
SD-YOLOv8: SAM-Assisted Dual-Branch YOLOv8 Model for Tea Bud Detection on Optical Images



Abstract
1. Introduction
- First, since only detecting tea buds in the foreground images is necessary for a tea bud picking machine, this study explores utilizing SAM to effectively distinguish the foregrounds and backgrounds of tea bud images and further improve the accuracy of tea bud detection.
- Second, a SAM-assisted dual-branch YOLOv8 (SD-YOLOv8) model is proposed to effectively extract heterogeneous features of optical tea bud images and foreground masks.
- Third, to evaluate the performance of the proposed SD-YOLOv8, an annotated self-built tea bud detection dataset with high-resolution optical images is implemented.
2. Methodology
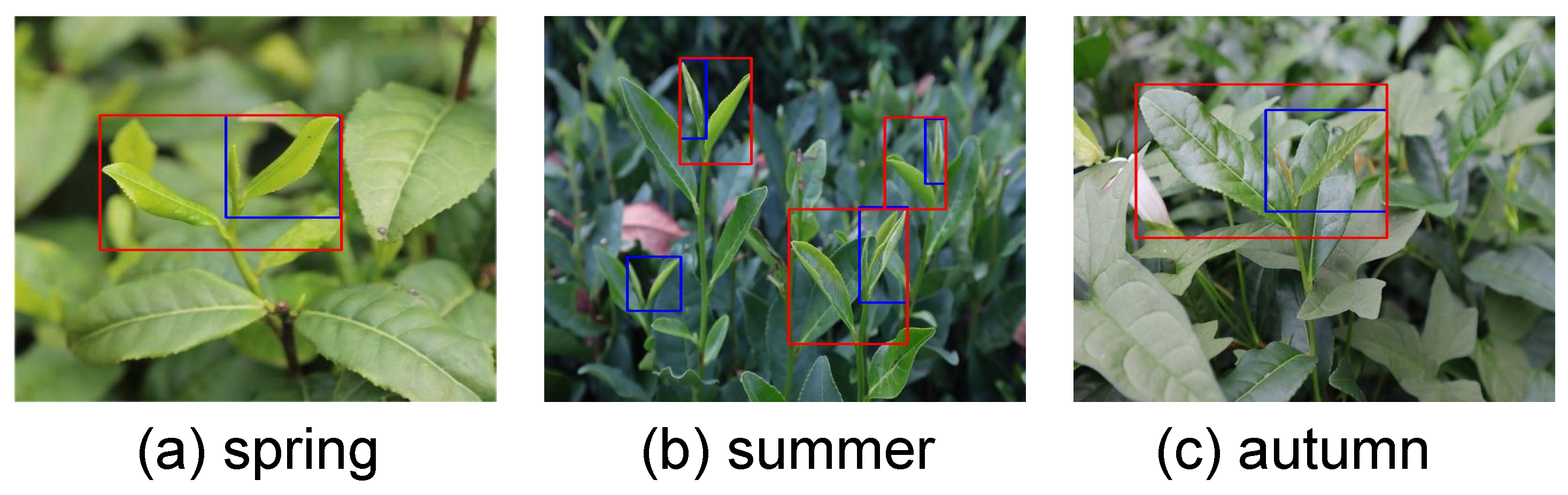
2.1. The Self-Built Tea Bud Detection Dataset
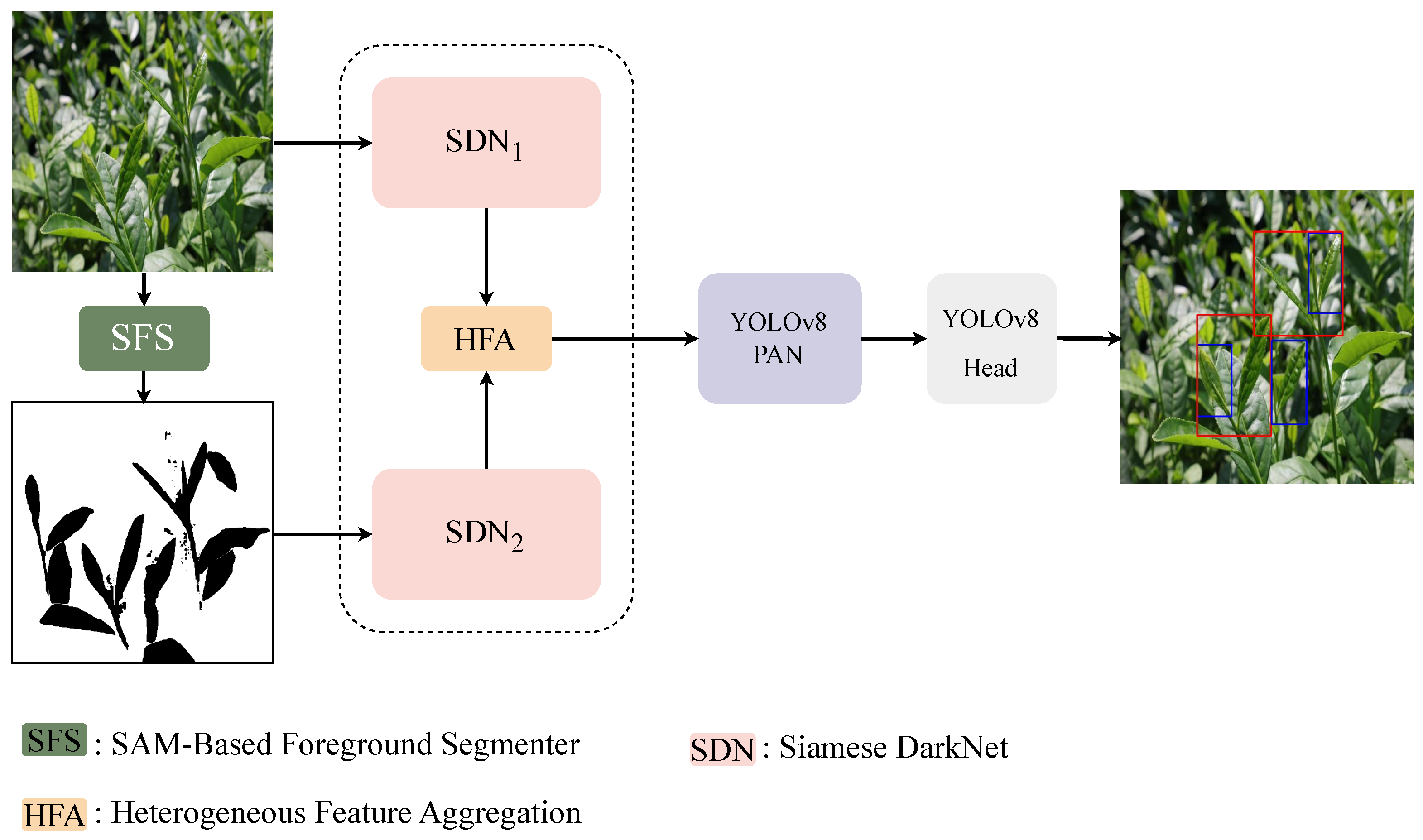
2.2. The SAM-Assisted Dual-Branch YOLOv8 (SD-YOLOv8)
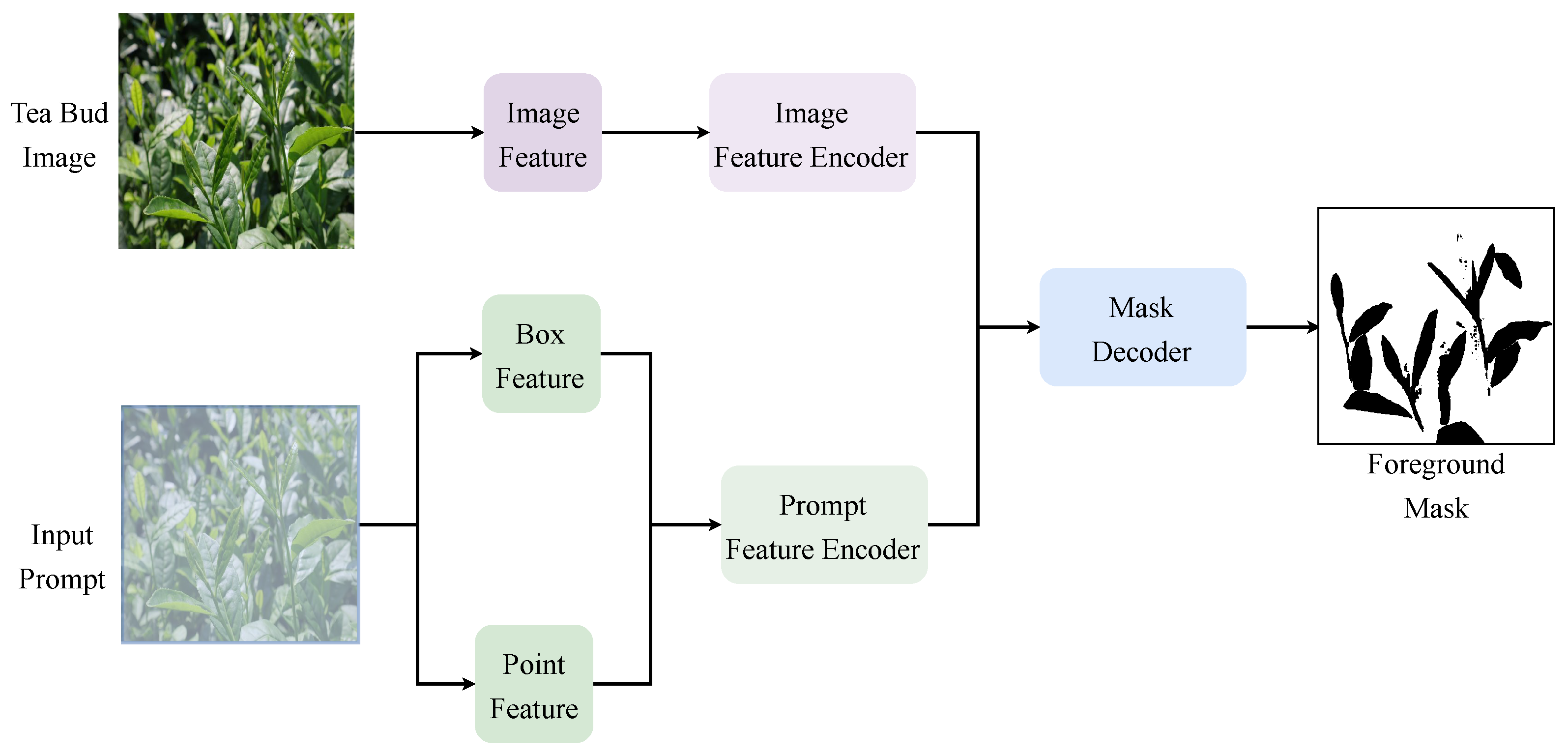
2.3. The SAM-Based Foreground Segmenter
2.3.1. The Global Feature Encoder in SFS
