1. Introduction
With the growing demand for natural resources, the utilization of clean and renewable energy helps to mitigate the energy crisis [
1]. As a type of renewable and clean energy resource, wave power possesses significant development potential. The accurate forecasting of the significant wave height is of substantial reference value for wave power applications in power generation [
2]. However, the harsh marine environment and extreme weather can cause intense wave motions, leading to rapid fluctuations in the significant wave height and thereby posing various challenges to accurate prediction.
Researchers from various countries have so far developed many effective frameworks for forecasting the significant wave height. In the early 1960s, the wave statistical theory developed rapidly, and ultimately, the fundamental evolution equation of wave spectra, namely the energy balance equation, was established based on the analysis of physical processes [
3]. The generation of waves is a complex process, which makes it quite difficult to formulate changes in the significant wave height through deterministic equations. In [
4], Soares and Cunha created a significant wave height forecasting system utilizing an autoregressive model (AR) and made evaluations at the Figueira da Foz location in Portugal. The findings indicated that the statistical model surpassed physical equations. In [
5], Ho and Yim attempted to use a transfer function (TF) model to predict wave changes in waters off Taiwan. The experimental results revealed that fixed parameters in the TF model are more suitable for predicting future wave height data compared to monthly varying parameters. In [
6], Reikard and Rogers employed the simulating waves nearshore (SWAN) physical model to predict the significant wave height at the Pacific and Gulf of Mexico coasts. From the findings, a conclusion can be drawn that when the prediction duration surpasses 6 h, the SWAN model exceeds the statistical model in performance.
Research above shows that considerable computational resources are required to predict the significant wave height through physical and statistical models, motivating the pursuit of more advanced models. Due to the rise of deep learning, neural networks have become the predominant technique for predicting the significant wave height [
7]. In contrast to conventional methods, neural networks exhibit outstanding nonlinear fitting abilities and can be customized for various application circumstances [
8]. In [
9], Deo et al. proposed an application of neural networks in which a three-layer feedforward network was developed for predicting the significant wave height in the Karwar region of India. This experiment indicates the breakthrough created by neural networks in the field of significant wave height prediction.
Recently, researchers discovered that the neural networks optimized with suitable sampling intervals and prediction steps could perform better. In [
10], Bazargan et al. integrated the simulated annealing algorithm to optimize the hyperparameters of artificial neural networks (ANN), enhancing the accuracy by 18%. In [
11], Wang et al. developed a BP neural network improved by the mind evolutionary algorithm (MAE) to forecast the significant wave height in the Bohai Sea and Yellow Sea of China, demonstrating that the MAE-BP model performs better than the BP neural network.
Nevertheless, due to the shortcomings of substantial computational resource requirements and overfitting in the mentioned neural networks, researchers are eager to design novel neural network models. With 1D wave power data, Bento et al. [
12] constructed an ocean wave power forecast model using the convolutional neural network (CNN), which demonstrated robust performance in both high and low wave power zones, providing an effective and cost-efficient data-driven solution to wave power prediction. In [
13], Hochreiter and Schmidhuber proposed the Long Short-Term Memory Networks (LSTMs), which have garnered great attention. By filtering memory cells, LSTM is capable of capturing long-term dependencies in time series. In [
14], Jörges et al. developed an LSTM-based machine learning model for predicting ETD sandbanks, which exhibits superior performance compared to feedforward neural networks above. In [
15], Pang and Dong designed a multivariate hybrid model, DSD-LSTM-m, and conducted experiments using datasets from three buoys located along the U.S. coast. Research shows that integration of two LSTM models outperforms a single LSTM model in prediction accuracy, and multi-variable input methods yield fitted curves with shorter delay distances. As an alternative improvement of the LSTM model, the GRU model offers faster training speed with a simpler structure. In [
16], Wang and Ying proposed a multivariate Hs prediction model based on LSTM-GRU: input variables include Hs, wind speed, dominant wave period, and average wave period. This model demonstrated better performance compared to standalone LSTM and GRU models. In their study, the method of interval prediction enables providing more forecasting information and reference values.
Recently, the convolutional neural network (CNN) has been preferred for its satisfactory spatial feature acquisition abilities, which profit from its distinctive feed-forward structure. Since CNN and LSTM have different advantages, a combination of them could improve predictive performance [
17]. Ensemble models (ConvLSTM and PredRNN, for instance) can, by extracting spatial and temporal features simultaneously, improve the accuracy of ocean forecasting [
18]. In [
19], Shen et al. designed a wind speed forecasting system for unmanned sailboats utilizing CNN-LSTM. The experimental results revealed that in comparison to single neural networks such as BP, RNN, CNN, and LSTM, the combined model appears to outperform them in the specific task of wind speed prediction. In [
20], Dong et al. used a CNN-LSTM model to predict load across four Australian states. The results of their experiments showed that the combined model exhibited better accuracy than individual neural networks in short-term load forecasting. In [
21], Zhang et al. utilized a CNN-LSTM model for significant wave height prediction and discovered that this combined framework substantially surpassed conventional models, including SVM, MLP, and LSTM. Based on WaveWatchIII (WW3) reanalysis data, Zhou et al. [
22] established a 2D significant wave height prediction model for the South and East China Seas; trained by data under normal and extreme conditions (non-typhoon and typhoon conditions), their model exhibited an improved wave height prediction accuracy under extreme weather events (like typhoons), but its performance in the coastal areas (along the Bohai Sea, for instance) was less impressive, largely due to the limited spatial resolution and parameterization of the input WW3 data. In [
23], Raj and Prakash presented a hybrid approach combining MVMD, CNN, and BiLSTM for predicting significant wave heights in Townsville and Emu Park, Australia. The experimental results indicated that the integrated model demonstrated superior performance compared to MLP, RF, and Catboost. Scala et al. [
24] put forth a stateful Conv-LSTM model for wave forecasting in the Mediterranean Sea, but their model showed room for improvement in coastal areas and under extreme weather conditions. They also revealed the strong correlation between the prediction error and geographical variability—their model showed higher accuracy in the western and central regions of the Mediterranean, while more errors occurred in the eastern and southern areas, and this discrepancy was more pronounced under extreme weather events.
