
Vision-Based Underwater Docking Guidance and Positioning: Enhancing Detection with YOLO-D


Abstract
1. Introduction
- A novel visual guidance framework was proposed for underwater drop-in docking. It incorporated cascaded detection and a positioning strategy that integrated the active and passive markers. The strategy utilized light arrays for long-distance guidance and AprilTag for close-range positioning, effectively combining the benefits of an extended operational range with high precision.
- This study introduced a novel network model, YOLO-D, designed to detect and localize docking marks under complex underwater visual conditions. The model utilized the adaptive convolution kernel, AKConv, which dynamically adjusted its sampling shape and parameter count based on the specific characteristics of the images and targets, thereby enhancing the accuracy and efficiency of feature extraction. To improve the detection of small underwater targets, the CONTAINER mechanism was incorporated for context enhancement and feature refinement. In addition, a BiFPN was integrated to enable efficient multi-scale feature fusion, allowing faster and more effective processing of multi-scale targets at various distances during underwater docking.
- We constructed a dedicated underwater docking marker dataset and conducted camera calibration, comparison, and ablation tests for underwater target detection. In comparison to the baseline model, YOLOv11n, the proposed YOLO-D method demonstrated enhancements of 1.5% in precision, 5% in recall, 4.2% in mAP@0.5, and 3.57% in the F1 score. In addition, a successful underwater landing docking visual guidance pool test was conducted, achieving a 90% recovery success rate. These results validated the feasibility of the proposed docking guidance method.
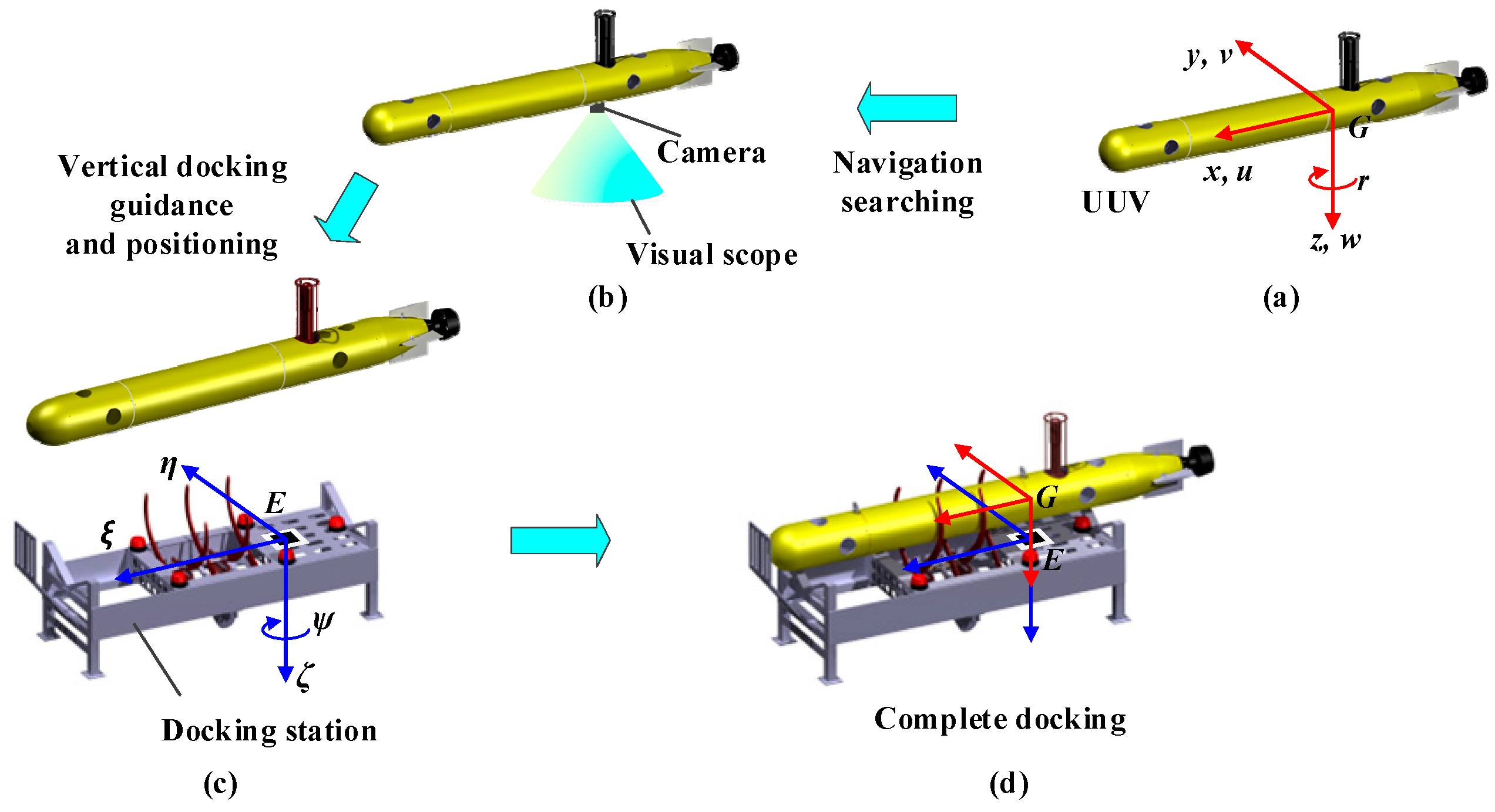
2. Docking Guidance and Positioning Framework
2.1. System Structure of Docking Guiding System
2.2. Docking Guidance Strategies
- Level I guidance adopted an array of lights as visual markers, offering a considerable visible range owing to their active light emission. However, at closer distances, light scattering introduced certain errors in estimating the center of the guidance light source, making this method suitable only for coarse posture adjustments during docking. In addition, in the final stages of docking, it became difficult to maintain all guidance lights within the field of view of the camera, leading to a high failure rate.