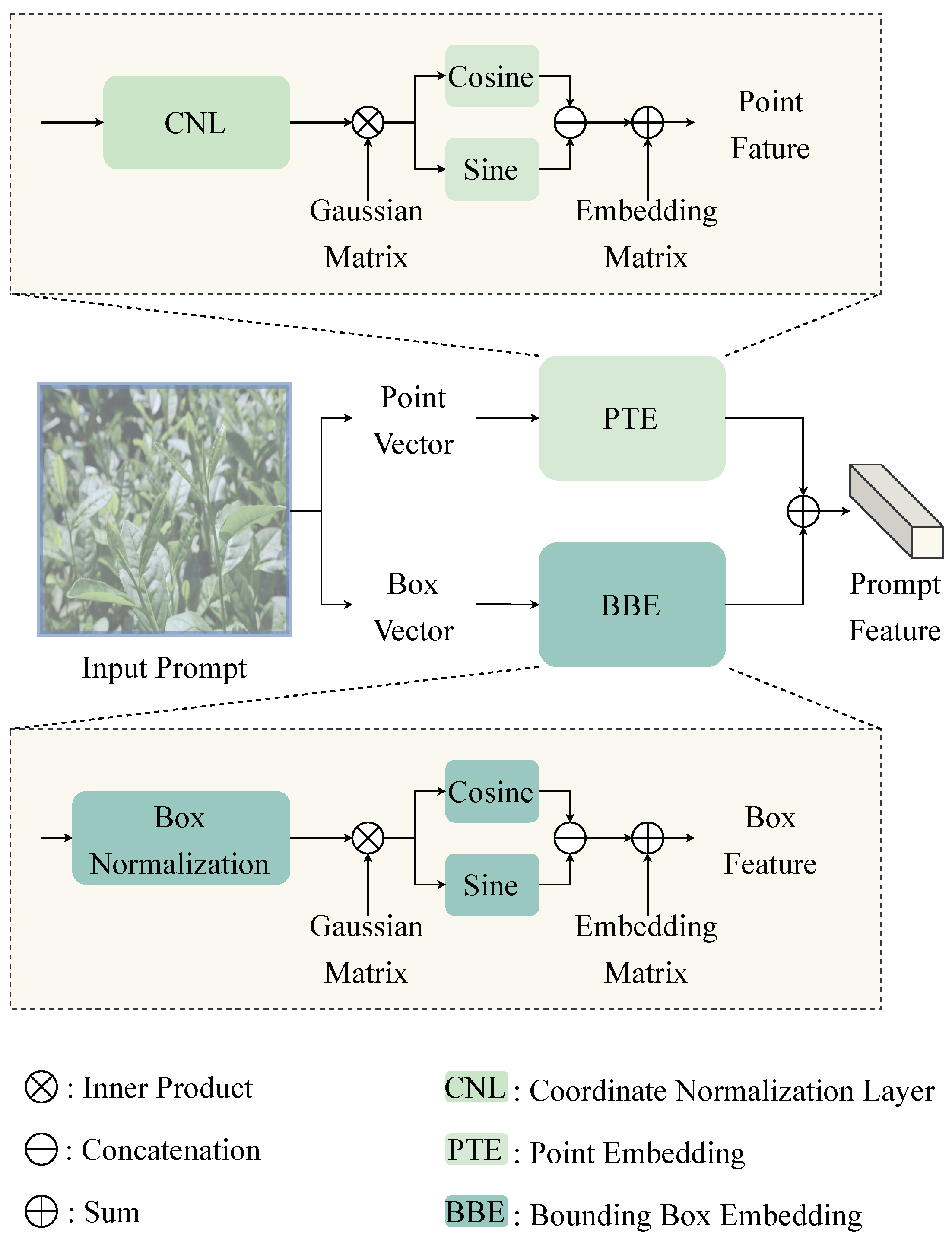
2.3.2. Prompt Encoder of SAM
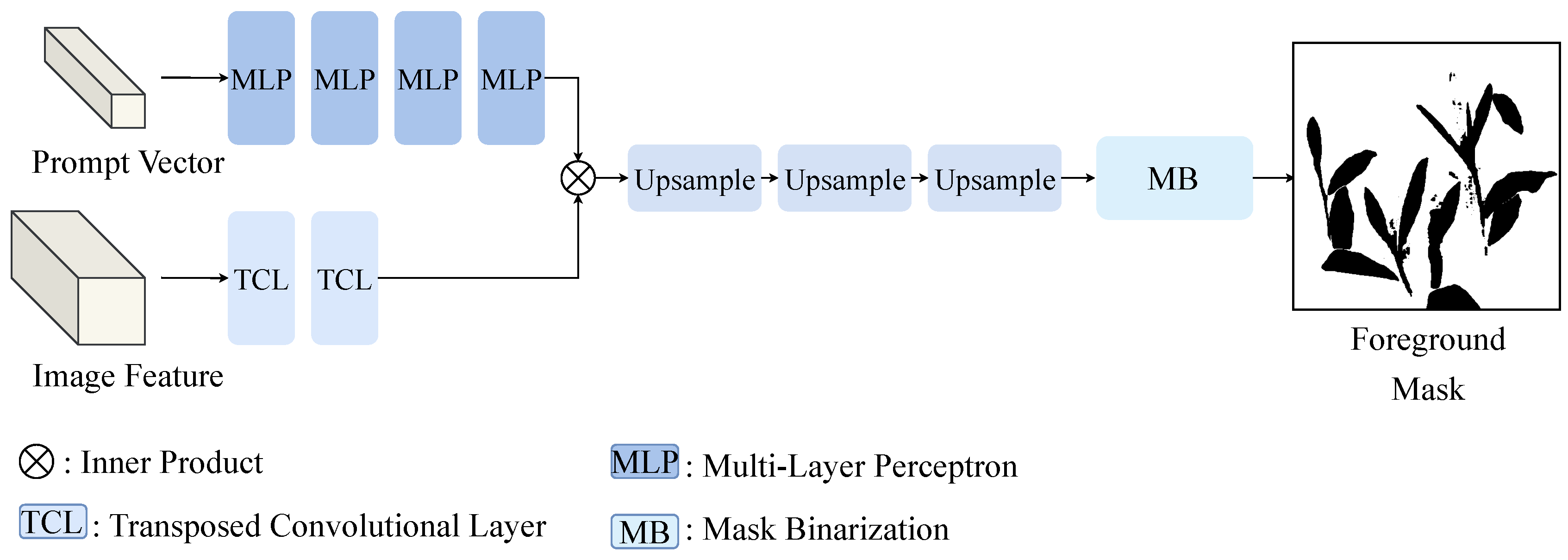
2.3.3. Mask Decoder of SAM
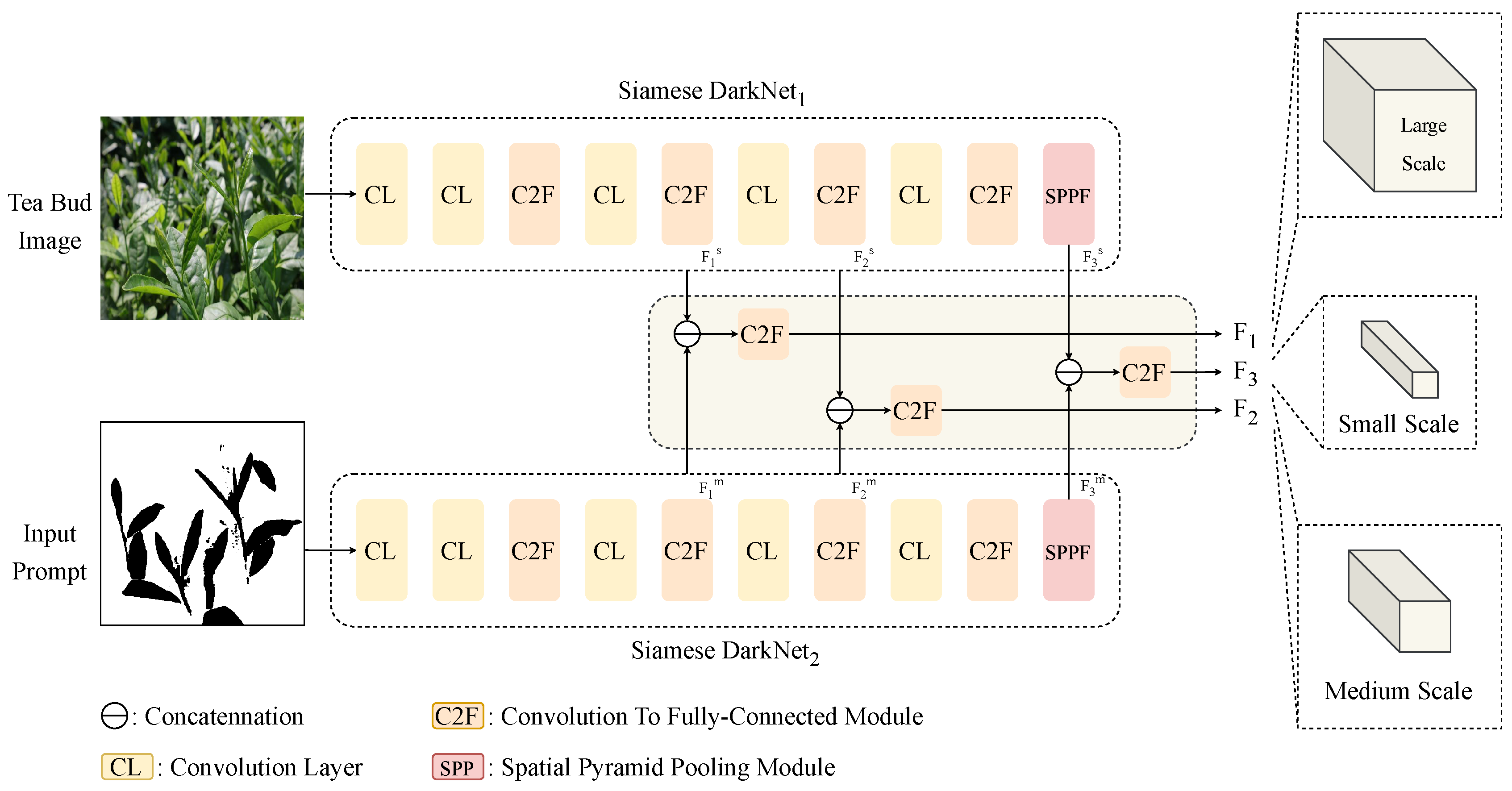
2.4. The Heterogeneous Feature Extractor
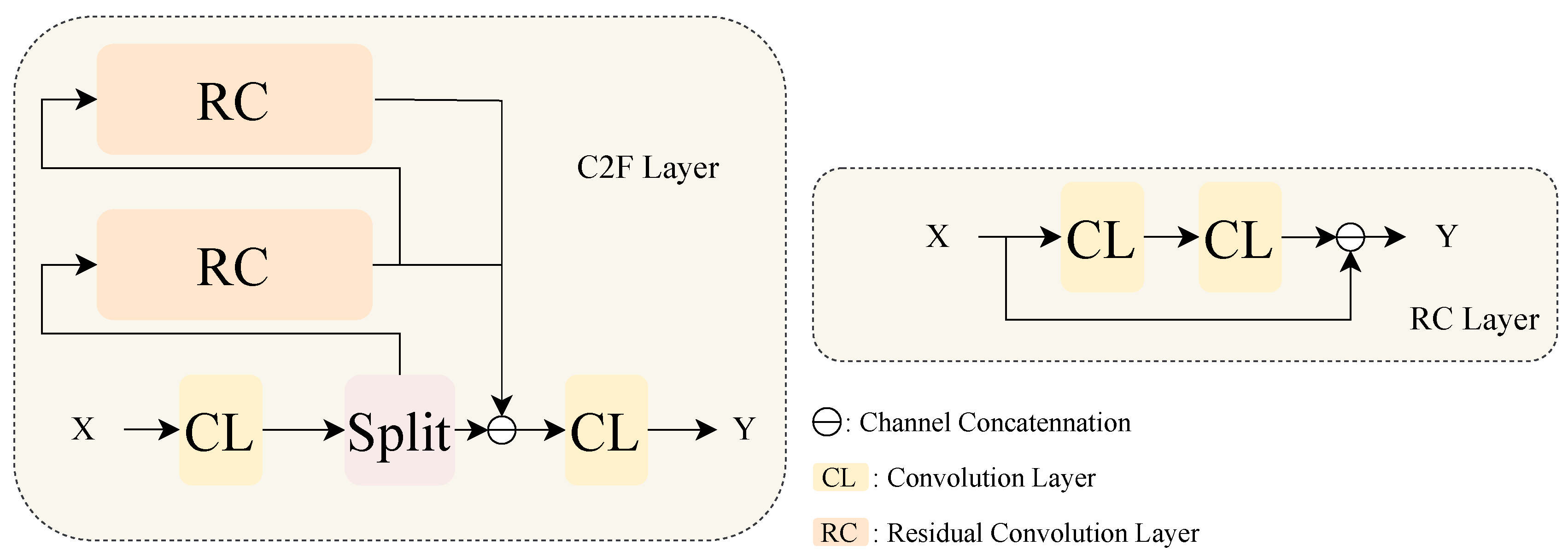
2.4.1. The Siamese DarkNet Encoder
2.4.2. The Heterogeneous Feature Aggregation
3. Experimental Settings
3.1. Evaluation Matrices
3.2. Settings of Experimental Environment and Model Parameters
4. Results and Discussion
4.1. Performance Evaluation of SD-YOLOv8
4.2. Ablation Analysis
4.3. Feature Visualization
4.4. Analysis of Foreground and Background Distinguishing Techniques
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, Q.; Yang, Y.; Hu, K.; Chen, J.; Djomo, S.N.; Yang, X.; Knudsen, M.T. Economic, environmental, and emergy analysis of China’s green tea production. Sustain. Prod. Consum. 2021, 28, 269–280. [Google Scholar] [CrossRef]
- Heiss, M.; Heiss, R. The Story of Tea: A Cultural History and Drinking Guide; Cookery, Food and Drink Series; Clarkson Potter/Ten Speed: Berkeley, CA, USA, 2007. [Google Scholar]
