
Research on Method for Intelligent Recognition of Deep-Sea Biological Images Based on PSVG-YOLOv8n


Abstract
1. Introduction
- (1)
- By integrating the PSA module and the C2f_SENetV2 module into both the backbone and neck networks, we have addressed issues such as color bias, low contrast, overexposure, and underexposure, thereby significantly enhancing the accuracy of the recognition of deep-sea organisms;
- (2)
- By incorporating the improved Slim-Neck module into the neck network, we have not only enhanced the model’s accuracy in recognizing deep-sea organisms but also reduced the complexity of the model;
- (3)
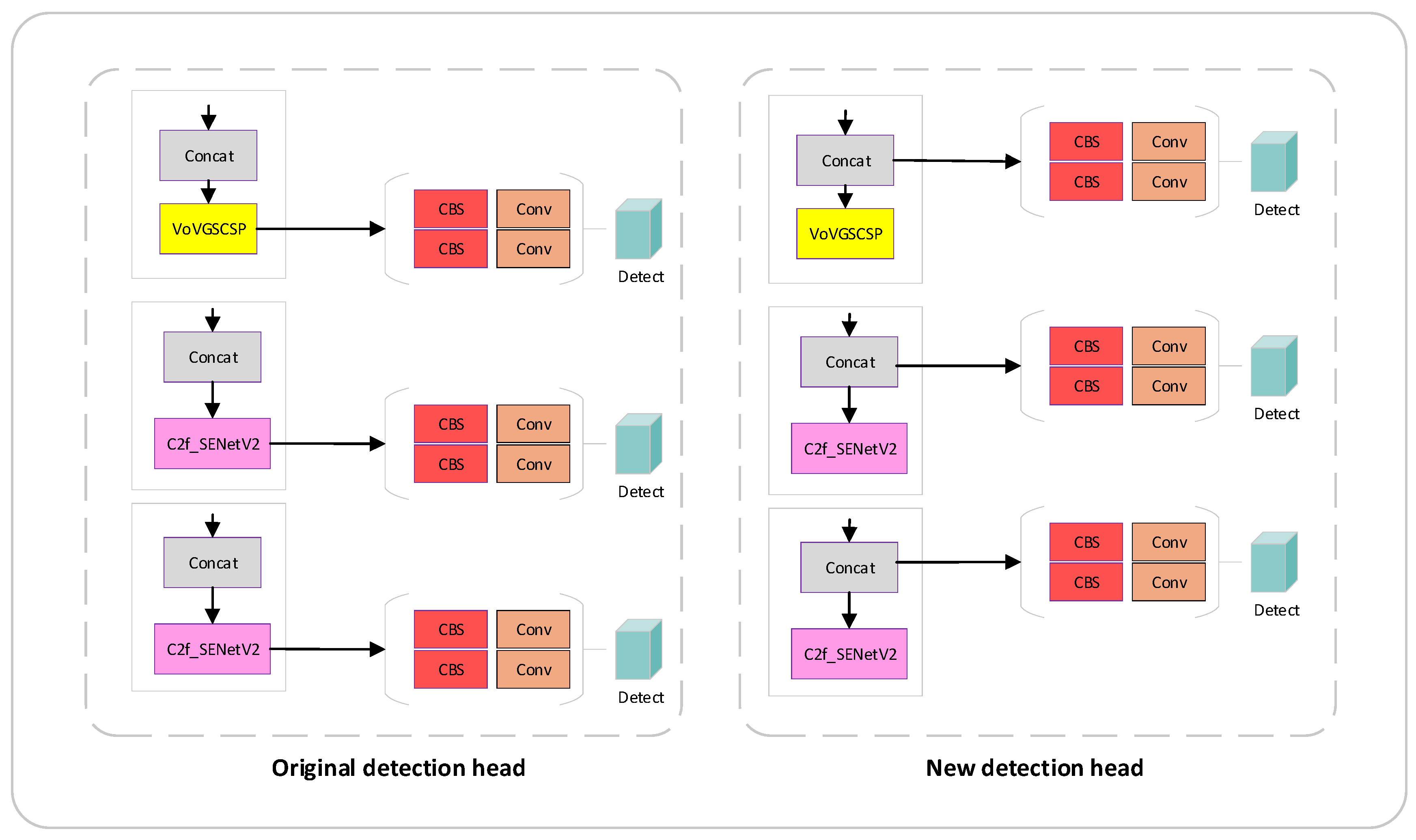
- We propose a novel detection head output scheme, which is more conducive to combining various models and improving the recognition accuracy;
- (4)
- We facilitated the identification and tracking tasks for the Jiaolong manned submersible, designed for deep-sea operations at depths of up to 7000 m, in carrying out tasks related to objects required for deep-sea work.
