
Seabed Sediment Classification Using Spatial Statistical Characteristics



Abstract
:1. Introduction
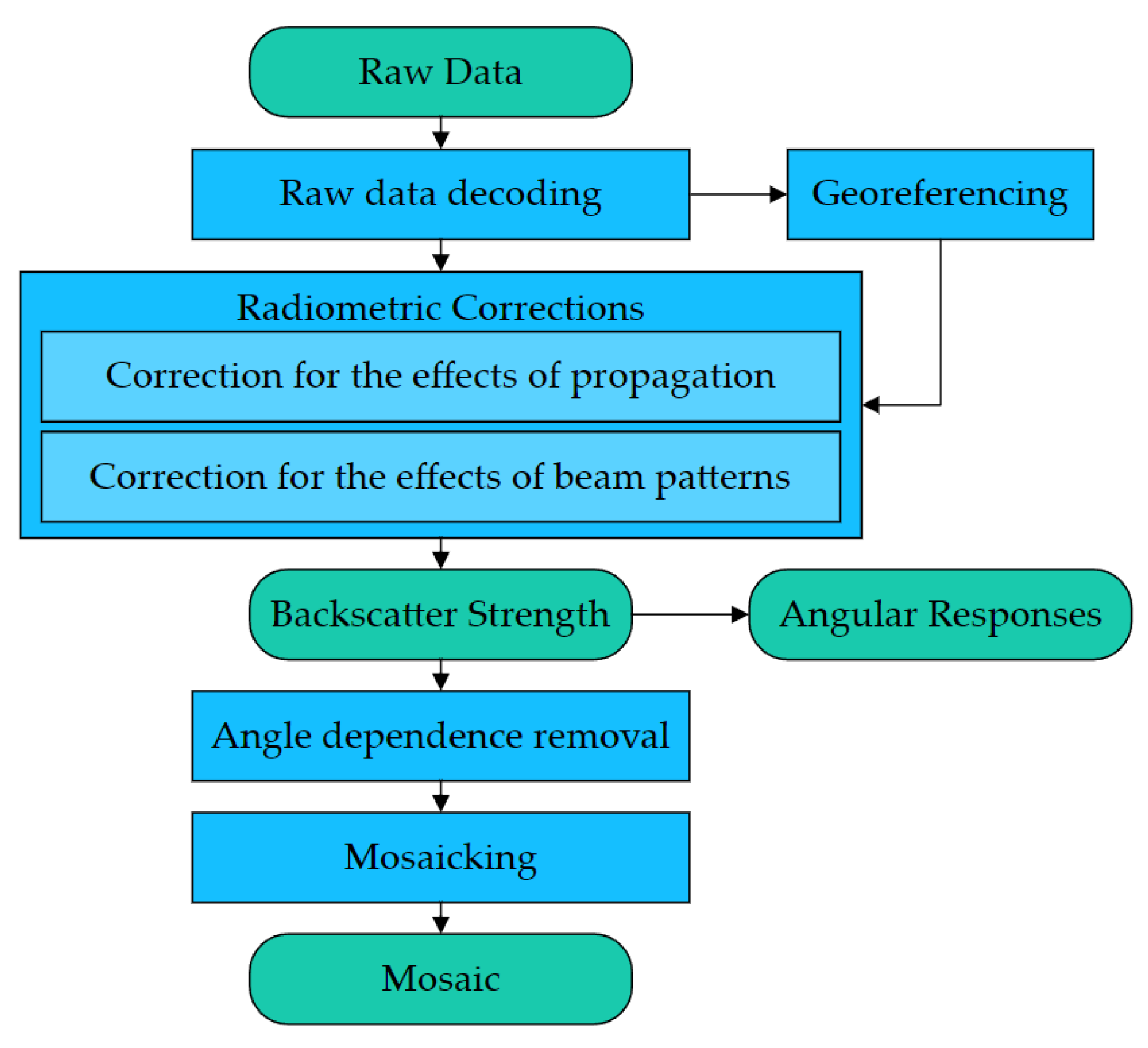
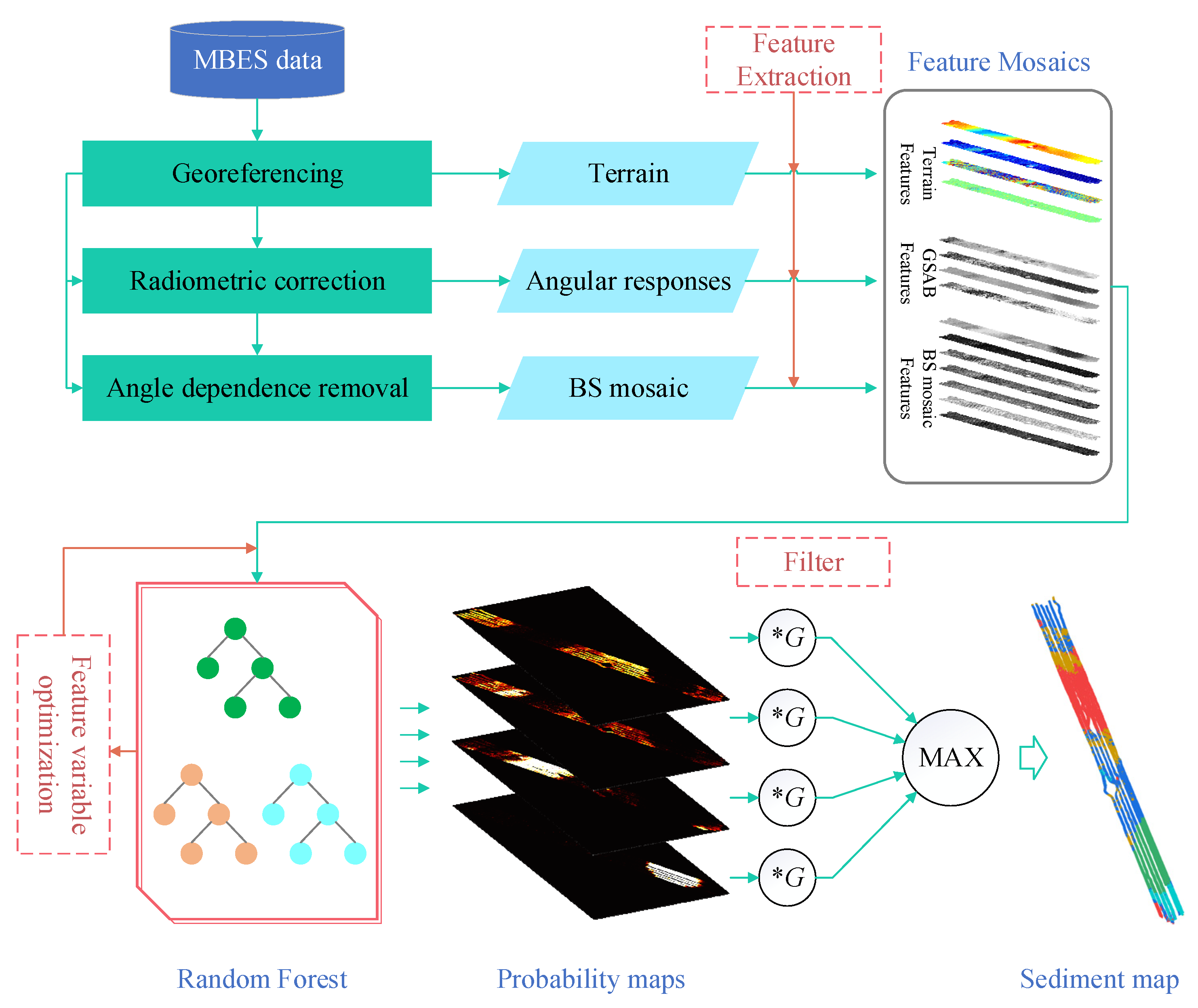
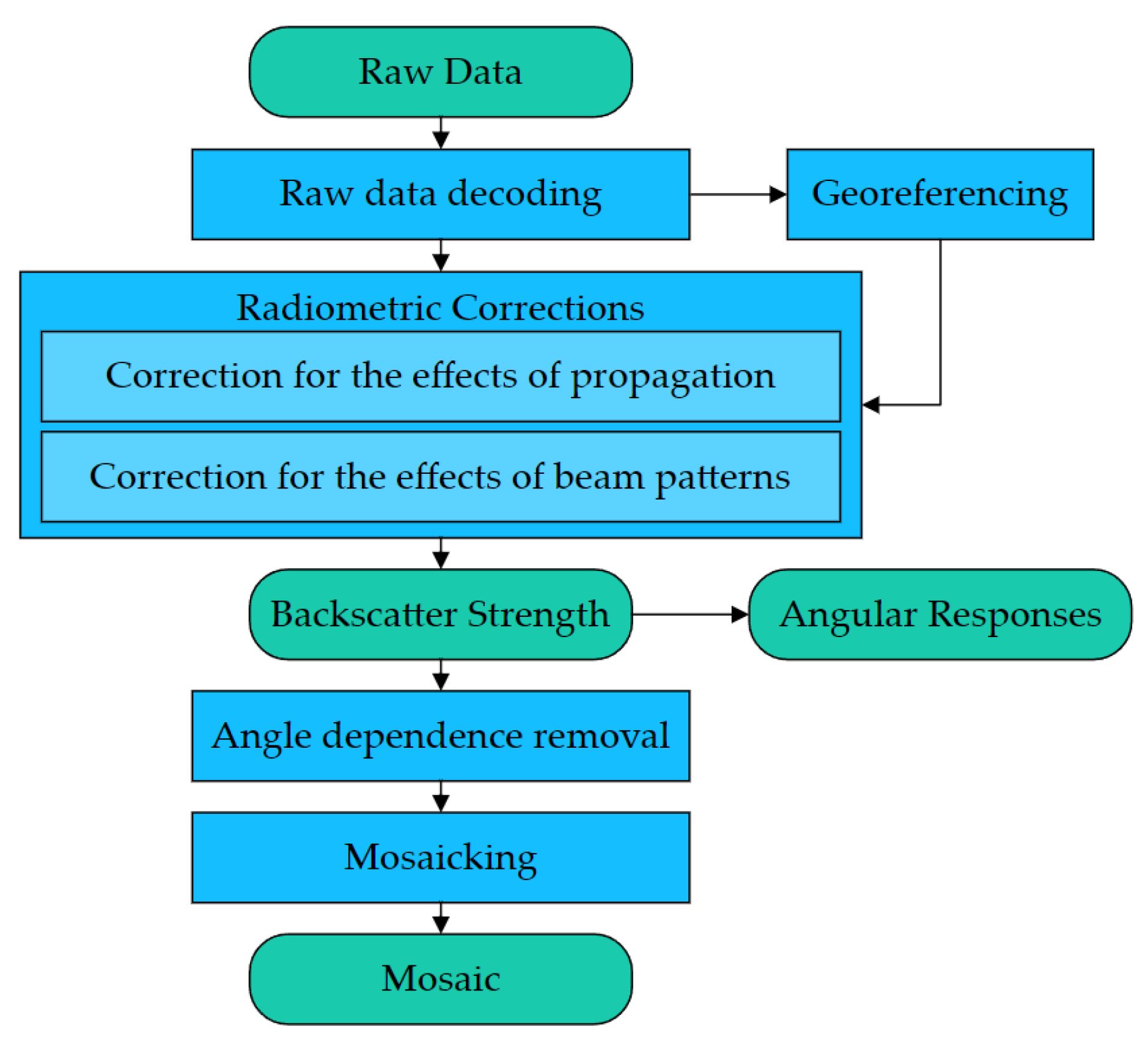
2. Methods
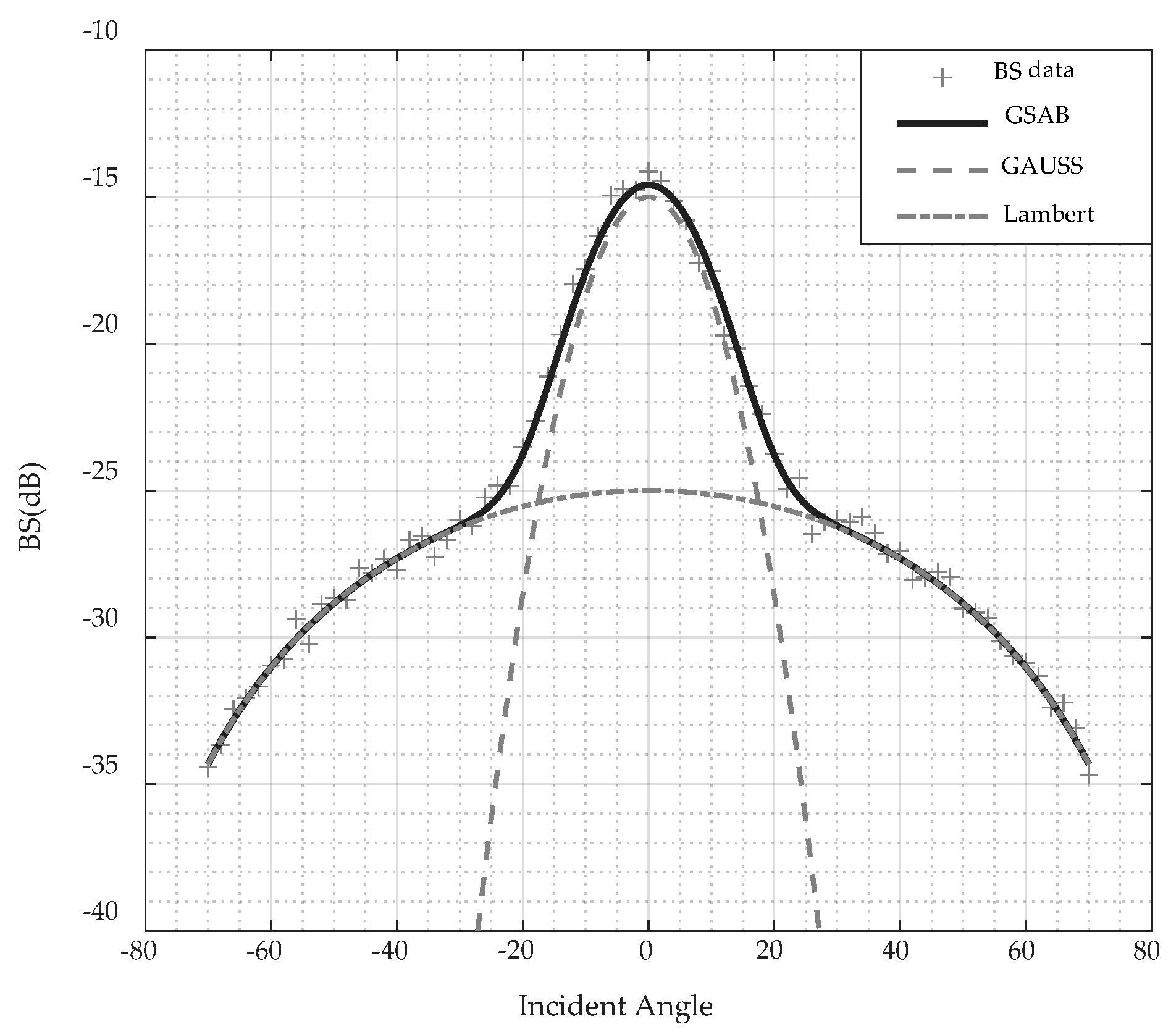
2.1. Robust Estimation of ARC with the GSAB Model and Huber Regression
2.2. Extraction of Geometric Features
