1. Introduction
Peanut is recognized as one of the world’s major oilseed and economic crops [
1]. As the largest producer and consumer of peanuts globally, China contributes 40% of the world’s total peanut production and consumption [
2]. The yield and quality of peanuts directly influence agricultural economics and food security. During the growth of peanuts, leaf diseases often impact both the yield and quality. Consequently, the detection of peanut leaf diseases is of paramount importance. Traditional manual detection methods are time-consuming and labor-intensive, rendering deep learning-based disease detection approaches highly desirable [
3,
4]. Deep learning generates substantial amounts of data, particularly in computer vision applications [
5]. In the harsh environments of agricultural fields, limited computational resources hinder the management of such vast data. While cloud computing offloads extensive data to servers for processing, increased communication latency presents new challenges. Although the advent of edge AI devices enables the mitigation of some of this pressure, factors such as data volume, real-time application requirements, energy consumption, communication, and storage introduce additional challenges [
6]. Furthermore, deep neural network inference frameworks can serve as auxiliary tools to address the challenges posed by various inference scenarios. However, constraints related to computing devices, deep neural networks, and inference frameworks complicate the efficient deployment of relevant applications in agricultural settings.
In recent years, deep neural networks have assumed an increasingly significant role in the detection of crop leaf diseases. By utilizing raw images as input, these networks automatically extract pertinent features, thereby facilitating the efficient and accurate detection and diagnosis of crop leaf diseases [
7]. The adoption of deep neural networks not only circumvents issues associated with manually designed feature extraction methods but also enhances the detection accuracy and robustness [
8]. Consequently, there have been a growing number of studies focused on employing deep neural networks for crop leaf disease detection, yielding notable research advancements. Lin et al. [
9] introduced an improved YOLOX-Tiny network that incorporated hierarchical mixed-scale units (HMUs) within the neck network for feature optimization and integrated a convolutional block attention module (CBAM) to enhance the detection of small lesions, resulting in superior performance in terms of both detection accuracy and speed. Li et al. [
10] integrated a lightweight ghost convolutional neural network (GhostNet) structure into the YOLOv8s network and introduced a triplet attention mechanism. Additionally, they employed an efficient complete intersection over union (ECIoU_Loss) function to replace the original complete intersection over union (CIoU_Loss) function, achieving significant optimization in terms of accuracy, model size, and computational complexity. Sangaiah et al. [
11] proposed a UAV T-yolo-Rice (UAV Tiny Yolo Rice) network, which incorporated YOLO detection layers, spatial pyramid pooling (SPP), a CBAM, and a sand clock feature extraction module (SCFEM), attaining optimal performance on a constructed rice leaf disease dataset. Clearly, the aforementioned studies have achieved substantial progress in the detection of crop leaf diseases. However, they have not addressed the deployment of crop leaf disease detection models in resource-constrained agricultural field environments.
Several researchers have deployed crop leaf disease detection models on edge AI devices to detect crop leaf diseases in harsh agricultural field environments. Li et al. [
12] modified the original backbone and neck of YOLOv4 by incorporating depthwise convolution and a hybrid attention mechanism and designing and evaluating four new network architectures, with the best-performing model being named DAC-YOLOv4. This model was applied to strawberry powdery mildew detection and achieved real-time detection speeds of 43 FPS and 20 FPS on a Jetson Xavier NX and Jetson Nano, respectively, demonstrating its effectiveness and practicality. Gajjar et al. [
13] designed a novel convolutional neural network architecture capable of identifying and classifying 20 types of healthy and diseased leaves across four plant species. Deployed on the NVIDIA Jetson TX1, this model performed the efficient, real-time detection of multiple leaves in the field and accurately identified various diseases. Xie et al. [
14] proposed a lightweight detection model, YOLOv5s-BiPCNeXt, for eggplant leaf disease detection in natural scenes. This model utilized the MobileNeXt backbone to reduce the parameters and computational complexity and integrated a multi-scale cross-spatial attention mechanism and content-aware feature recombination operator within the neck network. Ultimately, on the Jetson Orin Nano device a real-time detection speed of 26 FPS was achieved, outperforming other algorithms. Some researchers have deployed crop leaf disease detection models on embedded AI devices; however, efficient deployment remains a challenge, and there is a lack of experience regarding their deployment on embedded AI devices [
15].
