1. Introduction
Autonomous driving technology has received a lot of attention in recent years, as processing power, communication, and sensor technologies have rapidly developed. Moving vehicles such as cars, ships, and drones should be able to recognize and respond to adjacent obstacles swiftly in order to drive themselves without human intervention. To improve autonomous driving capabilities, technologies such as cameras, radar, LIDAR (laser imaging, detection, and ranging), GPS (Global Positioning System), and SONAR (sound navigation and ranging) are used for autonomous vehicles. In addition to these, maritime autonomous surface ships use an automatic identification system (AIS) and GPS to detect neighboring ships and prevent collisions with other ships. Small vessels, such as buoys, small boats, and kayaks, on the other hand, do not have AIS transmitters. Furthermore, illicit fishing boats that fish at night without permission switch off the AIS, potentially resulting in ship accidents. It is necessary for technology to recognize objects using video from cameras in order to prevent marine mishaps such as unexpected ship collisions. After identifying surrounding ships, information such as the moving line, speed, and direction of other ships is needed to plan a course to avoid collisions. Because object recognition in video is performed frame by frame, it is impossible to detect a change in the position of a given object over time. For path navigation, the object tracking technology is also required to determine the moving line, speed, direction, etc.
Several studies on video-based object detection and tracking have been carried out [
1,
2,
3,
4,
5,
6,
7,
8,
9]. Deep-learning-based object recognition, such as R-CNN (regions with convolutional neural network features) and YOLO (You Only Look Once), identifies the position of an object and predicts its type in an image stream from a camera [
1,
10]. DeepSORT, a tracking algorithm, assesses if it is the same object. However, when a camera is mounted onboard a ship, the image composition cannot be kept stable due to the ship’s motion. Because the object continuously experiences frame out and frame in, it is difficult to recognize as the same object in the situation. Additionally, ships of several sizes overlap each other in the video by moving in different directions, so the overlapping objects vanish from the screen. When a hidden object reappears, it is usually recognized as a different object. Therefore, in this paper, we propose an object recognition and tracking algorithm for moving video. As datasets, we used the SMD (Singapore Maritime Dataset) and a few crawling images. During training, thousands of training data are utilized and the transfer learning technique is employed to avoid a scarcity of training data and an imbalance of labels. The recognition models based on YOLO are proposed for object recognition. We employ YOLO for recognition because it can detect objects quickly, and object tracking necessitates a fast recognition rate. Then, we present a tracking algorithm that utilizes IoU_matching and ORB_and_size_matching for object tracking in videos with high motion.
The remainder of this paper is organized as follows.
Section 2 presents the background and related works.
Section 3 discusses the dataset for object recognition and tracking. In
Section 4, we propose four object recognition models based on YOLO and propose the object tracking algorithm in
Section 5. Then, we evaluate the proposed schemes for object recognition and tracking in
Section 6. Finally, we present conclusions in
Section 7.
2. Background and Related Works
Object recognition extracts the features of the object to be detected ahead of time and then recognizes those features inside a given image. Various object detection techniques, such as the Canny edge detector, Harris corner, HOG (histogram of oriented gradient), and SIFT (scale-invariant feature transform), have been presented in the past [
11,
12,
13,
14]. Deep learning has been increasingly popular in recent years. Recognition algorithms based on CNN (convolutional neural network) have been investigated extensively. Two-stage detectors such as R-CNN (regions with convolutional neural network features), VGG visual geometry group, and ResNet residual network have been suggested for object recognition [
10,
15,
16]. They find objects using region proposal and categorize objects using region classification. The downside of two-stage detectors is that they detect objects slowly, making real-time detection impractical. YOLO (You Only Look Once), a one-stage detector that conducts region proposal and classification simultaneously, has been proposed to facilitate real-time detection [
1].
The first YOLO, which is built on GoogLeNet, features a network structure with 24 convolutional layers and two fully-connected layers with a detection rate of 45 frames per second. In [
17], YOLOv2, also known as YOLO9000, proposes ten performance-enhancement elements to address the first YOLO’s poor detection rate and huge number of localization errors, and exhibits a 15 percent increase in mAP when compared to the initial YOLO. YOLOv3 is based on the YOLOv2 architecture; however, the backbone network is Darknet-53, and ResNet short connections are employed [
18]. In [
19], YOLOv4 used CSPDarknet53 for the backbone, SPP (spatial pyramid pooling) and PAN (path aggregation) for the neck, and YOLOv3 for the head. The BOF (bag of freebies) and BOS (bag of specials) methods were also used to improve accuracy and performance. Furthermore, it demonstrates that by employing a parallelized computational strategy, quick and accurate learning can be achieved even in a single GPU training environment.
Object tracking, a technique for detecting moving objects across time, extracts spatiotemporal similarities between successive frames to conduct particular object tracking. FairMOT (fair multi-object tracking), SORT (simple online and real-time tracking), and DeepSORT (deep simple online and real-time tracking) are object tracking algorithms [
2,
3,
4]. In [
2], FairMOT conducts object detection and Re-ID functions fairly, with a frame rate of 30 frames per second. To decrease computing cost, SORT employs the Kalman filter and the Hungarian algorithm [
3]. Because the Kalman filter predicts an object’s position based on its previous velocity, it is challenging to track in instances when two objects overlap or rapidly change direction. In [
4], DeepSORT uses the Hungarian algorithm by reflecting deep learning features (Re-ID) in the Kalman filter to track objects even when they overlap and change direction. To evaluate whether the object recognized for each frame is the same as the previous frame, ID labeling is conducted based on object similarities. DeepSORT can then track each of the many objects in a frame.
