1. Introduction
Since the beginning of the 21st century, the volume of global trade has been continuously increasing, driving the rapid development of the shipping industry, especially in the field of ocean shipping [
1]. This trend has also spurred the maritime industry to move towards intelligence, with enhancing the automation and intelligence levels of ships becoming a focal point [
2,
3]. As the core power unit in a ship’s engine room,
MDEs not only provide propulsion for ship navigation, but also drive generators to provide continuous and stable power for the entire ship’s operation [
4]. The internal structure of
MDEs is complex and relies on the coordinated operation of multiple subsystems. Any malfunction can adversely affect their operating performance, resulting in poor working conditions and reducing overall efficiency. In severe cases, engine shutdowns can occur, damaging associated equipment, disrupting the normal operation of the vessel, and posing a risk to the safety of personnel and property on board [
5]. Due to prolonged exposure to harsh operating environments,
MDE components experience severe wear, significantly increasing the risk of potential malfunctions and failures [
6], However, traditional
MDE condition monitoring techniques typically focus on monitoring the thermodynamic parameters of the engine, such as gas pressure and oil temperature. These parameters only show significant changes when the malfunction has reached a certain severity [
7]. Therefore, traditional condition monitoring techniques cannot predict the future trend of diesel engine status changes over a period of time. In contrast, more mature condition monitoring techniques utilize intelligent algorithms to learn from historical diesel engine operating data. Using the powerful nonlinear computing capabilities of intelligent algorithms, these techniques can calculate the trend changes in diesel engine status parameters over a period of time. By observing the trend changes in the status parameters, early warnings can be issued to effectively prevent potential failures. Therefore, by studying the condition monitoring technology of
MDE to predict the trend changes in their status parameters, faults can be detected in a timely manner during the latent period and relevant warnings can be issued. This not only gives the engine crew enough time to inspect the related equipment, but also reduces the subsequent maintenance costs and ensures the efficient operation of
MDE. This is of paramount importance in improving the reliability of
MDE.
The
EGT is an important thermal parameter of
MDE. To a certain extent, it can characterize the operating condition of the
MDE and the load distribution of each cylinder [
8]. Different degrees of variation in the
EGT can reflect faults in different subsystems of the
MDE, and the temperature changes relatively slowly with minimal interference from external factors [
9]. Real-time monitoring and prediction of the
EGT can provide insight into the health status of
MDE, ensuring the normal operation of ships [
10].
Currently, trend prediction research methods mainly focus on physics-based modeling and data-driven approaches. Model-based methods require the construction of accurate physical or mathematical models to describe the operational processes of the research object [
11]. Model-based methods face significant challenges in constructing accurate models of marine equipment in complex and dynamic environments such as ship engine rooms. In contrast, data-driven methods avoid the cumbersome modeling process. This method uses historical data collected by monitoring systems as the research object [
12], and conducts data analysis and processing, and uses relevant intelligent algorithms to establish trend prediction models, eliminating the influence of complex environmental changes on the trend of ship equipment status parameters. By establishing a unified standard trend prediction curve, engineers can assess the status of
MDEs in advance by observing the trend changes in the
EGT over a period of time, achieving real-time online monitoring of ships. In recent years, with the continuous updating and iteration of Internet technology, related intelligent algorithms have emerged. The data-driven equipment status parameter trend prediction has attracted widespread attention from industry professionals [
13].
Liu et al. analyzed the vibration signals of diesel engines, extracted fitted characteristic parameters, and successfully established a prediction model for the performance trend of diesel engines using radial basis function (
RBF) neural networks, thereby improving the prediction accuracy [
14]. Cui et al. developed a degradation model for solid oxide fuel cells (
SOFCs) based on the area-specific resistance (
ASR) and successfully predicted the full-cycle degradation trend of
SOFCs using the particle filtering algorithm [
15]. Wang et al. utilized the comprehensive degradation index (
CDI) in the time-frequency domain and long short-term memory (
LSTM) to construct a trend prediction model for the state of hydropower units, achieving the prediction of the degradation trend of hydropower units and improving the prediction accuracy [
16]. Theerthagiri et al. utilized the Seasonal ARIMA (
SARIMA) model combined with the weighted average method and feedback error analysis method to forecast crude oil prices, successfully improving the prediction accuracy and obtaining a more accurate trend of crude oil price changes [
