1. Introduction
Marine environments dominate the Earth’s surface area and host significant energy resources, including petroleum, natural gas, minerals, and marine biodiversity. Exploring the ocean not only advances scientific inquiry but also facilitates the sustainable exploitation of these resources. However, the physiological constraints of human operators render underwater tasks significantly more challenging than surface-level operations. Emerging trends in underwater object detection have received increasing scholarly attention, as they seek to leverage advanced computational techniques for the automated identification and precise localization of submerged entities, including marine organisms, shipwrecks, archaeological artifacts, divers, and underwater infrastructure. Accurate detection is instrumental in applications such as resource exploration, aquaculture management, and marine ecosystem conservation, in addition to its strategic significance in sectors like deep-sea resource extraction, commercial fisheries, and military surveillance. Despite substantial progress in deep learning-based object detection, underwater environments present a unique set of unresolved challenges. The propagation of light underwater is heavily influenced by attenuation and scattering, leading to diminished contrast and spatial feature distortions that vary with depth and the viewing angle. Additionally, the inherent scale variability of submerged targets—ranging from minute aquatic organisms to large shipwrecks—complicates the maintenance of spatial consistency across feature hierarchies. Furthermore, the dynamic postural variations exhibited by marine organisms introduce additional complexities, as even intra-class objects display significant morphological changes, further exacerbating detection difficulties. Consequently, robust spatial feature processing remains a critical factor in enhancing detection performance under these conditions.
To mitigate these limitations, this paper introduces a composite YOLOv11n-based framework designed to improve the fusion of local and global feature representations, thereby enhancing detection robustness and precision. Local feature extraction emphasizes intricate target characteristics, such as texture and edge details, whereas global feature modeling captures macroscopic attributes, including scale and color distributions. Additionally, global contextual awareness is incorporated to account for the environmental backdrop surrounding the detected object. By synergistically integrating these components, the proposed model aspires to fortify the accuracy of underwater object detection against the adversities posed by complex aquatic environments.
The enhanced framework, YOLO-DAFS, incorporates novel components: DualBottleneck, focal modulation, ADown, and ghost depth-separable convolution (GDConv). This introduction evaluates the advantages of these modules over existing alternatives, highlighting their suitability for underwater environments.
Firstly, the DualBottleneck module enhances feature extraction in the C3k2 block through a lightweight DualConv design, integrating 3 × 3 grouped convolutions and 1 × 1 pointwise convolutions to capture local spatial features (e.g., edges and textures) and global channel information, respectively. This approach ensures a balance between detail sensitivity and scale adaptability, effectively addressing light-attenuation-induced feature loss and accommodating diverse underwater target scales, from small sea urchins to large wrecks. Compared to attention-based bottlenecks, such as SE-Net and CBAM, DualBottleneck avoids computationally intensive global pooling and complex convolution. Compared to transformer-based bottlenecks, such as multi-head self-attention structures, it eliminates the need for large-scale matrix computations, offering lower complexity and enhanced robustness for small targets and low-contrast scenes.
Secondly, the C2PSF module leverages focal modulation to replace the original C2PSA block, bolstering multiscale feature representation and global context modeling. By employing multiscale depthwise convolutions, gated aggregation, and element-wise affine transformations, focal modulation dynamically integrates visual contexts across short-to-long ranges, preserving both local details and global structures. This design excels in distinguishing targets from complex underwater backgrounds and adapts to dynamic lighting variations. Compared with attention-free transformers and MLP Mixers, focal modulation can avoid two problems: the serialized global modeling of attention-free transformers may reduce sensitivity to fuzzy edges, and the fixed-patch processing of MLP Mixers is difficult to adapt to drastic changes in the target scale. This ensures heightened sensitivity to small underwater targets.
Thirdly, the ADown module optimizes feature downsampling by enhancing detail preservation while significantly reducing the computational overhead. Ablation studies (
Table 1, UTDAC2020 dataset) demonstrate that ADown reduces the parameters and FLOPs by approximately 14%, lowering the parameters from 3.677 M to 3.167 M and FLOPs from 8.5 GFLOPs to 7.1 GFLOPs. For instance, on a Jetson Nano with ~0.5 TFLOPS, the 14% FLOPs reduction theoretically shortens inference time from 17 ms (58.8 FPS) to 14.2 ms (70.4 FPS), yielding a ~19.7% FPS increase, though real-world gains may be tempered by memory access and I/O overheads. Similarly, the parameter reduction mitigates memory bandwidth constraints, reducing cache misses and data transfer latencies, further boosting FPS.
Lastly, the DyHead-GDC module optimizes the detection head by integrating ghost convolution and depthwise separable convolution, forming a lightweight GDConv structure. Compared to inverted residual blocks of MobileNet, GDConv mitigates the limited receptive field issue through ghost feature generation, offering richer feature diversity. Unlike the channel shuffle of ShuffleNet, which risks feature inconsistency due to randomization, GDConv ensures targeted feature enhancement. Relative to MBConv with the Squeeze-and-Excitation of efficientNet, GDConv preserves spatial information, improving the detection of small or blurred targets.
In summary, the DualBottleneck, focal modulation, ADown, and GDConv modules collectively enable YOLO-DAFS to achieve better performance in underwater object detection. By addressing low contrast, scale variability, and background complexity with lightweight, efficient, and robust designs, these components outperform attention-based, transformer-based, and other lightweight convolution alternatives. YOLO-DAFS not only delivers high accuracy and real-time processing but also supports practical applications in marine biology monitoring, underwater rescue, and archaeological exploration, offering a novel perspective for advancing underwater vision systems.
2. Related Work
Computer vision systems designed for visual recognition address two primary tasks: identifying existing objects within an image and precisely determining their spatial coordinates. This challenging task focuses on extracting target features from images or videos to enable precise localization. Over the past few decades, object detection has progressed through two primary phases: traditional algorithms and deep learning-based approaches.
The traditional algorithms for object detection primarily rely on handcrafted features, and the overall process comprises three fundamental steps. First, regions of interest (ROIs) are selected, identifying areas that are likely to contain objects. Second, feature extraction is performed on these candidate regions. Finally, the extracted features are used for object classification and localization. Viola et al. [
1] proposed the Viola–Jones (VJ) detector, which employs a sliding window technique to determine the presence of a target within a given region. However, it is computationally expensive and suffers from high time complexity.
Deep learning-based algorithms of object detection fall into two main types: single-stage and two-stage methods. Single-stage algorithms directly generate ultimate predictions through a single forward pass. Initially, the input image needs to be preprocessed, followed by feature extraction through convolutional operations. These extracted features are then fed into the detection head, where object localization and classification are performed to obtain the final detection results. Representative single-stage algorithms include the SSD [
2] and YOLO [
3] series. Conversely, two-stage algorithms operate in a sequential manner. First, region proposal networks generate candidate proposals for potential object locations, which are subsequently mapped to a fixed size. Second, a feature extraction network is used to extract target features from the candidate regions, after which object classification and localization are performed. Lastly, non-maximum suppression (NMS) is applied to eliminate redundant bounding boxes, providing the final detection results. R-CNN [
4] and Fast R-CNN [
5] are the representative two-stage algorithms.
