particularly those related to soil–anchor interaction forces, such as the anchor dead weight ratio and fluke geometry. The model likely fails to fully represent the driving and resisting forces influencing drag anchor penetration in soft clay, where resistance is highly dependent on undrained shear strength and strain-rate effects. Conversely, LR1, which demonstrated the lowest
AIC and
RMSE along with the highest Willmott Index (
WI), showed superior performance. The
CRM values showed that most models tended to underestimate the penetration depth, with LR3 showing the largest negative bias. This systematic underprediction implied that the model might be neglecting influential parameters such as the effect of strain-softening or progressive failure, often observed in clay under large deformations caused by dragging anchors. The anchor dead weight ratio (
Wd/
SuWs2) emerged as the most influential parameter for predicting penetration depth. This emphasized the fundamental role of gravitational forces in overcoming the cohesive resistance of clay during anchor embedment. Heavier anchors increased normal stress on the soil, promoting deeper penetration through shear failure mechanisms. The second most critical factor, the fluke width ratio (
Wf/
Ws) aligned with the concept that a wider fluke mobilized greater passive resistance by increasing the contact area and distributing the load across more soil volume. The gradient of undrained shear strength (
kLf/
Su) was also a significant predictor, underscoring the importance of vertical soil strength variation, which was common in marine clays due to consolidation and layering. Moreover, the fluke length ratio (
Lf/
Ws) and shank length ratio (
Ls/
Ws) contributed meaningfully by affecting the load transfer mechanism and anchor-soil interaction geometry. A longer fluke, for example, modified the embedment path and enhanced rotational stability, while a longer shank could either aid or hinder penetration depending on its effect on force alignment and resistance buildup.
Among these models, the LR 1 model demonstrated the best performance across all metrics. Specifically, the LR 1 model achieved the highest correlation coefficient, indicating a strong correlation between predicted and observed values. Additionally, LR 1 recorded one of the lowest RMSE values, reflecting minimal prediction error, whereas the LR 3 model exhibited the weakest performance, with the lowest value of R and the highest degree of the RMSE index. The AIC value for LR 1 was relatively lower, indicating an optimal balance between model fit and complexity. The CRM value for LR 1 was closest to zero, with unbiased predictions. Furthermore, LR 1 achieved the highest Willmott’s Index, demonstrating strong