
Comparison of Satellite Imagery for Identifying Seagrass Distribution Using a Machine Learning Algorithm on the Eastern Coast of South Korea

 , , and
, , and 
Abstract
1. Introduction
2. Materials and Methods
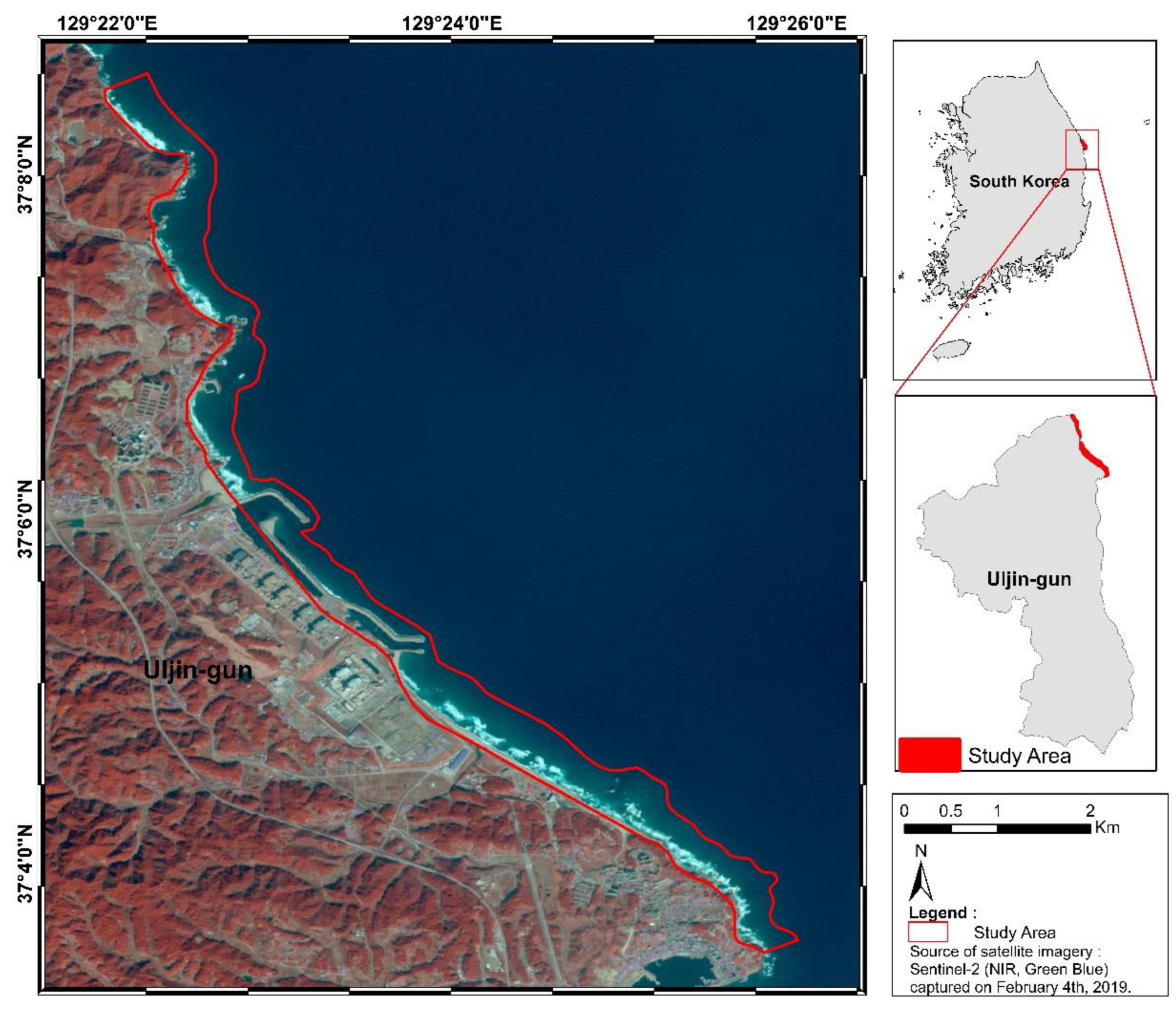
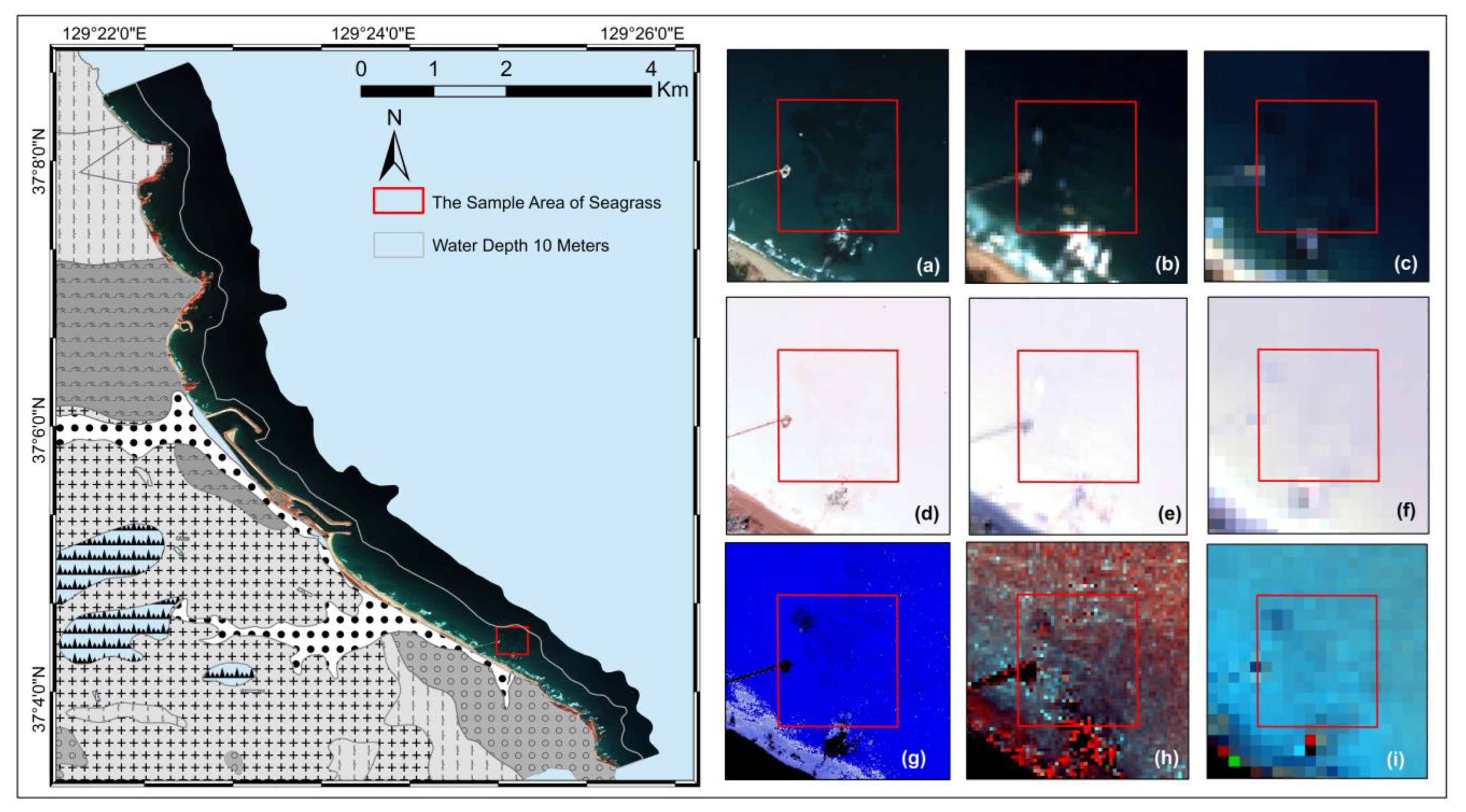
2.1. Study Area
2.2. Satellite Data
2.3. Image Processing
3. Results
3.1. Atmospheric Correction, Sunglint and Water Column Correction
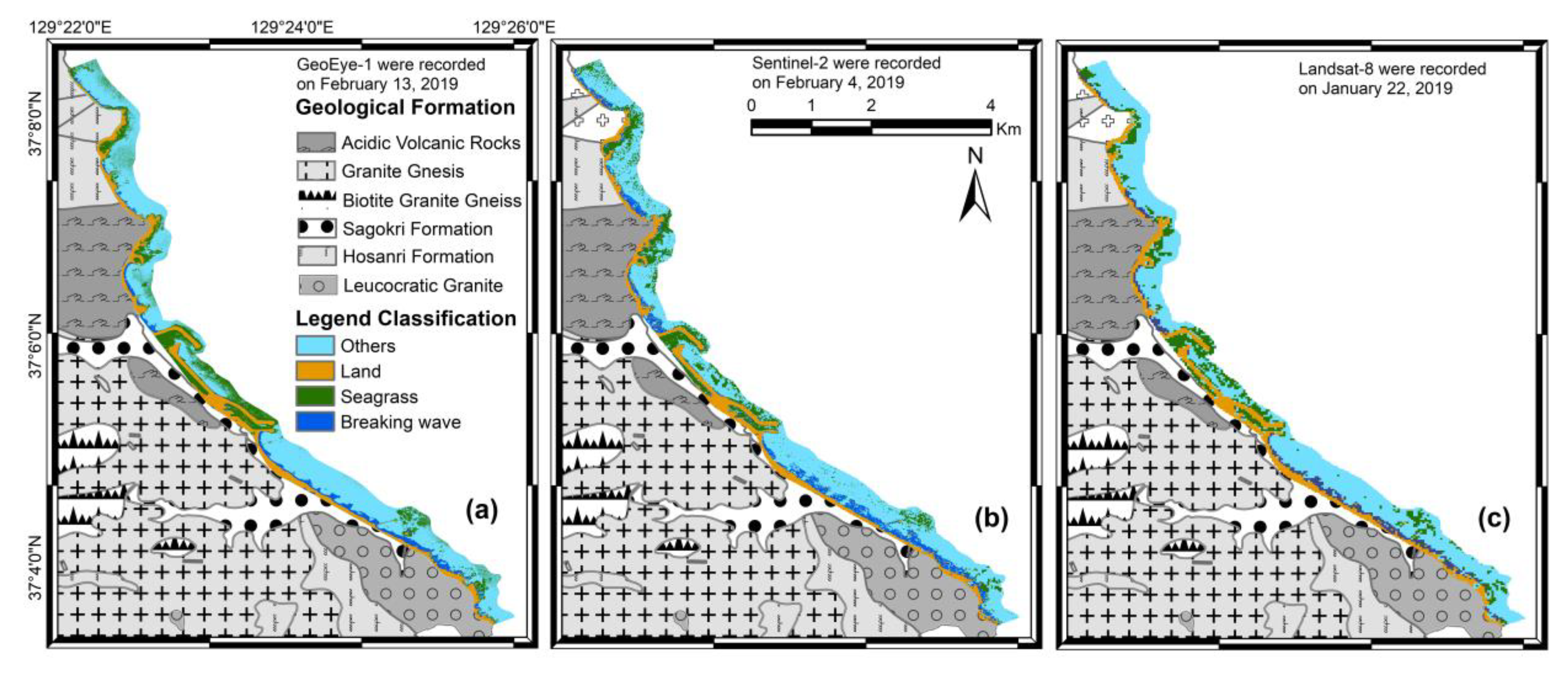
3.2. Image Classification
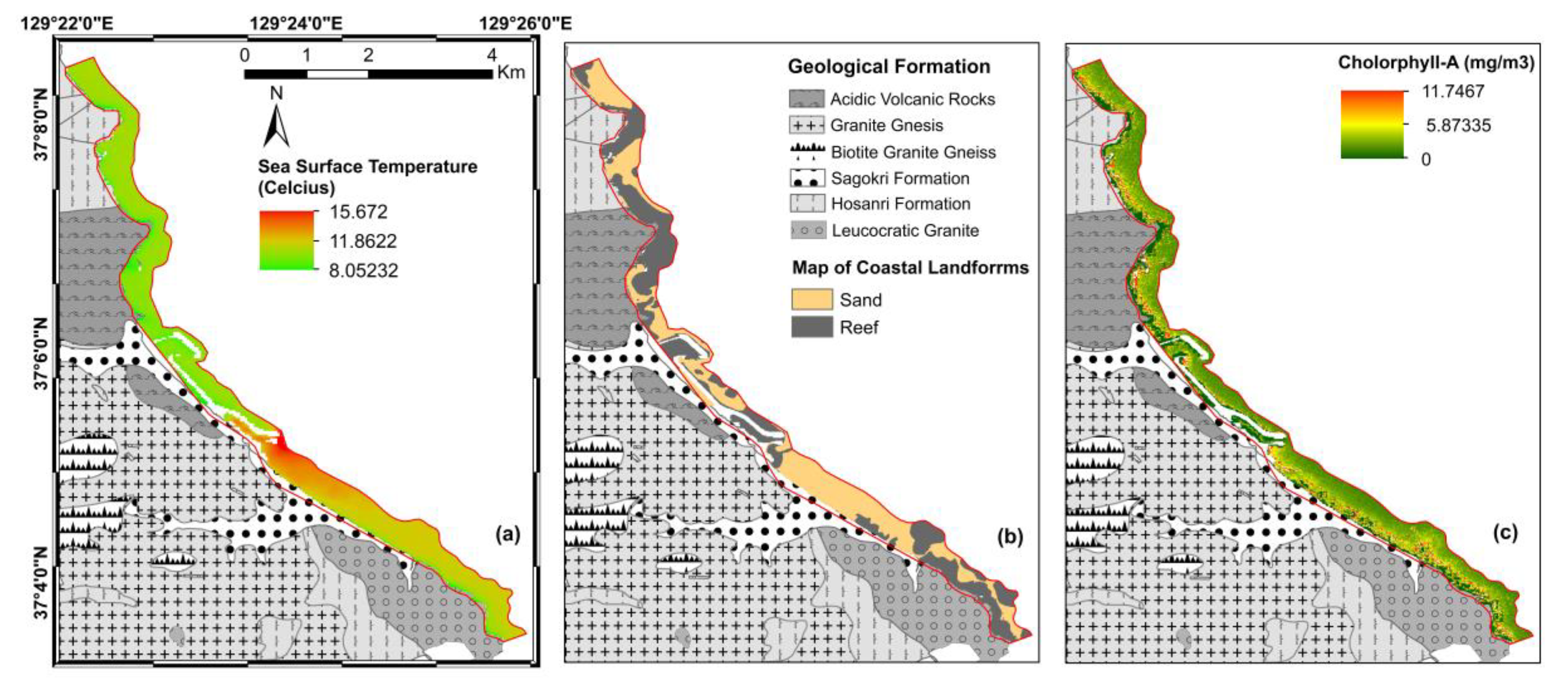
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Done, T.J.; Reichelt, R.E. Integrated Coastal Zone and Fisheries Ecosystem Management: Generic Goals and Performance Indices. Ecol. Appl. 1998, 8 (Suppl. S1), S110–S118. [Google Scholar] [CrossRef]
- Heckbert, S.; Costanza, R.; Poloczanska, E.; Richardson, A. Climate regulation as a service from estuarine and coastal ecosystems. In Treatise on Estuarine and Coastal Science; Elsevier: Amsterdam, The Netherlands, 2011; pp. 199–216. [Google Scholar]
- Larkum, A.W.D.; Orth, R.J.; Duarte, C.M. Seagrasses: Biology, Ecology and Conservation; Springer: Dordrecht, The Netherlands, 2006. [Google Scholar]
- den Hartog, C.; Kuo, J. Taxonomy and biogeography of seagrasses. In Seagrasses: Biology, Ecologyand Conservation; Springer: Dordrecht, The Netherlands, 2007; pp. 1–23. [Google Scholar]
- Zhao, J.; Liu, C.; Li, H.; Liu, J.; Jiang, T.; Yan, D.; Tong, J.; Dong, L. Review on Ecological Response of Aquatic Plants to Balanced Harvesting. Sustainability 2022, 14, 12451. [Google Scholar] [CrossRef]
- Oreska, M.P.J.; McGlathery, K.J.; Aoki, L.R.; Berger, A.C.; Berg, P.; Mullins, L. The greenhouse gas offset potential from seagrass restoration. Sci. Rep. 2020, 10, 7325. [Google Scholar] [CrossRef] [PubMed]
- Aben, R.C.; Velthuis, M.; Kazanjian, G.; Frenken, T.; Peeters, E.T.; Van de Waal, D.B.; Hilt, S.; Domis, L.N.D.S.; Lamers, L.P.; Kosten, S. Temperature response of aquatic greenhouse gas emissions differs between dominant plant types. Water Res. 2022, 226, 119251. [Google Scholar] [CrossRef]