With the continuous advancement of object detection methods, researchers have been striving to enhance detection accuracy in complex environments. In underwater image detection tasks, feature fusion and many attention mechanisms are widely employed to enhance the extraction of feature information. Ranjith Dinakaran et al. [
6] proposed a cascaded framework, named DCGAN + SSD, which combines SSD with a deep convolutional generative adversarial network (DCGAN) for underwater object detection. While this model achieved higher detection accuracy than the original SSD, its inference speed was inadequate for real time detection in autonomous underwater vehicles (AUVs). Other researchers, such as Duo et al. [
7], leveraged convolutional neural networks (CNNs) for marine data reconstruction and classification. Zhang Lin et al. [
8] developed an improved algorithm based on Faster R-CNN for detecting fish school locations to assist in underwater device path planning and tracking. However, Faster R-CNN primarily relies on local convolution operations, limiting its ability to capture global contextual information. CNNs extract features mainly through convolution and pooling operations, which inherently restricts their receptive field and restricts their capability to extract fine details throughout multiple scales. Song et al. [
9] introduced a two-stage detection method, the Boosting R-CNN. This method incorporates a novel regional proposal network, RetinaRPN, along with a probabilistic inference pipeline and boosting reweighting. While this method demonstrated outstanding performance in detecting blurred and low-contrast underwater images, it still faced challenges in effectively modeling global features, such as spatial relationships and contextual information between objects. Jia et al. [
10] enhanced the structure of the EfficientDet detector and proposed a novel marine organism detection model, EfficientDet-Revised (EDR). By integrating an MBConvBlock with a channel shuffle module, this approach facilitated information exchange across feature channels by eliminating fully connected layers in the attention module and replacing them with convolutional operations, thereby reducing network parameters. This optimization facilitated feature fusion from multiple scales and enhanced the model’s performance to extract features from diverse objects. However, EDR suffered from low-resolution high-level features, leading to suboptimal detection performance for tiny and densely packed objects. Dai et al. [
11] proposed the ERL-Net method, which incorporated an edge-guided attention module to capture salient boundaries and proposed a multiscale feature aggregation module along with a wide, yet asymmetric, receptive field. While ERL-Net demonstrated strong performance in underwater object detection tasks, the asymmetric receptive field increased computational complexity, and the multiscale feature aggregation process potentially led to the loss of local details in small objects and interference between targets. Given the high accuracy and fast inference speed, YOLO-based algorithms have also been widely applied to marine object detection. Traditional YOLO models adopt FPN/PAN structures and anchor-based mechanisms, which often give rise to the loss of small object information. To address this limitation, we selected YOLOv11, which employs an anchor-free mechanism, eliminating the conventional anchor box design. Instead, it directly predicts the center coordinates, width, height, and class probability of target objects for detection. Furthermore, YOLOv11 optimizes feature fusion with its BiFPN/PAN structure, which selectively enhances key information through learnable feature-weighting mechanisms.
As object detection technology continues to evolve, researchers have concentrated on improving model accuracy in complex environments. Attention mechanisms are frequently integrated into networks to enhance the target feature extraction, enabling the model to focus on important semantic information, thereby improving both computational efficiency and accuracy. Hu et al. [
12] proposed SE-Net, which enhances inter-channel dependencies through the SE module, adaptively recalibrating channel feature responses. This improvement strengthens the network’s feature representation capabilities while maintaining effective generalization. However, SE-Net only considers channel attention while ignoring spatial information, resulting in a limited detection capability for object position and shape. Liu et al. [
13] introduced the global attention mechanism (GAM) module, which mitigates information loss and enhances global interaction representation. By introducing a 3D arrangement strategy, GAM preserves cross-dimensional information and utilizes a multi-layer perceptron (MLP) to reinforce dependencies between channel and spatial dimensions. Although GAM emphasizes global contextual information, this focus may come at the expense of local feature representation. Woo et al. [
14] proposed the convolutional block attention module (CBAM), which effectually addresses some limitations of previous attention mechanisms by incorporating both spatial attention and channel. The module of channel attention assigns weights to channel features to highlight “important” features, while the module of spatial attention assigns weights to spatial features to emphasize their “position”. This design enables the network to better concentrate on key information in images, leading to more accurate feature extraction and improved detection performance. However, CBAM employs global average pooling and convolution operations to compute attention weights, which leads to the increasing number of parameters and may result in the loss of small object details. Wang et al. [
15] introduced the efficient channel attention (ECA) module, which utilizes a local cross-channel interaction strategy using 1D convolution to efficiently compute channel attention. ECA adaptively selects the convolution kernel size, significantly reducing computational complexity while maintaining performance. However, the limited size of local convolutions restricts ECA’s ability to capture complex global features, making it less effective in modeling global information. Additionally, ECA primarily focuses on channel attention while neglecting spatial information. Ouyang et al. [
16] proposed the efficient multiscale attention (EMA) module, which reshapes part of channels into the batch dimension and partitions them into multiple sub-features to make sure the uniform distribution of spatial semantic features within each feature group. This approach preserves channel features while reducing computational resource wastage. Furthermore, EMA recalibrates channel weights for each parallel branch, the method encodes the information of global features and captures pixel-level relationships through cross-dimensional interaction. However, EMA mainly relies on global information, resulting in the weaker modeling of local spatial features. Si et al. [
17] introduced the spatial and channel synergistic attention (SCSA) module, which consists of two components: Shared multi-semantic spatial attention (SMSA) and progressive channel self-attention (PCSA). The former integrates multi-semantic information and employs a progressive compression strategy to inject discriminative spatial priors into the channel self-attention of the latter. This process effectively guides channel recalibration and alleviates semantic discrepancies between different feature levels.
The proposed YOLO-DAFS effectively improves the network’s ability of local spatial features processing and global features representation through the integration of lightweight, dual-kernel convolution, a dynamic detection head, a downsampler, an attention-free focal modulation network module, and a spatial channel synergistic attention module. This design ensures a balance between local and global feature extraction while considering computational efficiency. The model demonstrates strong performance in both image classification and object detection on the UTDAC2020 and DUO datasets. YOLO-DAFS achieves a real-time detection speed of 217 FPS, meeting critical real-time processing requirements. The model has a size of 6.5 M. Additionally, its computational complexity remains moderate at 7.1 GFLOPs, with only a 0.5 GFLOP increase over YOLOv11n. These characteristics make it well suited for integration into underwater detection systems.
3. Methods
3.1. YOLOv11 Network
This study employs YOLOv11n as the benchmark model and introduces a modified network based on it, referred to as YOLO-DAFS.
3.1.1. Backbone
The backbone of YOLOv11 consists of CBS, C3k2, SPPF, and C2PSA modules. The CBS module covers a standard convolutional layer (Conv), batch normalization (BN), and the SiLU activation. The C3k2 module, inspired by the ELAN structure in YOLOv7, improves gradient flow through additional inter-layer connections, enhancing feature representation. The SPPF module applies dimensionality reduction to the input feature maps via a convolutional layer followed by three max-pooling layers, before fusing and upsampling the feature maps to retain multiscale target information. SPPF is modified from the SPP structure but implemented differently. SPP uses parallel multiscale pooling, while SPPF innovatively achieves the equivalent effect by serially repeating the same pooling core, which makes SPPF improve its computational efficiency by about 30%, while maintaining its accuracy. The C2PSA module extends the C2 module by incorporating a pointwise spatial attention (PSA) block, which uses a multiple head attention mechanism and a feedforward neural network to improve feature extraction and contextual awareness.
3.1.2. Neck
The neck of YOLOv11 network utilizes the path aggregation network (PANet), a bidirectional feature fusion framework that integrates both top-down and bottom-up pathways. Higher-level features capture rich semantic information, while lower-level features preserve detailed spatial information. PANet’s fusion mechanism effectively combines these features, ensuring the final output retains both the spatial and semantic content.
3.1.3. Head
The detection head of YOLOv11 adopts a decoupled structure, incorporating two additional depthwise separable convolution modules into the classification–detection head of YOLOv8. The detection task in YOLO consists of object localization, which focuses on boundary information, and classification, which emphasizes texture features. The decoupled head extracts coordinate and classification information through independent network branches, enabling separate learning and output processing. The use of depthwise separable convolution reduces both the parameter count and complexity of computation while improving the model’s generalization ability.
3.2. Enhanced YOLOv11 Network
The YOLOv11 algorithm includes five versions: n, s, m, l, and x. This study selects YOLOv11n as the benchmark model due to its low parameter count and fast detection speed. Based on this, an improved YOLOv11n-based underwater object detection algorithm is proposed. The enhancements include integrating the DualConv [
18] module into the C3k module’s bottleneck to refine the backbone; incorporating ghost convolution and depthwise separable convolution into the dynamic head [
19] to replace the original YOLOv11 detection head; introducing the lightweight feature extraction module ADown to replace the convolutional modules used for feature extraction and downsampling in the backbone; and combining focal modulation [
20] with the C2 module to form the C2PSF. Additionally, the SCSA attention module is added before the detection head. The improved YOLOv11 network structure is illustrated in
Figure 1.
