Abstract
Accurate offshore wind speed forecasting is crucial for ensuring stable energy production and safe offshore operations. However, the strong nonlinearity, non-stationarity, and chaotic behavior of offshore wind speed series make precise prediction extremely difficult. To overcome these difficulties, a two-stage synergistic prediction framework is proposed. In the first stage, a multi-strategy Black-winged Kite Algorithm (MBKA) is designed, incorporating quantum population initialization, improved migration behavior, and oppositional–mutual learning to reinforce global optimization performance under complex coastal conditions. On this basis, an entropy-driven adaptive Variational Mode Decomposition (VMD) method is implemented, where MBKA optimizes decomposition parameters using envelope entropy as the objective function, thereby improving decomposition robustness and mitigating parameter sensitivity. In the second stage, the denoised intrinsic mode functions are used to train an adaptive Neuro-Fuzzy Inference System (ANFIS), whose membership function parameters are optimized by MBKA to enhance nonlinear modeling capability and prediction generalization. Finally, the proposed framework is evaluated using offshore wind speed data from two coastal regions in Shanghai and Fujian, China. Experimental comparisons with multiple state-of-the-art models demonstrate that the MBKA–VMD–ANFIS framework yields notable performance improvements, reducing RMSE by 57.14% and 30.68% for the Fujian and Shanghai datasets, respectively. These results confirm the effectiveness of the proposed method in delivering superior accuracy and robustness for offshore wind speed forecasting.
1. Introduction
Wind energy, as a low-carbon and zero-emission renewable resource, has achieved remarkable progress over the past several decades [1]. These advancements are reflected not only in the continuous improvements in turbine efficiency and the substantial reduction in manufacturing costs, but also in the steady decline of the levelized cost of energy, which has gradually approached or even surpassed that of traditional fossil fuels [2]. According to the 2024 Global Offshore Wind Report released by the Global Wind Energy Council (GWEC), global offshore wind installations reached 10.8 gigawatt (GW) in 2023, representing a 24% year-on-year increase, with China contributing 6.3 GW and maintaining its position as the world’s leading offshore wind market for the sixth consecutive year [3], as illustrated in Figure 1.
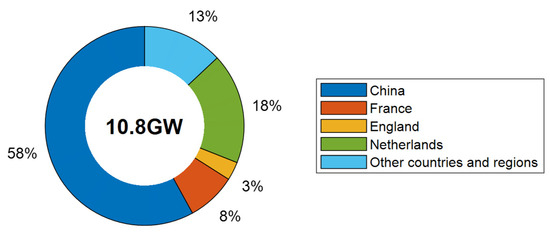
Figure 1.
New offshore wind installations by region.
Compared with onshore wind power, offshore wind energy offers unique advantages, including more stable and abundant wind resources, reduced surface friction, weaker wind shear, and minimal land occupation [4]. Moreover, due to the absence of complex terrain-induced disturbances, offshore wind fields exhibit superior spatial–temporal uniformity and predictability relative to onshore environments [5]. However, offshore wind speeds remain strongly influenced by abrupt disturbances, seasonal periodicity, and long-term climatic trends, resulting in pronounced volatility, nonlinearity, non-stationarity, and even chaotic behavior [6]. These complex characteristics make it difficult for traditional single-model forecasting approaches to achieve stable and reliable performance.
Existing research on wind speed forecasting can be broadly categorized into physical models, statistical models, artificial intelligence (AI) models, and hybrid models. Physical models, such as numerical weather prediction (NWP), rely on atmospheric dynamics to represent large-scale meteorological processes, but their high computational cost, limited spatial resolution, and insufficient representation of near-surface marine dynamics restrict their accuracy. Even when combined with error-correction techniques such as Kalman filtering, these models struggle to capture rapid small-scale variations [7,8]. Statistical models, including autoregressive integrated moving average (ARIMA) and seasonal ARIMA (SARIMA), are computationally efficient and well-suited for short-term forecasting; however, their reliance on stationarity assumptions prevents them from effectively modeling the strong nonlinearity of offshore wind speeds. Although incorporating wavelet decomposition or seasonal terms can improve local performance, generalization remains limited in highly dynamic offshore environments [9,10].
In recent years, AI models such as long short-term memory network (LSTM), gated recurrent unit network (GRU), Transformer [11] and ANFIS [12] have gained increasing attention due to their powerful nonlinear representation capabilities. Attention mechanisms and Transformer-based architectures have further enhanced the ability to capture complex spatiotemporal dependencies [13]. Nevertheless, these models are often sensitive to initial conditions and hyperparameter settings, making them susceptible to local optima and heavily dependent on expert experience for model tuning. To overcome these limitations, metaheuristic algorithms have been introduced to optimize network structures and weights, thereby improving forecasting accuracy and robustness. Hybrid forecasting models further enhance performance by integrating signal decomposition with AI learning, as demonstrated in methods such as Liu et al. [2], which proposed rime optimization (RIME)-based VMD with multi-headed self-attention-LSTM, and Gong et al.’s [13] proposed use of VMD decomposes the signal, with a fully connected network capturing temporal patterns and GRU making predictions. Despite their superior predictive accuracy, these models remain constrained by parameter sensitivity in decomposition techniques and the tendency of deep learning models to become trapped in local optima. Related work on the wind speed prediction is shown in Table 1.

Table 1.
Related work on the wind speed prediction.
Within such hybrid frameworks, ANFIS is particularly advantageous because it combines the interpretability of fuzzy inference systems with the adaptive learning capability of neural networks, enabling effective modeling of the complex nonlinear dynamics inherent in offshore wind speed data. Meanwhile, signal decomposition methods transform wind speed sequences into frequency-band components, providing structured and discriminative inputs for downstream predictors. Traditional empirical mode decomposition (EMD) can extract intrinsic mode functions (IMFs) adaptively but suffers from mode mixing; ensemble empirical mode decomposition (EEMD) reduces mode mixing by adding white noise but introduces noise residues. In contrast, VMD formulates signal decomposition as a variational optimization problem in the frequency domain, providing stable mode extraction without noise injection, thus avoiding mode mixing and improving decomposition quality.
Despite the strengths of VMD and ANFIS, several key challenges remain in offshore wind speed forecasting. The decomposition performance of VMD is highly sensitive to hyperparameters such as the number of modes K and the penalty factor α, and empirical selection often results in under-decomposition or over-decomposition. Similarly, the membership functions and rule parameters in ANFIS rely on gradient-based optimization and are prone to becoming trapped in local optima, limiting overall predictive accuracy. More critically, simultaneously optimizing both the VMD and ANFIS components results in a high-dimensional, non-convex, and multimodal optimization problem. Traditional optimization algorithms such as genetic algorithm (GA) [14], pelican optimization algorithm (POA) [15], weighted average algorithm (WAA) [16], whale optimization algorithm (WOA) [17], and red-tailed hawk algorithm (RTH) [18], generally exhibit insufficient global exploration capability, sensitivity to local optima, or unstable convergence behavior in such complex search spaces, making it difficult to obtain robust and reliable optimal solutions.
Motivated by these challenges, this study proposes a two-stage synergistic MBKA-VMD-EE-ANFIS offshore wind speed forecasting framework. An enhanced MBKA is first designed, incorporating three mechanisms tailored for complex optimization tasks: (1) quantum-based population initialization to enhance population diversity; (2) improved migration dynamics to strengthen the ability to escape local extrema; and (3) a dynamic opposition–mutual learning strategy to refine search directionality and accelerate convergence. In the first stage, MBKA is employed to realize an entropy-driven adaptive VMD, which automatically optimizes decomposition parameters by minimizing envelope entropy and achieves robust mode decomposition. In the second stage, the denoised IMFs are fed into a self-adjusting ANFIS predictor, whose membership functions and rule parameters are globally optimized by MBKA to substantially enhance nonlinear modeling capability and wind speed forecasting accuracy.
