



High Speed and Precision Underwater Biological Detection Based on the Improved YOLOV4-Tiny Algorithm
Abstract
:1. Introduction
2. Related Work
2.1. YOLOV4-Tiny
3. Methodology
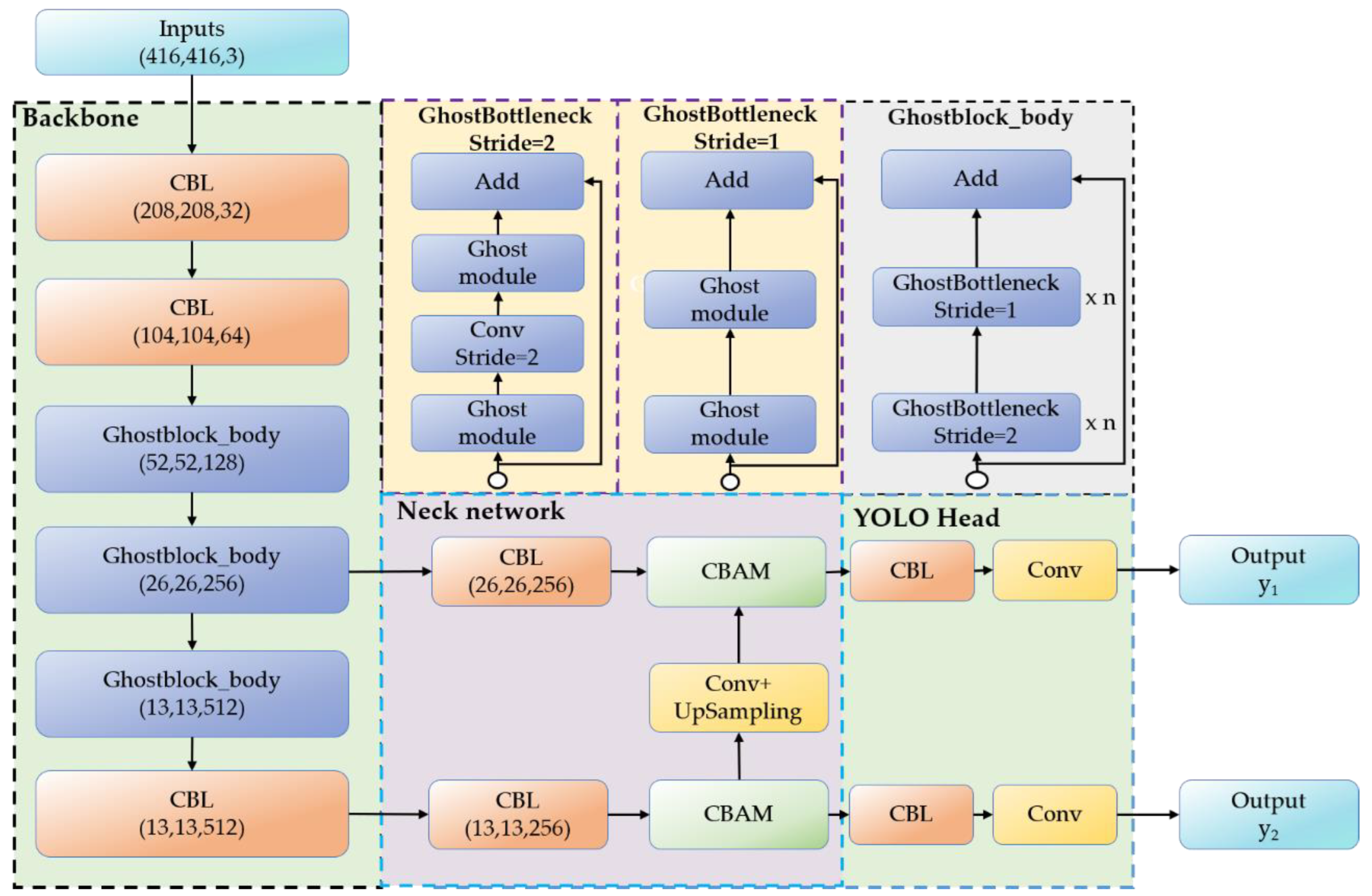
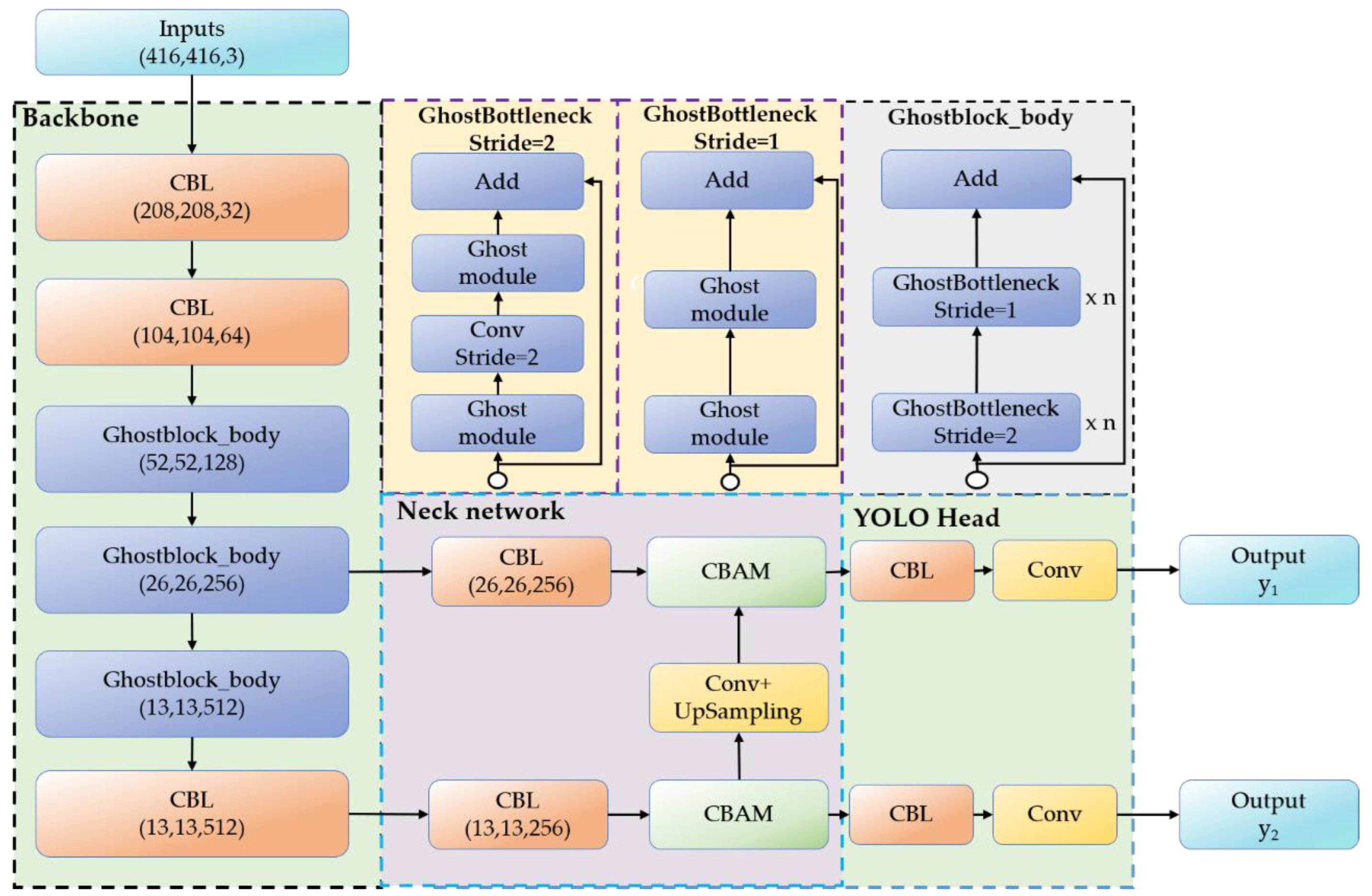
3.1. The Proposed YOLOV4-Tinier Network Structure
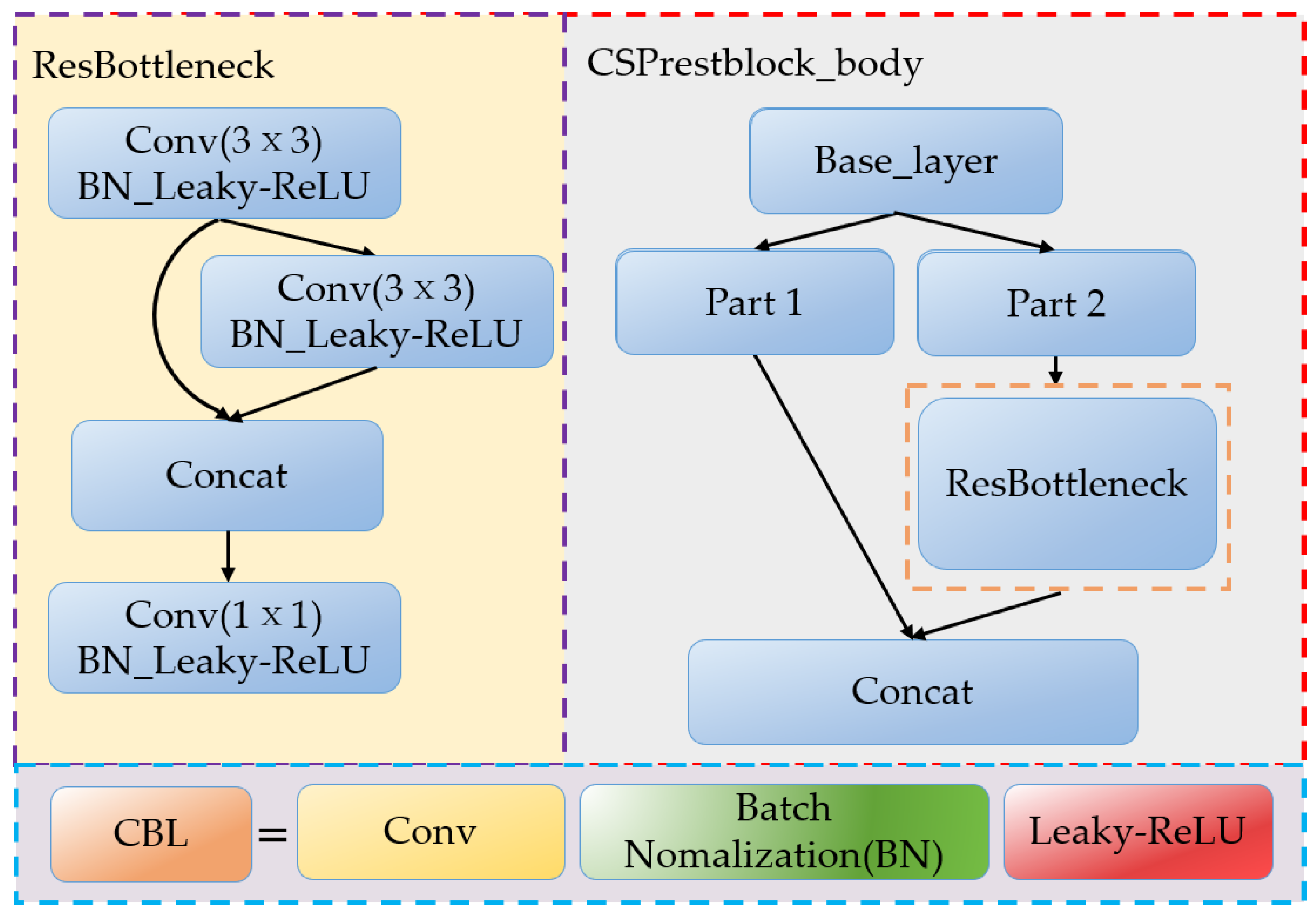
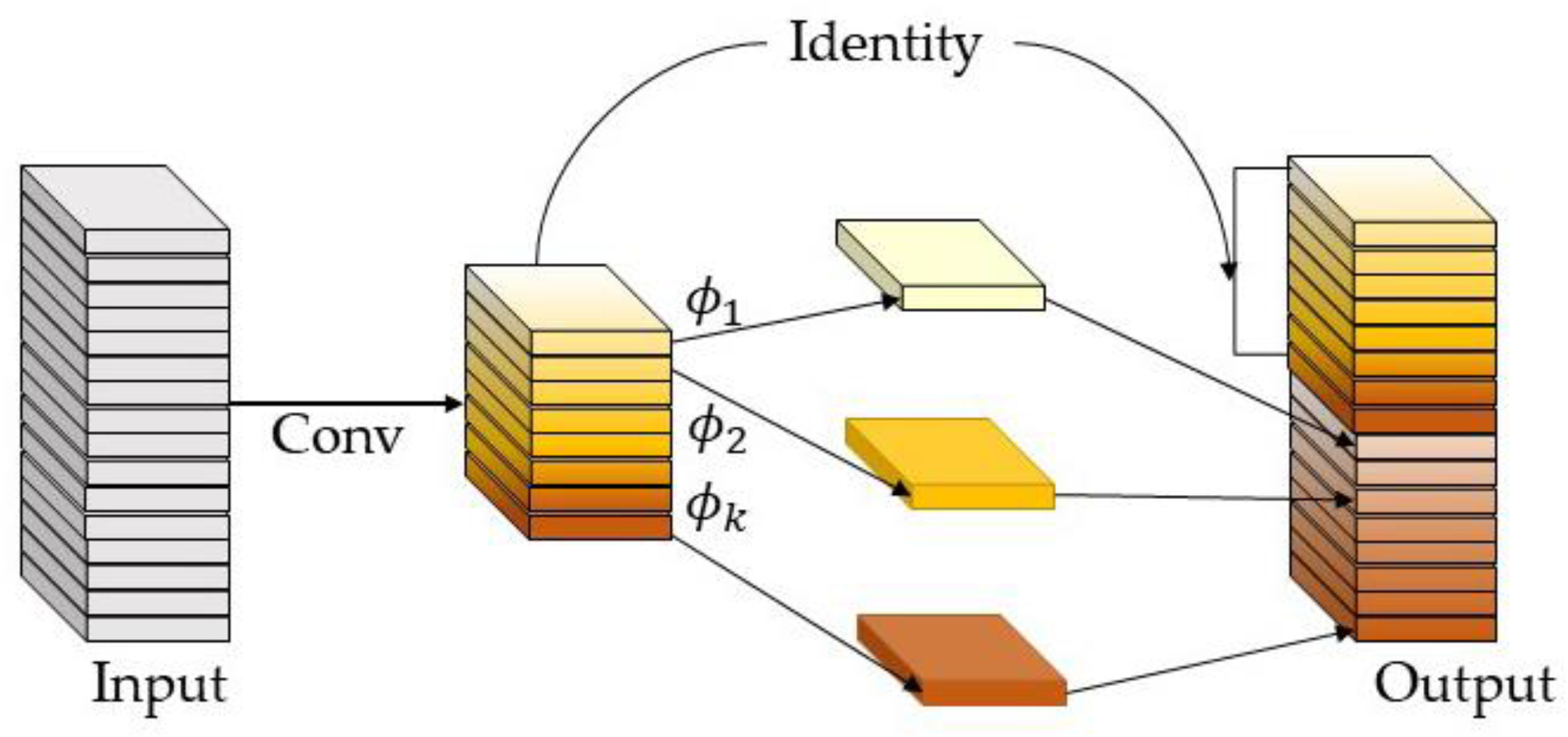