3.2.1. C3k2_Dual
The underwater environment is typically characterized by complex lighting conditions, scattering, and light attenuation, which result in low contrast between objects and backgrounds, making it difficult to distinguish color or texture features and resulting in false positives and missed detections. Additionally, underwater objects exhibit various scales, which presents a challenge for detection.
To boost the efficiency of information processing and the extraction feature of the backbone network, the lightweight DualConv with dual convolution kernels is integrated into the C3k2 module. The convolution filter structure of the DualConv is depicted in
Figure 2, where M represents the input channels’ number, N represents the convolution filters’ total number, and G indicates the number of convolution groups. A subset of the convolution kernels in the DualConv simultaneously perform 3 × 3 and 1 × 1 convolutions, while the remaining kernels perform only the 1 × 1 convolution. The N convolution filters are partitioned into G groups, each tasked with processing the entire input feature map. In each group, M/G input channels undergo processing by both 3 × 3 and 1 × 1 convolution kernels, while remanent (M − M/G) channels are subjected exclusively to 1 × 1 convolution kernel operations. This architecture effectively merges the principles of 3 × 3 group convolutions with 1 × 1 point convolutions. The former focus on extracting spatial features from localized regions of the feature map, emphasizing the shape and details of underwater organisms and enhancing local features, while efficiently organizing the convolution kernels to reduce model complexity and maintain the network’s representational ability. The latter serve as a global feature aggregator at the channel level, performing global channel information aggregation to effectively detect objects of varying scales.
Figure 3 illustrates the structures of the C3k, DualBottleneck, and bottleneck in C3k2-Dual.
3.2.2. DyHead-GDC
In object detection tasks, images often contain objects of different scales, and objects may appear in arbitrary shapes and positions within the image. Moreover, these objects may be represented through multiple modalities. Consequently, an effective object detection head must satisfy three key requirements to cope with these challenges. This study proposes a neoteric design, termed DyHead-GDC, which integrates a ghost depth-separable convolution (GDC) with the DyHead framework introduced by Xiyang Dai et al. This design not only reduces the parameter count and floating-point computations of DyHead but also maintains the detection accuracy. The dynamic detection head synergistically incorporates multiple attention mechanisms—operating across task-aware output channels, scale-aware feature hierarchies, and spatially aware locations—thereby enhancing its capacity to capture both localized details and global contextual features of objects. The elaborate structure of DyHead-GDC is depicted in
Figure 4, where the modulated DeformConv, spatial attention, and DyReLU activations correspond to the scale-, spatial-, and task-aware attention modules, respectively. The scale-aware attention module functions along the feature layer dimension, dynamically adjusting the weights assigned to multiscale features. This adaptability enables the detection head to more effectively select appropriate feature layers for objects of varying scales, thereby improving the representation of multiscale objects with an emphasis on global feature extraction. The spatial-aware attention module operates within the spatial dimension, leveraging deformable convolutions to dynamically adjust sampling points. This mechanism allows the network to prioritize critical regions of the feature map during training, placing a greater emphasis on local feature enhancement. Meanwhile, the task-aware attention module operates along the channel dimension, enabling distinct channels to adaptively specialize in tasks such as object classification and bounding box regression.
The GDConv module proposed in this work integrates ghost convolution [
21] with depth-separable convolution [
22] to effectively decrease both the parameters and the complexity of computation of the detection head. The ghost depth-separable convolution approach partitions the convolution process into two stages: initially, a standard convolution is employed to produce a small amount of main features; subsequently, depth-separable convolution is applied to these primary features to generate additional ghost features. The primary and ghost features are then concatenated, followed by batch normalization and an activation function to yield the final output features. By leveraging cost-efficient convolutions to generate an increased number of feature maps, this method significantly alleviates the computational burden and reduces the number of model parameters. Experimental evaluations demonstrate that the incorporation of ghost depth-separable convolution in DyHead-GDC results in a reduction of approximately 206,000 parameters and 1.2 GFLOPs compared to the original DyHead, while preserving the equivalent accuracy of detection. The architectural details of the GDConv module are illustrated in
Figure 4.
3.2.3. ADown
In the process of extracting object features in YOLO networks, multiple downsampling operations are typically performed. This can lead to a weakening of the object’s feature information. Therefore, an efficient downsampling module is crucial for the network’s feature extraction. This paper adopts the ADown [
23,
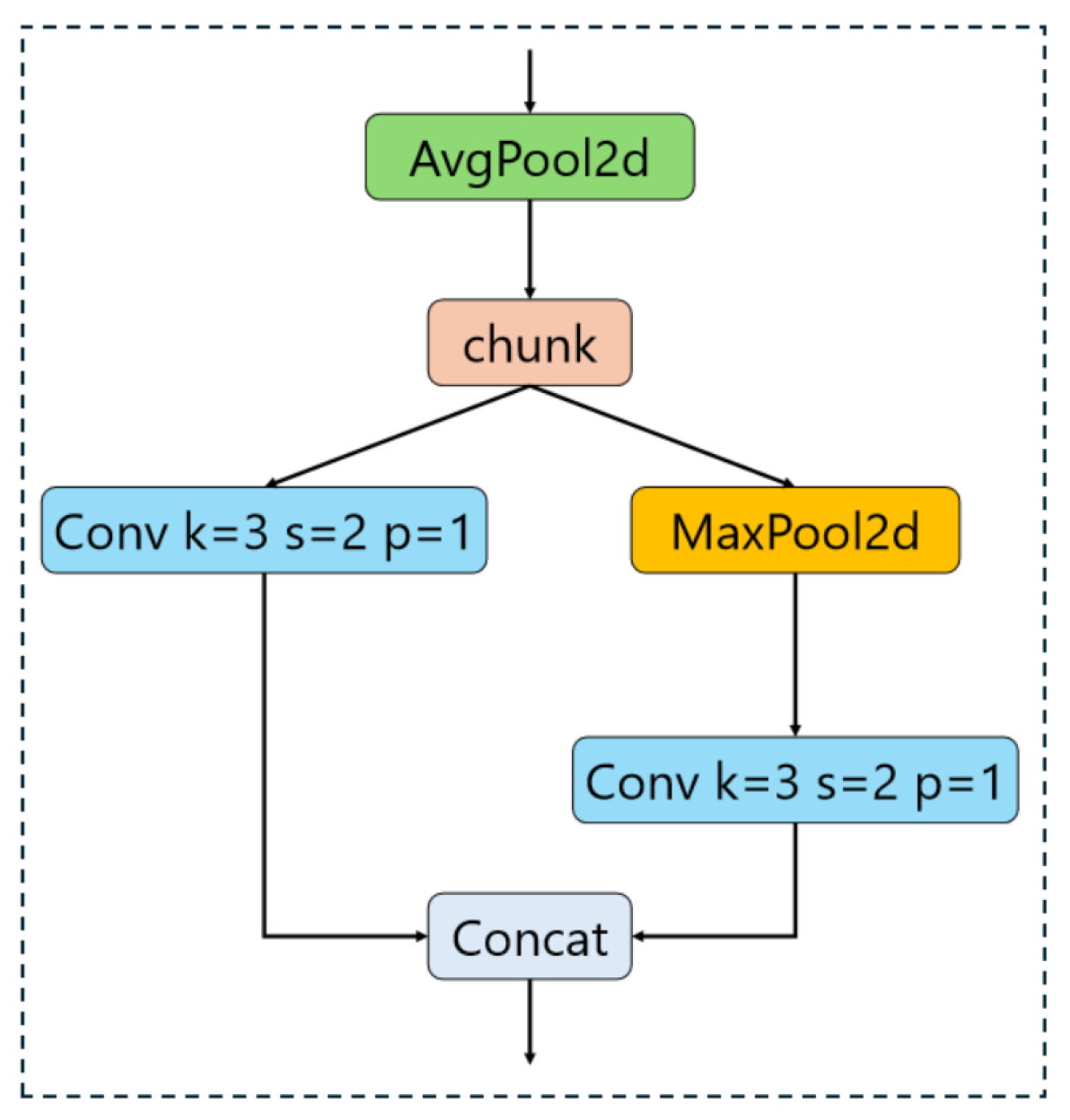
24] module as a substitute for the conventional backbone feature extraction and downsampling processes. The core objective of this module is to execute downsampling while simultaneously amplifying the receptive field of the feature maps, thereby enabling the capture of information across a broader spatial extent. This approach not only reduces the parameters of the model but also enhances its accuracy. It utilizes two different paths to process the input data.
