2.1. The DBCA-Net Algorithm Framework
Current cattle face segmentation and recognition algorithms often demonstrate high segmentation precision and recognition accuracy under controlled conditions. However, their performance degrades significantly in complex environments. For segmentation tasks, key limitations include insufficient extraction of fine-grained features and the influence of complex backgrounds. Interference from dense herds and environmental clutter frequently confounds features of cattle faces, hindering the network’s ability to precisely localize target regions. Moreover, the intricate textures and subtle differences along cattle face boundaries pose challenges for conventional segmentation methods, leading to a loss of detail in segmentation results.
In recognition tasks, performance is constrained by inadequate modeling of salient features and high inter-class feature similarity. Minimal differences between individual features make it difficult for existing algorithms to effectively distinguish key regions, reducing classification accuracy and robustness in complex scenarios. These challenges constitute significant bottlenecks in the practical application of current methods.
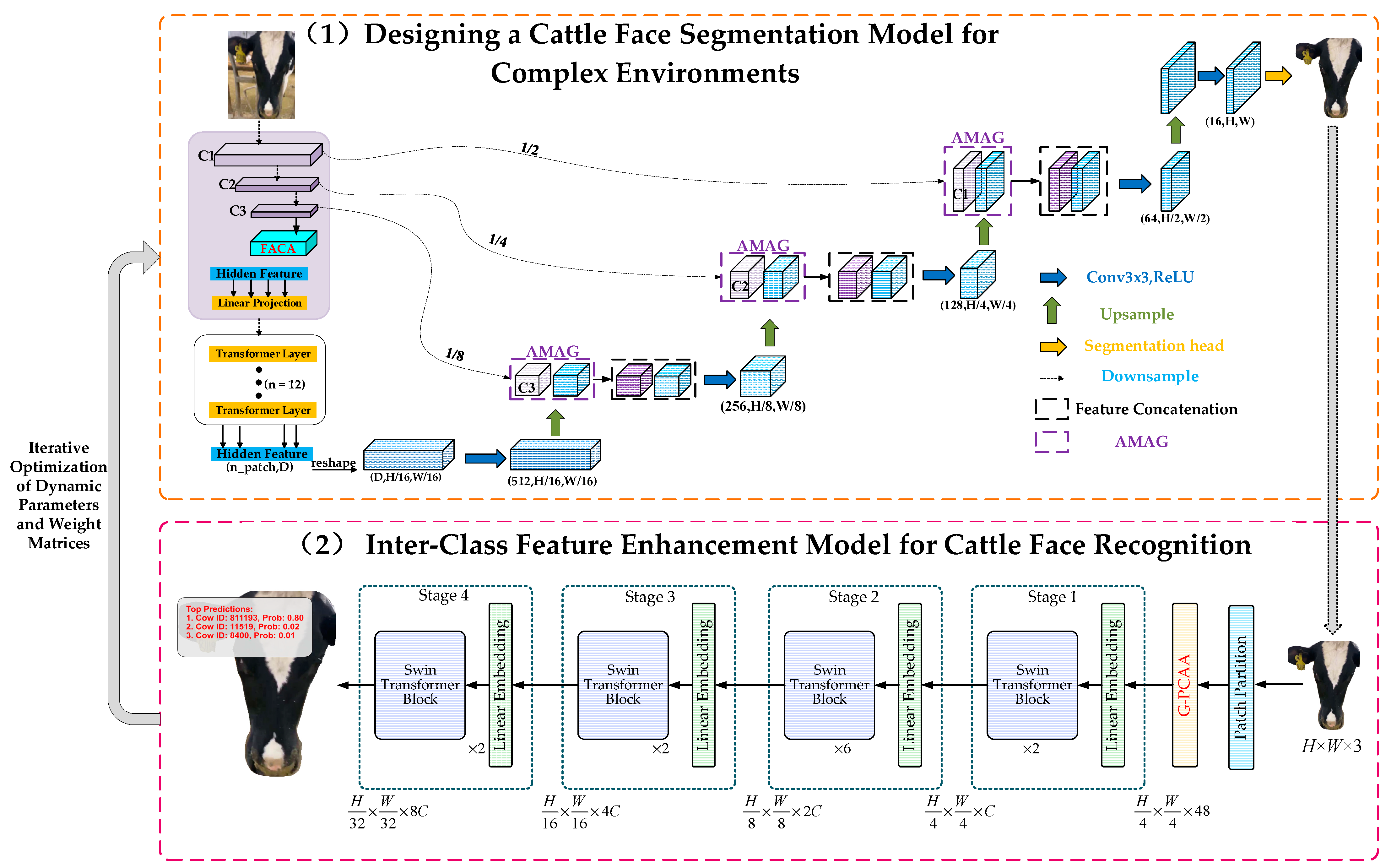
To overcome these issues, we propose a unified framework, DBCA-Net, specifically designed to optimize cattle face segmentation and recognition in complex environments. By integrating task-coordinated optimization and innovative modules, the framework establishes a dynamic feedback mechanism that significantly enhances segmentation precision and recognition accuracy in challenging conditions. The overall architecture of DBCA-Net is shown in
Figure 1.
As depicted in the structural diagram of DBCA-Net, the framework achieves accurate cattle face segmentation and identity recognition through the integration of innovative modules and task-level collaborative optimization. The segmentation network employs a hybrid encoder–decoder architecture with multi-scale decoding capabilities, enhanced by the Fusion-Augmented Channel Attention (FACA) mechanism. This design strengthens fine-grained feature extraction, effectively addressing challenges such as blurry segmentation boundaries and the loss of intricate details.
In the decoding phase, the Adaptive Multi-Scale Attention Gate (AMAG) module is introduced to adaptively fuse local and global features. Additionally, a closed-loop feedback mechanism dynamically optimizes feature representations and parameter updates, significantly enhancing segmentation robustness in complex environments.
