
A Deep Reinforcement Learning-Based Path-Following Control Scheme for an Uncertain Under-Actuated Autonomous Marine Vehicle




Abstract
:1. Introduction
2. Preliminaries and Problem Statement
2.1. Reinforcement Learning
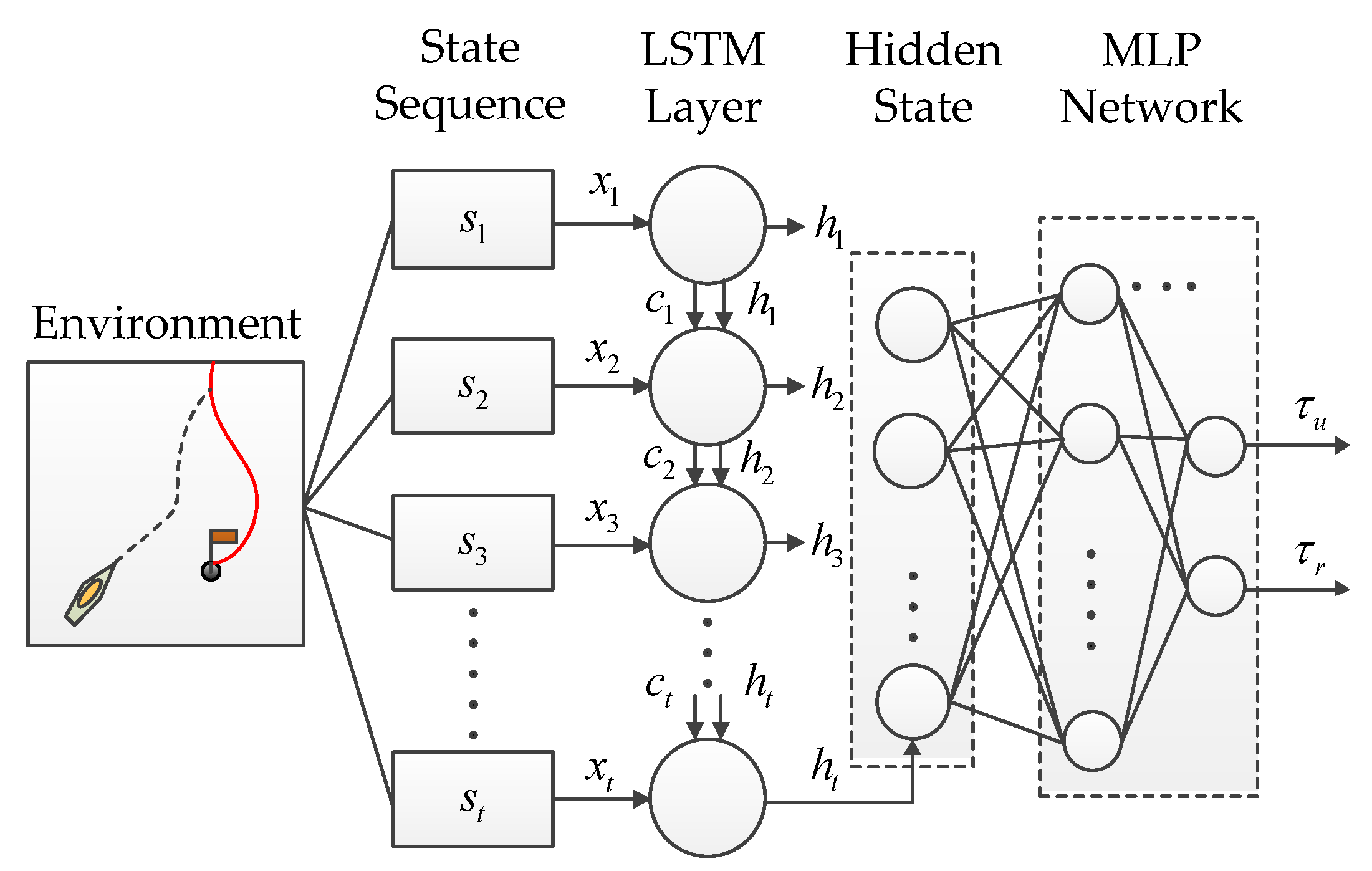
2.2. LSTM Network
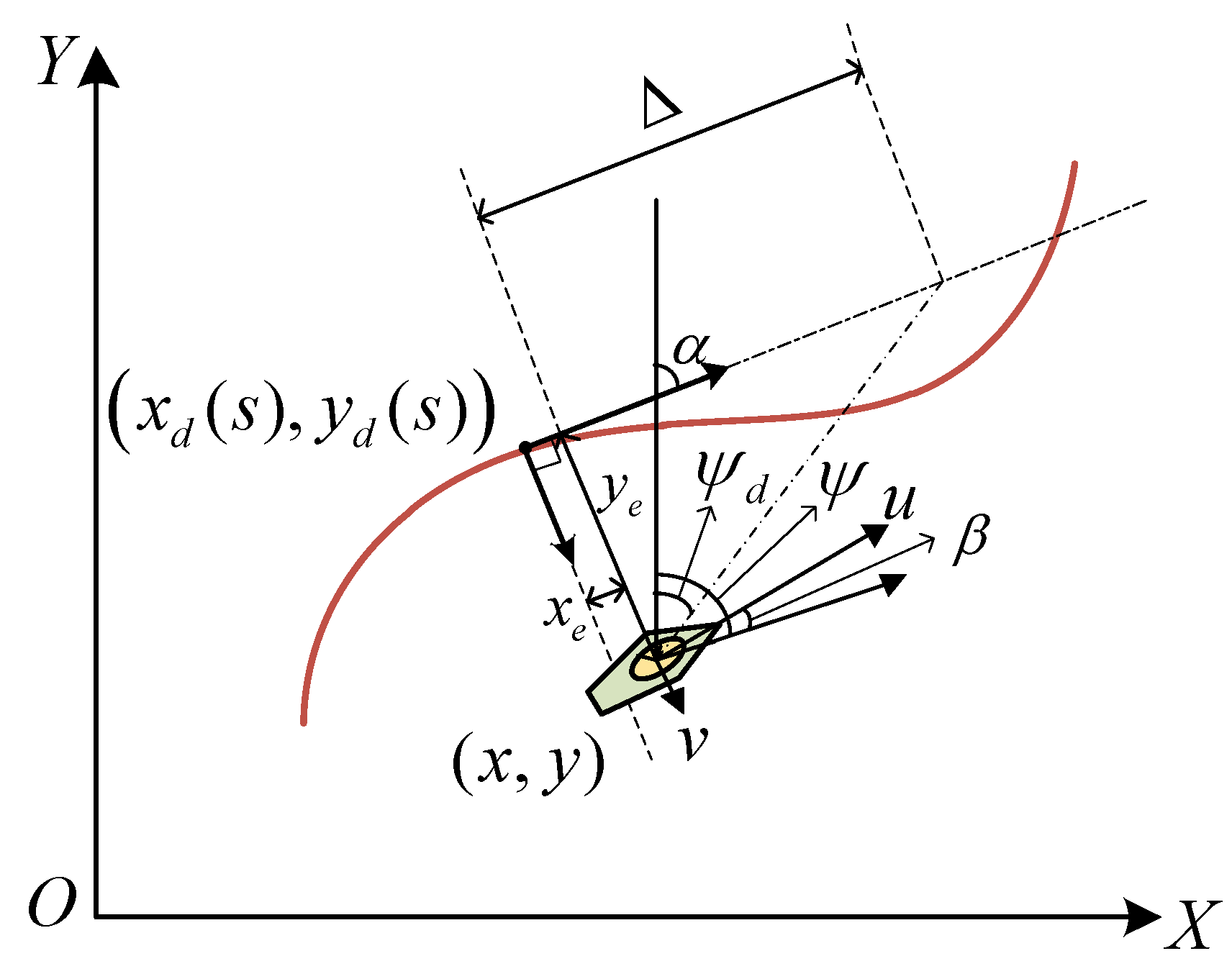
2.3. Under-Actuated AMV Model
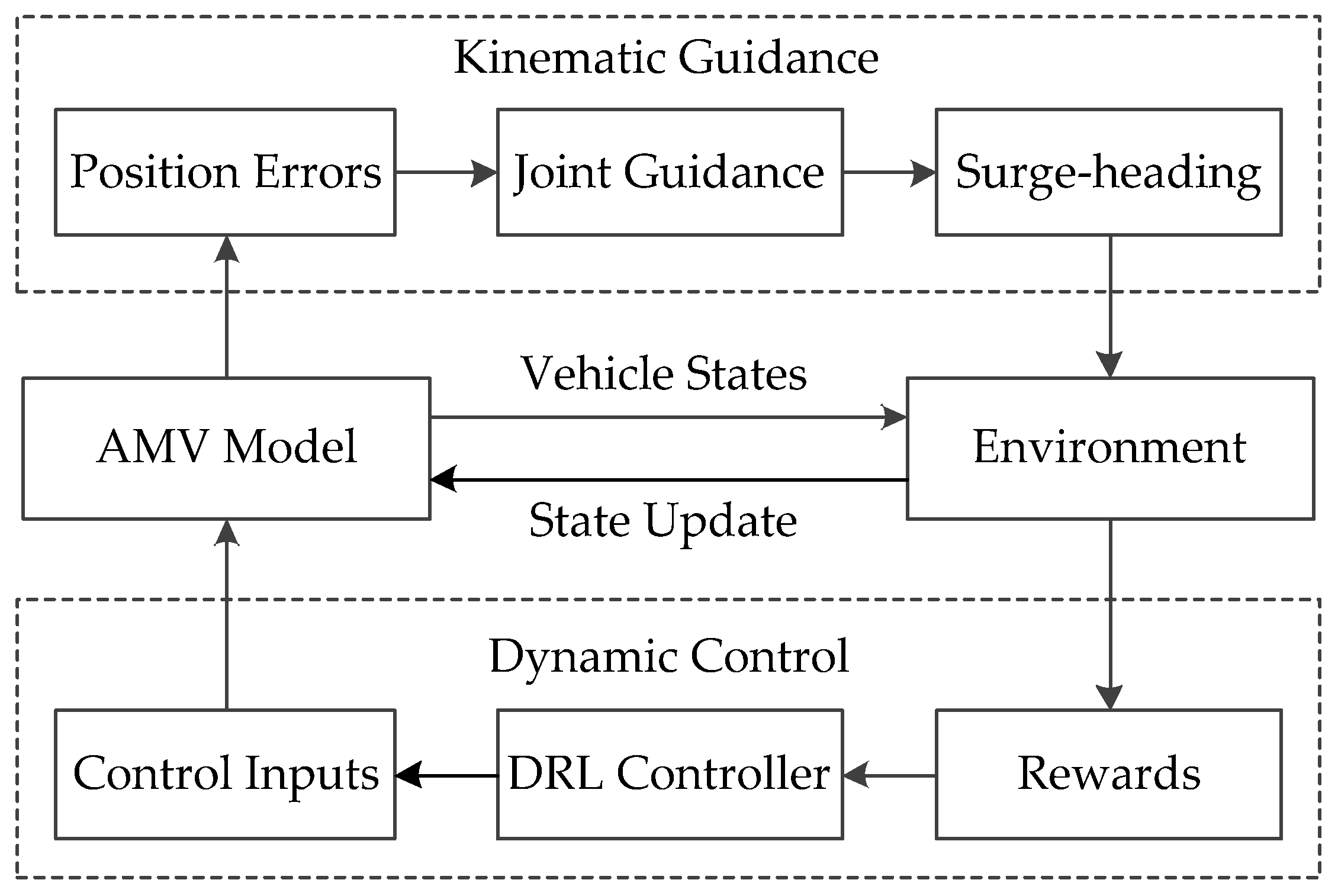
3. DRL-Based Path-Following Control Scheme
3.1. Kinematic Guidance Design
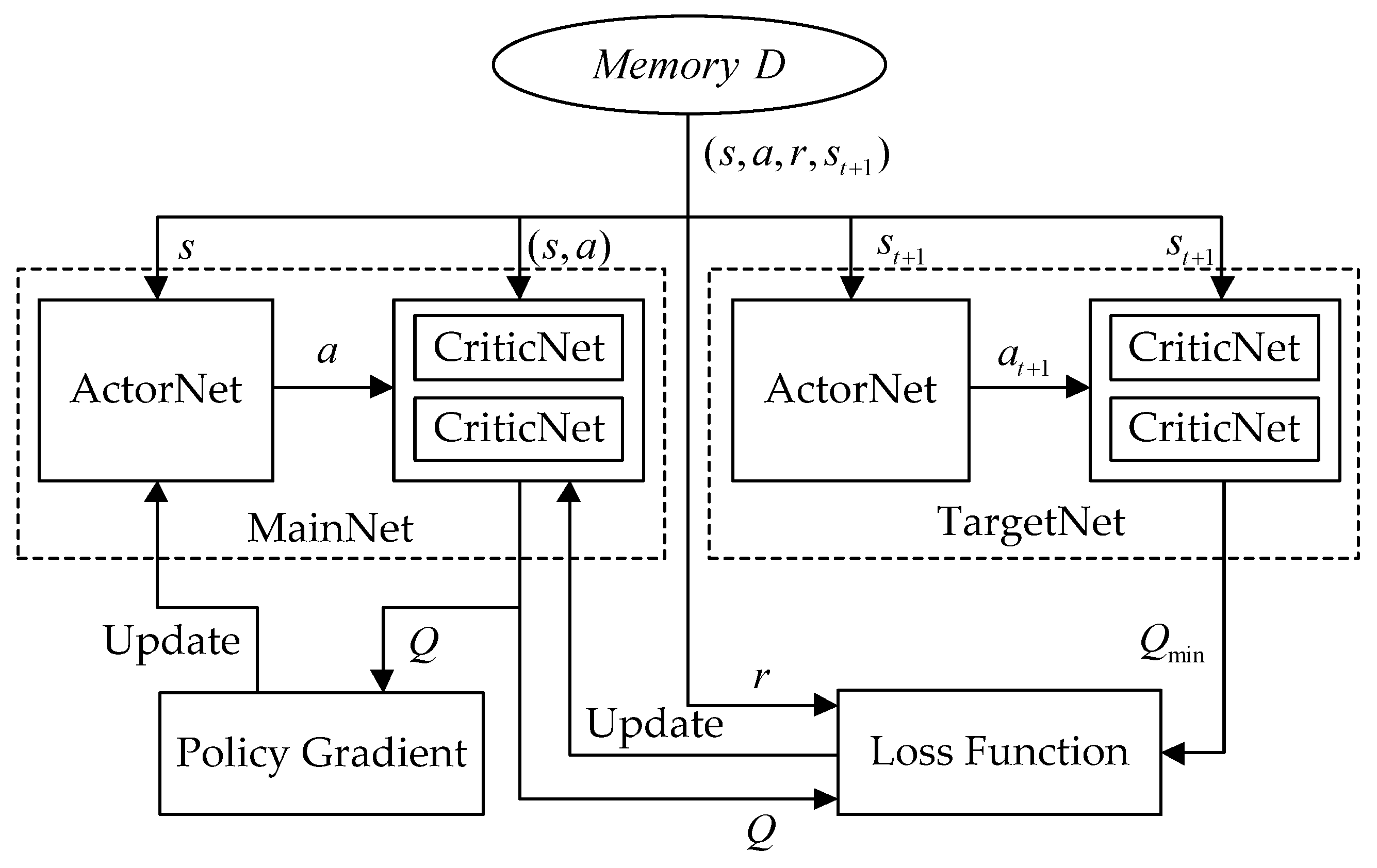
3.2. Dynamic Control Design
| Algorithm 1. Dynamic control algorithm of an AMV. |
| Inputs: Learning rate , and , regular factor , gradient threshold parameter , discount factor , sequence length , the maximum number of steps per training , updating cycle of target network parameter , training cycle , mini-batch . |
| Initialize: Critic network and actor network with random parameters , and , target network , and , experience replay buffer , navigation environment of an AMV. |
| Procedure: 1: for do 2: for do |
| 3: Select actions with exploration noise and obtain reward and next moment state |
| 4: Save transition tuple into 5: Sample transitions 6: Update Critic networks parameters as 7: if mod then |
| 8: Update actor network parameters as |
| 9: Update target network as end if end for |
| Outputs: Actor network parameter , critic network parameters and . |
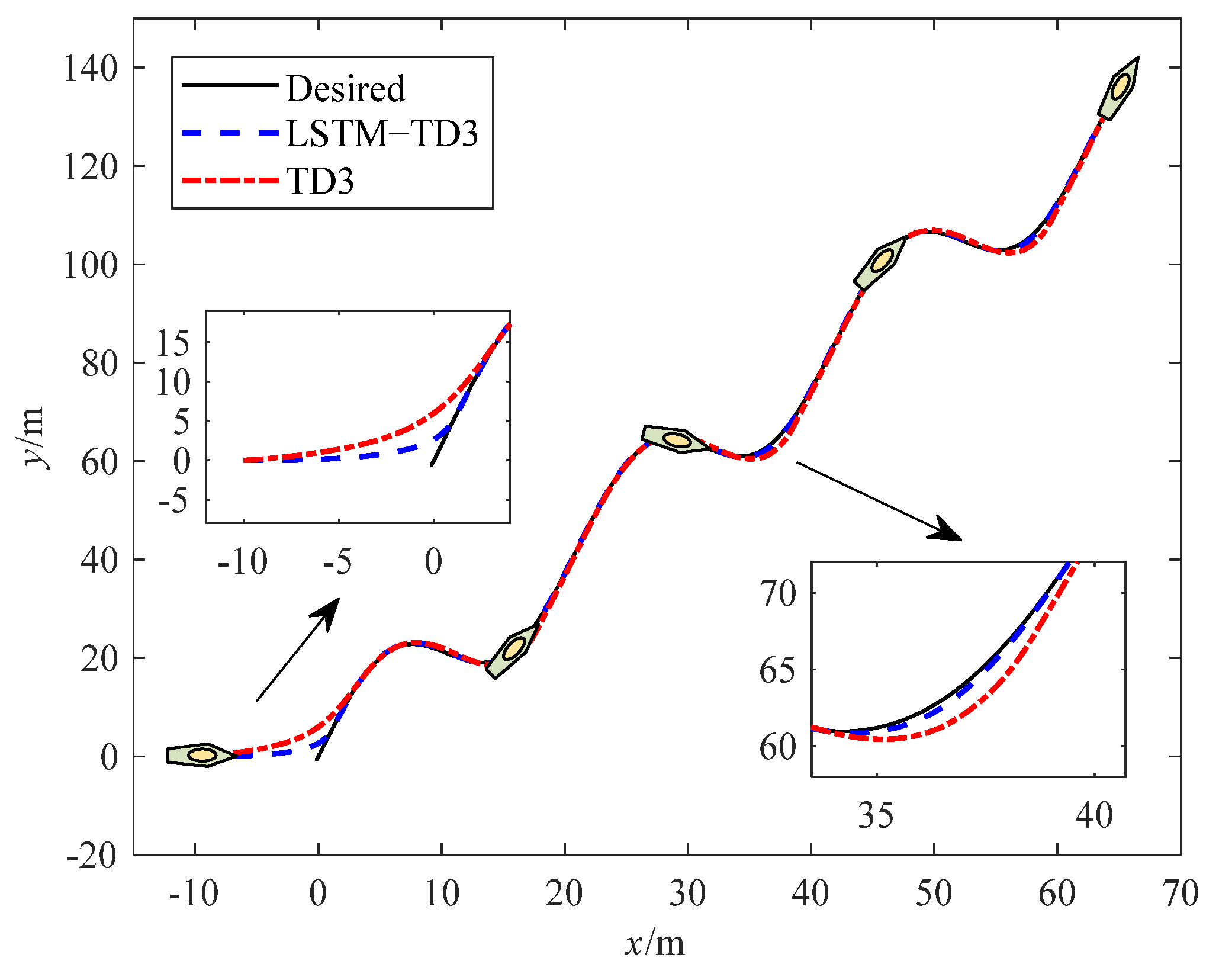
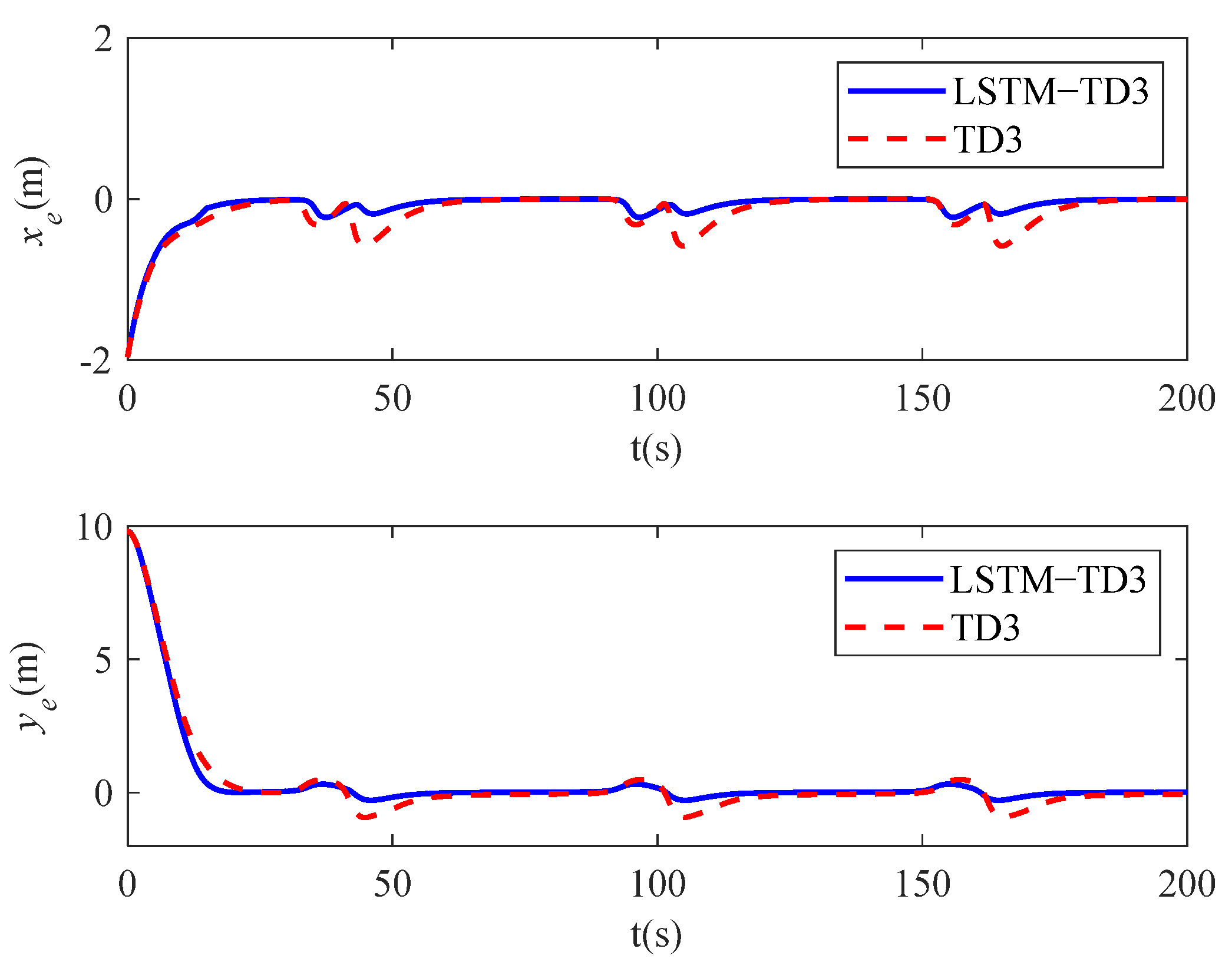
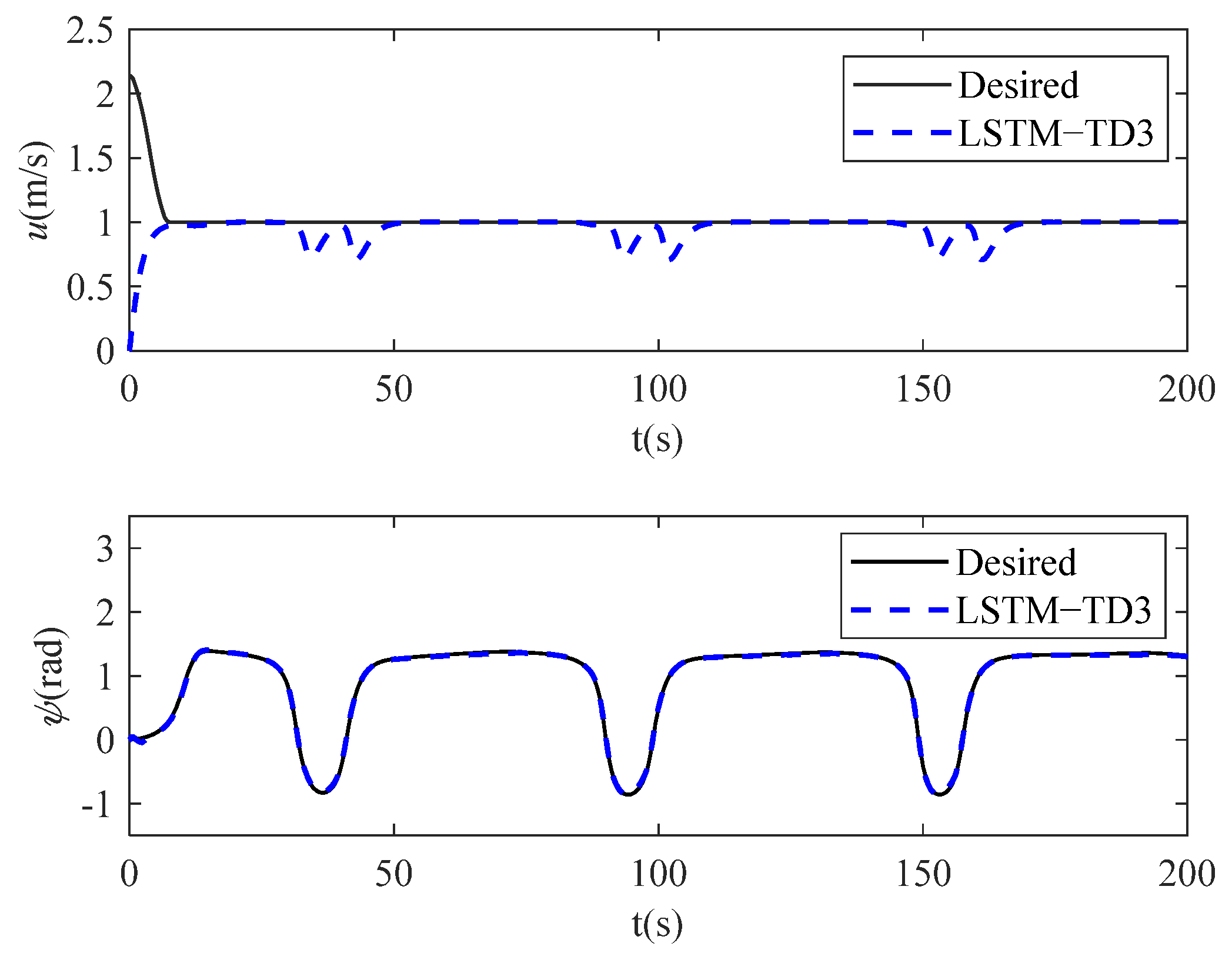
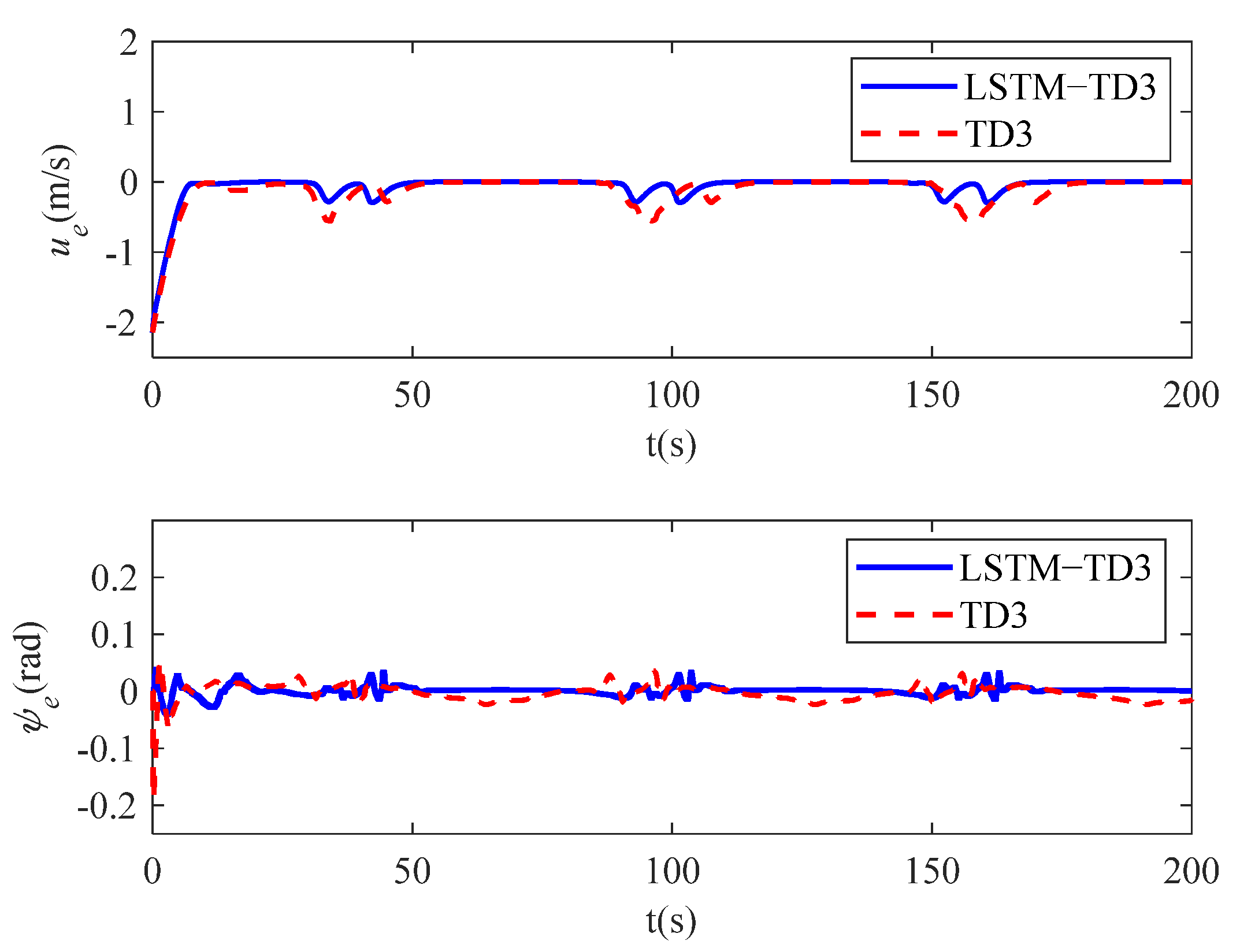
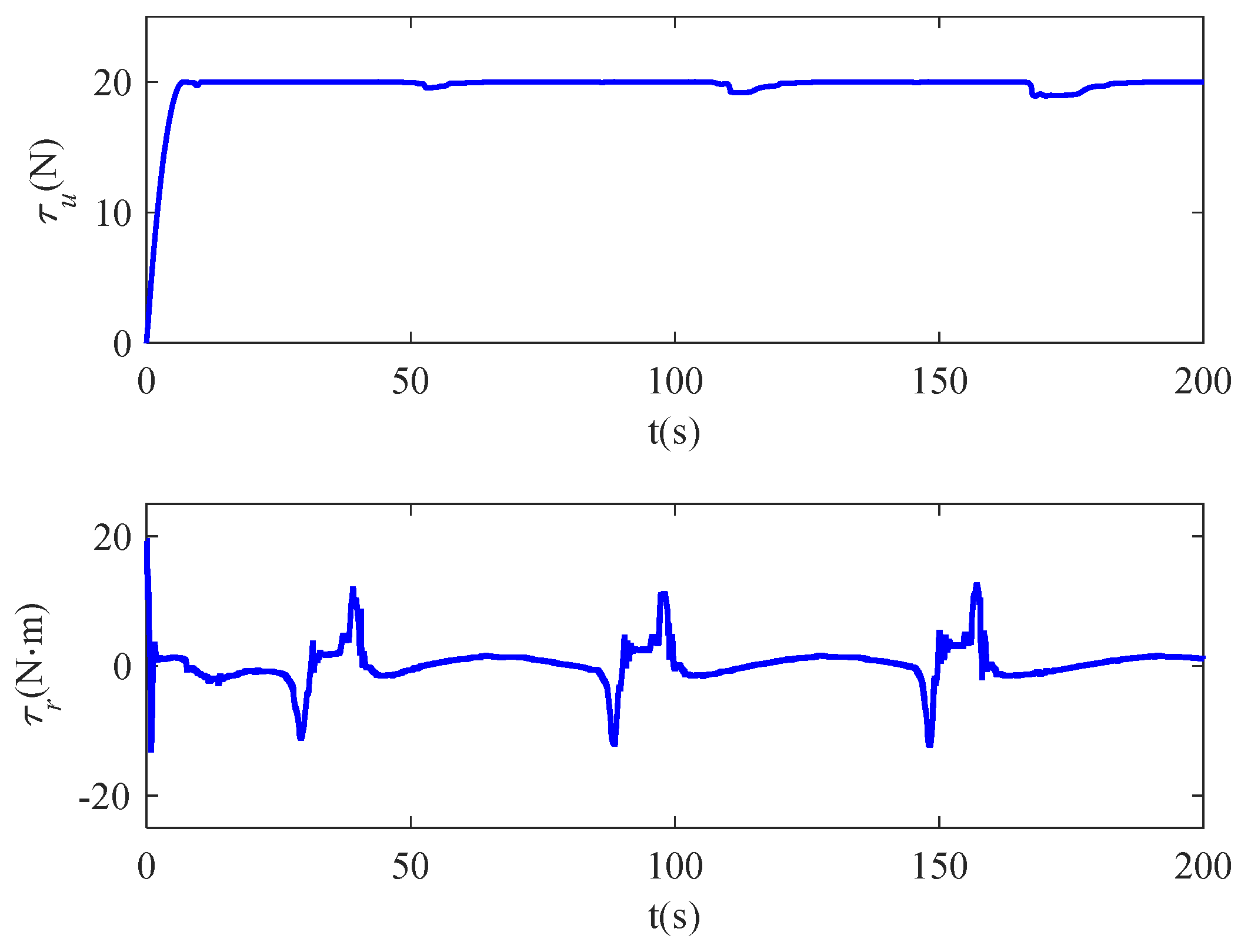