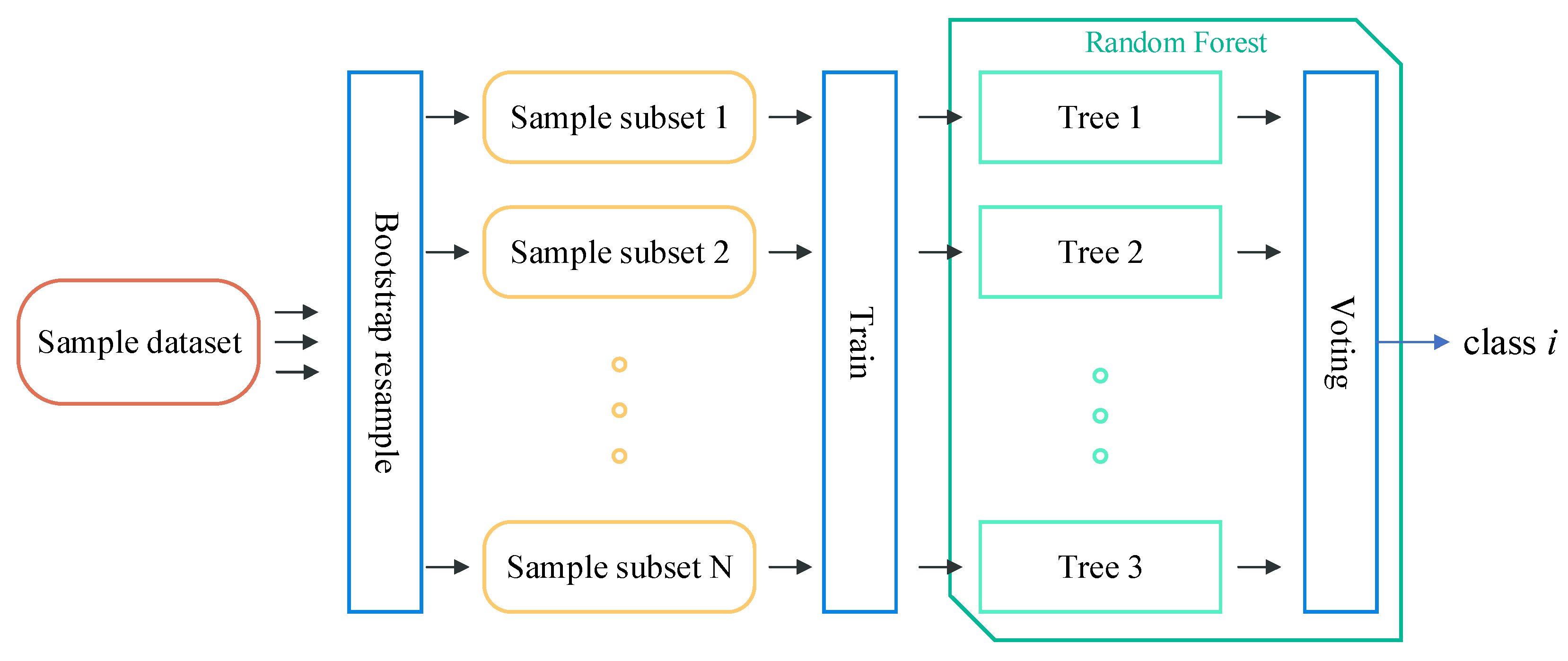
2.3. Feature Optimization
- For a decision tree, randomly sample N times from the sample dataset of size N with put-back, as the training subset of the tree.
- Randomly select m () features from a total of M features as the set of features used for the nodes division of this tree.
- Using the CART (Classification and Regression Tree) algorithm to grow the tree completely without pruning.
- Repeat the above steps until all trees have been generated.
- Set the decision tree Ti and the OOB data to correspond to i.
- Use Ti to classify and count the number of correctly classified .
- Perturb the value of Xj in , and mark the dataset after the perturbation as . Use Ti to classify and count the number of correctly classified .
