1. Introduction
The global demand for critical metals such as nickel, copper, cobalt, and rare earth elements continues to increase, while terrestrial resources are depleting, driving the shift toward deep-sea mineral resources [
1]. Although deep-sea mining holds great promise, it faces significant challenges due to the extreme conditions of high pressure, low temperature, and complex seafloor terrain [
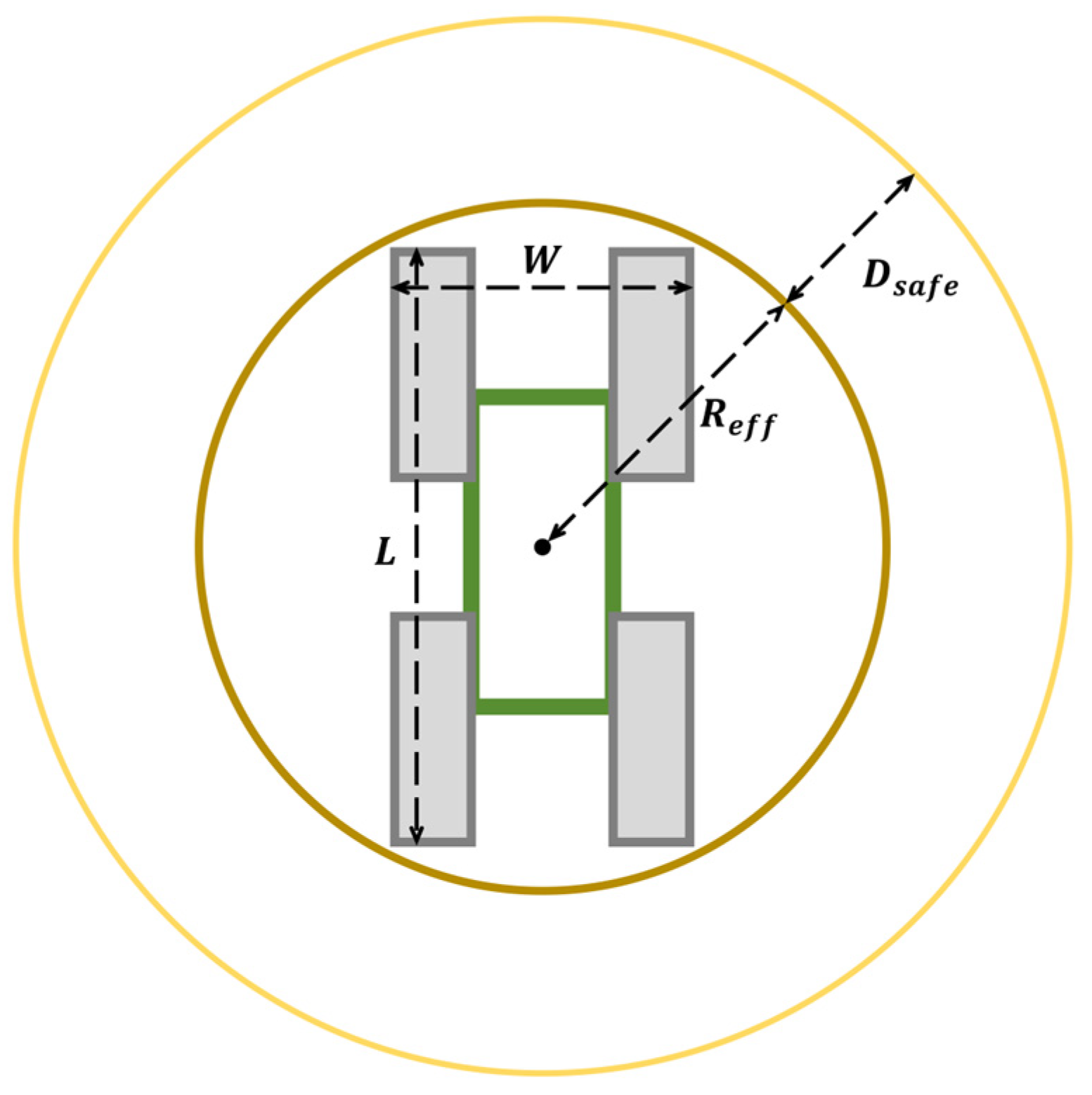
2]. Mining robots, as illustrated in
Figure 1, are central to this process, responsible for both mineral extraction and environmental monitoring. Deep-sea mining robots must possess highly accurate path following and real-time obstacle avoidance capabilities, effectively achieving dual-task control to operate efficiently and safely in such demanding environments [
3,
4].
In the field of path following for marine unmanned vehicles, Londhe [
5] proposed a robust task-space control method based on PID-like fuzzy control, incorporating feed-forward terms and disturbance estimators to handle external disturbances and ensure accurate path following. On the other hand, Dai [
6] combined Computational Fluid Dynamics (CFD) with PID control to develop a path following control model for underactuated unmanned underwater vehicles, successfully optimizing path following performance under complex ocean current conditions. Li [
7] applied a Model Predictive Control (MPC) method to address track slippage issues, introducing an enhanced path following control strategy that ensures smooth following and stability in challenging environments such as soft sediments. Yan [
8] proposed a robust MPC-based path following method utilizing a Finite-Time Extended State Observer (FTESO) to estimate and compensate for system uncertainties, improving the AUV’s disturbance rejection in dynamic environments. Chen [
9] introduced a path following controller for deep-sea mining vehicles based on the Improved Deep Deterministic Policy Gradient (IDDPG) algorithm, incorporating slip control and random resistance. The controller demonstrated superior path following performance in simulations, better adapting to the complexities of deep-sea mining environments.
Although significant advancements have been made in path following control methods, a critical challenge remains in practical operations: how to effectively avoid obstacles while maintaining high following accuracy. To address this challenge, many scholars have proposed various path planning and obstacle avoidance algorithms aimed at optimizing underwater robots’ movement control in complex environments. Zhou [
10] proposed an autonomous recovery path planning method for unmanned surface vehicles (USVs) based on the 3D-Sparse A* algorithm, optimizing waypoint generation to reduce computational load and improving path smoothness and accuracy during dynamic obstacle avoidance. Lyridis [
11] introduced an improved Ant Colony Optimization (ACO) algorithm enhanced by fuzzy logic for local path planning in USVs, significantly improving the efficiency and accuracy of dynamic obstacle avoidance in complex environments. Lu [
12] proposed a path planning method for deep-sea mining vehicles based on an improved Particle Swarm Optimization (IPSO) algorithm, which specifically addresses obstacle avoidance, path optimization, and crawler slippage, achieving efficient and safe navigation in complex seabed environments. Wang [
13] introduced a speed-adaptive robust obstacle avoidance method based on Deep Reinforcement Learning (DRL) for environmentally driven unmanned surface vehicles (USVs). This approach optimizes the avoidance strategy, significantly improving the USV’s obstacle avoidance capability and adaptability in large-scale, uncertain environments. Li [
14] proposed a path planning method for underwater obstacle avoidance in 3D unknown environments based on the Constrained Artificial Potential Field (C-APF) and Twin Delayed Deep Deterministic Policy Gradient algorithm. By combining classical path planning techniques with deep reinforcement learning, this method significantly enhances the obstacle avoidance capability of underwater robots in dynamic and complex environments.