- Level II guidance utilized a specific graphic, AprilTag, as an identification marker, estimating the pose by detecting its characteristic points. This method offered high positioning accuracy. However, its effectiveness was limited by underwater visibility, which is influenced by certain factors such as water quality, turbidity, and illumination. Consequently, it may be suitable for fine adjustments during docking.
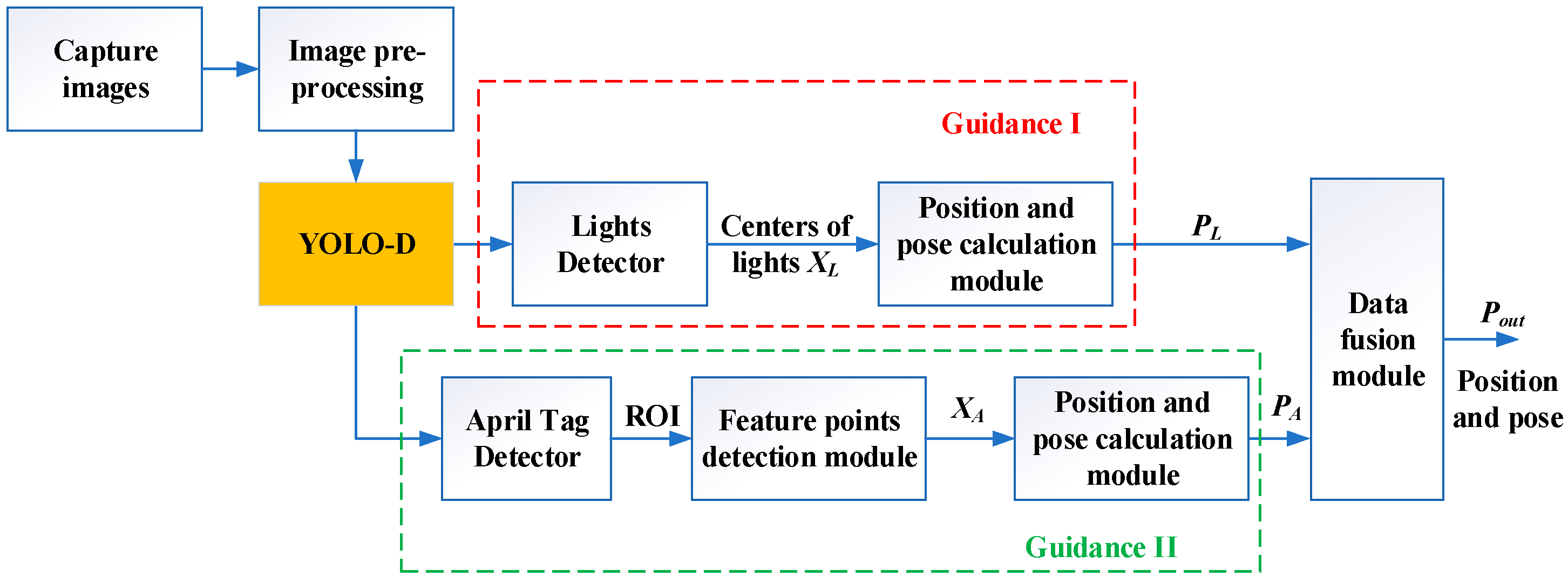
2.3. Docking Guidance Algorithms
| Algorithm 1: Docking Guidance Algorithm |
| 1: Capture images; 2: Perform image pre-processing: Gaussian and median filter are employed; 3: Run the YOLO-D module to detect lights and