1. Introduction
Over the past decade, target detection in remote sensing imagery has found extensive applications across diverse domains, including military surveillance, maritime monitoring, intelligent transportation systems, and disaster response. These applications demand high accuracy and efficiency in identifying objects of interest, particularly in complex environments. In aerial and satellite remote sensing images, target detection objects are mostly features with rich natural and social attributes, and ships are a typical detection object. Ship target detection on the sea surface has always been a research hotspot in the fields of remote sensing image processing, pattern recognition and computer vision, etc. Ships, as maritime transport carriers and important military targets, have a broad application prospect and important practical significance in the military and civil fields for their automatic detection.
The development of deep learning in the field of computer vision has provided powerful technical support for the extraction of massive remote sensing image information, which has greatly improved the accuracy and efficiency of remote sensing image target detection. However, in the field of optical remote sensing images, the current target detection algorithms still face many challenges, such as the high resolution of the image, complex background, small and dense targets, etc. For this reason, more and more attention has been focused on Convolutional Neural Network (CNN)-based remote sensing image processing especially ship detection in remote sensing images. For example, Liu et al. [
1] proposed FineShipNet, which effectively solves the problem of inadequate feature representation in remotely sensed ship images; Abhinaba et al. [
2] used a self-attentive residual network to achieve efficient recognition of remotely sensed ship images; Yang et al. [
3] proposed an SLT-Net network to solve the problem of long-tailed distribution of remotely sensed ship images, which has excellent generalization ability; Qiao et al. [
4] proposed a two-stage detector, Cascade R-CNN, which is suitable for detecting sparse targets in high-resolution images; Li et al. [
5] proposed PETDet, a method for fine-grained object detection, which achieves accurate and rapid fine-grained object recognition by combining an anchorless quality oriented proposal network (QOPN) with a new adaptive recognition loss (ARL).
Due to the simplicity and rapidity of single-stage detection methods, many other scholars have carried out research on single-stage detection methods for remotely sensed ship images. Fang et al. [
6] proposed YOLO-RSA for the ship scenes in [
7] and proposed a lightweight ship detector Lite-YOLOv5, but the lightweight aspect did not guarantee the stability of the accuracy; Wang et al. [
8] proposed an efficient and fast ship detection method based on yolo, but the algorithm still has room for improvement in the detection accuracy of small targets; Li et al. [
9] proposed an adaptive prototype comparison learning method, which effectively enhances the class separability of ship features, thus improving the performance of fine ship identification; Liu et al. [
10] proposed the SVSDet method, which enhances the network’s ability to extract fine-grained features by introducing the space-to-depth module to the backbone network and improving the neck structure using Bi-FPN. Although deep learning techniques have made significant progress in the field of remote sensing image target detection in recent years, existing methods still face many challenges when dealing with the task of ship detection in remote sensing images. These challenges are mainly reflected in the following aspects:
Difficulty in detecting small targets: ship targets in remote sensing images are usually small in size and have low contrast with the background, making it difficult for traditional target detection algorithms to accurately identify and locate these small targets. Existing detection methods tend to miss or misdetect small targets when dealing with them, especially when the targets are dense or the background is complex, leading to a further reduction in detection performance.
Complex background interference: remote sensing images usually contain complex background information, such as waves, clouds, port facilities, etc. This background information is similar to the characteristics of the targets of the ships, which can easily lead to false detection. Existing methods are often difficult to effectively distinguish between the target and the background when dealing with complex backgrounds; in particular, when the target and the background are similar in color and texture, the detection accuracy decreases significantly.
Multiscale target detection: ship targets in remote sensing images have significant multiscale characteristics, i.e., ships of different sizes may exist in the same scene at the same time. Existing detection methods often make it difficult to take into account the feature representations of different scales when dealing with multiscale targets, resulting in unbalanced detection performance for small and large targets.
Occlusion problem: in remote sensing images, ship targets may be partially occluded by clouds, other ships, or port facilities, resulting in incomplete target features. Existing methods often make it difficult to accurately recover the features of the occluded target when dealing with the occlusion problem, leading to a decrease in detection performance.
Task conflict problem: existing single-stage detection methods usually use a coupled head to process both classification and regression tasks, which may lead to conflicts between tasks. Since the classification and regression tasks share the same feature representation, the optimization of one task may adversely affect the other; in particular, when dealing with small targets and complex backgrounds, this conflict is more obvious.
To address the above problems, this paper proposes an end-to-end remote sensing ship target detection method called Ship-Yolo, which is a detector specifically designed for remote sensing of ships. First, to detect small targets, efficient local attention is integrated into the neck to form an EDC module, and inter-channel relationships and position information are considered, which enables the model to locate and identify the target area more accurately. In addition, inspired by Ge et al. [
11], a new lightweight asymmetric detection head named LADH-Head is designed, and the network recognizes the regression task and the classification task separately to avoid task conflicts. It is important to keep the model lightweight while improving its detection accuracy, so this paper proposes a lightweight backbone module, LiteConv, to replace the C3 module, which reduces computational redundancy and also improves the detection speed. Finally, a content-aware reorganization up-sampling module (CARAFE) is introduced to replace the up-sampling module in the original neck network.
The main contributions of this paper are as follows:
Fusing coordinate attention to the C3 [
12] module in the neck network, the EDC module can dynamically learn the importance of different channels in the feature map to better capture the key features of the target, further improve the detection accuracy and reduce the misidentification problem existing in the original method.
Propose a new type of lightweight asymmetric decoupling head, which deletes part of the convolution module and increases the residual network on the basis of the original decoupling head to improve the detection performance while keeping the model lightweight.
Design a lightweight module LiteConv to replace the C3 module in the backbone network, and reduce the redundancy of the feature map by partial convolution (PConv) [
13] to further reduce the FLOPs.
Replacing the proximity interpolation upsampling module with the CARAFE module, which has a larger sensory field during feature reorganization to better capture the global information, while the whole operator is more lightweight.
The remainder of the paper is organized as follows:
Section 2 describes the experimental methodology.
Section 3 describes the experiments and presents the results.
Section 4 draws conclusions.
