1. Introduction
With the increase in energy consumption, the non-renewability of traditional energy sources and the emission of greenhouse gases, among other reasons, more and more countries are turning to renewable energy sources in industry [
1,
2,
3]. Wind energy is basically a transformation of solar energy, with large energy reserves and no pollution, making it one of the best alternatives to fossil energy [
4,
5]. Therefore, mankind is actively researching the application prospects of wind power, and now, offshore wind power has become an important engine for green and sustainable development worldwide [
6,
7]. To ensure an uninterrupted power supply in the grid, it is imperative to continuously monitor and balance power generation and consumption, so an accurate and effective assessment of offshore wind power is essential [
8]. It has been observed in the literature that wind power forecasting is typically based on wind speed forecasts [
9,
10]. Therefore, in order to protect the grid from uncertainty, power system managers and wind power companies need accurate forecasts of future wind speed [
11]. On the time scale, wind speed forecasts can be divided into very-short-term forecasts, short-term forecasts, medium-term forecasts and long-term forecasts [
12], where short-term wind speed forecasts are important for improving wind turbine generation efficiency and economic load dispatch planning, while medium- and long-term forecasts are mainly used for wind farm planning and generation planning to control and reduce operating costs [
13,
14]. In addition, the accurate prediction of wind speed is of great importance for climate analysis [
15], biodiversity [
16,
17] and so on, so accurate prediction of offshore wind is of great importance [
18].
Offshore wind prediction is a challenging task due to the high volatility, uncertainty and intermittency of offshore wind speed [
19]. Wind speed prediction methods can fall into three main categories: physical, statistical machine-learning methods and deep learning methods [
10,
20,
21]. The physical approaches [
22] are to build systems (numerical weather prediction systems (NWP)). They use physical and meteorological variables to build a system based on thermodynamics and fluid mechanics, which has high calculation costs and is better suited to medium- and long-term planning [
23]. The classical statistical methods, auto-regression integrated moving average (ARIMA) [
19], assume the linear relationships of data. The machine learning methods, such as support vector regression (SVR) [
24] and k-nearest neighbors (KNN) methods [
25] show good performance in very-short-term and short-term wind forecasting. However, the statistical method ARIMA is incapable of capturing data’s nonlinear relationships and the machine learning methods actually simplify wind power prediction, which are unable to extract deep time series of feature information from complex wind speed data [
26]. To address the limitations of the above methods, many scholars have begun to use a recurrent neural network (RNN) [
27] and long short-term memory (LSTM) network [
28] to perform the prediction tasks of wind speed with good results [
29,
30].
The above methods lead to inferior performance in multi-node wind speed prediction because they overlook spatial dependencies, so it is critical to capture the unknown spatial dependencies among multi-nodes. Z. Qiaomu et al. [
31] proposed a predictive deep convolutional neural network (PDCNN), which exploits convolutional neural networks (CNN) to capture the spatial dependencies in wind data, to predict the wind speed of multiple stations at the same time. However, this method does not model the pair-wise dependencies among variables explicitly and cannot make full use of the spatial features of wind farms, which weakens the prediction performance [
7]. Recently, graph neural networks (GNN) achieved great success in modeling relational dependencies of data due to their permutation invariance and local connectivity [
32,
33]. M. Yu et al. [
7] connected all wind turbines in a certain range of wind farms by their geographical locations to form a graph to extract the spatial features of wind data for prediction. X. Geng et al. [
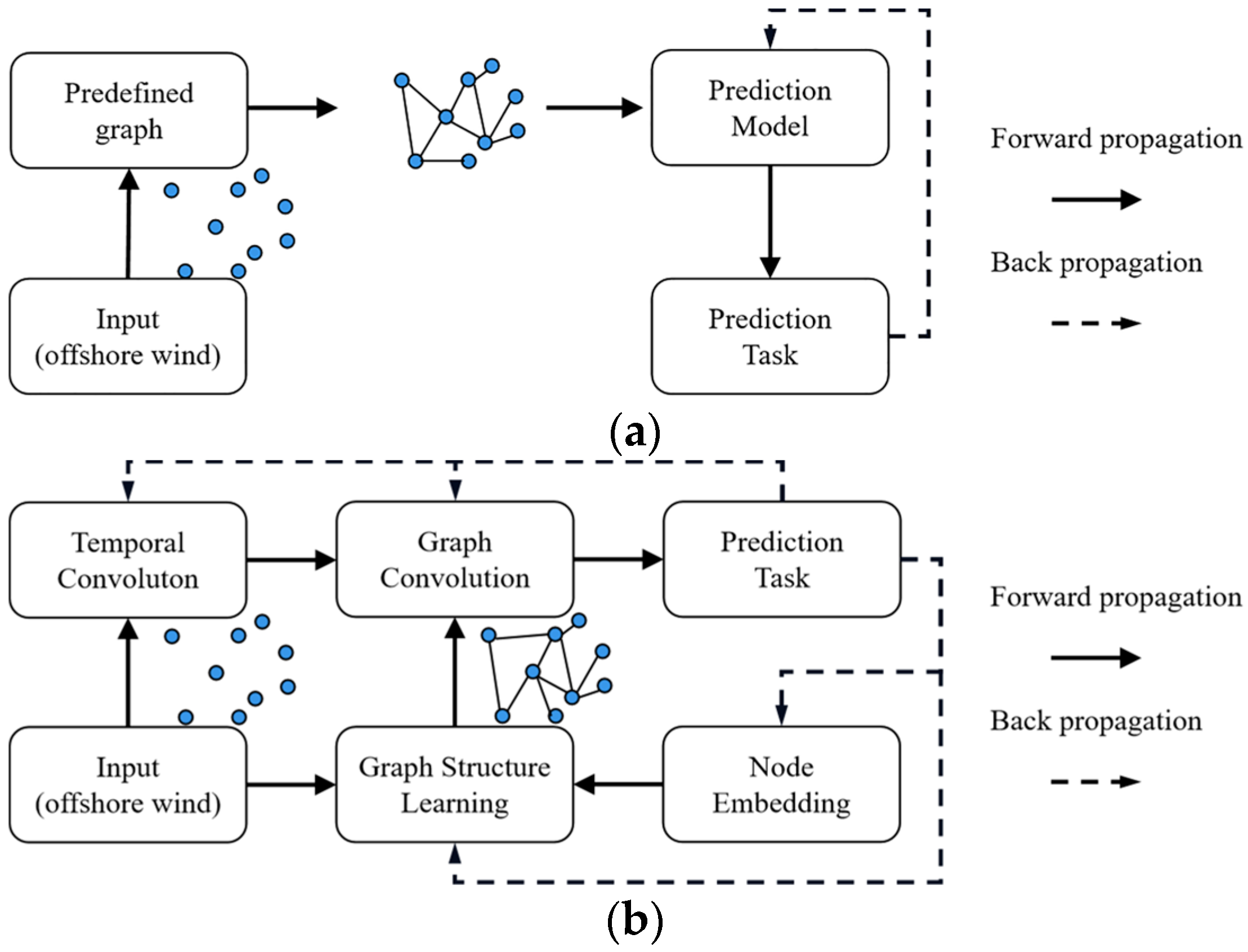
20] leveraged the geographic distance information of offshore wind nodes to construct a graph to predict multi-node offshore wind speed at the same time. These methods construct a predefined graph structure, as shown in
Figure 1a.
Though remarkable success has been achieved by generalizing GNN to the wind speed forecasting domain, there are still several important problems that remain to be addressed: (1) Unknown spatial dependencies. Existing GNN approaches [
7,
20] applied to wind speed prediction rely heavily on a pre-defined graph structure in order to perform the forecasting task. These methods construct the graph structure based on assumed geographic location information. This method assumes that the spatial associations are equal to the geographic distance of multi-nodes, which is not flexible and representative enough to describe the correlations. The graph structure remains constant during the training of the network and is independent of the downstream tasks, which is not optimal for the multi-scale wind speed prediction task. (2) Graph structure learning and GNN learning. The current GNN approaches ignore the fact that graph structures are not optimal and need to be learned during training. How best to learn both graph structures of unknown associations and GNNs in an end-to-end framework is a challenging task.
