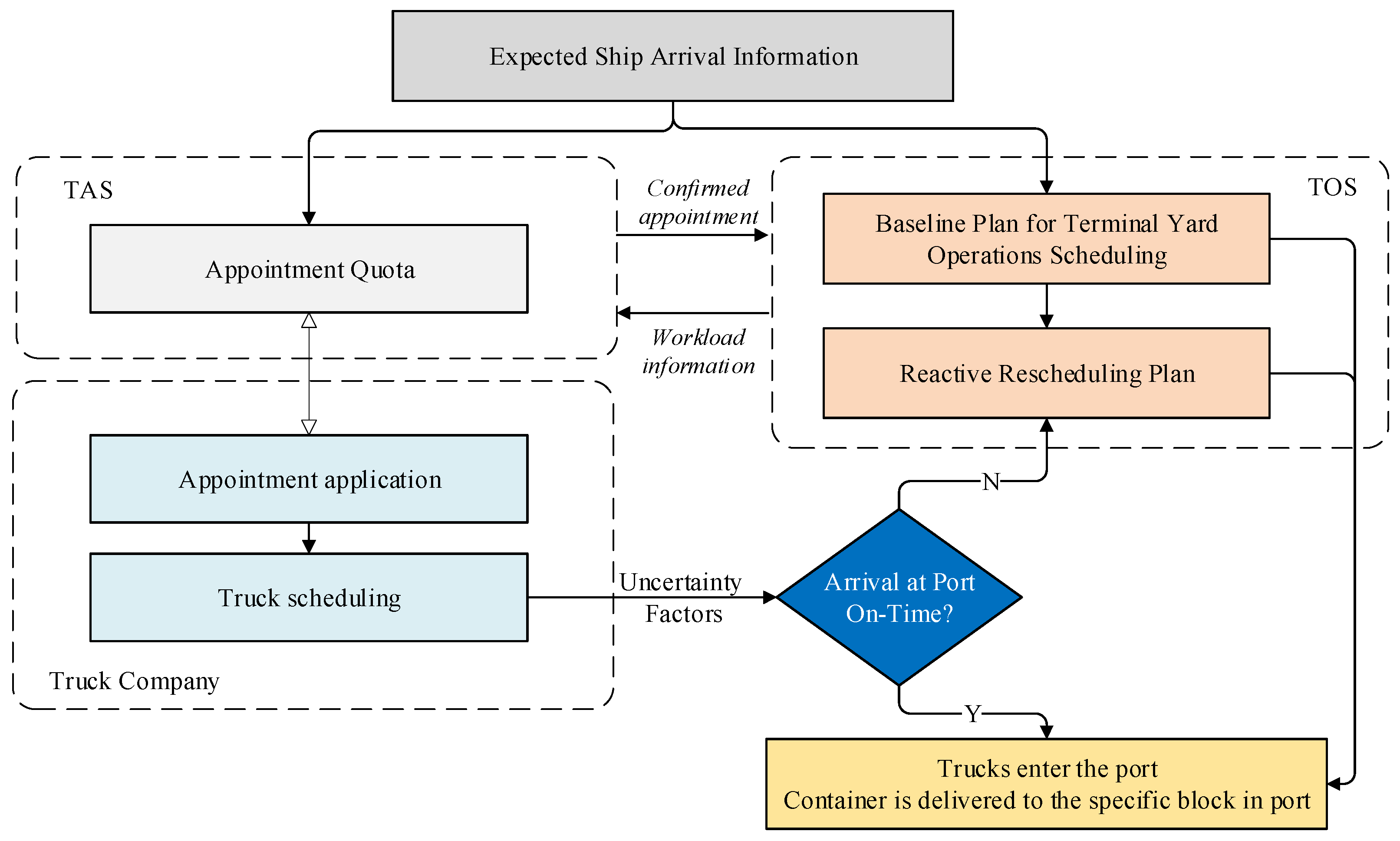
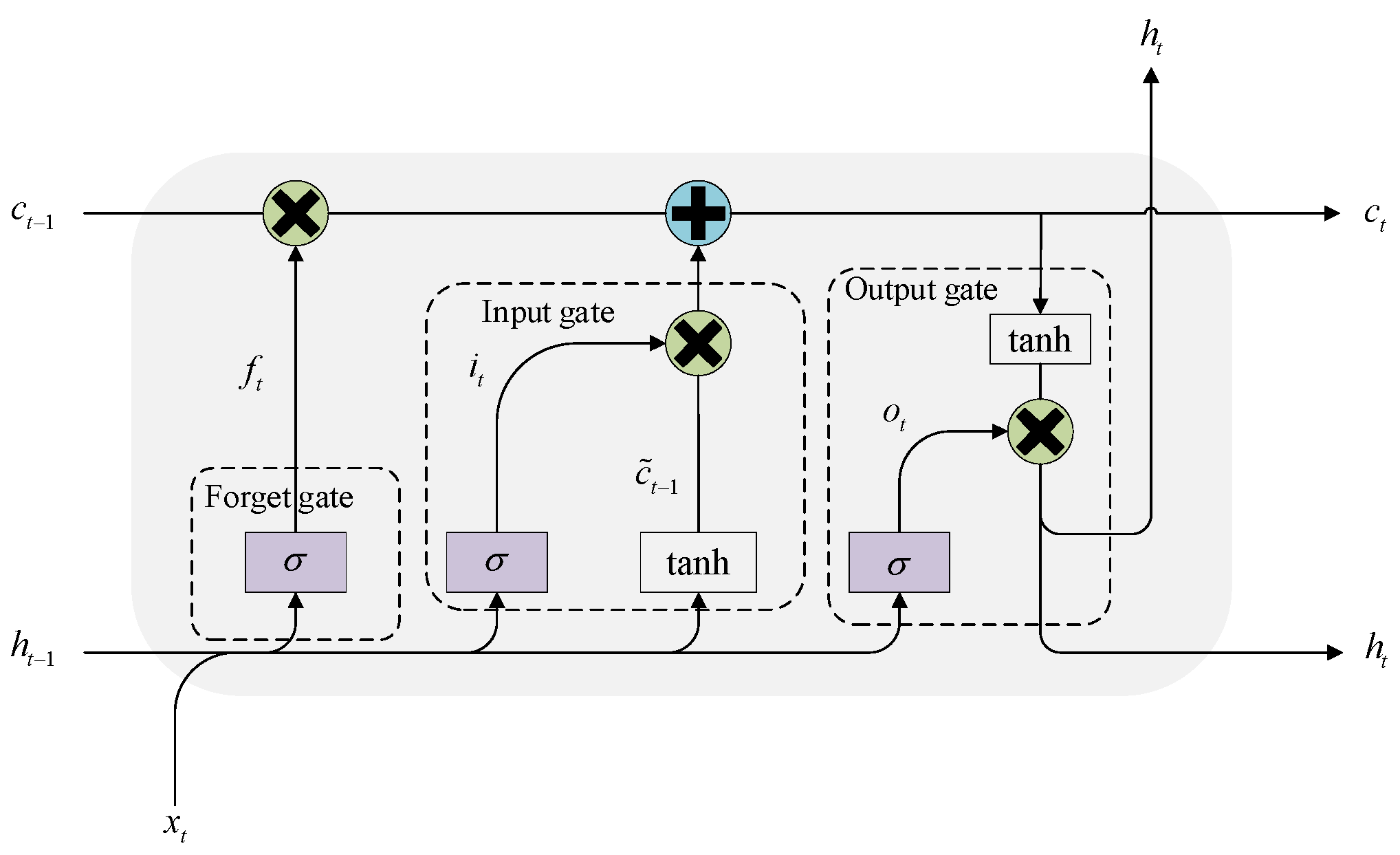
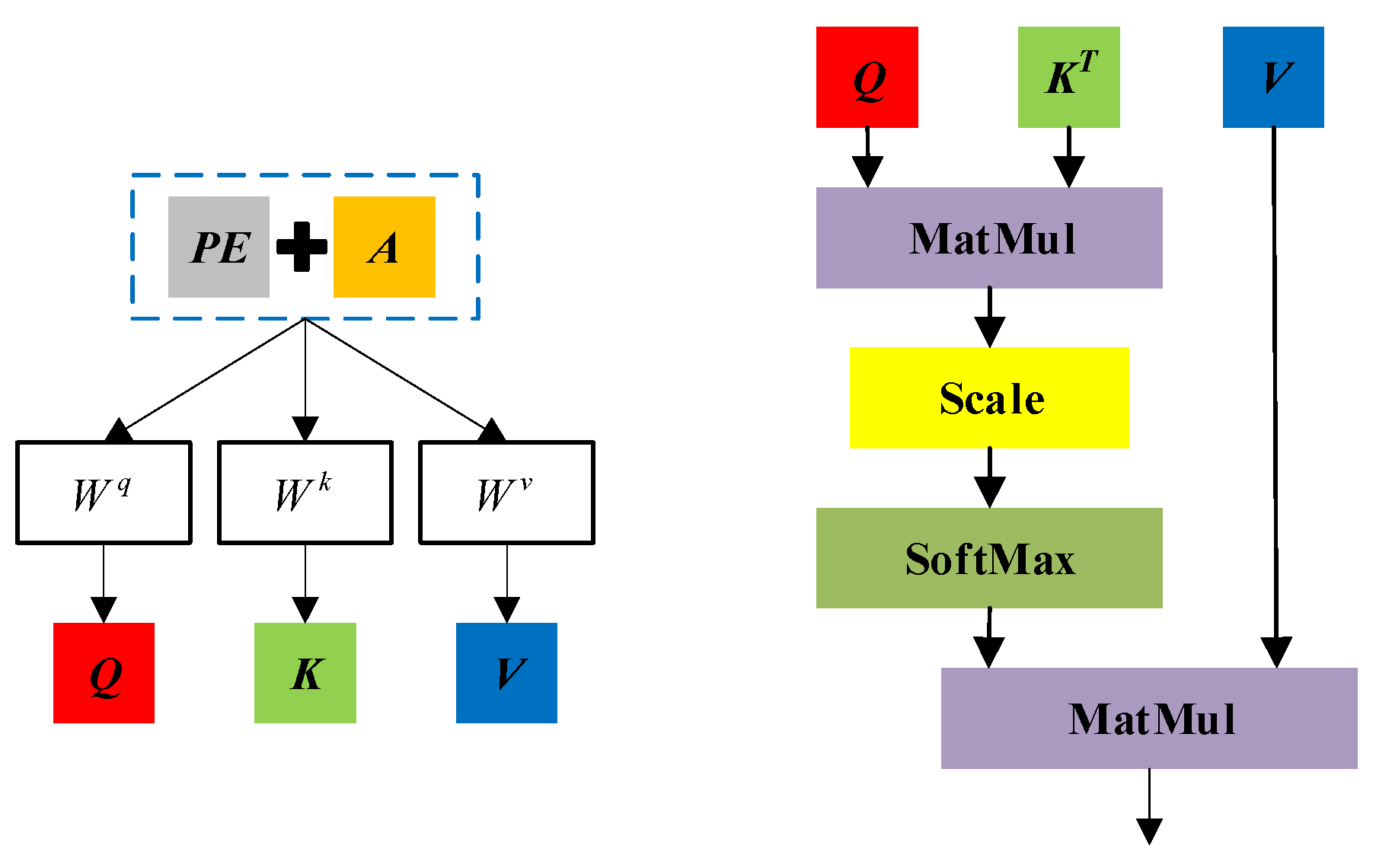
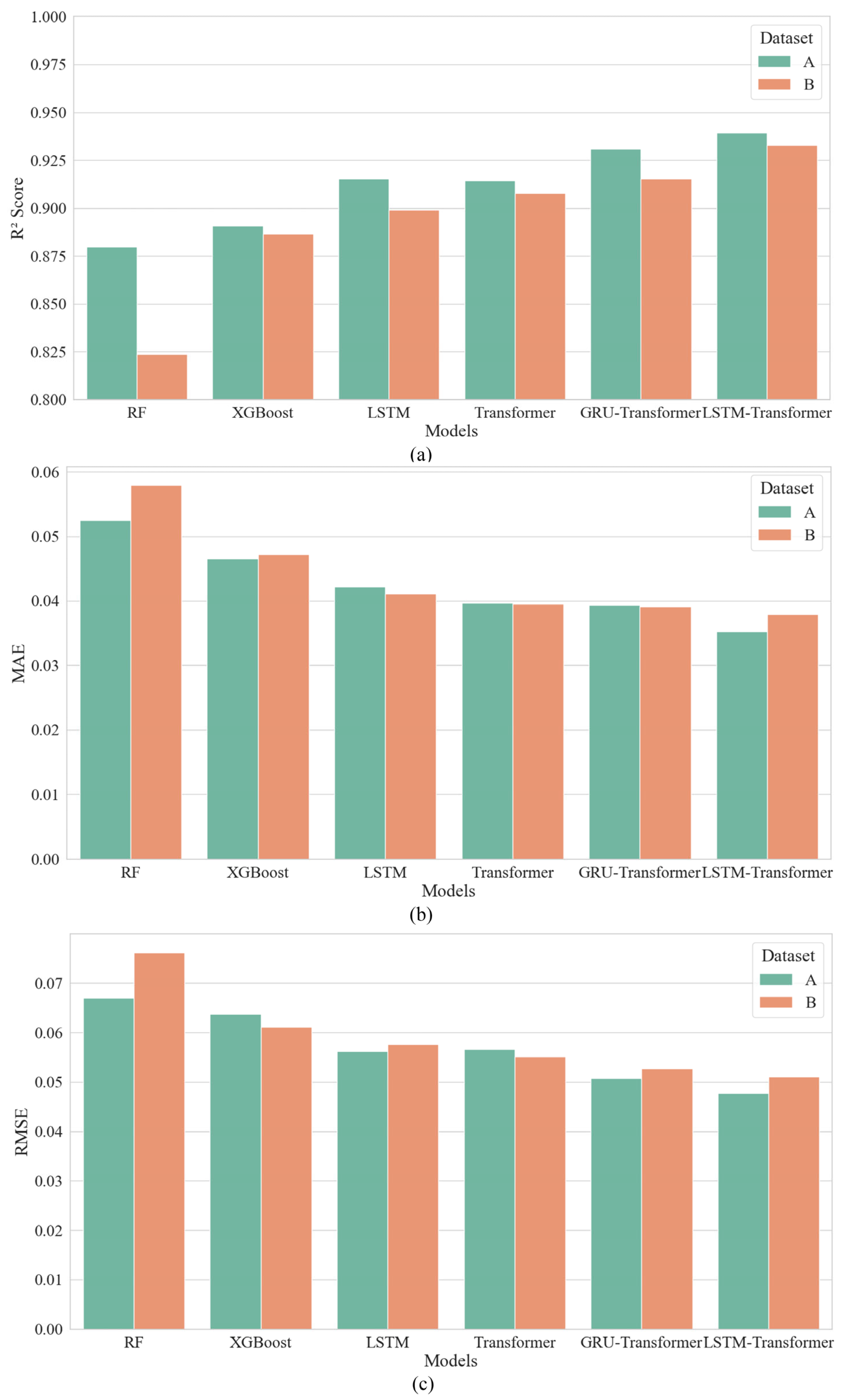
4.1. Selection of Feature Variables
To forecast the actual truck arrivals , it is essential to both understand the historical data of external truck arrivals and identify the factors influencing their arrivals. The scarcity of studies on factors influencing truck no-shows prompted interviews with container terminal operators and truck drivers. Respondents commonly indicated that uncertainties in truck arrivals are associated with weather, traffic conditions, appointment period, and truck appointments.