In the Multi-Scale Feature Decoder, different color coding is used to represent various feature maps. The light purple cube signifies the local feature map from the Hybrid Encoder, while the light blue cube represents the high-level semantic feature map from the Transformer module. The purple cube illustrates the output from the Adaptive Multi-Scale Attention Gate (AMAG) module. This output from AMAG is concatenated with the high-level semantic feature map from the Transformer module, forming a fused feature map. The concatenated feature map is then passed to the next stage of the Multi-Scale Feature Decoder, where further processing takes place.
For recognition, the network incorporates the GeLU-enhanced Partial Class Activation Attention (G-PCAA) module, which emphasizes salient region feature modeling to improve classification accuracy and stability. By leveraging the collaborative optimization of segmentation and recognition tasks, the DBCA-Net framework exhibits exceptional robustness and efficiency in addressing challenges posed by complex scenarios.
2.2. Cattle Face Segmentation Models in Complex Environment
2.2.1. Hybrid Encoder
The hybrid encoder in the original segmentation network integrates convolutional neural networks (CNNs) and Transformer modules, enabling the combination of local and global features for multi-scale feature modeling [
36]. This design supports semantic information extraction and detail restoration in segmentation tasks. However, cattle face segmentation faces challenges due to the complexity of ranch environments, where fine-grained cattle face features often overlap with background elements, complicating segmentation.
Existing hybrid encoders, while effective in global feature modeling, often dilute fine-grained local details. Furthermore, traditional convolutional methods have limitations in modeling inter-channel correlations, reducing their ability to emphasize critical channels. These factors hinder the performance of hybrid encoders in noisy scenarios, necessitating improvements in fine-grained feature modeling and the integration of global and local features.
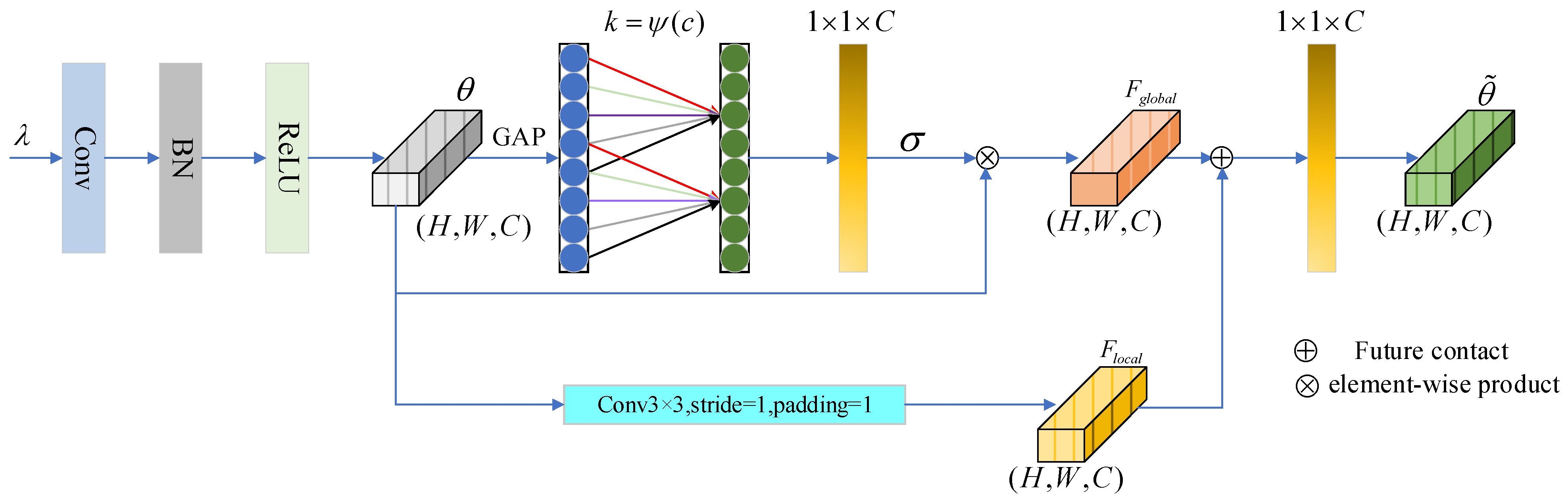
To address these issues, the Fusion-Augmented Channel Attention (FACA) mechanism is introduced at the final stage of convolutional feature extraction. FACA consists of a channel attention pathway and a local feature pathway. Global features are extracted using Global Average Pooling (GAP), and adaptive channel weights are generated via dynamic 1D convolution to enhance critical channels. Simultaneously, local fine-grained features are captured through convolution, incorporating detailed information from complex backgrounds.
FACA employs a dynamic weighting strategy to adaptively adjust the fusion of local and global features, allowing the model to suppress irrelevant information and emphasize key regions. Lightweight
convolution further refines the fused features, improving computational efficiency. This integration enhances segmentation accuracy and robustness for cattle face regions. The structure of the FACA mechanism is shown in
Figure 2.
The overall design of the FACA module consists of four main components: input preprocessing, channel attention pathway, local feature pathway, and feature fusion. The detailed implementation steps are as follows:
Output feature maps generated by the original hybrid encoder undergo input preprocessing, during which standard convolutional operations are applied to produce the initial feature representations.
The channel attention pathway is first computed for the feature representations by applying Global Average Pooling (GAP) to extract the global features, as described in Equation (1).
The variable represents the compression of the feature space along the channel dimension , allowing the model to concentrate on the global characteristics of each individual channel.
Subsequently, the function
is utilized to adaptively select the size of the convolutional kernel. A convolution operation is then applied to
, as described in Equation (2), to capture the inter-channel correlations within the feature map. The resulting weights are further processed using the sigmoid activation function
, yielding the channel attention weights
. The specific calculation for
is provided in Equation (3).