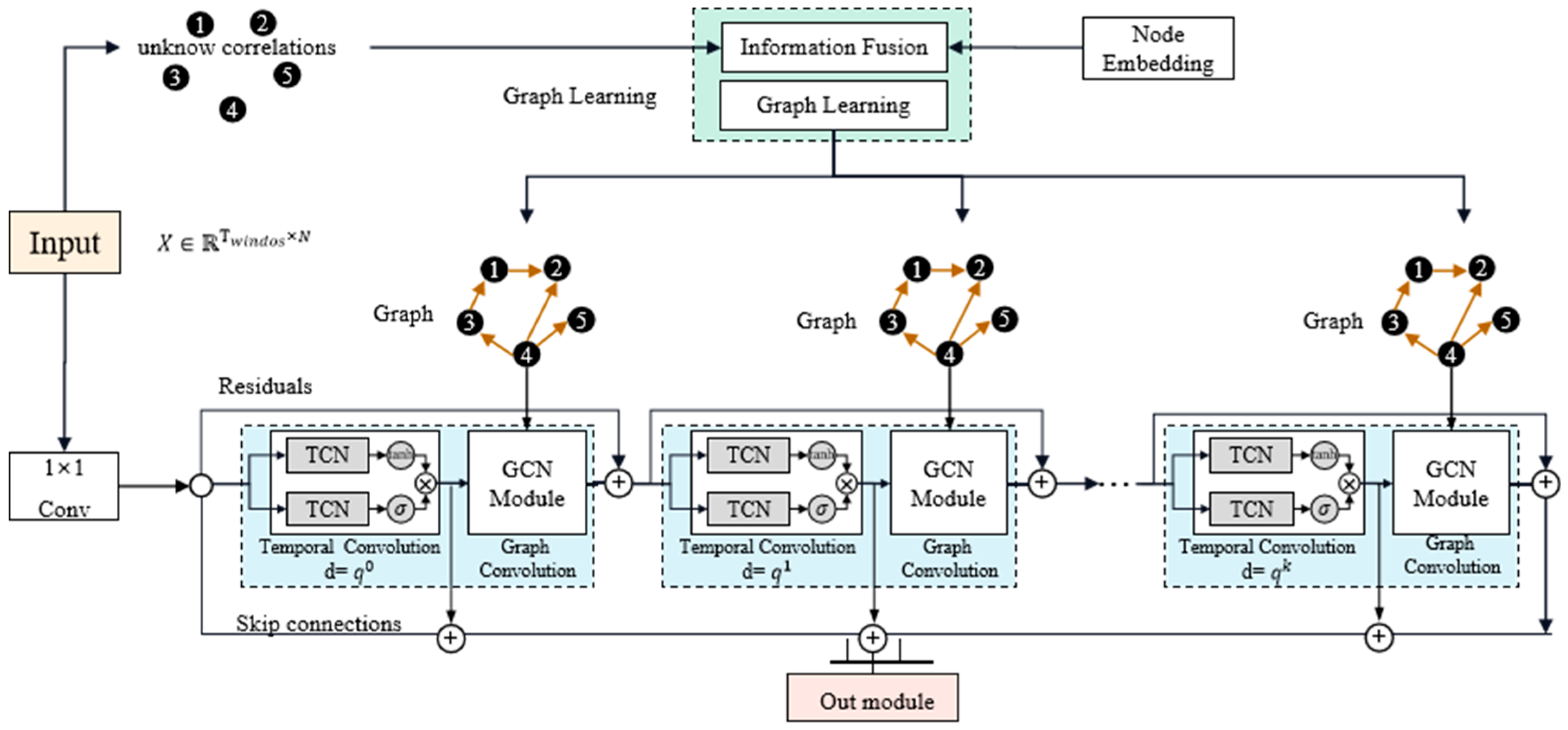
To cope with the above challenges, we propose an adaptive graph-learning convolutional network (AGLCN). Specifically, for challenge 1, an adaptive graph-learning method is proposed, which frees the need of GNN for a predefined structure. As shown in
Figure 1, the graph structures are automatically inferred based on both dynamic wind speed data and trainable node embedding [
34]. For challenge 2, the proposed network is an end-to-end framework, i.e., the parameters of the model can be learned via the gradient descent method. As shown in
Figure 1b, the model on the highest level consists of three core components: graph learning, graph convolution and temporal convolution. Temporal convolution is used to extract the temporal relationship of data. Moreover, to avoid the gradient disappearance problems of RNN-based methods [
35], we employ the CNN-based method because of its stable gradients and low memory requirements [
36,
37]. Graph convolution is used to capture the spatial feature of data based on the learned graph structure. Finally, the entire network is optimized based on predictive tasks. In summary, our main contributions are as follows:
We propose a novel graph-learning method to learn hidden associations in data, which does not require any prior knowledge as a guideline. It is more general than the existing GNN for wind speed prediction because our method can handle arbitrary multi-node time series without the need to pre-define the graph structure.
We design an end-to-end framework that integrates a graph structure learning module with temporal and graph convolution to achieve joint optimization, where temporal and graph convolution can efficiently extract temporal and spatial features.
Experiments on realistic multi-node wind speed forecasts show that our approach achieves optimal results for all comparative forecast scales (short-, medium- and long-term forecasts). Moreover, the graph structure learned by the model can be used to explore the correlation between multi-node wind speed from a data-driven perspective.
The rest of the paper is structured as follows:
Section 2 presents the problem formulation and concept of GNN. The details of our framework are presented in
Section 3. In
Section 4, our experimental results show the effectiveness and efficiency of the proposed method.
Section 5 presents the discussion.
Section 6 offers conclusions of the paper.
2. Preliminary
Problem formulation. The target of multi-node offshore wind speed forecasting is to predict future multi-node values by exploiting historical data. Let
denote the wind speed value monitored by N sensors at time step
t, where
denote the value of the
ith sensor at time step
t. Given a sequence of historical H time steps of observations on N sensors,
, and our goal is to predict the values of future L-step for the N sensors,
. We aim to build a map
from
to Y,
A graph describes the relationships between nodes in a network. Thus, in the following, we provide a formal definition of graph-related concepts.
Definition 1. (Graph). A graph is formulated as where V represents the set of nodes, and E denotes the set of edges.
Definition 2. (Adjacency Matrix). The adjacency matrix is a mathematical representation of a graph, denoted as with > 0 if and = 0 if .
Definition 3. (Node Embedding). The node embedding is denoted as , where N is the number of nodes, d represents the dimensions of node embedding and d << N. The node-embedding vector of the ith
node is expressed as . Node embedding is a low-dimensional representation of a node of a graph that contains structural information [34]. From a graph-based perspective, the sensors in the wind speed data are considered as nodes of a graph and the associations between the nodes are described by the graph structure.
4. Results
This section is organized as follows. We first present the dataset, including prediction areas and evaluation metrics of the experiment, define the baseline methods, and then compare and analyze the prediction performance on multi-scale wind speed predictions, where the baselines include GNN methods and non-GNN methods. After that, we investigate the hyper-parameters of the model. Finally, to emphasize the essential differences between our method and previous GNN methods, we analyze the learned graphs with the pre-defined graph, independently, as a discussion.
4.1. Data Sets
The dataset used for the experiments was CCMP V2.0 Wind Product, which is produced by Remote Sensing Systems and sponsored by NASA Earth Science funding (
www.remss.com, accessed on 2 February 2023). The CCMP adopted a variational assimilation analysis method to fuse a wide range of grid vector wind data, incorporating remote sensing systems, a global precipitation measurement microwave imager, buoy data from the national data buoy center, ERA interim data from the European Centre for Medium-Range Weather Forecasts [
50]. The product has a spatial resolution of 0.25° and a temporal resolution of 6 h, i.e., it produces four grids of vector wind per day, where the vector wind is the radial and latitudinal wind speed at 10 m from the sea surface. There were several reasons for utilizing CCMP as experimental data. Firstly, CCMP is an assimilated analytical product that undergoes quality control, addressing issues of data sparseness and dispersion in weather stations, buoys, and ship data collected in the past. Secondly, CCMP data are known to be more accurate and closer to actual observations compared to other reanalysis datasets such as ERA (European Centre for Medium-Range Weather Forecast Reanalysis) and NCEP (National Centers for Environmental Prediction) [
20].