2. Methodology
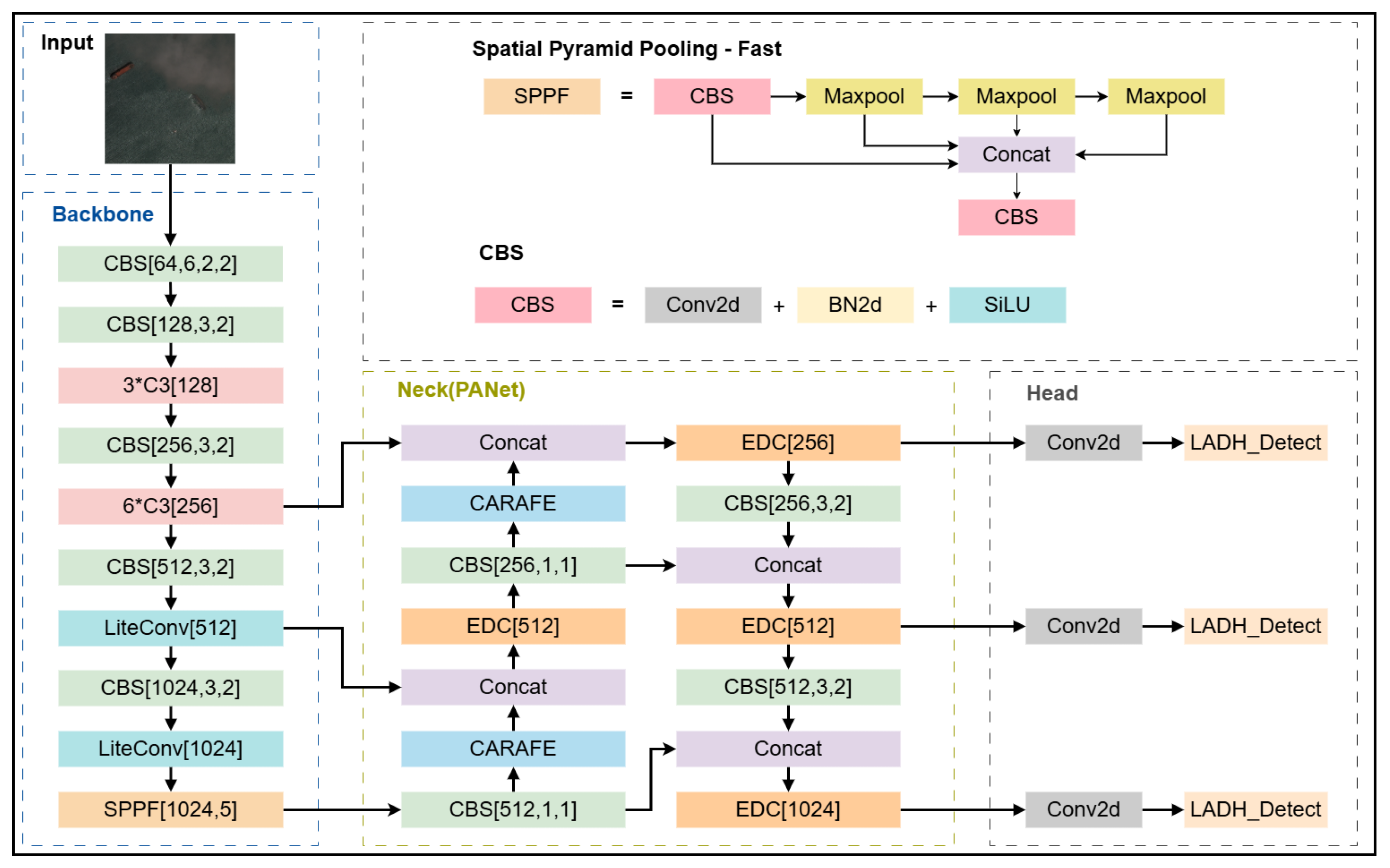
2.1. Network Architecture for YOLOv5
The Yolov5 framework is structured around three primary components: the backbone network, responsible for feature extraction; the neck structure, which facilitates multi-scale feature fusion; and the head module, tasked with final detection outputs. In the backbone network part, the CSPDarkNet53 architecture is used to extract key features from the input image, a process that involves a convolutional layer (Conv), the C3 module and the SPPF module. The convolutional layer consists of convolutional operations, batch normalization and SiLU activation functions. The C3 module effectively reduces the number of parameters of the model through the design of residual connections, which in turn speeds up the inference. The SPPF module is an optimization of the traditional SPP module, which uses three consecutive 5 × 5 maximal pooling layers in place of the original 5 × 5, 9 × 9, and 13 × 13 pooling layers, and in doing so, both fuses different scale features while improving processing efficiency. In the neck component, Yolov5 employs a Path Aggregation Network (PANet), which is a further extension of the Feature Pyramid Network (FPN). The PANet significantly improves the model’s capability in multi-scale target localization by adding bottom-up paths, which allow position information to be passed from shallow to deep features.
The Yolov5 family consists of five models at different scales: YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. These models share the same architectural design, although they differ in network width and depth.
2.2. Proposed Methodology
In this section, this paper explores in detail the main improvements in our proposed innovative approach. These include the EDC module in the neck network, the new lightweight asymmetric decoupling head LADH-Head, the lightweight module LiteConv in the backbone network, and the up-sampling operator CARAFE. The overall improvement model is shown in
Figure 1.