The variable
denotes the channel attention weights. These weights, computed through the channel attention pathway, are dynamically adjusted to emphasize the importance of each feature map channel, prioritizing channels relevant to the cattle face segmentation task while suppressing irrelevant or redundant ones. The obtained channel attention weights are then applied to the feature representation
, recalibrating the original features and producing the output
of the channel attention pathway.
The feature representation is further refined through the local feature pathway. By applying Same Padding to , the spatial dimensions and are preserved, producing the output of the local feature pathway. This pathway is specifically designed to capture fine-grained textures and boundary details within the cattle face region, effectively addressing the global channel attention pathway’s limitations in modeling local information. By complementing each other, the local and global features enhance the overall feature representation, achieving a balance between expressive power and computational efficiency.
Subsequently, the outputs from the channel attention pathway and the local feature pathway are fused using the operation defined in Equation (5). This fusion effectively integrates global contextual information with preserved local spatial features, resulting in a refined feature map. To restore the original channel dimension of the feature representation
, a
convolution is applied, producing the final output
. This final representation corresponds to a linear combination or redistribution of the original feature
across channels, selectively emphasizing critical channels while suppressing redundant or irrelevant information.
Here, and represent learnable weights that are dynamically updated during the model’s training process.
Employing an adaptive fusion strategy, the FACA mechanism balances the contributions of global channel attention and local detail features across scenarios of varying complexity. By effectively coordinating the importance of global and local information, the network dynamically adjusts its focus based on scene-specific characteristics. Global contextual information is extracted through the channel attention pathway using Global Average Pooling (GAP), enhancing the ability to capture overall features of the cattle face region. In contrast, the local feature pathway utilizes convolutional operations to capture fine-grained local features, reinforcing the representation of boundary and texture details. To optimize feature representation, a dynamic weighting strategy adjusts the fusion ratio between global channel attention and the local feature pathway according to the salience of global and local features in a given scene, ensuring a balanced and adaptive feature expression.
When cattle face images are situated in complex-background scenarios, such as environments with group occlusions or significant texture interference, the module assigns greater weight to the local feature pathway. This adjustment allows the network to prioritize the detailed boundaries of the cattle face region, thereby improving its ability to capture fine-grained local features. In contrast, for scenarios that emphasize global semantic information—such as under conditions of pronounced lighting variations or substantial background interference—the module increases the weight of the channel attention pathway. This adjustment enhances the network’s understanding of global features, facilitating the separation of cattle face regions from similar background features. By leveraging these dynamic adjustments, the FACA mechanism significantly enhances the network’s adaptability to complex backgrounds, addressing the limitations of traditional feature modeling methods in responding to diverse scenarios. As a result, it improves both the accuracy and robustness of cattle face segmentation tasks.
2.2.2. Multi-Scale Feature Decoder
Demonstrating exceptional performance in common medical segmentation tasks, the multi-scale decoder of the original segmentation network achieves multi-level fusion of high- and low-level features through progressive upsampling combined with skip connections. The spatial resolution of feature maps is restored using transposed convolutions or bilinear interpolation, ensuring that the output matches the input size. Transformer modules are incorporated to capture global contextual information, enhancing segmentation capabilities for complex structures, while the fusion of high- and low-resolution features improves boundary prediction accuracy.
For fine-grained segmentation tasks involving cattle faces in complex backgrounds, several limitations hinder the performance of the original decoder. High-resolution features often become dominated by low-resolution ones during repeated upsampling and feature fusion, making it difficult to preserve fine details such as hair textures and boundaries. While Transformer modules effectively model global contextual semantics, their ability to capture local feature details remains weak, leading to insufficient modeling of boundaries and texture details and causing an imbalance between global and local information. Additionally, edges and textures of cattle faces are easily confused with complex backgrounds, reducing the decoder’s focus on target regions and making it challenging to suppress background interference. These issues are further exacerbated by the decoder’s skip connections, which rely on simple concatenation of high- and low-level features without fully leveraging their complementary relationships, resulting in inefficient feature fusion. Collectively, these challenges limit the fine-grained segmentation performance of the original TransUNet in complex scenarios.
