
Towards Multi-AUV Collaboration and Coordination: A Gesture-Based Multi-AUV Hierarchical Language and a Language Framework Comparison System


Abstract
1. Introduction
- It updates and revises the Caddian language into the Caddian core language where:
- −
- all revisions and expansions are based on feedback from the diving community and results from trials;
- −
- revisions simplify some part of the language;
- −
- expansions add robot-to-human communication capabilities to the language;
- It involves the design of a new multi-AUV framework for cooperation and coordination of an AUV team and adds relevant components to the language;
- It proposes a hierarchical schema for designating a robot leader among AUVs;
- The proposed UHRI framework uses gestures as a means of communication, but it is agnostic, so the back-end can be used with other front-ends that recognise other means of communication besides gestures;
- It provides a Caddian corpus consisting of fifty million sentences in Caddian and evaluates it to enable researchers to know the main features of the language model and optimise the gesture recognition front-end accordingly;
- It proposes an evaluation framework for UHRI systems (evaluation criteria for UHRI-ECU);
- It compares, using ECU, the expanded language with other existing underwater human–robot interaction languages, thus providing an overview of the current state of UHRI languages.
2. Related Work
3. Methodology
4. Human–Robot Communication
4.1. Language Update and Revision
- Questions: each command in the Questions set refers to the possibility of asking the AUV a question or being questioned by it.
- Status: each command within this set refers to the ability to answer questions asked by the AUV.
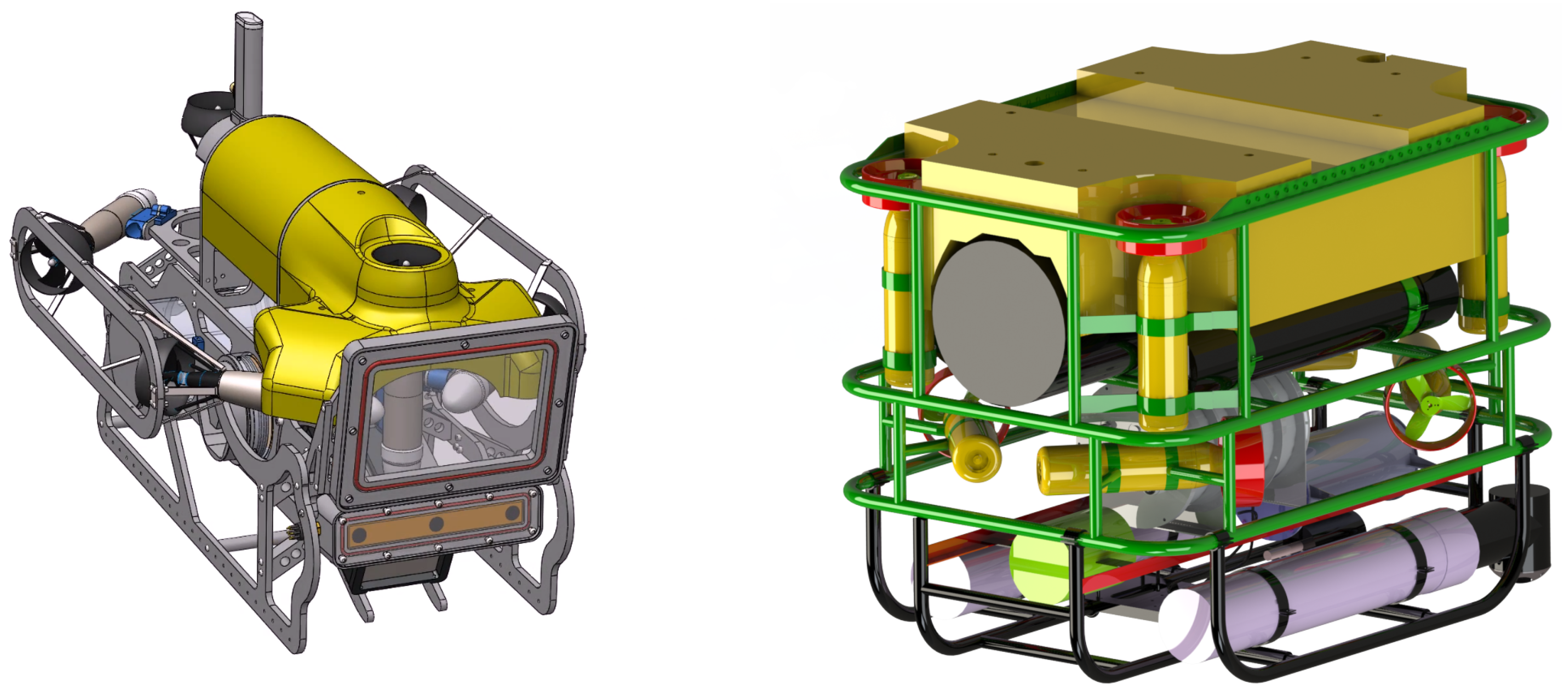
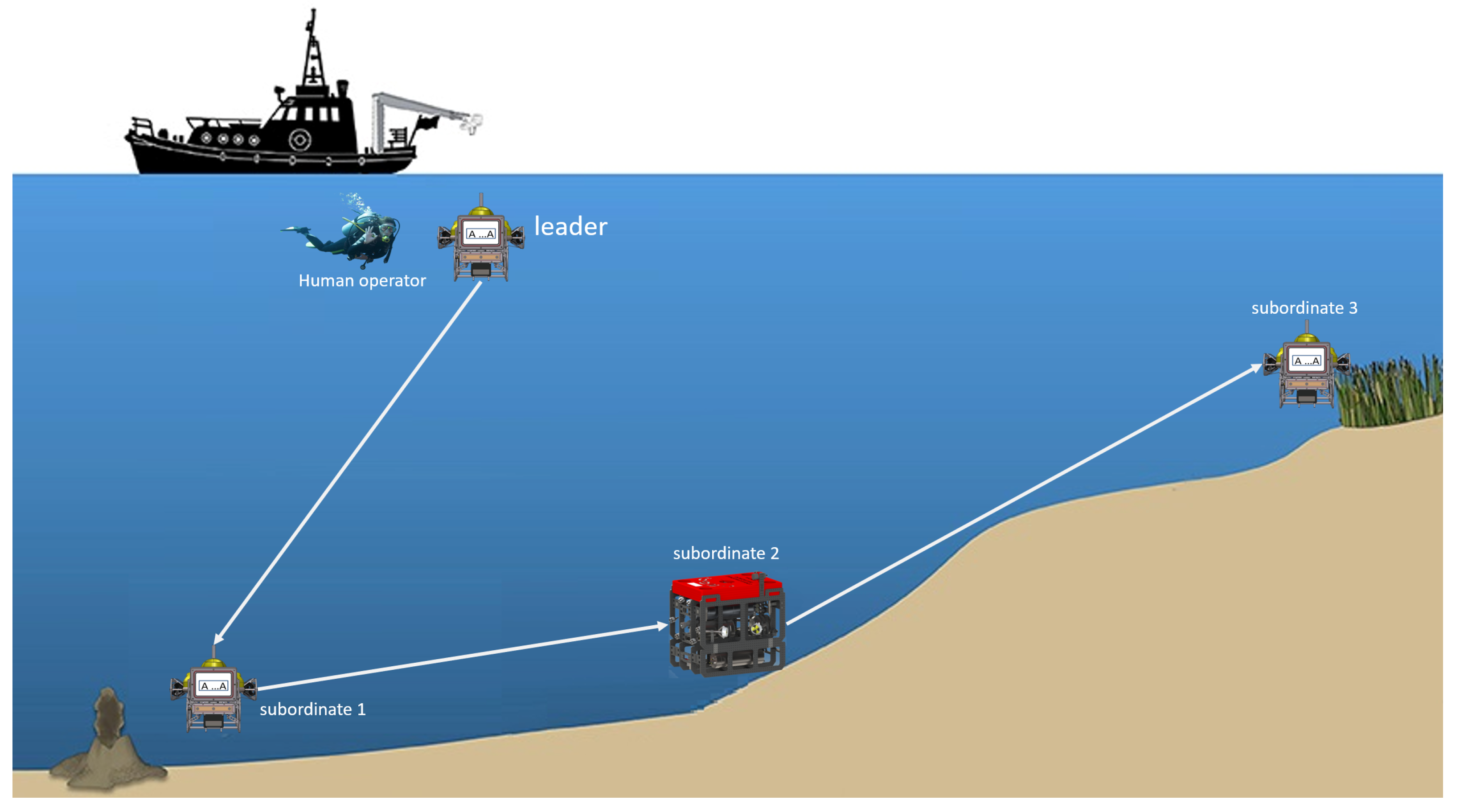
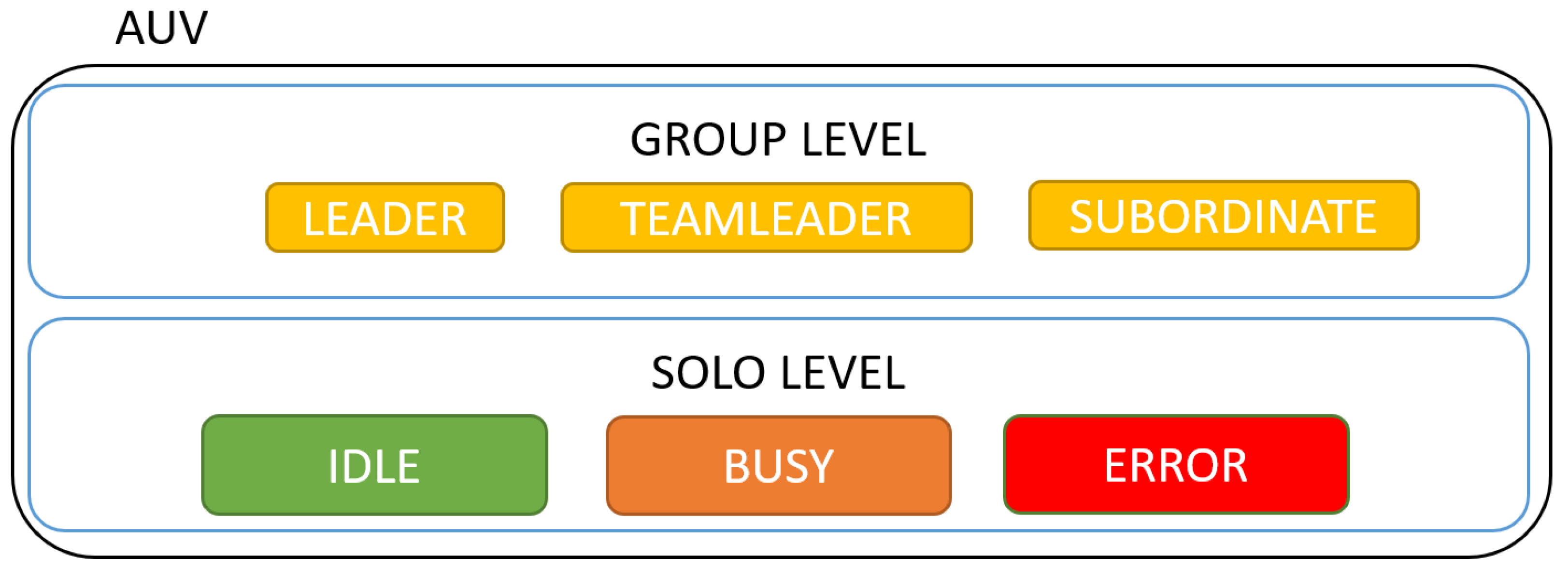
4.2. The New Framework for Multi-AUV Collaboration and Coordination
4.3. A Collaboration and Coordination Human–Robot Interaction Language
4.3.1. Syntax
4.3.2. Semantics
- set the identifier of the AUV to which he or she is speaking;
- describe the hierarchy of an individual team—in the presence of multiple teams, the description of each individual team has to be issued with a distinct command;
- describe the tasks for an AUV that can then be assigned later to the latter after identifying it.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Message/Command | Caddian | |
|---|---|---|
| “Group level” enabled, “Solo level” disabled | ||
| Set identification number n | A id n ∀ | |
| Set hierarchy for a mission where AUV #1 is leader and AUV #2 is team leader of | A mission 1 2 3 4 5 ∀ | |
| #3, #4 #5 and AUV #6 is team leader of #7, #8 | A mission 1 6 7 8 ∀ | |
| List of orders for AUV #3: take a picture of point of interest, tesselation of | A worker 3 /Fo P /Te 4 5 /boat ∀ | |
| 4 m × 5 m area then return to boat | ||
| “Group level” disabled, “Solo level” enabled | ||
| Ask for identification number | A U id ∀ | |
| Stating identification number (answer) | A id <num> ∀ | |
5. Experiments and Evaluation of the Language
