1. Introduction
Accurate estimation of fish populations is a critical task in fisheries management, marine biodiversity assessment, and aquaculture monitoring. The ability to track fish abundance and movement patterns is essential for ensuring sustainable fisheries, preventing overfishing, and maintaining ecological balance [
1]. According to the Food and Agriculture Organization (FAO), global fish production reached approximately 178 million metric tons in 2020, with over 50% originating from aquaculture [
2]. In commercial aquaculture, fish counting is used for stock assessment, optimizing feed allocation, and improving farm management, while in fisheries conservation, accurate population estimates help enforce regulations and assess ecosystem health [
3].
Traditional fish counting methods, which primarily rely on manual observation and video frame-based counting, remain widely used but pose significant challenges. These methods are labor-intensive, time-consuming, and prone to subjective errors, making them infeasible for large-scale applications [
4]. Furthermore, manual counting struggles in complex underwater environments where occlusions, varying lighting conditions, and high-density fish populations introduce substantial inaccuracies [
5]. The increasing demand for precise and efficient fish population monitoring has led to the development of automated fish counting systems, which leverage computer vision and deep learning to significantly enhance accuracy and scalability.
Recent advancements in computer vision and deep learning have significantly improved the accuracy and efficiency of automatic fish counting systems [
6]. Existing methods can be categorized into three primary approaches: density estimation, object detection and segmentation-based counting, and tracking-based counting.
Density-based methods estimate fish abundance by predicting a continuous density map across the image and integrating its values to approximate the number of fish present. These methods are particularly effective in environments where fish are densely packed and individual segmentation is impractical. Rather than detecting each fish directly, they model a spatial distribution of “fish likelihood” over the scene, typically using regression-based convolutional neural networks. For instance, Liu et al. [
7] proposed LGSDNet, a novel deep learning model that aggregates local-global contextual information and incorporates a self-distillation mechanism to enhance the counting performance in deep-sea aquaculture settings. Their method demonstrated improved resilience to low visibility, occlusions, and background noise commonly found in underwater scenarios. Similarly, Zhu et al. [
8] developed a semi-supervised density estimation framework leveraging proxy maps and limited annotations to count fish in recirculating aquaculture systems, enabling effective deployment in data-scarce conditions. Density estimation models are generally lightweight, robust to occlusions, and effective for estimating group-level abundance. However, they cannot distinguish individuals or fish species and are therefore unsuitable for behavior tracking or species-level population analysis.
Object detection and segmentation methods aim to identify and localize individual fish by drawing bounding boxes or generating pixel-wise segmentation masks for each instance. These approaches typically employ advanced object detection frameworks like YOLO or Faster R-CNN, or segmentation architectures like Mask R-CNN, which are trained on annotated datasets containing object-level fish labels. For example, Hong Khai et al. [
9] used Mask R-CNN to detect and count fish in underwater scenes. Their model achieved accurate detection even in cluttered or low-contrast environments, demonstrating the effectiveness of instance segmentation for complex aquatic imagery. In another study, Arvind et al. [
10] applied a deep instance segmentation approach using Mask R-CNN in pisciculture environments, achieving reliable tracking and individual identification even under partial occlusion or overlapping schools of fish. These methods offer fine-grained localization, species-level classification, and compatibility with downstream tasks like behavior analysis or biometric measurement. However, because they operate frame-by-frame without temporal association, they are prone to counting the same fish multiple times across consecutive frames, especially in continuous video sequences. This repeated detection without identity tracking is a critical limitation in real-world fish population monitoring tasks, where accurate cumulative counts are essential.
Tracking-based methods utilize object tracking algorithms to associate fish detections across video frames, allowing for identity-preserving, duplicate-free counting. These approaches typically couple real-time detectors (e.g., YOLO) with multi-object tracking (MOT) algorithms (e.g., SORT, ByteTrack), enabling both fish population monitoring and motion behavior analysis over time. For example, Kandimalla et al. [
11] developed an automated fish monitoring pipeline combining YOLOv4 detection with the Norfair tracker. Their system effectively detected, classified, and counted fish in fish passage videos while maintaining object identity, even in scenarios with frequent occlusion and re-entry. Additionally, Liu et al. [
12] proposed a dynamic tracking-based method tailored for counting Micropterus salmoides fry in highly occluded environments. By employing appearance-based association and fast target matching, their model achieved robust real-time tracking in challenging aquaculture conditions. Tracking-based methods are particularly valuable in long-term observation, fish movement tracking, and non-redundant population estimation.
Despite the advantages of tracking-based counting, existing methods still face significant challenges, including identity switches (ID switches), occlusions, and environmental variations [
13]. Current tracking frameworks such as SORT and DeepSORT lack robustness in handling high-density fish schools and suffer from tracking failures in challenging underwater scenarios [
14]. Additionally, occlusions and rapid fish movement lead to identity fragmentation, affecting counting accuracy. Addressing these challenges requires an improved tracking framework capable of maintaining consistent fish identities across frames while minimizing false associations [
15].
