
MrisNet: Robust Ship Instance Segmentation in Challenging Marine Radar Environments


Abstract
:1. Introduction
- (1)
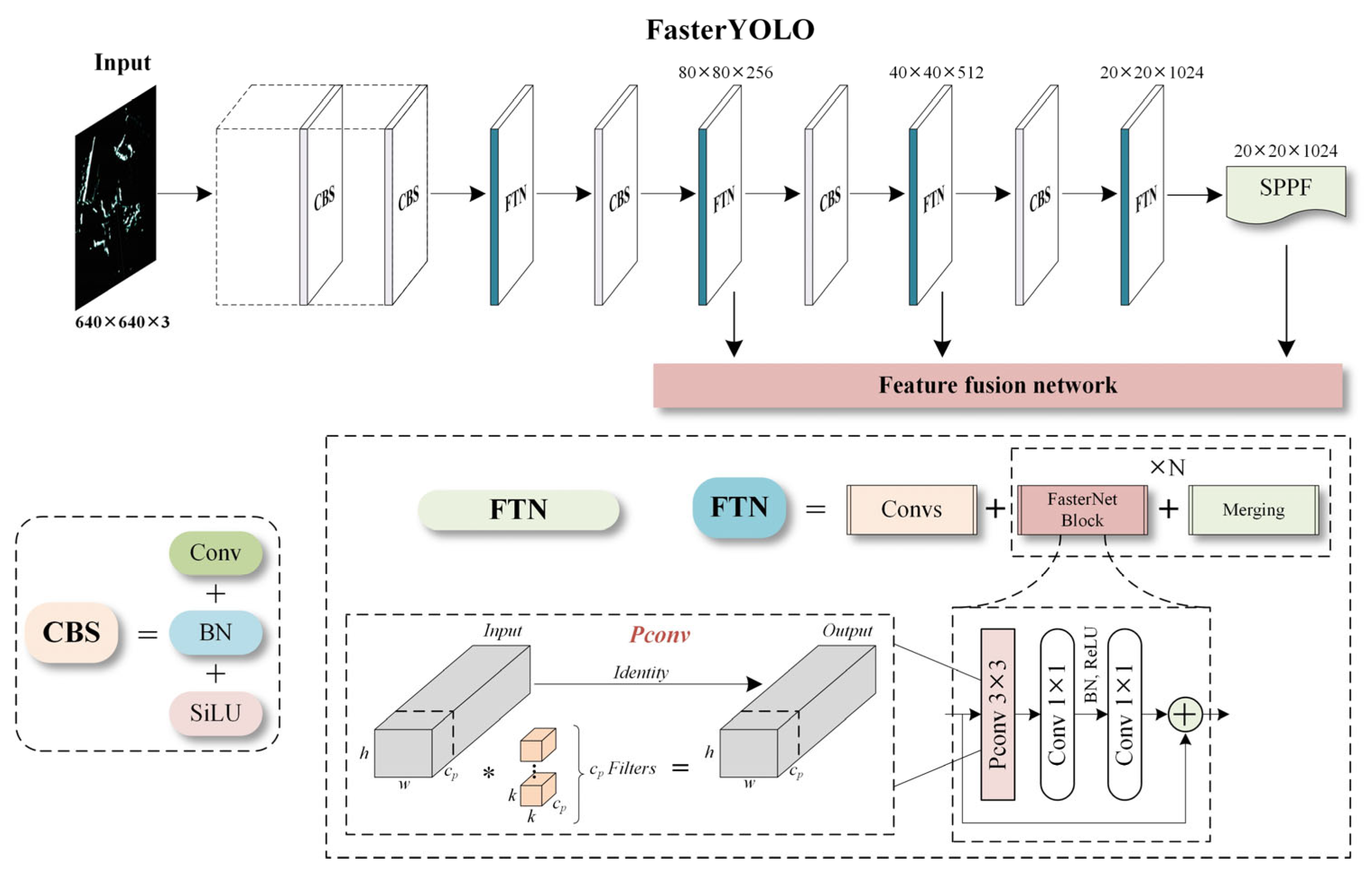
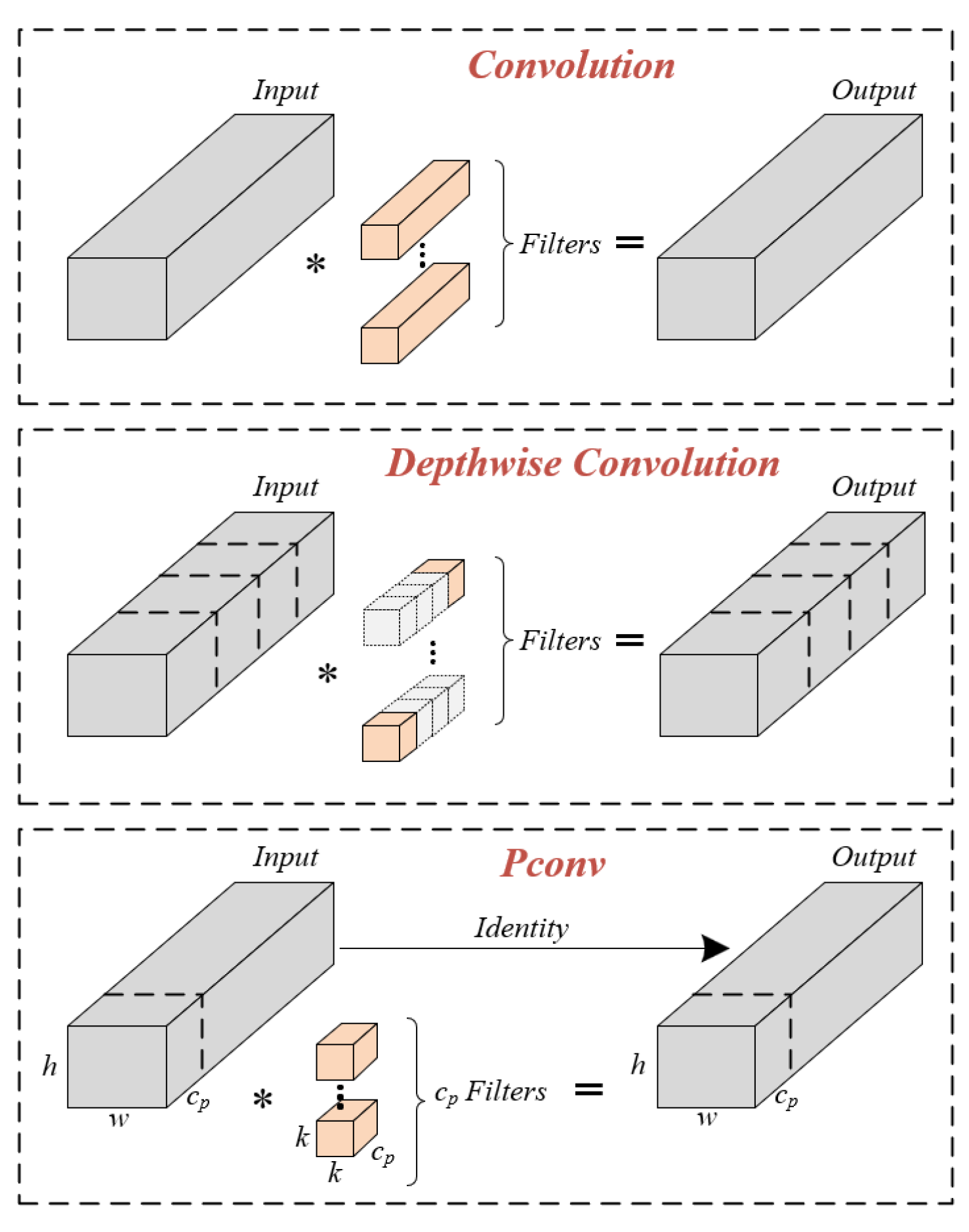
- We enhance the feature network to extract crucial ship features by employing more efficient convolutional modules.
- (2)
- A convolutional enhancement method that incorporates channel correlations is introduced to further enhance the generalization ability of the feature network.
- (3)
- An attention mechanism with contextual awareness is utilized to enhance the multi-scale feature fusion structure, enriching the representation of convolutional features at different levels and effectively integrating micro-level and global-level ship features.