- Guan, J. The Tea Industry in Modern China and Public Demand for Tea. In Proceedings of the Making Food in Local and Global Contexts; Nobayashi, A., Ed.; Springer: Singapore, 2022; pp. 173–185. [Google Scholar] [CrossRef]
- Huang, B.; Zou, S. Tea Image Recognition and Research on Structure of Tea Picking End-Effector. J. Electron. Cool. Therm. Control. 2024, 13, 51–60. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, Z.; Cao, C.; Luo, K.; Qin, K.; Huang, Y.; Cao, J. Design and operation of a deep-learning-based fresh tea-leaf sorting robot. Comput. Electron. Agric. 2023, 206, 107664. [Google Scholar] [CrossRef]
- Zhao, B.; Wei, D.; Sun, W.; Liu, Y.; Wei, K. Research on tea bud identification technology based on HSI/HSV color transformation. In Proceedings of the 2019 6th International Conference on Information Science and Control Engineering (ICISCE), Shanghai, China, 20–22 December 2019; IEEE: New York, NY, USA, 2019; pp. 511–515. [Google Scholar] [CrossRef]
- Zhang, L.; Zou, L.; Wu, C.; Chen, J.; Chen, H. Locating Famous Tea’s Picking Point Based on Shi-Tomasi Algorithm. Comput. Mater. Contin. 2021, 69, 1109–1122. [Google Scholar] [CrossRef]
- Shao, P.; Wu, M.; Wang, X.; Zhou, J.; Liu, S. Research on the tea bud recognition based on improved k-means algorithm. Matec Web Conf. 2018, 232, 03050. [Google Scholar] [CrossRef]
- Karunasena, G.; Priyankara, H. Tea bud leaf identification by using machine learning and image processing techniques. Int. J. Sci. Eng. Res. 2020, 11, 624–628. [Google Scholar] [CrossRef]
- Meng, J.; Wang, Y.; Zhang, J.; Tong, S.; Chen, C.; Zhang, C.; An, Y.; Kang, F. Tea Bud and Picking Point Detection Based on Deep Learning. Forests 2023, 14, 1188. [Google Scholar] [CrossRef]
- Nebauer, C. Evaluation of convolutional neural networks for visual recognition. IEEE Trans. Neural Netw. 1998, 9, 685–696. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Comparison of different computer vision methods for vineyard canopy detection using UAV multispectral images. Comput. Electron. Agric. 