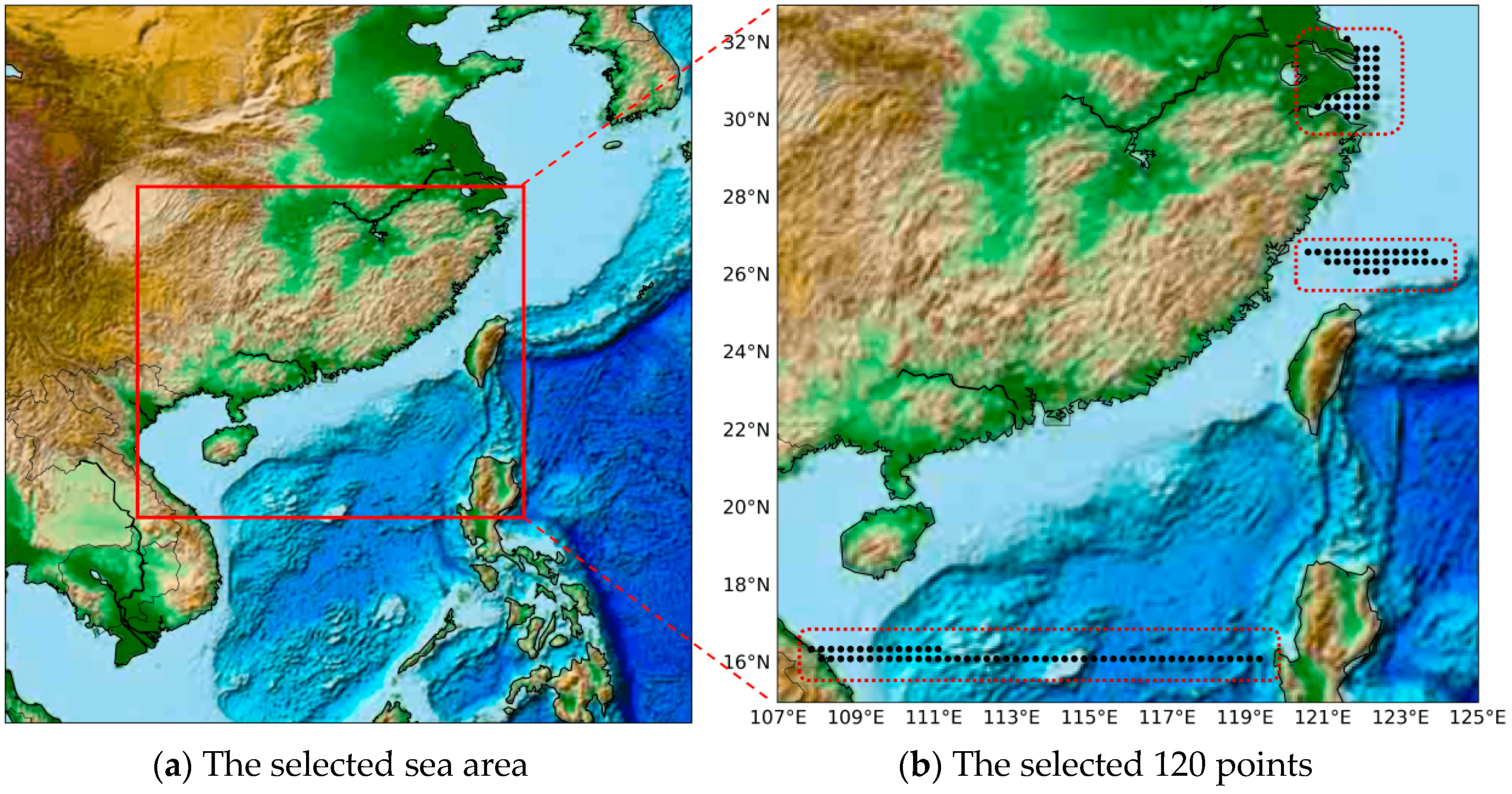
Wind data sets were extracted from the CCMP grid data in experiments covering the China Sea from 16° N to 42° N, 105° E to 127° E, as shown in
Figure 4a. The experiment dataset was a gridded product with a spatial resolution of 0.25°, including the four major seas of China: the Bohai Sea, Yellow Sea, East Sea and South Sea. As shown in
Figure 4b, we randomly selected 120 points from the entire experimental area (red dashed box). The temporal span of data was from January 2010 to April 2019, for a total of ten years. Because of the 6 h temporal resolution of the data, there were a total of 13,624 samples. We split the dataset into a training set (70%), validation set (10%), and test set (20%) in chronological order. The selection method and data in this paper were exactly the same as the main comparative baseline method STGN [
21].
4.2. Setups
In this paper, we employed root mean squared error (RMSE) and mean absolute error (MAE) to evaluate our models, both of which are widely used in regression tasks. Specifically, assuming
is the ground truth of
ith node and
is the predicted value of
ith node, where
N denotes the number of nodes, they were defined as follows:
In Equation (10), the MAE is the average of the absolute error between the true values and prediction values, which can reflect the overall prediction performance. The RMSE in Equation (11) is average of the square of the differences between the actual and predicted values. Compared to MAE, RMSE is more sensitive to values with large prediction errors in the data. For MAE and RMSE, lower values are better. In addition, when making a further comparison in the ablation experiment, we added mean absolute percentage error (MAPE) for observation, as shown in Equation (12). The closer the MAPE value is to 0%, the better the regression fit will be.
Implementation details. To demonstrate the good prediction performance of the model, experiments were conducted for both short- and long-term forecasts for wind speed prediction, with prediction scales of 6 h, 12 h, 18 h, 24 h (1 d), 48 h (2 d), 72 h (3 d), 96 h (4 d), 120 h (5 d), 144 h (6 d), and 168 h (7 d). Following the work of [
20], the length of the time window was 12 and the step size was 1. We used the Adam optimizer [
51] to train the wind speed prediction models. The batch size was 64 and the training epoch was 100. The learning rate started from 0.001 and the learning rate decay was ReduceLROnPlateau, where the patience was 20, the cooldown was 30 and the factor was 0.3. The CPU of the experimental device was i5-8400H, and GPU was NVIDIA’s GTX 1080 Ti. Our proposed method and model was implemented with pytorch-1.1.
4.3. Results and Analysis
We comprehensively evaluated the prediction performance of the proposed model AGLCN and eight other baseline methods based on wind datasets for the multi-scale prediction tasks. In order to have a fair and reasonable comparison, we used three types of baseline methods: (1) Methods that do not model multi-node spatial associations. (2) Non-graph structure methods that model multi-node spatial associations. (3) Modeling multi-node spatial associations using a predefined graph structure. Details of the baseline methods are described below.
Methods that do not model multi-node spatial associations.
Wavelet-DBN-RF [
52]: This model proposes a hybrid approach of deep learning and ensemble learning. It first decomposes the wind speed sequence using wavelet transform (WT) and extracts the high-dimensional features of the decomposed signal using a deep belief network (DBN). Each subsequence processed by the DBN is predicted using a light gradient boosting machine (LGBM) and random forest (RF). The experimental results show that the network improves the prediction performance of short-term wind speed prediction. DLinear [
53]: This model decomposes the time series into trend series and residual series through a simple structure and uses two single-layer linear networks to extract the features of data.
Non-graph structure methods that model multi-node spatial associations. (1) PDCNN [
31]: This work investigates the problem of predicting wind speed at multiple sites simultaneously and proposes a wind speed prediction model with a spatio-temporal correlation PDCNN. It integrates CNN and MLP to extract spatial features and temporal relationships, respectively. Experimental results show that the PDCNN outperforms traditional machine learning models. (2) CGRU [
54]: This model uses both CNN and recurrent networks GRU to extract the spatio-temporal correlations of data. Experiments show a good performance on time series data. (3) TPA [
55]: This work proposes a recurrent neural network with an attention mechanism. It uses RNN to extract temporal dependencies in multivariate time series data, while capturing unknown associations between variables using the attention mechanism. It achieves state-of-the-art performance on several real-world datasets.
Modeling multi-node spatial associations using predefined graph structures. (1) Multi-LSTMs [
56]: This work models the spatio-temporal information in wind speed data through graphs and proposes a framework to obtain forecasts for all nodes in the graph simultaneously. Experiments on real wind power data demonstrate that the model improves short-term prediction performance. (2). SGNN [
7]: This work constructs a graph structure of wind machines using geographic location information and proposes an SGNN (superposition graph neural network) for feature extraction. Experiments show that the method not only improves the prediction performance but also has good robustness. (3). STGN [
20]: This paper proposes spatio-temporal correlation graph neural networks that use graph convolution and channel attention to capture spatial correlation in multi-node wind speed data. The graph structure is constructed based on geographical distance information.