- (4)
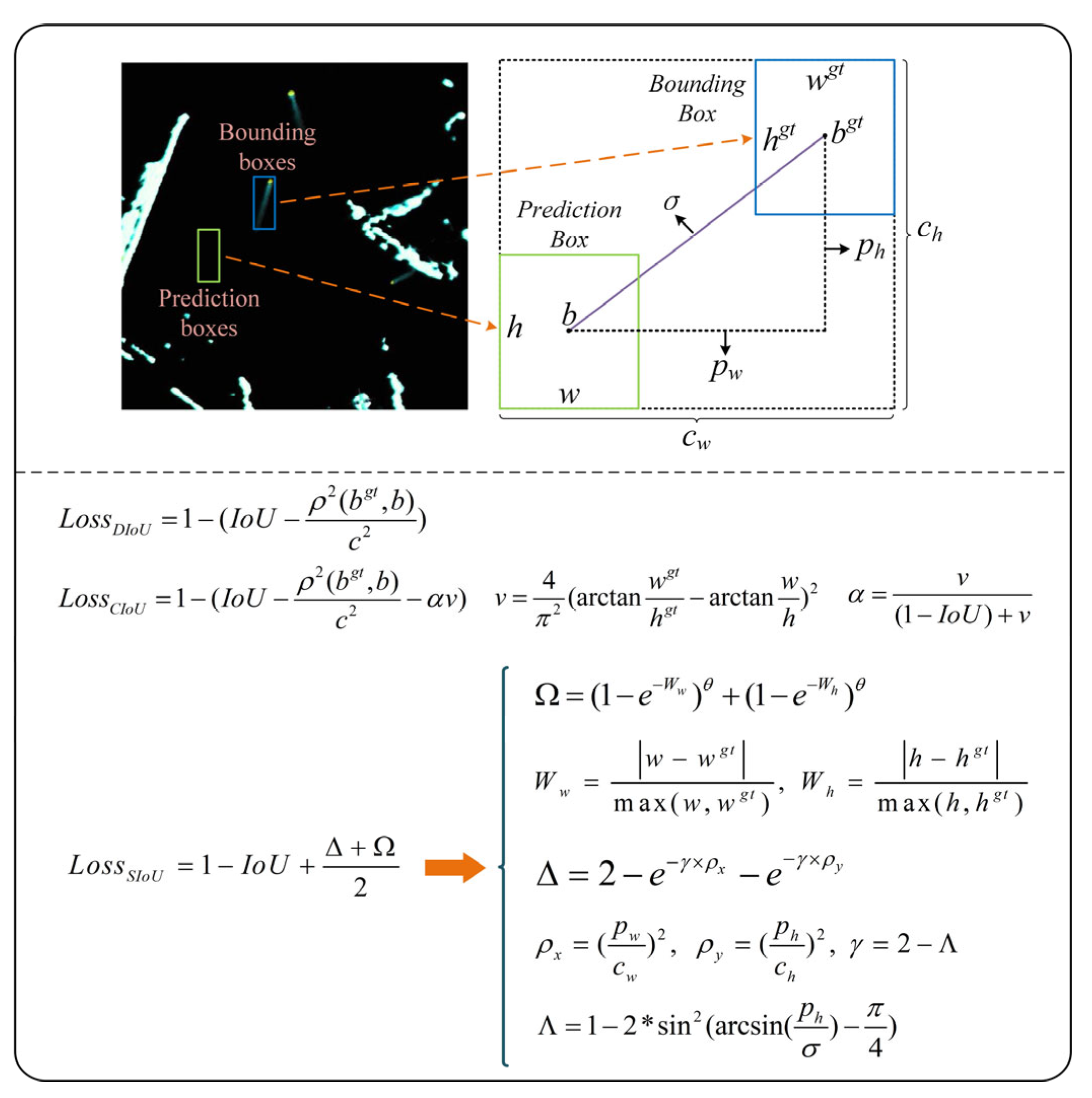
- The positioning loss estimation of predicted box is optimized to improve the precision of ship localization and enhance the segmentation performance for dense ship scenarios.
- (5)
- To evaluate the effectiveness of various algorithms for ship segmentation in radar images, a high-quality dataset called RadarSeg, consisting of 1280 radar images, is constructed.
2. Related Works
2.1. Ship Identification Methods under Radar and Other Scenarios
2.2. Optimization Method for Ship Identification Research
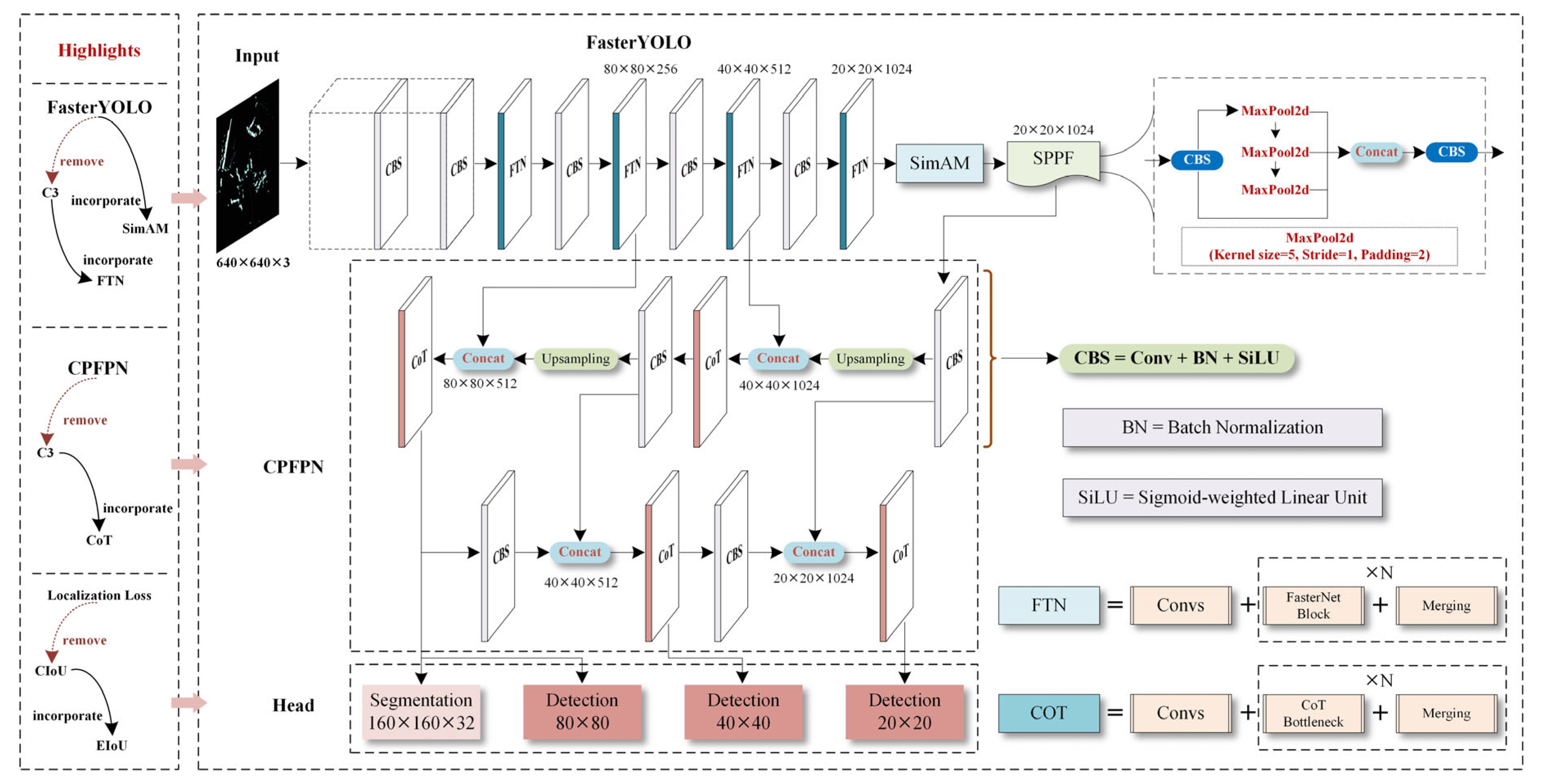
3. A Proposed Method
3.1. Feature Extraction Network
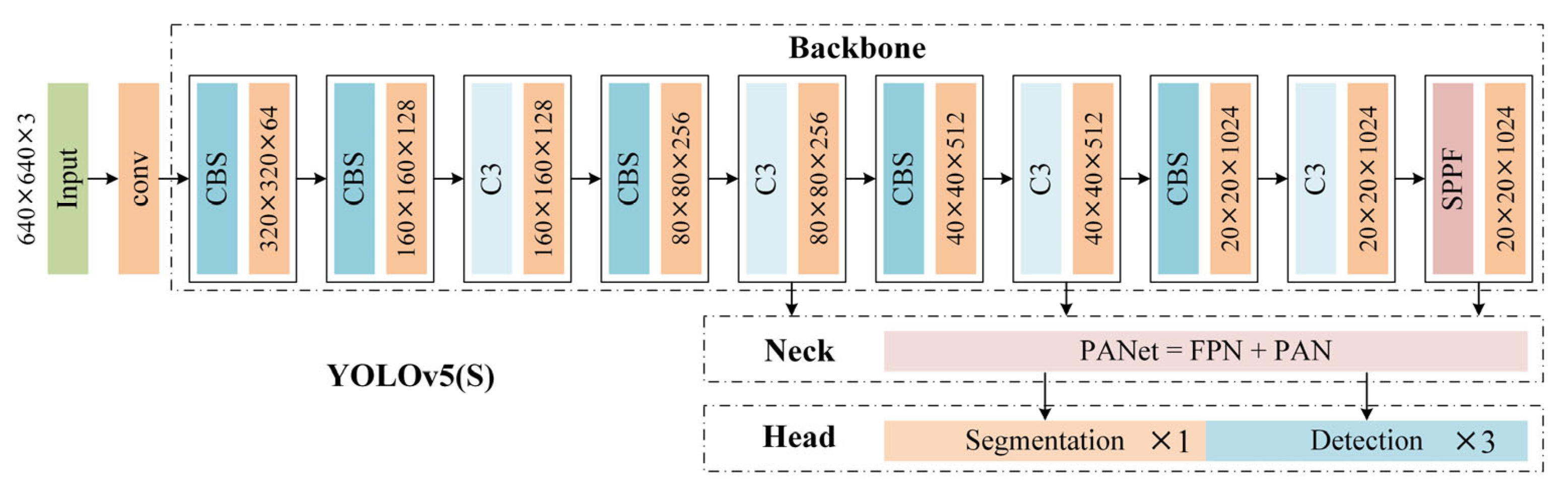
3.1.1. YOLOv5(S) Network
3.1.2. The Main Architecture of FasterYOLO Network
3.1.3. Feature Enhancement Mechanism Based on SimAM Attention
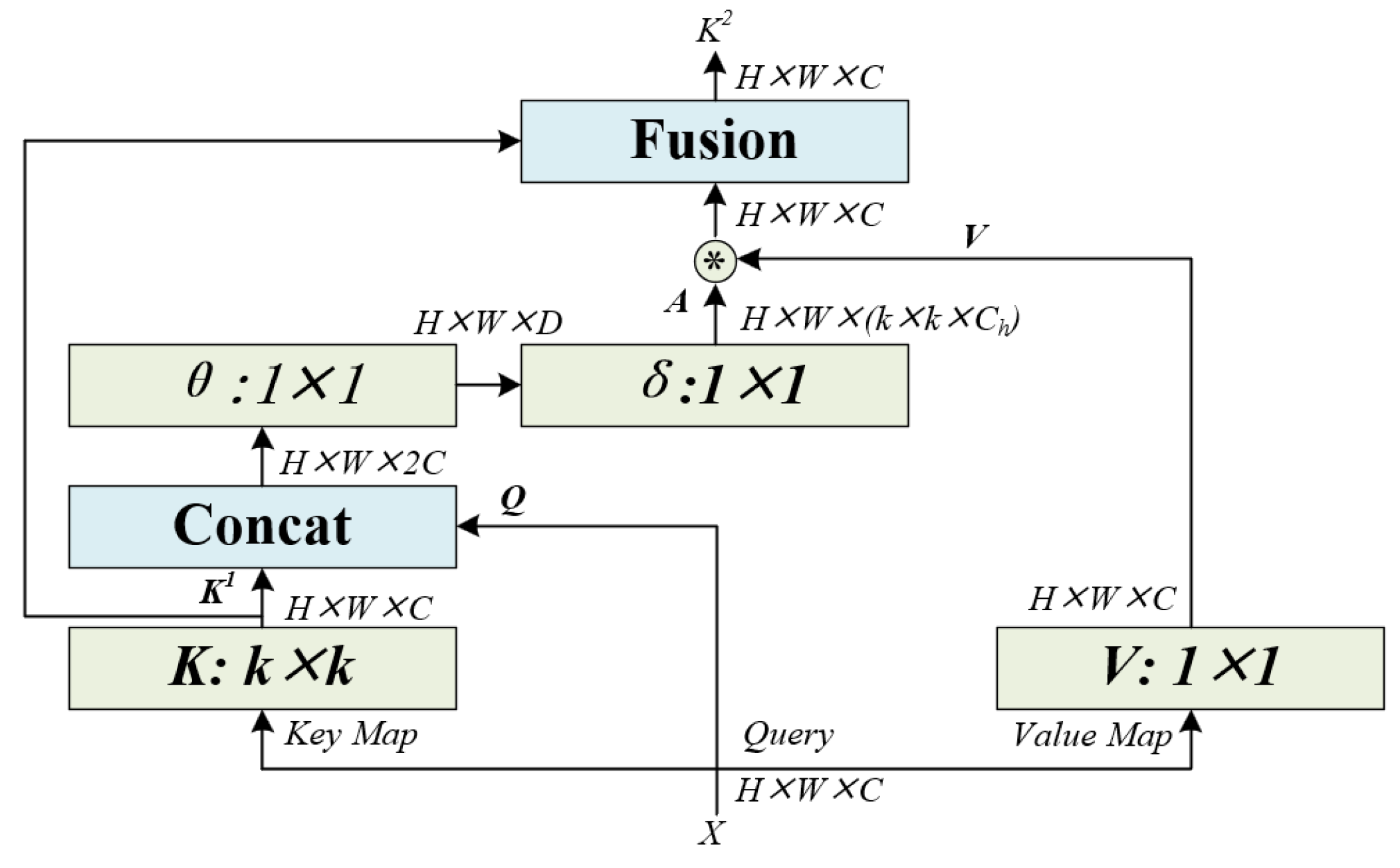
3.2. Feature Fusion Network
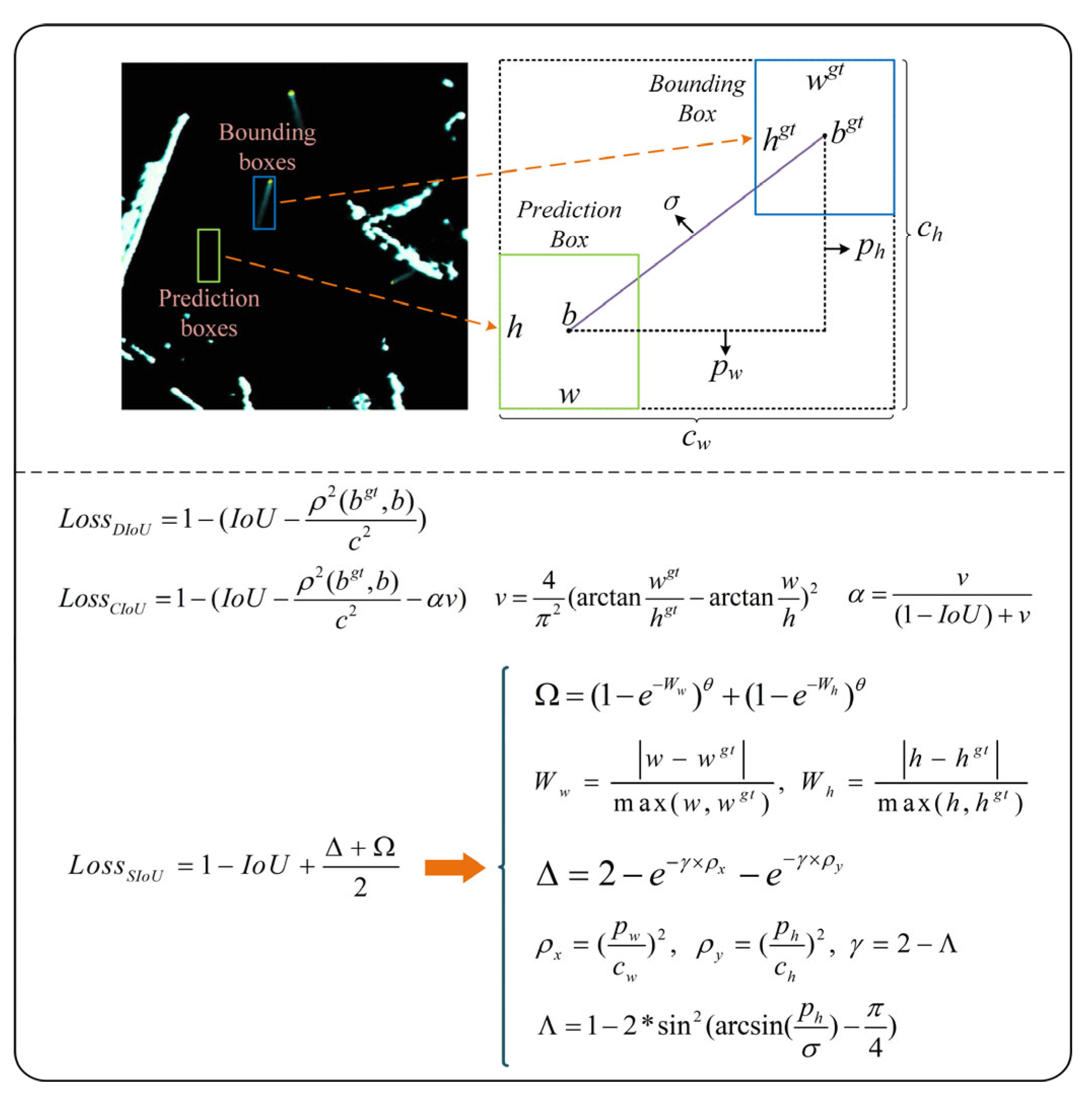
3.3. Ship Prediction Module
4. A Case Study
4.1. Dataset
4.2. Training Optimization Methods
4.3. Experimental Environment and Training Results
4.4. Comparisons and Discussion
4.4.1. Experimental Analysis of Different Algorithms
4.4.2. Ablation Experiments
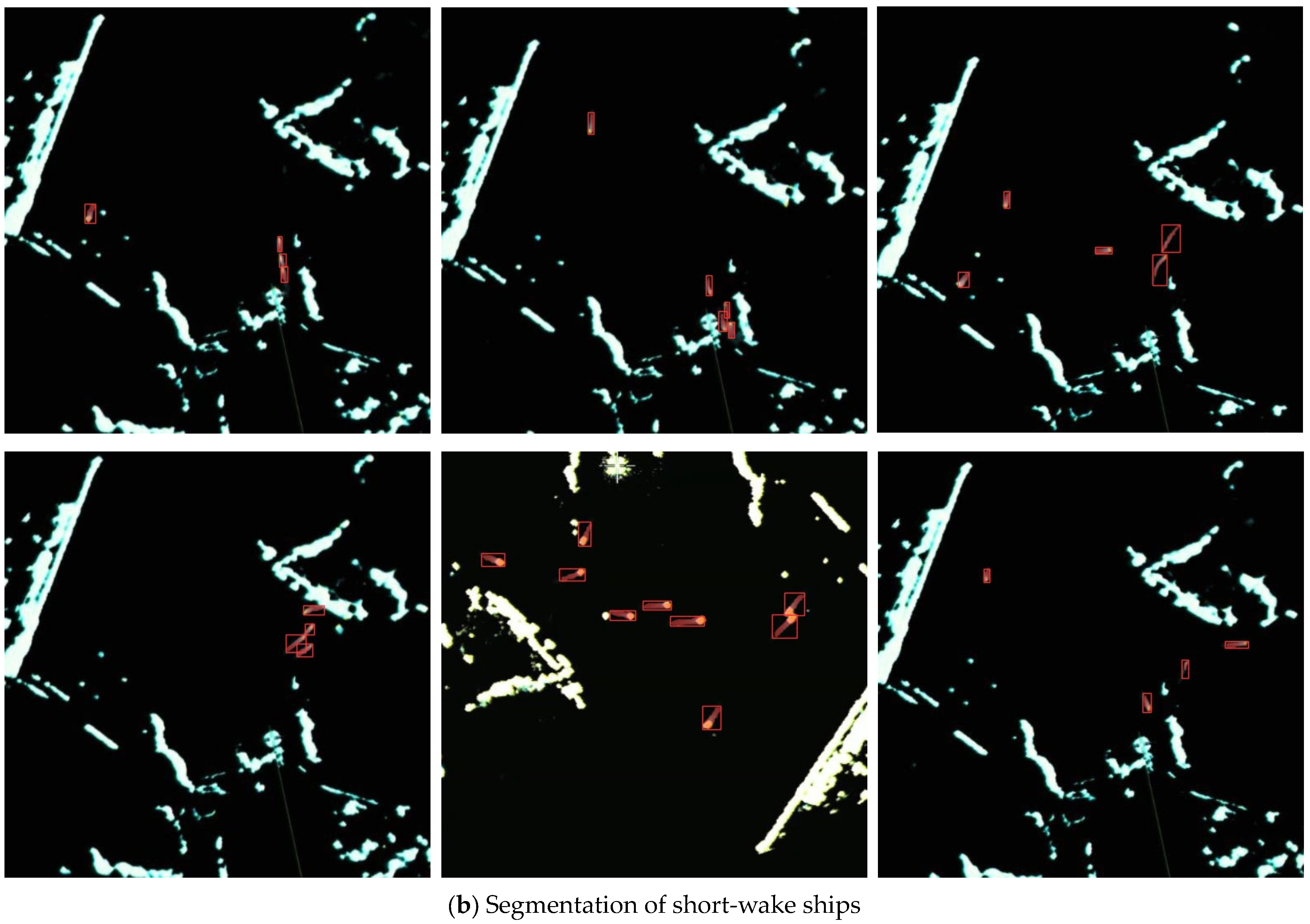
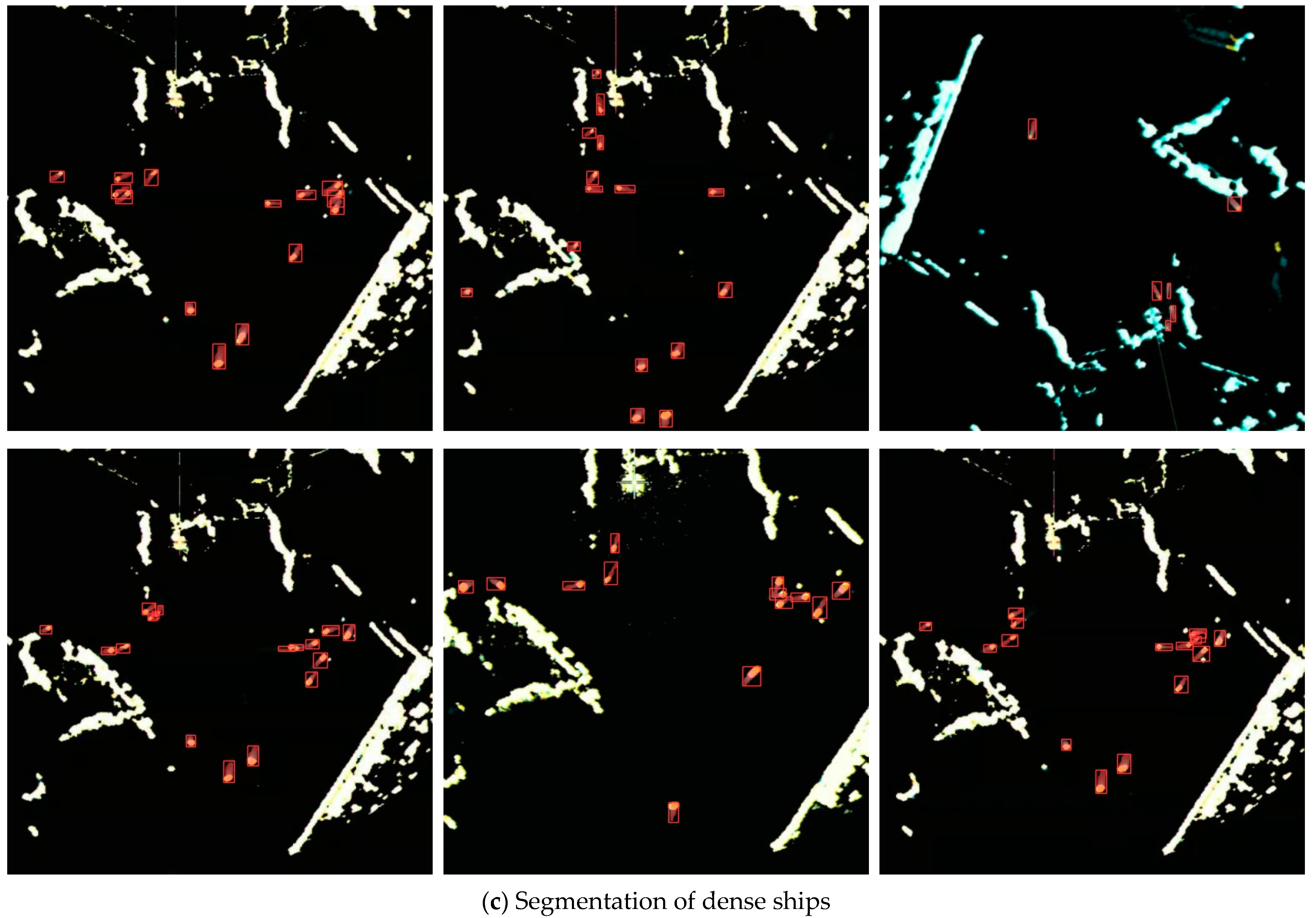
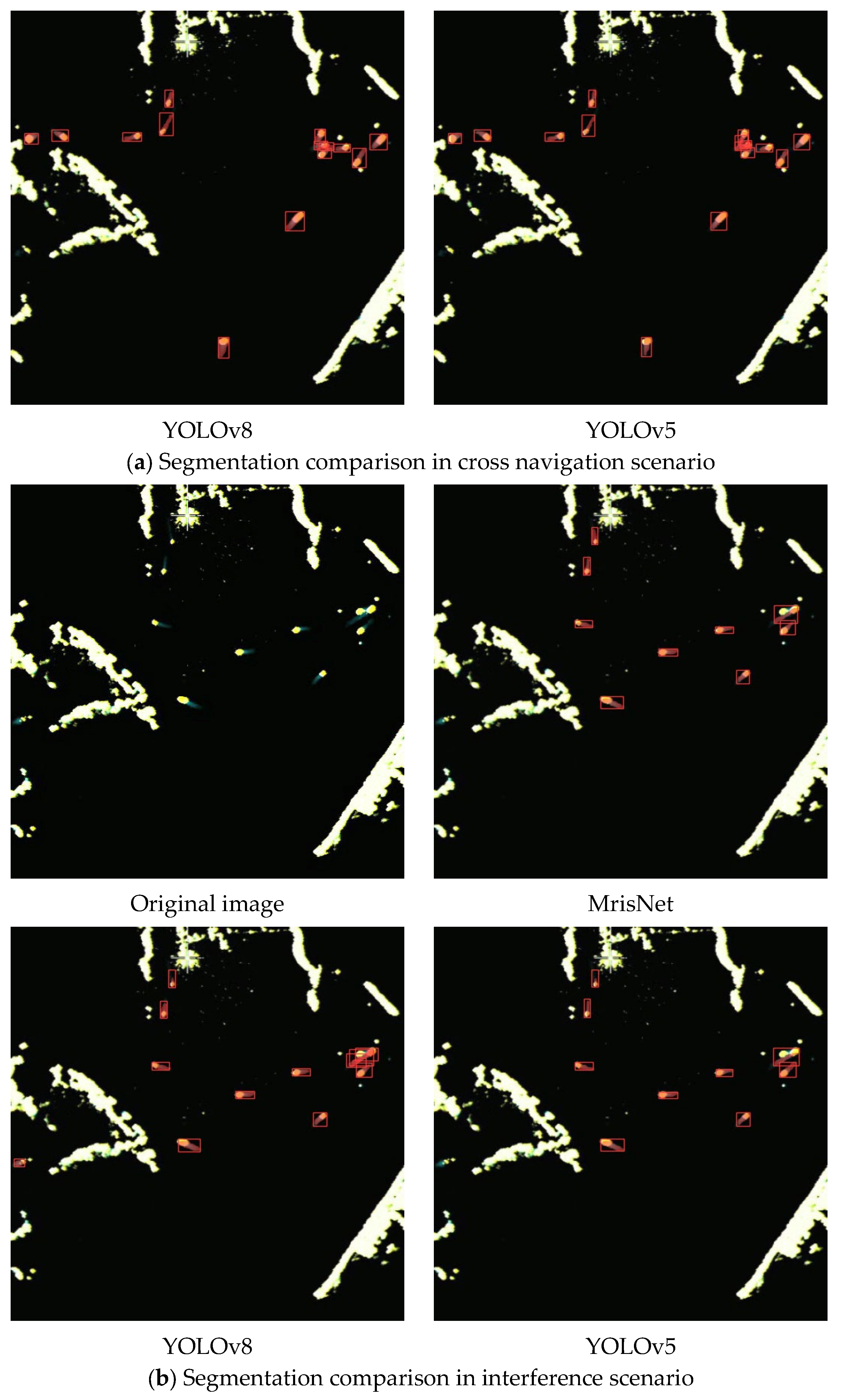
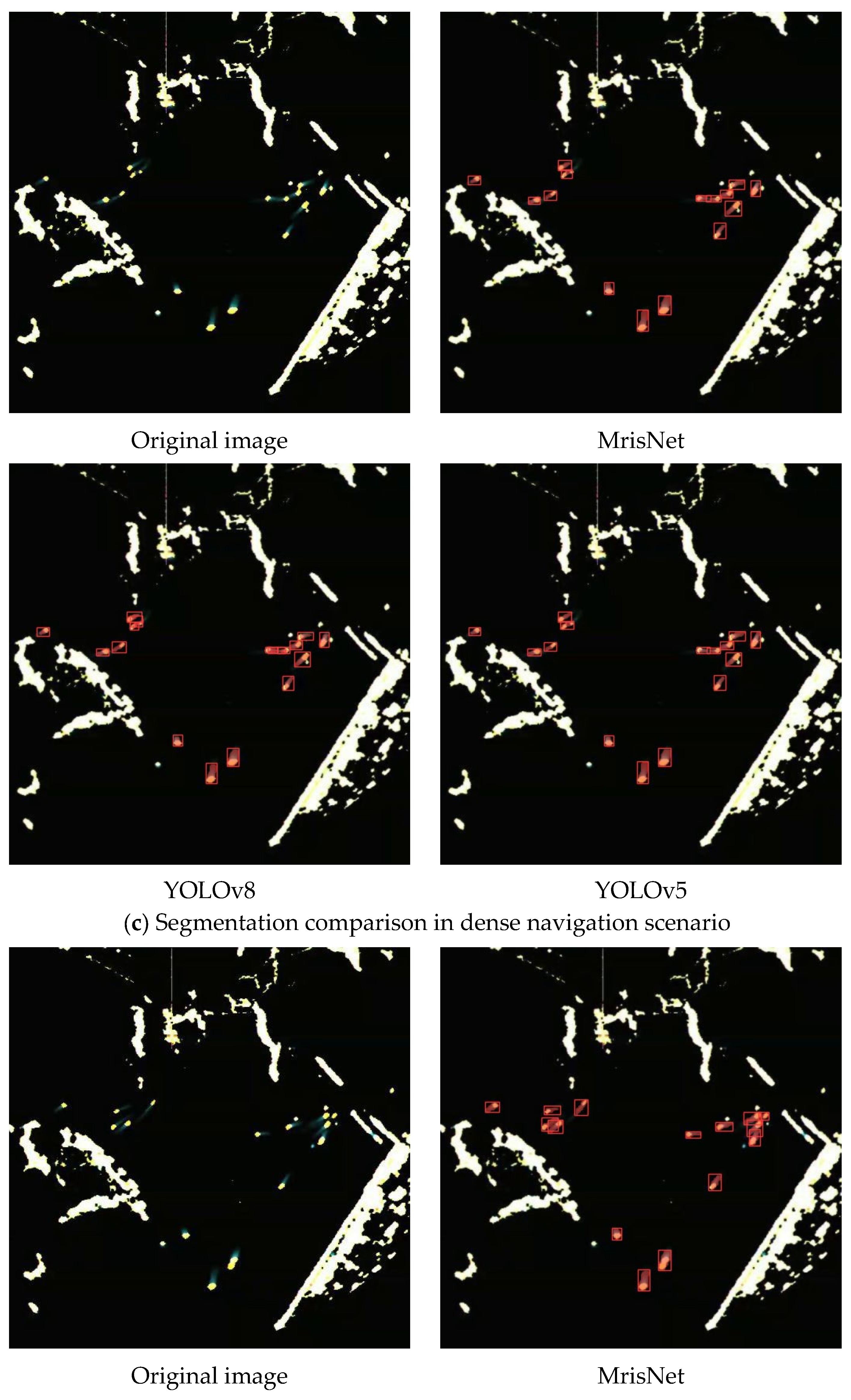
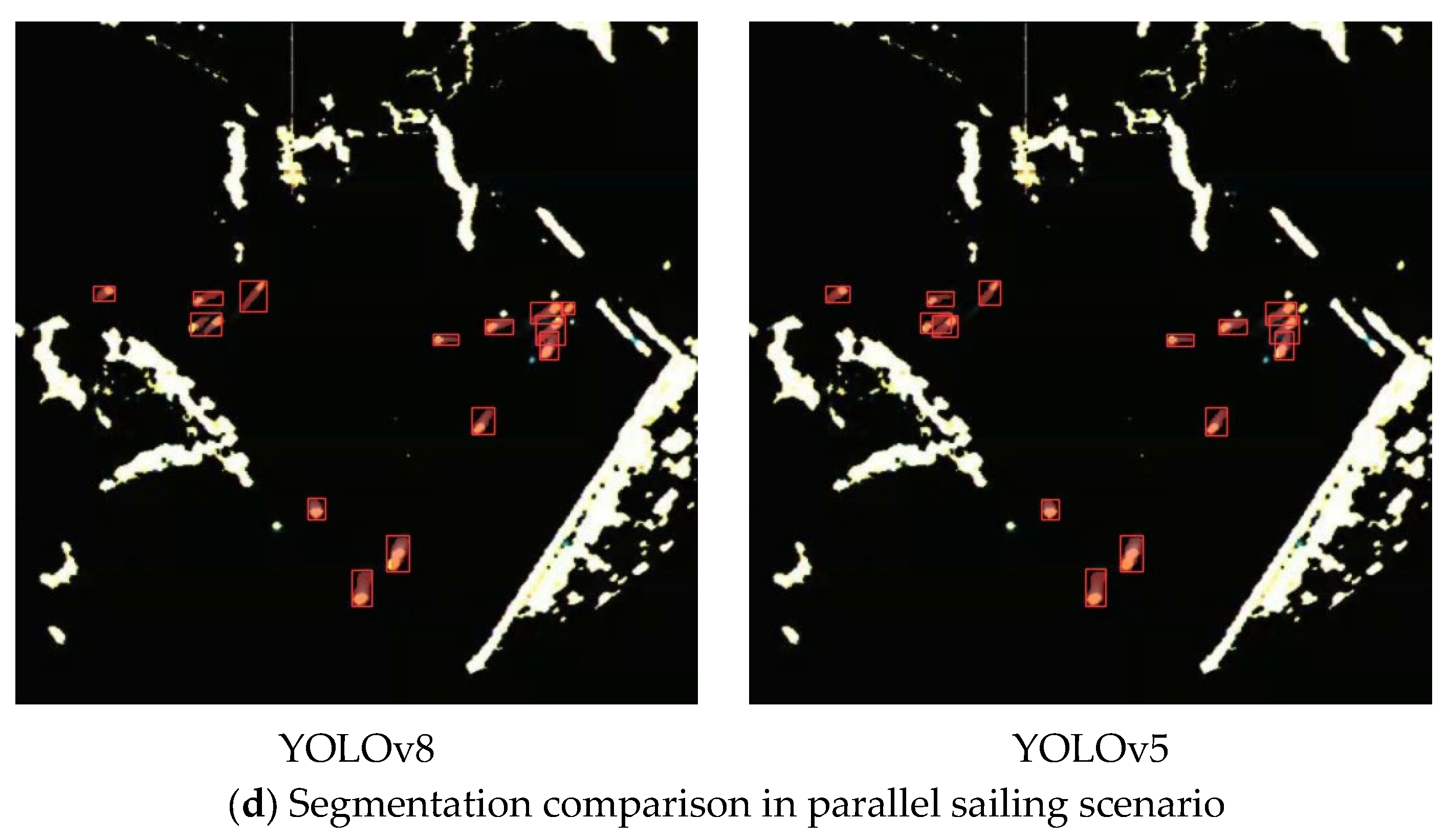
4.4.3. Comparisons in Radar Images
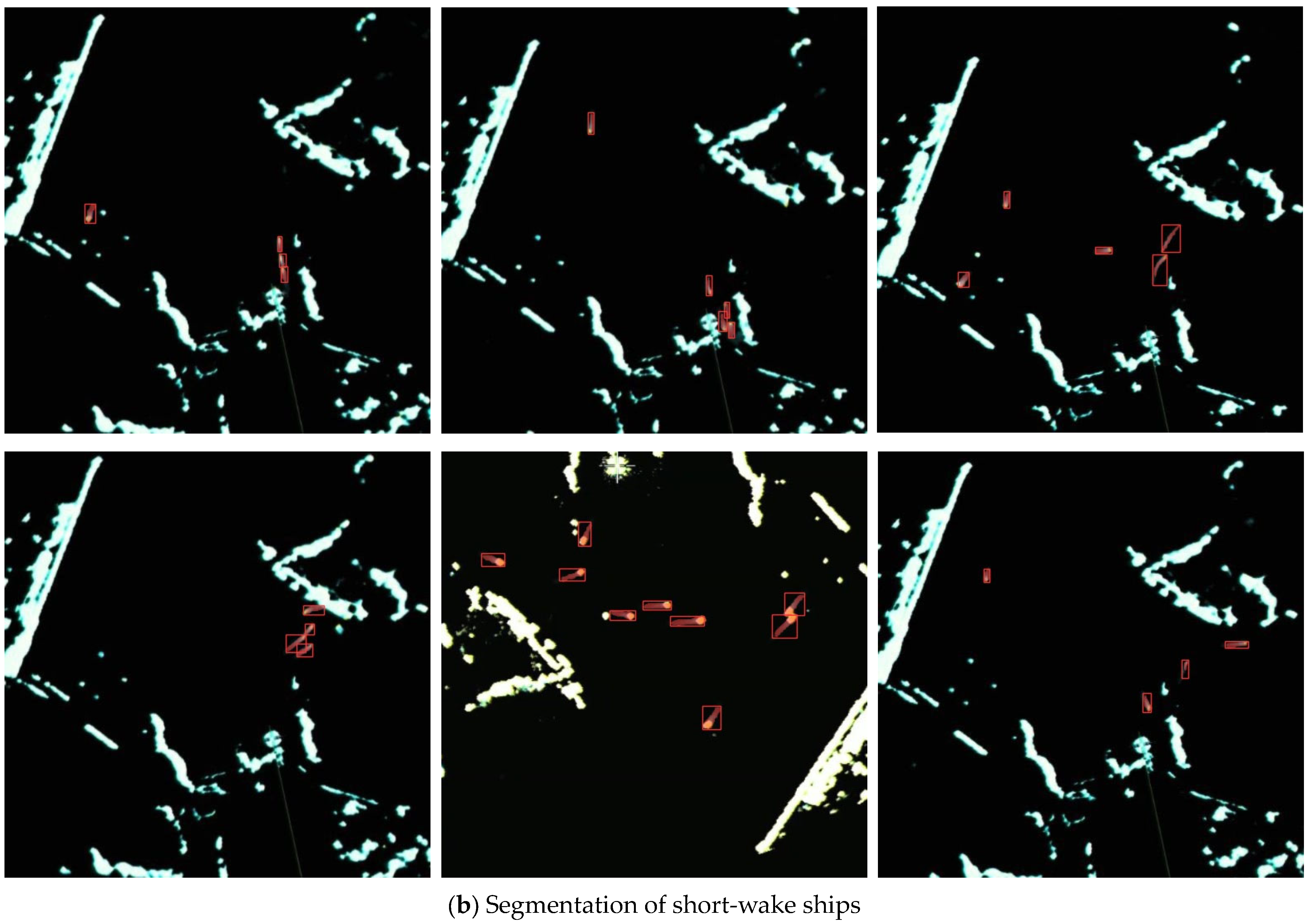
4.4.4. Comparisons of Small-Scale Ship Segmentation
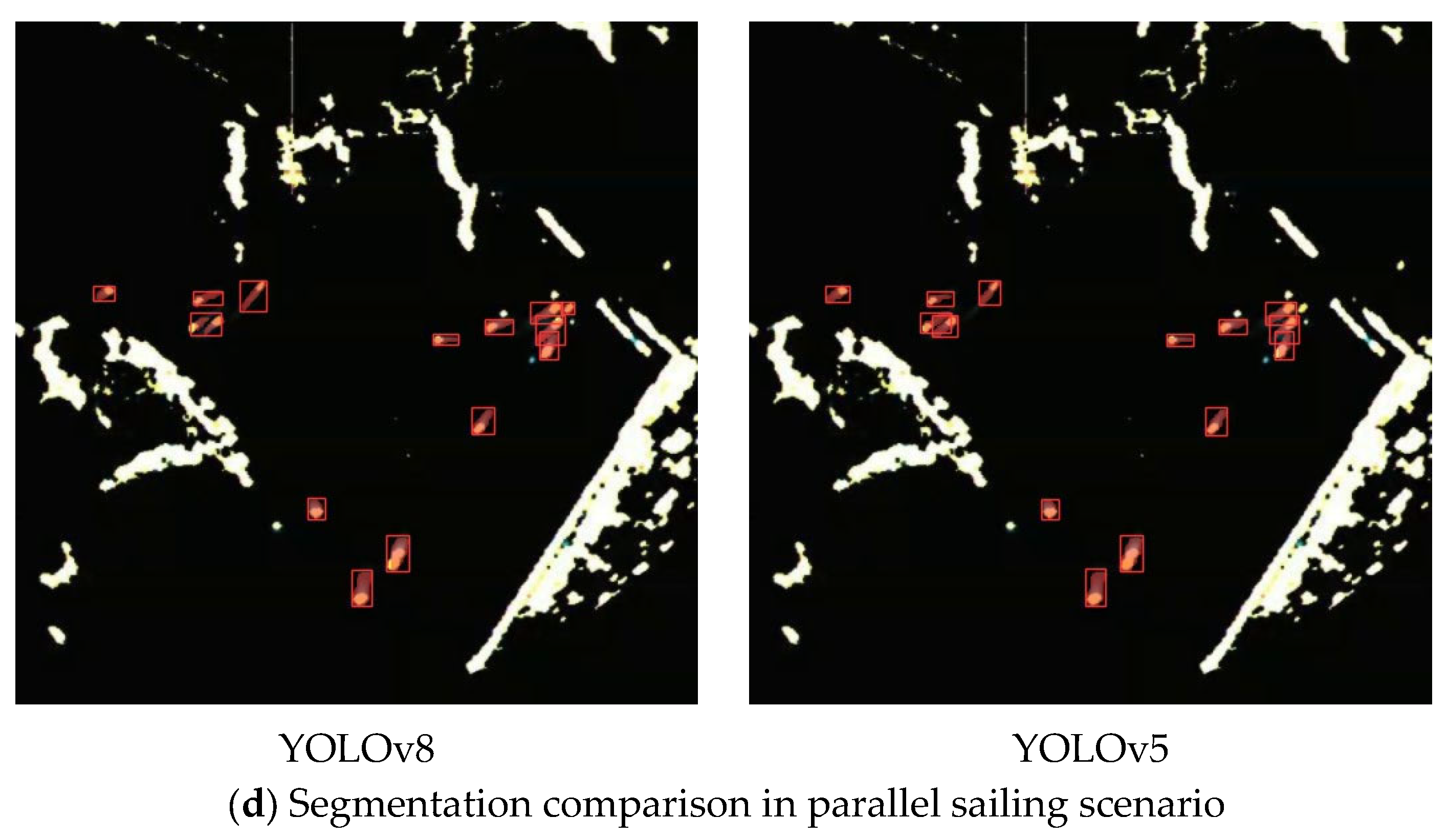
4.4.5. Ship Identification in Extreme Environments
