
Research on Path-Following Technology of a Single-Outboard-Motor Unmanned Surface Vehicle Based on Deep Reinforcement Learning and Model Predictive Control Algorithm


Abstract
1. Introduction
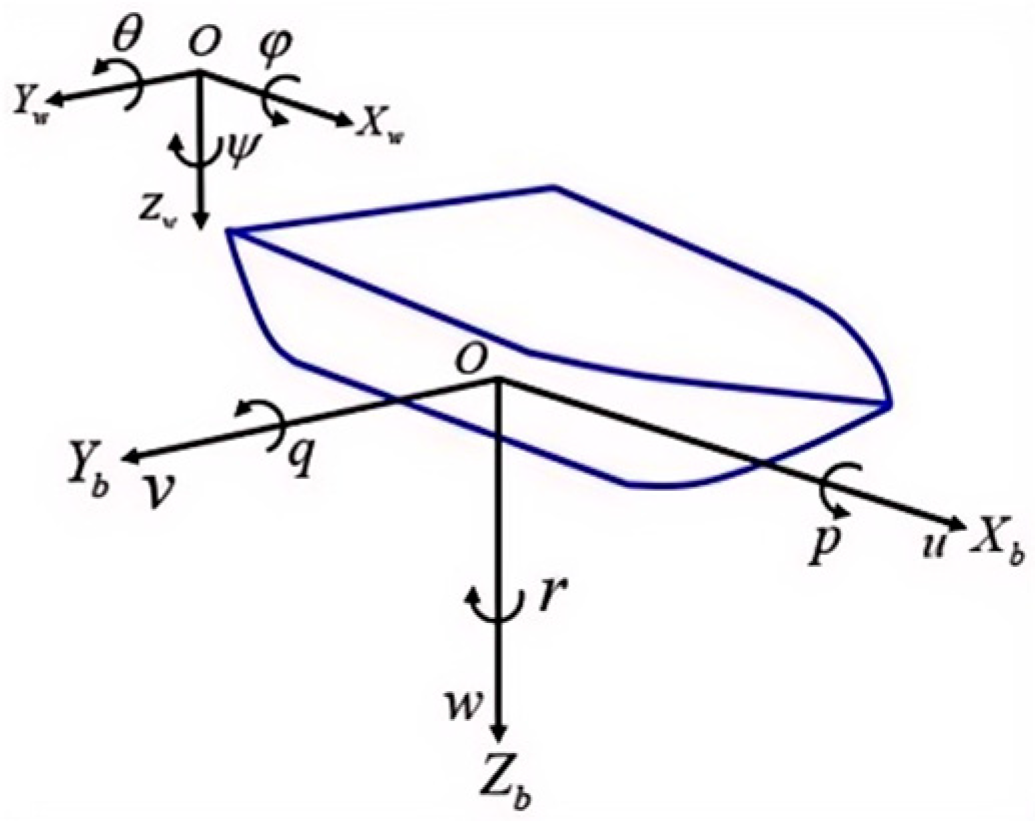
2. Kinematic Modeling
2.1. Kinematic Modeling of USV
2.2. Kinematic Modeling of the Outboard Motor
2.2.1. The Outboard Motor Model
2.2.2. The Servo Model