4.3.1. Comprehensive Comparison of Experimental Results
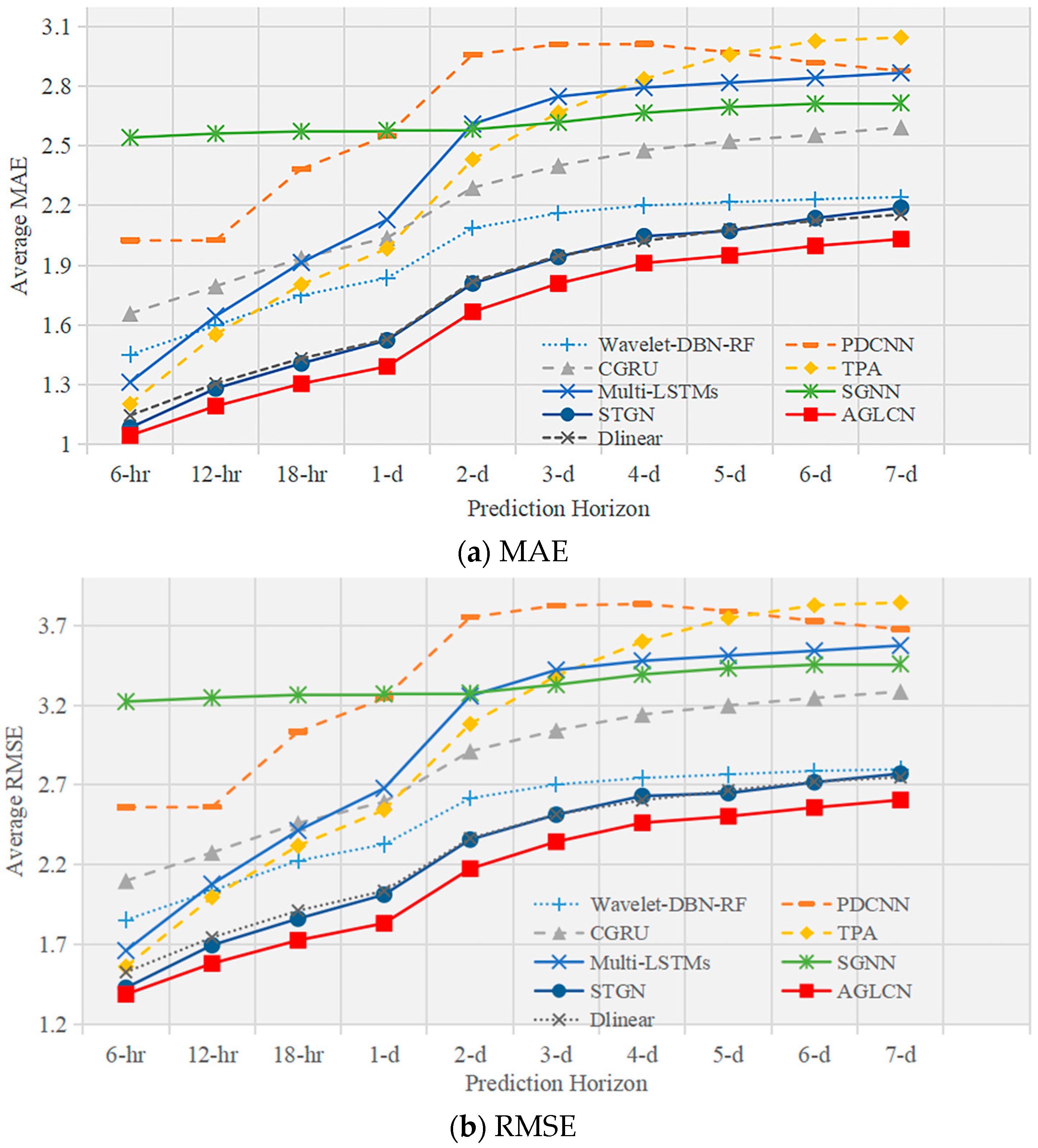
To verify the effectiveness of the proposed model by this paper, we conducted wind speed prediction experiments at multiple prediction scales and with different numbers of nodes. The overall prediction performances for wind speed, that are the averaged MAE and RMSE results for the 40-node and 120-node multi-scale wind forecasts, are shown in
Table 1,
Table 2,
Table 3 and
Table 4. The bold text in the table indicates the best prediction performance and underlining indicates the second-best prediction performance. Several observations from these results are worth highlighting:
- (1)
Our method achieves the best prediction performance at all prediction scales of 40 and 120 nodes; the details are shown in
Table 1,
Table 2,
Table 3 and
Table 4. Compared to the best baseline method, STGN, our method improves by an average of 9% in MAE and RMSE for 40-node wind speed predictions and 6% in MAE and RMSE for 120-node wind speed predictions. Long-term prediction of wind speed is a challenging task due to cumulative error, but our method still maintains a good performance. For wind speed prediction at nodes 40 and 120, the 7-day prediction errors of MAE and RMSE of our AGLCN method are lower than the 3-day and 4-day prediction errors of STGN, respectively.
- (2)
Methods that use attention mechanisms to model spatial associations (TPA) outperform the methods that use CNN (PDCNN, CGRU) and the methods that do not explicitly model spatial associations (Wavelet-DBN-RF) in short-term predictions (12 h). It shows that correct spatial modeling is effective. The important feature of CNN is translation invariance [
57], yet for the complex spatial patterns of wind data, it is rather a bottleneck that limits the performance of the model. In long-term wind speed prediction (time horizon > 4-day), PDCNN and CGRU are better than TPA. The input time window is 12 and the forecast length is greater than 4-day (prediction length > 24). It means that the input data information no longer provides enough information to support the long-term forecasts. In this case, the attention mechanism approach, TPA, which relies entirely on the extraction of relationships from the data, is inferior to the relationship extraction approach with inductive bias, i.e., CNN (PDCNN, CGRU). DLinear are implemented based on a transformer and have excellent long-time-series prediction capability. Although they did not carry out spatial modeling for data, they still have a remarkable prediction ability. As a result, their performance exceeds STGN when under a long prediction scale but is still inferior to AGLCN.
- (3)
Multi-LSTM and SGNN require a predefined graph structure to model spatial associations between multiple nodes. These two methods perform worse than the attention mechanism method, TPA, for the short-term prediction, but achieve better performance for the long-term prediction. Compared to Multi-LSTM, SGNN uses graph convolution operations, i.e., information propagation based on the graph, which also allows SGNN to achieve better results in long-term prediction. STGN basically achieves the second-best results (only worse than our AGLCN method) in both short- and long-term forecasting. The reason is that the model integrates the advantages of GNN and attention mechanisms.
In summary, attention mechanisms are effective at capturing relationships in the data for short-term forecasting, while graph structure plays an important role in long-term forecasting. Our AGLCN approach, on the other hand, constructs multi-node spatial correlations from an adaptive learned graph based on downstream tasks, achieving the best results in both short-term and long-term predictions, as shown in
Figure 5. It demonstrates the power of the graph structure in modeling spatial associations and the effectiveness of the designed graph-learning approach. A further analysis of the learned graph structure can be seen in
Section 5.
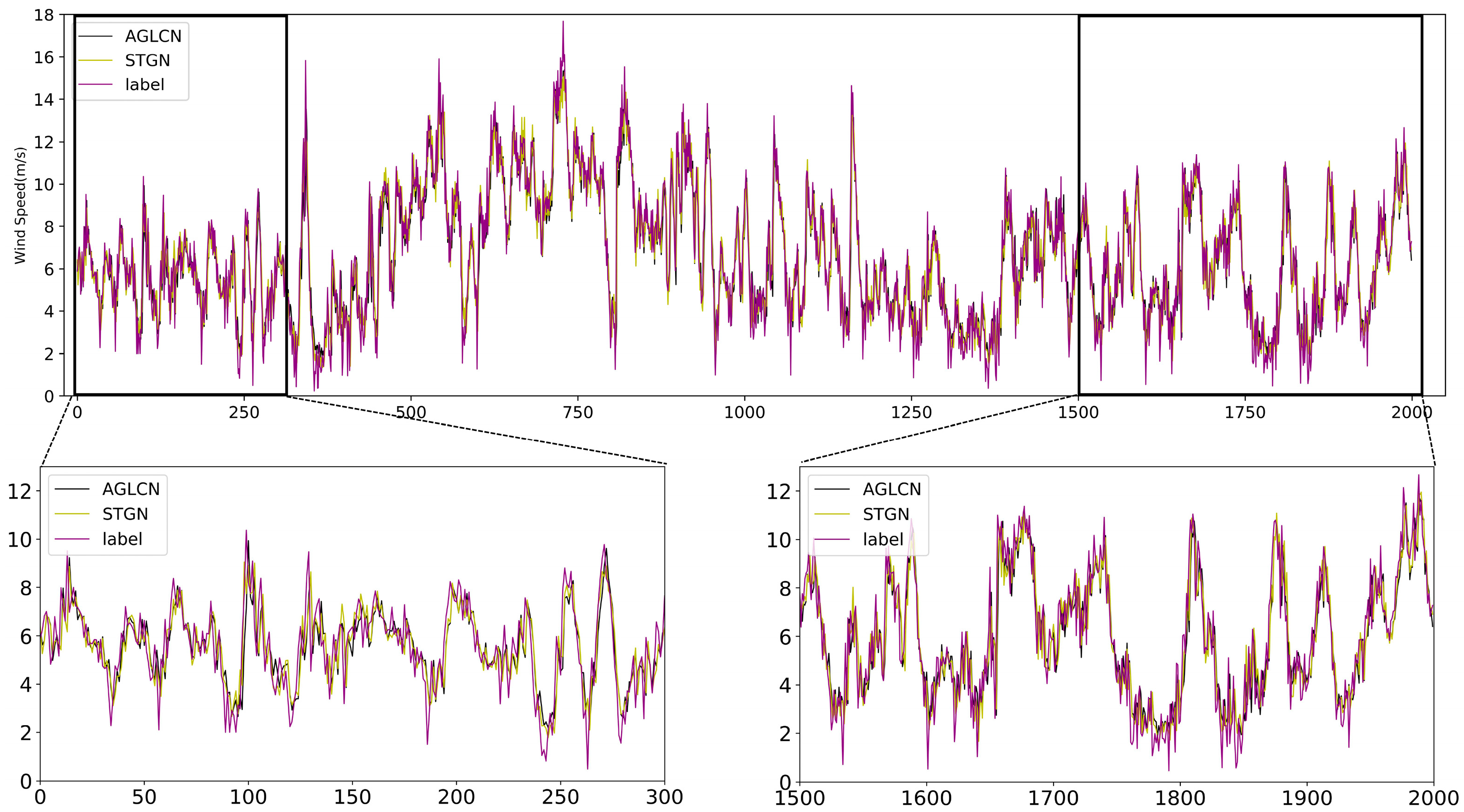
Figure 6 illustrates the visualization of the prediction results.
