1. Introduction
Corn is recognized as one of the most vital cereals globally and serves as a crucial source of feed for livestock and agriculture [
1]. Seeds play an essential role as the carriers of genetic information in crops. However, corn seeds are vulnerable to damage and mildew during storage and transportation, which can considerably reduce the seed sowing quality, thereby affecting the crop yield and leading to economic losses. Surface defects and varietal purity are crucial indicators of seed quality. Traditional seed defect detection methods often rely on manual operation, are inefficient and are prone to subjective factors. Therefore, it is crucial to investigate an objective and automatic identification method for the effective sorting of seeds before sowing, which is essential for ensuring crop yield and enhancing economic benefits [
2]. Extensive studies regarding the classification of corn seeds have attempted to overcome such challenges [
3,
4,
5,
6].
In recent years, the integration of machine vision with deep learning has seen increasing application [
7,
8,
9,
10,
11]. Compared with traditional machine learning methods, deep learning decreases the subjectivity of manual feature extraction and automatically extracts various complex features from input data. Altuntaş et al. [
12] used VGG19 to differentiate haploid and diploid seeds with up to 94.22% accuracy. Kurtulmuş [
13] compared three deep learning models and found that GoogleNet attained the highest classification accuracy of 95% for sunflower seed classification. Zhou et al. [
14] designed a method using a convolutional neural network (CNN) to reconstruct pixel spectral images. This method accurately identified the non-embryoid and embryoid forms for six distinct varieties of normal corn seeds with 93.33% and 95.56% accuracy, respectively. Luo et al. [
15] compared six CNN models to obtain the best algorithm for intelligently classifying weed seeds. The AlexNet network exhibited high accuracy and a low detection time, while GoogLeNet achieved the best accuracy.
In the sorting preprocessing process of seeds, the classification network mainly classified the regions in the image and determined and output the category label or probability of image. It had fewer levels, lower model complexity and a relatively simple network structure. But it could not accurately localize the seeds and achieve tasks such as seed counting or sorting due to the lack of location information [
16,
17]. The object detection network solved this problem effectively by involving both location and category information, but it was more complex and required higher computational resources compared to the classification network. A category of classical object detection algorithms is region-based candidate object detection, with representative algorithms including R-CNNs and Fast R-CNNs. An R-CNN uses a selective search method to generate candidate regions, which involves a large number of computations, and each candidate region needs to go through a deep convolutional network for feature extraction, which further increases the computational burden. A Faster R-CNN achieves the fast generation of candidate regions by introducing a region proposal network (RPN), but its overall speed is still relatively slow. This is attributed to the fact that a Faster RCNN remains a two-stage detection algorithm, necessitating the sequential execution of candidate region generation and feature extraction [
18]. In industrial inspection, this limits its application to large-scale, high-speed production lines. In contrast to two-stage detection methods, one-stage detection, such as the YOLO series, extracts features directly from the network to predict, classify and regress objects [
19]. Using an end-to-end approach, the normalized image is fed directly into the CNN, and the location information and class of the object is predicted via regression, which drastically reduces the latency and computational requirements. YOLO balances accuracy and speed, and this approach is more suitable for inspection in industry. Ouf [
20] used transfer learning and CNNs to classify leguminous seeds with different backgrounds, sizes and shapes. YOLOv4 exhibited higher accuracy and detection speed compared with a Faster R-CNN. Shi et al. [
21] applied the YOLOv5 series model to identify barley seeds and reported that the accuracy of the mixed dataset using the YOLOv5x6 model was substantially better than that of the single-class dataset. Thangaraj Sundaramurthy et al. [
22] used four different variants of YOLOv5 to identify corn seeds that were Fusarium infected from the processing lines. The results showed that the YOLOv5-s model showed the highest
mAP@50 of 99% for the detection of Fusarium infection in individual corn grain in images. The YOLOv5-n model performed well, with minimal training time and a higher inference speed for detection in real-time scenarios and videos.
The basic object detection network showed false and missed detection due to its insufficient ability to learn features, a complex detection background or smaller detection object. These cases were verified, and it was demonstrated through experiments that the improvement of the basic network could effectively reduce the number of false and missed detections [
23,
24]. To enhance the ability of the network to learn and capture features, researchers have opted to incorporate attention mechanisms or substitute the feature network to refine the model. Zhang et al. [
25] chose to introduce attention mechanisms in YOLOv5s to enable it to learn features better. The results showed that the CBAM (Convolutional Block Attention Module) accentuated pertinent information critical for coated seed recognition and could extract the features of seeds from images more effectively than the other three attention mechanisms. The improved network achieved the best performance in the self-built coated-seed dataset and increased the
mAP value by 1.22% compared with the original model. Zhang and Li [
26] incorporated the effective pyramid split attention (EPSA) into the backbone network of YOLOv5s. The results showed that the EPSA module improved the feature extraction ability for small targets with similar backgrounds. The proposed method addressed the problem of difficulty in detecting rape seeds at different key growth stages. Zhao et al. [
27] integrated four CBAM attention mechanisms into YOLOv5s and used CARAFE up-sampling to replace the neck of the model. The improved model enhanced the detection precision and achieved effective counting and localization of seed images. Xiao et al. [
28] engineered an improved YOLOv5 network to identify damaged Camellia oleifera seeds, incorporating both the BiFPN and CA. The accuracy of the final model was increased by 6.1%.
Although the improved model enhanced the detection precision, it introduced more computing owing to the enormous number of parameters in the deep learning network, leading to slower inference. Optimizing the model to be lightweight is a practical approach for model compression to achieve the real-time standards of industrial detection. Wang et al. [
29] designed a pruned YOLOv3 network. The model size after channel pruning was 4.07 MB, with an average accuracy of 98.33%. Furthermore, the model achieved rapid and non-destructive detection of kidney bean seeds. Beyaz and Saripinar [
30] classified sugar beet monogerm and multigerm seeds on the NVIDIA artificial intelligence boards. The experimental results proved that the accuracy of YOLOv4-tiny was only a little bit worse than that of YOLOv4, but YOLOv4-tiny had seven more frames per second (FPS) than YOLOv4. This suggested that models with a more simple structure had a significant advantage in terms of inference speed on embedded devices. Xia et al. [
31] replaced the backbone of the YOLOv5s with MobilenetV3-Small to detect defects on the surface of corn seeds. The final model size was 8.8 MB, with a detection accuracy of 92.8%. Jiao et al. [
32] combined μCT technology with the improved YOLOv7-tiny network to identify invisible internal endosperm cracks in corn seeds produced during the soaking process. This approach extracted crack information accurately and automatically, with a 93.8% accuracy and a 9.7 MB model size. Li et al. [
33] addressed problems such as low accuracy on edge location and heavy model parameters in detecting tomatoes by improving and simplifying the YOLOv10 model. The results showed that the parameters and FLOPs of the final model were reduced by 54% and 64.9%, respectively. The above research confirmed that model compression was an effective way to reduce the model size and balance the model computation and detection accuracy.
Currently, the YOLO series has been updated to YOLOv11. Each network in the YOLO series has its own characteristics: YOLOv7 introduces a dynamic label assignment strategy, which improves the training efficiency and detection performance of the model. YOLOv8 introduces a dynamic kernel attention mechanism and anchor-free detection technique, which performs better on tasks in complex scenarios. YOLOv9 uses multi-level auxiliary feature extraction and domain-specific augmentation strategies [
34]. YOLOv10 eliminates the traditional non-maximum suppression (NMS). A dual-label assignment strategy is implemented. YOLOv11 introduces the C3k2 module in the backbone network and enhances spatial attention using C2PSA [
35]. In tasks with simpler backgrounds such as the real-time detection of seeds on a conveyor belt, a more complex network architecture also means that more computational resources are required. The more simplified architecture of the YOLOv7 network in comparison still achieves excellent performance. The stability and reliability of YOLOv7 has been widely recognized in many real-time inspection tasks. Therefore, exploring practical improvements will more effectively support subsequent deployments.