- Phinn, S.; Roelfsema, C.; Kovacs, E.; Canto, R.; Lyons, M.; Saunders, M.; Maxwell, P. Mapping, Monitoring and Modelling Seagrass Using Remote Sensing Techniques. In Seagrasses of Australia; Springer International Publishing: Cham, Switzerland, 2018; pp. 445–487. [Google Scholar]
- Veettil, B.K.; Ward, R.D.; Lima, M.D.A.C.; Stankovic, M.; Hoai, P.N.; Quang, N.X. Opportunities for seagrass research derived from remote sensing: A review of current methods. Ecol. Indic. 2020, 117, 106560. [Google Scholar] [CrossRef]
- Dekker, A.; Brando, V.; Anstee, J.; Fyfe, S.; Malthus, T.; Karpouzli, E. Remote sensing of seagrass ecosystems: Use of spaceborne and airborne sensors. In Seagrasses: Biology, Ecologyand Conservation; Springer: Dordrecht, The Netherlands, 2007; pp. 347–359. [Google Scholar]
- Duffy, J.P.; Pratt, L.; Anderson, K.; Land, P.E.; Shutler, J.D. Spatial assessment of intertidal seagrass meadows using optical imaging systems and a lightweight drone. Estuar. Coast. Shelf Sci. 2018, 200, 169–180. [Google Scholar] [CrossRef]
- Dierssen, H.M.; Zimmerman, R.C.; Leathers, R.A.; Downes, T.V.; Davis, C.O. Ocean color remote sensing of seagrass and bathymetry in the Bahamas Banks by high-resolution airborne imagery. Limnol. Oceanogr. 2003, 48 Pt 2, 444–455. [Google Scholar] [CrossRef]
- Paul, M.; Lefebvre, A.; Manca, E.; Amos, C. An acoustic method for the remote measurement of seagrass metrics. Estuar. Coast. Shelf Sci. 2011, 93, 68–79. [Google Scholar] [CrossRef]
- Bakirman, T.; Gumusay, M.U.; Tuney, I. Mapping of The Seagrass Cover Along the Mediterranean Coast of Turkey Using Landsat 8 OLI Images. In Proceedings of the ISPRS—International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, XXIII ISPRS Congress, Prague, Czech Republic, 12–19 July 2016; Volume XLI-B8, pp. 1103–1105. [Google Scholar]
- Topouzelis, K.; Makri, D.; Stoupas, N.; Papakonstantinou, A.; Katsanevakis, S. Seagrass mapping in Greek territorial waters using Landsat-8 satellite images. Int. J. Appl. Earth Obs. Geoinf. 2018, 67, 98–113. [Google Scholar] [CrossRef]