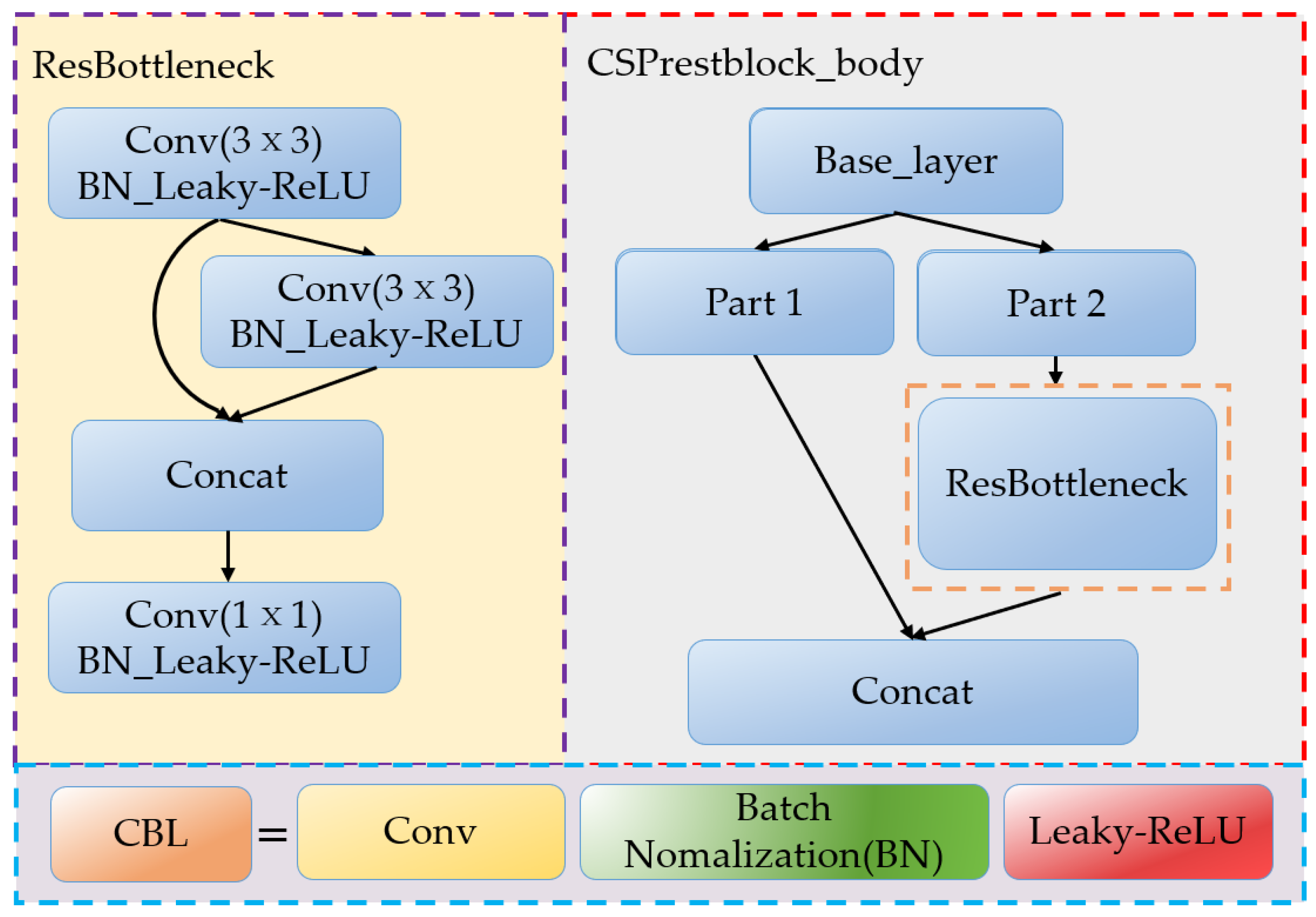
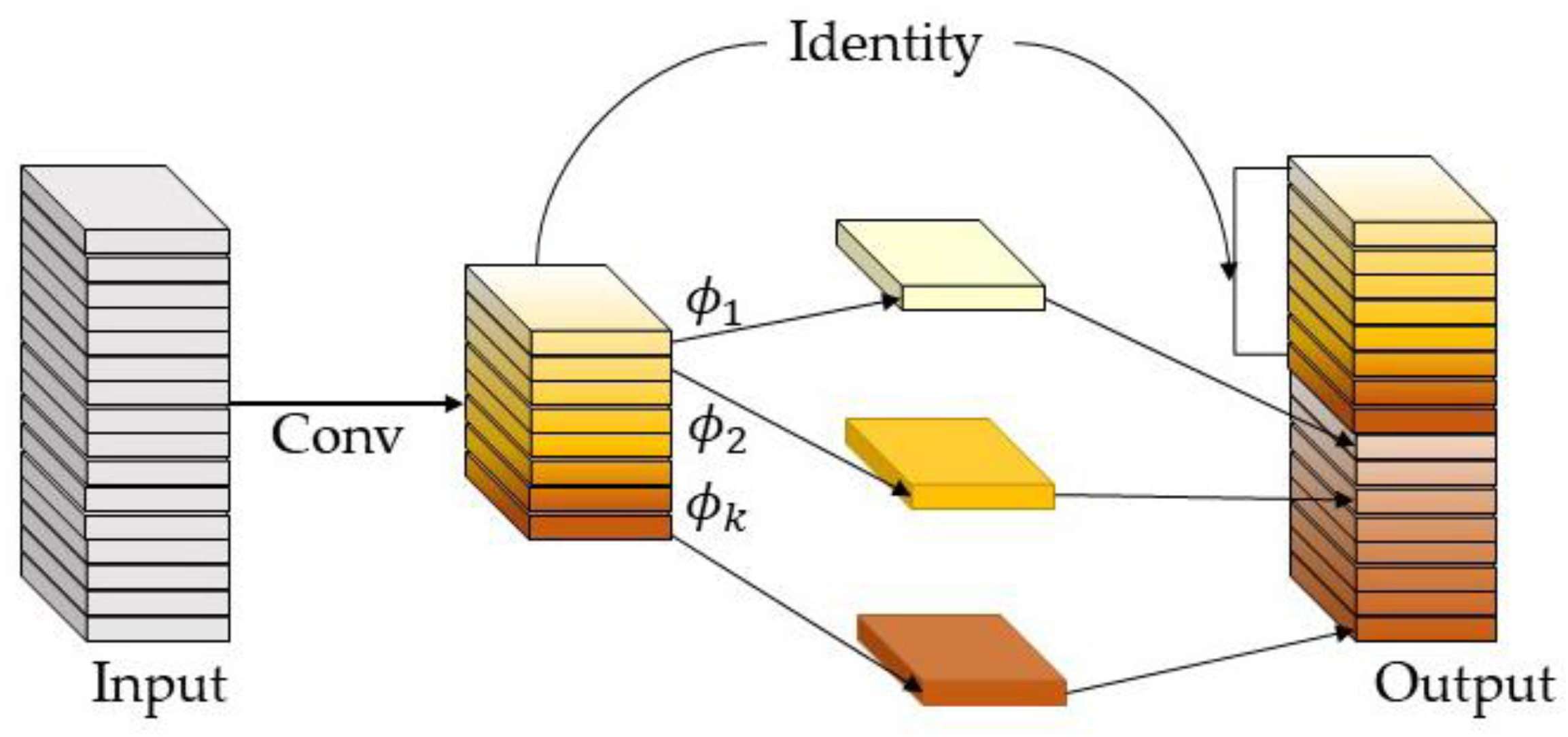
3.1.1. Improvement of Backbone Network
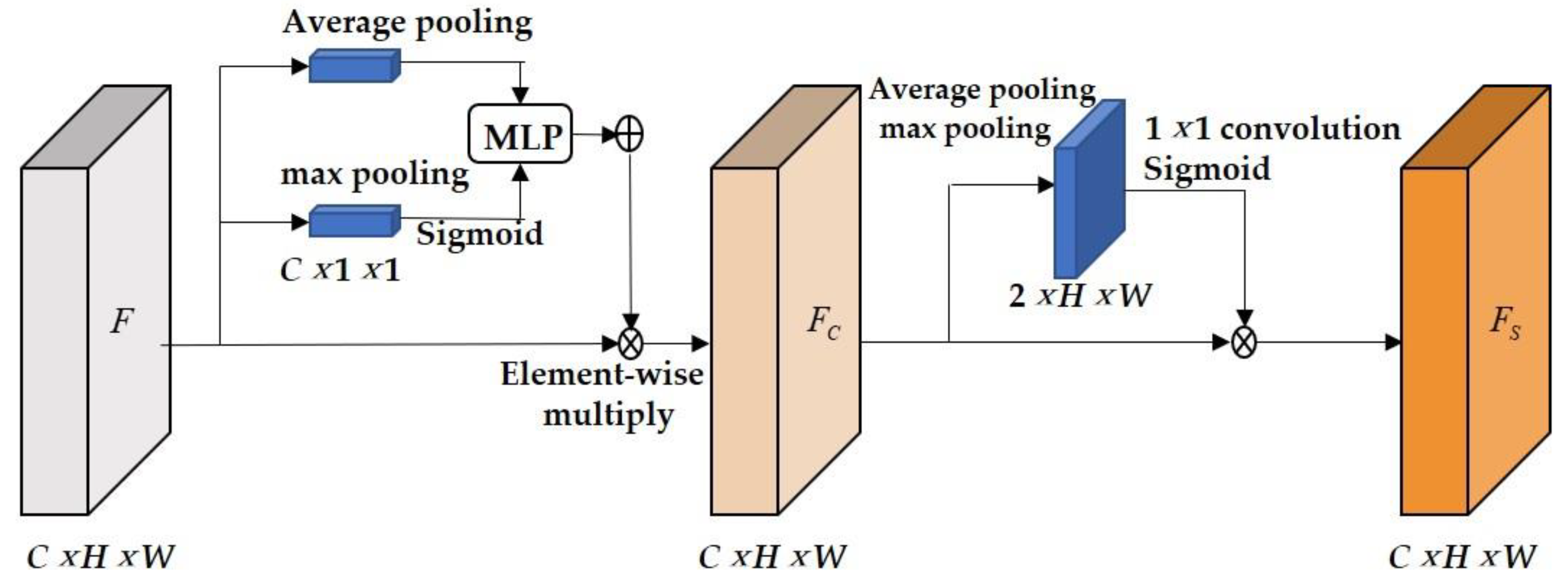
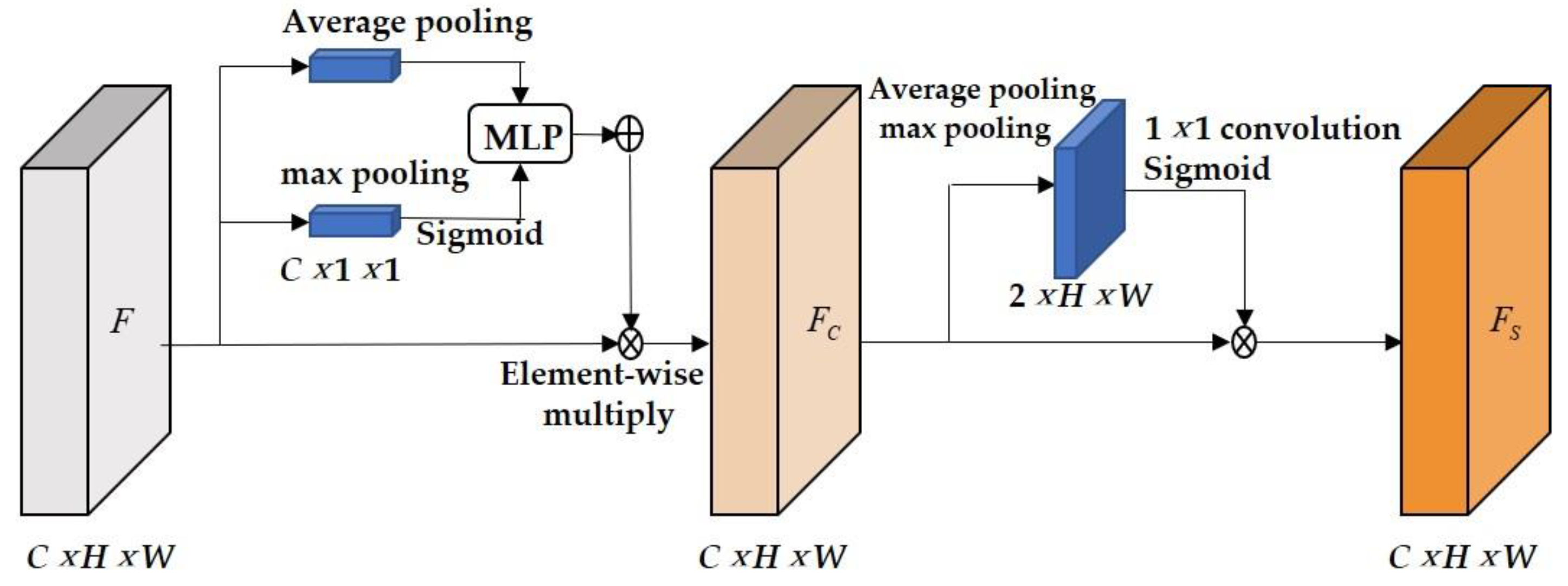
3.1.2. Improvement of the Neck Network
3.1.3. YOLOV4-Tinier Network Structure
3.2. Improvement of the Input to the Proposed Underwater Data Augmentation Algorithm
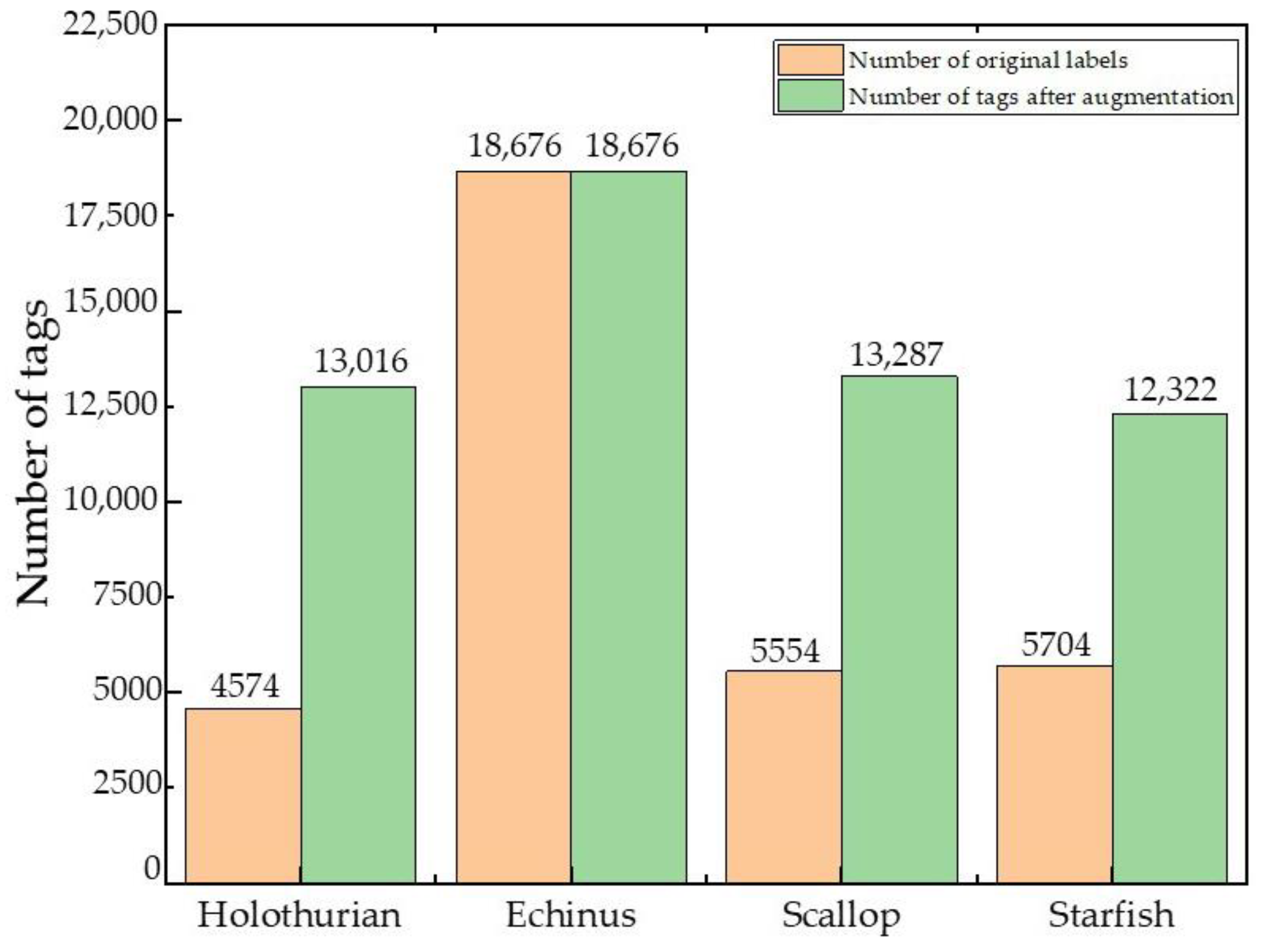