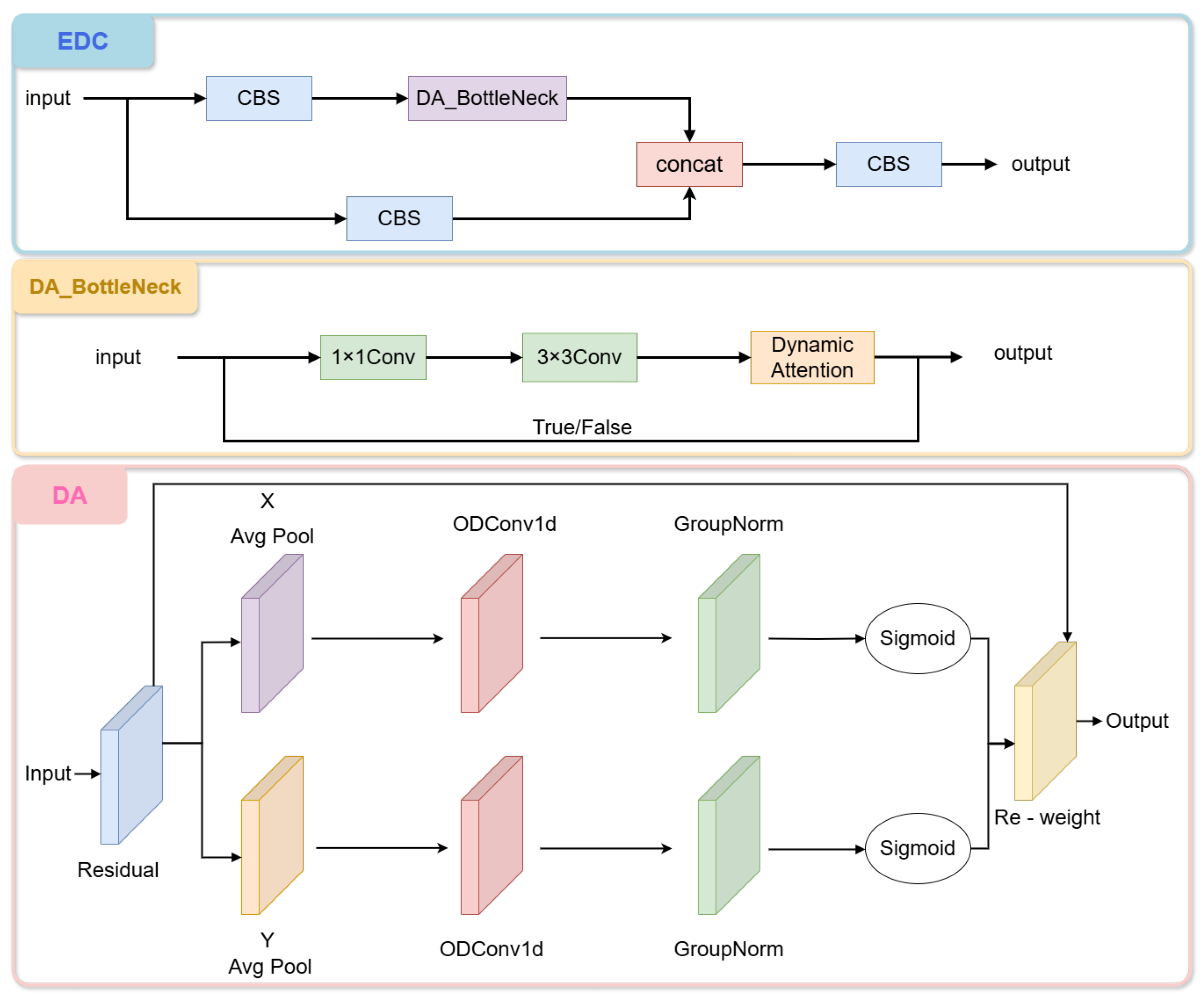
2.2.1. EDC
In deep learning networks, what needs to be focused on is the target region, and the attention mechanism can help the model focus more on the key features in the image that are relevant to target detection while ignoring unimportant background information. In this way, the model can identify and locate the target more accurately, achieving the effect of simplifying the model and accelerating the calculation. Due to the unique imaging characteristics of remote sensing images, which often present complex backgrounds and drastic changes in target orientation, this leads to the original YOLOv5 algorithm being prone to losing key feature information representing small targets during the sampling process. This loss of information can cause false alarms and missed detection phenomena, thus affecting the overall detection effect, so we add Efficient Local Attention (ELA) to the network.
The efficient local attention mechanism, proposed by Xu et al. [
14] in 2024, compares with previous attention mechanisms, such as CA [
15], ELA uses Group Normalization (GN), and GN performs stably in both small and large batches, which enhances the model’s generalization ability, and the mechanism demonstrates a significant progress in the application of deep neural networks. The module extracts feature vectors in the horizontal and vertical directions separately by employing a strip pooling [
16] technique in the spatial dimension. Through the adoption of a horizontally extended convolutional kernel configuration, the ELA module establishes distant spatial correlations through its anisotropic receptive field, effectively suppressing noise from non-target areas during prediction, thus generating informative target location features in each direction. Subsequently, ELA processes the feature vectors in these directions independently to generate attentional predictions, and integrates them through a product operation to ensure that the precise location information of the region of interest is retained.
In order to adapt to the remote sensing image detection requirements, this paper innovatively embeds ELA into the C3 module of YOLOv5 to form the EDC module in
Figure 2, and at the same time replaces the one-dimensional convolution in ELA with dynamic convolution (ODConv) [
17], which is named DA (Dynamic Attention). This improvement improves small-target detection accuracy by 12.7% (mAP@0.5) through multi-scale feature fusion and dynamic background suppression in complex maritime environments, and at the same time optimizes the drawback that the parameters of the convolution kernel in the ELA module need to be set manually.
Through this fusion, not only the spatial location information in the feature map is preserved, but also the model’s representation of key features is enhanced. This enhanced feature representation helps the model to identify and locate targets more accurately in remote sensing image detection, especially when dealing with complex scenes and multi-scale targets. Therefore, the EDC module shows its unique advantages in remote sensing image detection.
