
Research on an Apple Recognition and Yield Estimation Model Based on the Fusion of Improved YOLOv11 and DeepSORT

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Sources and Pre-Processing
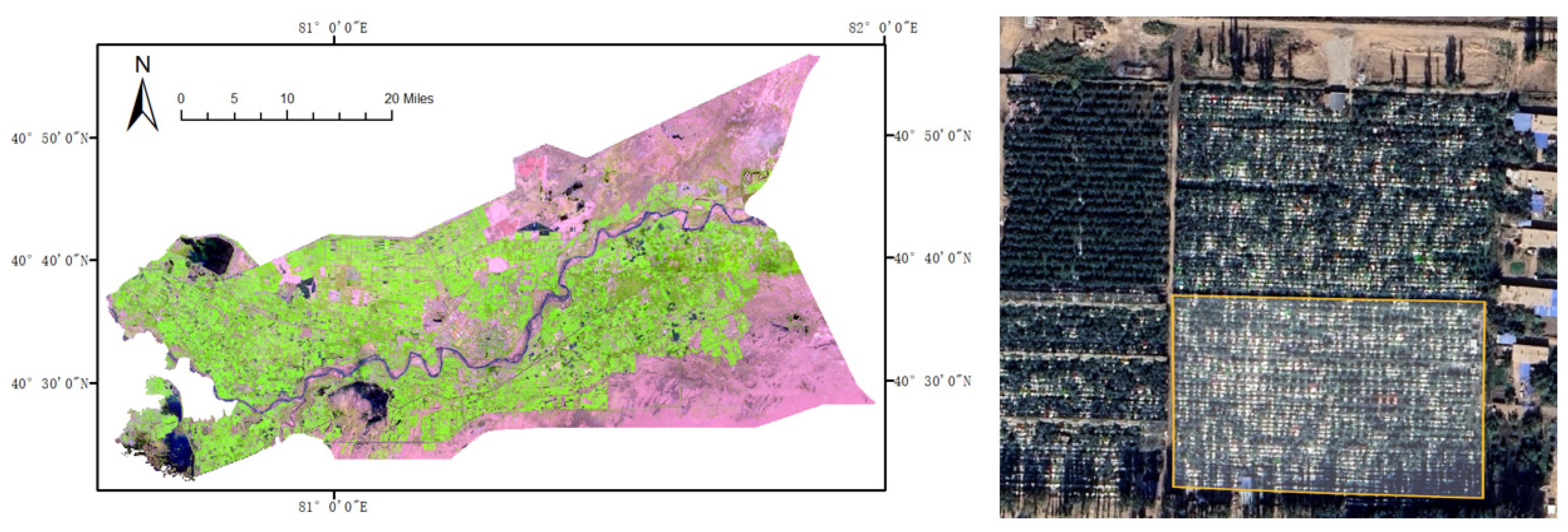
2.1.1. Data Sources
2.1.2. Data Pre-Processing
2.2. Experimental Environment and Parameter Configuration
2.3. Evaluation Index
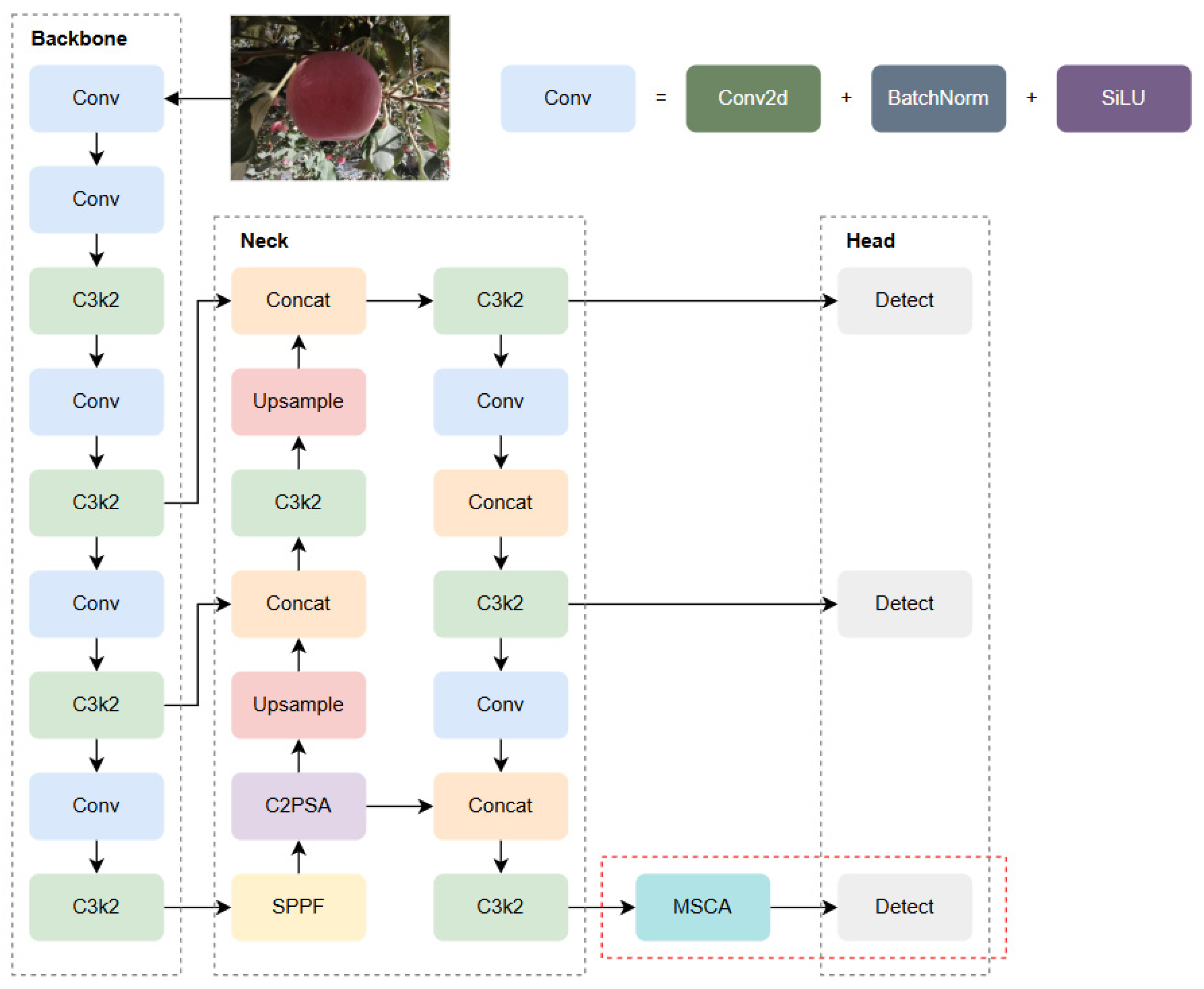
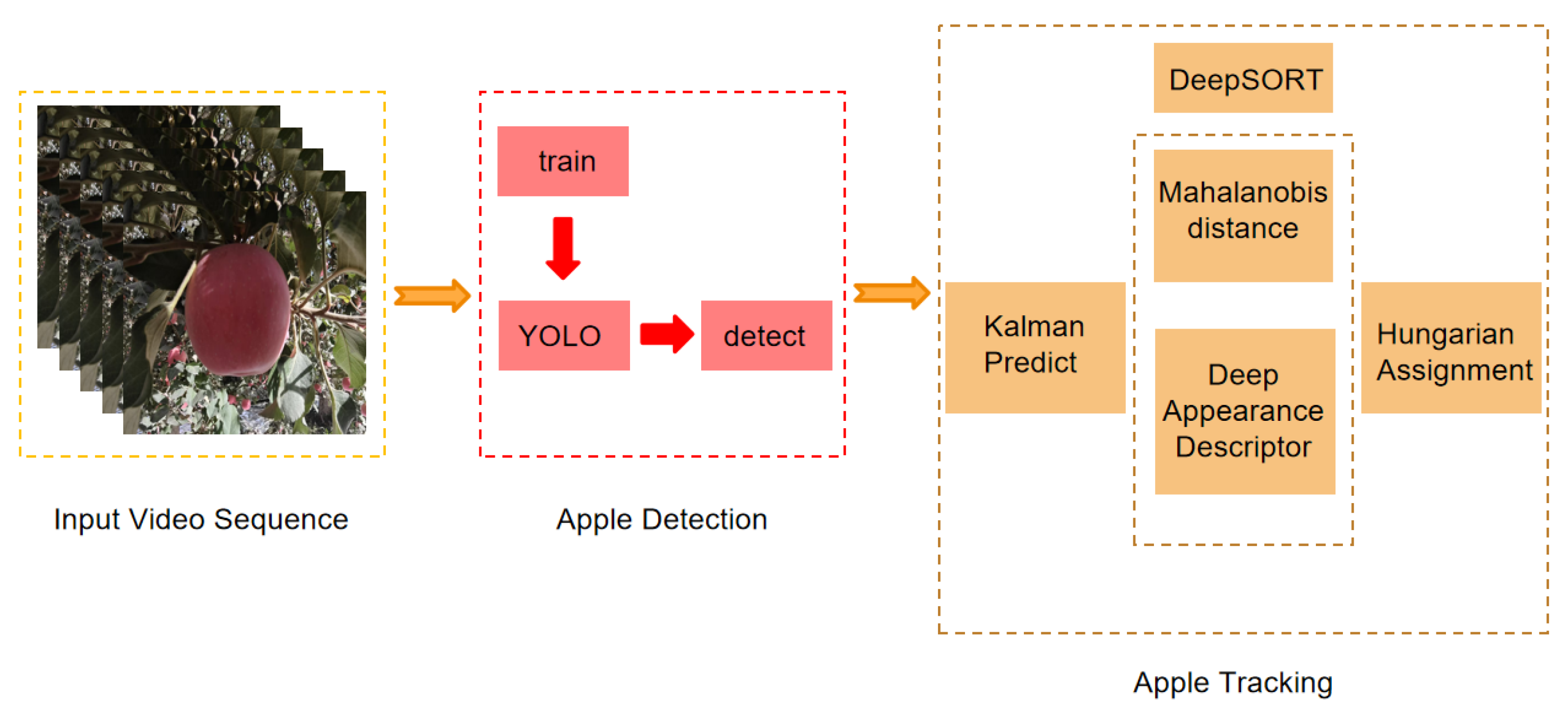
2.4. APYOLO Model
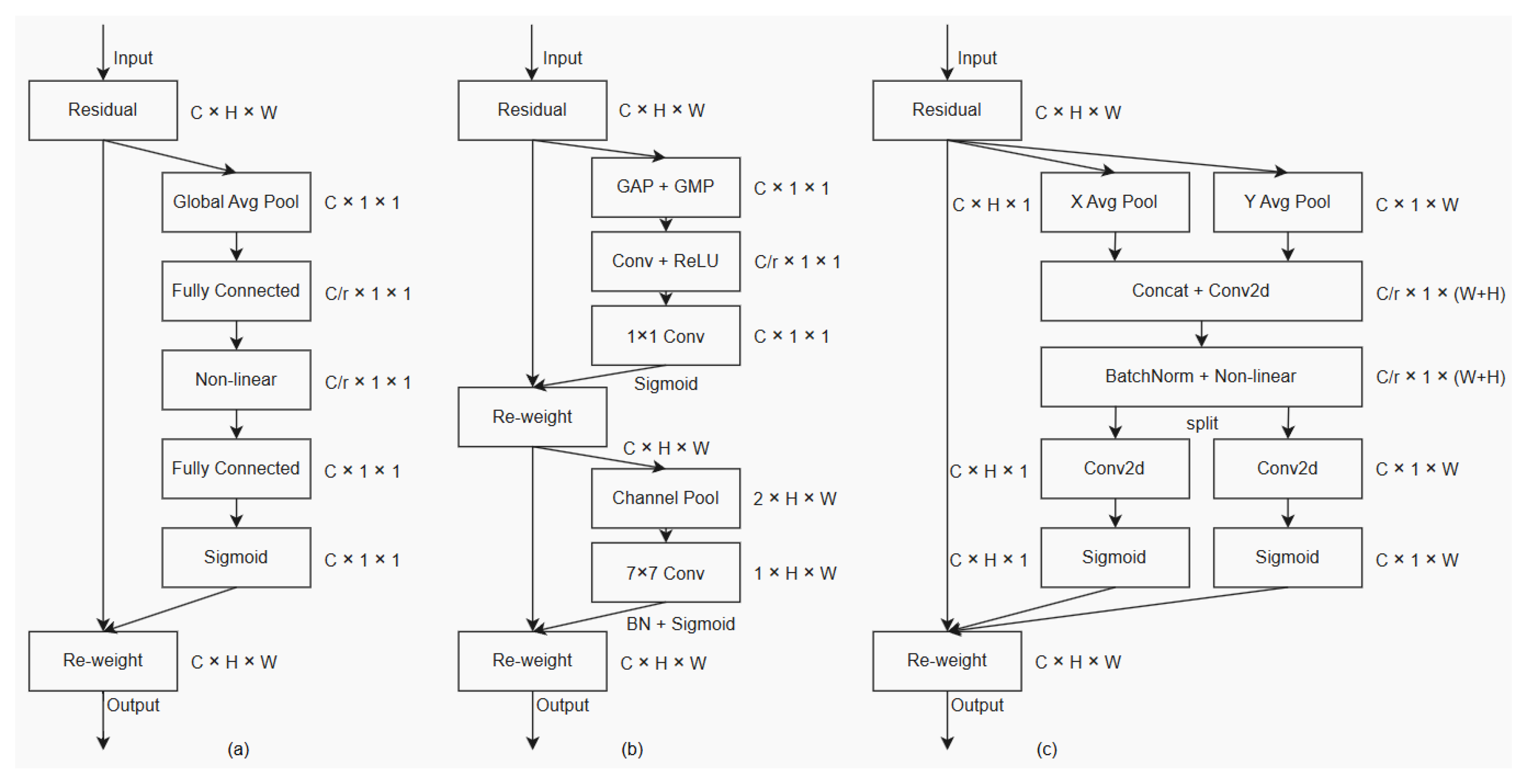
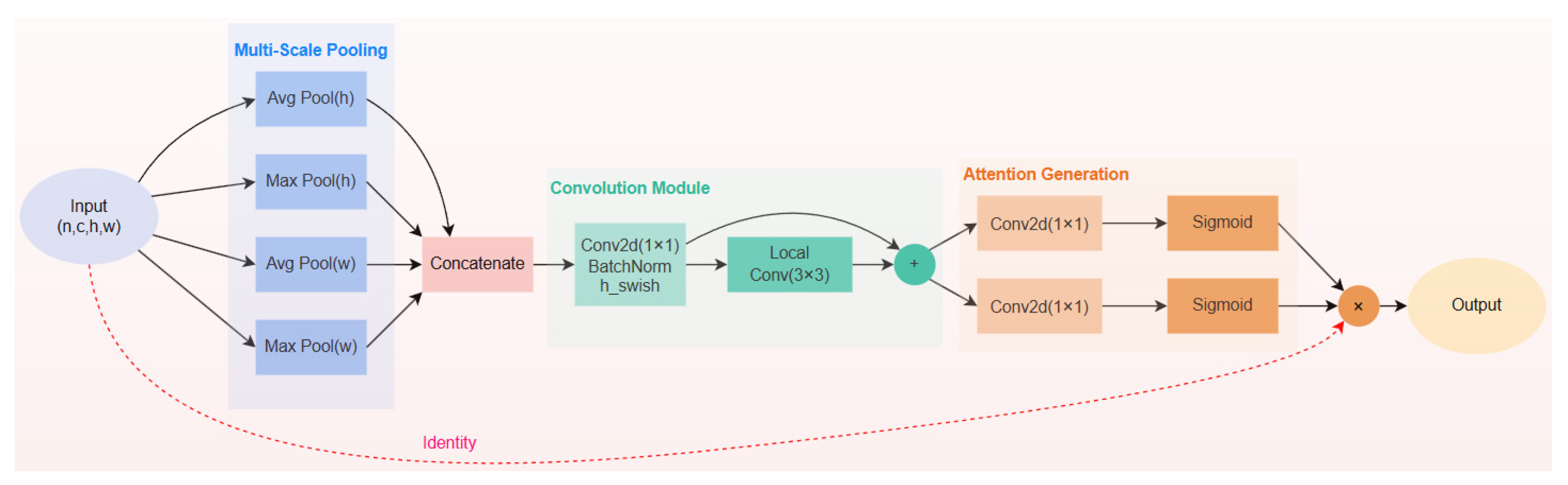
2.5. MSCA (Multi-Scale Channel Attention) Attention Mechanism
- (1)
- Multi-scale feature extraction: The multi-scale pooling component of the MSCA module performs pooling operations, such as average and maximum pooling, on input feature maps at different scales, capturing features of apples of various sizes. As