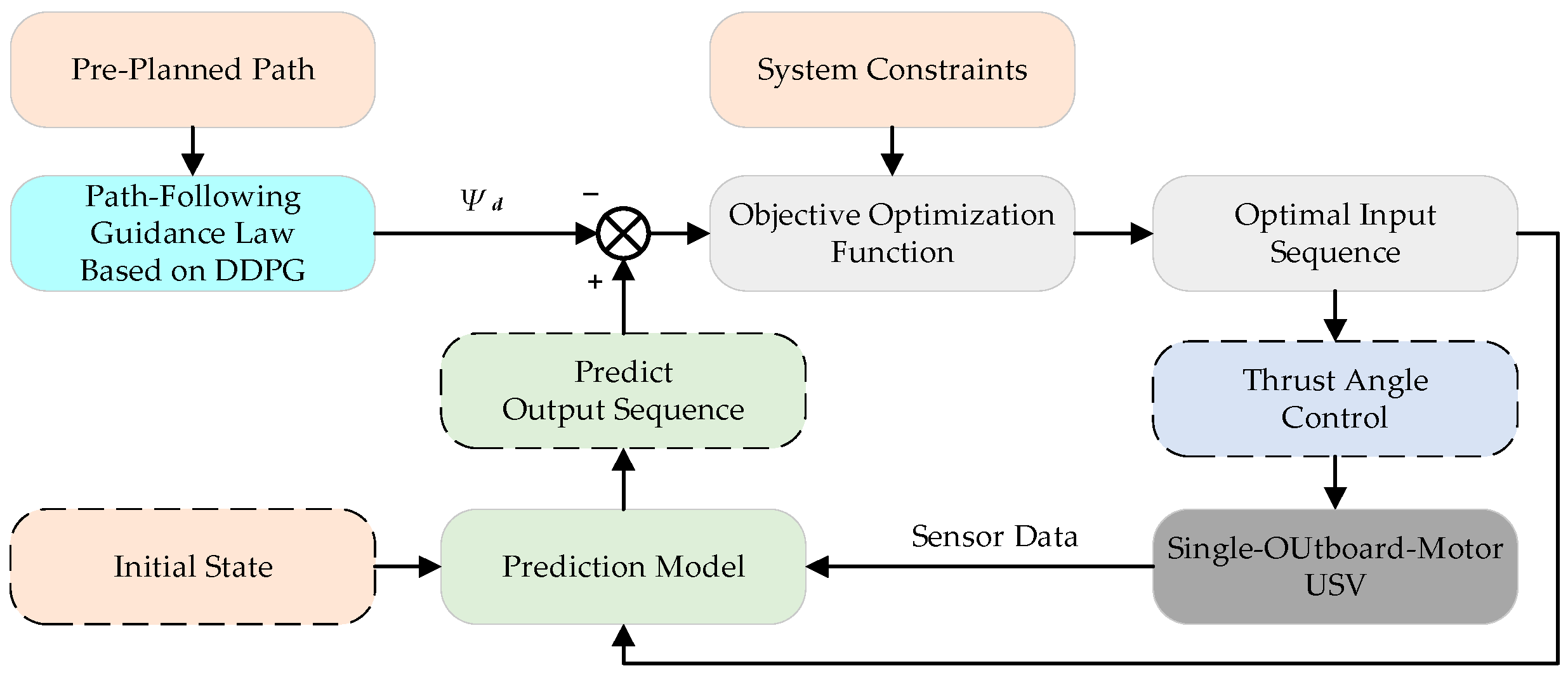
3. Path-Following Control Algorithm
3.1. Path-Following Guidance Law Based on DDPG Algorithm
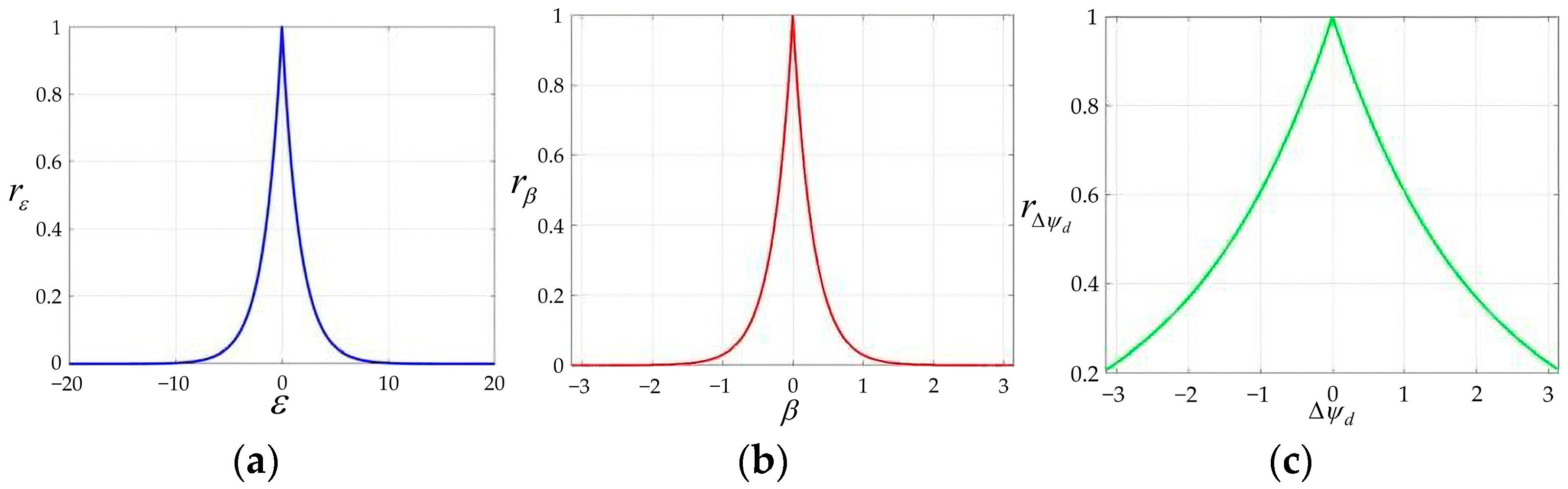
3.1.1. Design of the Markov Decision Process
3.1.2. Implementation of the DDPG Algorithm
- ➀
- Randomly initialize the Actor Network and Critic Network ; initialize the target network’s actor and ; initialize the experience replay buffer .