- Ha, N.T.; Manley-Harris, M.; Pham, T.D.; Hawes, I. A Comparative Assessment of Ensemble-Based Machine Learning and Maximum Likelihood Methods for Mapping Seagrass Using Sentinel-2 Imagery in Tauranga Harbor, New Zealand. Remote. Sens. 2020, 12, 355. [Google Scholar] [CrossRef]
- Traganos, D.; Reinartz, P. Mapping Mediterranean seagrasses with Sentinel-2 imagery. Mar. Pollut. Bull. 2018, 134, 197–209. [Google Scholar] [CrossRef] [PubMed]
- Pasqualini, V.; Pergent-Martini, C.; Pergent, G.; Agreil, M.; Skoufas, G.; Sourbes, L.; Tsirika, A. Use of SPOT 5 for mapping seagrasses: An application to Posidonia oceanica. Remote. Sens. Environ. 2005, 94, 39–45. [Google Scholar] [CrossRef]
- Baumstark, R.; Duffey, R.; Pu, R. Mapping seagrass and colonized hard bottom in Springs Coast, Florida using WorldView-2 satellite imagery. Estuar. Coast. Shelf Sci. 2016, 181, 83–92. [Google Scholar] [CrossRef]
- Su, L.; Huang, Y. Seagrass Resource Assessment Using WorldView-2 Imagery in the Redfish Bay, Texas. J. Mar. Sci. Eng. 2019, 7, 98. [Google Scholar] [CrossRef]
- Ryan, R.E.; Pagnutti, M. Enhanced absolute and relative radiometric calibration for digital aerial cameras. In Photogrammetric Week’09; Fritch, D., Ed.; Wichtmann Verlag: Heidelberg, Germany, 2009; pp. 81–90. [Google Scholar]
- Fan, Y.; Li, W.; Chen, N.; Ahn, J.-H.; Park, Y.-J.; Kratzer, S.; Schroeder, T.; Ishizaka, J.; Chang, R.; Stamnes, K. OC-SMART: A machine learning based data analysis platform for satellite ocean color sensors. Remote. Sens. Environ. 2021, 253, 112236. [Google Scholar] [CrossRef]
- Vanhellemont, Q.; Ruddick, K. Atmospheric correction of metre-scale optical satellite data for inland and coastal water applications. Remote. Sens. Environ. 2018, 216, 586–597. [Google Scholar] [CrossRef]
- Kay, S.; Hedley, J.D.; Lavender, S. Sun Glint Correction of High and Low Spatial Resolution Images of Aquatic Scenes: A Review of Methods for Visible and Near-Infrared Wavelengths. Remote. Sens. 2009, 1, 697–730. [Google Scholar] [CrossRef]
- Hedley, J.D.; Harborne, A.R.; Mumby, P.J. Technical note: Simple and robust removal of sun glint for mapping shallow-water benthos. Int. J. Remote Sens. 2005, 26, 2107–2112. [Google Scholar] [CrossRef]