Prediction tasks have gained great improvement with the development of neural networks; however, there remains potential for advancement. Due to the nonlinear and non-stationary features of the wave data, data processing techniques are applied to the prediction system, mitigating non-stationarity via signal decomposition and denoising. In [
25], Duan et al. attempted to integrate the empirical mode decomposition (EMD) with the autoregressive model (AR) to predict short-term significant wave height for Ponce and two additional locations, which outperformed AR. In [
26], Hao et al. utilized EMD to decompose the significant wave height data into modal components, and LSTM was applied to individually predict each modal component. This method of modal prediction surpasses the LSTM model with its excellent capacity to analyze patterns in data. By introducing random perturbations to EMD, EEMD enhances its ability to suppress noise. An EEMD-LSTM model was employed to forecast the significant wave height in the Indian Ocean by Song et al. [
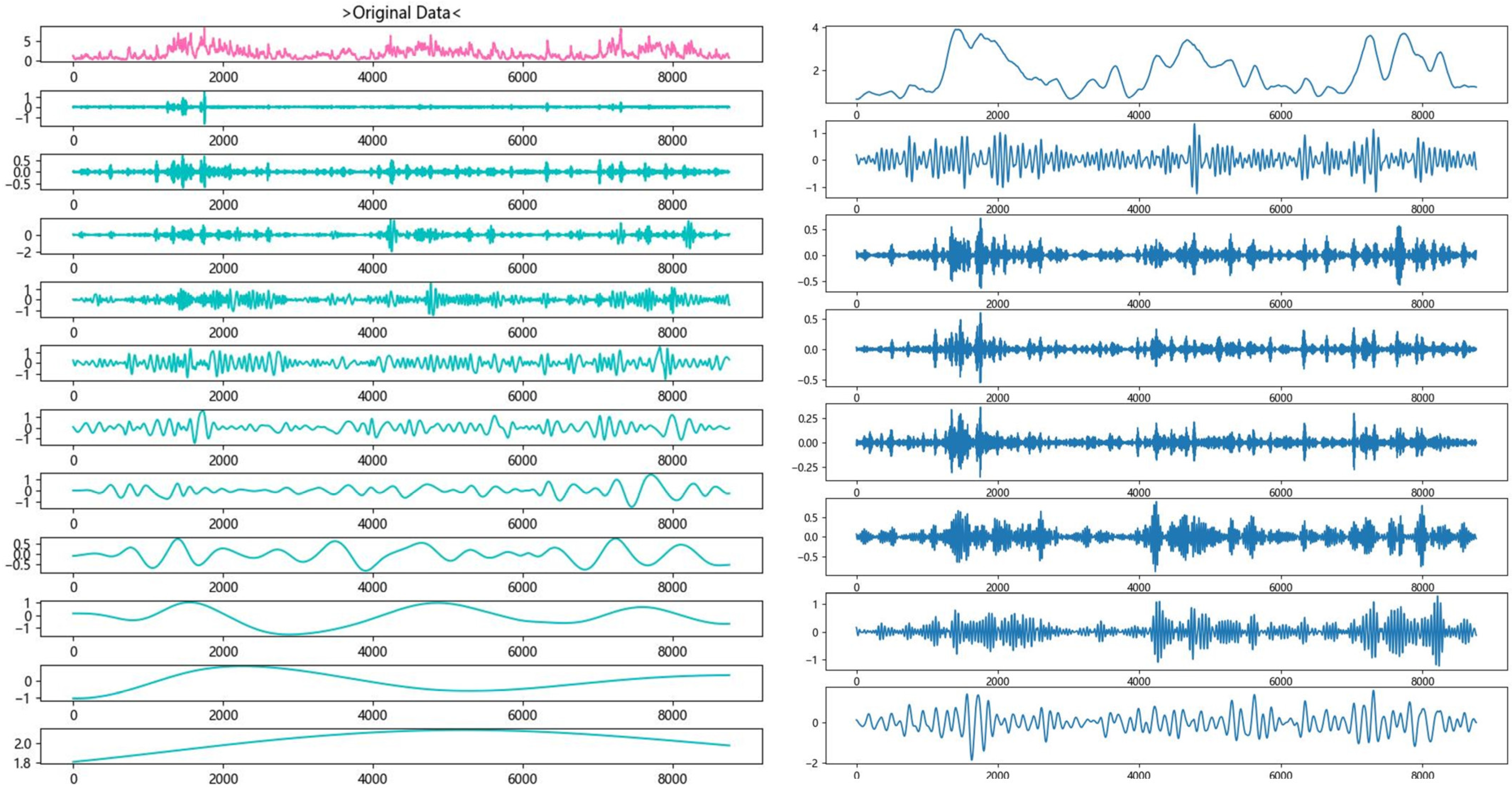
27], which improved accuracy based on EMD-LSTM. The Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) covers the inadequacy of the modal aliasing issue present in EEMD and enhances noise suppression effectiveness through automatic noise level adjustment. In [
28], Zhao et al. proposed a CEEMDAN-LSTM framework for predicting the significant wave height in the maritime region of Shandong Province, China. Findings showed that CEEMDAN surpassed EMD and EEMD. As a modified technique from EMD, the variational mode decomposition (VMD) significantly mitigates the problems of modal aliasing and boundary effect [
29,
30]. In [
31], Ding et al. utilized a VMD-LSTM model in the South China Sea, and in [
32], Zhang et al. developed a significant wave height forecasting system based on VMD-CNN. Results of their research demonstrate an enhancement in prediction performance using VMD relative to baseline models. In [
33], Ding et al. found that the secondary decomposition of CEEMDAN-processed data using VMD could enhance the stationarity of Hs data. In the research, a CEEMDAN-VMD-TimesNet model was employed to predict significant wave height in the South China Sea. Experimental results demonstrated that, for the 12-h forecast, the RMSE of the CEEMDAN-VMD-TimesNet model was reduced by 0.22 and 0.36 compared to CEEMDAN-TimesNet and TimesNet, respectively, indicating a significant improvement in forecasting accuracy.
Despite remarkable progress in predicting the significant wave height, there is still potential for improvements:
- (1)
Most methods neglect the effects of data augmentation. Methods of denoising could improve prediction accuracy; however, they encounter difficulties with incomplete decomposition and may cause a loss of crucial information.