- For i = 2, 3, …, Ntree, repeat steps 1~3.
- The importance score Dj of the feature Xj is calculated by the following formula:
- Scale the importance score of each feature to the range of 0~1, and sort from largest to smallest.
- Generate an RF model using features with a score of 1.
- Generate other RF models based on the following two rules by adding the less important features in turn:
- (1)
- Add no more than three features each time.
- (2)
- The maximum difference between the importance scores of the features added each time should be less than 0.2.
2.4. Probability Map Denoising and Sediment Mapping
- Input the feature vector to be classified into the trained RF model, and calculate the probability (i = 1, 2, …, Nclass) belonging to each type of sediment.
- Encode to generate a probability map according to the geographic location of the feature vector.
3. Experimental Section
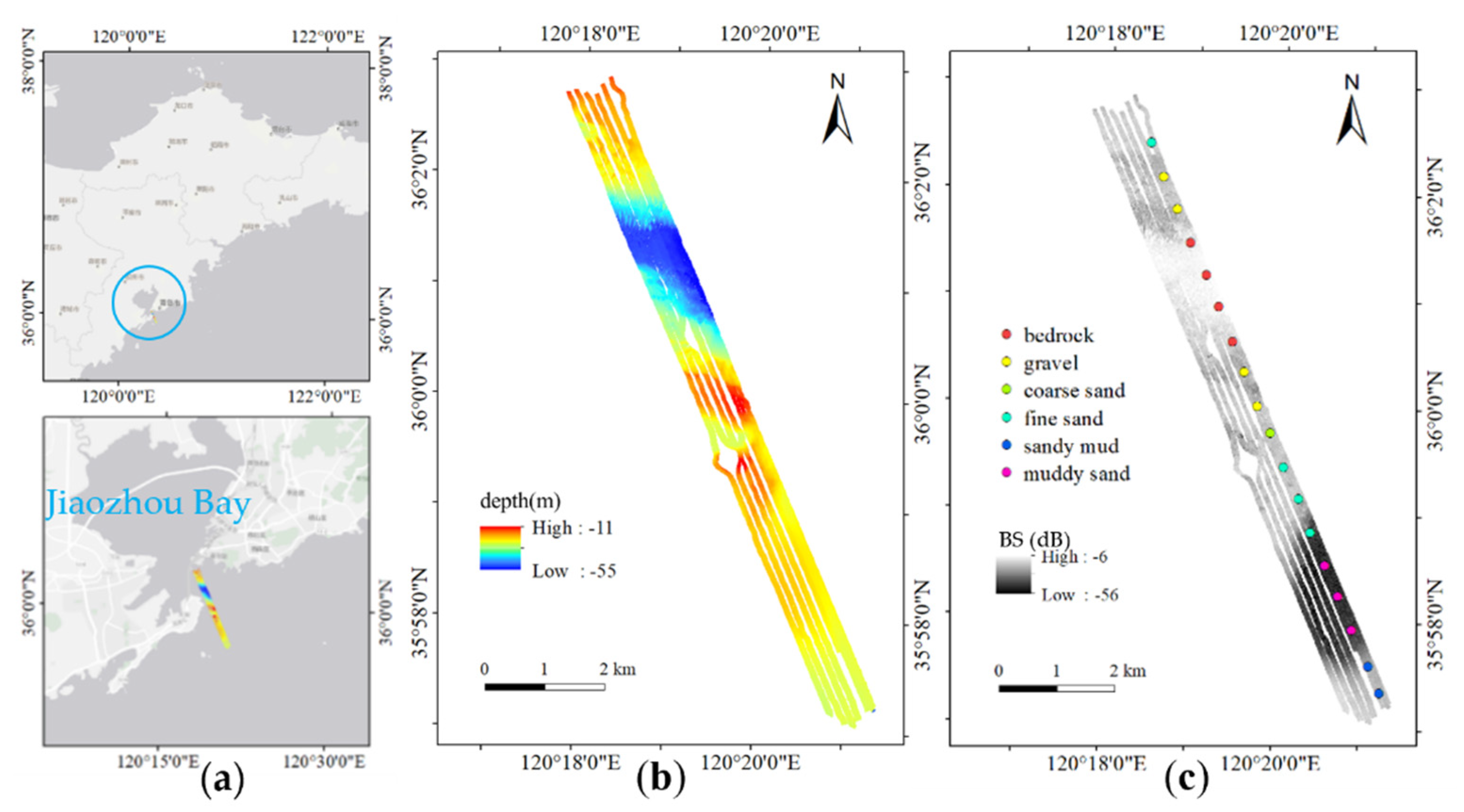
3.1. Data
3.2. Sediment Classification
3.2.1. Feature Extraction
3.2.2. Feature Selection and Sediment Classification
3.2.3. Denoising
3.3. Validity of AR Features Extracted by the GSAB Model
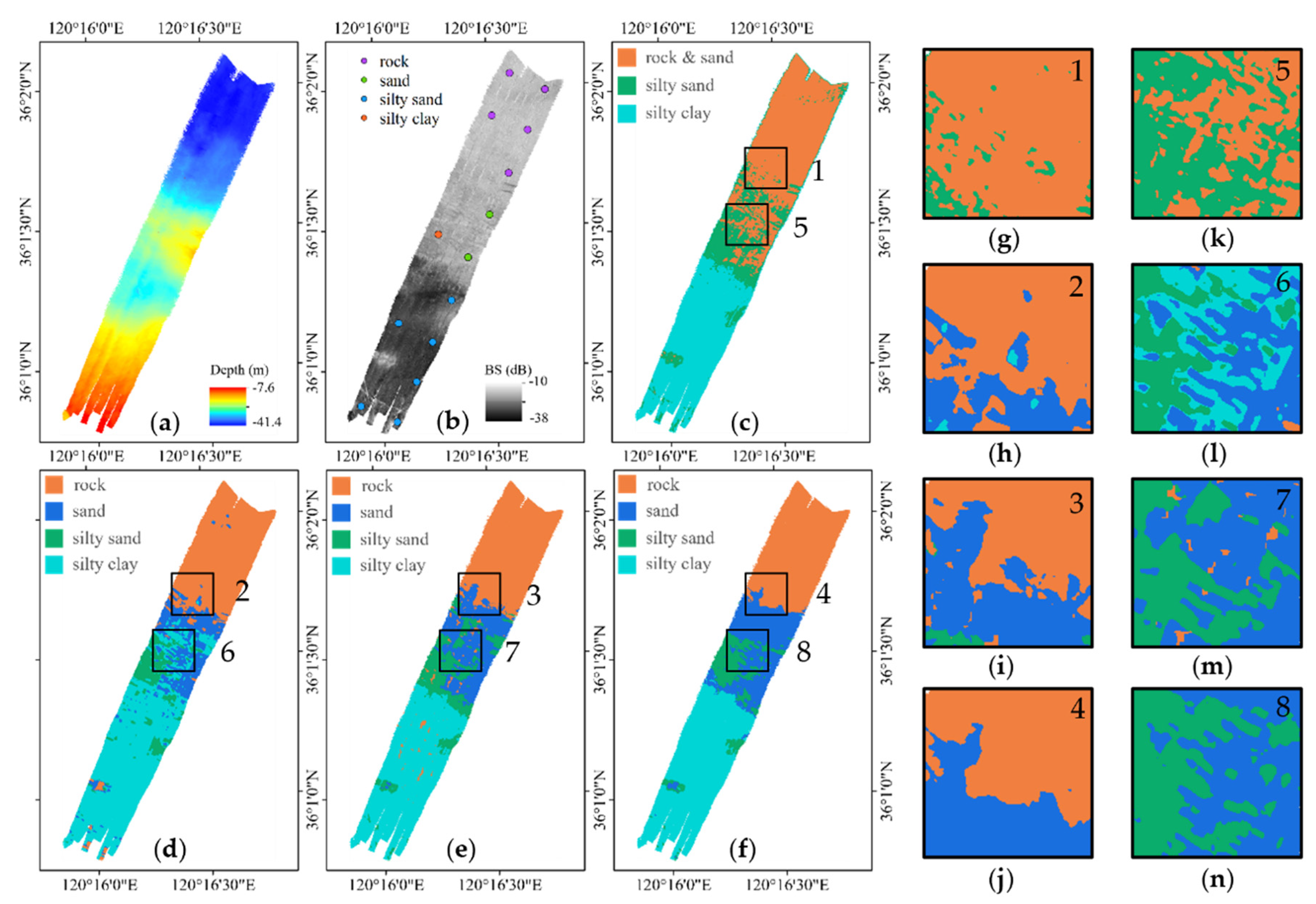
- Classification based on the statistical property of BS (Method 1), due to the single feature and the sensitivity of statistical property to factors of abnormal echoes and beam pattern residual, the classification model has a serious inadequacy of ability to distinguish sediments with small differences in BS, such as sandy mud, sand, and gravel, and the classification accuracy is low. For instance, the sandy mud in area 1 in Figure 11 is misclassified as gravel.
- Classification based on topographic and geomorphic features (Method 2) improved the ability to classify different sediments. It is shown that topographic and geomorphic features are necessary for sediment classification. However, the classification accuracy of sand is still not high, mainly due to the limitations of the classification capability. Furthermore, in confounding areas of multiple sediments, such as in area 2, the boundaries of the sediment in the sediment map of Method 2 are very messy.
- Classification with the addition of AR features (Method 3) has improved the results relative to Method 2, indicating that the AR features reflect the sediment properties better relative to other features, but are still influenced by the less robustness of the AR features extraction method. For instance, in area 3, a portion of sand is misclassified as gravel, resulting in a large area of sand scattered with some gravel in the sediment map of Method 3.
- Classification using the GSAB model parameters as AR features (Method 4) has the highest accuracy, indicating that the AR features extracted from the GSAB model can better describe the sediment properties and proves the validity of the method in this paper. In the sediment map of Method 4, the areas 4, 5, and 6 correspond to the areas 1, 2, and 3 of other methods, respectively, and have a more correct sediment distribution, more reasonable boundaries, and fewer sediment impurities.
4. Discussion
4.1. Comparison of Results from Different Classifiers
4.2. Limitations
4.2.1. The Influence of Different Operation Modes on AR Feature Extraction
4.2.2. The Influence of Mixed Sediments in Ping
4.2.3. The Influence of Abnormal Data on Feature Extraction