17]. Xu et al. developed a greenhouse microclimate trend prediction model based on an improved empirical mode decomposition (
IEMD)-optimized informer. By utilizing data from five different environmental factors, the model accurately predicts the development trend of environmental factors [
18]. Zhao et al. utilized an improved
AO algorithm to optimize the support vector regression (
SVR) prediction model, and achieved the matching of corresponding optimal parameters under different operating conditions. This allowed for the accurate prediction of the development trend of various operating state indicators of hydropower units over a certain time scale [
19]. Li et al. used the
LSTM method to establish a trend prediction model for the wear state parameters of oil products. They used the prediction results as the test set to establish a deep belief networks (
DBN) prediction model for predicting device power. This method achieved continuous prediction of the wear state of lubricating oil with objective factors and was successfully applied to the prediction of power trends of power plant turbines with subjective factors [
20]. Zhang et al. employed an
LSTM network to establish a multi-input multi-output model for predicting the
EGT of
MDE. They validated the effectiveness of this model using historical operational data from actual ships [
8]. Liu et al. utilized an attention mechanism and a
LSTM network to establish a trend prediction model for the
EGT of
MDE. They optimized the
LSTM network parameters using the particle swarm algorithm, thereby improving the accuracy of the prediction model. Additionally, they implemented fault prediction by analyzing the distribution of residuals between predicted and actual values [
21]. Li et al. used the chaotic bat algorithm to optimize the hyperparameters of the
LightGBM network and established a trend prediction model for the
EGT of aircraft engines. They demonstrated the model’s effectiveness in monitoring the performance of aircraft engines using historical operational data from a specific aircraft engine [
22].
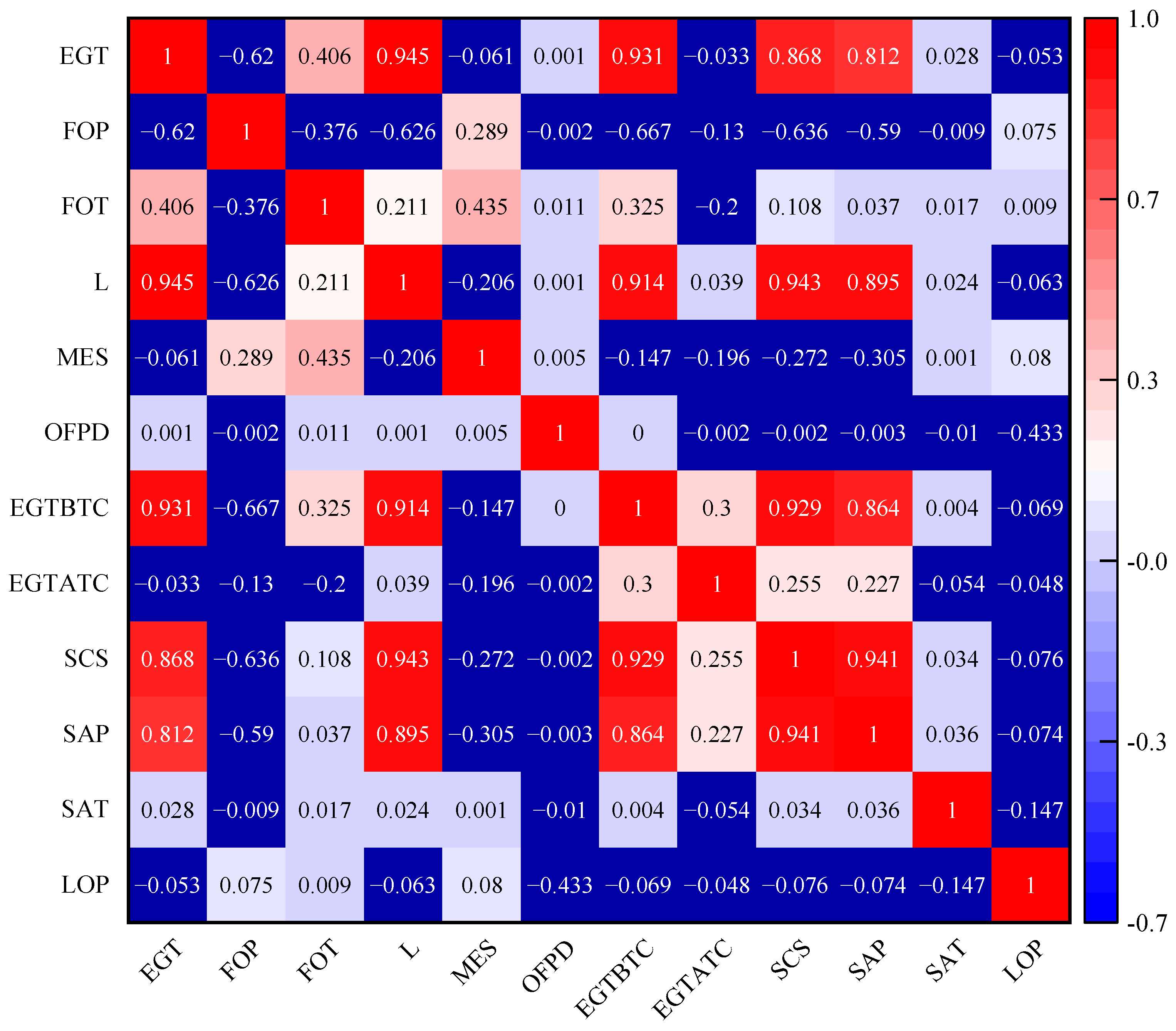
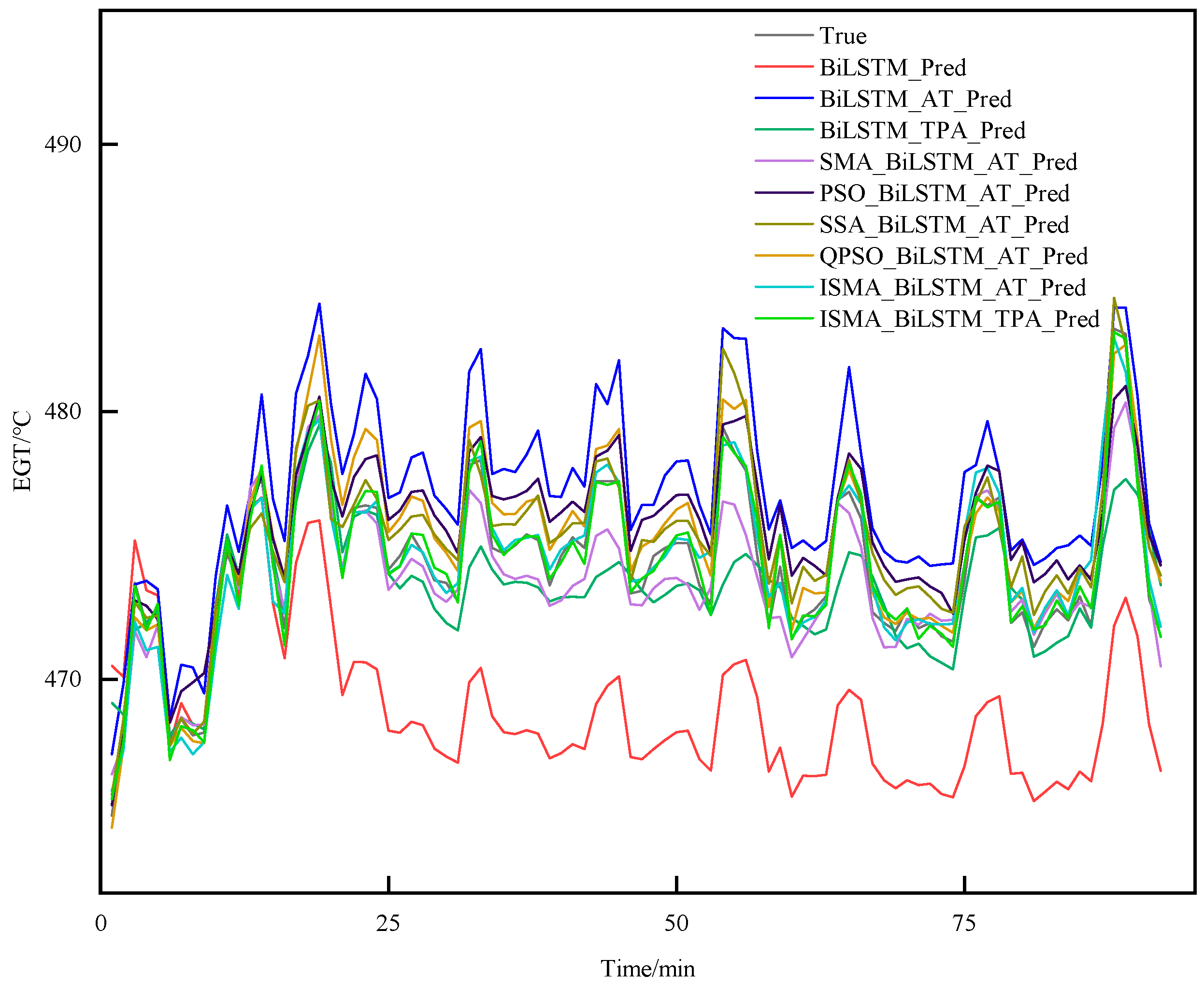
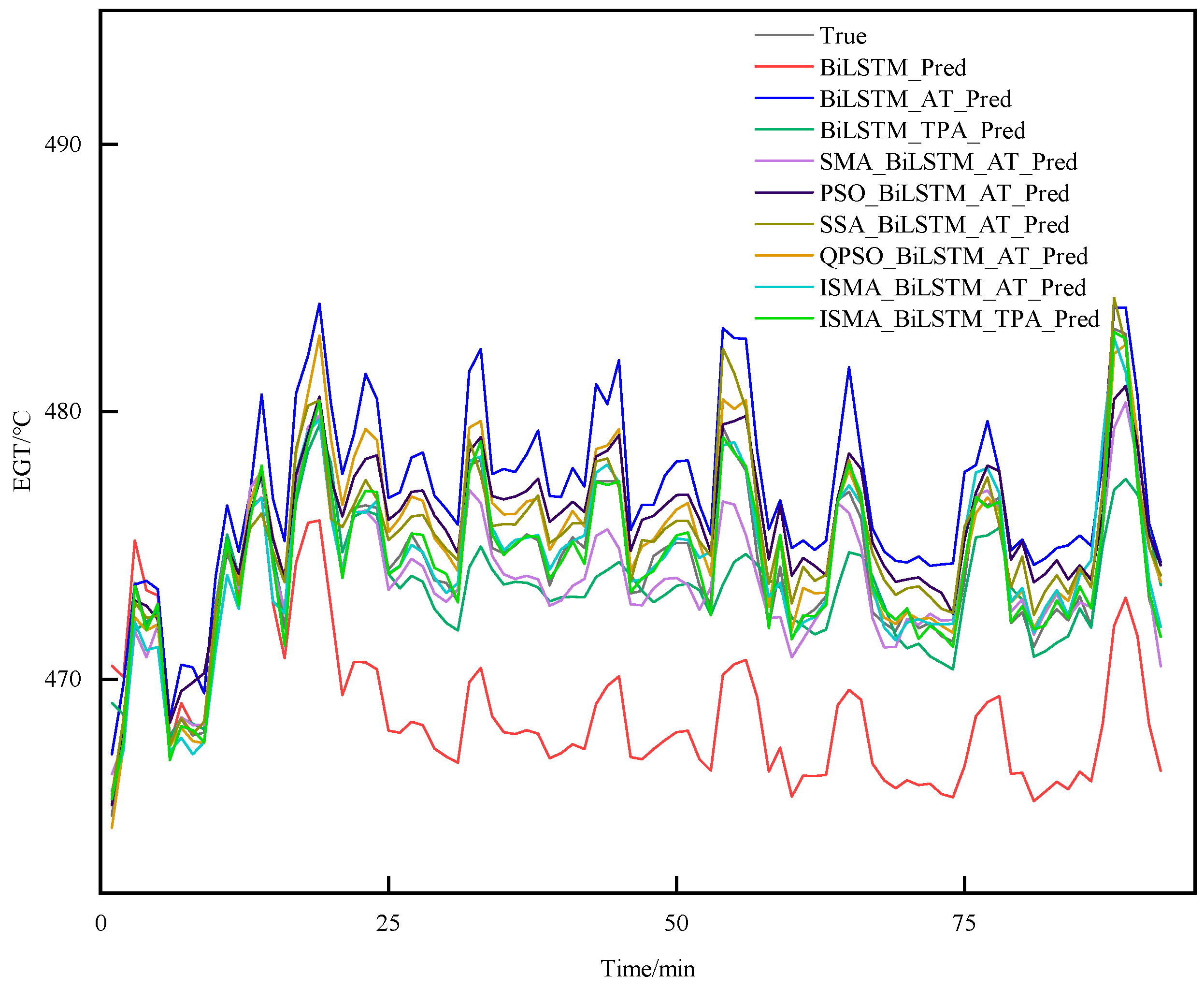
The existing trend prediction research can be divided into two main categories: equipment degradation trend prediction models and real-time equipment status trend prediction models. Equipment degradation trend prediction methods require the use of operational data from the entire lifecycle of the equipment as the research object MDEs. Currently, there is limited research on real-time status monitoring of MDEs, despite their critical role in ensuring the safe navigation of ships and the safety of crew and property. Therefore, this paper proposes a trend prediction method based on a BiLSTM-TPA neural network for short-term EGT trend prediction. Firstly, the PCA method is used to determine the feature variables with strong correlation to the EGT as the inputs to the model, thereby avoiding redundant input feature vectors. Then, the BiLSTM network is employed to learn the internal positive and negative features among the input variables. The TPA mechanism is integrated to further capture the inherent relationships among the variables under different sequences and time steps. Finally, the ISMA is used to optimize the hyperparameters of the BiLSTM-TPA network to obtain the EGT trend. This paper critically reviews the challenges in predicting the status parameters of MDE-related equipment, highlighting issues such as insufficient prediction accuracy and inappropriate selection of parameters. In response, it introduces a novel short-term trend prediction method for the EGT of MDEs, designated as the ISMA-BiLSTM-TPA. This method effectively addresses the latency issues inherent in traditional time-series prediction models. Comparative analyses with existing algorithms demonstrate the superior performance of the proposed method, evidenced by significant improvements across several metrics. Specifically, the MSE values decreased by 36.9302, 8.0956, 2.9568, 0.7334, 1.1768, and 0.4284; the MAPE values were reduced by 1.0823%, 0.4639%, 0.1679%, 0.084%, 0.1133%, and 0.0158%; the RMSE values saw reductions of 5.6775, 2.2645, 1.1848, 0.4234, 0.6130, and 0.1506; and the R2 values experienced increments of 16.9%, 11.8%, 9.70%, 7.4%, 5.7%, and 2.4%, respectively. These results not only underscore the efficacy of the ISMA-BiLSTM-TPA approach in enhancing predictive accuracy but also its potential in revolutionizing the domain of MDE monitoring and predictive analysis.
The subsequent sections of this paper cover the following content:
Section 2 introduces methods such as Pearson correlation analysis (
PCA),
BiLSTM model,
TPA mechanism, and the
SMA based on reverse learning and hybrid nonlinear inertia weight decay.
Section 3 discusses the short-term trend prediction of the
EGT of
MDE based on the
ISMA-BiLSTM-TPA model, including the evaluation index of the prediction model and experimental setup configurations.
Section 4 introduces the research object and experimental data, organizes input feature parameters and experimental data, and sets optimization parameters for the prediction model. Finally, the analysis and discussion of the short-term
EGT trend prediction results for the
6L34DF type are presented, followed by conclusions in the concluding section.
