
A Novel ViT Model with Wavelet Convolution and SLAttention Modules for Underwater Acoustic Target Recognition


Abstract
1. Introduction
2. Theory and Models
2.1. Attention in Transformer Models
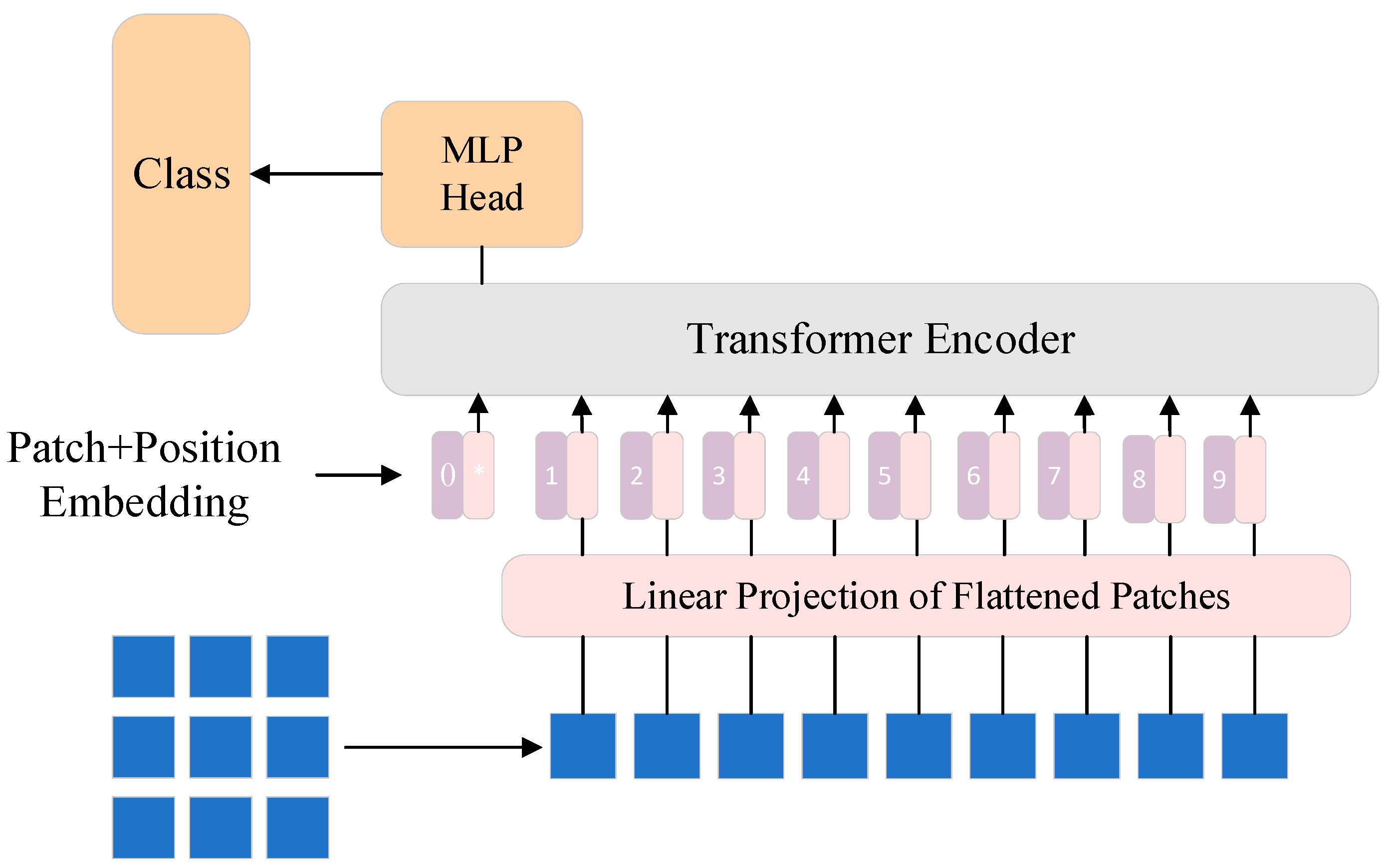
2.2. Vision Transformer
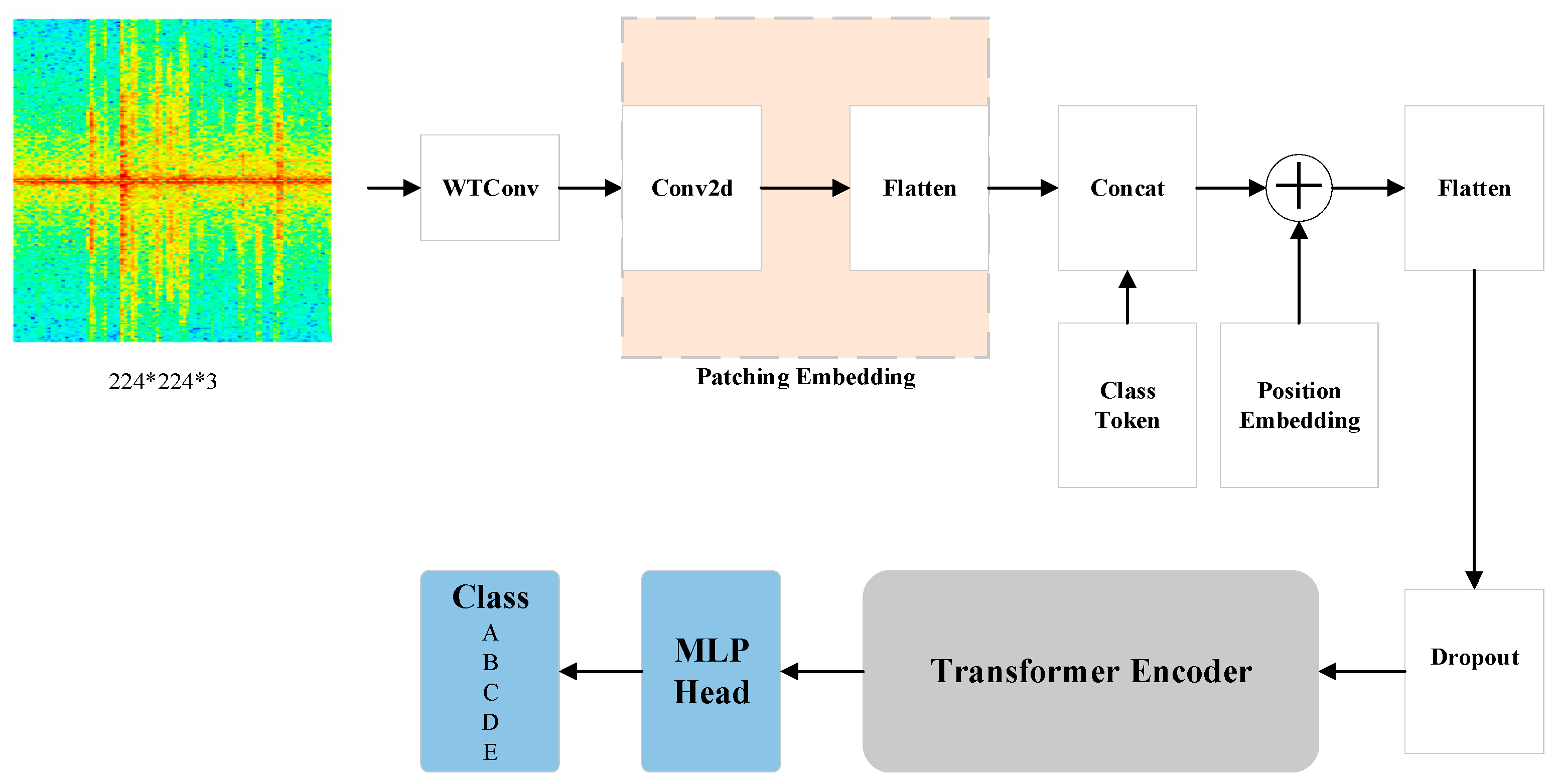
2.3. WS-ViT Model
3. Results and Discussion
3.1. Dataset and Preprocessing
3.2. Training Parameters
3.3. Evaluation Metrics
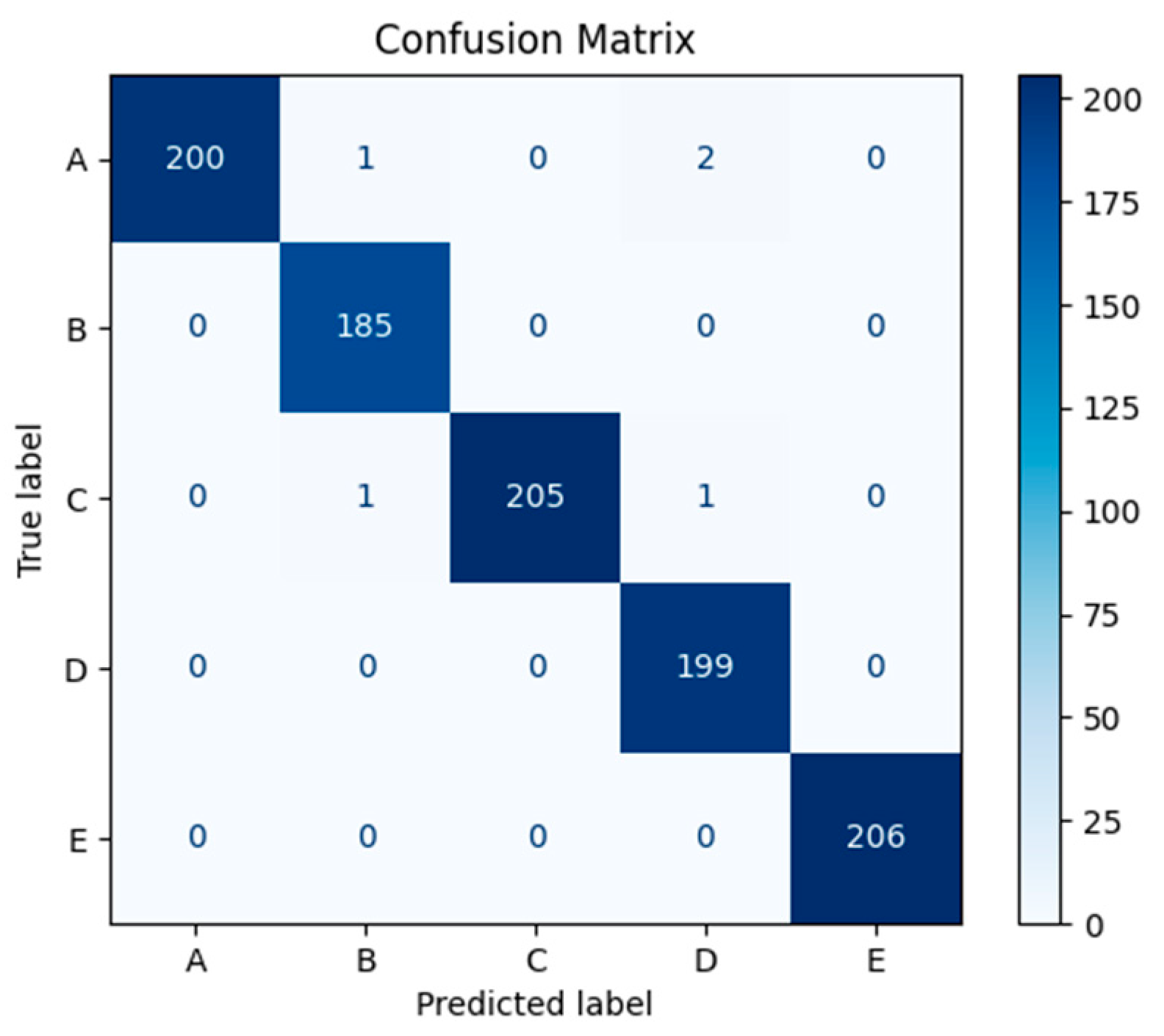
3.4. Analysis of Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yuan, F.; Ke, X.; Cheng, E. Joint Representation and Recognition for Ship-Radiated Noise Based on Multimodal Deep Learning. J. Mar. Sci. Eng. 2019, 7, 380. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S. A Wave Structure Based Method for Recognition of Marine Acoustic Target Signals. J. Acoust. Soc. Amer. 2015, 137, 2242. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, D.; Han, X.; Zhu, Z. Feature Extraction of Underwater Target Signal Using Mel Frequency Cepstrum Coefficients Based on Acoustic Vector Sensor. J. Sensors 2016, 2016, 7864213. [Google Scholar] [CrossRef]
- Zhang, Q.; Da, L.; Zhang, Y.; Hu, Y. Integrated Neural Networks Based on Feature Fusion for Underwater Target Recognition. Appl. Acoust. 2021, 182, 108261. [Google Scholar]
- Li, H.; Cheng, Y.; Dai, W.; Li, Z. A Method Based on Wavelet Packets-Fractal and SVM for Underwater Acoustic Signals Recognition. In Proceedings of the 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, China, 19–23 October 2014. [Google Scholar]