This study proposed the YOLO-SBWL method, which combines machine vision and deep learning to achieve both the classification of healthy seeds and distinction of damaged seeds during transportation on the conveyor belt. The major contributions include the following: (1) A self-built, real-time image acquisition system was used to obtain a dataset of corn seeds, and data augmentation was performed on the original data to expand the dataset. (2) This study inserted the SimAM into the YOLOv7 network to effectively increase attention to the key features of corn seeds when the texture details of a seed become blurred due to rapid movement and to enhance the recognition accuracy between healthy and defective seeds by assigning weights to each feature. (3) In order to solve the problem of false detection caused by too much similarity between healthy seeds of different varieties, the PAFPN structure was replaced with the BiFPN to enhance the information exchange on different scales and improve the feature fusion ability of the model. In addition, the CIoU loss function was replaced with Wise-IoU to speed up the convergence of the model. (4) The improved model was compressed using the LAMP method and subsequently fine-tuned. This effectively reduced the model size and improved the detection speed.
2. Materials and Methods
2.1. Experimental Sample
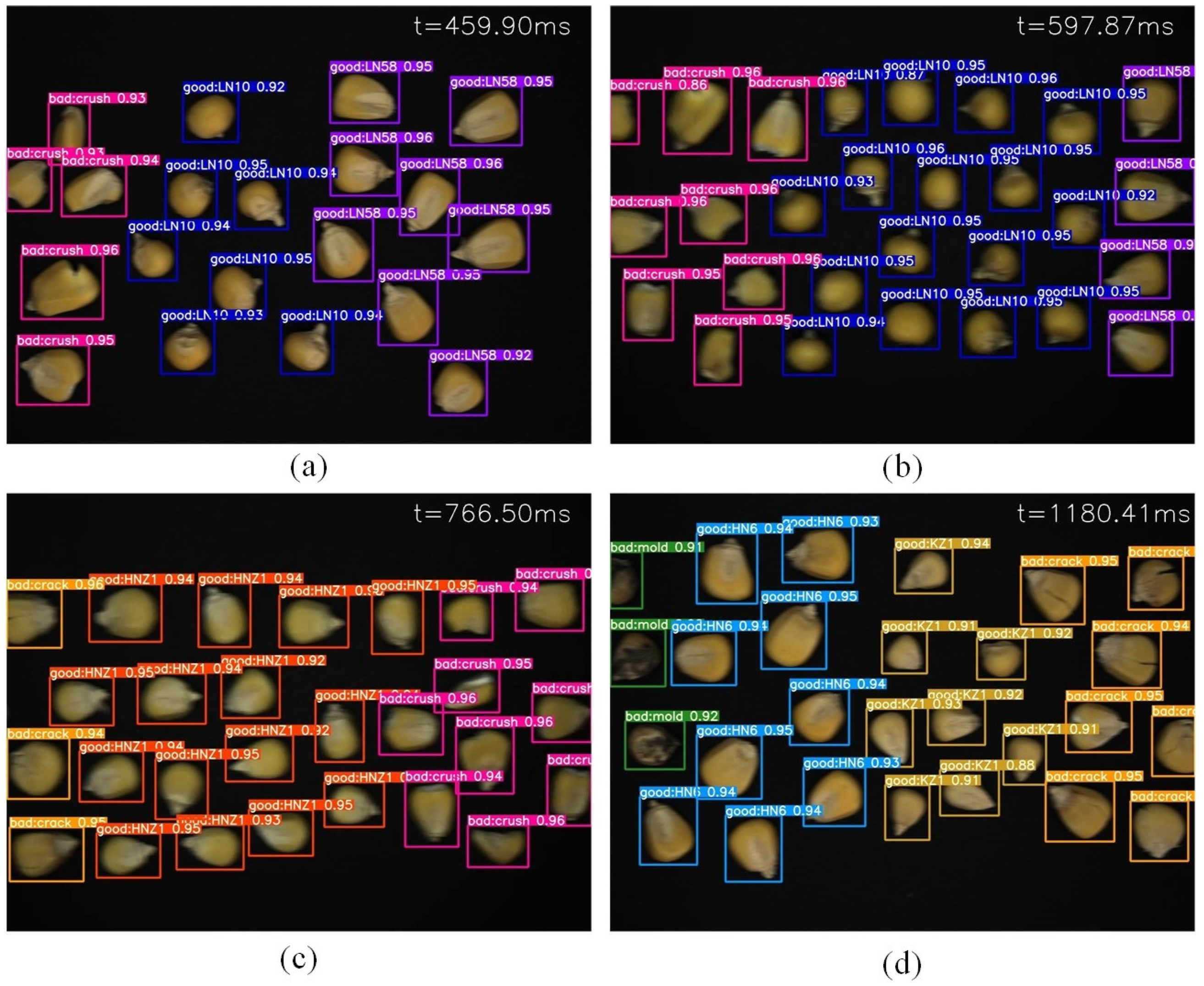
The seeds were purchased from the Huiheng seed business department in Harbin, Heilongjiang, China. The producers of the seeds were Fuyu Yinong Seed Industry Co. and Gongzhuling Lvyu Seed Industry Science and Technology Co., both located in Jilin Province, China. This study used 4000 corn seeds of 5 corn varieties as the experimental materials. The five types of seeds were KenNian1, HuangNianZao1, LiangNuo10, HuangNuo6 and LiangNuo58. HuangNuo6 and LiangNuo58 had similar shape appearance, while HuangNianZao1 and KenNian1 were similar in color but smaller in shape. The different types of corn seeds had completely different textures and appearances. The seeds were artificially screened prior to the experiment to remove impurities and seeds unsuitable for the experiment. Each category had three types of defects, including cracks, crush and mold. These categories had different colors, sizes and shapes, which added diversity and complexity.
Table 1 lists the names of seeds and the corresponding number of categories.
2.2. Image Acquisition
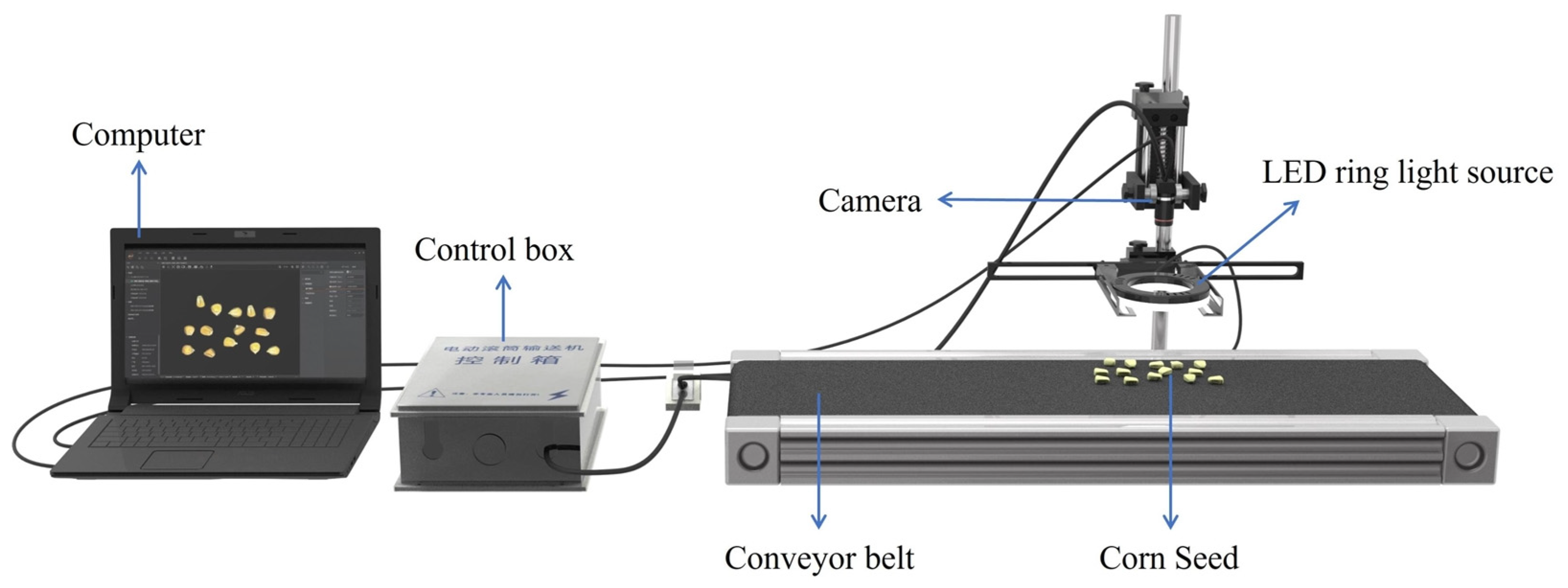
The image acquisition system comprised a camera (MV-CS016-10GC, HIKVISION, Hangzhou, China), a lens (MVL-MF0828M-8MP, HIKVISION, Hangzhou, China), white LED ring light source, conveyor belt, corn seeds and computer (
Figure 1). The camera was a 1.6-megapixel CMOS camera with a net-mouth face array, a 1440 × 1080-pixel resolution and a frame rate of 65.2 fps. The camera had a pixel size of 3.45 μm × 3.45 μm. The 1440 × 1080-pixel resolution ensured that the camera was able to cover more details of the seeds. The frame rate of the camera met the real-time requirements of industrial inspection. It was chosen because it is an industrial camera that performs well in terms of image detail and capture speed, and its application is in the field of industrial detection for machine vision [
36]. Additionally, it supports a Gigabit Ethernet interface, characterized by high speed, high stability and high resolution. These characteristics were essential for the real-time capture of rapidly moving seed images. The exposure time of the camera in this experiment was set to 3500 microseconds in normal mode.