apples in orchards vary in size, multi-scale feature extraction ensures more comprehensive feature capture, reducing the risk of missed or false detections caused by size variations.
- (2)
- Feature fusion and enhancement: By concatenating and applying convolution operations to the features pooled at different scales, the MSCA module effectively fuses multi-scale features. The resulting fused features contain richer information, enhancing the model’s ability to represent apple characteristics and improving recognition accuracy.
- (3)
- Channel attention mechanism: The attention generation component processes the fused features to generate channel attention weights, adaptively adjusting the importance of different channels. In orchard environments, where complex backgrounds and significant leaf interference are common, the channel attention mechanism enables the model to focus on channels relevant to apple features, suppressing background and irrelevant information to improve detection accuracy.
- (4)
- Improving model robustness: Through the integration of multi-scale features and the channel attention mechanism, the MSCA module enhances the model’s adaptability to varying orchard conditions. Whether dealing with lighting changes, occlusion, or apples at different growth stages, the MSCA module helps stabilize the model’s performance, improving both robustness and generalization.
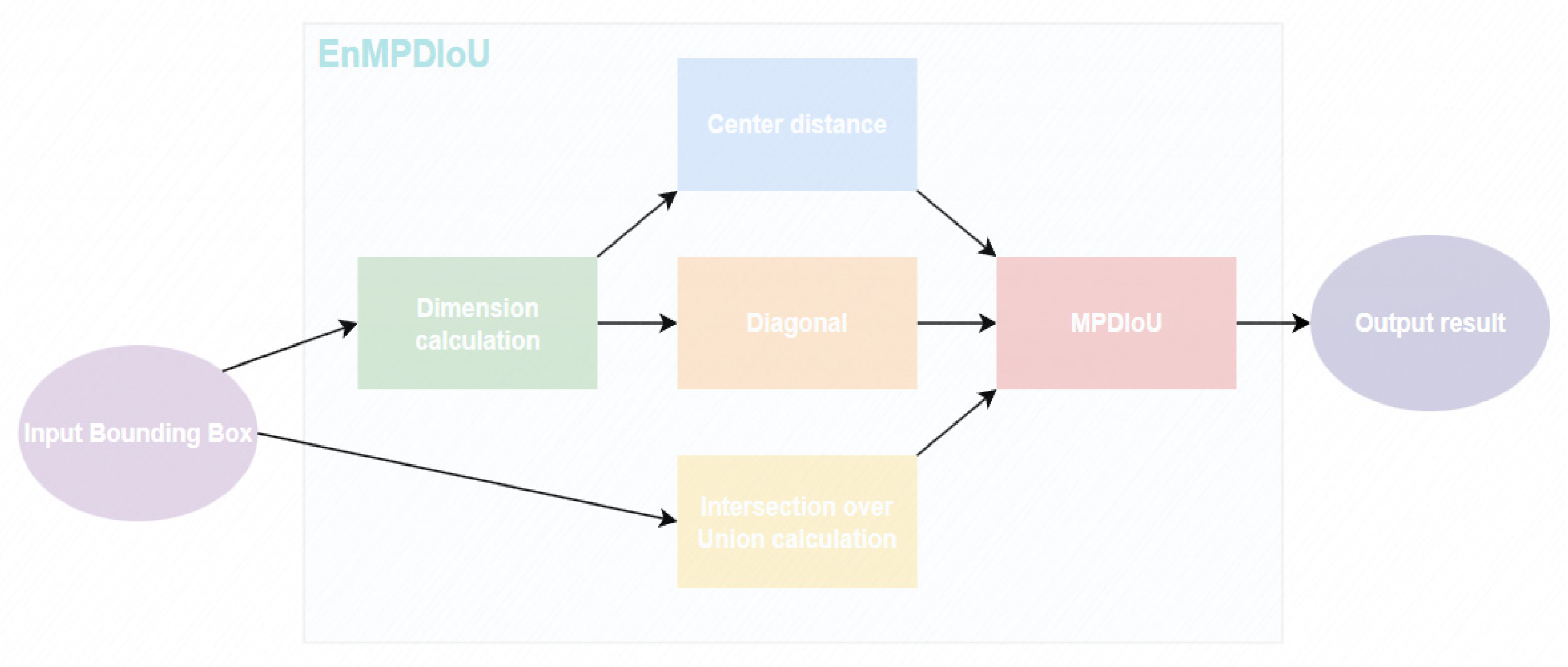
2.6. EnMPDIoU Loss Function
- (1)
- Displacement-oriented metrics: These metrics quantify the pixel-level discrepancies between predicted and ground-truth bounding box coordinates, exhibiting particular sensitivity to scale variations in cluttered, multi-object environments.