3. A Prediction Model of the Short-Term Trend of the EGT
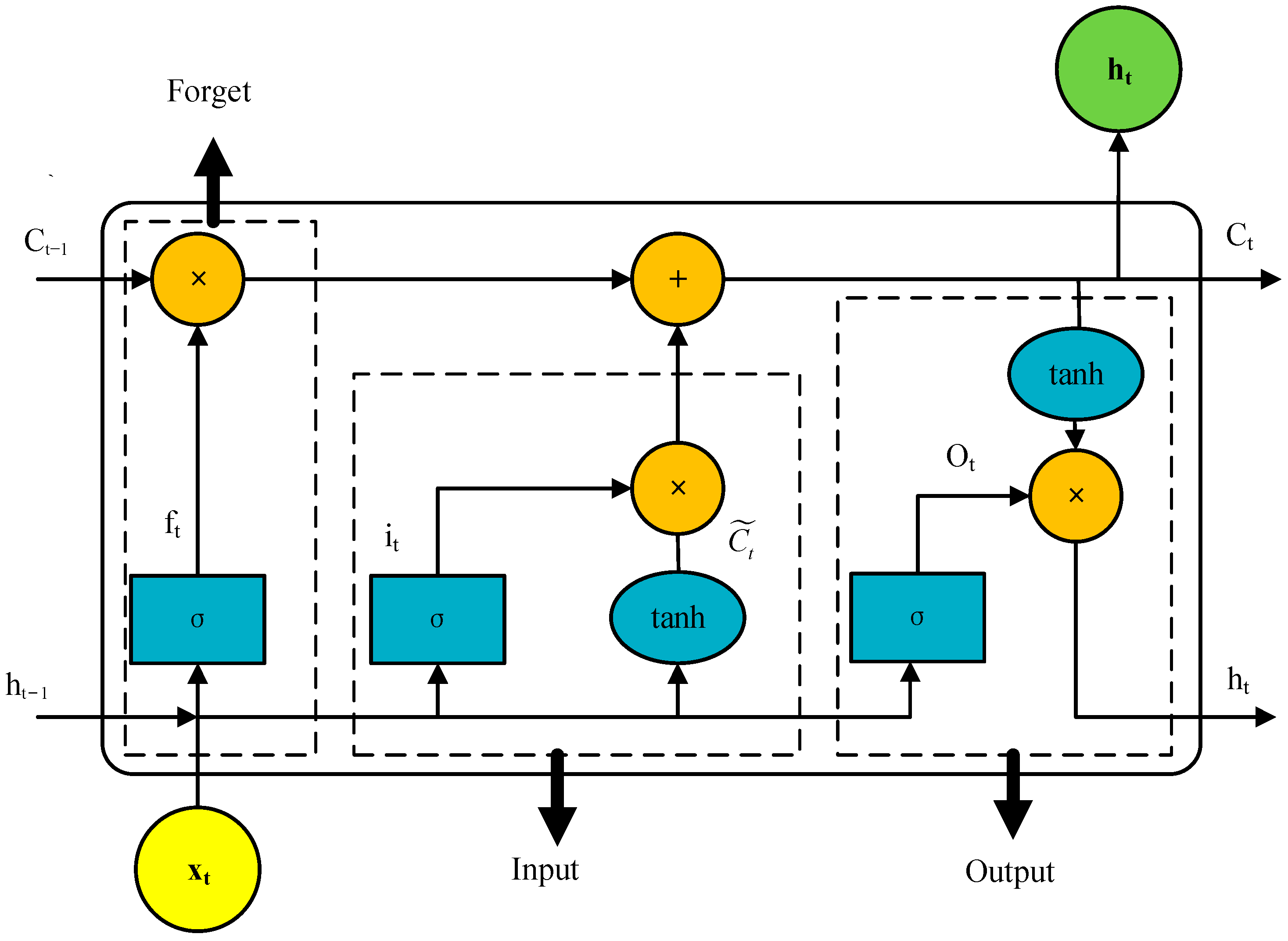
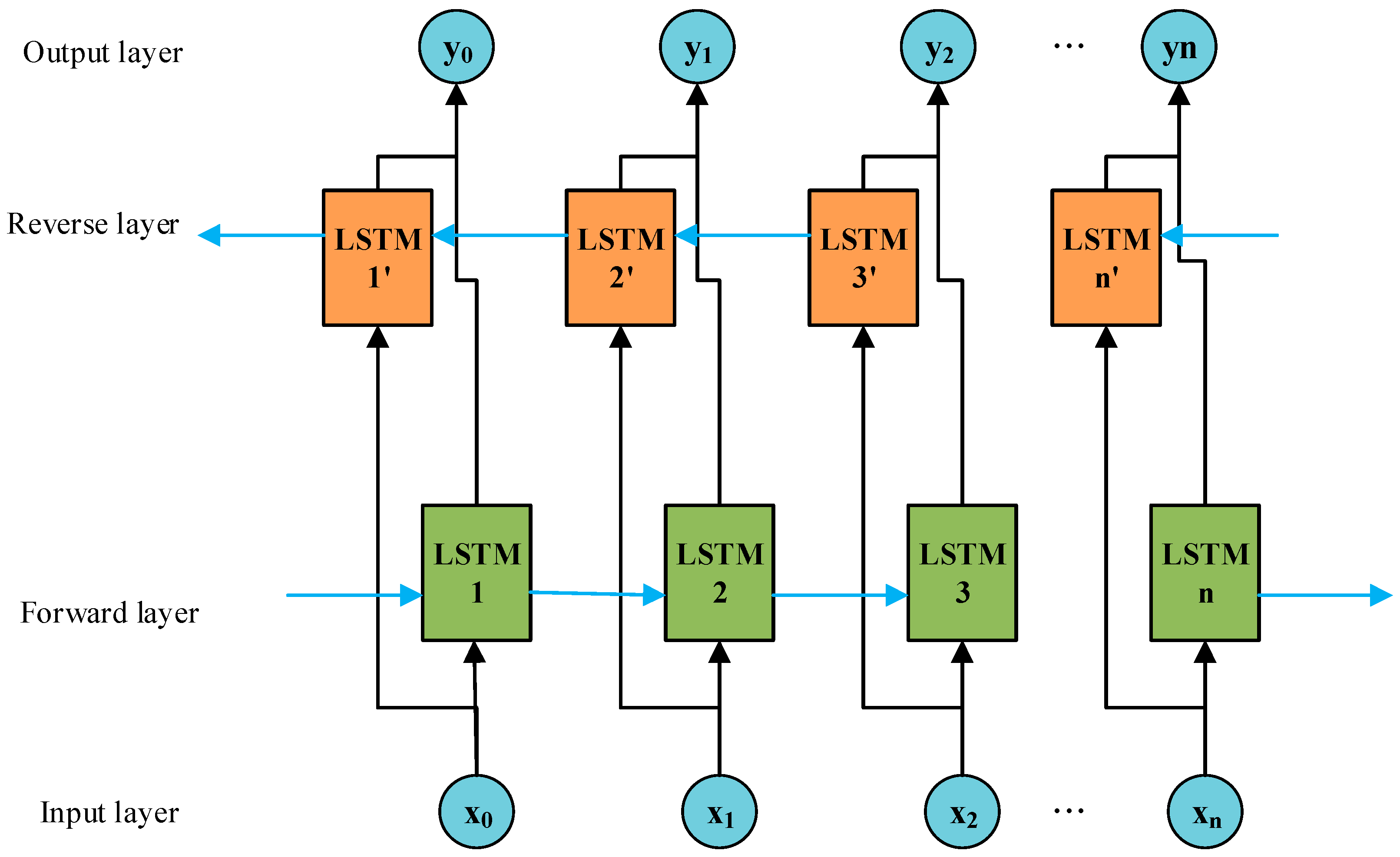
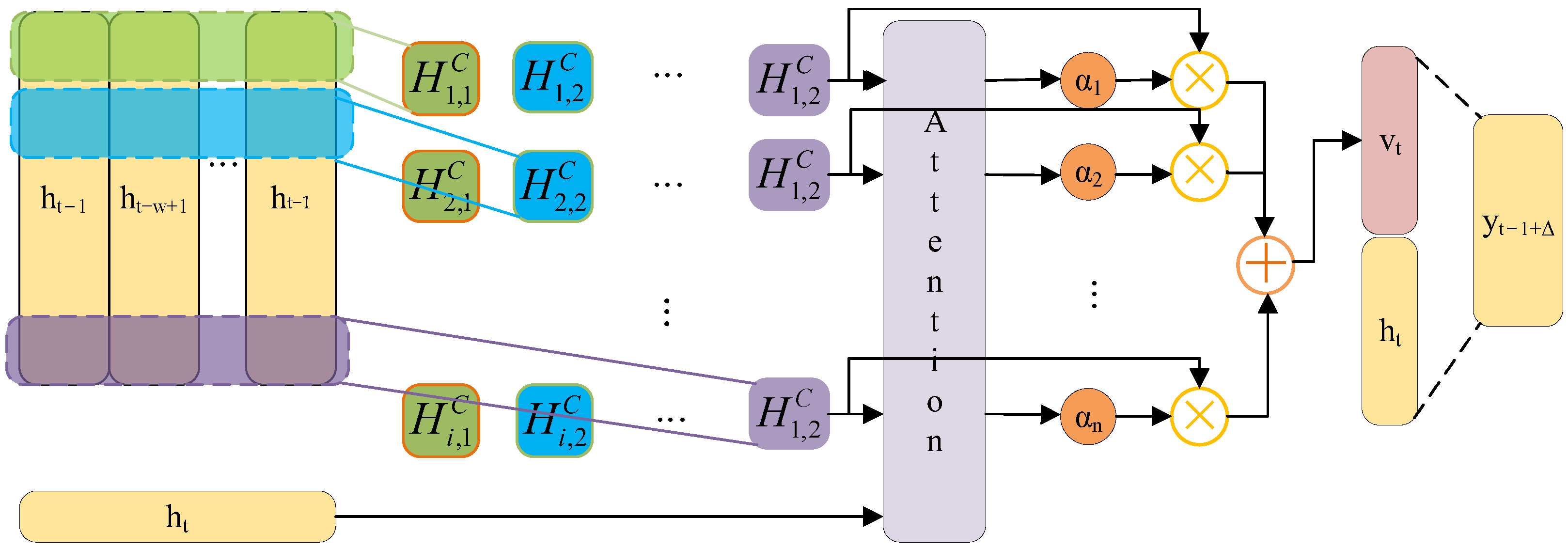
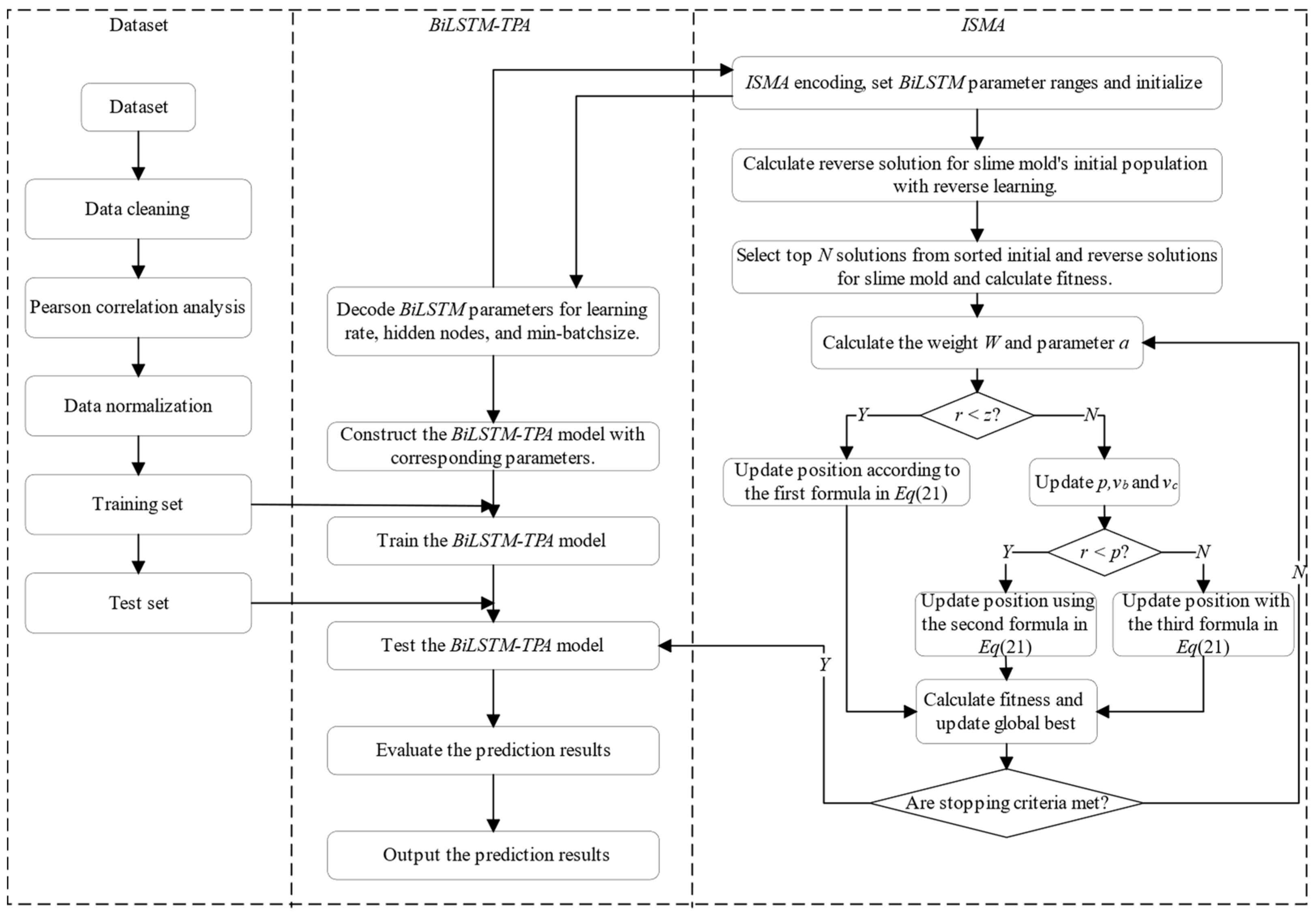
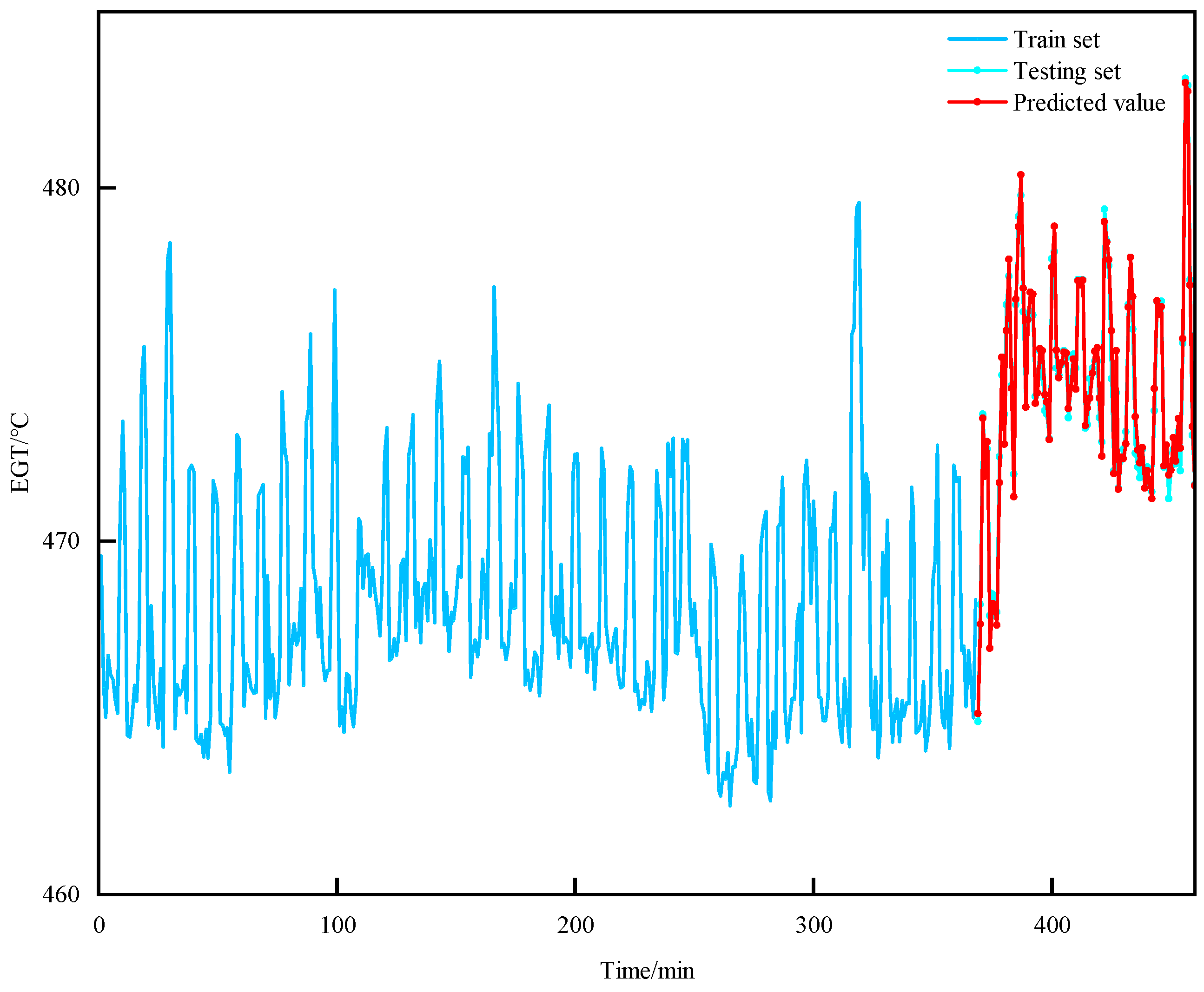
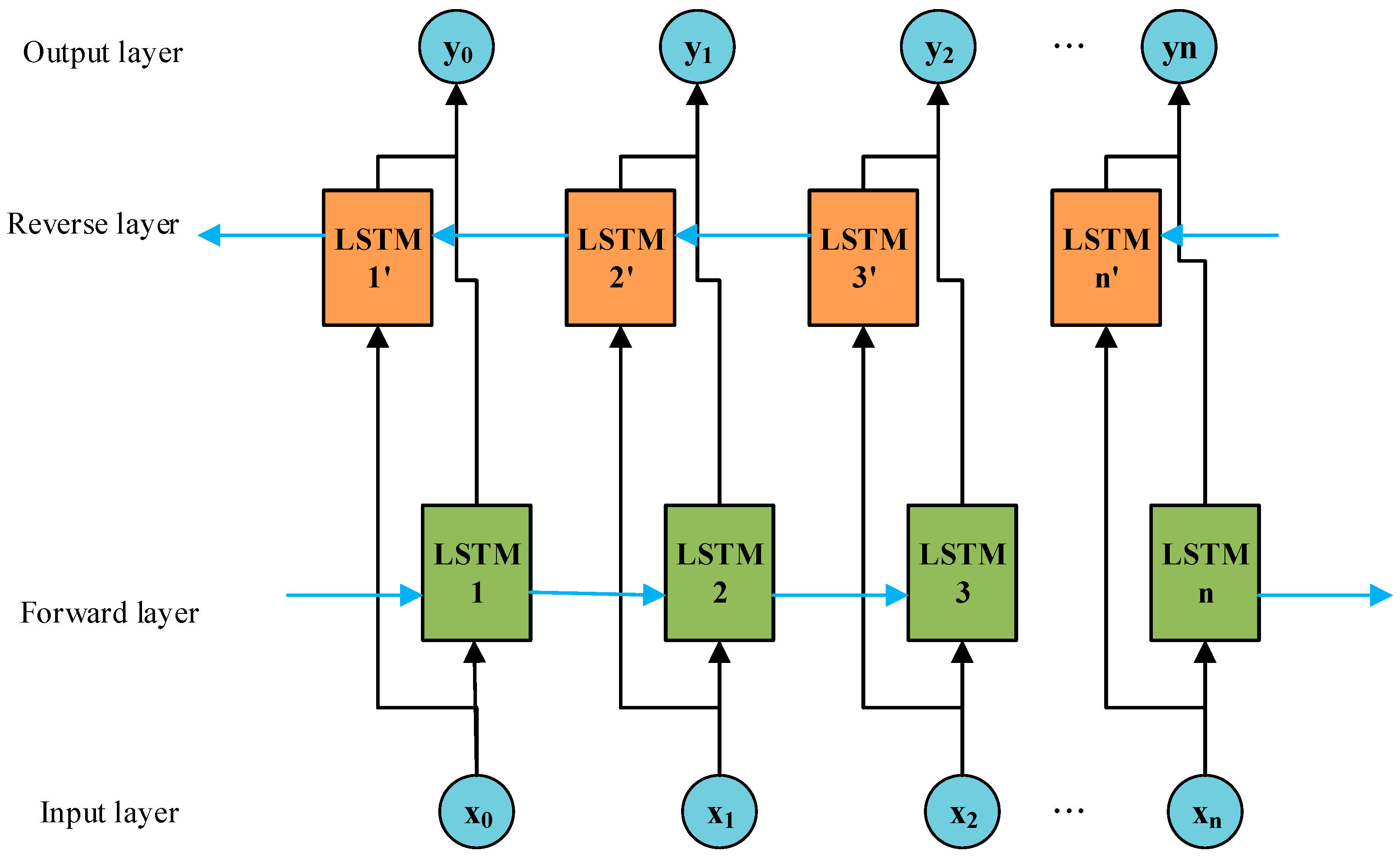
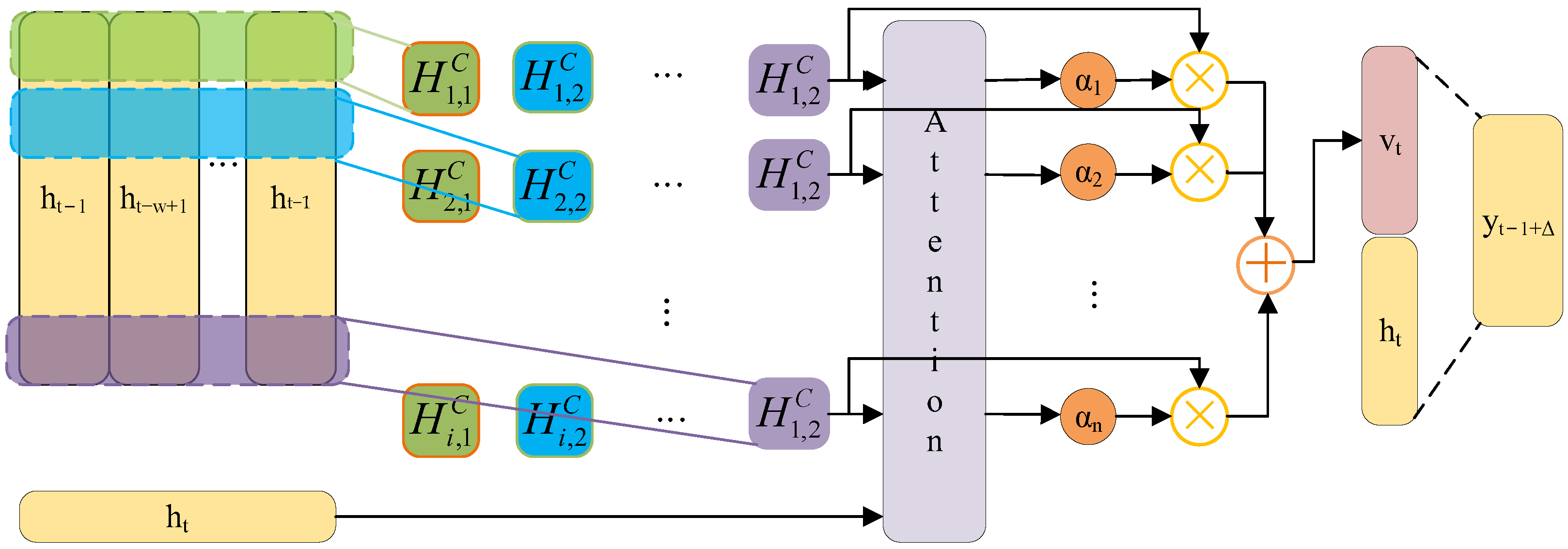
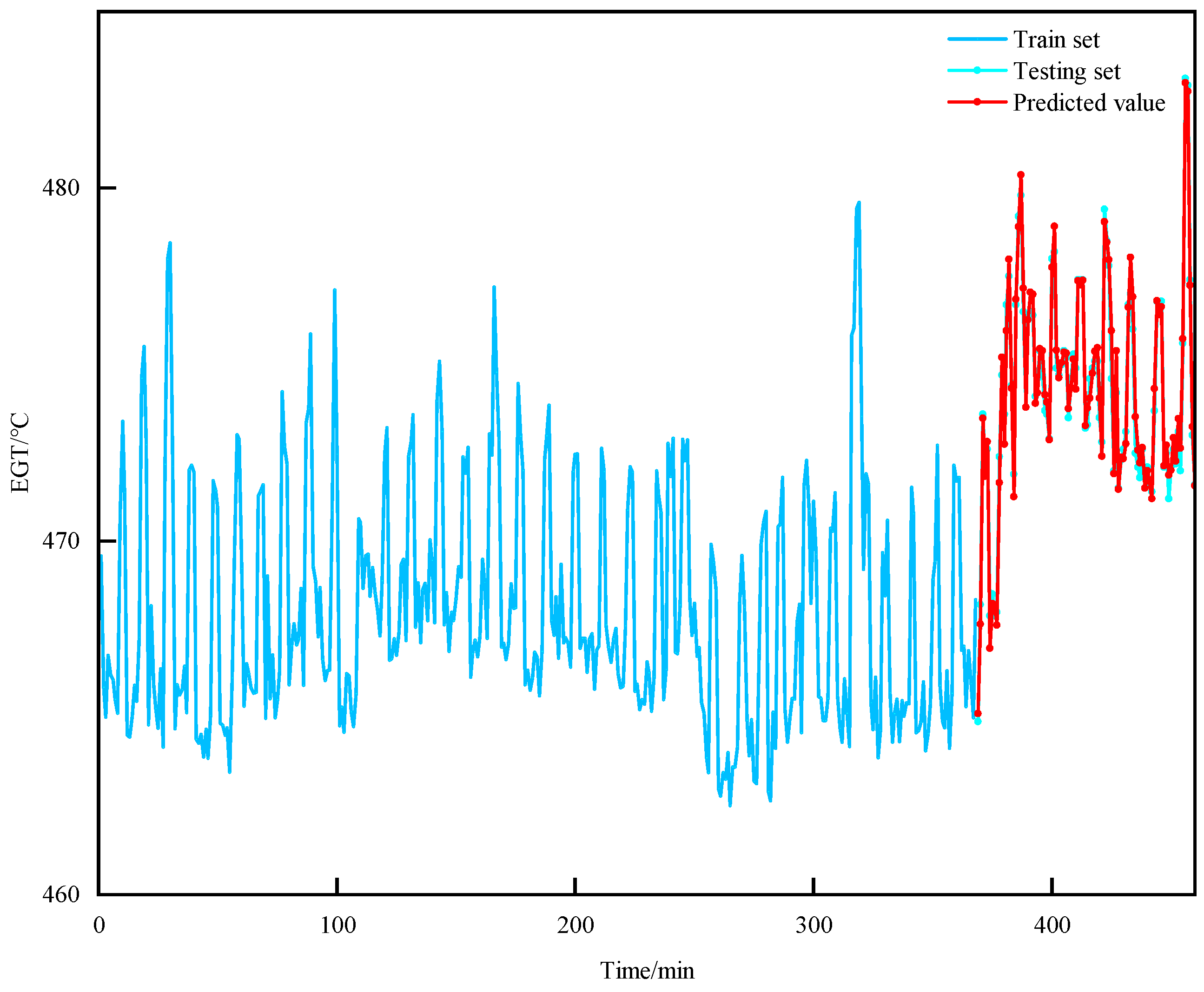
The EGT of MDE is a classic time series, characterized by continuity, volatility, and randomness in the variation patterns. When predicting short-term EGT trends, the current temperature value is closely related to the information from preceding and succeeding time periods. Therefore, this paper adopts the BiLSTM network as the foundational model for short-term EGT trend prediction to facilitate bidirectional interaction of data. On this basis, introducing the TPA mechanism helps to capture the interdependencies among multidimensional variable sequences at different time periods. Additionally, by utilizing an ISMA to find the optimal hyperparameter configuration in the BiLSTM network, the prediction model’s overall efficiency and the ability to generalize are significantly improved.