The seeds were placed randomly on the conveyor belt to avoid contact and overlap. The dimensions of the conveyor belt were 1000 × 365 × 70 mm (length × width × height), with a roller diameter of 57 mm and reduction ratio of 46. The motor controller was connected to the computer using RS485 serial communication, and the speed of the conveyor belt was controlled using the computer. The conveyor speed was adjustable in the 0.0–0.3-m·s
−1 range. This range was limited by the equipment, and the maximum adjustable speed was 0.3 m·s
−1. For instance, Wang et al. [
37] set the conveyor speed to 0.09 m·s
−1, and Zhao et al. [
27] stated in their experiment that the conveyor speed could be adjusted within the range of 0.0–1.5 m s
−1. Similarly, to maximize the utilization of the hardware, the conveyor speed was averagely quantized into 5 levels within its maximum range and converted into rpm for control in this experiment.
2.3. Dataset Processing and Annotation
The images included in the dataset used in the study were captured during the motion of the conveyor belt and collected in May 2024. The dataset comprised images captured at different conveyor belt speeds with an equal number of pictures at each speed to ensure data balancing and avoided bias due to the different number of images at each speed. During image acquisition, the images were captured frame by frame to guarantee all types of seeds were captured in the shots at each speed. The other external environmental factors, such as background, light intensity and camera height, remained settled. The captured images were saved in the JPG format, and the repeated images were removed. Overall, 1180 images were selected, and the training set/validation set/test set ratio was 8:1:1. The training set, validation set and test set for each of the five speed categories contained 188, 24 and 24 samples, respectively.
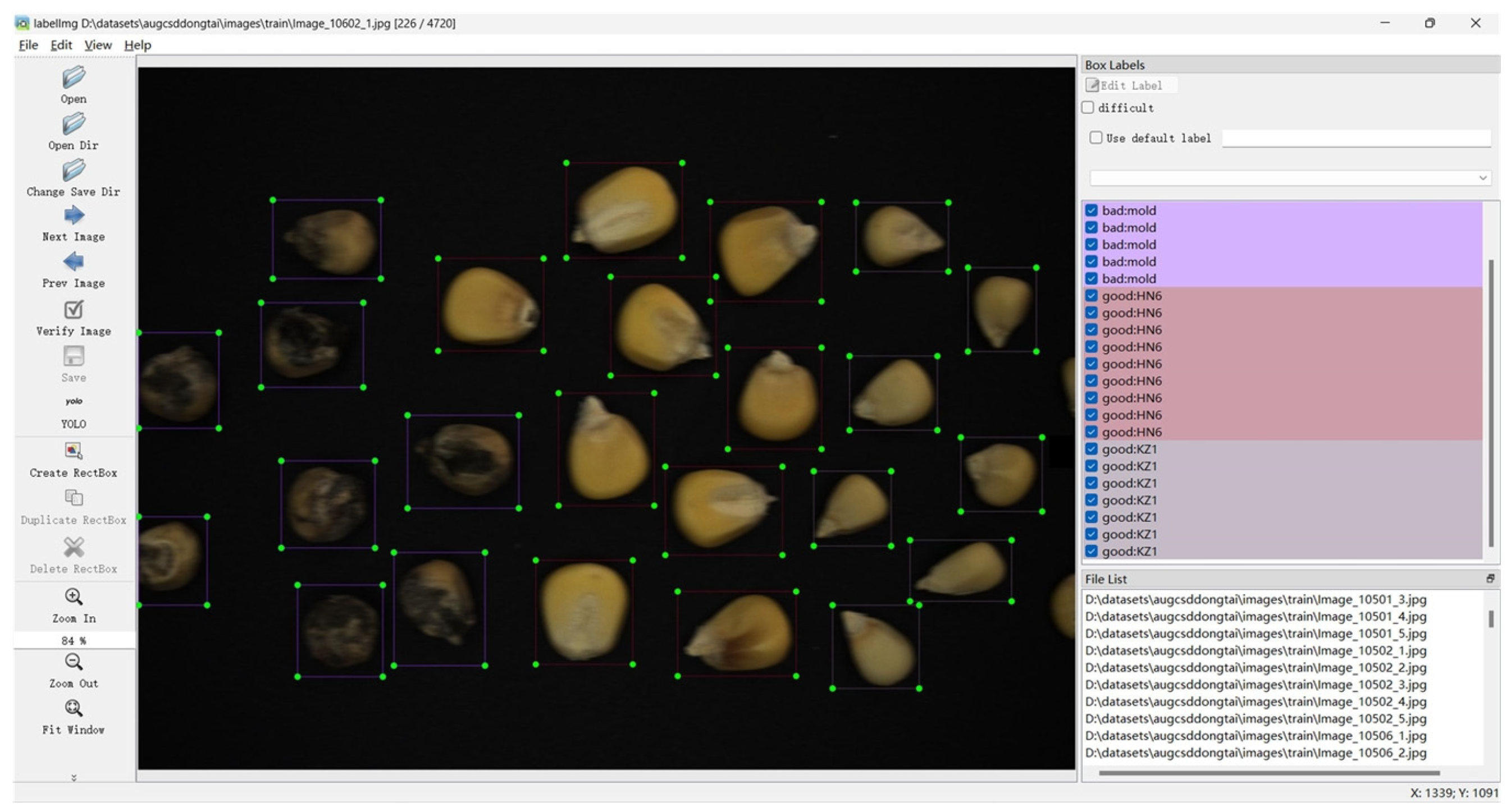
In this study, LabelImg was selected as a tool for image annotation. Its main function was to label rectangular bounding boxes, and it supported saving labels to multiple formats, which was sufficient to meet the needs for labeling independent seeds (
Figure 2). Each seed was designated a corresponding bounding box to ensure all pixels were completely enclosed within the rectangular area. The four points on each bounding box represented the coordinate information of the enclosed seed. The label files were saved in TXT format. However, the tasks, such as polygons or 3D objects, could not be addressed by using LabelImg, compared to more advanced annotation tools, such as LabelMe [
38], CVAT [
39] and VoTT [
40].
2.4. Data Augmentation
Data augmentation was used to extend the dataset in this study, enrich the image dataset and reduce data overfitting [
41]. Data augmentation effectively expanded the data, making the sample data more diverse due to the small dataset. The data augmentation techniques included contrast enhancement, horizontal mirroring, vertical mirroring, adding Gaussian noise and brightness enhancement (
Figure 3). Among them, brightness and contrast were enhanced by 50% of the original image, respectively. The noise value for adding Gaussian noise was set to 0, with a standard deviation of 0.5. Horizontal mirroring and vertical mirroring were obtained by flipping horizontally and vertically.
Contrast enhancement made the light and dark areas of an image more distinct by adjusting the distribution of pixel values in the images. This adjustment process could significantly enhance the details and clarity of the image for subsequent analysis and processing. Horizontal mirroring and vertical mirroring increased the diversity of the data and effectively expanded the dataset. The addition of Gaussian noise could simulate the various disturbances that might be encountered in the real world, enhancing the robustness and generalization ability of the model. Brightness enhancement could simulate different lighting conditions at the time of shooting. Finally, the expanded dataset contains 5900 images.