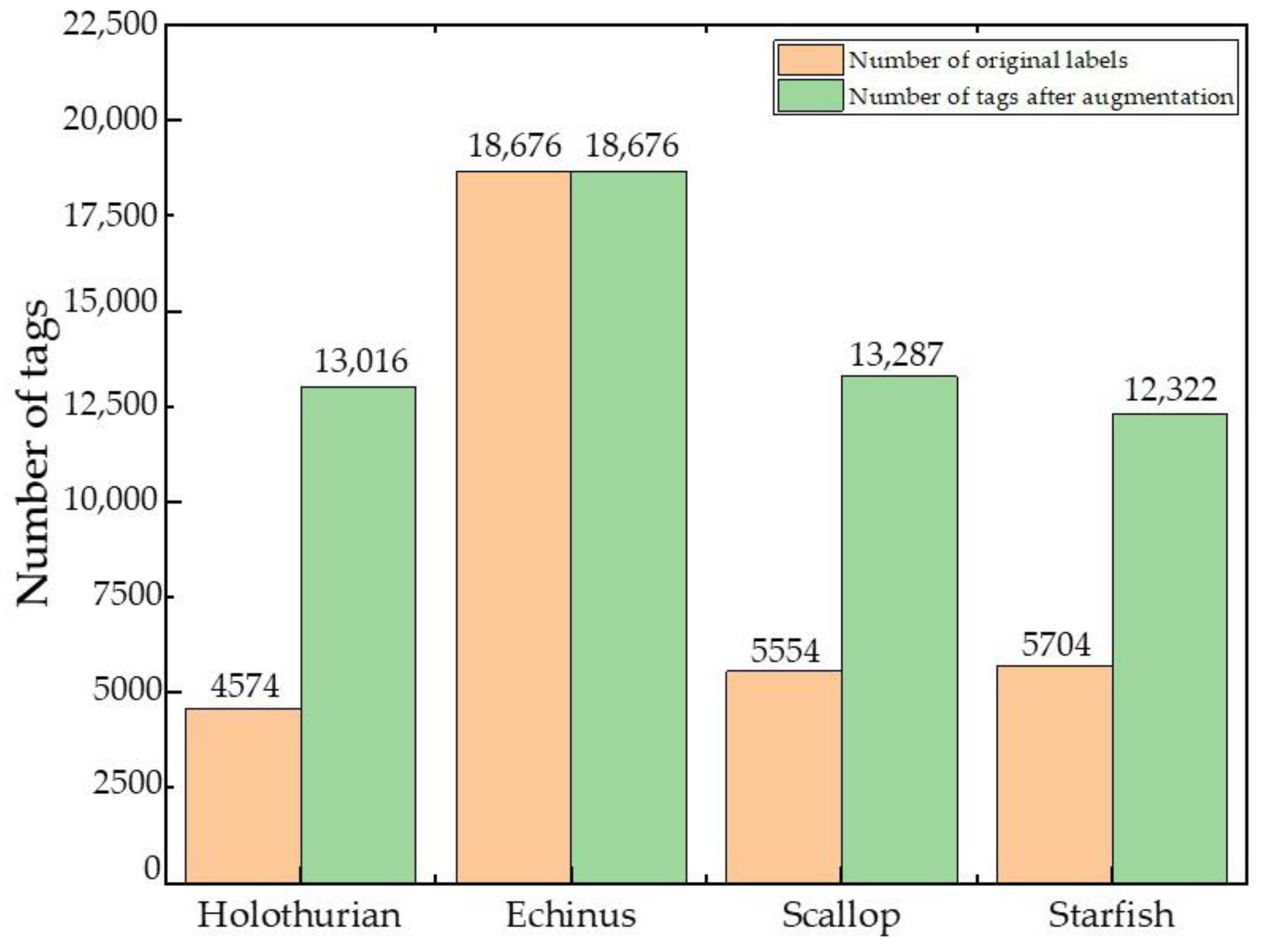
3.2.1. The Data Balance of the Proposed Underwater Data Augmentation Algorithm
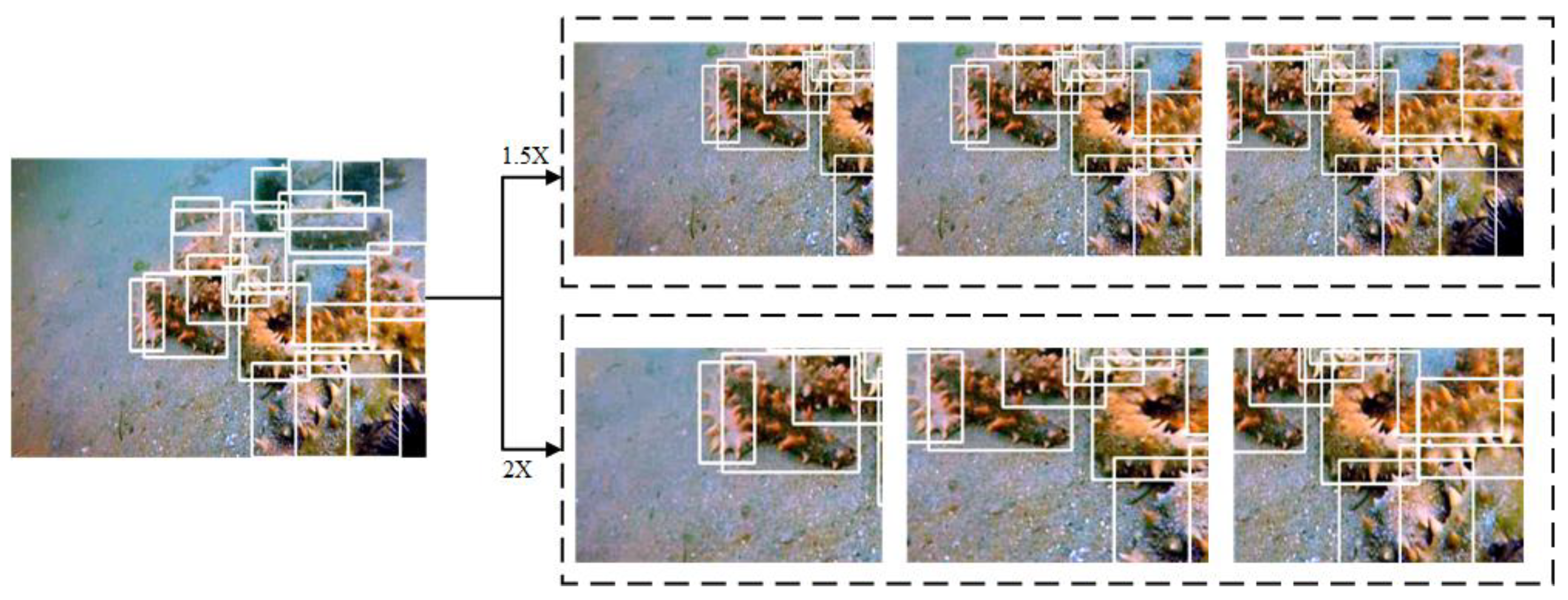
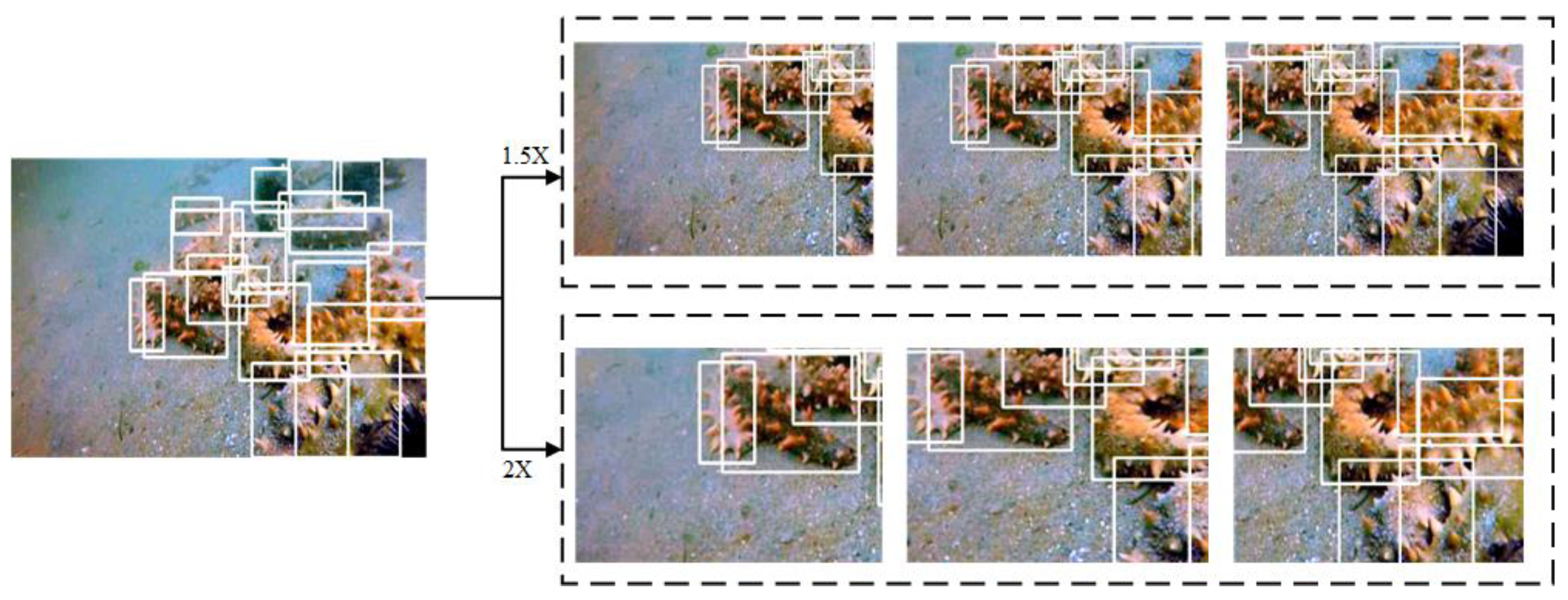
3.2.2. Image Restoration and Splice of Proposed Underwater Data Augmentation Algorithm
4. Experimental Settings
4.1. Experimental Environment
4.2. Experimental Datasets
4.3. Parameter Settings
