
Research on the Visual SLAM Algorithm for Unmanned Surface Vehicles in Nearshore Dynamic Scenarios



Abstract
1. Introduction
- To address the challenge of extracting invalid feature points from water and sky regions during nearshore navigation, a shore segmentation based on Otsu’s method is proposed. The input image is converted to the HSV color space, where the H channel is isolated. Otsu’s method is then applied for shore segmentation, followed by morphological operations to denoise and refine boundaries, ultimately generating masks for water and sky regions.
- YOLOv8 instance segmentation is embedded into the visual SLAM system to detect priori dynamic objects, producing dynamic object masks. Feature points within these masked regions are identified and excluded. For non-priori dynamic feature points, the motion consistency check method is applied to validate the static/dynamic status of remaining feature points, further eliminating potential dynamic interference and enhancing localization accuracy in dynamic environments.
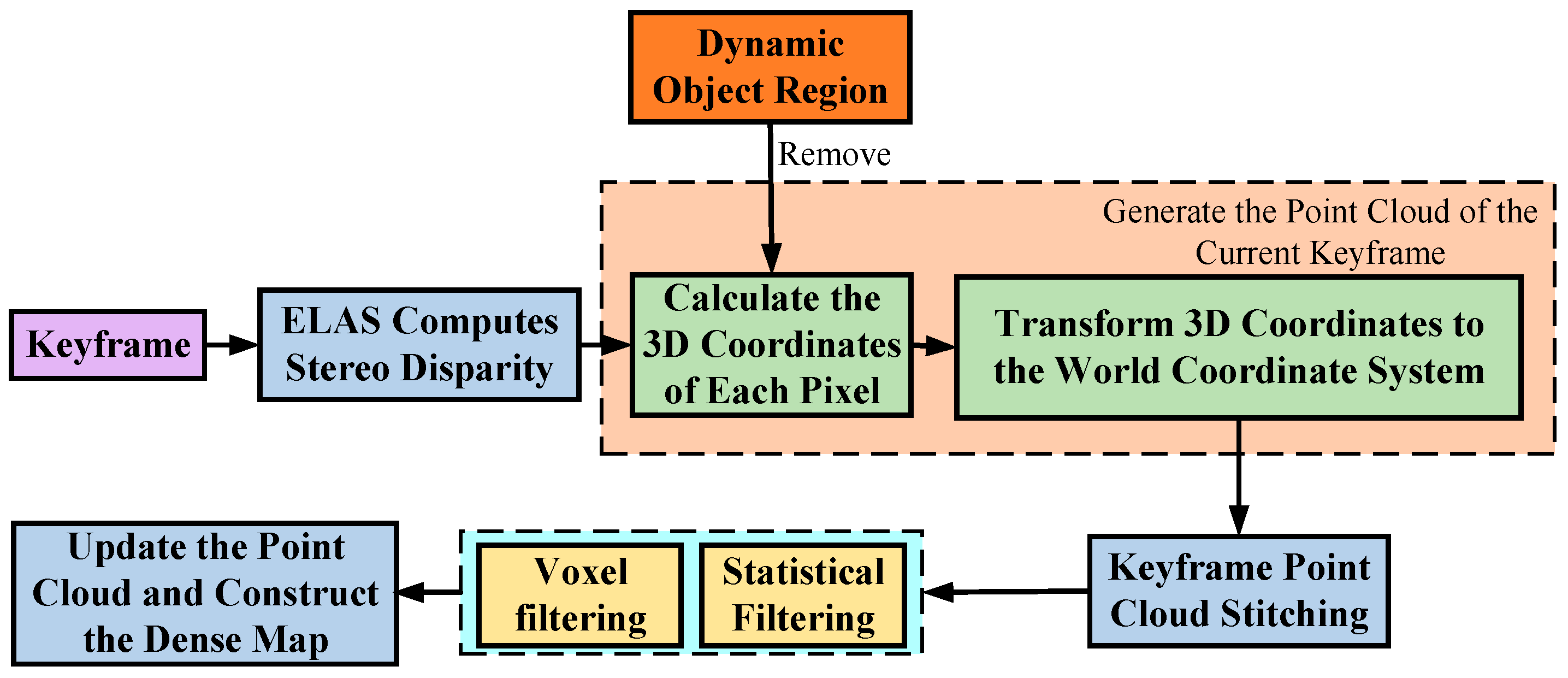
- A dense mapping thread is added, leveraging the efficient large-scale stereo matching (ELAS) [29] algorithm to compute depth information and construct 3D point clouds. By removing dynamic objects from images, ghosting artifacts in point cloud data caused by moving objects are eliminated, enabling the construction of static dense maps.