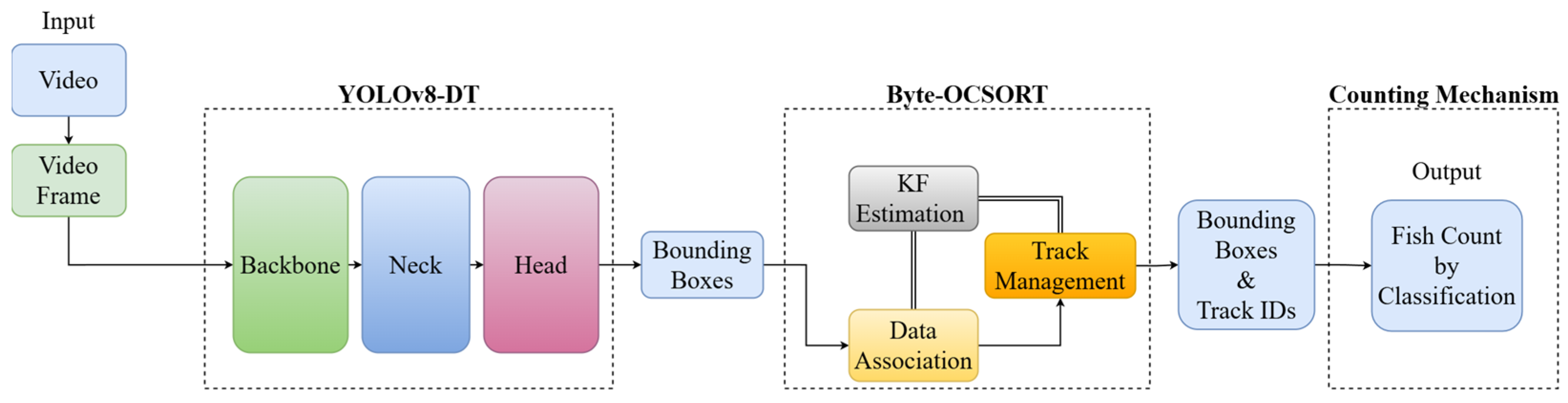
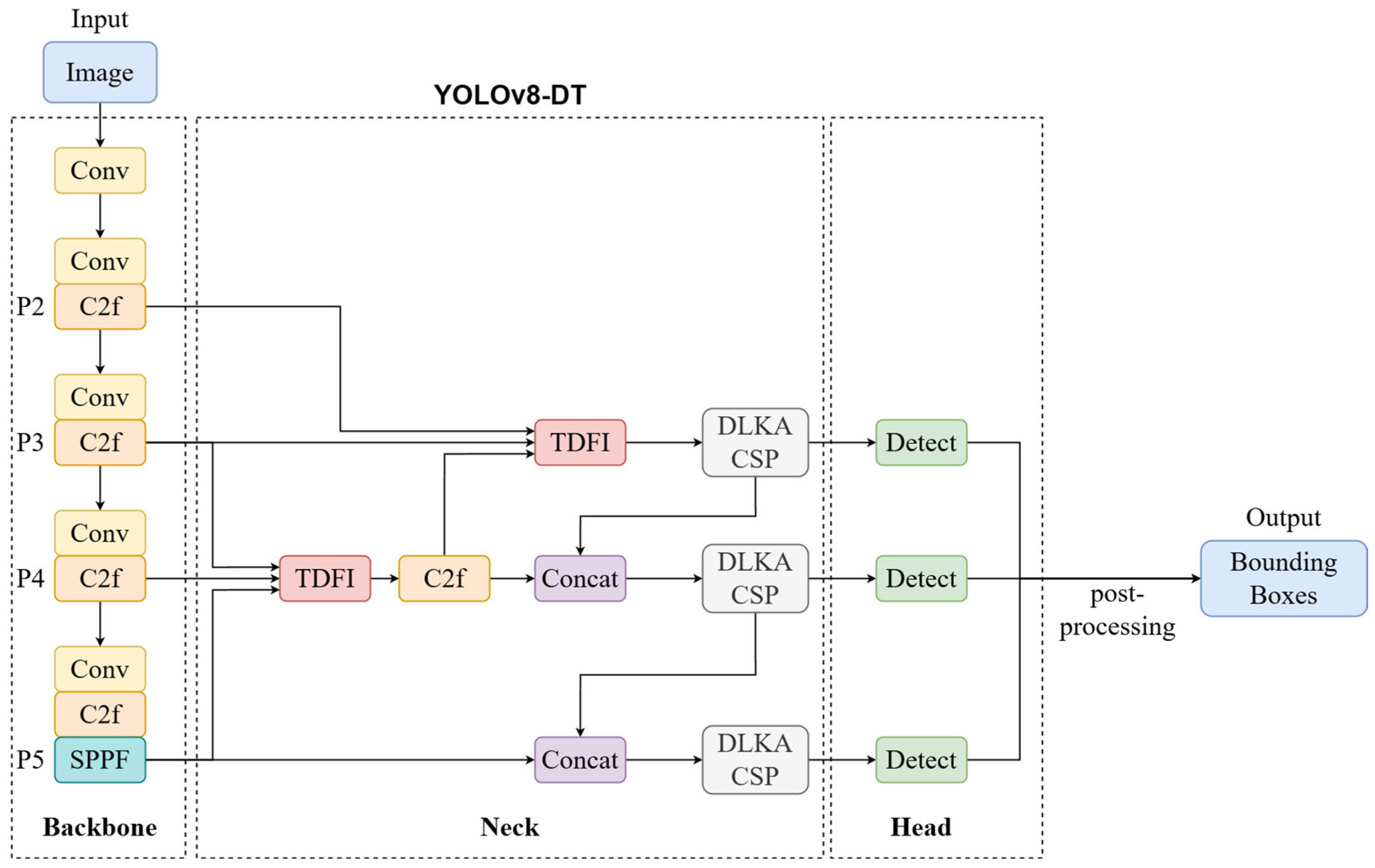
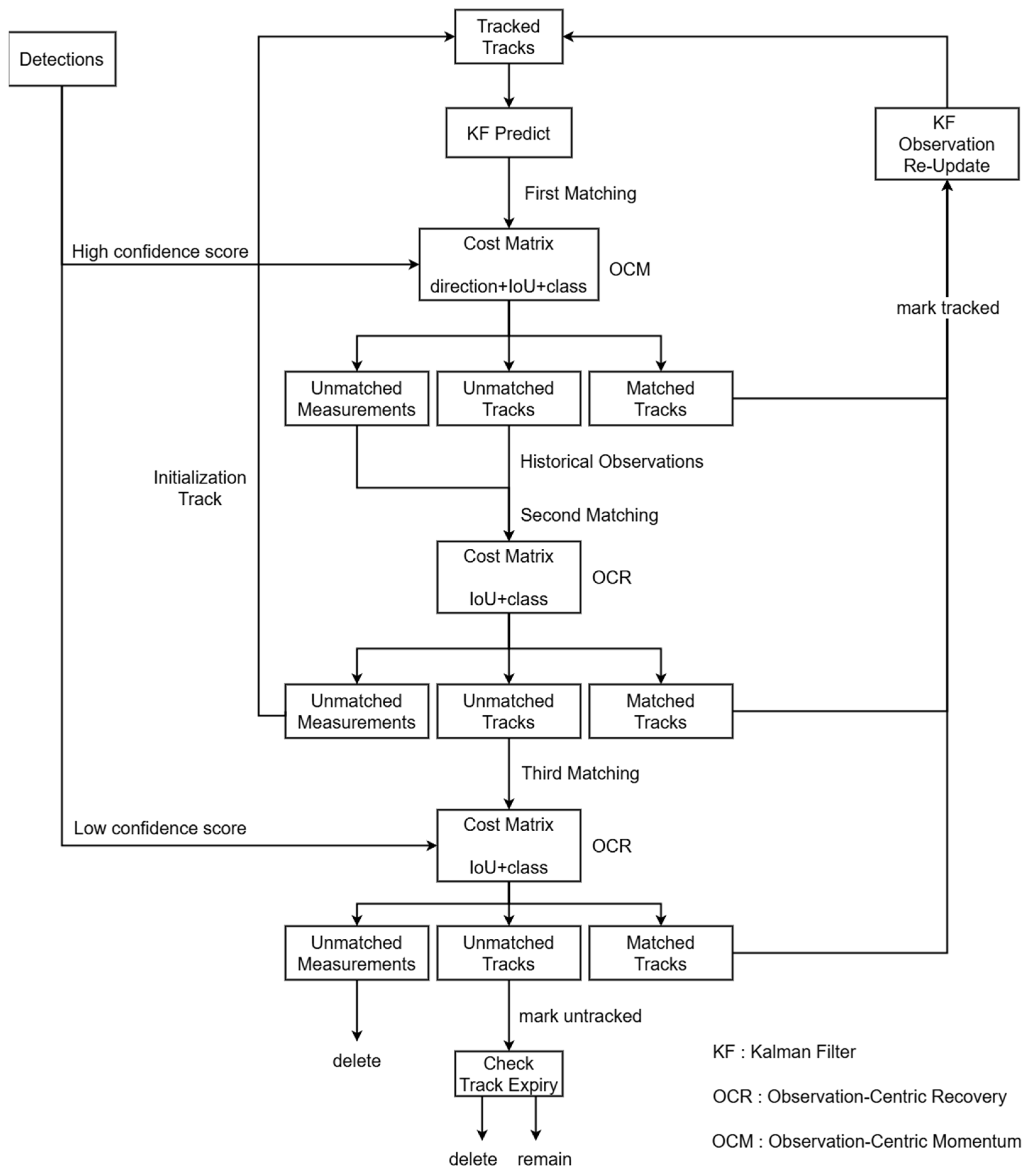
This paper proposes an advanced fish counting framework that integrates a modified YOLOv8-based detection model, termed YOLOv8-DT, with an enhanced object tracking algorithm, Byte-OCSORT. YOLOv8-DT incorporates the Deformable Large Kernel Attention Cross Stage Partial (DLKA CSP) module to enhance feature extraction for irregularly shaped fish and the Triple Detail Feature Infusion (TDFI) module to improve small-object detection under occlusions. Byte-OCSORT extends the OC-SORT tracking framework by incorporating ByteTrack’s high-confidence and low-confidence detection matching strategy while integrating class constraints for multi-species tracking. This novel approach improves tracking robustness, reduces ID-switch occurrences, and enhances counting accuracy in complex underwater environments. The key contributions of this paper are as follows:
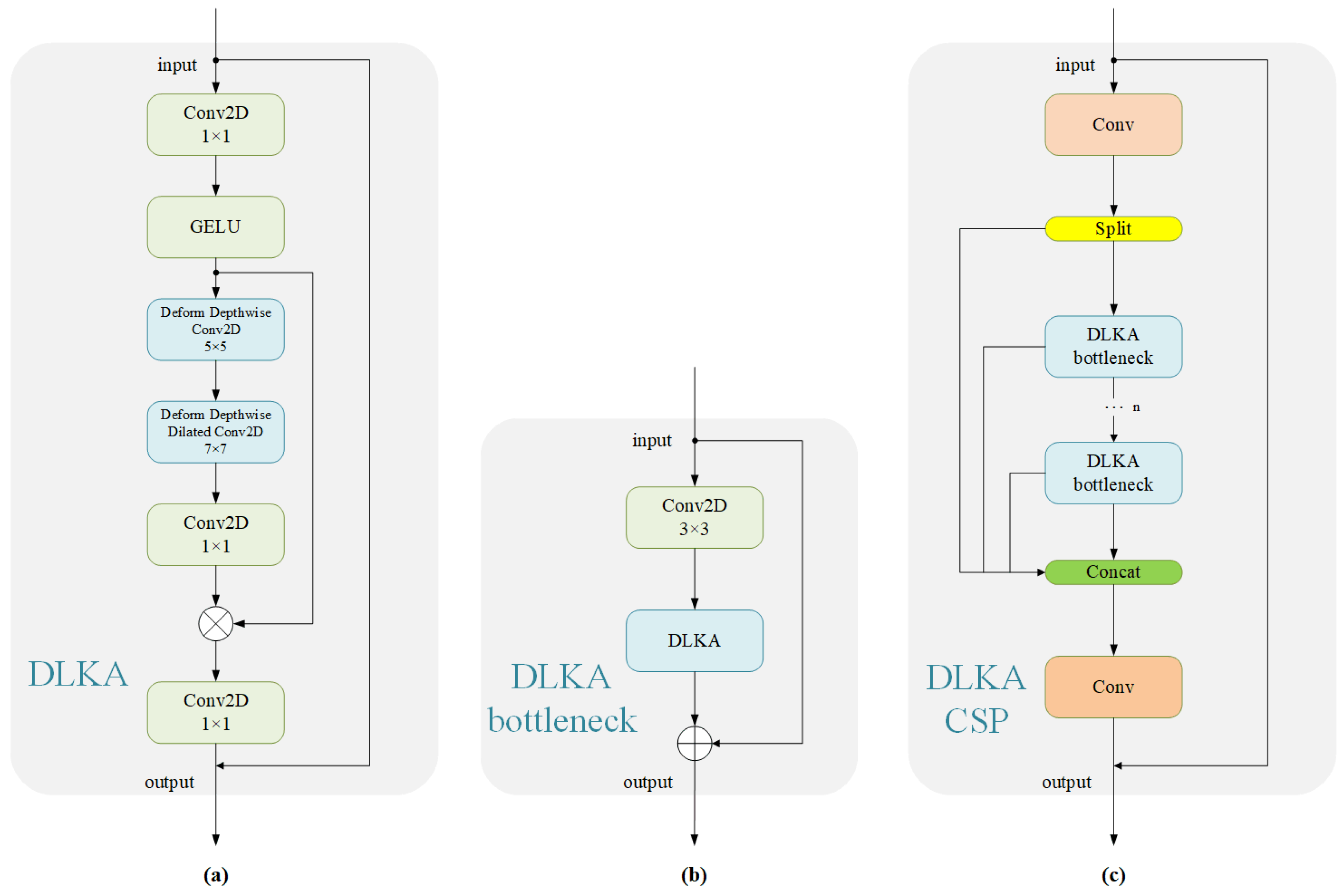
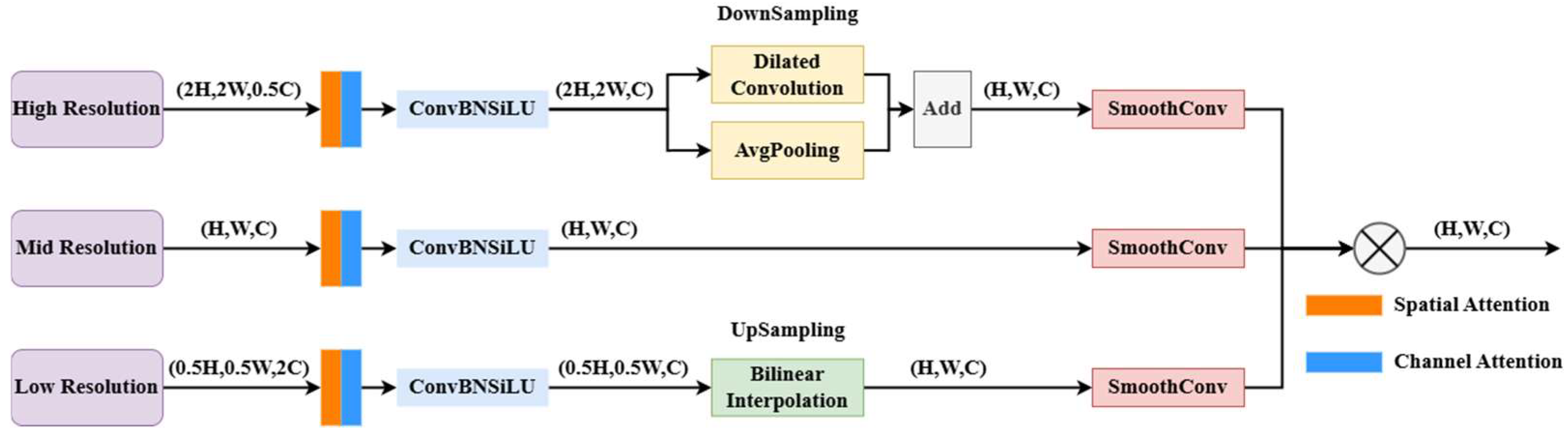
We propose a modified YOLOv8-based detection model, termed YOLOv8-DT, by integrating DLKA CSP and TDFI modules into the YOLOv8n backbone to enhance small-object detection and robustness in occluded conditions. DLKA CSP improves feature extraction by dynamically adjusting the receptive field using deformable convolutions and large kernel attention, enhancing adaptability to irregular fish shapes and varying underwater conditions. TDFI refines multi-scale feature fusion by integrating high-resolution spatial details with global semantics, improving small-object detection and occlusion handling;