- Traganos, D.; Aggarwal, B.; Poursanidis, D.; Topouzelis, K.; Chrysoulakis, N.; Reinartz, P. Towards Global-Scale Seagrass Mapping and Monitoring Using Sentinel-2 on Google Earth Engine: The Case Study of the Aegean and Ionian Seas. Remote. Sens. 2018, 10, 1227. [Google Scholar] [CrossRef]
- Mederos-Barrera, A.; Marcello, J.; Eugenio, F.; Hernández, E. Seagrass mapping using high resolution multispectral satellite imagery: A comparison of water column correction models. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 102990. [Google Scholar] [CrossRef]
- Chandra, M.A.; Bedi, S.S. Survey on SVM and their application in image classification. Int. J. Inf. Technol. 2021, 13, 1–11. [Google Scholar] [CrossRef]
- Kim, J.B.; Park, J.-I.; Jung, C.-S.; Lee, P.-Y.; Lee, K.-S. Distributional range extension of the seagrass Halophila nipponica into coastal waters off the Korean peninsula. Aquat. Bot. 2009, 90, 269–272. [Google Scholar] [CrossRef]
- Lee, K.S.; Kim, S.H.; Kim, Y.K. Current Status of Seagrass Habitat in Korea. In The Wetland Book; Springer: Dordrecht, The Netherlands, 2018; pp. 1589–1596. [Google Scholar]
- Short, F.; Carruthers, T.; Dennison, W.; Waycott, M. Global seagrass distribution and diversity: A bioregional model. J. Exp. Mar. Biol. Ecol. 2007, 350, 3–20. [Google Scholar] [CrossRef]
- Hyun, J.-H.; Choi, K.-S.; Lee, K.-S.; Lee, S.H.; Kim, Y.K.; Kang, C.-K. Climate Change and Anthropogenic Impact Around the Korean Coastal Ecosystems: Korean Long-term Marine Ecological Research (K-LTMER). Estuaries Coasts 2020, 43, 441–448. [Google Scholar] [CrossRef]
- Kim, M.; Qin, L.-Z.; Kim, S.H.; Song, H.-J.; Kim, Y.K.; Lee, K.-S. Influence of Water Temperature Anomalies on the Growth of Zostera marina Plants Held Under High and Low Irradiance Levels. Estuaries Coasts 2020, 43, 463–476. [Google Scholar] [CrossRef]
- Qin, L.-Z.; Kim, S.H.; Song, H.-J.; Suonan, Z.; Kim, H.; Kwon, O.; Lee, K.-S. Influence of Regional Water Temperature Variability on the Flowering Phenology and Sexual Reproduction of the Seagrass Zostera marina in Korean Coastal Waters. Estuaries Coasts 2020, 43, 449–462. [Google Scholar] [CrossRef]
