
Real-Time Instance Segmentation for Detection of Underwater Litter as a Plastic Source




Abstract
1. Introduction
1.1. Detection of Marine Plastic
1.2. Computer Vision: Instance Segmentation
2. Material and Methods
2.1. Dataset
2.1.1. Low Visibility
2.1.2. Visual Noise
2.1.3. Objects of Different Forms
2.2. Machine Learning Models
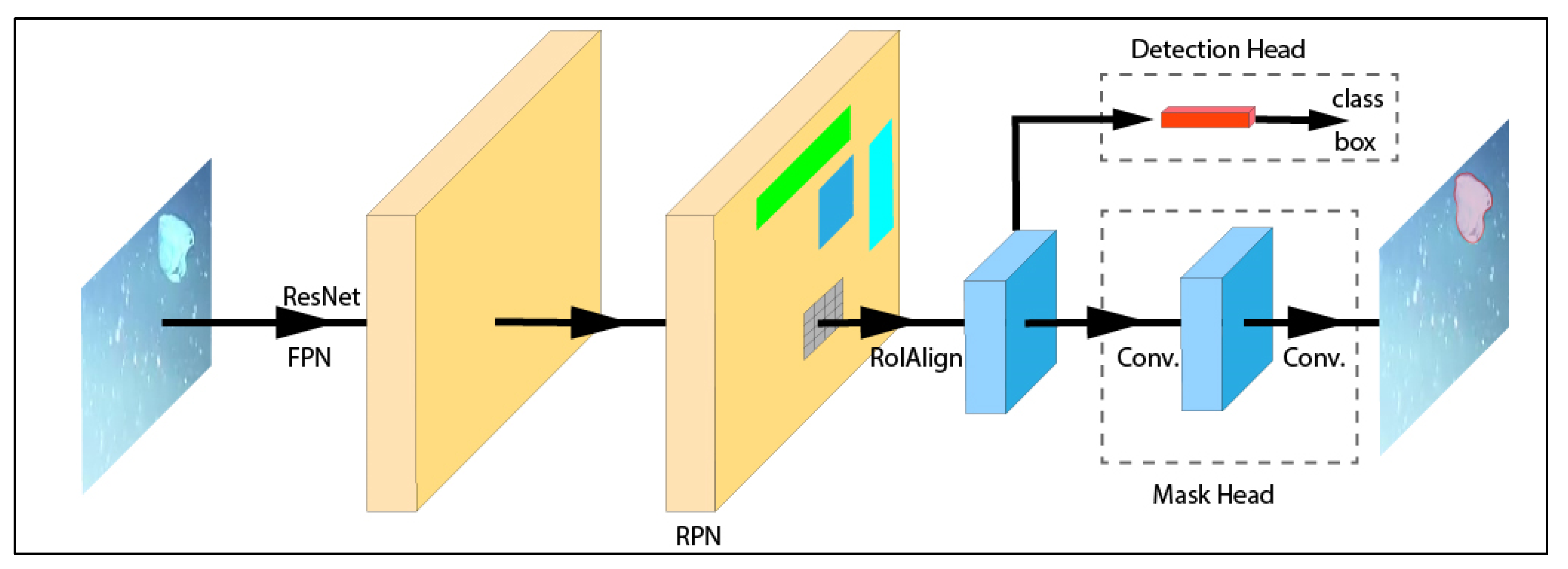
2.2.1. The Mask R-CNN
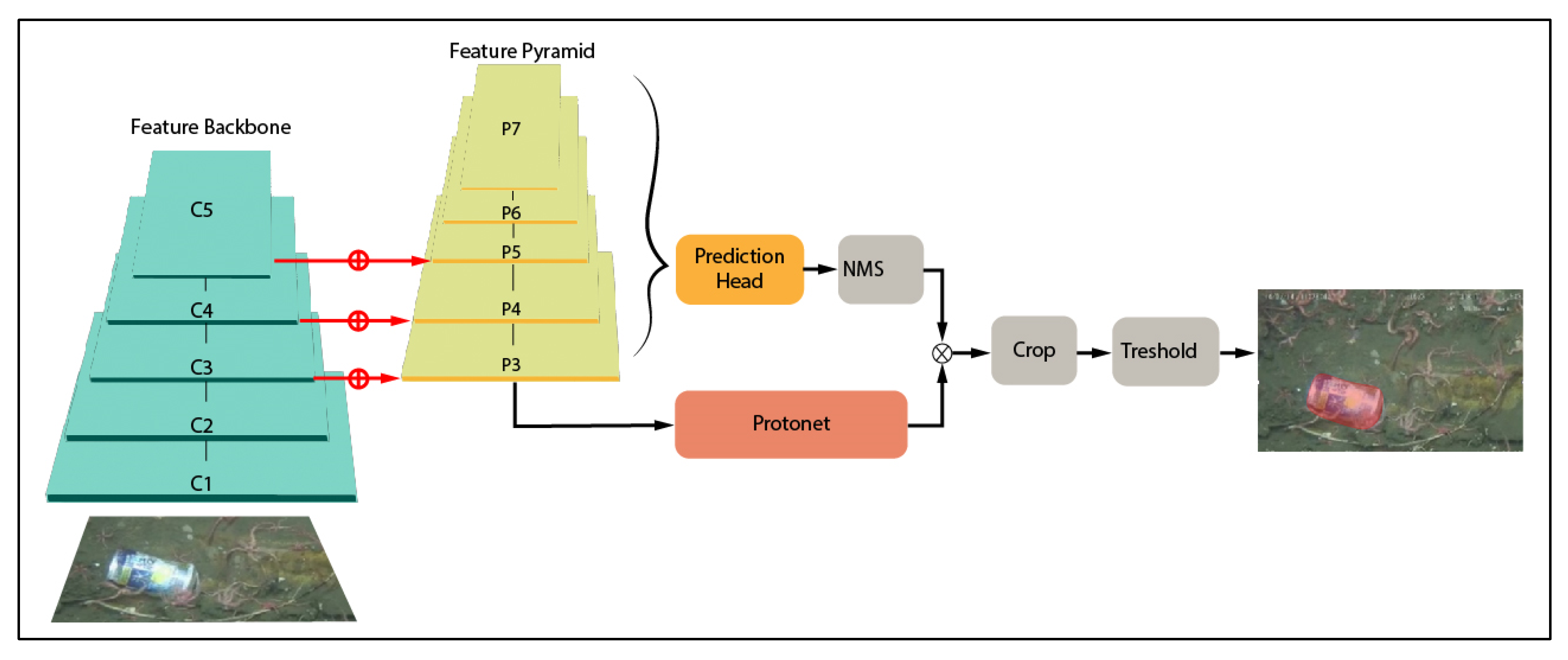
2.2.2. YOLACT
2.3. Training
2.3.1. Mask R-CNN
2.3.2. YOLACT
2.4. Evaluation
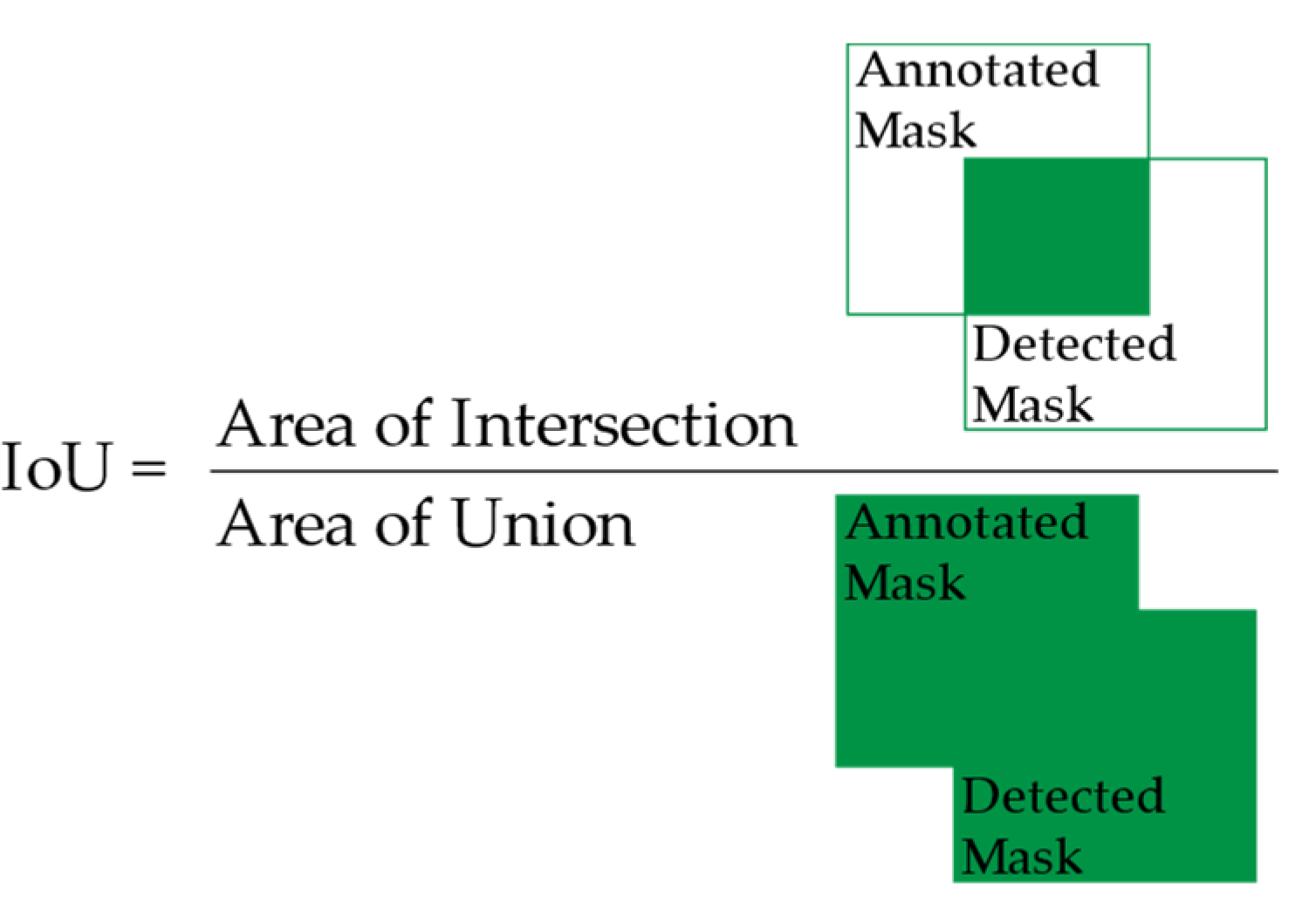
2.4.1. Intersection over Union (IoU)
2.4.2. Precision (P)
2.4.3. Recall (R)
2.4.4. Accuracy Metrics—Average Precision () and Mean Average Precision ()
3. Results
3.1. Qualitive Analysis
3.2. Quantitative Analysis
3.2.1. Comparison between Mask R-CNN and YOLACT
3.2.2. Comparison to Other Models
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- National Geographic Society. Why the Ocean Matters. 2023. Available online: https://education.nationalgeographic.org/resource/why-ocean-matters/ (accessed on 9 June 2023).
- National Geographic Society. Ocean Trash: 5.25 Trillion Pieces and Counting, but Big Questions Remain. 2022. Available online: https://education.nationalgeographic.org/resource/ocean-trash-525-trillion-pieces-and-counting-big-questions-remain/ (accessed on 9 June 2023).
- United Nations Statistics Division. Conserve and Sustainably Use the Oceans, Sea and Marine Resources for Sustainable Development. 2022. Available online: https://unstats.un.org/sdgs/report/2022/Goal-14/ (accessed on 9 June 2023).