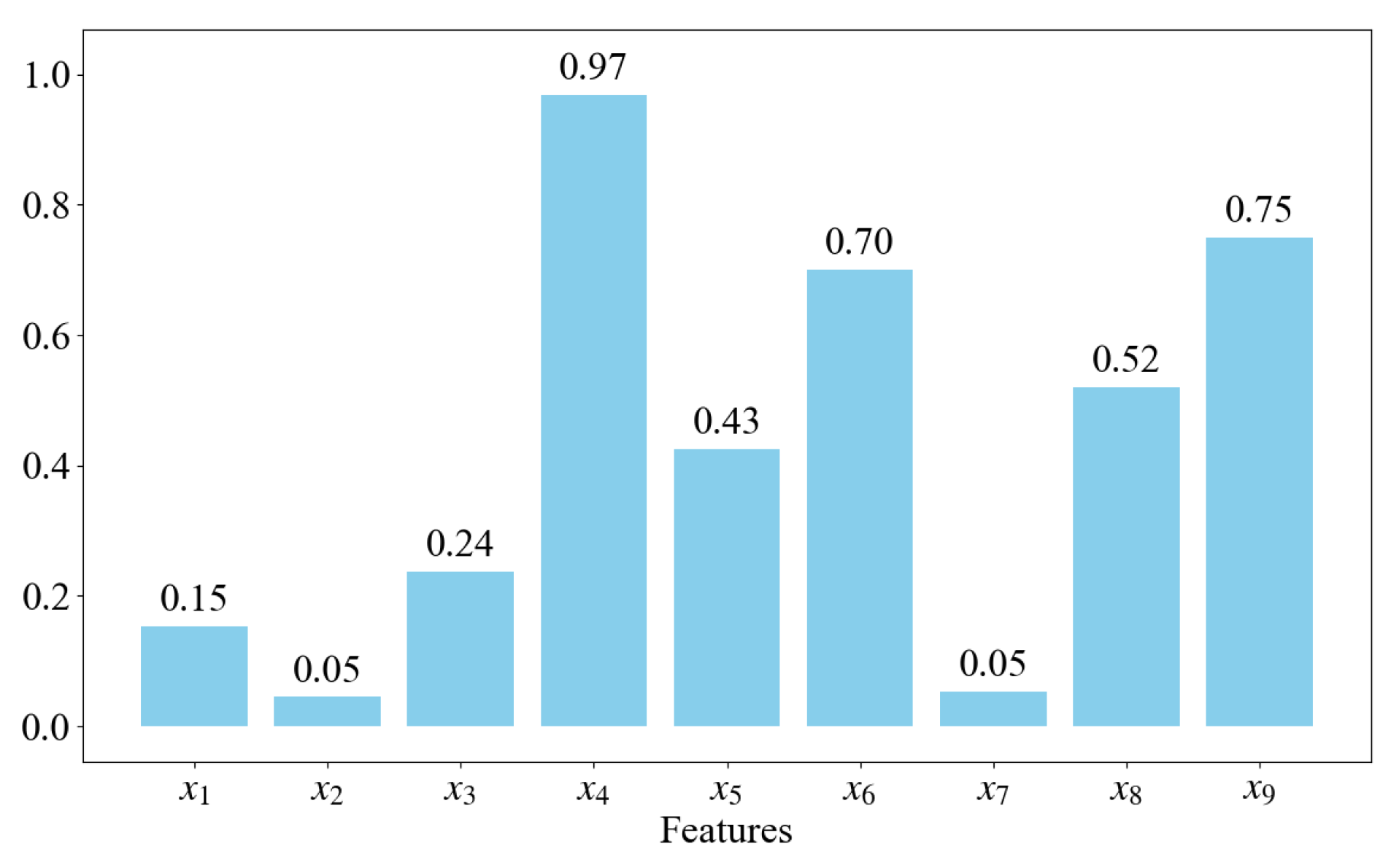
Therefore, based on the literature review and expert interviews, this paper identifies nine factors that are associated with truck appointment no-shows. Given that each day is divided into 12 two-hour appointment periods, historical data are analyzed on an appointment period basis. Assuming it is appointment period , and there is a need to forecast the actual truck arrivals for this appointment period . The nine relevant influencing factors are listed below, followed by brief rationales for their inclusion:
the appointment period.
