
Loss Function Optimization Method and Unsupervised Extraction Approach D-DBSCAN for Improving the Moving Target Perception of 3D Imaging Sonar


Abstract
1. Introduction
2. Data Collection and Annotation Method
2.1. Data Collection
2.2. Data Annotation
3. Loss Function Optimization and Semantic Segmentation Task
3.1. Loss Function
- is the loss weight for point ;
- is the local density of point , estimated using the nearest neighbor distance;
- is a hyperparameter controlling the weight variation, typically , to emphasize sparse regions.
- N is the total number of points in the point cloud;
- is the basic loss function (e.g., cross-entropy or mean squared error) for the true class and predicted class of point ;
- is the weight for point , emphasizing sparse regions. This density-weighted loss function reduces the risk of overfitting in dense regions by assigning lower weights while improving segmentation accuracy in sparse regions by assigning higher weights.
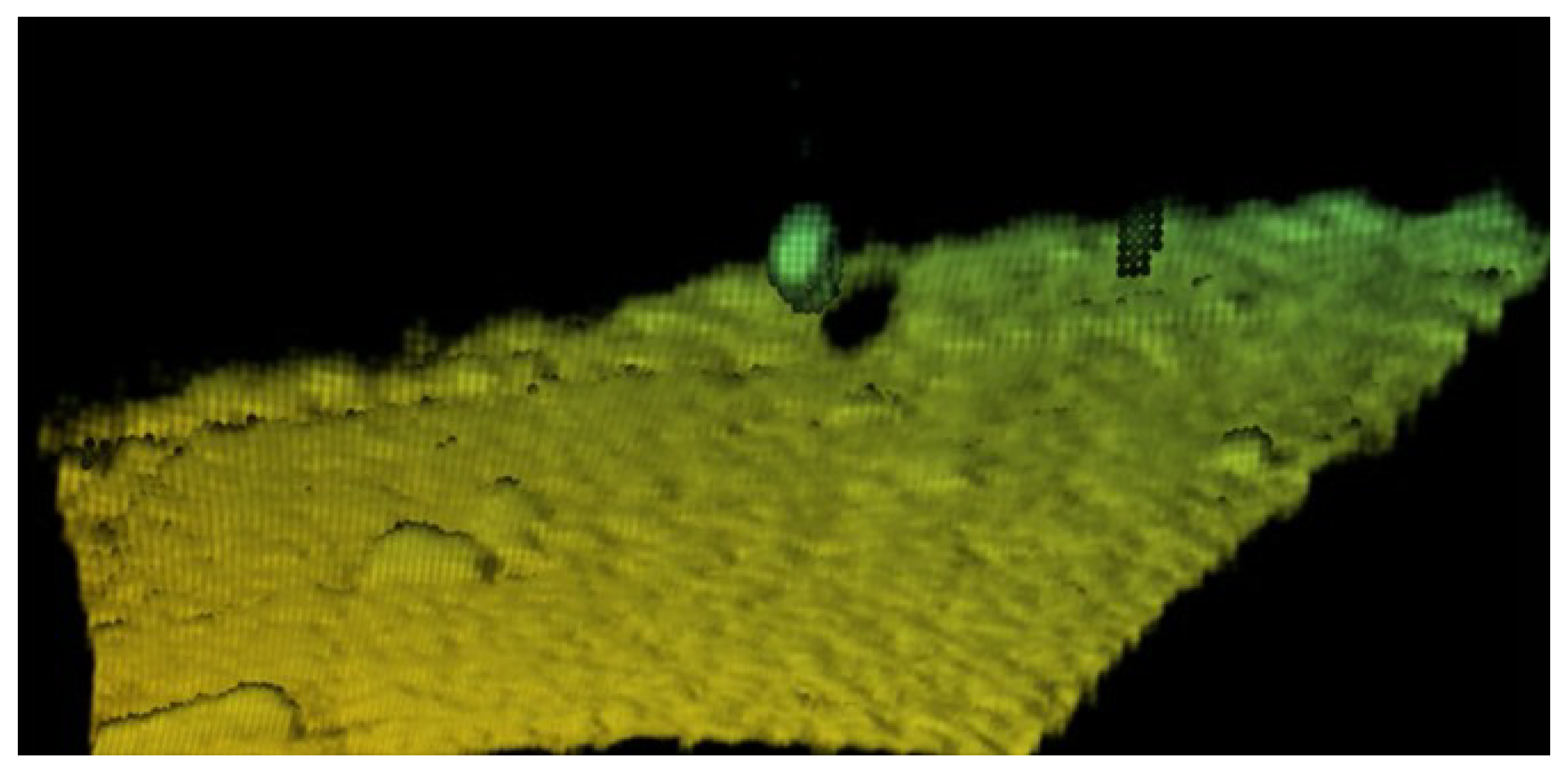
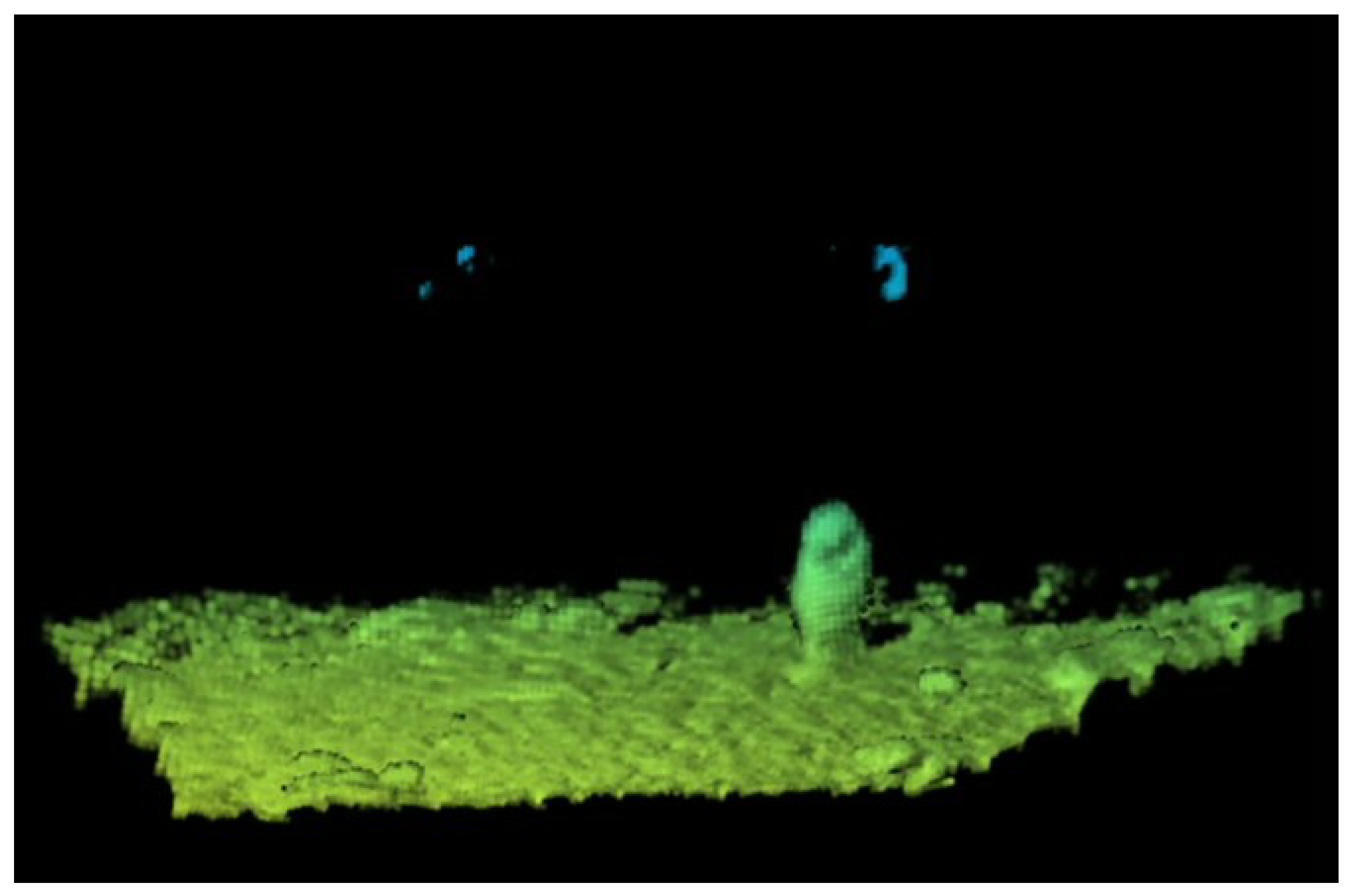
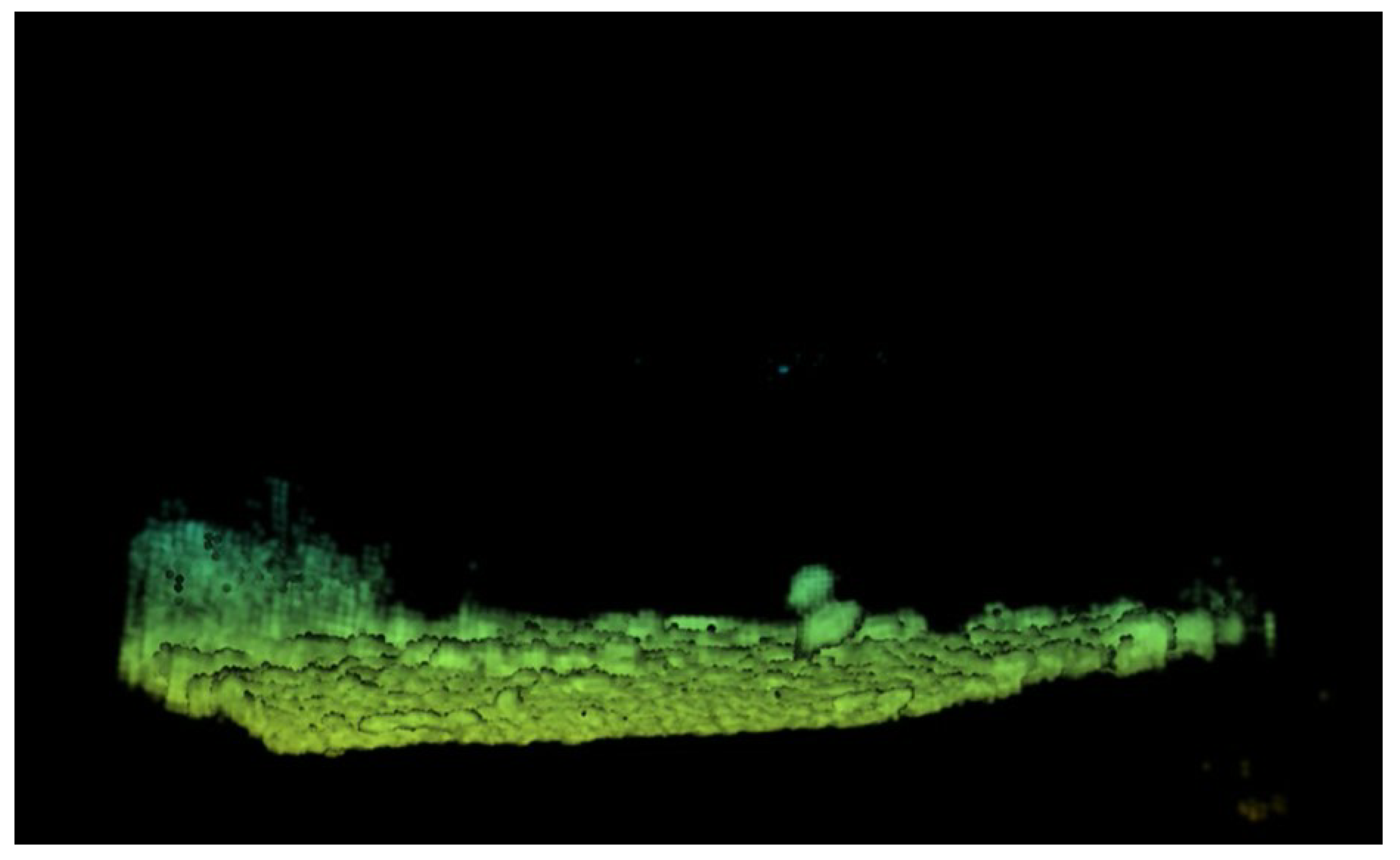
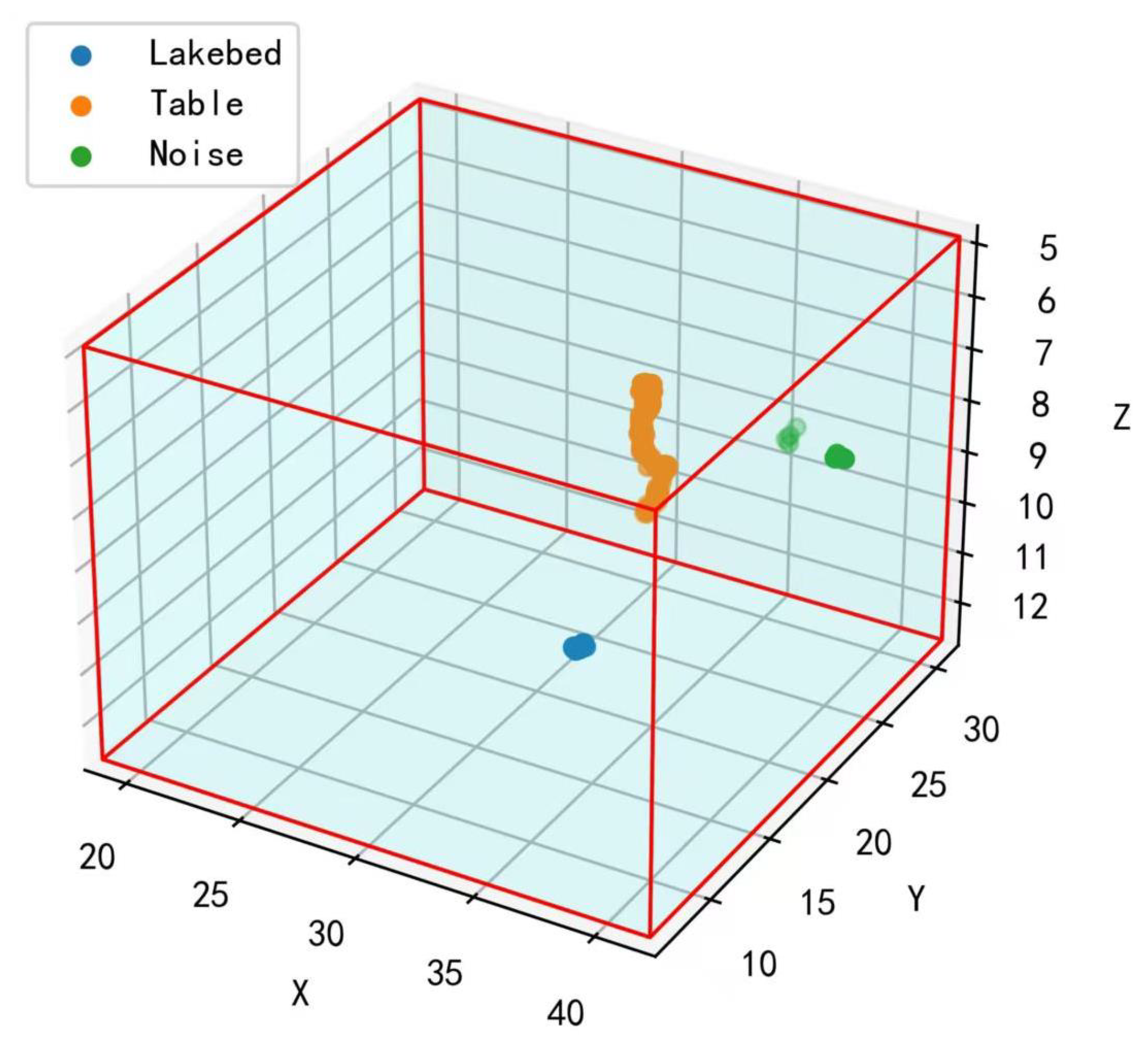
3.2. Semantic Segmentation Experiment