- ➁
- Begin a new episode by initializing the USV’s state randomly in the environment as the initial state . At each time step, the current state vector and action policy are combined with exploration noise to produce the action vector , which defines the USV’s desired heading angle. The heading controller then tracks this angle, and the environment provides the updated state vector . Meanwhile, rewards are computed using environmental data, such as cross-track and heading angle errors. Interaction data generated at each time step are saved in the experience replay buffer .
- ➂
- Randomly sample N interaction data from the experience replay buffer to update the networks. Update the Critic Network by minimizing the loss function , where represents the target value output by the target Critic Network. Update the Actor Network based on the sampled gradients, with the gradient formula given by the following:
- ➃
- Perform soft updates on the parameters of the target Critic Network and target Actor Network, with the update formula as follows:
- ➄
- Return to step 2 to continue learning at the next time step. When reset conditions are met or learning exceeds the set time steps, start a new episode.
3.2. Heading Controller Design Based on MPC Algorithm
4. Experimental Results and Analysis
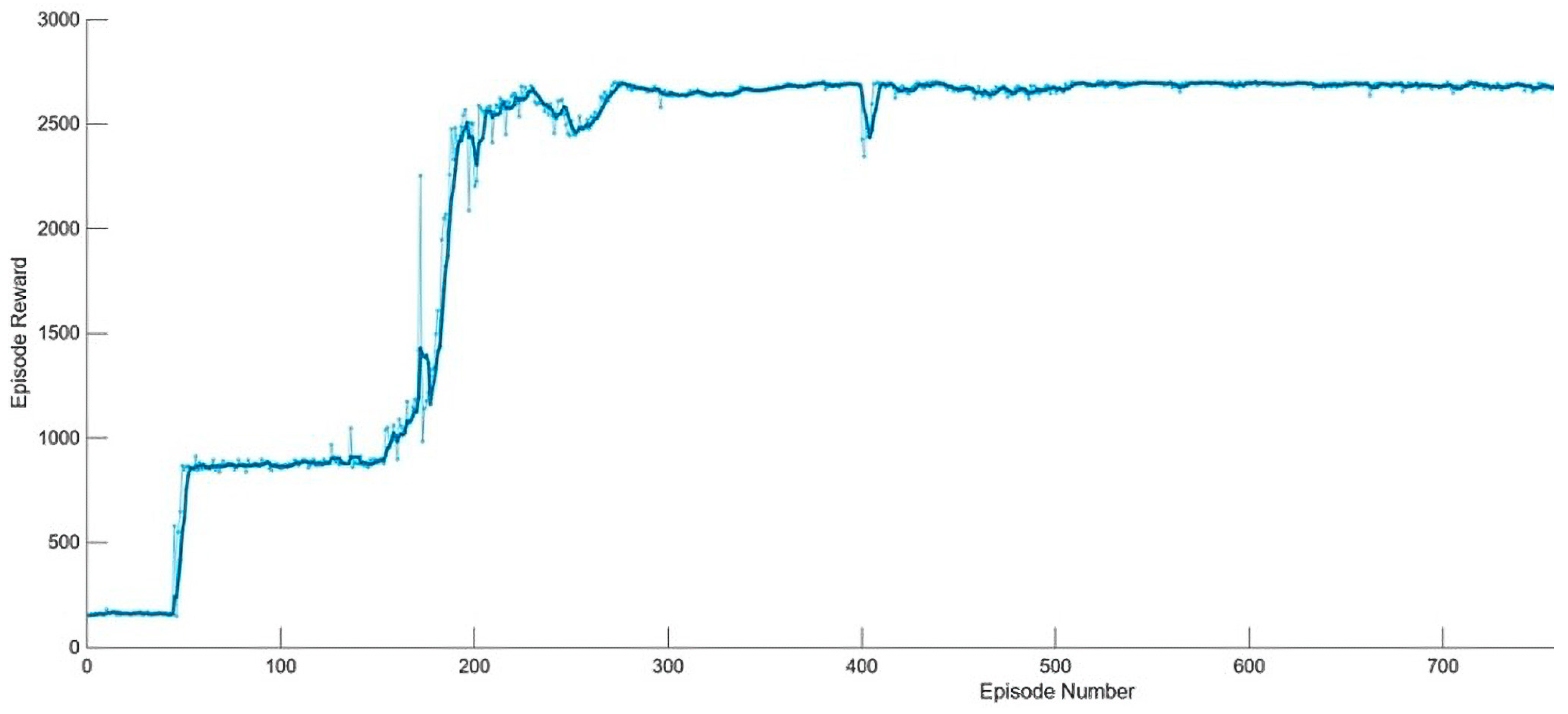
4.1. Agent Training and Results Analysis
4.2. Simulation Comparative Experiment
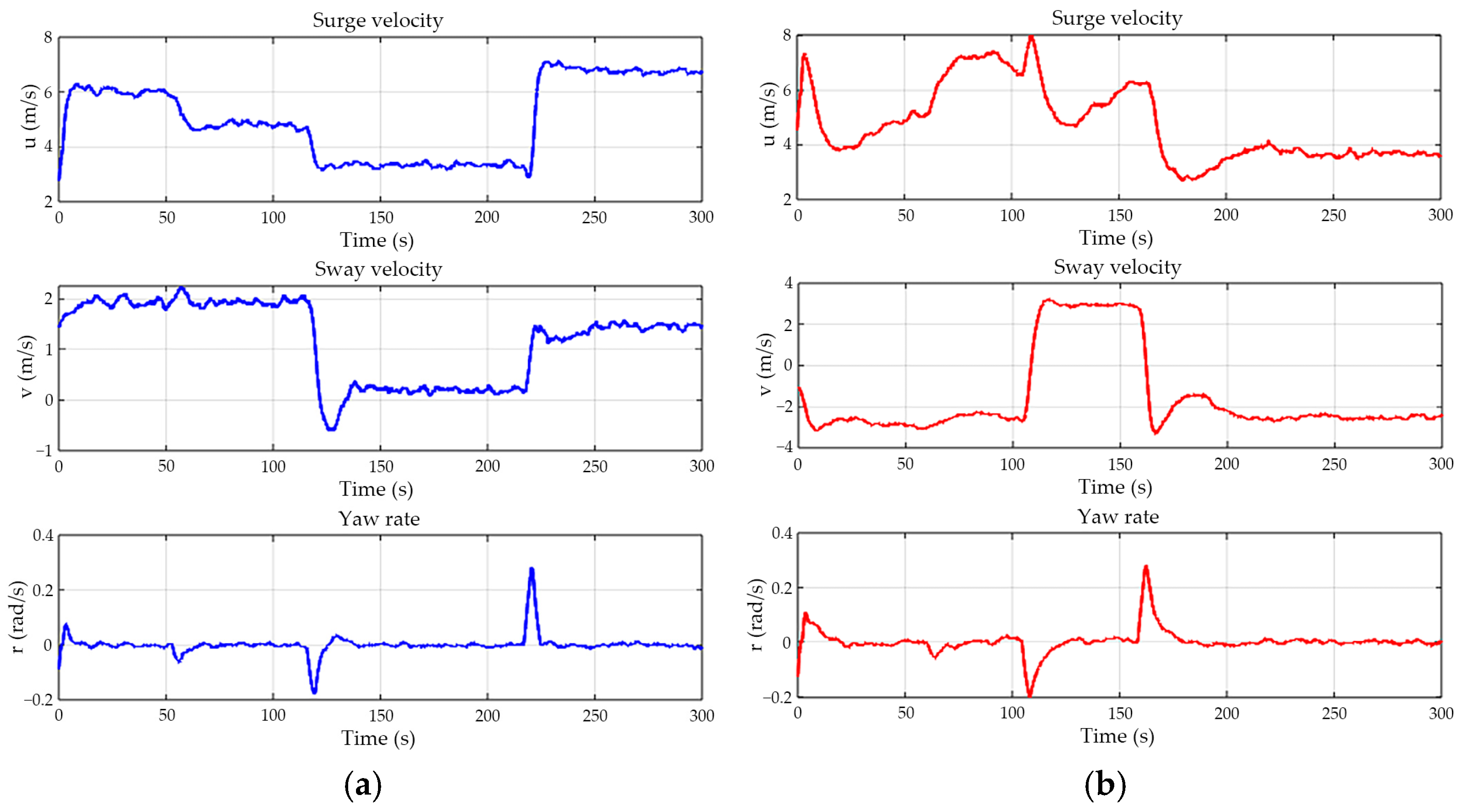
4.3. Real Ship Comparative Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| USVs | unmanned surface vehicles |
| DDPG | Deep Deterministic Policy Gradient |
| MPC | model predictive control |
| VF | vector field |
| LOS | line of sight |
| ALOS | adaptive los |
| IDLOS | integral–differential los |
| USGES | uniform semi-global exponential stability |
| DQN | deep q-network |
| RBF NN | radial basis function neural networks |
| DOF | degrees of freedom |
| QP | quadratic programming |
References
- Zhao, L.; Qiu, S.; Chen, Y. Enhanced Water Surface Object Detection with Dynamic Task-Aligned Sample Assignment and Attention Mechanisms. Sensors 2024, 24, 3104. [Google Scholar] [CrossRef]
- Chen, Y.; Hong, X.; Cui, B.; Peng, R. Implementation of an Efficient Image Transmission Algorithm for Unmanned Surface Vehicles Based on Semantic Communication. J. Mar. Sci. Eng. 2023, 11, 2280. [Google Scholar] [CrossRef]
