1. Introduction
Maritime surveillance and vessel detection are critical for ensuring maritime safety, traffic management, and environmental monitoring. With the increasing complexity of maritime activities, there is a growing demand for robust and reliable detection algorithms. However, the dynamic nature of the marine environment, particularly the varying lighting conditions from day to night, poses significant challenges to vessel detection. Traditional electro-optical (EO) imaging systems perform well under ideal lighting, but struggle in low-light or high-glare environments, such as during sunrise, sunset, or night-time. The visual appearance of vessels is heavily influenced by lighting and surface reflectance properties: under low-light or shadowed conditions (e.g., overcast skies or sunset), vessels exhibit darker tones and a lower pixel intensity, resulting in insufficient contrast against the background. Conversely, under strong lighting, the high reflectivity of vessel surfaces causes their brightness to closely resemble the background (e.g., water surfaces or nearshore ports), making them visually blend in. This dynamic contrast issue renders traditional detection methods based on color or texture features inadequate for complex marine environments, especially in all-weather monitoring scenarios where diurnal lighting variations exacerbate the challenges.
Meanwhile, infrared imaging technology plays a vital role in day–night maritime surveillance. By capturing thermal radiation characteristics, it compensates for the limitations of EO imaging in low-light or night-time conditions. Unlike EO imaging, infrared imaging does not rely on visible light and can clearly depict thermal signatures of vessels in complete darkness, enabling all-weather monitoring. However, its limitations include: (1) a lower resolution compared to EO images, resulting in less clarity in target details (e.g., textures or structures); (2) high sensitivity to temperature variations, making it susceptible to environmental factors such as the sea surface temperature and weather conditions—for instance, reduced temperature differences between vessels and the sea surface in summer or winter can diminish the target–background contrast; and (3) the lack of color information, which restricts its application in target recognition and classification.
Despite these challenges, the integration of infrared imaging and electro-optical (EO) imaging offers a robust technical solution for all-weather vessel detection. During the day, EO imaging systems provide high-resolution visual information, while at night, infrared imaging compensates for the limitations of EO systems by detecting thermal signatures. Through the effective cross-modal training of these two imaging modalities, the continuous and robust detection of vessel targets can be achieved, significantly enhancing the performance of maritime surveillance systems. For example, recent works such as Sun et al. [
1] have proposed arbitrary-direction ship detection methods capable of handling multiscale imbalance, demonstrating an improved performance in complex maritime scenes. Zhang et al. [
2] introduced a cross-sensor detection framework leveraging dynamic feature discrimination and center-aware calibration, which significantly enhances generalization across different modalities. These advances provide valuable insights into addressing the challenges of orientation and scale diversity.
In summary, this paper makes three key contributions: (1) A nearshore vessel dataset for day–night transition scenarios, categorizing vessels into 11 classes and including challenging conditions such as strong lighting, multi-scale scenes, and low-visibility night-time images, totaling 4705 images. (2) An end-to-end detection model based on cascaded spatial priors and dynamic upsampling. (3) The comprehensive validation of our method using the vessel category from the WSODD public dataset.
2. Related Works
2.1. Algorithms Based on Ship Detection Technology
In recent years, object detection frameworks based on convolutional neural networks (CNNs) have advanced rapidly. These include region-based detection algorithms such as R-CNN [
3], Fast R-CNN [
4], Faster R-CNN [
5], and Mask R-CNN [
6], as well as regression-based detection algorithms like SSD [
7], RetinaNet [
8], and the YOLO (You Only Look Once) [
9] series released since 2015. All of these methods have been widely applied to ship detection tasks. These methods leverage end-to-end learning to automatically extract high-level features of vessels, significantly enhancing the detection accuracy and robustness. For instance, Faster R-CNN employs a Region Proposal Network (RPN) to generate candidate regions and integrates CNNs for target classification and bounding box regression, demonstrating an exceptional performance in vessel detection.
To improve the vessel detection performance in day–night transition scenarios, Yuan et al. [
10] proposed the Feature-Enhanced R-CNN (FE R-CNN) algorithm, which utilizes a Feature Refinement Feature Pyramid Network (FR-FPN) module to enhance upsampling rates and eliminate aliasing effects, while extracting global multi-scale and semantic information through bidirectional cross-scale channels. Guo et al. [
11] innovatively employed a balanced feature pyramid structure to integrate multi-scale features, combined with an L1 regularization loss function, significantly enhancing the multi-scale ship detection performance in complex scenarios. Qi et al. [
12] optimized the Fast R-CNN by adopting an image-downscaling strategy, effectively improving the detection efficiency. To address the challenge of small-target ship detection, Chen Z et al. [
13] proposed a hybrid model combining generative adversarial networks (GAN) and convolutional neural networks, which improved the recognition accuracy of small-sized ships. Liu et al. [
14] introduced wavelet pooling during the downsampling of image feature maps, iteratively applying wavelet decomposition to create a hierarchical structure, forming a Wavelet Convolutional Neural Network (WCNN), which improved the detection of small vessels in complex marine environments. Fan et al. [
15] addressed the challenge of small and blurry vessels blending into their surroundings by proposing the CSDP-YOLO algorithm, enhancing the model’s ability to extract features from such targets. Wang Y [
16] enhanced the loss function and improved the small-target data augmentation, achieving high-precision and rapid ship recognition. Wang et al. [
17] combined a multi-path aggregation network to boost the detection capability for ships of varying sizes. Cen J et al. [
18] introduced a feature fusion attention mechanism into YOLOv7 to strengthen the feature extraction, enabling the model to accurately localize ships in complex environments. Yu et al. [
19] developed a contrastive learning strategy for small targets in infrared images, providing a viable approach for infrared-based vessel detection. To tackle the complexity of background information in optical images, Xu et al. [
20] proposed the CSCGhost algorithm for detecting vessels in marine operations, offering a solution for day–night transition environments. Wang et al. [
21] introduced the high–low frequency (HiLo) attention into the intra-scale feature interaction module to enhance the extraction of both high- and low-frequency features.