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Panneerselvam, B.; Muniraj, K.; Thomas, M.; Ravichandran, N.; Bidorn, B. Identifying Influencing Groundwater Parameter on Human Health Associate with Irrigation Indices Using the Automatic Linear Model (ALM) in a Semi-Arid Region in India. Environ. Res. 2021, 202, 111778. [Google Scholar] [CrossRef] [PubMed]
- Ramalingam, S.; Panneerselvam, B.; Kaliappan, S.P. Effect of High Nitrate Contamination of Groundwater on Human Health and Water Quality Index in Semi-Arid Region, South India. Arab. J. Geosci. 2022, 15, 242. [Google Scholar] [CrossRef]
- Fonseca, L.; Calder, B. Geocoder: An Efficient Backscatter Map Constructor. In Proceedings of the U.S. Hydro 2005 Conference, San Diego, CA, USA, 22 September 2005. [Google Scholar]
- TANG, Q.H.; JI, X.; DING, J.S.; ZHOU, X.H.; LI, J. Research Progress and Prospect of Acoustic Seabed Classification Using Multibeam Echo Sounder. Adv. Mar. Sci. 2019, 37, 1–10. [Google Scholar] [CrossRef]
- Preston, J. Automated Acoustic Seabed Classification of Multibeam Images of Stanton Banks. Appl. Acoust. 2009, 70, 1277–1287. [Google Scholar] [CrossRef]
- Brown, C.J.; Todd, B.J.; Kostylev, V.E.; Pickrill, R.A. Image-Based Classification of Multibeam Sonar Backscatter Data for Objective Surficial Sediment Mapping of Georges Bank, Canada. Cont. Shelf Res. 2011, 31, S110–S119. [Google Scholar] [CrossRef]
- Koop, L.; Snellen, M.; Simons, D.G. An Object-Based Image Analysis Approach Using Bathymetry and Bathymetric Derivatives to Classify the Seafloor. Geosciences 2021, 11, 45. [Google Scholar] [CrossRef]
- Shang, X.; Robert, K.; Misiuk, B.; Mackin-McLaughlin, J.; Zhao, J. Self-Adaptive Analysis Scale Determination for Terrain Features in Seafloor Substrate Classification. Estuar. Coast. Shelf Sci. 2021, 254, 107359. [Google Scholar] [CrossRef]
- Ji, X.; Yang, B.; Tang, Q. Seabed Sediment Classification Using Multibeam Backscatter Data Based on the Selecting Optimal Random Forest Model. Appl. Acoust. 2020, 167, 107387. [Google Scholar] [CrossRef]
- Hughes Clarke, J.E.; Mayer, L.A.; Wells, D.E. Shallow-Water Imaging Multibeam Sonars: A New Tool for Investigating Seafloor Processes in the Coastal Zone and on the Continental Shelf. Mar. Geophys. Res. 1996, 18, 607–629. [Google Scholar] [CrossRef]
- JIN, S.; LI, J.; WU, Z.; BIAN, G.; CUI, Y. 3D Histogram of Backscatter Strength for Seafloor Substrates Classification. Acta Geod. Cartogr. Sin. 2019, 48, 124–131. [Google Scholar] [CrossRef]
- YANG, F.; ZHU, Z.; LI, J.; FENG, C.; XING, Z.; WU, Z. Seafloor Classification Based on Combined Multibeam Bathymetry and Backscatter Using Deep Convolution Neural Network. Acta Geod. Cartogr. Sin. 2021, 50, 71–84. [Google Scholar] [CrossRef]
- Hasan, R.C.; Ierodiaconou, D.; Laurenson, L.; Schimel, A. Integrating Multibeam Backscatter Angular Response, Mosaic and Bathymetry Data for Benthic Habitat Mapping. PLoS ONE 2014, 9, e97339. [Google Scholar] [CrossRef] [Green Version]
- Hellequin, L.; Lurton, X.; Augustin, J.M. Postprocessing and signal corrections for multibeam echosounder images. In Proceedings of the Oceans’97, MTS/IEEE Conference, Halifax, NS, Canada, 6–9 October 1997; pp. 23–26. [Google Scholar] [CrossRef]
- JIN, S.; XIAO, F.; BIAN, G.; WANG, M.; SUN, W. A Method for Extracting Seabed Feature Parameters Based on the Angular Response Curve of Multibeam Backscatter Strength. GEOMATICS Inf. Sci. WUHAN UNIVERS 2014, 39, 1493–1498. [Google Scholar] [CrossRef]
