


Research on Ship Trajectory Prediction Method Based on Difference Long Short-Term Memory

Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution
- Ship trajectory prediction faces the complexity of time series data, and the navigation patterns and trajectory features of ships may be different in different time periods. The D-LSTM model can automatically learn and extract the dynamic time series features so that the model can adapt to the changes in the data in the complex voyage segments and better predict the ship’s future trajectory.
- The recent deep learning-based ship trajectory prediction model is compared with the D-LSTM model to demonstrate the effectiveness of D-LSTM in solving the inaccurate and time-consuming trajectory prediction problem caused by frequent ship maneuvering in complex waterways.
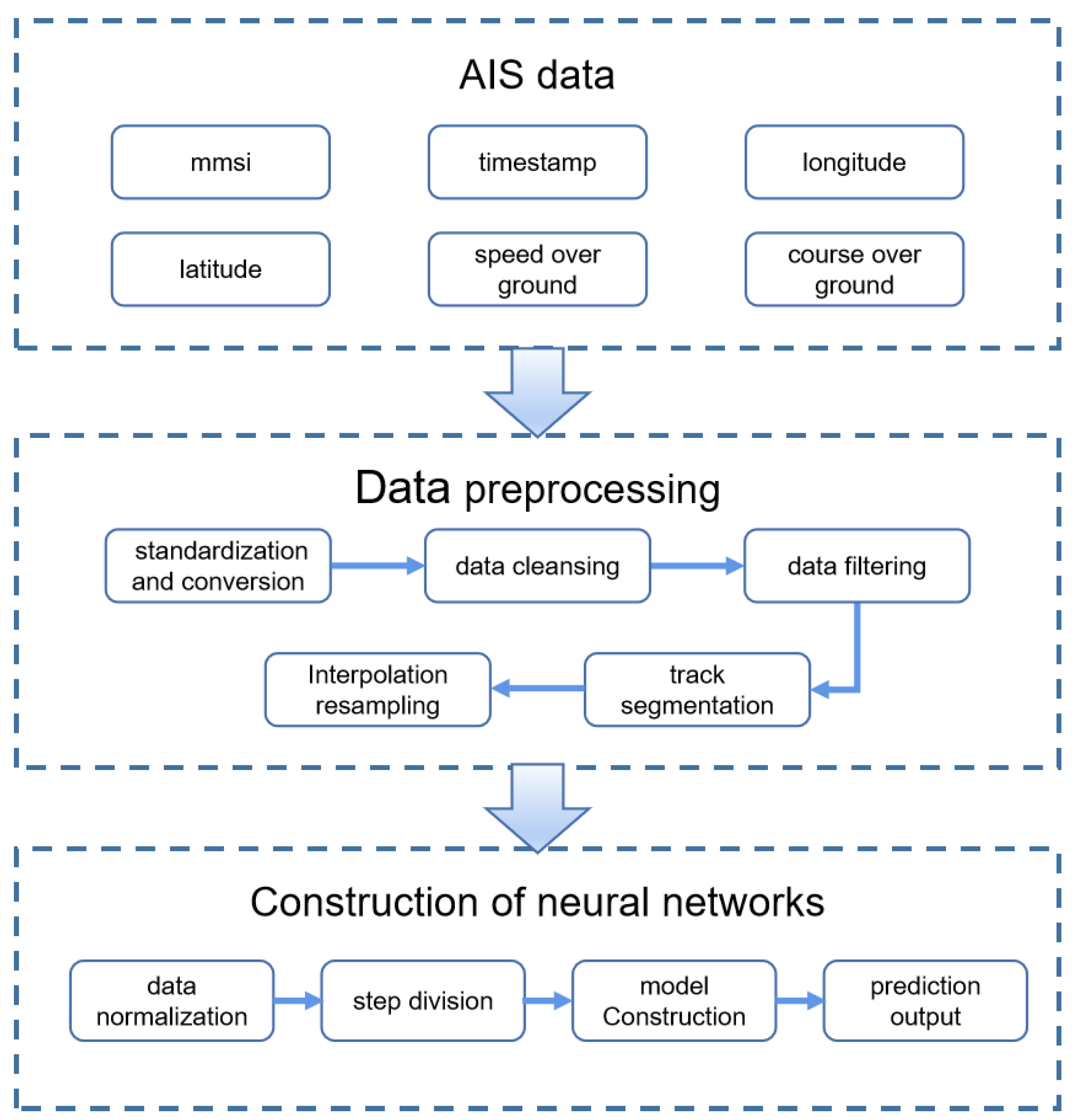
2. Model Construction
2.1. Data Preprocessing
- Data standardization and conversion: In order to reduce data size and improve transmission efficiency, the AIS data are encoded or scaled in some way during transmission and need to be transformed and normalized for subsequent analysis and modeling. For example, the raw data for an automatic identification system are the true latitude and longitude values multiplied by a fixed multiple (usually 600,000), which has the advantage of reducing the data storage space by converting floating-point numbers to integers so that an inverse operation involving dividing by the exact multiple is required to recover the true latitude and longitude values. The timestamps in the AIS raw data are encoded in UNIX timestamps (in seconds from 1 January 1970) and therefore need to be converted to datetime format.
- Data cleansing: inaccurate, incomplete, or invalid data are removed by performing data cleansing. Dealing with missing values, outliers, and duplicates is part of this. Among them, duplicate values or the existence of missing values of a feature in a single trajectory point can be directly deleted for processing. Outliers are detected and processed using thresholds; for example, according to the ITU Radiocommunication Sector M.1371-4 Recommendation points with a heading value greater than 155.2 are deleted, and the points with an SOG > 51.1 are also meaningless because they belong to the noise data and are deleted.
- Data filtering: According to the experimental requirements of this paper, the data features related to trajectory prediction are denoted TimeStamp, LAT, LON, SOG, and COG. Specific ship types, sailing states, and sailing regions are chosen for filtering to lessen the impact of unimportant factors on the prediction model.