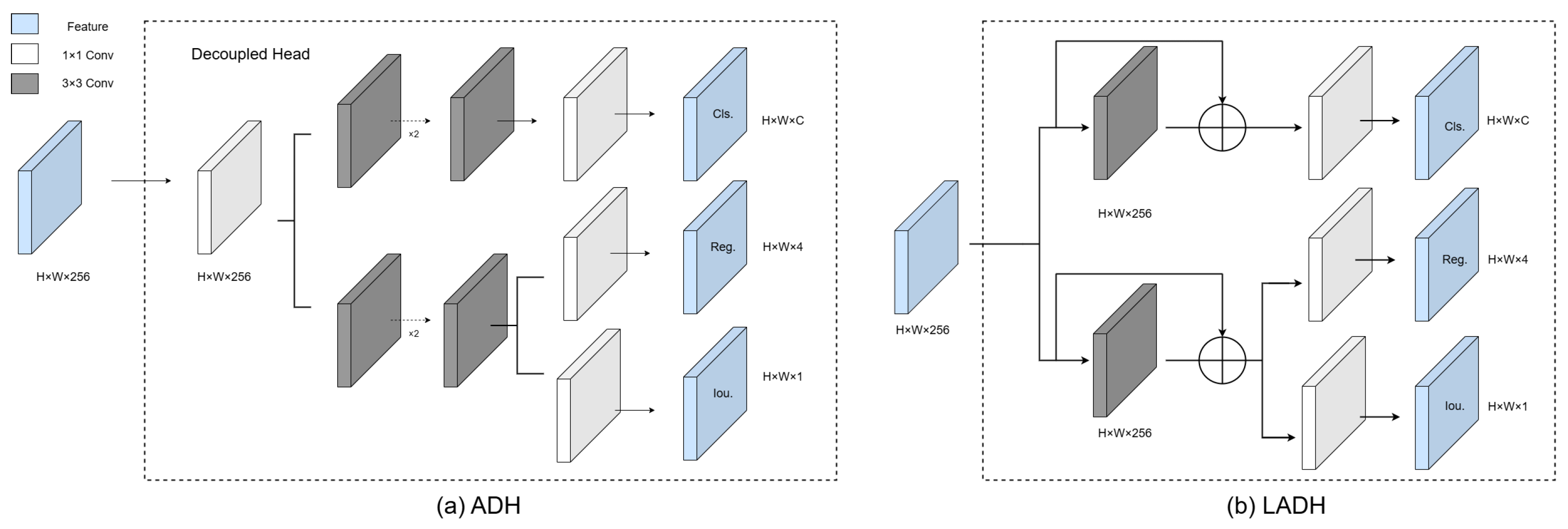
2.2.2. LADH-Head
In target detection tasks, classification and regression tasks usually share the same feature representation, which may lead to conflicts between the tasks. Specifically, the classification branch processes categorical probability distributions through softmax activation, whereas the regression branch outputs continuous coordinate values via linear transformations. Since the objectives of these two tasks are different, sharing feature representations may result in the optimization of one task adversely affecting the other, especially when dealing with small targets and complex backgrounds. To solve this problem, this paper proposes LADH-Head, which avoids conflicts between tasks and improves the detection performance of the model by decoupling the classification and regression tasks.
As shown in the ADH-Head [
18] shown in
Figure 3, the input image is split into two paths into the head network after outputting the feature maps through the backbone and neck networks. For the classification branch, each position on each feature map predicts a classification probability distribution without directly predicting the anchor frame, i.e., no information about the size and position of the anchor frame is involved. The classification branch focuses on category prediction and uses a simplified structure with residual connections to preserve feature integrity. The regression branch, on the other hand, is responsible for predicting the position and size of the anchor frame, again using a convolutional layer, but the output is the offset and aspect ratio of the anchor frame. The regression branch prioritizes spatial accuracy and employs lightweight convolutions to reduce computational overhead. The design prioritizes task-specific optimization while maintaining model efficiency by removing redundant operations (e.g., 1 × 1 convolutions). The decoupling header allows the network to optimize the classification and localization tasks separately, allowing each task to be more focused on learning its unique features. For small targets, this focus allows for better capture of their subtle features, making small targets easier to recognize by the detection network in complex backgrounds.
It is experimentally verified that this decoupling head contributes greatly to the improvement of the model detection accuracy, but at the same time, it also greatly increases the complexity of the model. In view of this, we lighten and improve the original decoupling head, as shown in
Figure 3, LADH-Head removes the 1 × 1 dimensionality reduction convolution operation, and we formulate an adaptive width allocation mechanism where the head dimension dynamically adjusts according to backbone-neck feature hierarchy proportions. At the same time, we removed the additional 3 × 3 convolutional modules in both branches. This was done to reduce the amount of computation and to prevent information from being lost in too many convolutional layers. In addition, residual connectivity was introduced for each CBS (Convolution-Batch Normalization-SiLU) module with the aim of simplifying the optimization process of the network and to improve the performance of the detection header without adding additional computational burden.
LADH reduces the computational effort of the model and improves the computational efficiency of the model by removing the 1 × 1 dimensionality-decreasing convolution and the additional 3 × 3 convolution module. Remote sensing images usually have high resolution, so the detection model needs to process a large amount of data. LADH makes it more efficient in processing high-resolution remote sensing images by simplifying the design of the detection head. And due to the reduction in the number of convolutional layers, the number of parameters of LADH is reduced compared to ADH. This means smaller model size and easier deployment to devices with limited memory. In addition, the design of LADH reduces the loss of information during transmission. By avoiding too many convolutional layers, the model is better able to retain the original features, which improves the accuracy of the detection. Finally, LADH introduces residual connectivity, which helps alleviate the problem of vanishing gradients and makes the network easier to train. Residual connectivity simplifies the optimization process by allowing the gradient to flow directly to earlier layers.
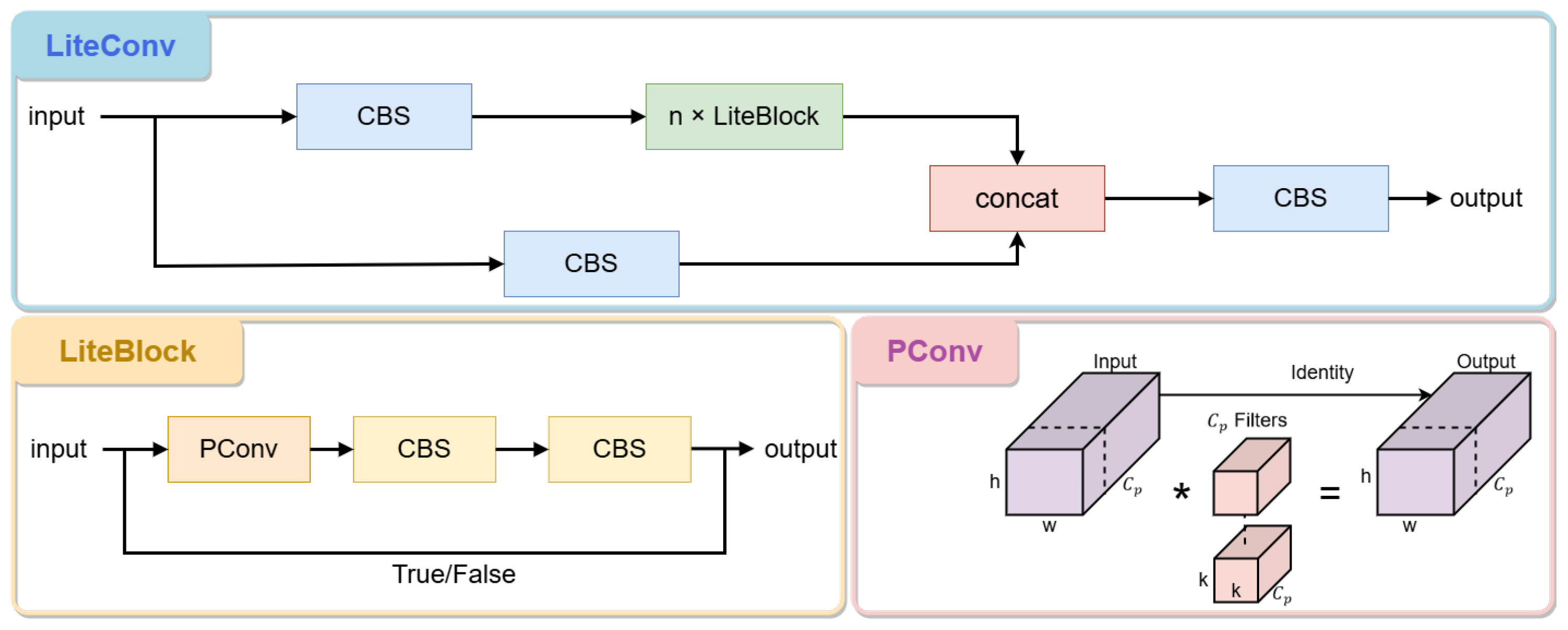
2.2.3. LiteConv
The occlusion problem is a common challenge in remote sensing image target detection tasks. Since ship targets may be partially occluded by clouds, other ships or port facilities, traditional convolution operations are often difficult to accurately extract effective features when dealing with the occluded region, resulting in degradation of detection performance. To address this problem, this paper proposes LiteConv, which reduces the redundancy of the feature maps by introducing PConv, thereby reducing the computational complexity of the model and improving the detection speed.