Furthermore, compared with existing forecasting approaches, the proposed framework provides improved robustness and adaptability across different offshore regions and sea-state conditions, owing to its capacity for adaptive decomposition and globally optimized nonlinear reasoning. Nevertheless, this enhancement introduces an inevitable trade-off, as the framework requires additional computational time due to the metaheuristic optimization process. Despite this cost, the substantial gains in prediction accuracy, stability, and cross-regional generalization make the approach highly beneficial for practical offshore wind forecasting applications.
The major contributions of this study are summarized as follows:
- A multi-strategy MBKA is proposed, integrating adaptive population diversity enhancement and guided exploration mechanisms to improve global optimization performance in complex offshore environments.
- An entropy-driven adaptive VMD method is developed, in which MBKA optimizes decomposition parameters via envelope entropy, significantly reducing parameter sensitivity and improving decomposition stability.
- A self-adjusting ANFIS prediction model is constructed, and MBKA is employed to adaptively optimize its fuzzy rules and parameters, thereby enhancing nonlinear representation and forecasting capability.
- Extensive experiments on real offshore wind speed datasets from coastal regions of Shanghai and Fujian demonstrate that the proposed framework achieves superior forecasting accuracy and stability compared with multiple advanced benchmark models.
2. Proposed Multi-Strategy BKA for Optimization
2.1. Black-Winged Kite Algorithm (BKA)
The Black-winged Kite [19] is a small raptor known for its blue–gray upperparts and white underparts, as well as its distinctive predatory behavior and population dynamics. The BKA models the kite’s migration and attack behaviors [20] and integrates Cauchy mutation with the Leader strategy. This design improves global search ability and accelerates convergence, achieving an effective balance between global exploration and local exploitation for complex optimization tasks.
In the Attacking behavior stage, the Black-winged Kite employs two hunting strategies: hovering in the air while waiting to attack and hovering while searching for prey. In the BKA, this phase serves as a mechanism for global exploration, where the mathematical expression is as follows:
where and represent the positions of the i-th black-winged kite in the j-th dimension at the t-th and t+1-th iteration steps, respectively. The parameter r is a random number between 0 and 1, and p is fixed at 0.9 in the primal algorithm, which means Black-winged Kites spend 90% of their hunting time hovering while searching for prey. And n is a function that decreases linearly with respect to the number of iterations, as shown in Equation (2). T represents the total iteration count, and t denotes the current iteration count.
During the exploitation phase, BKA models the migratory behavior of black-winged kites by combining the Leader strategy with migration dynamics. If the current leader’s fitness is lower than that of a randomly selected individual, it relinquishes its role and joins the migrating group, indicating that it is no longer capable of guiding the population. Conversely, if its fitness is higher, it continues to lead the population toward the destination. This mechanism enables dynamic leader selection to ensure effective migration. The migration behavior is formulated as follows:
Here and represent the current position and the fitness value at any position in the j-th dimension during the t-th iteration, respectively. represents the leader Black-winged Kite. And m is a nonlinear modulation factor used to adjust the movement intensity of the individual. It is defined as Equation (4):
represents the Cauchy mutation, where and . Its probability density function is as follows:
2.2. The Proposed Multi-Strategy BKA (MBKA)
Although BKA integrates Cauchy mutation and the Leader strategy to enhance optimization, it still tends to fall into local optima because it struggles to maintain an effective balance between global exploration and local exploitation. To address the challenges of complex offshore environments, we propose MBKA, a multi-strategy enhanced version of BKA designed to improve overall optimization performance.
MBKA introduces Quantum Population Initialization [20], where an improved circular chaotic map and quantum computing techniques generate a more uniform and diverse initial population, thereby accelerating convergence. In addition, a dropout mechanism and Lévy flight are incorporated into the migration behavior to enhance exploitation accuracy, especially in the later optimization stages. The OML [21] dynamically introduces opposite solutions, enabling the algorithm to explore new regions of the search space and reducing the likelihood of premature convergence. Building on dynamic opposition-based learning, the mutual learning strategy further strengthens both exploration and exploitation, achieving a more robust balance between discovering new regions and refining existing solutions.
2.2.1. Quantum Population Initialization
During BKA initialization, the positions of Black-winged Kites are generated in an overly random manner. To improve diversity, a diversified initialization strategy is adopted; an improved circular chaotic map produces a more uniformly distributed set of initial solutions, while quantum computing further enhances population diversity. Circle Chaotic Mapping [22] generates chaotic sequences on a unit circle through a simple recursive formulation. Its definition is given as follows:
Here, and denote the current iteration and updated state position. And means modulo operator. From Figure 2a, when a = 0.2 and b = 0.5, it can be observed that the frequency distribution demonstrates unevenness. To address this issue, the original formula is modified, resulting in the improved Circle Chaotic Mapping formula, as shown in Equation (7). The frequency distribution of the improved mapping, depicted in Figure 2b, becomes more uniform.
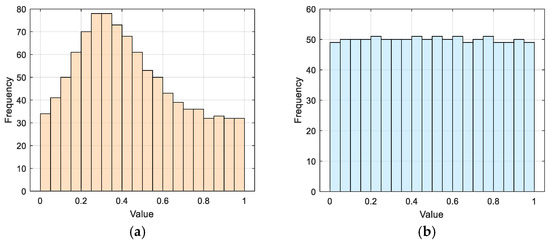
Figure 2.
The frequency distribution graph of Circle Chaotic Mapping. (a) When a = 0.2 and b = 0.5; (b) When a = 0.4204 and b = 0.0305.
Subsequently, the following Equation (8) is used for population initialization, where lb and ub are the lower and upper bounds of the problem.
In quantum computing, qubits can represent multiple states simultaneously in a superposition. Leveraging this characteristic, the concept of quantum computing is introduced during the initialization phase to generate a more diverse initial population using a set of qubits. Additionally, by utilizing the principles of qubits and quantum gates, the quality of the initial population can be improved. During subsequent iterations, the algorithm can perform searches based on solutions superior to the original positions, thereby enhancing its global search capability and exploratory performance. In quantum computing theory, the two fundamental states of a qubit are represented as and , forming the basic unit of quantum information storage. A qubit in quantum computing can exist in a superposition of these two states, expressed as . Here, and are complex numbers representing the probability amplitudes of the respective states, satisfying the normalization condition: . When a superposed quantum state is observed, it collapses to either (with a probability of ) or (with a probability of ). The qubit can be expressed in terms of sine and cosine matrices based on its probability amplitudes, as shown in the formula: , where and . Individuals are constructed using qubits, with the probability amplitudes representing the position of each individual. Thus, the quantum spatial position and the state matrix of an individual correspond as follows [20]:
Furthermore, a linear transformation defines the mapping from the quantum space to the solution space and , represented by the following:
Assuming the current state is represented by a sine or cosine position, the inverse transformation is applied as per Equation (11). Based on the obtained rotation angle , corresponding state can be calculated. These two positions form the two state vectors of the initial qubit.
Additionally, for the purpose of creating a more varied initial population, mutation updates are applied. In quantum computing, devices used for quantum state logic transformation are referred to as quantum logic gates. This study employs dynamic quantum rotation gate , represented by Equation (12). Through the quantum rotating gate , the angle of the original qubit is updated to the new angle .
After the rotation gate mutations, the individuals’ positions at the sine and cosine points are assessed and compared. The individuals showing the best performance are then chosen to constitute the final initial population.
2.2.2. Improved Migration Behavior
During the migration phase of the BKA, the integration of both the Cauchy mutation strategy and the Leader strategy improve the global search ability and speed of convergence. Nevertheless, the algorithm is susceptible to being trapped in local optima in the final stages. To mitigate this, this study replaces the Cauchy mutation with Lévy flight and introduces a dropout mechanism to prevent the algorithm from converging to local optima. The Lévy flight, a random walk process characterized by a heavy-tailed step-length distribution, is mathematically formulated in Equation (13) [23]. This formulation utilizes two independent variables, u and v, which are drawn from normal distributions. Specifically, their distributions are defined as and , where the parameter is calculated according to Equation (14). And is the stability index of the Lévy distribution, often taken as 1.5 in experiments. is the Gamma function. The modified migration phase formula is shown in Equation (15). Here, Levy represents the Lévy flight, and k denotes the step size of the Lévy flight.