YOLOv12 [
22] is a recent variant in the YOLO family and it improves speed and detection precision using efficient convolutional backbones and attention modules. However, CNN-based detectors inherently rely on localized receptive fields and struggle to model long-range dependencies, which can limit their performance in complex scenarios such as overlapping vessels or low-contrast lighting. In contrast, the emergence of transformer-based object detectors introduces a paradigm shift. Transformers, originally designed for NLP tasks, excel at modeling global attention and spatial relationships. Their use in computer vision, particularly through models like DETR (DEtection TRansformer) [
23], allows end-to-end object detection without the need for hand-crafted anchors or region proposal networks. However, early DETR variants suffered from slow convergence and poor small-object detection. To overcome these issues, recent transformer-based models like RT-DETR (Real-Time DETR) [
24] have emerged, integrating convolutional backbones with transformer heads and improving the convergence and speed, making them viable for real-time applications. RT-DETR represents a hybrid approach, where the global context modeling of transformers is combined with efficient CNN-based encoders.
We summarize the related work with respect to the proposed CGDU-DETR and state-of-the-art (SOTA) methods of ship detection technology in
Table 1.
Despite the significant advancements in deep learning-based vessel detection, existing methods are often limited to specific environments. As demonstrated in our subsequent experiments, their adaptability to day–night transitions remains suboptimal. To further enhance the model’s ability to extract features across diverse environmental conditions, we will incorporate a novel sampling strategy.
2.2. Algorithms Based on Sampling Technology
Feature upsampling is a core component of dense prediction models, primarily aimed at progressively increasing the resolution of feature maps. In tasks such as object detection, instance segmentation, and image super-resolution, the resolution of feature maps is significantly reduced after multiple downsampling operations (e.g., convolution and pooling). To generate results consistent with the input image resolution, upsampling operations are required to restore low-resolution feature maps to their original size. To enhance model flexibility, learnable upsampling methods have been introduced for specific tasks, such as deconvolution in object detection and pixel shuffling in vision tasks [
25,
26]. However, these methods often suffer from checkerboard artifacts, which are detrimental to more challenging feature extraction tasks. With the advancement of deep learning, dynamic upsamplers have demonstrated significant potential in various tasks. For instance, CARAFE [
27] employs dynamic convolution to generate content-aware kernels for upsampling input features. Subsequently, SAPA [
28] proposed using high-resolution guidance features alongside low-resolution input features to generate dynamic kernels, enabling the upsampling process to be guided by high-resolution structures. However, SAPA’s reliance on high-resolution guidance features increases the computational complexity, limiting its applicability. Modern network architectures often incorporate multi-scale features, such as in Feature Pyramid Networks (FPNs), where shallow features are upsampled and fused with deep features.
To address the high computational cost associated with dynamic convolution, we deviate from traditional kernel-based methods and focus on the core of upsampling—point sampling—to redefine the upsampling process. We employ a single-input dynamic upsampler [
29], which assumes that the input features are expanded into a continuous feature map via bilinear interpolation. Based on this, the sampler generates content-aware sampling points to resample the continuous feature map. We summarize the related work with respect to the proposed CGDU-DETR and state-of-the-art (SOTA) methods of sampling technology in
Table 2.
3. The Method Proposed in This Paper
3.1. The Overall Algorithm Architecture
The task of vessel recognition and classification in nearshore environments is fraught with challenges due to the complexity of the surroundings and dynamic lighting conditions. During the day, electro-optical (EO) images provide rich visual information, but are susceptible to strong light reflections and complex backgrounds, which reduce the contrast between targets and their surroundings, particularly when vessel colors resemble seawater or nearshore structures, significantly increasing the detection difficulty [
30]. At night, infrared images, by capturing thermal radiation characteristics, effectively compensate for the limitations of EO imaging under low-light conditions. However, their lower resolution and lack of detail exacerbate the difficulty of vessel classification. Furthermore, the diurnal transition introduces significant variations in data distribution, making single-modal detection methods inadequate for all-weather scenarios. Existing methods exhibit limited adaptability to dynamic lighting conditions, struggling to cope with the complex lighting variations and background interference in nearshore environments. Therefore, there is an urgent need to design a model capable of adaptively fusing EO and infrared image features to achieve robust vessel recognition under all-weather conditions.