We introduce Byte-OCSORT, an enhanced tracking algorithm that combines ByteTrack’s two-stage matching strategy with OC-SORT’s motion estimation for improved multi-species tracking. A Class-Aware Cost Matrix (CCM) prevents ID mismatches between different fish species, reducing tracking errors in dense and diverse aquatic environments. The two-stage association strategy ensures robust tracking by retaining low-confidence detections, minimizing identity loss, and improving long-term tracking stability;
We conduct extensive experiments to compare YOLOv8-DT and Byte-OCSORT with state-of-the-art models on real-world fish counting datasets. YOLOv8-DT achieves higher mAP and precision than baseline models, particularly in small-object detection. Byte-OCSORT significantly reduces ID-switch occurrences and enhances tracking robustness, especially in high-density and multi-species environments.
3. Experiments and Discussion
3.1. Datasets and Augmentation
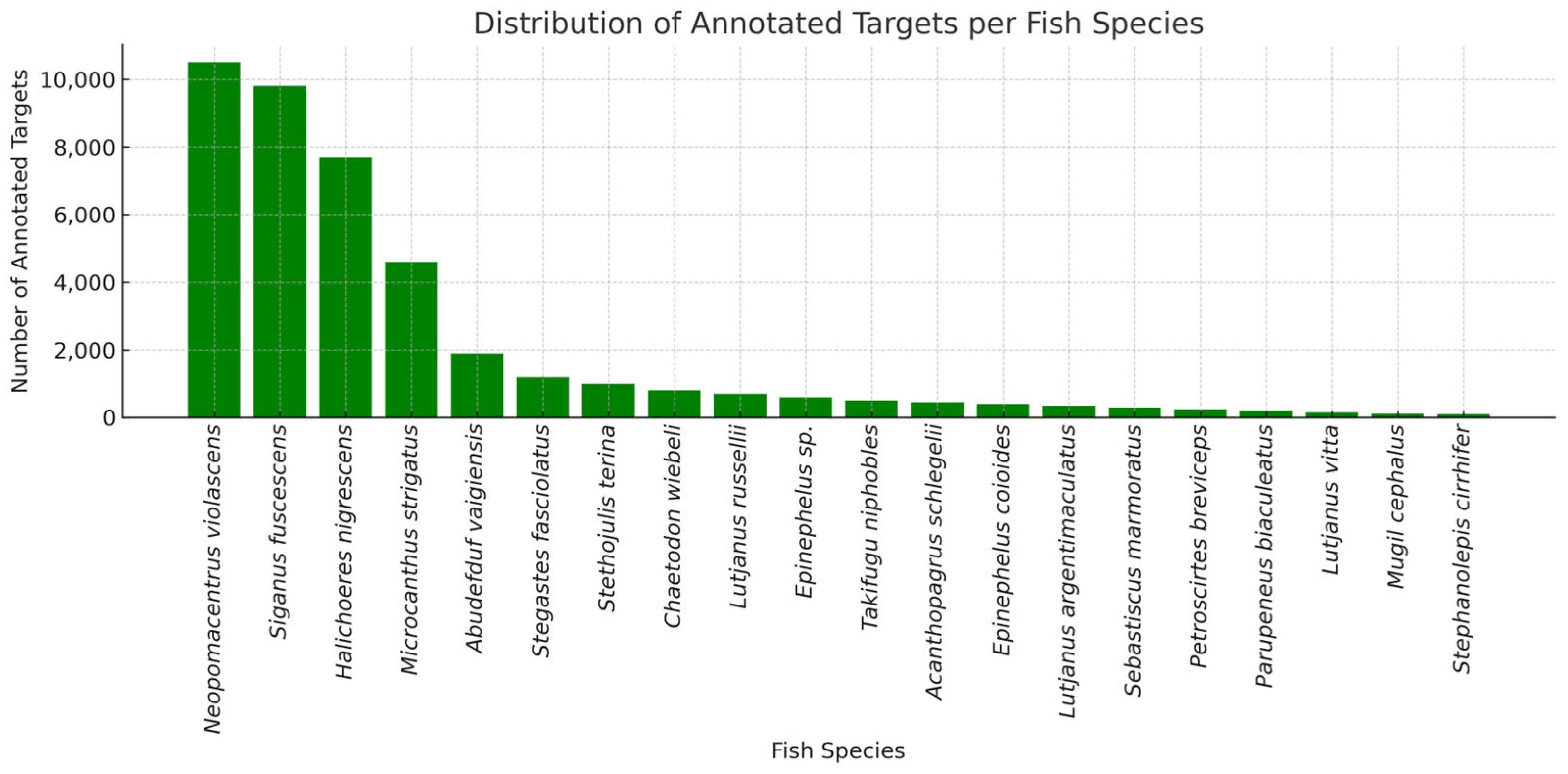
The dataset used for object detection consists of fish images captured by Coral EcosystemCabled Observatory (CECO) in Dongshan, China, annotated in the YOLO format with bounding boxes. It contains 19 distinct fish species, with a total of over 40,000 annotated individual fish targets across several thousand underwater frames. However, as shown in