2. Method
2.1. YOLOv8n Network Architecture
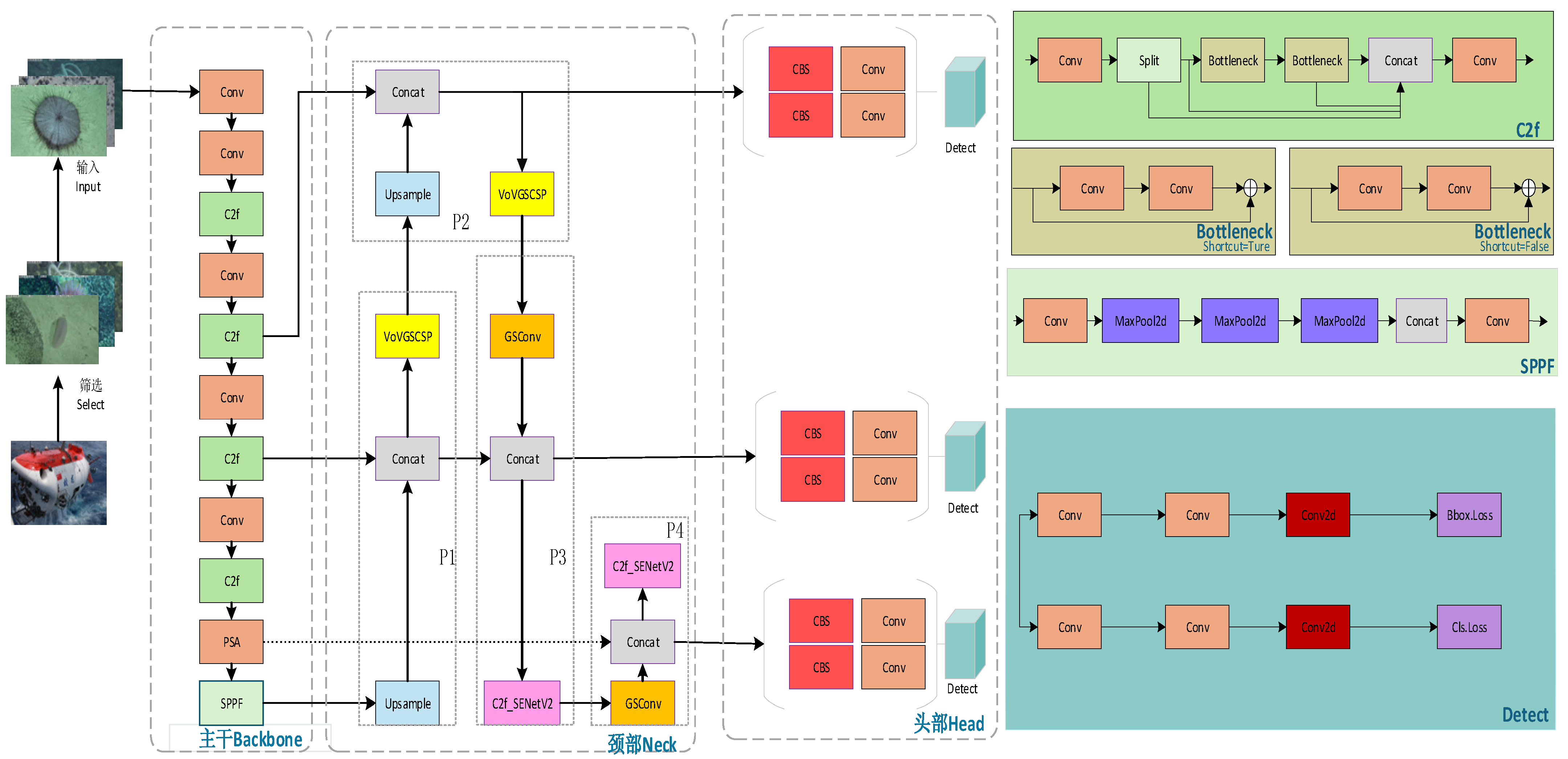
2.2. Improved YOLOv8n Model (PSVG-YOLOv8n Model)
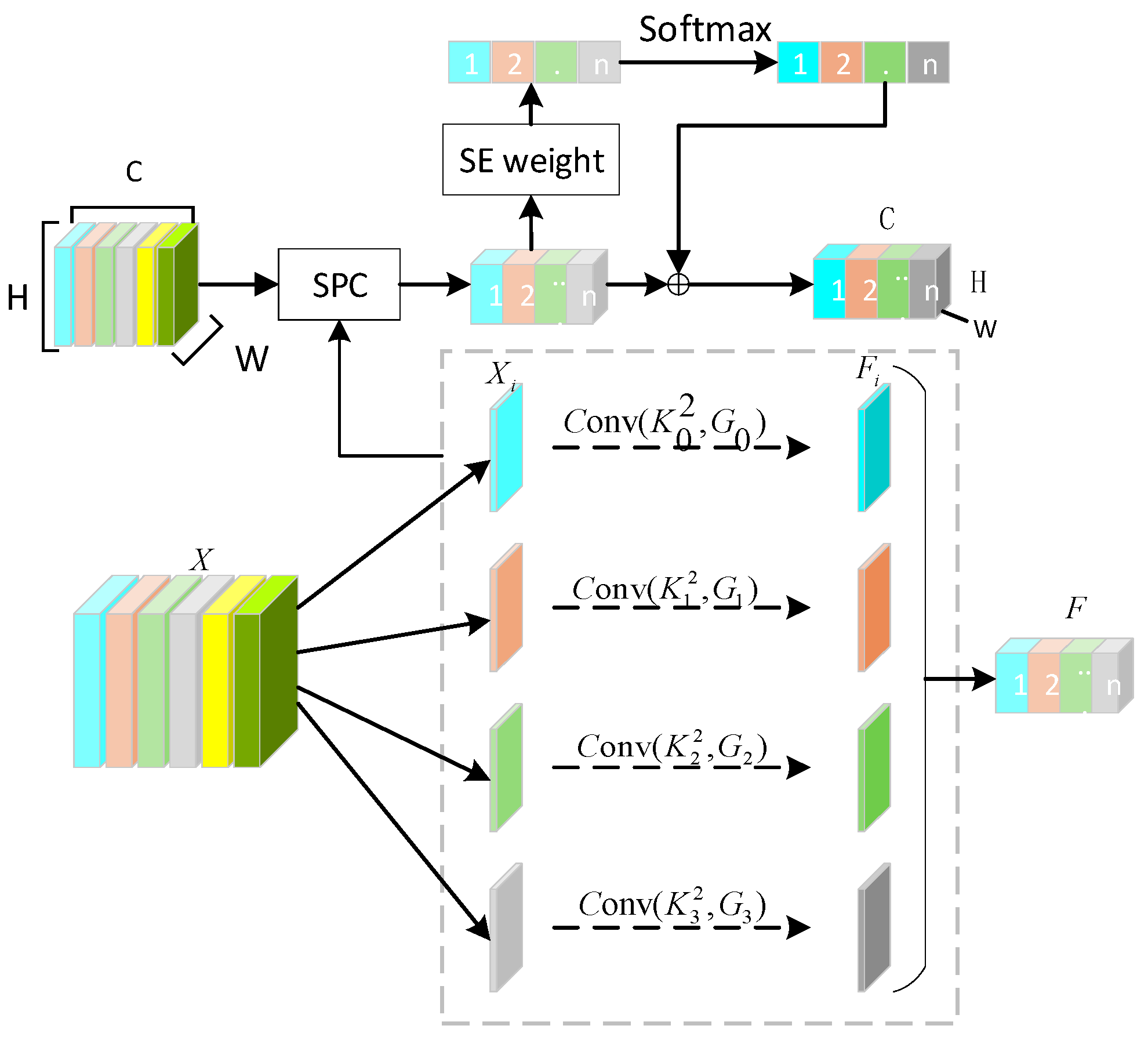
2.3. Efficient Pyramid Compression Attention Module (PSA)
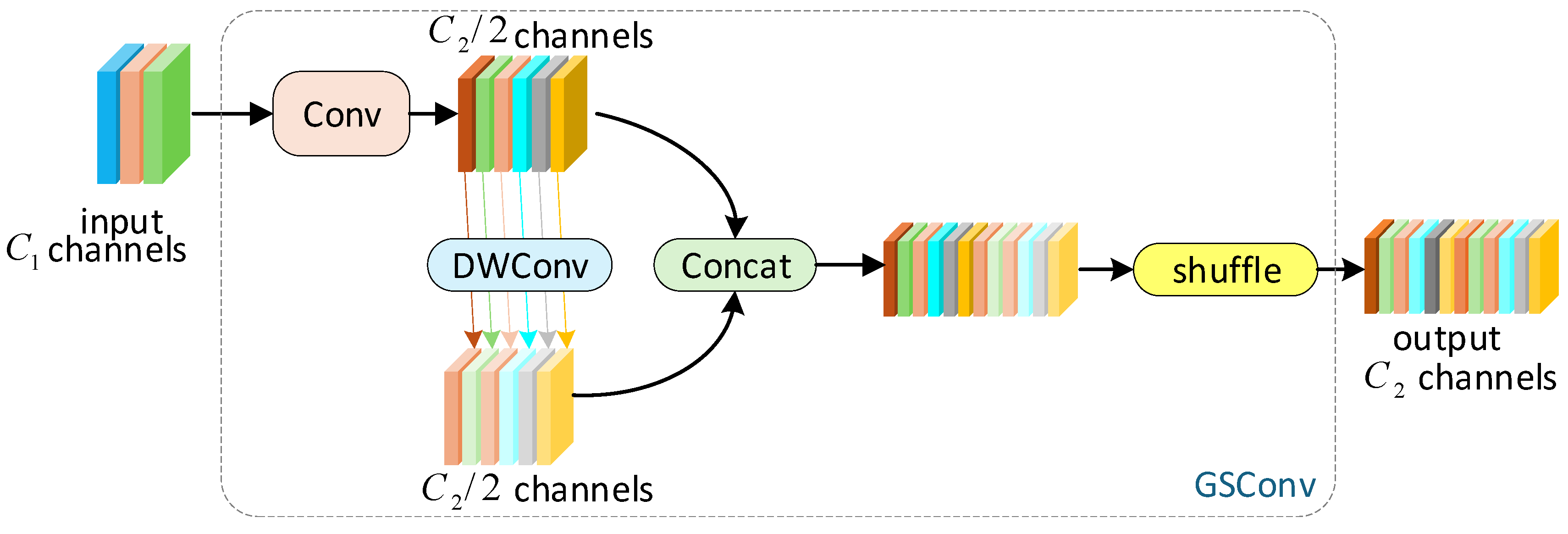
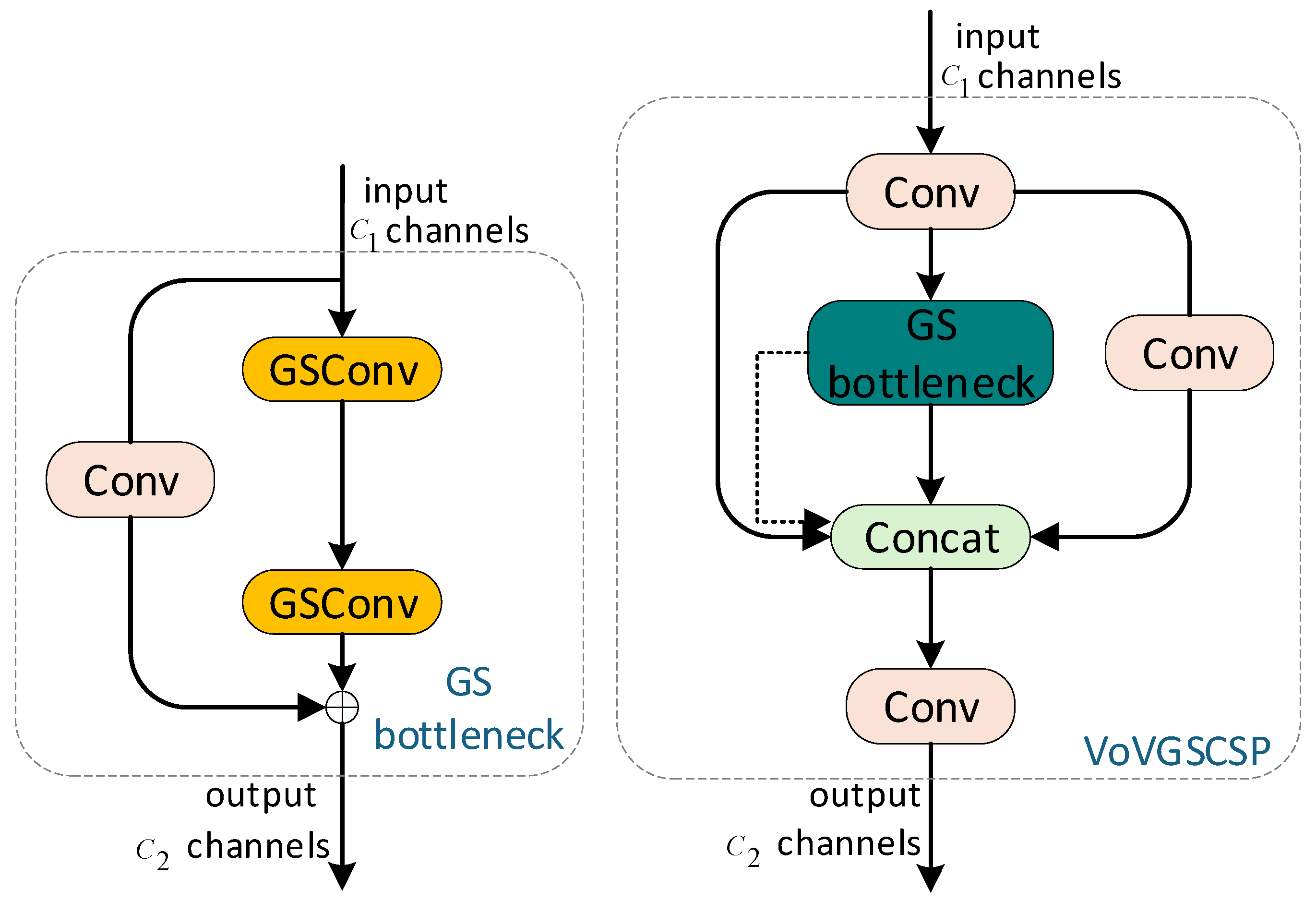
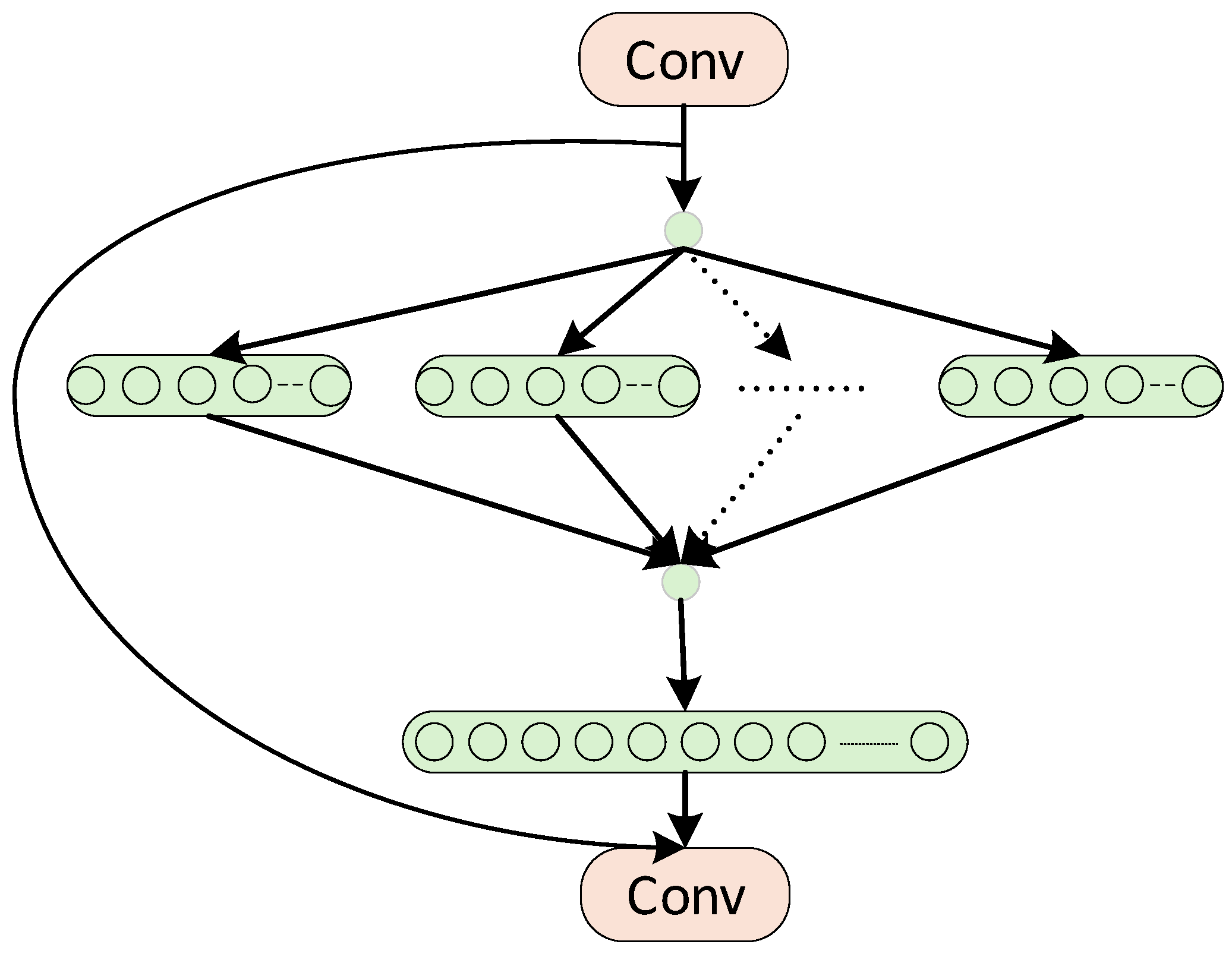
2.4. Slim-Neck Module (GSconv + VoVGSCSP)
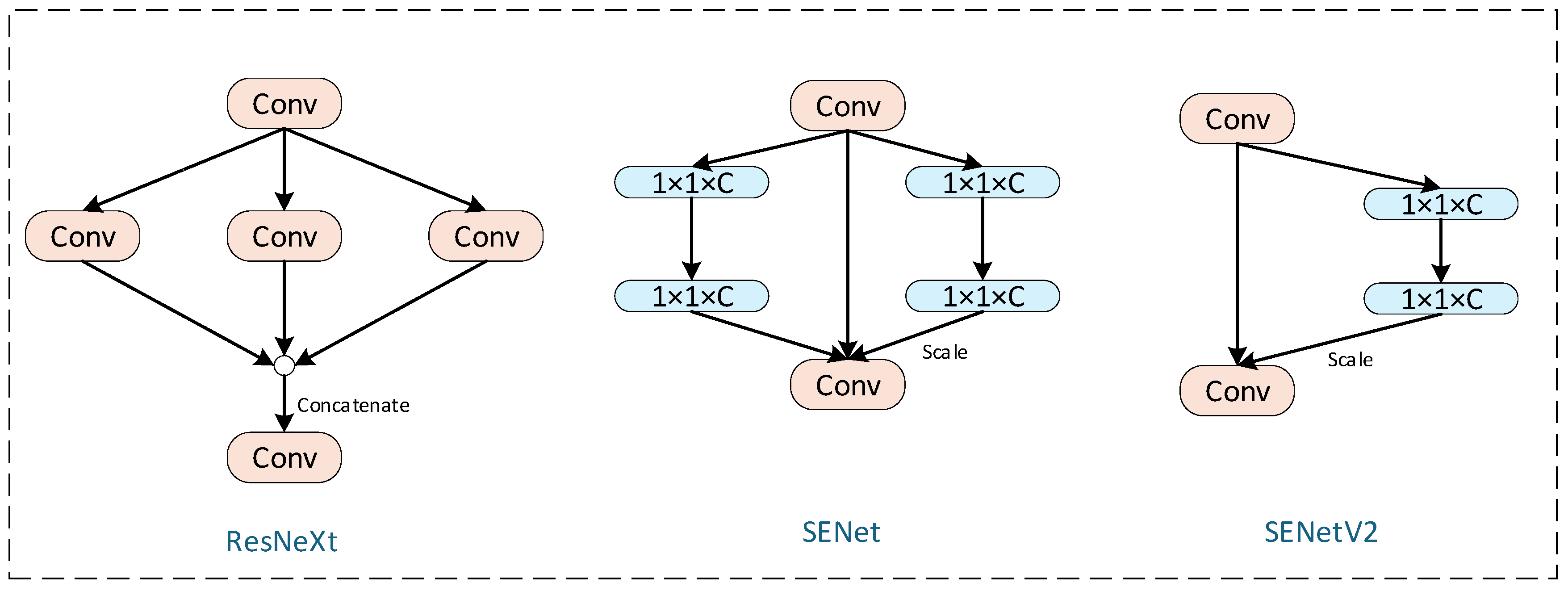
2.5. Squeeze–Excitation Residual Module (C2f_SENetV2)
2.6. Detection Head Improvements
3. Experiments and Results
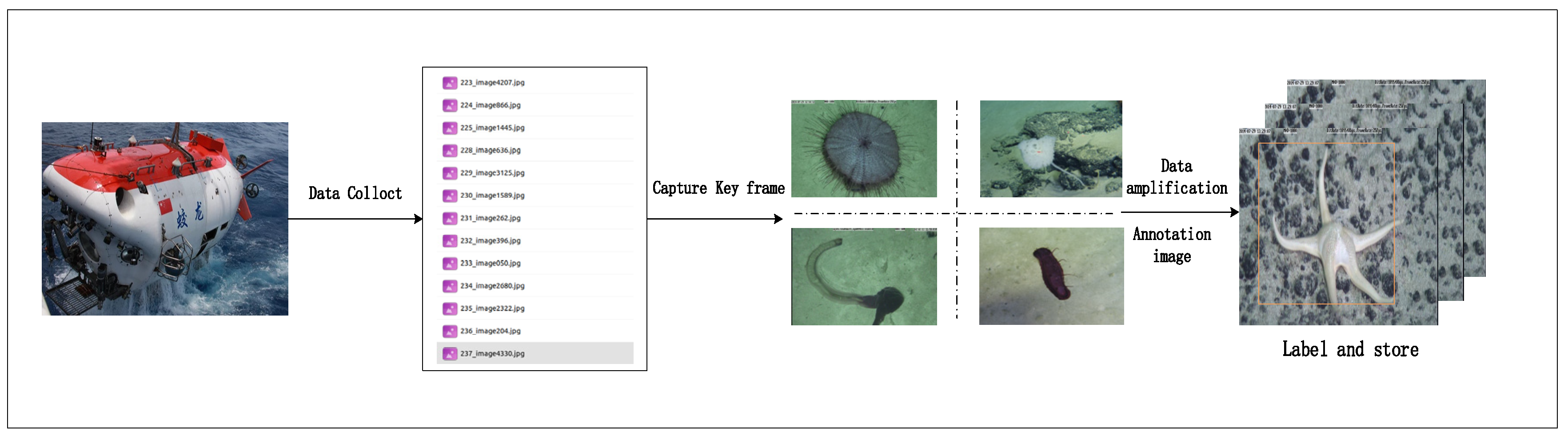
3.1. Dataset Creation and Processing
3.2. Experimental Environment and Parameter Configuration
3.3. Evaluation Criteria
3.4. Experimental Results and Analysis
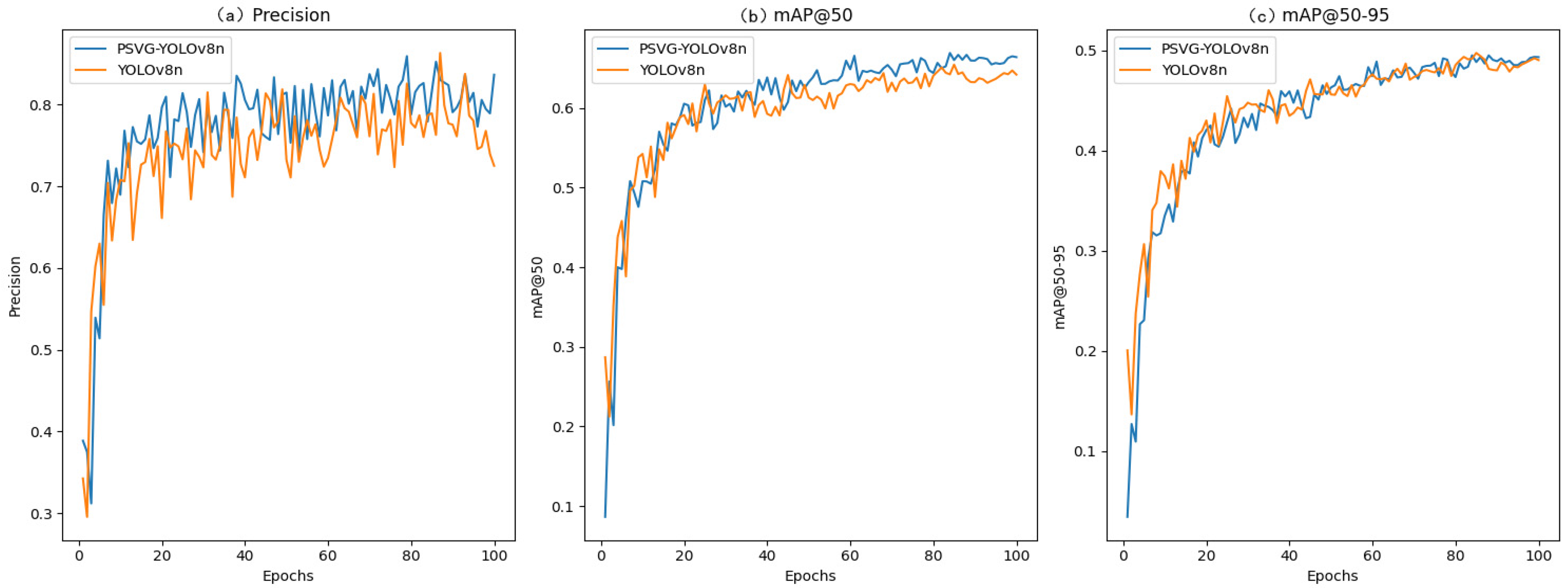
3.4.1. Experimental Comparison Before and After Model Improvement
3.4.2. Ablation Experiments
3.4.3. Comparative Tests of Different Models
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Danovaro, R.; Gambi, C.; Dell’Anno, A.; Corinaldesi, C. Deep-sea biodiversity informs the design of marine protected areas. Nature 2008, 456, 201–204. [Google Scholar]