2.5. YOLOv7 Network Architecture
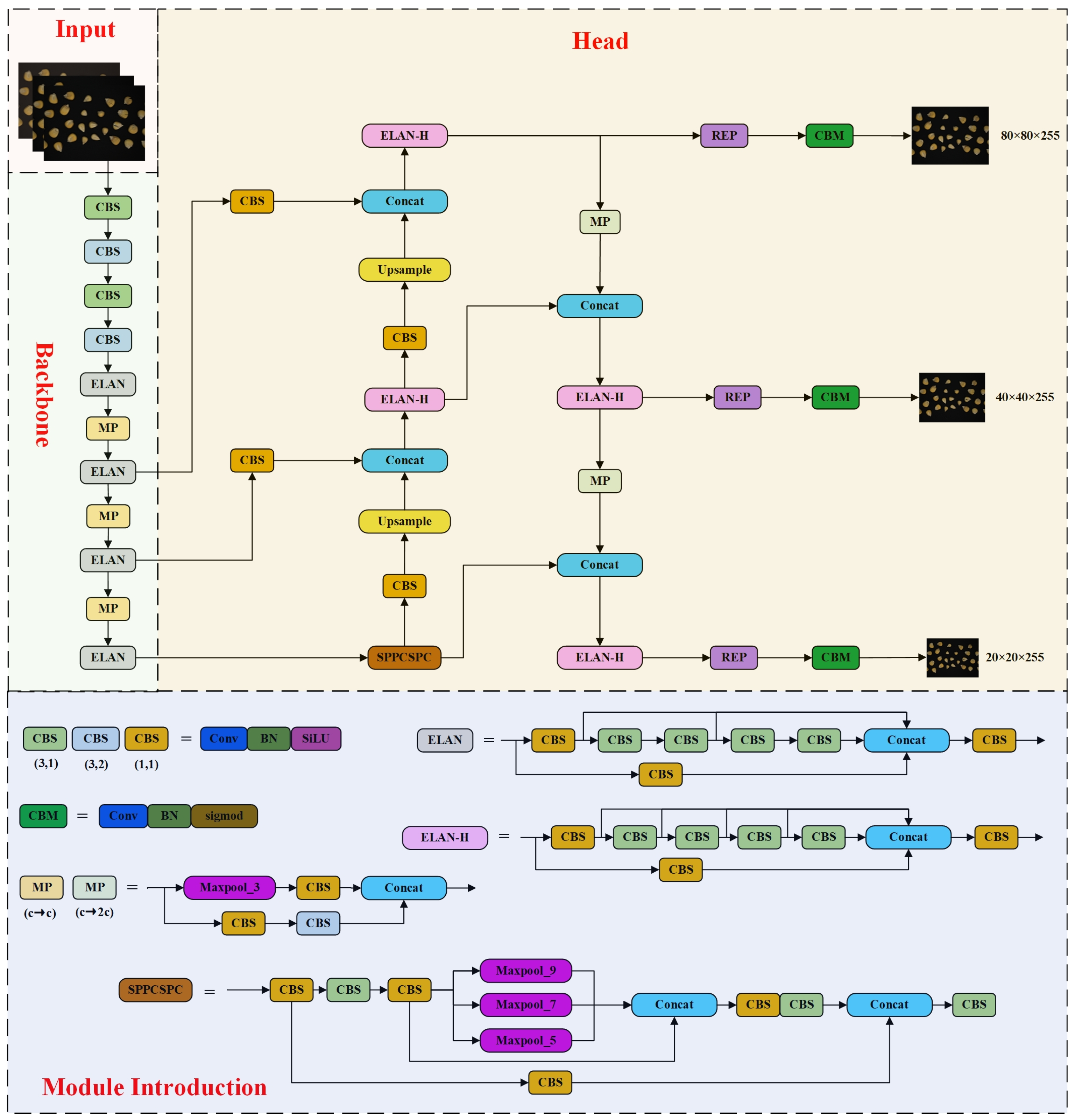
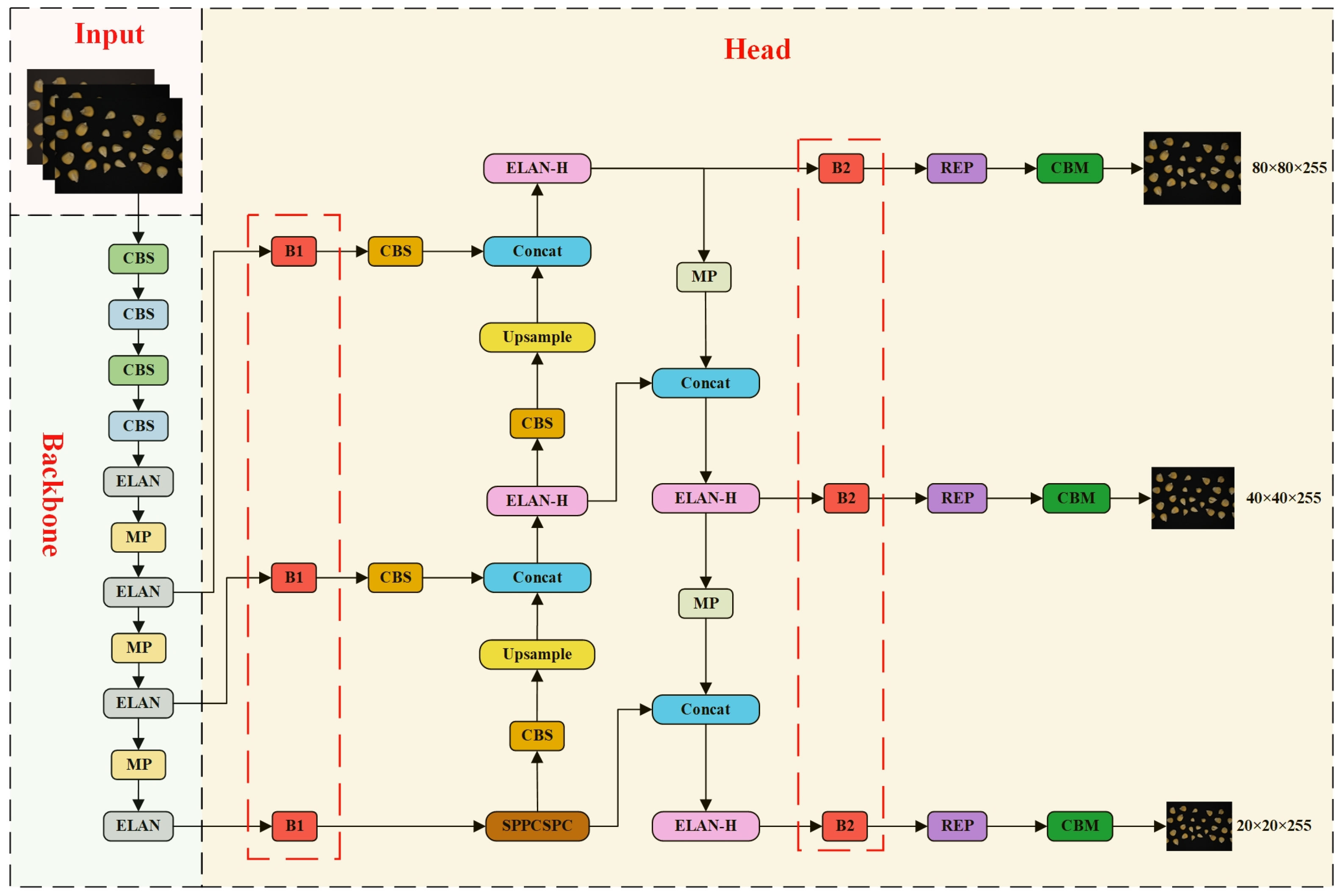
The YOLO series exemplifies one-stage object detection algorithms, achieving end-to-end detection through a singular CNN. With the iteration of the YOLO series, the model complexity and network structure gradually increases. It requires a large amount of training data to adequately train the network, which is a limitation for some application scenarios, as collecting a large amount of well-labeled training data is a time consuming and costly process. However, in the task of detecting corn seeds in real time, a more stable network brings stability to the task, and with the continuous improvement of the YOLO series, YOLOv7 strikes a good balance between accuracy and detection speed. Similar to the detection approach of the YOLOv4 and YOLOv5 models, YOLOv7 comprises an input, backbone, head and prediction.
Figure 4 shows the model structure of YOLOv7. The input module resizes the image to a consistent pixel dimension, aligning with the size requirements of the backbone network, thus minimizing computational complexity [
42]. The backbone module comprises CBS, ELAN and MP structures. Among them, the CBS is constituted of a two-dimensional convolutional layer, a batch normalization (BN) layer and SiLU activation function. The ELAN module is constituted of multi-branch convolution and is mainly used to enhance the feature representation of the CNN. The MP module comprises Maxpool and a CBS structure. The feature extraction module is constituted of a PAFPN structure. The head module contains the REP and CBM structures. The CBM module comprises a convolutional layer, BN and sigmoid activation function.
