
A Semi-Supervised Machine Learning Model to Forecast Movements of Moored Vessels

 , ,
, ,  ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Machine Learning Inference Methodologies for Prediction of Moored Ships’ Motions
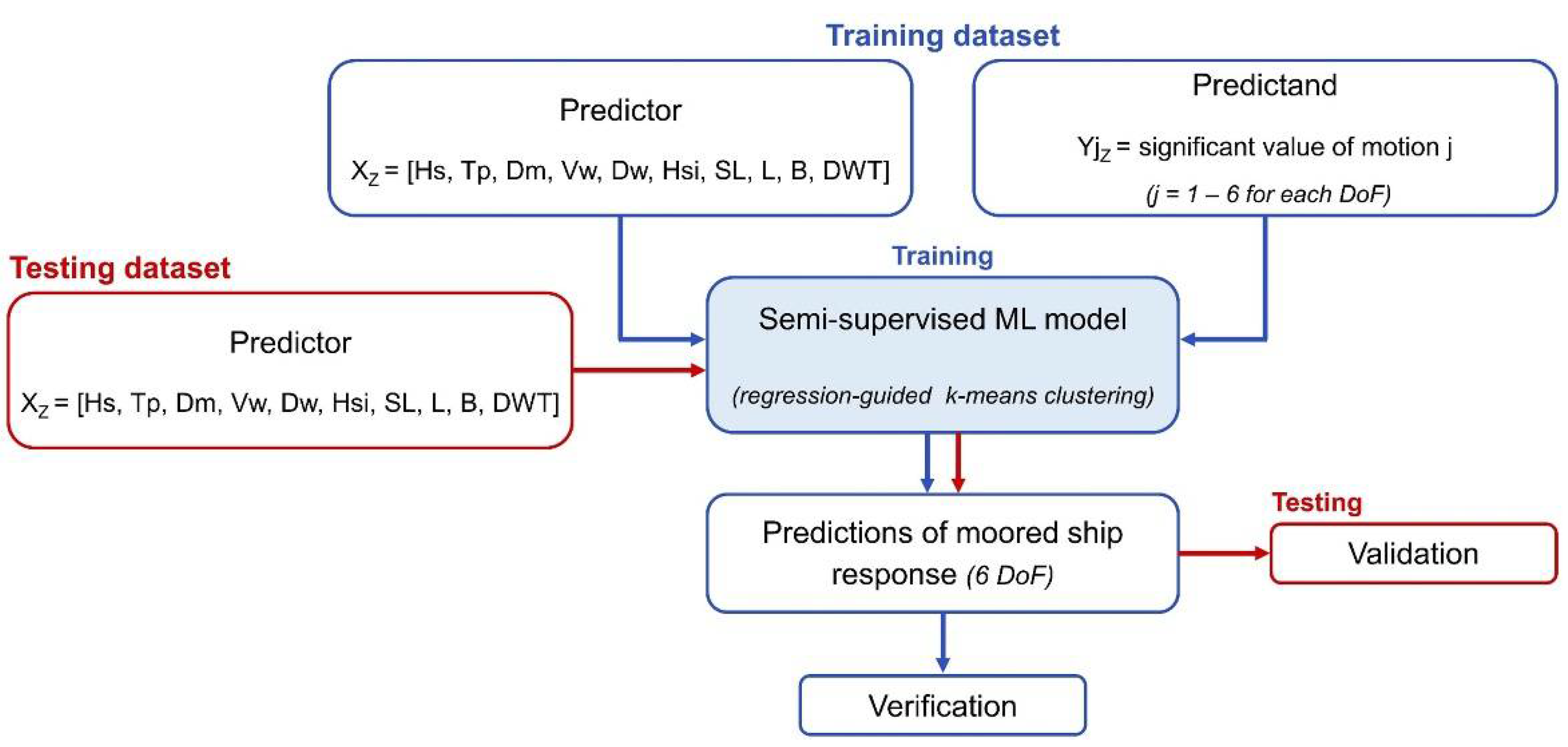
2.2.1. Semi-Supervised Learning-Based Model
- Definition of predictor (X) and predictand (Y) matrices.
- Standardization of X and Y variables in order to equalize the contribution of the different variables.
- Multiple linear regression fitting, establishing the linear dependency function between the response variables (predictand, Y) and the input variables (predictor, X). The linear relationship is defined by the expression:where X and Y are the predictor and predictand matrices, respectively; B is the matrix of fitting coefficients from the multiple linear regression; and E is the matrix of residual error between estimations—obtained from regression—and real measured values. The estimations from the regression are obtained as Ŷ = X·B.Y = X·B + E
- Weighted concatenation of the X matrix and the Ŷ predictions through the following expression:where α is the weighting factor.Z = [(1 − α)·X, α·Ŷ]When α = 0, only the X predictor matrix is considered in the clustering procedure, resulting in a completely unsupervised learning-based method. Conversely, when α = 1, only the Ŷ predictions matrix is considered in the classification procedure, resulting in a completely supervised learning-based method. When 0 < α < 1, an intermediate semi-supervised learning-based model is defined.
