
TRFM-LS: Transformer-Based Deep Learning Method for Vessel Trajectory Prediction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Related Work
1.2. Contribution
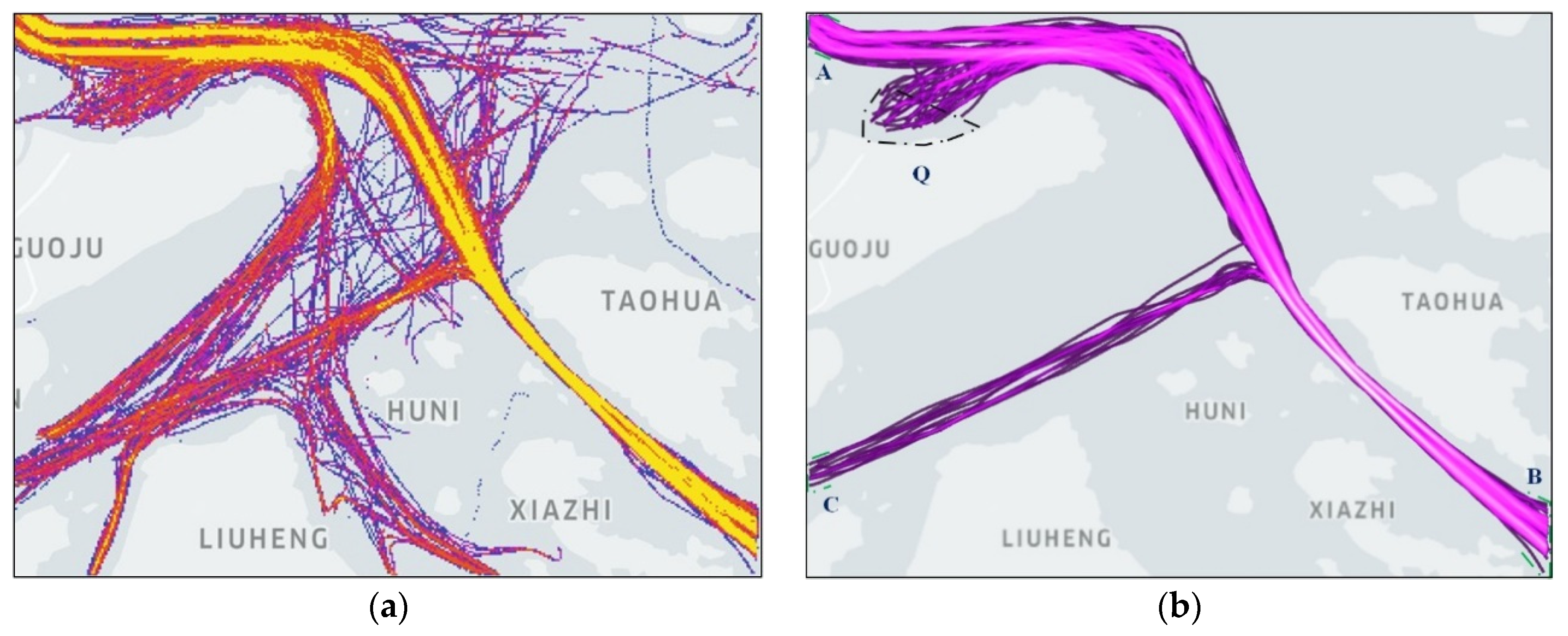
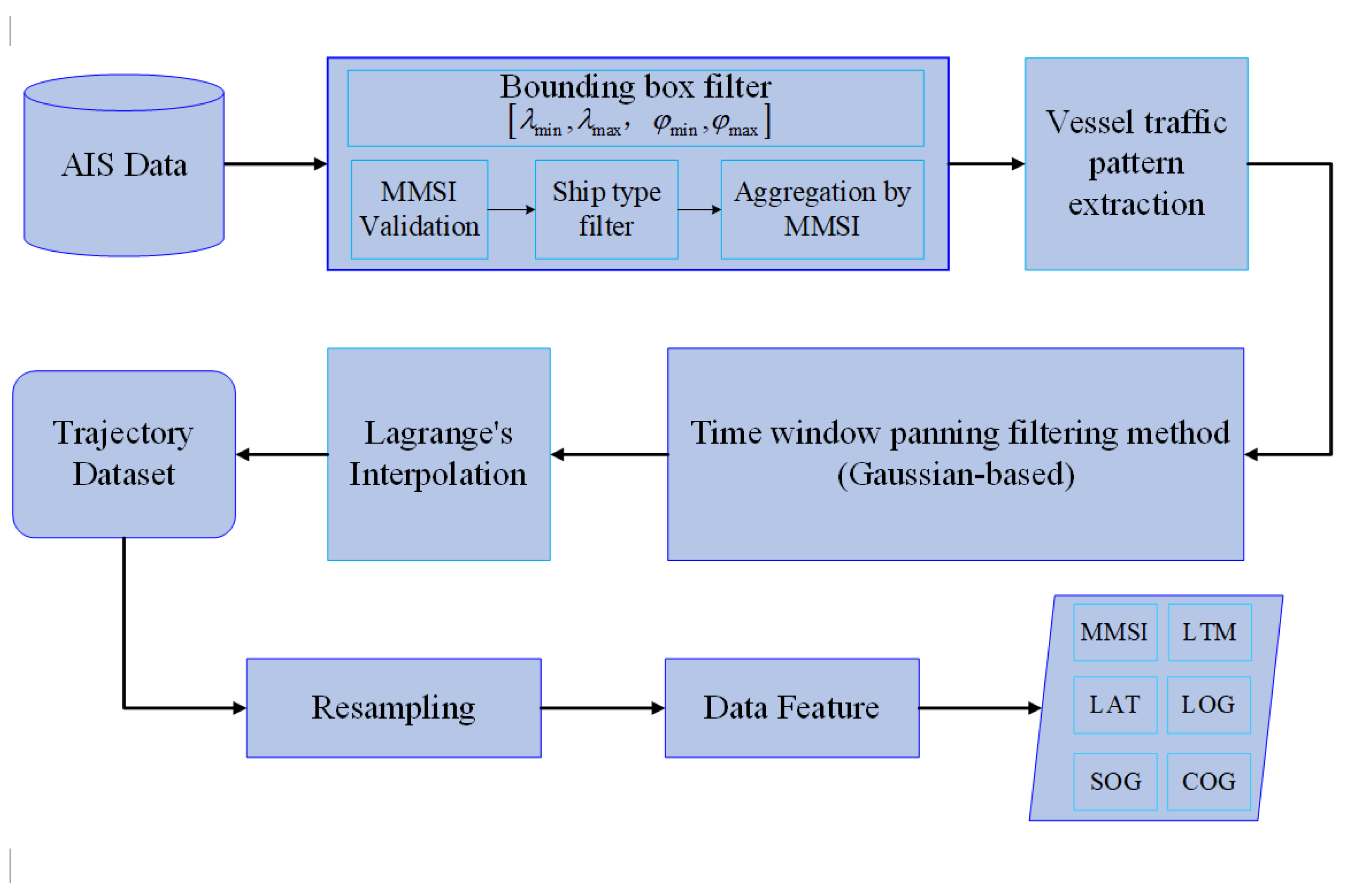
2. Vessel Traffic Spatiotemporal Pattern Extraction and Data Processing
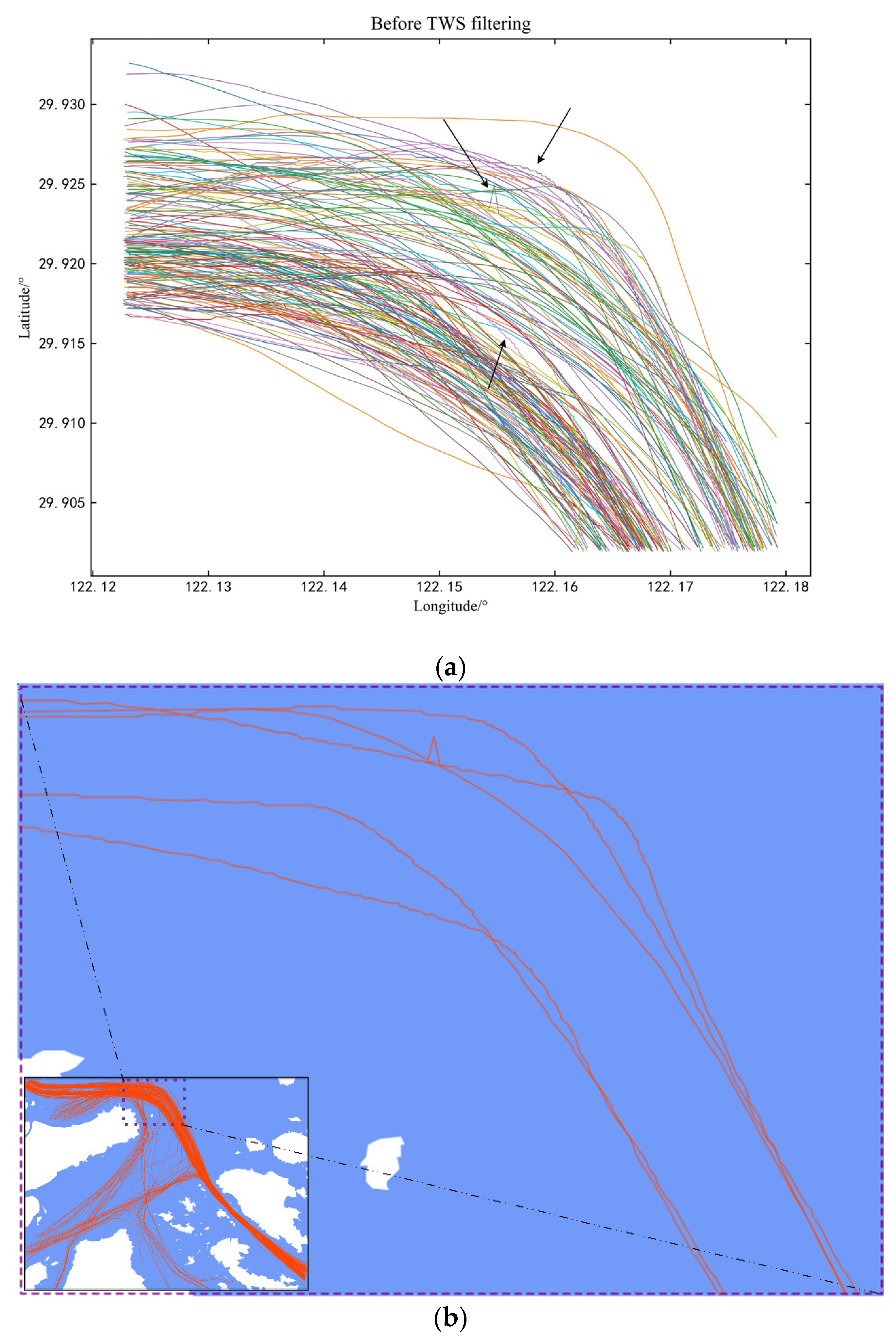
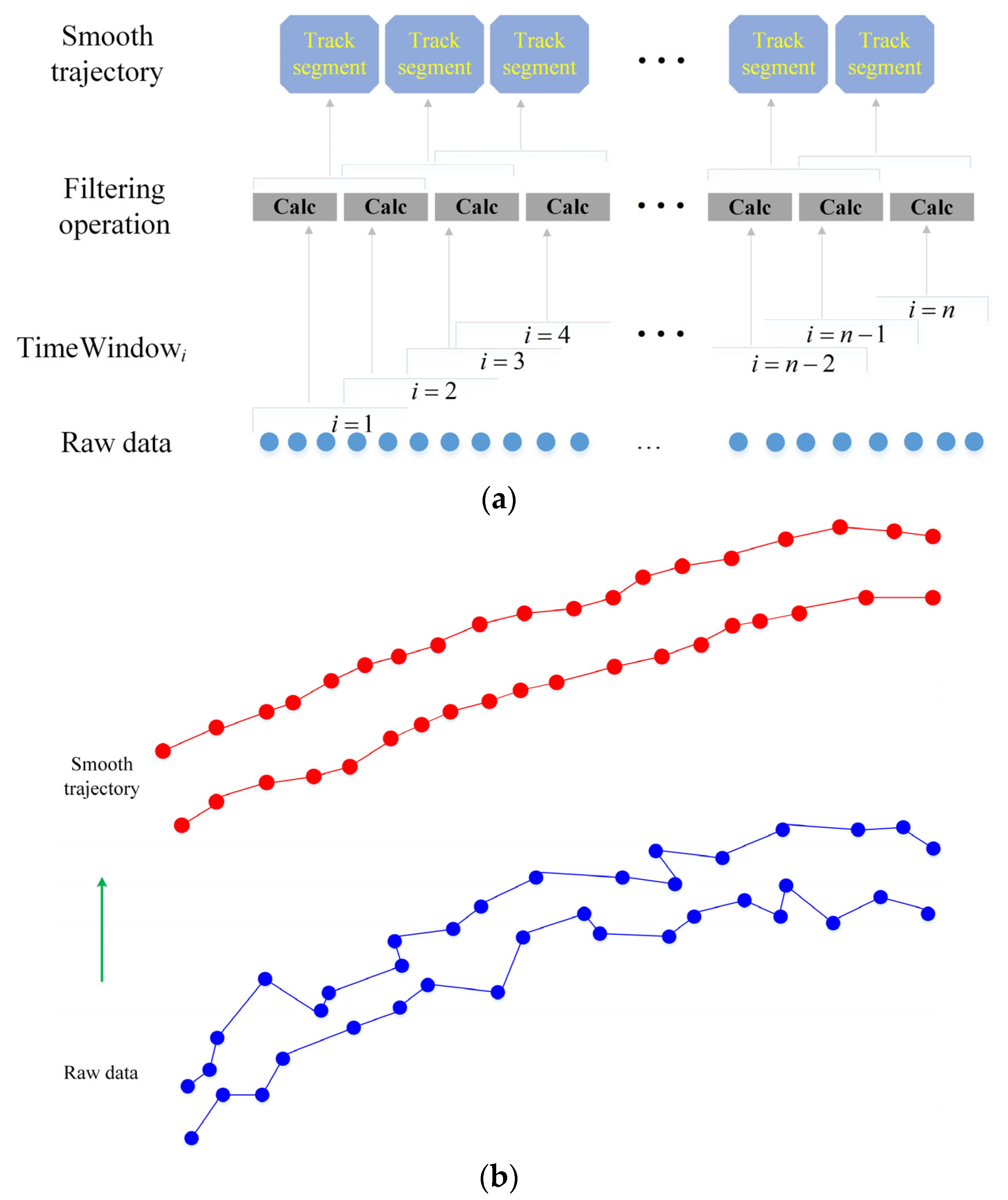
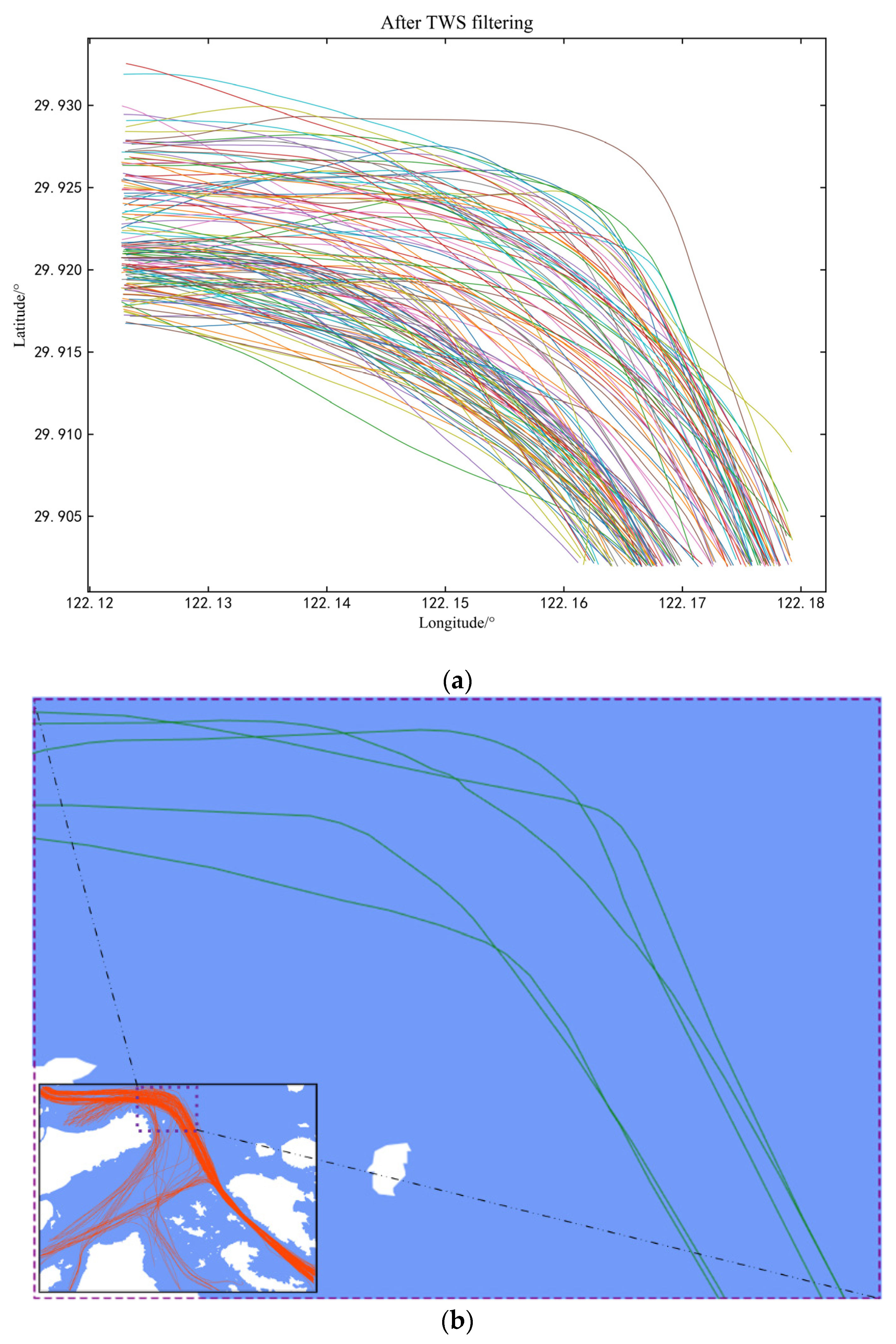
2.1. A Time Window Panning Filtering Method for Trajectories
2.2. Other Preprocessing of Trajectory Data
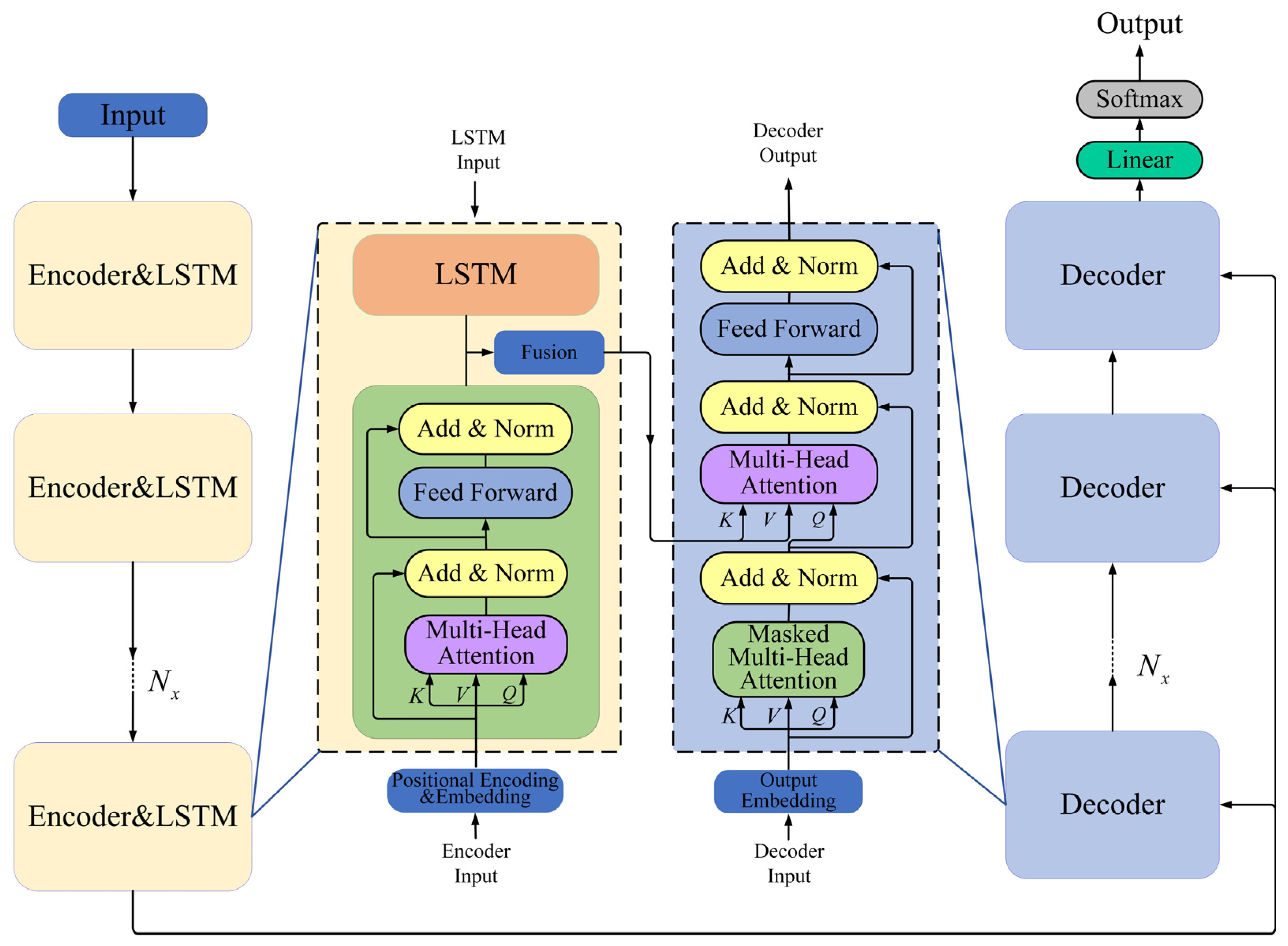
3. Methodology
3.1. Transformer Model Main Architecture
3.1.1. Positional Encoding
3.1.2. Encoder–Decoder Transformer
3.2. TRFM-LS Trajectory Prediction Model
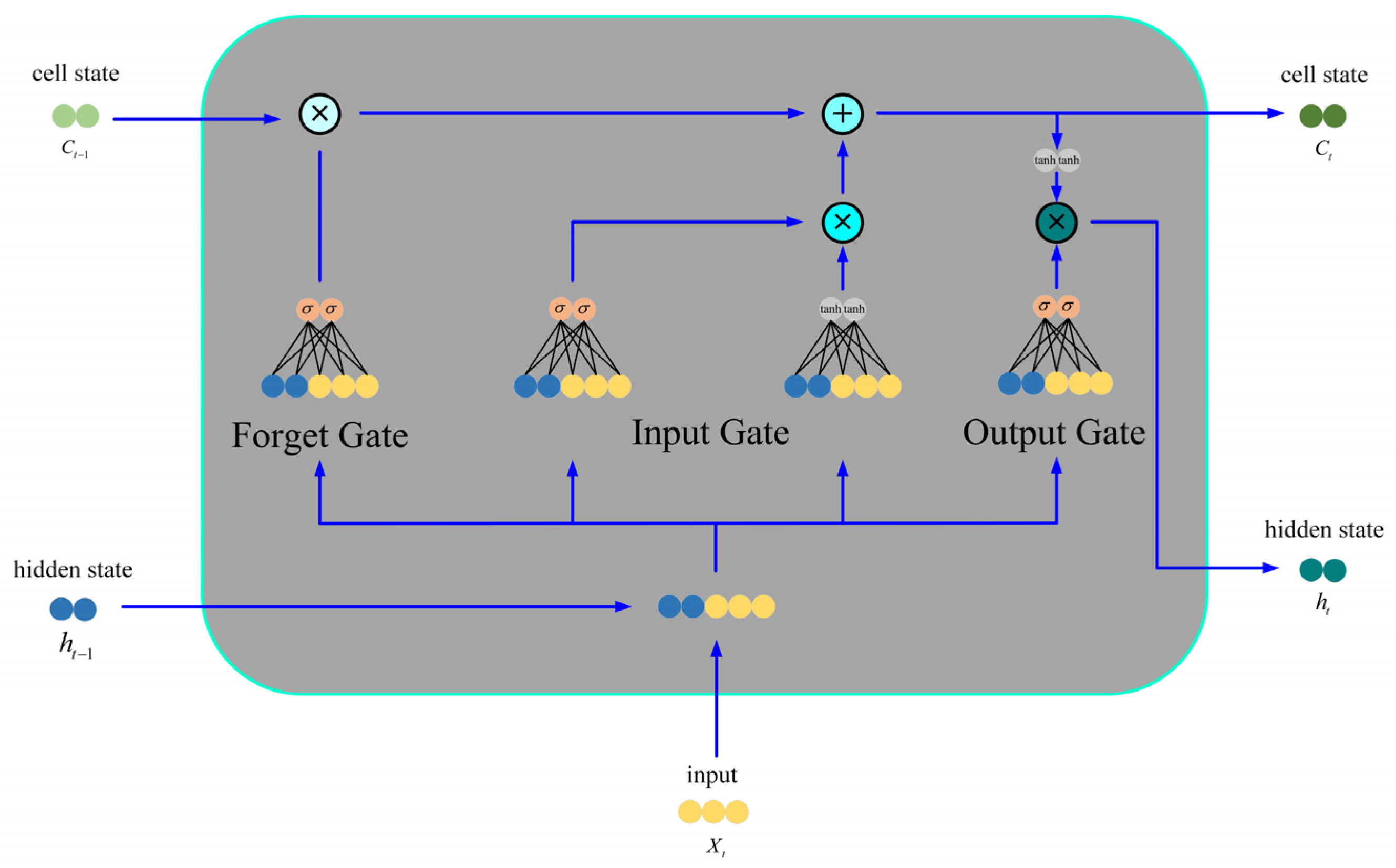
3.2.1. Transformer–LSTM Fusion Structure
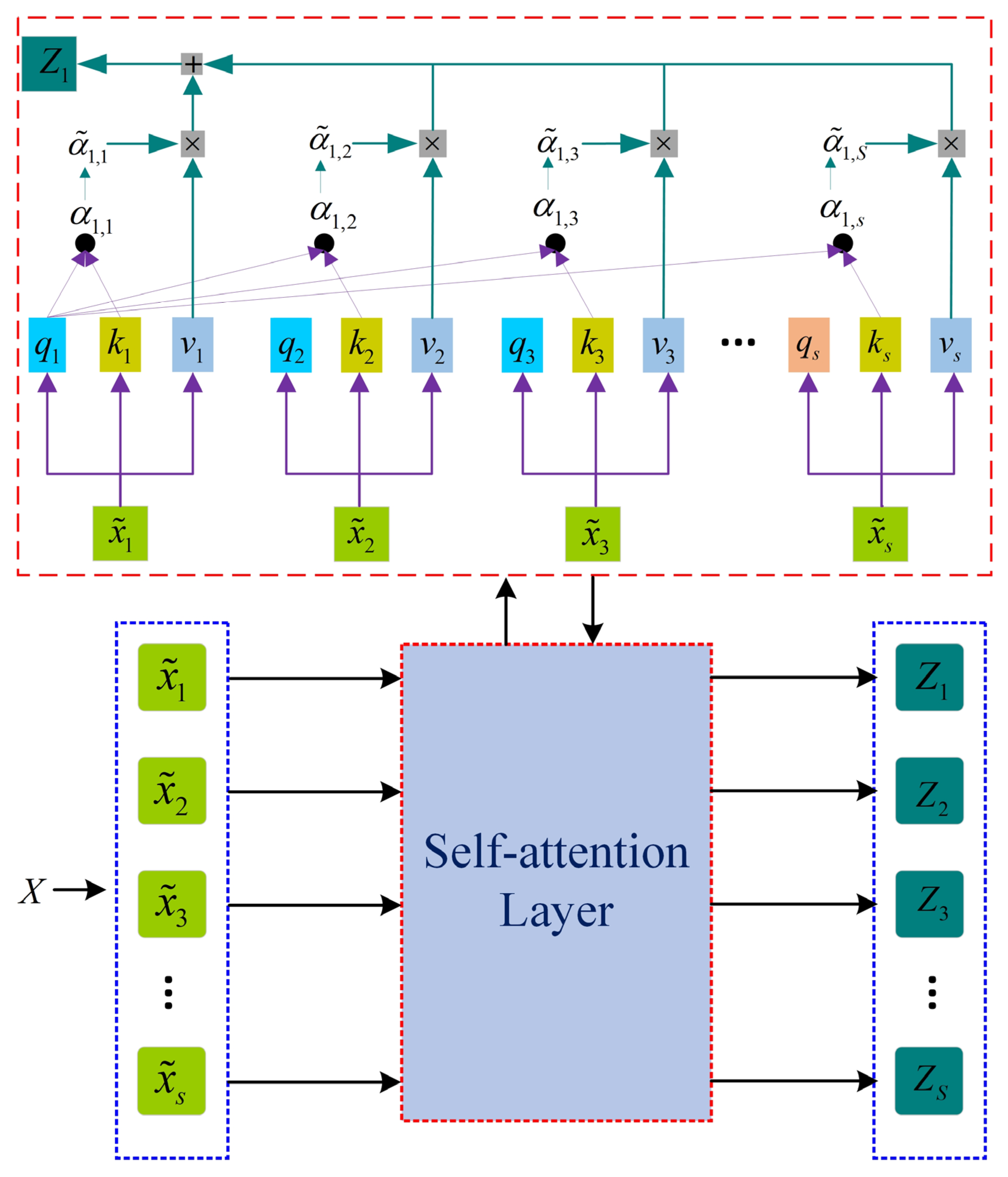
3.2.2. Multi-Headed Self-Attention Mechanism
3.3. Fully Connected Feedforward Layer
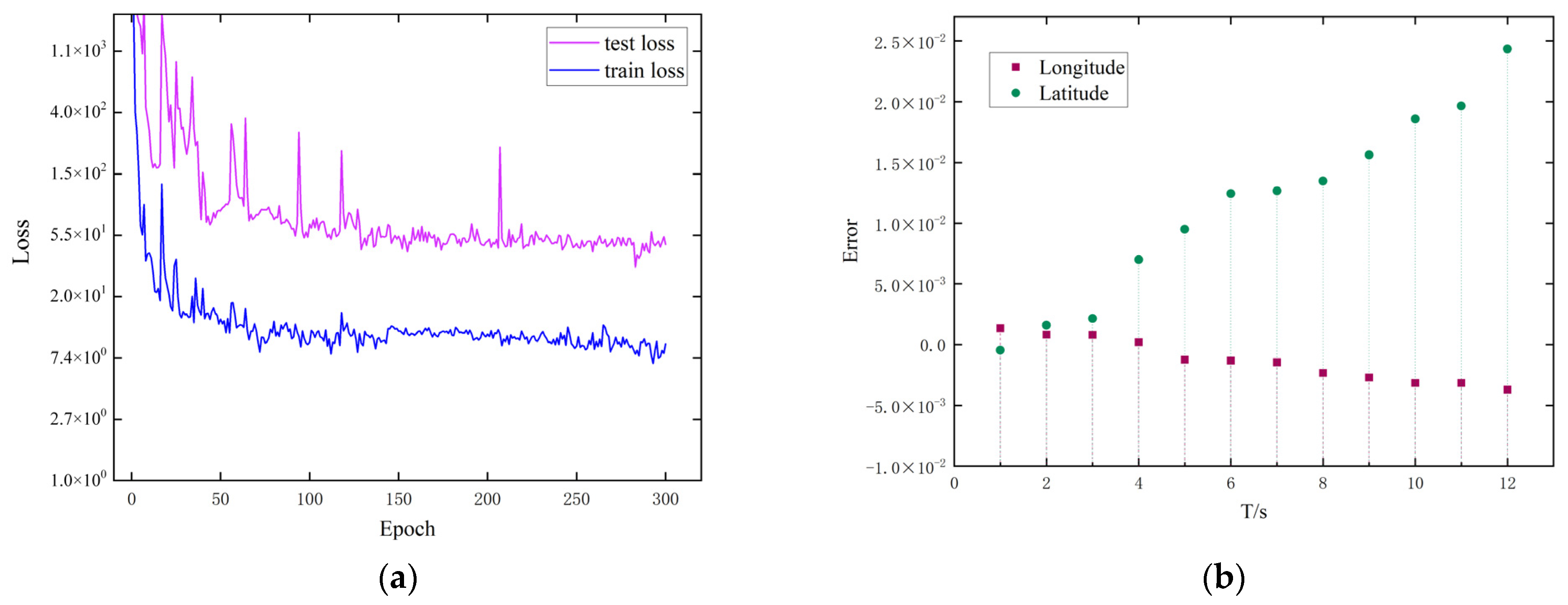