- Zhang, L.; Li, Q.; Li, Y. Transferable Deep Learning Model for the Identification of Fish Species in Various Fishing Grounds. J. Mar. Sci. Eng. 2023, 12, 415. [Google Scholar]
- Sun, H.; Zhang, Q.; Li, Z. Enhancing underwater image quality for object detection using generative adversarial networks. Ocean Eng. 2024, 260, 111234. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Mu, R.; Zeng, X. A review of deep learning research. KSII Trans. Internet Inf. Syst. (TIIS) 2019, 13, 1738–1764. [Google Scholar]
- Abouhalima, M.; das Neves, L.; Taveira-Pinto, F.; Rosa-Santos, P. Machine Learning in Coastal Engineering: Applications, Challenges, and Prospects. J. Mar. Sci. Eng. 2024, 12, 638. [Google Scholar] [CrossRef]
- Yang, Y.; Ye, Z.; Su, Y.; Zhao, Q.; Li, X.; Ouyang, D. Deep learning for in vitro prediction of pharmaceutical formulations. Acta Pharm. Sin. B 2019, 9, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Sun, B.Y.; Mei, Y.P.; Yan, N.; Chen, Y. UMGAN: Underwater Image Enhancement Network for Unpaired Image-to-Image Translation. J. Mar. Sci. Eng. 2023, 11, 447. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Zhang, M.; Li, X. Improved YOLOv8-Based Underwater Target Detection Algorithm. J. Mar. Sci. Eng. 2023, 11, 753. [Google Scholar]