Various studies on image-based ship recognition and tracking have been conducted in the shipbuilding industry. In [
5], the object recognition model uses YOLOv2, and the neural network topology is tweaked to improve precision. The training data consist of 159 images collected from the SMD dataset; however, because the labels are not uniformly distributed, the detection performance for each class differs significantly. Furthermore, while the derived model is capable of real-time processing at 30 frames per second, recall, precision, and mAP show relatively low performance results of 76%, 66%, and 69.79%, respectively. In [
7], Ship-YOLOv3 was proposed to increase the accuracy of ship target detection. When compared to the YOLO3, precision and recall rise by 12.5% and 11.5%, respectively. However, because it only has three labels and utilizes data from a camera mounted on the bridge, it is not suited for the video with high motion. In [
6], an object detection model and object tracking method are implemented using YOLOv3 and DeepSORT, respectively. When compared to previous versions, the enhanced YOLOv3 increases mAP and FPS by 5% and 2%, respectively. It demonstrates that DeepSORT outperforms six other tracking algorithms. However, it is insufficient to apply to maritime autonomous surface ships because it was only tested with four videos from a fixed camera.
3. Dataset
This section discusses the dataset for object detection and tracking. We used the SMD [
20].
3.1. Singapore Maritime Dataset
The SMD, which is a video captured both day and night in Singapore waterways, is utilized as training and testing data. Videos can be divided into three categories. These are 40 onshore videos captured with a camera mounted on land, 11 onboard videos captured with a camera mounted on a moving ship, and 30 near-infrared videos. In addition to video, SMD delivers a ground truth label file that contains object information in individual frames. Ferry, buoy, vessel/ship, speed boat, boat, kayak, sail boat, swimming human, flying bird/plane, and other are the ten classifications of objects visible in the video. For training the model, we utilize the ground truth label file as a label.
3.2. Extraction of an Object from Video
The video must be converted into images because the data input to train the model are images. In this paper, the image dataset was created in such a way that one image was saved every five frames. Because successive frames have a high degree of resemblance, overfitting may occur for objects exposed in the same form, and therefore all frames of the video are not selected. We extracted 47,705 object images from 59 videos (36 onshore videos and 23 near-infrared videos). The number of objects extracted from SMD is shown in
Table 1. As shown in the table, the vessel/ship class has the most labels (34,075), whereas the swimming person class has none in SMD. When training the model, if the labels are uneven, overfitting or bias for a certain class may emerge. To prevent overfitting and bias, we collected 127 object images including buoy, vessel/ship, boat, kayak, sail boat, and swimming person classes by using web crawling.
Table 1 illustrates the total number of 47,832 objects collected by SMD and web crawling for each class. Swimming person objects account for 120 of the 47,832 labeling objects, as indicated in the table. For model training and validation, the entire image was segmented into 7:3, respectively.
4. Object Recognition
In this section, four deep learning models are utilized to find a deep learning model that could recognize 10 different types of objects in the ocean in real time and with high accuracy.
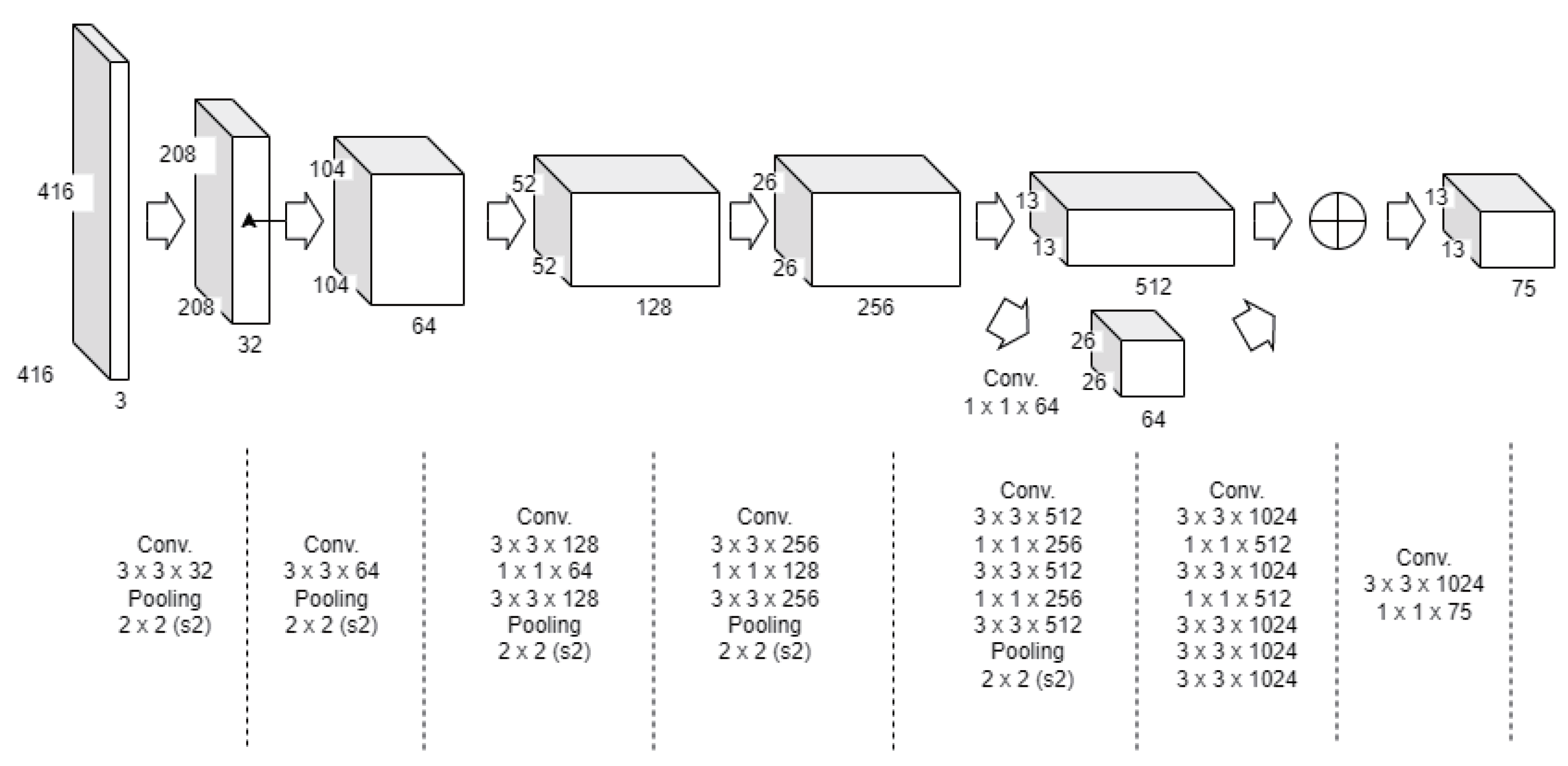
Table 2 shows the configurations of four recognition models. Model 1 is the YOLOv2 model that has 22 convolution layers and 5 max pooling layers. Model 2 is a tweaked version of Model 1 for performance improvement. The following are the differences between Model 1 and Model 2. First, after the 13th convolution layer, a 1 × 1 convolution layer is inserted in the original YOLOv2 neural network.