- Sharma, S.; Sharma, V.; Chatterjee, S. Microplastics in the Mediterranean Sea: Sources, Pollution Intensity, Sea Health, and Regulatory Policies. Front. Mar. Sci. 2021, 8, 494. [Google Scholar] [CrossRef]
- Alabi, O.A.; Ologbonjaye, K.I.; Awosolu, O.; Alalade, O.E. Public and Environmental Health Effects of Plastic Wastes Disposal: A Review. J. Toxicol. Risk Assess. 2019, 5, 1–13. [Google Scholar] [CrossRef]
- Gallo, F.; Fossi, C.; Weber, R.; Santillo, D.; Sousa, J.; Ingram, I.; Nadal, A.; Romano, D. Marine litter plastics and microplastics and their toxic chemicals components: The need for urgent preventive measures. Environ. Sci. Eur. 2018, 30, 13. [Google Scholar] [CrossRef] [PubMed]
- Newman, S.; Watkins, E.; Farmer, A.; Brink, P.T.; Schweitzer, J.P. The economics of marine litter. Mar. Anthropog. Litter 2015, 367–394. [Google Scholar] [CrossRef]
- Pabortsava, K.; Lampitt, R.S. High concentrations of plastic hidden beneath the surface of the Atlantic Ocean. Nat. Commun. 2020, 11, 4073. [Google Scholar] [CrossRef] [PubMed]
- Voyer, M.; Schofield, C.; Azmi, K.; Warner, R.; McIlgorm, A.; Quirk, G. Maritime security and the Blue Economy: Intersections and interdependencies in the Indian Ocean. J. Indian Ocean Reg. 2017, 14, 28–48. [Google Scholar] [CrossRef]
- Maes, T.; Barry, J.; Leslie, H.A.; Vethaak, A.D.; Nicolaus, E.E.M.; Law, R.; Lyons, B.P.; Martinez, R.; Harley, B.; Thain, J.E. Below the surface: Twenty-five years of seafloor litter monitoring in coastal seas of North West Europe (1992–2017). Sci. Total Environ. 2018, 630, 790–798. [Google Scholar] [CrossRef] [PubMed]