- (2)
Given the complexity of the significant wave height data, methods of point prediction exhibit a lack of practical value, and their predictive accuracy markedly diminishes when dealing with extreme cases.
- (3)
Attention should be drawn to the customization of models and parameters. While optimization algorithms are applied to neural networks, some exhibit local optimal problems in high-dimensional spaces of extensive hyperparameters and fail to fully exploit the model’s potential.
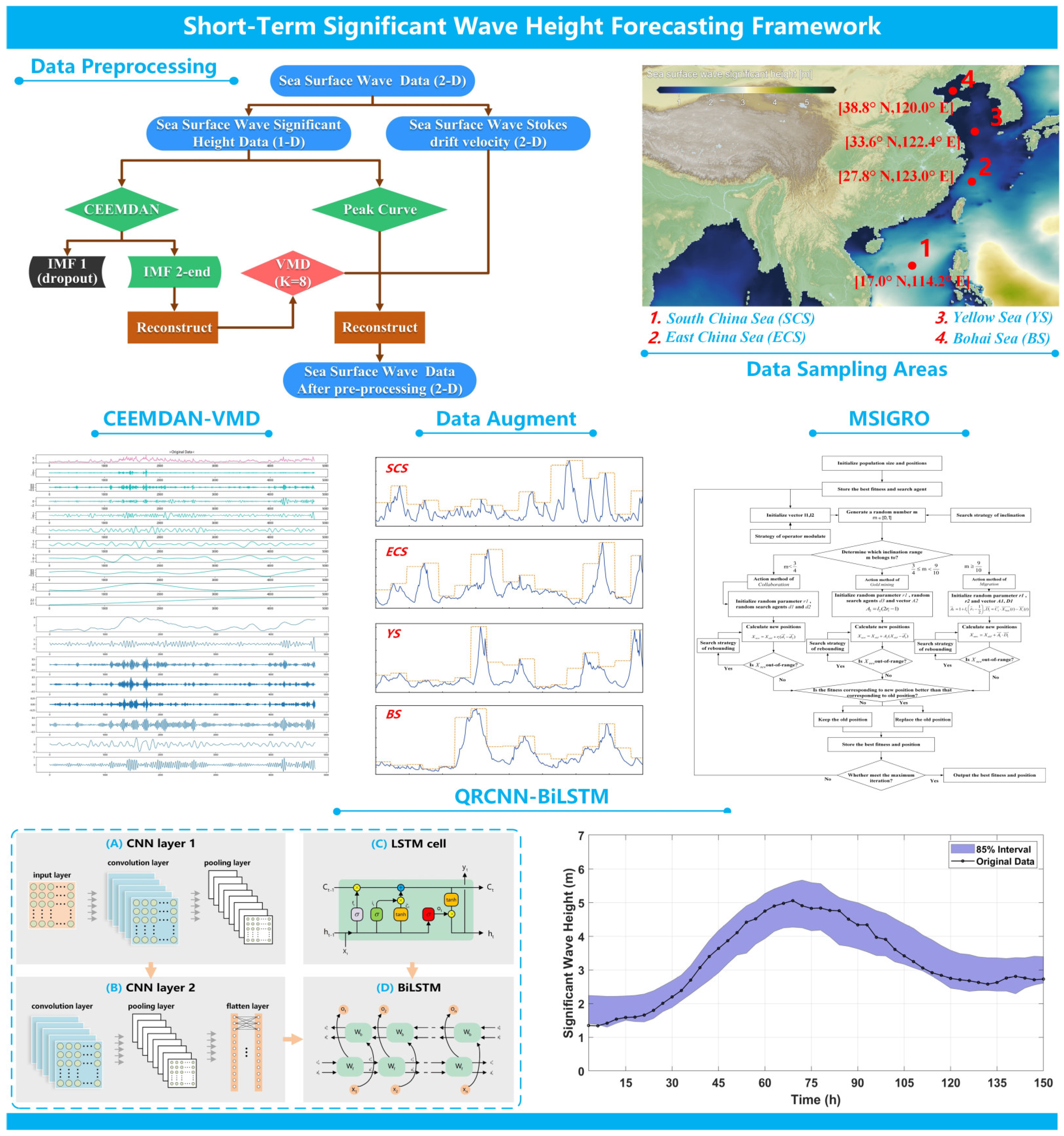
To this end, we propose a significant wave height prediction system based on data preprocessing, combined neural networks, and multi-strategy improved optimization algorithms. The contribution of this paper can be summarized as follows:
- (1)
Two techniques of data processing are adopted: data denoising through a hybrid modal decomposition technique of CEEMDAN-VMD and data augmentation by integrating the extracted peak information into the denoised data. These enable the deep learning framework to focus on the trend in wave variations.