- K-means algorithm-based clustering of Z. By means of an iterative procedure, each subset of data is grouped to the nearest cluster centroid in terms of Euclidean distance. The positions of the cluster centroids V are calculated as the mean value of all the subsets of data contained in each cluster “k”. Thus, the positions of cluster centroids are updated at each iterative step.where Nk is the number of elements in the k-th cluster.Instead of random initialization, the initial position of cluster centroids is established by a previous application of the Max-Diss algorithm to the Z dataset. In this way, an initial set of centroids distributed throughout the n-dimensional space of the Z matrix is defined to start the iterative clustering procedure.Once the clustering is completed, the prediction model is defined by the mean (μ) and standard deviation (σ) of predictand values in each cluster.
- Prediction of output variables. The predictions of response variables are assigned as the value of the nearest centroid (i.e., k-nearest algorithm) through a Euclidean distance evaluation.
2.2.2. Supervised Learning-Based Model
2.2.3. Unsupervised Learning-Based Model
2.3. Application and Performance Assessment
2.3.1. Initial Version of the Model
2.3.2. Extended Version with IW Predictor Variables
3. Results and Discussion
3.1. Initial Version of the Model
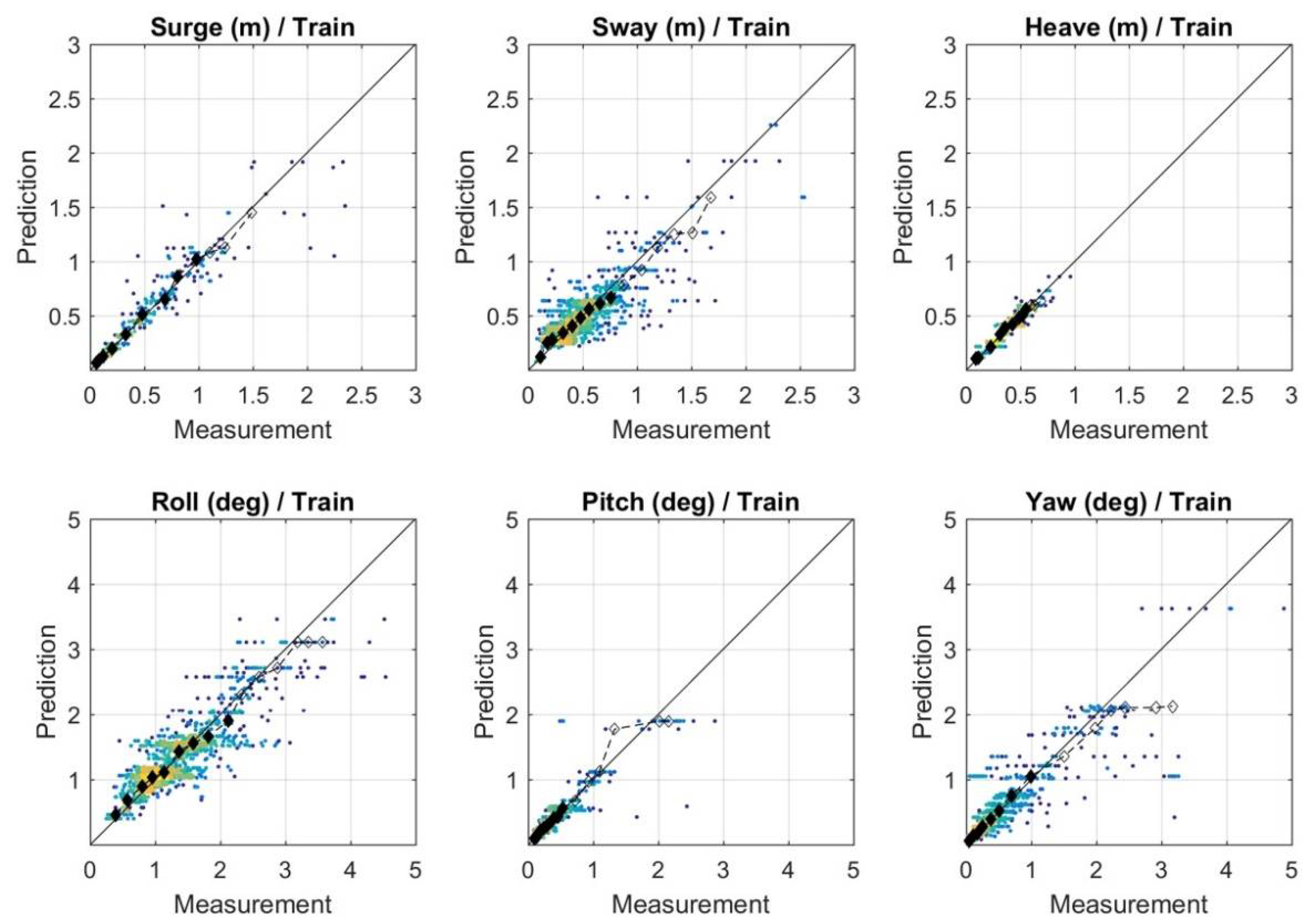
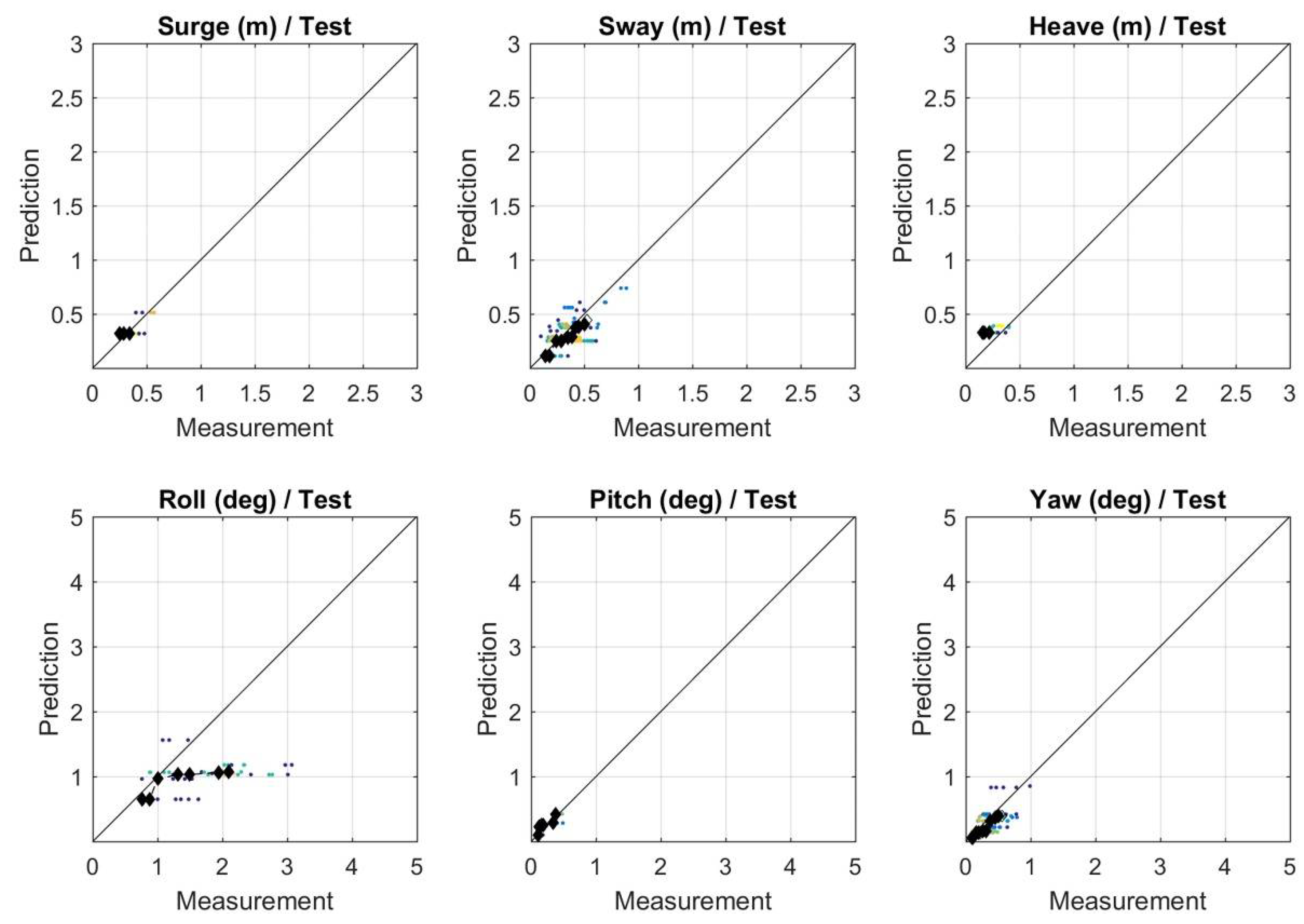
3.1.1. Performance Assessment
3.1.2. Comparative Analysis of Different AI Techniques for Prediction of Moored Ships’ Motions
3.2. Extended Version with IW Predictor Variables
3.2.1. Performance Assessment
3.2.2. Comparative Analysis with the Initial Version of the Model for Prediction of Moored Ships’ Motions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Puertos del Estado; Ministerio de Fomento. Recommendations for Maritime Works—Series 3—Planning, Management and Operation in Port Areas: ROM 3.1-99—Design of the Maritime Configuration of Ports, Approach Channels and Harbour Basins; Puertos del Estado: Madrid, Spain, 1999.