AprilTag; 4: Calculate the number of lights , and the number of AprilTag ; 5: While and do 6: If 7: Obtain the pixel values of the lights from YOLO-D; 8: Calculate position and pose by RPnP algorithm; 9: Perform smoothing filtering; 10: Reset the counter ; 11: else 12: Counter Accumulation ; 13: end if 14: If 15: Obtain the pixels of the vertices of the ROI where the AprilTag is located. from YOLO-D; 16: Extract the Contours of AprilTag using CANNY Algorithm; 17: Calculate position and pose from the vertices of AprilTag; 18: Perform smoothing filtering; 19: Reset the counter ; 20: else 21: Counter Accumulation ; 22: end if 23: Fusion calculate position and pose with and . 24: end while 25: Docking procedure ends. |
3. Target Detection and Positioning Methods
3.1. YOLOv11
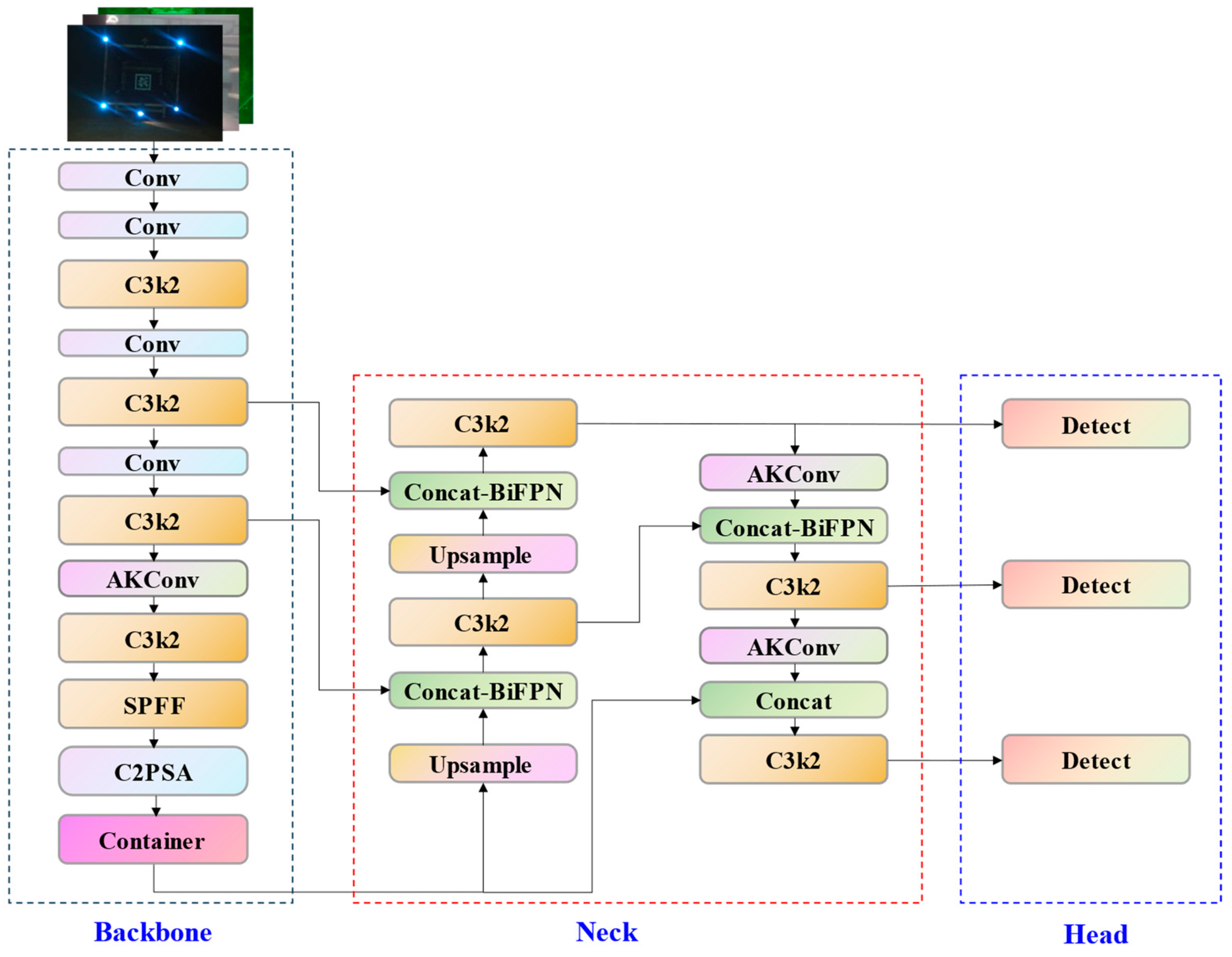
3.2. YOLO-D Network Model
3.3. Core Enhancement Modules
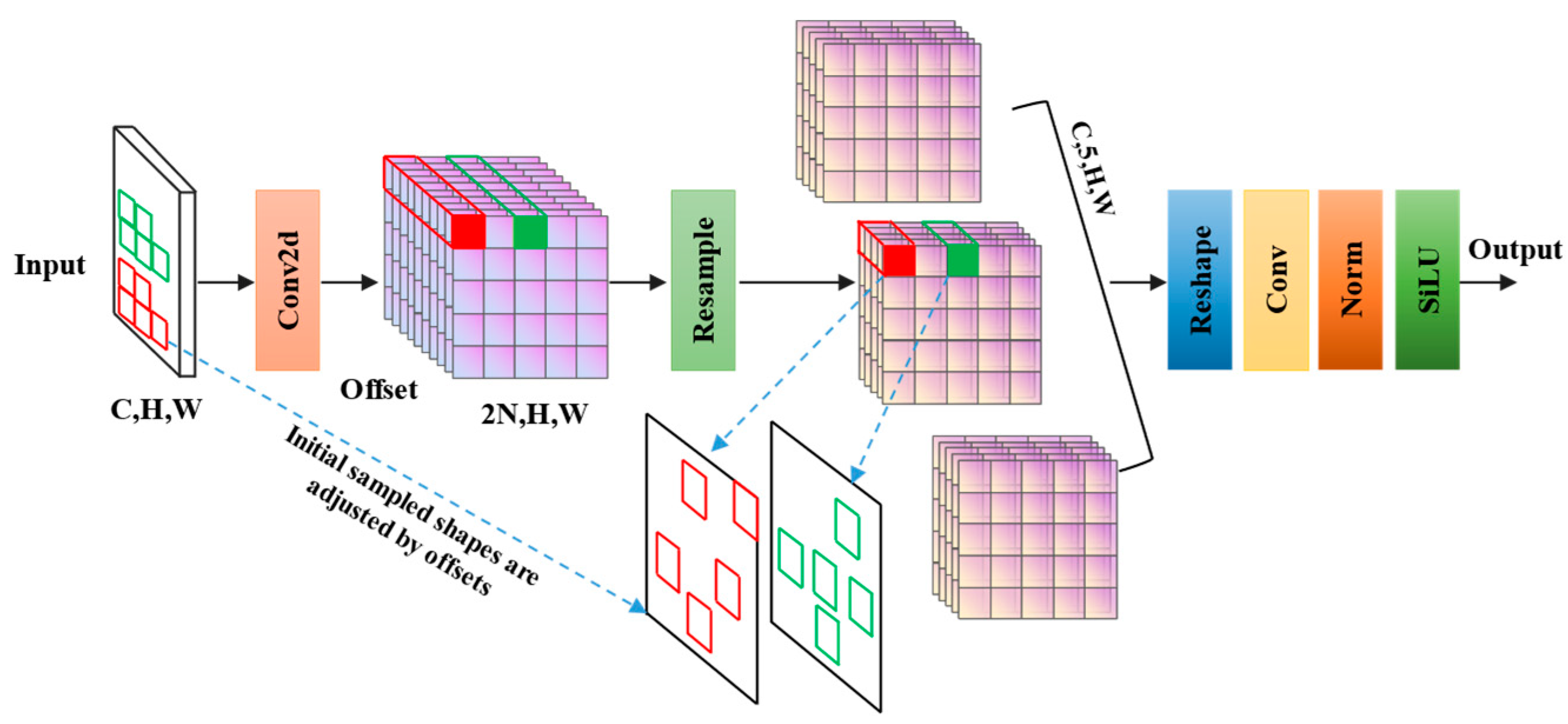
3.3.1. Adaptive Kernel Convolution Module (AKConv)
3.3.2. Context Aggregation Network (CONTAINER)
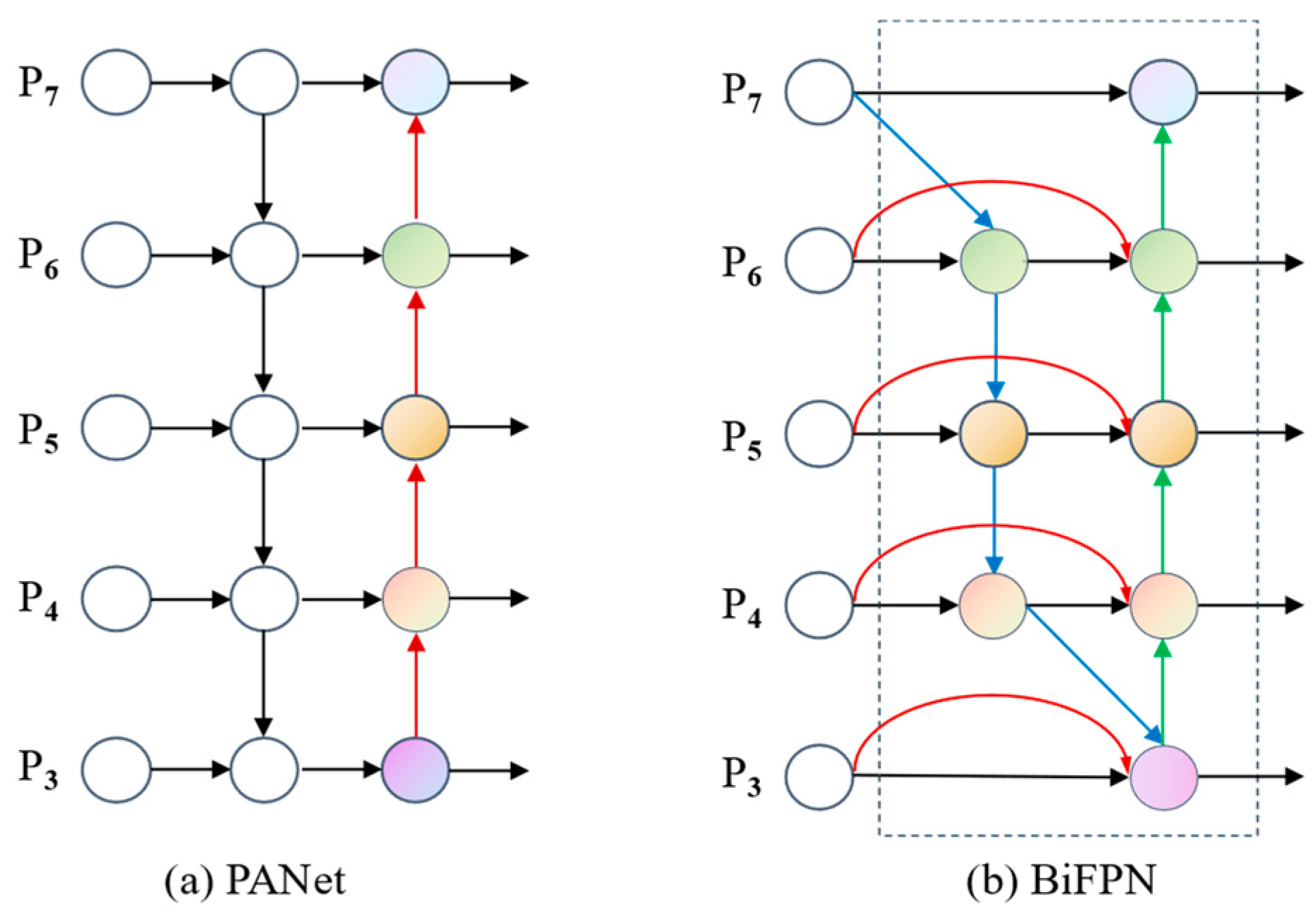
3.3.3. Bidirectional Feature Pyramid Network (BiFPN)
3.4. Position and Pose Calculation Methods
3.4.1. Camera Models
3.4.2. Multi-Marker Positioning Methods
4. Experimental Results and Discussion
4.1. Experimental Setup and Datasets
4.1.1. Datasets
4.1.2. Experimental Setup
- Training Computer Configuration
- 2.