- (2)
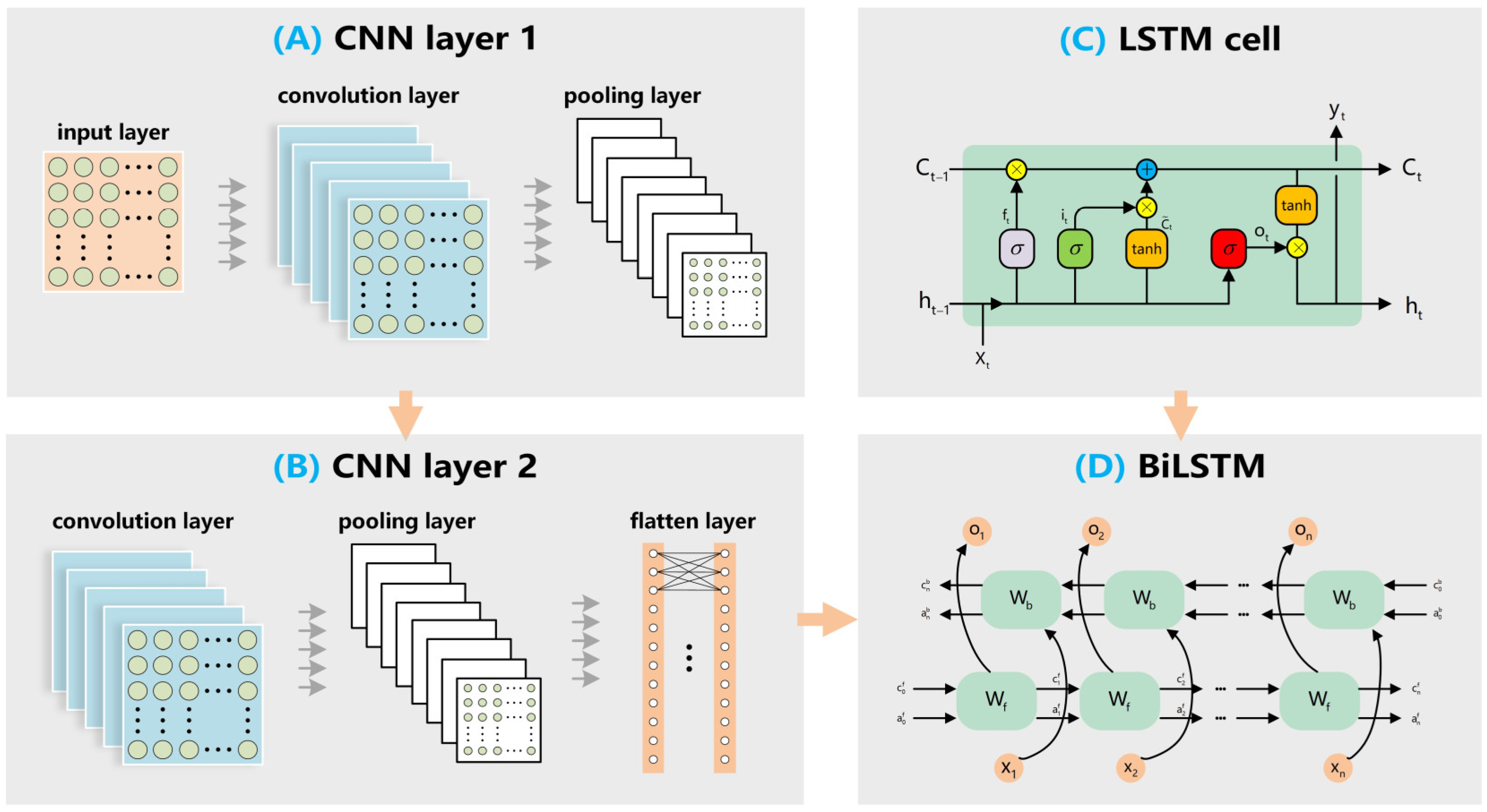
A combination neural network model is developed, consisting of two layers of CNN and one layer of BiLSTM. CNN can identify short-term correlations among various temporal features, and BiLSTM comprises two opposing LSTM layers, which can capture long-term dependencies.
- (3)
The quantile regression (QR) is used to achieve interval prediction and introduces three evaluation metrics: PICP, Mean Prediction Interval Width (MPIW), and Average Interval Score (AIS). Compared to others, the proposed method provides a better quality of interval prediction.
- (4)
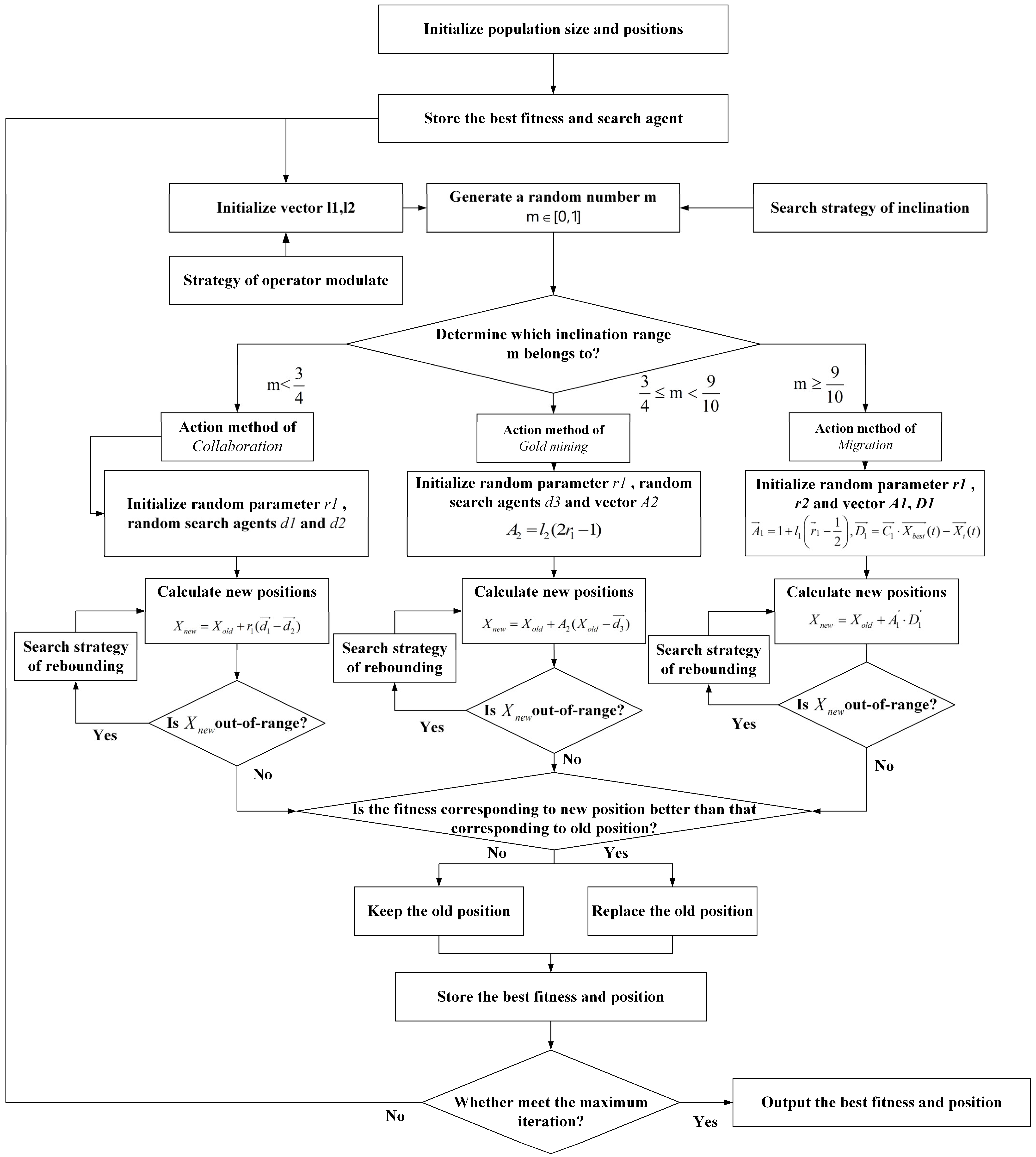
Multi-strategy improved gold rush optimizer (MSIGRO) is utilized to optimize the hyperparameters of the network layers. In high-dimensional optimization space, the original GRO’s ability of optimization is obviously insufficient. Therefore, three improvement strategies are proposed to enhance the algorithm’s optimization ability.