While significant achievements have been made in the single tasks of path following and obstacle avoidance for marine unmanned robots, the challenge of effectively optimizing these dual tasks collaboratively remains unsolved. Wu [
15] proposed a trajectory following method for deep-sea mining vehicles based on MPC, addressing track slippage and environmental disturbances, enabling precise path following and effective obstacle avoidance in dynamic deep-sea environments. However, the study was only tested in an environment with a single obstacle and did not consider dual-task collaborative control in dense obstacle scenarios, which limits its applicability in more complex environments. Nevertheless, the study provides a solid technical foundation for solving the dual-task collaborative control problem and lays the groundwork for further algorithm optimization and practical applications.
Although MPC has achieved some results in dual-task control for path following and obstacle avoidance, its application to dual-task collaboration still faces limitations. First, MPC relies on accurate environmental modeling and state estimation, and in dynamic and uncertain environments like the deep sea, the accuracy and real-time computational capacity of the model may be constrained. Additionally, MPC requires trade-offs between different objectives and relies on predefined models and control strategies, making it difficult to adapt to rapidly changing complex environments. In contrast, DRL, as a data-driven approach, overcomes these limitations by learning and optimizing through interaction with the environment. DRL does not rely on precise environmental models and can adjust control strategies in real time, effectively coordinating the trajectory-following and obstacle avoidance tasks. Especially in complex deep-sea mining environments, DRL offers stronger adaptability and robustness. By designing appropriate reward functions, DRL can dynamically optimize the collaboration between the two tasks, achieving more efficient and stable control.
To provide a clearer comparison of existing approaches in marine unmanned robots,
Table 1 summarizes the main methods used for path following and obstacle avoidance. The comparison highlights their respective strengths and limitations, particularly in terms of adaptability, dual-task collaboration, and suitability for deep-sea mining applications.
While progress has been made in single-task control, research on the collaborative control of path following and obstacle avoidance is still limited. Therefore, the primary objective of this study is to develop a dual-task control algorithm that simultaneously optimizes both path following precision and obstacle avoidance performance, addressing the operational demands of deep-sea mining robots in complex and dynamic environments. This approach aims to enhance the overall efficiency and reliability of robotic operations under challenging conditions.
Distinguishing itself from previous works, this study leverages DRL to improve adaptability in the highly nonlinear, unpredictable nature of deep-sea mining operations. While DRL has demonstrated effectiveness in individual tasks of path following and obstacle avoidance, its application to an integrated dual-task framework remains underexplored. To bridge this gap, we propose a dual-task collaborative control framework that optimizes both objectives simultaneously, achieving superior performance within the same training time and computational budget. Furthermore, we introduce a Dynamic Multi-Step Update mechanism, which significantly enhances dual-task coordination while maintaining computational efficiency. By refining the update strategy without introducing substantial overhead, the Dynamic Multi-Step Update mechanism enables more stable and effective policy learning, leading to a marked improvement in the overall operational effectiveness of deep-sea mining robots.
The remainder of the paper is organized as follows: Notations frequently used in this paper are summarized in
Table 2.
Section 2 outlines the methodology, including the optimization of dynamics, noise incorporation, and reward design.
Section 3 discusses training environments, highlighting the advantages of the Dual-Task Environment.
Section 4 details the TD3 algorithm enhanced with Dynamic Multi-Step Update and its performance evaluation. Finally,
Section 5 concludes the study and suggests future research directions.
3. Environment Optimization
This section presents a training environment optimization framework aimed at enhancing the robustness and adaptability of the deep-sea mining robot in complex underwater conditions. To this end, a Dual-Task Environment (DTE) is developed, integrating the Random Obstacle Environment (ROE) for generalization and the Obstructed Path Environment (OPE) for structured navigation challenges. By dynamically alternating between these two settings, the DTE ensures a balanced training approach that strengthens both path following accuracy and obstacle avoidance capabilities. The following sections detail the environment design, training methodology, and simulation-based performance evaluation.
3.1. Environment Set Up for Dual-Task
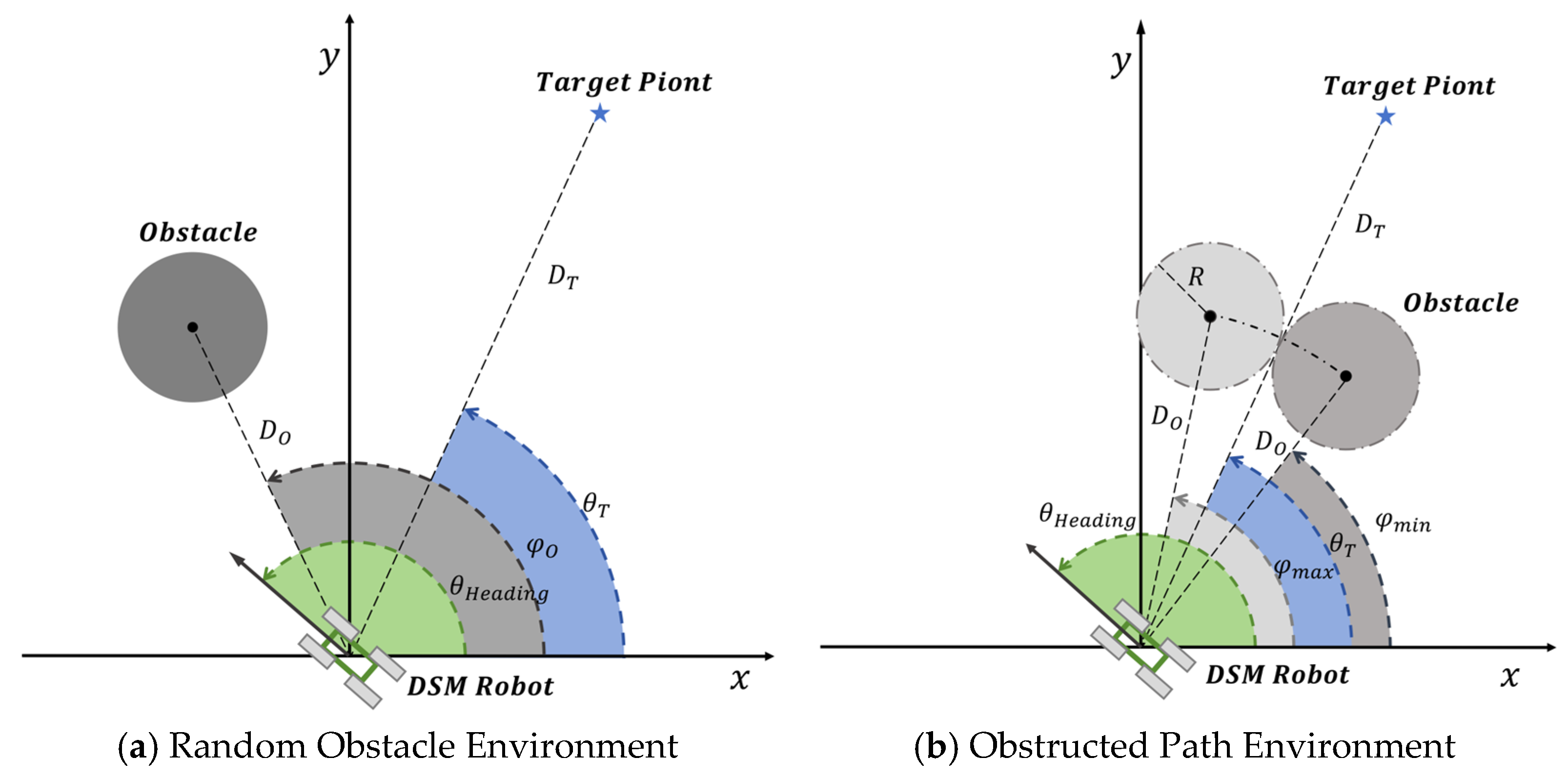
Deep-sea mining robots must simultaneously achieve path following and obstacle avoidance, requiring extensive training across diverse environments to enhance their overall adaptability. This study builds on the conventional Random Obstacle Environment and proposes a novel Obstructed Path Environment. Additionally, a Dual-Task Environment is developed by integrating ROE and OPE to provide tailored training support for reinforcement learning, as illustrated in
Figure 4.