4. Unsupervised Inter-Frame Association Extraction Method D-DBSCAN and Target Detection Task
4.1. D-DBSCAN
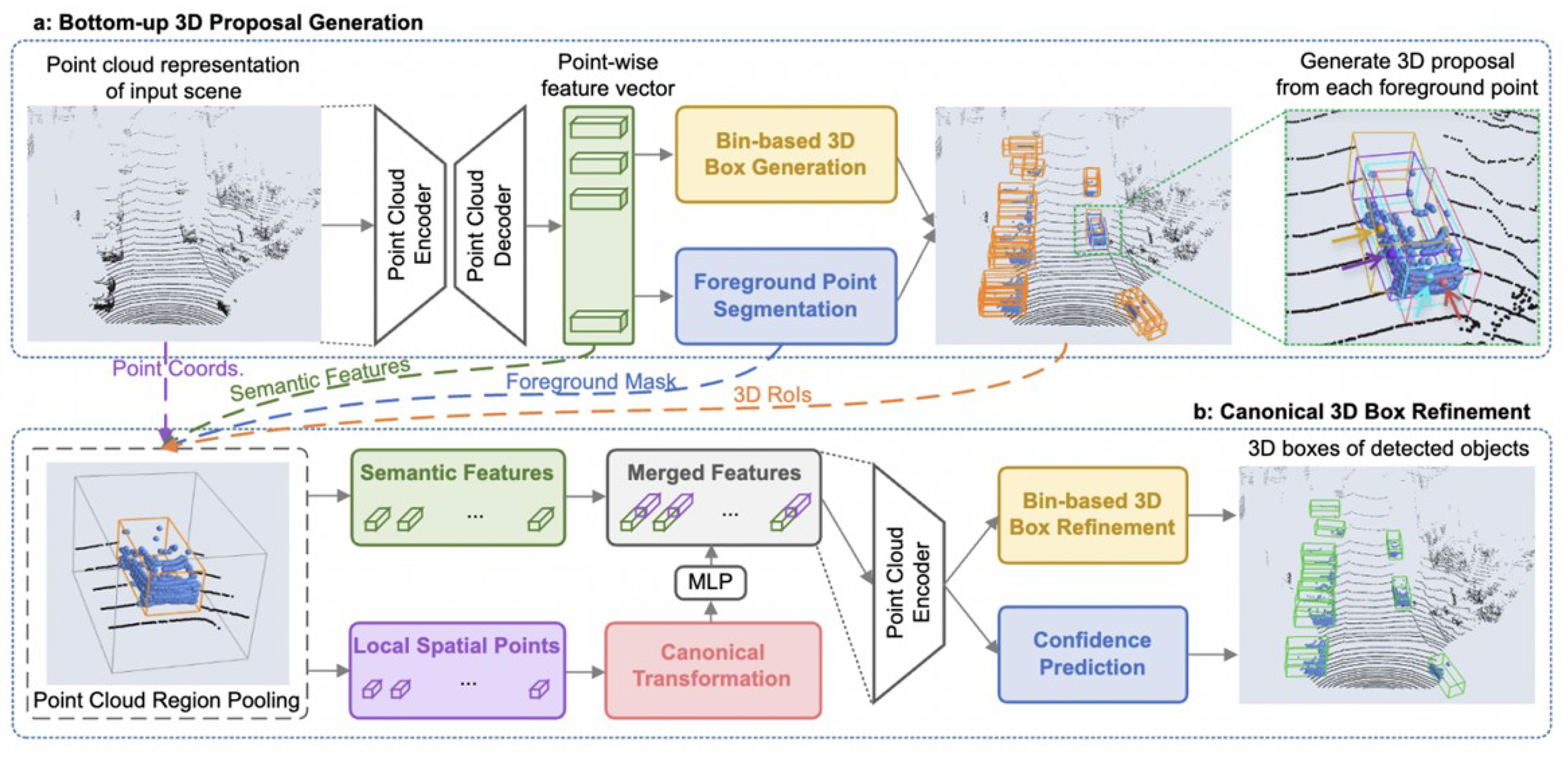
4.2. Object Detection Task
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Steiniger, Y.; Kraus, D.; Meisen, T. Survey on deep learning based computer vision for sonar imagery. Eng. Appl. Artif. Intell. 2022, 114, 105157. [Google Scholar] [CrossRef]
- Davis, A.; Lugsdin, A. High speed underwater inspection for port and harbour security using Coda Echoscope 3D sonar. In Proceedings of the OCEANS 2005 MTS/IEEE, Washington, DC, USA, 17–23 September 2005; pp. 2006–2011. [Google Scholar]
- Hożyń, S. A review of underwater mine detection and classification in sonar imagery. Electronics 2021, 10, 2943. [Google Scholar] [CrossRef]
- Ferreira, F.; Djapic, V.; Micheli, M.; Caccia, M. Forward looking sonar mosaicing for mine countermeasures. Ann. Rev. Control 2015, 40, 212–226. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, M.; Shao, G.; Cheng, J.; Liu, J. Target detection of forward-looking sonar image based on improved YOLOv5. IEEE Access 2022, 10, 18023–18034. [Google Scholar] [CrossRef]