- Hughes Clarke, J.E.; Li, M.Z.; Sherwood, C.R.; Hill, P.R. Optimal use of multibeam technology in the study of shelf morphodynamics. In Sediments, Morphology and Sedimentary Processes on Continental Shelves: Advances in Technologies, Research and Applications, 1st ed.; International Association of Sedimentologists: Gent, Belgium, 2013; pp. 3–28. [Google Scholar] [CrossRef]
- Diesing, M.; Mitchell, P.; Stephens, D. Image-Based Seabed Classification: What Can We Learn from Terrestrial Remote Sensing? ICES J. Mar. Sci. J. du Cons. 2016, 73, 2425–2441. [Google Scholar] [CrossRef]
- Schimel, A.C.G.; Beaudoin, J.; Parnum, I.M.; Le Bas, T.; Schmidt, V.; Keith, G.; Ierodiaconou, D. Multibeam Sonar Backscatter Data Processing. Mar. Geophys. Res. 2018, 39, 121–137. [Google Scholar] [CrossRef]
- Lurton, X.; Lamarche, G. (Eds.) Backscatter Measurements by Seafloor-Mapping Sonars. Guidelines and Recommendations. 2015. Available online: https://niwa.co.nz/static/BWSG_REPORT_MAY2015_web.pdf (accessed on 15 September 2021).
- Augustin, J.M.; Lurton, X. Image amplitude calibration and processing for seafloor mapping sonars. In Proceedings of the IEEE Oceans’ 2005 European Conference, Brest, France, 20–23 June 2005; pp. 698–701. [Google Scholar]
- Augustin, J.; Edy, C.; Savoye, B.; Le Drezen, E. Sonar mosaic computation from multibeam echo sounder. In Proceedings of the OCEANS’94, Oceans Engineering for Today’s Technology and Tomorrow’s Preservation, Brest, France, 13–16 September 1994; Volume 432, pp. II/433–II/438. [Google Scholar] [CrossRef]
- Lamarche, G.; Lurton, X.; Verdier, A.-L.; Augustin, J.-M. Quantitative Characterisation of Seafloor Substrate and Bedforms Using Advanced Processing of Multibeam Backscatter—Application to Cook Strait, New Zealand. Cont. Shelf Res. 2011, 31, S93–S109. [Google Scholar] [CrossRef] [Green Version]
- Brekhovskikh, L.M.; Lysanov, Y.P. Fundamentals of Ocean Acoustics, 3rd ed.; Springer: New York, NY, USA, 2003. [Google Scholar] [CrossRef]
- Lurton, X.; Jackson, D.R. An Introduction to Underwater Acoustics. J. Acoust. Soc. Am. 2004, 115, 443. [Google Scholar] [CrossRef] [Green Version]
- Huber, P.J. Robust Statistics. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1248–1251. [Google Scholar]
- Colenutt, A.; Mason, T.; Cocuccio, A.; Kinnear, R.; Parker, D. Nearshore Substrate and Marine Habitat Mapping to Inform Marine Policy and Coastal Management. J. Coast. Res. 2013, 165, 1509–1514. [Google Scholar] [CrossRef]
- Cui, X.; Liu, H.; Fan, M.; Ai, B.; Ma, D.; Yang, F. Seafloor Habitat Mapping Using Multibeam Bathymetric and Backscatter Intensity Multi-Features SVM Classification Framework. Appl. Acoust. 2021, 174, 107728. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man. Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Baraldi, A.; Panniggiani, F. An Investigation of the Textural Characteristics Associated with Gray Level Cooccurrence Matrix Statistical Parameters. IEEE Trans. Geosci. Remote Sens. 1995, 33, 293–304. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- FANG, K.; WU, J.; ZHU, J.; SHIA, B. A Review of Technologies on Random Forests. Stat. Inf. FORUM 2011, 26, 32–38. [Google Scholar] [CrossRef]
- YAO, D.; YANG, J.; ZHAN, X. Feature Selection Algorithm Based on Random Forest. J. Jilin Univ. Technol. Ed. 2014, 44, 142–146. [Google Scholar] [CrossRef]
- Folk, R.L.; Andrews, P.B.; Lewis, D.W. Detrital Sedimentary Rock Classification and Nomenclature for Use in New Zealand. New Zeal. J. Geol. Geophys. 1970, 13, 937–968. [Google Scholar] [CrossRef] [Green Version]