The ROE, shown in
Figure 4a, is a commonly used setup to evaluate the path following and obstacle avoidance capabilities of intelligent agents. The specific configurations are as follows:
Robot Initial Position: The robot’s initial position is randomly generated within a circular area centered at the origin (0, 0), with an initial heading angle uniformly distributed between and .
Target Position: The target is randomly placed on a circular arc 100 m away from the origin, with an angular span in the range of .
Obstacle Placement: Obstacles are randomly positioned in the potential trajectory area between the robot and the target. The obstacles are distributed along a circular arc with a central angle spanning [0°, 180°]. To ensure sufficient clearance, obstacles are placed at least 100 m away from both the origin and the target. Their radii range between 2 m and 15 m. While the obstacle placement is random, it rarely blocks the direct path between the robot and the target, occasionally creating hindrances.
ROE provides a simplified environment widely adopted in reinforcement learning for deep-sea mining tasks. While effective for training basic path following strategies, it often lacks the complexity to sufficiently simulate dual-task scenarios, where simultaneous path following and dynamic obstacle avoidance are critical.
To address the limitations of the ROE in training effective obstacle avoidance strategies, this study introduces the OPE. The core idea is to strategically place obstacles in positions that are more likely to directly block the robot’s path to the target, thereby enhancing the robot’s learning potential in complex avoidance tasks. As shown in
Figure 4b, the OPE imposes additional constraints on obstacle distribution based on the initial positions of the robot and the target. The valid angular range for obstacle placement is rigorously constrained according to Equation (16).
Here, obstacle centers are randomly generated within the range, ensuring that the obstacles intersect with the direct path between the robot and the target.
The OPE enhances the specificity and complexity of avoidance strategy training by carefully controlling obstacle placement. Under OPE conditions, the robot must overcome direct obstructions, thereby improving its ability to handle challenging avoidance scenarios. However, while the OPE increases the complexity and difficulty of avoidance tasks, it may reduce the success rate of path following tasks.
To balance these trade-offs, this study combines ROE and OPE into a unified framework termed the DTE. The DTE is a comprehensive training framework designed to balance the training requirements for both path following and obstacle avoidance. In the DTE, each training episode alternates randomly between ROE and OPE, ensuring that the robot acquires the adaptability and task versatility required for different scenarios. Specifically, the DTE dynamically adjusts obstacle distribution characteristics (as in the OPE) and obstacle randomness (as in the ROE) throughout the training process, enabling the robot to achieve more holistic and robust training outcomes.
The DTE aims to balance the agent’s performance in path following and obstacle avoidance.
Section 3.2 will evaluate its effectiveness through training analysis across different environments.
3.2. Training Process
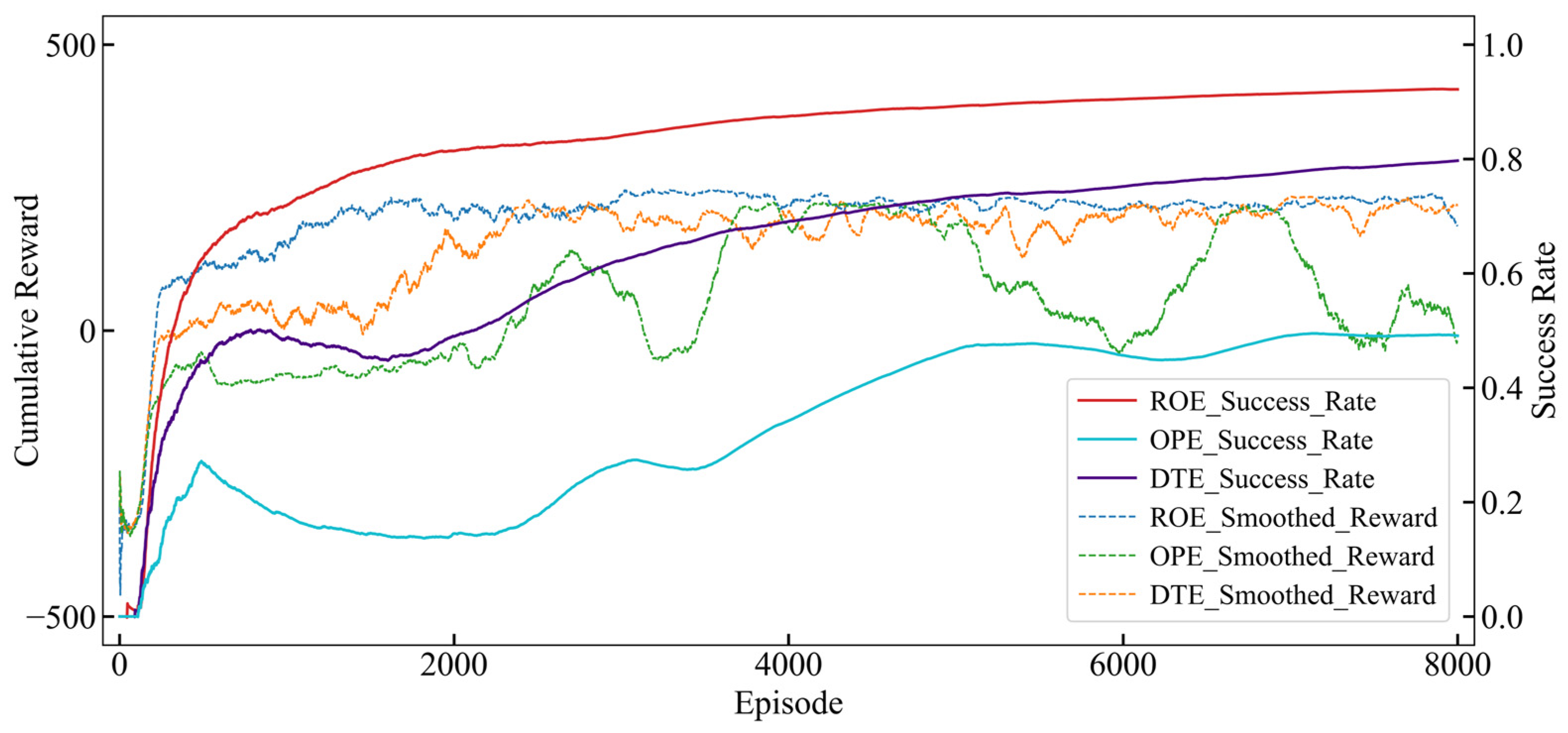
This section presents a comprehensive analysis of the training process across three distinct environments: ROE, OPE, and DTE. The evaluation is conducted using two key performance metrics: cumulative reward and success rate, as illustrated in
Figure 5. A rigorous assessment of these metrics provides deeper insights into the learning efficiency and adaptability of the proposed approach in diverse operational scenarios.