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wei, Y.; Liu, Y.; Lei, Y.; Lian, R.; Lu, Z.; Sun, L. A new method of rainfall detection from the collected X-band marine radar images. Remote Sens. 2022, 14, 3600. [Google Scholar] [CrossRef]
- Li, B.; Xu, J.; Pan, X.; Chen, R.; Ma, L.; Yin, J.; Liao, Z.; Chu, L.; Zhao, Z.; Lian, J. Preliminary investigation on marine radar oil spill monitoring method using YOLO model. J. Mar. Sci. Eng. 2023, 11, 670. [Google Scholar] [CrossRef]
- Wen, B.; Wei, Y.; Lu, Z. Sea clutter suppression and target detection algorithm of marine radar image sequence based on spatio-temporal domain joint filtering. Entropy 2022, 24, 250. [Google Scholar] [CrossRef] [PubMed]
- He, W.; Ma, F.; Liu, X. A recognition approach of radar blips based on improved fuzzy c means. Eurasia J. Math. Sci. Technol. Educ. 2017, 13, 6005–6017. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, X.; Su, N.; Huang, Y.; Guan, J. False-alarm-controllable radar detection for marine target based on multi features fusion via CNNs. IEEE Sens. J. 2021, 21, 9099–9111. [Google Scholar] [CrossRef]
- Chen, X.; Mu, X.; Guan, J.; Liu, N.; Zhou, W. Marine target detection based on Marine-Faster R-CNN for navigation radar plane position indicator images. Front. Inf. Technol. Electron. Eng. 2022, 23, 630–643. [Google Scholar] [CrossRef]
- Wang, Y.; Shi, H.; Chen, L. Ship detection algorithm for SAR images based on lightweight convolutional network. J. Indian Soc. Remote Sens. 2022, 50, 867–876. [Google Scholar] [CrossRef]