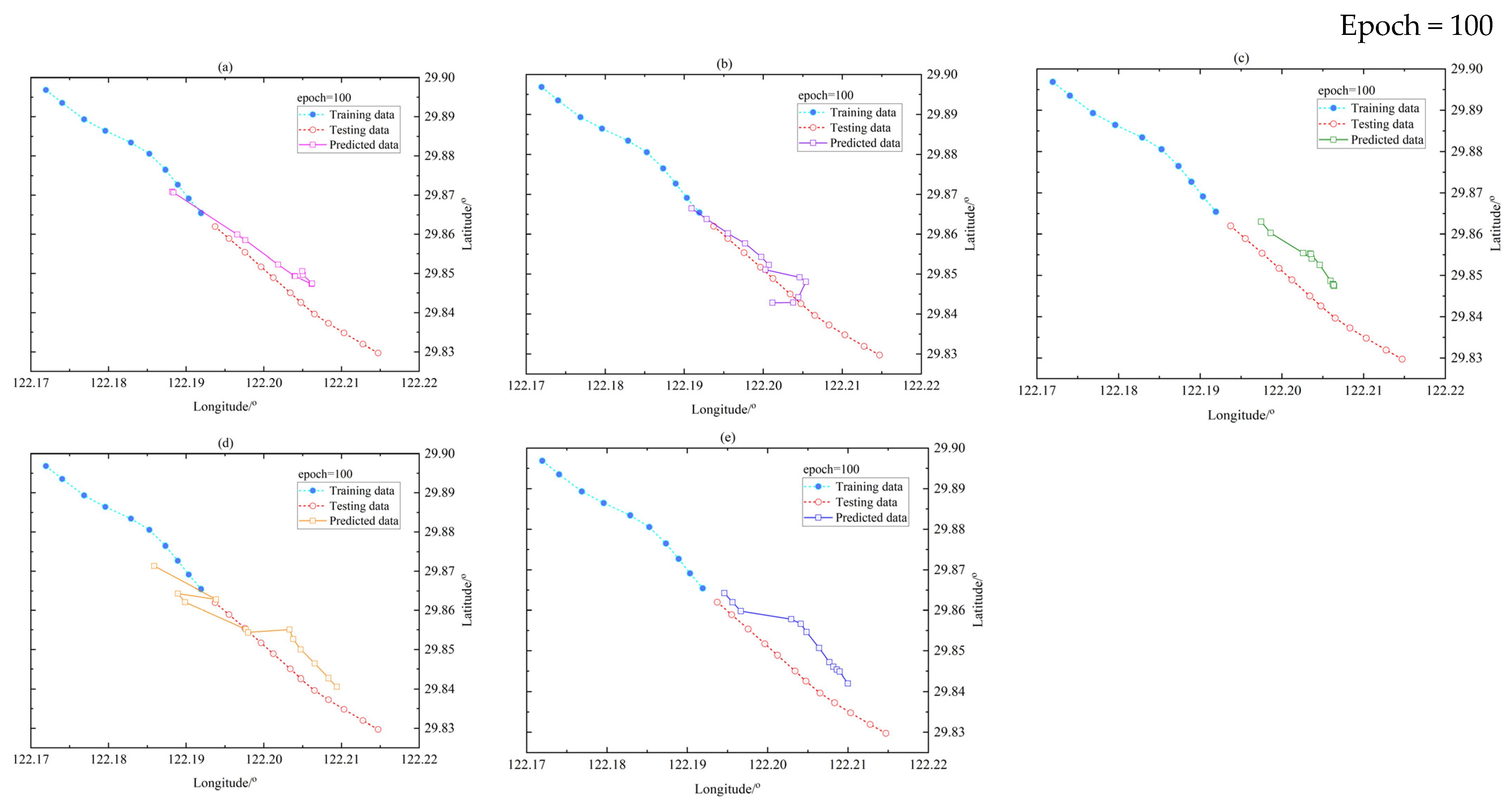
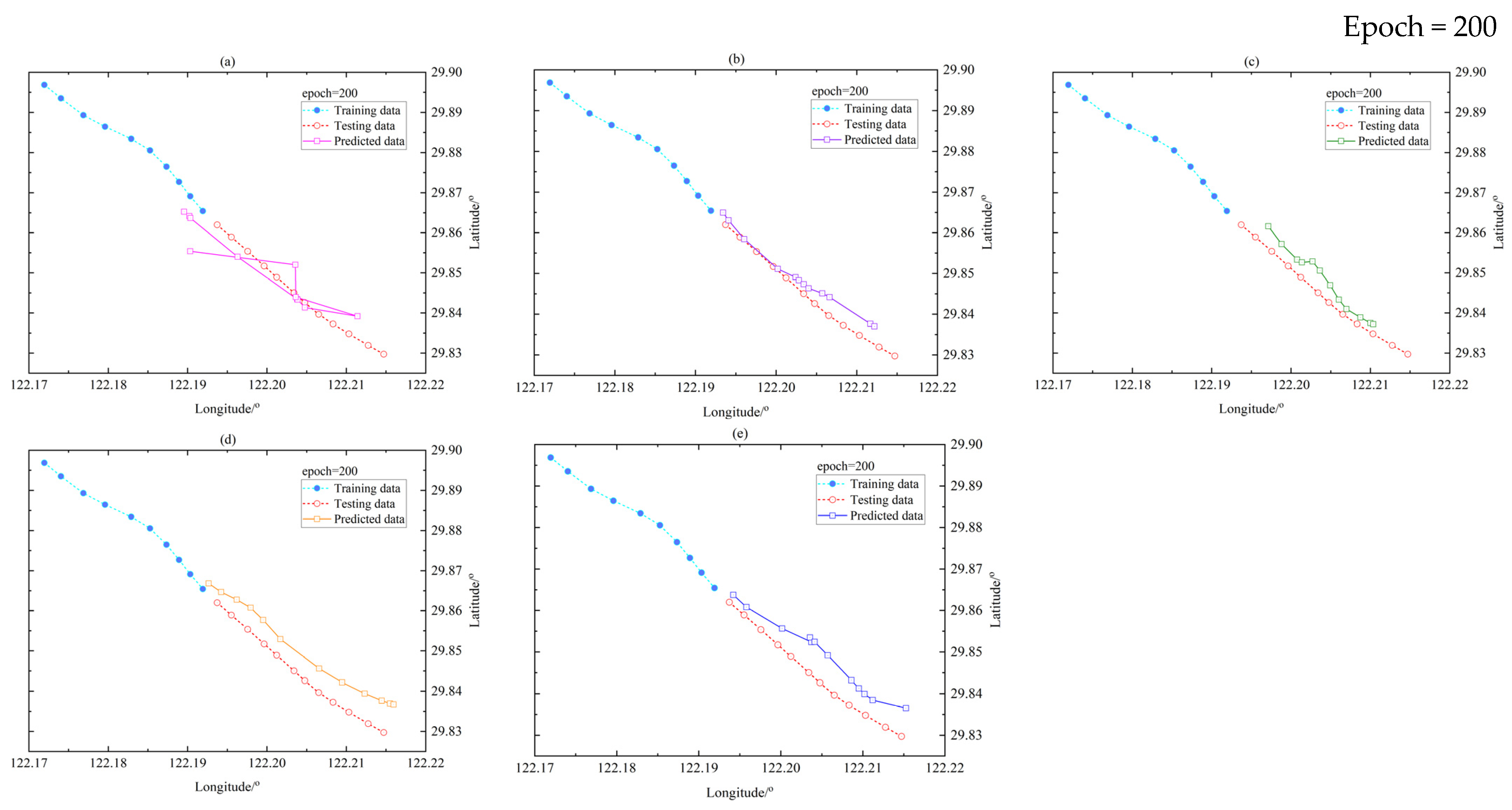
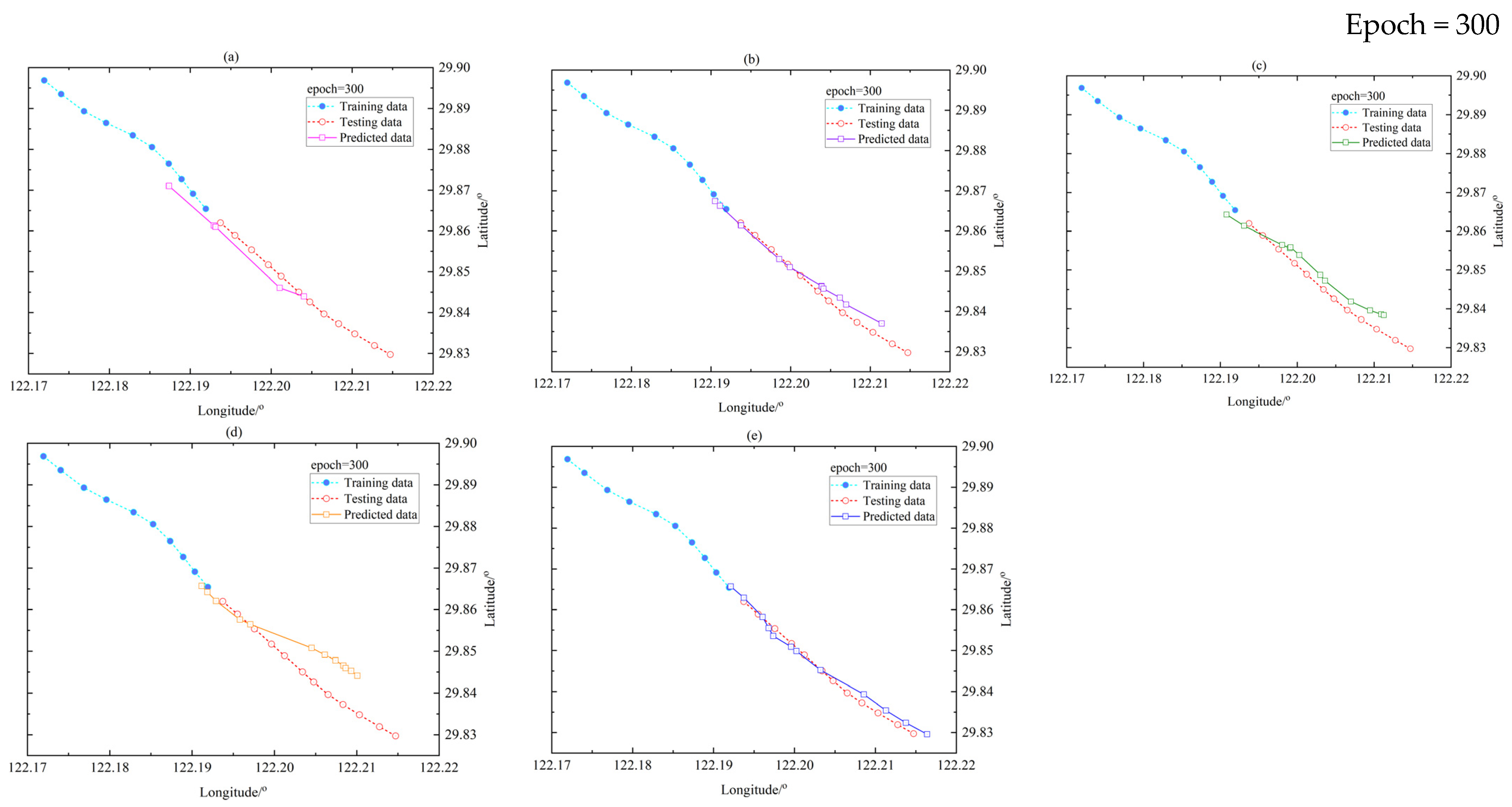
4. Experiments and Results
4.1. Dataset Preparation
4.2. Experimental Design
4.3. Results
4.3.1. Model Comparison
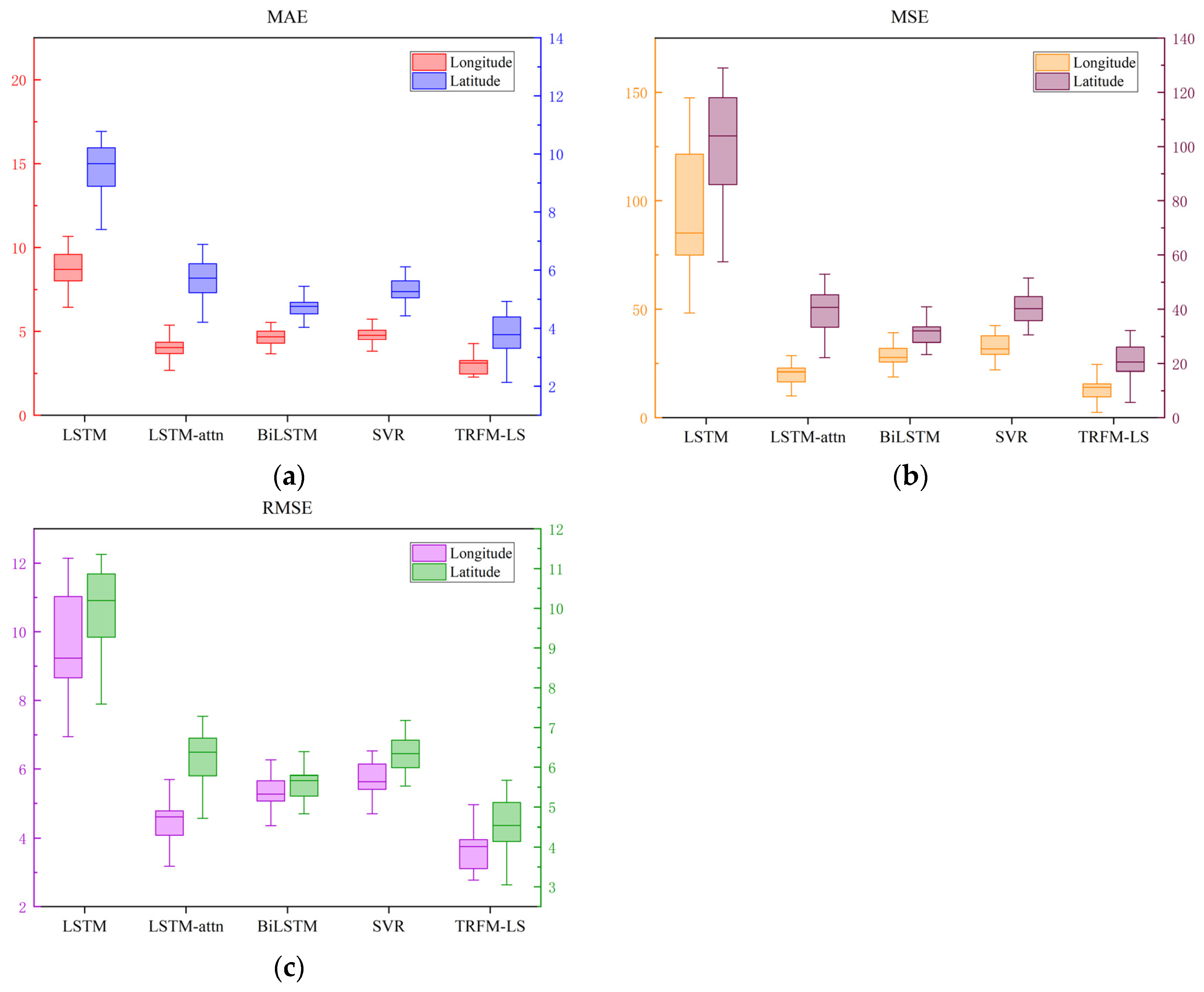
4.3.2. Evaluation Metrics
5. Conclusions
6. Discussion
6.1. Limitations
6.2. Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rødseth, Ø.J.; Perera, L.P.; Mo, B. Big Data in Shipping—Challenges and Opportunities. In Proceedings of the 15th International Conference on Computer Applications and Information Technology in the Maritime Industries (COMPIT 2016), Lecce, Italy, 9–11 May 2016. [Google Scholar]
- Liu, H.; Jurdana, I.; Lopac, N.; Wakabayashi, N. BlueNavi: A Microservices Architecture-Styled Platform Providing Maritime Information. Sustainability 2022, 14, 2173. [Google Scholar] [CrossRef]