- Puertos del Estado; Ministerio de Fomento. Recommendations for Maritime Works—Series 2—Inner Harbor Structures: ROM 2.0-11—Recommendations for the Design and Construction of Berthing and Mooring Structures; Puertos del Estado: Madrid, Spain, 2012.
- Working Group PTC II-24. Criteria for Movements of Moored Ships in Harbours: A Practical Guide; Supplement to Bulletin No 88; PIANC General Secretariat: Brussels, Belgium, 1995; Volume 88. [Google Scholar]
- MarCom Working Group. Criteria for the (Un)loading of Container Vessels; PIANC Report 115; PIANC General Secretariat: Brussels, Belgium, 2012. [Google Scholar]
- Bruun, P. Breakwaters versus Mooring. Dock Harb. Auth. 1981, XLII, 730. [Google Scholar]
- Thoresen, C.A. Port Designer’s Handbook: Recommendations and Guidelines; Thomas Telford Publishing: London, UK, 2003. [Google Scholar]
- D’Hondt, E. Port and terminal construction design rules and practical experience. In Proceedings of the 12th International Harbour Congress, Antwerp, Belgium, 22–27 September 1999. [Google Scholar]
- Ueda, S.; Shiraishi, S. The Allowable Ship Motions for Cargo Handling at Wharves; Port and Harbour Research Institute—PHRI: Yokosuka City, Japan, 1988; Volume 27, pp. 3–61.
- Gaythwaite, J.W. Mooring of Ships to Piers and Wharves; ASCE Manuals and Reports on Engineering Practice; American Society of Civil Engineers: Reston, VA, USA, 2014. [Google Scholar] [CrossRef]
- Danish Hydraulic Institute (DHI). MIKE 21 Maritime—MIKE 21 Mooring Analysis—User Guide 2022; Danish Hydraulic Institute (DHI): Hørsholm, Denmark, 2022. [Google Scholar]
- Mynett, A.E.; Keuning, P.J.; Vis, F.C. The Dynamic Behaviour of Moored Vessels Inside a Habour Configuration; Delft Hydraulics Laboratory: Birmingham, UK, 1985. [Google Scholar]
- Maritime Research Institute Netherlands (MARIN). aNyMOOR.TERMSIM; Maritime Research Institute Netherlands (MARIN): Wageningen, The Netherlands; Available online: https://www.marin.nl/en/facilities-and-tools/software/ (accessed on 12 July 2022).
- Tension Technology International. OPTIMOOR. Mooring Analysis Software for Ships & Barges; Technical Notes 01; Tension Technology International: Schoonhoven, The Netherlands, April 2016. [Google Scholar]
- Arcadis. SHIP-MOORINGS, Version 10; Arcadis: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Pinheiro, L.V.; Fortes, C.J.E.M.; Santos, J.A.; Fernandes, J.L.M. Numerical simulation of the behaviour of a moored ship inside an open coast harbour. In Proceedings of the 5th International Conference on Computational Methods in Marine Engineering, MARINE 2013, Hamburg, Germany, 29–31 May 2013. [Google Scholar]
- Pinheiro, L.V.; Santos, J.A.; Fortes, C.J.; Fernandes, J.L. Numerical Software Package SWAMS—Simulation of Wave Action on Moored Ships; DuraSpace: Atlanta, GA, USA, 2013. [Google Scholar]
- Pinheiro, L.V.; Fortes, C.; Santos, J.; Fernandes, J.L. Coupling of a Boussinesq Wave Model with a Moored Ship Behavior Model. Coast. Eng. Proc. 2012, 1, 69. [Google Scholar] [CrossRef]
- Bhautoo, P.S. Dynamic mooring analysis to investigate long period wave-induced vessel motions at Esperance Port. In Proceedings of the Australasian Coasts and Ports 2017 Conference, Cairns, Australia, 21–23 June 2017. [Google Scholar]
- Bingham, H.B. A hybrid Boussinesq-panel method for predicting the motion of a moored ship. Coast. Eng. 2000, 40, 21–38. [Google Scholar] [CrossRef]
- Christensen, E.D.; Jensen, B.; Mortensen, S.B.; Hansen, H.F.; Kirkegaard, J. Numerical simulation of ship motion in offshore and harbour areas. In Proceedings of the International Conference on Offshore Mechanics and Arctic Engineering—OMAE, Estoril, Portugal, 15–20 June 2008; Volume 6. [Google Scholar]
- Drimer, N.; Glozman, M.; Stiassnie, M.; Zilman, G. Forecasting the motion of berthed ships in harbors. In Proceedings of the 15th International Workshop on Water Waves and Floating Bodies, Dan Caesarea, Israel, 27 February–1 March 2000. [Google Scholar]
- Kwak, M.; Moon, Y.; Pyun, C. Computer simulation of moored ship motion induced by harbor resonance in Pohang New Harbor. Coast. Eng. Proc. 2012, 1, 68. [Google Scholar] [CrossRef]