4. Simulation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jorge, V.A.; Granada, R.; Maidana, R.G.; Jurak, D.A.; Heck, G.; Negreiros, A.P.; Dos Santos, D.H.; Gonçalves, L.M.; Amory, A.M. A Survey on Unmanned Surface Vehicles for Disaster Robotics: Main Challenges and Directions. Sensors 2019, 19, 702. [Google Scholar] [CrossRef]
- Liu, T.; Dong, Z.; Du, H.; Song, L.; Mao, Y. Path Following Control of the Underactuated USV Based on the Improved Line-of-Sight Guidance Algorithm. Pol. Marit. Res. 2017, 24, 3–11. [Google Scholar] [CrossRef]
- Mu, D.; Wang, G.; Fan, Y.; Bai, Y.; Zhao, Y. Fuzzy-Based Optimal Adaptive Line-of-Sight Path Following for underactuated unmanned surface vehicle with uncertainties and time-varying disturbances. Math. Probl. Eng. 2018, 2018, 7512606. [Google Scholar] [CrossRef]
- Koh, S.; Zhou, B.; Fang, H.; Yang, P.; Yang, Z.; Yang, Q.; Guan, L.; Ji, Z. Real-time deep reinforcement learning based vehicle navigation. Appl. Soft Comput. 2020, 96, 106694. [Google Scholar] [CrossRef]
- Mu, D.; Wang, G.; Fan, Y.; Bai, Y.; Zhao, Y. Path following for podded propulsion unmanned surface vehicle: Theory, simulation and experiment. IEEJ Trans. Electr. Electron. Eng. 2018, 13, 911–923. [Google Scholar] [CrossRef]
- Lekkas, A.M.; Fossen, T.I. Integral LOS Path Following for Curved Paths Based on a Monotone Cubic Hermite Spline Parametrization. IEEE Trans. Control Syst. Technol. 2014, 22, 2287–2301. [Google Scholar] [CrossRef]
- Fossen, T.I.; Lekkas, A.M. Direct and indirect adaptive integral line-of-sight path-following controllers for marine craft exposed to ocean currents. Int. J. Adapt. Control Signal Process. 2017, 31, 445–463. [Google Scholar] [CrossRef]