Figure 6, the dataset exhibits a highly skewed distribution in the number of annotated fish targets per species. For instance, Neopomacentrus violascens accounts for over 10,000 individual bounding box annotations, while rare species such as Stephanolepis cirrhifer are represented by as few as 12 annotated targets. This long-tailed distribution poses a significant challenge to training fair and generalizable detection and tracking models.
To address this issue and improve model generalization, data augmentation was applied to all fish species with fewer than 500 images, increasing their sample sizes to at least 500 images per class. The augmentation strategies included horizontal flipping to simulate different fish orientations, optical distortion to mimic lens-warping effects in underwater footage, grid distortion to introduce realistic shape variations, and elastic transformation to enhance adaptability to non-rigid deformations. Motion blur was also applied to simulate fish movement in dynamic water conditions, along with random brightness and contrast adjustment to adapt to varying lighting conditions. Additionally, RGB shift was used to imitate color distortions caused by underwater environments, and safe cropping was introduced to ensure data diversity while preserving object integrity. These eight augmentation techniques were combined to simulate diverse underwater conditions, as shown in
Figure 7, allowing the model to effectively detect fish across different environmental scenarios.
To ensure fair model evaluation, stratified sampling was used to divide the dataset into training, validation, and test sets, ensuring that each species is proportionally represented in each subset. The dataset was split into 80% training set for model training, 