- (2)
- Overlap-centric metrics: These metrics evaluate the spatial alignment of bounding boxes through intersection-over-union (IoU) computations. However, they suffer from gradient degradation in cases of partial overlap.
- (1)
- Isometric error penalization: Current methods assign identical loss values to geometrically distinct prediction errors (e.g., a 5px center deviation versus a 5px edge misalignment).
- (2)
- Convergence latency: Methods based on current BBR loss metrics typically exhibit slower parameter stabilization compared to more advanced error metrics, as observed in evaluations on the COCO dataset.
- (3)
- Rotational invariance deficiency: Current methods fail to account for angular displacements, which is a significant limitation in tasks involving oriented object detection.
- (1)
- Sensitivity to noise: Since incorporates multiple detailed factors of the bounding box, such as center-point distances and width–height deviations, it becomes more sensitive to noise. Noise interference can lead to significant fluctuations in the value, affecting the accurate evaluation of bounding box regression results. For instance, slight image jitters or inherent image noise may cause accurate bounding box predictions to deviate significantly under , thereby interfering with model training.
- (2)
- Relatively high computational complexity: Although simplifies the calculation process, it introduces additional calculations, such as the minimum point distance, compared to the traditional IoU metric. In real-time applications with high computational and time requirements, this increased complexity can become a limiting factor. For example, in real-time video streaming, excessive calculations can cause delays, preventing the system from meeting real-time processing requirements.
- (3)
- Limitations on small target detection: For small target detection, the size of the bounding box itself is small. When calculating , a small deviation may lead to a relatively large change in the value, thereby affecting the evaluation of the small target detection effect. In addition, the bounding boxes of small targets are more easily affected by image resolution and sampling methods, further increasing the difficulty of evaluation. For example, for small apple targets in low-resolution images, small errors in their bounding boxes may be magnified under calculations, making it difficult for the model to accurately determine the position of small targets.
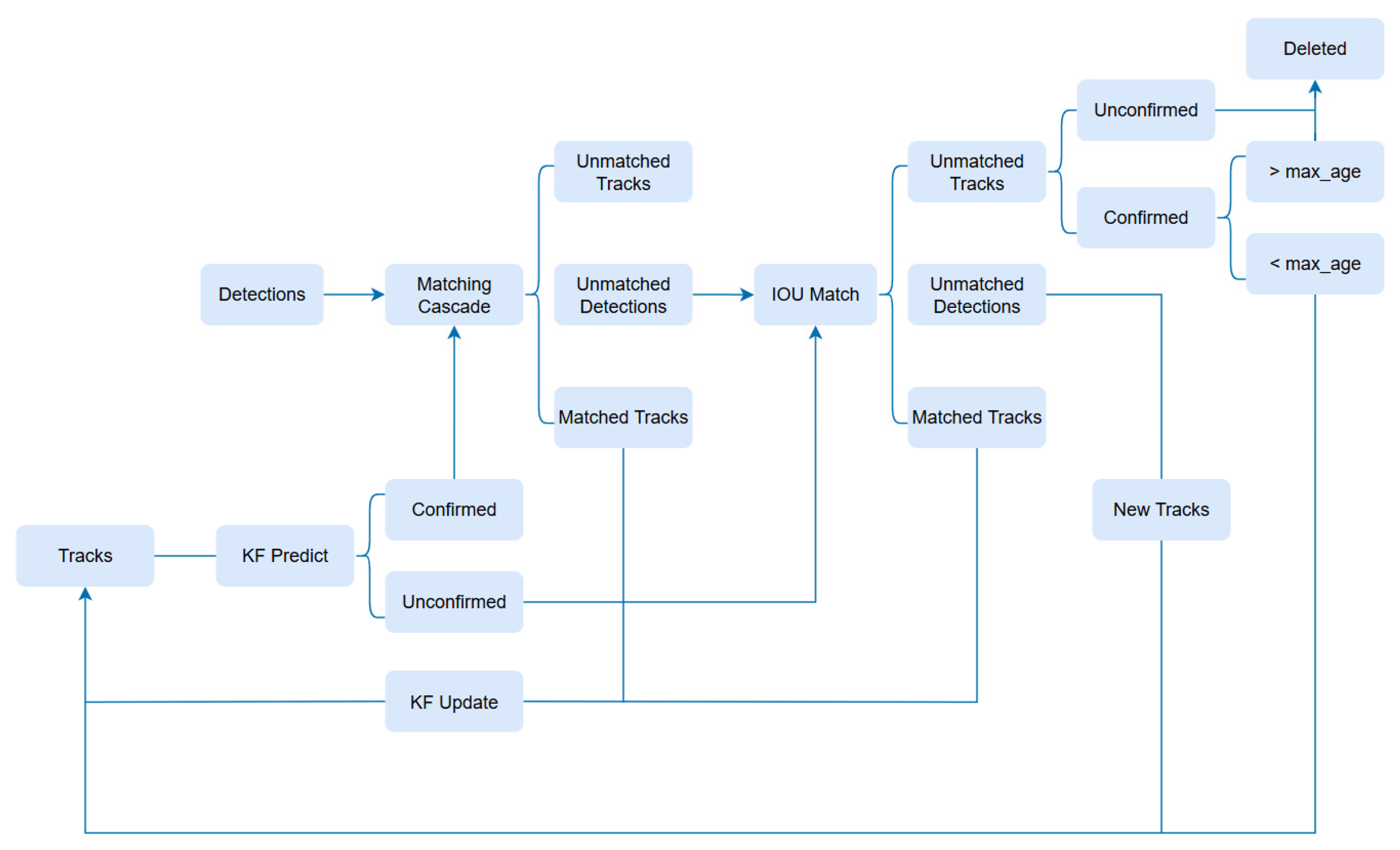
2.7. DeepSORT Model
3. Results
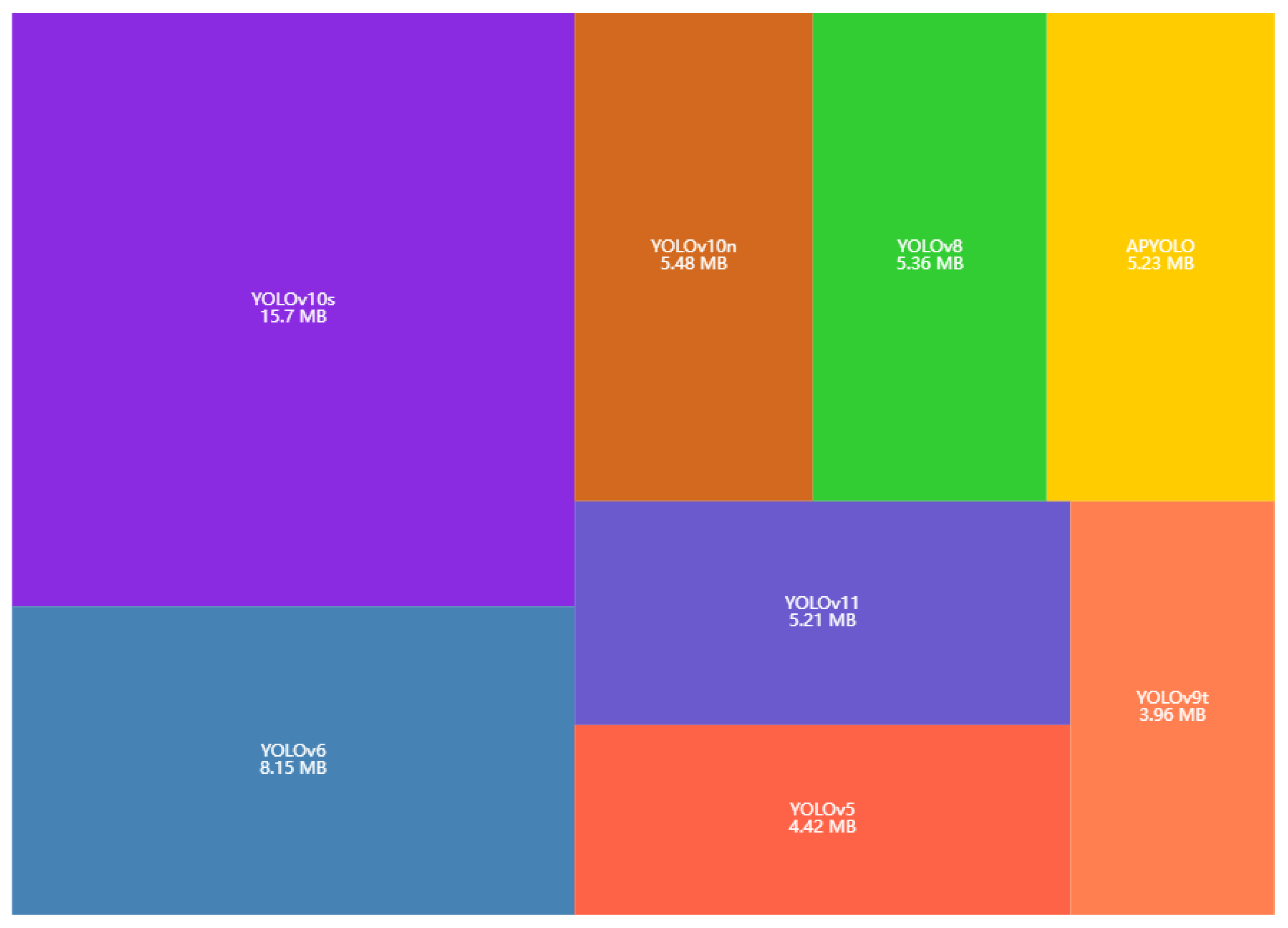
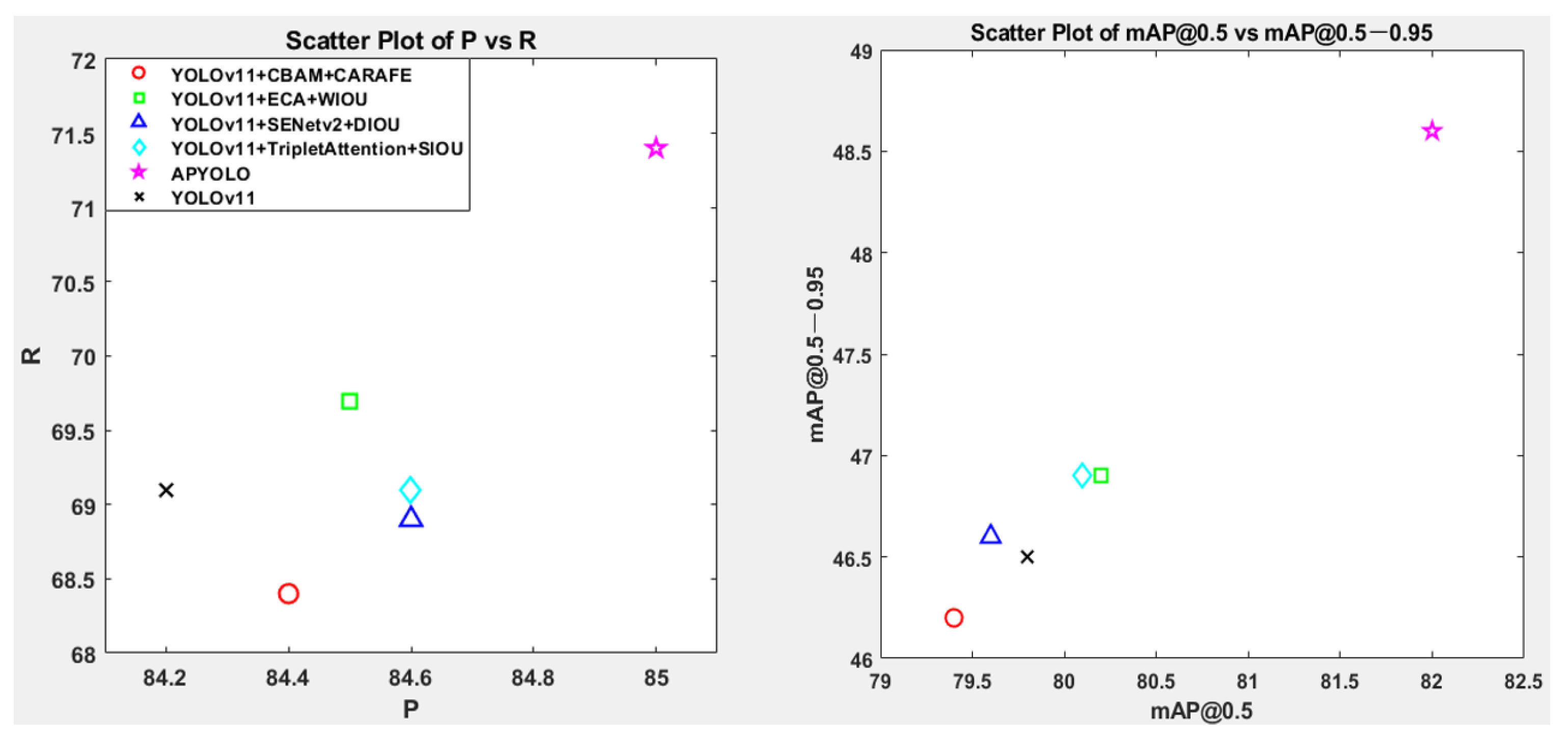
3.1. Comparison of Different Models
3.2. Ablation Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, Z.; Fu, H.; Wu, J.; Han, W.; Huang, W.; Zheng, W.; Li, T. Dynamic Task Planning for Multi-Arm Apple-Harvesting Robots Using LSTM-PPO Reinforcement Learning Algorithm. Agriculture 2025, 15, 588. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, J.; Guo, B.; Wei, Q.; Zhu, Z. An Apple Detection Method Based on Des-YOLO v4 Algorithm for Harvesting Robots in Complex Environment. Math. Probl. Eng. 2021, 2021, 7351470. [Google Scholar]