- Tan, H.; Li, Y.; Zhu, M.; Deng, Y.; Tong, M. Detection of Overlapping Fish Counts through Image Enhancement and Improved Faster R-CNN Network. Trans. Chin. Soc. Agric. Eng. 2022, 38, 167–176. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wageeh, Y.; Mohamed HE, D.; Fadl, A.; Anas, O.; ElMasry, N.; Nabil, A.; Atia, A. YOLO fish detection with Euclidean tracking in fish farms. J. Ambient Intell. Humaniz. Comput. 2021, 12, 5–12. [Google Scholar] [CrossRef]
- Liu, D.; Feng, G.; Wang, H. Multi-scale feature fusion for underwater object detection based on deep learning. Ocean Eng. 2025, 270, 111567. [Google Scholar]
- Wang, L.; Zhang, Y.; Liu, H. Underwater Object Detection Using YOLOv8 with Polarized Self-Attention Mechanism. Int. J. Comput. Vis. Pattern Recognit. 2023, 45, 245–260. [Google Scholar]
- Li, H.; Zhang, Y. Optimizing YOLOv8 Architecture with Slim-neck and GSConv for Autonomous Vehicle Detection. Int. J. Image Process. 2023, 29, 405–420. [Google Scholar]
- Zhu, X.; Li, L.; Li, J. Hyperspectral Image Classification Model Using Squeeze and Excitation Network with Deep Learning. J. Imaging 2022, 8, 243. [Google Scholar]
- Guo, A.; Sun, K.; Zhang, Z. A lightweight YOLOv8 integrating FasterNet for real-time underwater object detection. J. Real-Time Image Process. 2024, 21, 49. [Google Scholar] [CrossRef]
- Anjing, G.; Yirui, W.; Lijun, G.; Zhang, R.; Yu, Y.; Gao, S. An adaptive position-guided gravitational search algorithm for function optimization and image threshold segmentation. Eng. Appl. Artif. Intell. 2023, 121, 106040. [Google Scholar]
- Shi, X.; Wang, H. Lightweight underwater object detection network based on improved YOLOv4. J. Harbin Eng. Univ. 2023, 44, 154–160. [Google Scholar]
- Hu, D.; Yu, M.; Wu, X.; Hu, J.; Sheng, Y.; Jiang, Y.; Zheng, Y. DGW-YOLOv8: A small insulator target detection algorithm based on deformable attention backbone and WIoU loss function. IET Image Process. 2024, 18, 1096–1108. [Google Scholar] [CrossRef]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 9355–9366. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An efficient pyramid squeeze attention block on convolutional neural network. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 1161–1177. [Google Scholar]
- Zhao, Z.; Wang, L.; Xu, D. Segmentation and Detection via Split and Concatenate Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Image Process. 2018, 27, 5610–5622. [Google Scholar]
- Li, J.; Chen, S.; Yang, Z. Frequency-based Feature Extraction for Few-Shot Learning. Pattern Recognit. 2020, 104, 107331. [Google Scholar]
- Shen, J.; Wu, T. Learning Spatially-Adaptive Squeeze-Excitation Networks for Image Synthesis and Image Recognition. arXiv 2021, arXiv:2112.14804. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Shi, X.; Ren, Y.; Tang, J.; Fu, W.; Liu, B. Working Tools Study for JiaoLong Manned Submersible. Mar. Technol. Soc. J. 2019, 53, 56–64. [Google Scholar] [CrossRef]
- Feng, X.; Shen, Y.; Wang, D. A Review of the Development Status of Image-based Data Augmentation Methods. Comput. Sci. Appl. 2021, 11, 370. [Google Scholar]
- Hestness, J.; Ardalani, N.; Diamos, G. Beyond human-level accuracy: Computational challenges in deep learning. In Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming, Washington, DC, USA, 16–20 February 2019; pp. 1–14. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value or Type |
|---|---|
| Epochs | |
| Batch size | |
| Optimizer | SGD |
| Image size | |
| Initial learning rate | |
| Optimizer momentum | |
| Weight decay |
| YOLOv8n | Slim-Neck | SENetV2 | PSA | Detection | Precision (%) | Mean Average Precision | |
|---|---|---|---|---|---|---|---|
| mAP50 (%) | mAP50-95 (%) | ||||||
| 1 | × | × | × | × | 78.7 | 64.9 | 49.8 |
| 2 | √ | × | × | × | 81.1 | 66.1 | 50.1 |
| 3 | × | √ | × | × | 82.6 | 65.8 | 50.3 |
| 4 | × | × | √ | × | 81.2 | 66.7 | 49.8 |
| 5 | √ | √ | × | × | 80.7 | 66.7 | 50.5 |
| 6 | √ | × | √ | × | 80.4 | 64.8 | 48.4 |
| 7 | × | √ | √ | × | 77.0 | 63.0 | 47.5 |
| 8 | √ | √ | √ | × | 79.5 | 64.9 | 49.1 |
| 9 | √ | √ | √ | √ | 79.9 | 67.2 | 50.9 |
| Model | Precision (%) | Mean Average Precision | |
|---|---|---|---|
| mAP50 (%) | mAP50-95 (%) | ||
| SSD | 54.4 | 62.2 | 42.6 |
| YOLOv3 | 45.7 | 58.5 | 34.4 |
| YOLOv5s | 82.4 | 66.5 | 48.2 |
| YOLOv7 | 53.6 | 55.1 | 33.5 |