agreement between predicted and observed values. Comparatively, LR 3 had the lowest WI and the highest CRM, with its poor predictive capability. The superior performance of LR 1 can be attributed to its ability to effectively capture the underlying patterns and dependencies within the dataset. Overall, the consistent performance of LR 1 across all statistical indices validates its robustness and accuracy in predicting the anchor holding capacity in clay seabed, making it the most reliable model among the six LR models. The implemented sensitivity analysis demonstrated that the anchor dead weight ratio () had the highest level of effectiveness in modeling the holding capacity of DEA using the LR model.
The study performed a sensitivity analysis on a linear regression model to assess how dimensionless parameters affect drag anchor holding capacity prediction in clay seabed. The anchor dead weight ratio () had the greatest impact on prediction accuracy, followed by the fluke width ratio (), fluke length ratio (), undrained shear strength gradient ratio (), and shank length ratio (). This analysis underscores the critical role of anchor geometry, especially fluke dimensions, and seabed shear strength in controlling holding capacity. Consequently, these findings provide essential guidance for optimizing anchor design through strategic parameter prioritization.
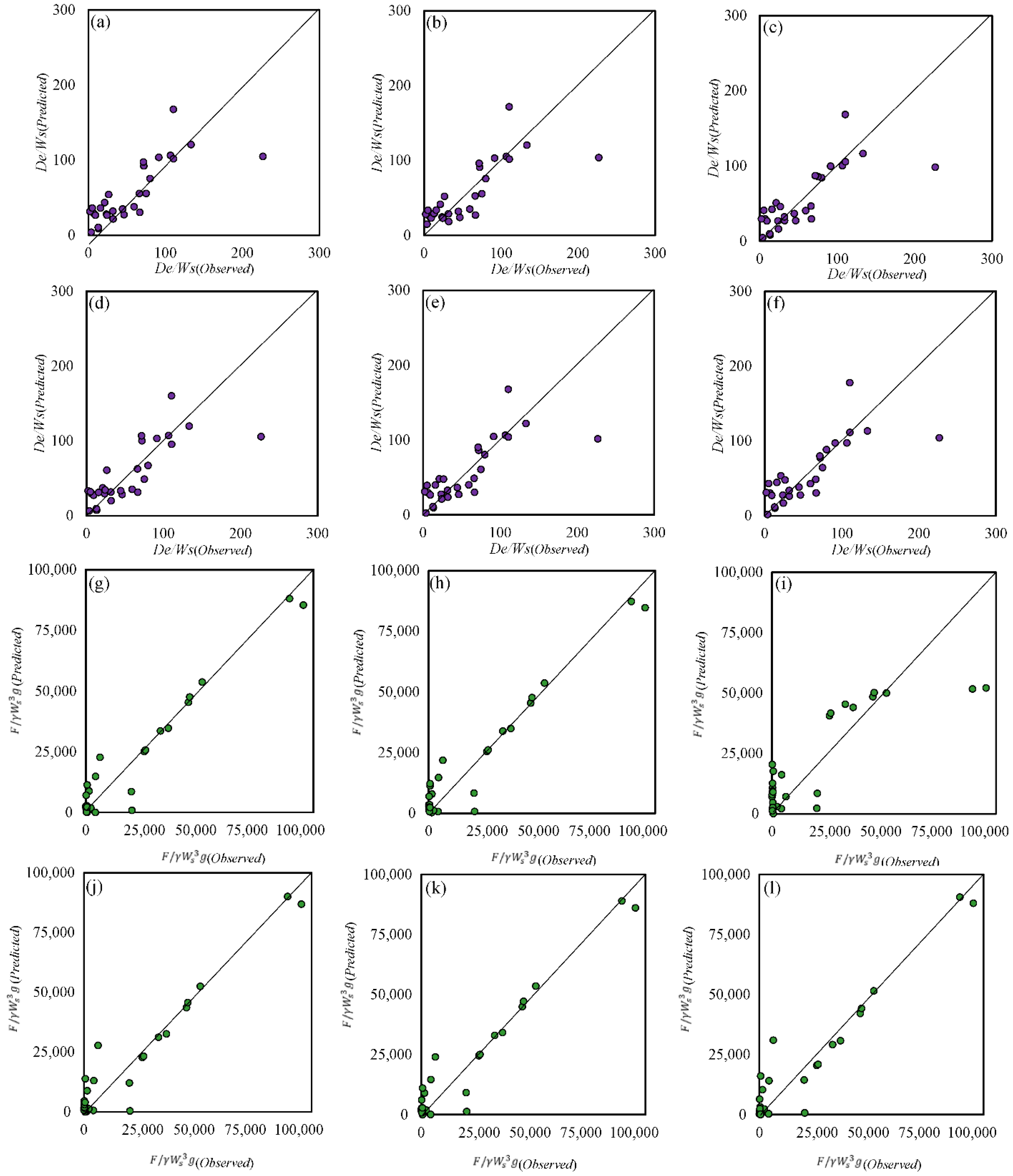
Figure 5 illustrates the scatter plot for the LR models to predict the penetration depth of the drag embedment anchor in the clay seabed. Regarding the modeling results, LR 1, LR 2, LR 4, LR 5, and LR 6 demonstrated relatively strong agreement between observed and predicted values, as most points cluster near the diagonal line. This suggests that these models provided reasonably accurate penetration depth estimates, with LR 1 appearing to have the best fit. However, the LR 3 model showed significant deviation from the ideal diagonal line, with a wider spread of points. This indicated higher prediction errors and lower accuracy compared to the other models, corroborating its poor performance as previously observed in the statistical indices such as
RMSE and
AIC. The greater scatter suggested that the LR 3 model struggled to generalize the relationship between input variables and penetration depth. Furthermore, all models exhibited some degree of underprediction, as indicated by the clustering of points below the diagonal line. This aligned with the negative
CRM values from the statistical analysis, confirming that the models tend to underestimate the penetration depth. Overall, while the LR 1 model was the most accurate, the LR 3 model performed the worst. The results highlight the limitations of linear regression in capturing complex nonlinear relationships in seabed penetration depth prediction.