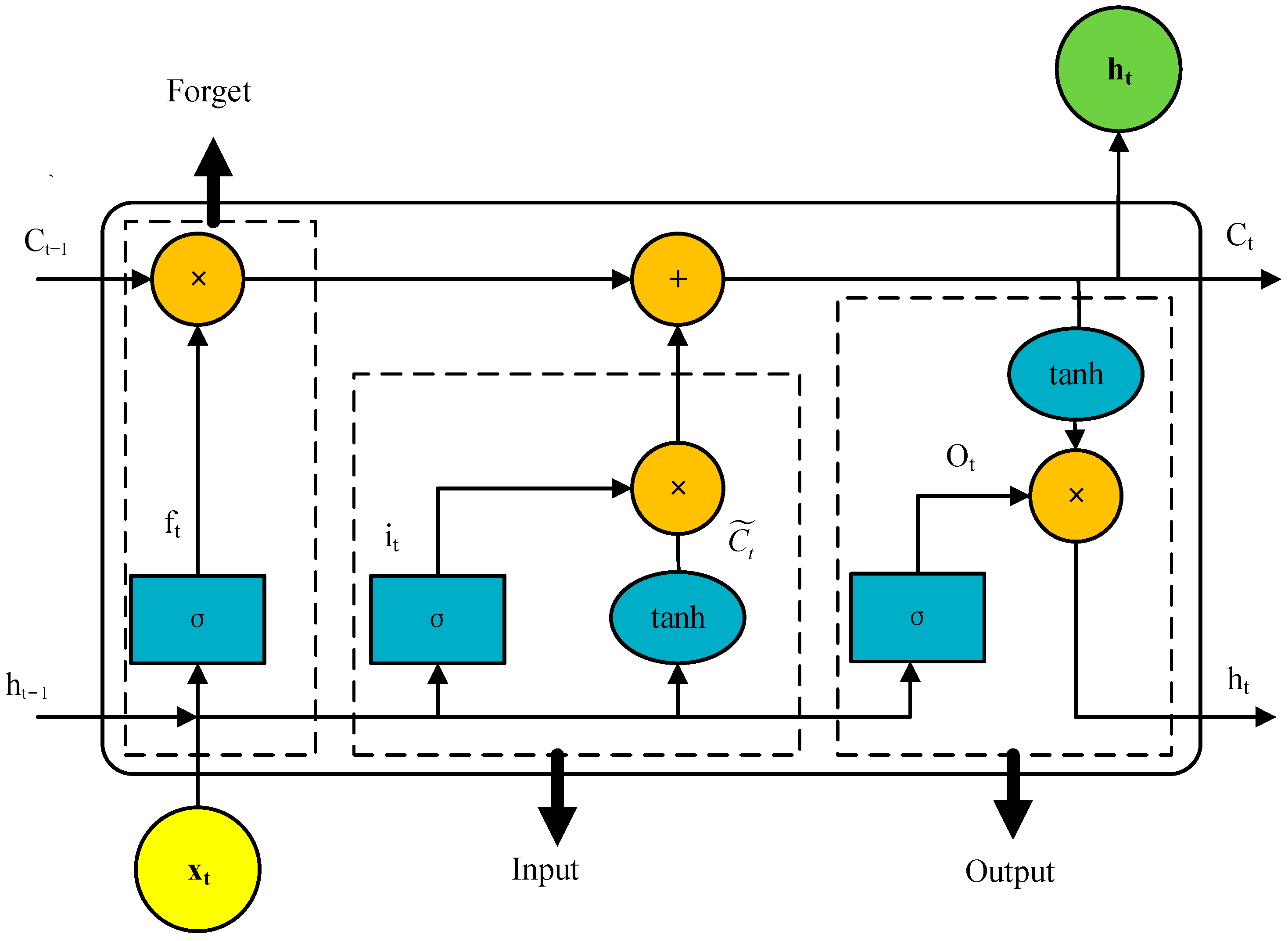
The traditional
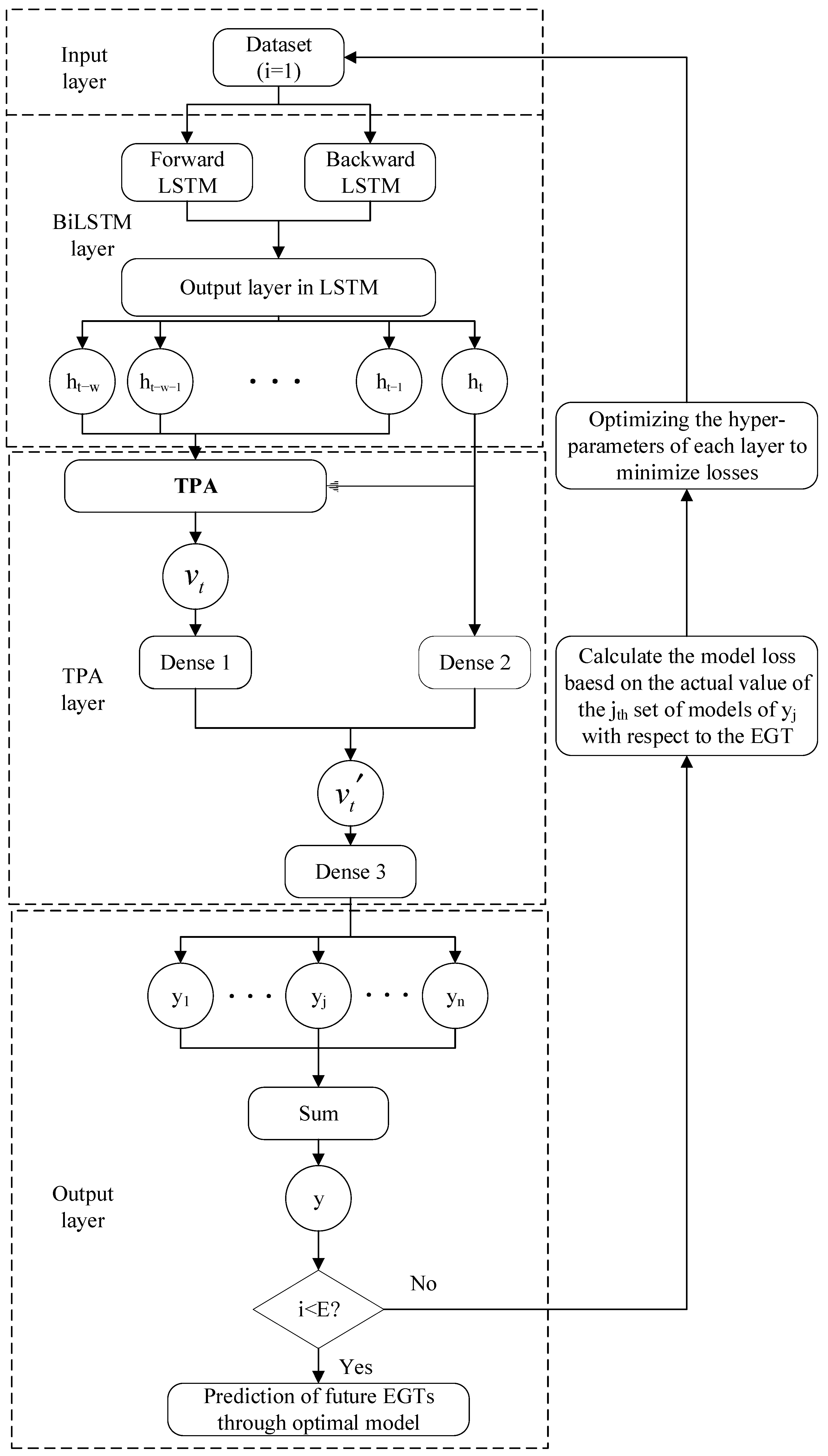
BiLSTM-TPA prediction model employs an empirical method to conduct multiple experiments for adjusting the network model’s hyperparameters, aiming to achieve the desired prediction accuracy. However, the model (as detailed in
Figure 5) has a complex internal structure, contains numerous hyperparameters. Manually adjusting hyperparameters through trial and error introduces a significant workload and may impact the accuracy of prediction results. Therefore, this study introduces the
ISMA to optimize the hyperparameters in the
BiLSTM-TPA network, with the complete optimization process illustrated in
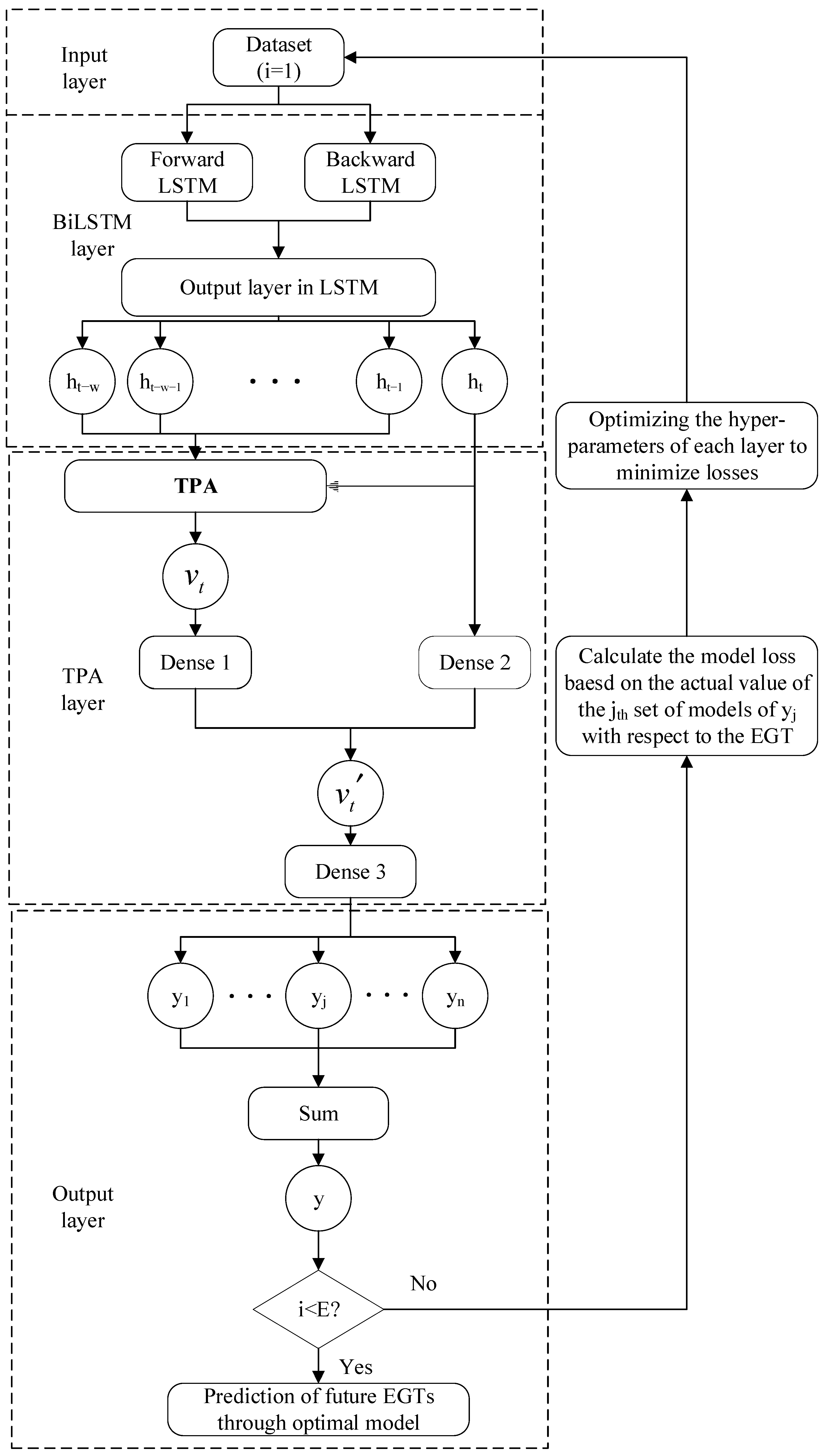
Figure 6. The comprehensive algorithm consists of five main modules: input,
ISMA,
BiLSTM,
TPA, and output. The input module performs data cleaning on the data collected by the shipboard monitoring system, then selects features related to the