During optimization, individuals in the BKA population gradually converge toward the leader. Although this mechanism enhances local search accuracy by intensively exploring the vicinity of the current best solution, it inevitably reduces population diversity and increases the risk of being trapped in a local optimum. To address this issue, a dropout mechanism is incorporated into the migration process. This mechanism not only improves the biological realism of the algorithm but also strengthens its ability to escape local optima. When the distance between the i-th individual and the leader exceeds d times the average distance, and a random number is less than q, the individual is considered to drop out. The dropout mechanism is formulated as follows:
Here, r is randomly generated within (−0.5, 0.5), and is a random number in the range (0, 1). The parameter q represents the dropout rate, set to 0.3, and d is the dropout distance ratio factor, with a value of 0.1. Parameter dist is the Euclidean distance between the i-th Black-winged Kite and the leader Black-winged Kite. denotes the current leader position, and represents the position of the i-th Black-winged Kite. Parameter mean is the average distance between the individual and the leader.
2.2.3. Oppositional–Mutual Learning Strategy (OML)
OML [21] includes two strategies: dynamic opposition learning and mutual learning stages. The introduction of dynamic opposition learning aims to prevent the algorithm from prematurely converging when encountering complex problems. Additionally, dynamic opposition learning is an enhanced form of opposition learning that aids the population in learning from opposite points within asymmetric and evolving search spaces. The dynamic opposition learning formula is as follows:
Within each generation, the individual with the best fitness is identified as the optimal solution, which serves as the criterion for comprehensive evaluation. However, individuals with poorer fitness may possess better knowledge in certain dimensions. Based on the individual is anticipated to learn from other individuals, the mutual learning strategy is introduced. Its formula is as follows:
Here, r, r1, r2 represents a random number ranging (0, 1), and are the global maximum and minimum positions of the group in the j-th dimension, and is not equal to .
2.3. Time Complexity Analysis
The time complexity of the proposed MBKA depends on the population size N, problem dimension mmm, and maximum iterations T. The computational cost comprises three stages: initialization, attacking, and migration. In the initialization stage, quantum population initialization generates four candidate solutions for each individual, resulting in a cost of O(4Nm).
During each iteration, MBKA integrates attacking, migration, and OML strategies. The attacking phase performs sinusoidal and scale-based position updates with boundary checks, yielding a complexity of O(NmT). The migration phase, involving distance estimation, Lévy perturbation, and adaptive movement decisions, also incurs O(NmT). The OML mechanism further improves diversity through dynamic opposition or pairwise mutual learning, adding another O(NmT). Leader updating and diversity monitoring introduce only minor overhead of O(Nm) per iteration. Considering all core components, the overall computational complexity of MBKA is approximated as follows:
This linear dependence on population size and problem dimension ensures that MBKA remains scalable and computationally efficient for high-dimensional optimization problems.
3. Proposed Hybrid Short-Term Offshore Wind Speed Prediction Model
To address the challenges posed by the complex environment and nonstationary characteristics inherent in offshore wind speed signals, we propose a two-stage synergistic enhancement framework. In the first stage, an entropy-driven adaptive VMD denoising framework is proposed to effectively suppress noise and irrelevant fluctuations, thereby enhancing the quality and interpretability of the input signals. In the second stage, a parameters self-tuning ANFIS model via MBKA is developed to better capture the intrinsic nonlinear dynamic signal, which improve the learning capability and generalization performance of the predictive model. Together, the two stages work synergistically to enhance both the quality of the input features and the adaptability of the prediction model, thereby significantly improving offshore wind speed forecasting accuracy and stabilization under complex and variable marine conditions.
3.1. Entropy-Driven Adaptive VMD Denoising Methods
VMD is a signal processing method [24] that decomposes an input signal into a set of finite bandwidth sub-signals by solving a constrained variational problem. Compared to traditional decomposition methods, VMD offers significant advantages in terms of signal adaptability, noise robustness, and mode independence, making it particularly suitable for handling complex nonlinear and nonstationary signals. The center frequencies of these modes are adaptively determined. This method ensures signal integrity and mode independence during the decomposition process. For a given signal , the variational problem with constraints in VMD is formulated as Equation (20) [25]:
The constraint condition is given as Equation (21):
where implies the k-th mode of the signal, represents the Dirac delta function, is the time derivative operator, and denotes the center frequency of the k-th mode. The parameter j stands for the imaginary unit, and indicates convolution operator.
To address this constraint, penalty terms and the Lagrange multiplier are introduced. This combination takes advantage of the convergence benefits of quadratic penalties with constrained weights and enforces the constraint effectively using the Lagrange multiplier. Consequently, the optimization problem is adjusted into an unconstrained version, as shown Equation (22):
Furthermore, the Alternating Direction Method of Multipliers (ADMM) [26] is employed to solve the problem of Equation (22). ADMM is a robust optimization approach that divides intricate problems into simpler, more manageable components. By optimizing these components step by step and ensuring variable consistency, ADMM effectively manages large-scale optimization tasks. Through iterative updates, the optimal solutions for frequency domain value of the k-th mode IMF , center frequency update , and the Lagrange multipliers Fourier transform in n+1-th iteration can be derived, and Equations (23)–(25) represent their iterative expressions:
Here n denotes the iteration number, and , , , and represent the Fourier transform forms of , , , and , respectively. These Fourier transforms allow the problem to be solved in the frequency domain, facilitating easier manipulation and convergence of the iterative updates. The frequency domain updates are then converted back to the time domain, enabling the retrieval of the optimal values for , , and at each iteration. is the LaGrange multiplier update step size.
However, a critical limitation of VMD lies in its reliance on manually pre-defined parameters, particularly the number of modes and the penalty term . Improper selection of these parameters may lead to mode mixing, insufficient decomposition, or over-decomposition, thereby compromising the interpretability and accuracy of the resulting components. Moreover, since the optimal parameter values are highly signal-dependent, empirical tuning becomes inefficient and lacks generalizability across different datasets or application scenarios. This necessitates the development of adaptive parameter selection strategies to ensure robust and meaningful signal decomposition. To address these issues, we propose a novel adaptive denoising framework, termed the MBKA-VMD-EE.
To adaptively determine the optimal parameters of VMD, the MBKA is employed, wherein the envelope entropy (EE) of each IMF is utilized as the fitness function, as is shown in Figure 3.
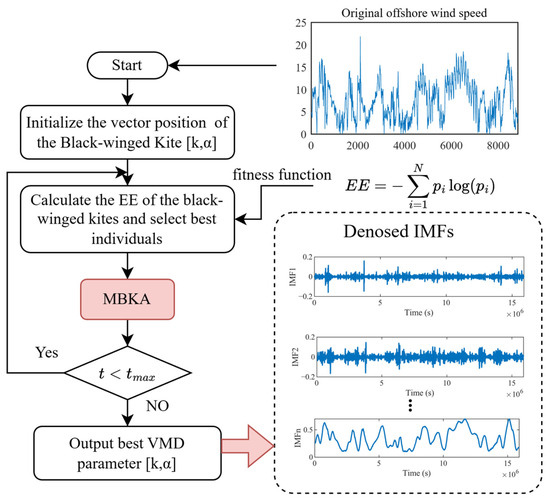
Figure 3.
Entropy−driven adaptive VMD denoising framework.
Specifically, for each candidate set of parameters and , the VMD algorithm decomposes the original signal into IMFs. For each IMF , its analytic signal is first obtained via the Hilbert transform, and the instantaneous envelope is computed as follows:
The envelope entropy is then calculated based on the normalized energy distribution of the envelope signal:
This entropy measures the complexity and sparsity of each IMF. A lower envelope entropy indicates a more regular and energy-concentrated mode, which is desirable in decomposition. The sum of envelope entropies across all IMFs is taken as a scalar objective to guide the optimization process, promoting decompositions that are both physically meaningful and well-separated.
Compared to conventional entropy-based measures such as sample entropy and Shannon entropy, envelope entropy offers several advantages: (1) it is computationally efficient and free from sensitive parameter tuning (e.g., embedding dimension, tolerance), (2) it demonstrates higher robustness to noise by leveraging the smoothed nature of the envelope signal, and (3) it captures localized energy fluctuations, making it well-suited for analyzing nonstationary and oscillatory signals. These properties make envelope entropy particularly effective for guiding adaptive decomposition in VMD frameworks.