- Terblanche, L.; Van Der Molen, W. Numerical Modelling of long waves and moored ship motions. In Proceedings of the Coasts and Ports 2013, Sydney, Australia, 11–13 September 2013. [Google Scholar]
- Wenneker, I.; Borsboom, M.; Pinkster, J.; Weiler, O. A Boussinesq-Type Wave Model Coupled to a Diffraction Model to Simulate Wave-Induced Ship Motion. In Proceedings of the 31st PIANC International Navigation Congress, Estoril, Portugal, 14–18 May 2006. [Google Scholar]
- Cornett, A.; Wijdeven, B.; Boeijinga, J.; Ostrovsky, O. 3-D Physical Model Studies of Wave Agitation and Moored Ship Motions at Ashdod Port. In Proceedings of the 8th International Conference on Coastal and Port Engineering in Developing Countries—COPEDED, Chennai, India, 20–24 February 2012. [Google Scholar]
- Yan, L. Experimental study of the wharf structure influence on ship mooring conditions. In Proceedings of the 5th International Conference on Intelligent Systems Design and Engineering Applications—ISDEA 2014, Hunan, China, 15–16 June 2014. [Google Scholar]
- Rosa-Santos, P.J.; Taveira-Pinto, F. Experimental study of solutions to reduce downtime problems in ocean facing ports: The Port of Leixões, Portugal, case study. J. Appl. Water Eng. Res. 2013, 1, 80–90. [Google Scholar] [CrossRef]
- Rosa-Santos, P.; Taveira-Pinto, F.; Veloso-Gomes, F. Experimental evaluation of the tension mooring effect on the response of moored ships. Coast. Eng. 2014, 85, 60–71. [Google Scholar] [CrossRef]
- Shi, X. A Comparative Study on the Motions of a Mooring LNG Ship in Bimodal Spectral Waves and Wind Waves. IOP Conf. Ser. Earth Environ. Sci. 2018, 189, 052047. [Google Scholar] [CrossRef]
- Van Der Molen, W.; Rossouw, M.; Phelp, D.; Tulsi, K.; Terblanche, L. Innovative technologies to accurately model waves and moored ship motions. In Proceedings of the CSIR Third Biennial Conference, Pertoria, South Africa, 30 August–1 September 2010. [Google Scholar]
- Weiler, O.; Cozijn, H.; Wijdeven, B.; Le-Guennec, S.; Fontaliran, F. Motions and mooring loads of an LNG-carrier moored at a jetty in a complex bathymetry. In Proceedings of the ASME 2009 28th International Conference on Ocean, Offshore and Arctic Engineering, Honolulu, HI, USA, 31 May–5 June 2009; Volume 1. [Google Scholar]
- Sande, J.; Figuero, A.; Tarrío-Saavedra, J.; Peña, E.; Alvarellos, A.; Rabuñal, J.R. Application of an analytic methodology to estimate the movements of moored vessels based on forecast data. Water 2019, 11, 1841. [Google Scholar] [CrossRef]
- Alvarellos, A.; Figuero, A.; Carro, H.; Costas, R.; Sande, J.; Guerra, A.; Peña, E.; Rabuñal, J. Machine learning based moored ship movement prediction. J. Mar. Sci. Eng. 2021, 9, 800. [Google Scholar] [CrossRef]
- López, M.; Iglesias, G. Long wave effects on a vessel at berth. Appl. Ocean Res. 2014, 47, 63–72. [Google Scholar] [CrossRef]
- Sakakibara, S.; Kubo, M. Characteristics of low-frequency motions of ships moored inside ports and harbors on the basis of field observations. Mar. Struct. 2008, 21, 196–223. [Google Scholar] [CrossRef]
- Li, S.; Qiu, Z. Prediction and simulation of mooring ship motion based on intelligent algorithm. In Proceedings of the 28th Chinese Control and Decision Conference, CCDC 2016, Yinchuan, China, 28–30 May 2016. [Google Scholar]
- De Bont, J.; van der Molen, W.; van der Lem, J.; Ligteringen, H.; Mühlestein, D.; Howie, M. Calculations of the Motions of a Ship Moored with MoormasterTM Units. In Proceedings of the 32nd PIANC Congress, Liverpool, UK, 10–14 May 2010. [Google Scholar]
- Londhe, S.N.; Deo, M.C. Wave tranquility studies using neural networks. Mar. Struct. 2003, 16, 419–436. [Google Scholar] [CrossRef]
- Kankal, M.; Yüksek, Ö. Artificial neural network approach for assessing harbor tranquility: The case of Trabzon Yacht Harbor, Turkey. Appl. Ocean Res. 2012, 38, 23–31. [Google Scholar] [CrossRef]