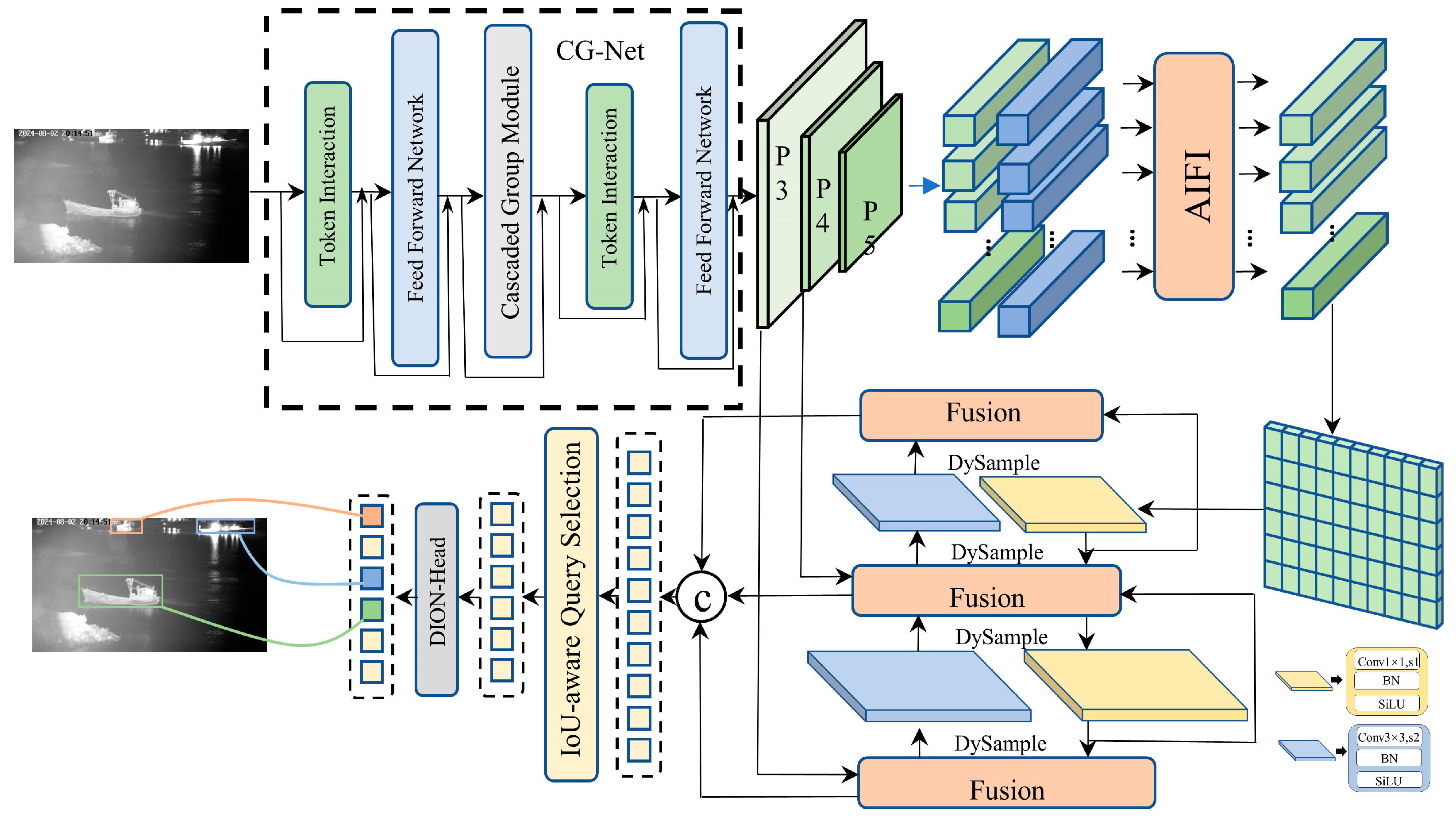
To address the aforementioned challenges, this paper proposes a cascaded spatial prior-based dynamic upsampling network for vessel recognition, named the CGDU-DETR (Cascaded Group and Dynamic Upsample-DETR). This network aims to fully leverage the complementary advantages of electro-optical (EO) and infrared images to achieve robust detection in all-weather nearshore environments. The core design of the CGDU-DETR includes the following key innovations: (1) A cascaded feature extraction module as the backbone—independently extracts features from EO and infrared images, preserving the unique information of each modality. (2) Efficient upsampling and resolution restoration—integrates learnable upsampling methods to progressively restore feature map resolution, ensuring the accurate detection of small vessels.
Figure 1 illustrates the overall architecture of the proposed network.
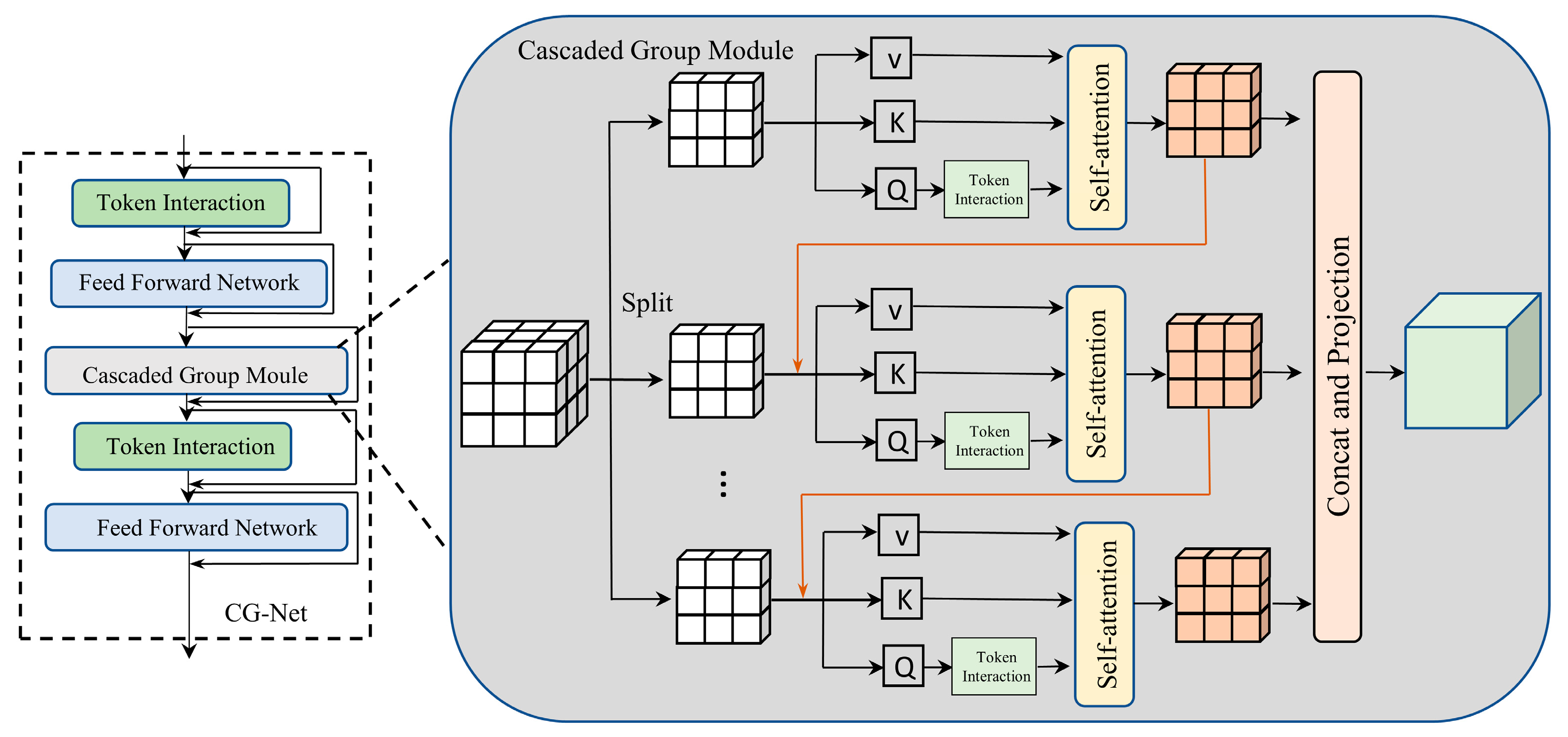
3.2. Proposed CG-Net Based on Cascade Module
We propose a CG-Net network based on cascaded spatial priors, as illustrated in
Figure 2. The network consists of two Token Interaction components, two Feed-Forward Network (FFN) components, and a Cascaded Group Module. The Cascaded Group Module incorporates multi-layer grouped convolutions [
31], a cascaded group decay module, and a reparameterization strategy, focusing on enhancing the model’s feature extraction capabilities and computational efficiency.
The CG-Net network employs memory-efficient self-attention layers and FFN layers for feature extraction. Specifically, it utilizes a self-attention layer, denoted as
, to blend the spatial features of the input. The overall expression of CG-Net is given by Equation (1).
where
represents the
i-th complete input feature. After passing through
FFN layers and the Cascaded Group Module,
is transformed into
. This design reduces the memory and computational overhead caused by self-attention layers while incorporating more FFN layers to facilitate effective fusion across different feature channels, thereby enhancing the model’s ability to extract detailed features.
The Cascaded Group Module is fundamentally inspired by the cascaded group attention mechanism. Built upon this mechanism, the module constructs a cascaded spatial prior network by explicitly distributing attention computations across multiple heads, where each head processes distinct subsets of the complete feature. Formally, this attention mechanism can be expressed as:
In the above formula, we divide the input feature
along the channel dimension into h groups, and each group inputs an independent attention head for processing, which is the number of heads. In this study, the number of h designs is 3. It can be seen from
Figure 2 that the network we designed consists of three attention heads. Each group of inputs has an independent attention sub-module for the attention calculation, thereby achieving parallel subspace learning. Meanwhile, each attention header also contains three attention headers, where
is the abbreviation of Query, and its calculation formula is
=
. In layman’s terms, this letter represents what kind of information the Internet is looking for. And
is the abbreviation of the key, and its calculation formula is