- Xie, K.; Yang, J.; Qiu, K. A dataset with multibeam forward-looking sonar for underwater object detection. Sci. Data 2022, 9, 739. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; Volume 4490, p. 4499. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 12697, p. 12705. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 652, p. 660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 770, p. 779. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-based 3D single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; Volume 11040, p. 11048. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; Volume 806, p. 814. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. Int. Conf. Mach. Learn. 2023, 23803, 23828. [Google Scholar]
- Choy, C.; Gwak, J.Y.; Savarese, S. 4D spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 3075, p. 3084. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; Volume 3354, p. 3361. [Google Scholar]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Pensky, M. Sparse convolutional neural networks. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; Volume 806, p. 814. [Google Scholar]
- Wang, Y.; Lv, K.; Huang, R.; Song, S.; Yang, L.; Huang, G. Glance and focus: A dynamic approach to reducing spatial redundancy in image classification. Adv. Neural Inf. Process. Syst. 2020, 33, 2432–2444. [Google Scholar]
- Hahsler, M.; Piekenbrock, M.; Doran, D. dbscan: Fast density-based clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Tran. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Khan, K.; Rehman, S.U.; Aziz, K.; Fong, S.; Sarasvady, S. DBSCAN: Past, present and future. In Proceedings of the Fifth International Conference on the Applications Of Digital Information and Web Technologies (ICADIWT 2014), Chennai, India, 17–19 February 2014; Volume 232, p. 238. [Google Scholar]
- Xie, H.; Yuan, B.; Xie, W. Moving target detection algorithm based on LK optical flow and three-frame difference method. Appl. Sci. Technol. 2016, 3, 23–27. [Google Scholar]
- Lei, L.; Guo, D. Multitarget detection and tracking method in remote sensing satellite video. Comput. Intell. Neurosci. 2021, 2021, 7381909. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Ma, H.; Sun, Y.; Liu, M. A novel point cloud compression algorithm based on clustering. IEEE Robot. Autom. Lett. 2019, 4, 2132–2139. [Google Scholar] [CrossRef]