- López, I.; López, M.; Iglesias, G. Artificial neural networks applied to port operability assessment. Ocean Eng. 2015, 109, 298–308. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, X.; Ma, Y.; Dong, G. Wave estimation within a port using a fully nonlinear Boussinesq wave model and artificial neural networks. Ocean Eng. 2020, 216, 108073. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, X.; Touwang, Z.; Ma, Y.; Dong, G. Wave forecasting within a port using WAVEWATCH III and artificial neural networks. Ocean Eng. 2022, 255, 111475. [Google Scholar] [CrossRef]
- Camus, P.; Mendez, F.J.; Medina, R.; Cofiño, A.S. Analysis of clustering and selection algorithms for the study of multivariate wave climate. Coast. Eng. 2011, 58, 453–462. [Google Scholar] [CrossRef]
- Espejo, A.; Camus, P.; Losada, I.J.; Méndez, F.J. Spectral ocean wave climate variability based on atmospheric circulation patterns. J. Phys. Oceanogr. 2014, 44, 2139–2152. [Google Scholar] [CrossRef]
- Izaguirre, C.; Menéndez, M.; Camus, P.; Méndez, F.J.; Mínguez, R.; Losada, I.J. Exploring the interannual variability of extreme wave climate in the Northeast Atlantic Ocean. Ocean Model. 2012, 59, 31–40. [Google Scholar] [CrossRef]
- Camus, P.; Mendez, F.J.; Medina, R.; Tomas, A.; Izaguirre, C. High resolution downscaled ocean waves (DOW) reanalysis in coastal areas. Coast. Eng. 2013, 72, 56–68. [Google Scholar] [CrossRef]
- Camus, P.; Mendez, F.J.; Medina, R. A hybrid efficient method to downscale wave climate to coastal areas. Coast. Eng. 2011, 58, 851–862. [Google Scholar] [CrossRef]
- Camus, P.; Tomás, A.; Díaz-Hernández, G.; Rodríguez, B.; Izaguirre, C.; Losada, I.J. Probabilistic assessment of port operation downtimes under climate change. Coast. Eng. 2019, 147, 12–24. [Google Scholar] [CrossRef]
- Campos, Á.; García-Valdecasas, J.M.; Molina, R.; Castillo, C.; álvarez-Fanjul, E.; Staneva, J. Addressing long-term operational risk management in port docks under climate change scenarios-A Spanish case study. Water 2019, 11, 2153. [Google Scholar] [CrossRef]
- Diaz-Hernandez, G.; Mendez, F.J.; Losada, I.J.; Camus, P.; Medina, R. A nearshore long-term infragravity wave analysis for open harbours. Coast. Eng. 2015, 97, 78–90. [Google Scholar] [CrossRef]
- Diaz-Hernandez, G.; Lara, J.L.; Losada, I.J. Extended long wave hindcast inside port solutions to minimize resonance. J. Mar. Sci. Eng. 2016, 4, 9. [Google Scholar] [CrossRef]
- Morim, J.; Hemer, M.; Wang, X.L.; Cartwright, N.; Trenham, C.; Semedo, A.; Young, I.; Bricheno, L.; Camus, P.; Casas-Prat, M.; et al. Robustness and uncertainties in global multivariate wind-wave climate projections. Nat. Clim. Change 2019, 9, 711–718. [Google Scholar] [CrossRef]
- Cannon, A.J. Regression-guided clustering: A semisupervised method for circulation-to-environment synoptic classification. J. Appl. Meteorol. Climatol. 2012, 51, 185–190. [Google Scholar] [CrossRef]
- Camus, P.; Rueda, A.; Méndez, F.J.; Losada, I.J. An atmospheric-to-marine synoptic classification for statistical downscaling marine climate. Ocean Dyn. 2016, 66, 1589–1601. [Google Scholar] [CrossRef]
- Yin, J.C.; Zou, Z.J.; Xu, F. On-line prediction of ship roll motion during maneuvering using sequential learning RBF neuralnetworks. Ocean Eng. 2013, 61, 139–147. [Google Scholar] [CrossRef]
- Wang, H.; Wu, F.; Lei, D. Prediction of Ship Heave Motion Using Regularized BP Neural Network with Cross Entropy Error Function. Int. J. Comput. Intell. Syst. 2021, 14, 192. [Google Scholar] [CrossRef]
- Wu, J.; Peng, H.; Ohtsu, K.; Kitagawa, G.; Itoh, T. Ship’s tracking control based on nonlinear time series model. Appl. Ocean Res. 2012, 36, 1–11. [Google Scholar] [CrossRef]
- Gómez, R.; Camarero, A.; Molina, R. Development of a Vessel-Performance Forecasting System: Methodological Framework and Case Study. J. Waterw. Port Coast. Ocean Eng. 2016, 142, 04015016. [Google Scholar] [CrossRef]
- Alvarellos, A.; Figuero, A.; Carro, H.; Costas, R.; Sande, J.; Guerra, A.; Peña, E.; Rabuñal, J. Aal-varell/Ship-Movement-Dataset: Outer Port of Punta Langosteira Ship Movement Dataset; CERN: Geneve, Switzerland, 2021. [Google Scholar] [CrossRef]
- Puertos del Estado; Ministerio de Fomento. Conjunto De Datos: REDCOS; Puertos del Estado: Madrid, Spain, 2015.