- Chen, Y.; Hong, X.; Chen, W.; Wang, H.; Fan, T. Experimental Research on Overwater and Underwater Visual Image Stitching and Fusion Technology of Offshore Operation and Maintenance of Unmanned Ship. J. Mar. Sci. Eng. 2022, 10, 747. [Google Scholar] [CrossRef]
- Xiao, G.; Tong, C.; Wang, Y.; Guan, S.; Hong, X.; Shang, B. CFD simulation of the safety of unmanned ship berthing under the influence of various factors. Appl. Sci. 2021, 11, 7102. [Google Scholar] [CrossRef]
- Aguiar, A.P.; Hespanha, J.P.; Kokotović, P.V. Path-following for nonminimum phase systems removes performance limitations. IEEE Trans. Autom. Control 2005, 50, 234–239. [Google Scholar] [CrossRef]
- Zhao, Y.; Qi, X.; Ma, Y.; Li, Z.; Malekian, R.; Sotelo, M.A. Path following optimization for an underactuated USV using smoothly-convergent deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6208–6220. [Google Scholar] [CrossRef]
- Lekkas, A.M.; Fossen, T.I. A time-varying lookahead distance guidance law for path following. IFAC Proc. 2012, 45, 398–403. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Shamsuddin, P.N.F.b.M.; Mansorand, M.A.b. Motion control algorithm for path following and trajectory tracking for unmanned surface vehicle: A review paper. In Proceedings of the CRC 2018: The 3rd International Conference on Control, Robotics and Cybernetics, Penang, Malaysia, 26–28 September 2018. [Google Scholar]
- Shan, Q.; Wang, X.; Li, T.; Chen, C.L.P. Finite-time control for USV path tracking under input saturation with random disturbances. Appl. Ocean Res. 2023, 138, 103628. [Google Scholar] [CrossRef]
- Fossen, T.I.; Breivik, M.; Skjetne, R. Line-of-sight path following of underactuated marine craft. IFAC Proc. 2003, 36, 211–216. [Google Scholar] [CrossRef]
- Nelson, D.R.; Barber, D.B.; McLain, T.W.; Beard, R.W. Vector field path following for miniature air vehicles. IEEE Trans. Robot. 2007, 23, 519–529. [Google Scholar] [CrossRef]
- Wang, S.; Sun, M.; Xu, Y.; Liu, J.; Sun, C. Predictor-based fixed-time LOS path following control of underactuated USV with unknown disturbances. IEEE Trans. Intell. Veh. 2023, 8, 2088–2096. [Google Scholar] [CrossRef]
- Liu, Z.; Song, S.; Yuan, S.; Ma, Y.; Yao, Z. ALOS-Based USV path-following control with obstacle avoidance strategy. J. Mar. Sci. Eng. 2022, 10, 1203. [Google Scholar] [CrossRef]
- Zhou, G.; Lin, J.; Wu, J.; Liu, Z.; Wu, G.; Zhao, D.; Xu, C.; Zhang, H. An integral-differential LOS algorithm for USV path-tracking control. In Proceedings of the ACAIB 2023: The 3rd International Conference on Automation Control, Algorithm, and Intelligent Bionics, Xiamen, China, 28–30 April 2023. [Google Scholar]