Figure 6a presents the visualization using the best baseline method at 106 data points, while
Figure 6b displays the visualization of our method’s prediction results at different scales. It is evident from
Figure 6a that our method achieves more accurate prediction results. Additionally,
Figure 6b shows that our method maintains a strong prediction performance across multiple scales. For further visualization of the prediction results, please refer to
Figure A4 in
Appendix A.
4.3.2. Hyper-Parameter Study
In this section, we present the hyper-parameter study of the proposed model and compare the detailed performance of the model under different hyper parameters.
Table 5 shows the hyper-parameter search process for our proposed model, with the list of main parameters on the left, the search range in the middle, and the best hyper-parameter settings on the right. The number of channels refers to the channels in the TCN and GCN modules, K is the number of stacking layers of TCN and GCN, and d is dilation factor which determines the received field of the model. During the training process, the model was trained by the Adam optimizer with a gradient clip of 5. The learning rate decay was ReduceLROnPlateau, where patience was 20, the cooldown was 30, and factor was 0.3. The selection range for the following hyper parameters was as follows: the number of channels was [4, +∞], the number of layers of model K and dilation factor d was [1, +∞], the dimension of the node embedding was [1, +∞], the learning rate was (0, +∞]. The reason that the number of channels was at least four was that we conducted the convolution operation with four different convolution kernel size simultaneously in TCN, so the number of channels was preferably a multiple of four [
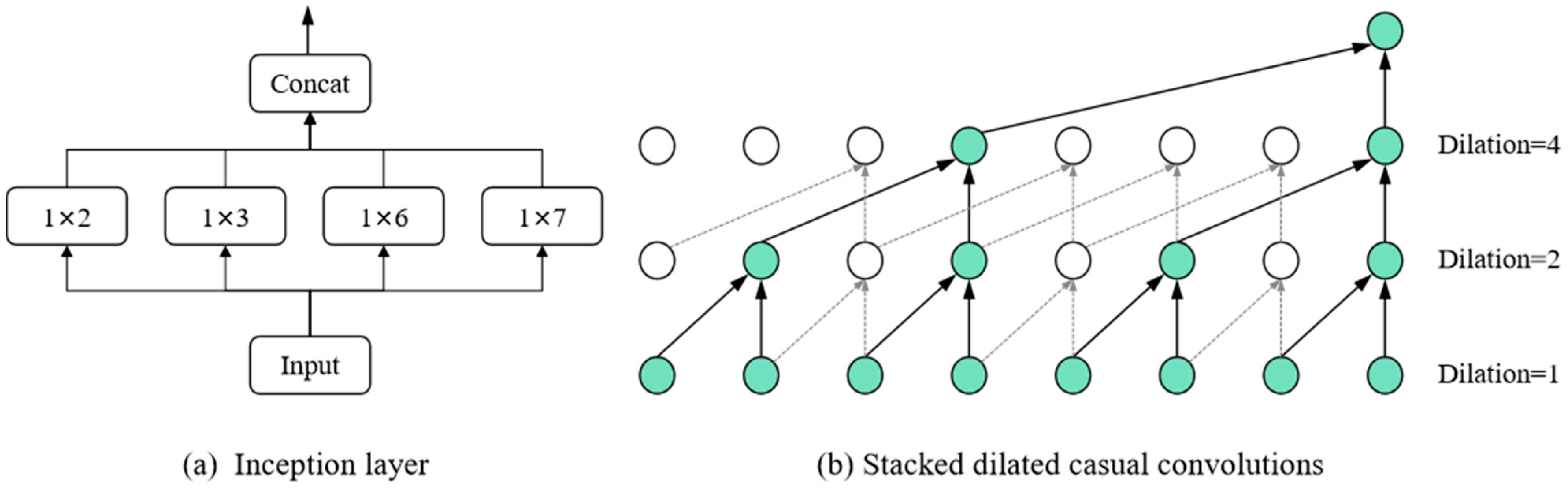
47]. For the number of channels and the dimension of node embedding, too-small settings lead to a poor model-learning ability, while too-large settings lead to too many model parameters and thus an overfitting phenomenon. Together, the number of layers of the model and the dilation factor d determine the receptive field of the model. A receptive field that is too small will result in a model that does not take full advantage of the input data, while a receptive field that is too large will result in a model that is overfilled with zeros and affects performance. Thus, the general receptive field will be slightly longer than the length of the input window.
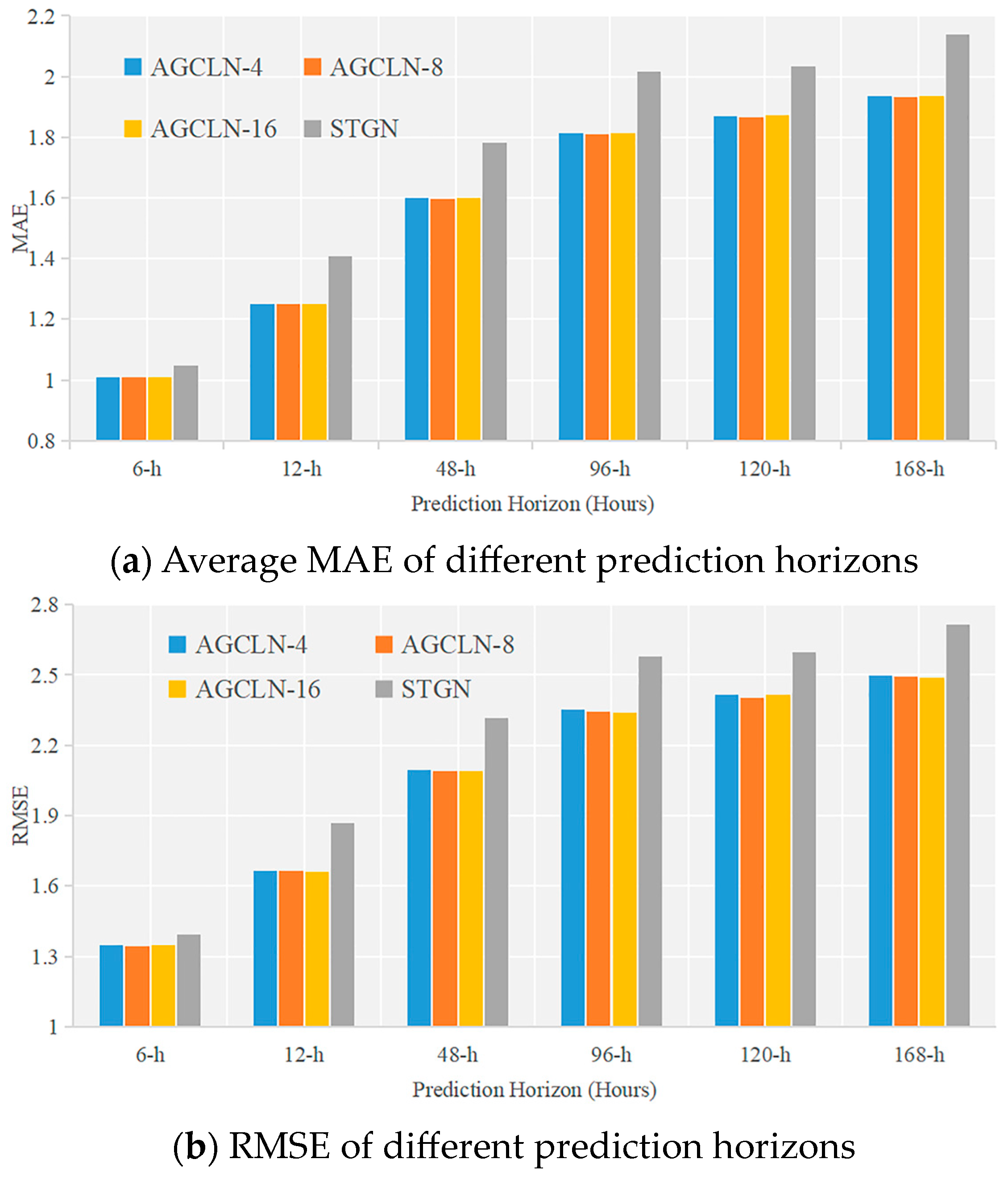
We first investigated the effect of the number of channels on the prediction performance of our model. Since we used four convolutions simultaneously in our temporal convolution (Equation (8)) to extract temporal dependencies, the number of channels was best set to a multiple of four. Here, we show experiments with three channel counts of 4, 8 and 16, as shown in
Figure 7. To better show the effect of the number of channels on the performance, we have also included the model STGN, which achieved the best performance in the baseline approach, as a comparison. As shown in the figure, our model maintains a stable prediction performance for a different number of channels, all outperforming STGN. The larger number of channels represents more model parameters, but our model maintains excellent performance even with a small number of channels, demonstrating the validity of the model. On balance, we choose eight as the number of channels in the model.