- Charoenlerkthawin, W.; Namsai, M.; Bidorn, K.; Rukvichai, C.; Panneerselvam, B.; Bidorn, B. Effects of Dam Construction in the Wang River on Sediment Regimes in the Chao Phraya River Basin. Water 2021, 13, 2146. [Google Scholar] [CrossRef]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? In Machine Learning and Data Mining in Pattern Recognition (Lecture Notes in Computer Science); Perner, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar] [CrossRef]
- Simons, D.G.; Snellen, M. A Bayesian Approach to Seafloor Classification Using Multi-Beam Echo-Sounder Backscatter Data. Appl. Acoust. 2009, 70, 1258–1268. [Google Scholar] [CrossRef]
- Yu, X.; Zhai, J.; Zou, B.; Shao, Q.; Hou, G. A Novel Acoustic Sediment Classification Method Based on the K-Mdoids Algorithm Using Multibeam Echosounder Backscatter Intensity. J. Mar. Sci. Eng. 2021, 9, 508. [Google Scholar] [CrossRef]
- Calvert, J.; Strong, J.A.; Service, M.; McGonigle, C.; Quinn, R. An Evaluation of Supervised and Unsupervised Classification Techniques for Marine Benthic Habitat Mapping Using Multibeam Echosounder Data. ICES J. Mar. Sci. 2015, 72, 1498–1513. [Google Scholar] [CrossRef] [Green Version]
- Panneerselvam, B.; Muniraj, K.; Duraisamy, K.; Pande, C.; Karuppannan, S.; Thomas, M. An Integrated Approach to Explore the Suitability of Nitrate-Contaminated Groundwater for Drinking Purposes in a Semiarid Region of India. Environ. Geochem. Health 2022, 1–17. [Google Scholar] [CrossRef]
- Panneerselvam, B.; Muniraj, K.; Pande, C.; Ravichandran, N.; Thomas, M.; Karuppannan, S. Geochemical Evaluation and Human Health Risk Assessment of Nitrate-Contaminated Groundwater in an Industrial Area of South India. Environ. Sci. Pollut. Res. 2021, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Hasan, R.C.; Ierodiaconou, D.; Monk, J. Evaluation of Four Supervised Learning Methods for Benthic Habitat Mapping Using Backscatter from Multi-Beam Sonar. Remote Sens. 2012, 4, 3427–3443. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Yang, B.; Tang, Q. Acoustic Seabed Classification Based on Multibeam Echosounder Backscatter Data Using the PSO-BP-AdaBoost Algorithm: A Case Study from Jiaozhou Bay, China. IEEE J. Ocean. Eng. 2020, 46, 509–519. [Google Scholar] [CrossRef]
- Kim, W.; Kanezaki, A.; Tanaka, M. Unsupervised Learning of Image Segmentation Based on Differentiable Feature Clustering. IEEE Trans. Image Process. 2020, 29, 8055–8068. [Google Scholar] [CrossRef]
- LI, C. Study on Beam Patten Correction of Multi-Sector Multibeam Sonar and Seabed Sediment Classification. Master’s Thesis, Wuhan University, Wuhan, China, 2020. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Definition | Variable | Formula | Notes |
|---|---|---|---|---|
| Topography | Bathymetry | z | x, y are geographical coordinates | |
| Slope | slope | |||
| Aspect | aspect | |||
| Surface curvature | curvature | |||
| GLCM | Contrast | Con | is the probability that the two pixels at the distance d and the angle θ have grayscale i, j, respectively. | |
| Energy | Asm | |||
| Entropy | Ent | |||
| Correlation | Cor | |||
| Homogeneity | Hom | |||
| Dissimilarity | Dis |
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | |
|---|---|---|---|---|---|
| A | √ | √ | √ | ||
| B | √ | √ | √ | ||
| C | √ | √ | √ | √ | |
| D | √ | √ | |||
| depth | √ | √ | √ | √ | √ |
| slope | √ | √ | √ | √ | |
| aspect | √ | √ | |||
| curvature | √ | ||||
| BS | √ | √ | √ | ||
| Con | √ | ||||
| Asm | √ | ||||
| Ent | √ | √ | |||
| Cor | √ | ||||
| Hom | √ | ||||
| Dis | √ | ||||
| sandy mud | 0.96 | 0.86 | 0.96 | 0.97 | 0.96 |
| muddy sand | 0.98 | 0.56 | 0.98 | 0.99 | 0.99 |