- Embedded Computer Configuration
- 3.
- Underwater Camera Configuration
4.1.3. Evaluation Metrics
4.2. Comparison Experiments
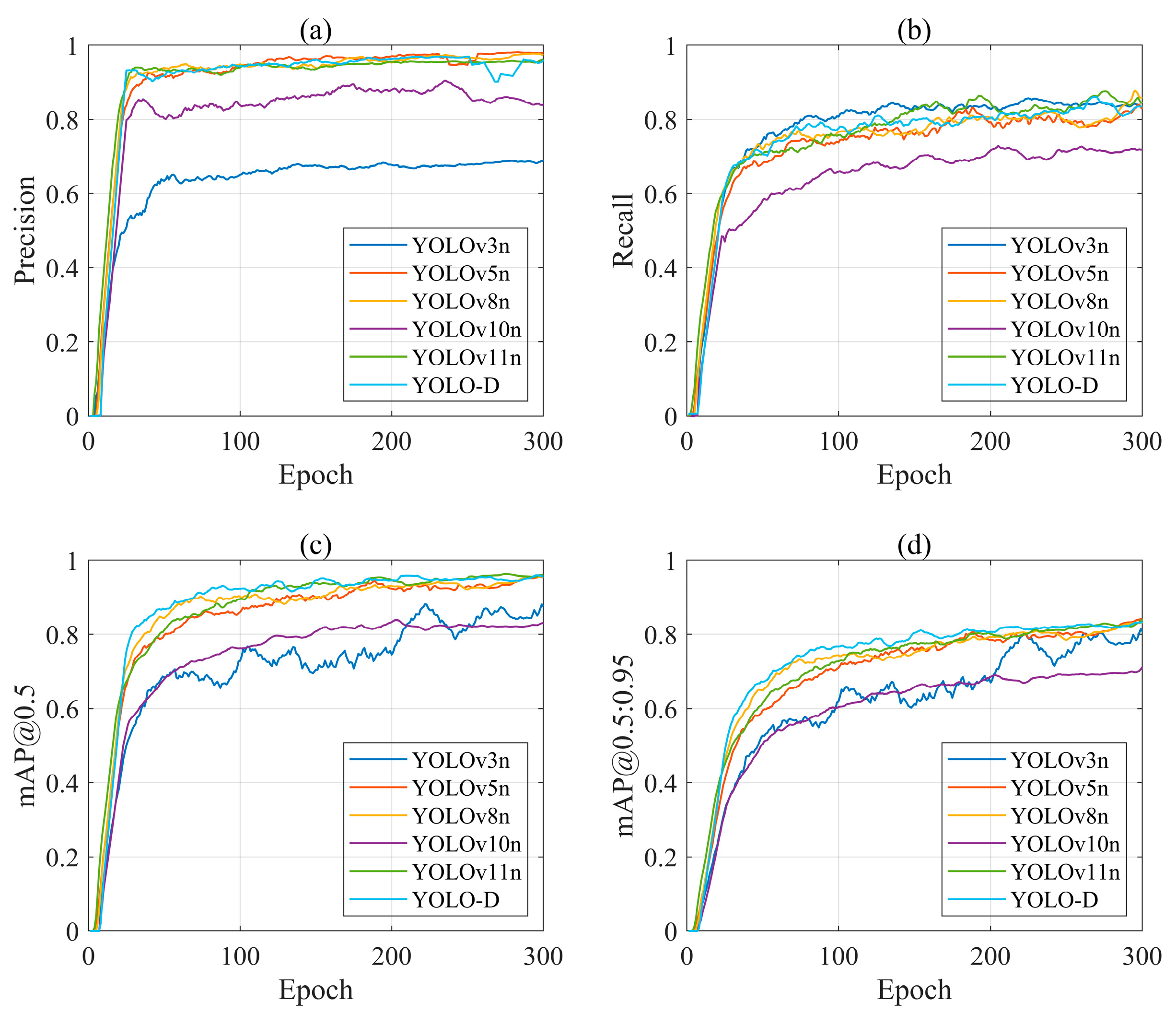
4.2.1. Comparison of Training Processes
4.2.2. Comparative Tests for Target Detection
4.3. Ablation Experiments
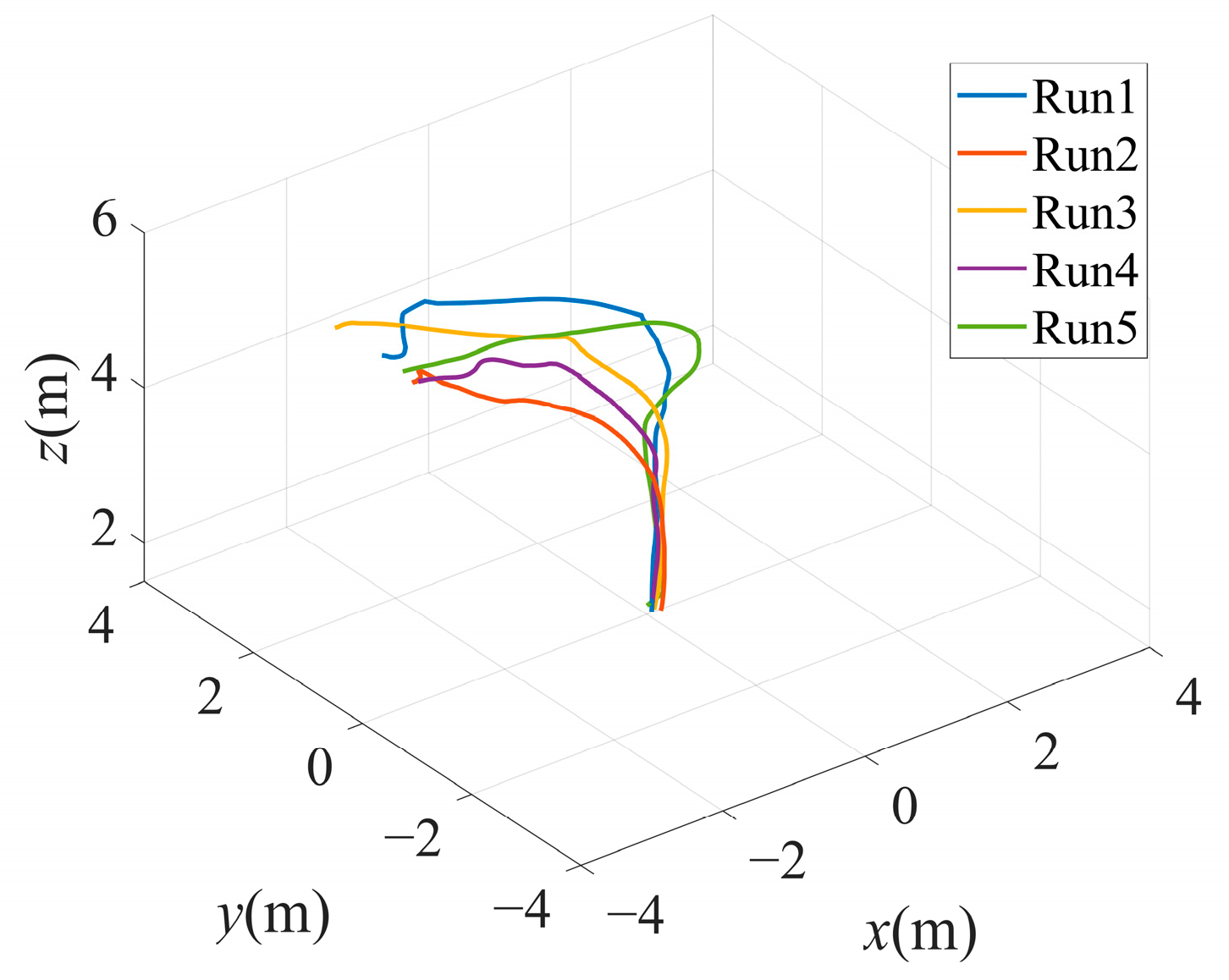
4.4. Underwater Docking Positioning Experiment
- The current dataset requires improvement in both quantity and quality, owing to the challenges of capturing underwater docking images. In addition, data enhancement methods can be used to improve the precision and recall of underwater target detection.
- Although YOLO-D incorporated the BiFPN architecture to enhance the feature fusion capabilities, the detection and processing efficiency of underwater micro-small targets remained a significant challenge. Therefore, further research on more advanced architectures is required to address this issue.
- The proposed algorithm imposed high demands on the inferencing capabilities of device hardware. Future research will focus on model lightweighting to enhance computational performance and reduce hardware dependence. This will enable deployment in low-cost embedded systems while simultaneously lowering the power consumption of underwater unmanned equipment control systems.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, A.; Fouda, M.M.; Do, D.-T.; Almaleh, A.; Alqahtani, A.M.; Rahman, A.U. Underwater target detection using deep learning: Methodologies, challenges, applications and future evolution. IEEE Access 2024, 12, 12618–12635. [Google Scholar] [CrossRef]
- Xu, Z.; Haroutunian, M.; Murphy, A.J.; Neasham, J.; Norman, R. An underwater visual navigation method based on multiple ArUco markers. J. Mar. Sci. Eng. 2021, 9, 1432. [Google Scholar] [CrossRef]
- Yan, Z.; Gong, P.; Zhang, W.; Li, Z.; Teng, Y. Autonomous Underwater Vehicle Vision Guided Docking Experiments Based on L-Shaped Light Array. IEEE Access 2019, 7, 72567–72576. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, X.; Wang, J.; Wang, H. Pseudo-3D vision-inertia based underwater self-localization for AUVs. IEEE Trans. Veh. Technol. 2020, 69, 7895–7907. [Google Scholar] [CrossRef]
- Lv, F.; Xu, H.; Shi, K.; Wang, X. Estimation of Positions and Poses of Autonomous Underwater Vehicle Relative to Docking Station Based on Adaptive Extraction of Visual Guidance Features. Machines 2022, 10, 571. [Google Scholar] [CrossRef]
- Trslić, P.; Weir, A.; Riordan, J.; Omerdic, E.; Toal, D.; Dooly, G. Vision-based localization system suited to resident underwater vehicles. Sensors 2020, 20, 529. [Google Scholar] [CrossRef]
- Pan, W.; Chen, J.; Lv, B.; Peng, L. Optimization and Application of Improved YOLOv9s-UI for Underwater Object Detection. Appl. Sci. 2024, 14, 7162. [Google Scholar] [CrossRef]