Then, we investigated the effects of stacking layers K and dilation factor d on the model performance. The receptive field is jointly affected by the number of stacked layers and the dilation factor. When the dilation factor is equal to 1, it is a standard convolutional operation. Given the time window length 12, we conducted the four combinations (2,1), (2,2), (3,1) and (3,2) with receptive fields of 13, 19, 19 and 43, respectively, as shown in
Table 6. When the receptive field was larger than the input time window, we padded the input with 0. As shown in
Table 6, we can observe that our model maintains good performance for different combinations of stacking layers k and dilation factors d, all outperforming the baseline method STGN. Overall, the combination of (3,1) achieved the best results.
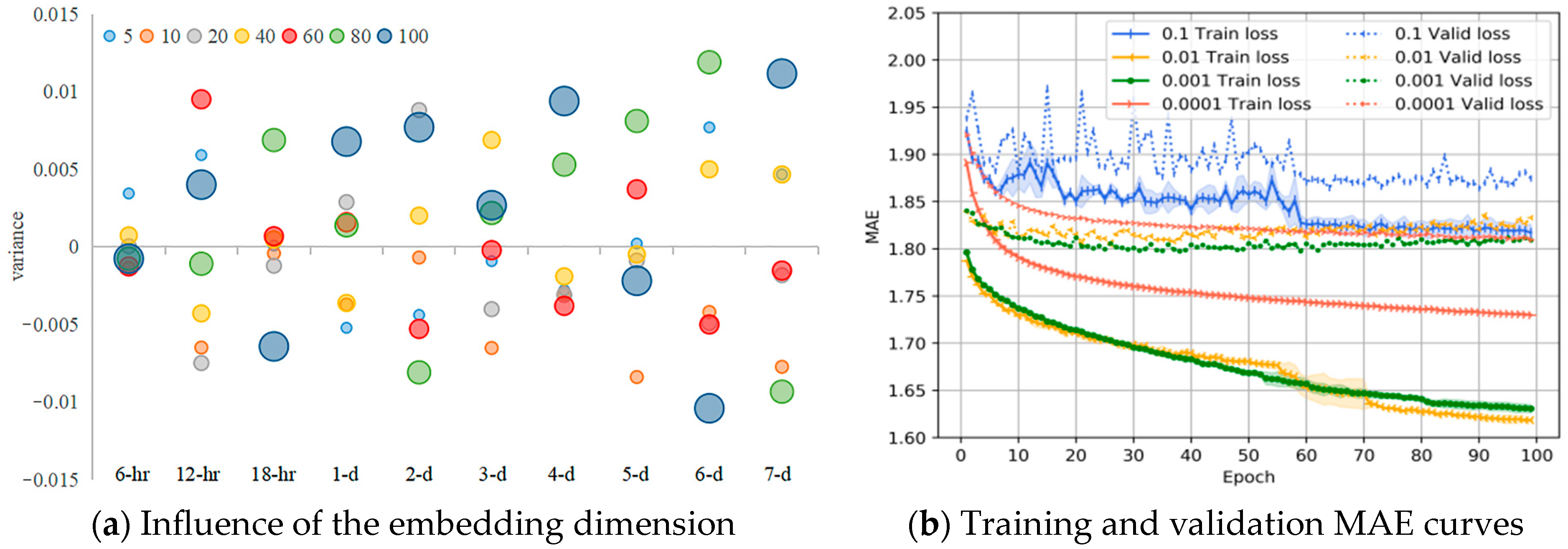
Here, we study the influence of the node-embedding dimension in our network. We find that the model AGLCN achieves good performance in all embedding dimensions. To better demonstrate the correlation between node-embedding dimensions and prediction performance, we counted the variance of different node-embedding dimensions. The result is shown in
Figure 8a, where the horizontal coordinates are the prediction scales, the vertical coordinates are the variances, and the size of the circles represents the number of model parameters in different dimensions (the larger the dimension, the larger the number of parameters). The mean values of the RMSE for different node embedding dimensions at different prediction scales (6 h, 12 h, 18 h, 1 d, 2 d, 3 d, 4 d 5 d, 6 d, 7 d) are 1.345, 1.523, 1.660, 1.774, 2.090, 2.251, 2.334, 2.411, 2.456, 2.500 m/s. We can observe that our model also maintains a strong robustness in the node-embedding dimension, i.e., the node embedding expresses little correlation with the prediction performance (the variance random). Altogether, we set the node-embedding dimension to 10.
We visualized the training process of the models at different learning rates at 40 nodes as shown in
Figure 8b, where the solid line represents the training MAE and the dashed line represents the validation MAE. We randomly initialized the seed and train of each model three times with the same optimizer and parameters. From the figure, we can see that the learning rate has a greater impact on the model compared to the other hyper parameters. Specifically, when the learning rate was 0.1, the learning rate was too large leading to difficulties in convergence and large fluctuations in both training and validation losses (blue curve). The best results for training and validation loss were achieved when the learning rate was 0.001 (green curve). At a learning rate of 0.01, there was a higher validation loss (yellow curve), and at a learning rate of 0.0001, the training and validation loss converged more slowly (tomato curve). These four learning rates (0.1, 0.01, 0.001, 0.0001) on the test set produced a MAE of 1.804, 1.744, 1.729 and 1.74 and a RMSE of 2.342, 2.264, 2.245 and 2.263.
4.3.3. Time Complexity
We analyzed the time complexity of the main components of the proposed model AGLCN, which is summarized in
Table 7. Our model contains three main components, the graph-learning module, the graph convolution and the time convolution module. The graph-learning layer operations are focused on computing the graph matrix with time complexity O(N
2M), where N denotes the number of nodes, and M represents the dimension of node embedding. Since we decoupled the information propagation and feature transformation operations in graph convolution, the main operation of graph convolution is the information propagation on the graph. The time complexity of the graph convolution layer was O(SN
2D), where S represents the information diffusion step, N represents the number of nodes and D is the input dimension. The time complexity of the temporal convolution module equalled O(Nlc
ic
o/d), where l is the input sequence length, c
i is the number of input channels, c
o is the number of output channels, and d is the dilation factor. The time complexity of the temporal convolution module mainly depends on N×l, which is the size of the input feature map.
4.3.4. Statistical Analysis
To ensure that the AGLCN can improve prediction accuracy, we conducted a statistical test [
58]. Specifically, we utilized a paired two-tailed
t-test to assess the predictive ability between the proposed AGLCN model and the baseline methods. The methods used an α = 0.05 significance level and were based on the “one-to-one” rule, i.e., we compared the AGLCN’s predicted values with the predicted values of other models one by one.
Table 8 shows the statistical results of the paired two-tailed
t-test. The results illustrate that our model has significant differences with the other state-of-the-art models. The statistical analysis proves that the forecasting performance of our model is superior to the other models at a 5% statistical significance level.
4.3.5. Ablation Study
To validate the effectiveness of our proposed key components, we conducted a series of ablation experiments on the different components of the model and carried out prediction with a prediction window of 6 h on 40-node datasets. AGLCN and its variants are defined as follows:
- (1)
AGLCN-NE. In this variant, the graph-learning module is based on only the trainable node embedding.
- (2)
AGLCN-DI. In this variant, the graph-learning module is based on only the dynamic node-level input.
- (3)
AGLCN-PE. In this variant, we replaced the graph-learning module with the predefined graph structure.
- (4)
AGLCN-SO. In this variant, we removed the softmax function of Equation (3) to demonstrate the effect of using the function to normalize the graph matrix.
The results of the ablation study are shown in
Table 9. Compared to the AGLCN-NE and AGLCN-DI, a better performance is achieved for all information (node embedding and node-level input) considered, indicating the information fusion of the node embedding and input is important. The prediction performance of AGLCN is better than that of AGCLN-SO, which demonstrates the importance of using softmax in graph-learning methods. In fact, it is a popular practice to normalize the graph matrix using the softmax function [
35,
41]. The prediction performance of variants using predefined graph structures (AGCLN-PE) is worse than AGCLN, indicating the effectiveness of adaptive graph learning. Overall, it can be seen that the key components all contribute to the improvement of the proposed model.