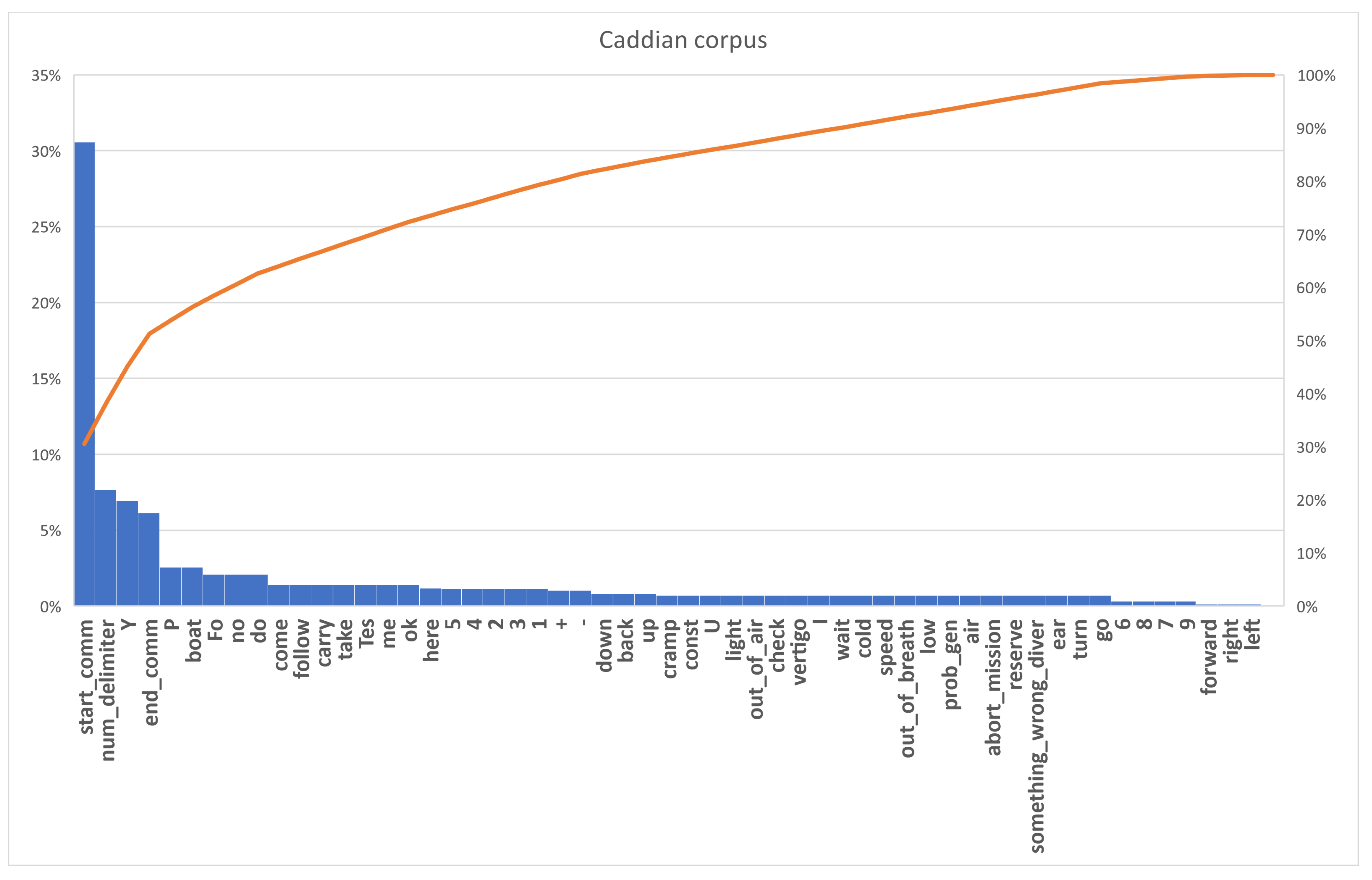
5.1. The Caddian Corpus
5.1.1. Experimental Setup
5.1.2. Evaluation of the Caddian Corpus
5.2. The ECU Framework and Language Comparison
5.2.1. Evaluation Criteria
- Context-free grammar: whether or not the language has a context-free grammar. A context-free grammar is structured in such a way as to make it easier and more intuitive to understand the grammatical rules by removing some of the ambiguities that may be present in other forms of grammar. The ease of analysis which this entails affects language learning, which it represents, since learning becomes a matter of recognising individual units of syntax and the rules for combining them. In addition, a CFG has the advantage of simplicity of representation—it can be represented in a standardised form, such as the BNF, which simplifies the description of the grammar and facilitates its implementation in a language analysis system, making its programming and the creation of syntactic control rules more efficient. Both these factors make it possible to create more efficient and accurate syntactic analysis tools. Finally, it provides expandability—new syntactic constructs or terms can be added to the language without having to completely redesign the grammar. This is possible because a context-free grammar is based on defining syntactic rules that specify how different parts of speech combine to create grammatically correct sentences. These rules can be modified or extended to accommodate new syntactic constructions or new words.