The scatter plots of the LR models used to predict the capacity of drag embedment anchors in the clay seabed are shown in
Figure 6. The models LR 1, LR 2, LR 4, LR 5, and LR 6 showed impressive predictive capabilities, with their data points closely mirroring the diagonal line, indicating high accuracy. Notably, LR 1 stood out with the strongest correlation between predicted and actual values, solidifying its position as the top-performing model. In contrast, LR 3 demonstrated poor predictive power, characterized by significant deviations from the diagonal line and a wider scatter of data points, which aligns with its previously observed high error rate and low correlation coefficient. Hence, the results reaffirm that LR 1 is the most reliable model, while LR 3 is the least effective for predicting drag embedment anchor capacity in clay seabed.
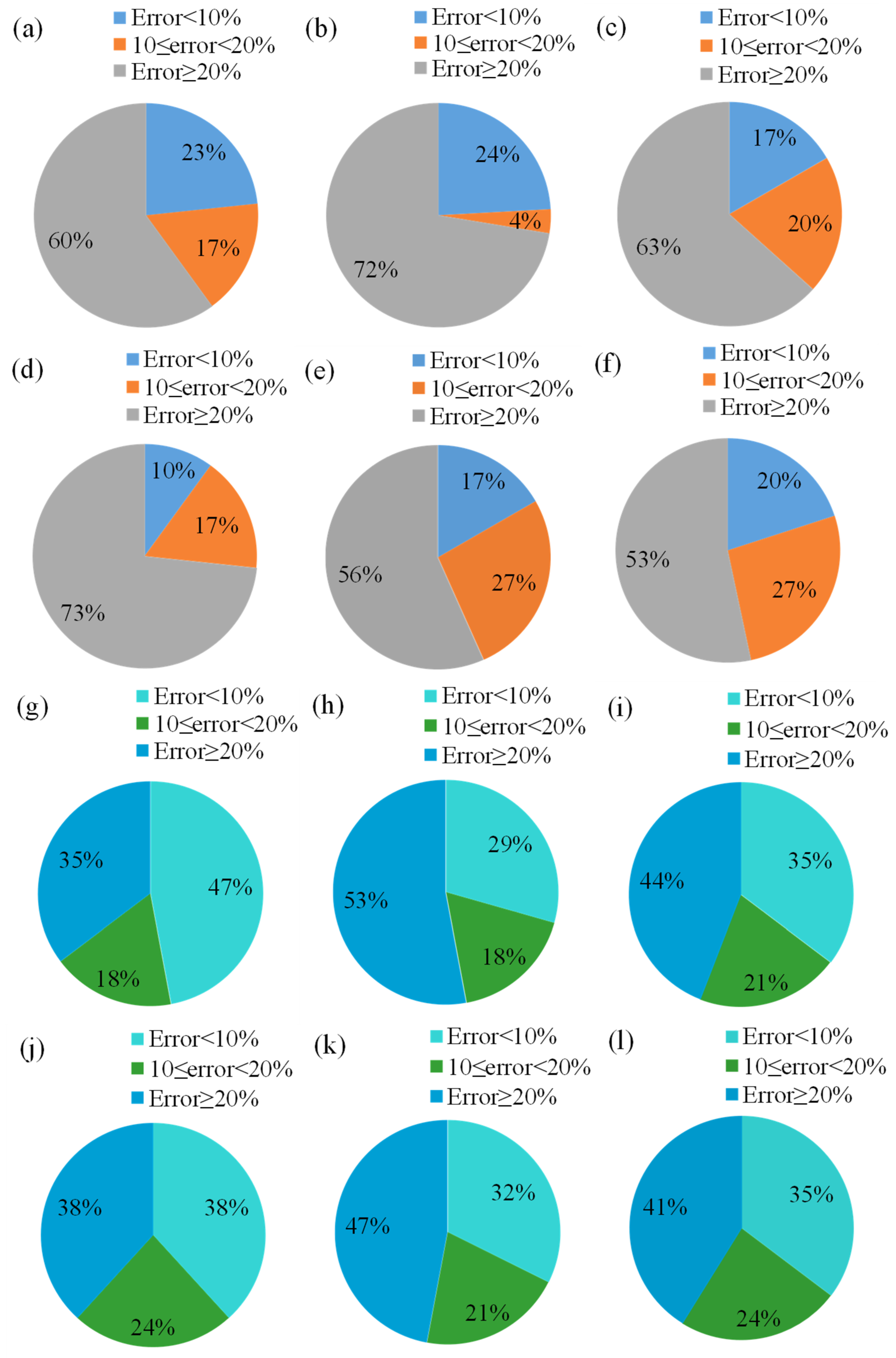
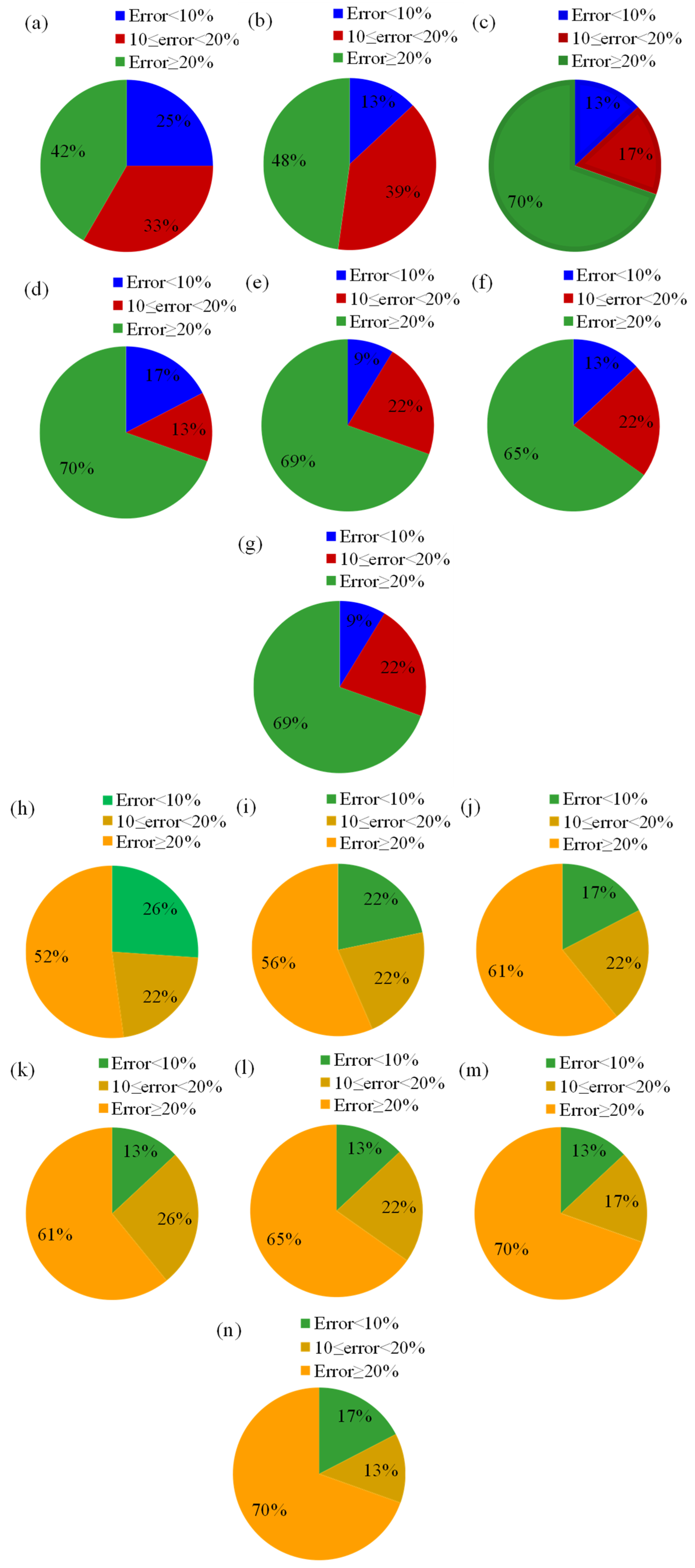
When examining the most accurate predictions (error < 10%), LR 2 slightly outperformed the others with 24% of its predictions falling within this range, followed by LR 1 (23%) and LR 6 (20%). LR 4 performed the worst in this category with only 10%. Mid-range errors (10–20%) varied across models, with LR 5 and LR 6 showing the highest at 27%, while LR 2 showed the least (4%), suggesting that LR 2 was more polarized between highly accurate and poor predictions. Based on the error distribution plots for LR 1 to LR 6 in predicting the penetration depth of drag embedment anchors in clay seabed, it could be concluded that LR 1 was the best-performing model in terms of error distribution. Among all six linear regression models, LR 1 exhibited a strong balance between prediction accuracy and error minimization. Specifically, LR 1 achieved 23% of predictions with an error less than 10%, which was among the highest across all models, and 17% of predictions within the 10–20% error range, indicating that 40% of its predictions fell within an acceptable error margin below 20%. LR 1 had a lower proportion of high-error predictions (≥20%) at 60%, compared to most other models, such as LR 2 (72%) and LR 4 (73%). While LR 6 slightly outperformed LR 1 in reducing high-error predictions (53%), LR 1 compensated by achieving a more favorable distribution in the low-error (<10%) category, closely rivaling LR 2 (24%) and surpassing LR 6 (20%). Given this analysis, LR 1 offered a reliable and well-rounded performance, combining a high percentage of accurate predictions with a moderate level of high-error outcomes. Therefore, LR 1 could be considered the most effective model for predicting penetration depth based on its superior error distribution profile.