- Fossen, T.I.; Pettersen, K.Y.; Galeazzi, R. Line-of-Sight Path Following for Dubins Paths with Adaptive Sideslip Compensation of Drift Forces. IEEE Trans. Control Syst. Technol. 2014, 23, 820–827. [Google Scholar] [CrossRef]
- Liu, Z.; Song, S.; Yuan, S.; Ma, Y.; Yao, Z. ALOS-Based USV Path-Following Control with Obstacle Avoidance Strategy. J. Mar. Sci. Eng. 2022, 10, 1203. [Google Scholar] [CrossRef]
- Rout, R.; Subudhi, B. Inverse optimal self-tuning PID control design for an autonomous underwater vehicle. Int. J. Syst. Sci. 2017, 48, 367–375. [Google Scholar] [CrossRef]
- Yu, C.; Xiang, X.; Lapierre, L.; Zhang, Q. Nonlinear guidance and fuzzy control for three-dimensional path following of an underactuated autonomous underwater vehicle. Ocean Eng. 2017, 146, 457–467. [Google Scholar] [CrossRef]
- Xiang, X.; Yu, C.; Zhang, Q. Robust fuzzy 3D path following for autonomous underwater vehicle subject to uncertainties. Comput. Oper. Res. 2017, 84, 165–177. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, X.; Lapierre, L.; Zhang, Q.; Li, W. Approach-angle-based three-dimensional indirect adaptive fuzzy path following of under-actuated AUV with input saturation. Appl. Ocean Res. 2021, 107, 102486. [Google Scholar] [CrossRef]
- Sahu, B.K.; Subudhi, B. Adaptive tracking control of an autonomous underwater vehicle. Int. J. Autom. Comput. 2014, 11, 299–307. [Google Scholar] [CrossRef]