- Li, S.; Fu, X.; Dong, J. Improved ship detection algorithm based on YOLOX for SAR outline enhancement image. Remote Sens. 2022, 14, 4070. [Google Scholar] [CrossRef]
- Zhao, C.; Fu, X.; Dong, J.; Qin, R.; Chang, J.; Lang, P. SAR ship detection based on end-to-end morphological feature pyramid network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4599–4611. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. HTC+ for SAR ship instance segmentation. Remote Sens. 2022, 14, 2395. [Google Scholar] [CrossRef]
- Zhao, D.; Zhu, C.; Qi, J.; Qi, X.; Su, Z.; Shi, Z. Synergistic attention for ship instance segmentation in SAR images. Remote Sens. 2021, 13, 4384. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Q.; Dong, Q.; Han, Z.; Luo, X.; Wei, D. Ship instance segmentation based on rotated bounding boxes for SAR images. Remote Sens. 2023, 15, 1324. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, X.; Wei, S.; Shi, J.; Ke, X.; Xu, X.; Zhan, X.; Zhang, T.; Zeng, T. Scale in scale for SAR ship instance segmentation. Remote Sens. 2023, 15, 629. [Google Scholar] [CrossRef]
- Sun, Y.; Su, L.; Yuan, S.; Meng, H. DANet: Dual-branch activation network for small object instance segmentation of ship images. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6708–6720. [Google Scholar] [CrossRef]
- Sun, Y.; Su, L.; Luo, Y.; Meng, H.; Li, W.; Zhang, Z.; Wang, P.; Zhang, W. Global Mask R-CNN for marine ship instance segmentation. Neurocomputing 2022, 480, 257–270. [Google Scholar] [CrossRef]
- Guo, M.; Guo, C.; Zhang, C.; Zhang, D.; Gao, Z. Fusion of ship perceptual information for electronic navigational chart and radar images based on deep learning. J. Navig. 2019, 73, 192–211. [Google Scholar] [CrossRef]