The traditional convolution operation is often interfered by invalid pixels (e.g., occluded parts) when dealing with occluded regions, resulting in inaccurate feature extraction. PConv, by introducing a masking mechanism [
19], is able to automatically ignore the invalid information in the occluded region and focus on feature extraction in the valid region. Specifically, PConv gradually shrinks the invalid region with the inference process of the network by dynamically updating the mask, and ultimately retains only the features in the valid region. This design not only avoids incorrect judgement of the masked region, but also reduces the computation of the model. For the feature map with input as
, the number of floating-point operations (FLOP) for normal convolution and partial convolution are, respectively:
where c and
denote the number of channels, the FLOPs associated with PConv is reduced by a staggering 16 times compared to conventional convolution for a ratio of
to c equal to 1 to 4. This significant reduction greatly improves the efficiency of network inference and greatly reduces the model’s parameter count.
In order not to add extra training burden, the proposed method integrates PConv with the ground C3 module in the backbone network, named Lightweight Convolutional LiteConv. As shown in
Figure 4, the BottleNeck in the C3 module is replaced with LiteBlock, and PConv is backed by two 1 × 1 convolutional layers to embody the behavior of point-by-point convolution (PWConv). We effectively replace the original C3 module in the CSPDarkNet53 [
20] backbone to further speed up the inference of remote sensing image detection. To enhance feature learning, we insert two 1 × 1 convolutional layers after PConv, where the first 1 × 1 convolutional layer can perform initial linear transformations on the features, and the second 1 × 1 convolutional layer can further adjust these transformed features. This successive transformation can help the network learn more complex feature representations. And each 1 × 1 convolutional layer is usually followed by a nonlinear activation function (e.g., ReLU [
21]). Two consecutive 1 × 1 convolutional layers means that the network can introduce nonlinearity twice at different levels, which helps the network to capture more complex patterns. This improvement successfully achieves a reduction in model parameters and highlights the ability to extract spatial features while keeping the detection performance unchanged.
2.2.4. CARAFE
In remote sensing image target detection tasks, up-sampling techniques are crucial for improving image resolution. Traditional up-sampling methods (e.g., nearest neighbor interpolation [
22] and bilinear interpolation [
23]) are usually based on predefined interpolation kernels, which make it difficult to capture complex local contextual information, and this limitation is more obvious especially when dealing with high-resolution remote sensing images.
Deconvolution [
24], a representative learnable upsampling method, achieves pixel generation through the inverse process of convolution. The Pixel Shuffle technique, on the other hand, innovatively converts channel information into spatial information to achieve feature map size. In addition, the Guided Upsampling (GUM) [
25] technique samples pixels through learnable offsets for more accurate interpolation. Although these methods exploit local contextual information or achieve adaptive interpolation to some extent, they are either limited to a small range of information or are computationally expensive.
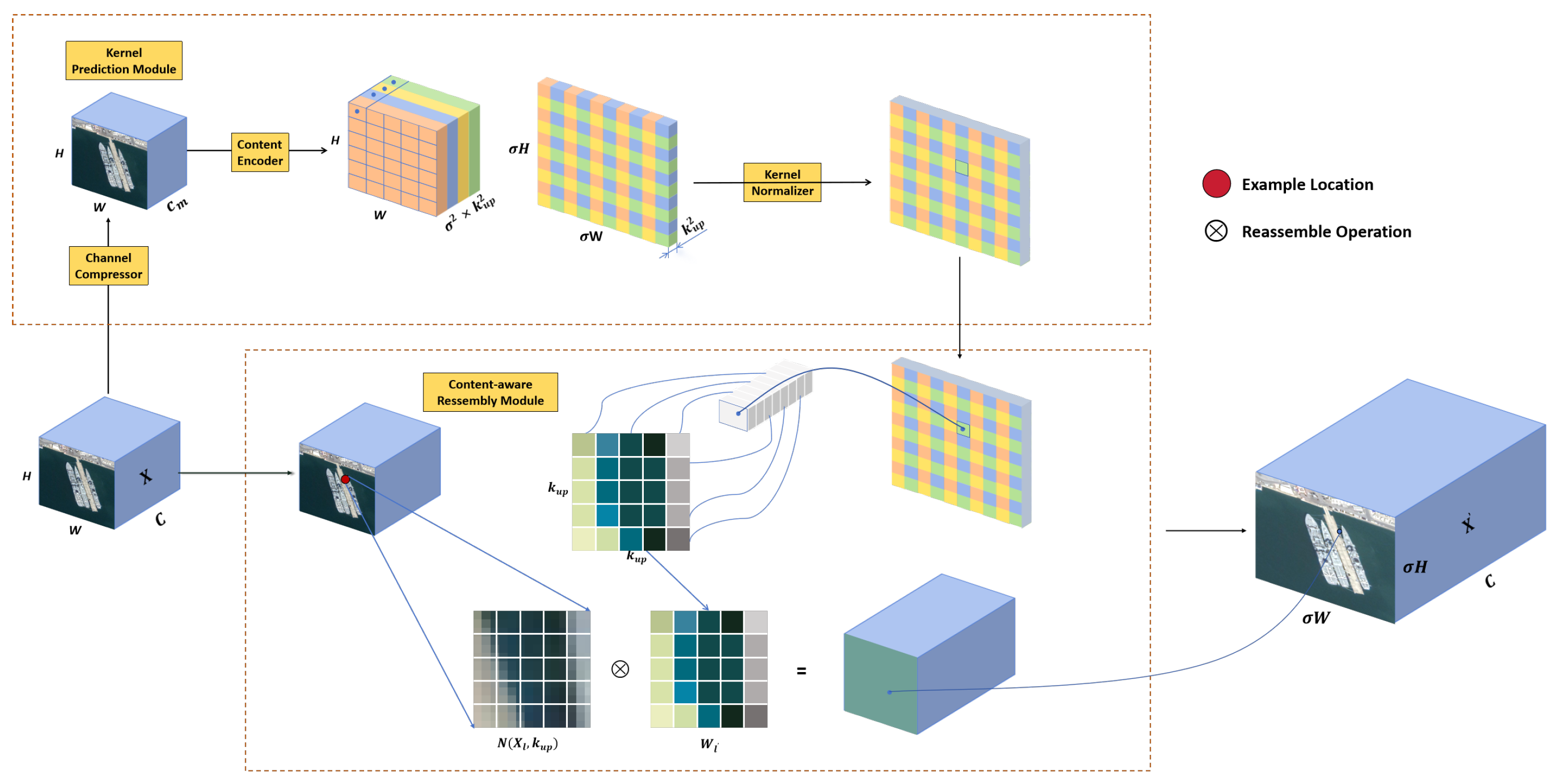
Based on this, we propose a lightweight solution for remote sensing images by replacing the original nearest-neighbor interpolation up-sampling in Yolov5 with the content-aware and feature recombination operator. As shown in
Figure 5, CARAFE is able to better capture complex texture and spatial information in remote sensing images while maintaining computational efficiency by dynamically predicting the recombination kernel at each target location. The proposed enhancement simultaneously augments feature map semantics (increasing mAP by 2.3%) and expands the effective receptive field by 1.8×, leading to statistically significant improvements in both detection accuracy and robustness against complex backgrounds.
3. Experimental Analysis