- Puertos del Estado; Ministerio de Fomento. Conjunto De Datos: REDMAR; Puertos del Estado: Madrid, Spain, 2020.
- García-Valdecasas, J.; Pérez Gómez, B.; Molina, R.; Rodríguez, A.; Rodríguez, D.; Pérez, S.; Campos, Á.; Rodríguez Rubio, P.; Gracia, S.; Ripollés, L.; et al. Operational tool for characterizing high-frequency sea level oscillations. Nat. Hazards 2021, 106, 1149–1167. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Motion | Training Data | Testing Data |
|---|---|---|
| Surge | 364 (95.8%) | 16 (4.2%) |
| Sway | 1451 (90.2%) | 158 (9.8%) |
| Heave | 364 (95.3%) | 18 (4.7%) |
| Roll | 1348 (96.4%) | 51 (3.6%) |
| Pitch | 1348 (96.4%) | 51 (3.6%) |
| Yaw | 1248 (88.8%) | 158 (11.2%) |
| Type of Motion | Training Data | Testing Data |
|---|---|---|
| Surge | 131 (90.3%) | 14 (9.7%) |
| Sway | 708 (85.7%) | 118 (14.3%) |
| Heave | 131 (89.1%) | 16 (10.9%) |
| Roll | 787 (94.4%) | 47 (5.6%) |
| Pitch | 787 (94.4%) | 47 (5.6%) |
| Yaw | 683 (85.3%) | 118 (14.7%) |
| Type of Motion | Number of Clusters | α Factor | CV | EV | ||||
|---|---|---|---|---|---|---|---|---|
| Optimum | Range | Optimum | Range | Optimum | Range | Optimum | Range | |
| Surge | 49 | 49 | 0.6 | [0.6, 0.7] | 0.20 | [0.20, 0.21] | 0.97 | 0.97 |
| Sway | 36 | [25, 36] | 0.3 | [0.2, 0.3] | 0.31 | [0.31, 0.33] | 0.84 | [0.80, 0.84] |
| Heave | 25 | 25 | 0.6 | [0.5, 0.7] | 0.11 | [0.11, 0.12] | 0.91 | [0.91, 0.92] |
| Roll | 36 | [25, 36] | 0.1 | [0.1, 0.4] | 0.24 | [0.24, 0.25] | 0.86 | [0.82, 0.86] |
| Pitch | 25 | 25 | 0.2 | [0.1, 0.4] | 0.22 | [0.22, 0.23] | 0.82 | 0.82 |
| Yaw | 25 | [25, 36] | 0.3 | [0.2, 0.4] | 0.47 | [0.36, 0.49] | 0.82 | [0.82, 0.86] |
| Training | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Surge | Sway | Heave | Roll | Pitch | Yaw | ||||||||
| R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (°) | R2 | RMSE (°) | R2 | RMSE (°) | ||
| Supervised ML | Multiple linear regression 1 | 0.82 | 0.20 | 0.72 | 0.19 | 0.90 | 0.05 | 0.73 | 0.39 | 0.70 | 0.21 | 0.79 | 0.31 |
| Gradient Boosting 2 | 0.86 | 0.11 | 0.92 | 0.04 | 0.92 | 0.03 | 0.91 | 0.11 | 0.98 | 0.04 | 0.95 | 0.06 | |
| Unsupervised ML | K-means 1 | 0.89 | 0.15 | 0.75 | 0.17 | 0.94 | 0.04 | 0.78 | 0.34 | 0.84 | 0.14 | 0.78 | 0.32 |
| Semi-supervised ML | Regression-Guided K-means 1 | 0.88 | 0.15 | 0.77 | 0.16 | 0.90 | 0.05 | 0.80 | 0.32 | 0.85 | 0.13 | 0.81 | 0.30 |
| Deep Learning | Artificial Neural Networks 2 | 0.99 | 0.03 | 0.99 | 0.02 | 0.95 | 0.05 | 0.99 | 0.06 | 0.98 | 0.02 | 0.98 | 0.01 |
| Range | 2.3 m | 2.5 m | 0.9 m | 4.3° | 2.8° | 4.8° | |||||||
| Testing | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Surge | Sway | Heave | Roll | Pitch | Yaw | ||||||||
| R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (°) | R2 | RMSE (°) | R2 | RMSE (°) | ||
| Supervised ML | Multiple linear regression 1 | 0.51 | 0.23 | 0.50 | 0.15 | 0.55 | 0.08 | 0.47 | 1.06 | 0.35 | 0.19 | 0.17 | 0.37 |
| Gradient Boosting 2 | - | 0.39 | - | 0.11 | - | 0.09 | - | 1.04 | - | 0.24 | - | 0.28 | |
