1. Introduction
In modern agriculture, apples, as a widely grown fruit, are rich in nutrients, low in fat, high in carbohydrates, and contain vitamins C and E. They can be grown under a variety of conditions and have high economic value [
1]. Due to the complex environment of modern apple orchards, fruit harvesting still relies on manual labor, but faces challenges such as high labor intensity, long cycle time, and low efficiency [
2]. In contrast, automated harvesting technology is gradually emerging with its high efficiency and precision. Through advanced technologies such as image recognition, machine learning, and robotic arms, automated picking equipment can recognize and pick apples more quickly, significantly improving picking efficiency. However, when apple picking is performed in a natural environment, it often faces the problem of fruit occlusion, i.e., apples are occluded by leaves, branches, or other fruits, which makes it difficult for picking equipment to accurately recognize the target fruit. This problem not only affects the efficiency and accuracy of picking but also may lead to the unnecessary waste of resources and fruit damage. Secondly, to protect the fruits from pests and birds, and to reduce the amount of insecticides and fungicides on the surface of the fruits, most orchards use bagging techniques to protect the fruits [
3]. This practice, although effective, poses additional difficulties in apple detection. In addition to the above technical difficulties, how to develop lightweight models for resource-constrained devices (e.g., edge devices and mobile devices) is also a hot topic in current research. These devices usually have limited computational resources and storage space, so how to ensure the accuracy of model detection while realizing the lightweight of the model has become an urgent problem [
4].
With the rapid development of computer vision and deep learning technology, machine learning provides new solutions for apple recognition [
5]. The advancement of agricultural modernization has also led to the introduction of more and more automated and intelligent equipment into agricultural production. Accurate recognition of crops by target detection techniques is a key step in automating harvesting. In the specific application scenario of apple harvesting, the introduction of deep learning technology greatly improves the accuracy and efficiency of target detection technology. Traditional apple recognition methods are often limited by factors such as lighting conditions, fruit shading, and morphological diversity, making it difficult to achieve efficient and accurate recognition. The apple recognition algorithm based on deep learning, through the construction of the deep convolutional neural network (CNN) and other models, can automatically learn the complex features of apples from a large amount of image data [
2], including color, texture, shape, and contextual information, so as to achieve the accurate positioning and recognition of apple fruits.
Deep learning in target detection is mainly categorized into two types: second-order algorithms and one-stage algorithms. Second-order algorithms include R-CNN [
6], Faster R-CNN [
7], and so on. This type of method first generates a series of potential candidate target regions through a region proposal network, and then performs further classification and bounding box regression on these regions for precise localization and identification. Such methods have significant advantages in target detection accuracy, especially when facing challenges such as complex backgrounds, illumination changes, or partial occlusion of the target, and still show strong robustness. However, its relatively high computational complexity due to its need to generate and process a large number of candidate regions may limit its application in some scenarios with high real-time requirements. In contrast, one-stage algorithms, such as SSD [
8,
9] and the Yolo series [
10,
11,
12,
13,
14], take a more direct and efficient approach. They directly predict both the class and location of the target in a single forward pass, without the need to generate candidate regions, and thus have higher computational efficiency and faster detection speeds. By optimizing the network structure and loss function, these algorithms are able to significantly reduce the computational cost while maintaining high detection accuracy, making them more suitable for automated agricultural harvesting systems with high real-time requirements.
Yang et al. [
15] addressed the challenges of apple fruit detection by improving the YOLOv7 algorithm, incorporating preprocessing for overlapping images, dataset partitioning, the introduction of the MobileOne module, enhancements to the SPPCSPS module, and the addition of an auxiliary detection head. These improvements led to a 6.9% increase in accuracy, a 10% boost in recall, and 5% and 3.8% improvements in mAP1 and mAP2, respectively. However, despite these significant results in apple detection, the performance gains came at the cost of increased computational complexity and model size, posing challenges for deployment and inference speed in practical applications. Wu et al. [
16] constructed the DNE-APPLE dataset and proposed the DNE-YOLO model, achieving an accuracy of 90.7%, a recall of 88.9%, and an mAP50 of 94.3% under complex weather conditions, with a computational complexity of 25.4 GFLOPs and 10.46 M parameters. While the model exhibits excellent performance under complex weather conditions, its adaptability to other environmental factors (such as intense sunlight and shadows) may be limited. HAO et al. [
17] introduced the YOLO-RD-Apple Orchard model, leveraging RGB and Depth images for detecting occluded apples, achieving an AP value of 93.1%, a 70% reduction in parameters, and a detection speed of 40.5 FPS. FU et al. [
18] designed an apple recognition method based on Faster R-CNN, achieving average precisions of 90.9%, 85.8%, 89.9%, and 84.8% under conditions of no occlusion, occlusion by branches, occlusion by leaves, and overlapping occlusion by fruits, respectively, with a processing time of 0.241 s per image. This method has certain advantages in handling multi-category occlusion problems, but may be constrained by computational resources and inference speed. Lu et al. [
19] improved the YOLOv4 model by adding the CBAM module for detecting apples of different maturity stages, achieving detection accuracies of 86.2%, 87.5%, and 92.6% for early, mid, and harvest stages, respectively. The model excels in feature extraction and detection accuracy but may be limited by the diversity and complexity of orchard environments. Furthermore, the model’s parameters and computational complexity need further optimization to adapt to more resource-constrained scenarios. Zhen et al. [
20] improved the YOLOv7 model by combining Partial Convolution (PConv), Efficient Channel Attention (ECA) modules, and Sparrow Search Algorithm (SSA) optimization, resulting in increases of 4.15%, 0.38%, and 1.39% in accuracy, recall, and mean average precision, respectively, with reductions of 22.93% and 27.41% in parameters and computational operations. Despite achieving significant results in natural orchard apple detection, the model may still be affected by the complexity of orchard environments and does not consider the issue of bagging in most orchards in reality. In the detection of bagged fruits, the traditional methods face many challenges due to very little related research. Liu et al. [
21] proposed a method to attenuate the effect of light on the identification of apple fruits in plastic bags. This method uses a watershed algorithm to segment the original image into irregular blocks based on the edge detection results of R-G grayscale images. Compared with the watershed algorithm based on gradient images, this segmentation method reduces the number of blocks by 20.31%, while being able to preserve the fruit edges. Afterwards, a support vector machine is used to classify the blocks based on the color and texture features extracted from each block. The experimental results show that the proposed method reduces the false negative rate (FNR) from 21.71% to 4.65% and the false positive rate (FPR) from 14.53% to 3.50%, which significantly improves the accuracy of the recognition as compared to the pixel classification-based image recognition method. However, despite the success of this method, with the rapid development of deep learning techniques, especially the advancement in the field of target detection, we have the possibility to further improve the detection performance.