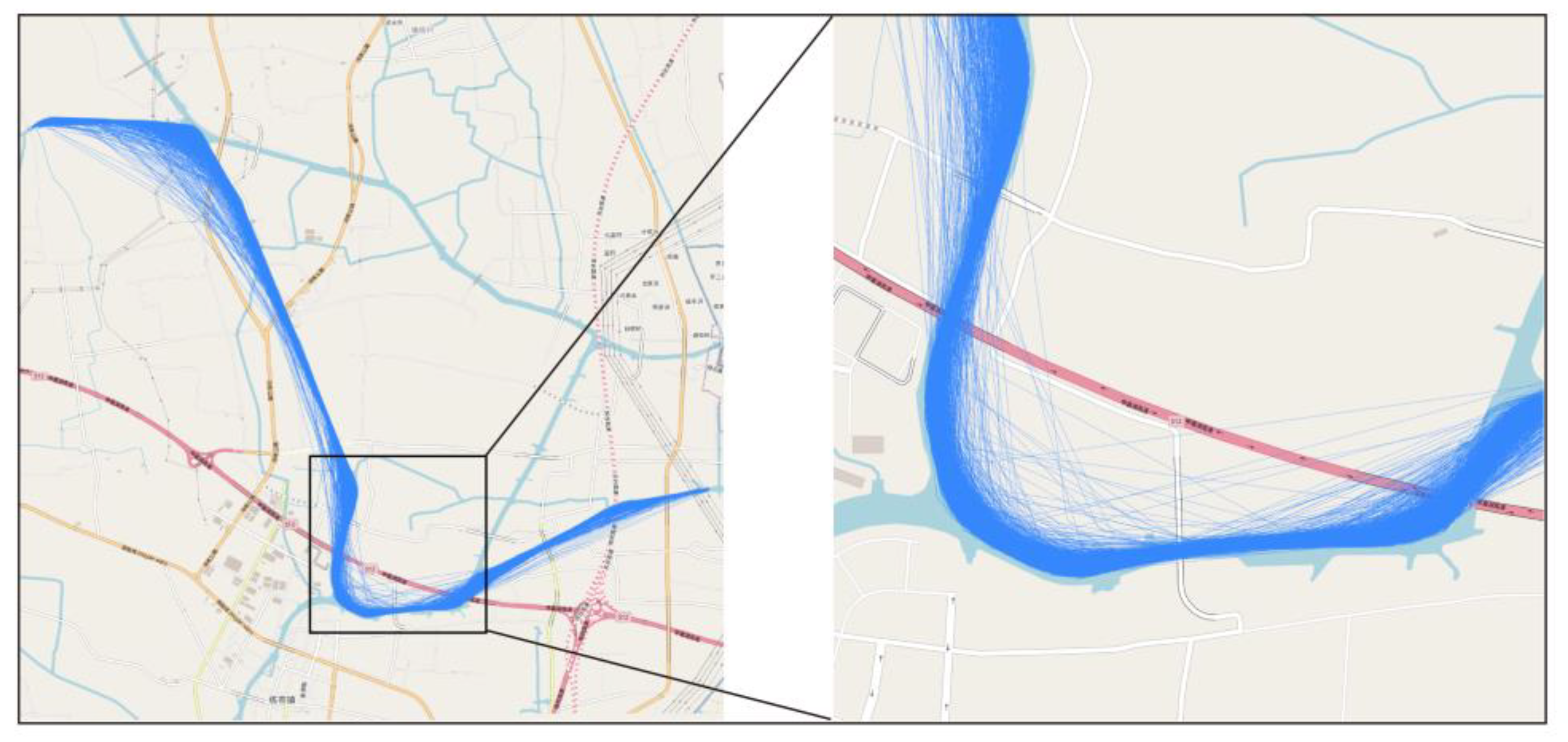
- Track segmentation: Track segmentation is necessary to prevent track drift issues brought on by round trips or other factors. The time interval between successive AIS signals from the same vessel is detected to evaluate whether segmentation is required. When there is a gap of more than six minutes between two pieces of data, segmentation is interrupted, and the track segment with the fewest track points is deleted.
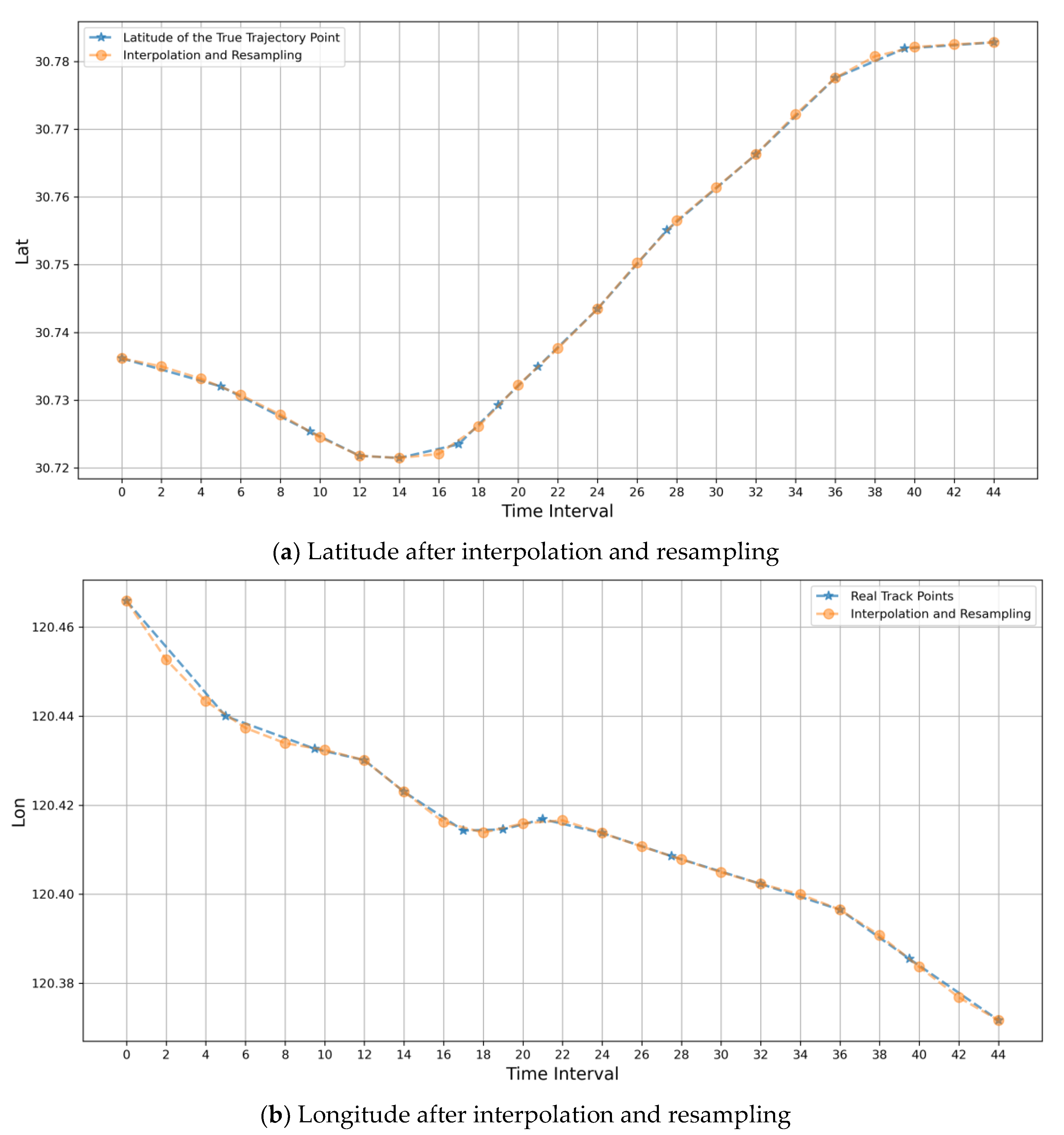
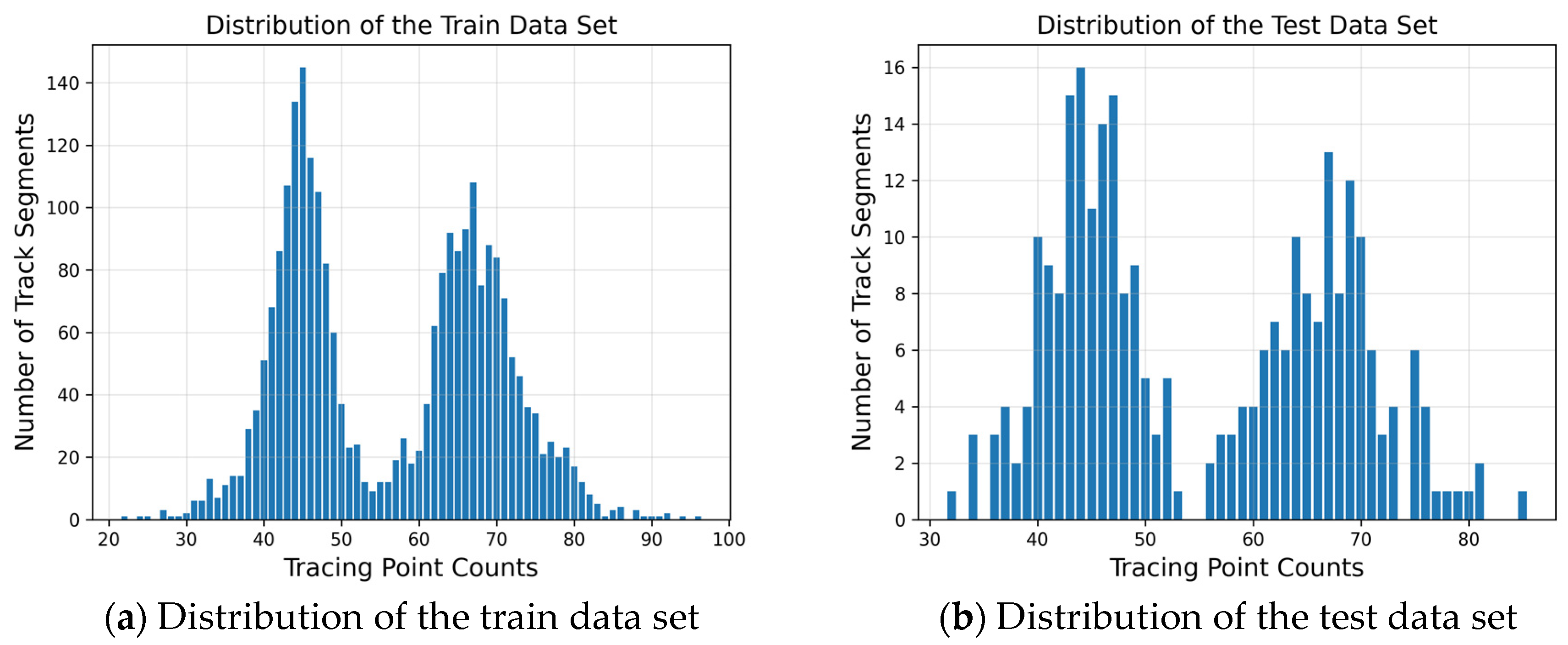
- Interpolation resampling: Because each ship’s AIS data for each trajectory segment are not distributed at equal time intervals, they need to be interpolated. Currently, the most widely used methods are Lagrangian interpolation and spline interpolation. Although Lagrange interpolation passes through all known points as a polynomial function, as the order of the polynomials gets higher and more computationally intensive the interpolation accuracy does not get better and better; on the contrary, the function curve oscillates violently, i.e., the Runge phenomenon. Therefore, to make the function curve able to pass through all the known points and avoid Runge phenomenon, this paper adopts the segmented function; that is, the trajectory points in the trajectory segment are divided into a number of segments; each segment corresponds to an interpolating function. To avoid jittering the curves of functions of too high an order too drastically and creating poor curve fitting with too low an order, cubic spline interpolation is taken to finally obtain an interpolating function sequence, and resampling occurs at two-minute intervals between each track point.