Despite LR1’s relative superiority, a portion of its predictions exhibited errors greater than 10% due to both methodological and physical limitations. Linear regression inherently struggled to model the complex, nonlinear interactions that governed DEA behavior, such as plastic deformation, strain-softening, and soil–anchor interface dynamics. These simplifications introduced model bias, especially since real soil behavior, particularly in layered clay or dilative sand, was highly nonlinear, anisotropic, and spatially variable. Furthermore, while the use of Buckingham π groups reduced complexity, it assumed scale invariance and failed to capture critical interaction terms or second-order effects. Important factors such as anchor installation velocity, cyclic loading, soil heterogeneity, and time-dependent behaviors like consolidation were excluded. The dataset used to train the model was drawn from diverse experimental sources with different quality and scope, and it did not adequately represent the full parameter space, particularly under boundary or extreme conditions, thereby limiting the model’s generalization. Additionally, natural seabed conditions exhibited inherent uncertainty and spatial variability, meaning that parameters such as friction angle (φ), undrained shear strength (Su), and unit weight (γ) could vary significantly over small spatial scales, further contributing to prediction errors.
It is worth noting that the dataset used in this study was compiled from various experimental and analytical sources, which inherently differ in scope, boundary conditions, instrumentation precision, and reporting formats. These variations introduced noise and heterogeneity that challenged the linear regression (LR) models’ ability to learn consistent patterns. The inconsistency may arise from non-uniform data collection methods, variable anchor geometries, or different testing scales, which limit the generalization capability of the model. This is evident in the uncertainty analysis, where even the best-performing model (LR 1) exhibited (
Table 5,
Figure 6) that the training model is highly sensitive to the quality and representativeness of the input data.
Although the dimensional analysis provided a rigorous foundation using Buckingham’s π theorem, it assumes that all influential mechanisms are sufficiently captured by the selected parameters. However, omitting dynamic and time-dependent factors, e.g., installation velocity and soil anisotropy) may contribute to nonlinear interactions that the linear model cannot fully resolve. These limitations were further exacerbated by the following:
Scale differences among datasets;
Nonuniform boundary conditions in the source experiments;
Unmodeled nonlinearities, especially in clay, where strain-softening and progressive failure dominate;
Hence, the relatively low rate of <10% error predictions is more a reflection of dataset fragmentation and unmodeled interactions than of model structure alone. To improve prediction, accuracy, and reliability, future efforts will focus on the following:
Curating a high-fidelity, standardized experimental dataset for DEA performance under controlled conditions.
Including additional physical variables, such as installation velocity, cyclic load amplitude/frequency, and time-dependent consolidation, either directly or through surrogate dimensionless parameters.
Exploring hybrid modeling techniques, combining dimensional analysis with nonlinear machine learning (e.g., Random Forests, Support Vector Regression), to capture complex interactions beyond the capability of linear regression.
The LR 1 model had 47% of predictions with an error of less than 10%, 18% fell within the 10–20% range, and 35% had an error of greater than 20%. This model showed the highest percentage of highly accurate predictions. For the LR 2 model, only 29% of predictions were within <10% error, while 53% exceeded 20% error, the worst among all models. The LR 3 model showed a balanced distribution with 35% < 10% error, 21% between 10–20%, and 44% ≥ 20%. LR 4 presented an even distribution with 38% < 10%, 24% in 10–20%, and 38% ≥ 20%, indicating moderate accuracy. For the LR 5 model, 32% of predictions had less than 10% error, while 21% were in the mid-range, and 47% had ≥20% error. Furthermore, the LR 6 model was similar to LR 3, with 35% less than 10% error, 24% mid-range, and 41% higher than 20% error. Among the models, LR 1 outperformed the others, offering the lowest proportion of high-error predictions (35%) and the highest proportion of accurate predictions (47%), making it the most reliable for predicting anchor capacity. LR 2 performed the worst, with more than half its predictions exceeding 20% error. Models LR 3, LR 4, LR 5, and LR 6 displayed moderate performance but still had a significant portion of high-error predictions. Hence, LR 1 was the best-performing model, demonstrating both qualitative robustness and quantitative superiority in predicting drag embedment anchor capacity in clay seabed.
Table 5 represents the results of the uncertainty analysis for the LR models to predict the penetration depth and holding capacity of the drag embedment anchor in the clay seabed. All LR models showed mean values near zero, indicating minimal bias. LR 3 had the smallest mean error (−0.0016), followed closely by LR 5 (−0.0122) and LR 6 (−0.0291), while LR 4 had a slight positive bias (0.0143). These results suggested that all models were generally unbiased in their predictions. LR 1 had the lowest variability (30.50), indicating more consistent predictions, while LR 3 (31.44) and LR 6 (31.43) showed the highest variability. LR 1 had the narrowest 95% CI range (−11.44, 11.34), indicating greater precision, while LR 6 had the widest interval (−11.77, 11.71), reflecting higher uncertainty. LR 1 again had the smallest WUB (11.39), while LR 3 and LR 6 had the widest (11.74). LR 1 stood out as the most reliable model, with low variability, minimal uncertainty, and a tight confidence interval, reflecting high precision and consistency in its predictions. Conversely, LR 6 and LR 3 exhibited greater uncertainty and variability, making them less consistent. So, this analysis suggested that LR 1 provided the most stable and precise predictions for penetration depth in clay seabed among the six models evaluated.