- Mao, D.; Zhang, Y.; Zhang, Y.; Pei, J.; Huang, Y.; Yang, J. An efficient anti-interference imaging technology for marine radar. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5101413. [Google Scholar] [CrossRef]
- Zhang, C.; Fang, M.; Yang, C.; Yu, R.; Li, T. Perceptual fusion of electronic chart and marine radar image. J. Mar. Sci. Eng. 2021, 9, 1245. [Google Scholar] [CrossRef]
- Dong, G.; Liu, H. A new model-data co-driven method for radar ship detection. IEEE Trans. Instrum. Meas. 2022, 71, 2508609. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Zhou, S.; Wang, Y.; Hou, Y. Arbitrary-oriented ship detection through center-head point extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5612414. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, W.; Quan, S.; Yang, H.; Xiong, H.; Zhang, Z.; Yu, W. Region-based polarimetric covariance difference matrix for PolSAR ship detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5222016. [Google Scholar] [CrossRef]
- Qi, X.; Lang, P.; Fu, X.; Qin, R.; Dong, J.; Liu, C. A regional attention-based detector for SAR ship detection. Remote Sens. Lett. 2022, 13, 55–64. [Google Scholar] [CrossRef]
- Yin, Y.; Cheng, X.; Shi, F.; Zhao, M.; Li, G.; Chen, S. An enhanced lightweight convolutional neural network for ship detection in maritime surveillance system. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5811–5825. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, don’t walk: Chasing higher flops for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Vienna, Austria, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics. Available online: https://github.com/ultralytics/yolov5 (accessed on 21 September 2023).