2. System Introduction
2.1. System Framework
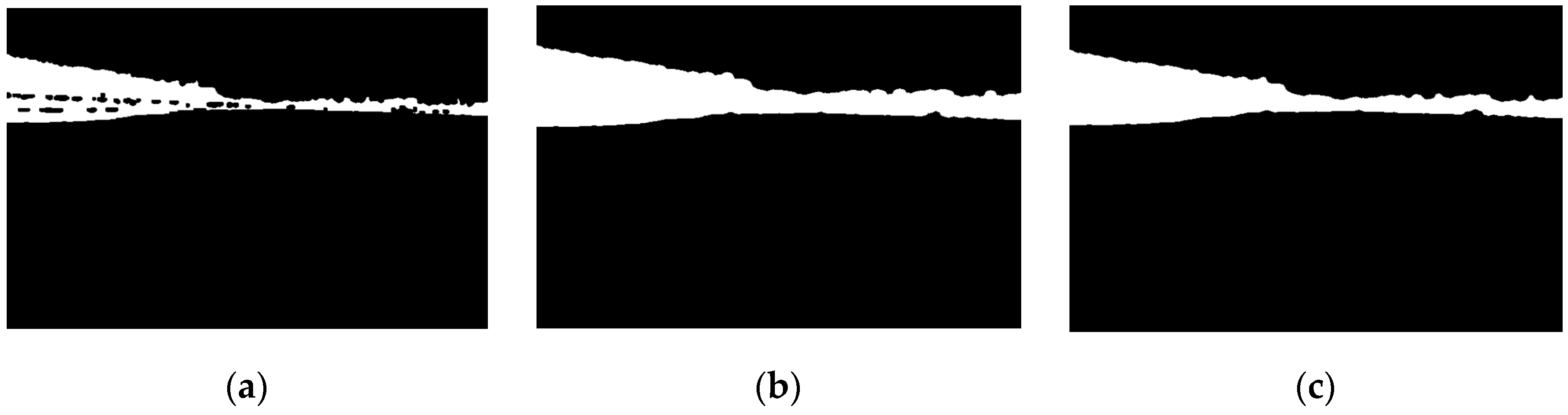
2.2. Shore Segmentation Based on Otsu’s Method
2.3. Dynamic Object Detection and Removal
2.3.1. Priori Dynamic Object Detection
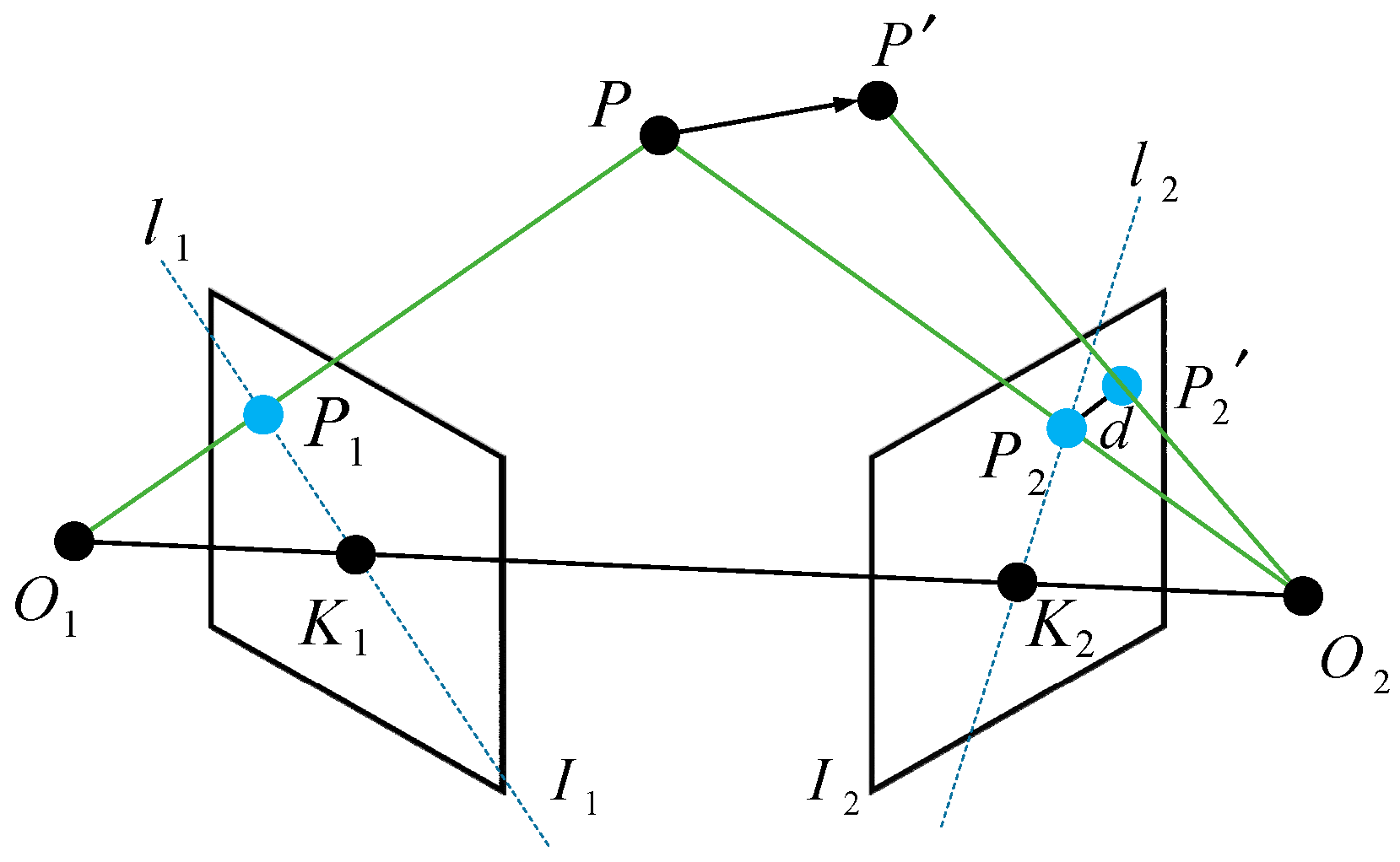
2.3.2. Non-Priori Dynamic Feature Point Detection
2.4. Dense Mapping Based on Stereo Matching
3. Experiments and Analysis of Results
3.1. Experimental Conditions and Datasets
3.2. Experiment on Shore Segmentation Based on Otsu’s Method
3.3. Non-Priori Dynamic Feature Point Removal Experiment
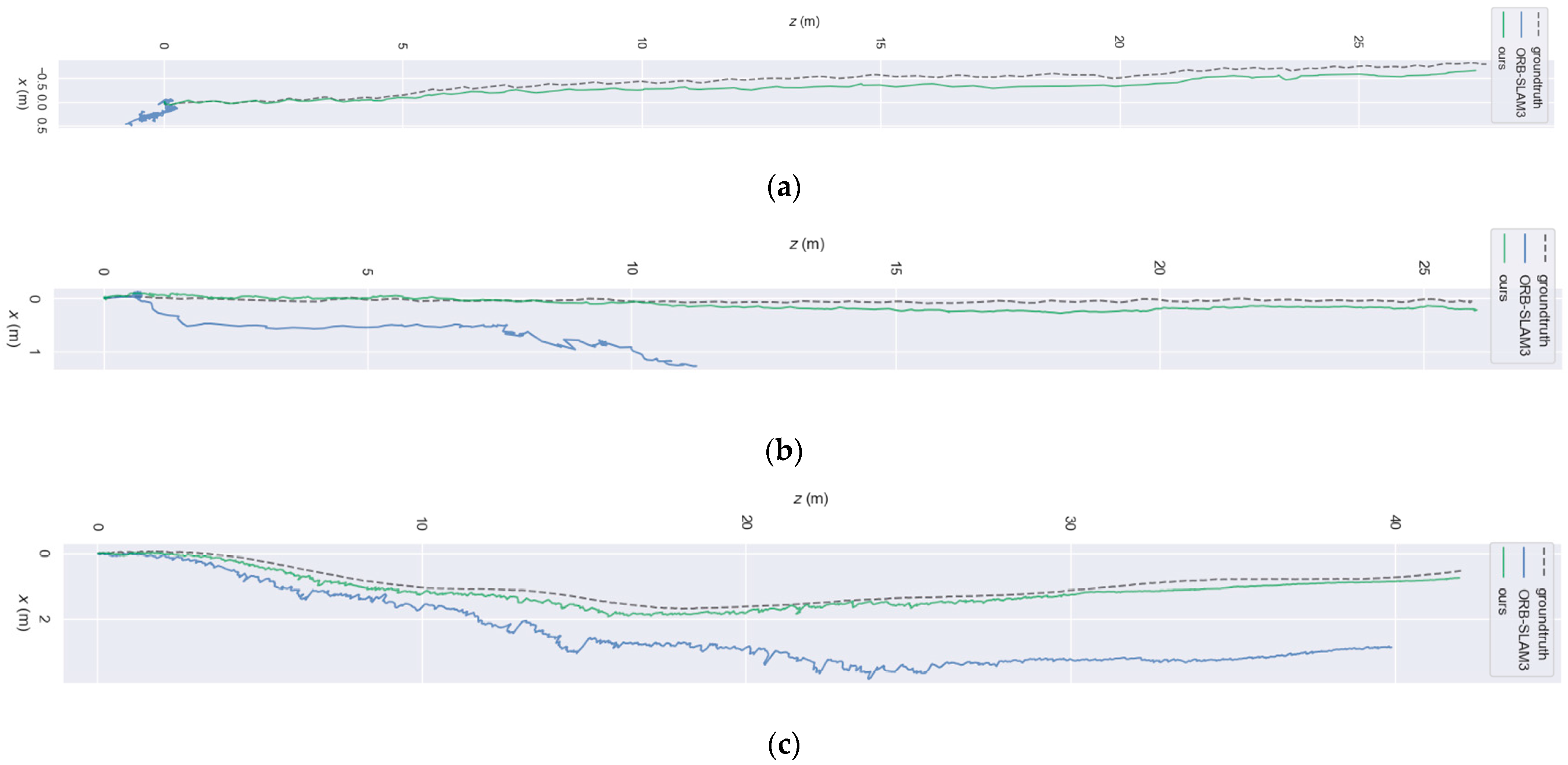
3.4. Visual SLAM Localization Validation
3.5. Comparison with Other Dynamic SLAM Algorithms
3.6. Validation of Static Dense Mapping
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghazali, M.H.M.; Satar, M.H.A.; Rahiman, W. Unmanned Surface Vehicles: From a Hull Design Perspective. Ocean Eng. 2024, 312, 118977. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Qin, T.; Cao, S.; Pan, J.; Shen, S. A General Optimization-Based Framework for Global Pose Estimation with Multiple Sensors. arXiv 2019, arXiv:1901.03642. [Google Scholar]
- Cheng, J.; Zhang, L.; Chen, Q.; Hu, X.; Cai, J. A Review of Visual SLAM Methods for Autonomous Driving Vehicles. Eng. Appl. Artif. Intell. 2022, 114, 104992. [Google Scholar]
- Wu, H.; Chen, Y.; Yang, Q.; Yan, B.; Yang, X. A Review of Underwater Robot Localization in Confined Spaces. J. Mar. Sci. Eng. 2024, 12, 428. [Google Scholar] [CrossRef]
- Tan, W.; Liu, H.; Dong, Z.; Zhang, G.; Bao, H. Robust Monocular SLAM in Dynamic Environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar]