In the Random Obstacle Environment (ROE), the agent demonstrated rapid convergence, with a stable increase in cumulative reward. After approximately 2000 episodes, the cumulative reward plateaued at around 230, and the success rate surpassed 80%. This suggests that the relatively straightforward nature of the path following task in the ROE facilitated the agent’s ability to quickly develop effective navigation strategies. However, the limited complexity of obstacles in this environment may have restricted the agent’s capacity to acquire advanced obstacle avoidance skills.
In contrast, the OPE presented significantly greater challenges, as reflected by the instability of cumulative rewards throughout the training process. During the initial training phase, the cumulative reward increased rapidly but soon entered a prolonged stagnation period, during which it remained negative. It was not until approximately 2000 episodes that the reward began to rise again, turning positive at around 2300 episodes. However, due to the heightened complexity of the OPE, the cumulative reward exhibited persistent fluctuations throughout the training process, oscillating between −50 and the stabilized value of 230 observed in the ROE. This instability underscores the increased difficulty posed by the dynamic and obstructed nature of the environment, which required the agent to continuously adjust its strategies. Moreover, the overall success rate declined during the reward stagnation period and only began to recover once the cumulative reward started increasing again. Nevertheless, the final success rate remained below 50%, highlighting the considerable challenges introduced by the intricate obstacle arrangements in the OPE.
The DTE, designed as a hybrid training strategy integrating the characteristics of the ROE and the OPE, enabled the agent to concurrently learn both path following and obstacle avoidance tasks. In the early training phase, the cumulative reward increased rapidly but then entered a stagnation period before 1500 episodes—a characteristic similar to that observed in the OPE. However, due to the mixed training approach, this stagnation phase was significantly shorter, and the cumulative reward remained predominantly positive during this period. As training progressed, the cumulative reward continued to rise, eventually oscillating around 200 after surpassing the stabilized value of 230 observed in the ROE. This indicates that the DTE exhibited greater stability than the OPE while still being slightly less stable than the ROE, with a notably slower convergence rate than the latter.
The success rate in the DTE initially followed a trend similar to that in the OPE, declining during the cumulative reward stagnation period and only beginning to recover once the reward started increasing again. However, a key distinction was that the success rate in the DTE continued to rise steadily throughout the later stages of training, mirroring the trend observed in the ROE. Ultimately, after 8000 episodes, the success rate stabilized at approximately 80%, demonstrating the agent’s ability to adapt to dual-task scenarios. While the training process was inherently more complex, the DTE provided a structured learning framework that enhanced the agent’s capacity to balance path following and obstacle avoidance behaviors under dynamic conditions, contributing to its overall performance across diverse scenarios.
In summary, the ROE facilitated foundational training for path following, while the OPE significantly enhanced the agent’s obstacle avoidance capabilities. By integrating these characteristics, the DTE serves as a robust platform for comprehensive dual-task evaluation.
Section 3.3 will further validate the agent’s performance through simulated testing across these environments.
3.3. Dual-Task Simulation Testing
This section evaluates the performance of controllers trained in three environments (ROE, OPE, and DTE) to assess their capabilities in path following and obstacle avoidance tasks. The evaluation consists of two parts: pure path following tests (without obstacles) and randomized obstacle avoidance tests. Each controller was subjected to 500 tests in its respective environment, with each test independently initialized using a randomized starting state and obstacle configuration. This ensures a diverse and unbiased assessment of the controller’s generalization ability across different scenarios.
Path following performance across different training environments: The evaluation of path following tasks was conducted on straight and S-shaped paths in three training environments: ROE, OPE, and DTE. In the context of path following tasks for deep-sea mining operations, the selected path designs aim to rigorously evaluate the robot’s capabilities in both straight-line and turn navigation. The straight path represents stable movement in constrained or relatively flat seabed environments, whereas the S-shaped path effectively simulates the robot’s ability to maneuver through complex terrain and avoid obstacles in operational settings. The performance metrics, including trajectory deviation and average speed, are summarized in
Table 5 and illustrated in
Figure 6.
To further evaluate the effectiveness of controllers trained in different environments, trajectory deviation and speed performance were assessed across both straight and S-shaped path following tasks.
For the straight path scenario, the controller trained in the ROE exhibited the highest precision, with the smallest trajectory deviation of 0.169 m. This indicates that training in a relatively structured environment optimized for path following tasks enabled the agent to achieve superior tracking accuracy. The DTE yielded a moderate trajectory deviation of 0.409 m, reflecting a balanced trade-off between precision and adaptability. In contrast, the controller trained in the OPE exhibited the largest trajectory deviation of 0.685 m, likely due to the increased complexity and dynamic obstacle arrangements encountered during training, which may have prioritized obstacle avoidance over strict trajectory adherence.
A similar trend was observed in the more challenging S-shaped path task. The ROE-trained controller maintained a trajectory deviation of 0.432 m, slightly outperforming the DTE-trained controller, which exhibited a deviation of 0.604 m. Meanwhile, the OPE-trained controller demonstrated the highest deviation at 0.734 m, indicating the heightened difficulty in maintaining precise path tracking under curved and complex trajectories.
Despite these variations in trajectory deviation, the average speed remained consistent at approximately 0.8 m/s across all environments. This suggests that differences in training strategies primarily influenced trajectory precision rather than the controller’s capability to maintain a stable velocity. The results highlight the trade-offs between training environments, with the ROE favoring precision, OPE emphasizing adaptability to complex conditions, and DTE achieving a balance between the two.
Obstacle avoidance performance across different training environments: The obstacle avoidance performance was evaluated by analyzing the completion rate across 500 independently initialized, randomly generated obstacle scenarios for each environment, as detailed in
Table 5, with one such scenario illustrated in
Figure 7. The completion rate is defined as the proportion of successful target-reaching instances out of 500 independently randomized initialization tests. To ensure a diverse set of obstacle configurations, each environment was uniquely initialized, thereby more accurately simulating the unpredictability and complexity of real-world deep-sea mining operations. This randomized initialization enables a comprehensive assessment of the algorithm’s adaptability to varying environmental conditions. The results indicate substantial performance differences across the three environments, underscoring the distinct challenges posed by different randomized obstacle distributions.
In the ROE, the controller failed to complete any obstacle avoidance tasks, with a completion rate of 0%, highlighting the inadequacy of this setting for training robust obstacle avoidance capabilities. The OPE-trained controller achieved a completion rate of only 6.6%, likely due to constrained obstacle placements increasing task difficulty. Both the OPE and ROE utilize unilateral obstacle avoidance strategies, which limit their effectiveness in handling more complex scenarios. In contrast, the DTE-trained controller significantly outperformed both, achieving a completion rate of 85.4%. This demonstrates the effectiveness of the bilateral obstacle avoidance strategies employed in the DTE, enabling dynamic adaptability to complex obstacle configurations and successful task completion.
3.4. Summary
This section presents a comprehensive investigation into the path following and obstacle avoidance capabilities of deep-sea mining robots, focusing on the design, training, and simulation testing of three distinct training environments: ROE, OPE, and DTE. The ROE is well suited for fundamental path following tasks, demonstrating robust stability and trajectory accuracy. However, its random obstacle distribution limits its training efficacy for obstacle avoidance. The OPE addresses this limitation by refining obstacle placement, significantly enhancing the robot’s obstacle avoidance capabilities. Nonetheless, its support for path following is weaker, and the high complexity of obstacle avoidance tasks reduces overall training efficiency. To achieve a balanced optimization of dual-task performance, this study introduces the DTE, which dynamically integrates the strengths of the ROE and OPE, enabling the robot to achieve a well-rounded performance in both tasks.