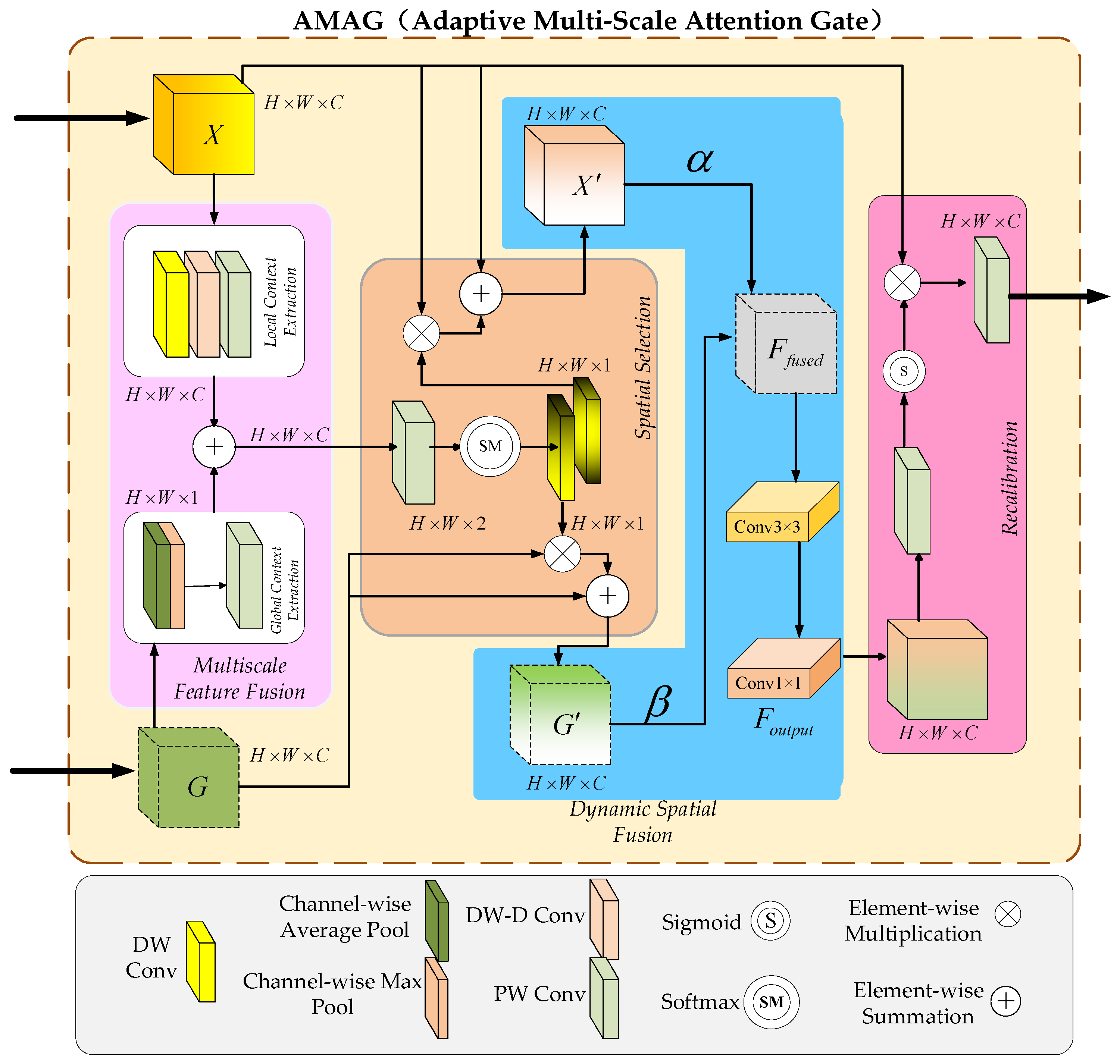
Addressing the limitations of the original segmentation network decoder in fine-grained cattle face segmentation, this paper introduces an improved module—AMAG (Adaptive Multi-Scale Attention Gate). Embedded into the decoder’s feature fusion process, AMAG strengthens multi-scale feature fusion capabilities to tackle challenges such as insufficient fine-grained feature representation, imbalance between local and global information, background interference, and inefficient feature integration.
The AMAG module integrates spatial attention and multi-scale feature aggregation to effectively filter out background noise while enhancing relevant features. To achieve matching between feature maps of different dimensions, the module uses pointwise convolutions to align the feature maps. Within the decoder, AMAG operates in two steps: first, it fuses downsampled high-level semantic features with local semantic features from the hybrid encoder. Then, it concatenates the fused feature maps with the originally input downsampled high-level features to produce the final output, which is passed to the next stage of the multi-scale decoder. The AMAG module operates in parallel, processing multiple feature maps simultaneously, allowing for efficient interaction with the segmentation head and refinement of the segmentation output.
In fine-grained cattle face segmentation tasks, AMAG enhances the capture of details such as hair textures and boundaries through a multi-scale feature fusion mechanism. A dynamic attention mechanism ensures a balanced contribution of local and global information, achieving a harmonious integration of boundary details and overall structural information. Furthermore, a spatial selection mechanism emphasizes key regions of cattle faces, effectively suppressing interference from complex backgrounds. By incorporating AMAG, the segmentation accuracy and robustness of the original decoder are significantly improved in challenging background conditions, providing reliable support for high-precision fine-grained cattle face segmentation tasks. The structural design of AMAG (Adaptive Multi-Scale Attention Gate) is illustrated in
Figure 3.
Designing the AMAG (Adaptive Multi-Scale Attention Gate) module aims to enhance the original decoder’s ability to extract fine-grained features and improve the multi-scale fusion of local and global information. This module is composed of four key components: Multi-Scale Feature Fusion, Spatial Selection, Dynamic Spatial Fusion, and Recalibration.
Multi-Scale Feature Fusion leverages Depthwise Convolution (DW) to extract fine-grained features from the local patterns identified by the convolutional neural network. To broaden the receptive field and capture richer contextual information, Dilated Convolution (DW-D) is incorporated. Pointwise Convolution (PW) subsequently integrates multi-channel local features, enhancing the capacity to represent intricate fine-grained details, as shown in Equation (6).
Here, represents the local feature maps fed into the AMAG module.
For the global features output by the Transformer module, channel-wise max pooling and average pooling are employed to extract critical semantic information from the global semantic features. The extracted semantic information is further refined using Pointwise Convolution (PW) to ensure dimensional consistency between the global semantic features and the local features, as illustrated in Equation (7).
Here, represents the global semantic features fed into the AMAG module.
Subsequently, the transformed local feature
is added to the transformed global feature
, resulting in the final fused feature
for this module, as illustrated in Equation (8).
Spatial Selection applies dynamic weight assignment to the channels of the feature maps fused in the first part, directing attention to the most critical feature channels while minimizing the impact of redundant or irrelevant ones. By emphasizing fine-grained features of cattle faces, this strategy not only enhances feature representation but also effectively suppresses interference from background noise, as demonstrated in Equations (9)–(12).
The fused feature undergoes a Softmax operation, after which the Spatial Selection module dynamically adjusts the channel-wise weights of the feature map. These weights are then applied to through element-wise multiplication, followed by the addition of the original local and global features input into the AMAG module. This process highlights the critical fine-grained feature channels of cattle faces while effectively suppressing irrelevant and redundant information from other channels.