2.2. Neural Network Model
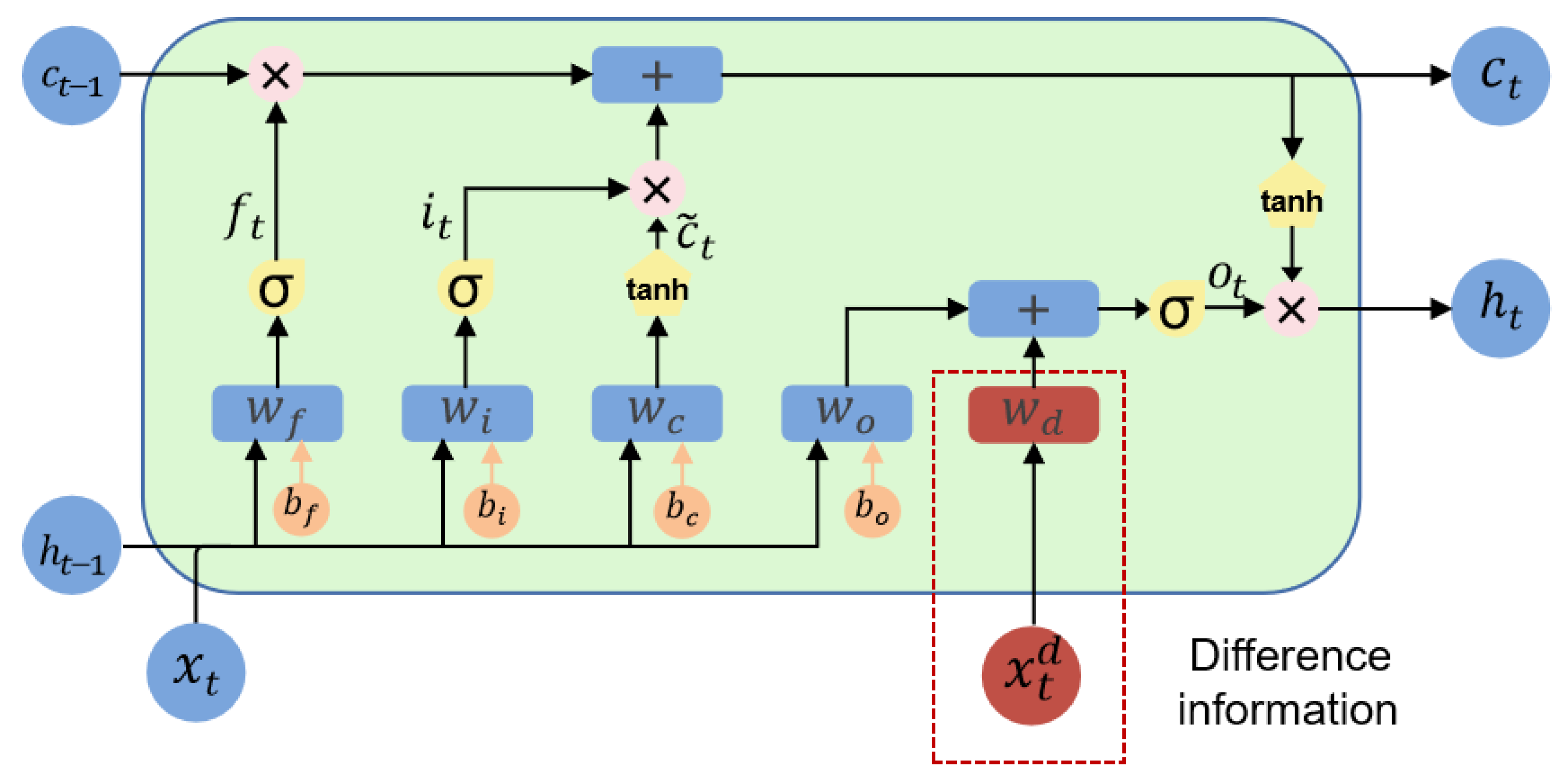
2.2.1. LSTM Model
- Input gate: It manages the preservation of input data only in certain areas. It makes a Sigmoid function-based decision regarding how much input data should be incorporated into the cell state for the current time step.
- Forget gate: The amount of data from the previous cell state to be forgotten is determined by a sigmoid function. More historical knowledge is lost when the value is closer to 0, whereas more historical knowledge is kept when the value is closer to 1.
- Update of the cell state: The tanh activation function processes the output from the previous instant and the input from the current moment to create the input activation vector c. The cell state is then updated by first multiplying the previous moment’s cell state by the forgetting gate by the elements; this is followed by the multiplication of the current input activation vector c by the input gate by the elements.
- Output gate: This regulates the selective exposure of the output data. The amount of data from the cell state that should be output is determined using a sigmoid function.
- Output: The cell state is processed using the tanh activation function to determine the output of the current time step, which is then multiplied by the output gate’s outcome.