One pathway applies spatial downsampling to half of the input channels followed by convolution, which aids in preserving richer contextual information;
The other pathway performs max pooling on the remaining half of the channels before applying convolution, enabling the extraction of localized maximum feature values.
The ADown module’s architecture is illustrated in
Figure 5. This configuration enables the network to capture finer details during the downsampling process. By employing convolution kernels of varying sizes and diverse pooling techniques, the module enhances the richness of the feature representation. Ultimately, the outputs from the two embranchments are concatenated, yielding a comprehensive feature representation that effectively combines information derived from distinct receptive fields.
3.2.4. Attention Module
In object detection tasks, it is imperative for the model to effectively capture both local, fine-grained features and global contextual information. In scenarios with intricate background environments, the inadequate comprehension of the global context or the insufficient modeling of global information can impede the model’s capability to differentiate between target object and background or neighboring objects. This deficiency may lead to the erroneous classification of background regions as objects or the loss of critical object features within a complex surrounding background, consequently diminishing the detection accuracy.
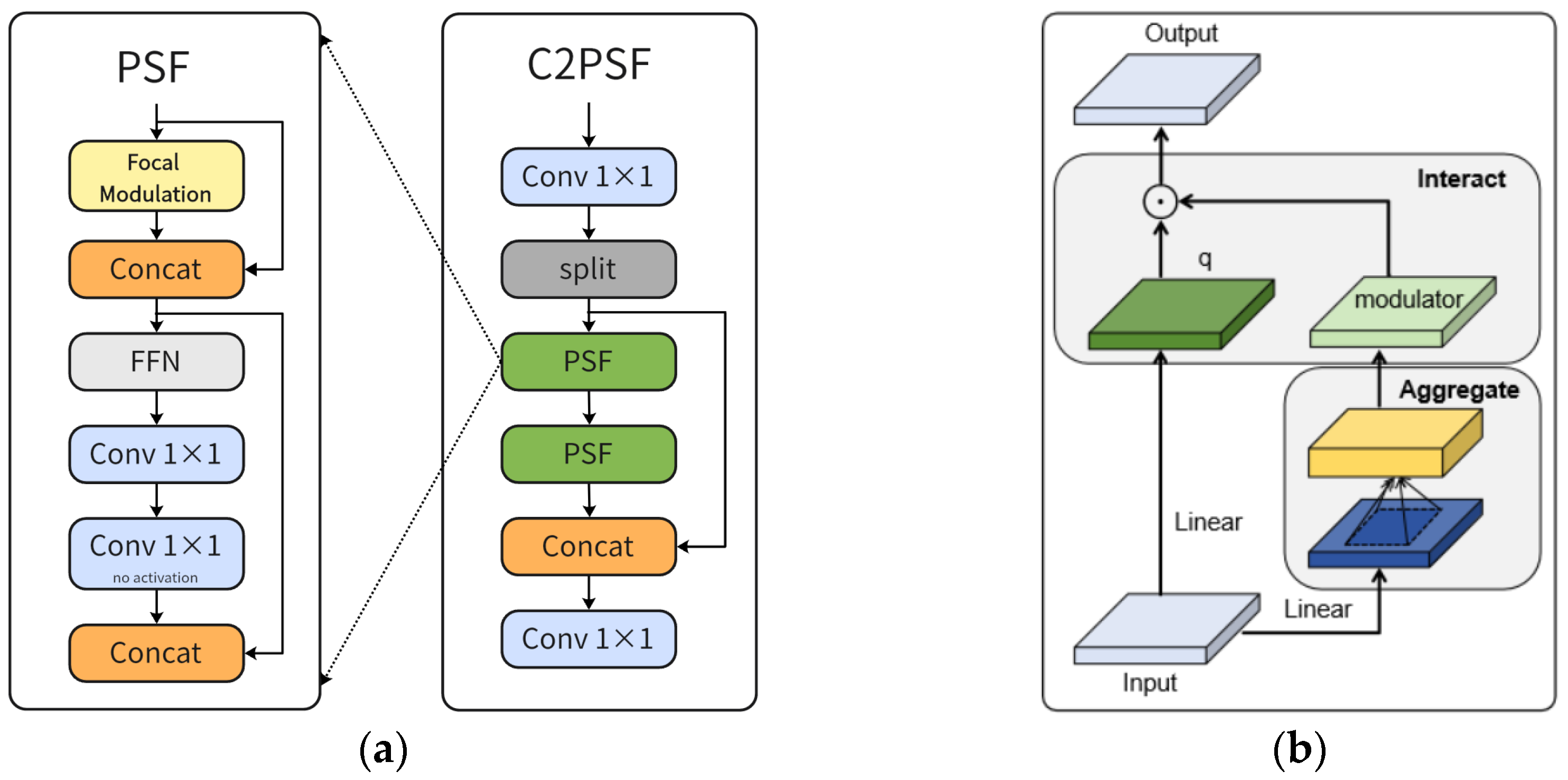
Figure 6 depicts the architectural details of the C2PSF and focal modulation modules. This paper replaces the existing attention mechanism with the focal modulation module, combining it to form the C2PSF module. This modification aims to bolster the model’s multiscale representation capacity, feature extraction proficiency, and ability to process global contextual information, particularly for detecting small objects and handling complex background scenarios. The focal modulation mechanism consists of three key components: focal context contextualization, gated aggregation, and element-wise affine transformation. Focal context contextualization is accomplished through a sequence of deep convolutional layers that encode visual context across a spectrum of spatial ranges, from short to long distances. These layers effectively extract visual features at varying scales, enabling the network to comprehend multiple levels of image content. Gated aggregation selectively gathers contextual information for each query token and incorporates it into the modulator via a gating mechanism, allowing the model to efficiently consolidate pertinent contextual features. This step enhances the model’s capability to differentiate objects from the background while preserving sensitivity to local details and improving its grasp of the global structure. The element-wise affine transformation embeds modulation information into the query, enabling the model to dynamically adjust query tokens based on contextual cues. This refinement strengthens the capacity of model to capture and represent critical visual features, thereby elevating detection performance in intricate or dynamic visual settings.