10% validation set for hyperparameter tuning and model selection, and 10% test set for final performance evaluation. This stratified sampling approach prevents class imbalance issues from affecting model performance, ensuring that the network learns to detect both abundant and rare species effectively.
For object tracking, a single underwater test video was used, recorded at 1920 × 1080 resolution, 30 FPS, and approximately 5 min in duration. To ensure comprehensive evaluation, this video was carefully selected to contain four typical tracking scenarios within different segments, including fast motion, multi-scale fish, dense schools with occlusions, and sparse distributions. These embedded scenarios reflect diverse real-world conditions in marine environments. The video was fully annotated in MOT17 format, with frame-level bounding boxes, unique object IDs, and trajectory associations, enabling precise and fair benchmarking of Byte-OCSORT against other tracking algorithms.
3.2. Implementation Details
The experiments were conducted on an NVIDIA GeForce RTX 3060 (12G) GPU with PyTorch 2.2.2, Python 3.10, and CUDA 11.8 dependencies. The model was trained from scratch without using pretrained weights. The input image size was set to 640 × 640, and the batch size for training was 32. The training process lasted for 150 epochs. Stochastic Gradient Descent (SGD) was used as the optimization function to train the model. The hyperparameters of SGD were set to a momentum of 0.937, an initial learning rate of 0.001, and a weight decay of 0.0005.
3.3. Detection Results