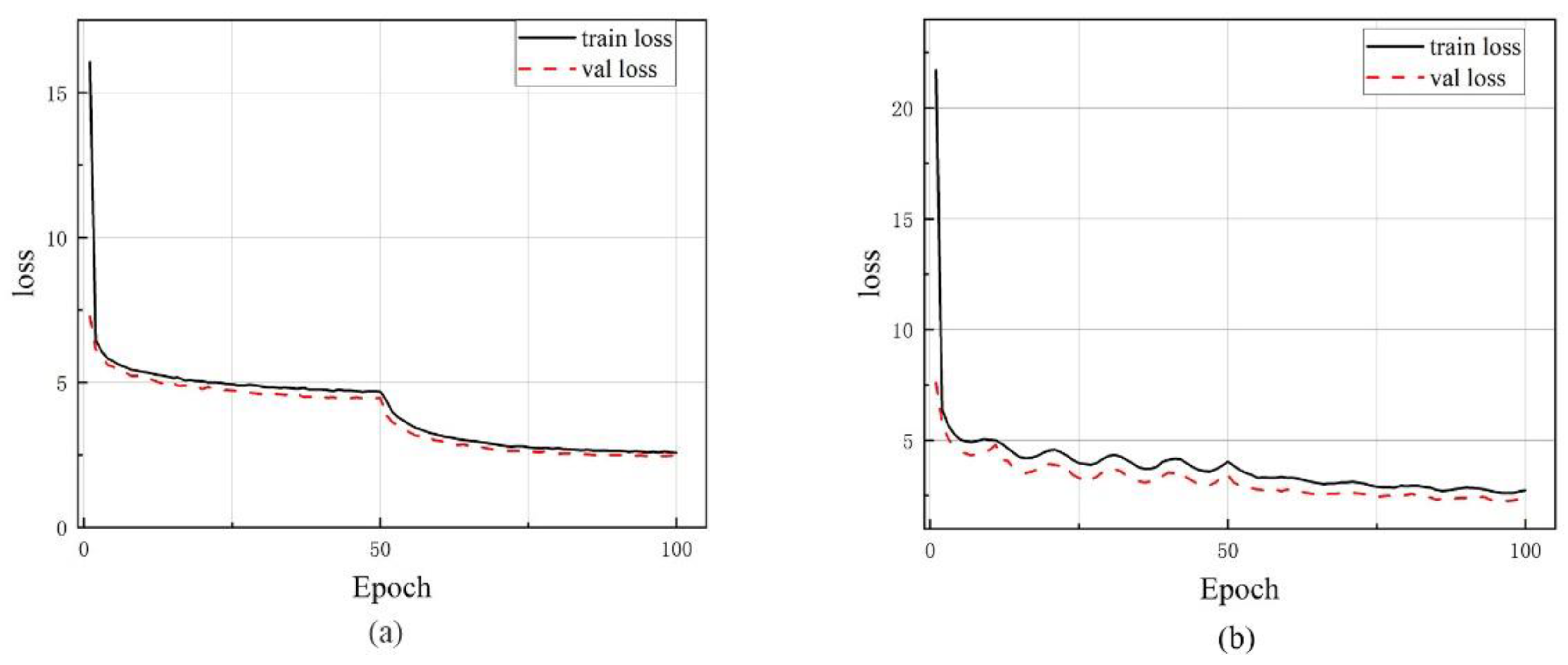
4.3.1. Training Parameter Settings
4.3.2. Transfer Learning Parameter Settings
4.4. Evaluation Indexes of Model Performance
4.5. Experimental Results and Analysis
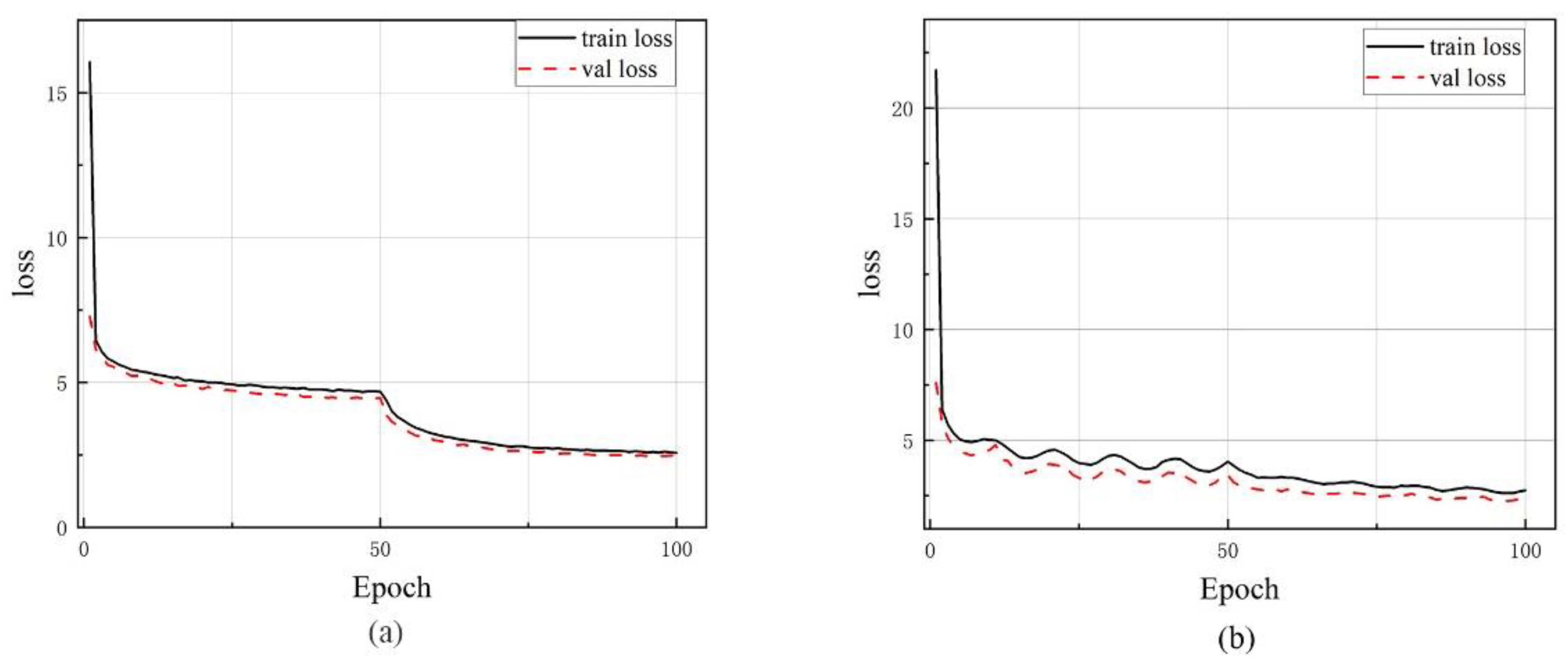
4.5.1. Effectiveness of Proposed Underwater Data Augmentation Algorithm
4.5.2. Ablation Experiments for YOLOV4-Tinier
4.5.3. Real-Time Performance of YOLOV4-Tinier
4.5.4. Performance of mAP on the Proposed Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chen, Y.; Ling, Y.; Zhang, L. Accurate Fish Detection under Marine Background Noise Based on the Retinex Enhancement Algorithm and CNN. J. Mar. Sci. Eng. 2022, 10, 878. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar]
- Sung, M.; Yu, S.; Girdhar, Y. Vision based real-time fish detection using convolutional neural network. In Proceedings of the OCEANS 2017, Aberdeen, DC, USA, 19–22 June 2017. [Google Scholar]
- Kou, L.; Xiang, J.; Bian, J. Controllability Analysis of a Quadrotor-like Autonomous Underwater Vehicle. In Proceedings of the 2018 IEEE 27th International Symposium on Industrial Electronics (ISIE), Cairns, Qld, Australia, 13–15 June 2018. [Google Scholar]
- Drews, J.P.; Nascimento, D.; Moraes, F. Transmission Estimation in Underwater Single Images. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013. [Google Scholar]
- Palazzo, Simone, Francesca Fish species identification in real-life underwater images. In Proceedings of the 3rd ACM International Workshop on Multimedia Analysis for Ecological Data, Lisboa, Portugal, 10–14 October 2022.