During training, the DTE exhibited superior adaptability, achieving relatively high cumulative rewards and success rates among the three environments, underscoring its potential for complex tasks. In path following, the DTE closely matched the ROE in trajectory accuracy and speed. In obstacle avoidance, its success rate far exceeded that of the other environments. Overall, the DTE provides robust support for the stability and operational efficiency of deep-sea mining robots in complex operational scenarios. In the next section, the study will further optimize the algorithm design based on the DTE to address more intricate and dynamic operational demands.
4. Algorithm Optimization
This section introduces an optimization methodology for enhancing the adaptability and decision-making efficiency of the TD3 algorithm in complex dual-task scenarios. To this end, a Dynamic Multi-Step Update mechanism is proposed, which extends the target Q-value estimation to multi-step returns, integrating both immediate rewards and long-term returns to improve policy learning. The mechanism dynamically adjusts trajectory selection during the multi-step return calculation, ensuring a balance between computational efficiency and optimization performance. To evaluate its effectiveness, training performance under different DMSU parameter settings is analyzed, followed by a comprehensive assessment of its impact on path following accuracy, strategy stability in obstacle avoidance, and robustness in multi-directional obstacle scenarios.
4.1. The Principle of Dynamic Multi-Step Update
To further enhance the adaptability and performance of the TD3 algorithm in complex dual-task scenarios, this study introduces the Dynamic Multi-Step Update mechanism. The DMSU extends the calculation range of target Q-values to multi-step returns, integrating immediate rewards with long-term returns to significantly improve the agent’s policy learning capability. Moreover, the DMSU dynamically adjusts the trajectory selection during the multi-step return calculation without imposing additional constraints, ensuring a balance between computational efficiency and effectiveness.
The target Q-value is calculated as shown in Equation (17).
where
and
denote the state and action at time step
;
is the hyperparameter of the DMSU, defining the maximum number of steps for multi-step returns;
and
are the two target Critic networks that evaluate the state–action pairs at time step
.
During training, the DMSU adjusts the target Q-value calculation based on the trajectory length.
Complete trajectory calculation: When the remaining trajectory steps are greater than or equal to , the full n-step return is computed as shown in Equation (17).
Incomplete trajectory calculation: When the remaining trajectory steps are fewer than
, all remaining step rewards are calculated, and the target Q-value for steps beyond
is set to zero. The simplified target Q-value is given by Equation (18).
This dynamic adjustment mechanism ensures the rationality and stability of target Q-value computation even in the presence of incomplete trajectories, thereby improving the algorithm’s generalization ability.
To visualize the integration of the DMSU into the TD3 algorithm, the improved algorithmic framework is depicted in
Figure 8. The framework retains the dual-Critic structure of TD3 while enabling dynamic trajectory adjustment through the DMSU. The trajectories stored in the experience replay buffer are dynamically adapted to the logic of the DMSU, ensuring full utilization of trajectory information and stable training. The detailed algorithmic procedure is presented in Algorithm 1.
| Algorithm 1: Optimized TD3 (reducing to the original TD3 algorithm when ) |
| Input: | initial critic networks , and actor network with random parameters , , |
| Input: | initial target networks , , |
| Input: | initial replay buffer |
| Input: | initial hyperparameters: actor network learning rate , critic network learning rate , target network soft update rate , mini-batch size , memory pool size , update actor interval , discount factor , learning time step , standard deviation , , target action noise clipping , exploration noise decaying coefficient , policy noise , , , , exploration noise , , total episodes , random seed 24, max step length |
| for to do |
| | Select action |
| | Observe: reward , new state , Store trajectory , , , in with max size |
| | Sample: mini-batch of trajectories , , , from , then update critic using: |
| | , |
| | , , |
| | , , |
| | if |
| | Update by the deterministic policy gradient: |
| | |
| | Update target networks by: |
| | , |
| | , |
| | . |
| | end if |
| end for |
The Dynamic Multi-Step Update (DMSU) enhances the agent’s ability to optimize long-term objectives by incorporating multi-step returns while ensuring stable target Q-value computation under varying trajectory lengths. This mechanism mitigates the stochasticity of single-step rewards, leading to smoother policy updates and improved adaptability to complex task scenarios. Additionally, the flexibility and compatibility of the DMSU allow it to seamlessly integrate into the TD3 framework, preserving the stability of TD3 while significantly improving its learning efficiency in dual-task scenarios. As the core parameter of the DMSU, the step limit plays a critical role in balancing short-term and long-term returns. Therefore, subsequent sections investigate the training and testing performance of agents under different values, providing empirical evidence for optimizing algorithms in deep-sea mining dual-task control scenarios.