In summary, despite the initial results achieved in the field of apple research based on target detection, several unresolved challenges remain. In particular, most of the existing methods focus on the detection of naked apple fruits, while ignoring the additional challenges added to the detection task by the protective measures of bagging commonly used in orchards. The accuracy and generalization performance of recognition when dealing with variable environmental conditions, such as light fluctuations, object occlusion and fruit overlapping, have yet to be enhanced [
22]. In addition, current models generally have high computational complexity and large parameter scales, which hinder their deployment on resource-constrained mobile or embedded platforms, and thus limit their practical applications. To address these limitations, this paper proposes a lightweight apple detection model for natural environments based on improved YOLOv11, AAB-YOLO. The main contributions of this paper are as follows:
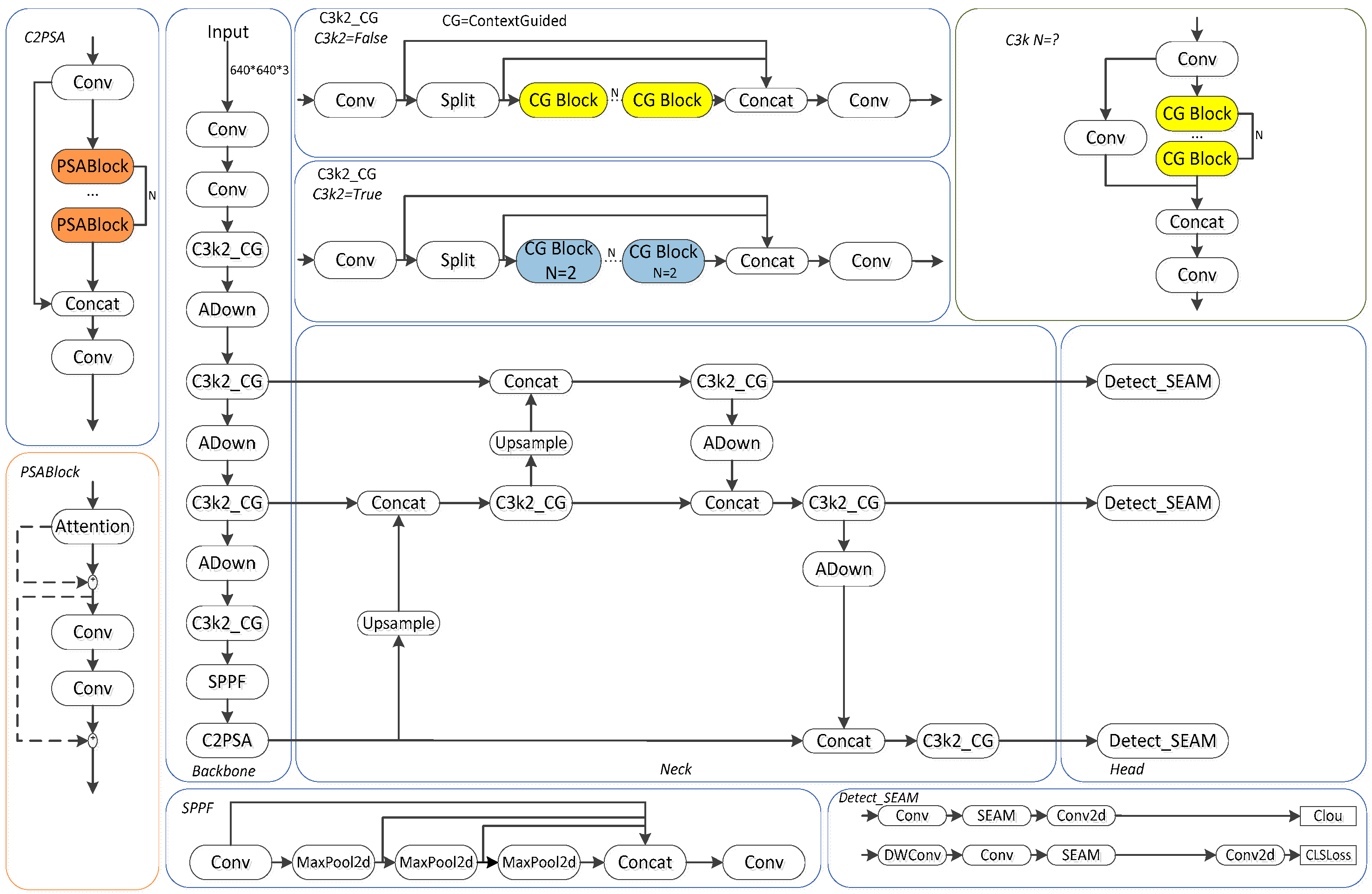
Specialized agricultural dataset: developed a 3140-image dataset capturing real-world bagged/unbagged apples under varied shading and lighting conditions, addressing critical gaps in agricultural object detection.