Figure 1 shows the structure of Model 2. As shown in the figure, the additional convolution layer increases tiny object detection accuracy by acting as a pass-through layer that mixes the upper layer’s feature map with the lower layer’s feature map [
5]. Second, the number of anticipated bounding boxes (anchors) per cell was raised from five to nine, which resulted in a higher recall rate but a significantly lower mAP. Because recall and mAP have a trade-off relationship, depending on the number of anchors, when the number of anchors grows, recall rises as more bounding boxes are discovered, but mAP (mean average precision) falls. Third, the k-means algorithm was used to adjust the anchor size to fit the dataset. Finally, transfer learning is also utilized to help with faster learning and better prediction. Darknet19 448.conv.23, a pretrained convolutional weight with the imageNet dataset, is utilized to train the model.
The neural network structure for Model 3 is CSPDarknet53 for the backbone, SPP (spatial pyramid pooling) and PAN (path aggregation network) for the neck, and YOLOv3 for the head. To improve performance, Model 4 employs a number of techniques on the YOLOv4 neural network structure. First, the mosaic technique, which is one of the BOS’s data augmentation techniques, is used. The mosaic technique creates a single image by combining four separate images with bounding boxes, and four images can be learned with just one input. Because the size of an object shrinks when images are merged, learning naturally encounters numerous little things, and as a result, small object detection performance can be enhanced. In addition, despite the fact that the number of anchors remains at nine, a new anchor size was created using the k-means algorithm, as in Model 2, based on the dataset utilized in this paper. Finally, yolov4.conv.137, a pretrained convolution weight with the Microsoft COCO dataset, is used to train the model. For object tracking, we employ Model 4 as a detection model.
5. Object Tracking
In this section, we discuss the tracking algorithm for objects in moving video. The following requirements must be satisfied in order to track objects in a moving video caused by a moving ship. First, an object should be identified as the same object when it is framed out and then framed in again. Second, when many objects overlap and an object is hidden, it should be identified as the same object when it reappears.
To satisfy these requirements, each frame of a video is detected and tracked. As indicated in
Section 4, Model 4 is utilized for recognition and returns the number, type, and coordinates of the bounding box. If the frame contains more than one bounding box, the tracking algorithm outlined in Algorithm 1 is used. For each bounding box, IoU_matching is conducted. IoU_matching calculates the IoU (intersection over union) value of the current frame’s object and all previous frames’ objects. Then, it determines the object with the maximum IoU value, and objects having IoU values above the threshold are stored in overlapIDList. If the IoU_matching result value is 1, because one object exists in the frame, it is determined that it is the same as the object with the maximum IoU value in the previous frame. If the IoU_matching result is 0 or greater than 2, ORB_size_matching is conducted.
| Algorithm 1 Tracking |
| 1: for each bounding box do |
| 2: result = IoU_matching() |
| 3: if result == 1 then |
| 4: detected object is identical to the object with the highest IoU among the objects in the previous frame |
| 5: else |
| 6: ORB_size_matching() |
| 7: end if |
| 8: end for |
IoU_matching is described in Algorithm 2. Assuming that the current frame number is n, the preceding frame to be compared is the
th frame. IoU value is calculated using the bounding box of the object in the current frame and every bounding box from the previous frame. The overlapping region between objects is measured in IoU, which ranges from 0 to 1. The maximum IoU value indicates that the two objects are the most closely located. The object and IoU value pair are saved in overlapIDList if the object was recognized in the previous frame and the IoU value is 0.2 or greater. The overlapIDList is the list of object and IoU value pairs with IoU values greater than the threshold. If many objects overlap, overlapIDList stores multiple object and IoU value pairs for one object. By comparing the calculated IoU value with the maximum IoU value, the maximum IoU value is updated. If the length of overlapIDList is not 0, the length is returned. IoU values are computed in the
nd frame with bounding boxes repeatedly if overlapIDList length is 0.
| Algorithm 2 IoU_matching() |
| 1: n: frame number currently in use |
| 2: prev: previous frame number to be compared |
| 3: Framen: nth frame |
| 4: overlapIDList: list of objects having IoU values above the threshold |
| 5: |
| 6: for prev = n − 1 to n − 2 do |
| 7: for each bounding box of objects recognized in the Frameprev do calculates IoU value |
| 8: if IoU value ≥ 0.2 then |
| 9: the object is stored in overlapIDList |
| 10: if IoU value > maximum IoU then |
| 11: maximum IoU = IoU value |
| 12: end if |
| 13: end if |
| 14: end for |
| 15: if the length of overlapIDList is not 0 then |
| 16: return the length of overlapIDList |
| 17: end if |
| 18: end for |
| 19: |
| 20: return the length of overlapIDList |
ORB_size_matching conducts ORB (oriented FAST and rotated BRIEF)-based feature matching and compares object sizes. Algorithm 3 describes ORB_size_matching. In the and frames, if the overlapIDList length is 0, there are no objects with an IoU value greater than the threshold. However, because the IoU may be low due to the quick movement, ORB matching is conducted using the objects in the IDList where the presently tracked objects are stored. If the length of overlapIDList is not 0, because there are two or more objects with an IoU value greater than the threshold, ORB matching is conducted with all objects in overlapIDList. ORB matching determines object similarity by comparing features between objects. If the ORB matching similarity is greater than 0.3, the ratio is calculated for size matching. If the ratio is between 0.9 and 1.1, the input object is the same as the object with the highest similarity. If the ratio is not between 0.9 and 1.1 and the object accuracy detected by YOLO is 0.6 or above, it is considered a new object with a lot of similarities but different sizes. It is also recognized as a new object even if the ORB similarity is less than 0.3 and the object accuracy detected by YOLO is 0.6 or greater.