4.2. Training Process
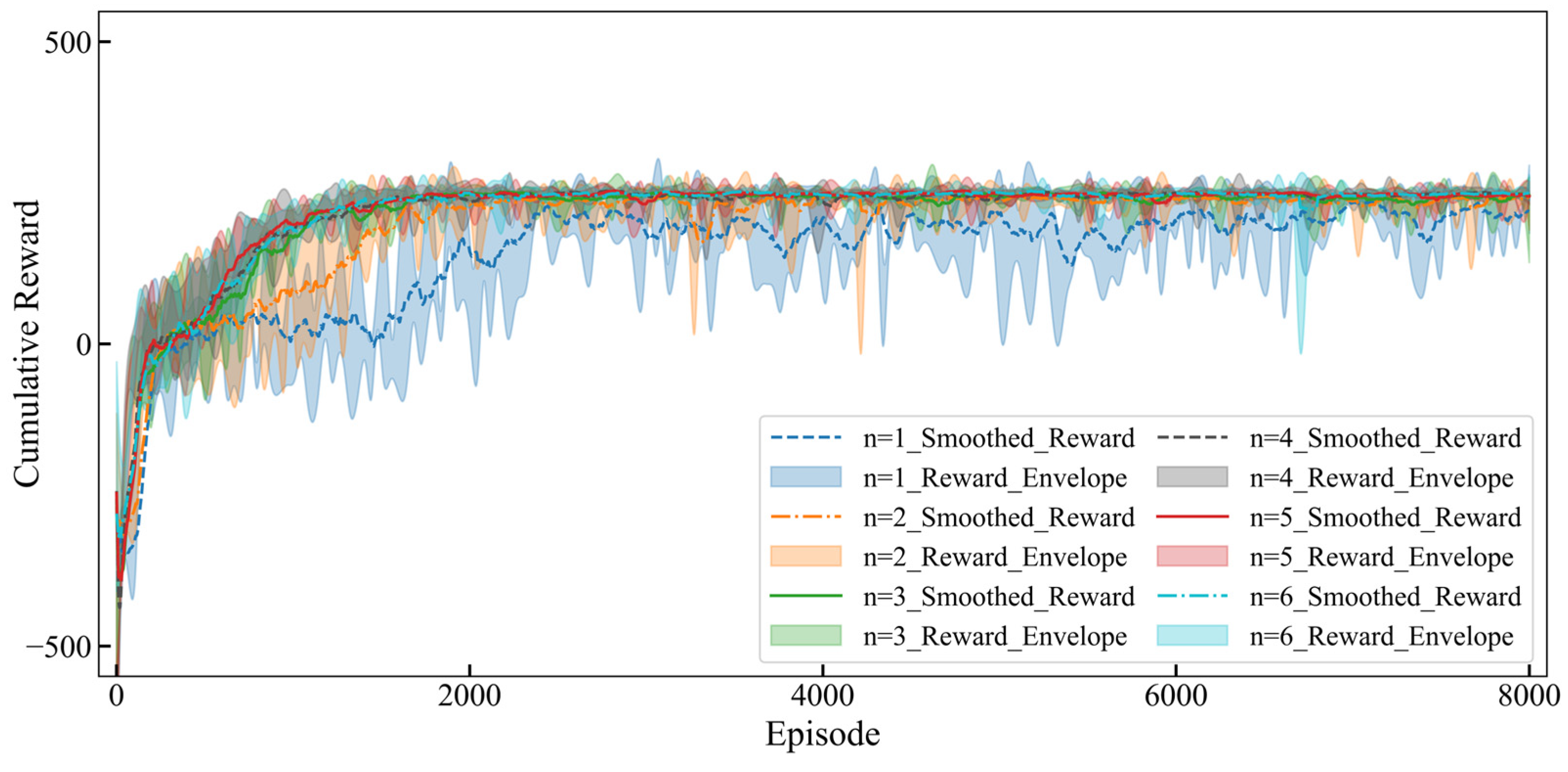
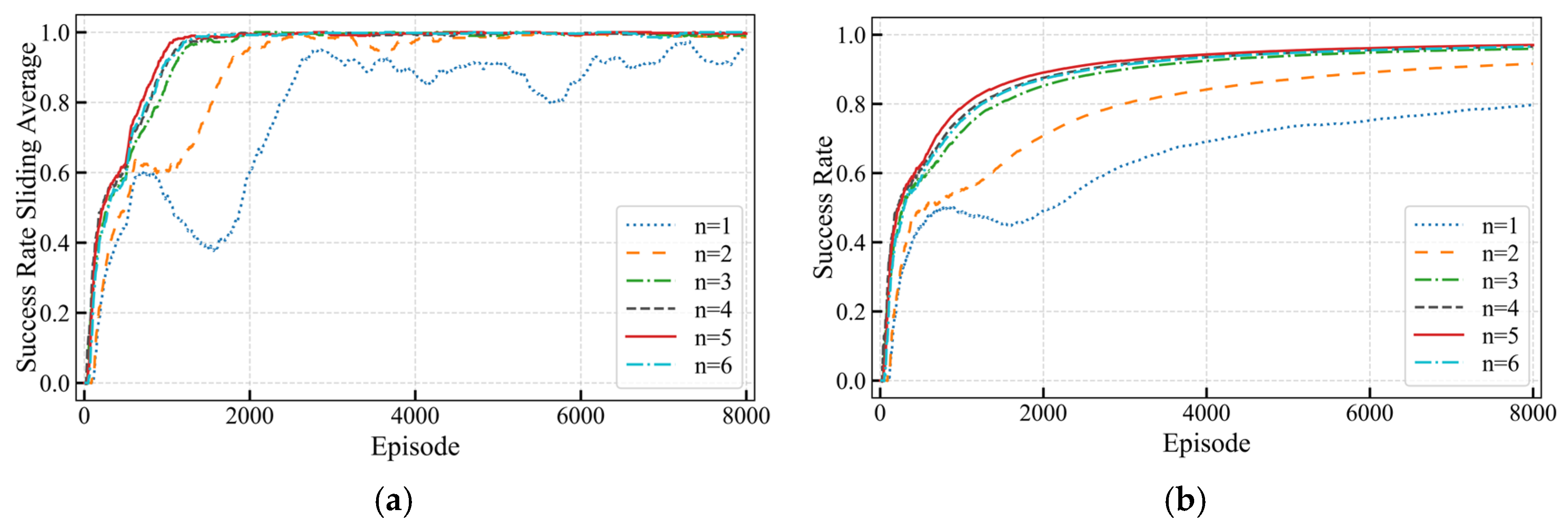
In analyzing the impact of different multi-step settings (
) on the training process of the Dynamic Multi-Step Update (DMSU), significant differences in performance were observed through cumulative reward trends and success rates, as illustrated in
Figure 9 and
Figure 10. The evaluation was conducted over 8000 training episodes for each setting.
Figure 9 presents the smoothed reward curves and their envelopes across iterations, while
Figure 10 compares the sliding average success rates and overall success rates.
As increased, the training performance exhibited noticeable variations. For , although the cumulative rewards grew slowly in the early stages, the short-term update strategy struggled to adapt to complex tasks, leading to higher reward fluctuations and significantly lower final success rates compared to other settings. When , both reward growth rates and success rates improved noticeably, but some fluctuations persisted during training, suggesting that multi-step updates in this range strike a moderate balance between short-term gains and long-term learning outcomes. At , the training achieved its best performance. The reward curve stabilized, and the final success rate reached its peak, indicating outstanding training stability and efficiency in both path following and obstacle avoidance tasks. However, for , the increased step count likely introduced more noise due to computational complexity, resulting in larger reward fluctuations and slightly lower final success rates compared to .
Overall,
emerged as the optimal multi-step update setting, demonstrating a superior balance between stability and efficiency while ensuring long-term benefits for path following and obstacle avoidance tasks. Compared to traditional single-step updates, the DMSU effectively mitigates the impact of single-step reward fluctuations and dynamically enhances the adaptability of the agent to complex task scenarios. In the upcoming
Section 4.3, simulation tests will further evaluate the impact of different multi-step settings on control performance and assess the practical effectiveness of the improved DMSU algorithm in path following and obstacle avoidance tasks, providing additional validation for its efficacy.
4.3. Dual-Task Simulation Testing
4.3.1. Path Following Without Obstacles
To comprehensively evaluate the performance of the DMSU strategy in path following tasks, this section conducts detailed simulation tests on controllers with varying multi-step update settings. The test paths include a straight path and an S-shaped path. Each controller was subjected to 500 repetitions on each test path to comprehensively assess following accuracy and speed performance in scenarios with varying path complexities. The results are summarized in
Table 6, and the following trajectories are visualized in
Figure 11.
For the straight path tests, the controller with demonstrated the smallest trajectory deviation of 0.128 m, indicating optimal accuracy. This was closely followed by , with a deviation of 0.144 m. In contrast, (representing the original TD3 algorithm) showed a much higher deviation of 0.413 m, significantly underperforming. These results validate the notable improvement in following accuracy achieved through the Dynamic Multi-Step Update strategy. Additionally, the average speed across all settings remained close to 0.8 m/s, with achieving the highest average speed of 0.826 m/s, slightly exceeding at 0.822 m/s.
For the more complex S-shaped path tests, the controller with achieved the lowest trajectory deviation of 0.179 m, showcasing the best following accuracy, followed by with a deviation of 0.195 m, which also falls within acceptable limits. However, the deviation for increased to 0.282 m, likely due to excessive update steps causing instability or disturbances. In terms of speed, all configurations maintained an average speed near 0.8 m/s. The highest average speed of 0.823 m/s was observed for , but its reduced accuracy indicates potential trade-offs in performance.
Overall, the results from both the straight and S-shaped paths demonstrate that the Dynamic Multi-Step Update strategy significantly enhances following accuracy in path following tasks. Notably, the configurations with and outperformed the others. achieved the lowest trajectory deviation in complex path scenarios, while delivered the best balance of accuracy and speed, exhibiting superior overall performance. By comparison, (original TD3 algorithm) showed markedly inferior results, further validating the effectiveness of the Dynamic Multi-Step Update strategy. In conclusion, is identified as the optimal multi-step update configuration, providing a solid foundation for high-performing controllers in subsequent tasks. The next section will further evaluate the multi-step update strategy’s performance in obstacle avoidance tasks to comprehensively validate its practical applicability.