EGT through
PCA to be used as the experimental dataset. In the
BiLSTM module, decode the relevant hyperparameters according to the principles of the
ISMA to obtain the number of nodes in each hidden layer, the min-batchsize, and the learning rate. the
TPA module is responsible for weighted processing of the results from the hidden layers. The output module is responsible for generating the final prediction results, calculating the
RMSE value between the actual and predicted values, and passing it back to the
ISMA module as the fitness value. The
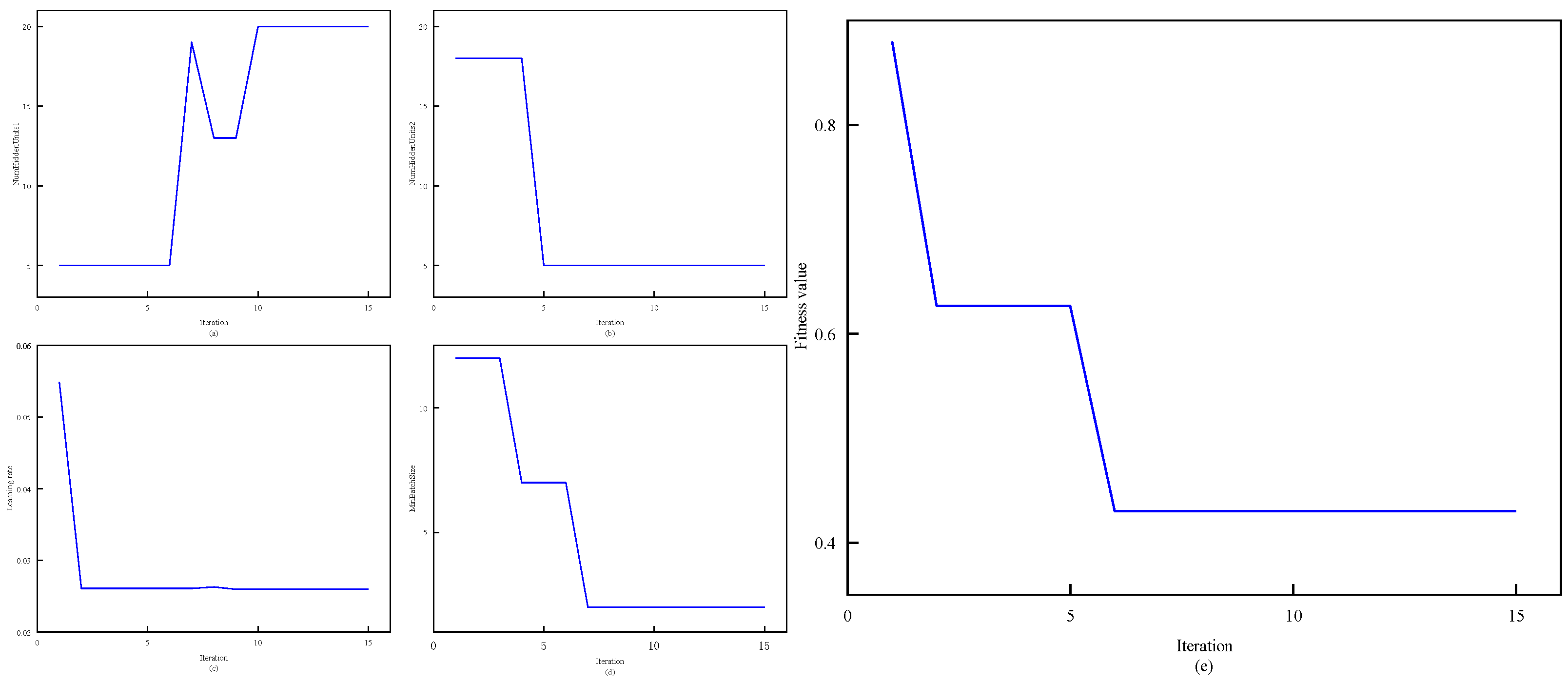
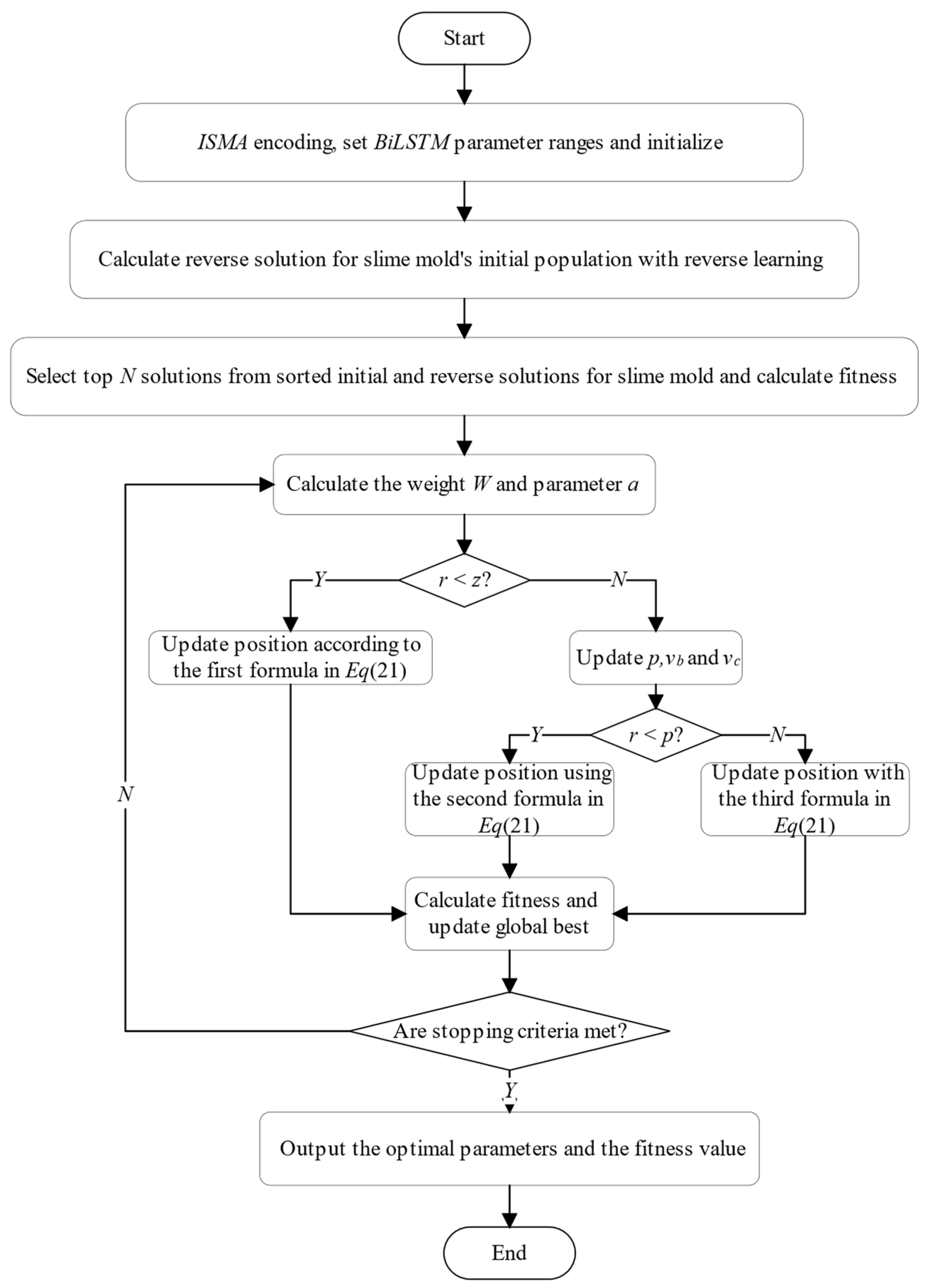
ISMA module adjusts the position of the slime mold population based on the fitness value, achieving population updates and a global optimal search, ultimately obtaining a set of optimized hyperparameters.