- Kremers, B.J.; Citrin, J.; Ho, A.; van de Plassche, K.L. Two-step clustering for data reduction combining DBSCAN and k-means clustering. Contrib. Plasma Phys. 2023, 63, e202200177. [Google Scholar] [CrossRef]
- Cervenka, P.; De Moustier, C. Sidescan sonar image processing techniques. IEEE J. Ocean. Eng. 2002, 18, 108–122. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | CODA Specification |
|---|---|
| Frequency | 375, 610 kHz |
| Beam Count | 128 × 128 (16,384 total) |
| Field of View Coverage | 50° × 24°, 24° × 50° (standard) |
| Pressure Depth | 600–3000 m (1968–9842 ft) |
| Sonar Dimensions | 380 × 300 × 160 mm (15 × 12 × 6 in) |
| Sonar Weight | 24.6 kg/54.2 lb |
| Method | Lakebed | Noise | Tire | Mannequin | Table | mIOU |
|---|---|---|---|---|---|---|
| Baseline | 98.520 | 27.913 | 0.000 | 70.924 | 10.948 | 41.661 |
| OURS | 99.280 | 30.052 | 0.283 | 78.735 | 34.698 | 48.6 (+6.939) |
| Category | PointRCNN | OURS |
|---|---|---|
| Tire | 25.165 | 48.210 |
| Mannequin | 81.810 | 93.431 |
| Table | 10.214 | 39.525 |