First, we compare YOLOv8-DT with several baseline object detection models, including YOLOv5n, YOLOv6n, YOLOv8n, and MobileNetV4-SSD.
Table 1 presents the quantitative results in terms of params, precision, recall, mAP
50, mAP
50:95, and APs (small). Precision and recall are fundamental metrics in object detection, defined as:
where
(true positives) refers to correctly detected objects,
(false positives) are incorrect detections, and
(false negatives) represent missed detections. YOLOv8-DT outperforms all other models across all metrics, achieving the highest mAP
50 (0.971) and mAP
50:95 (0.742), significantly surpassing YOLOv8n by 1.4% and 4.2%, respectively. The mean Average Precision (mAP) is computed as:
where
represents the precision–recall curve, and
denotes the number of object categories. The mAP
50 evaluates performance at an IoU (Intersection over Union) threshold of 0.5, while mAP
50:95 averages results over multiple IoU thresholds (from 0.5 to 0.95 with a step of 0.05). We also report APs (small), which measure the average precision for small objects (area < 32
2 pixels), based on the COCO evaluation protocol. This metric reflects the model’s ability to detect small-sized fish, such as juveniles or distant targets, and is computed over the same IoU thresholds as mAP
50:95. Furthermore, YOLOv8-DT achieves the highest precision (0.95) and recall (0.947), demonstrating its strong detection capability under complex underwater conditions. Particularly in APs (small), YOLOv8-DT reaches 0.71, a 5.9% improvement over YOLOv8n, highlighting its superior small-object detection performance.