4.4. Conclusions
To comprehensively demonstrate the validity of the proposed AGLCN, we performed validation on the real-world public CCMP V2.0 Wind Product. Detailed data descriptions and experimental settings are provided in
Section 4.1 and
Section 4.2. The experiment results on 40-node and 120-node multi-scale wind forecasts tasks proved the effectiveness of the proposed method, as detailed in
Section 4.3.1. In addition, we used statistical analysis to ensure the superiority of the proposed approach compared to the baseline method, as detailed in
Section 4.3.4. The hyper-parametric experiment in
Section 4.3.3 proved that our method has good robustness. The detailed time complexity of each module of the model can be found in
Section 4.3.3.
5. Discussion
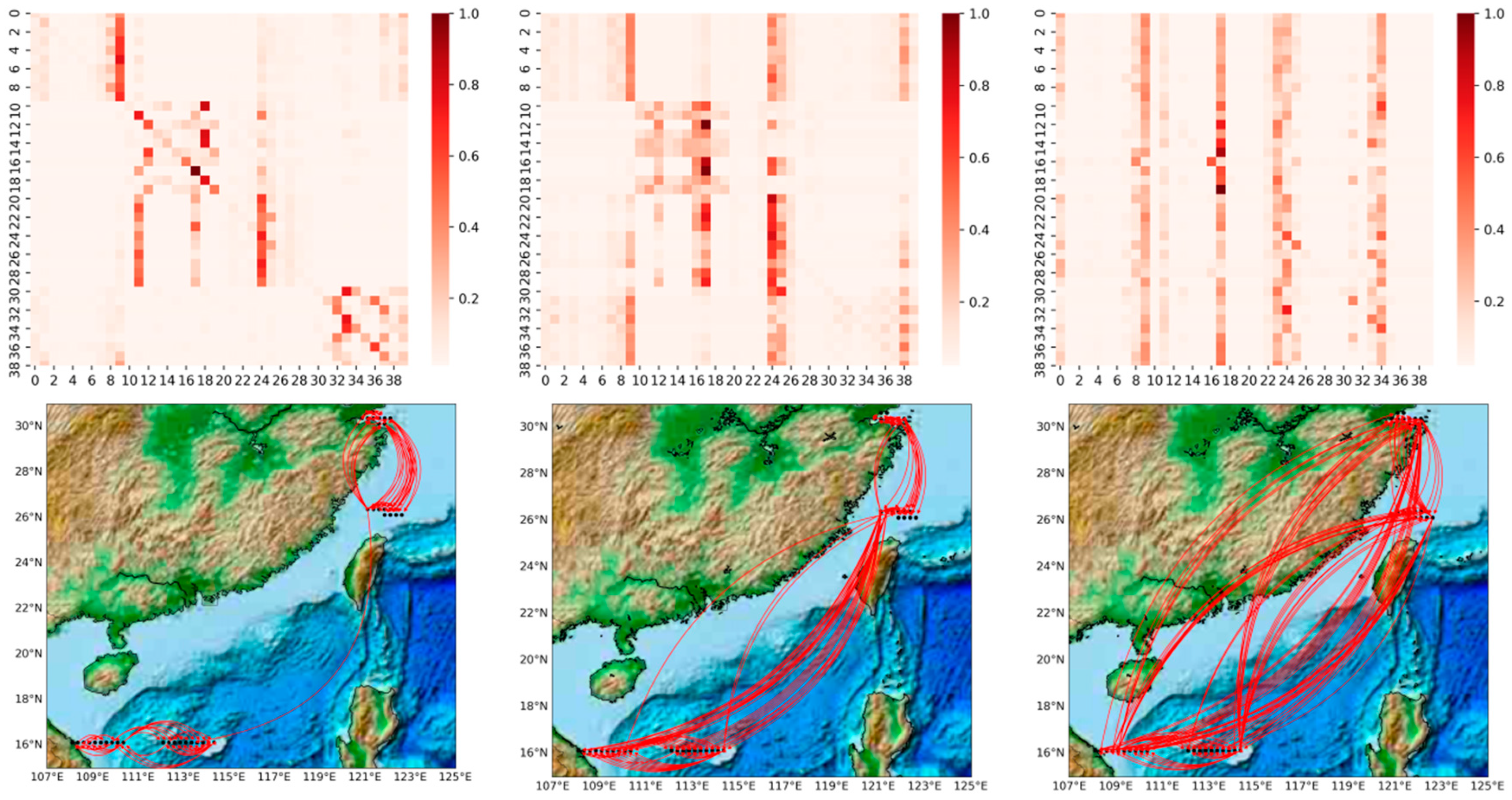
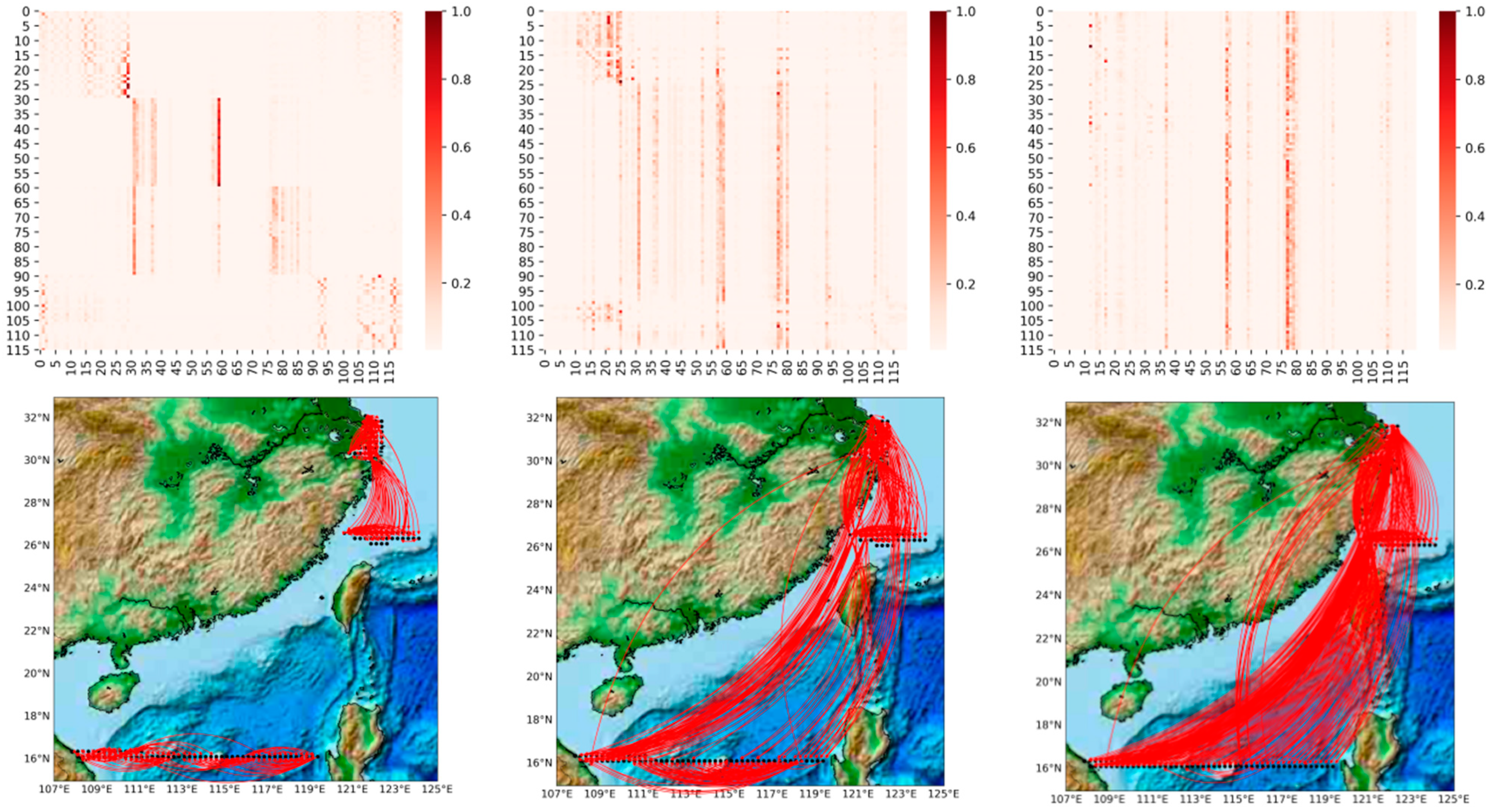
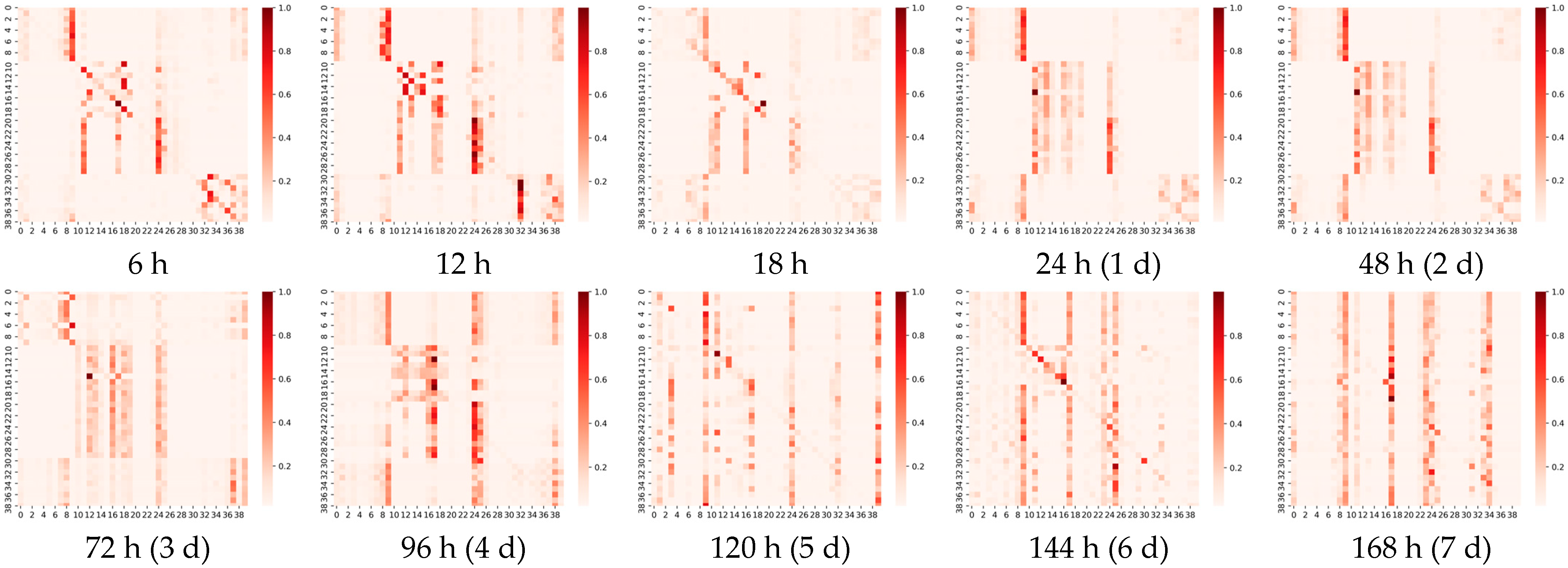
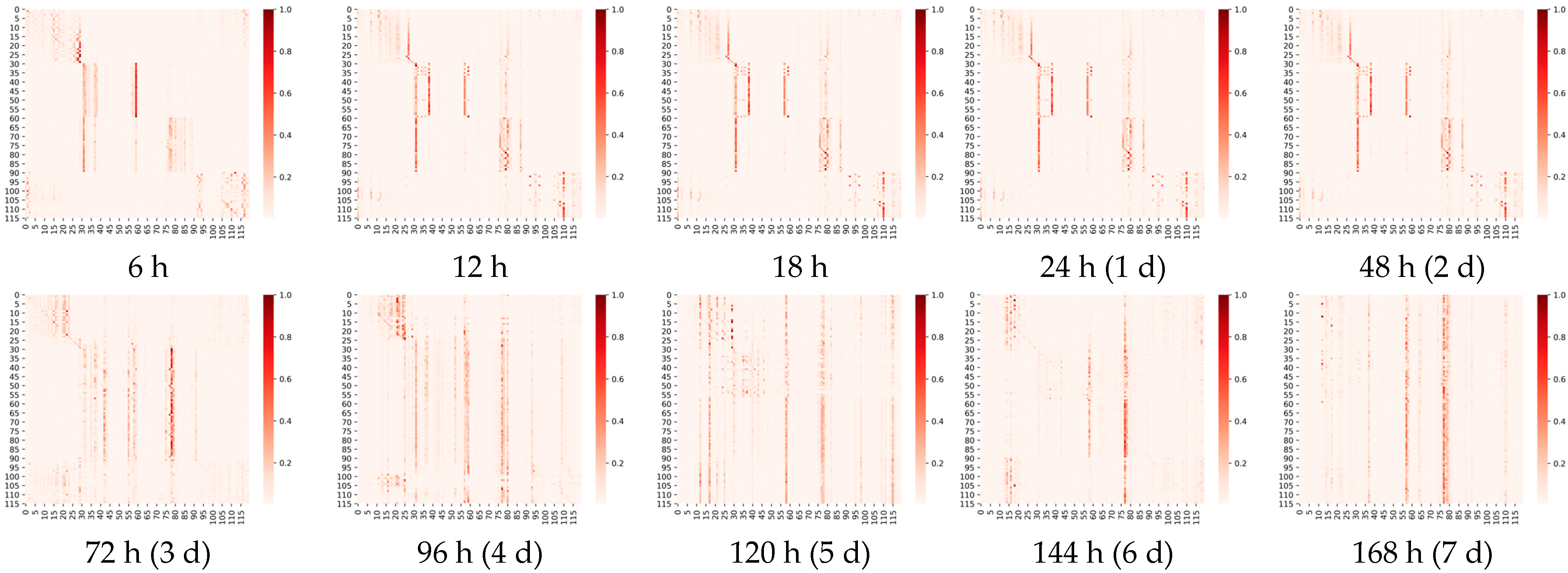
In this section, we visualize and analyze the graph matrix obtained by the model learning under different prediction scales, as illustrated in
Figure 9 (For more detail, refer to
Figure A1,
Figure A2 and
Figure A3 in the
Appendix A). It represents the node associations captured adaptively at different prediction scales (6 h, 4-day and 7-day), where the heat map of the edge weights of the matrix is shown above, and we visualize the association on the actual map below for a better view. The shades of orange in the heat map represent the strength of the correlation between two wind speed points, including the correlations of the points with themselves. The horizontal and vertical axes, respectively, contain 40 points taken at different longitudes and latitudes, ordered from 0 to 40 in ascending order of latitude, or in ascending order of longitude if the latitudes are the same.
It can be observed that: 1. The graph structure is adaptively learned based on downstream tasks; 2. The graph structure can capture associations over long distances. Comparing the three heat maps in
Figure 9, we can find that the learned graph structures are very different. The graph matrices obtained by our model are trained under different prediction scales independently, i.e., different downstream tasks. A more obvious local focus (i.e., the influence relationship is distance-dependent; the closer the distance, the greater the influence) is found in the heat map of
Figure 9a; for example, the region where nodes 11–19, 32–39 are located shows a stronger association (darker colors). As the prediction scale is extended, we find that the local focus becomes weaker and weaker. For example, in the heat map in
Figure 9b, the region where nodes 11–19 are located still shows a strong association, but the local focus in the region where nodes 32–39 are located has disappeared. In