- Pham, C.K.; Ramirez-Llodra, E.; Alt, C.H.S.; Amaro, T.; Bergmann, M.; Canals, M.; Company, J.B.; Davies, J.; Duineveld, G.; Galgani, F.; et al. Marine Litter Distribution and Density in European Seas, from the Shelves to Deep Basins. PLoS ONE 2014, 9, e95839. [Google Scholar] [CrossRef] [PubMed]
- Schwarz, A.; Ligthart, T.; Boukris, E.; van Harmelen, T. Sources, transport, and accumulation of different types of plastic litter in aquatic environments: A review study. Mar. Pollut. Bull. 2019, 143, 92–100. [Google Scholar] [CrossRef] [PubMed]
- Valdenegro-Toro, M. Submerged marine debris detection with autonomous underwater vehicles. In Proceedings of the 2016 International Conference on Robotics and Automation for Humanitarian Applications (RAHA), Kollam, India, 18–20 December 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Madricardo, F.; Ghezzo, M.; Nesto, N.; Mc Kiver, W.J.; Faussone, G.C.; Fiorin, R.; Riccato, F.; Mackelworth, P.C.; Basta, J.; De Pascalis, F.; et al. How to Deal with Seafloor Marine Litter: An Overview of the State-of-the-Art and Future Perspectives. Front. Mar. Sci. 2020, 7, 830. [Google Scholar] [CrossRef]
- Tudor, D.T.; Williams, A.T. Marine Debris-Onshore, Offshore, and Seafloor Litter. In Encyclopedia of Coastal Science; Springer: Amsterdam, The Netherlands, 2019; pp. 1125–1129. [Google Scholar] [CrossRef]
- Erbe, C.; Duncan, A.; Vigness-Raposa, K.J. Introduction to Sound Propagation Under Water. In Exploring Animal Behavior Through Sound; Springer: Berlin/Heidelberg, Germany, 2022; Volume 1, pp. 185–216. [Google Scholar]