- Hu, G.; Wang, K.; Peng, Y.; Qiu, M.; Shi, J.; Liu, L. Deep Learning Methods for Underwater Target Feature Extraction and Recognition. Comput. Intell. Neurosci. 2018, 2018, 1214301. [Google Scholar] [CrossRef] [PubMed]
- Xiaoping, S.; Jinsheng, C.; Yuan, G. A New Deep Learning Method for Underwater Target Recognition Based on One-Dimensional Time-Domain Signals. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; pp. 1048–1051. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a Convolutional Neural Network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN Architectures for Large-Scale Audio Classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Xue, L.; Zeng, X.; Jin, A. A Novel Deep-Learning Method with Channel Attention Mechanism for Underwater Target Recognition. Sensors 2022, 22, 5492. [Google Scholar] [CrossRef] [PubMed]
- Kamal, S.; Satheesh Chandran, C.; Supriya, M.H. Passive Sonar Automated Target Classifier for Shallow Waters Using End-to-End Learnable Deep Convolutional LSTMs. Eng. Sci. Technol. Int. J. 2021, 24, 860–871. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Feng, S.; Zhu, X. A Transformer-Based Deep Learning Network for Underwater Acoustic Target Recognition. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1505805. [Google Scholar] [CrossRef]
- Li, P.; Wu, J.; Wang, Y.; Lan, Q.; Xiao, W. STM: Spectrogram Transformer Model for Underwater Acoustic Target Recognition. J. Mar. Sci. Eng. 2022, 10, 1428. [Google Scholar] [CrossRef]
- Yao, H.; Gao, T.; Wang, Y.; Wang, H.; Chen, X. Mobile_ViT: Underwater Acoustic Target Recognition Method Based on Local–Global Feature Fusion. J. Mar. Sci. Eng. 2024, 12, 589. [Google Scholar] [CrossRef]
- Tang, J.; Ma, E.; Qu, Y.; Gao, W.; Zhang, Y.; Gan, L. UAPT: An Underwater Acoustic Target Recognition Method Based on Pre-Trained Transformer. Multimed. Syst. 2025, 31, 50. [Google Scholar] [CrossRef]
- Dong, W.; Fu, J.; Zou, N.; Zhao, C.; Miao, Y.; Shen, Z. CAF-ViT: A Cross-Attention Based Transformer Network for Underwater Acoustic Target Recognition. Ocean Eng. 2025, 318, 120049. [Google Scholar] [CrossRef]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer Nature: Cham, Switzerland, 2024; pp. 363–380. [Google Scholar]
- Guo, J.; Chen, X.; Tang, Y.; Wang, Y. SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization. arXiv 2024, arXiv:2405.11582. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An Underwater Vessel Noise Database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Types of Ships | Samples |
|---|---|---|
| A | fishing boats, trawlers, mussel boats, tugboats and dredgers | 1888 |
| B | motorboats, pilot boats and sail boats | 1574 |
| C | passenger ferries | 4268 |
| D | ocean liners and ro-ro vessels | 2465 |
| E | background noise | 1147 |
| Training Parameters | Values/Setting |
|---|---|