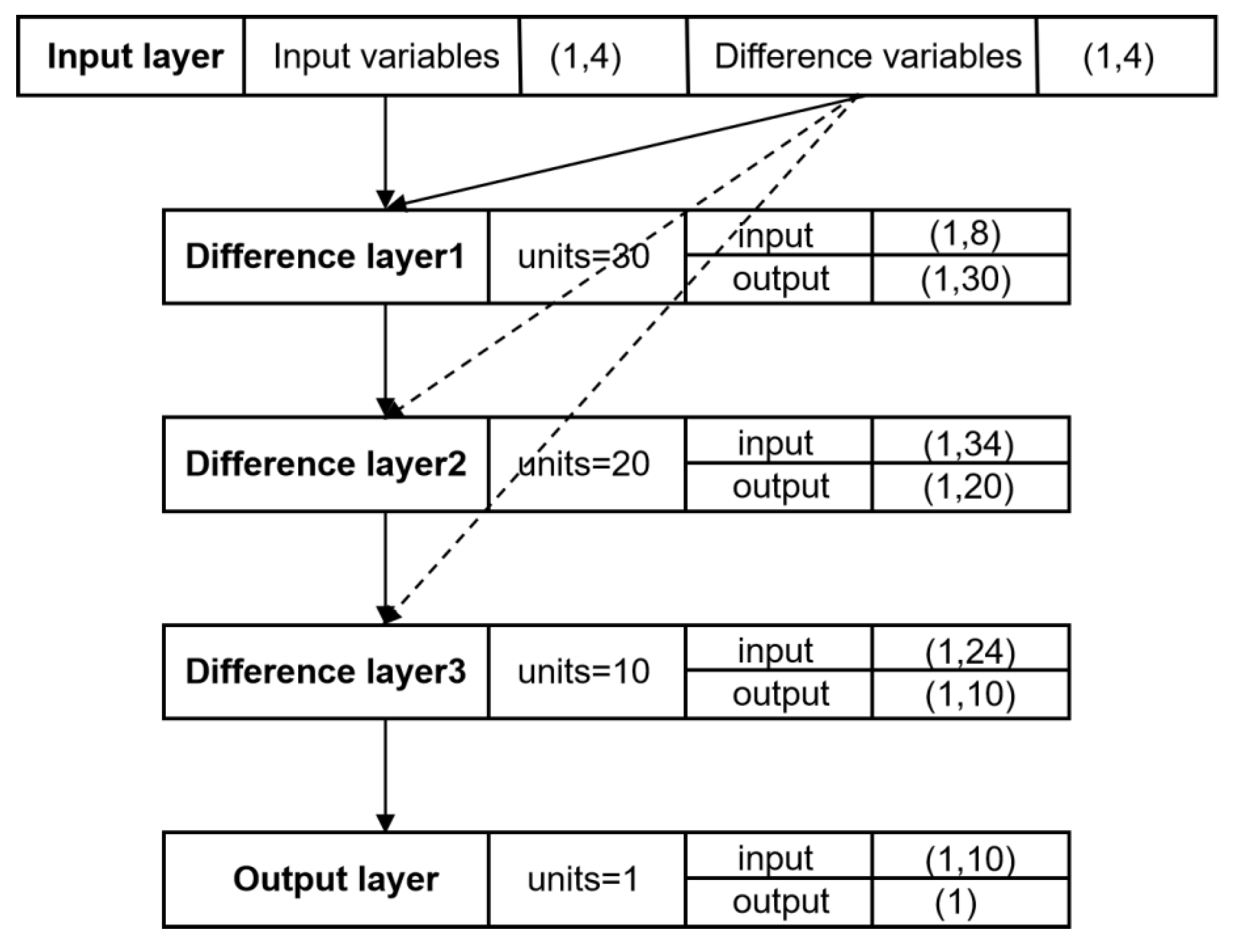
2.2.2. D-LSTM Model
3. Experimental Results and Analysis
3.1. Data Selection
3.2. Evaluation Metrics
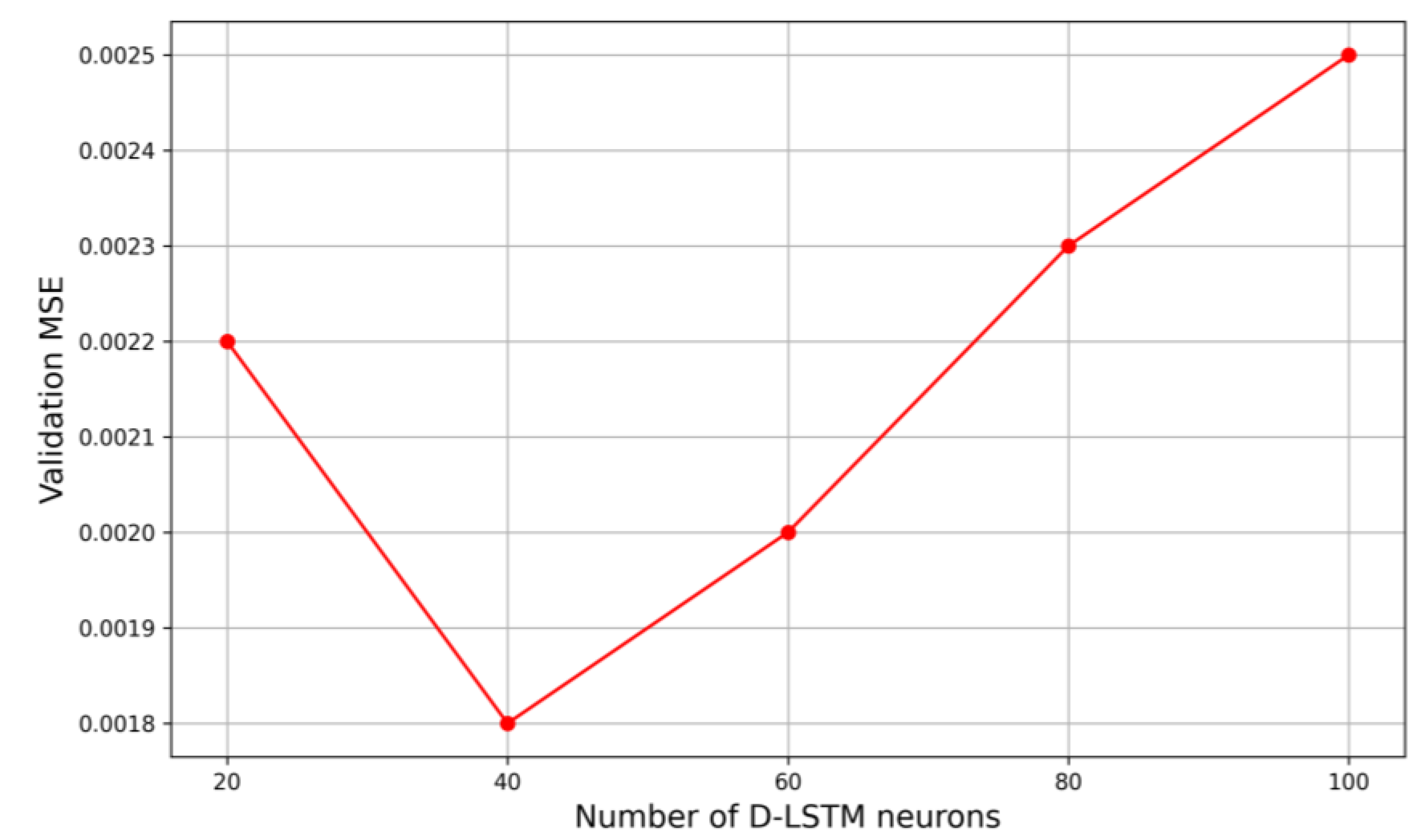
3.3. D-LSTM Architecture and Comparison Models
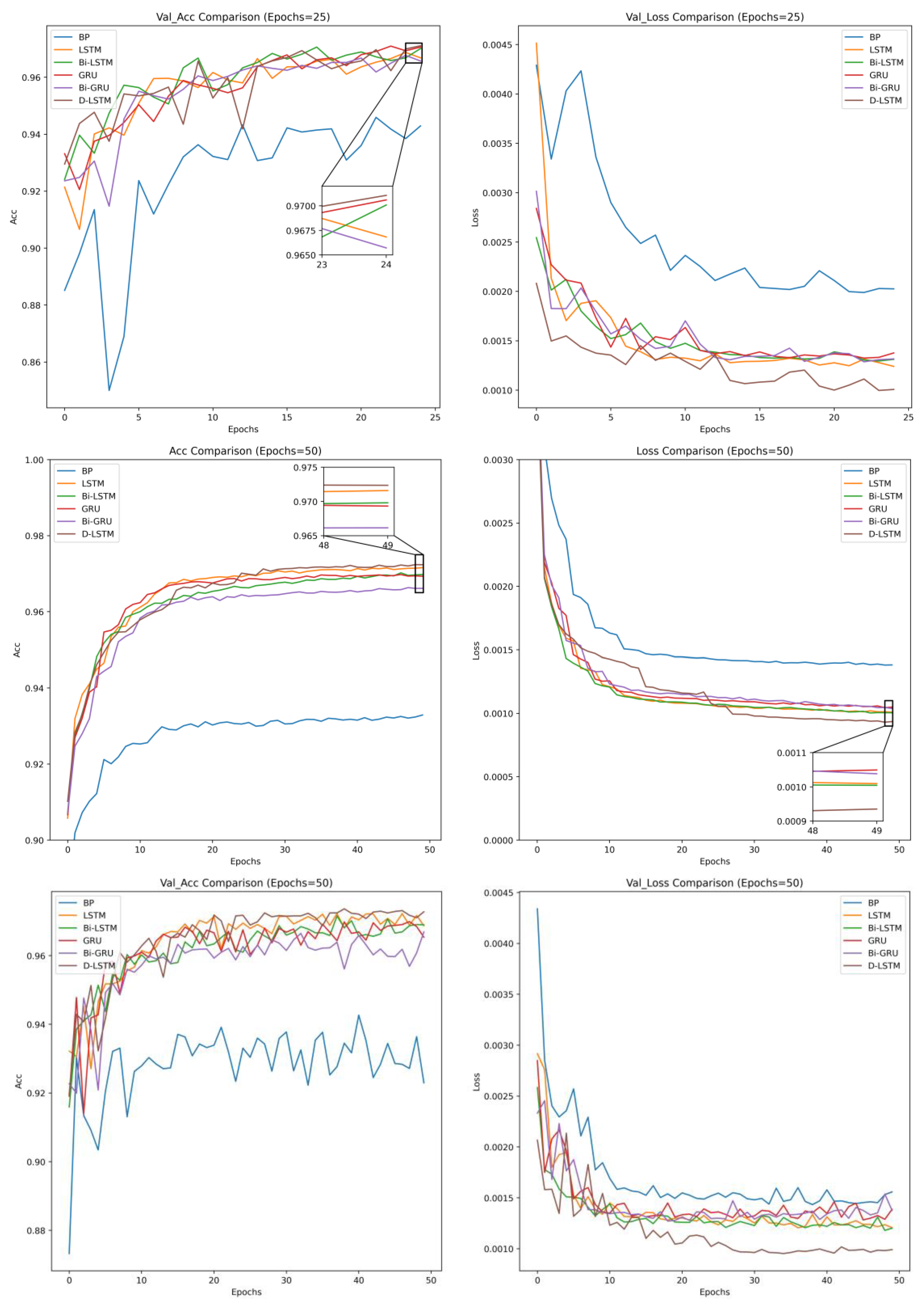
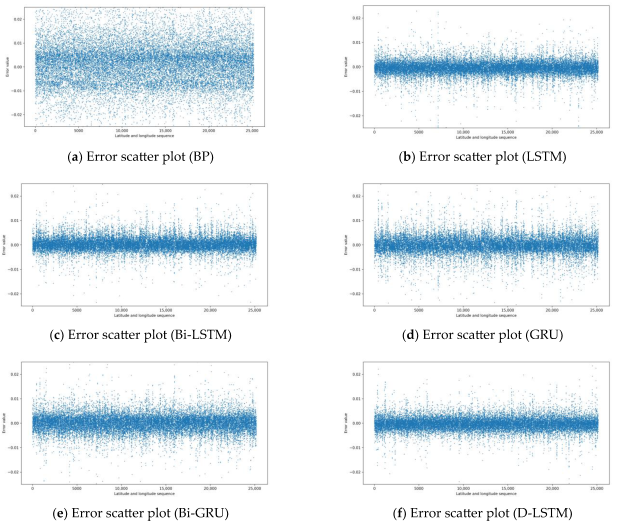
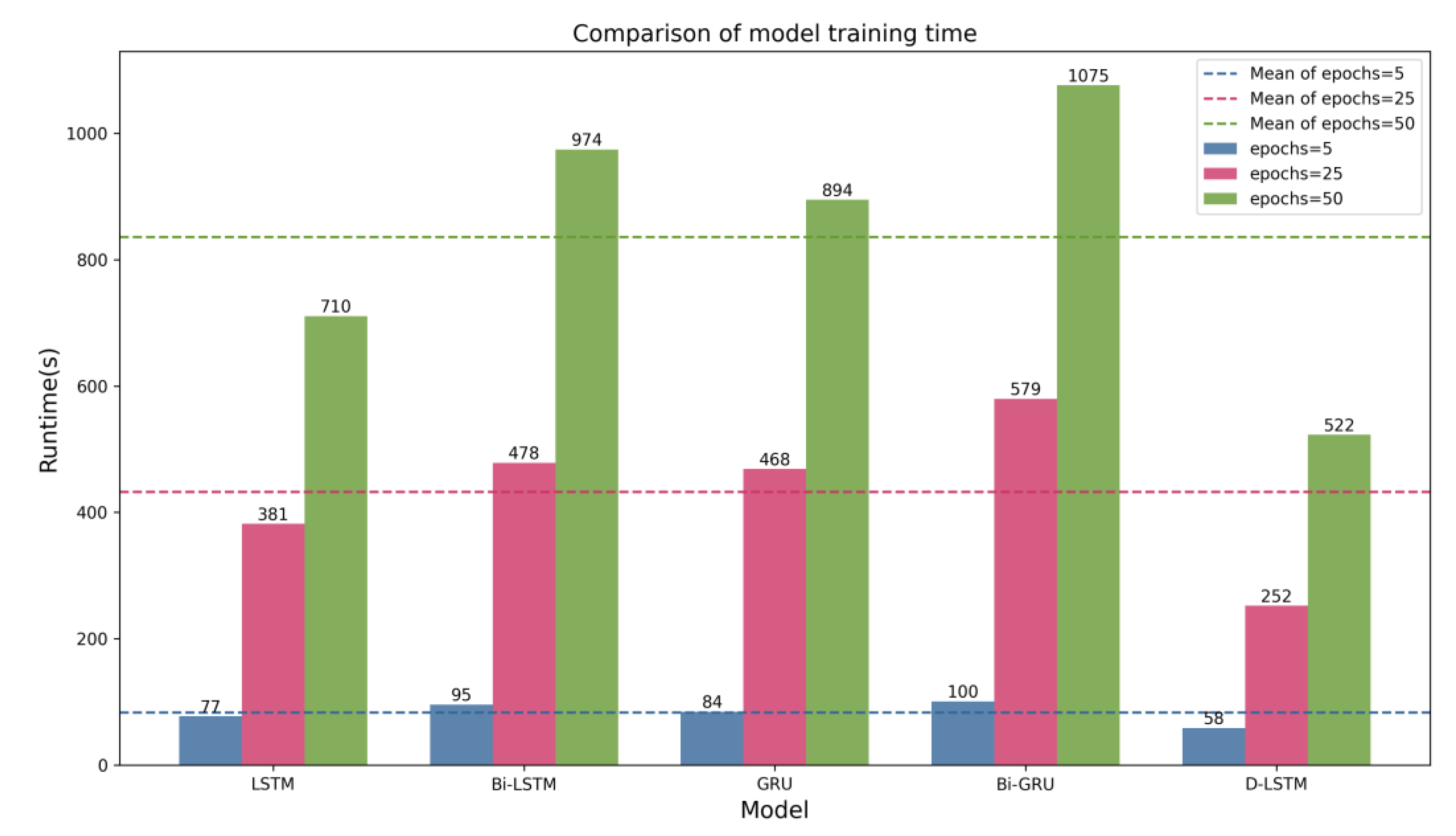
3.4. Analysis of Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fan, J. Research on ship positioning navigation and track prediction based on big data technology. Ship Sci. Technol. 2018, 40, 31–33. [Google Scholar]
- Xu, T.; Cai, F.; Hu, Q.; Yang, C. Research on estimation of AIS vessel trajectory data based on Kalman filter algorithm. Mod. Electron. Tech. 2014, 37, 97–100+104. [Google Scholar] [CrossRef]
- Jiang, B.; Guan, J.; Zhou, W.; Chen, X. Vessel trajectory prediction algorithm based on polynomial fitting kalman filtering. J. Signal Process. 2019, 35, 741–746. [Google Scholar] [CrossRef]
- Guo, S.; Liu, C.; Guo, Z.; Feng, Y.; Hong, F.; Huang, H. Trajectory prediction for ocean vessels base on k-order multivariate markov chain. In Wireless Algorithms, Systems, and Applications; Chellappan, S., Cheng, W., Li, W., Eds.; Springer International Publishing: Cham, Vietnam, 2018; pp. 140–150. [Google Scholar] [CrossRef]
- Rong, H.; Teixeira, A.P.; Guedes Soares, C. Ship trajectory uncertainty prediction based on a gaussian process model. Ocean. Eng. 2019, 182, 499–511. [Google Scholar] [CrossRef]
- Qiao, S.; Shen, D.; Wang, X.; Han, N.; Zhu, W. A self-adaptive parameter selection trajectory prediction approach via hidden markov models. IEEE Trans. Intell. Transp. Syst. 2015, 16, 284–296. [Google Scholar] [CrossRef]
- Murray, B.; Perera, L.P. A data-driven approach to vessel trajectory prediction for safe autonomous ship operations. In Proceedings of the Thirteenth International Conference on Digital Information Management (ICDIM), Berlin, Germany, 24–26 September 2018. [Google Scholar] [CrossRef]