- Ease of learning the language and user interface: this feature describes in language testing if the ease of learning the language was evaluated.
- Feedback: this feature indicates whether the language has included communication feedback from the robot to the human operator. Effective feedback enables human operators to better understand the state of the system, correctly perform the actions necessary to complete an assigned task, and improve the trust and safety of human operators. In fact, feedback can also affect human operators’ perceptions of the reliability and quality of systems, and can, therefore, be an important factor in choosing which systems to use in certain applications.
- Single task execution speed: this feature describes whether in testing the language framework how task execution speed was evaluated.
- Task execution accuracy: this feature describes whether the accuracy of the responses provided by the robotic systems was evaluated in the testing of the language framework.
- Adaptability: this feature describes whether the ability of the systems to adapt to unforeseen or unexpected situations, such as sudden changes in environmental conditions, was predicted in the language framework. It refers to the construction of conditional statements, such as “If the visibility is poor, then wait for five minutes”, or “If the current starts to increase, then return to the base”. These conditional statements serve as examples of how the language framework can incorporate environmental conditions and adapt the robot’s behavior accordingly.
- Robustness: in testing the language, the ability of the systems to maintain performance even in the presence of hardware or software errors or failures, such as the loss of one or more sensors, was evaluated.
- Parameters reconfiguration: the language allows reconfiguration of mission parameters. In an underwater human robot interaction context, it is important to provide for the ability to reconfigure mission parameters because environmental conditions and mission requirements may change over time. For example, the navigational depth of an underwater robot may need to be changed due to an unexpected current or an unexpected obstacle. The ability to reconfigure mission parameters in real time allows robots to adapt to changing environmental conditions and perform their tasks more efficiently and accurately. In addition, reconfiguring mission parameters can enable robots to optimise their performance and save energy, thereby increasing mission autonomy.
- Gesture based: the language is gesture based or not. The other medium used is indicated if this was not the case. The use of gestures, in fact, can help overcome difficulties in submarine communication where audio and voice are limited. Gestures can be easily visible and recognizable even in unclear water or low light. In addition to this, gesture-based communication, which has already been adopted by the underwater community, can reduce the fatigue and stress of human personnel interacting with underwater robots, as it does not require the use of voice devices or other tools that may be cumbersome or impractical in the underwater environment.
- Human to robot: language enables human–robot communication. It is the pivotal feature of the chosen languages, but it is shown for completeness.
- Robot to human: language enables robot–human communication. In an underwater human robot interaction language, the robot may have to provide important information to the human, such as the conditions of the surrounding environment. In addition, the robot may have to report any problems or malfunctions to the human. Thus, effective and well-structured two-way communication can improve collaboration between human and robot, increasing the efficiency and safety of operations performed in the underwater environment.
- Collaboration: the language allows or provides for collaboration between AUVs. In some application scenarios, multiple AUVs may need to be used simultaneously to perform complex tasks. For example, a team of AUVs could be used to conduct detailed mapping of a marine area, where each vehicle has a specific task or, in the case of environmental emergencies, such as oil spills or marine pollution, a team of AUVs can be used to assess the size and extent of damage, map the affected area, and support recovery activities. In this case, effective communication between vehicles can improve the efficiency of the work performed. In addition to this, in an underwater environment, environmental conditions can be changeable and unpredictable, and a fleet of AUVs can collaborate to manage these situations. In addition, collaboration between AUVs can improve the efficiency of work performed and increase the safety of operations. Effective communication between vehicles can enable optimal task distribution and sharing of collected information, avoiding duplication of effort and maximising coverage of the marine area of interest.
- Scalability: in testing the framework, the ability of the robotic systems to operate effectively and efficiently, even when the number of AUVs involved increases, was evaluated.
- Overall efficiency: this criterion checks how long it took the systems to perform a specific task, such as how long it took a group of AUVs to complete an assigned task.
- Hierarchical organization: the language allows a hierarchical organization of AUVs and consequently of their tasks. This factor is very important for coordination of activities—when there are multiple AUVs operating simultaneously, it is important to have a hierarchical system to coordinate activities effectively and safely. This helps to avoid collisions and conflicts of activities. The ability to set a hierarchical order is, in addition, essential for resource management because it allows for efficient management of available resources, such as battery life, payload capacity, and availability of specific sensors. It simultaneously ensures flexibility and adaptability; the hierarchy of AUVs makes it easy to adapt activities according to terrain conditions, operator demands, or resource availability. For example, a lower-level hardware AUV could be tasked to monitor a specific area, while a higher-level hardware AUV could be tasked to perform a more complex search mission.