2024, 225, 109277. [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, W.; Zhao, L.; Li, J.; Shang, S.; Ding, X.; Wang, T. Detection and classification of tea buds based on deep learning. Comput. Electron. Agric. 2022, 192, 106547. [Google Scholar] [CrossRef]
- Wang, S.; Wu, D.; Zheng, X. TBC-YOLOv7: A refined YOLOv7-based algorithm for tea bud grading detection. Front. Plant Sci. 2023, 14, 1223410. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Li, Y.; Ma, R.; Zhang, R.; Cheng, Y.; Dong, C. A Tea Buds Counting Method Based on YOLOv5 and Kalman Filter Tracking Algorithm. Plant Phenomics 2023, 5, 0030. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, Z.; Lin, G.; Chen, P.; Li, X.; Zhang, S. Detection and Localization of Tea Bud Based on Improved YOLOv5s and 3D Point Cloud Processing. Agronomy 2023, 13, 2412. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An attention mechanism-improved YOLOv7 object detection algorithm for hemp duck count estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Liu, Z.; Zhuo, L.; Dong, C.; Li, J. YOLO-TBD: Tea Bud Detection with Triple-Branch Attention Mechanism and Self-Correction Group Convolution. Ind. Crop. Prod. 2025, 226, 120607. [Google Scholar] [CrossRef]
- Xia, C.; Zhang, H.; Gao, X.; Li, K. Exploiting background divergence and foreground compactness for salient object detection. Neurocomputing 2020, 383, 194–211. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, Y.; Guo, J.; Li, Y.; Gao, X.; Zhang, J. IRSAM: Advancing Segment Anything Model for Infrared Small Target Detection. In Proceedings of the Computer Vision—ECCV 2024, Milan, Italy, 29 September–4 October 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer: Cham, Switzerlan, 2025; pp. 233–249. [Google Scholar]
- Zhang, Y.; Yin, M.; Bi, W.; Yan, H.; Bian, S.; Zhang, C.H.; Hua, C. ZISVFM: Zero-Shot Object Instance Segmentation in Indoor Robotic Environments With Vision Foundation Models. IEEE Trans. Robot. 2025, 41, 1568–1580. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Ashish, V. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, I. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerlan, 2020; pp. 213–229. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Season | Percentage | Scale (Before Data Augmentation) | Scale (Before Data Augmentation) |
|---|---|---|---|
| Spring | 25.6 % | 327 | 1635 |
| Summer | 30.7 % | 230 | 1150 |
| Autumn | 43.7 % | 192 | 960 |
| Model | P | R | mAp % |
|---|---|---|---|
| Faster R-CNN | 0.599 | 0.599 | 60.7% |
| DETR | 0.627 | 0.605 | 64.6% |
| YOLOv5 | 0.723 | 0.665 | 72.4% |
| YOLOv7 | 0.831 | 0.773 | 80.6% |
| YOLOv8 | 0.796 | 0.751 | 81.6% |
| SD-YOLOv8 | 0.831 | 0.778 | 86.0% |
| Model | P | R | mAP% |
|---|---|---|---|
| YOLOv8 | 0.796 | 0.751 | 81.6% |
| YOLOv8-CR-R | 0.809 | 0.765 | 84.1% |
| YOLOv8-CR-G | 0.828 | 0.752 | 82.9% |
| YOLOv8-CR-B | 0.813 | 0.762 | 82.8% |
| YOLOv8-4C | 0.816 | 0.771 | 83.8% |
| SD-YOLOv8 | 0.831 | 0.778 | 86.0% |
| Model | P | R | F1 |
|---|---|---|---|
| YOLOv8 | 0.64 | 0.05 | 0.0927% |
| SD-YOLOv8 | 0.51 | 0.02 | 0.0384% |
