1. Introduction
Marine diesel engines are the heart of ships and play a crucial role in operation. They can efficiently convert the chemical energy of fuel into mechanical energy, driving the ship’s navigation and providing a strong power supply for the ship. The diesel engine performance directly affects the ship’s speed, range, and reliability [
1,
2]. In ocean voyages, stable operation of the diesel engine helps to guarantee that the ship will arrive at the destination on time, and thus ensures high efficiency in cargo transportation. In addition, it can also drive the ship’s power generation equipment and the power supply for the ship’s life, communication, navigation, and other systems, therefore maintaining the normal operation of the ship and the crew’s living needs, and solidifying its position as indispensable core equipment in a ship [
3].
Over the course of long-term operation of ship diesel engines, various factors, such as mechanical wear and tear, fuel quality problems, improper operation, etc., inevitably lead to the occurrence of various engine failures [
4,
5]. These failures will not only lead to ships stopping, delaying trips and increasing maintenance costs, but may also cause safety accidents, resulting in casualties and huge economic losses [
6].
Currently, marine diesel engine fault resolution methods mainly include traditional diagnostic techniques based on expert experience, data-driven machine learning methods, and emerging deep learning techniques [
7,
8]. Traditional methods rely on expert experience and ship alarm systems, but with the increasing level of ship intelligence and automation, these methods can hardly meet the requirements of modern diesel engine system condition assessment. In recent years, data-driven fault diagnosis techniques based on Support Vector Machines (SVM), Back Propagation Neural Networks (BPNN), k-Nearest Neighbors (KNN), and Random Forests (RF) have gradually emerged. These methods mine potential information for fault diagnosis by collecting large-scale equipment state data [
9]. However, these methods have limitations in dealing with complex systems, such as insufficient mining of nonlinear features of data and poor classification performance on unbalanced datasets. In addition, deep learning techniques such as graph convolutional networks (GCN) have also been applied in marine diesel engine fault diagnosis, but they have a high demand for data volume and computational resources, and still face the problem of insufficient model generalization ability in practical applications [
10]. Although these existing methods have improved the efficiency of fault diagnosis to a certain extent, they still suffer from insufficient diagnostic accuracy, poor real-time performance, and high dependence on specialized knowledge in the face of the complex failure modes and dynamic operating environments of marine diesel engines. Therefore, there is an urgent need for a more efficient and intelligent fault diagnosis method that can integrate multi-source information to meet the actual needs of marine diesel engine fault diagnosis.
A knowledge graph leverages graph structures as a semantic network to represent and organize knowledge [
11]. It constructs a body of knowledge through entities (e.g., people, places, events, etc.), relationships (e.g., “belongs to”, “is located in”, “is associated with”, etc.), and attributes (e.g., characteristics of the entity) to form a complex semantic network structure. The core function of a knowledge graph is to integrate fragmented information into structured knowledge, so as to realize the efficient storage of information, as well as associated queries and reasoning processes [
12]. In the process of diagnosing faults in marine diesel engines, knowledge graphs can correlate and integrate information such as fault phenomena, maintenance experience, sensor data, and the physical structure of the diesel engine, so as to realize accurate positioning and reasoning about the cause of the fault. Not only can these graphs make up for the shortcomings of traditional methods that rely too much on specialized knowledge, but they also provide a more efficient and intelligent solution for the fault diagnosis of marine diesel engines through intelligent reasoning and correlation analysis.