- “Open sea trials” or “Pool or closed water testing”: language was tested in open sea or only in pool or closed water. Open water trials are as crucial as pool or closed-water trials for the following reasons:
- −
- Real-world conditions and test validity: open-water testing allows underwater robotic systems to be tested under real-world conditions, similar to those that may be encountered during real-world underwater operations. This can provide important information about the robot’s performance, capabilities, and limitations under real-world conditions.
- −
- Complex environment and variance of conditions: the marine environment is complex and dynamic, with currents, waves, and other environmental variables that can affect robot performance. Conducting trials in the open ocean allows for testing the ability of underwater robots to adapt to a wide range of conditions, improving their ability to perform real-world missions in diverse conditions.
- −
- human–robot collaboration: open-water trials allow testing of human–robot collaboration in a real-world environment, helping to identify any challenges or communication issues that may not emerge during pool or closed-water trials.
- Community feedback: the language has received feedback from end-users such as professional and amateur divers. It is important to have a part of the language of underwater human robot interaction derived from feedback from the community of professional and amateur divers for several reasons:
- −
- Domain knowledge: the community of professional and amateur divers has in-depth knowledge of the underwater domain and the activities that are performed in this environment. Incorporating their feedback into the language of underwater human robot interaction helps to ensure that the language is appropriate for the context and takes into account important aspects that might be overlooked by those who are not experts in scuba diving.
- −
- Usability: incorporating feedback from professional and amateur divers can improve the usability of underwater robotic systems. Divers can provide useful information about the ease of use of underwater robotic systems, their training requirements, and their ability to meet users’ needs.
- −
- Safety: professional and amateur divers have a thorough understanding of the risks and challenges that can be encountered in an underwater environment. Incorporating their feedback can help improve the safety of underwater robotic systems, helping to prevent accidents and to ensure that underwater robots operate safely and responsibly.
- Open data: the language framework makes databases of examples or data available to the scientific community, which is useful for reproducing experiments and improving the framework. In addition to these two elements, open data are critical for knowledge sharing that can lead to greater collaboration among researchers and the discovery of new techniques and ideas.
5.2.2. Comparison with Existing U-HRI Languages
- A Visual Language for Robot Control and Programming: A Human-Interface Study (2007) [33]
- Gesture-based Language for Diver-Robot Underwater Interaction ( Caddian 2015) [9]
- A Novel Gesture-Based Language for Underwater Human–Robot Interaction [10], Underwater Stereo-Vision Dataset for Human–Robot Interaction (HRI) in the Context of Diver Activities [12] and Underwater Vision-Based Gesture Recognition: A Robustness Validation for Safe Human–Robot Interaction [22] (Caddian 2018–2021)
- Robot Communication Via Motion: A Study on Modalities for Robot-to-Human Communication in the Field [39] (2019–2022)
- HREyes: Design, Development, and Evaluation of a Novel Method for AUVs to Communicate Information and Gaze Direction [42] (2022)
- This work (2023)
6. Challenges and Mitigation Strategies
7. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Denoble, P.J.; Caruso, J.L.; Dear, G.d.L.; Pieper, C.F.; Vann, R.D. Common causes of open-circuit recreational diving fatalities. Undersea Hyperb. Med. J. 2008, 35, 393–406. [Google Scholar]
- Richardson, D. PADI Open Water Diver Manual; PADI: Rancho Santa Margarita, CA, USA, 2010. [Google Scholar]
- Halstead, B. Line dancing and the buddy system. South Pac. Underw. Med. Soc. J. 2000, 30, 701–713. [Google Scholar]
- Li, S.; Qu, W.; Liu, C.; Qiu, T.; Zhao, Z. Survey on high reliability wireless communication for underwater sensor networks. J. Netw. Comput. Appl. 2019, 148, 102446. [Google Scholar] [CrossRef]
- CMAS Swiss Diving. Segni Convenzionali. 2003. Available online: https://www.cmas.ch/docs/it/downloads/codici-comunicazione-cmas/it-Codici-di-comunicazione-CMAS.pdf (accessed on 6 June 2023).
- Jorge Mezcua. Diving Signs You Need to Know. HTML Page. 2012. Available online: http://www.fordivers.com/en/blog/2013/09/12/senales-de-buceo-que-tienes-que-conocer/ (accessed on 6 June 2023).
- Recreational Scuba Training Council. Common Hand Signals for Recreational Scuba Diving. Online PDF. 2005. Available online: http://www.neadc.org/CommonHandSignalsforScubaDiving.pdf (accessed on 6 June 2023).
- Scuba Diving Fan club. Most Common Diving Signals. HTML Page. 2016. Available online: http://www.scubadivingfanclub.com/Diving_Signals.html (accessed on 6 June 2023).