- Wang, J.; Ding, H.; Hu, B. Ship trajectory prediction model based on sliding window PSO-LSSVR. J. Wuhan Univ. Technol. 2022, 44, 35–43+59. [Google Scholar]
- Mazzarella, F.; Fernandez Arguedas, V.; Vespe, M. Knowledge-based vessel position prediction using historical ais data. In Proceedings of the 2015 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 6–8 October 2015. [Google Scholar] [CrossRef]
- Qi, L.; Zheng, Z. Trajectory prediction of vessels based on data mining and machine learning. J. Digit. Inf. Manag. 2016, 14, 33–40. [Google Scholar]
- Jin, X. Analysisand Prediction Method of Vessel Trajectory; Beijing University of Posts and Telecommunications: Beijing, China, 2018. [Google Scholar]
- Gan, S.; Liang, S.; Li, K.; Deng, J.; Cheng, T. Trajectory length prediction for intelligent traffic signaling: A data-driven approach. IEEE Trans. Intell. Transp. Syst. 2018, 19, 426–435. [Google Scholar] [CrossRef]
- Hexeberg, S.; Flaten, A.L.; Eriksen, B.-O.H.; Brekke, E.F. AIS-based vessel trajectory prediction. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi′an, China, 10–13 July 2017. [Google Scholar] [CrossRef]
- Lv, G.; Hu, X.; Zhang, Q.; Wei, J. Federated spectral clustering algorithm for ship AIS trajectory AIS. Appl. Res. Comput. 2022, 39, 70–74+89. [Google Scholar] [CrossRef]
- Xu, T.; Liu, X.; Yang, X. BP neural network-based ship track real-time prediction. J. Dalian Marit. Univ. 2012, 38, 9–11. [Google Scholar] [CrossRef]
- Quan, B.; Yang, B.; Hu, K.; Guo, C.; Li, Q. Prediction model of ship trajectory based on LSTM. Comput. Sci. 2018, 45 (Suppl. S2), 126–131. [Google Scholar]
- Hu, Y.; Xia, W.; Hu, X.; Sun, H.; Wang, Y. Vessel trajectory prediction based on recurrent neural network. Syst. Eng. Electron. 2020, 42, 871–877. [Google Scholar]