Rationale: different two-hour slots exhibit distinct arrival patterns, influenced by operational shifts, driver schedules, and peak congestion hours.
the weather conditions of the appointment period .
Rationale: adverse weather (e.g., heavy rain, fog) can cause significant delays or cancelations, thus influencing the actual truck arrivals.
the traffic congestion coefficient of the appointment period .
Rationale: road congestion directly affects arrival reliability, contributing to lateness or no-shows.
the truck appointments of the appointment period .
Rationale: the truck appointments reflect the baseline demand; however, external disruptions can drive a wedge between appointments and actual arrivals.
the truck no-shows of the appointment period .
Rationale: the missed truck may arrive in the next appointment period, which will affect the actual truck arrivals.
the truck appointments of the appointment period .
Rationale: appointments in the previous time period may overflow into period when delays or rescheduling occur, thereby impacting arrivals in the current period.
the traffic congestion coefficient of the appointment period .
Rationale: traffic congestion in the prior period can cause a chain reaction of delays, with trucks arriving later than planned.
the actual truck arrivals of appointment period .
Rationale: including data from an earlier time period helps capture longer-term or lagged effects not fully reflected by a single previous period.
the actual truck arrivals of appointment period .
Rationale: empirical evidence suggests autocorrelation in sequential arrival data, making the most recent actual arrivals a strong predictor.
By incorporating these nine feature variables, we aim to comprehensively account for the temporal dimension (i.e., sequential appointment periods), exogenous factors (e.g., weather, traffic), and historical patterns (previous periods’ appointments, no-shows, and arrivals), and their inclusion is anticipated to improve the accuracy of the model.
4.2. Data Collection and Processing
4.2.1. Data Collection
The historical data of relevant influencing factors from 20 January to 11 February, March 1 to 20 March 2023, and 1 April to 30 June 2024, at a container terminal in Tianjin Port, China, are collected to constitute the raw datasets of feature variables X and target variable Y which are then input into the prediction model. We name the former dataset as Data A and the latter dataset as Data B. Data A consists of 504 samples collected over a period of 42 days, while Data B consists of 1092 samples collected over a period of 91 days.