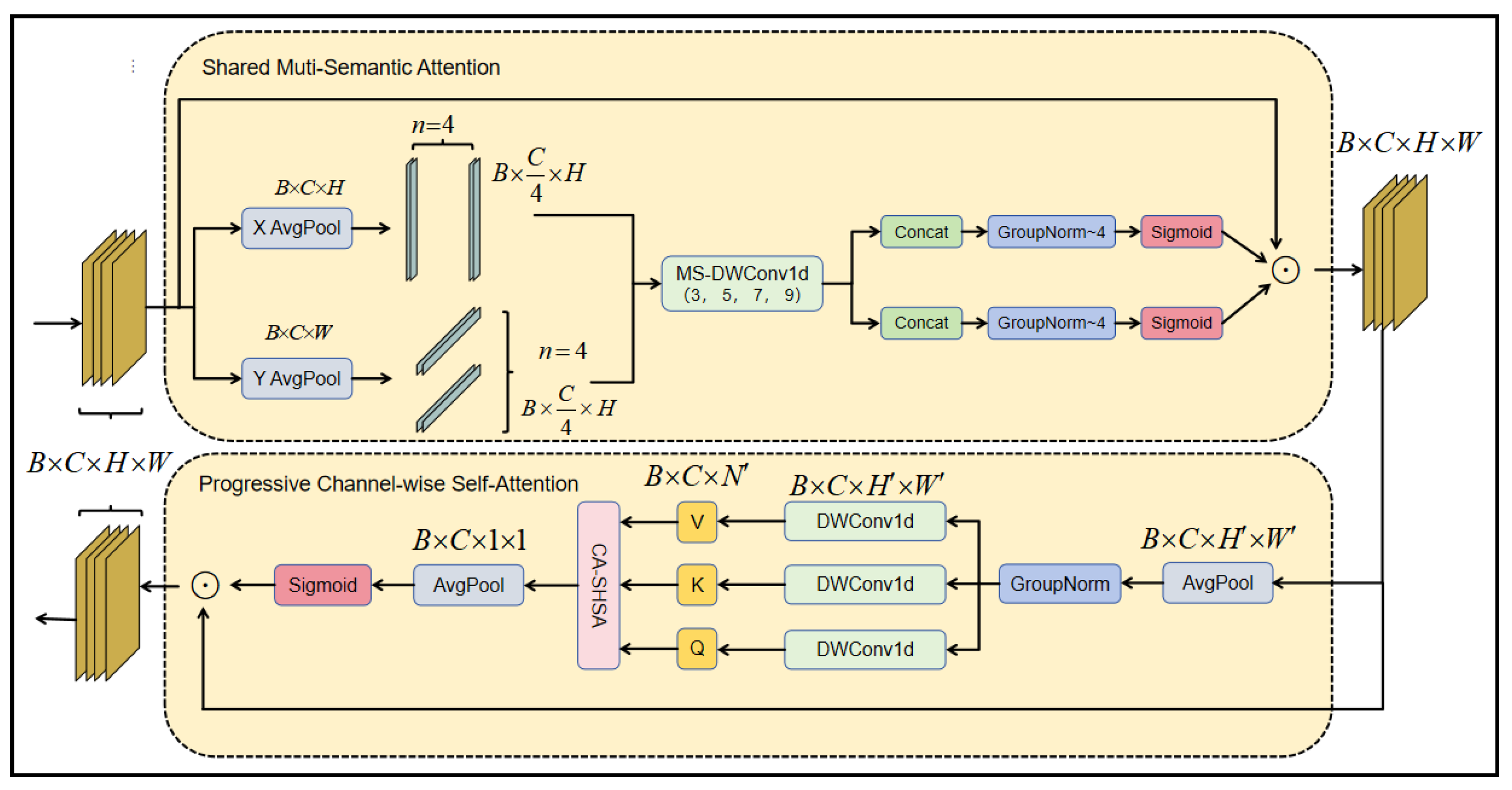
Furthermore, the SCSA module is incorporated between the feature pyramid and the detection head. The SCSA module comprises two sub-modules: SMSA and PCSA, which are integrated in a sequential, modular fashion. The SMSA sub-module extracts comprehensive semantic features from the multiscale spatial information provided by the feature pyramid, employing a progressive compression strategy to infuse this spatial information into the PCSA sub-module. Subsequently, PCSA efficiently calculates similarities among inter-channels, mitigating semantic disparities among the sub-features derived from SMSA. This collaborative mechanism enhances the model’s feature representation capacity, thus improving the detection accuracy in complex scenarios. The architectural design of the SCSA module is illustrated in
Figure 7.
Focal modulation replaces traditional self-attention mechanisms to achieve multiscale contextual fusion with linear computational complexity, thereby addressing scale variations of underwater targets.
SCSA focuses on cross-channel relationship modeling and spatial detail enhancement, specifically designed to mitigate background interference and small object omission.
The two modules employ a stage-wise processing strategy to prevent a functional overlap:
4. Experiment
4.1. Datasets
To demonstrate the efficacy of the proposed approach, we performed comprehensive experiments on the UTDAC2020, DUO, and RUOD datasets. The datasets were divided into training, testing, and validation sets in a ratio of 8:1:1.
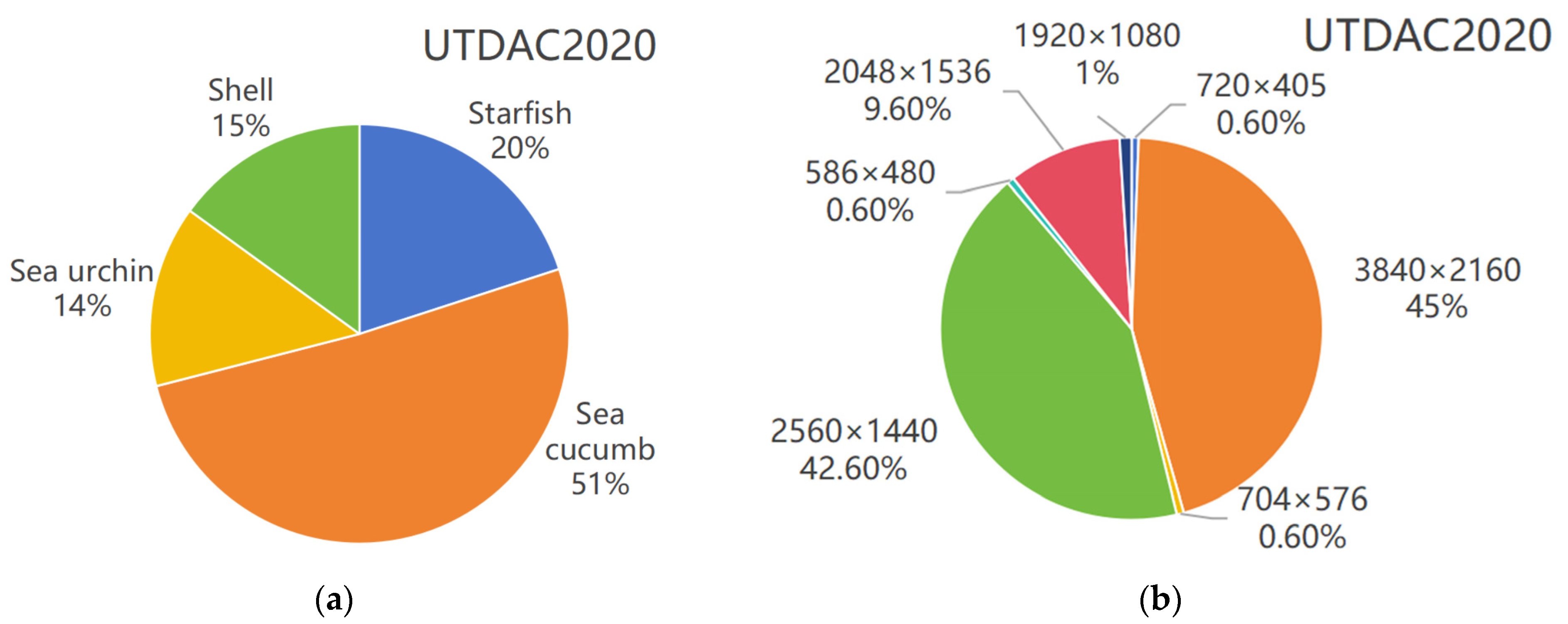
The UTDAC2020 dataset comprises 7383 annotated images spanning four marine species categories: sea urchins, starfish, sea cucumbers, and scallops. The dataset exhibits significant resolution diversity, with image dimensions ranging from high-definition (3840 × 2160, 2560 × 1440) to standard resolutions (2048 × 1536, 1920 × 1080) and smaller formats (720 × 405, 704 × 576, 586 × 480). The detailed information of the dataset is shown in the
Figure 8.