For estimating the capacity of DEA in the clay seabed, the LR 1 model possessed a mean error of −4,332,392, which, while negative, was within an acceptable range compared to other models. It performed better than LR 3 (−15,376,462) and was relatively close to LR 2, LR 5, and LR 6 in terms of error magnitude. The standard deviation for the LR 1 model was 5,404,922, which was moderate and indicates a reasonable level of consistency in its predictions. It was higher than LR 4 but comparable to LR 5 and LR 6, and notably lower than LR 3. LR 1 had a CI of (−6,218,258 to −2,446,525), which was moderately narrow, indicating a good level of confidence in its prediction range. Its WUB was 1,885,867, while higher than LR 4.
3.2. Sandy Seabed
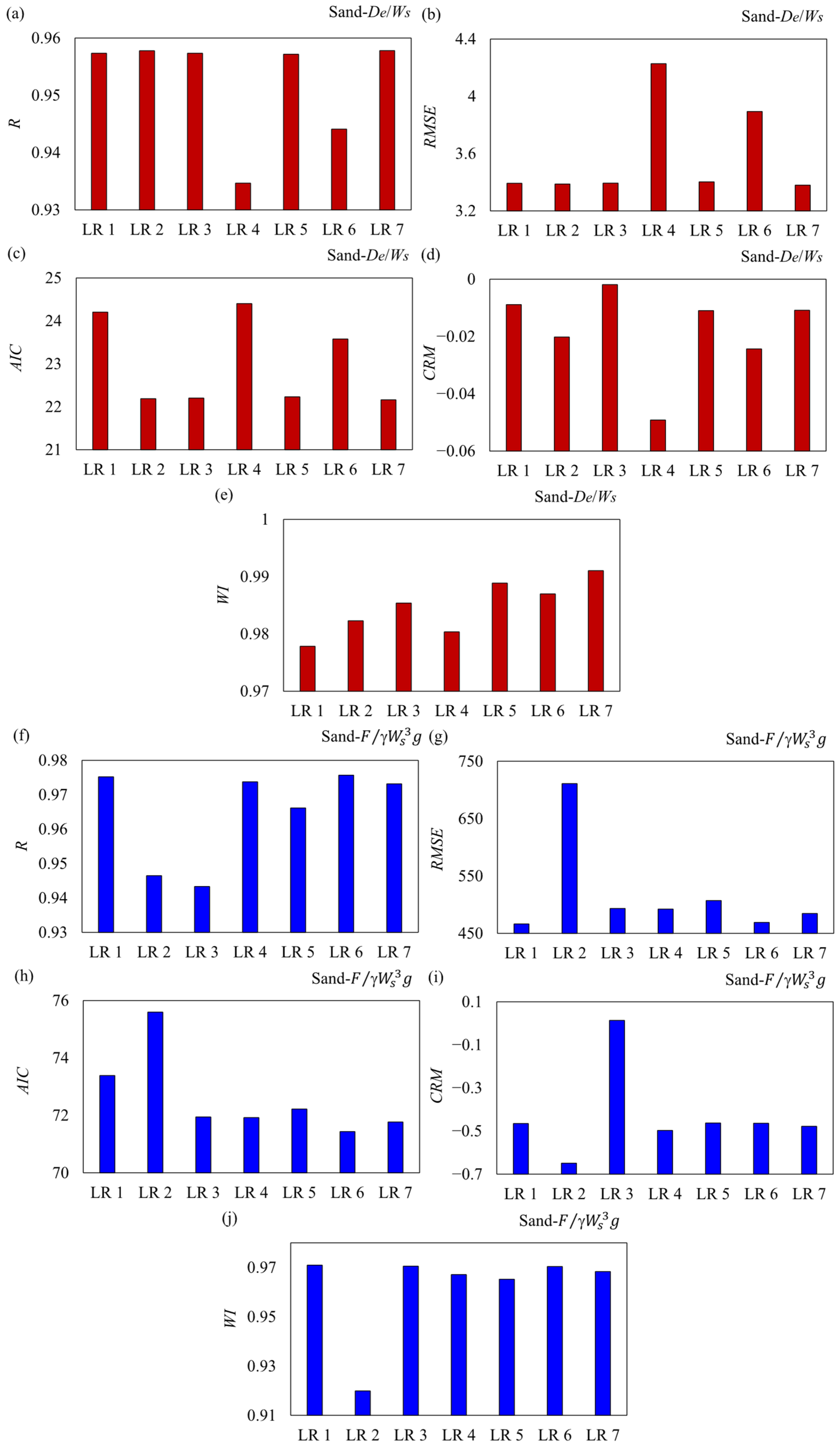
Figure 7 demonstrates the results of the statistical indices calculated for the LR models to predict the penetration depth of drag embedment anchors in the sand seabed. To predict the penetration depth in the clay seabed by the LR 1 model, all input parameters
were applied, whereas these inputs were, respectively, eliminated one by one for LR 2 to LR 7. The analysis revealed that LR 1 and LR 2 achieved the highest
R metric of 0.96, indicating a strong correlation with the actual data. However, LR 4 had the lowest
R criterion of 0.93, suggesting weaker predictive performance and an inability to effectively capture the relationship between input parameters and the target variable. In terms of prediction accuracy, LR 1 achieved an
RMSE of 3.39, which was slightly higher than LR 2’s
RMSE of 3.2. While LR 2 had the lowest
RMSE, LR 1 still demonstrated strong predictive accuracy, with errors significantly lower than LR 4, which had the highest
RMSE of 4.2. This further confirmed LR 4’s poor performance, as reflected in its higher prediction errors. When evaluating model optimization, LR 1 exhibited an
AIC value of 24.2, which was slightly higher than LR 2 and LR 3 (
AIC = 22). However, LR 1’s
AIC value was still lower than LR 4’s
AIC of 25, indicating that LR 1 was well-optimized with minimal overfitting compared to LR 4, which showed signs of poor data representation. In terms of bias, LR 1 achieved a
CRM of −0.0089, indicating a negligible underestimation of the target value. This performance was comparable to LR 2, which had a
CRM of 0.00 (no bias), and significantly better than LR 4, which had the most negative
CRM of −0.05, reflecting a substantial underestimation of the target value. This highlighted LR 1 as a balanced and reliable model. Finally, LR 1 achieved a
WI value of 0.978, demonstrating excellent agreement with the actual data. While LR 2, LR 3, LR 6, and LR 7 achieved a slightly higher
WI of 0.99, LR 1’s
WI was still significantly better than LR 4’s
WI of 0.97, which confirmed its poor agreement with the actual data.