- Shin, J.; Kwak, D.J.; Lee, Y. Adaptive Path-Following Control for an Unmanned Surface Vessel Using an Identified Dynamic Model. IEEE/ASME Trans. Mechatron. 2017, 22, 1143–1153. [Google Scholar] [CrossRef]
- Lamraoui, H.C.; Zhu, Q. Path following control of fully-actuated autonomous underwater vehicle in presence of fast-varying disturbances. Appl. Ocean Res. 2019, 86, 40–46. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, X.; Cao, T.; Bu, R. Active disturbance rejection control for ship path following with Euler method. Ocean Eng. 2022, 247, 110516. [Google Scholar] [CrossRef]
- Zhang, G.; Huang, H.; Wan, L.; Li, Y.; Cao, J.; Su, Y. A novel adaptive second order sliding mode path following control for a portable AUV. Ocean Eng. 2018, 151, 82–92. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, X.; Bu, R. Radial Basis Function Neural Network Sliding Mode Control for Ship Path Following Based on Position Prediction. J. Mar. Sci. Eng. 2021, 9, 1055. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C.; Wei, Y.; Zhang, C. Three-Dimensional Path Following of an Underactuated AUV Based on Neuro-Adaptive Command Filtered Backstepping Control. IEEE Access 2018, 6, 74355–74365. [Google Scholar] [CrossRef]
- Yan, Z.; Yang, Z.; Zhang, J.; Zhou, J.; Jiang, A.; Du, X. Trajectory tracking control of UUV based on backstepping sliding mode with fuzzy switching gain in diving plane. IEEE Access 2019, 7, 166788–166795. [Google Scholar] [CrossRef]
- Zhou, J.; Zhao, X.; Chen, T.; Yan, Z.; Yang, Z. Trajectory tracking control of an underactuated AUV based on backstepping sliding mode with state prediction. IEEE Access 2019, 7, 181983–181993. [Google Scholar] [CrossRef]