Dynamic Spatial Fusion further enhances the interaction between the optimized local feature
and the global contextual feature
, both derived from the Spatial Selection module. This module employs a dynamic weight allocation mechanism to adjust the weights of local and global features. Local features are enriched with higher-level contextual information, while global features are refined to emphasize fine-grained local details. The bidirectional interaction and mutual enhancement between local and global features result in a cohesive representation, effectively integrating fine-grained cattle face details with global contextual information. This integrated feature representation significantly improves the ability to capture fine-grained details within the global context. The evolution of the weight matrix is detailed in Equations (12) and (13).
Global average pooling is applied to the optimized local and global features obtained from the second stage, followed by a linear transformation. A Sigmoid activation function is subsequently employed to calculate the dynamic weight matrices for the local and global features, denoted as
and
, respectively. The learnable projection matrices
and
dynamically evolve with iterative updates during the algorithm. Using the weight matrices
and
, an element-wise weighted fusion of the optimized local and global features is performed, producing an enhanced and interactively fused feature representation, as detailed in Equation (14).
Further extraction of contextual spatial information is performed on the cross-enhanced features, followed by restoring the original number of channels. This process produces the interaction-enhanced feature map, as described in Equation (15).
Leveraging the dynamic spatial interaction mechanism, the AMAG module enhances the contribution of fine-grained facial features to global contextual understanding while simultaneously strengthening the global context’s interpretation of local facial details. This reciprocal enhancement improves segmentation consistency, effectively unifying local and global feature interactions.
Recalibration starts by applying Pointwise Convolution (PW) to the fused feature
from the third stage, further refining spatial information across channels. A Sigmoid activation function is then employed to generate attention weights, which emphasize critical features while suppressing redundant ones. These attention weights are subsequently applied to recalibrate the original local feature
. After recalibration, another Pointwise Convolution (PW) is performed on the recalibrated feature to adjust its dimensionality and further enhance its representation. This process ensures that the recalibrated feature is better optimized for downstream tasks and enables the multi-scale decoder to fully leverage the fine-grained multi-scale feature information provided by the AMAG module. The methodology is detailed in Equation (16).
To enhance the decoder’s feature extraction capabilities in complex scenarios, the Adaptive Multi-Scale Attention Gate (AMAG) module is incorporated into the decoder of the TransUNet segmentation network. By integrating mechanisms such as multi-scale feature fusion, spatial selection, dynamic spatial interaction, and recalibration, AMAG effectively addresses the challenge of insufficient fusion between fine-grained local features and global contextual information, significantly boosting the model’s performance in fine-grained cattle face segmentation tasks. Multi-Scale Feature Fusion and Spatial Selection focus on capturing detailed local textures and global semantic information while dynamically highlighting critical regions and suppressing background interference, thereby improving the model’s attention to facial textures and boundary details. Dynamic Spatial Fusion and Recalibration further enable bidirectional interaction and optimization between local and global features, ensuring a cohesive and efficient feature integration. These mechanisms collectively provide the decoder with precise and robust multi-scale feature representations, enhancing its ability to handle complex segmentation tasks.
An improved multi-scale decoder utilizes the dynamic adjustment mechanism of the AMAG module to effectively balance the fusion of fine-grained local features and global semantic information in complex scenarios. When detailed features are critical, the module prioritizes attention to local boundaries and textures; when semantic consistency takes precedence, it enhances the modeling of global contextual information. This adaptive adjustment mechanism significantly enhances the network’s ability to adapt to diverse and challenging environments, addressing the shortcomings of traditional segmentation methods in handling complex backgrounds. As a result, it substantially improves both the performance and accuracy of cattle face segmentation tasks.
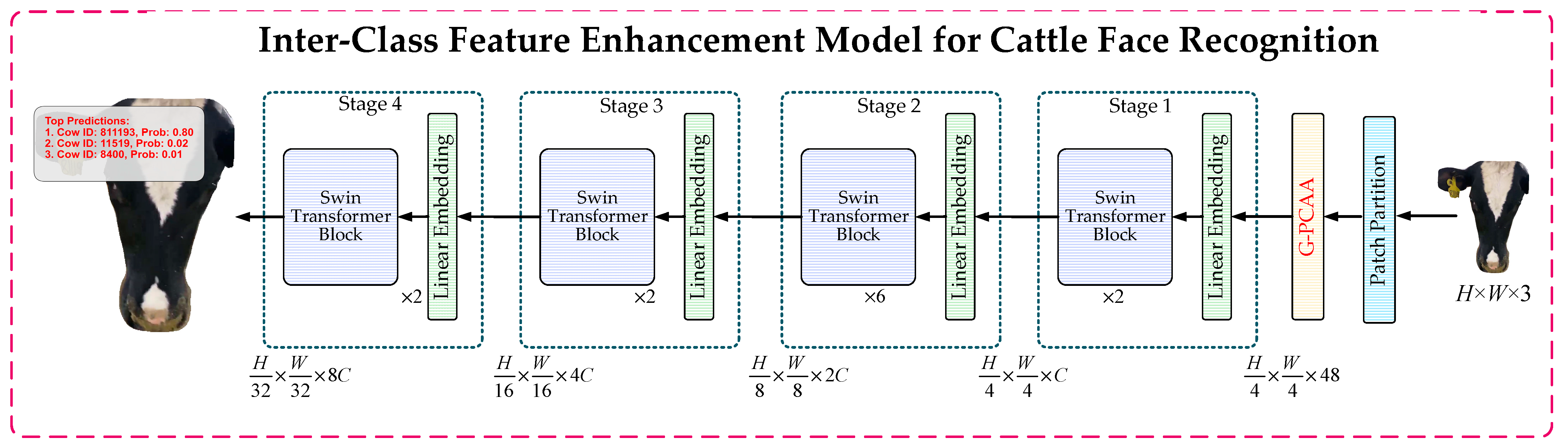
2.3. Inter-Class Feature Enhancement Model for Cattle Face Recognition
Recognition networks currently employed for cattle face recognition tasks adopt a hierarchical feature extraction strategy to progressively capture multi-scale features while integrating local feature modeling with global semantic information. These networks exhibit a certain degree of robustness in handling complex backgrounds. By leveraging their multi-layer architecture, they effectively extract fine-grained features, and the incorporation of global semantic enhancement modules enables the modeling of long-range dependencies, providing strong support for cattle face recognition. However, limitations remain in specific stages of the recognition process, particularly during the Patch Partition stage. At this stage, feature extraction relies solely on basic patch-based operations, lacking targeted modeling for category-salient regions. This shortcoming leads to inadequate feature extraction from cattle face regions. Furthermore, the networks struggle with interactive fusion of local details and global semantic information, as they overly depend on local window features. This reliance hinders the effective integration of local details with global context in complex backgrounds, ultimately restricting further improvements in recognition performance.