- Qin, H.; Li, J.; Peng, Y.; Zhang, C. DeepFish: Accurate underwater live fish recognition with a deep architecture. Neurocomputing 2016, 187, 49–58. [Google Scholar] [CrossRef]
- Han, F.; Yao, J.; Zhu, H.; Wang, C. Marine organism detection and classification from underwater vision based on the deep CNN method. Math. Probl. Eng. 2020, 2020, 3937580. [Google Scholar] [CrossRef]
- Arvind, C.S.; Prajwal, R.; Bhat, P.N. Fish detection and tracking in pisciculture environment using deep instance segmentation. In Proceedings of the TENCON IEEE Region 10 Conference, Osaka, Japan, 16–19 November 2020. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 20–23 June 1995. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, J.; Xu, C.; Jiang, L.; Xiao, Y.; Deng, L. Detection and analysis of behavior trajectory for sea cucumbers based on deep learning. IEEE Access 2019, 99, 18832–18840. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Wu, H.; He, S.; Deng, Z.; Kou, L.; Huang, K.; Sou, F.; Cao, Z. Fishery monitoring system with AUV based on YOLO and SGBM. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 3–5 June 2019. [Google Scholar]
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106–135. [Google Scholar] [CrossRef]
- Zhao, T.T.; Xiao, L.Y.; Zhi, Y.Z.; Tao, F. MobileNet-Yolo based wildlife detection model: A case study in Yunnan Tongbiguan Nature Reserve. China J. Intell. Fuzzy. Syst. 2021, 41, 2171–2181. [Google Scholar] [CrossRef]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A real-time object detection method for constrained environments. IEEE Access 2019, 99, 1935–1944. [Google Scholar] [CrossRef]
- Jiang, Z.C.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improver YOLOV4-Tiny. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hsiao, Y.H.; Cheng, C.C.; Lin, S.L. Real-world underwater fish recognition and identification using sparse representation. Ecol. Inform. 2014, 23, 13–21. [Google Scholar] [CrossRef]
- Jiao, Q.; Liu, M.; Ning, B.; Zhao, F.; Dong, L.; Kong, L. Image Dehazing Based on Local and Non-Local Features. Fractal. Fract. 2022, 6, 262. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the CVF International Conference on Computer Vision, Seoul, Republic of Korea, 20–26 October 2019. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- NgoGia, T.; Li, Y.; Jin, D.; Guo, J.; Li, J.; Tang, Q. Real-Time Sea Cucumber Detection Based on YOLOv4-Tiny and Transfer Learning Using Data Augmentation. In Proceedings of the International Conference on Swarm Intelligence, Qingdao, China, 17–20 July 2021. [Google Scholar]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Li, Z. YOLOv4-5D: An Effective and Efficient Object Detector for Autonomous Driving. IEEE Trans. Instrum. Meas. 2021, 70, 4503613. [Google Scholar]
- Li, X.; Pan, J.; Xie, F.; Zeng, J.; Li, Q.; Huang, X. Fast and accurate green pepper detection in complex backgrounds via an improved Yolov4-tiny model. Comput. Electron. 2021, 191, 106–115. [Google Scholar] [CrossRef]
- Wang, C.; Liao, H.; Wu, Y. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, K.M.; Xiang, Y.Z.; Shao, Q.R.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the IEEE Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, H.; Wang, Q.; Yang, F.; Zhang, W.; Zuo, W. Data augmentation for object detection via progressive and selective instance-switching. arXiv 2019, arXiv:1906.00358. [Google Scholar]
- Amer, K.O.; Elbouz, M.; Alfalou, A.; Brosseau, C. Enhancing underwater optical imaging by using a low-pass polarization filter. Opt. Express 2019, 27, 621–643. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.; Cheng, Y.F.; Li, L.; Zhang, K.H.; Liu, Y.F. Underwater Image Restoration via DCP and Yin–Yang Pair Optimization. J. Mar. Sci. Eng. 2022, 10, 360. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | AP (%) | mAP@0.5 | |||
|---|---|---|---|---|---|
| Starfish | Echinus | Holothurian | Scallop | (%) | |
| Original dataset | 49 | 39 | 29 | 4 | 30.05 |
| Mosaic dataset | 51 | 44 | 28 | 3 | 31.56 |
| Proposed dataset | 86 | 86 | 76 | 75 | 80.77 |
| YOLOV4-Tiny | GhostNet | CBAM | mAP (%) | Model Size (MB) |
|---|---|---|---|---|
| √ | 82.09 | 23.10 | ||
| √ | √ | 77.32 | 16.13 | |
| √ | √ | 83.16 | 23.76 | |
| √ | √ | √ | 80.77 | 16.40 |
| Model | Average Test Time (ms) | fps | Model Size (MB) |
|---|---|---|---|
| YOLOV3-Tiny | 17.32 | 57.63 | 34.9 |
| YOLOV4-Tiny | 13.22 | 75.28 | 23.10 |
| YOLOV4-Tinier | 11.5 | 86.96 | 16.40 |
| Model | Scallop | Echinus | Holothurian | Starfish | mAP | ||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | @0.5 | |
| Faster-RCNN | 49.09 | 84.97 | 50.11 | 79.59 | 40.64 | 74.17 | 61.14 | 86.29 | 74.91 |
| YOLOV3- | 88.35 | 55.3 | 88.93 | 34.21 | 90.79 | 55 | 90.05 | 60.17 | 67.72 |
| Tiny | |||||||||
| YOLOV4-Tiny | 87.7 | 73.86 | 91.21 | 53.83 | 89.2 | 57.58 | 91.56 | 74.39 | 82.09 |
| YOLOV4 | 87.05 | 72.14 | 92.46 | 48.98 | 88.98 | 56.89 | 90.84 | 73.44 | 80.77 |
| -Tinier | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, K.; Cheng, Y.; Tian, Z.; Zhang, K. High Speed and Precision Underwater Biological Detection Based on the Improved YOLOV4-Tiny Algorithm. J. Mar. Sci. Eng. 2022, 10, 1821. https://doi.org/10.3390/jmse10121821
Yu K, Cheng Y, Tian Z, Zhang K. High Speed and Precision Underwater Biological Detection Based on the Improved YOLOV4-Tiny Algorithm. Journal of Marine Science and Engineering. 2022; 10(12):1821. https://doi.org/10.3390/jmse10121821
Chicago/Turabian StyleYu, Kun, Yufeng Cheng, Zhuangtao Tian, and Kaihua Zhang. 2022. "High Speed and Precision Underwater Biological Detection Based on the Improved YOLOV4-Tiny Algorithm" Journal of Marine Science and Engineering 10, no. 12: 1821. https://doi.org/10.3390/jmse10121821
APA StyleYu, K., Cheng, Y., Tian, Z., & Zhang, K. (2022). High Speed and Precision Underwater Biological Detection Based on the Improved YOLOV4-Tiny Algorithm. Journal of Marine Science and Engineering, 10(12), 1821. https://doi.org/10.3390/jmse10121821