=
. It represents the description of each position information of the image in the process of extracting information from the image by the network.
is the abbreviation of the Value, representing the information that the network truly intends to “extract and transmit”. Its calculation formula is
=
. After generating the corresponding Query (
), Key (
), and Value (
) vectors for each group, they are concatenated after the calculation by the multi-head attention mechanism and projected back to the original dimension through a linear transformation. This module aims to enhance the information interaction among different subspaces and improve the feature expression ability.
Finally, the j-th segmented head operates on the j-th segmented portion of the input feature . Specifically, the self-attention scores are computed on , denoted as , where represents the number of channels and h is the total number of segmented heads. , and are projection layers that map the segmented portions of the input features into different subspaces. Specifically, these layers transform the input feature segments into distinct representations for further processing. Meanwhile, is a linear layer used to project the concatenated output features back to the same dimensionality as the input.
3.3. Dynamic Feature Upsampling Algorithm
The dynamic sampling algorithm first generates offsets through a linear projection and then resamples the input feature map using PyTorch’s grid_sample function [
29]. Specifically, given a feature map
, offsets
are generated via a linear layer and added to the original sampling grid
to obtain a new set of sampling points. Finally, the feature map
is resampled using these updated points to produce the upsampled feature map
.
We replace the initial sampling positions from nearest-neighbor interpolation to bilinear interpolation to better handle the relationships between sampling points. Additionally, a static or dynamic range factor is introduced to constrain the movement range of the offsets, preventing prediction errors caused by overlapping sampling points. Finally, the feature map is grouped along the channel dimension
j, with each group generating independent offsets to enhance the flexibility of upsampling. By dynamically generating offsets and combining them with bilinear interpolation, the algorithm achieves efficient and content-aware upsampling. The process can be formally expressed as:
where
represents the generated offsets and
is the input feature map. The final upsampled feature map
is produced using the grid_sample function, which can be formally expressed as:
In day–night transition scenarios, the dynamic sampling algorithm generates content-aware sampling points, enabling the adaptive adjustment of the upsampling process based on the input feature map’s content. This approach better preserves key features in electro-optical (EO) and infrared imaging, such as vessel edges and textures, while mitigating the impact of lighting variations on feature reconstruction. Specifically, during night-time infrared imaging, the thermal radiation characteristics of vessels may become more pronounced. The dynamic sampling algorithm can capture these features through adaptive sampling points, thereby enhancing the detection accuracy.