Shu et al. proposed a method based on knowledge graphs to analyze ship collision accidents. Using 241 collision investigation reports issued by the China Maritime Safety Administration (CMSA) from 2018 to 2021, they constructed a Ship Collision Accident Knowledge Graph (SCAKG) and demonstrated the potential of the method in accident cause analysis and judicial process acceleration through case retrieval [
13]. Gan et al. researched and developed the BERT-MCNN model to construct a knowledge graph based on deep learning for knowledge extraction and management of marine pollution regulations. The required information was extracted from Chinese and International Maritime Organization (IMO) laws and regulations related to marine pollution prevention to form a knowledge graph. The model achieved 92.4% and 92.7% accuracy in the multi-relationship extraction and named entity recognition tasks, respectively, and can effectively support the decision-making of port state surveillance and inspection (PSC) officers during on-site inspections [
14]. Meng et al. introduced an approach for creating a knowledge graph of power equipment faults, leveraging the BERT-BiLSTM-CRF model. The method recognizes and extracts the equipment entities in the electric power technical literature and identifies relationships among entities through dependency syntax analysis, and finally stores the knowledge in the form of ternary groups in the Neo4j database. The model outperforms traditional methods in terms of precision in Chinese entity detection and relationship extraction, and is able to construct the knowledge graph of power equipment faults more effectively [
15]. Xie et al. explored the development and application of knowledge graphs for aircraft fault diagnosis. They introduced a fault knowledge extraction method combining deep learning and heuristic rules to build a model-specific fault knowledge graph from structured and unstructured data. Additionally, they developed a Q&A system based on the fault knowledge graph, enabling precise answers to maintenance engineers’ questions and enhancing the traceability of the responses [
16]. Xiao et al. proposed a knowledge graph-based semantic web approach for identifying counterfeit ship licenses. By constructing a ship knowledge graph, key features of ship violations, such as monitoring ships, expired certificates, and multiple trajectories, can be extracted and combined with inference techniques to identify violating ships. This method not only improves the effective utilization of ship data, but also enhances decision-making abilities surrounding ship safety management, which provides a new approach for intelligent maritime traffic management [
17].
Current research on knowledge graph technology in the field of marine diesel engine fault diagnosis remains relatively scarce. This study proposes a knowledge graph construction method based on BiLSTM-CRF for marine diesel engine faults, aiming at integrating the multi-source heterogeneous data of marine diesel engines and mining the deep semantic associations of fault phenomena and their potential causes and corresponding solutions through knowledge graph technology. Therefore, the accuracy and real-time of fault diagnosis are optimized, and the research and practice of knowledge graph technology in this field are further promoted.
The structure of the paper is outlined below.
Section 2 describes the approach to constructing knowledge graphs based on deep learning.
Section 3 demonstrates the specific knowledge graph and compares it with other models, and the conclusions are summarized
Section 4.
2. Methods
2.1. Research Framework
The technical framework for constructing a knowledge graph of marine diesel engine failures encompasses data acquisition, knowledge modeling, knowledge extraction, and knowledge storage, as illustrated in
Figure 1. Data acquisition, the foundation of knowledge graph construction, involves collecting marine diesel engine failure data from multiple sources, including technical documents, maintenance manuals, historical failure records, etc., to ensure their comprehensiveness and accuracy, thus providing raw materials for subsequent knowledge modeling.
Knowledge modeling, which transforms unstructured data into a structured form, is also known as ontology model building. It involves defining entity types and attributes, and the relationships between them [
18]. In this process, the triad serves as the basic unit of the knowledge graph, consisting of entities, relations, and entity pairs, e.g., (diesel engine, fault location, crankshaft). This structure helps convert unstructured data into the form of a query-able graph, determining the quality and usefulness of the graph. Knowledge extraction involves identifying and extracting valuable information from unstructured data, utilizing natural language processing techniques, such as entity recognition and relationship extraction, to ensure accurate extraction of fault-related knowledge points from the text [
19]. Knowledge storage refers to saving the extracted and modeled knowledge in a graph database format for easy retrieval and analysis. Choosing the right storage technology is crucial to ensure the scalability and query efficiency of the knowledge graphs.
2.2. Data Acquisition
Marine diesel engine failure data are a source of knowledge. The main data sources include technical documents from patent websites, online failure cases, the literature library on marine diesel engine failures, and laboratory failure data. A total of 2000 marine diesel engine failure data were used in this study. The specific data collection methods were as follows. For patent websites, we used web crawlers to systematically collect technical documents related to marine diesel engine failures. These documents were filtered based on relevance and date of publication to ensure up-to-date and relevant information. For online fault cases, we accessed dedicated marine engineering forums and databases, where experienced engineers share their troubleshooting experiences. We also utilized academic search engines to retrieve peer-reviewed papers from the literature library, focusing on experimental results and case studies that provide insight into failure mechanisms.