2.6. Improvement to YOLOv7
Herein, the corn seeds were categorized into five and three groups based on varieties and defects, respectively. The high similarity between the color and shape of corn seeds meant that their features in the images were blurred owing to the relative motion during the rapid movement of the conveyor belt. Therefore, it was difficult to achieve the expected result by directly using the YOLOv7 basic network. To enhance detection outcomes, the YOLOv7 network underwent modifications to better align with the research needs.
2.6.1. Introduction of Attention Mechanism
In practical industrial applications, selecting an appropriate attention mechanism is vital for boosting the efficiency and performance of the network. False and missed detection of seeds inevitably occurs in the production line. This study chose to insert an attention mechanism into YOLOv7 to strengthen the attention to feature information of corn seeds. SENet stands as a quintessential example of channel attention mechanisms, which calculate the channel attention by 2D pooling and can considerably improve the performance of current mainstream network models [
43]. Subsequently, Woo et al. [
44] reported that spatial information is important for capturing objects in vision tasks. As a result, the CBAM is proposed; unlike the SENet, the CBAM concatenates channel attention with spatial attention and utilizes convolution to calculate spatial attention. The performance of the model can be enhanced to some degree by inserting this attention mechanism.
However, spatial attention computed via convolution can only extract partial information and fails to build the interdependency necessary for vision tasks. The spatial attention mechanism focuses on the spatial locations on the feature map and generates a spatial attention map by capturing the spatial information of each channel. However, when features become blurred, the difference in information on spatial locations may diminish, making it difficult for the spatial attention mechanism to accurately distinguish between features at different locations. Existing spatial attention mechanisms usually generate attention mappings based on fixed rules or patterns and lack dynamic adaptability to different scenes and features. Therefore, Yang et al. [
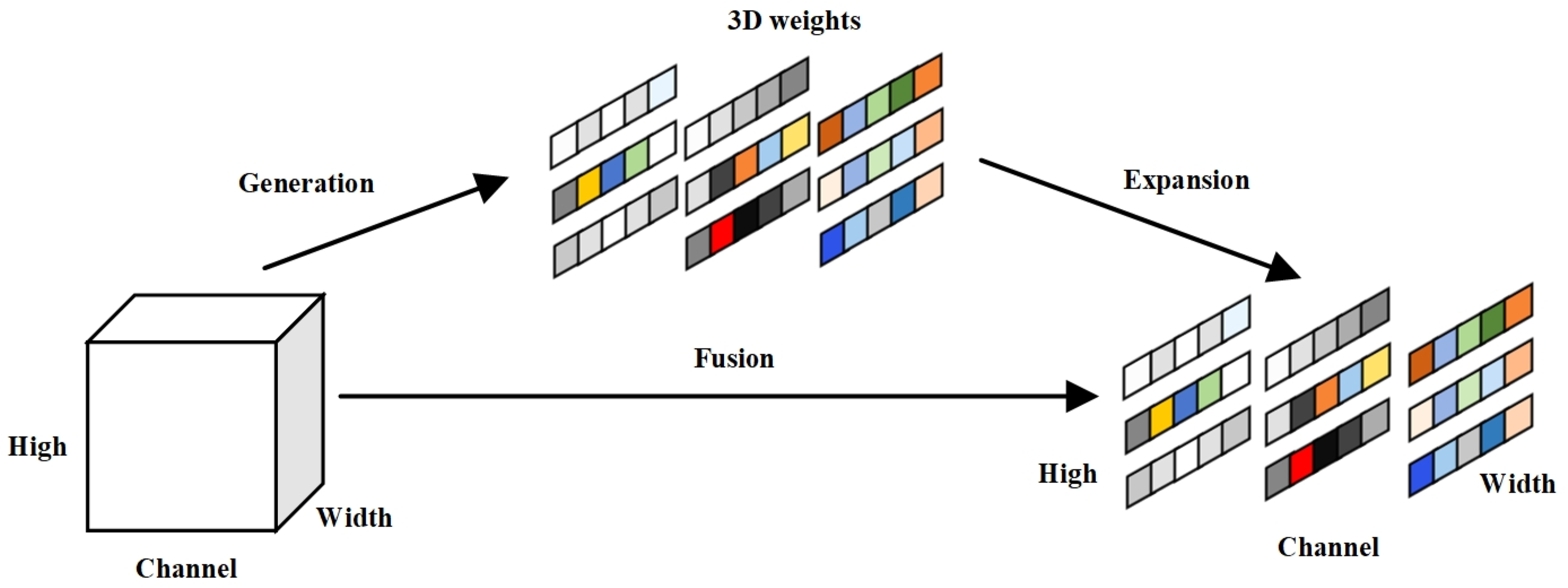
45] proposed a simple and parameter-free attention mechanism called the SimAM. This module is based on a neuroscience theory, referring to the principle that channel attention and spatial attention work in concert in the human brain, and the module designs an energy function specifically to assess the weight of each discrete neuron, not just connecting the two in series or parallel (
Figure 5). It fully utilizes the weight information from all neurons without introducing any additional parameters, thereby ensuring operational efficiency [
46].
In the SimAM, if a neuron contains abundant information, it will exhibit distinctive firing patterns compared to its surrounding neurons, effectively suppressing them. Consequently, neurons demonstrating spatial suppression should be prioritized. The energy function of activated neuron is defined using the Formulas (1)–(3):
where
is the linear transformation of
t;
is the linear transformations of
xi;
t is the target neuron of the input feature in a single channel;
xi is the neuron other than the target neuron; and
M is the number of neurons in the channel. The energy function is finally given by Formula (4).
The solutions of
wt and
bt can be obtained using the following formulas:
The minimum energy equation can be derived using Formula (9):
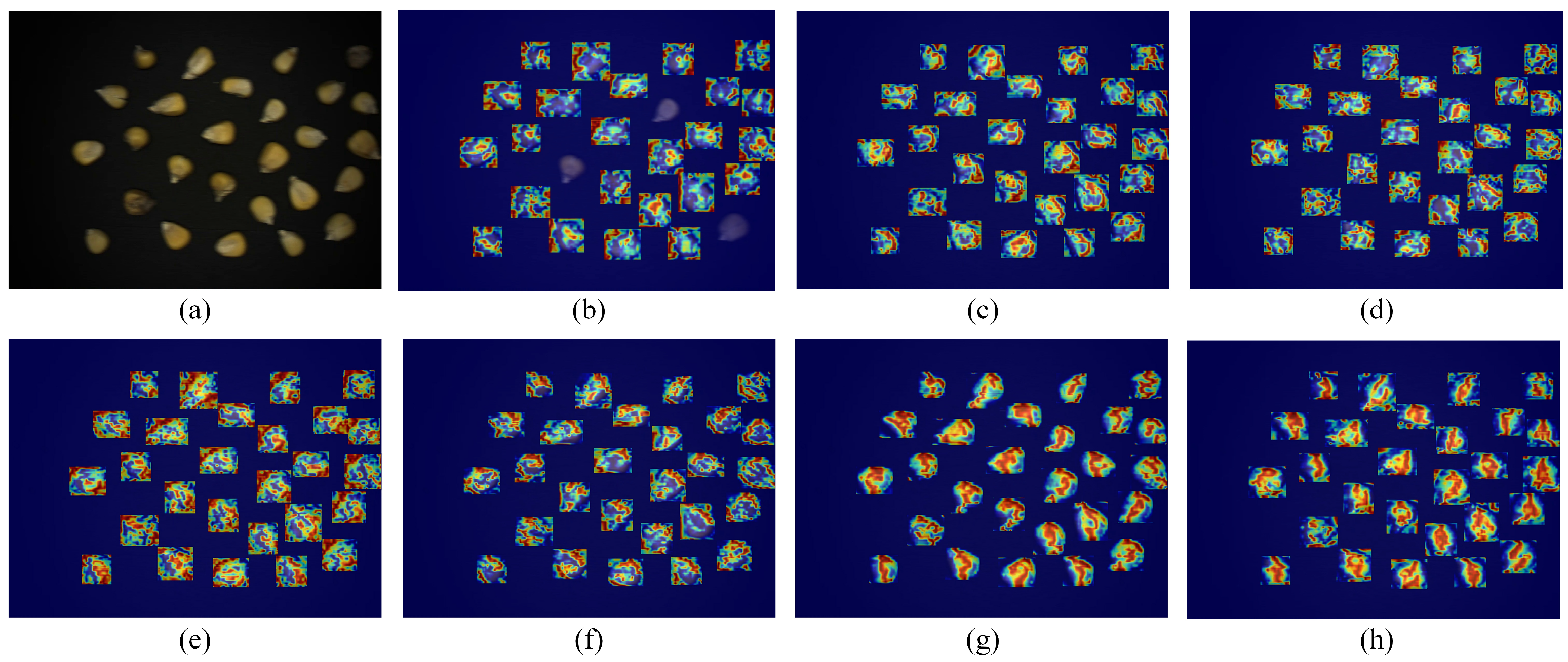
From Formula (9), the less energy a neuron possesses, the more pronounced its distinction from surrounding neurons, making it more significant. Compared with other attention mechanisms, the SimAM can obtain three-dimensional attention weights from the input feature maps. The damaged seeds were distinguished more accurately by introducing the above three attention mechanisms before and after the feature extraction network; the added positions were called Block1 (B1) and Block2 (B2) (
Figure 6). The recognition results of the three attention mechanisms added at the above positions were compared in the experiments.