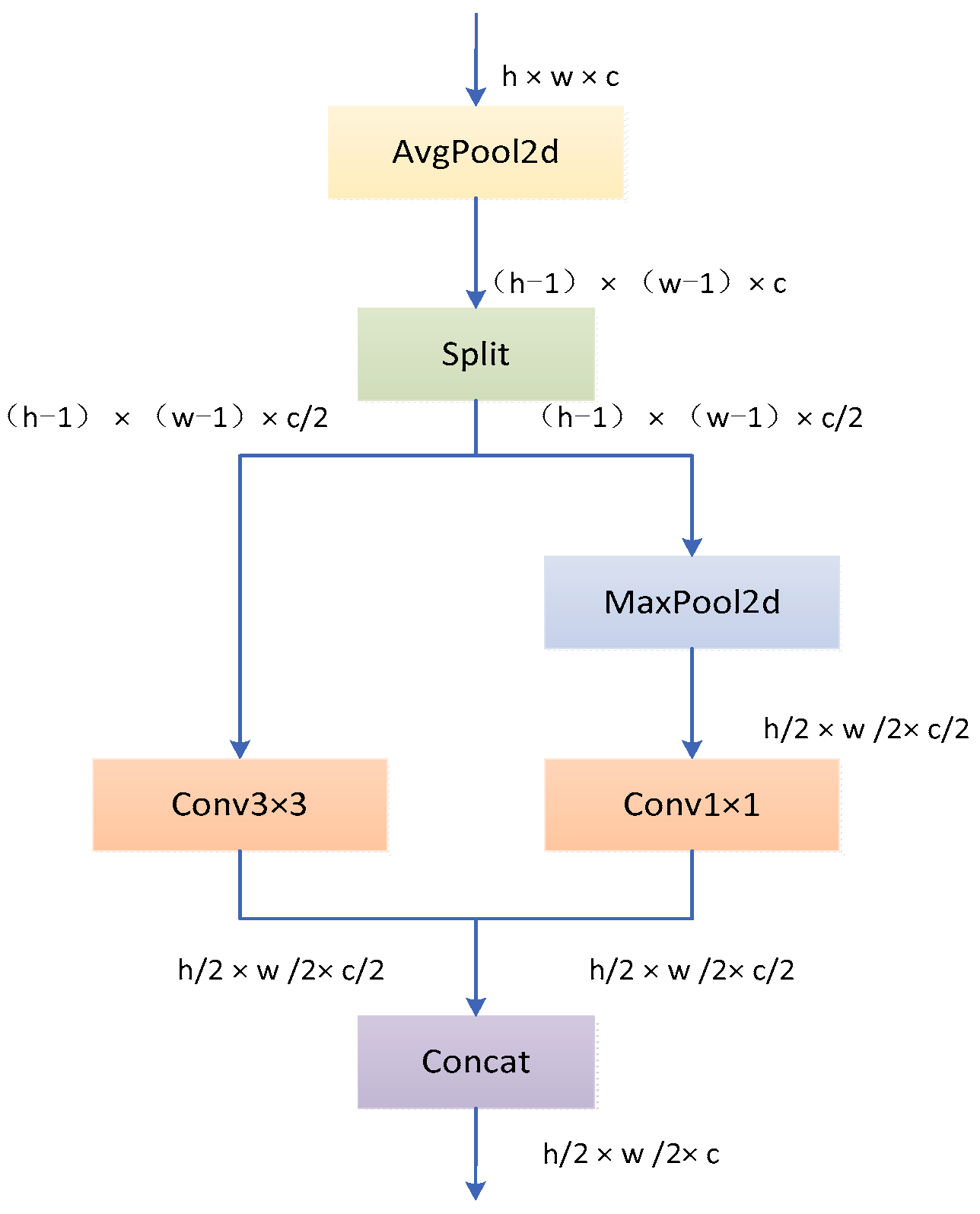
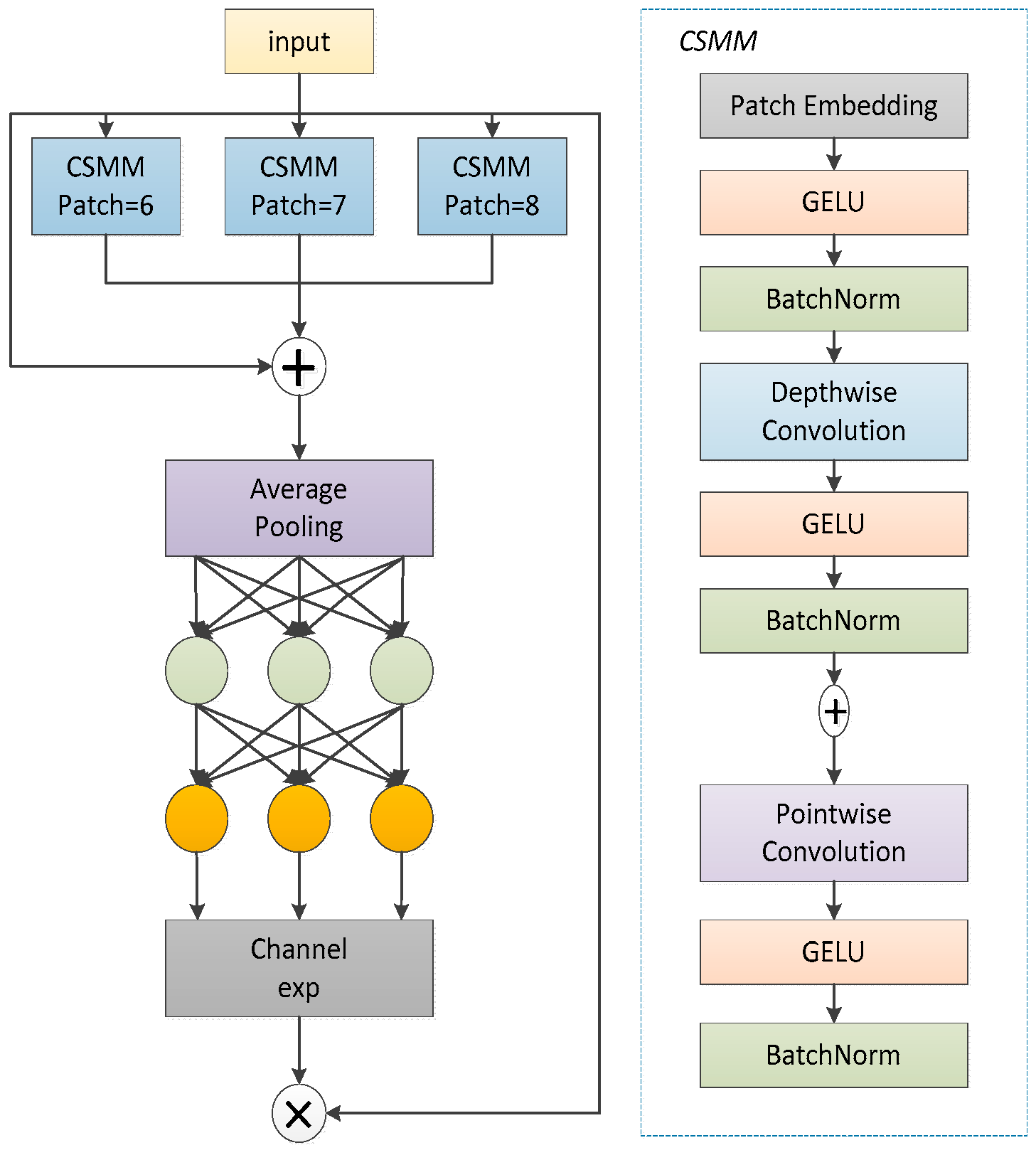
Enhanced feature extraction: introduced the ADown module with optimized convolutional downsampling, preserving critical spatial information while reducing computational complexity.