| YOLOv8n | 78.7 | 64.9 | 49.8 |
| YOLOv11n | 85.2 | 63.8 | 49.3 |
| PSVG-YOLOv8n | 79.9 | 67.2 | 50.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Shi, X.; Yang, J.; Gao, X.; Ren, Y. Research on Method for Intelligent Recognition of Deep-Sea Biological Images Based on PSVG-YOLOv8n. J. Mar. Sci. Eng. 2025, 13, 810. https://doi.org/10.3390/jmse13040810
Chen D, Shi X, Yang J, Gao X, Ren Y. Research on Method for Intelligent Recognition of Deep-Sea Biological Images Based on PSVG-YOLOv8n. Journal of Marine Science and Engineering. 2025; 13(4):810. https://doi.org/10.3390/jmse13040810
Chicago/Turabian StyleChen, Dali, Xianpeng Shi, Jichao Yang, Xiang Gao, and Yugang Ren. 2025. "Research on Method for Intelligent Recognition of Deep-Sea Biological Images Based on PSVG-YOLOv8n" Journal of Marine Science and Engineering 13, no. 4: 810. https://doi.org/10.3390/jmse13040810
APA StyleChen, D., Shi, X., Yang, J., Gao, X., & Ren, Y. (2025). Research on Method for Intelligent Recognition of Deep-Sea Biological Images Based on PSVG-YOLOv8n. Journal of Marine Science and Engineering, 13(4), 810. https://doi.org/10.3390/jmse13040810