- Spengler, A.; Costa, M.F. Methods applied in studies of benthic marine debris. Mar. Pollut. Bull. 2008, 56, 226–230. [Google Scholar] [CrossRef] [PubMed]
- Ardana, I.W.R.; Purnama, I.B.I.; Yasa, I.M.S. Application of Object Recognition for Plastic Waste Detection and Classification Using YOLOv3. In Proceedings of the 3rd International Conference on Applied Science and Technology, iCAST 2020, Padang, Indonesia, 24–25 October 2020; pp. 652–656. [Google Scholar] [CrossRef]
- Jia, T.; Kapelan, Z.; de Vries, R.; Vriend, P.; Peereboom, E.C.; Okkerman, I.; Taormina, R. Deep learning for detecting macroplastic litter in water bodies: A review. Water Res. 2023, 231, 119632. [Google Scholar] [CrossRef] [PubMed]
- Bolya, D.; Fanyi, C.Z.; Yong, X.; Lee, J. YOLACT Real-Time Instance Segmentation. 2019. Available online: https://github.com/dbolya/yolact (accessed on 16 July 2022).
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6399–6408. [Google Scholar] [CrossRef]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8570–8578. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. SOLO: A Simple Framework for Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8587–8601. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Gong, Z.; Zhong, P.; Hu, W. Diversity in Machine Learning. IEEE Access 2019, 7, 64323–64350. [Google Scholar] [CrossRef]
- Hong, J.; Fulton, M.; Sattar, J. TrashCan: A Semantically-Segmented Dataset towards Visual Detection of Marine Debris (Preprint). 2020. Available online: https://www.researchgate.net/publication/343005360_TrashCan_A_Semantically-Segmented_Dataset_towards_Visual_Detection_of_Marine_Debris (accessed on 22 June 2023).