The data of truck arrivals, indexed by container identity (ID), are collected from the TOS. TOS refers to the software system used to manage and coordinate operations within a terminal. It handles tasks such as resource allocation, scheduling, and tracking of cargo, vehicles, and personnel to ensure efficient terminal operations. For each container, gate-in time, appointment start time, appointment end time, as well as delivery truck ID, etc., are recorded in the system. According to the above information, truck appointments, truck no-shows, and actual truck arrivals for each appointment period can be counted. In addition, this paper obtains relevant weather information and the traffic congestion coefficient for each appointment period drawn from a weather website and Baidu Maps’ big data platform, respectively.
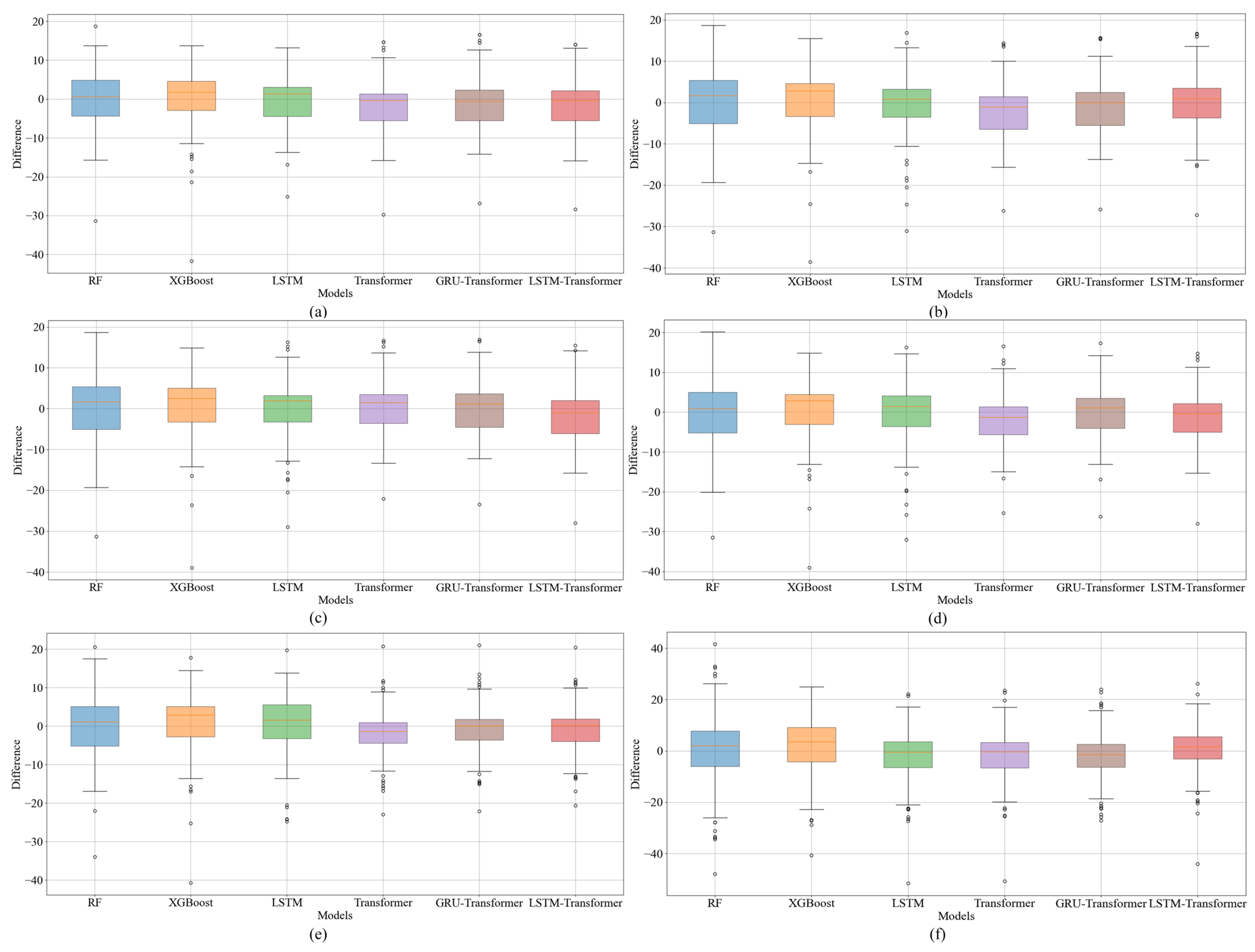
To evaluate the model’s predictive performance and stability across different time scales, we first combined Data A and Data B to form a comprehensive dataset for model training. This unified training approach leverages the full range of information from both datasets, potentially enhancing the model’s ability to learn diverse patterns. After training the model on the combined dataset of Data A and Data B, we treated Data A and Data B separately for prediction. This approach allows us to assess whether the model can consistently perform well under varying temporal contexts and capture underlying patterns that may differ due to seasonal, operational, or external factors (e.g., weather, traffic). The separate treatment of Data A and Data B also allows us to explore whether there are significant differences in truck arrival patterns between the two periods, which could provide insights into the impact of temporal variations on prediction accuracy. For example, the weather conditions and traffic patterns in 2023 and 2024 may differ due to changes in port operations or external factors.
4.2.2. Outlier Detection and Missing Values Handling
This paper employs the box plot method to detect outliers. The primary advantage of box plots is that they are resilient to outliers, enabling them to accurately and consistently represent the data’s distribution while aiding in data cleaning. For detected outliers, we treat them as missing values, as missing values can be imputed using information from existing variables. Rather than removing missing values, which would result in information loss, we use the KNN imputer for imputation, which calculates the values of k neighboring samples that are similar to the missing value sample to fill the missing values.