- Liu, K.; Peng, L.; Tang, S. Underwater object detection using TC-YOLO with attention mechanisms. Sensors 2023, 23, 2567. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, G.; Luan, K.; Yi, C.; Li, M. Image-fused-guided underwater object detection model based on improved YOLOv7. Electronics 2023, 12, 4064. [Google Scholar] [CrossRef]
- Wang, L.; Ye, X.; Wang, S.; Li, P. ULO: An underwater light-weight object detector for edge computing. Machines 2022, 10, 629. [Google Scholar] [CrossRef]
- Chen, X.; Fan, C.; Shi, J.; Wang, H.; Yao, H. Underwater target detection and embedded deployment based on lightweight YOLO_GN. J. Supercomput. 2024, 80, 14057–14084. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight underwater object detection based on yolo v4 and multi-scale attentional feature fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, F.; Ling, Y.; Zhang, S. YOLO-Based 3D Perception for UVMS Grasping. J. Mar. Sci. Eng. 2024, 12, 1110. [Google Scholar] [CrossRef]
- Li, Y.; Liu, W.; Li, L.; Zhang, W.; Xu, J.; Jiao, H. Vision-based target detection and positioning approach for underwater robots. IEEE Photonics J. 2022, 15, 8000112. [Google Scholar] [CrossRef]
- Liu, S.; Ozay, M.; Xu, H.; Lin, Y.; Okatani, T. A Generative Model of Underwater Images for Active Landmark Detection and Docking. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar]
- Lwin, K.N.; Mukada, N.; Myint, M.; Yamada, D.; Yanou, A.; Matsuno, T.; Saitou, K.; Godou, W.; Sakamoto, T.; Minami, M. Visual docking against bubble noise with 3-D perception using dual-eye cameras. IEEE J. Ocean. Eng. 2018, 45, 247–270. [Google Scholar] [CrossRef]
- Sun, K.; Han, Z. Autonomous underwater vehicle docking system for energy and data transmission in cabled ocean observatory networks. Front. Energy Res. 2022, 10, 960278. [Google Scholar] [CrossRef]
- Liu, S.; Xu, H.; Lin, Y.; Gao, L. Visual navigation for recovering an AUV by another AUV in shallow water. Sensors 2019, 19, 1889. [Google Scholar] [CrossRef]
- Zhang, T.; Li, D.; Lin, M.; Wang, T.; Yang, C. AUV terminal docking experiments based on vision guidance. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; pp. 1–5. [Google Scholar]
- Lwin, K.N.; Yonemori, K.; Myint, M.; Yanou, A.; Minami, M. Autonomous docking experiment in the sea for visual-servo type undewater vehicle using three-dimensional marker and dual-eyes cameras. In Proceedings of the 2016 55th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Tsukuba, Japan, 20–23 September 2016. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. AKConv: Convolutional kernel with arbitrary sampled shapes and arbitrary number of parameters. arXiv 2023, arXiv:2311.11587. [Google Scholar]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. LDConv: Linear deformable convolution for improving convolutional neural networks. Image Vis. Comput. 2024, 149, 105190. [Google Scholar] [CrossRef]
- Nie, R.; Shen, X.; Li, Z.; Jiang, Y.; Liao, H.; You, Z. Lightweight Coal Flow Foreign Object Detection Algorithm. In Proceedings of the International Conference on Intelligent Computing, Tianjin, China, 5–8 August 2024; pp. 393–404. [Google Scholar]