4.3.2. Validation of Strategy Consistency and Stability in Obstacle Avoidance
To verify the consistency and stability of the agent’s strategy in obstacle avoidance tasks, we conducted repeated simulations under identical random obstacle distribution environments for different step-length constraints (
). For each step-length setting, three trials were performed using a fixed set of randomly generated obstacles in the environment, and their trajectories were recorded to evaluate repeatability and consistency. The results are presented in
Figure 12.
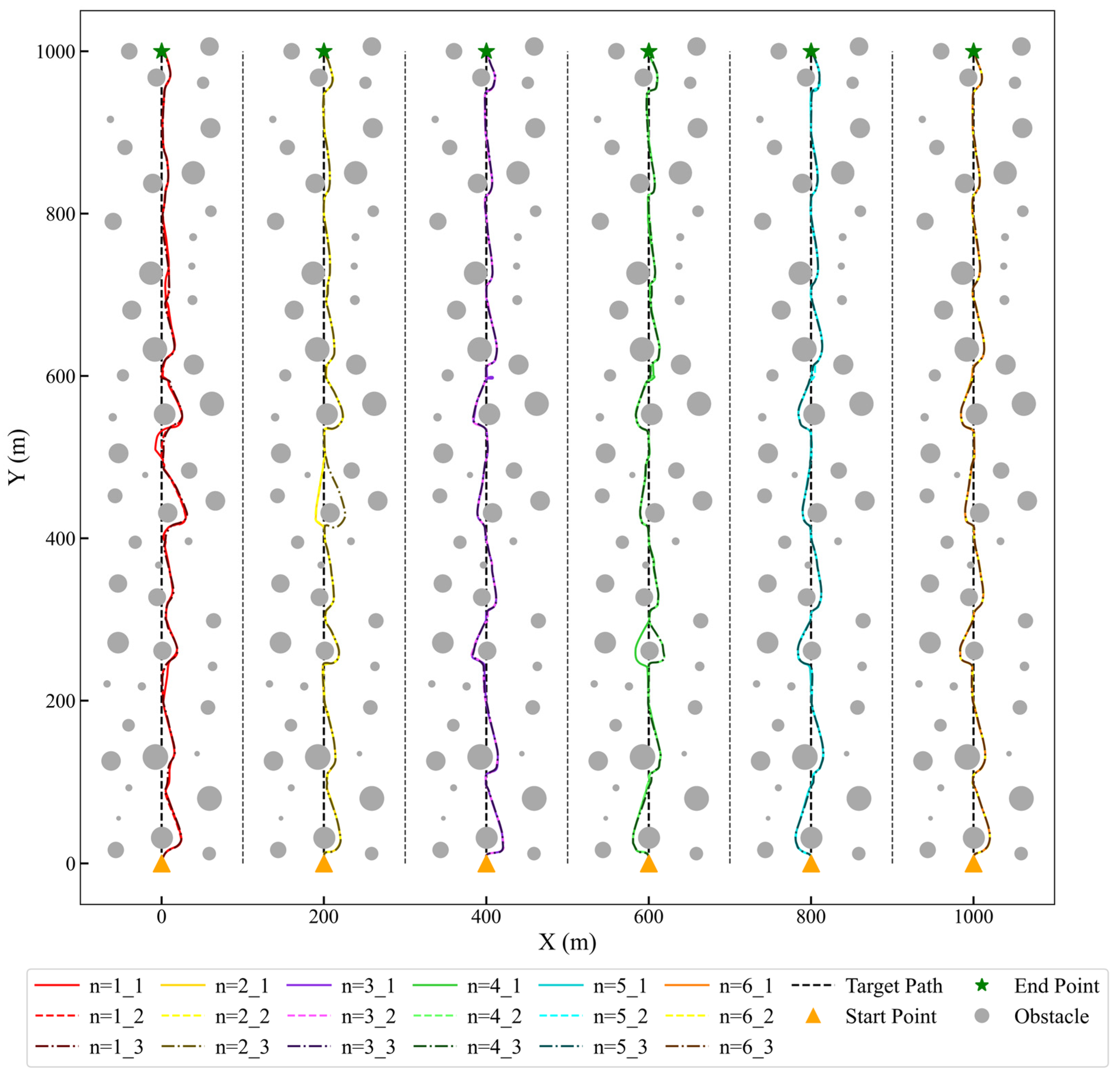
As shown in
Figure 12, under identical obstacle distribution environments, the three repeated trajectories for different step-length settings exhibited high overlap on the overall path. Particularly for
and
, the trajectories across three trials were nearly identical, demonstrating the agent’s highly stable execution capability in obstacle avoidance tasks under consistent conditions. Even in regions with dense or complex obstacles, the overlap of trajectories remained high, indicating reliable repeatability in complex environments. For
, the limited step-length constraint reduced the generalization capability of the agent’s strategy, leading to slight deviations in certain regions. However, the overall repeatability remained within an acceptable range, further validating the significant impact of step-length parameters on the stability of the agent’s learning strategy.
The experimental results clearly demonstrate that the agent’s strategies in obstacle avoidance tasks possess a high degree of repeatability and consistency. This underscores the rationality and effectiveness of the training method and experimental design. High trajectory repeatability not only enhances the reliability of the experimental results, but also lays a solid foundation for subsequent tests in more complex environments. The next subsection will further evaluate the robustness and adaptability of the agent’s obstacle avoidance strategies in randomized dynamic obstacle environments.
4.3.3. Robustness Test in Multi-Directional Obstacle Avoidance
To evaluate the robustness and adaptability of the DMSU strategy in complex multi-directional obstacle environments, we conducted comprehensive tests under eight distinct directional obstacle scenarios, each with varying step-length constraints. For each step-length setting, 500 simulation trials were performed for each direction, with obstacles independently and randomly initialized in every trial. In total, 8 × 500 unique obstacle environments were generated to ensure a diverse and comprehensive assessment of the deep-sea mining robot’s obstacle avoidance capability.
Multi-directional obstacle avoidance evaluation is essential due to the inherent unpredictability of deep-sea mining operations. Variations in environmental disturbances, local flow conditions, and obstacle distributions can lead to non-uniform navigation challenges across different movement directions. A robust obstacle avoidance strategy must maintain consistent performance across diverse orientations to ensure operational reliability. Additionally, unpredictable external perturbations, such as fluctuating water flow, may introduce asymmetries in obstacle encounters, further necessitating a comprehensive multi-directional evaluation.
By systematically analyzing performance across a large set of randomly generated directional scenarios, this study ensures that the proposed method remains effective under varying obstacle configurations and environmental conditions, reinforcing its reliability in practical deep-sea mining applications.