- Chen, X.; Liu, Z.; Zhang, J.; Zhou, D.; Dong, J. Adaptive sliding-mode path following control system of the underactuated USV under the influence of ocean currents. J. Syst. Eng. Electron. 2018, 29, 1271–1283. [Google Scholar] [CrossRef]
- Liang, X.; Wan, L.; Blake, J.I.; Shenoi, R.A.; Townsend, N. Path Following of an Underactuated AUV Based on Fuzzy Backstepping Sliding Mode Control. Int. J. Adv. Robot. Syst. 2016, 13, 122. [Google Scholar] [CrossRef]
- Qiu, B.; Wang, G.; Fan, Y.; Mu, D.; Sun, X. Path Following of Underactuated Unmanned Surface Vehicle Based on Trajectory Linearization Control with Input Saturation and External Disturbances. Int. J. Control Autom. Syst. 2020, 18, 2108–2119. [Google Scholar] [CrossRef]
- Wang, N.; Sun, Z.; Yin, J.; Zou, Z.; Su, S. Fuzzy unknown observer-based robust adaptive path following control of underactuated surface vehicles subject to multiple unknowns. Ocean Eng. 2019, 176, 57–64. [Google Scholar] [CrossRef]
- Havenstrøm, S.T.; Rasheed, A.; San, O. Deep reinforcement learning controller for 3D path following and collision avoidance by autonomous underwater vehicles. Front. Robot. AI 2021, 7, 211. [Google Scholar] [CrossRef]
- Meyer, E.; Heiberg, A.; Rasheed, A.; San, O. COLREG-compliant collision avoidance for unmanned surface vehicle using deep reinforcement learning. IEEE Access 2020, 8, 165344–165364. [Google Scholar] [CrossRef]
- Sola, Y.; Le Chenadec, G.; Clement, B. Simultaneous control and guidance of an auv based on soft actor–critic. Sensors 2022, 22, 6072. [Google Scholar] [CrossRef]