- Suo, Y.; Chen, W.; Claramunt, C.; Yang, S. A ship trajectory prediction framework based on a recurrent neural network. Sensors 2020, 20, 5133. [Google Scholar] [CrossRef] [PubMed]
- Ma, Q.; Zhang, D.; Wang, P.; Liu, Z. Application of bidirectional gated cycle unit in ship trajectory prediction. J. Saf. Environ. 2023, 23, 1–10. [Google Scholar] [CrossRef]
- Gao, D.; Zhu, Y.; Zhang, J.; He, Y.; Yan, K.; Yan, B. A novel mp-lstm method for ship trajectory prediction based on ais data. Ocean. Eng. 2021, 228, 108956. [Google Scholar] [CrossRef]
- Liu, R.W.; Liang, M.; Nie, J.; Lim, W.Y.B.; Zhang, Y.; Guizani, M. Deep learning-powered vessel trajectory prediction for improving smart traffic services in maritime internet of things. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3080–3094. [Google Scholar] [CrossRef]
- Jiang, D.; Shi, G.; Li, N.; Ma, L.; Li, W.; Shi, J. TRFM-ls: Transformer-based deep learning method for vessel trajectory prediction. J. Mar. Sci. Eng. 2023, 11, 880. [Google Scholar] [CrossRef]
- Altan, D.; Marijan, D.; Kholodna, T. SafeWay: Improving the safety of autonomous waypoint detection in maritime using transformer and interpolation. Marit. Transp. Res. 2023, 4, 100086. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, X.; Yang, C.; Xiong, W. A novel soft sensor modeling approach based on difference-lstm for complex industrial process. IEEE Trans. Ind. Inform. 2022, 18, 2955–2964. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| validation_split | monitor | loss | optimizer |
| 0.1 | val_loss | MSE | Adam |
| batch_size | learning_rate | factor | min_lr |
| 32 | 0.01 | 0.5 | 0.001 |
| Model | Epochs | ) | ) | Runtime (s) | |
|---|---|---|---|---|---|
| BP | 5 | 2.0991 | 0.2498 | 0.9604 | 25.7735 |
| RNN | 5 | 12.5483 | 6.9686 | −0.1043 | 43.4832 |