- Kim, J.-H.; Park, S.H.; Kim, Y.K.; Kim, S.H.; Park, J.-I.; Lee, K.-S. Seasonal growth dynamics of the seagrass Zostera caulescens on the eastern coast of Korea. Ocean Sci. J. 2014, 49, 391–402. [Google Scholar] [CrossRef]
- Vanhellemont, Q.; Ruddick, K. Atmospheric correction of Sentinel-3/OLCI data for mapping of suspended particulate matter and chlorophyll-a concentration in Belgian turbid coastal waters. Remote Sens. Environ. 2021, 256, 112284. [Google Scholar] [CrossRef]
- Vanhellemont, Q. Adaptation of the dark spectrum fitting atmospheric correction for aquatic applications of the Landsat and Sentinel-2 archives. Remote. Sens. Environ. 2019, 225, 175–192. [Google Scholar] [CrossRef]
- Vanhellemont, Q. Daily metre-scale mapping of water turbidity using CubeSat imagery. Opt. Express 2019, 27, A1372–A1399. [Google Scholar] [CrossRef]
- Vanhellemont, Q. Sensitivity analysis of the dark spectrum fitting atmospheric correction for metre- and decametre-scale satellite imagery using autonomous hyperspectral radiometry. Opt. Express 2020, 28, 29948–29965. [Google Scholar] [CrossRef] [PubMed]
- Kutser, T.; Hedley, J.; Giardino, C.; Roelfsema, C.; Brando, V.E. Remote sensing of shallow waters—A 50 year retrospective and future directions. Remote. Sens. Environ. 2020, 240, 111619. [Google Scholar] [CrossRef]
- Lyzenga, D.R. Passive remote sensing techniques for mapping water depth and bottom features. Appl. Opt. 1978, 17, 379–383. [Google Scholar] [CrossRef] [PubMed]
- Siregar, V.P.; Agus, S.B.; Subarno, T.; Prabowo, N.W. Mapping shallow waters habitats using OBIA by applying several approaches of depth invariant index in North Kepulauan Seribu. IOP Conf. Ser. Earth Environ. Sci. 2018, 149, 012052. [Google Scholar] [CrossRef]
- Aljahdali, M.H.; Elhag, M. Calibration of the depth invariant algorithm to monitor the tidal action of Rabigh City at the Red Sea Coast, Saudi Arabia. Open Geosciences. 2020, 12, 1666–16678. [Google Scholar] [CrossRef]