- Chiarella, D.; Bibuli, M.; Bruzzone, G.; Caccia, M.; Ranieri, A.; Zereik, E.; Marconi, L.; Cutugno, P. Gesture-based language for diver-robot underwater interaction. In Proceedings of the OCEANS 2015, Genova, Italy, 18–21 May 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Chiarella, D.; Bibuli, M.; Bruzzone, G.; Caccia, M.; Ranieri, A.; Zereik, E.; Marconi, L.; Cutugno, P. A Novel Gesture-Based Language for Underwater Human–Robot Interaction. J. Mar. Sci. Eng. 2018, 6, 91. [Google Scholar] [CrossRef]
- Chomsky, N. Three models for the description of language. IRE Trans. Inf. Theory 1956, 2, 113–124. [Google Scholar] [CrossRef]
- Gomez Chavez, A.; Ranieri, A.; Chiarella, D.; Zereik, E.; Babić, A.; Birk, A. CADDY Underwater Stereo-Vision Dataset for Human–Robot Interaction (HRI) in the Context of Diver Activities. J. Mar. Sci. Eng. 2019, 7, 16. [Google Scholar] [CrossRef]
- Mišković, N.; Pascoal, A.; Bibuli, M.; Caccia, M.; Neasham, J.A.; Birk, A.; Egi, M.; Grammer, K.; Marroni, A.; Vasilijević, A.; et al. CADDY project, year 3: The final validation trials. In Proceedings of the OCEANS 2017, Aberdeen, UK, 19–22 June 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Stilinović, N.; Nađ, Đ.; Mišković, N. AUV for diver assistance and safety-Design and implementation. In Proceedings of the OCEANS 2015, Genova, Italy, 18–21 May 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Mišković, N.; Pascoal, A.; Bibuli, M.; Caccia, M.; Neasham, J.A.; Birk, A.; Egi, M.; Grammer, K.; Marroni, A.; Vasilijević, A.; et al. CADDY Project, Year 1: Overview of Technological Developments and Cooperative Behaviours. IFAC-PapersOnLine 2015, 48, 125–130. [Google Scholar] [CrossRef]
- Nađ, Đ.; Mandić, F.; Mišković, N. Using Autonomous Underwater Vehicles for Diver Tracking and Navigation Aiding. J. Mar. Sci. Eng. 2020, 8, 413. [Google Scholar] [CrossRef]
- Odetti, A.; Bibuli, M.; Bruzzone, G.; Caccia, M.; Spirandelli, E.; Bruzzone, G. e-URoPe: A reconfgurable AUV/ROV for man-robot underwater cooperation. IFAC-PapersOnLine 2017, 50, 11203–11208. [Google Scholar] [CrossRef]
- CADDY Underwater Stereo-Vision Dataset. Website. 2019. Available online: http://www.caddian.eu (accessed on 6 June 2023).
- Jiang, Y.; Zhao, M.; Wang, C.; Wei, F.; Wang, K.; Qi, H. Diver’s hand gesture recognition and segmentation for human–robot interaction on AUV. Signal Image Video Process. 2021, 15, 1899–1906. [Google Scholar] [CrossRef]
- Yang, J.; Wilson, J.P.; Gupta, S. DARE: AI-based Diver Action Recognition System using Multi-Channel CNNs for AUV Supervision. arXiv 2020, arXiv:2011.07713. [Google Scholar]
- Martija, M.A.M.; Dumbrique, J.I.S.; Naval, P.C., Jr. Underwater Gesture Recognition Using Classical Computer Vision and Deep Learning Techniques. J. Image Graph. 2020, 8, 9–14. [Google Scholar] [CrossRef]
- Gomez Chavez, A.; Ranieri, A.; Chiarella, D.; Birk, A. Underwater Vision-Based Gesture Recognition: A Robustness Validation for Safe Human–Robot Interaction. IEEE Robot. Autom. Mag. 2021, 28, 67–78. [Google Scholar] [CrossRef]
- Birk, A. A Survey of Underwater Human-Robot Interaction (U-HRI). Curr. Robot. Rep. 2022, 3, 199–211. [Google Scholar] [CrossRef]
- Sattar, J.; Dudek, G. Where is your dive buddy: Tracking humans underwater using spatio-temporal features. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 3654–3659. [Google Scholar] [CrossRef]
- Buelow, H.; Birk, A. Gesture-recognition as basis for a human robot interface (HRI) on a AUV. In Proceedings of the OCEANS’11 MTS/IEEE KONA, Waikoloa, HI, USA, 19–22 September 2011; pp. 1–9. [Google Scholar] [CrossRef]
- DeMarco, K.J.; West, M.E.; Howard, A.M. Sonar-Based Detection and Tracking of a Diver for Underwater Human-Robot Interaction Scenarios. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 2378–2383. [Google Scholar] [CrossRef]
- Chavez, A.G.; Pfingsthorn, M.; Birk, A.; Rendulić, I.; Misković, N. Visual diver detection using multi-descriptor nearest-class-mean random forests in the context of underwater Human Robot Interaction (HRI). In Proceedings of the OCEANS 2015, Genova, Genova, Italy, 18–21 May 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Islam, M.J.; Sattar, J. Mixed-domain biological motion tracking for underwater human–robot interaction. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4457–4464. [Google Scholar] [CrossRef]
- Chavez, A.G.; Mueller, C.A.; Birk, A.; Babic, A.; Miskovic, N. Stereo-vision based diver pose estimation using LSTM recurrent neural networks for AUV navigation guidance. In Proceedings of the OCEANS 2017, Aberdeen, UK, 19–22 June 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Xia, Y.; Sattar, J. Visual Diver Recognition for Underwater Human-Robot Collaboration. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6839–6845. [Google Scholar] [CrossRef]
- Remmas, W.; Chemori, A.; Kruusmaa, M. Diver tracking in open waters: A low-cost approach based on visual and acoustic sensor fusion. J. Field Robot. 2021, 38, 494–508. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, M.; Wang, C.; Wei, F.; Hong, Q. A Method for Underwater Human–Robot Interaction Based on Gestures Tracking with Fuzzy Control. Int. J. Fuzzy Syst. 2021, 23, 2170–2181. [Google Scholar] [CrossRef]