- Qin, X.; Yu, C.; Liu, B.; Zhang, Z. YOLO8-FASG: A High-Accuracy Fish Identification Method for Underwater Robotic System. IEEE Access 2024, 12, 73354–73362. [Google Scholar] [CrossRef]
- Chen, Z.; Feng, J.; Yang, Z.; Wang, Y.; Ren, M. YOLOv8-ACCW: Lightweight grape leaf disease detection method based on improved YOLOv8. IEEE Access 2024, 12, 123595–123608. [Google Scholar] [CrossRef]
- Gao, P.; Lu, J.; Li, H.; Mottaghi, R.; Kembhavi, A. Container: Context aggregation network. arXiv 2021, arXiv:2106.01401. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ma, D.; Yang, J. Yolo-animal: An efficient wildlife detection network based on improved yolov5. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; pp. 464–468. [Google Scholar]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-based YOLO for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Du, B.; Wan, F.; Lei, G.; Xu, L.; Xu, C.; Xiong, Y. YOLO-MBBi: PCB surface defect detection method based on enhanced YOLOv5. Electronics 2023, 12, 2821. [Google Scholar] [CrossRef]
- Kim, J.-Y.; Kim, I.-S.; Yun, D.-Y.; Jung, T.-W.; Kwon, S.-C.; Jung, K.-D. Visual Positioning System Based on 6D Object Pose Estimation Using Mobile Web. Electronics 2022, 11, 865. [Google Scholar] [CrossRef]
- Wang, P.; Xu, G.; Cheng, Y.; Yu, Q. A simple, robust and fast method for the perspective-n-point problem. Pattern Recognit. Lett. 2018, 108, 31–37. [Google Scholar] [CrossRef]
- Gong, X.; Lv, Y.; Xu, X.; Wang, Y.; Li, M. Pose Estimation of Omnidirectional Camera with Improved EPnP Algorithm. Sensors 2021, 21, 4008. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Xia, X.; Xin, L.; He, W. RPnP Pose Estimation Optimized by Comprehensive Learning Pigeon-Inspired Optimization for Autonomous Aerial Refueling. In Proceedings of the International Conference on Guidance, Navigation and Control, Tianjin, China, 5–7 August 2022; pp. 6117–6124. [Google Scholar]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. Sar ship detection based on yolov5 using cbam and bifpn. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 2147–2150. [Google Scholar]
- Liu, X.; Chu, Y.; Hu, Y.; Zhao, N. Enhancing Intelligent Road Target Monitoring: A Novel BGS YOLO Approach Based on the YOLOv8 Algorithm. IEEE Open J. Intell. Transp. Syst. 2024, 5, 509–519. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An improved YOLO algorithm for fast and accurate underwater object detection. Symmetry 2022, 14, 1669. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Project | Parameter Values |
|---|---|---|
| Hardware environment | CPU | 16v CPU Intel(R) Xeon(R) Gold 6430 |
| CPU RAM | 120 GB | |
| GPU | NVIDIA GeForce RTX 4090 | |
| GPU RAM | 24 GB | |
| Software environment | Operating system | Ubuntu 18.04 |
| Programming language | Python v3.8 | |
| Deep learning framework | Pytorch v1.8.1 | |