Among them, the sensor timing data of the laboratory diesel engine are structured data, and the document database and fault cases obtained from the web page are unstructured data, accounting for the majority of data sources.
Fault data are stored as unstructured data. Unstructured data are those that do not conform to a fixed format or schema, and they cannot be organized and stored with a predefined data model like structured data. Unstructured data are usually free-form and has no fixed data model or schema, so it is difficult to be processed by traditional database management systems and needs to be preprocessed for knowledge extraction.
2.3. Knowledge Modeling
Extracted conceptual information is categorized to identify the entity types and relational structures within the knowledge graph. On this basis, an ontology is constructed to define entities, attributes, and relationships that establish the structure of the knowledge graph. In a knowledge graph, entities represent specific objects or abstract concepts, forming the core structure, and being interconnected through their attributes and relationships [
20]. In the knowledge graph of marine diesel engine faults, entities include fault phenomena, such as destructive faults like burnt wattage and cylinder holding, fault locations, such as broken gears and low pumping capacity of water pumps, the cause of the faults, e.g., abrasive faults due to wear and tear of components, and the corresponding resolution operation for each fault. Attributes are descriptive pieces of information associated with an entity that are used to provide additional details or characteristics about the entity, a description of a particular feature, or the state of the entity. They are often used to enhance the description of an entity to make it more specific and detailed. A relationship is a semantic link connecting two entities, which describes the interrelationship or interaction between the entities.
The ontology model was constructed using Protégé software, version 5.5.0, which was developed at Stanford University [
21]. The seven-step process provides a systematic framework for ontology construction [
22]. It clearly organizes the whole building process, from determining the scope, considering reuse, and enumerating clauses, to defining classes, attributes, and constraints, and up to creating instances, providing a systematic framework for users to build and manage ontologies in a rational and orderly manner in the Protégé software package. This combination of tools and processes enhances the rigor and consistency of ontology development.
2.4. Knowledge Extraction
Constructing a knowledge graph for marine diesel engine faults heavily relies on knowledge extraction. The goal is to identify valuable information from unstructured text and transform it into structured data for subsequent storage and query. This process involves preprocessing the text to enhance data quality and processability, as well as applying advanced deep learning models to recognize and extract key information [
23]. In this section, the steps of text preprocessing and the adopted BiLSTM-CRF model will be introduced in detail, which together support the core task of efficiently extracting knowledge from a large amount of unstructured data. The BiLSTM-CRF model is a powerful sequence annotation model combining bi-directional long- and short-term memory networks and conditional random fields, which is specially used for extracting entities from text. Entity relationships are defined in accordance with the ontology model, and the knowledge extraction task is completed by matching the extracted entities with the relationships. In these two subsections, we will show how to transform raw text into structured information in a knowledge graph.
2.4.1. Text Preprocessing
The acquired marine diesel engine fault data is unstructured text, which may contain a large amount of duplicate information and inconsistent formatting. Therefore, preprocessing is needed, including data cleaning, removing or correcting erroneous information and data, segmenting long text, and manually labeling entities.
In the present study, to ensure the reliability of the collected unstructured information, data sources were strictly screened. Technical documents published by authoritative institutions, peer-reviewed academic papers, and online fault case databases with good reputations were preferentially selected. The same or similar fault information obtained from different sources was cross-checked and verified. Experts in the field of marine diesel engines were invited to review the data collected. Experts judged the accuracy and credibility of data based on their professional knowledge and practical experience. For questionable or inconsistent data, we further traced the original source or request more detailed evidence.
Special symbols in the text should be removed, such as the time unit “h”, the frequency unit “Hz”, and the power unit “W”. At the same time, specific parameters of ships and equipment involved in fault cases and documents should also be eliminated.
In this study, we employ the BMES tagging scheme, an extension of the BIO framework that introduces labels for the middle segment (M) and single-word entities (S). Here, B indicates the beginning of an entity, M represents the middle portion, E marks the end, and S is used for standalone entities.