2.6.2. Improved PAFPN for Enhancing Feature Fusion
The FPN was a multi-scale feature fusion technique. It seamlessly integrated features from various levels via top–down pathways and lateral connections. FPN effectively combined high-level and low-level semantic information. However, anchor boxes were generated for multiple feature maps in the process of feature fusion, which greatly affected the detection speed. Repeated fused features also affect the feature representation of the model.
The PAFPN used in YOLOv7 adds bottom–up paths on top of the FPN, improving the positional accuracy of the entire feature pyramid without affecting the location information of the fused feature map. However, adding such a path means that the network has to perform additional up-sampling, down-sampling and feature fusion operations. These additional computational steps increase the overall computational cost.
Compared to the PAFPN, the BiFPN removes nodes with only one input and integrates skip connections, which enable direct feature transmission across different layers. It reduces the redundancy of information due to the repeated fusion of features and makes the utilization of features more efficient.
Figure 7 shows the structures of the FPN, PAFPN and BiFPN. The reason for selecting the BiFPN to replace the FPN in this paper was due to the diverse shapes and sizes of corn seeds detected in images, which generated input features at various resolutions during training, each contributing differently to the output features. The BiFPN addressed this issue by incorporating an additional weight to adjust for the contribution of various input features on the output features. The BiFPN outperforms the PAFPN by simplifying the structure of the PAFPN to some extent and reducing feature fusion operations and network parameters. However, compared to the structure of the FPN, the BiFPN is still more complex.
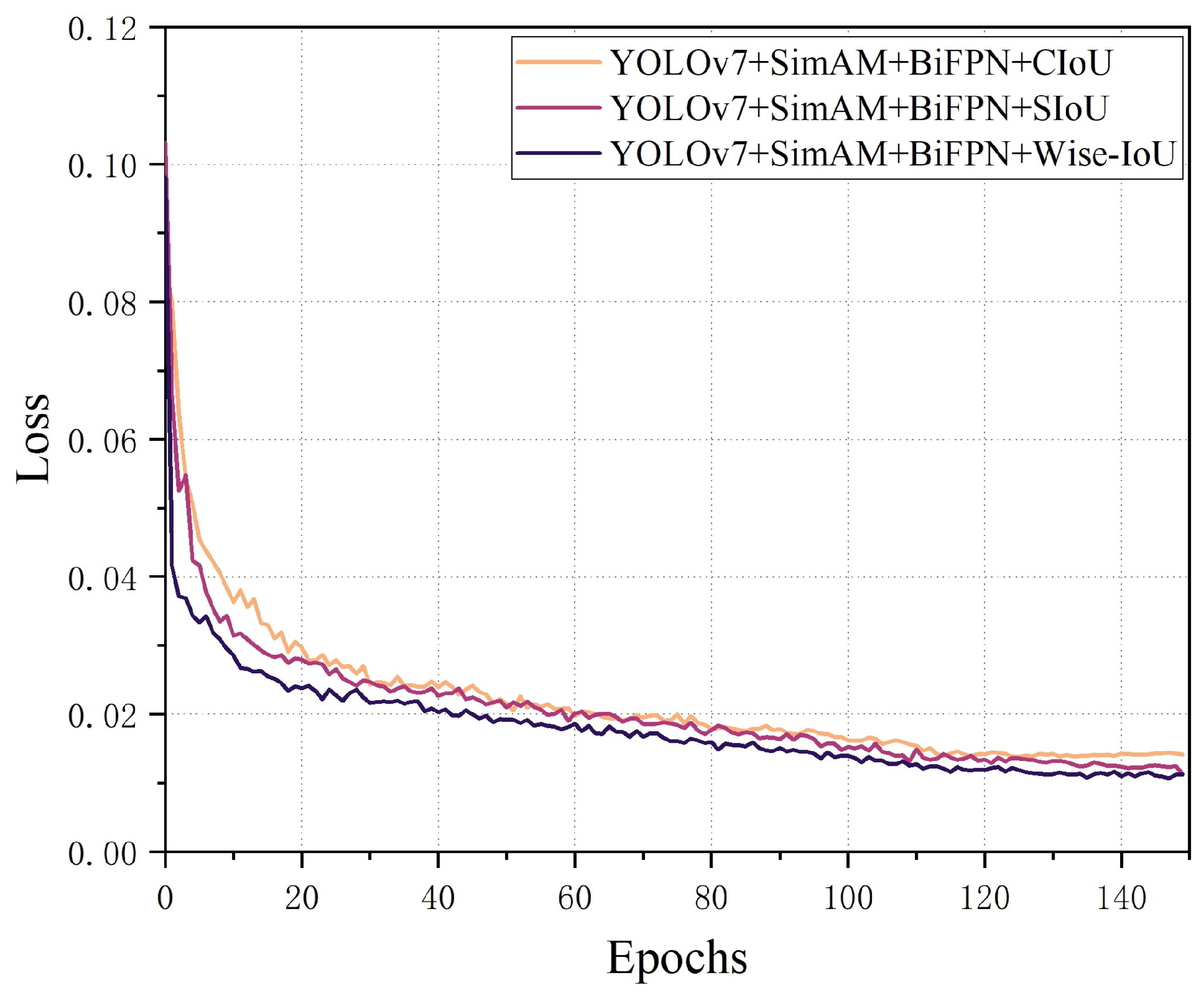
2.6.3. Improvements to the Loss Function
The loss function significantly impacts the accuracy of predictions and the effectiveness of the model. In the YOLOv7 network, it comprises confidence, coordinate and classification losses [
47]. The original loss function CIoU of YOLOv7 was more concerned with the overlap area, distance from the center point and aspect ratio. As the conveyor speed increased, the distinction between the moldy corn seeds and the background became indistinct, which caused the predicted boxes to appear at different locations from the ground truth boxes, affecting the stability of the model and increasing the training burden.
The Scaled Intersection over Union (SIoU) redefined the penalty metric by considering the vector angle between desired regressions, which mainly addressed the bias of traditional IoUs in target scale changes. It was more focused on scale matching, but the performance was not flexible when the SIoU dealt with small differences in the object.
In cases where the object boundary was not clear enough, the image quality was affected as the conveyor belt ran. It affected the quality of the samples in the dataset. The CIoU and SIoU loss function failed to consider the balance between different quality samples. Therefore, this study replaced CIoU with Wise-IoU based on a dynamic, non-monotonic focusing mechanism [
48]. The formula is as follows:
where
RWIoU amplifies
LIoU of the common-quality anchor box; and
LIoU reduces
RWIoU of the high-quality anchor box.
β is the outlier degree of the anchor box;
r is a non-monotonic focus factor. In the smallest box encompassing both the predicted box and the ground truth box,
Wg represents the width, and
Hg denotes the height.