- Dudek, G.; Sattar, J.; Xu, A. A Visual Language for Robot Control and Programming: A Human-Interface Study. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 2507–2513. [Google Scholar] [CrossRef]
- Backus, J.W. The Syntax and Semantics of the Proposed International Algebraic Language of the Zurich ACM-GAMM Conference. In Proceedings of the International Conference on Information Processing, Paris, France, 15–20 June 1959. [Google Scholar]
- Islam, M.J.; Ho, M.; Sattar, J. Understanding human motion and gestures for underwater human–robot collaboration. J. Field Robot. 2019, 36, 851–873. [Google Scholar] [CrossRef]
- Cuan, C.; Lee, E.; Fisher, E.; Francis, A.; Takayama, L.; Zhang, T.; Toshev, A.; Pirk, S. Gesture2Path: Imitation Learning for Gesture-aware Navigation. arXiv 2022, arXiv:2209.09375. [Google Scholar]
- Menix, M.; Miskovic, N.; Vukic, Z. Interpretation of divers’ symbolic language by using hidden Markov models. In Proceedings of the 2014 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 26–30 May 2014; pp. 976–981. [Google Scholar] [CrossRef]
- Mišković, N.; Bibuli, M.; Birk, A.; Caccia, M.; Egi, M.; Grammer, K.; Marroni, A.; Neasham, J.; Pascoal, A.; Vasilijević, A.; et al. Overview of the FP7 project “CADDY—Cognitive Autonomous Diving Buddy”. In Proceedings of the OCEANS 2015, Genova, Italy, 18–21 May 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Fulton, M.; Edge, C.; Sattar, J. Robot Communication Via Motion: Closing the Underwater Human-Robot Interaction Loop. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4660–4666. [Google Scholar] [CrossRef]
- Enan, S.S.; Fulton, M.; Sattar, J. Robotic Detection of a Human-Comprehensible Gestural Language for Underwater Multi-Human-Robot Collaboration. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 3085–3092. [Google Scholar] [CrossRef]
- Zahn, M. Development of an underwater hand gesture recognition system. In Proceedings of the Global Oceans 2020: Singapore—U.S. Gulf Coast, Live Virtual, 5–14 October 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Fulton, M.; Prabhu, A.; Sattar, J. HREyes: Design, Development, and Evaluation of a Novel Method for AUVs to Communicate Information and Gaze Direction. arXiv 2022, arXiv:2211.02946. [Google Scholar]
- Zhang, Y.; Jiang, Y.; Qi, H.; Zhao, M.; Wang, Y.; Wang, K.; Wei, F. An Underwater Human–Robot Interaction Using a Visual–Textual Model for Autonomous Underwater Vehicles. Sensors 2023, 23, 197. [Google Scholar] [CrossRef]
- Šarić, M. LibHand: A Library for Hand Articulation, 2011. Version 0.9. Available online: http://www.libhand.org/ (accessed on 6 June 2023).
- Yang, L.; Zhao, S.; Wang, X.; Shen, P.; Zhang, T. Deep-Sea Underwater Cooperative Operation of Manned/Unmanned Submersible and Surface Vehicles for Different Application Scenarios. J. Mar. Sci. Eng. 2022, 10, 909. [Google Scholar] [CrossRef]
- Islam, M.J.; Ho, M.; Sattar, J. Dynamic Reconfiguration of Mission Parameters in Underwater Human-Robot Collaboration. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6212–6219. [Google Scholar] [CrossRef]











| Slang Messages | ||
|---|---|---|
| out_of_breath = breath | K = cramp | V = vertigo |
| ear = ear | b = Something is wrong [on me] | cold = cold |
| prob_gen = generic problem (danger) | Reserve = on reserve (50 bar left) | out_of_air = to be out of air |
| low = low on air | ||
| + = up | − = down | const = stay at this depth |
| Ok = ok | No = no | U = don’t understand |
| I = I, me | Y = you | boat = boat |
| Turn = Turn of 180° degrees | ||
| Group | Commands/Messages | |
|---|---|---|
| Problems | 9 messages/commands Confirmed | |
| Movement | 13 messages/commands Confirmed | |
| Interrupt | 4 messages/commands Confirmed | |
| Setting variables | 9 messages/commands Confirmed | |
| Feedback | 3 messages/commands Confirmed | |
| Works | 9 messages/commands Confirmed | Turn of 180 degrees |
| Questions (new Group) | Where is the boat? | How much air do you have left? |
| Are you ok? | Is there any danger? | |
| Status (new Group) | Low on air | On reserve |
| Message/Command | Caddian | |
|---|---|---|
| Problems | ||
| I have an ear problem | A ear ∀ | |
| I am Out of breath | A out_of_breath ∀ | |
| I am out of air [air almost over] | A out_of_air ∀ | |
| Something is wrong [diver] | A ƀ∀ | |
| Something is wrong, danger [environment] | A prob_gen ∀ | |
| I’m cold | A cold ∀ | |
| I have a cramp | A cramp ∀ | |
| I have vertigo | A vertigo ∀ | |
| Movement | ||
| Take me to the boat | A Y take me boat ∀ | |
| A I follow Y A Y come boat ∀ | ||
| Take me to the point of interest | A Y take me P ∀ | |
| A I follow Y A Y come P ∀ | ||
| Return to/come X | A Y come P ∀ | |
| A Y come boat ∀ or A boat ∀ | ||
| i.e., go to point of interest, boat, come here | A Y come here ∀ | |
| Go X Y | A Y go forward n ∀, A Y go back n ∀ | |
| and | A Y go left n ∀, A Y go right n ∀ | |
| A Y go up n ∀, A Y go down n ∀ | ||
| n ∈ <num> | ||
| You lead (I follow you) | A I follow Y ∀ | |
| I lead (you follow me) | A Y follow me ∀ | |