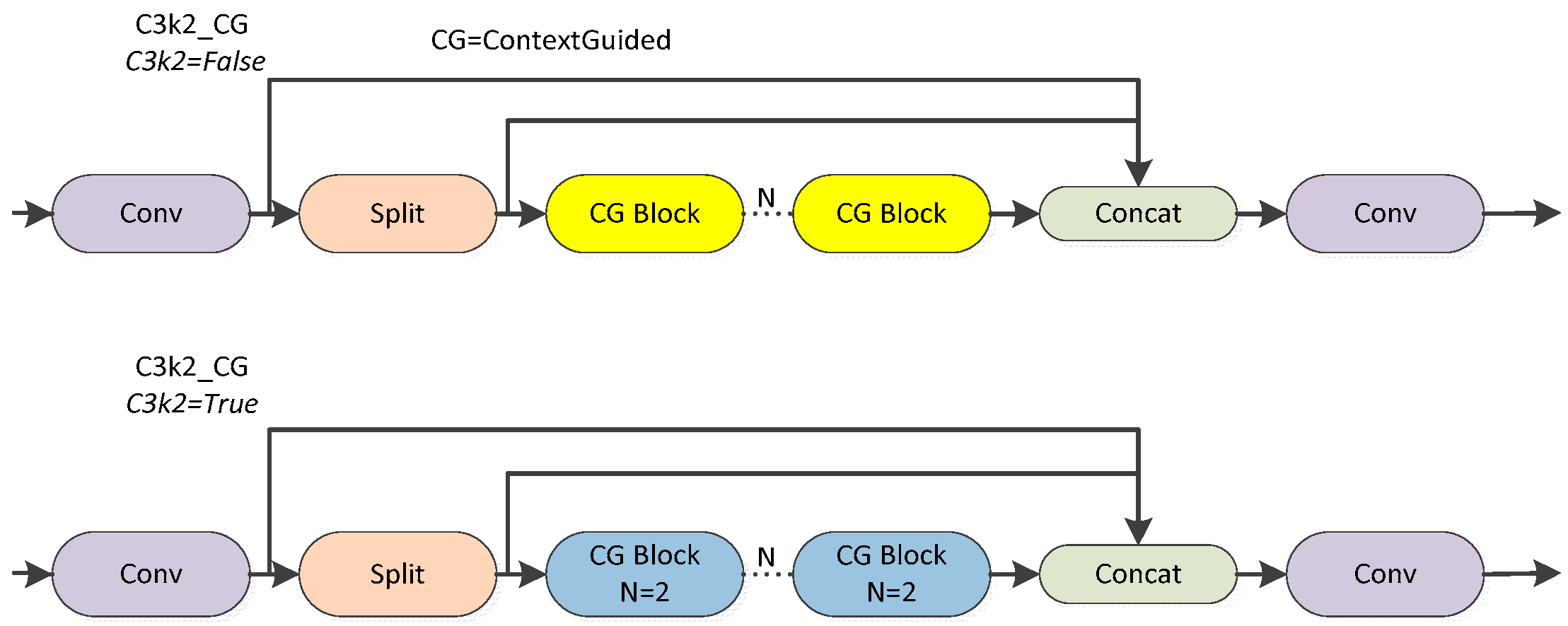
Contextual scene understanding: integrated C3k2_ContextGuided module to fuse multi-scale contextual features, improving detection in complex orchard environments.
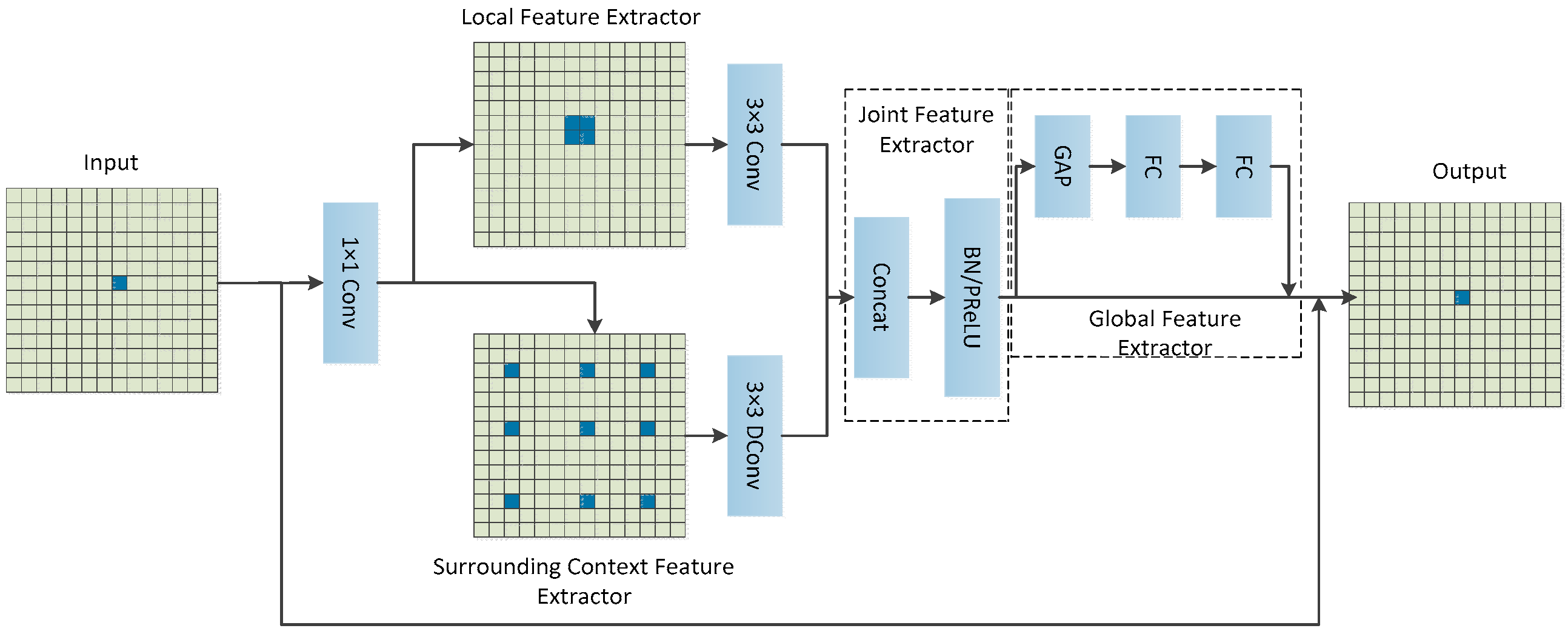
Occlusion robustness: proposed Detect_SEAM module specifically designed to handle apple occlusions in natural foliage settings.