3.1. Optimization of the BiLSTM-TPA Prediction Model Based on the ISMA
This study incorporates the
ISMA for hyperparameter optimization within the
BiLSTM network mode. Initially, establish the value boundaries for the hyperparameters within the
BiLSTM network model. Subsequently, the
BiLSTM module decodes the hyperparameters passed in by the
ISMA to obtain and the number of nodes in each hidden layer, the min-batchsize, learning rate. Following this, the prediction model is trained and learned, calculating the root mean square error (
RMSE) between the predicted
EGT values and actual
EGT values. Then, this
RMSE value is relayed back to the
ISMA module to serve as a fitness value, allowing the adjustment of the population members’ positions according to this current fitness value in the pursuit of the global optimal solution. Ultimately, a set of optimized hyperparameters is obtained.
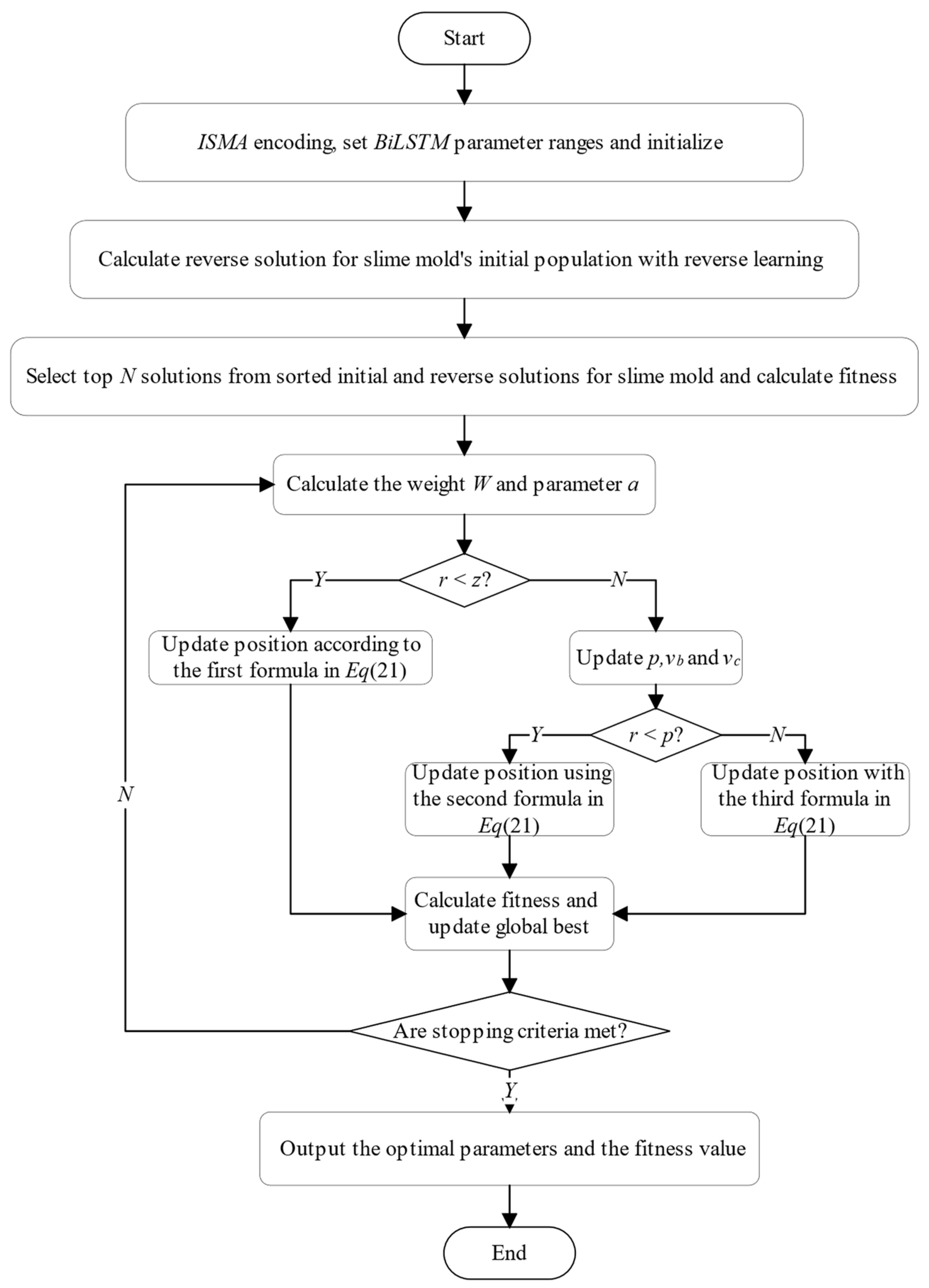
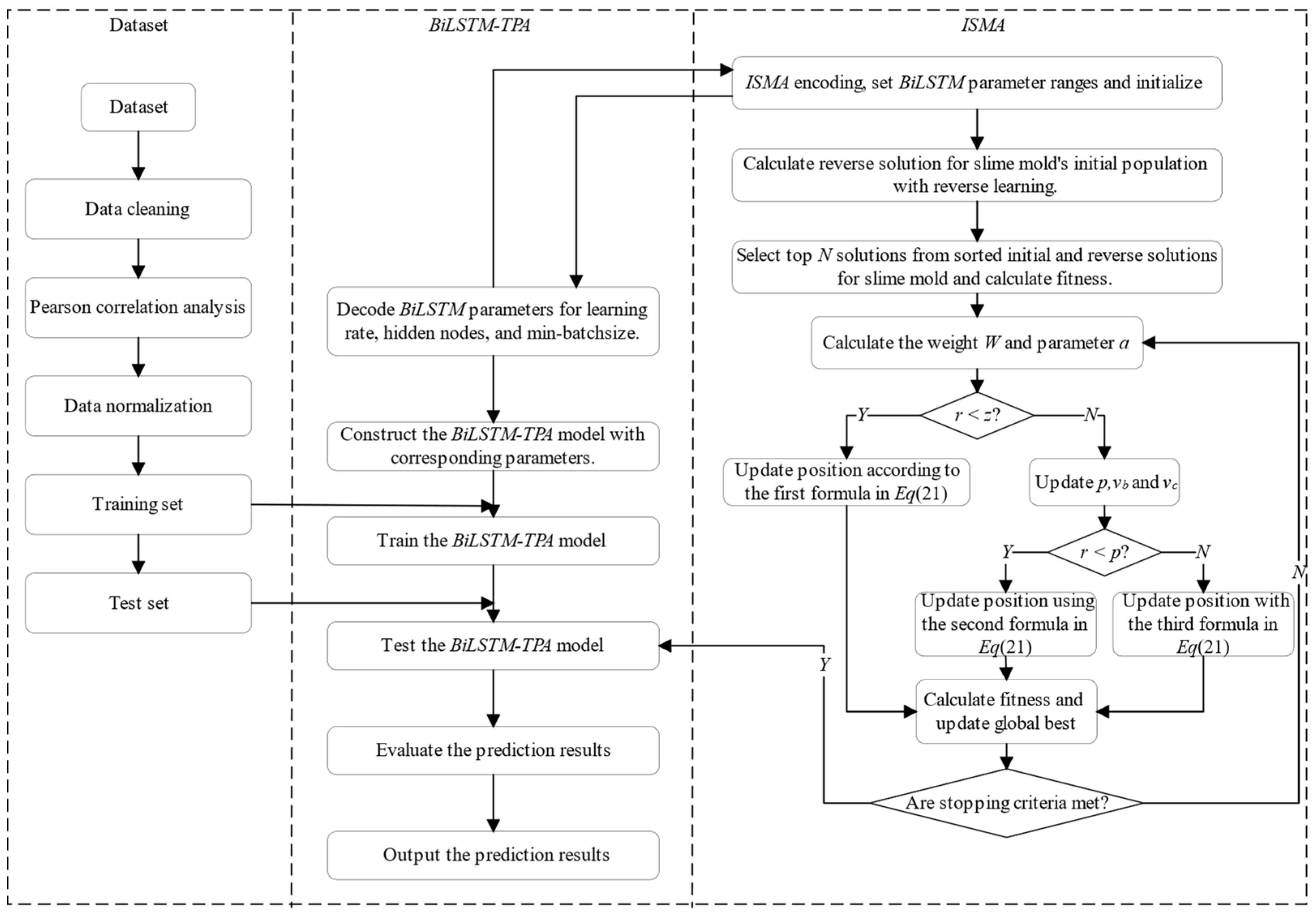
Figure 7 illustrates the
ISMA, with the comprehensive steps for calculation detailed as follows.
Step 1: Determine the range of values for the hyperparameters of the BiLSTM module.
Step 2: Initialize parameters for the ISMA, including the search dimension (D), population size (N), and maximum number of iterations (tmax). Randomly generate initial slime mold population individuals, ensuring that the position of each slime mold individual corresponds to a combination of hyperparameters of the BiLSTM model.
Step 3: Follow the reverse learning strategy to calculate the reverse solution for the initial population, and comprehensively evaluate the current solutions and reverse solutions. By merging the better-fit 50% of current solutions and 50% of reverse solution individuals, form the initial population for the ISMA.
Step 4: Determine the initial fitness value of the slime mold population.
Step 5: Calculate the parameter (a) and the weight (W).
Step 6: Produce a random number (r) and contrast (r) with parameter (z). Should r be smaller than z, refresh the position of the individual based on the initial equation in Equation (21). If not, proceed to adjust p, vb, and vc further Contrast r with parameter p; should r be lower than p, revise the individual’s location using the second equation in Equation (21); otherwise, continue with the modification as per the third equation in Equation (21).
Step 7: Recalculate the fitness of slime mold population individuals, and update the global optimum.