- Villacrés, J.; Viscaino, M.; Delpiano, J.; Vougioukas, S.; Cheein, F.A. Apple orchard production estimation using deep learning strategies: A comparison of tracking-by-detection algorithms. Comput. Electron. Agric. 2023, 204, 107513. [Google Scholar] [CrossRef]
- Gao, F.; Fang, W.; Sun, X.; Wu, Z.; Zhao, G.; Li, G.; Li, R.; Fu, L.; Zhang, Q. A novel apple fruit detection and counting methodology based on deep learning and trunk tracking in modern orchard. Comput. Electron. Agric. 2022, 197, 107000. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Wang, X.; Yang, T.; Chen, Z.; Liu, J.; He, Y. NLDETR-YOLO: A decision-making method for apple thinning period. Sci. Hortic. 2025, 341, 113991. [Google Scholar]
- Wang, C.; Wang, Y.; Liu, S.; Lin, G.; He, P.; Zhang, Z.; Zhou, Y. Study on pear flowers detection performance of YOLO-PEFL model trained with synthetic target images. Front. Plant Sci. 2022, 13, 911473. [Google Scholar] [CrossRef]
- Shi, Y.; Duan, Z.; Qing, S.; Zhao, L.; Wang, F.; Yuwen, X. YOLOV9S-Pear: A lightweight YOLOV9S-Based improved model for young Red Pear Small-Target recognition. Agronomy 2024, 14, 2086. [Google Scholar] [CrossRef]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural object detection with you look only once (yolo) algorithm: A bibliometric and systematic literature review. arXiv 2024, arXiv:2401.10379. [Google Scholar] [CrossRef]
- Liu, Z.; Abeyrathna, R.R.D.; Sampurno, R.M.; Nakaguchi, V.M.; Ahamed, T. Faster-YOLO-AP: A lightweight apple detection algorithm based on improved YOLOv8 with a new efficient PDWConv in orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Sekharamantry, P.K.; Melgani, F.; Malacarne, J.; Ricci, R.; Silva, R.d.A.; Junior, J.M. A seamless deep learning approach for apple detection, depth estimation, and tracking using YOLO models enhanced by multi-head attention mechanism. Computers 2024, 13, 83. [Google Scholar] [CrossRef]
- Wei, P.; Yan, X.; Yan, W.; Sun, L.; Xu, J.; Yuan, H. Precise extraction of targeted apple tree canopy with YOLO-Fi model for advanced UAV spraying plans. Comput. Electron. Agric. 2024, 226, 109425. [Google Scholar] [CrossRef]
- Wu, H.; Mo, X.; Wen, S.; Wu, K.; Ye, Y.; Wang, Y.; Zhang, Y. DNE-YOLO: A method for apple fruit detection in Diverse Natural Environments. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 102220. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, J.; Yang, K.; Guan, M. YOLO-ACT: An adaptive cross-layer integration method for apple leaf disease detection. Front. Plant Sci. 2024, 15, 1451078. [Google Scholar]
- Akdoğan, C.; Özer, T.; Oğuz, Y. PP-YOLO: Deep learning based detection model to detect apple and cherry trees in orchard based on Histogram and Wavelet preprocessing techniques. Comput. Electron. Agric. 2025, 232, 110052. [Google Scholar]
- Gwak, H.J.; Jeong, Y.; Chun, I.J.; Lee, C.H. Estimation of fruit number of apple tree based on YOLOv5 and regression model. J. IKEEE 2024, 28, 150–157. [Google Scholar]