In summary, we proposed the CGDU-DETR algorithm, which innovatively integrates the CG-Net and Dynamic Feature Upsampling Algorithm. The CGDU-DETR is a transformer-based detection model enhanced with grouped attention and dynamic sampling, purpose-built to handle the unique challenges of maritime object detection under changing light conditions. The overall algorithm process is shown in Algorithm 1:
| Algorithm 1: CGDU-DETR Algorithmic Pipeline |
(expanded to 3 channels). Output: Detected objects with class labels and bounding boxes.
Feature Extraction: (use CG-Net backbone to extract multiscale features )
Attention-based Intrascale Feature Interaction (AIFI): into a sequence)
(process sequence via attention mechanism)
(reshape output back to spatial dimensions)
Dynamic Feature Upsampling: using upsampling and cross-scale interaction)
Prediction and Matching: Predict bounding boxes and class logits from fused features. Match predictions to ground truth using Hungarian algorithm with IoU-based cost. IoU-aware Query Selection (Training only): Adjust classification supervision using bounding box regression accuracy. =(c, b) (ground truth, c is the predicted class label, b is the predicted bounding box coordinates) (predicted value) (update loss)
Return: Final detections with class probabilities and bounding boxes.
|
4. Experiments and Analysis
4.1. Proposed Dataset
The image dataset used in this study was captured using electro-optical (EO) and infrared cameras from March 2024 to October 2024 at locations including the Nandu River in Haikou and Sanya Port in Hainan. The dataset comprises a total of 4705 day–night transition images from both EO and infrared modalities, with each image containing at least one vessel from twelve distinct categories. These categories include fishing boats, construction vessels, cargo ships, law enforcement vessels, speedboats, tugboats, yachts, motorboats, inflatable boats, passenger ships, sailboats, and garbage collection vessels.
Figure 3 illustrates the complex environments of different vessel categories under varying day–night conditions: (a) An overcast environment—two vessels of significantly different scales. (b) Early-morning low-light conditions—a backlit fishing boat. (c) Strong lighting conditions—two overlapping vessels, where the law enforcement vessel is partially occluded and blends into the background shoreline due to lighting. (d) Night-time infrared image—a fishing boat. (e) Night-time infrared image—a law enforcement vessel. (f) Strong lighting conditions—a construction vessel.
In day–night transition scenarios, EO and infrared imaging exhibit significant feature variations due to changing lighting conditions. Additionally, vessel targets present diverse characteristics at different scales, making vessel detection and classification tasks particularly challenging.
4.2. Experimental Environment Setup
We implemented the CGDU-DETR model using Python 3.11 and conducted training and testing on a GeForce RTX 3090 GPU. The operating system used throughout the training and testing processes was Ubuntu. Specific details of the experimental environment are provided in
Table 3.
To ensure thorough training of the CGDU-DETR network, we set the batch size to four, enabling us to evaluate the effectiveness of our designed CG-Net as the backbone network. The initial learning rate was set to 0.01, and Stochastic Gradient Descent (SGD) was employed as the optimizer to update the gradients for the IoU-aware Query Selection method. The training process spanned 300 epochs, with input image slices for day–night transition scenarios resized to 640 × 640.
4.3. Experimental Metrics
To demonstrate the advantages of the CGDU-DETR model, this study employs precision (
), recall (
), mean average precision (
),
,
, and Giga Floating Point Operations (GFLOPs) as evaluation metrics. Assuming the day–night transition vessel images contain labels for
N + 1 categories, let
represent the number of vessel objects labeled as class
i but predicted as class
.
,
, and
represent the number of true positives (
), false negatives (
), and false positives (
), respectively. Based on these definitions, precision (
) and recall (
) can be expressed as:
The mean average precision (
) can be expressed as:
means average precision at a strict Intersection over Union (IoU) threshold of 0.5. This is considered a “loose match” and is easier to satisfy. It emphasizes detecting the object, but not necessarily with precise localization. is the mean over 10 IoU thresholds from 0.50 to 0.95 in steps of 0.05. It is a more comprehensive and stricter metric, rewarding models that produce accurate bounding boxes. GFLOPs measure the computational complexity of a model—how many billions of operations it performs during inference on a single input.
4.4. Experimental Analysis
Table 4 presents a comparison between the proposed CGDU-DETR model and other state-of-the-art object detection algorithms, including YOLOv9-C [
32], YOLOv10-N [
33], YOLOv12 [
22], and RT-DETR [
24]. Specifically, we compare the proposed network with these methods, and the experimental data are shown in
Table 4. To further demonstrate the detection performance of the algorithm for each vessel category, we present the detection results of YOLOv12 and the CGDU-DETR for each vessel class in
Table 5 and
Table 6, respectively.