- Inamdar, D.; Rowan, G.S.; Kalacska, M.; Arroyo-Mora, J.P. Water column compensation workflow for hyperspectral imaging data. MethodsX 2022, 9, 101601. [Google Scholar] [CrossRef]
- Manuputty, A.; Gaol, J.L.; Agus, S.B.; Nurjaya, I.W. The utilization of Depth Invariant Index and Principle Component Analysis for mapping seagrass ecosystem of Kotok Island and Karang Bongkok, Indonesia. IOP Conf. Ser. Earth Environ. Sci. 2017, 54, 12083. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Colkesen, I. A kernel functions analysis for support vector machines for land cover classification. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 352–359. [Google Scholar] [CrossRef]
- Lenz, B.; Barak, B. Data Mining and Support Vector Regression Machine Learning in Semiconductor Manufacturing to Improve Virtual Metrology. In Proceedings of the 2013 46th Hawaii International Conference on System Sciences, IEEE, Wailea, HI, USA, 7–10 January 2013; pp. 3447–3456. [Google Scholar]
- Baek, W.-K.; Jung, H.-S. Performance Comparison of Oil Spill and Ship Classification from X-Band Dual- and Single-Polarized SAR Image Using Support Vector Machine, Random Forest, and Deep Neural Network. Remote. Sens. 2021, 13, 3203. [Google Scholar] [CrossRef]
- Tzeng, Y.-C.; Fan, K.-T.; Chen, K.-S. An Adaptive Thresholding Multiple Classifiers System for Remote Sensing Image Classification. Photogramm. Eng. Remote. Sens. 2009, 75, 679–687. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Bakirman, T.; Gumusay, M.U. Assessment of Machine Learning Methods for Seagrass Classification in the Mediterranean. Balt. J. Mod. Comput. 2020, 8, 315–326. [Google Scholar] [CrossRef]
- Gallant, A.L. The Challenges of Remote Monitoring of Wetlands. Remote. Sens. 2015, 7, 10938–10950. [Google Scholar] [CrossRef]
- Zhang, C.; Selch, D.; Xie, Z.; Roberts, C.; Cooper, H.; Chen, G. Object-based benthic habitat mapping in the Florida Keys from hyperspectral imagery. Estuar. Coast. Shelf Sci. 2013, 134, 88–97. [Google Scholar] [CrossRef]
- Stumpf, R.P.; Holderied, K.; Sinclair, M. Determination of water depth with high-resolution satellite imagery over variable bottom types. Limnol. Oceanogr. 2003, 48 Pt 2, 547–556. [Google Scholar] [CrossRef]