- Jurdana, I.; Lopac, N.; Wakabayashi, N.; Liu, H. Shipboard Data Compression Method for Sustainable Real-Time Maritime Communication in Remote Voyage Monitoring of Autonomous Ships. Sustainability 2021, 13, 8264. [Google Scholar] [CrossRef]
- Chen, P.; Li, M.; Mou, J. A Velocity Obstacle-Based Real-Time Regional Ship Collision Risk Analysis Method. J. Mar. Sci. Eng. 2021, 9, 428. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Zaman, B.; Marijan, D.; Kholodna, T. Interpolation-Based Inference of Vessel Trajectory Waypoints from Sparse AIS Data in Maritime. J. Mar. Sci. Eng. 2023, 11, 615. [Google Scholar] [CrossRef]
- Zhao, S.; Tang, C.; Liang, S.; Wang, D. Track prediction of vessel in controlled waterway based on improved Kalman filter. J. Comput. Appl. 2012, 32, 3247–3250. [Google Scholar] [CrossRef]
- Zhang, Z.; Ni, G.; Xu, Y. Trajectory prediction based on AIS and BP neural network. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; pp. 601–605. [Google Scholar]
- Sørensen, K.A.; Heiselberg, P.; Heiselberg, H. Probabilistic Maritime Trajectory Prediction in Complex Scenarios Using Deep Learning. Sensors 2022, 22, 2058. [Google Scholar] [CrossRef] [PubMed]
- Murray, B.; Perera, L.P. A dual linear autoencoder approach for vessel trajectory prediction using historical AIS data. Ocean Eng. 2020, 209, 107478. [Google Scholar] [CrossRef]
- Gupta, A.; Johnson, J.; Li, F.F.; Savarese, S.; Alahi, A. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, Z.; Ni, G.; Xu, Y. Ship Trajectory Prediction based on LSTM Neural Network. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1356–1364. [Google Scholar]
- Ding, M.; Su, W.; Liu, Y.; Zhang, J.; Li, J.; Wu, J. A Novel Approach on Vessel Trajectory Prediction Based on Variational LSTM. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 206–211. [Google Scholar]
- Bao, K.; Bi, J.; Gao, M.; Sun, Y.; Zhang, X.; Zhang, W. An Improved Ship Trajectory Prediction Based on AIS Data Using MHA-BiGRU. J. Mar. Sci. Eng. 2022, 10, 804. [Google Scholar] [CrossRef]