The subsequent chapters of the paper are arranged as follows:
Section 2 primarily illustrates the principles of hybrid mode decomposition and the probabilistic deep learning framework.
Section 3 will provide the principles of data selection, system parameter design, and system evaluation indexes.
Section 4 describes the construction methodology of the significant wave height prediction framework and exhibits the prediction outcomes across four datasets.
Section 5 evaluates the proposed framework and other models via four groups of experiments. Finally,
Section 6 gives the conclusion.
5. Four Groups of Experiments
This chapter analyzes and contrasts the proposed prediction model through four groups of experiments, validating the criticality of data processing, the benefits of customizing deep learning networks compared to baseline models, the enhancement effects of the proposed improved strategies of the algorithm, and various forecasting time periods.
5.1. Experiment 1
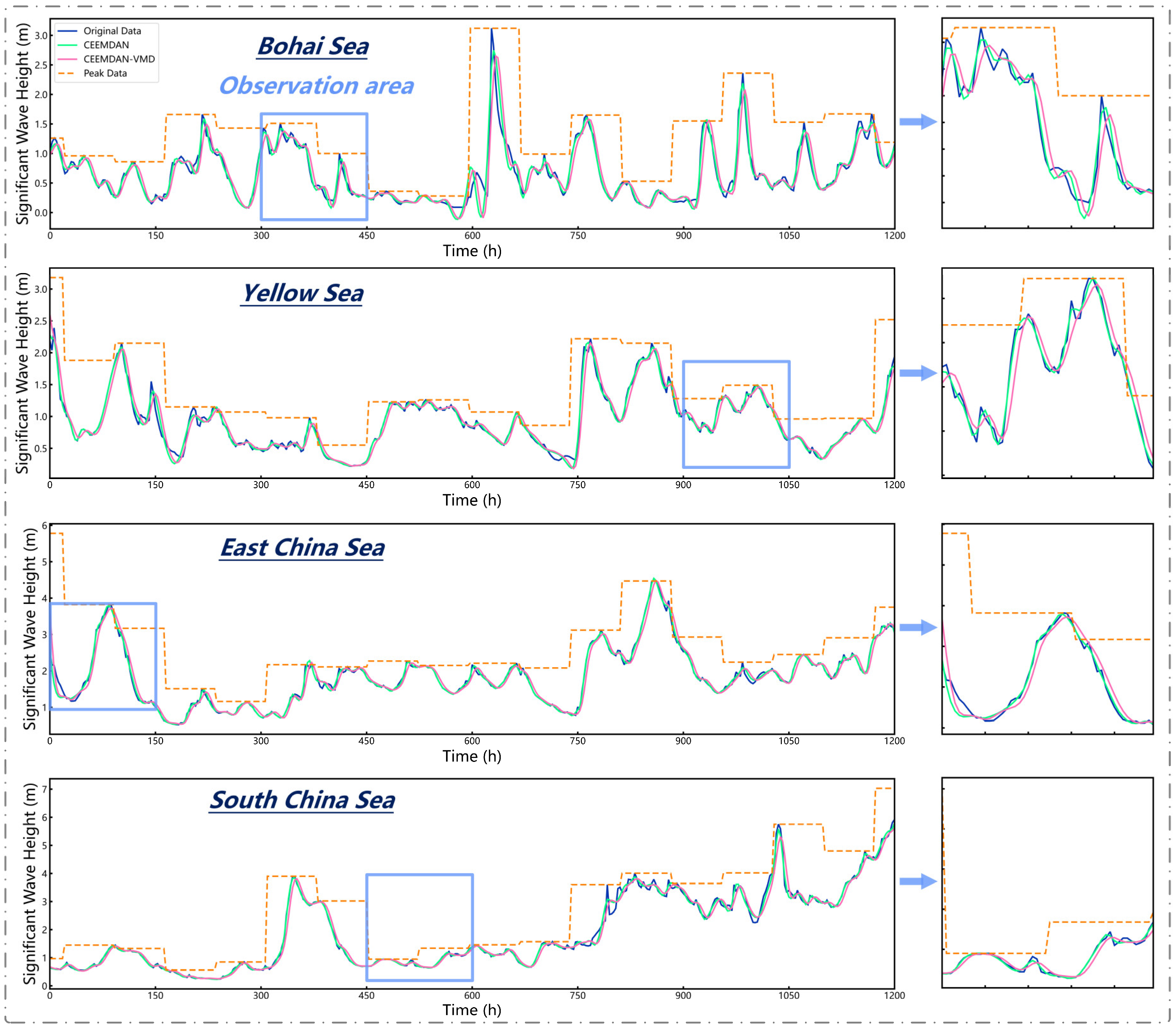
We compared the data processed through denoising and augmentation with that processed by other methods, while maintaining the CNN-BiLSTM framework unchanged.
Table 5 illustrates the experimental outcomes of various data processing techniques, and
Table 6 shows the results of different modal decomposition methods.