3.2. Parameters Self-Tuning ANFIS Model via MBKA
ANFIS is a hybrid intelligent system that integrates artificial neural networks with fuzzy logic [27]. This combination leverages the interpretability of fuzzy rules and the adaptive learning capability of neural networks, making it well-suited for modeling nonlinear and complex systems. As a neuro-fuzzy model, ANFIS can represent knowledge through interpretable if–then rules while refining parameters through data-driven training. The standard ANFIS architecture consists of five layers, each executing a specific computational function and passing its outputs forward. For a system with two inputs and and one output , the structure can be described as follows:
Layer 1, referred to as the fuzzy layer, consists of adaptive nodes that are each responsible for generating membership degrees for linguistic labels. Where and represent the system inputs, denotes the output of the i-th node in the first layer. and represent the adaptive node, with its membership function described as follows:
The equation defines the membership value, which ranges from 0 to 1. Among common forms, the Gaussian membership function is widely used in fuzzy systems due to its smoothness and continuity. It models the degree to which an input belongs to a fuzzy set and is expressed by Equation (29), where x is the input variable, c is the center determining the peak location, and σ is the standard deviation controlling the curve width.
Layer 2 is the Rule Layer, which computes the firing strength of each rule using fuzzy logic operators. Each node is fixed and outputs the product of the incoming membership values. Let denote the output of the i-th node, where the membership values and are obtained from Layer 1. Thus, the firing strength in Layer 2 is given by Equation (30):
Layer 3 performs normalization of the firing strengths obtained in Layer 2. Each node computes the normalized firing strength of its corresponding rule by dividing its firing strength by the sum of all rule strengths. Thus, the output of the i-th node is given by Equation (31), where is the firing strength of the i-th rule and is the total strength of all rules.
Layer 4 is the Consequent Layer. This layer calculates the output of each rule based on a linear function of its inputs. The output of Layer 4 can be represented by Equation (32). denotes the output of the i-th node in Layer 4, and is the normalized activation strength passed from Layer 3. represents the weighted output of the i-th rule, which is a first-order polynomial determined by the following parameters: , the linear parameter associated with input ; , the linear parameter associated with input ; and , the constant term, also known as the consequent parameter.
Layer 5 is the Output Layer. This layer aggregates the outputs of all rules to generate the final output of the system. The sum of all input signals is calculated using Equation (33). Here, denotes the output of the -th node in Layer 5, is the normalized weight, and is the output from Layer 4, which is the result of the first-order polynomial.
After the premise parameters are determined, the adaptive network’s total output is represented by a linear combination of the consequent parameters. The constructed network functions similarly to a Sugeno fuzzy model. The overall output of the system, denoted as z, can be expressed as follows:
ANFIS is highly sensitive to its initial parameter settings, which influence both convergence behavior and final prediction accuracy. Conventional initialization of antecedent and consequent parameters, such as membership function centers and widths, typically relies on heuristics or trial-and-error and often fails to reach globally optimal configurations. This limitation is particularly problematic for nonlinear and nonstationary tasks such as offshore wind speed forecasting, where atmospheric instability and environmental noise complicate modeling.
To address these challenges, this study employs MBKA, a metaheuristic optimizer, to adaptively calibrate the membership function parameters c and σ. Leveraging its global search capability, MBKA provides more accurate initialization for ANFIS, enabling the model to better capture complex dependencies in offshore wind speed data and reduce prediction errors. The proposed self-tuning ANFIS uses RMSE as the objective function guiding the MBKA optimization, ensuring a quantitative evaluation of parameter performance. Through iterative evolution, MBKA determines the optimal membership function configuration for initializing the ANFIS fuzzy layer. This data-driven initialization significantly enhances ANFIS’s ability to model nonlinear input–output relationships and improves robustness under varying conditions, making the framework well-suited for real-world offshore wind forecasting.
3.3. The Two-Stage Synergistic Enhancement Framework for Offshore Wind Speed Prediction
To address the non-stationarity and complex dynamics intrinsic to offshore wind speed signals, this study introduces a two-stage synergistic enhancement framework that unifies signal decomposition and predictive modeling within a single optimization scheme, as illustrated in Figure 4.
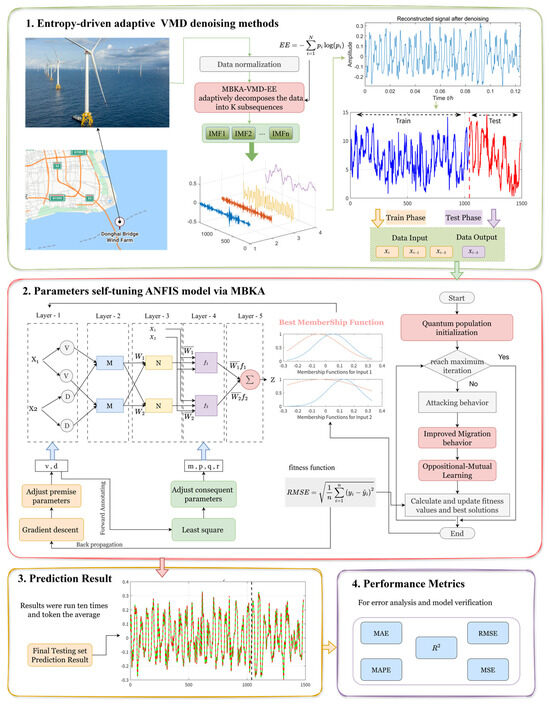
Figure 4.
Flow of the two-stage synergistic enhancement prediction framework.
The proposed framework employs MBKA to coordinate both signal denoising and model parameter tuning. In the first stage, MBKA adaptively determines the key parameters of VMD, namely the number of modes and the penalty factor. Guided by an entropy-based objective, this adaptive decomposition effectively suppresses noise and redundant fluctuations while retaining information-rich components, thereby producing cleaner and more interpretable sub-signals that represent distinct temporal dynamics. In the second stage, the same MBKA mechanism is applied to optimize the parameters of the ANFIS membership functions, enhancing the model’s learning capability and generalization performance. Through this two-stage synergistic process, the framework achieves a comprehensive improvement in predictive accuracy. The fully trained and optimized model is then employed for future offshore wind speed forecasting, and its performance is rigorously evaluated using standard metrics such as RMSE and MAPE to assess both the effectiveness and robustness of the proposed approach.
4. Experiment Results and Discussion
4.1. Dataset Introduction
To comprehensively evaluate the adaptability and generalization capability of the proposed forecasting model under varying environmental conditions, two representative offshore wind speed datasets with different sources and time periods were employed. These datasets were collected from two distinct regions along the eastern coast of China and exhibit differences in collection timeframes, climatic characteristics, and data structures. The dataset was divided into a 70% training set and a 30% testing set. And a one-step-ahead prediction strategy is adopted, where the previous n time steps are used to forecast the subsequent time step.
The first dataset was obtained from the Donghai offshore wind farm in Shanghai, covering the period from 1 January to 31 October 2019, with a sampling interval of 15 min and wind speed measured in meters per second. This dataset focuses solely on wind speed, and is publicly available on the Kaggle platform. Its statistical metrics are shown in Table 2. Figure 5a illustrates the temporal variation in wind speed at the wind farm, revealing pronounced fluctuations and nonstationary behavior. Figure 5b presents the probability density distribution of wind speed, while Figure 5c summarizes its basic statistical characteristics, including mean and standard deviation.
Table 2.
Statistical metrics of wind speed at the Shanghai and Fujian offshore wind farm.