From
Table 4, it can be observed that the proposed CGDU-DETR model demonstrates an outstanding performance in vessel detection tasks under day–night transition environments, significantly outperforming other comparative models. The experimental results indicate that the CGDU-DETR achieves the best performance across multiple evaluation metrics. Specifically, the CGDU-DETR achieves an
of 93.4%, representing improvements of 2.75% over YOLOv9-C (90.9%), 3.43% over YOLOv10-N (90.3%), 2.86% over YOLOv12 (90.8%), and 1.52% over RT-DETR (92.0%). Particularly in terms of
, the CGDU-DETR achieves 95.2%, significantly surpassing other models with improvements of 8.68% over YOLOv9-C (87.6%), 14.42% over YOLOv10-N (83.2%), 24.44% over YOLOv12 (76.5%), and 7.69% over RT-DETR (88.4%). Additionally, the CGDU-DETR achieves
and
values of 96.6% and 88.2%, respectively, representing improvements of 4.77% and 0.68% over YOLOv9-C (92.2% and 87.6%), 6.74% and 7.82% over YOLOv10-N (90.5% and 81.8%), 5.11% and 7.30% over YOLOv12 (91.9% and 82.2%), and 4.09% and 5.76% over RT-DETR (92.8% and 83.4%). These results further validate the robustness of our designed model under different IoU thresholds.
On the other hand, in terms of the model parameters, although the CGDU-DETR has a higher computational cost (27.3 GFLOPs) compared to YOLOv10-N (8.4 GFLOPs) and YOLOv12 (6.5 GFLOPs), its performance improvement is significant, particularly excelling in detection tasks under complex lighting conditions. Compared to RT-DETR, the CGDU-DETR improves and by 1.52% and 7.69%, respectively, while reducing the computational cost by 53.2%. This demonstrates that the CGDU-DETR significantly enhances the detection accuracy and recall while maintaining the computational efficiency.
Additionally,
Table 5 and
Table 6 present a comparison between the proposed CGDU-DETR model and the state-of-the-art YOLOv12 model on a private dataset for vessel recognition and classification, with a focus on their performance in day–night transition environments. The experimental results demonstrate that the CGDU-DETR model significantly outperforms YOLOv12 in detecting multiple vessel categories, particularly excelling in complex categories such as cargo ships and law enforcement vessels. Specifically, the CGDU-DETR achieves an
and
of 1.0 for cargo ship detection, significantly surpassing YOLOv12’s 0.736 and 0.657. For law enforcement vessel detection, the CGDU-DETR achieves an
of 98.2
, far exceeding YOLOv12’s 60%. Furthermore, the CGDU-DETR exhibits higher recall rates for categories such as fishing boats, motorboats, and inflatable boats compared to YOLOv12, indicating its ability to more effectively detect true targets with lower miss rates. These performance improvements are primarily attributed to the CG-Net mechanism and the dynamic feature upsampling algorithm in the CGDU-DETR model, which enable the model to better adapt to day–night transition environments and maintain high accuracy and low miss rates in complex backgrounds.
These significant performance improvements are primarily attributed to the design of the CGDU-DETR model. By introducing the CG-Net and the dynamic feature upsampling algorithm, we effectively enhanced the model’s ability to extract multi-scale features, particularly excelling in complex lighting conditions such as night-time infrared and daytime electro-optical image vessel detection tasks in the dataset. The CG-Net module reduces computational redundancy through grouped attention mechanisms while improving feature diversity, and the dynamic feature upsampling algorithm enhances the model’s adaptability to lighting variations by dynamically adjusting feature weights. These designs enable the CGDU-DETR to significantly improve the detection accuracy and recall while maintaining the computational efficiency.
In this study, we successfully accomplished the task of vessel detection in day–night transition environments and validated the effectiveness of our designed model in real-world scenarios. As demonstrated by the detection results on actual images shown in
Figure 4, the model exhibits an excellent detection performance under complex lighting conditions. Specifically, the model can accurately identify and localize various categories of vessel targets, including fishing boats, construction vessels, law enforcement vessels, tugboats, and more. Additionally, it demonstrates strong robustness in the fusion detection of night-time infrared and daytime electro-optical images.
In practical detection tasks, our model not only accurately detects vessel targets, but also effectively handles complex background interference, such as backlighting and strong light reflections. In scenarios with strong light reflections during the day, the model can still accurately distinguish vessel targets from background interference, demonstrating high detection precision, as shown in
Figure 4c. Additionally, in night-time infrared images, the model significantly improves the detection performance under low-light conditions by integrating thermal feature information. These excellent performances in real-world applications are primarily attributed to the designed cascaded CG-Net network and dynamic feature upsampling algorithm in the model, which enable it to better adapt to complex lighting variations and background interference.
4.5. Ablation Experiments
To evaluate the contribution of each key component in the proposed CGDU-DETR model, we conducted a series of ablation experiments. These experiments systematically removed or replaced specific modules to analyze their impact on the overall performance. The results are summarized in
Table 7. Removing the CG-Net module and using a basic CNN network as the backbone reduces the mean average precision (
) by 3.3% and the recall by 6.9% compared to the original model. This demonstrates that the cascaded group attention CG-Net module can focus on critical regions, improving the detection accuracy of different vessel categories under complex lighting and night-time infrared conditions. Additionally, replacing the dynamic feature upsampling algorithm with traditional sampling methods reduces the
by 2.5% and the recall by 6.1% compared to the original model. This is because the dynamic feature upsampling algorithm adaptively adjusts feature weights, ensuring high-quality feature reconstruction and enhancing the performance in low-light and high-glare scenarios.
4.6. Generalization Experiment
To validate the generalization ability of the proposed CGDU-DETR model on unseen data, we conducted experiments on the WSODD (Water Surface Object Detection Dataset) public dataset. The WSODD dataset includes multiple categories for object detection tasks, but to focus on the vessel detection task, we selected only the vessel category data for validation. The following describes the generalization experiment:
Dataset selection and preprocessing: all images containing the vessel category were extracted from the WSODD dataset to ensure the diversity and representativeness of the dataset.
Model configuration: The pre-trained CGDU-DETR model was employed, with CG-Net as its backbone network combined with a dynamic feature upsampling algorithm. The model was not exposed to the WSODD dataset during training to ensure the objectivity of the generalization evaluation.