YEDDA is an open source text annotation tool dedicated to named entity recognition and other sequence annotation tasks. It supports BIO, BMES and other annotation modes, allowing custom labels and shortcuts to improve annotation efficiency. The interface is intuitive, easy to operate, supports cross-platform use, and can export annotation results for model training [
24]. Therefore, YEDDA was used to annotate the text of marine diesel engine faults. The annotation categories are pre-divided into “Phenomenon of Failure (PHE)”, “Position of Failure (POS)”, “Reason for Failure (REA)”, and “Resolution Operation (OPE)”. The annotation interface is intuitive and easy to use in YEDDA, e.g., “black smoke” is a fault phenomenon, “B-PHE” indicates the beginning of the fault phenomenon category entity, “M-PHE” is the middle part of the malfunction phenomenon category entity, “E-PHE” is the end of the malfunction phenomenon category entity, and “O” means that the entity does not belong to any annotation category. This rule can indicate that the text of the entity labeling is complete. The labeling results for the sentence “black smoke is the ship’s diesel engine incomplete combustion characteristics” are shown in
Table 1.
The dataset was divided into training, validation, and test sets at a ratio of 8:1:1.
Table 2 highlights the quantities of the three entity types.
2.4.2. BiLSTM-CRF Model
As a deep learning method, the BiLSTM-CRF model is highly effective for knowledge graph construction, leveraging its advanced sequence modeling and relationship identification features [
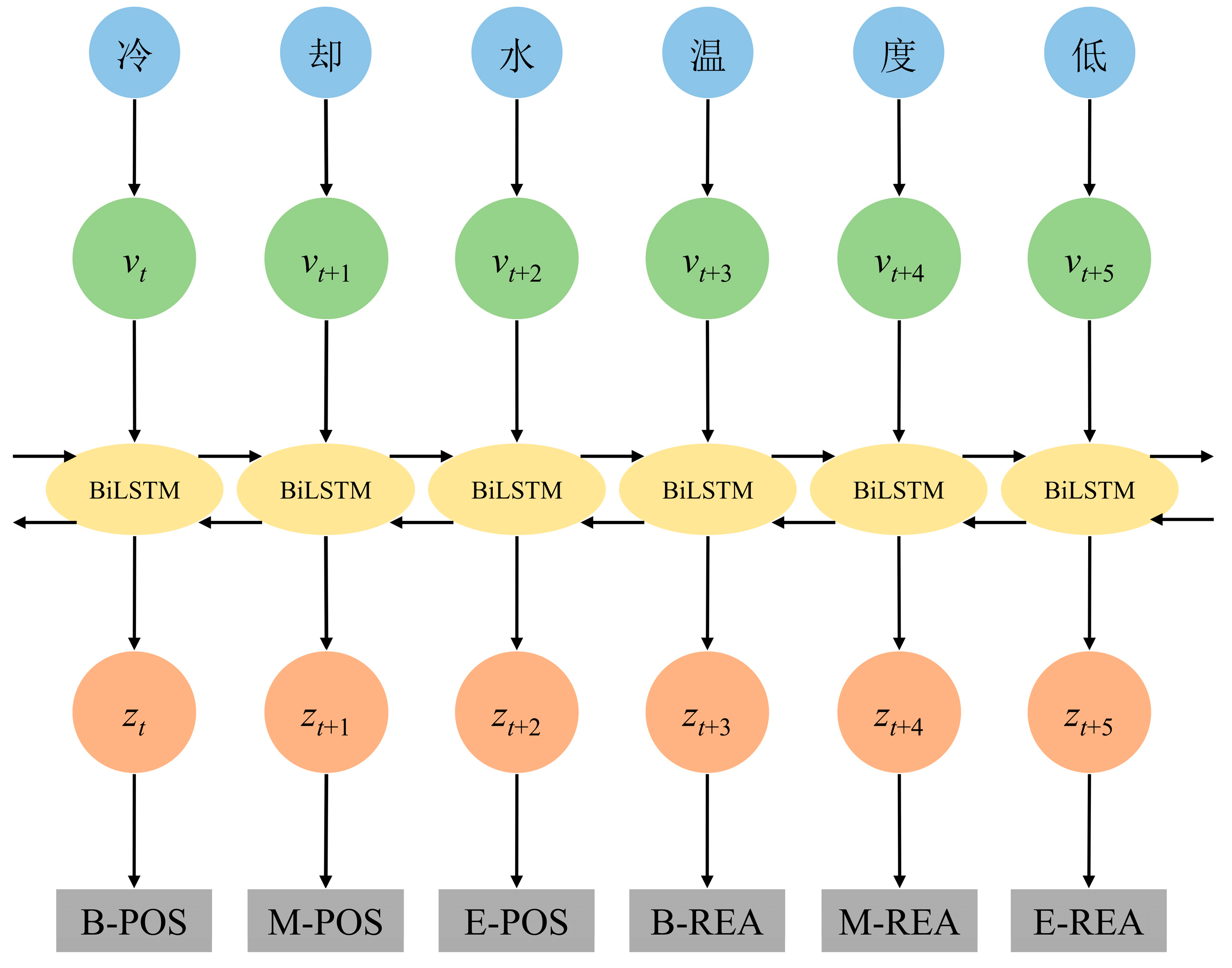
25]. The BiLSTM part encodes the text through a bidirectional long and short-term memory network, which is able to capture bidirectional dependencies in the text for better understanding of the contextual information. By employing a conditional random field, the CRF part effectively decodes sequences, capturing label transition probabilities and boosting the precision of entity recognition and relationship extraction. Compared with traditional HMM, CRF, and other models, BiLSTM-CRF automatically learns deep semantic features of text through neural networks, avoids the limitations of artificial feature engineering, and effectively solves the problem of illegal combination of label sequences by using the label transfer constraint of CRF. Additionally, although BERT has stronger semantic representation ability through large-scale pre-training, the fault text of marine diesel engines is characterized by dense domain terms and a limited scale of annotation data. BiLSTM-CRF is more lightweight and efficient compared to BERT-BiLSTM-CRF, making it more suitable for scenarios with limited computational resources and requiring faster inference speeds. The overall architecture of the BiLSTM-CRF model is illustrated in