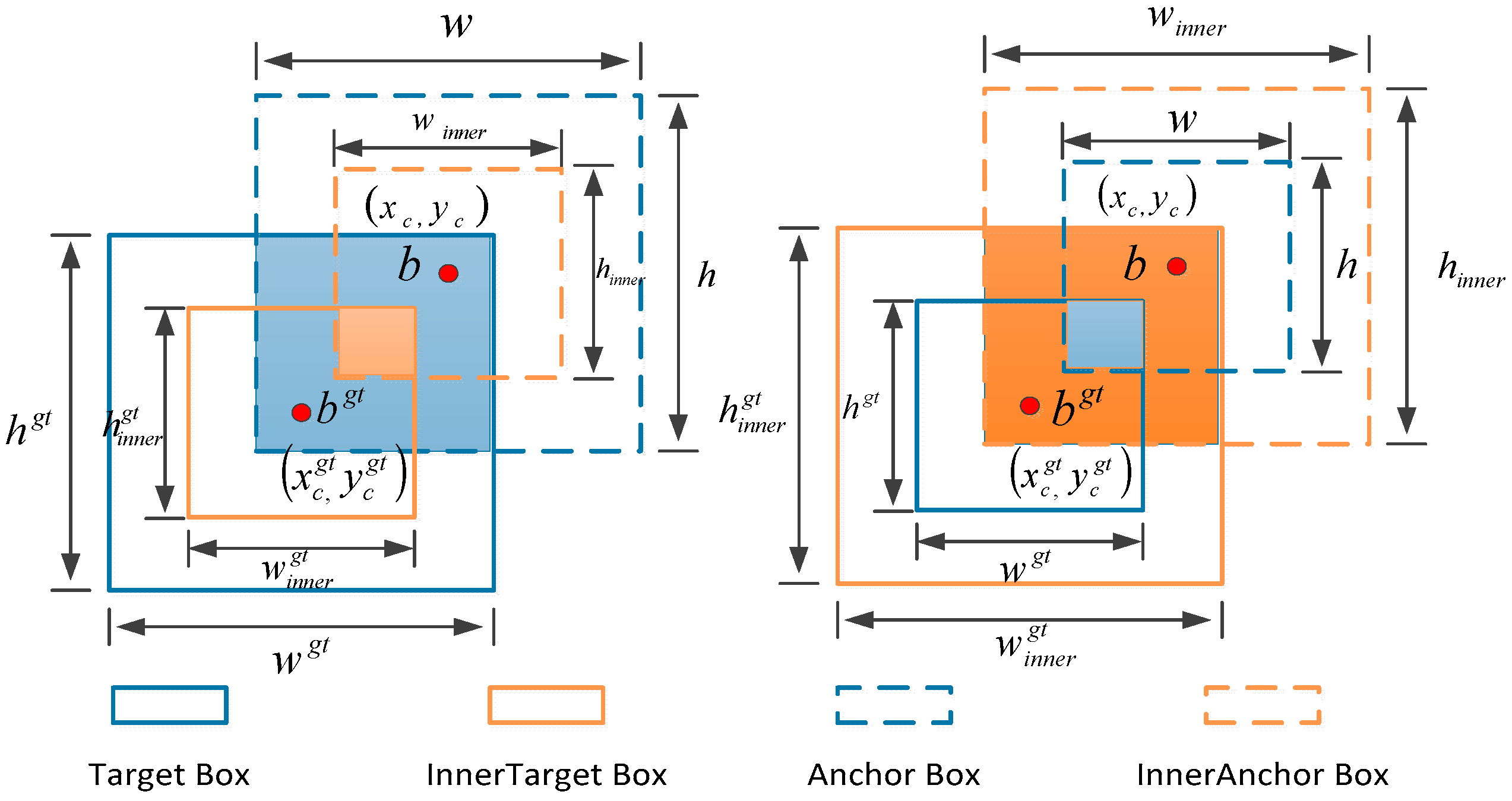
Efficient training strategy: adopted Inner_EIou loss function to simultaneously enhance detection accuracy and training efficiency across diverse scenarios.
These integrated innovations collectively enable the accurate detection of bagged/unbagged apples under challenging conditions, demonstrating significant advancements in agricultural vision systems.
3. Experiment and Results
3.1. Experimental Configuration and Evaluation Indicators
The system used for the experiments in this paper is Windows 11 operating system with 16 GB of RAM; the hardware CPU used for the experiments is an Intel® Xeon® Gold 6152 CPU with 10 cores, manufactured by Intel Corporation, USA. The GPU used is an NVIDIA GeForce RTX 3090 Laptop GPU, manufactured by NVIDIA Corporation, USA; the software used for the experiments is Pycharm 2023.3.4; and the language based on Python is adopted as the Pytorch deep learning framework, and the Python version is Python 3.8.
In the experiments of this paper, the hyperparameters used in the training and validation process of all models are kept consistent, and the experimental parameters used in the network training process of this paper are shown in
Table 1.
In order to evaluate the model performance, precision, recall, mean accuracy (mAP), the number of parameters (Params), GFLOPs, and the model weight file size (in MB) are selected as the evaluation metrics for the experiment.
Precision is an important metric to measure the prediction accuracy of the target detection model. It indicates the proportion of true positive samples among all instances predicted as positive by the model. The calculation formula is as follows:
TP, FP, and FN denote the number of true positive, false positive, and false negative instances, respectively.
Recall reflects the completeness of the model in detecting the target. It indicates the proportion of all actually existing positive samples that are successfully detected by the model. The formula is calculated as follows:
AP (Average Precision) is defined as the average of precision at all different levels of recall for a single category. The formula is as follows:
The mAP is a key metric for measuring the performance of a target detection model in a multi-category scenario. It is obtained by averaging the average precision (AP) for each category. The calculation formula is as follows:
IoU (Intersection over Union) is a measure of the degree of overlap between the predicted frame and the real frame, calculated as the area of intersection between the predicted frame and the real frame divided by their concatenated area. The prediction is considered correct when the IoU value is greater than or equal to 50%. mAP50 is the mean average precision under the 50% IoU threshold. In this paper, mAP50 is adopted as the evaluation metric.
GFLOPs is a measure of the computational complexity of the model, which indicates the number of floating-point operations (in billions) that the model can perform per second. The GFLOPs value is usually computed by the forward propagation of the model, which reflects the computational performance of the model during inference or training. The higher value of the GFLOPs indicates that the model’s computational complexity is higher, and more computational resources may be required. The model weights file size is the size of the storage space required to store the model weights. Smaller weight files can be more easily deployed and used on different hardware platforms and reduce storage costs.
3.2. Ablation Experiments
In order to verify the effectiveness of the improved module proposed in this paper in complex natural scenarios, eight sets of ablation experiments were conducted under the same dataset and training conditions, and the results of the experiments are shown in
Table 2.