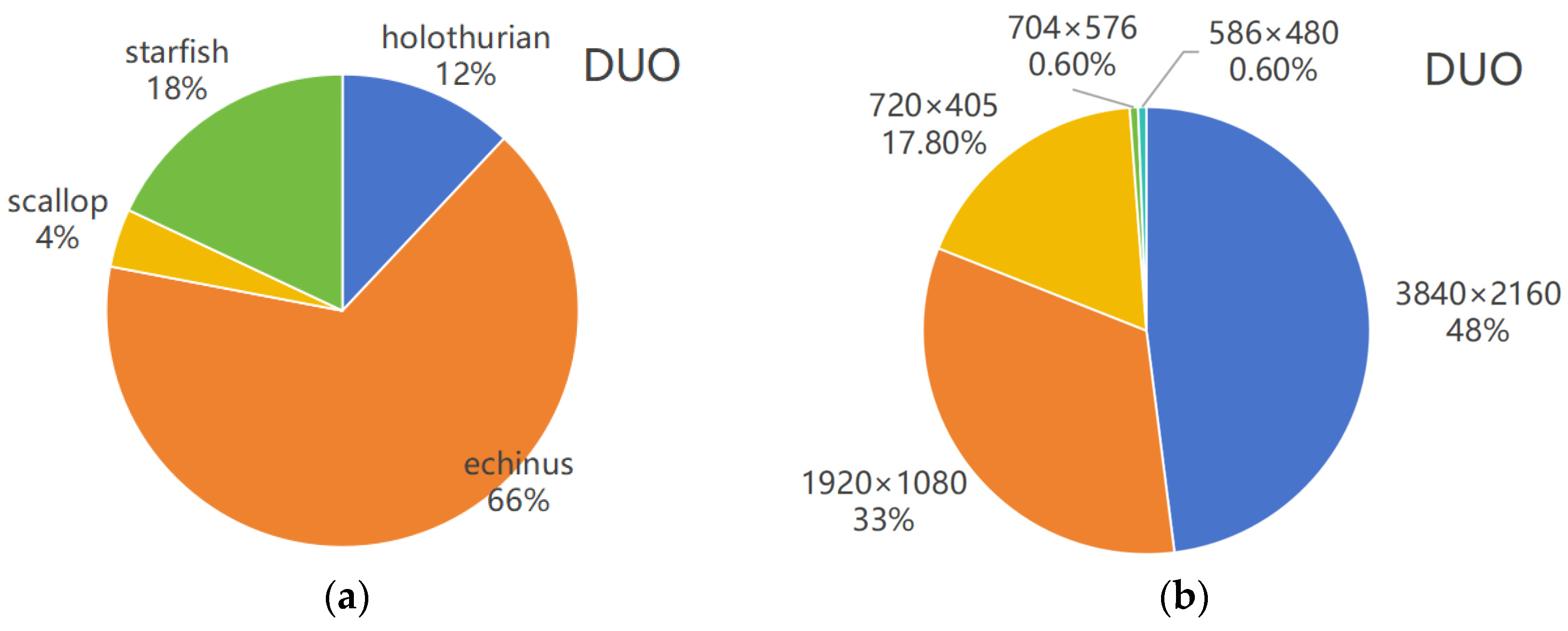
The DUO dataset contains 7782 annotated underwater images representing four distinct marine organism categories: needle urchins, sea cucumbers, scallops, and starfish. The image collection spans multiple resolution standards, including ultra-high definition (3840 × 2160), full HD (1920 × 1080), and various lower resolutions (ranging from 720 × 405 to 586 × 480 pixel dimensions). The detailed information of the dataset is shown in the
Figure 9.
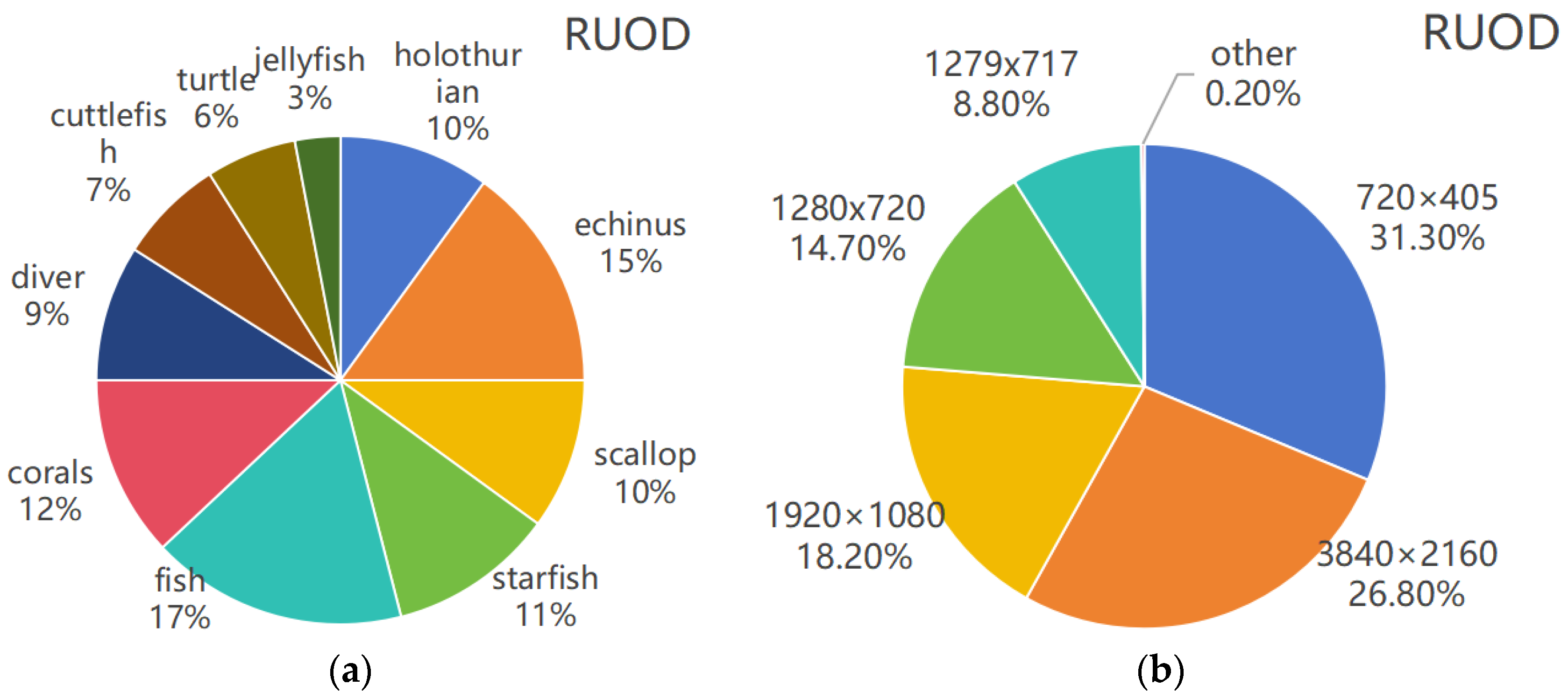
The RUOD dataset contains 14,000 annotated underwater images representing 10 different categories of marine life: sea cucumbers, sea urchins, scallops, starfish, fish, coral, diver, cuttlefish, turtle, jellyfish. The images are captured across a variety of resolution standards, including ultra HD (3840 × 2160), full HD (1920 × 1080), and a total of more than 3048 different resolutions. In
Figure 10. only several common resolutions are listed. The detailed information of the dataset is shown in the
Figure 10.
4.2. Experimental Setting
In this study, the experimental configuration is specified as follows: the operating system is Windows, the processor is an Intel® Core™ i9-14900KF (Santa Clara, CA, USA), the graphics card is an NVIDIA GeForce RTX 4070Ti SUPER (16 GB), Santa Clara, CA, USA, and the memory is 64 GB. The proposed methods were implemented in Python 3.9.20 and experimentally validated using PyTorch 2.3.1 with CUDA 12.1. Given GPU memory constraints, we configured a batch size of 16. This study employes the Stochastic gradient Descent (SGD) optimizer with momentum because it uses only one or a small number of samples at a time to update the model, which results in fast computation and low memory consumption. At the same time, the randomness of an SGD gradient update can avoid falling into the local optimum and improve the generalization ability of the model.