Evaluation metrics: the mean average precision (), recall (), and were adopted as the primary evaluation metrics, with particular attention paid to the model’s performance under complex backgrounds and varying lighting conditions.
To evaluate the generalization ability of the proposed CGDU-DETR model, we conducted experiments on a public dataset and compared its performance with several state-of-the-art methods, including YOLOv9-C, YOLOv10-N, YOLOv12, and RT-DETR. The results are summarized in
Table 8.
The proposed CGDU-DETR model achieves an of 95.1%, significantly outperforming YOLOv9-C (86.3%), YOLOv10-N (87.1%), YOLOv12 (85.2%), and RT-DETR (90.1%). This demonstrates the superior detection accuracy of the CGDU-DETR in handling diverse vessel categories under varying conditions. The CGDU-DETR achieves a recall rate of 92.4%, which is notably higher than YOLOv9-C (78.9%), YOLOv10-N (79.4%), YOLOv12 (79.3%), and RT-DETR (85.4%). This indicates that the model effectively reduces false negatives and improves the detection of true-positive targets.
The experimental results on the public dataset validate the strong generalization ability of the proposed CGDU-DETR model. Its excellent performance in terms of its detection accuracy, recall, and robustness across different IoU thresholds demonstrates its potential for real-world maritime surveillance applications. The integration of the cascaded group module and the dynamic feature upsampling algorithm plays a critical role in achieving these results.
4.7. Computational Complexity Analysis of CGDU-DETR
In order to strictly evaluate the efficiency of the proposed CGDU-DETR, we conducted a comprehensive analysis of the computational complexity, including the time complexity and space complexity. In the field of deep learning, the measurement of time complexity is generally measured by the FLOPs value. Specifically, the number of floating-point operations required for a model to complete one forward propagation is a specific quantitative indicator of the time complexity. Space complexity is a measure of the memory usage of a model during its runtime. It is related to the number of parameters, the batchsize set in the neural network, etc. This section details the computational costs related to the backbone (CG-Net), the neck (FPN-style feature fusion), and the head (Dine-head) under the configuration of 300 training epochs with an input resolution of 640 × 640, batch processing sizes of 4, and 3760 training images.
- (1)
Time Complexity Analysis
The total floating-point operations (FLOPs) for one forward–backward pass in the CGDU-DETR can be decomposed as follows:
- a.
Single Forward–Backward Pass.
Given an input resolution of 640 × 640, the computational cost scales quadratically with the spatial dimensions. The FLOPs for the backbone are derived as:
where n = 640 (input resolution) and c = 192 (dominant feature channels in CG-Net).
- b.
Neck (FPN + PAN Feature Fusion).
The neck consists of 1 × 1 convolutions, RepC3 blocks, and Dynamic Feature Upsampling. The computational cost is dominated by the RepC3 modules, which contain reparameterizable convolutions:
where
is the feature map resolution (scaling with the input size).
- c.
Head (DION-head).
The decoder employs multi-head self-attention (MHSA) and feed-forward networks (FFN) with 300 object queries. The complexity is dominated by the attention mechanism:
where
L = 3 (decoder layers),
q = 300 (queries), and
d = 256 (feature dimension).
Since backpropagation typically requires 2.5× the FLOPs of a forward pass, the total per-iteration cost is:
- d.
Full Training Complexity.
For 300 epochs with a batch size of four, the total number of iterations is:
Thus, the total training FLOPs are
- (2)
Space Complexity Analysis.
The space complexity is shown in
Table 9.
The memory consumption is dominated by the model parameters, optimizer states (Adam requires 4× parameters), and feature maps.
The overall space complexity is
where
4.09 M (parameters),
,
, and
.
5. Limitations and Future Work
Although the CGDU-DETR demonstrates a robust performance in ship detection under diurnal illumination changes, the current model relies solely on static image inputs and does not explicitly model the temporal motion patterns of maritime targets. In practical maritime surveillance scenarios, dynamic trajectory information—such as that provided by the Automatic Identification System (AIS)’s data or BeiDou satellite navigation—can offer critical spatiotemporal cues to further enhance the detection reliability, particularly in cases of occlusion, glare, or sensor blindness.
In future work, we plan to construct a multi-modal dataset that incorporates both visual imagery and ship trajectory information, and to explore detection frameworks that integrate visual and temporal modalities. Specific directions include the following: (1) introducing transformer-based temporal modeling modules to learn ship movement patterns and behavioral trends; (2) fusing spatial features from images with temporal features from trajectory sequences to improve the model’s persistence on weak or ambiguous targets; and (3) enabling a short-term trajectory prediction to support continuous monitoring and early-warning capabilities in complex environments.
By integrating visual and trajectory data, future iterations of the model are expected to move beyond static detection, achieving unified detection, identification, tracking, and prediction in all-weather, full-process maritime monitoring systems.
6. Conclusions
In this study, we propose an end-to-end detection model based on cascaded spatial priors and dynamic upsampling (CGDU-DETR) for ship detection tasks in day–night transition environments. The experimental results show that the CGDU-DETR achieves an AP of 93.4% on the day–night transition dataset, representing a 2.86% improvement over YOLOv12, and a recall of 95.2%, representing a 24.44% improvement over YOLOv12. Particularly for complex categories such as cargo ships and law enforcement vessels, the CGDU-DETR significantly outperforms YOLOv12, with improvements of 35.9% in AP and 63.7% in recall. Furthermore, generalization experiments on the WSODD public dataset further validate the robustness of the model, with the CGDU-DETR achieving an AP of 95.1%, representing an 11.6% improvement over YOLOv12. In practical detection tasks, the CGDU-DETR demonstrates an excellent performance, effectively handling complex lighting conditions such as strong reflections and low light. In scenarios with strong light reflections, the model can accurately distinguish ship targets from background interference, demonstrating a superior performance in ship classification and detection, and effectively identifying overlapping ships. In night-time environments, the model efficiently extracts thermal features of ships from infrared images and achieves precise ship classification. Although the CGDU-DETR has a higher parameter count of 27.3 GFLOPs compared to YOLOv12’s 6.5 GFLOPs, its significant improvements in its detection accuracy and recall demonstrate its efficiency. These results indicate that the CGDU-DETR has significant advantages in ship detection tasks under day–night transition environments, effectively handling complex lighting and background interference, and providing reliable technical support for all-weather maritime surveillance.