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA; 2017; pp. 6000–6010. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Jocher, G. YOLO by Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 21 September 2023).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 9157–9166. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. arXiv 2020, arXiv:2003.10152. [Google Scholar]
- Peng, S.; Jiang, W.; Pi, H.; Li, X.; Bao, H.; Zhou, X. Deep snake for real-time instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8533–8542. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic feature pyramid network for object detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Box | Mask | |||||||
|---|---|---|---|---|---|---|---|---|
| Algorithms | P | R | mAP50 | mAP50-95 | P | R | mAP50 | mAP50-95 |
| YOLACT | 0.901 | 0.86 | 0.92 | 0.492 | 0.875 | 0.826 | 0.871 | 0.349 |
| SOLOv2 | 0.897 | 0.871 | 0.926 | 0.508 | 0.882 | 0.855 | 0.884 | 0.367 |
| Mask R-CNN | 0.97 | 0.975 | 0.991 | 0.717 | 0.938 | 0.942 | 0.952 | 0.495 |
| Deepsnake | 0.939 | 0.94 | 0.964 | 0.603 | 0.917 | 0.919 | 0.911 | 0.424 |
| Swin-Transformer (T) | 0.979 | 0.976 | 0.991 | 0.725 | 0.937 | 0.94 | 0.953 | 0.519 |
| HTC+ | 0.913 | 0.883 | 0.936 | 0.528 | 0.903 | 0.881 | 0.892 | 0.373 |
| SA R-CNN | 0.946 | 0.958 | 0.97 | 0.594 | 0.911 | 0.905 | 0.919 | 0.401 |
| YOLOv5(N) | 0.957 | 0.961 | 0.981 | 0.618 | 0.913 | 0.908 | 0.92 | 0.406 |
| YOLOv5(S) | 0.962 | 0.965 | 0.988 | 0.655 | 0.932 | 0.933 | 0.94 | 0.477 |