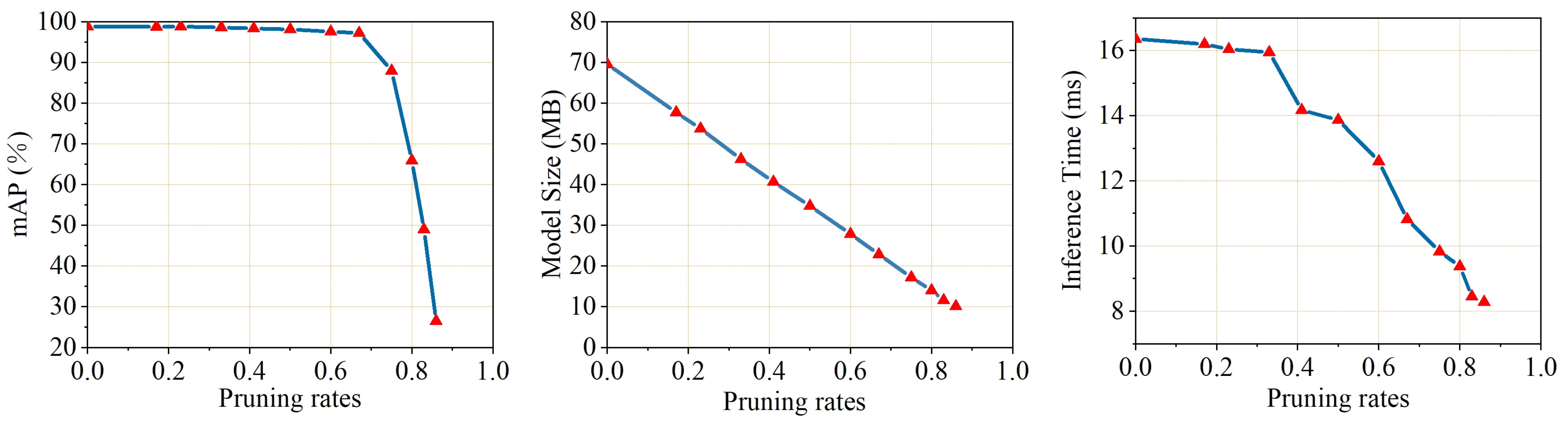
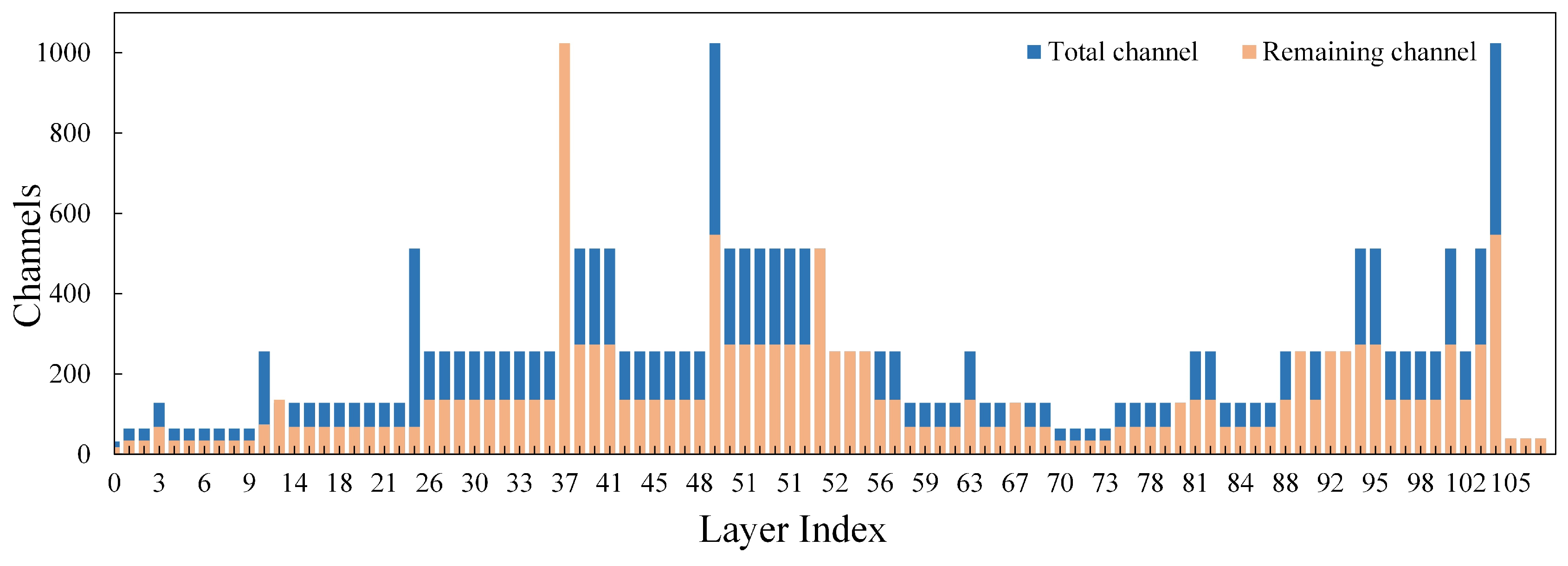
2.7. Model Pruning
The improved model often fails to achieve the desired results regarding the inference time because of the large amount of complexity and number of parameters of the YOLO network. Compared to simply replacing a lightweight backbone, channel pruning achieves a better balance between accuracy and model size, facilitating easier deployment on embedded devices or small computing platforms. The principle of the channel pruning algorithm involves identifying and eliminating irrelevant network channels and their associated input–output relations [
49,
50]. Consequently, this study applied the LAMP score within the channel pruning algorithm to prune the enhanced YOLOv7 network. This score is the basis for deciding whether to keep the structure of that channel during the pruning process; it is the magnitude or absolute value of the weights [
51]. In neural networks, the weight of each connection determines the importance of the input signal, and the principle of the LAMP score is based on calculating the square of the magnitude of the weights of the target connection and normalizing it to the sum of the squared weight magnitudes of all the surviving weights in the same layer. Assuming that the weight term satisfies
u <
v, i.e.,
W[
u] <
W[
v], the formula for LAMP score is as follows:
where
u and
v denote the index mapping of the weights in ascending order, respectively.
W[
u] and
W[
v] denote the weight mapped by indexes
u and
v, respectively. According to Formula (15), the larger the weight, the larger the corresponding LAMP score. Weights with lower scores are less important and can be pruned.
The two specific steps of pruning the network in this study were included as follows:
2.8. Model Evaluation Metrics
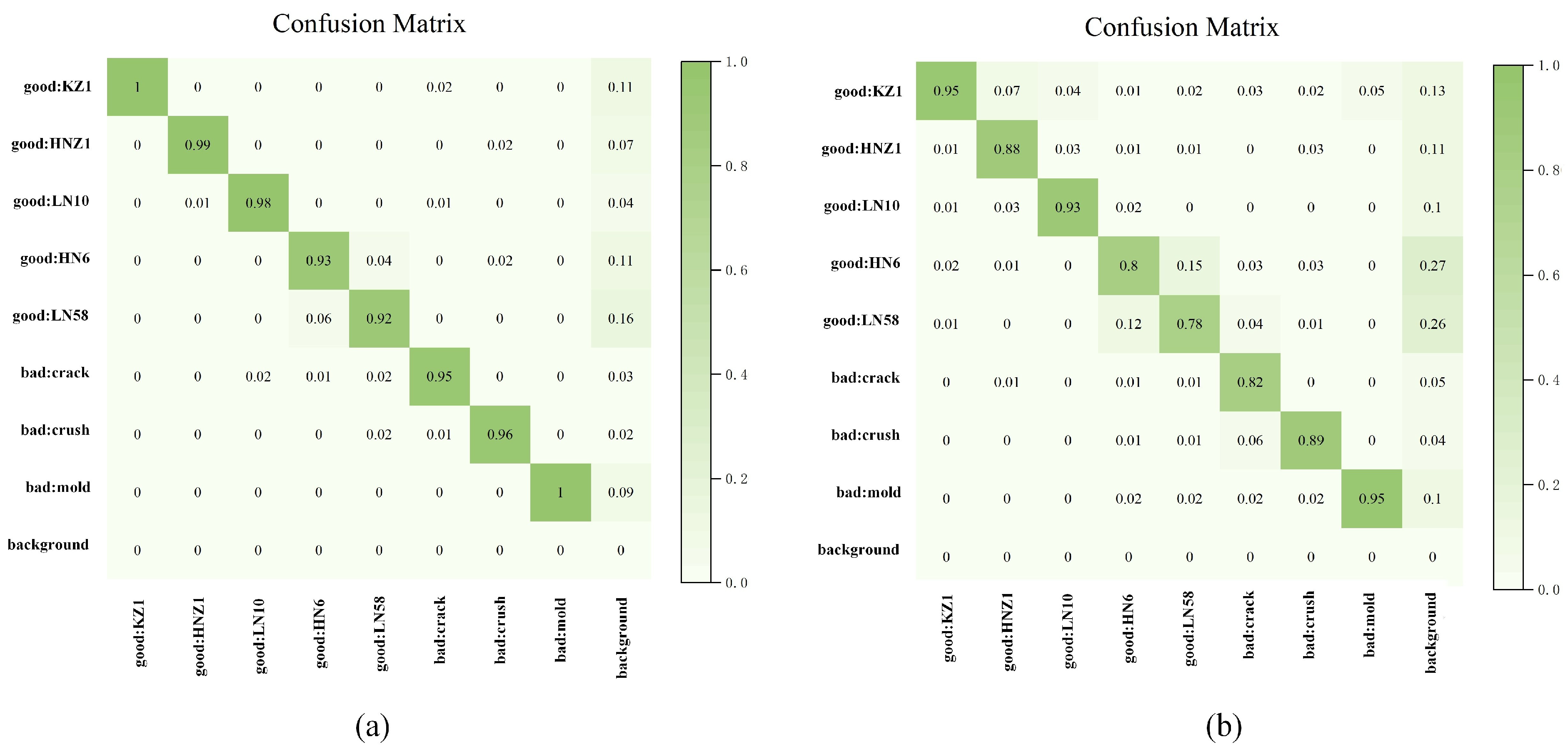
The performance of the model was verified by adopting five evaluation criteria, including the precision, recall,
F1 score,
mAP value and the detection time. The calculations of the precision,
F1 score, recall and
mAP are expressed as Formulas (16)–(19):
where the
mAP is the mean of the average precision (
AP) when corn seeds are detected; a higher value means a better detection result for corn seeds.