- Park, J.-I.; Kim, J.-H.; Park, S.H. Growth dynamics of the deep-water Asian eelgrass, Zostera asiatica, in the eastern coastal waters of Korea. Ocean Sci. J. 2016, 51, 613–625. [Google Scholar] [CrossRef]
- Halasan, L.; Dy, D. Chlorophyll content of Thalassia hemprichii (Ehrenberg) Ascherson leaves in some coastal areas of Cebu Island, Central Philippines. Ann. Trop. Res. 2018, 40, 35–44. [Google Scholar] [CrossRef]
- Dawes, C.J. Marine Botany, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1998. [Google Scholar]
- Yoon, Y.H. Spatio-temporal Fluctuation of Phytoplankton Size Fractionation in the Uljin Marine Ranching Area (UMRA), East Sea of Korea. Korean J. Environ. Biol. 2016, 34, 151–160. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category of the Class | Description | Sources |
|---|---|---|
| Seagrass | Define the distribution of seagrass habitats. | The in-situ data was obtained from Korea Institute of Ocean Science and Technology (KIOST). |
| Breaking wave | Define the image that contains sea wave disturbance. | |
| Land | Include port, mixed barren land, natural grasses, field, and other grasses. | Korea Institute of Geoscience and Mineral Resource (KIGAM). |
| Others | Define the water in the coastal area/ocean water. |
| Parameter | Parameter |
|---|---|
| Kernel type | Gaussian basis function |
| C values | 5792.61 |
| Gamma values | 32 |
| GeoEye-1 | Sentinel-2 | Landsat-8 OLI | |
|---|---|---|---|
| Before correction | 5.5 | 4 | 9.5 |
| After atmospheric correction | 0.000976 | 0.000603 | 0.000534 |
| After sunglint correction | 0.000276 | 0.000604 | 0.000548 |
| After Lyzenga correction | 0.189 | 0.024 | 0.015 |
| Class Name | Others | Land | Seagrass | Breaking Wave | Sum | User’s Accuracy |
|---|---|---|---|---|---|---|
| Others | 377 | 0 | 24 | 0 | 401 | 0.94 |
| Land | 2 | 388 | 0 | 9 | 401 | 0.96 |
| Seagrass | 69 | 0 | 332 | 0 | 401 | 0.82 |
| Breaking wave | 15 | 6 | 0 | 380 | 401 | 0.94 |
| Producer’s Accuracy | 0.80 | 0.98 | 0.93 | 0.97 | ||
| Overall Accuracy | 92% | |||||
| Kappa Accuracy | 0.89 | |||||