Therefore, the quantitative analysis indicated that LR 1 was one of the most accurate and reliable models, demonstrating a strong correlation (R = 0.96), low prediction error (RMSE = 3.39), minimal bias (CRM = −0.0089), and excellent agreement with the actual data (WI = 0.978). While LR 2 performed slightly better in some metrics, LR 1 consistently outperformed LR 4, which showed high error, significant underestimation, and poor agreement. Therefore, LR 1 can be considered the best model for predicting the target value, particularly when considering its overall balance of performance across all metrics. The sensitivity analysis showed that the anchor dead weight ratio () was identified as the most influential input parameter to model the penetration depth of DEA in the sand seabed.
Regarding the performed sensitivity analysis, the best LR model predicting drag embedment anchor penetration in sand seabed showed that the anchor dead weight ratio (Wd/SuWs2) was the most influential dimensionless parameter. The shank length ratio (Ls/Ws), fluke length ratio (Lf/Ws), peak friction angle (φ), dilation angle (ψ), and fluke width ratio (Wf/Ws) followed in descending order. These findings illustrated the critical role of geometric and geotechnical factors in anchor penetration and offered valuable insights for optimizing anchor design and performance in the sand seabed.
As per the simulation results, LR 1 demonstrated the highest R index of 0.975, indicating the strongest predictive capability and correlation with the target variable. In comparison, LR 5 and LR 7 achieved slightly lower R values of 0.973, while LR 2 exhibited the weakest correlation with an R index of approximately 0.93, reflecting lower accuracy in capturing the relationship between input features and the target variable. In terms of prediction accuracy, LR 1 achieved an RMSE of 466.51, which was significantly lower than LR 2’s RMSE of 711, the highest among all models. This indicates that LR 1 minimized prediction errors more effectively than LR 2, which showed significant errors and poor performance. While LR 3, LR 4, and LR 5 also demonstrated relatively low RMSE values (around 450), LR 1’s RMSE was competitive and reflected strong predictive accuracy. When evaluating model fit and complexity, LR 1 achieved an AIC value of 73.38, which was lower than LR 2’s AIC of 76 (indicating poor fit and potential overfitting) and comparable to the optimal AIC values of LR 3, LR 4, and LR 5 (around 71–72). This suggests that LR 1 was well-optimized with minimal overfitting and balanced complexity. In terms of bias, LR 1 exhibited a CRM value of −0.465, indicating a slight underestimation of the target variable. While this was higher than the near-zero CRM values of LR 5, LR 6, and LR 7, it was significantly better than LR 2 and LR 4, which showed strong underestimation with CRM values of approximately −0.6. LR 3 exhibited a positive CRM of 0.1, indicating slight overestimation. Despite its slight underestimation, LR 1 demonstrated a relatively balanced performance in terms of bias. Finally, LR 1 achieved a WI value of 0.971, indicating excellent agreement with the actual data. This was among the highest WI values, alongside LR 5, LR 6, and LR 7, which also achieved WI values of approximately 0.97. In contrast, LR 2 exhibited the lowest WI value of 0.92, reflecting poor agreement and weak performance.
Thus, the quantitative analysis revealed that LR 1 was the best-performing model, demonstrating the highest correlation (R = 0.975), low prediction error (RMSE = 466.51), minimal overfitting (AIC = 73.38), and excellent agreement with the actual data (WI = 0.971). While LR 5 and LR 7 also performed well, LR 1 consistently outperformed LR 2, which showed high error, strong underestimation, and poor agreement. Therefore, LR 1 can be considered the most accurate and reliable model for predicting the target value, based on its overall balance of performance across all metrics. Regarding the sensitivity analysis, the friction angle (φ) was the most significant input parameter to estimate the holding capacity of the DEA in the sand seabed.
Based on the sensitivity analysis, the linear regression modeling for drag embedment anchor holding capacity in sand seabed indicated that sand friction angle (φ) was the strongest predictor. Moreover, dilation angle (ψ), fluke length ratio (Lf/Ws), anchor dead weight ratio (Wd/(Su·Ws2), fluke width ratio (Wf/Ws), and shank length ratio (Ls/Ws) significantly influenced the model performance. Both soil properties and anchor geometry were crucial for modeling anchor holding capacity in the sand seabed.