Figure 2. The input text "冷却水温度低" (cooling water temperature low) is used as an example to demonstrate how the model processes and tags each character in the sequence. The specific structure of the BiLSTM-CRF model is discussed in depth next.
BiLSTM consists of two LSTM networks that process sequence data in both forward and backward directions, allowing it to capture bidirectional dependencies and achieve a more precise understanding of contextual information. Entity recognition in a knowledge graph involves identifying and categorizing key information from text into meaningful entities, such as names of individuals or locations. BiLSTM is able to recognize the boundaries and categories of these entities by learning the feature representations in the text sequences. In addition, in the relationship extraction task, BiLSTM can analyze the semantic connections between entities and identify the types of relationships between them, such as “belonging to”, “located in”, etc. In this way, the BiLSTM model offers robust support for knowledge graph construction, which automatically extracts structured knowledge from text. Its structure is shown in
Figure 3. The computational form is illustrated in Equation (1).
is the output of the input gate;
represents the sigmoid function;
is the output of the forgetting gate;
is the candidate cell state;
is the updated cell state;
is the output of the output gate;
is the hidden state of the current time step;
,
,
, and
are the composite weight matrixes; and
,
,
,
are the offset terms. The general form is shown in Equations (2)–(4).
In this formulation, and denote the forward and backward hidden states, respectively, and are the weight matrices, is the input while is the final output, and and are the weight matrices of the output layer.
As can be seen from the structure diagram, BiLSTM comprises a forward LSTM and a backward LSTM, with the forward LSTM processing the inputs sequentially from the beginning to the end of the sequence to capture the context information from left to right, and the backward LSTM analyzing the inputs from the end position to the start position of the sequence to capture the context information from right to left. At each time step, the forward LSTM and backward LSTM generate their respective hidden states that incorporate contextual information before and after the current moment. The hidden states generated by the forward and backward LSTMs are combined to form a feature vector that captures bidirectional context information for downstream tasks.