| Interrupt | ||
| Stop [interruption of action] | A Y no do ∀ or A no ∀ | |
| Let’s go [continue previous action] | A Y ok do ∀ or A Y do ∀ | |
| Abort mission | ||
| General evacuation | ||
| Setting variables | ||
| Slow down (during a stop decrease default movement speed) | A speed − ∀ | |
| Accelerate (during a stop increase default movement speed) | A speed + ∀ | |
| Keep this level (any action is carried out at this level) | A level const ∀ | |
| Free level (“Keep this level” command does not apply anymore) | A level free ∀ | |
| Level Off (AUV cannot fall below this level, no matter what diver | A level limit ∀ | |
| says: the robot interrupts any action, if the action forces him | ||
| to break this rule) | ||
| Set point of interest henceforth any action may refer | A P ∀ | |
| to a point of interest) | ||
| Give me light (switch on the on board lights) | A light + ∀ | |
| No more light (switch off the on board lights) | A light - ∀ | |
| Give me air (switch on the on board oxygen cylinder) | A air + ∀ | |
| No more air (switch off the on board oxygen cylinder) | A air - ∀ | |
| Feedback | ||
| No (answer to repetition of the list of gestures) | A no ∀ | |
| Ok (answer to repetition of the list of gestures) | A ok ∀ | |
| I don’t understand (repeat please). No idea. | A U ∀ | |
| Works | ||
| Tessellation X * Y area | A Te n m ∀ | |
| A Te n ∀ [square] | ||
| Tessellation of point of interest/boat/here | A Te P ∀ | |
| Photograph of X * Y area | A Fo n m ∀ | |
| A Fo n ∀ [square] | ||
| Photograph of point of interest/boat/here | A Fo P ∀ | |
| Wait n minutes | A wait n ∀ | |
| Tell me what you’re doing | A check ∀ | |
| Carry a tool for me | A carry ∀ | |
| Stop carrying the tool for me [release] | A no carry ∀ | |
| Turn of 180° degrees | A turn ∀ | |
| Make a photograph of this area n*m X times | A for X Fo n m end ∀ | |
| n,m,X | n,m,X ∈ <num> | |
| Questions | ||
| Where is the boat? | A U boat ∀ | |
| Are you ok? | A U ƀ∀ | |
| Is there any danger? | A U prob_gen ∀ | |
| How much air do you have left? | A U air ∀ | |
| Status | ||
| Low on air | A low ∀ | |
| On reserve | A reserve ∀ | |
 |  |  |  |
| Written form: 1 | Written form: 2 | Written form: 3 | Written form: 4 |
| Semantics: 1 | Semantics: number 2 | Semantics: number 3 | Semantics: number 4 |
 |  |  |  |
| Written form: 5 | Written form: boat | Written form: carry | Written form: mosaic |
| Semantics: number 5 | Semantics: boat | Semantics: carry equipment | Semantics: do a mosaic |
 |  |  |  |
| Written form: ok | Written form: ∀ | Written form: A | Written form: Fo |
| Semantics: confirmation | Semantics: End communication | Semantics: Start message | Semantics: Take a photo |
| ECU | Language Frameworks | ||||||
|---|---|---|---|---|---|---|---|
| Framework Parameters | #1 | #2 | #3 | #4 | #5 | #6 | #7 |
| Context-free grammar | 1 | 1 | 1 | 1 | 0 | 0 | 1 |
| Ease of learning the language and user interface | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Feedback | 0 | 1 | 1 | 0 | N/A | N/A | 1 |
| Single-task execution speed | 1 | 0 | 0 | 1 | N/A | N/A | 0 |
| Task execution accuracy | 1 | 1 | 1 | 1 | N/A | N/A | 1 |
| Adaptability | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Robustness | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Parameters reconfiguration | 0 | 1 | 1 | 1 | N/A | N/A | 1 |
| Gesture-based | ARTag | 1 | 1 | 1 | kineme | lukeme | 1 |
| Human to robot | 1 | 1 | 1 | 1 | 0 | 0 | 1 |
| Robot to human | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| Collaboration | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Scalability | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Overall efficiency | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Hierarchical organization | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Open sea trials | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| Pool or closed-water testing | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Community feedback | 0 | 0 | 1 | 0 | 1 | 1 | 1 |
| Open data | N/M 1 | 1 | 1 | N/M 1 | N/M 1 | N/M 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chiarella, D. Towards Multi-AUV Collaboration and Coordination: A Gesture-Based Multi-AUV Hierarchical Language and a Language Framework Comparison System. J. Mar. Sci. Eng. 2023, 11, 1208. https://doi.org/10.3390/jmse11061208
Chiarella D. Towards Multi-AUV Collaboration and Coordination: A Gesture-Based Multi-AUV Hierarchical Language and a Language Framework Comparison System. Journal of Marine Science and Engineering. 2023; 11(6):1208. https://doi.org/10.3390/jmse11061208
Chicago/Turabian StyleChiarella, Davide. 2023. "Towards Multi-AUV Collaboration and Coordination: A Gesture-Based Multi-AUV Hierarchical Language and a Language Framework Comparison System" Journal of Marine Science and Engineering 11, no. 6: 1208. https://doi.org/10.3390/jmse11061208
APA StyleChiarella, D. (2023). Towards Multi-AUV Collaboration and Coordination: A Gesture-Based Multi-AUV Hierarchical Language and a Language Framework Comparison System. Journal of Marine Science and Engineering, 11(6), 1208. https://doi.org/10.3390/jmse11061208