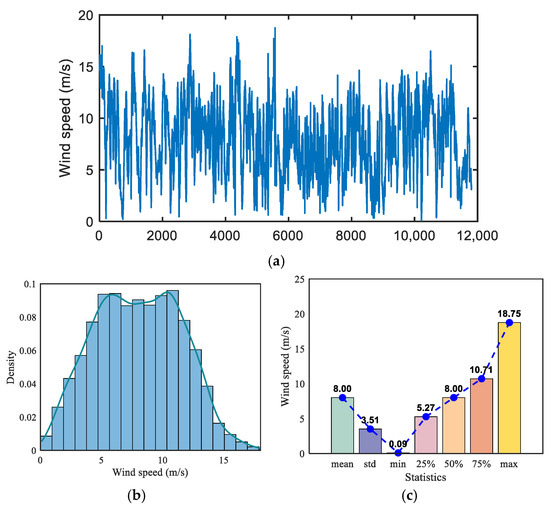
Figure 5.
Analysis of wind speed dataset of offshore wind farms in Shanghai. (a) Wind speed fluctuation chart in Shanghai wind farms; (b) wind speed probability density distribution; and (c) wind speed statistical characteristics.
The second dataset was sourced from meteorological forecasts for an offshore wind farm in Fujian Province, publicly provided via the Heywhale platform. The data were collected between 1 May and 31 July 2023, at the same 15 min sampling interval. This dataset includes multiple meteorological variables such as wind speed, wind direction, and temperature across five observation sites. In this study, wind speed at a height of 100 m from the f5 station was selected as the primary analysis target. Figure 6a displays a wind rose diagram characterizing the joint distribution of wind speed and direction; Figure 6b shows the wind speed’s probability density distribution; and Figure 6c presents its statistical properties, reflecting the fundamental wind resource characteristics of the site. The observable volatility and uncertainty in the sequence pose considerable challenges for modeling, thus necessitating signal decomposition techniques for effective preprocessing and simplification of the forecasting task.
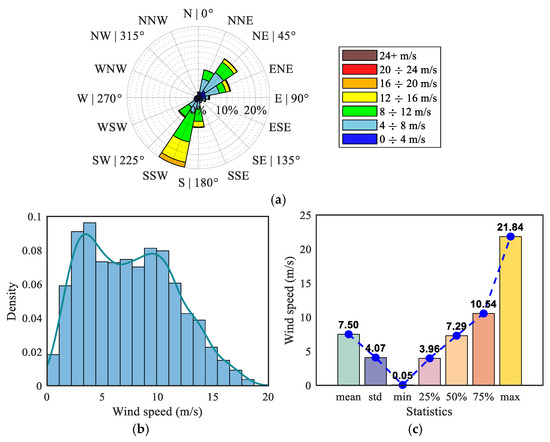
Figure 6.
Analysis of wind speed dataset of offshore wind farms in Fujian. (a) Wind speed rose diagram for Shanghai wind farms; (b) wind speed probability density distribution; (c) Wind speed statistical characteristics.
4.2. Experimental Settings
To comprehensively evaluate the proposed framework, two groups of experiments were designed. The first group focuses on comparing the proposed MBKA with several representative optimization algorithms for optimizing the membership function parameters of ANFIS. Specifically, we selected the classical GA and three recently developed swarm-intelligence optimizers, WOA, POA, and RTH, because they represent different generations and search paradigms within intelligent optimization. In addition, the WAA which was based on weighted average position was included to provide a robust baseline. Prior to experimentation, we expected the improved MBKA to deliver faster convergence, higher optimization accuracy, and better robustness than these benchmark algorithms. When incorporated into the ANFIS training process, MBKA was also anticipated to generate smoother and more accurate prediction curves by avoiding local optima and enhancing global–local search balance.
The second group of experiments compares the proposed methods with several advanced forecasting models. The baseline models include BP, CNN, LSTM, and Transformer. MBKA-MLP, MBKA-RBF, and MBKA-ANFIS evaluate the effect of using MBKA for parameter optimization in different network structures. Furthermore, ICEEMDAN-MBKA-ANFIS, TVFEMD-MBKA-ANFIS, and VMD-MBKA-ANFIS incorporate signal decomposition techniques to assess the additional benefits of noise reduction and feature enhancement. The model configurations and parameter settings used in all experiments are summarized in Table 3.
Table 3.
Model parameters and reference.
Each experiment is conducted over 10 independent runs, and five performance metrics are recorded as mean and standard deviation. Model performance was evaluated using RMSE, MAE, MAPE, and , as defined in Table 4, where denotes the actual value and is the predicted value. These metrics collectively measure prediction accuracy, error magnitude, and the explanatory power of the model. Lower RMSE, MAE, and MAPE values indicate better predictive accuracy, while higher values reflect a stronger fit between predicted and observed data.
Table 4.
Performance metrics.
4.3. Adaptive Denoise Results
The MBKA is firstly used to optimize the VMD parameters applied to the wind speed datasets of two offshore wind farms. Drawing on parameter design guidelines from article [33], the population size and number of iterations were set to 6 and 50, respectively, with the optimization objective defined as the minimization of envelope entropy. The parameters’ search space was defined as , . Through repeated experimental trials, the optimal VMD parameter combination for the Donghai Offshore Wind Farm in Shanghai was determined to be and , while the most effective values for the Fujian Wind Farm were found to be and . The integration of MBKA with VMD in the preprocessing stage effectively attenuates noise while preserving the intrinsic characteristics of the original signal, thereby enhancing the quality and reliability of the input data for subsequent forecasting models. Figure 7a and Figure 8a illustrate the time domain waveforms of the IMFs for Shanghai and Fujian, respectively. Correspondingly, Figure 7b and Figure 8b depict the spectral distributions of each IMF, offering insights into their frequency domain characteristics across the two regions.
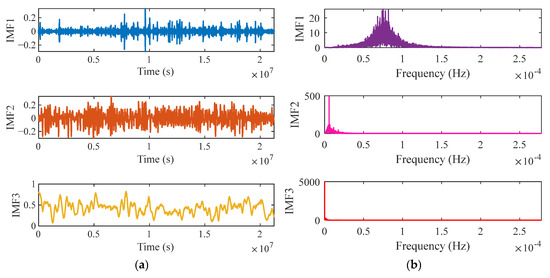
Figure 7.
Visualization of VMD−decomposed IMFs for the Shanghai Donghai Wind Farm. (a) Shows time domain waveform of each IMF; (b) shows spectral distribution of each IMF.
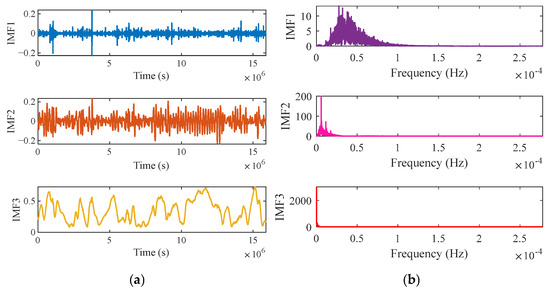
Figure 8.
Visualization of VMD−decomposed IMFs for the Fujian Wind Farm. (a) Shows time domain waveform of each IMF; (b) shows spectral distribution of each IMF.
After reconstructing the signal by summing all decomposed components, Table 5 shows that the reconstructed data deviates only slightly from the original across all metrics, indicating that VMD effectively preserves the statistical properties of the signal. MSE and standard deviation show minor reductions, reflecting smoother and less fluctuating sequences. As illustrated in Figure 9, the FFT spectra of both signals remain highly consistent. The SNR exhibits a small improvement, especially in the Shanghai dataset, suggesting clearer signals after VMD processing. Moreover, energy, kurtosis, and skewness remain nearly unchanged, confirming that the reconstruction introduces no notable distortion. Overall, these results verify that VMD achieves effective denoising while maintaining key signal characteristics.
Table 5.
Comparison of performance indicators of original and reconstructed data.
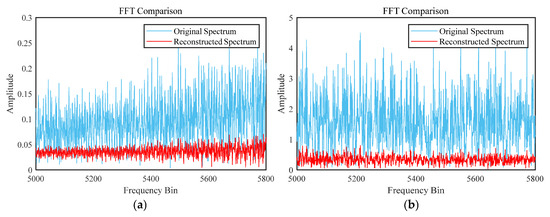
Figure 9.
Comparative analysis of denoised FFT spectra in Shanghai and Fujian. (a) Comparison of FFT spectra before and after noise reduction in Shanghai; (b) comparison of FFT spectra before and after noise reduction in Fujian.