| sand | 0.84 | 0.41 | 0.79 | 0.86 | 0.84 |
| gravel | 0.93 | 0.51 | 0.86 | 0.87 | 0.89 |
| bedrock | 0.98 | 0.8 | 0.95 | 0.97 | 0.98 |
| Overall accuracy | 93.7% | 63.2% | 91.2% | 93.3% | 93.4% |
| Kappa | 0.92 | 0.54 | 0.89 | 0.92 | 0.92 |
| Method 1 | Method 2 | Method 3 | Method 4 | |
|---|---|---|---|---|
| sandy mud | 0.36 | 0.92 | 0.96 | 0.96 |
| muddy sand | 0.99 | 0.97 | 0.98 | 0.98 |
| sand | 0.55 | 0.75 | 0.77 | 0.84 |
| gravel | 0.39 | 0.85 | 0.86 | 0.93 |
| bedrock | 0.99 | 0.97 | 0.99 | 0.98 |
| overall accuracy | 62.2% | 89.6% | 91.3% | 93.3% |
| kappa | 0.52 | 0.87 | 0.89 | 0.92 |
| A0 (dB) | B0 (°) | C0 (dB) | D0 | |
|---|---|---|---|---|
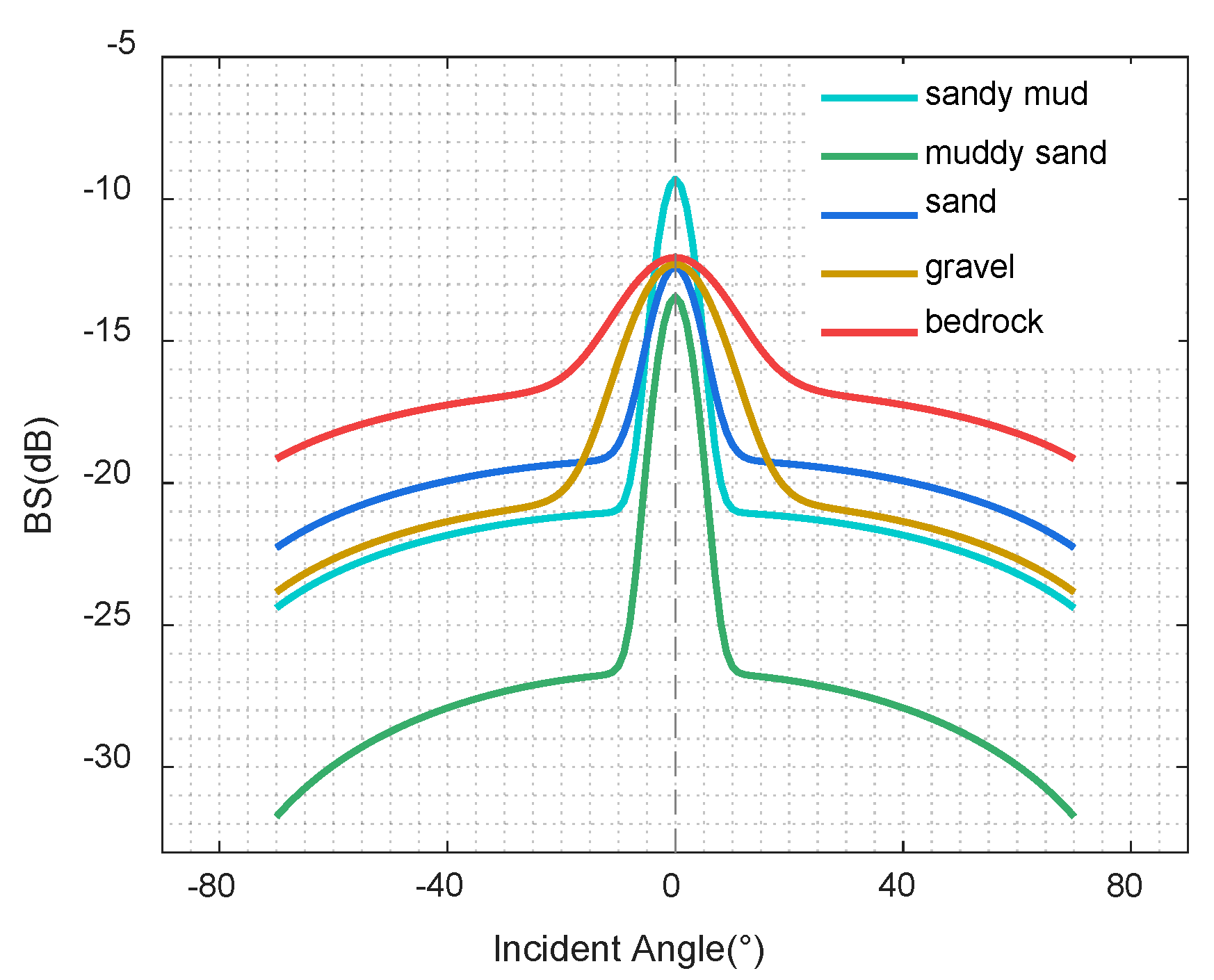
| sandy mud | −9.60 | 2.849 | −20.99 | 0.73 |
| muddy sand | −13.65 | 2.941 | −26.65 | 1.09 |
| sand | −13.42 | 3.868 | −19.14 | 0.67 |
| gravel | −12.99 | 7.012 | −20.53 | 0.71 |
| bedrock | −13.92 | 8.404 | −16.62 | 0.54 |
| Methods | Categories | User’s Accuracy (%) | Producer’s Accuracy (%) | Average Accuracy (%) | Overall (%) | Kappa |
|---|---|---|---|---|---|---|
| DFC | muddy sand | 94.6 | 100 | 97.3 | 81.9 | 0.75 |
| sand | 54.6 | 60.9 | 57.8 | |||
| gravel & sandy mud | 83.6 | 87.7 | 85.7 | |||
| bedrock | 100 | 73.3 | 86.7 | |||
| BPNN | sandy mud | 95 | 83.2 | 89.1 | 84.2 | 0.8 |
| muddy sand | 78.1 | 99 | 88.6 | |||
| sand | 78.5 | 69.6 | 74.1 | |||
| gravel | 78.7 | 77.4 | 78.1 | |||
| bedrock | 92.9 | 92 | 92.5 | |||
| SVM | sandy mud | 86 | 96.3 | 91.2 | 86.3 | 0.83 |
| muddy sand | 98 | 97.3 | 97.7 | |||
| sand | 69.5 | 79.7 | 74.6 | |||
| gravel | 83.6 | 66.3 | 75.0 | |||
| bedrock | 97.2 | 92 | 94.6 | |||
| Our Method | sandy mud | 95.8 | 97 | 96.4 | 93.3 | 0.92 |
| muddy sand | 98.6 | 97.4 | 98.0 | |||
| sand | 84.5 | 84 | 84.3 | |||
| gravel | 89.6 | 96.3 | 93.0 | |||
| bedrock | 96.7 | 98.9 | 97.8 |
| Methods | Categories | User’s Accuracy (%) | Producer’s Accuracy (%) | Average Accuracy (%) | Overall (%) | Kappa |
|---|---|---|---|---|---|---|
| DFC | rock & sand | 89.8 | 73.3 | 81.55 | 82.1 | 0.72 |
| silty sand | 62 | 81.7 | 71.85 | |||
| silty clay | 95.2 | 100 | 97.6 | |||
| BPNN | rock | 95.2 | 100 | 97.6 | 83.7 | 0.78 |
| sand | 85.4 | 69.5 | 77.45 | |||
| silty sand | 97.6 | 68.3 | 82.95 | |||
| silty clay | 67.4 | 96.7 | 82.05 | |||
| SVM | rock | 80 | 100 | 90 | 84.6 | 0.79 |
| sand | 81.8 | 75 | 78.4 | |||
| silty sand | 78.9 | 75 | 76.95 | |||
| silty clay | 100 | 88.3 | 94.15 | |||
| Our Method | rock | 100 | 100 | 100 | 92.9 | 0.9 |
| sand | 83.1 | 90 | 86.55 | |||
| silty sand | 90.7 | 81.7 | 86.2 | |||
| silty clay | 98.4 | 100 | 99.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Zhao, J.; Li, S.; Zhang, H. Seabed Sediment Classification Using Spatial Statistical Characteristics. J. Mar. Sci. Eng. 2022, 10, 691. https://doi.org/10.3390/jmse10050691
Zhang Q, Zhao J, Li S, Zhang H. Seabed Sediment Classification Using Spatial Statistical Characteristics. Journal of Marine Science and Engineering. 2022; 10(5):691. https://doi.org/10.3390/jmse10050691
Chicago/Turabian StyleZhang, Quanyin, Jianhu Zhao, Shaobo Li, and Hongmei Zhang. 2022. "Seabed Sediment Classification Using Spatial Statistical Characteristics" Journal of Marine Science and Engineering 10, no. 5: 691. https://doi.org/10.3390/jmse10050691
APA StyleZhang, Q., Zhao, J., Li, S., & Zhang, H. (2022). Seabed Sediment Classification Using Spatial Statistical Characteristics. Journal of Marine Science and Engineering, 10(5), 691. https://doi.org/10.3390/jmse10050691