We anticipate that the tracking algorithm can be utilized to predict trajectory. If the current frame’s object is the same as the previous frame’s object, the tracking object’s coordinate is saved in the prediction list. As previously stated, the suggested detection model obtains the coordinate information of the tracking object. Trajectory prediction approaches in [
21,
22,
23,
24] use the coordinate information to forecast the trajectory.
| Algorithm 3 ORB_size_matching() |
| 1: IDList: list of the objects that are currently being tracked |
| 2: |
| 3: if the length of overlapIDList == 0 then |
| 4: List = IDList |
| 5: else |
| 6: List = overlapIDList |
| 7: end if |
| 8: |
| 9: The input object and all of the objects in the List are matched using ORB |
| 10: |
| 11: if the object with the highest similarity is recognized in the previous frame then |
| 12: if similarity > 0.3 then |
| 13: ratio = |
| 14: if 0.9 <= ratio <= 1.1 then |
| 15: the input object is identical to the object with the highest matching accuracy |
| 16: else |
| 17: if YOLO’s object detection accuracy >= 0.6 then |
| 18: the input object is recognized as new object |
| 19: end if |
| 20: end if |
| 21: else |
| 22: if YOLO’s object detection accuracy >= 0.6 then |
| 23: the input object is recognized as new object |
| 24: end if |
| 25: end if |
| 26: end if |
6. Evaluation
The proposed object recognition models were evaluated by examining the performance metrics such as precision, recall, etc., for validation data. Then, object tracking scheme was evaluated by measuring tracking precision. For performance evaluation, we utilized the dataset discussed in
Section 3. The experiments for object recognition and tracking were conducted on a server with Intel Xeon E5-2620 CPU, four 16 GB RAMs, and two GTX 1080Ti GPUs. The OS and framework are Ubuntu 18.04.5 LTS and Darknet, respectively.
6.1. Object Recognition
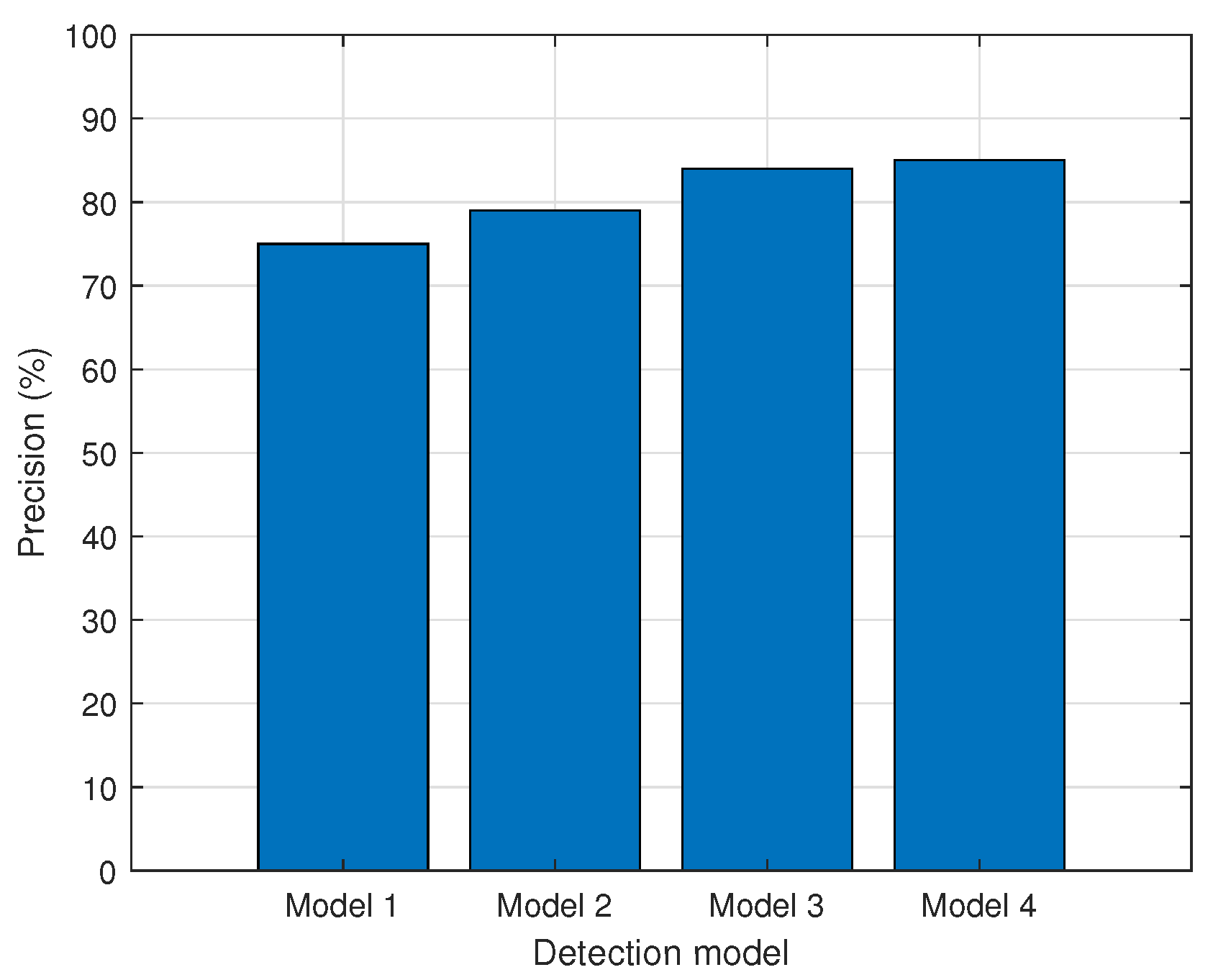
The precision, recall, F1 score, average IoU, and mAP are used to evaluate the performance of object recognition models. The accuracy of the model’s predictions is referred to as precision. The precision is defined as the ratio of accurately predicted results among all prediction results, as indicated in Equation (
1).
where
(true positive) refers to predicting a true result as true, while
(false positive) refers to predicting a false result as true. The precision of each model is shown in
Figure 2. In the results, Models 3 and 4, based on YOLOv4, are more accurate than YoLOv2-based models.