FP,
FN and
TP are the numbers of false positive, false negative and true positive cases, respectively.
4. Conclusions
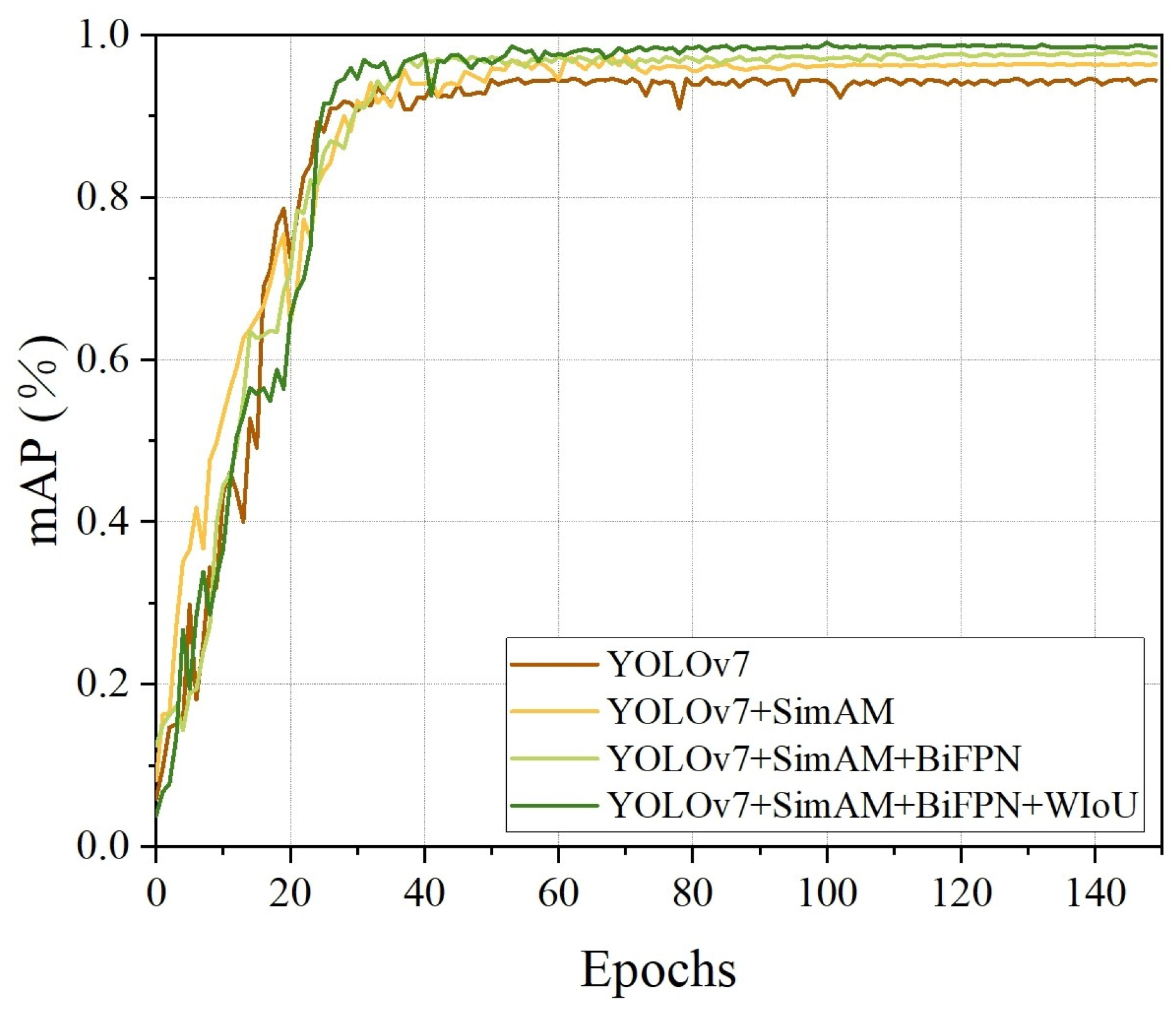
The features of corn seeds in the images can become blurred during the transportation process because of the similar appearance of corn seeds. These problems can produce false detection, missed detection and low precision in identifying the varieties and defects of corn seeds. Herein, the proposed YOLO-SBWL method for identifying the varieties and defects of corn seeds was based on machine vision and an improved YOLOv7 network. It combined the SimAM module, BiFPN structure, Wise-IoU loss function and LAMP channel pruning method. YOLO-SBWL enhanced its learning ability and detection precision while effectively reducing computational complexity. The proposed YOLO-SBWL model achieved a mAP of 97.21%, which was 2.59% higher than the original network. The number of parameters in this model decreased by 68.09%, and the model size decreased by 67.21%. This demonstrated that the channel pruning method was an effective model compression strategy. The average accuracy of YOLO-SBWL for corn seeds during the conveyor belt movement remained above 96.17%, and the inference times were within 11 ms. In addition, YOLO-SBWL outperformed seven baseline networks, including Faster R-CNN, YOLOv5-m, YOLOv5s, YOLOv7, YOLOv7-tiny, YOLOv8 and YOLOv11, in terms of accuracy. The proposed method achieved the non-destructive and efficient real-time detection of varieties and defects in corn seeds. Future research will focus on integrating different external environments so that the model can adapt to more complex environments.
Although the YOLO-SBWL method proposed in this study demonstrated significant advantages in detecting corn seeds in real time, it still presented some limitations. Firstly, this study was conducted using a custom dataset for training and testing, where the seeds did not overlap or make contact. If applied to more complex conditions, such as densely packed seeds or occlusion, the improvement strategies proposed for addressing the recognition problem of the model may be affected. Under compact or occluded conditions, important features of damaged seeds may be obscured, leading to multiple prediction boxes during seed recognition and potentially impacting the prediction results of the model.
Secondly, the damaged seeds used in this experiment, such as those with mold or cracks, were all externally damaged. Detecting internal damage or potential changes in seeds may require spectral information beyond visible light, which is difficult to achieve with RGB imaging.
In terms of equipment, the experiments were conducted with fixed lighting and camera parameter settings, and the adjustable speed range of the conveyor belt was limited by the hardware itself. This limits our exploration of variable environmental conditions, such as changing the lighting scenario or increasing the operating speed, which deserve further investigation.
In the future, we plan to consider more potential environmental variables, such as varying lighting conditions and a wider range of seed types, to enhance the robustness and versatility of our model. We will also explore the use of spectral information in conjunction with deep learning for the study of internal seed damage and classification. Lastly, we will experiment with better model pruning algorithms to achieve a better balance between model performance and image quality, making it easier to deploy the model on embedded devices for real-time detection.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}