To evaluate the efficacy and generalizability of our proposed method for ship detection in remote sensing imagery, we conducted experiments on two widely used datasets: ShipRSImageNet and DOTA. These datasets encompass diverse scenarios, facilitating a thorough evaluation of the model’s effectiveness. Yolov5 was selected as the base framework. In this series of algorithms, Yolov5s obtained an excellent balance between speed and accuracy. Therefore, we used Yolov5s as the baseline model with improvements and optimizations. In this section, we describe the experimental environment setup, the characteristics of the dataset, the evaluation metrics and the analysis of the final experimental results.
3.1. Experimental Environment
The experimental setup is shown in
Table 1, and all experiments were performed in the same configuration.
In this experiment, we set the resolution of the images to 1024 pixels × 1024 pixels. The initial learning rate used during training was 0.01, and a training cycle (epoch) of 300 iterations was performed for each experiment. To ensure that the anchor frame size matched the dataset we used, we adopted the following strategy: firstly, the preset anchor frame size was removed from the configuration file and its parameter was set to 3. Subsequently, we used the K-means clustering algorithm [
26] to automatically generate the anchor frame size suitable for target detection. Otherwise, all other model parameters were maintained with the same settings as the baseline model.
3.2. Datasets
3.2.1. ShipRSImageNet
The dataset contains 3435 images from various sensors, satellite platforms, positions and seasons. Each image is approximately 930 × 930 pixels and contains ships with different scales, orientations and aspect ratios (AR). The images were annotated by satellite image interpretation experts into 50 object classes. The fully annotated ShipRSImageNet contains 17,573 ship instances. In contrast to other existing remote sensing image datasets, the dataset used uses both horizontal and directional bounding boxes as well as polygons to annotate the images, providing detailed information about the orientation, background, marine environment, and location of the target, making it well suited for ship-only remote sensing image detection.
In order to evaluate the performance of the model more comprehensively, we classify the ShipRSImageNet dataset into the following four categories of typical scenarios:
Small target images: images containing a large number of small-sized ship targets, where the target occupies a small proportion of pixels in the image, making detection more difficult.
Cloudy and foggy occlusion image: contains ship targets that are partially occluded by clouds or fog, and the target features are incomplete, increasing the complexity of detection.
Busy harbor image: contains dense ship targets in the harbor area, with complex background and mutual occlusion between targets, making detection more difficult.
Dark and weak environment images: images taken under low-light conditions, with low contrast between the target and the background, making detection more difficult.
Table 2 shows example images of four types of typical scenes and their characteristics in the ShipRSImageNet dataset. The complexity and diversity of the dataset can be visualized through these example images.
3.2.2. DOTA
The DOTA dataset [
27], proposed by Wuhan University, is a large-scale benchmark dataset designed for optical remote sensing image analysis. The dataset contains a total of 2806 aerial images, each with a resolution of 4000 × 4000 pixels and a spatial resolution covering different scales from 10 to 300 m. The dataset is annotated with 18,828 instance objects of 15 typical target categories, including aircraft (PL), ship (SH), storage tank (ST), baseball field (BD), tennis court (TC), basketball court (BC), track and field (GTF), harbor (HA), bridge (BR), large vehicle (LV), small vehicle (SV), helicopter (HC), roundabout (RA), football field (FF), football stadium (SBF) and swimming pool (SP). Since the size of the original image is too large to be directly input into the neural network, the image is usually segmented into 1024 × 1024 pixels sub-images using the cutter tool accompanying the YOLO framework. The segmented images are divided into training and validation sets in the ratio of 8:2 to meet the requirements of deep learning models on input size and data distribution.
3.3. Evaluation Indicators
3.3.1. Precision
Precision
P is the proportion of samples predicted by the model to be in the positive category that are actually in the positive category. It measures the accuracy of the model’s predictions, i.e., how many of the anchor frames predicted by the model actually contain the target. The precision formula is:
True Positives (
) correspond to accurately identified targets, whereas False Positives (
) represent erroneous detections where background clutter or non-target objects are misclassified as positive instances.