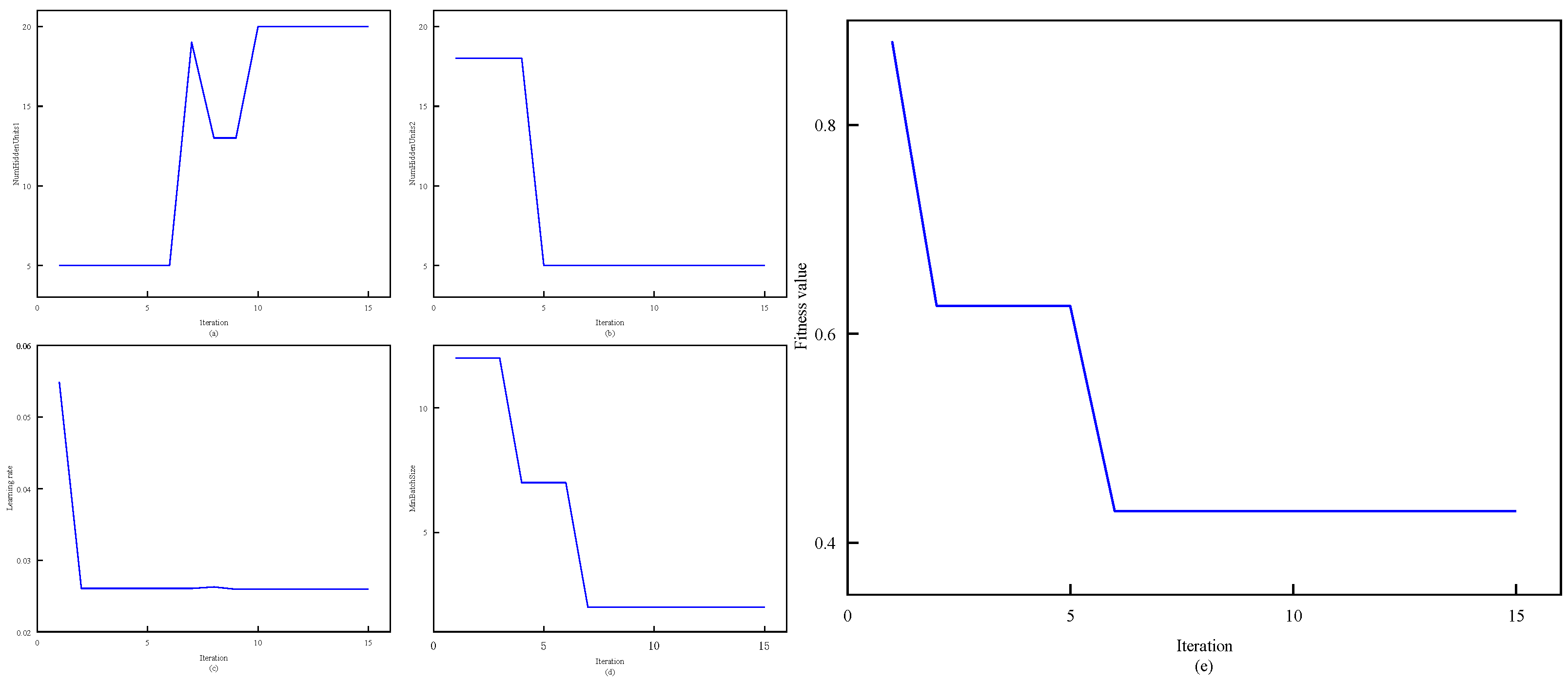
Step 8: Check if the algorithm meets the termination condition. If it does, output the global optimum solution, which corresponds to the optimal parameters of the BiLSTM model. (the number of nodes in each hidden layer, min-batchsize, learning rate); if not, repeat Steps 5 to 8.
3.2. The Evaluation Index
The effectiveness of the
EGT prediction algorithm for
MDE largely depends on the accuracy of the trend prediction model. The higher the prediction accuracy, the greater its significance for guiding intelligent operation and maintenance of the ship’s engine room. To objectively evaluate the accuracy of the prediction results, it is necessary to establish corresponding evaluation indicators to verify the effectiveness and feasibility of the proposed experimental method. This paper aims to adopt the mean square error (
MSE), the mean absolute percentage error (
MAPE), the coefficient of determination (
R2), and
RMSE as the evaluation index for assessing the accuracy of predictions [
37,
38]. The specific calculation equations are as follows:
In the equation, and . It denotes the measured value sequence of the EGT in the ship-end monitoring system and the output sequence of the predicted value of the prediction model, respectively.
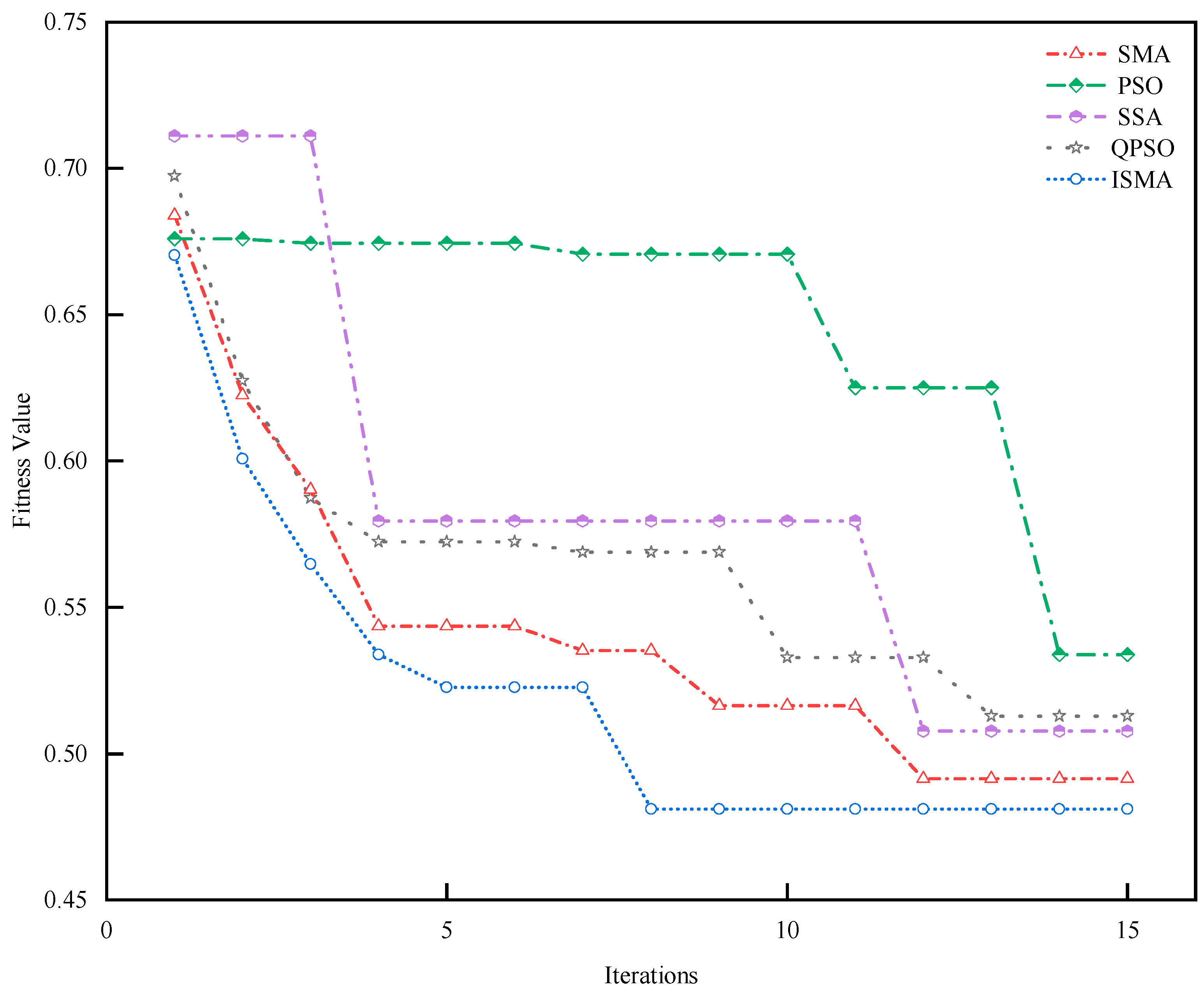
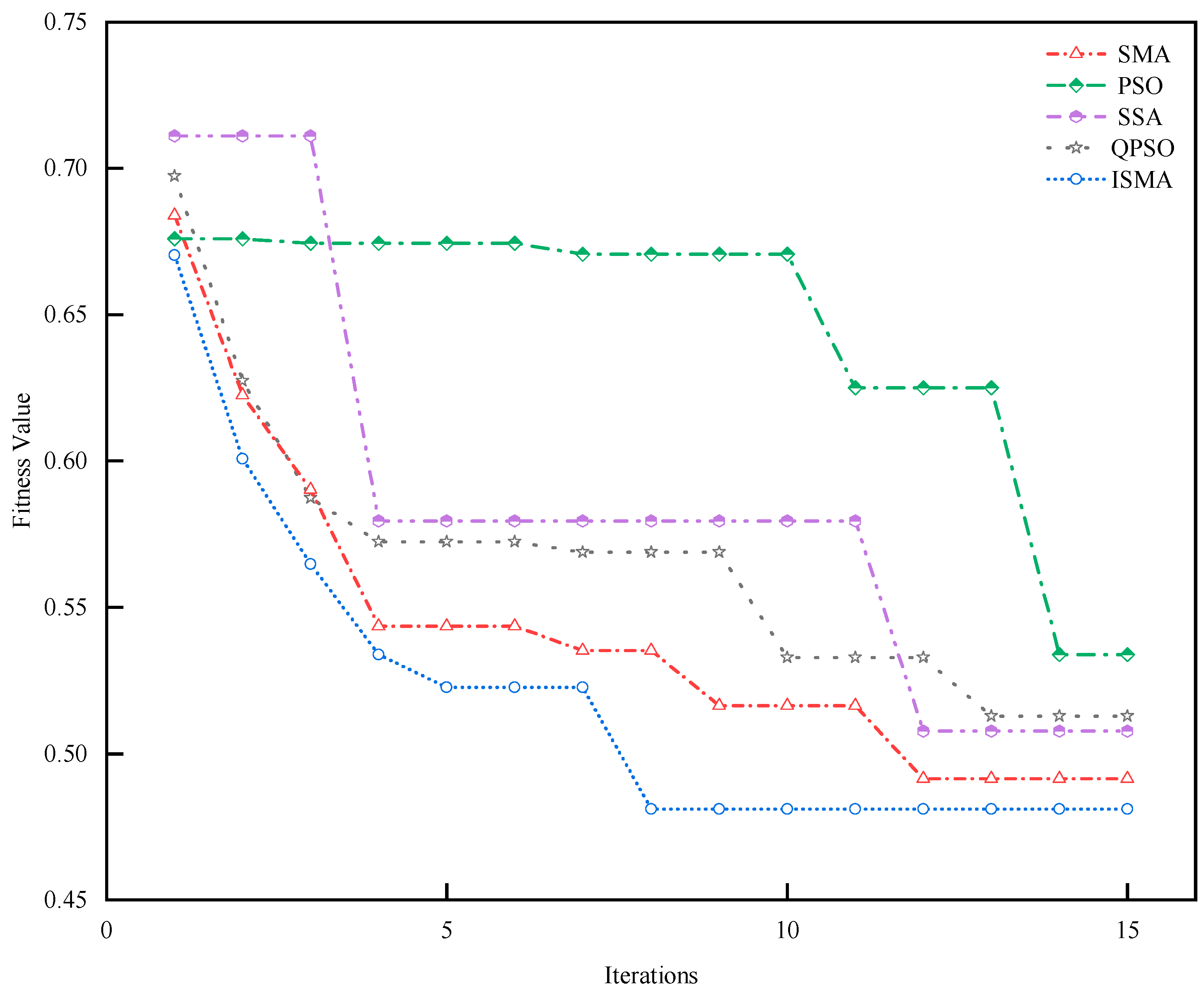
To verify the effectiveness of the short-term EGT trend prediction method proposed in this paper, this study introduces several prediction models, including the BiLSTM, BiLSTM-AT, BiLSTM-TPA, SMA-BiLSTM-AT, ISMA-BiLSTM-AT, and QPSO-BiLSTM-AT, and this study compared the outcomes of these models with those of the method proposed in this paper.
3.3. Experimental Configuration
The configuration of the experimental environment is shown in
Table 2.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}