CRF is a statistical model for sequence annotation tasks, widely used in tasks such as named entity recognition (NER) in knowledge graph construction [
26]. The core advantage of CRF is its ability to take into account the dependencies between labels, thus improving the accuracy and consistency of the annotation. In knowledge graphs, CRF is usually used to annotate text sequences and identify the entities and their categories in them. By introducing a state transfer matrix, CRF is able to utilize contextual information to annotate each element in the sequence, ensuring the global optimality of the annotation result. This capability enables CRF to excel in complex sequence annotation tasks, especially in scenarios where complex relationships between tags need to be considered. The formula used in the CRF model to calculate the score for a given input and label sequence is shown in Equation (5).
is the firing probability at the
i-th position and
is the transfer probability between labels. Equation (6) represents the conditional probability of a tag sequence
y given an input sequence
x:
where
is the exponent of the score function and
is the normalization factor. Equation (7) represents the label sequence
that maximizes the partition function given the input sequence
x. This is the decoding process used to find the most probable label sequence.
2.4.3. Evaluation Indicators
The evaluation metrics employed in this chapter primarily include precision (
P), recall (
R), and F1-score (
F1) as the key assessment criteria. The above evaluation metrics are often used in deep learning-related models with a certain degree of credibility, and the specific computation process is shown in Equations (8)–(10).
represents the count of samples the model accurately classified as positive, indicates the number of samples mistakenly predicted as positive, and refers to the samples incorrectly classified as negative. The -score, ranging from 0 to 1, reflects the model’s accuracy, with higher values signifying superior predictions.
2.5. Knowledge Storage
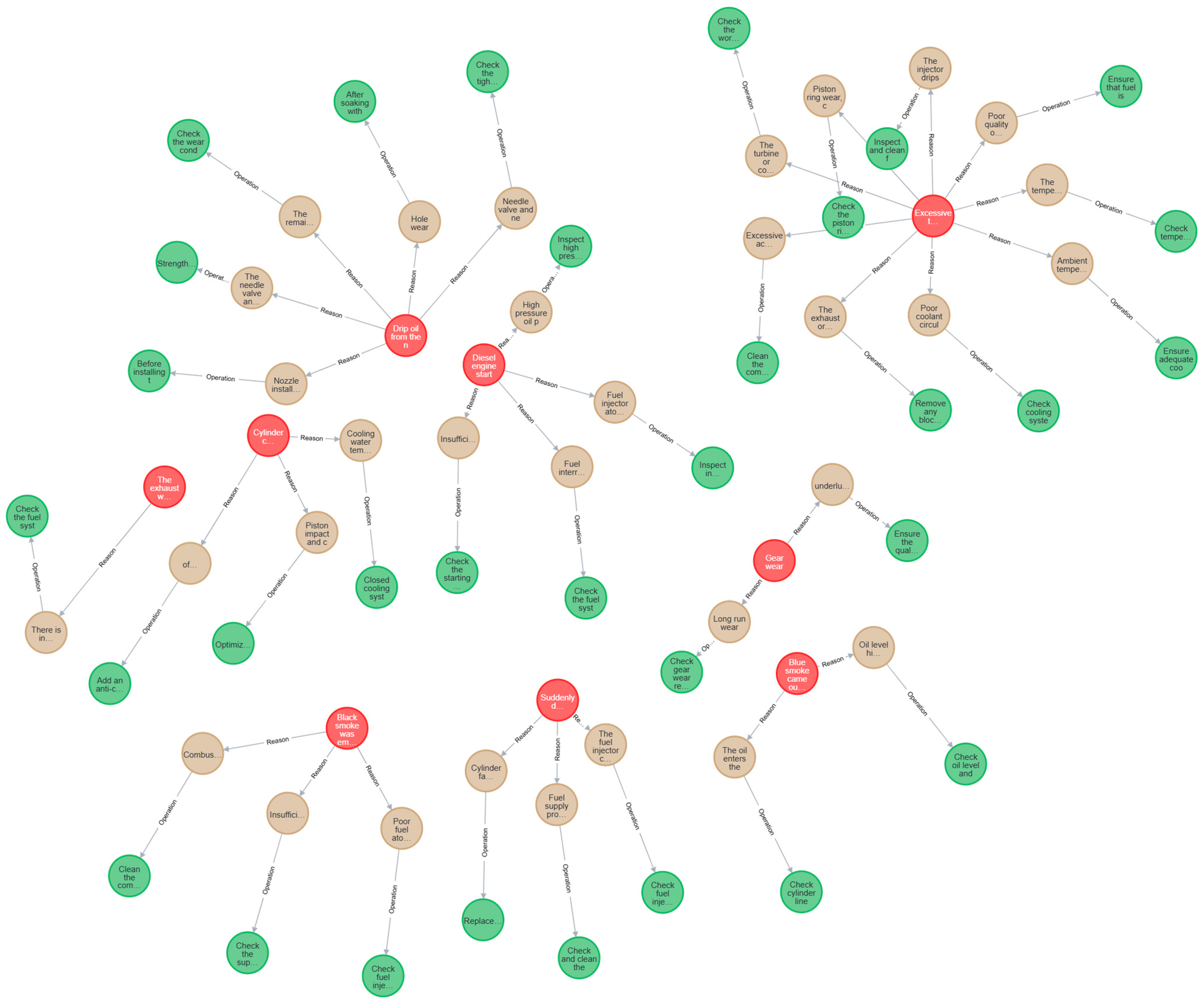