| mAP | 39.063 | 60.389 (+21.3) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Huang, A.; Sun, Z.; Huang, R.; Huang, G.; Zhao, Q. Loss Function Optimization Method and Unsupervised Extraction Approach D-DBSCAN for Improving the Moving Target Perception of 3D Imaging Sonar. J. Mar. Sci. Eng. 2025, 13, 529. https://doi.org/10.3390/jmse13030529
Yu J, Huang A, Sun Z, Huang R, Huang G, Zhao Q. Loss Function Optimization Method and Unsupervised Extraction Approach D-DBSCAN for Improving the Moving Target Perception of 3D Imaging Sonar. Journal of Marine Science and Engineering. 2025; 13(3):529. https://doi.org/10.3390/jmse13030529
Chicago/Turabian StyleYu, Jingfeng, Aigen Huang, Zhongju Sun, Rui Huang, Gao Huang, and Qianchuan Zhao. 2025. "Loss Function Optimization Method and Unsupervised Extraction Approach D-DBSCAN for Improving the Moving Target Perception of 3D Imaging Sonar" Journal of Marine Science and Engineering 13, no. 3: 529. https://doi.org/10.3390/jmse13030529
APA StyleYu, J., Huang, A., Sun, Z., Huang, R., Huang, G., & Zhao, Q. (2025). Loss Function Optimization Method and Unsupervised Extraction Approach D-DBSCAN for Improving the Moving Target Perception of 3D Imaging Sonar. Journal of Marine Science and Engineering, 13(3), 529. https://doi.org/10.3390/jmse13030529