- Tong, H. An adaptive error constraint line-of-sight guidance and finite-time backstepping control for unmanned surface vehicles. Ocean Eng. 2023, 285, 115298. [Google Scholar] [CrossRef]
- Fossen, T.I. An adaptive line-of-sight (ALOS) guidance law for path following of aircraft and marine craft. IEEE Trans. Control Syst. Technol. 2023, 31, 2887–2894. [Google Scholar] [CrossRef]
- Hong, Z.; Wang, X.; Li, M.; Gu, Y.; Zhao, J.; Cao, X. Predictive Path Following for Unmanned Surface Vessel Based on Adaptive Line-of-Sight. In Proceedings of the CCC 2023: The 42nd Chinese Control Conference, Tianjin, China, 24–26 July 2023. [Google Scholar]
- Papelis, Y.; Weate, M. Operations Architecture and Vector Field Guidance for the Riverscout Subscale Unmanned Surface Vehicle. In Proceedings of the DHSS 2013: The 3rd International Defense and Homeland Security Simulation Workshop, Athens, Greece, 25–27 September 2013. [Google Scholar]
- Niu, H.; Lu, Y.; Savvaris, A.; Tsourdos, A. Efficient path following algorithm for unmanned surface vehicle. In Proceedings of the OCEANS 2016, Shanghai, China, 10–13 April 2016. [Google Scholar]
- Woo, J.; Kim, N. Vector field based guidance method for docking of an unmanned surface vehicle. In Proceedings of the PACOMS 2016: The 12th Pacific-Asia Offshore Mechanics Symposium, Gold Coast, Australia, 4–7 October 2016. [Google Scholar]
- Caharija, W.; Pettersen, K.Y.; Calado, P.; Braga, J. A comparison between the ILOS guidance and the vector field guidance. IFAC-PapersOnLine 2015, 48, 89–94. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, Y.; Zhao, G.; Wang, H.; Zhao, Y. Path-following control method for surface ships based on a new guidance algorithm. J. Mar. Sci. Eng. 2021, 9, 166. [Google Scholar] [CrossRef]
- Liu, Z.; Yu, L.; Xiang, Q.; Qian, T.; Lou, Z.; Xue, W. Research on USV Trajectory Tracking Method Based on LOS Algorithm. In Proceedings of the 2021 14th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 11–12 December 2021; pp. 408–411. [Google Scholar] [CrossRef]
- Gonzalez-Garcia, A.; Castañeda, H. Guidance and control based on adaptive sliding mode strategy for a USV subject to uncertainties. IEEE J. Ocean. Eng. 2021, 46, 1144–1154. [Google Scholar] [CrossRef]
- Xu, H.T.; Guedes Soares, C. Waypoint-following for a marine surface ship model based on vector field guidance law. Marit. Technol. Eng. 2016, 3, 409–418. [Google Scholar]