- Deng, H.; Ergu, D.; Liu, F.; Ma, B.; Cai, Y. An Embeddable Algorithm for Automatic Garbage Detection Based on Complex Marine Environment. Sensors 2021, 21, 6391. [Google Scholar] [CrossRef] [PubMed]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef]
- GitHub—Ahmedfgad/Mask-RCNN-TF2: Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow 2.0. Available online: https://github.com/ahmedfgad/Mask-RCNN-TF2 (accessed on 17 July 2022).
- GitHub—Matterport/Mask_RCNN: Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. Available online: https://github.com/matterport/Mask_RCNN (accessed on 17 July 2022).
- Kurbiel, T. Gaining an Intuitive Understanding of Precision, Recall and Area Under Curve|by Thomas Kurbiel|Towards Data Science. 2020. Available online: https://towardsdatascience.com/gaining-an-intuitive-understanding-of-precision-and-recall-3b9df37804a7 (accessed on 18 July 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Train Instances | Validation Instances | Total Instances | Ratio (Train–Val) |
|---|---|---|---|---|
| animal_crab | 246 | 63 | 309 | 0.80–0.20 |
| animal_eel | 259 | 84 | 343 | 0.76–0.24 |
| animal_etc | 170 | 65 | 235 | 0.72–0.28 |
| animal_fish | 611 | 153 | 764 | 0.80–0.20 |
| animal_shells | 188 | 61 | 249 | 0.76–0.24 |
| animal_starfish | 262 | 136 | 398 | 0.66–0.34 |
| plant | 405 | 102 | 507 | 0.80–0.20 |
| rov | 2633 | 684 | 3447 | 0.76–0.20 |
| trash_bag | 727 | 181 | 910 | 0.80–0.20 |
| trash_bottle | 100 | 26 | 126 | 0.79–0.21 |
| trash_branch | 268 | 68 | 336 | 0.80–0.20 |
| trash_can | 366 | 93 | 461 | 0.79–0.20 |
| trash_clothing | 65 | 17 | 82 | 0.79–0.21 |
| trash_container | 407 | 103 | 510 | 0.80–0.20 |
| trash_cup | 47 | 12 | 59 | 0.80–0.20 |
| trash_net | 94 | 33 | 130 | 0.72–0.25 |
| trash_pipe | 114 | 42 | 156 | 0.73–0.27 |
| trash_rope | 88 | 29 | 117 | 0.75–0.25 |
| trash_snack_wrapper | 67 | 17 | 84 | 0.80–0.20 |
| trash_tarp | 90 | 31 | 122 | 0.74–0.25 |
| trash_unknown_instance | 2203 | 553 | 2761 | 0.80–0.20 |
| trash_wreckage | 130 | 35 | 165 | 0.79–0.21 |
| Property | Mask R-CNN | YOLACT |
|---|---|---|
| Backbone | ResNet-101 | Resnet-101 |
| 𝒎𝑨𝑷 | 0.377 | 0.365 |
| 0.588 | 0.563 | |
| 0.425 | 0.413 | |
| 0.103 | 0.096 | |
| of pre-trained weights on COCO2017 evaluation | 0.361 | 0.298 |
| GPU | Mask R–CNN | YOLACT |
|---|---|---|
| Nvidia GTX 1050 Ti (lower-end GPU) | 1.6 FPS | 5.1 FPS |
| Nvidia Quadro P4000 (higher-end GPU) | 6.1 FPS | 41.2 FPS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corrigan, B.C.; Tay, Z.Y.; Konovessis, D. Real-Time Instance Segmentation for Detection of Underwater Litter as a Plastic Source. J. Mar. Sci. Eng. 2023, 11, 1532. https://doi.org/10.3390/jmse11081532
Corrigan BC, Tay ZY, Konovessis D. Real-Time Instance Segmentation for Detection of Underwater Litter as a Plastic Source. Journal of Marine Science and Engineering. 2023; 11(8):1532. https://doi.org/10.3390/jmse11081532
Chicago/Turabian StyleCorrigan, Brendan Chongzhi, Zhi Yung Tay, and Dimitrios Konovessis. 2023. "Real-Time Instance Segmentation for Detection of Underwater Litter as a Plastic Source" Journal of Marine Science and Engineering 11, no. 8: 1532. https://doi.org/10.3390/jmse11081532
APA StyleCorrigan, B. C., Tay, Z. Y., & Konovessis, D. (2023). Real-Time Instance Segmentation for Detection of Underwater Litter as a Plastic Source. Journal of Marine Science and Engineering, 11(8), 1532. https://doi.org/10.3390/jmse11081532