4.4. Experimental I: Comparison with Various Optimization Algorithms
This section evaluates the performance of ANFIS combined with six optimization algorithms: GA, POA, RTH, WOA, WAA, and BKA. All algorithms share the same population size, dimensionality, and number of iterations as MBKA, while their parameter settings follow relevant literature. Table 6 and Table 7 report the mean and standard deviation of prediction metrics over 10 runs on two offshore wind speed datasets, with visual comparisons shown in Figure 10. For the Shanghai dataset, MBKA-ANFIS yields the lowest mean error across nearly all metrics, along with the smallest standard deviations, reflecting both high accuracy and excellent stability. For the Fujian dataset, its advantage is even more apparent, as its RMSE is approximately 20% lower than that of BKA-ANFIS.
Table 6.
Test results of ANFIS models based on different optimization algorithms in Shanghai. (Numbers in bold indicate the best performance in the comparison algorithms).
Table 7.
Test results of ANFIS models based on different optimization algorithms in Fujian. (Numbers in bold indicate the best performance in the comparison algorithms).
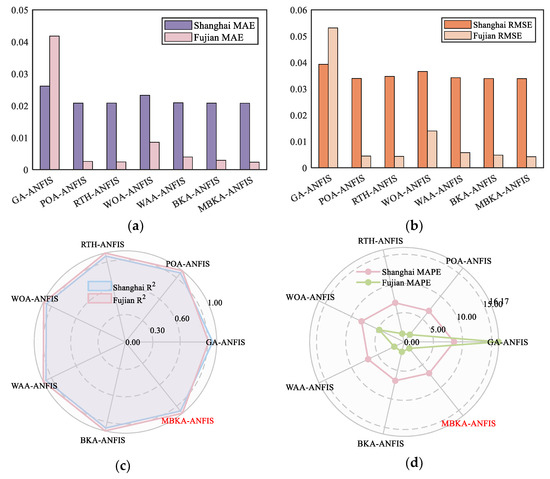
Figure 10.
Comparison of five metrics across different optimization algorithms. (a) Shows comparison of MAE; (b) shows comparison of RMSE; (c) shows comparison of R2; and (d) shows comparison of MAPE.
Figure 11 illustrates the convergence behavior of MBKA-ANFIS against other hybrid models. In both subfigures, MBKA-ANFIS shows rapid convergence, reaching a significantly lower fitness value within the first 10–20 iterations and maintaining it throughout. It consistently achieves the lowest final fitness values across both datasets, underscoring its robustness and generalization capability.
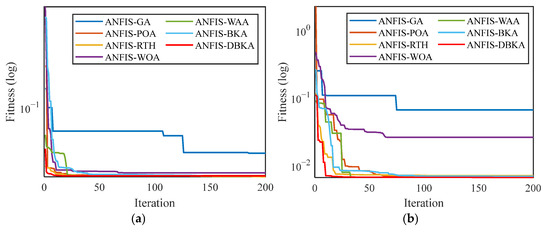
Figure 11.
Convergence curves of ANFIS models based on different optimization algorithms. (a) Convergence curve of the models in Shanghai dataset. (b) Convergence curve of the models in Fujian dataset.
Figure 12 and Figure 13 present the prediction results on the test sets. Visual comparison reveals that MBKA-ANFIS most closely matches the actual wind speed series, effectively capturing both global trends and local variations. This alignment is especially clear in the zoomed-in regions, where the model accurately traces peaks and troughs. Quantitatively, the concordance with real data is further validated by high determination coefficients, achieving an R2 of 0.96 for the Shanghai dataset and an outstanding R2 of 0.99 for the Fujian dataset, demonstrating the model’s excellent fidelity to the true wind speed dynamics.
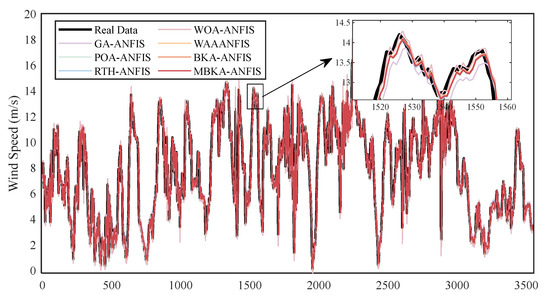
Figure 12.
ANFIS prediction results with different optimizers for the Shanghai test set.
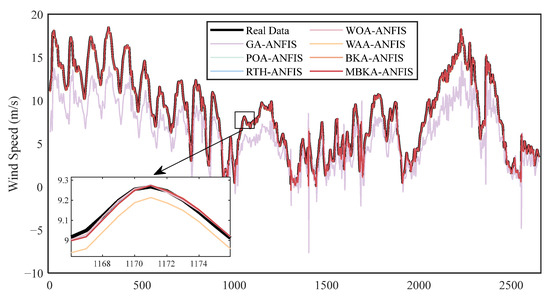
Figure 13.
ANFIS prediction results with different optimizers for the Fujian test set.
In summary, the enhanced MBKA accelerates convergence and improves adaptability in ANFIS parameter optimization. The proposed parameters self-tuning MBKA-ANFIS model consistently achieves higher prediction accuracy and greater stability than alternative methods, confirming its suitability for offshore wind forecasting and its broader applicability in marine renewable energy scenarios.
4.5. Experimental II: Comparison with Advanced Model
To comprehensively evaluate the proposed MBKA-VMD-EE-ANFIS model, eleven comparative experiments were conducted. Baseline models included BP, CNN, LSTM, and Transformer. MBKA-MLP, MBKA-RBF, and MBKA-ANFIS applied MBKA for parameter optimization, while ICEEMDAN-MBKA-ANFIS, TVFEMD-MBKA-ANFIS, and VMD-MBKA-ANFIS incorporated signal decomposition for preprocessing. The VMD parameters [25] were manually set to and . MBKA-ANFIS, VMD-MBKA-ANFIS, and MBKA-VMD-EE-ANFIS were further employed in ablation studies to assess the contribution of each module.
Table 8 and Table 9 report the prediction performance on the Shanghai and Fujian offshore datasets, respectively, providing a comprehensive comparison across mainstream and proposed models. Figure 14 visualizes these results. The proposed model consistently outperforms all benchmarks across evaluation metrics. For Shanghai, it achieves the lowest RMSE, MAE, and MAPE, significantly exceeding both conventional offshore wind speed prediction models. A similar trend is observed in Fujian, with RMSE reduced to 1.79 × 10−3 and MAPE to 0.6%, confirming both high accuracy and strong generalizability.
Table 8.
Test results of different offshore wind speed prediction models for Shanghai. (Numbers in bold indicate the best performance in the comparison algorithms).
Table 9.
Test results of different offshore wind speed prediction models for Fujian. (Numbers in bold indicate the best performance in the comparison algorithms).
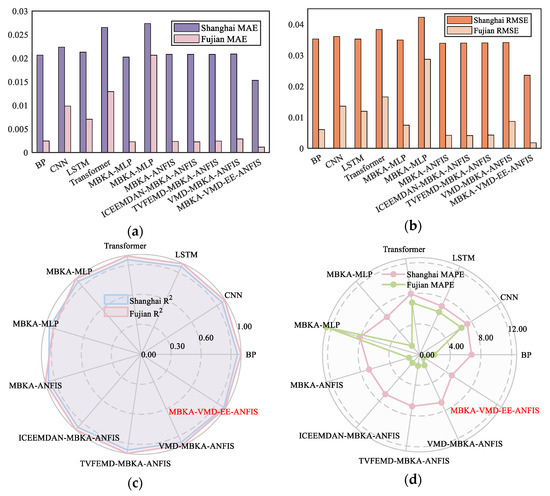
Figure 14.
Comparison of five metrics across advanced offshore wind speed prediction models. (a) Shows comparison of MAE; (b) shows comparison of RMSE; (c) shows comparison of R2; and (d) shows comparison of MAPE.