| Class Name | Others | Land | Seagrass | Breaking Wave | Sum | User’s Accuracy |
|---|---|---|---|---|---|---|
| Others | 358 | 0 | 26 | 17 | 401 | 0.89 |
| Land | 5 | 383 | 0 | 13 | 401 | 0.95 |
| Seagrass | 110 | 0 | 291 | 0 | 401 | 0.72 |
| Breaking wave | 3 | 4 | 0 | 394 | 401 | 0.98 |
| Producer’s Accuracy | 0.75 | 0.98 | 0.91 | 0.92 | ||
| Overall Accuracy | 88% | |||||
| Kappa Accuracy | 0.85 | |||||
| Class Name | Others | Land | Seagrass | Breaking Wave | Sum | User’s Accuracy |
|---|---|---|---|---|---|---|
| Others | 351 | 0 | 43 | 7 | 401 | 0.87 |
| Land | 14 | 368 | 0 | 19 | 401 | 0.91 |
| Seagrass | 93 | 0 | 307 | 1 | 401 | 0.76 |
| Breaking wave | 51 | 40 | 0 | 310 | 401 | 0.77 |
| Producer’s Accuracy | 0.64 | 0.90 | 0.87 | 0.91 | ||
| Overall Accuracy | 83% | |||||
| Kappa Accuracy | 0.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Widya, L.K.; Kim, C.-H.; Do, J.-D.; Park, S.-J.; Kim, B.-C.; Lee, C.-W. Comparison of Satellite Imagery for Identifying Seagrass Distribution Using a Machine Learning Algorithm on the Eastern Coast of South Korea. J. Mar. Sci. Eng. 2023, 11, 701. https://doi.org/10.3390/jmse11040701
Widya LK, Kim C-H, Do J-D, Park S-J, Kim B-C, Lee C-W. Comparison of Satellite Imagery for Identifying Seagrass Distribution Using a Machine Learning Algorithm on the Eastern Coast of South Korea. Journal of Marine Science and Engineering. 2023; 11(4):701. https://doi.org/10.3390/jmse11040701
Chicago/Turabian StyleWidya, Liadira Kusuma, Chang-Hwan Kim, Jong-Dae Do, Sung-Jae Park, Bong-Chan Kim, and Chang-Wook Lee. 2023. "Comparison of Satellite Imagery for Identifying Seagrass Distribution Using a Machine Learning Algorithm on the Eastern Coast of South Korea" Journal of Marine Science and Engineering 11, no. 4: 701. https://doi.org/10.3390/jmse11040701
APA StyleWidya, L. K., Kim, C.-H., Do, J.-D., Park, S.-J., Kim, B.-C., & Lee, C.-W. (2023). Comparison of Satellite Imagery for Identifying Seagrass Distribution Using a Machine Learning Algorithm on the Eastern Coast of South Korea. Journal of Marine Science and Engineering, 11(4), 701. https://doi.org/10.3390/jmse11040701