| Model | P | R | mAP% |
|---|---|---|---|
| YOLOv8 | 0.796 | 0.751 | 81.6% |
| SE-YOLOv8 | 0.801 | 0.732 | 82.4% |
| CBAM-YOLOv8 | 0.797 | 0.755 | 83.4% |
| SD-YOLOv8 | 0.831 | 0.778 | 86.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wu, D.; Xu, F. SD-YOLOv8: SAM-Assisted Dual-Branch YOLOv8 Model for Tea Bud Detection on Optical Images. Agriculture 2025, 15, 712. https://doi.org/10.3390/agriculture15070712
Zhang X, Wu D, Xu F. SD-YOLOv8: SAM-Assisted Dual-Branch YOLOv8 Model for Tea Bud Detection on Optical Images. Agriculture. 2025; 15(7):712. https://doi.org/10.3390/agriculture15070712
Chicago/Turabian StyleZhang, Xintong, Dasheng Wu, and Fengya Xu. 2025. "SD-YOLOv8: SAM-Assisted Dual-Branch YOLOv8 Model for Tea Bud Detection on Optical Images" Agriculture 15, no. 7: 712. https://doi.org/10.3390/agriculture15070712
APA StyleZhang, X., Wu, D., & Xu, F. (2025). SD-YOLOv8: SAM-Assisted Dual-Branch YOLOv8 Model for Tea Bud Detection on Optical Images. Agriculture, 15(7), 712. https://doi.org/10.3390/agriculture15070712