- Gonzalez-Garcia, A.; Castañeda, H.; Garrido, L. USV Path-Following Control Based On Deep Reinforcement Learning and Adaptive Control. In Proceedings of the Global Oceans 2020: Singapore—U.S. Gulf Coast, Biloxi, MS, USA, 5–30 October 2020; pp. 1–7. [Google Scholar]
- Zhao, Y.; Qi, X.; Incecik, A.; Ma, Y.; Li, Z. Broken lines path following algorithm for a water-jet propulsion USV with disturbance uncertainties. Ocean Eng. 2020, 201, 107118. [Google Scholar] [CrossRef]
- Mou, J.; He, Y.; Zhang, B.; Li, S.; Xiong, Y. Path Following of a Water-Jetted USV Based on Maneuverability Tests. J. Mar. Sci. Eng. 2020, 8, 354. [Google Scholar] [CrossRef]
- Yang, Z.; Lai, S.; Hong, X.; Shi, Y.; Cheng, Y.; Qing, C. DFAEN: Double-order knowledge fusion and attentional encoding network for texture recognition. Expert Syst. Appl. 2022, 209, 118223. [Google Scholar] [CrossRef]
- Xu, Z.; Hong, X.; Chen, T.; Yang, Z.; Shi, Y. Scale-aware squeeze-and-excitation for lightweight object detection. IEEE Robot. Autom. Lett. 2022, 8, 49–56. [Google Scholar] [CrossRef]
- Zhong, W.; Li, H.; Meng, Y.; Yang, X.; Feng, Y.; Ye, H.; Liu, W. USV path following controller based on DDPG with composite state-space and dynamic reward function. Ocean Eng. 2022, 266, 112449. [Google Scholar] [CrossRef]
- Han, Z.; Wang, Y.; Sun, Q. Straight-path following and formation control of USVs using distributed deep reinforcement learning and adaptive neural network. IEEE/CAA J. Autom. Sin. 2023, 10, 572–574. [Google Scholar] [CrossRef]
- Zhu, D.; Pan, Y.-J.; Wang, T.; Liu, S.; Pei, W. Improved Line-of-Sight Path Following Control for Underactuated USVs with Unknown Parameters Using Q-learning. In Proceedings of the 2024 IEEE 7th International Conference on Industrial Cyber-Physical Systems (ICPS), St. Louis, MO, USA, 12–15 May 2024; pp. 1–6. [Google Scholar]
- Hong, S.M.; Ha, K.N.; Kim, J.Y. Dynamics modeling and motion simulation of usv/uuv with linked underwater cable. J. Mar. Sci. Eng. 2020, 8, 318. [Google Scholar] [CrossRef]
- Setiawan, F.A.; Kadir, R.E.A.; Gamayanti, N.; Santoso, A.; Bilfaqih, Y.; Hidayat, Z. Dynamic modelling and controlling unmanned surface vehicle. In Proceedings of the SIDIIC 2019: The Sustainable Islands Development Initative International Conference, Surabaya, Indonesia, 2–3 September 2019. [Google Scholar]
- Liu, T.; Dong, Z.; Du, H.; Song, L.; Mao, Y. Path following control of the underactuated USV based on the improved line-of-sight guidance algorithm. Pol. Marit. Res. 2017, 24, 3–11. [Google Scholar] [CrossRef]