In
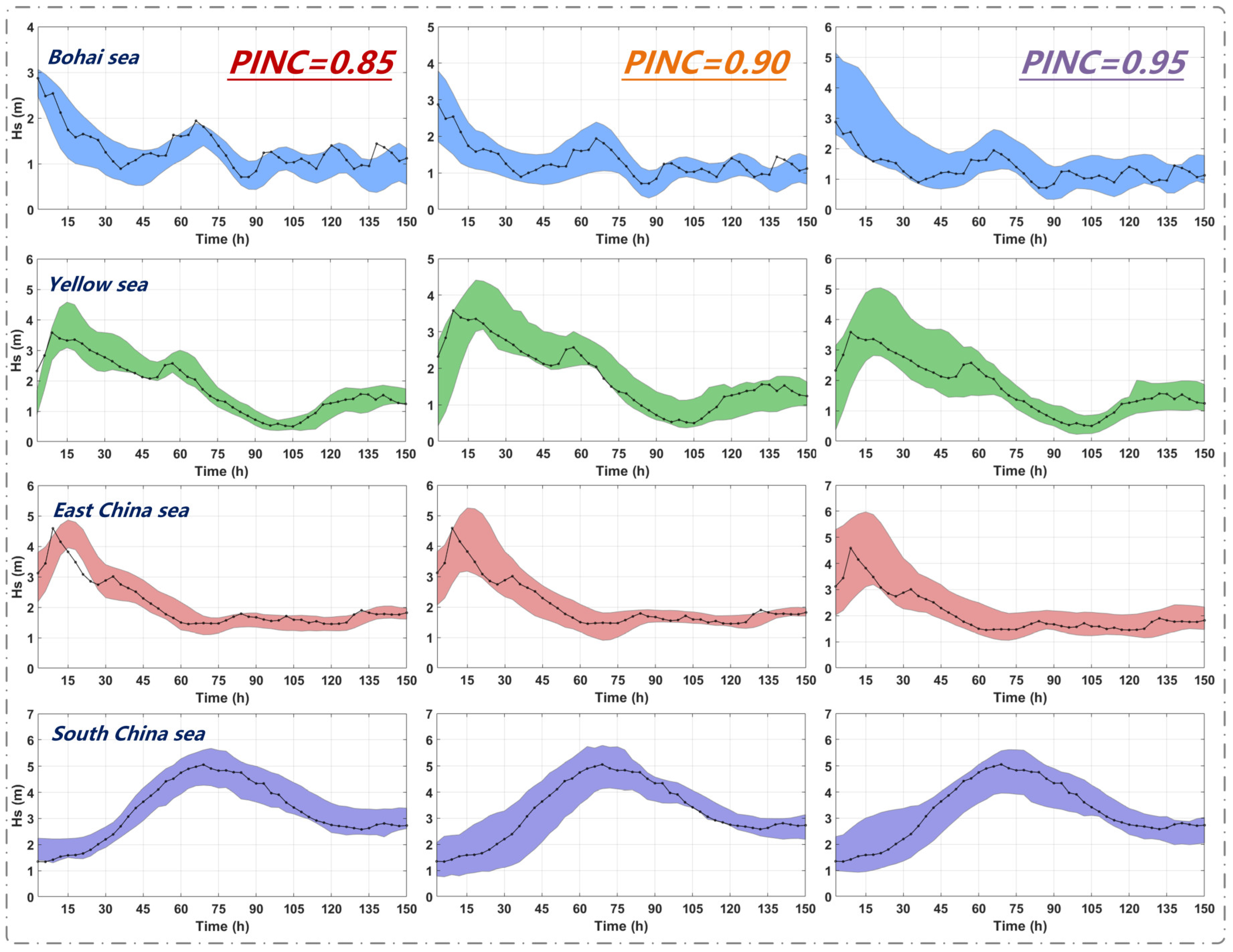
Table 5, with a PINC of 0.85, the PICP of the proposed method for the Bohai Sea data is 0.88, exhibiting a 16% increase compared to the prediction results of the unprocessed data. However, the RMSE under the three PINCs is higher than the values obtained by other methods in the majority of test cases. In the Yellow Sea data, when PINC is 0.90, the interval coverage remains consistent with CEEMDAN (without VMD); however, the average interval width is reduced, which means more accuracy. The interval score of unprocessed data is notably higher at −15.115, but with a PICP of 0.82, resulting in an invalid prediction. Compared with the forecasts based on the original data (with a PICP of 0.90 and an RMSE of 0.2487), the processing method with CEEMDAN alone shows little effect in increasing the interval forecast performance, but when combined with data augmentation, it reduces the RMSE from 0.1535 to 0.1257. The introduction of VMD reduces the model’s point forecast performance because of deeper denoising but improves the interval forecast performance. In the East China Sea data, when PINC is 0.95, the AIS of the proposed method is −27.0615, exceeding other methods. The South China Sea data exhibit worse stationarity, complicating predictions and leading to generally wider intervals than those of other regions. The PINC 0.95 prediction results indicate that, at the same coverage, the interval width of the proposed method is 1.4433 with the highest AIS. Though the CEEMDAN-VMD method reduces the RMSE by around 15%, it achieves broader coverage at a narrower interval width, and thus, comprehensively, forecasts obtained this way are considered more reliable.
Table 6 illustrates an evaluation of the influence of various modal decomposition methods on predictive performance, with data augmentation techniques remaining constant. At a PINC of 0.85, the proposed CEEMDAN-VMD method demonstrates a notable enhancement in the data from the Yellow Sea and East China Sea. At a PINC of 0.90, across the majority of datasets (Bohai Sea, Yellow Sea, South China Sea), numerous methods exhibit nearly the same interval coverage capabilities; however, CEEMDAN-VMD shows superior prediction quality with the narrowest interval width. The wavelet decomposition method shows stable performance in interval prediction and outperforms the method with VMD alone, and with a smaller RMSE, the CEEMDAN-VMD method demonstrates excellent performance in both point and interval forecasting. When the PINC is 0.95, other approaches fail to attain comprehensive coverage across all datasets, demonstrating that the proposed method exhibits the most robust generalization capability. At deep water regions (South China Sea), the wavelet decomposition method achieves a higher RMSE than other methods, but its RMSE and MAE on the other three datasets (Bohai Sea, Yellow Sea, and East China Sea) are generally lower than the other methods, indicating that this method is more suitable for forecasting in shallower water regions.
5.2. Experiment 2
This experiment primarily validates the necessity of customized prediction models for ocean wave height data. We compared the prediction results of the CNN, LSTM, GRU (
Table 7), and CNN-BiLSTM while maintaining complete consistency in the data processing system and optimization algorithms. The experimental evaluation indexes show that the deep learning framework in this paper outperformed the baseline model in prediction accuracy. The experimental results are given in
Table 8.