| batch size | 8 |
| training epochs | 200 |
| initial learning rate | 0.001 |
| optimization algorithm | SDG |
| learning rate | cosine annealing |
| loss function | cross-entropy |
| Model | Accuracy |
|---|---|
| ResNet18 | 92.2% |
| VGG16 | 94.6% |
| ResNet152 | 96.8% |
| ViT | 97.4% |
| WS-ViT | 99.5% |
| Model | Training Time (Seconds per Epoch) | FLOPs (G) |
|---|---|---|
| ViT | 194 | 11.29 |
| WS-ViT | 139 | 9.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Wang, B.; Fang, T.; Liu, B. A Novel ViT Model with Wavelet Convolution and SLAttention Modules for Underwater Acoustic Target Recognition. J. Mar. Sci. Eng. 2025, 13, 634. https://doi.org/10.3390/jmse13040634
Guo H, Wang B, Fang T, Liu B. A Novel ViT Model with Wavelet Convolution and SLAttention Modules for Underwater Acoustic Target Recognition. Journal of Marine Science and Engineering. 2025; 13(4):634. https://doi.org/10.3390/jmse13040634
Chicago/Turabian StyleGuo, Haoran, Biao Wang, Tao Fang, and Biao Liu. 2025. "A Novel ViT Model with Wavelet Convolution and SLAttention Modules for Underwater Acoustic Target Recognition" Journal of Marine Science and Engineering 13, no. 4: 634. https://doi.org/10.3390/jmse13040634
APA StyleGuo, H., Wang, B., Fang, T., & Liu, B. (2025). A Novel ViT Model with Wavelet Convolution and SLAttention Modules for Underwater Acoustic Target Recognition. Journal of Marine Science and Engineering, 13(4), 634. https://doi.org/10.3390/jmse13040634