- Lin, Y.; Huang, Z.; Liang, Y.; Liu, Y.; Jiang, W. Ag-Yolo: A rapid citrus fruit detection algorithm with global context fusion. Agriculture 2024, 14, 114. [Google Scholar] [CrossRef]
- Jing, J.; Zhang, S.; Sun, H.; Ren, R.; Cui, T. YOLO-PEM: A lightweight detection method for young “Okubo” peaches in complex orchard environments. Agronomy 2024, 14, 1757. [Google Scholar] [CrossRef]
- Sawant, K.; Shirwaikar, R.D.; Ugavekar, R.R.; Chodankar, C.S.; Tirodkar, B.N.; Padolkar, A.; Gawas, P. Fruit Identification using YOLO v8 and Faster R-CNN—A Commparative Study. In Proceedings of the 2024 International Conference on Distributed Computing and Optimization Techniques (ICDCOT), Bengaluru, India, 15–16 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Ali, M.L.; Zhang, Z. The YOLO framework: A comprehensive review of evolution, applications, and benchmarks in object detection. Computers 2024, 13, 336. [Google Scholar] [CrossRef]
- Karthikeyan, M.; Subashini, T.S.; Srinivasan, R.; Santhanakrishnan, C.; Ahilan, A. YOLOAPPLE: Augment Yolov3 deep learning algorithm for apple fruit quality detection. Signal Image Video Process. 2024, 18, 119–128. [Google Scholar]
- Gao, Z.; Zhou, K.; Hu, Y. Apple maturity detection based on improved YOLOv8. In Proceedings of the Fourth International Conference on Computer Vision, Application, and Algorithm (CVAA 2024), Chengdu, China, 11–13 October 2024; SPIE: Bellingham, DC, USA, 2025; Volume 13486, pp. 539–544. [Google Scholar]
- Wang, D.; Song, H.; Wang, B. YO-AFD: An improved YOLOv8-based deep learning approach for rapid and accurate apple flower detection. Front. Plant Sci. 2025, 16, 1541266. [Google Scholar]
- Han, B.; Zhang, J.; Almodfer, R.; Wang, Y.; Sun, W.; Bai, T.; Dong, L.; Hou, W. Research on Innovative Apple Grading Technology Driven by Intelligent Vision and Machine Learning. Foods 2025, 14, 258. [Google Scholar] [CrossRef]
- Bai, Y.; Yu, J.; Yang, S.; Ning, J. An improved YOLO algorithm for detecting flowers and fruits on strawberry seedlings. Biosyst. Eng. 2024, 237, 1–12. [Google Scholar]
- Zou, H.; Lv, P.; Zhao, M. Detection of Apple Leaf Diseases Based on LightYOLO-AppleLeafDx. Plants 2025, 14, 599. [Google Scholar] [CrossRef]
- Zhang, M.; Ye, S.; Zhao, S.; Wang, W.; Xie, C. Pear Object Detection in Complex Orchard Environment Based on Improved YOLO11. Symmetry 2025, 17, 255. [Google Scholar] [CrossRef]
- Del Brio, D.; Tassile, V.; Bramardi, S.J.; Fernández, D.E.; Reeb, P.D. Apple (Malus domestica) and pear (Pyrus communis) yield prediction after tree image analysis. Rev. Fac. Cienc. Agrar. UNCuyo 2023, 55, 1–11. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, X.; Wang, H.; Wei, H.; Zhang, Y.; Zhou, G. Pear Fruit Detection Model in Natural Environment Based on Lightweight Transformer Architecture. Agriculture 2024, 15, 24. [Google Scholar] [CrossRef]