4.2.3. Data Processing
By collecting original data, we can find that the traffic congestion coefficient is a continuous variable greater than one, and we retain three decimals. The truck appointments, the truck no-shows, and the actual arrivals are integer variables greater than zero and do not need to be processed. Weather conditions typically encompass sunny, cloudy, rainy, foggy, and snowy days. Given that adverse weather conditions such as rain, fog, and snow significantly affect driving safety, these conditions are converted into binary variables, classified as “adverse” or “non-adverse”. There are 12 appointment periods in a day, and the appointment time period can be regarded as a multi-categorical variable, which is a discrete integer ranging from 1 to 12. If the discrete values are directly input, the model may mistakenly regard the relationship between these values as an ordered or linear relationship. Therefore, when building the model, we use the one-hot encoding technology to convert x1 into 12 dummy variables. This approach can help the model better understand the categorical nature of this feature, avoid introducing wrong ordinal assumptions, and improve the accuracy of the model.
Table 1 illustrates the details of the datasets. These features are on vastly different scales, which complicates the training process of the model. To address this, this paper adopts data normalization. Normalization is a technique in deep learning that minimizes the likelihood of gradient explosions, accelerates convergence, stabilizes training, and boosts model performance [
28]. Thus, before being input into algorithms, all raw data except binary variables and dummy variables are normalized using the following formula:
where the range of the normalized data are [0, 1], where
and
represent the minimum and maximum values of the sample data
, respectively.
Table 2 presents the statistics of the two datasets. It can be seen that some factors of the two datasets have obvious differences in mean value, standard deviation (Std), skewness, and kurtosis. It indicates that there are differences in the centralized tendency, dispersion degree, and the sharpness of the two datasets. Training the LSTM-Transformer model on two datasets that have certain different statistical characteristics can significantly enhance the model’s performance and generalization capabilities. The training set comprises 80% of the two datasets, used for training model parameters. Then, 20% of each dataset is taken as the test set which is used for evaluating model performance.
4.3. Hyper-Parameter Tuning
To effectively train the model, it is essential to preset hyper-parameters that affect the learning process, such as the number of neurons, learning rate, and batch size. The learning efficiency and convergence of a model can vary based on hyper-parameter settings, and inappropriate hyper-parameters can lead to reduced performance. As there is no universally optimal value for hyper-parameters, it is necessary to find the best settings through hyper-parameter tuning. However, manually tuning hyper-parameters is both time-consuming and inefficient, and it is challenging to ensure that the optimal values are found. To address this challenge, we employ Optuna, an open-source hyper-parameter optimization framework grounded in Bayesian optimization algorithms. Optuna enables efficient and automatic hyper-parameter search by intelligently exploring the hyper-parameter space [
29]. It supports multiple optimization algorithms, including tree-structured parzen estimator (TPE), and integrates seamlessly with leading machine learning libraries such as PyTorch 1.8.0, TensorFlow, Scikit-Learn, and XGBoost [
25].
During the training phase, we employed mean square error (MSE) as the loss function and ADAM [
30] as the optimizer. The hyper-parameter tuning process involved 100 trials, where each trial evaluated a unique combination of hyper-parameters. The model was trained for 100 epochs in each trial to refine predictions and better approximate actual values.
Figure 5 illustrates the optimization process, with the
x-axis representing the trial number (i.e., the number of evaluations of hyperparameter combinations) and the
y-axis representing the model loss. This figure allows us to observe the changes in model performance throughout the optimization process, showing whether the objective value improves as the number of trials increases. The results demonstrate that Optuna effectively reduced the model loss, indicating successful optimization of the hyper-parameters.
Table 3 shows the hyper-parameters of the LSTM-Transformer model that we tuned using Optuna, the search range of hyper-parameters, and the best hyper-parameters determined by Optuna after 100 trials.
Figure 6 shows the interaction between hyper-parameters and the impact of different values on model performance, where the
x-axis represents different hyper-parameters, with each vertical axis corresponding to a hyper-parameter, and the
y-axis shows the value range of each hyper-parameter. Each line represents a trial, connecting the hyper-parameter values with the objective value. This figure helps analyze the relationship between hyper-parameter combinations and model performance, identifying which combinations lead to better optimization results.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}