The proportion of correctly recognized objects out of the total objects that the recognition model should recognize is referred to as recall. In other words, recall is the fraction of true predictions that the model predicts among those that are actually true. It is expressed in Equation (
2).
where
(false negative) refers to predicting a true result as false. As shown in
Figure 3, Model 4 has a 90 percent recall rate, which is a minimum of 3% and a maximum of 15% higher than other models.
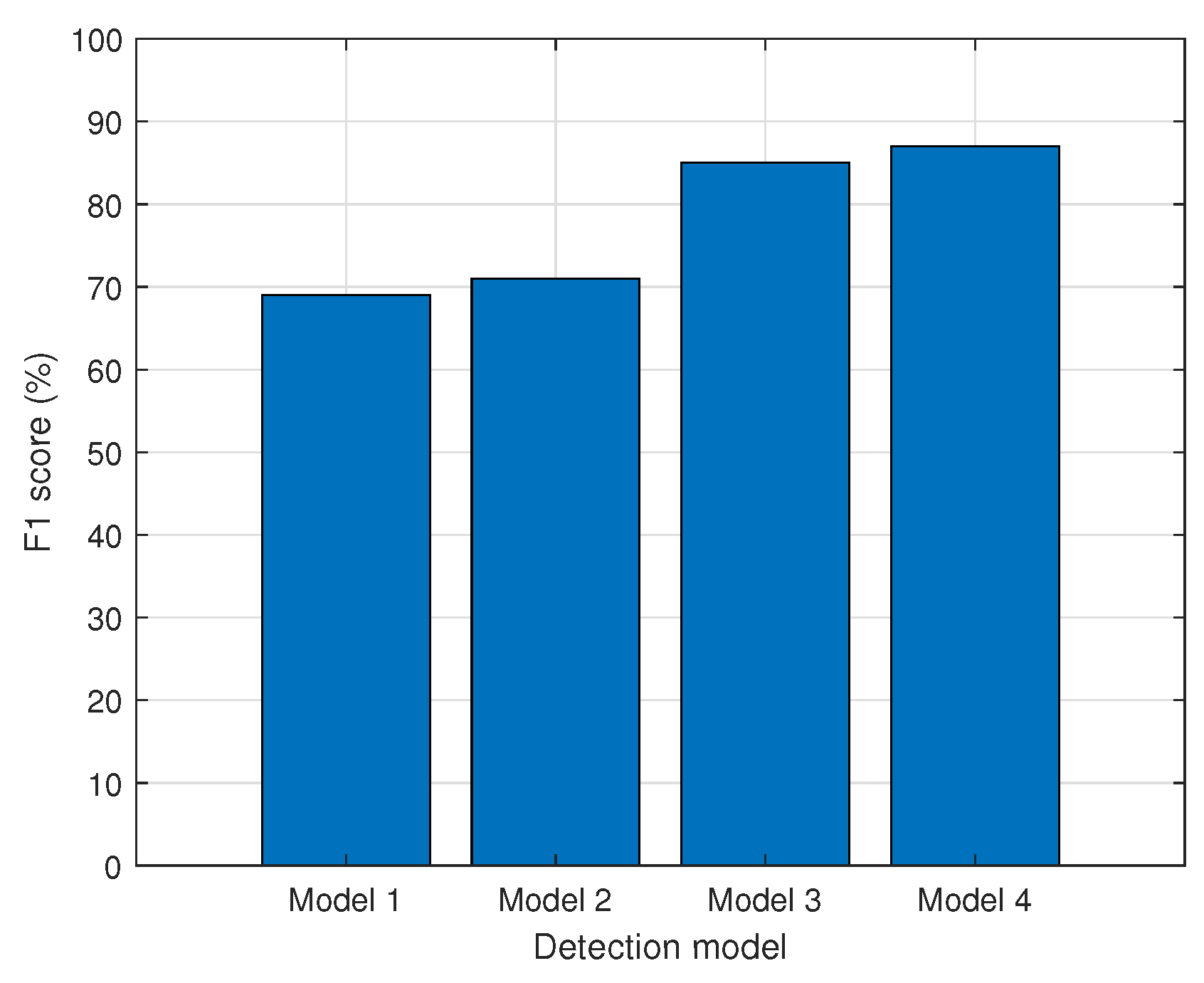
The F1 score takes into account both precision and recall, which are inversely proportional. The F1 score is calculated as the harmonic mean of precision and recall, as expressed in Equation (
3). The F1 score ranges from 0 to 1, where the closer the model is to 1, the better. The results are presented in
Figure 4. Model 4 has an F1 score of 87%, and its object recognition performance was the best among the other models, with scores ranging from 69% to 85%.