Figure 15 and Figure 16 display the predicted versus actual wind speeds on the test sets. While traditional models exhibit substantial deviations, particularly during volatile periods, LSTM and Transformer show partial improvements but remain inconsistent across abrupt transitions. In contrast, the proposed model closely tracks both global and local patterns, as clearly illustrated in the magnified views, especially in the Fujian dataset.
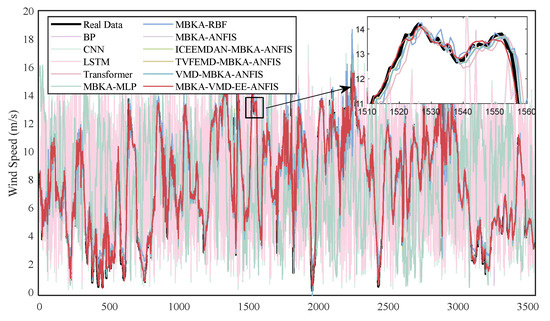
Figure 15.
Testing set output results of prediction models for Shanghai.
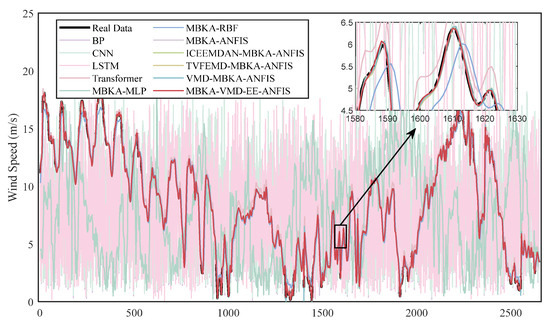
Figure 16.
Testing set output results of prediction models for Fujian.
In summary, the proposed MBKA-VMD-EE-ANFIS model demonstrates superior predictive performance, robustness, and transferability across offshore wind datasets, confirming its practical viability for accurate and reliable wind speed forecasting in real-world applications.
4.6. Discussion
The effectiveness of the proposed model is further reflected in the improvement rates and performance differences in the forecasting metrics. To comprehensively evaluate its predictive capability, the percentage improvements in , RMSE, MAE, and MAPE were calculated. These improvement ratios, derived using Equations (35)–(38), provide a quantitative basis for comparing the proposed approach with baseline models. Superscript p and subscript c denote the previous model and the competitor model, respectively.
Table 10 quantitatively summarizes the relative improvement percentages of various models across five performance metrics for both the Shanghai and Fujian datasets. The results focus on evaluating the effectiveness of the proposed MBKA-ANFIS and MBKA-VMD-EE-ANFIS models in comparison with classical and hybrid baselines. In comparison with BP and MBKA-ANFIS, the MBKA-ANFIS model exhibits generally superior performance across most evaluation metrics, indicating the effectiveness of integrating the MBKA into the ANFIS framework. However, when compared with VMD-MBKA-ANFIS, a slight performance degradation is observed. This decline can be attributed to the limitations of manually setting VMD parameters based on empirical knowledge, which may yield favorable denoising results on one dataset but fail to generalize effectively to others. Such manual parameter selection lacks adaptability and can potentially lead to the loss of intrinsic signal features during decomposition.
Table 10.
Changes in performance expressed as percentages.
In contrast, the proposed MBKA-VMD-EE-ANFIS model addresses this issue by leveraging a metaheuristic algorithm to adaptively optimize the VMD parameters, enabling dataset-specific denoising and preserving critical data characteristics. This advantage is clearly demonstrated by the substantial performance gains when comparing MBKA-VMD-EE-ANFIS against VMD-MBKA-ANFIS. Specifically, the RMSE improves by 30.93% in Shanghai and 79.40% in Fujian, while the MAPE shows corresponding improvements of 27.11% and 57.29%, respectively. Similar enhancements are also observed across other evaluation indicators, highlighting the robust generalization capability and superior predictive accuracy of the proposed model across diverse wind speed scenarios.
5. Conclusions and Future Work
This study proposes a two-stage synergistically enhanced hybrid framework for offshore wind speed forecasting to address the inherent non-stationarity of offshore wind speed sequences and the limitations of traditional methods that rely heavily on empirical parameter tuning. An improved MBKA is first developed by integrating quantum-based population initialization, enhanced migration behavior, and an opposition–mutual learning strategy, thereby substantially strengthening the algorithm’s convergence efficiency and global search capability under complex offshore optimization scenarios. On this basis, MBKA is employed to jointly optimize the decomposition parameters of VMD and the key membership function parameters of ANFIS, effectively enhancing the model’s nonlinear representation capacity and overall forecasting performance.
In the experimental section, MBKA demonstrates faster convergence speed, higher optimization accuracy, and stronger ability to escape local optima compared with multiple state-of-the-art optimization algorithms. Furthermore, the proposed framework consistently outperforms eight baseline models and all ablation variants. Validation using measured offshore wind speed data from Shanghai and Fujian confirm that the framework not only exhibits excellent error convergence and predictive accuracy but also maintains strong generalization capability and robustness across regions, thereby verifying both its theoretical soundness and its practical feasibility for deployment in diverse offshore environments.
More importantly, the findings of this study have direct practical implications for the offshore wind industry. More accurate wind speed forecasts can significantly improve wind farm operational scheduling, reduce turbine operational risks, and enhance the reliability of coastal grid integration and power dispatch planning. These advantages suggest that the proposed framework holds strong potential to replace existing empirical or conventional model-based forecasting approaches, providing a powerful technical basis for the efficient and large-scale development of future offshore wind power systems.
Despite the promising results achieved in this work, several avenues for improvement remain. First, although the MBKA-optimized ANFIS offers interpretability and high predictive performance, its relatively shallow structure may be insufficient to capture the highly complex nonlinear spatiotemporal dependencies inherent in offshore wind speed dynamics. Future research may explore deeper or hybrid neural architectures to further enhance representational capacity. Second, while VMD effectively handles nonstationary signals, a single-layer decomposition may not fully eliminate residual noise or hidden modes. Future studies will consider multi-level, multi-stage, or recursive decomposition strategies, such as multilayer VMD or hybrid VMD–EMD approaches to further enhance the stability and robustness of data preprocessing.
Author Contributions
Conceptualization, Y.L. and F.M.; methodology, Y.L. and F.M.; software, Y.L.; validation, F.M.; formal analysis, Y.L.; investigation, F.M.; writing—original draft preparation, Y.L.; writing—review and editing, F.M.; visualization, Y.L.; supervision, F.M.; funding acquisition, F.M. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Engineering Research Center of Integration and Application of Digital Learning Technology, Ministry of Education (1411011), the National Natural Science Foundation of China (Grant No. 52201401), the Shanghai Committee of Science and Technology (Grant No. 23010502000), the Chenguang Program of Shanghai Education Development Foundation, and the Shanghai Municipal Education Commission (Grant No. 24CGA52).