- Wang, R.; Peng, C.; Gao, J.; Gao, Z.; Jiang, H. A dilated convolution network-based LSTM model for multi-step prediction of chaotic time series. Comput. Appl. Math. 2020, 39, 30. [Google Scholar] [CrossRef]
- Gao, D.; Zhu, Y.; Zhang, J.; He, Y.; Yan, K.; Yan, B. A novel MP-LSTM method for ship trajectory prediction based on AIS data. Ocean Eng. 2021, 228, 108956. [Google Scholar] [CrossRef]
- Capobianco, S.; Millefiori, L.M.; Forti, N.; Braca, P.; Willett, P. Deep Learning Methods for Vessel Trajectory Prediction Based on Recurrent Neural Networks. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 4329–4346. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Giuliari, F.; Hasan, I.; Cristani, M.; Galasso, F. Transformer Networks for Trajectory Forecasting. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10335–10342. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017), Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Neural Information Processing Systems Foundation: La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Neural Information Processing Systems Foundation, Vancouver, BC, Canada, 6–12 December 2020; Available online: https://dl.acm.org/doi/abs/10.5555/3495724.3495883 (accessed on 16 March 2023).
- Sun, G.; Zhang, C.; Woodland, P.C. Transformer Language Models with LSTM-Based Cross-Utterance Information Representation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7363–7367. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.; Salakhutdinov, R. Transformer-{XL}: Attentive Language Models beyond a Fixed-Length Context; Association for Computational Linguistics-ACL: Florence, Italy, 2019; pp. 2978–2988. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Cai, L.; Janowicz, K.; Mai, G.; Yan, B.; Zhu, R. Traffic transformer: Capturing the continuity and periodicity of time series for traffic forecasting. Trans. GIS 2020, 24, 736–755. [Google Scholar] [CrossRef]