To mitigate potential model overfitting, we conducted preliminary experiments to determine the optimal number of training epochs for each dataset. Based on the observed convergence behavior of the loss function, we fixed the training duration at 100 epochs for both the UTDAC2020 and DUO datasets, as further training beyond this point did not yield significant improvements. Furthermore, Mosaic data augmentation was employed, providing an additional safeguard against overfitting.
4.3. Experimental Metrics
In this study, the evaluation metrics employed include the mean average precision (mAP), parameters (Params), and Giga floating-point operations per second (GFLOPS). These metrics collectively gauge the overall efficacy of the detection approach across all categories. For the assessment of mAP, two distinct Intersection over Union (IoU) thresholds were utilized: mAP50 and mAP50:95.
To compute mAP, precision (P) and recall (R) need to be calculated, and the mathematical formulation can be expressed as follows:
where TP (True positive) indicates how many positive samples are accurately identified, FP (false positive) corresponds to the number of negative samples falsely classified as positive, TN (True negative) represents the count of negative samples accurately identified, and FN (false negative) denotes the number of positive samples mistakenly classified as negative.
The formula for the mAP is given as follows:
In Equation (4), APᵢ denotes the average precision (AP) for the i-th category, with N representing the total number of categories within the dataset. The AP quantifies the model’s performance for one specific category, whereas the mAP is computed as the average of the AP values across all categories, offering a unified metric to evaluate the model’s overall effectiveness.
The Params refers to the total trainable parameters in the network, representing the computational space complexity. The GFLOPS measures the computational time complexity, indicating the number of floating-point operations executed per second in billions. Numerically, GFLOPS is equivalent to the total Giga floating-point operations (GFLOPs) performed in one second.
The formulas for computing the Params and floating-point operations (FLOPs) for a given convolutional layer are as follows:
In Equation (5), K represents the kernel size of the convolution, where h and w denote the height and width of the kernel, respectively. C represents the number of channels, with in and out indicating the number of input and output channels, respectively. In Equation (6), H and W denote the height and width of the input tensor.
4.4. Results
To examine the efficiency of the proposed algorithm, we performed ablation studies on the YOLO-DAFS model utilizing the UTDAC2020 and DUO datasets. Additionally, we benchmarked our approach against cutting-edge methods using the same UTDAC2020 and DUO datasets. Through comprehensive experimentation, we substantiated the effectiveness of the proposed methodology.
4.4.1. Ablation Experiment
We conducted ablation experiments on both the UTDAC2020 and DUO datasets to evaluate the efficacy of the proposed enhancements. As presented in
Table 1 and
Table 2, method A denotes the integration of the C3k2-Dual module, B signifies the adoption of the DyHead-GDC detection head, C indicates the incorporation of the ADown module, D corresponds to the implementation of the C2PSF module alongside the SCSA attention mechanism.
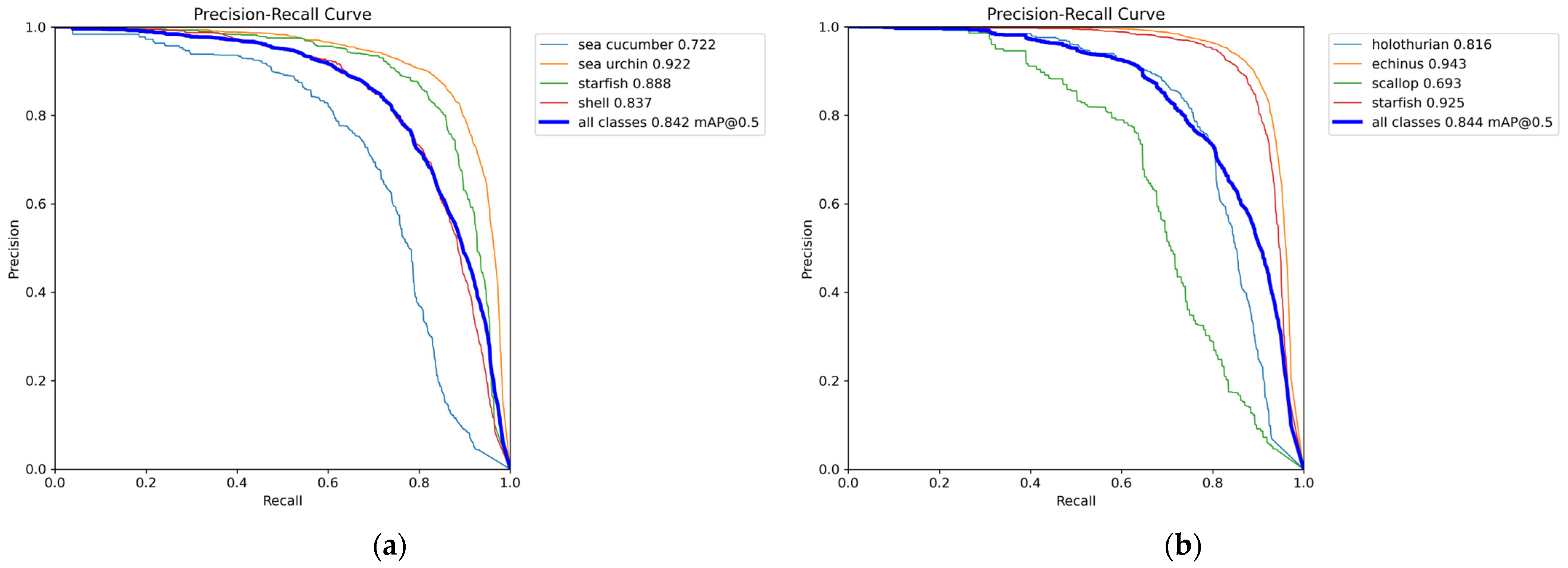
Figure 11 shows the comparison of the precision-recall curves of YOLO-DAFS on the UTDAC2020 and DUO datasets.
To rigorously evaluate the individual and joint effects of C2PSF and SCSA, we conduct controlled the experiments on the UTDAC2020 and DUO datasets by gradually integrating each module into YOLOv11n + A + B + C. The relevant ablation experiment results are shown in
Table 3. When deployed alone, C2PSF is mainly used to achieve multiscale context fusion, but mAP50 showed a slight performance degradation of 0.5% and 0.5% on two datasets, mAP50:95 showed a slight performance degradation of 0.1% and 0.8% on two dataset. When deployed alone, SCSA is mainly used to mitigate background interference and small target misses and reduce semantic differences between sub-features, but the performance of mAP50 was decreased by 0.4% and 0.9% on two datasets, the performance of mAP50:95 was decreased by 0% and 0.8%. However, their combined ensemble showed a synergistic performance: the full model (A + B + C + D) achieved a 0.7% and 0.2% mAP50:95 boost, confirming that C2PSF’s multiscale context normalization and SCSA’s spatial channel refinement are complementary and not overlapping. This was physically manifested, as the backbone processing features of C2PSF provided scale-invariant priors for SCSA’s subsequent noise suppression and detail recovery in the detection head. This pipeline specialization is critical for underwater scenes, further validating the effectiveness of the staged attention design.
4.4.2. Visualization
The qualitative comparison of visualization outcomes is depicted in
Figure 12. In this figure, (a) illustrates the ground truth images, featuring bounding boxes and category annotations that are either manually or algorithmically generated to assess the precision of the detection algorithm. Subfigure (b) displays the detection outcomes of the YOLOv11n algorithm, whereas (c) showcases the detection results of the YOLO-DAFS algorithm (our proposed method).
From the visual analysis, it is evident that YOLO-DAFS surpasses YOLOv11n in detection accuracy for both single-object and multi-object scenarios, exhibiting greater robustness and consistency. Conversely, YOLOv11n demonstrates instances of false positives and missed detections in specific cases, while YOLO-DAFS achieves more precise target identification and a reduced false positive rate. Furthermore, under challenging environmental conditions—such as substantial lighting variations, significant occlusions, or pronounced background interference—YOLO-DAFS sustains superior detection accuracy. In contrast, YOLOv11n proves more vulnerable to such perturbations, resulting in less reliable detection performance. These advancements underscore the efficacy of YOLO-DAFS in addressing complex detection challenges.