- Zhang, Z.; Lei, X.; Huang, K.; Sun, Y.; Zeng, J.; Xyu, T.; Yuan, Q.; Qi, Y.; Herbst, A.; Lyu, X. Multi-Scenario pear tree inflorescence detection based on improved YOLOv7 object detection algorithm. Front. Plant Sci. 2024, 14, 1330141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Yang, R.; He, Y.; Hu, Z.; Gao, R.; Yang, H. CA-YOLOv5: A YOLO model for apple detection in the natural environment. Syst. Sci. Control Eng. 2024, 12, 2278905. [Google Scholar]
- Ma, S.; Xu, Y. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Azhar, M.I.H.; Zaman, F.H.K.; Tahir, N.M.; Hashim, H. People tracking system using DeepSORT. In Proceedings of the 2020 10th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 21–22 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 137–141. [Google Scholar]
- Pereira, R.; Carvalho, G.; Garrote, L.; Nunes, U.J. Sort and deep-SORT based multi-object tracking for mobile robotics: Evaluation with new data association metrics. Appl. Sci. 2022, 12, 1319. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, X.; Liu, B. Video object tracking based on YOLOv7 and DeepSORT. arXiv 2022, arXiv:2207.12202. [Google Scholar]
- Parico, A.I.B.; Ahamed, T. Real time pear fruit detection and counting using YOLOv4 models and deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef] [PubMed]
- Itakura, K.; Narita, Y.; Noaki, S.; Hosoi, F. Automatic pear and apple detection by videos using deep learning and a Kalman filter. Osa Contin. 2021, 4, 1688–1695. [Google Scholar] [CrossRef]
- Kodors, S.; Lacis, G.; Zhukov, V.; Bartulsons, T. Pear and apple recognition using deep learning and mobile. Eng. Rural Dev. 2020, 20, 1795–1800. [Google Scholar]
- Wu, Z.; Sun, X.; Jiang, H.; Mao, W.; Li, R.; Andriyanov, N.; Soloviev, V.; Fu, L. NDMFCS: An automatic fruit counting system in modern apple orchard using abatement of abnormal fruit detection. Comput. Electron. Agric. 2023, 211, 108036. [Google Scholar] [CrossRef]
- Pan, S.; Ahamed, T. Pear Recognition System in an Orchard from 3D Stereo Camera Datasets Using Deep Learning Algorithms. In IoT and AI in Agriculture: Self-Sufficiency in Food Production to Achieve Society 5.0 and SDG’s Globally; Springer Nature: Singapore, 2023; pp. 219–252. [Google Scholar]
- Ma, J.; Liu, B.; Ji, L.; Zhu, Z.; Wu, Y.; Jiao, W. Field-Scale yield prediction of winter wheat under different irrigation regimes based on dynamic fusion of multimodal UAV imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103292. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar]
- Zhou, W.; Song, C.; Liu, C.; Fu, Q.; An, T.; Wang, Y.; Sun, X.; Wen, N.; Tang, H.; Wang, Q. A Prediction Model of Maize Field Yield Based on the Fusion of Multitemporal and Multimodal UAV Data: A Case Study in Northeast China. Remote Sens. 2023, 15, 3483. [Google Scholar] [CrossRef]
- Shamsuddin, D.; Danilevicz, M.F.; Al-Mamun, H.A.; Bennamoun, M.; Edwards, D. Multimodal Deep Learning Integration of Image, Weather, and Phenotypic Data Under Temporal Effects for Early Prediction of Maize Yield. Remote Sens. 2024, 16, 4043. [Google Scholar] [CrossRef]
- Cheng, T.; Li, M.; Quan, L.; Song, Y.; Lou, Z.; Li, H.; Du, X. A multimodal and temporal network-based yield Assessment Method for different heat-tolerant genotypes of wheat. Agronomy 2024, 14, 1694. [Google Scholar] [CrossRef]