- Sun, Y.; Liu, M.; Meng, M.Q.-H. Improving RGB-D SLAM in Dynamic Environments: A motion Removal Approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar]
- Wang, R.; Wan, W.; Wang, Y.; Di, K. A New RGB-D SLAM Method with Moving Object Detection for Dynamic Indoor Scenes. Remote Sens. 2019, 11, 1143. [Google Scholar] [CrossRef]
- Fan, Y.; Han, H.; Tang, Y.; Zhi, T. Dynamic Objects Elimination in SLAM Based on Image Fusion. Pattern Recognit. Lett. 2019, 127, 191–201. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, Y.; Meng, M.Q.-H. Improving Monocular Visual SLAM in Dynamic Environments: An Optical-Flow-Based Approach. Adv. Robot. 2019, 33, 576–589. [Google Scholar] [CrossRef]
- Dai, W.; Zhang, Y.; Li, P.; Fang, Z.; Scherer, S. Rgb-d Slam in Dynamic Environments Using Point Correlations. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 373–389. [Google Scholar] [CrossRef] [PubMed]
- Samadzadeh, A.; Nickabadi, A. SRVIO: Super Robust Visual Inertial Odometry for Dynamic Environments and Challenging Loop-Closure Conditions. IEEE Trans. Robot. 2022, 39, 2878–2891. [Google Scholar] [CrossRef]
- Zhang, Y.; Bujanca, M.; Luján, M. NGD-SLAM: Towards Real-Time SLAM for Dynamic Environments without GPU. arXiv 2024, arXiv:2405.07392. [Google Scholar]
- Cai, D.; Li, R.; Hu, Z.; Lu, J.; Li, S.; Zhao, Y. A Comprehensive Overview of Core Modules in Visual SLAM Framework. Neurocoputing 2024, 590, 127760. [Google Scholar] [CrossRef]