To address the limitations of existing recognition networks in category saliency modeling and the interaction between local and global features, the G-PCAA (GeLU-enhanced Partial Class Activation Attention) mechanism is introduced into the feature extraction process following the Patch Partition stage. This attention mechanism substantially improves the network’s ability to focus on critical regions of cattle faces, while optimizing the feature representation of salient regions. Additionally, it ensures the integrity and semantic consistency of inter-class regional features in complex scenarios.
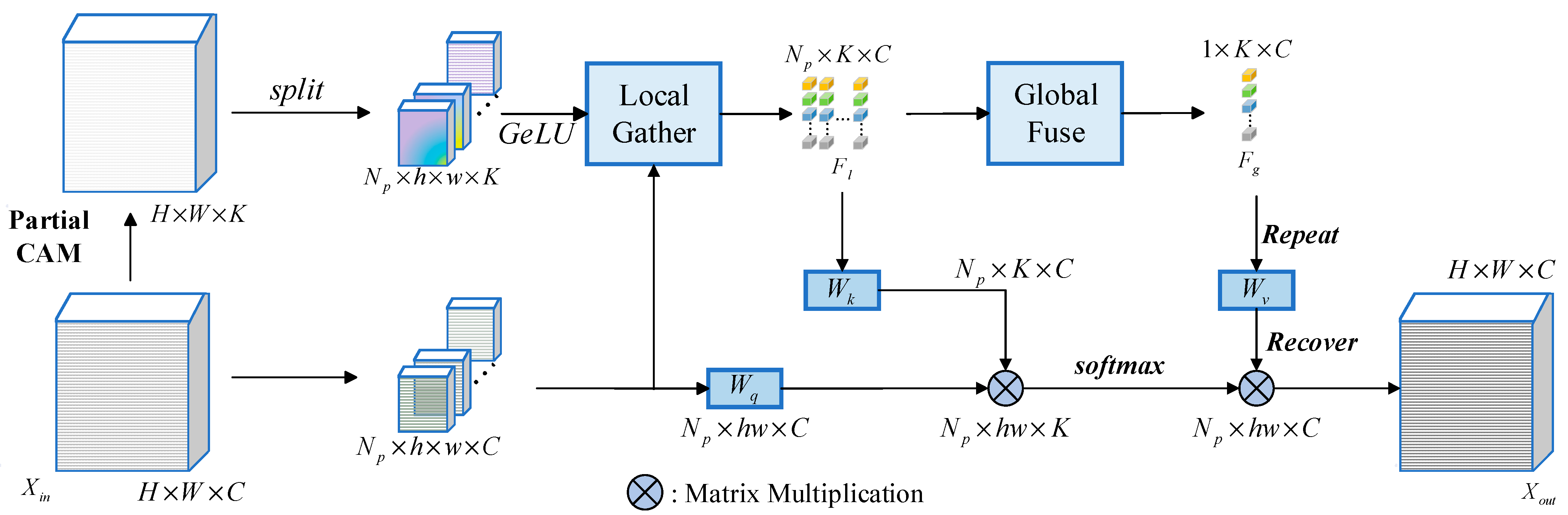
Figure 4 presents the architecture of the inter-class feature enhancement model designed for cattle face recognition.
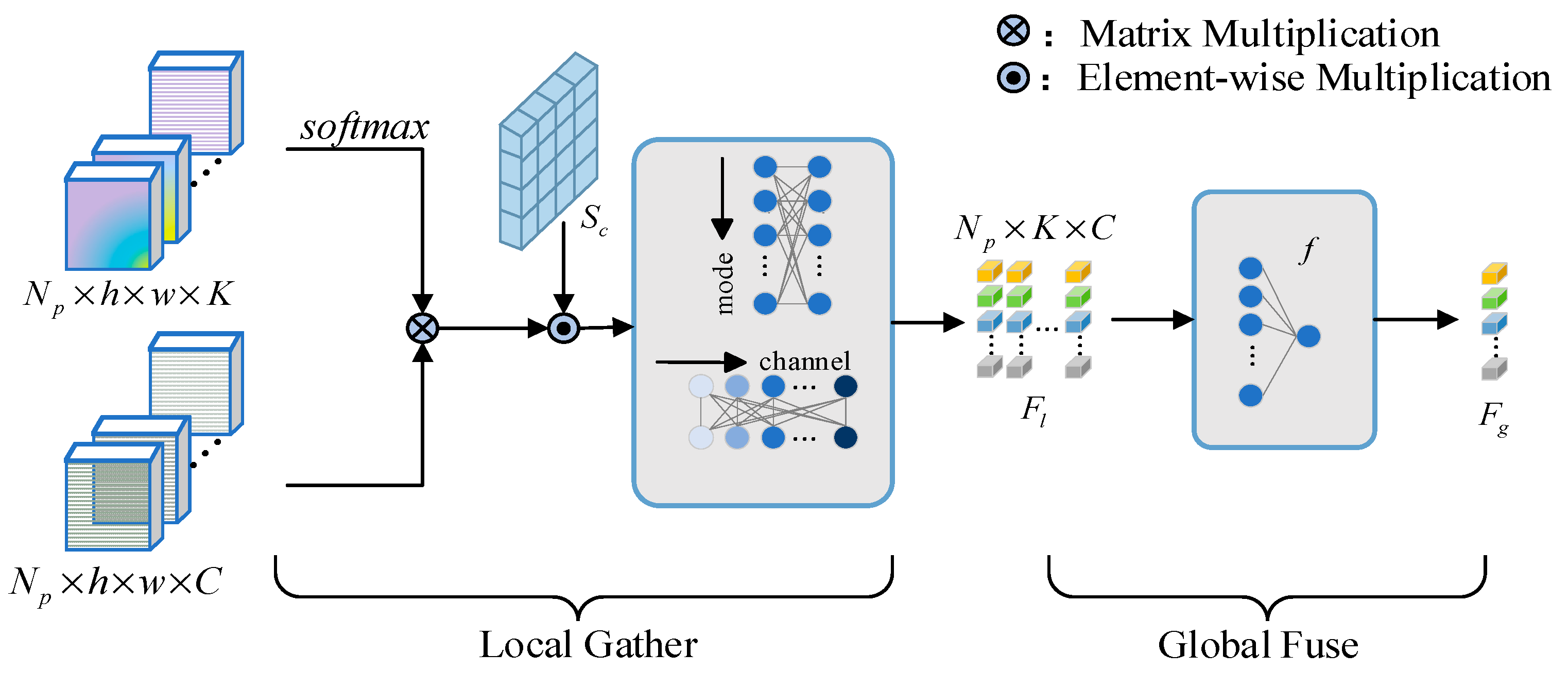
G-PCAA module design comprises four components: Partial CAM, local class center generation, global class representation generation, and feature enhancement and aggregation [
37]. To further optimize inter-class feature representation, GeLU (Gaussian Error Linear Unit) activation is introduced between the output of Partial CAM and the local class center generation stage. By smoothing the activation of generated saliency maps, GeLU enhances the flexibility of nonlinear representation during the class center generation phase, enabling features to adapt more effectively to distribution variations in different scenarios. Additionally, the smoothing of gradient flow improves the optimization stability of the entire module. These improvements significantly enhance the flexibility and expressiveness of feature modeling, providing robust support for fine-grained feature extraction and inter-class feature enhancement in cattle face recognition tasks. The structure of G-PCAA is shown in
Figure 5.
Partial CAM processes the input features
, derived from the output of the Patch Partition stage, to enhance the network’s attention to task-relevant category regions. This module focuses on generating class-specific activation feature maps that highlight critical areas for the recognition task. Specifically, by applying Pointwise Convolution (PW) to
, the network produces the class-specific activation feature maps
, as shown in Equation (17):
where
, and
represents the number of task-specific categories.
Adaptive average pooling is subsequently applied to the class-specific activation feature maps to perform block-level processing. The GeLU activation function is then introduced to further enhance the feature representation by generating sub-block class-specific activation feature maps, improving the flexibility and effectiveness of feature modeling. This process is formulated in Equation (18).
In this context, denotes the scaling factor for the block size, while represents the dimensionality of the features, defined as . Global average pooling partitions the input features into sub-blocks, where . Each sub-block has dimensions , satisfying and .
The GeLU activation function enhances the nonlinear representational capacity of the activation process, mitigating gradient saturation issues and improving the precision of class-specific activation feature maps within each sub-block. This enables the network to capture fine-grained features of cattle faces more effectively. To assign class labels to each sub-block feature map, max pooling is applied across sub-blocks, as expressed in Equation (19):