In the data of the Bohai Sea and Yellow Sea, when PINC is 0.85, the baseline models exhibit coverage below 85%. Despite both models achieving a PICP of 96% for the Yellow Sea data, CNN-BiLSTM surpasses the other models in the MPIW and AIS metrics. At a PINC of 0.95, CNN-BiLSTM achieves predictions with a 100% coverage rate on two datasets. In the East China Sea data, the PICP of the LSTM model aligns perfectly with that of the combined model; however, the performance of MPIW is inferior to that of the combined model. At a PINC of 0.85, the PICP of the CNN and GRU models are 0.78 and 0.72, respectively, evidently inferior to that of the combined model. In these two sea areas characterized by milder waves, CNN-LSTM significantly reduces the RMSE by 25–50% and reaches an MAE around 0.2, demonstrating the robustness of this hybrid model.
In the South China Sea data, when PINC is 0.85, the PICP of CNN-BiLSTM is 96%, representing a 10% enhancement over CNN and LSTM and a 12% increase over GRU, with a confidence interval width of merely 1.0975. At PINC levels of 0.90 and 0.95, all networks can attain complete coverage. The CNN-BiLSTM model can sustain a high average interval score (AIS) exceeding −30 across all confidence levels. Our customized deep learning model has demonstrated superior performance over the four datasets.
5.3. Experiment 3
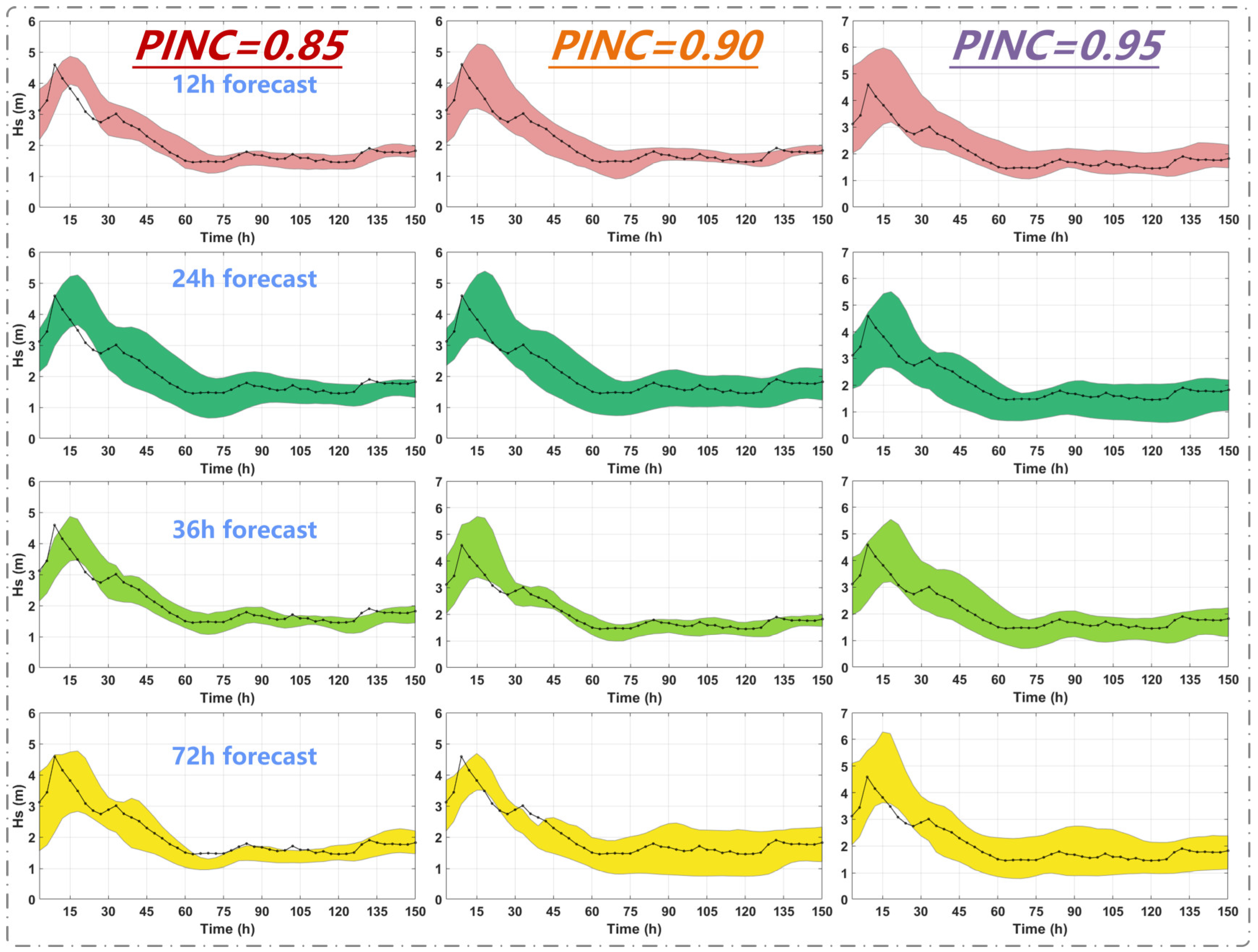
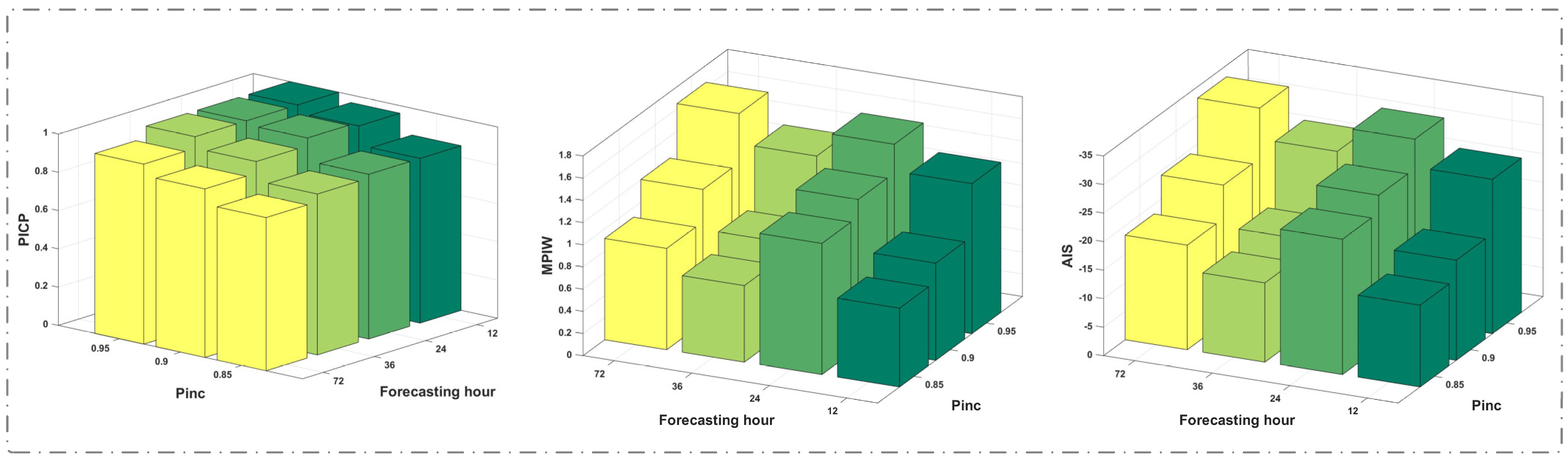
This experiment uses the dataset from the East China Sea and constant training sampling points (96 steps, 288 h in total), while varying the one-time output hours (12, 24, 36, and 72 h) to investigate the effect of various prediction hours on predictive performance.