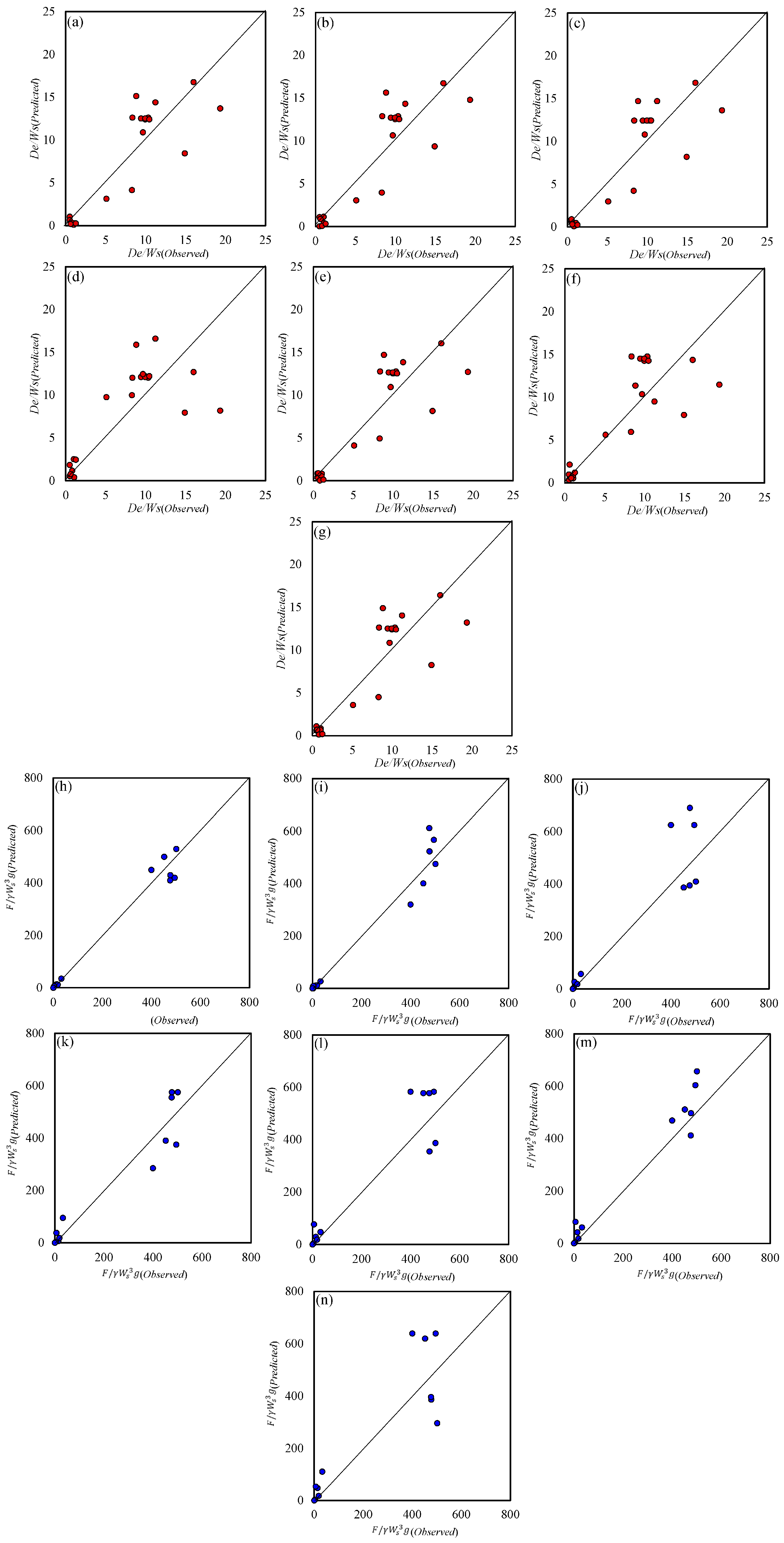
The scatter plots in
Figure 8 display the comparison between observed and predicted values of the penetration depth-to-weight ratio (
De/
Ws) for the LR models (LR 1 to LR 7). The scatter plot for LR 1 showed the data points were more closely clustered around the diagonal line, indicating better accuracy and minimal deviation between observed and predicted values. Other models, especially LR 2 and LR 4, exhibited higher scatter and more deviation from the diagonal line, suggesting poorer prediction accuracy. LR 1 and LR 7 demonstrated a more balanced distribution around the diagonal line, showing that the model captured both lower and higher values effectively. In contrast, the LR 3 and LR 5 models tended to overestimate or underestimate the penetration depth in certain regions. LR 1 exhibited fewer outliers and tighter clustering of data points, while LR 2 and LR 4 had several data points deviating far from the ideal line, which indicated higher error margins. LR 1 showed the highest correlation coefficient, approximately 0.96, indicating a strong linear relationship between observed and predicted values. Other models, such as LR 2 and LR 4, had lower R values, around 0.93–0.94, reflecting weaker correlations. Hence, the LR 1 model outperformed the other models in terms of correlation, accuracy, and bias minimization. The scatter plot for LR 1 showed better clustering around the diagonal line, while the quantitative metrics confirmed the highest correlation coefficient and the lowest
RMSE. Therefore, LR 1 was the most reliable and accurate model for predicting the penetration depth in the sand seabed.
For the anchor holding capacity in the sand seabed predicted by LR 1, the predicted values were closely aligned with the diagonal line, with minimal deviation and a strong agreement between the observed and predicted values. However, the LR 2 and LR 4 models showed greater dispersion from the diagonal line, indicating poorer predictive performance. It was worth noting that the LR 1 model displayed tight clustering around the ideal line, reflecting better accuracy and consistency, whereas models like LR 3 and LR 5 exhibited scattered points with higher variance, leading to less reliable predictions. LR 1 exhibited fewer outliers and less spread in the data points, while LR 4 and LR 6 showed significant deviations from the diagonal, which increased the error rate. So, the LR 1 model presented the highest degree of correlation coefficient, with a strong linear relationship between observed and predicted values.