Figure 8 provides qualitative detection results for different models.
3.4. Tracking Results
For the tracking evaluation, Byte-OCSORT was compared against mainstream tracking algorithms, including SORT, ByteTrack, and OC-SORT. The results, presented in
Table 2, show that Byte-OCSORT achieves the highest MOTA (72.3) and IDF1 (69.4) while significantly reducing ID switches to 16, demonstrating its ability to maintain stable identities for fish across frames. Although we did not explicitly compute species-specific classification or counting errors, the use of class labels in the association process via the Class Cost indirectly reflects classification consistency. Therefore, tracking performance—especially ID switches—serves as a proxy to evaluate the reliability of classification-based counting across species. The Multiple Object Tracking Accuracy (MOTA) is defined as:
where
and
represent false negatives and false positives,
denotes identity switches, and
is the ground truth number of objects. The IDF1 score measures the accuracy of identity preservation in tracking, defined as:
where
,
, and
represent true positive, false positive, and false negative identity assignments, respectively. In comparison, SORT suffers from frequent ID switches (108) due to its reliance solely on motion information, while ByteTrack improves stability by integrating high-confidence and low-confidence detection association, reducing ID switches to 67. OC-SORT further refines motion estimation, leading to a MOTA of 67.8 and ID switches of 35, improving tracking robustness. However, Byte-OCSORT, which integrates the advantages of both the ByteTrack two-stage matching strategy and category constraints, outperforms all competitors, demonstrating superior tracking robustness and accuracy.
3.5. Ablation Study
To evaluate the contributions of the proposed modules in both detection and tracking components, we conducted ablation studies on YOLOv8-DT and Byte-OCSORT.
For the detection component, we tested the impact of integrating the DLKA CSP and TDFI modules into the YOLOv8n baseline.
Table 3 summarizes the experimental results of YOLOv8n, YOLOv8n-DLKA, YOLOv8n-TDFI, and the complete YOLOv8-DT. The results demonstrate that incorporating DLKA CSP increases mAP
50 from 0.957 to 0.965 and mAP
50:95 from 0.7 to 0.725, indicating that DLKA CSP improves object localization accuracy. On the other hand, TDFI enhances recall from 0.928 to 0.946 and APs (small) from 0.671 to 0.695, showing that it is particularly effective in detecting small objects and improving feature fusion across frames. When combining both modules in YOLOv8-DT, the model reaches the highest overall performance across all metrics, confirming the complementary benefits of these enhancements. The effectiveness of these modules is further visualized in
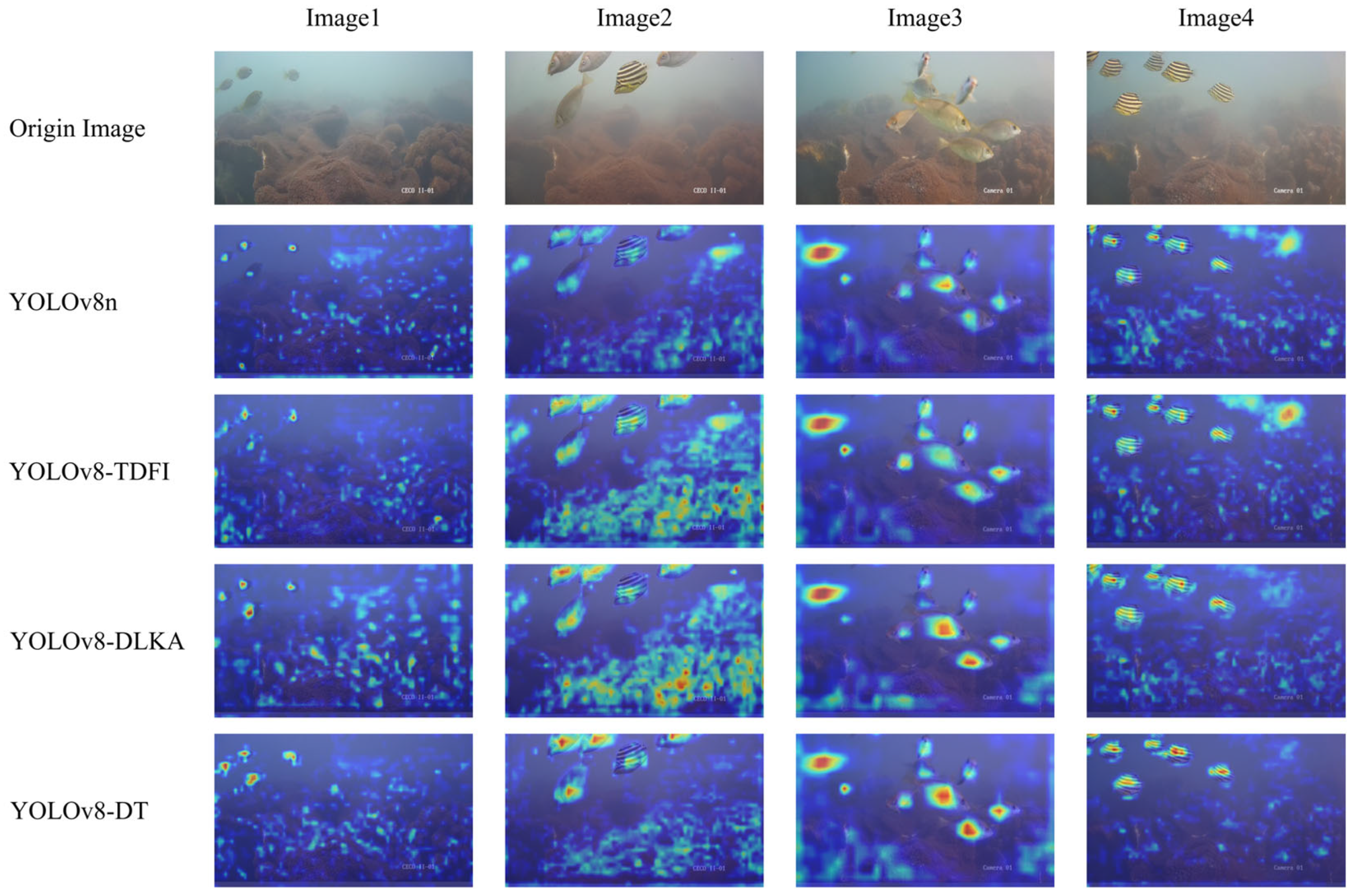
Figure 9, where the heatmaps illustrate that YOLOv8-DT generates more concentrated attention regions on fish targets, indicating improved feature representation and higher detection confidence.
Regarding the tracking component, we examined the effects of introducing the BYTE association strategy and the Class-Aware Cost Matrix to OC-SORT.