- Fang, Y.; Huang, Z.; Pu, J.; Zhang, J. AUV position tracking and trajectory control based on fast-deployed deep reinforcement learning method. Ocean Eng. 2022, 245, 110452. [Google Scholar] [CrossRef]
- Zhang, T.; Tian, R.; Wang, C.; Xie, G. Path-Following Control of Fish-like Robots: A Deep Reinforcement Learning Approach. IFAC-PapersOnLine 2020, 53, 8163–8168. [Google Scholar] [CrossRef]
- Woo, J.; Yu, C.; Kim, N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle. Ocean Eng. 2019, 183, 155–166. [Google Scholar] [CrossRef]
- Han, Z.; Wang, Y.; Sun, Q. Straight-Path Following and Formation Control of USVs Using Distributed Deep Reinforcement Learning and Adaptive Neural Network. IEEE/CAA J. Autom. Sin. 2023, 10, 572–574. [Google Scholar] [CrossRef]
- Sun, Y.; Ran, X.; Zhang, G.; Wang, X.; Xu, H. AUV path following controlled by modified Deep Deterministic Policy Gradient. Ocean Eng. 2020, 210, 107360. [Google Scholar] [CrossRef]
- Zheng, Y.; Tao, J.; Sun, Q.; Sun, H.; Chen, Z.; Sun, M.; Xie, G. Soft Actor–Critic based active disturbance rejection path following control for unmanned surface vessel under wind and wave disturbances. Ocean Eng. 2022, 247, 110631. [Google Scholar] [CrossRef]
- Liang, Z.; Qu, X.; Zhang, Z.; Chen, C. Three-Dimensional Path-Following Control of an Autonomous Underwater Vehicle Based on Deep Reinforcement Learning. Pol. Marit. Res. 2022, 29, 36–44. [Google Scholar] [CrossRef]
- Liu, Y.; Peng, Y.; Wang, M.; Xie, J.; Zhou, R. Multi-usv system cooperative underwater target search based on reinforcement learning and probability map. Math. Probl. Eng. 2020, 2020, 7842768. [Google Scholar] [CrossRef]