where
has dimensions
, and
refers to the original one-hot encoded task-specific class labels with dimensions
. By combining the sub-block class-specific activation feature maps with their corresponding class labels, this method establishes an effective association between features and their respective class labels. This improves the model’s ability to focus on fine-grained cattle face features, thereby enhancing the overall performance of the recognition network.
Patch Partition in the original recognition model performs only basic image segmentation, lacking focus on category-salient regions and limiting the effectiveness of extracting key features from cattle faces. Partial CAM addresses this limitation by significantly enhancing attention to category-relevant regions through localized saliency modeling. Furthermore, GeLU improves the dynamic nonlinear modeling of features, ensuring precise and high-quality representation of critical cattle face regions.
Local Class Center generation processes the previously obtained and the input feature map by applying split and flatten operations, resulting in and for . These outputs have dimensions and , respectively, where , representing the total number of pixels in each sub-block.
GeLU-activated sub-block class-specific attention weights
are also processed through split and flatten operations, producing outputs with dimensions
. Here,
indicates the attention strength corresponding to each class. During the calculation of the Local Class Center
, element-wise multiplication and dimensional adjustment are applied to align matrix dimensions. The Local Class Center for each sub-block is computed as follows:
Here, denotes the Softmax operation, and has dimensions , representing the feature representation of the sub-block for each class.
Addressing the limitations of the original network in constructing fine-grained local features, the Local Class Center generation module utilizes GCU to optimize class center adaptability to dynamic variations in feature distributions. This improves the quality of class center representations while GeLU enhances scalability across diverse scenarios. The module effectively strengthens feature modeling for cattle faces in complex backgrounds, providing precise class-aware semantic representations for subsequent global feature integration.
Global Class Representations, the third component, utilize each Local Class Center as the fundamental unit for convolutional and neural network operations. This process generates an enhanced local feature for each sub-block by integrating relational information across local class centers. By propagating this information, the operation refines the representation of class-specific channels within each sub-block while simultaneously enriching the local class center with hierarchical and contextual information from neighboring sub-blocks. Consequently, each sub-block not only reflects semantic details from its own region but also incorporates broader contextual dependencies, enhancing the granularity and expressiveness of class-specific feature representations.