Figure 9c, the local focus has disappeared and only a few points are affecting the global nodes, i.e., a few very distinct vertical lines. This phenomenon is proved by projecting the edge weights from the heat map onto the real map. It is in line with practice, because the impact lagged in the process, so the influence of the surrounding nodes is greater in short-term forecasts. In the medium- and long-term forecasts, the influence between long distances gradually dominates, with the surrounding point effects still clearly observable in the 4-day forecast and long distance effects clearly dominating in the 7-day forecast. In medium- to long-term forecasting, our model captures long-range correlations well, free from the limitations of distance-based graphs.
It is important to note that the end purpose of this work is to improve forecasting performance using the adaptive learning graph, rather than identifying the causal relationship of the nodes. Inferring causality among multivariate time series requires a nontrivial extension that spans beyond the current study. A perfect golden and standard measure for the quality of the learned graph does not exist, except forecasting accuracy. In summary, our work demonstrates the ability to use adaptive graph structures for multi-node wind speed prediction and the potential to capture spatial dependence between nodes.
6. Conclusions
In this paper, we propose a general graph neural network framework for multi-node offshore wind speed named adaptive graph-learning convolutional networks (AGLCN). It aims to address the difficulty of existing methods to capture the unknown complex spatial dependencies between nodes and frees the need for an a priori graph structure. The proposed graph-learning method can automatically construct a graph structure based on dynamic wind speed data. To efficiently and effectively capture temporal dependencies in data, we employed a gated temporal convolutional network because of the parallel computational efficiency and gradient stability. We designed a general network framework AGLCN to integrate graph learning, as well as temporal and graph convolutional modules in a framework to jointly optimize these features. Experiments were conducted using real-world wind speed data from the China Sea, which demonstrated that our model achieved state-of-the-art results in all multi-scale wind speed predictions.
However, our SDGL has two potential limitations. The time complexity of the graph-learning method is O(N2), indicating that the computation cost grows quadratically with the number of nodes, which is not feasible in the face of large graphs with thousands of nodes. In addition, the spatial relationships between variables in the short-term view could differ from it in the long-term. Thus, we would like to further investigate these two topics in the future. Graph-learning methods with linear complexity will be studied to efficiently process large-scale graph nodes in the real world. Second, it is essential to learn multiple graph structures to capture the scale-specific spatial relationships among nodes.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