The ablation experiments reveal that the original YOLOv11n model has 2.58 M parameters, 6.3 GFLOPs, and a weight file size of 5.20 MB, with precision, recall, mAP50, and mAP@50-95 of 0.948, 0.865, 0.917, and 0.813, respectively. While demonstrating strong initial performance in accuracy and recall, its parameter count and computational complexity are relatively high. Upon integrating the ADown module to replace the original downsampling layer, GFLOPs decrease by 15.9%, parameters are reduced by 24.6%, recall improves by 1.04%, and mAP@50-95 marginally increases to 0.818, indicating that lightweight modifications preserve high-precision detection while slightly enhancing mid-to-high IoU threshold detection capabilities. The C3k2_ContextGuided module, leveraging context-aware mechanisms to enhance feature extraction, reduces parameters by 15.5% and GFLOPs by 22.2%, while elevating mAP50 to 0.919. However, mAP@50-95 drops slightly to 0.808, potentially due to trade-offs between feature enhancement and lightweight design affecting high-threshold detection stability. When the Detect_SEAM module is introduced alone, GFLOPs decrease by 7.94% and parameters by 3.4%, with its spatial attention mechanism effectively suppressing background interference to boost mAP@50-95 to 0.815, although lightweighting gains are moderate.
Synergistic benefits emerge through modular combinations: Combining ADown with C3k2_ContextGuided reduces parameters by 34.11% and GFLOPs by 30.16%, maintaining mAP50 at 0.919 but lowering mAP@50-95 to 0.801, reflecting the challenges of complexity reduction on high-IoU detections. The ADown-Detect_SEAM pairing lowers GFLOPs by 23.8% while increasing precision to 0.957 and mAP@50-95 to 0.810, suggesting that attention mechanisms compensate for information loss from lightweighting. Integrating C3k2_ContextGuided with Detect_SEAM reduces parameters by 18.9% and GFLOPs by 22.2%, lifting mAP50 to 0.919 but decreasing mAP@50-95 to 0.795, indicating that while context awareness and attention improve primary metrics, strict IoU threshold adaptability requires further tuning. When all three modules are combined, recall and mAP50 improve significantly, yet mAP@50-95 reaches 0.805, highlighting inherent trade-offs between multi-modular lightweighting and high-threshold detection. Finally, adopting the Inner_EIou loss function enables the model to maintain parametric and computational efficiency while recovering mAP@50-95 to 0.801, demonstrating that loss optimization effectively balances lightweight design and high-precision detection for superior metric harmonization.
When fusing the ADown, C3k2_ContextGuided, Detect_SEAM, and Inner_EIou modules, the model achieves a high-precision detection performance of mAP50 0.921 with a reduction of 37.6% in the number of parameters, 38.1% in the number of GFLOPs, 38.0% in the number of weights, and the recall rate is improved by 1.04%. The experiments show that the improved scheme in this paper effectively balances the efficiency and precision requirements of the apple detection task in the natural environment through multi-scale context modeling and the attention mechanism while significantly reducing the model complexity, providing a reliable technical path for lightweight deployment.
Based on the detailed experimental results mentioned above, we further visualized the impact of integrating different modules through the generation of heatmaps, as shown in
Figure 11. These heatmaps provide an intuitive understanding of how each module contributes to the model’s performance, particularly in terms of feature extraction and target detection. After incorporating the ADown module, the heatmaps revealed a more focused attention on critical regions, suggesting that the module effectively reduced unnecessary computations while preserving key information. This lightweight approach not only decreased the model’s complexity but also enhanced its recall rate for apple detection. The introduction of the C3k2_ContextGuided module further refined the model’s feature extraction capabilities. The heatmaps generated after adding this module demonstrated a more nuanced understanding of the apple’s context, capturing fine details that were previously overlooked. This context-aware mechanism significantly improved the model’s accuracy while maintaining its lightweight nature. Similarly, when only the Detect_SEAM module was integrated, the heatmaps exhibited an enhanced ability to suppress background interference. The spatially enhanced attention mechanism in this module allowed the model to better distinguish apples from their surroundings, leading to improved detection stability in complex environments. When combining multiple modules, such as ADown with C3k2_ContextGuided or Detect_SEAM, the heatmaps displayed a synergistic effect. The combination of these modules not only further reduced the model’s complexity and computational load but also significantly improved its recognition accuracy for apples. Finally, the heatmaps generated by integrating all proposed modules—ADown, C3k2_ContextGuided, Detect_SEAM, and Inner_EIou—demonstrated the model’s exceptional detection performance.
3.3. Comparative Experiments with Other Models
In order to further verify the effectiveness of the improved network model in this paper in the task of apple detection in natural environments, under the same experimental parameters, datasets, and training strategies, the experimental results of the improved network model are compared with those of other mainstream target detection models at the current stage, which include the following: the YOLOv5s, the YOLOv6s [
29], and the YoLov8n [
23]. The reason for selecting these models as benchmarks is that they have broad applications and recognition in the field of object detection, and to varying degrees, they have achieved lightweight designs, which align well with the research objectives of this paper. P, R, mAP@50, mAP@50-95, the number of parameters, GFLOPs, and the model weight file size were used as evaluation metrics. The experimental results are shown in
Table 3.
From the experimental results, we know that the YOLOv6s detection algorithm has a larger number of parameters and computational volume, and generates a larger model weight file, so the analysis concludes that the YOLOv6s algorithm cannot meet the needs of this dataset in terms of lightweight real-time detection; YOLOv5s has a smaller difference between the number of parameters, computational volume, and the size of the model weights and AAB-YOLO, but AAB-YOLO has a clear advantage over YOLOv5s in terms of recall and mAP50; YOLOv8n has a slightly higher number of parameters, computational volume, and model weight size compared to AAB-YOLO, and AAB-YOLO outperforms YOLOv8n in terms of the two key performance indicators, namely recall and mAP50, and shows a higher detection precision compared to YOLOv8n. Compared to the benchmark model YOLOv11n, the improved network outperforms the original network in all metrics. However, it is worth noting that although AAB-YOLO achieves excellent results on mAP@50, it does not perform as well as the other models on the metric mAP@50-95. This may be due to AAB-YOLO’s weakened ability to generalize to some complex scenarios while pursuing a lightweight design, resulting in a decrease in detection accuracy at high IoU thresholds. Future research can further explore how to improve the model’s ability to generalize to complex scenes and accurately predict the target bounding box while maintaining the lightweight advantage. Through the above analysis and comprehensively considering each evaluation index, the proposed AAB-YOLO model in this paper greatly improves the detection effect compared to other models and is more suitable for apple detection in natural environments.