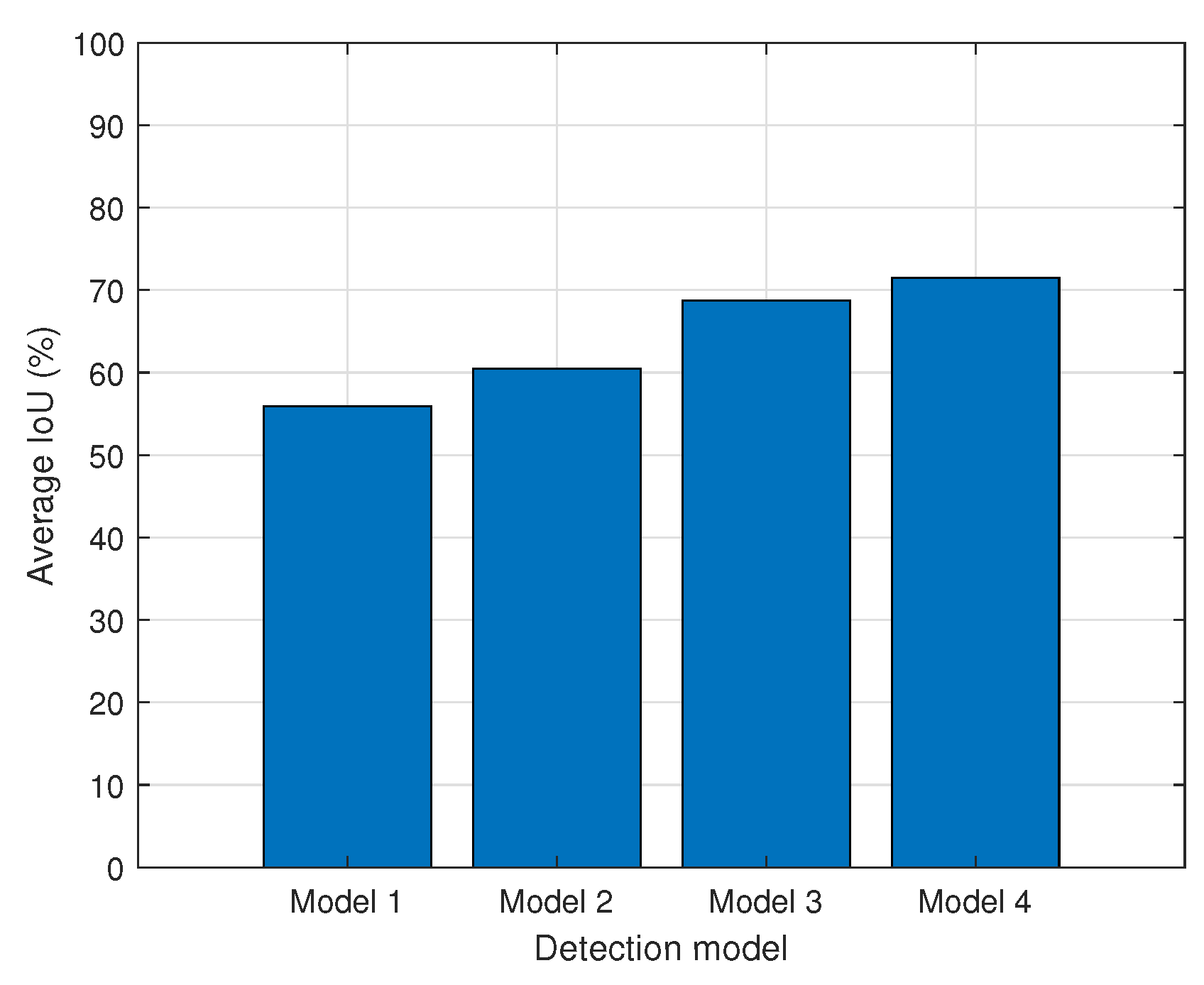
IoU is a measure of how close the projected bounding box is to the ground truth bounding box. As defined in Equation (
4), IoU is the ratio of the union and intersection of two areas. For each model,
Figure 5 shows the average IoU value for all classes. As shown in the figure, objects of 10 classes are detected more accurately by YOLOv4-based models than by YOLOv2-based models.
We provide the test cases to describe the differences in average IoU for each recognition model.
Figure 6 provides object recognition results for each model of the maritime environment image. Bounding boxes for a total of ten objects and projected object classes are shown in the image. The recognition of nearby buoys and large vessels/ships is precise. In the upper left corner of the image, Model 1 and Model 2 both have bounding boxes that do not fit the size of the objects. The bounding box, on the other hand, is drawn to match the size of the object in Models 3 and 4.
Figure 7 depicts a black-and-white marine image with four objects. The bounding box is placed in a non-object in Model 1 and one item is detected as two objects in Model 2. Model 3 does not detect objects hidden behind huge vessel/ship objects, while Model 4 does. Model 4 clearly outperforms other models in terms of object recognition in night images.
Finally, we measured mAP (mean average precision) to evaluate the quantitative performance of recognition models. The area under the curve in the precision–recall graph is used to calculate AP. The average of all APs in all classes is referred to as the mAP. In
Figure 8, Model 4 has the best identification performance, indicating that it is the most acceptable model for ship recognition.
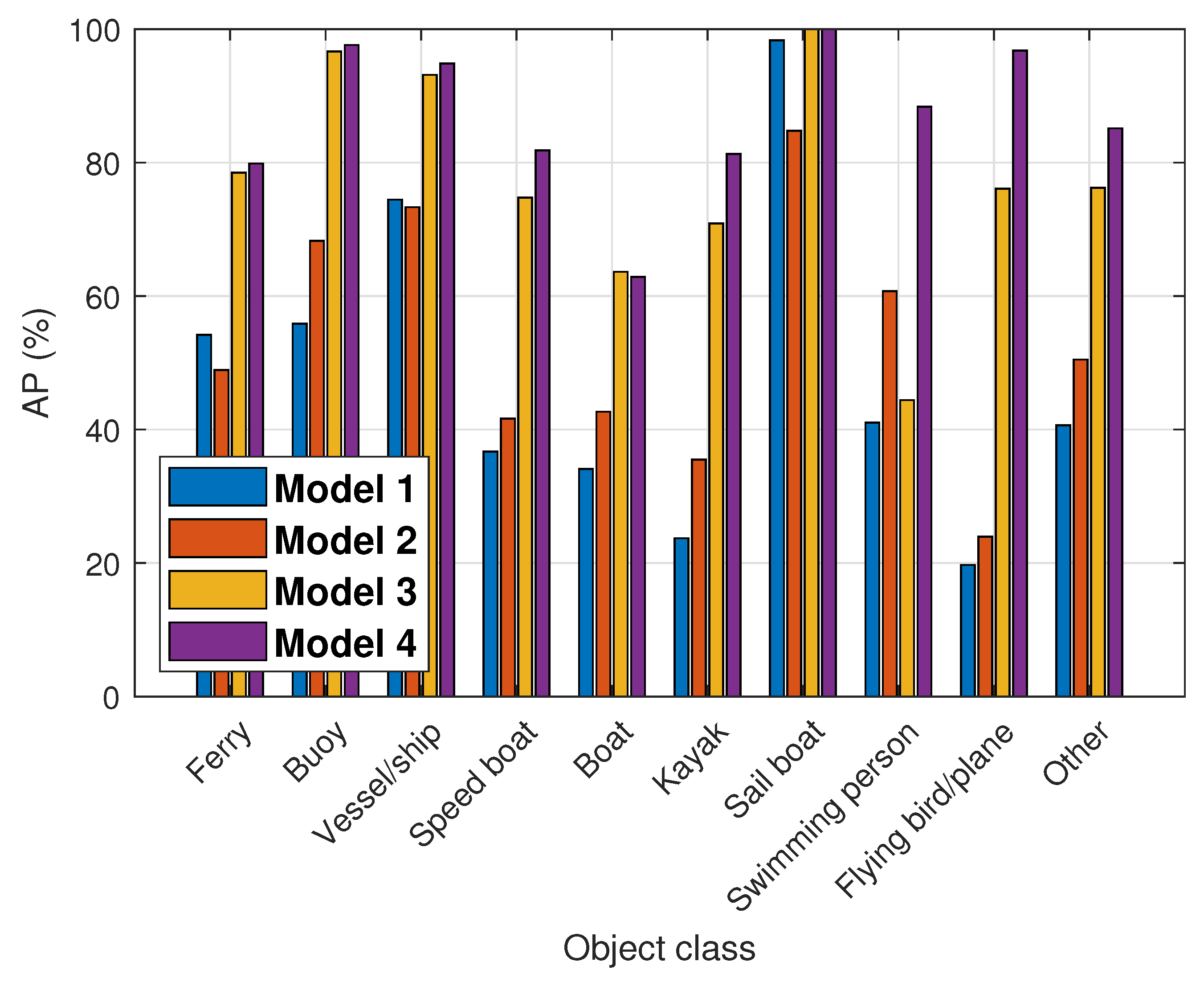
Figure 9 shows the APs of the models for each class. In the results, Model 4 can recognize the 10 different object classes that can be detected in the maritime environment with reasonable accuracy.