| Unsupervised ML | K-means 1 | 0.43 | 0.17 | 0.48 | 0.14 | 0.52 | 0.14 | 0.50 | 0.89 | 0.66 | 0.10 | 0.55 | 0.17 |
| Semi-supervised ML | Regression-Guided K-means 1 | 0.65 | 0.07 | 0.53 | 0.13 | 0.53 | 0.11 | 0.51 | 0.90 | 0.72 | 0.08 | 0.58 | 0.15 |
| Deep Learning | Artificial Neural Networks 2 | - | 0.10 | - | 0.15 | - | 0.12 | - | 0.90 | - | 0.11 | - | 0.15 |
| Type of Motion | Number of Clusters | α Factor | CV | EV |
|---|---|---|---|---|
| Optimum | Optimum | Optimum | Optimum | |
| Surge | 25 | 0.4 | 0.15 | 0.99 |
| Sway | 25 | 0.3 | 0.38 | 0.80 |
| Heave | 25 | 0.5 | 0.05 | 0.99 |
| Roll | 25 | 0.2 | 0.24 | 0.81 |
| Pitch | 49 | 0.4 | 0.16 | 0.89 |
| Yaw | 36 | 0.3 | 0.37 | 0.86 |
| Training | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Surge | Sway | Heave | Roll | Pitch | Yaw | ||||||||
| R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (⁰) | R2 | RMSE (⁰) | R2 | RMSE (⁰) | ||
| Semi-supervised ML | Regression-Guided K-means; initial | 0.88 | 0.15 | 0.77 | 0.16 | 0.90 | 0.05 | 0.80 | 0.32 | 0.85 | 0.13 | 0.81 | 0.30 |
| Regression-Guided K-means; without IW | 0.95 | 0.10 | 0.75 | 0.15 | 0.95 | 0.03 | 0.83 | 0.30 | 0.90 | 0.11 | 0.81 | 0.30 | |
| Regression-Guided K-means; with IW | 0.95 | 0.11 | 0.72 | 0.17 | 0.94 | 0.03 | 0.82 | 0.31 | 0.93 | 0.09 | 0.82 | 0.29 | |
| Testing | |||||||||||||
| Surge | Sway | Heave | Roll | Pitch | Yaw | ||||||||
| R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (m) | R2 | RMSE (m) | ||
| Semi-supervised ML | Regression-Guided K-means; initial | 0.65 | 0.07 | 0.53 | 0.13 | 0.53 | 0.11 | 0.51 | 0.90 | 0.72 | 0.08 | 0.58 | 0.15 |
| Regression-Guided K-means; without IW | 0.51 | 0.14 | 0.46 | 0.13 | 0.52 | 0.11 | 0.53 | 0.91 | 0.65 | 0.09 | 0.55 | 0.13 | |
| Regression-Guided K-means; with IW | 0.49 | 0.14 | 0.49 | 0.12 | 0.51 | 0.10 | 0.53 | 0.85 | 0.69 | 0.08 | 0.52 | 0.13 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romano-Moreno, E.; Tomás, A.; Diaz-Hernandez, G.; Lara, J.L.; Molina, R.; García-Valdecasas, J. A Semi-Supervised Machine Learning Model to Forecast Movements of Moored Vessels. J. Mar. Sci. Eng. 2022, 10, 1125. https://doi.org/10.3390/jmse10081125
Romano-Moreno E, Tomás A, Diaz-Hernandez G, Lara JL, Molina R, García-Valdecasas J. A Semi-Supervised Machine Learning Model to Forecast Movements of Moored Vessels. Journal of Marine Science and Engineering. 2022; 10(8):1125. https://doi.org/10.3390/jmse10081125
Chicago/Turabian StyleRomano-Moreno, Eva, Antonio Tomás, Gabriel Diaz-Hernandez, Javier L. Lara, Rafael Molina, and Javier García-Valdecasas. 2022. "A Semi-Supervised Machine Learning Model to Forecast Movements of Moored Vessels" Journal of Marine Science and Engineering 10, no. 8: 1125. https://doi.org/10.3390/jmse10081125
APA StyleRomano-Moreno, E., Tomás, A., Diaz-Hernandez, G., Lara, J. L., Molina, R., & García-Valdecasas, J. (2022). A Semi-Supervised Machine Learning Model to Forecast Movements of Moored Vessels. Journal of Marine Science and Engineering, 10(8), 1125. https://doi.org/10.3390/jmse10081125