In this study, Neo4j is used for knowledge storage. Neo4j, as a popular graph database, has been widely employed in knowledge graph storage due to its powerful graph data storage and querying capabilities. It employs nodes and edges in a graph structure to represent entities and their relationships, and this structure can intuitively reflect the complex relationships between entities and facilitate the query and analysis of the graph structure. Within the Neo4j framework, each node encapsulates entity-specific attributes, serving as a structured data container. Relationships (represented as directed edges) explicitly define association types and directional dependencies between entities, establishing semantically meaningful connections that support advanced graph-based reasoning.
4. Conclusions
The main contribution of this study is to establish a comprehensive knowledge graph framework for marine diesel engine faults and overcome the challenge of data heterogeneity through the proposed multi-source fusion strategy. The BiLSTM-CRF hybrid model sets a new benchmark in technical document understanding, with improved accuracy compared to traditional knowledge extraction methods. The implemented inference engine demonstrates unique value in bridging the symptom–cause–solution triad, providing actionable insights beyond traditional diagnostic systems. These advances not only improve fault diagnosis capabilities but also lay the foundation for an intelligent maintenance decision system for the maritime industry.
During the research process, we constructed a complete technical framework, covering key aspects such as data acquisition, knowledge modeling, knowledge extraction, and knowledge storage. The data acquisition session collected a large amount of unstructured text data related to ship diesel engine faults, which provided abundant raw materials for subsequent modeling and extraction. In the knowledge modeling stage, the ontology model was constructed by Protégé software, which clarified the entity types, attributes and relationships, and laid the groundwork for building the knowledge graph. In the knowledge extraction session, the BiLSTM-CRF model plays an important role, which combines the powerful context capturing capability of BiLSTM and the modeling advantage of CRF on label dependencies, effectively enhancing the precision of entity recognition and relationship extraction. Ultimately, the Neo4j graph database is employed to achieve the storage and efficient retrieval of knowledge, and a structured knowledge graph of marine diesel engine faults is constructed.