- Mu, D.; Wang, G.; Fan, Y.; Sun, X.; Qiu, B. Modeling and identification for vector propulsion of an unmanned surface vehicle: Three degrees of freedom model and response model. Sensors 2018, 18, 1889. [Google Scholar] [CrossRef] [PubMed]
- Sonnenburg, C.R.; Woolsey, C.A. Modeling, identification, and control of an unmanned surface vehicle. J. Field Robot. 2013, 30, 371–398. [Google Scholar] [CrossRef]
- Ueno, M.; Tsukada, Y. Estimation of full-scale propeller torque and thrust using free-running model ship in waves. Ocean Eng. 2016, 120, 30–39. [Google Scholar] [CrossRef]
- Öztürk, O.B.; Başar, E. Multiple linear regression analysis and artificial neural networks based decision support system for energy efficiency in shipping. Ocean Eng. 2022, 243, 110209. [Google Scholar] [CrossRef]
- Taktak-Meziou, M.; Ghommam, J.; Derbel, N. Adaptive backstepping neural network approach to ship course control. In Proceedings of the SSD 2011: The 8th International Multi-Conference on Systems, Signals and Devices, Sousse, Tunisia, 22–25 March 2011. [Google Scholar]
- Wang, C.; Zhang, X.; Cong, L.; Li, J.; Zhang, J. Research on intelligent collision avoidance decision-making of unmanned ship in unknown environments. Evol. Syst. 2019, 10, 649–658. [Google Scholar] [CrossRef]
- Du, Y.; Zhang, X.; Cao, Z.; Wang, S.; Liang, J.; Zhang, F.; Tang, J. An optimized path planning method for coastal ships based on improved DDPG and DP. J. Adv. Transp. 2021, 2021, 7765130. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Length overall | 8 m |
| Extreme breadth | 2.3 m |
| Load draft | 0.55 m |
| Maximum speed | 25 kn |
| Propeller diameter | |
| Maximum propulsion angle | 30° |
| Parameter | Value |
|---|---|
| Number of neurons in the hidden layer | 256 |
| Optimizer | Adam |
| Network learning rate | 0.0001 |
| Soft update factor | 0.005 |
| Reward discount factor | 0.99 |
| Batch size | 256 |
| Experience replay pool size | 1 × 106 |
| Parameter | Value |
|---|---|
| Predicted step length | 10 |
| Dwell time | 0.1 s |
| Propulsion angle constraints | |
| Propulsion angular velocity constraint | |
| Weight parameters | 1 |
| Weight parameters | 1 |
| Parameter | Value |
|---|---|
| Starting point of the path | (0, 0) |
| End point of the path | (0, 500) |
| Direction angle of the path | 90° |
| Initial position of the USV | (40, 0) |
| Initial heading angle of the USV | 0° |
| Parameter | Value |
|---|---|
| Front visual distance (m) | 20 |
| The adaptive gain coefficient | 0.0013 |