After obtaining the enhanced local class centers,
convolution and linear transformations are applied to
, resulting in
. These features are then weighted by coefficients
, and the global class center
is computed using the following equations:
where
represents the global class center features for each class.
The original recognition model faced challenges in effectively integrating local and global features. Global Class Representations resolve this issue by consolidating local class centers, ensuring consistency and integrity in global feature representations. The introduction of GeLU further enhances the adaptability and flexibility of feature expressions, allowing the model to capture richer and more precise semantic representations of cattle face features. This improvement provides a robust foundation for higher-level recognition tasks. The combined structure of the second and third components is depicted in
Figure 6.
Feature Enhancement and Aggregation, the fourth component, processes the global class center features and enhanced local class center representations by dividing the input features
of the one sub-block, with dimensions
. The relationship between each image pixel and the assigned class label is then calculated, producing the attention map
, which represents the attention score for each class within the one sub-block, as shown in Equation (23):
Here, is the attention map for the one sub-block, and denotes a Softmax operation applied along each class dimension. and are learnable linear projection matrices that project and into the query and key spaces, respectively.
The resulting attention map
is then used to query the global class center
, projecting it into the value space and calculating the final output
for each sub-block through matrix multiplication, as shown in Equation (24):
Here, represents the learnable linear projection matrix used to project into the value space. Finally, the output of each sub-block, , is combined and reshaped to match the original input dimensions, , ensuring dimensional consistency for the G-PCAA module’s output.
The G-PCAA attention mechanism effectively addresses the limitations of the Patch Partition stage in the original recognition network, which lacked focus on salient regions. By modeling local class-specific features and leveraging GeLU activation, the module smooths gradient flows, stabilizes training, and enhances the nonlinear representation capacity. This allows the model to capture critical semantic information in cattle face regions, particularly in areas of high relevance, improving both class-specific attention and the integration of contextual dependencies.
2.4. Iterative Optimization of Dynamic Parameters and Weight Matrices
In fine-grained segmentation tasks for cattle faces, the feature representation capability of the segmentation network is critical to achieving robust performance in complex-background scenarios. To enhance the network’s ability to model local details and global semantics in a unified manner, a feedback-based iterative method for optimizing dynamic parameters and weight matrices is proposed, extending the existing dual-branch network. By leveraging predicted class probabilities of cattle IDs from the recognition network, this method dynamically adjusts the parameters of the FACA (Fusion-Augmented Channel Attention) mechanism and allocates weight matrices for the AMAG (Adaptive Multi-Scale Attention Gate) module in real time. These adjustments significantly strengthen the network’s ability to capture fine-grained features in cattle face regions and improve the integration of global contextual information.
2.4.1. Dynamic Parameter Tuning in the FACA Module
FACA mechanism is designed to capture fine-grained and boundary features in cattle face regions, addressing limitations in conventional global–local interaction models that inadequately focus on local details. Dynamic adjustment of parameters
and
lies at the core of FACA, enabling effective weight distribution along local feature pathways. This adjustment enhances the capture of fine-grained and boundary features while maintaining robust interactions between global and local features. Dynamic parameter updates are calculated iteratively through the following Equations (25) and (26):
Here, represents the feedback signal, derived from the difference in predicted probabilities of cattle ID classes output by the recognition network. This signal balances classification confidence with segmentation performance. Feedback scaling factors and control the influence of the feedback signal on the dynamic parameters and , ensuring adaptive optimization based on contextual demands.
During the optimization process, the scaling factors
and
are designed to decay progressively with training iterations, preventing parameter oscillations caused by excessive reliance on the feedback signal. The decay process is governed by the following Equations (27) and (28):
Here, and denote the initial scaling factors, both set to 0.5, while , the decay rate, is set to 0.05. A smaller feedback signal indicates higher confidence from the recognition network regarding its current classification output, prompting FACA to prioritize capturing fine-grained local features. Conversely, a larger feedback signal shifts FACA’s focus toward enhancing attention on critical global features, ensuring a balanced emphasis on both local details and global context.
2.4.2. Iterative Optimization of Weight Matrices in the AMAG Module
The AMAG module employs a dynamic spatial interaction mechanism to enhance the integration and interaction between local features and global contextual information. This mechanism facilitates bidirectional interaction and complementation, significantly improving the decoder’s ability to fuse multi-scale features. By dynamically adjusting the weight matrices
and
, the module optimizes the multi-scale relationships between local and global features. The weight matrix adjustments are governed by the following Equations (29) and (30):
Here,
and
are feedback scaling factors that decay progressively over training iterations. The decay is described by the following Equations (31) and (32):
In these equations, and denote the initial feedback scaling factors, both set to 0.5, while the decay rate is set to 0.05. When the feedback signal is relatively small, the network emphasizes refining local features. Conversely, when is large, the module shifts its focus to enhancing attention on critical global features, achieving a balanced integration of multi-scale information for improved feature representation.
Establishing a feedback mechanism enables the AMAG module to dynamically adjust based on the confidence level of the feedback signal from the recognition network. When the feedback signal is high, the module reduces the influence of multi-scale feature fusion, preventing excessive reliance on local features and mitigating the risk of overfitting. Conversely, when the feedback signal is low, the module strengthens the interaction between local and global features, enhancing the representation of fine-grained details.
Leveraging the predicted probabilities from the recognition network as feedback signals allows for dynamic adjustments to the parameters of the FACA module and the weight matrices of the AMAG module. This approach enables the segmentation network to continuously refine its feature extraction strategies based on the recognition network’s outputs, improving its ability to focus on and represent fine-grained information. Furthermore, this mechanism enhances DBCA-Net’s capacity to integrate global contextual information with local details, resulting in improved performance in fine-grained segmentation tasks.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}