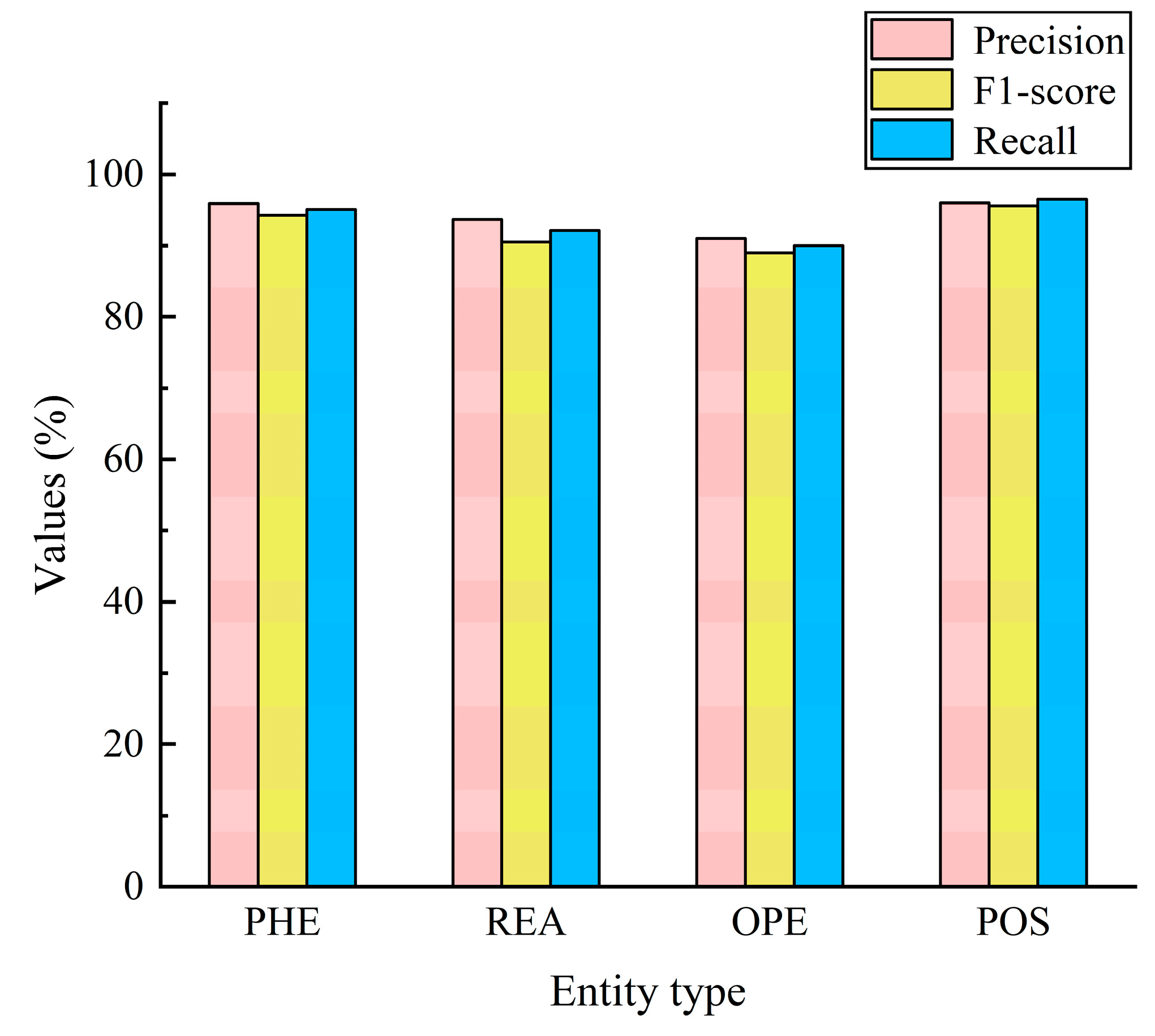
The BiLSTM-CRF model outperforms other traditional models in terms of precision, recall, and F1-score, as demonstrated by the experimental results. In addition, the visual representation of the knowledge graph clearly presents the causal network between fault phenomena, causes, and resolution operations, providing intuitive guidance for fault diagnosis and prevention. Through knowledge reasoning, potential associations can also be identified to further optimize ship health management.
In summary, the knowledge graph construction method for marine diesel engine faults based on BiLSTM-CRF proposed in this paper not only effectively integrates multi-source information, but also notably improves the efficiency and accuracy of fault diagnosis, thereby offering a robust basis for the intelligent management and maintenance of marine diesel engines, with both theoretical importance and practical relevance. In the future, we will further optimize the model, expand the data sources, and investigate the role of knowledge graphs in enhancing fault diagnosis for marine equipment, driving the marine industry towards greater intelligence.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}