| YOLOv5(M) | 0.966 | 0.968 | 0.988 | 0.669 | 0.923 | 0.924 | 0.933 | 0.467 |
| YOLOv5(L) | 0.965 | 0.971 | 0.986 | 0.668 | 0.924 | 0.925 | 0.937 | 0.466 |
| YOLOv5(X) | 0.967 | 0.971 | 0.989 | 0.671 | 0.925 | 0.924 | 0.939 | 0.463 |
| YOLOv7 | 0.968 | 0.965 | 0.98 | 0.675 | 0.919 | 0.917 | 0.924 | 0.412 |
| YOLOv8(S) | 0.961 | 0.909 | 0.956 | 0.608 | 0.917 | 0.851 | 0.914 | 0.377 |
| YOLOv8(M) | 0.967 | 0.956 | 0.982 | 0.662 | 0.923 | 0.914 | 0.935 | 0.446 |
| YOLOv8(L) | 0.958 | 0.973 | 0.982 | 0.663 | 0.92 | 0.925 | 0.927 | 0.47 |
| YOLOv8(X) | 0.969 | 0.964 | 0.977 | 0.659 | 0.925 | 0.922 | 0.94 | 0.465 |
| Mris_APFN | 0.966 | 0.965 | 0.981 | 0.65 | 0.92 | 0.923 | 0.935 | 0.452 |
| MrisNet | 0.986 | 0.98 | 0.993 | 0.737 | 0.952 | 0.948 | 0.96 | 0.508 |
| Algorithms | PARAMs/(M) | GFLOPs |
|---|---|---|
| SOLOv2 | 61.3 | 232.6 |
| YOLACT | 53.72 | 240.2 |
| HTC+ | 95.53 | 1289.5 |
| SA R-CNN | 53.79 | 101.9 |
| Mask R-CNN | 62.74 | 244.8 |
| Swin-Transformer (T) | 88 | 745 |
| Deepsnake | 16.37 | 25.94 |
| YOLOv5(N) | 1.8 | 6.7 |
| YOLOv5(S) | 7.1 | 25.7 |
| YOLOv5(M) | 20.65 | 69.8 |
| YOLOv5(L) | 45.27 | 146.4 |
| YOLOv5(X) | 84.2 | 264 |
| YOLOv7 | 36.1 | 141.9 |
| YOLOv8(S) | 11.23 | 42.4 |
| YOLOv8(M) | 25.96 | 110 |
| YOLOv8(L) | 43.79 | 220.1 |
| YOLOv8(X) | 68.4 | 343.7 |
| Mris_APFN | 10.3 | 20.6 |
| MrisNet | 13.8 | 23.5 |
| Methods | Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | Model 7 |
|---|---|---|---|---|---|---|---|
| YOLOv5(S) | * | * | * | * | * | * | * |
| +FasterYOLO | * | * | * | * | * | * | |
| +SimAM | * | * | * | * | * | ||