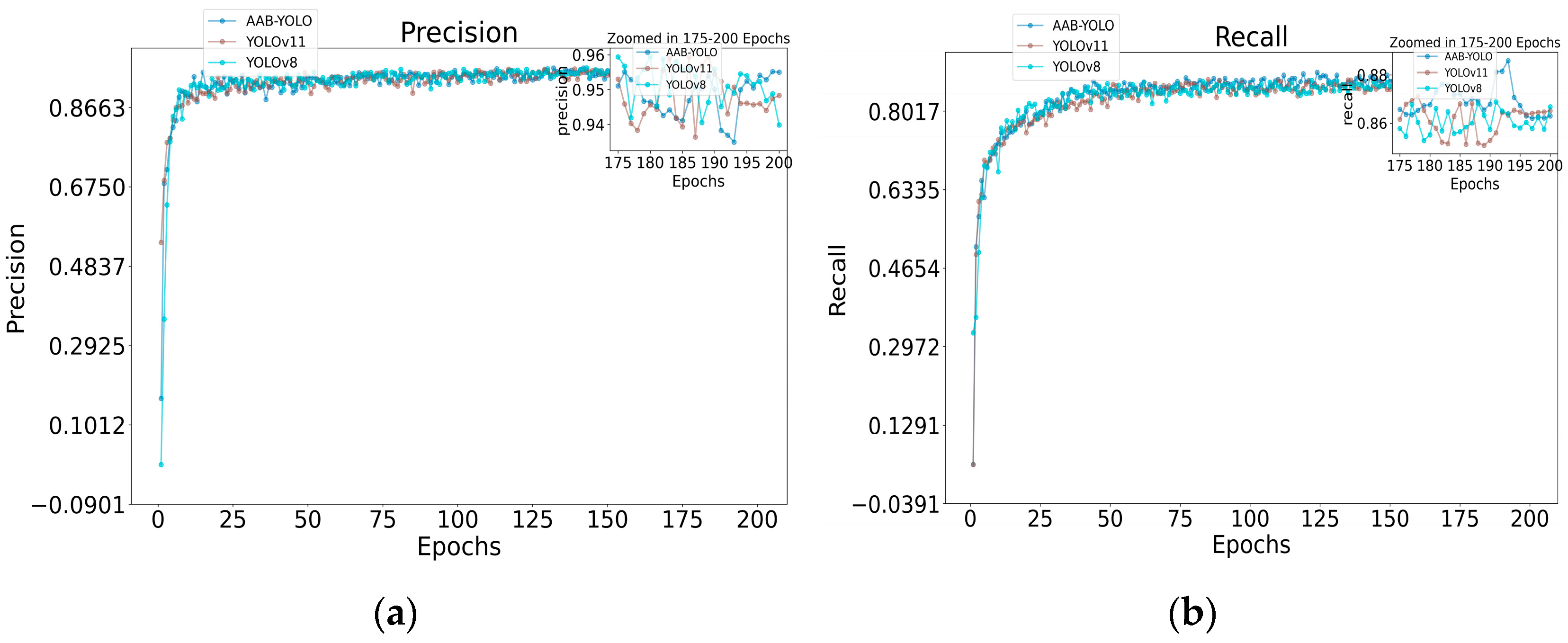
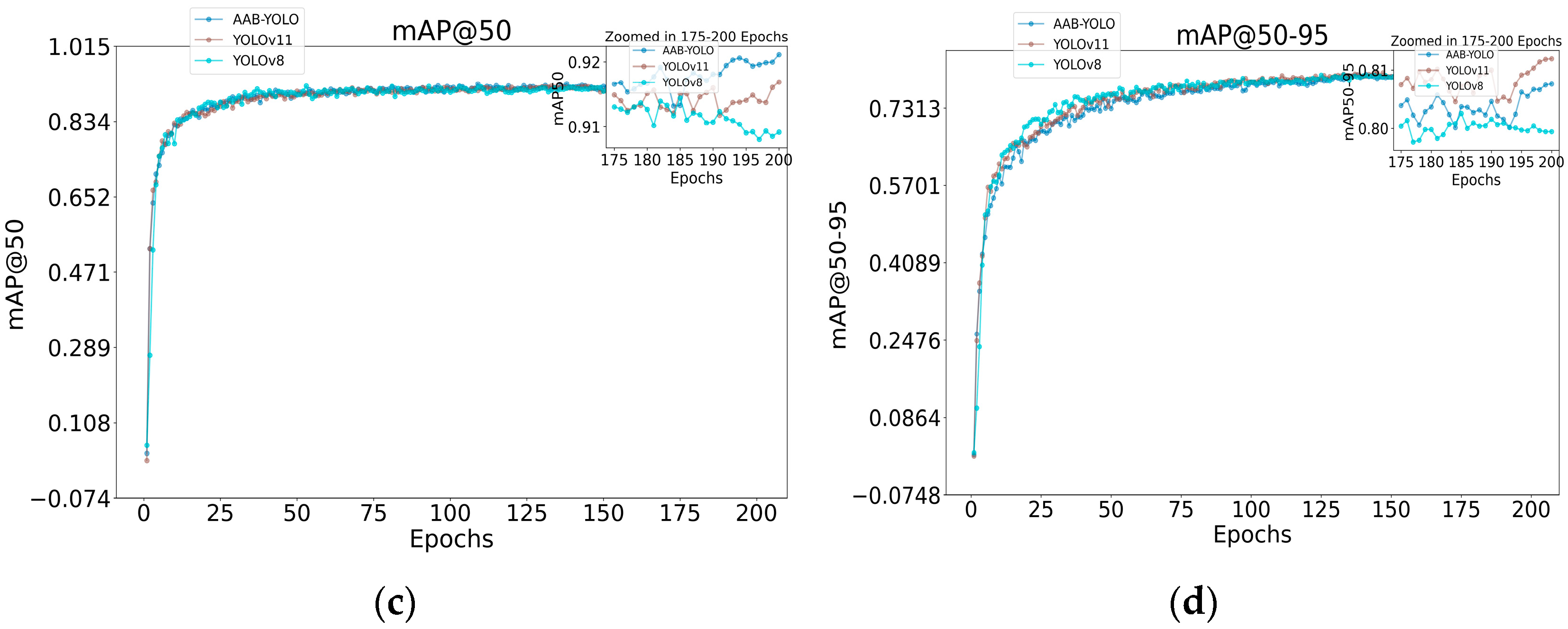
Figure 12 illustrates the comparison curves of precision, recall, map@50, and map@50-95 for YOLOv11n and the improved model AAB-YOLO. Specifically, as can be seen from the comparison of the precision curves, the YOLOv11n model shows high precision in the early stage of training, but as the number of training rounds increases, its performance fluctuates but remains at a relatively high level overall. However, the AAB-YOLO model has a slightly worse performance relative to YOLOv11n at the beginning of training, but as the number of training rounds accumulates, its performance gradually surpasses that of YOLOv11n and stably maintains at a higher precision level at the later stage, and the overall precision curve of AAB-YOLO is stable without obvious fluctuations, showing good generalization ability and stability. This trend is also reflected in the mAP@50 curve comparison. Meanwhile, in the recall curve comparison, we can see that the AAB-YOLO model’s recall continues to increase during the training process and eventually surpasses the YOLOv11n model, showing stronger target detection capability. Notably, the comparison results with YOLOv8n show that AAB-YOLO outperforms YOLOv8n in terms of precision, recall, and mAP@50 metrics, which is more obvious especially when the number of training rounds is high. This result further validates the overall superiority of the AAB-YOLO model in apple detection tasks in natural environments.