- Havenstrøm, S.T.; Sterud, C.; Rasheed, A.; San, O. Proportional integral derivative controller assisted reinforcement learning for path following by autonomous underwater vehicles. arXiv 2020, arXiv:2002.01022. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, P.; Peng, Y.; Liu, D. Roll motion prediction of unmanned surface vehicle based on coupled CNN and LSTM. Future Internet 2019, 11, 243. [Google Scholar] [CrossRef]
- Li, J.; Tian, Z.; Zhang, G.; Li, W. Multi-AUV Formation Predictive Control Based on CNN-LSTM under Communication Constraints. J. Mar. Sci. Eng. 2023, 11, 873. [Google Scholar] [CrossRef]
- Fossen, T.I. Handbook of Marine Craft Hydrodynamics and Motion Control; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Chu, Z.; Sun, B.; Zhu, D.; Zhang, M.; Luo, C. Motion control of unmanned underwater vehicles via deep imitation reinforcement learning algorithm. IET Intell. Transp. Syst. 2020, 14, 764–774. [Google Scholar] [CrossRef]
- Wang, N.; Gao, Y.; Yang, C.; Zhang, X. Reinforcement learning-based finite-time tracking control of an unknown unmanned surface vehicle with input constraints. Neurocomputing 2022, 484, 26–37. [Google Scholar] [CrossRef]
- Xie, S.; Chu, X.; Zheng, M.; Liu, C. A composite learning method for multi-ship collision avoidance based on reinforcement learning and inverse control. Neurocomputing 2020, 411, 375–392. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Discount factor | 0.99 |
| State sequence length | 20 |
| Training cycle | 1000 |