To further elucidate the performance improvements of the proposed method in object detection tasks, we employed the LayerCAM algorithm for a heatmap-based visualization analysis, comparing the attention distributions of YOLO-DAFS and YOLOv11n.
LayerCAM leverages gradient information from feature layers to produce highly interpretable heatmaps, emphasizing the regions of focus within the model and facilitating an in-depth evaluation of enhancements in detection accuracy. The visualization results are presented in
Figure 13, where (a) depicts the ground truth images, annotated with manually or algorithmically defined bounding boxes and category labels for accuracy assessment. Subfigure (b) illustrates the heatmap visualization derived from the three-layer feature pyramid output of YOLOv11n using LayerCAM, while (c) presents the corresponding heatmap visualization for the three-layer feature pyramid output of YOLO-DAFS. The analysis reveals that YOLO-DAFS demonstrates a more focused attention distribution, precisely encompassing the target regions, thereby outperforming YOLOv11n. In contrast, YOLOv11n occasionally exhibits inadequate attention to target areas or erroneous focus on background elements in certain instances. These findings underscore the enhanced feature extraction and target discrimination capabilities of YOLO-DAFS, which enable more effective object localization and contribute to improved detection accuracy and reliability.
4.4.3. Comparison with Other Methods
To thoroughly assess the efficacy of the proposed method, we conducted comparisons with several established approaches using the UTDAC2020 and DUO datasets. As detailed in
Table 4, the proposed method exhibits competitive performance across multiple metrics, including mAP50, mAP50:95, model parameters, and floating-point operations (FLOPs), evaluated on both datasets.
In order to comprehensively verify the generalization ability of the model, this study uses a new independent dataset, RUOD. This dataset not only adds new species to the target category not covered by the previous two but also expands the diversity of the test environment by constructing a new collection scenario. This rigorously designed validation framework provides a more reliable benchmark for evaluating the adaptation of models in real, complex scenarios.
The results of YOLO-DAFS on these datasets highlight its proficiency in underwater object detection. As evidenced in
Table 4, the proposed model not only delivers high detection accuracy but also retains an advantage in terms of model efficiency. This benefit can be attributed to the lightweight network architecture inherited from the original YOLO framework. In addition, the performance on the RUOD dataset also verifies the generalization ability of the proposed method beyond the UTDAC2020 and DUO datasets.
5. Conclusions
Research on underwater object detection holds substantial value for marine environment and resource development, conservation efforts, and biodiversity preservation. It empowers scientists and engineers to monitor marine organisms, underwater terrain, and environmental changes with greater efficiency and precision. Moreover, underwater object detection is pivotal in marine archaeology and military applications. In archaeological contexts, it facilitates the accurate identification of historical relics and artifacts, while in military scenarios, it enhances the effectiveness and security of underwater combat and defense systems.
In this study, we introduced a composite-enhanced model, YOLO-DAFS, built upon the YOLOv11 framework. This model incorporates a lightweight dual convolution mechanism into the C3k2 module, where one convolutional kernel captures spatial features and another integrates feature information. A group convolution strategy was employed to optimize the arrangement of convolutional kernels, reducing the model complexity while maintaining robust network representation capabilities. Additionally, DyHead-GDC was implemented to improve the model’s perception across the scale, spatial, and task dimensions, thereby elevating the detection accuracy. DyHead combined with GDConv for lightweight processing reduces the number of parameters and the computational requirements while maintaining the performance of the dynamic detection head. A novel lightweight downsampling module, ADown, was introduced, combining convolutional kernels of varying sizes with pooling operations to enhance feature representation. Within the attention mechanism, the C2PSA module was replaced by a focal modulation-based C2PSF module, and the SCSA module was integrated prior to the detection head, further refining the model’s performance in visual tasks. The collaborative design of C2PSF and SCSA helps solve the key challenges of underwater object detection: C2PSF handles object size changes through multiscale feature fusion, and SCSA enhances small object detection and suppresses background interference through spatial channel joint attention. Ablation experiments show that the performance improvement when the two modules work together is significantly better than that when they are used alone, which verifies the complementarity between the modules. Experimental evaluations on the UTDAC2020 and DUO underwater datasets prove that YOLO-DAFS surpasses the baseline YOLO model across multiple datasets. In terms of lightweight optimization, the proposed approach refines the network architecture, achieving performance gains without a substantial increase in the parameter count. By optimizing weight-sharing mechanisms, streamlining feature extraction processes, and minimizing redundant parameters, the model incurs only an approximate increase of 0.6 M parameters and 0.5 GFLOPs compared to YOLOv11n, while delivering markedly improved detection performance.
In comparison to traditional detection methods, the lightweight YOLO-DAFS model maintains high accuracy with a reduced computational overhead, making it particularly advantageous for marine biology researchers studying marine organisms and their habitats. It also supports underwater rescue operations by enabling the rapid detection and localization of individuals requiring assistance. The model’s lightweight design renders it highly suitable for deployment on embedded edge computing platforms, such as Unmanned underwater vehicles (UUVs) and AUVs, thereby contributing significantly to marine exploration and monitoring tasks.
Despite its strong performance in underwater object detection, certain limitations remain. The detection accuracy may decline when underwater environments closely resemble target objects or when dataset class distributions are imbalanced. Future work will explore the integration of pruning and knowledge distillation techniques to further reduce the model parameters and the computational demands, aiming to deploy the processed model to the embedded device and striving for a more efficient lightweight detection network. Additionally, advanced deep learning methodologies will be investigated to bolster the model’s robustness in complex underwater settings.
The proposed YOLO-DAFS model is poised to advance marine biology research by assisting scientists in detecting and analyzing marine organisms and their habitats. It also offers practical utility in underwater rescue missions by enabling the swift identification and localization of individuals in distress, thereby broadening its real-world applicability.
6. Prospect
While the proposed method yields encouraging outcomes in underwater object detection, opportunities for refinement persist. The model size has expanded by approximately 1.2 M parameters relative to the baseline model. In the future, we aim to further enhance the model by implementing techniques such as pruning and knowledge distillation to achieve greater lightweight efficiency. In addition, we plan to put the pruned and knowledge-distillated model in environments with different turbidity, illumination, and color aberrations for embedded deployment testing. Moreover, we plan to investigate more effective and resource-efficient algorithms and methodologies to optimize the detection performance in increasingly challenging underwater environments, and we are optimistic about the potential of these efforts. In addition, we intend to test the generalization ability of the model to ensure the effectiveness of the model.
Dependence on RGB visual data alone imposes constraints in complex underwater settings. A prominent future direction involves multimodal data fusion to bolster detection capabilities in low-visibility conditions. For example, combining RGB data with sonar (acoustic imaging) could enhance perception in murky waters, while integrating RGB with polarized light could improve the resolution of underwater target textures and edges.
In underwater applications, such as marine organism monitoring, seabed exploration, and shipwreck investigations, real-time object detection and tracking are essential. Potential enhancements include the integration of multi-object tracking (MOT) algorithms, such as ByteTrack, to improve the tracking reliability in underwater contexts. The adoption of transformer-based tracking could leverage historical frame data to refine detection outcomes. Additionally, optimizing real-time inference through low-power solutions, such as TensorRT and ONNX acceleration, could enhance the computational efficiency and enable low-latency object detection on underwater platforms.
The future of underwater object detection is expected to progress toward lightweight, intelligent, and multimodal fusion frameworks, incorporating adaptive feature extraction, data augmentation, and efficient tracking technologies. These developments will facilitate the broader deployment of underwater drones and intelligent monitoring systems. As computational hardware evolves and open-source ecosystems advance, underwater object detection will assume a pivotal role in marine ecosystem surveillance, underwater archaeology, and AUVs, offering robust support for ocean exploration and conservation efforts.


 and
and 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}