Table 4 compares OC-SORT, OC-SORT + BYTE (removing class constraints), OC-SORT + Class Cost (removing two-stage matching), and the full Byte-OCSORT model. The results indicate that adding two-stage matching (OC-SORT + BYTE) improves MOTA from 67.8 to 70.5 but only slightly increases IDF1 from 62.1 to 63.2, suggesting that it primarily improves overall tracking accuracy but has a limited impact on identity consistency. Conversely, introducing class constraints (OC-SORT + Class Cost) raises IDF1 to 66.5 and reduces ID switches to 25, proving effectiveness in minimizing ID mismatches among different fish species. The full Byte-OCSORT model, which combines both improvements, achieves the best tracking performance with a MOTA of 72.3, IDF1 of 69.4, and only 16 ID switches, highlighting the necessity of both strategies for achieving optimal tracking stability.
Figure 10 illustrates the Byte-OCSORT’s tracking results in a real-world video scenario.
4. Conclusions
In this paper, we propose an enhanced fish counting framework that integrates YOLOv8-DT for object detection and Byte-OCSORT for multi-object tracking. The framework is specifically designed for underwater fish counting tasks, addressing challenges such as occlusions, varying fish shapes, and dense distributions. By leveraging a track-by-detection strategy, the proposed system ensures accurate trajectory tracking and prevents duplicate counting, enabling robust and precise population estimation.
The YOLOv8-DT model incorporates two key improvements: the DLKA CSP module and the TDFI module. The DLKA CSP module dynamically adjusts the receptive field, enhancing feature extraction to better capture irregular fish shapes and posture variations. Meanwhile, the TDFI module integrates multi-scale temporal features by fusing high-resolution spatial details with global contextual information, significantly improving small-object detection and reducing false positives caused by motion blur.
Experimental results demonstrate that YOLOv8-DT outperforms existing models, achieving a mAP50 of 0.971 and a mAP50:95 of 0.742, with notable improvements in precision and recall. Meanwhile, Byte-OCSORT integrates a two-stage matching strategy with class-aware association, improving tracking robustness. It achieves the highest MOTA (72.3) and IDF1 (69.4), with the lowest number of ID switches (16), proving its effectiveness in reducing identity mismatches.
Despite the improvements, our method has certain limitations. First, the computational complexity of YOLOv8-DT is slightly higher than the baseline YOLOv8n, which may hinder real-time deployment in embedded systems. Second, the framework’s performance under varying environmental conditions—such as water turbidity and suspended sediment concentration—has not been quantitatively evaluated, although these factors can significantly impact detection visibility and accuracy. Finally, the generalization of the model to diverse marine species still requires broader validation to ensure robustness across different underwater ecosystems.
To address these limitations, future work will focus on optimizing computational efficiency for real-time deployment, expanding the dataset to include a wider range of species and environmental conditions, and incorporating adaptive modules or domain adaptation strategies to improve robustness under challenging water quality scenarios. Additionally, self-supervised learning strategies will be investigated to improve the model’s generalization capability while alleviating the dependency on extensive labeled data. These enhancements aim to improve both scalability and practicality of the proposed system in real-world marine monitoring applications.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}