- Fan, C.; Zhang, Y.; Pan, Y.; Li, X.; Zhang, C.; Yuan, R.; Wu, D.; Wang, W.; Pei, J.; Huang, H.; et al. Multi-Horizon Time Series Forecasting with Temporal Attention Learning. In Proceedings of the KDD’19: 25th Acm Sigkdd International Conferencce on Knowledge Discovery and Data Mining (KDD), Anchorage, AK, USA, 4–8 August 2019; pp. 2527–2535. [Google Scholar]
- Cinar, Y.G.; Mirisaee, H.; Goswami, P.; Gaussier, E.; Ait-Bachir, A.; Strijov, V. Position-Based Content Attention for Time Series Forecasting with Sequence-to-Sequence RNNs. In Neural Information Processing, Proceedings of the ICONIP 2017 24th International Conference on Neural Information Processing (ICONIP), Guangzhou, China, 14–18 November 2017; Liu, D., Xie, S., Li, Y., Zhao, D., ElAlfy, E., Eds.; Springer: Cham, Switzerland, 2017; Volume 10638, pp. 533–544. [Google Scholar] [CrossRef]
- Fan, Z.; Gong, Y.; Liu, D.; Wei, Z.; Wang, S.; Jiao, J.; Duan, N.; Zhang, R.; Huang, X. Mask Attention Networks: Rethinking and Strengthen Transformer. arXiv 2021, arXiv:2103.13597. [Google Scholar]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, D.; Shi, G.; Li, N.; Ma, L.; Li, W.; Shi, J. TRFM-LS: Transformer-Based Deep Learning Method for Vessel Trajectory Prediction. J. Mar. Sci. Eng. 2023, 11, 880. https://doi.org/10.3390/jmse11040880
Jiang D, Shi G, Li N, Ma L, Li W, Shi J. TRFM-LS: Transformer-Based Deep Learning Method for Vessel Trajectory Prediction. Journal of Marine Science and Engineering. 2023; 11(4):880. https://doi.org/10.3390/jmse11040880
Chicago/Turabian StyleJiang, Dapeng, Guoyou Shi, Na Li, Lin Ma, Weifeng Li, and Jiahui Shi. 2023. "TRFM-LS: Transformer-Based Deep Learning Method for Vessel Trajectory Prediction" Journal of Marine Science and Engineering 11, no. 4: 880. https://doi.org/10.3390/jmse11040880
APA StyleJiang, D., Shi, G., Li, N., Ma, L., Li, W., & Shi, J. (2023). TRFM-LS: Transformer-Based Deep Learning Method for Vessel Trajectory Prediction. Journal of Marine Science and Engineering, 11(4), 880. https://doi.org/10.3390/jmse11040880