- Kim, J.; Cho, J. Exploring a multimodal mixture-of-YOLOs framework for advanced real-time object detection. Appl. Sci. 2020, 10, 612. [Google Scholar] [CrossRef]
- Fei, X.; Guo, M.; Li, Y.; Yu, R.; Sun, L. ACDF-YOLO: Attentive and Cross-Differential Fusion Network for Multimodal Remote Sensing Object Detection. Remote Sens. 2024, 16, 3532. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
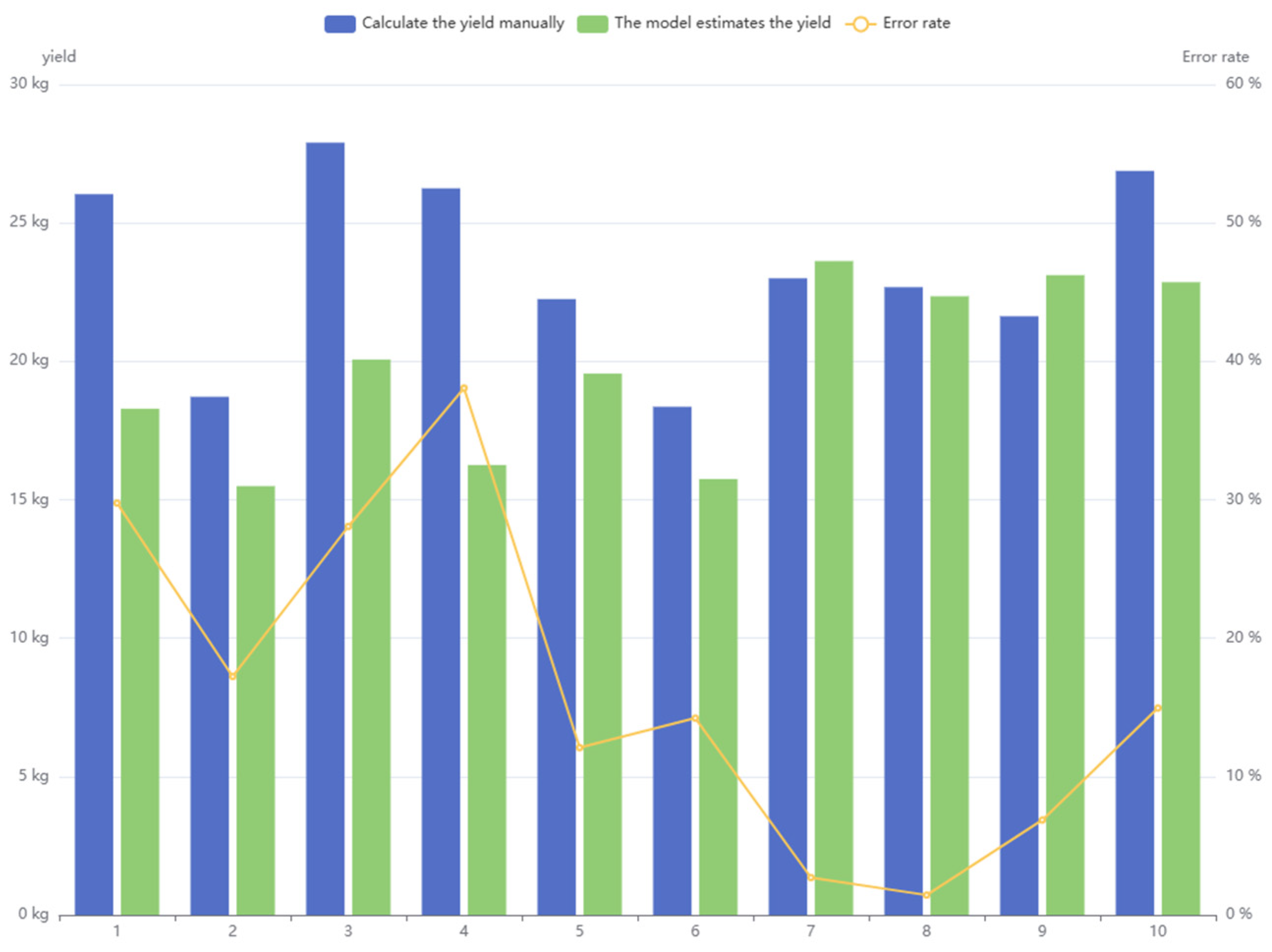
| Number of Fruit Trees | Number of Fruits | Average Weight of Fruits (kg) |
|---|---|---|
| 1 | 84 | 0.31 |
| 2 | 72 | 0.26 |
| 3 | 93 | 0.30 |
| 4 | 75 | 0.35 |
| 5 | 89 | 0.25 |
| 6 | 68 | 0.27 |
| 7 | 115 | 0.20 |
| 8 | 108 | 0.21 |
| 9 | 103 | 0.21 |
| 10 | 72 | 0.31 |
| Parameter | Numerical Value |
|---|---|
| Optimizer | SGD |
| Initial learning rate | 0.01 |
| Momentum factor | 0.937 |
| Weight decay | 0.0005 |
| Patience | 30 |
| Batch size | 32 |
| Image size | 640 × 640 |
| Model | P/% | R/% | mAP@0.5/% | mAP@0.5–0.95/% | Param | GFLOPs | Inference/ms |
|---|---|---|---|---|---|---|---|
| APYOLO | 85.0 | 71.4 | 82.0 | 48.6 | 2,595,771 | 6.44 | 10.6 |
| YOLOv5 | 83.9 | 68.9 | 79.4 | 46.0 | 2,188,019 | 5.92 | 9.36 |
| YOLOv6 | 84.3 | 67.5 | 78.5 | 45.2 | 4,159,843 | 11.56 | 9.55 |
| YOLOv8 | 84.5 | 69.8 | 80.6 | 46.9 | 2,690,403 | 6.94 | 14.26 |
| YOLOv9t | 85.0 | 69.4 | 80.1 | 46.8 | 1,765,123 | 6.70 | 26.96 |
| YOLOv10n | 82.4 | 68.9 | 79.2 | 45.7 | 2,707,430 | 8.39 | 11.87 |
| YOLOv10s | 83.0 | 69.9 | 79.9 | 46.1 | 8,067,126 | 24.77 | 17.74 |
| YOLOv11 | 84.2 | 69.1 | 79.8 | 46.5 | 2,590,035 | 6.44 | 10.20 |
| Number | MSCA | EnMPDIoU | P/% | R/% | mAP@0.5/% | mAP@0.5–0.95/% | Param | GFLOPs | Inference/ms |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 84.2 | 69.1 | 79.8 | 46.5 | 2,590,035 | 6.44 | 10.2 | ||
| 2 | √ | 88.5 | 71.3 | 82.1 | 48.5 | 2,595,771 | 6.44 | 10.6 | |
| 3 | √ | 84.0 | 71.7 | 81.8 | 48.7 | 2,590,035 | 6.44 | 10.2 | |
| 4 | √ | √ | 85.0 | 71.4 | 82.0 | 48.6 | 2,595,771 | 6.44 | 10.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Z.; Wu, Y.; Zhao, W.; Zhang, S.; Li, X. Research on an Apple Recognition and Yield Estimation Model Based on the Fusion of Improved YOLOv11 and DeepSORT. Agriculture 2025, 15, 765. https://doi.org/10.3390/agriculture15070765
Yan Z, Wu Y, Zhao W, Zhang S, Li X. Research on an Apple Recognition and Yield Estimation Model Based on the Fusion of Improved YOLOv11 and DeepSORT. Agriculture. 2025; 15(7):765. https://doi.org/10.3390/agriculture15070765
Chicago/Turabian StyleYan, Zhanglei, Yuwei Wu, Wenbo Zhao, Shao Zhang, and Xu Li. 2025. "Research on an Apple Recognition and Yield Estimation Model Based on the Fusion of Improved YOLOv11 and DeepSORT" Agriculture 15, no. 7: 765. https://doi.org/10.3390/agriculture15070765
APA StyleYan, Z., Wu, Y., Zhao, W., Zhang, S., & Li, X. (2025). Research on an Apple Recognition and Yield Estimation Model Based on the Fusion of Improved YOLOv11 and DeepSORT. Agriculture, 15(7), 765. https://doi.org/10.3390/agriculture15070765