| +CPFPN | * | * | * | * | |||
| +SIoU | * | ||||||
| +DIoU | * | ||||||
| +EIoU | * | ||||||
| Rmask | 0.933 | 0.937 | 0.94 | 0.945 | 0.944 | 0.94 | 0.948 |
| Pmask | 0.932 | 0.942 | 0.943 | 0.946 | 0.941 | 0.938 | 0.952 |
| mAP50 | 0.94 | 0.949 | 0.95 | 0.957 | 0.945 | 0.942 | 0.96 |
| mAP50-95 | 0.477 | 0.489 | 0.492 | 0.505 | 0.49 | 0.488 | 0.508 |
| Algorithms | Detected Ships | True Ships | False Alarms | Recall | Pr |
|---|---|---|---|---|---|
| YOLACT | 1296 | 1117 | 179 | 0.8007 | 0.8619 |
| YOLOv8(S) | 1288 | 1170 | 118 | 0.8387 | 0.9084 |
| Mask R-CNN | 1389 | 1299 | 90 | 0.9312 | 0.9352 |
| MRNet | 1382 | 1301 | 81 | 0.9326 | 0.9414 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, F.; Kang, Z.; Chen, C.; Sun, J.; Deng, J. MrisNet: Robust Ship Instance Segmentation in Challenging Marine Radar Environments. J. Mar. Sci. Eng. 2024, 12, 72. https://doi.org/10.3390/jmse12010072
Ma F, Kang Z, Chen C, Sun J, Deng J. MrisNet: Robust Ship Instance Segmentation in Challenging Marine Radar Environments. Journal of Marine Science and Engineering. 2024; 12(1):72. https://doi.org/10.3390/jmse12010072
Chicago/Turabian StyleMa, Feng, Zhe Kang, Chen Chen, Jie Sun, and Jizhu Deng. 2024. "MrisNet: Robust Ship Instance Segmentation in Challenging Marine Radar Environments" Journal of Marine Science and Engineering 12, no. 1: 72. https://doi.org/10.3390/jmse12010072
APA StyleMa, F., Kang, Z., Chen, C., Sun, J., & Deng, J. (2024). MrisNet: Robust Ship Instance Segmentation in Challenging Marine Radar Environments. Journal of Marine Science and Engineering, 12(1), 72. https://doi.org/10.3390/jmse12010072