6.2. Object Tracking
We defined tracking precision as Equation (
5) in order to evaluate the tracking accuracy of objects such as vessel/ships. The tracking precision refers to the percentage of keeping the same tracking ID for each object in successive frame images. For example, a tracking ID of 1 was issued to an object when it initially appeared. We assume that the tracking ID is changed to 2 after 200 frames, and the object is no longer visible after 100 frames. The total number of frames with the object is 300, with 200 frames having tracking ID 1. According to Equation (
5), the tracking precision is 200/300 = 66.67%. The average tracking precision is defined as the ratio of the number of objects with the same tracking ID to the total number of objects in all frames, as given by Equation (
6). In Equation (
6),
is the number of objects in a frame.
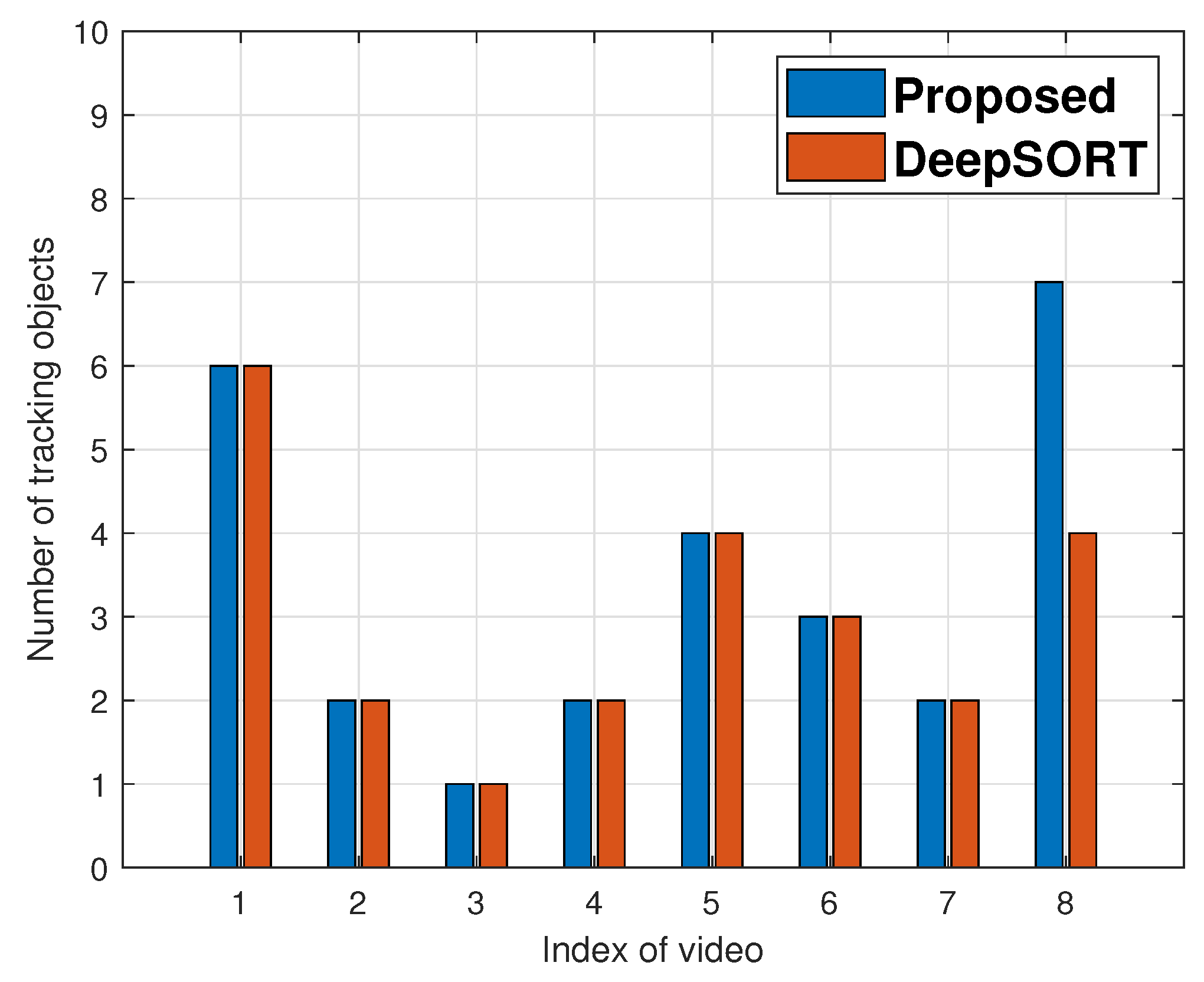
For performance evaluation of object tracking, we used the proposed tracking algorithm and DeepSORT for eight onboard videos, and the track precision results are shown in
Figure 10. The
x-axis and
y-axis are the index of onboard video and average tracking precision, respectively. Except for the eighth video, the proposed tracking scheme has tracking precision greater than or equivalent to DeepSORT in the results. DeepSORT performs better in the eighth video. However, as seen in
Figure 11, DeepSORT tracks fewer objects than the proposed approach. In the eighth video, the proposed algorithm tracks seven objects, while DeepSORT only tracks four. DeepSORT achieves better tracking accuracy than the proposed scheme because it eliminates objects from tracking if the tracking accuracy falls below a threshold. The proposed tracking algorithm, on the other hand, tracks objects even when tracking precision is poor.