3.3.2. Recall
Recall,
R, is the proportion of samples that are actually positive classes that are correctly predicted as positive by the model. It measures the ability of the model to detect targets, i.e., how many of all real targets are detected by the model. The formula for recall is:
where
(False Negative) denotes the number of targets that are actually targets but not detected by the model.
3.3.3. Mean Average Precision
The mean Average Precision (mAP) represents the average value of the area under the Precision-Recall (PR) curve for each category in the dataset. When evaluating detection results, we employ two specific mAP metrics: mAP@0.5 and mAP@0.5:0.95. Here, mAP@0.5 refers to the average precision calculated under the condition of a fixed Intersection over Union (IoU) threshold of 0.5, while mAP@0.5:0.95 denotes the average of the mean precision values computed with the IoU threshold ranging from 0.5 to 0.95 in increments of 0.05. These metrics provide a detailed and comprehensive evaluation standard for assessing the performance of object detection algorithms.
3.3.4. FLOPs
We use Gflops, i.e., one billion floating-point operations per second, as a metric of computational complexity and as a reference for whether the model is lightweight or not. Gflops serves as a metric for quantifying the computational throughput of model inference, which is crucial for real-time target detection tasks. Lower Gflops means that the model can process the image faster, resulting in a higher frame rate.
3.4. Results
In order to confirm the effectiveness of the Ship-Yolo method in the remote sensing image ship detection task, we conducted extensive experiments on the ShipRSImageNet dataset. On the DOTA dataset, we analyzed the AP values for each category as well as the average AP values. In this section, the experimental results are presented in detail and an in-depth analysis of the performance of the model is presented.
3.4.1. Model Performance Comparison
We compared and analyzed the proposed model with some of the remaining versions of the Yolo algorithm and the remote sensing ship detectors designed by other scholars for the ShipRSImageNet dataset, and the results of the analyses are shown in
Table 3. The comparative experiments for the DOTA dataset are shown in
Table 4.
Table 3 illustrates the performance comparison on the ShipRSImageNet dataset, where our proposed model outperforms existing baseline methods across key metrics, including precision, recall, and mAP@0.5. These results underscore the model’s enhanced capability in accurately detecting ship targets under varying conditions. Although the computational complexity (GFLOPs) of Ship-Yolo is slightly higher than some of the compared models, its significant improvement in detection performance validates its effectiveness.
As indicated in
Table 4, for the DOTA dataset, Ship-Yolo achieves higher detection precision for categories such as baseball diamonds (BDs) compared to other algorithms, and its mean average precision (mAP) also surpasses that of the other methods. This highlights the model’s exceptional detection performance and robust generalization capabilities.
3.4.2. Analysis of the Training Process
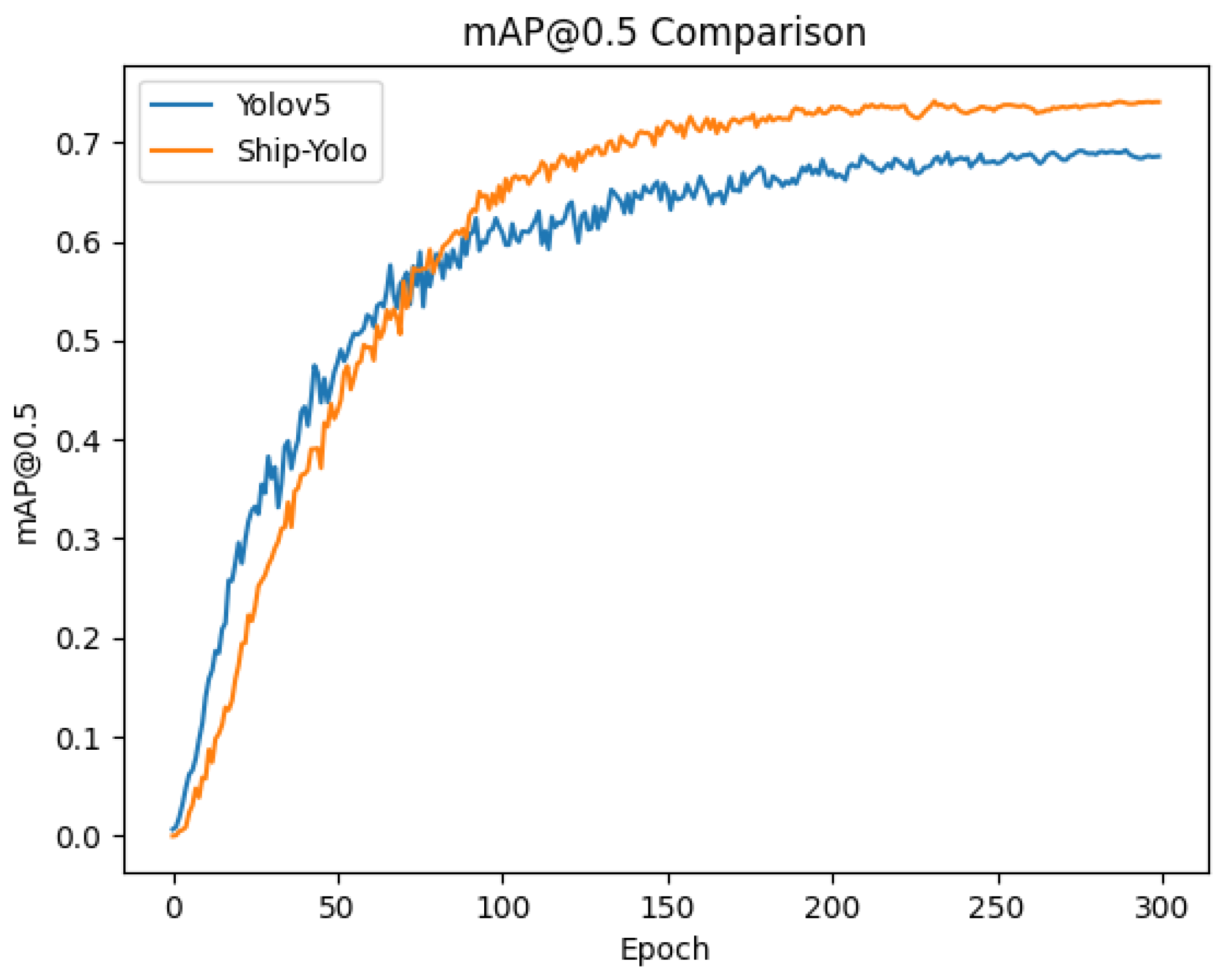
To further analyze the training process of Ship-Yolo, we plotted the mAP@0.5 curves of the proposed model and the baseline model (YOLOv5s) during training on the ShipRSImageNet dataset, as illustrated in
Figure 6. Additionally, we conducted the same experiment on the DOTA dataset and provided a comparative analysis of the parameters, as summarized in
Table 5.