- Zhong, F.; Wang, S.; Zhang, Z.; Chen, C.; Wang, Y. Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Wang, R.; Wang, Y.; Wan, W.; Di, K. A Point-Line Feature Based Visual SLAM Method in Dynamic Indoor Scene. In Proceedings of the 2018 Ubiquitous Positioning, Indoor Navigation and Location-Based Services (UPINLBS), Wuhan, China, 22–23 March 2018; pp. 1–6. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2018. [Google Scholar]
- Han, S.; Xi, Z. Dynamic Scene Semantics SLAM Based on Semantic Segmentation. IEEE Access 2020, 8, 43563–43570. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, Y.; Miura, J. RDS-SLAM: Real-Time Dynamic SLAM Using Semantic Segmentation Methods. IEEE Access 2021, 9, 23772–23785. [Google Scholar] [CrossRef]
- Yu, Y.; Zhu, K.; Yu, W. YG-SLAM: GPU-Accelerated RGBD-SLAM Using YOLOv5 in a Dynamic Environment. Electronics 2023, 12, 4377. [Google Scholar] [CrossRef]
- Geiger, A.; Roser, M.; Urtasun, R. Efficient Large-Scale Stereo Matching. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 25–38. [Google Scholar]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. Automatica 1975, 11, 23–27. [Google Scholar]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object Detection Using YOLO: Challenges, Architectural Successors, Datasets and Applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Vijayakumar, A.; Vairavasundaram, S. YOLO-Based Object Detection Models: A Review and its Applications. Multimed. Tools Appl. 2024, 83, 83535–83574. [Google Scholar] [CrossRef]
- Hussain, M. YOLOv1 to v8: Unveiling Each Variant–A Comprehensive Review of YOLO. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Name | Number of Left Images (Frames) | Number of Right Images (Frames) | IMU Data (Entries) | Image Size (Pixels) |