| Maximum number of steps | 1000 |
| Capacity of buffer | 100,000 |
| Learning rate | 0.001 |
| Optimizer | Adam |
| Gradient threshold parameter | 1 |
| Regular factor | 0.00005 |
| Mini-batch | 128 |
| Parameters | Value |
|---|---|
| Input layer of actor network | 11 |
| Input layer of critic network | 13 |
| Fully connected layer | 200 |
| LSTM layer of actor network | 100 |
| LSTM layer of critic network | 100 |
| Output layer of actor | 2 |
| Output layer of critic | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, X.; Jiang, Y.; Zhang, R.; Long, F. A Deep Reinforcement Learning-Based Path-Following Control Scheme for an Uncertain Under-Actuated Autonomous Marine Vehicle. J. Mar. Sci. Eng. 2023, 11, 1762. https://doi.org/10.3390/jmse11091762
Qu X, Jiang Y, Zhang R, Long F. A Deep Reinforcement Learning-Based Path-Following Control Scheme for an Uncertain Under-Actuated Autonomous Marine Vehicle. Journal of Marine Science and Engineering. 2023; 11(9):1762. https://doi.org/10.3390/jmse11091762
Chicago/Turabian StyleQu, Xingru, Yuze Jiang, Rubo Zhang, and Feifei Long. 2023. "A Deep Reinforcement Learning-Based Path-Following Control Scheme for an Uncertain Under-Actuated Autonomous Marine Vehicle" Journal of Marine Science and Engineering 11, no. 9: 1762. https://doi.org/10.3390/jmse11091762
APA StyleQu, X., Jiang, Y., Zhang, R., & Long, F. (2023). A Deep Reinforcement Learning-Based Path-Following Control Scheme for an Uncertain Under-Actuated Autonomous Marine Vehicle. Journal of Marine Science and Engineering, 11(9), 1762. https://doi.org/10.3390/jmse11091762