As can be seen from the figure, Ship-Yolo’s average detection accuracy is slightly lower than the baseline model in the initial stage of training. However, as the number of training cycles increases, Ship-Yolo gradually outperforms the baseline model and maintains a stable performance advantage in the later stages of training. This phenomenon suggests that Ship-Yolo may require more training cycles to optimize its parameter configuration, but its final performance is significantly better than the baseline model.
The parameter indicators of the baseline model and the proposed model in this paper are compared in
Table 5, and the results of the analysis show that Ship-Yolo’s detection on the DOTA dataset is significantly better than the baseline model.
3.4.3. Detection Results in Different Scenarios
To ascertain the efficacy of Ship-Yolo in various maritime contexts for detection purposes, we performed visual comparisons for four types of typical scenarios (small targets, busy harbors, cloudy occlusion, and dark and weak environments) on the ShipRSImageNet dataset.
Figure 7 shows the detection results of Ship-Yolo and the baseline model in these scenes.
As can be seen from
Figure 7, Ship-Yolo’s detection results in different scenes are better than the baseline model. Especially in the small target and cloud occlusion scenarios, Ship-Yolo is able to detect the target more accurately, which reduces the cases of missed detection and false detection. Ship-Yolo also shows strong robustness in busy harbors and dark and weak environment scenes, and can effectively handle complex backgrounds and low-contrast targets.
3.4.4. Ablation Experiment
In order to verify the effectiveness of each module in Ship-Yolo, we conducted ablation experiments by gradually adding the EDC, LADH-Head, LiteConv and CARAFE modules and evaluating their effects on the model performance. The experimental results are shown in
Table 6, the symbol “
√” indicates the addition of this module, while “-” indicates the omission of this module.
As shown in
Table 6, by integrating the efficient local attention mechanism with the C3 module in the neck network to form the EDC module, the performance across all evaluation metrics has been significantly improved. Specifically, the application of this module increased the precision from 68.3% to 74.1%, while also achieving notable advancements in the two mAP metrics: mAP@0.5 increased from 68.2% to 72.9%, and mAP@0.5:0.95 improved from 56.5% to 61.2%. These results demonstrate that the EDC module effectively enhances the model’s ability to distinguish small objects from the background. Furthermore, although the standalone introduction of the LADH module can improve accuracy metrics to some extent, this advancement is accompanied by a surge in computational complexity as measured by Gflops, highlighting the importance of lightweight model design. While the standalone addition of the LiteConv and CARAFE modules does not contribute as significantly to model accuracy as the former two, they effectively reduce the computational complexity of the model. Through further experiments involving the addition of two, three, and four modules, we conclude that the proposed EDC, LADH, LiteConv, and CARAFE modules all consistently enhance the performance of the Ship-Yolo model. In the field of military applications, given the lack of high-performance computing resources such as GPUs on reconnaissance platforms like unmanned aerial vehicles (UAVs), the proposed method is well-suited for military reconnaissance systems, including remote sensing satellites and UAVs, aiming to reduce model complexity and unnecessary computational burden. While ensuring reconnaissance performance, this method promotes the efficient identification of remote sensing targets in military reconnaissance systems. Additionally, within the domains of urban planning and environmental surveillance, this study contributes an innovative lightweight network architecture design to existing detection technologies. By integrating partial convolution and a lightweight detection head network into the YOLO series algorithms, the proposed method effectively enhances target detection performance on mobile devices.
4. Conclusions
In this study, this article presents Ship-Yolo, an advanced ship detection method for remote sensing imagery, built upon the Yolov5 framework. The proposed approach incorporates several key enhancements specifically designed to address the challenges posed by small and densely distributed targets, resulting in improved detection accuracy and robustness. To enhance the model’s ability to express key features, a coordinate attention mechanism is integrated into the C3 module of the neck network, forming the EDC module. This module effectively learns the importance of different channels in the feature map, thereby better capturing the key features of targets, especially in complex scenes and multi-scale target detection scenarios, further improving detection accuracy. Additionally, to address the conflict between classification and regression tasks in the coupled head, a novel lightweight asymmetric decoupled head is proposed. This decoupled head separates classification and regression tasks, avoiding interference between tasks, thereby enhancing the model’s detection performance while maintaining its lightweight nature. Furthermore, to further improve the model’s efficiency, a lightweight module named LiteConv is designed to replace the C3 module in the backbone network. The LiteConv module reduces redundancy in feature maps through partial convolution, thereby lowering the model’s computational complexity and increasing detection speed. Finally, to better capture global information, the content-aware reassembly upsampling module is introduced to replace the original upsampling module in the neck network. The CARAFE module has a larger receptive field during feature reassembly, enabling better capture of global information while maintaining a lightweight design.
The proposed architecture exhibits consistent improvements on ShipRSImageNet, with the integrated EDC-LADH-LiteConv-CARAFE pipeline delivering 5.9% higher mAP than the previous best results. Ablation tests quantify individual module efficacy: EDC enhances small-target detection (3.2%), LADH reduces task conflict (2.1%), LiteConv improves efficiency (1.7× speedup), and CARAFE boosts context modeling (1.5%). Results on the DOTA dataset also reflect the effectiveness of the proposed model and verify its strong generalization capability. While our model achieves 88.6% AP (SH), slightly below Oriented R-CNN (88.2%), it excels in multiscale detection (e.g., LV, SV) due to EDC and CARAFE.
Although the Ship-Yolo method achieves significant performance improvements in remote sensing image ship detection tasks, its computational complexity remains higher than some comparative algorithms. In the future, we plan to explore the use of lightweight backbone networks, such as FalconNet [
31], to further reduce computational costs. In addition to this, the model is ineffective in detecting heavily occluded regions, and we plan to improve the performance of occluded ship detection by enhancing the shared information between and within parts using graph neural networks.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