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| VMD | Variational Mode Decomposition |
| IMFs | Intrinsic Mode Functions |
| ANFIS | Adaptive Neuro-Fuzzy Inference System |
| BKA | Black-winged Kite Algorithm |
| MBKA | Dynamic Black-winged Kite Algorithm |
| OML | Oppositional–mutual learning strategy |
| RMSE | Root Mean Square Error |
| GWEC | Global Wind Energy Council |
| GW | Gigawatts |
| OWEC | Offshore wind energy conversion systems |
| NFL | No Free Lunch |
| ANNs | Artificial neural networks |
| ELM | Extreme Learning Machine |
| RBF | Radial Basis Function |
| GRNN | Generalized Regression Neural Network |
| LSTM | Long Short-Term Memory |
| MLP | Multilayer perceptron |
| AI | Artificial intelligence |
| RWT | Repetitive Wavelet Transform |
| ARIMA | Autoregressive Integrated Moving Average |
| GA | Genetic Algorithm |
| POA | Pelican Optimization Algorithm |
| RTH | Red-tailed hawk algorithm |
| WOA | Whale Optimization Algorithm |
| WAA | Weighted Average Algorithm |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| Coefficient of determination |
References
- Alkhalidi, M.; Al-Dabbous, A.; Al-Dabbous, S.; Alzaid, D. Evaluating the Accuracy of the ERA5 Model in Predicting Wind Speeds Across Coastal and Offshore Regions. J. Mar. Sci. Eng. 2025, 13, 149. [Google Scholar] [CrossRef]
- Liu, W.; Bai, Y.; Yue, X.; Wang, R.; Song, Q. A Wind Speed Forcasting Model Based on Rime Optimization Based VMD and Multi-Headed Self-Attention-LSTM. Energy 2024, 294, 130726. [Google Scholar] [CrossRef]
- Cem, E.; Cebi, S. Fuzzy Set-Based Approaches in Wind Energy Research: A Literature Review. In Intelligent and Fuzzy Systems; Kahraman, C., Cevik Onar, S., Cebi, S., Oztaysi, B., Tolga, A.C., Ucal Sari, I., Eds.; Lecture Notes in Networks and Systems; Springer Nature Switzerland: Cham, Switzerland, 2024; Volume 1090, pp. 425–433. ISBN 978-3-031-67191-3. [Google Scholar]
- Li, J.; Wang, G.; Li, Z.; Yang, S.; Chong, W.T.; Xiang, X. A Review on Development of Offshore Wind Energy Conversion System. Int. J. Energy Res. 2020, 44, 9283–9297. [Google Scholar] [CrossRef]
- Sadiq, R.; Wang, Z.; Chung, C.Y. A Multi-Model Multi-Objective Robust Damping Control of GCSC for Hybrid Power System with Offshore/Onshore Wind Farm. Int. J. Electr. Power Energy Syst. 2023, 147, 108879. [Google Scholar] [CrossRef]
- Liu, X.; Lin, Z.; Feng, Z. Short-Term Offshore Wind Speed Forecast by Seasonal ARIMA—A Comparison Against GRU and LSTM. Energy 2021, 227, 120492. [Google Scholar] [CrossRef]
- Cassola, F.; Burlando, M. Wind Speed and Wind Energy Forecast Through Kalman Filtering of Numerical Weather Prediction Model Output. Appl. Energy 2012, 99, 154–166. [Google Scholar] [CrossRef]
- Roulston, M.S.; Kaplan, D.T.; Hardenberg, J.; Smith, L.A. Using Medium-Range Weather Forcasts to Improve the Value of Wind Energy Production. Renew. Energy 2003, 28, 585–602. [Google Scholar] [CrossRef]
- Aasim; Singh, S.N.; Mohapatra, A. Repeated Wavelet Transform Based ARIMA Model for Very Short-Term Wind Speed Forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar] [CrossRef]
- Lin, S.; Wang, S.; Xu, X.; Li, R.; Shi, P. GAOformer: An Adaptive Spatiotemporal Feature Fusion Transformer Utilizing GAT and Optimizable Graph Matrixes for Offshore Wind Speed Prediction. Energy 2024, 292, 130404. [Google Scholar] [CrossRef]
- Feng, L.; Zhou, Y.; Luo, Q.; Wei, Y. Complex-Valued Artificial Hummingbird Algorithm for Global Optimization and Short-Term Wind Speed Prediction. Expert. Syst. Appl. 2024, 246, 123160. [Google Scholar] [CrossRef]
- Zhang, Z.; Yin, J. Spatial-Temporal Offshore Wind Speed Characteristics Prediction Based on an Improved Purely 2D CNN Approach in a Large-Scale Perspective Using Reanalysis Dataset. Energy Convers. Manag. 2024, 299, 117880. [Google Scholar] [CrossRef]
- Gong, Z.; Wan, A.; Ji, Y.; AL-Bukhaiti, K.; Yao, Z. Improving Short-Term Offshore Wind Speed Forecast Accuracy Using a VMD-PE-FCGRU Hybrid Model. Energy 2024, 295, 131016. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic Algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Trojovský, P.; Dehghani, M. Pelican Optimization Algorithm: A Novel Nature-Inspired Algorithm for Engineering Applications. Sensors 2022, 22, 855. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; De Waele, W. Weighted Average Algorithm: A Novel Meta-Heuristic Optimization Algorithm Based on the Weighted Average Position Concept. Knowl. Based Syst. 2024, 305, 112564. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Ferahtia, S.; Houari, A.; Rezk, H.; Djerioui, A.; Machmoum, M.; Motahhir, S.; Ait-Ahmed, M. Red-Tailed Hawk Algorithm for Numerical Optimization and Real-World Problems. Sci. Rep. 2023, 13, 12950. [Google Scholar] [CrossRef]
- Wang, J.; Wang, W.; Hu, X.; Qiu, L.; Zang, H. Black-Winged Kite Algorithm: A Nature-Inspired Meta-Heuristic for Solving Benchmark Functions and Engineering Problems. Artif. Intell. Rev. 2024, 57, 98. [Google Scholar] [CrossRef]
- Wu, R.; Huang, H.; Wei, J.; Ma, C.; Zhu, Y.; Chen, Y.; Fan, Q. An Improved Sparrow Search Algorithm Based on Quantum Computations and Multi-Strategy Enhancement. Expert. Syst. Appl. 2023, 215, 119421. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, X.; Yang, Z.; Li, X.; Wang, P.; Ding, R.; Liu, W. An Enhanced Differential Evolution Algorithm with a New Oppositional-Mutual Learning Strategy. Neurocomputing 2021, 435, 162–175. [Google Scholar] [CrossRef]
- Wang, W.; Tian, J. An Improved Nonlinear Tuna Swarm Optimization Algorithm Based on Circle Chaos Map and Levy Flight Operator. Electronics 2022, 11, 3678. [Google Scholar] [CrossRef]
- Viswanathan, G.M.; Afanasyev, V.; Buldyrev, S.V.; Havlin, S.; Stanley, H.E. Levy Ights in Random Searches. Phys. A 2000, 282, 1–12. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Li, S.; Guo, L.; Zhu, J.; Chen, J.; Liu, M.; Cui, X.; Li, L. Medium-Term Offshore Wind Speed Multi-Step Forecasting Based on VMD and GRU-MATNet Model. Ocean Eng. 2025, 325, 120737. [Google Scholar] [CrossRef]
- Chan, R.H.; Tao, M.; Yuan, X. Constrained Total Variation Deblurring Models and Fast Algorithms Based on Alternating Direction Method of Multipliers. SIAM J. Imaging Sci. 2013, 6, 680–697. [Google Scholar] [CrossRef]
- Jang, J.-S.R. ANFIS: Adaptive-Network-Based Fuzzy Inference System. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Qin, H.; Huang, L.; Li, K.; Cheng, G. Short-Term Offshore Wind Power Prediction Based on VMD-SE-BP Neural Network Model. In Proceedings of the 2024 IEEE 2nd International Conference on Power Science and Technology (ICPST), Dali, China, 9–11 May 2024; pp. 1476–1481. [Google Scholar]
- Wu, H.; Meng, K.; Fan, D.; Zhang, Z.; Liu, Q. Multistep Short-Term Wind Speed Forecasting Using Transformer. Energy 2022, 261, 125231. [Google Scholar] [CrossRef]
- Surendran, R.; Alotaibi, Y.; Subahi, A.F. Wind Speed Prediction Using Chicken Swarm Optimization with Deep Learning Model. Comput. Syst. Sci. Eng. 2023, 46, 3371–3386. [Google Scholar] [CrossRef]
- Indraswari, R.; Arifin, A.Z. RBF Kernel Optimization Method with Particle Swarm Optimization on SVM Using the Analysis of Input Data’s Movement. J. Ilmu Komput. Inf. 2017, 10, 36. [Google Scholar] [CrossRef]
- Parmaksiz, H.; Yuzgec, U.; Dokur, E.; Erdogan, N. Mutation Based Improved Dragonfly Optimization Algorithm for a Neuro-Fuzzy System in Short Term Wind Speed Forecasting. Knowl. Based Syst. 2023, 268, 110472. [Google Scholar] [CrossRef]
- Sun, X.; Liu, H. Multivariate Short-Term Wind Speed Prediction Based on PSO-VMD-SE-ICEEMDAN Two-Stage Decomposition and Att-S2S. Energy 2024, 305, 132228. [Google Scholar] [CrossRef]
















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).