We use the test case to describe the difference in tracking precision between the proposed tracking algorithm and DeepSORT. In the 70th, 75th, 80th, and 95th frames,
Figure 12 depicts the results of ship tracking using the suggested system and DeepSORT. The proposed scheme and DeepSORT assign tracking IDs 1 and 2, respectively, in the 70th frame, because, to the ship’s up and down movement, the tracked ship is located at the frame boundary in the 75th frame, but the tracking ID remains the same. The ship has vanished from view since the 80th frame. In the 95th frame, the ship reappears, and the proposed technique recognizes it as the same ship and provides it the same tracking ID as before. DeepSORT, on the other hand, treats it as a new ship and assigns it a new tracking ID. DeepSORT evaluates if they are identical based on the location of the object, whereas the proposed tracking algorithm assesses whether they are identical based on the features of the object. As a result, for video with high motion, such as onboard video of SMD, the proposed tracking algorithm outperforms DeepSORT.
7. Conclusions
In this study, we presented four object recognition models and evaluated the performance of them. Model 4 has an mAP of greater than 80%, indicating that it is capable of recognizing ships and obstacles. For object tracking, we proposed the tracking algorithm that utilizes overlapped IoU area, ORB-based object feature similarity measurement, and object size comparison. The proposed algorithm’s performance was measured using tracking accuracy in high-motion videos. The proposed tracking algorithm outperforms DeepSORT in terms of object tracking accuracy.
Author Contributions
Conceptualization, H.P., S.-H.H. and D.A.; methodology, H.P. and D.A.; software, H.P.; validation, H.P., S.-H.H., T.K. and D.A.; data curation, H.P. and D.A.; writing—original draft preparation, D.A.; writing—review and editing, S.-H.H., T.K. and D.A.; visualization, H.P. and D.A.; supervision, D.A.; funding acquisition, D.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by DNA+Drone Technology Development Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science and ICT (No. NRF-2020M3C1C2A01080819).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LIDAR | Laser imaging, detection, and ranging |
| GPS | Global Positioning System |
| SONAR | Sound navigation and ranging |
| VGG | Visual geometry group |
| ResNet | Residual network |
| R-CNN | Regions with convolutional neural network features |
| YOLO | You Only Look Once |
| SMD | Singapore Maritime Dataset |
| CNN | Convolutional neural network |
| BOF | Bag of freebies |
| BOS | Bag of specials |
| SPP | Spatial pyramid pooling |
| PAN | Path aggregation |
| HOG | Histogram of oriented gradient |
| SIFT | Scale-invariant feature transform |
| FairMOT | Fair multi-object tracking |
| SORT | Simple online and real-time tracking |
| DeepSORT | Deep simple online and real-time tracking |
| ORB | Oriented FAST and rotated BRIEF |
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. arXiv 2020, arXiv:2004.01888. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Lee, S.J.; Roh, M.I.; Oh, M.J. Image-based ship detection using deep learning. Ocean. Syst. Eng. 2020, 10, 415–434. [Google Scholar]
- Jie, Y.; Leonidas, L.; Mumtaz, F.; Ali, M. Ship detection and tracking in inland waterways using improved YOLOv3 and Deep SORT. Symmetry 2021, 13, 308. [Google Scholar] [CrossRef]
- Huang, H.; Sun, D.; Wang, R.; Zhu, C.; Liu, B. Ship target detection based on improved YOLO network. Math. Probl. Eng. 2020, 2020, 9440212. [Google Scholar] [CrossRef]
- Chen, X.; Qi, L.; Yang, Y.; Luo, Q.; Postolache, O.; Tang, J.; Wu, H. Video-based detection infrastructure enhancement for automated ship recognition and behavior analysis. J. Adv. Transp. 2020, 2020, 7194342. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Xu, X.; Yang, Y.; Wu, H.; Tang, J.; Zhao, J. Augmented ship tracking under occlusion conditions from maritime surveillance videos. IEEE Access 2020, 8, 42884–42897. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Deriche, R. Using Canny’s criteria to derive a recursively implemented optimal edge detector. Int. J. Comput. Vis. 1987, 1, 167–187. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Singapore Maritime Dataset. Available online: https://www.kaggle.com/mmichelli/singapore-maritime-dataset (accessed on 1 January 2022).
- Capobianco, S.; Millefiori, L.M.; Forti, N.; Braca, P.; Willett, P. Deep learning methods for vessel trajectory prediction based on recurrent neural networks. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 4329–4346. [Google Scholar] [CrossRef]
- Zamboni, S.; Kefato, Z.T.; Girdzijauskas, S.; Norén, C.; Dal Col, L. Pedestrian trajectory prediction with convolutional neural networks. Pattern Recognit. 2022, 121, 108252. [Google Scholar] [CrossRef]
- Jiang, H.; Chang, L.; Li, Q.; Chen, D. Trajectory prediction of vehicles based on deep learning. In Proceedings of the 2019 4th International Conference on Intelligent Transportation Engineering (ICITE), Singapore, 5–7 September 2019; pp. 190–195. [Google Scholar]
- Xu, Y.; Piao, Z.; Gao, S. Encoding crowd interaction with deep neural network for pedestrian trajectory prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5275–5284. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}