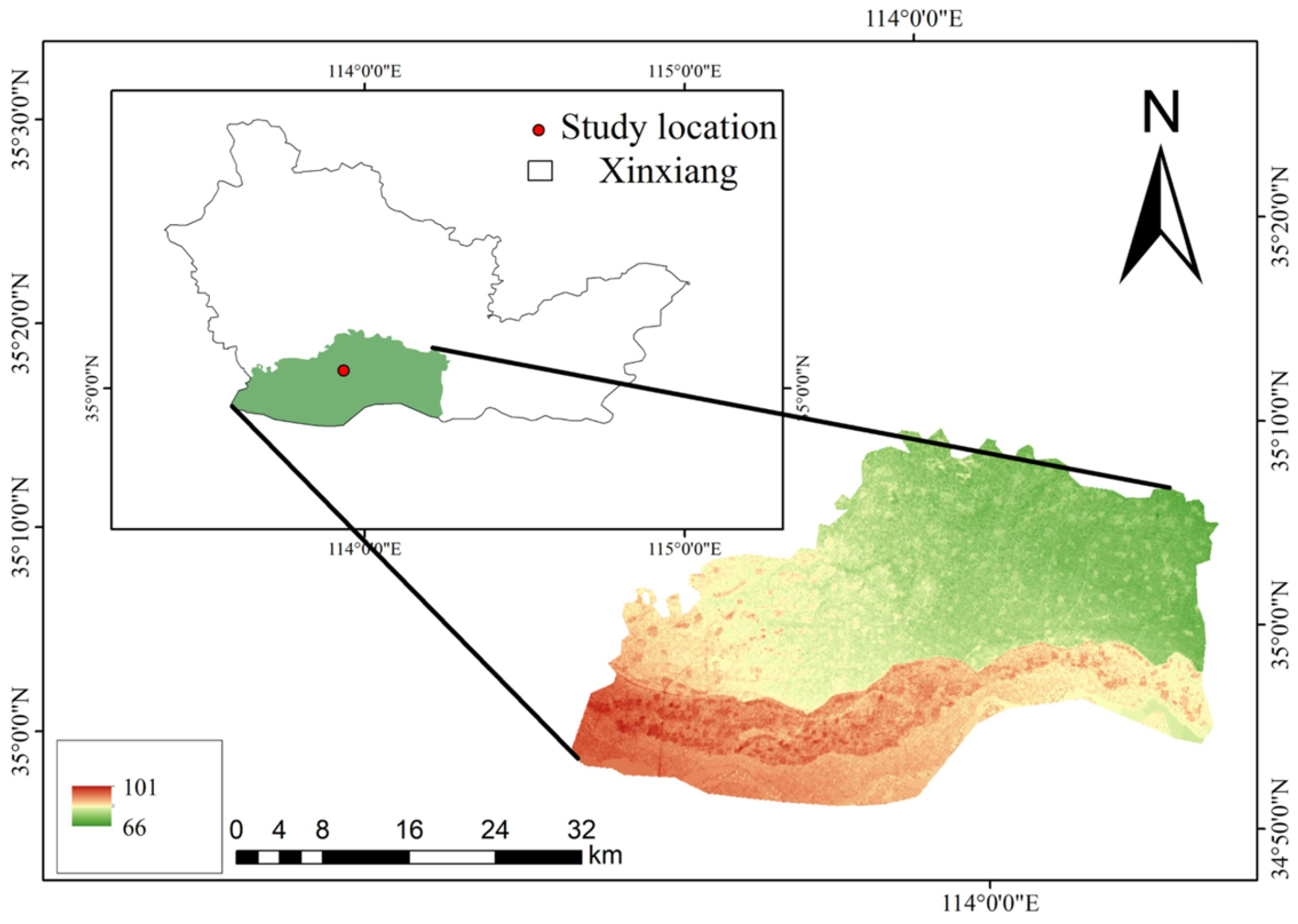
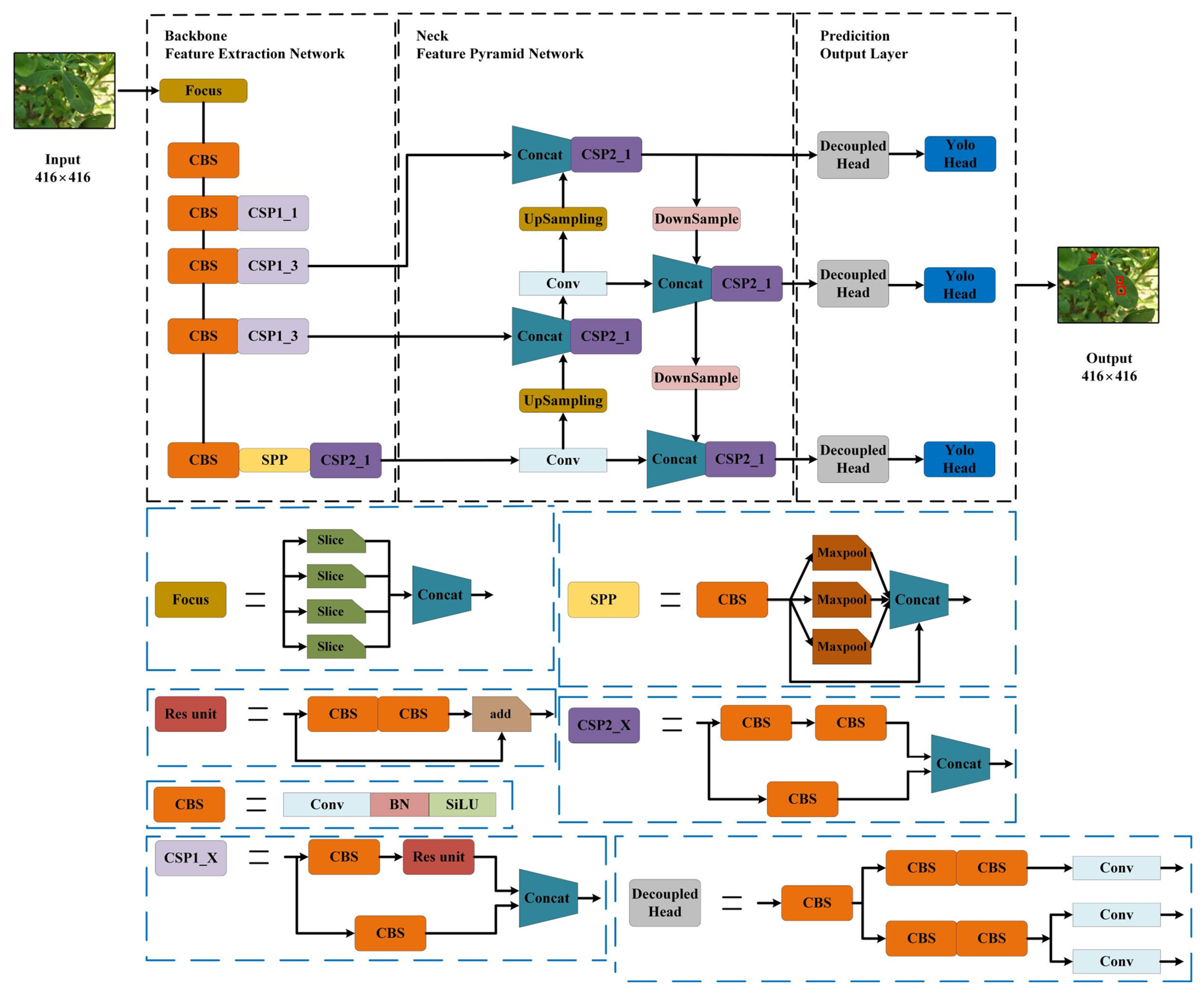
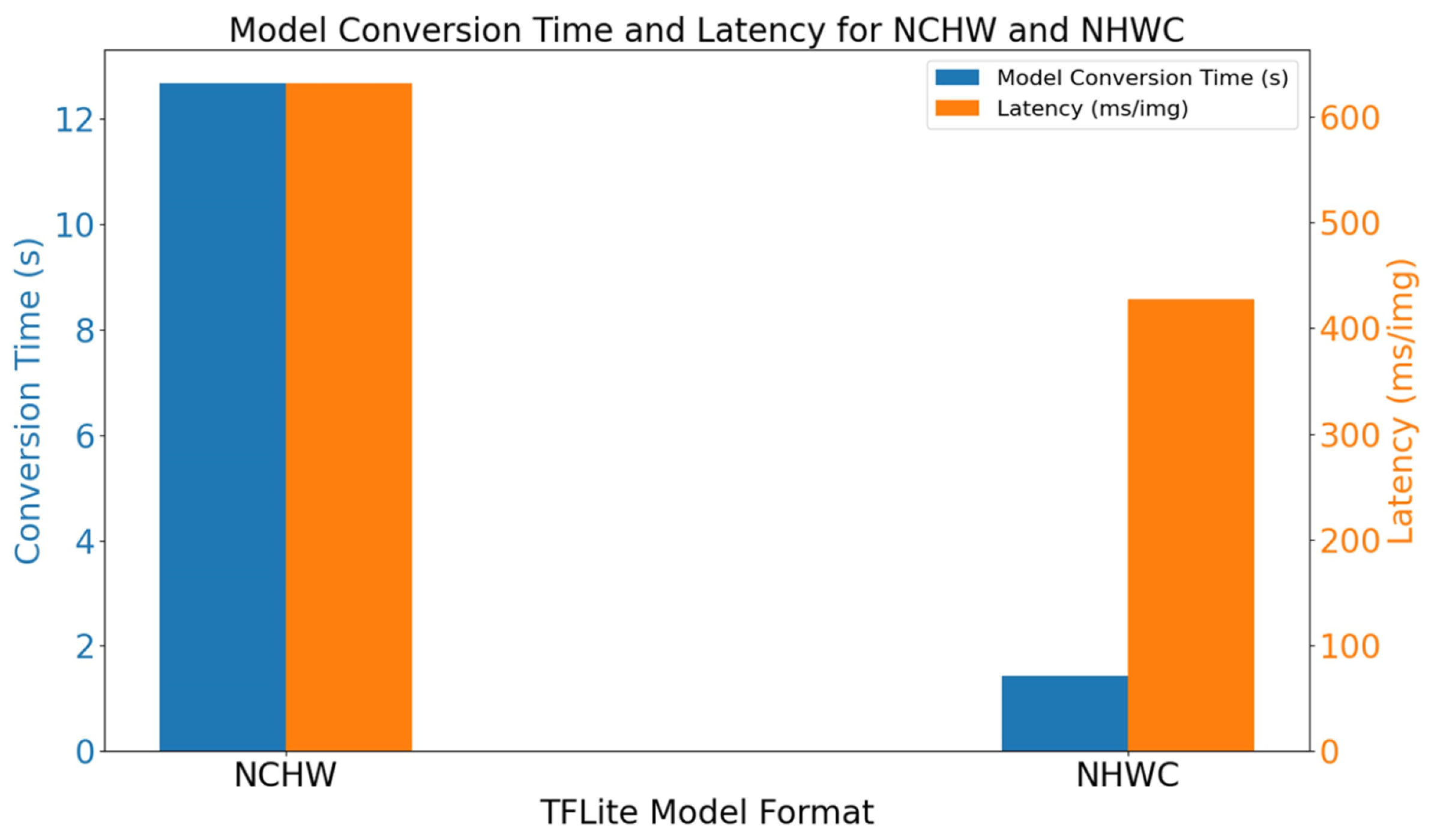
This study addresses the efficient deployment of crop leaf disease detection models in resource-constrained environments. A case study was conducted using the YOLOX-Tiny network on the Jetson Nano B01 device, providing deployment experience regarding the application of crop leaf disease detection models in agricultural field settings and advancing intelligent agricultural applications under resource limitations. The experiments initially focused on three aspects of efficient deployment optimization: the fusion of ReLU and convolution operations, the integration of EfficientNMS_TRT to accelerate post-processing within the