3.4. Visual Analysis
3.4.1. Comparison of Detection in Natural Environment
To enhance the methodology for evaluating the performance of the AAB-YOLO algorithm, we show the detection results of YOLOv11n and the improved AAB-YOLO model on the test image dataset in
Figure 13.
First of all, in terms of target recognition accuracy, both AAB-YOLO and YOLOv11 show strong recognition ability. In most detection scenarios, both can accurately recognize target objects. However, in terms of detail processing and avoiding missed detections, AAB-YOLO shows some advantages. Especially in some complex scenes, such as when the number of target objects is large, densely distributed, or there is occlusion, AAB-YOLO can more accurately recognize the target objects and reduce the occurrence of missed detection. This is reflected in the second set of comparison images, in which AAB-YOLO successfully captures the target object in the lower left corner, while YOLOv11 fails to detect it.
Secondly, both have their own performance in terms of the positioning accuracy of the bounding box. YOLOv11 is able to fit the target object more closely in some cases, with higher accuracy of the bounding box. AAB-YOLO, on the other hand, is able to cover the main part of the target object more accurately in general, although the bounding box may be relatively large in some cases. It is worth noting that AAB-YOLO is able to maintain stable localization accuracy in complex scenes and is not easily interfered by background noise or neighboring objects, which reflects its strong robustness. Although AAB-YOLO shows excellent performance in many aspects, there may still be some room for improvement in its detection results in some specific situations. For example, in cases where the target objects are very densely distributed or occluded from each other, AAB-YOLO may need to further optimize its detection algorithm to improve the fit and accuracy of the bounding box.
3.4.2. Comparison of Detection Under Different Light
In order to comprehensively evaluate the detection performance of the AAB-YOLO model under different lighting conditions, we adjusted the brightness of the images to simulate the detection effect under different lighting environments, as shown in
Figure 14.
First of all, under normal light conditions (group a), both models show excellent detection accuracy, can accurately frame the target object, and the bounding box is highly consistent with the actual position of the target object. At this point, the detection results of AAB-YOLO and YOLOv11 are comparable and both are satisfactory.
However, when the lighting conditions turn dim (group b images), AAB-YOLO shows its advantage in detection stability. In the dim environment, AAB-YOLO is able to recognize and frame the target object more stably, especially in the complex situation of dense targets or occlusion, and its detection effect still maintains at a high level. In contrast, YOLOv11 was able to detect targets in dimly lit environments, but the redundancy of the bounding box increased. This may be due to the relatively weak adaptation of YOLOv11 to light changes, whereas AAB-YOLO is more robust in this regard.
Under strong light conditions (group c images), both models encountered some challenges. Although AAB-YOLO still manages to maintain good detection accuracy in most cases, its bounding box fit is slightly weaker than that of YOLOv11 in some of the images. Especially in the region with strong light reflections, YOLOv11 is able to fit the target object more closely in some cases, showing its specific adaptability in bright light conditions.
In summary, the detection performance of AAB-YOLO and YOLOv11 under different light conditions has its own characteristics. Under normal light conditions, both perform equally well; in dim environments, AAB-YOLO has higher detection stability and better adaptability to light changes; and under bright light conditions, YOLOv11 may have better adaptability in some specific scenarios.
3.4.3. Heatmap
To further validate the performance of the AAB-YOLO model on the task of detecting apples in natural environments, this paper uses the gradient-weighted class-activation mapping [
30] (Grad-CAM+++) method for visualization and analysis, as shown in
Figure 15.
From the heatmap, it can be concluded that both the YOLOv11n and AAB-YOLO models can effectively identify and localize the target region in the image when detecting apples in natural environments, but the thermal response of the AAB-YOLO model in the target region is more concentrated and of higher intensity, which suggests that the model can more accurately localize the target object. On the other hand, the thermal region of the YOLOv11 model is relatively dispersed, and part of the response spreads into the background, which may have localization bias. It is further verified that the AAB-YOLO model outperforms the original model in target localization accuracy, background suppression ability, and detection consistency.
4. Discussion
The AAB-YOLO framework achieves an effective balance between detection accuracy and computational efficiency for the apple recognition task in complex orchard scenarios. The experimental results show that compared with YOLOv11, the framework significantly improves mAP50 (from 0.917 to 0.921) and recall (+1.04%), while the parameters are reduced by 37.7%. However, its lightweight design leads to a slight decrease in mAP@50-95, which reflects the architecture’s focus on real-time optimization and possibly compromises on dense fruit localization accuracy. By introducing ADown sampling and the C3k2_ContextGuided module, the framework effectively preserves multiscale features and enhances contextual information fusion, which significantly improves the robustness of the model under light variations and partial occlusion conditions. In particular, the Detect_SEAM module, through targeted optimization of feature extraction and contextual association modeling of occluded targets, effectively solves the leakage detection problem caused by the occlusion of branches and leaves, and significantly enhances the recognition ability of apples under occluded conditions, making the detection effect more suitable for the practical application requirements of automated picking systems.
However, there is still room for improving the performance of the framework in extreme complex scenes. When severe occlusion, motion blur, or extreme light angles are simultaneously present, the detection accuracy drops significantly, suggesting that temporal context information (e.g., video detection frameworks) or hybrid Transformer-CNN architectures can be introduced in the future to enhance scene understanding. In addition, the recall optimization strategy for small apples may lead to an increase in false detections in fruit-dense regions, and dynamic anchor adjustment or adaptive thresholding mechanisms based on spatial density should be further explored to balance precision and recall.
From the perspective of technology translation, the low power consumption of AAB-YOLO makes it easy to be deployed in resource-constrained orchard environments, especially in small-scale farmer scenarios, showing significant advantages. Future research could focus on multimodal data fusion (e.g., combining thermal or hyperspectral imaging) to enhance environmental adaptability, developing energy-efficient compression techniques to extend the endurance of field devices, and introducing lifelong learning strategies to adapt to seasonal changes in orchards, thereby promoting the intelligence and utility of agricultural automation systems. This framework provides an important foundation for building a new generation of agricultural automation systems, effectively bridging algorithmic innovation and practical application needs.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}