|---|---|---|---|---|
| Scene 1 (cloudy) | 741 | 741 | 17,665 | 640 × 360 |
| Scene 1 (sunny) | 897 | 897 | 21,138 | 640 × 360 |
| Scene 2 | 1050 | 1050 | 25,064 | 640 × 360 |
| Data Sequence | Dyna-SLAM [23] (Mask-CNN) | DS-SLAM [21] (SegNet) | RDS-SLAM [27] (Mask-CNN) | Detect-SLAM [18] (SSD) | Ours (YOLOv8) |
|---|---|---|---|---|---|
| w_xyz | 0.015 | 0.025 | 0.057 | 0.024 | 0.014 |
| w_rpy | 0.035 | 0.444 | 0.160 | 0.030 | 0.038 |
| w_halfsphere | 0.025 | 0.030 | 0.026 | 0.051 | 0.020 |
| w_static | 0.006 | 0.008 | 0.021 | — | 0.007 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhang, L.; Yu, Q.; Xing, B. Research on the Visual SLAM Algorithm for Unmanned Surface Vehicles in Nearshore Dynamic Scenarios. J. Mar. Sci. Eng. 2025, 13, 679. https://doi.org/10.3390/jmse13040679
Zhang Y, Zhang L, Yu Q, Xing B. Research on the Visual SLAM Algorithm for Unmanned Surface Vehicles in Nearshore Dynamic Scenarios. Journal of Marine Science and Engineering. 2025; 13(4):679. https://doi.org/10.3390/jmse13040679
Chicago/Turabian StyleZhang, Yanran, Lan Zhang, Qiang Yu, and Bowen Xing. 2025. "Research on the Visual SLAM Algorithm for Unmanned Surface Vehicles in Nearshore Dynamic Scenarios" Journal of Marine Science and Engineering 13, no. 4: 679. https://doi.org/10.3390/jmse13040679
APA StyleZhang, Y., Zhang, L., Yu, Q., & Xing, B. (2025). Research on the Visual SLAM Algorithm for Unmanned Surface Vehicles in Nearshore Dynamic Scenarios. Journal of Marine Science and Engineering, 13(4), 679. https://doi.org/10.3390/jmse13040679