| LSTM | 5 | 1.3127 | 0.1492 | 0.9764 | 77.2647 |
| Bi-LSTM | 5 | 1.5549 | 0.1800 | 0.9715 | 95.8038 |
| GRU | 5 | 1.3585 | 0.1589 | 0.9748 | 84.5002 |
| Bi-GRU | 5 | 1.4595 | 0.1677 | 0.9734 | 100.9159 |
| D-LSTM | 5 | 1.2505 | 0.1435 | 0.9772 | 58.8807 |
| BP | 25 | 1.7917 | 0.2072 | 0.9672 | 127.3508 |
| RNN | 25 | 1.4989 | 0.1667 | 0.9736 | 222.0595 |
| LSTM | 25 | 1.0147 | 0.1232 | 0.9805 | 381.7424 |
| Bi-LSTM | 25 | 1.0072 | 0.1275 | 0.9798 | 478.4366 |
| GRU | 25 | 1.0824 | 0.1352 | 0.9786 | 468.6859 |
| Bi-GRU | 25 | 1.0925 | 0.1303 | 0.9794 | 579.7488 |
| D-LSTM | 25 | 0.9982 | 0.1200 | 0.9810 | 252.3140 |
| BP | 50 | 1.7229 | 0.1533 | 0.9757 | 304.3560 |
| RNN | 50 | 34.1576 | 20.8596 | −2.3055 | 394.6542 |
| LSTM | 50 | 0.9982 | 0.1243 | 0.9803 | 710.7541 |
| Bi-LSTM | 50 | 0.9594 | 0.1170 | 0.9815 | 974.3503 |
| GRU | 50 | 1.0218 | 0.1338 | 0.9788 | 894.6607 |
| Bi-GRU | 50 | 1.0648 | 0.1362 | 0.9784 | 1075.7852 |
| D-LSTM | 50 | 0.9644 | 0.1203 | 0.9809 | 522.9541 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, X.; Suo, Y. Research on Ship Trajectory Prediction Method Based on Difference Long Short-Term Memory. J. Mar. Sci. Eng. 2023, 11, 1731. https://doi.org/10.3390/jmse11091731
Tian X, Suo Y. Research on Ship Trajectory Prediction Method Based on Difference Long Short-Term Memory. Journal of Marine Science and Engineering. 2023; 11(9):1731. https://doi.org/10.3390/jmse11091731
Chicago/Turabian StyleTian, Xiaobin, and Yongfeng Suo. 2023. "Research on Ship Trajectory Prediction Method Based on Difference Long Short-Term Memory" Journal of Marine Science and Engineering 11, no. 9: 1731. https://doi.org/10.3390/jmse11091731
APA StyleTian, X., & Suo, Y. (2023). Research on Ship Trajectory Prediction Method Based on Difference Long Short-Term Memory. Journal of Marine Science and Engineering, 11(9), 1731. https://doi.org/10.3390/jmse11091731