Figure 9 shows the error distribution of the LR models for the estimation of the penetration depth of drag embedment anchors in the sand seabed. Amongst the LR models, the LR 1 model showed the best performance, with 25% of predictions falling within 10% error, 33% within 10–20% error, and 42% exceeding 20% error, with better generalization and higher accuracy compared to other models. On the other hand, the LR 3, LR 4, and LR 5 models exhibited the worst performance, with 70% of errors exceeding 20%, suggesting that these models struggled to capture the complex nonlinear relationship between input variables and penetration depth. LR 2 showed moderate performance, with 13% of predictions within 10% error and 48% exceeding 20% error, while LR 6 and LR 7 showed similar patterns, with only 9% of predictions within 10% error, 22% within 10–20% error, and 69% exceeding 20% error, reflecting their limited predictive capability. The high error rates in these models may have been due to the presence of outliers, poor feature selection, or the inherent limitations of linear regression in handling complex seabed-anchor interactions. The fact that LR 1 had the highest correlation coefficient, as demonstrated in previous scatter plots, aligned with its superior error distribution, further confirming its reliability and accuracy in predicting the penetration depth. Thus, the LR 1 model was considered the most effective model among the seven, as it achieved the lowest error distribution and the highest correlation coefficient, making it the most suitable for practical applications in predicting anchor performance in the sand seabed.
For predicting the drag embedment anchor capacity in the sand seabed, a significant proportion of errors fell in the highest error category (≥20%) for most models, suggesting that while the LR models captured some trends in anchor capacity, they exhibited considerable prediction inaccuracies. For instance, models LR 6 and LR 7 showed the highest proportion of errors exceeding 20% (around 70%), whereas models LR 1 and LR 2 performed relatively better with lower percentages of high-error predictions (52% and 56%, respectively). This indicated that simpler linear regression models struggled with capturing the complex nonlinear relationships governing drag embedment anchor behavior in the sandy seabed. The variability in error distributions across different models suggested that some LR models may have benefited from refined parameter selection, improved feature engineering, or the inclusion of nonlinear or interaction terms to enhance predictive accuracy. Additionally, the relatively small proportion of low-error predictions (error < 10%) across all models implied that LR-based approaches alone may not have been sufficient for precise capacity prediction. More sophisticated machine learning models, such as neural networks or ensemble methods, could have potentially improved predictive accuracy by capturing complex dependencies between input parameters and anchor capacity more effectively. In conclusion, LR 1 was the best model in terms of error distribution, with the lowest proportion of high-error predictions and a relatively higher proportion of low-error predictions.
Table 6 demonstrates the results of the uncertainty analysis for the LR models to predict the penetration depth and anchor capacity in the sand seabed. LR 1 was the best-performing model based on the uncertainty analysis, with an underestimating performance. It had a mean close to zero (−0.095), with minimal bias, and a low standard deviation (3.47), along with a narrow WUB (1.5), indicating low uncertainty. LR 4 and LR 6 were the least reliable models due to higher standard deviations (4.29 and 3.97, respectively), wider WUB values (1.855 and 1.722, respectively), and wider confidence intervals (−2.381, 1.329 and −1.987, 1.457). LR 2, LR 3, LR 5, and LR 7 also performed well, with low standard deviations, narrow WUB values, and narrow confidence intervals. However, LR 1 stood out as the most reliable and precise model overall. Thus, the uncertainty analysis confirmed that LR 1 was the most reliable and precise model for predicting the penetration depth of a drag embedment anchor in a sand seabed. It demonstrated minimal bias, consistent predictions, low uncertainty, and high precision, making it the best choice for that application. Models like LR 4 and LR 6 should have been avoided due to their higher variability and uncertainty.
For the prediction of the drag embedment anchor capacity in the sand seabed, the mean values for most LR models were negative, indicating that the models tended to underestimate penetration depth. The standard deviation was relatively high across all models, particularly for LR 2 (613.14) and LR 3 (504.49), suggesting significant variability in predictions. LR 3 was the only model with a positive mean value, indicating occasional overestimation. Models with higher standard deviations exhibited greater uncertainty in their predictions, reflecting inconsistencies in model performance. LR 2 had the highest WUB (265), indicating substantial uncertainty, while LR 1 and LR 6 had lower WUB values (167 and 168.5, respectively), suggesting relatively more stable predictions. The models with more negative mean values (e.g., LR 2) tended to have higher WUBs, indicating that stronger underestimation was associated with greater uncertainty. LR 2 had the widest interval (−647 to −117), indicating the greatest uncertainty, while LR 3 had a wide but more balanced range (−210 to 226), reflecting both underestimation and overestimation. Most models had consistently negative confidence intervals, reinforcing the tendency toward underestimation. A wider confidence interval suggested lower reliability, while narrower intervals indicated greater confidence in predictions.
The present study highlighted critical advancements in offshore mooring technology by addressing a key engineering challenge: predicting the performance of DEAs with scientific rigor. By developing first-of-their-kind LR models and applying Buckingham’s theorem, the study provided a data-driven, dimensionless framework to accurately estimate penetration depth and holding capacity in both clay and sand seabed, essential for ensuring structural stability and safety of floating offshore structures. The integration of sensitivity, error, and uncertainty analyses further validated the models’ reliability, offering engineers a practical, efficient tool to optimize DEA design and deployment across diverse marine environments. This mattered because of the following factors:
- -
Safety and reliability: Accurate predictions prevent anchor failure, crucial for offshore operations.
- -
Innovation: First explicit LR models for DEAs, bridging theory and practice (see
Appendix A).
- -
Broad applicability: Validated for both clay and sand, covering major seabed types.
- -
Efficiency: Simplified complex geotechnical calculations into actionable engineering tools.
This work directly supported cost-effective, safer offshore energy infrastructure, e.g., wind farms, platforms, ships, etc.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}