| Observer gain coefficient | 0.2 |
| Determine radius (m) | 8 |
| 0.83 | |
| 0 | |
| 1.1 |
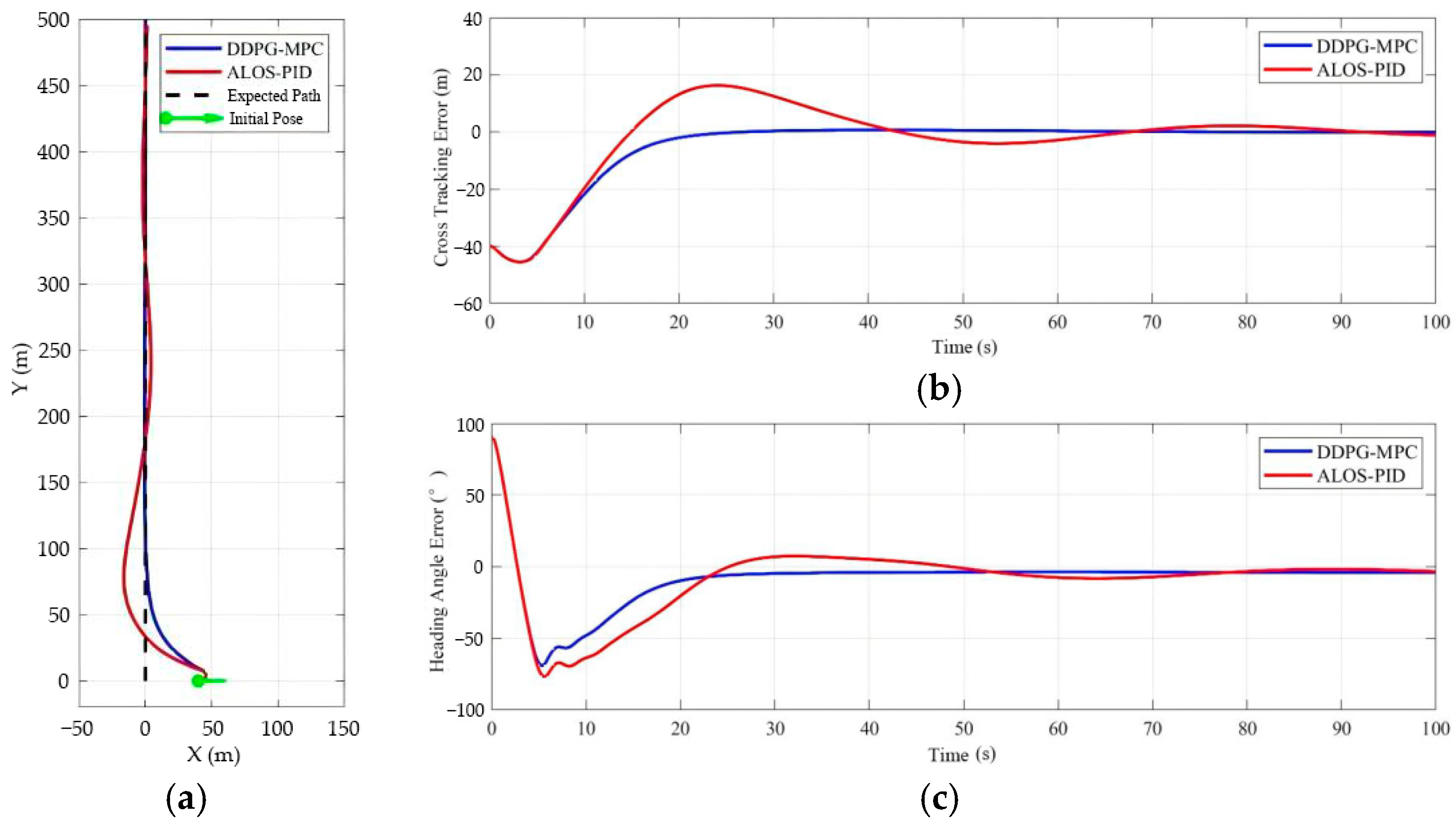
| Algorithm | Average Cross Error (m) | Average Heading Angle Error (°) |
|---|---|---|
| ALOS-PID | 7.871 | 14.0 |
| DDPG-MPC (Ours) | 4.955 | 11.1 |
| Parameter | Value |
|---|---|
| Knuckle point of the path | (0, 0), (0, 300), (50, 300), (50, 0), (100, 0), (100, 300), (150, 300), (150, 0), (200, 0), (200, 300) |
| Initial position of the USV | (−30, −30) |
| Initial heading angle of the USV | 0° |
| Agorithm | Average Cross Error (m) | Average Heading Angle Error (°) |
|---|---|---|
| ALOS-PID | 4.801 | 10.8 |
| DDPG-MPC (Ours) | 4.394 | 11.3 |
| Parameter | Value |
|---|---|
| The latitude and longitude of the path point | (N 22.704023, E 113.644455), (N 22.700570, E 113.646854), (N 22.694336, E 113.648297), (N 22.690591, E 113.645698), (N 22.689223, E 113.648798) |
| Initial position of the USV | The latitude and longitude: (N 22.704600, E 113.644300) |
| Initial heading angle of the USV | 20.0° |
| Algorithm | Average Cross Error (m) | Average Heading Angle Error (°) |
|---|---|---|
| ALOS-PID | 7.233 | 34.6 |
| DDPG-MPC (Ours) | 6.747 | 13.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, B.; Chen, Y.; Hong, X.; Luo, H.; Chen, G. Research on Path-Following Technology of a Single-Outboard-Motor Unmanned Surface Vehicle Based on Deep Reinforcement Learning and Model Predictive Control Algorithm. J. Mar. Sci. Eng. 2024, 12, 2321. https://doi.org/10.3390/jmse12122321
Cui B, Chen Y, Hong X, Luo H, Chen G. Research on Path-Following Technology of a Single-Outboard-Motor Unmanned Surface Vehicle Based on Deep Reinforcement Learning and Model Predictive Control Algorithm. Journal of Marine Science and Engineering. 2024; 12(12):2321. https://doi.org/10.3390/jmse12122321
Chicago/Turabian StyleCui, Bin, Yuanming Chen, Xiaobin Hong, Hao Luo, and Guanqiao Chen. 2024. "Research on Path-Following Technology of a Single-Outboard-Motor Unmanned Surface Vehicle Based on Deep Reinforcement Learning and Model Predictive Control Algorithm" Journal of Marine Science and Engineering 12, no. 12: 2321. https://doi.org/10.3390/jmse12122321
APA StyleCui, B., Chen, Y., Hong, X., Luo, H., & Chen, G. (2024). Research on Path-Following Technology of a Single-Outboard-Motor Unmanned Surface Vehicle Based on Deep Reinforcement Learning and Model Predictive Control Algorithm. Journal of Marine Science and Engineering, 12(12), 2321. https://doi.org/10.3390/jmse12122321