Author Contributions
W.W.: Conceptualization, Methodology, Investigation, Formal analysis, Data Curation, Writing—Original Draft. X.F.: Conceptualization, Methodology, Investigation, Formal analysis, Writing—Original Draft, Writing—Review and Editing. Z.H. (Corresponding Author): Conceptualization, Supervision, Project administration, Funding acquisition, Writing—Review and Editing. Y.Z.: Methodology, Resources, Supervision, Writing—Review and Editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 62161010 and 62361024, and the Key Research and Development Project of Hainan, grant number ZDYF2022GXJS348 and ZDYF2024GXJS021. The patent arising from the work completed under these grants is owned by the research institution, not the funding agency.
Data Availability Statement
The dataset is available on request from the authors: The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sun, Z.; Leng, X.; Zhang, X.; Zhou, Z.; Xiong, B.; Ji, K.; Kuang, G. Arbitrary-Direction SAR Ship Detection Method for Multiscale Imbalance. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5208921. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, S.; Sun, Z.; Liu, C.; Sun, Y.; Ji, K.; Kuang, G. Cross-Sensor SAR Image Target Detection Based on Dynamic Feature Discrimination and Center-Aware Calibration. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5209417. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yuan, M.; Meng, H. FE R-CNN: Feature Enhance R-CNN for Few-Shot Ship Object Detection. In Proceedings of the 2024 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2024; IEEE: New York, NY, USA, 2024; pp. 567–572. [Google Scholar]
- Guo, H.; Yang, X.; Wang, N.; Song, B.; Gao, X. A rotational libra R-CNN method for ship detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5772–5781. [Google Scholar] [CrossRef]
- Qi, L.; Li, B.; Chen, L. Improved Faster R-CNN Ship Target Detection Algorithm. China Shipbuild. 2020, 61 (Suppl. 1), 959. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Liu, Q.; Ning, M. SAR ship target detection method based on improved faster R-CNN. In Proceedings of the Sixth International Conference on Information Science, Electrical, and Automation Engineering (ISEAE 2024), Wuhan, China, 27 September 2024; SPIE: Bellingham, WA, USA, 2024; Volume 13275, p. 1327502. [Google Scholar]
- Fan, X.; Hu, Z.; Zhao, Y.; Chen, J.; Wei, T.; Huang, Z. A small ship object detection method for satellite remote sensing data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 11886–11898. [Google Scholar] [CrossRef]
- Wang, Y.; Ning, X.; Leng, B.; Fu, H. Ship detection based on deep learning. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 275–279. [Google Scholar]
- Wang, W.; Li, Y.; Zhang, Y.; Hang, P.; Liu, S. MPANet-YOLOv5: Multi-path Aggregation Network for Complex Maritime Target Detection. J. Hunan Univ. (Nat. Sci.) 2022, 49, 69–76. [Google Scholar]
- Cen, J.; Feng, H.; Liu, X.; Hu, Y.; Li, H.; Li, H.; Huang, W. An Improved Ship Classification Method Based on YOLOv7 Model with Attention Mechanism. Wirel. Commun. Mob. Comput. 2023, 2023, 196323. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Y.; Wu, S.; Hu, Z.; Xia, X.; Lan, D.; Liu, X. Infrared Small Target Detection Based on Multiscale Local Contrast Learning Networks. Infrared Phys. Technol. 2022, 123, 104107. [Google Scholar] [CrossRef]
- Xu, X.; Song, Y.; Ge, Q.; Huang, Y. Optimization of Ship Small Target Detection Based on YOLOv10 in Complex Ocean Environment. In Proceedings of the 2024 IEEE International Conference on Unmanned Systems (ICUS), Nanjing, China, 18–20 October 2024; IEEE: New York, NY, USA, 2024; pp. 1094–1099. [Google Scholar]
- Wang, Y.; Li, X. Ship-DETR: A Transformer-Based Model for EfficientShip Detection in Complex Maritime Environments. IEEE Access 2025, 13, 66031–66039. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23 August 2020. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super resolution with non-local sparse attention. In Proceedings of the IEEE Conference on Computer Vision Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3517–3526. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration us ing swin transformer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE:Context-aware reassembly of features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Lu, H.; Liu, W.; Ye, Z.; Fu, H.; Liu, Y.; Cao, Z. SAPA: Similarity-aware point affiliation for feature upsampling. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6027–6037. [Google Scholar]
- Chen, J.; Hu, Z.; Wu, W.; Zhao, Y.; Huang, B. LKPF-YOLO: A Small Target Ship Detection Method for Marine Wide-Area Remote Sensing Images. IEEE Trans. Aerosp. Electron. Syst. 2024, 61, 2769–2783. [Google Scholar] [CrossRef]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Computer Vision–ECCV 2024, Proceedings of the 18th European Conference, Milan, Italy, 29 September–4 October 2024, Proceedings, Part XXXI; Springer Nature: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}