| CUDA | v11.1 | |
| Experimental hyperparameters | Image size | 800 × 600 |
| Learning rate | 0.01 | |
| Momentum | 0.937 | |
| Weight decay | 0.0005 | |
| Batch size | 32 | |
| Epoch | 300 |
| Project | Parameter Values |
|---|---|
| CPU | 12-core Arm® Cortex®-A78AE v8.2 64-bit |
| GPU | 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores |
| AI computing power | 275 TOPS |
| Graphics memory | 64 GB LPDDR5 |
| RAM | 64 GB |
| Power range | 15–75 W |
| Project | Parameter Values |
|---|---|
| Image Resolution | |
| Pixel Size | |
| Maximum Frame Rate | 40 fps |
| Data Transfer Interface | USB |
| Case | Models | Precision | Recall | F1 Score | mAP@ 0.5 | mAP@ 0.5:0.95 | Parameters (M) | Speed (FPS) |
|---|---|---|---|---|---|---|---|---|
| 1 | YOLOv3n | 94.90% | 79.70% | 86.64% | 90.50% | 80.00% | 103.67 | 56.50 |
| 2 | YOLOv5n | 96.30% | 79.10% | 86.86% | 91.10% | 79.10% | 2.50 | 101.01 |
| 3 | YOLOv8n | 93.00% | 83.90% | 88.22% | 92.80% | 80.80% | 3.01 | 103.09 |
| 4 | YOLOv10n | 95.40% | 73.30% | 82.90% | 84.80% | 72.90% | 2.70 | 90.91 |
| 5 | YOLOv11n | 95.90% | 79.20% | 86.75% | 90.30% | 77.70% | 2.58 | 95.24 |
| 6 | YOLO-D | 97.40% | 84.20% | 90.32% | 94.50% | 84.10% | 3.03 | 61.35 |
| Case | Models | Precision | Recall | F1 Score | mAP @0.5 | Parameters (M) | |||
|---|---|---|---|---|---|---|---|---|---|
| Baseline | BiFPN | AKConv | Container | ||||||
| 1 | √ | 95.90% | 79.20% | 86.75% | 90.30% | 2.58 | |||
| 2 | √ | √ | 92.20% | 81.50% | 86.52% | 91.90% | 2.58 | ||
| 3 | √ | √ | 95.00% | 80.50% | 87.15% | 90.50% | 2.28 | ||
| 4 | √ | √ | 96.20% | 80.00% | 87.36% | 91.30% | 3.33 | ||
| 5 | √ | √ | √ | 95.50% | 83.40% | 89.04% | 90.70% | 2.28 | |
| 6 | √ | √ | √ | 96.20% | 83.70% | 89.52% | 92.80% | 3.33 | |
| 7 | √ | √ | √ | 95.50% | 80.50% | 87.36% | 91.50% | 3.03 | |
| 8 | √ | √ | √ | √ | 97.40% | 84.20% | 90.32% | 94.50% | 3.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, T.; Sima, C.; Zhang, W.; Wang, J.; Guo, J.; Zhang, L. Vision-Based Underwater Docking Guidance and Positioning: Enhancing Detection with YOLO-D. J. Mar. Sci. Eng. 2025, 13, 102. https://doi.org/10.3390/jmse13010102
Ni T, Sima C, Zhang W, Wang J, Guo J, Zhang L. Vision-Based Underwater Docking Guidance and Positioning: Enhancing Detection with YOLO-D. Journal of Marine Science and Engineering. 2025; 13(1):102. https://doi.org/10.3390/jmse13010102
Chicago/Turabian StyleNi, Tian, Can Sima, Wenzhong Zhang, Junlin Wang, Jia Guo, and Lindan Zhang. 2025. "Vision-Based Underwater Docking Guidance and Positioning: Enhancing Detection with YOLO-D" Journal of Marine Science and Engineering 13, no. 1: 102. https://doi.org/10.3390/jmse13010102
APA StyleNi, T., Sima, C., Zhang, W., Wang, J., Guo, J., & Zhang, L. (2025). Vision-Based Underwater Docking Guidance and Positioning: Enhancing Detection with YOLO-D. Journal of Marine Science and Engineering, 13(1), 102. https://doi.org/10.3390/jmse13010102