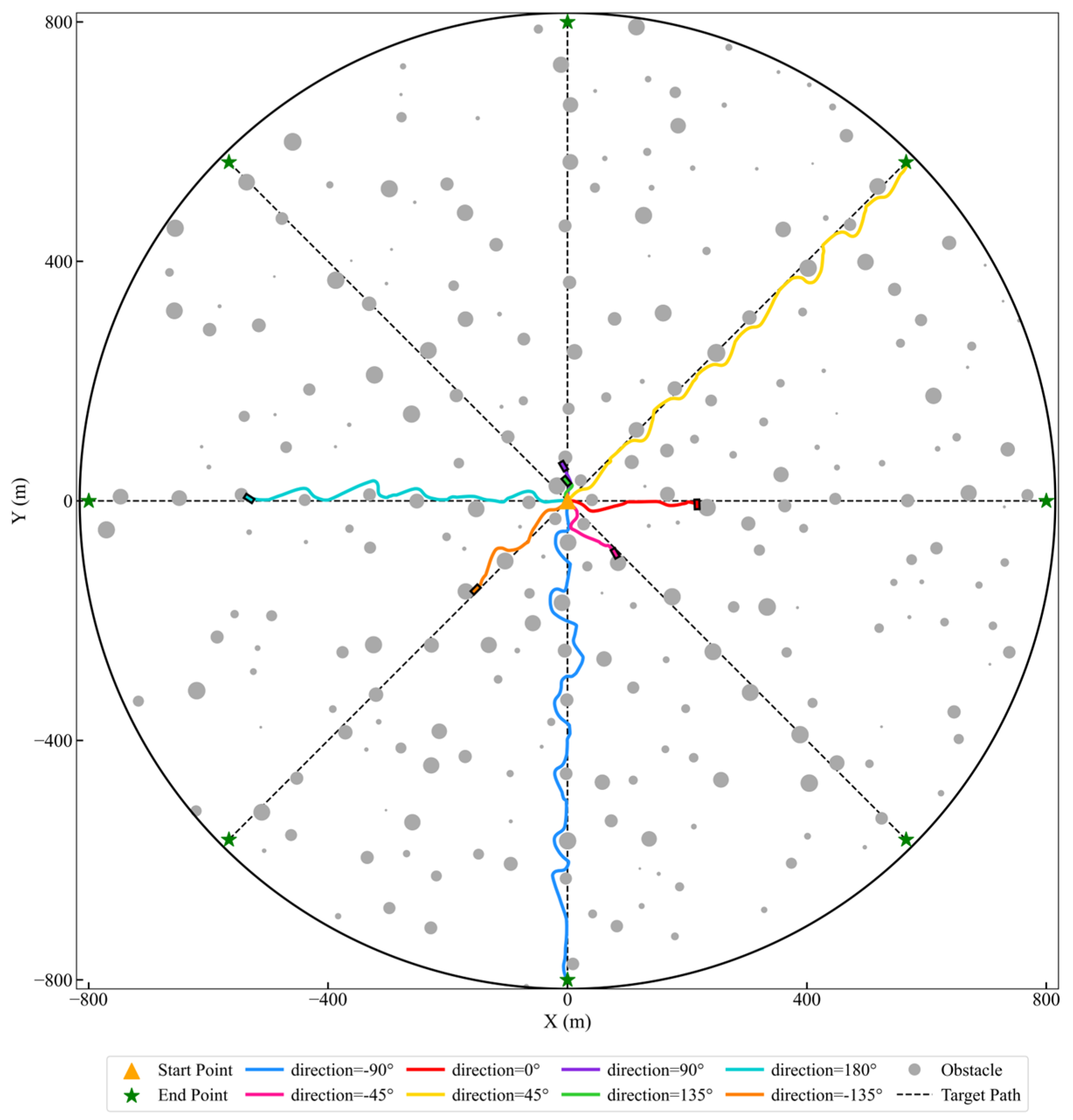
Table 7 presents the obstacle avoidance completion rates across eight directions under different step-length constraints. The completion rate is defined as the proportion of successful target-reaching instances in 500 independently randomized initialization tests for a given direction and step-length constraint. The results indicate that when the step length was constrained to
, the completion rate reached 99.98%, demonstrating exceptional robustness and stability. This highlights that a reasonable step-length configuration can effectively optimize the agent’s adaptability to complex dynamic environments. However, for
, while the overall completion rate remained high, a slight decrease in certain directions (e.g., 135° and 180°) suggests that excessive step lengths might introduce computational complexity, reducing local path-planning efficiency.
The obstacle avoidance trajectories under step-length constraints of
and
are illustrated in
Figure 13 and
Figure 14, respectively. For
, the agent’s trajectories in certain directions, such as −90° and 180°, showed significant deviations from the target path, indicating that shorter step lengths limited the agent’s ability to effectively plan continuous paths. In contrast, for
, the trajectories across all directions were highly consistent and closely aligned, demonstrating superior path consistency and planning capabilities. This further validates that the controller under
exhibits exceptional path-planning stability and robustness in complex obstacle environments.
These findings lead to the conclusion that a well-balanced step-length setting (e.g., ) effectively ensures both continuity and stability in path planning, enabling the agent to exhibit remarkable adaptability and robustness in complex multi-directional environments. In contrast, excessively short step lengths (e.g., ) may restrict the agent’s global path-planning capabilities, while excessively large step lengths (e.g., ) could introduce local inefficiencies due to increased computational complexity. The results underscore the critical role of step-length optimization in enhancing dynamic obstacle avoidance performance, providing a strong foundation for future algorithmic applications in complex environments.
5. Conclusions
This study introduces an optimized Deep Reinforcement Learning algorithm based on the Dynamic Multi-Step Update to systematically investigate and validate dual-task control for path following and obstacle avoidance in deep-sea mining vehicles under complex dynamic environments. By designing three training environments (ROE, OPE, and DTE), the research focuses on analyzing the performance of controllers across different scenarios, ultimately selecting the DTE as the optimal training environment. Under the DTE, the robot demonstrated enhanced capabilities in both path following and obstacle avoidance, overcoming the limitations of single-task environments and exhibiting remarkable balance and adaptability. Furthermore, the step length parameter, as a critical hyperparameter in the DMSU, played a decisive role in improving training efficiency, control precision, and algorithm stability. Systematic simulation tests confirmed that the controller achieved optimal comprehensive performance in path following and obstacle avoidance when the step length was set to a specific value.
In the path following tests, the simulation results under different step-length settings revealed that the controller with the specific step length achieved one of the lowest trajectory deviations on both straight and S-shaped paths, demonstrating the significant impact of the Dynamic Multi-Step Update mechanism on improving following accuracy. Specifically, it achieved the lowest trajectory deviation in the straight path test and the second lowest in the S-shaped path test. In randomized obstacle avoidance tests, the controller with the specific step length achieved a nearly 100% obstacle avoidance success rate across eight directions, with stable and repeatable trajectory performance, showcasing exceptional robustness and task execution capabilities. A comprehensive analysis of the simulation results validated the effectiveness and reliability of the improved algorithm in complex dynamic environments.
While the proposed method demonstrates promising performance in simulation, several aspects require further investigation to bridge the gap between the current study and real-world deep-sea mining operations.
Future research will focus on extending the control algorithm to real-world three-dimensional deep-sea environments, where the presence of complex and irregular seabed topographies poses significant challenges for obstacle avoidance. Additionally, the current study employs a simplified dynamic model with limited consideration of external disturbances, such as ocean currents and sediment dynamics. To enhance the system’s robustness, future work will incorporate more comprehensive hydrodynamic modeling and adaptive disturbance rejection mechanisms.
Furthermore, the proposed framework currently operates in an open-loop manner, lacking real-time perception and environmental feedback. To address this limitation, integrating sonar-based perception and simultaneous localization and mapping (SLAM) techniques will be a key focus. This enhancement will enable the deep-sea mining robot to construct a dynamic environmental representation, facilitating real-time decision-making and adaptive control in unstructured and evolving conditions.
By addressing these limitations, future studies aim to develop a more intelligent and autonomous deep-sea mining robot capable of operating efficiently in complex and unpredictable underwater environments, ultimately contributing to the advancement of deep-sea resource exploration and utilization.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}