Figure 7 and
Figure 8 show the visual results of interval predictions and evaluation indexes, respectively.
Figure 7 shows that, at a consistent confidence level, the coverage of interval predictions exhibits a declining trend as the prediction hour increases. In
Figure 8, when PINC remains constant, it is evident that PICP progressively decreases with the growth of the prediction hours, signifying a gradual decline in the prediction level as the prediction hour increases. While the coverage rates of the 24-h forecast are not greatly distinct from that of the 36-h prediction, the MPIW and AIS suggest that the predictive quality of the 24-h forecast is worse, leading to the use of a 36-h output. Furthermore, when the output size extends to 36 h, the model still achieves effective prediction results with high coverage at a high confidence level.
Figure 8 shows that when the forecasting hour is 72, the predictive performance deteriorates markedly, and at a PINC of 0.95, the complete interval coverage rate is unattainable. Consequently, we can ascertain that for multi-step forecasting of ocean wave heights, 12-, 24-, and 36-h predictions are optimal selections.
5.4. Experiment 4
In this section, enhancements in the performance of the proposed novel strategies are verified across various algorithms utilizing the single-objective test function set (CEC2005). We choose the Gray Wolf Optimizer (GWO), the Sparrow Search Algorithm (SSA), and the Gold Rush Optimization (GRO) to carry out experiments.
Table 9 gives the mathematical formulas, and
Figure 9 shows the results. The population size and evolution iteration are set consistently at 50 and 500, respectively. The results demonstrate a great enhancement in the capabilities of the three algorithms following the multi-strategy improvements.
For instance, in F1, GRO attained a maximum fitness of merely after 500 iterations, whereas MSIGRO succeeded in achieving a fitness below , demonstrating an enhancement of over . For SSA, MSISSA achieved optimization in only 305 generations, resulting in an improvement of over 25%.
The search strategy of rebounding, while not augmenting computational power, notably improves the population’s capacity to avoid local optimum. In F9, the original GWO exhibits a gradual decline after 300 iterations, with the optimal fitness keeping above 1; however, the incorporation of the search strategy of rebounding brings about a decrease below . The above results imply that the efficiencies of algorithms obtain great improvements enhanced by the proposed strategies.
6. Summary
This paper proposes a method for short-term significant wave height prediction based on data processing and a probabilistic deep learning model, which delivers high-quality forecasts across various sea area datasets. The data processing module initially employs the hybrid mode decomposition method for denoising, greatly decreasing the non-stationarity of the original effective wave height data. By integrating the denoised data with the peak information derived from the original valid wave height data, the loss of critical information can be mitigated. The deep learning module comprises neural network layers of CNN and BiLSTM, utilizing quantile regression for probability interval prediction. Furthermore, the proposed three strategies enhance the GRO for hyperparameter optimization, improving the integration efficiency of the deep learning model, which provides wide applicability. The four research areas along the Chinese coast serve as a database, and different models are established for experimentation. Through evaluations of these models’ performance, the following conclusions can be drawn:
The application of the hybrid modal decomposition method significantly reduces the variance of the Hs sequence. Specifically, the processed results mitigate the variance of the Hs sequence with maximum reductions of 3.6% and 3%, which effectively reduces non-stationarity.
Although data denoising inevitably leads to the loss of critical information, incorporating peak information helps train deep learning models and compensates for this limitation. After applying comprehensive data processing, single models still struggle to capture both the temporal and spatial characteristics of Hs sequences and input features. In contrast, the hybrid model demonstrates stable and reliable performance in Hs prediction tasks. Furthermore, by evaluating different forecast hours, it can be found that the model ensures full interval coverage of at least a 36-h forecast at 0.95 PINC.
Nonetheless, the proposed model retains deficiencies. While our model demonstrates robust performance on unseen data within 2021–2023, its generalization to entirely unseen years (e.g., 2024 and beyond) requires further validation. This is a common challenge in data-driven wave forecasting, and we will address this limitation through extended temporal validation in future work. Although this study focuses on Chinese coastal zones due to data availability constraints, the proposed QRCNN-BiLSTM framework is designed to be generalizable to other regions. The methodology is not dependent on location-specific conditions and requires only two essential inputs for global application: significant wave height (Hs) and wave velocity data. To apply the model to global waters, we provide detailed documentation of the model architecture and training protocol in
Section 3.1. Future work will systematically evaluate the model’s transferability across diverse oceanic regimes.
We plan to properly take additional factors into consideration, including the mean period of sea surface wind waves and wave direction, to enhance prediction accuracy. Future research will focus on creating more advanced and efficient models to increase practical application value.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}