TensorRT model, and the conversion of the model format from NCHW to NHWC in the TensorFlow Lite model. Furthermore, TensorRT and TensorFlow Lite were compared in terms of memory usage, power consumption, and inference latency. Finally, a comparative experiment on real-time video detection was conducted by combining EfficientNMS_TRT with DeepStream. This research provides valuable experience for the efficient deployment of crop leaf disease detection models on edge devices in intelligent agriculture.
5. Discussion
Many previous investigations have focused on improving deep neural network architectures to enhance the accuracy of crop leaf disease recognition. Different object detection networks have been adopted for various detection tasks. Lin et al. [
47] introduced an improved YOLOv8n model that integrated FasterNeXt, depthwise separable convolution, and the generalized intersection over union (GIoU_Loss) function to achieve the real-time detection of peanut leaf diseases while maintaining high accuracy. Chen et al. [
48] proposed the CACPNET model, which combined an efficient channel attention (ECA) module with channel pruning, making it suitable for the recognition of common plant diseases. On the other hand, Guo et al. [
49] constructed a peanut leaf spot prediction model by feeding feature maps—derived from a CNN enhanced with a squeeze-and-excitation (SE) module—into a long short-term memory (LSTM) network, using multi-year meteorological data and peanut leaf spot occurrence records.
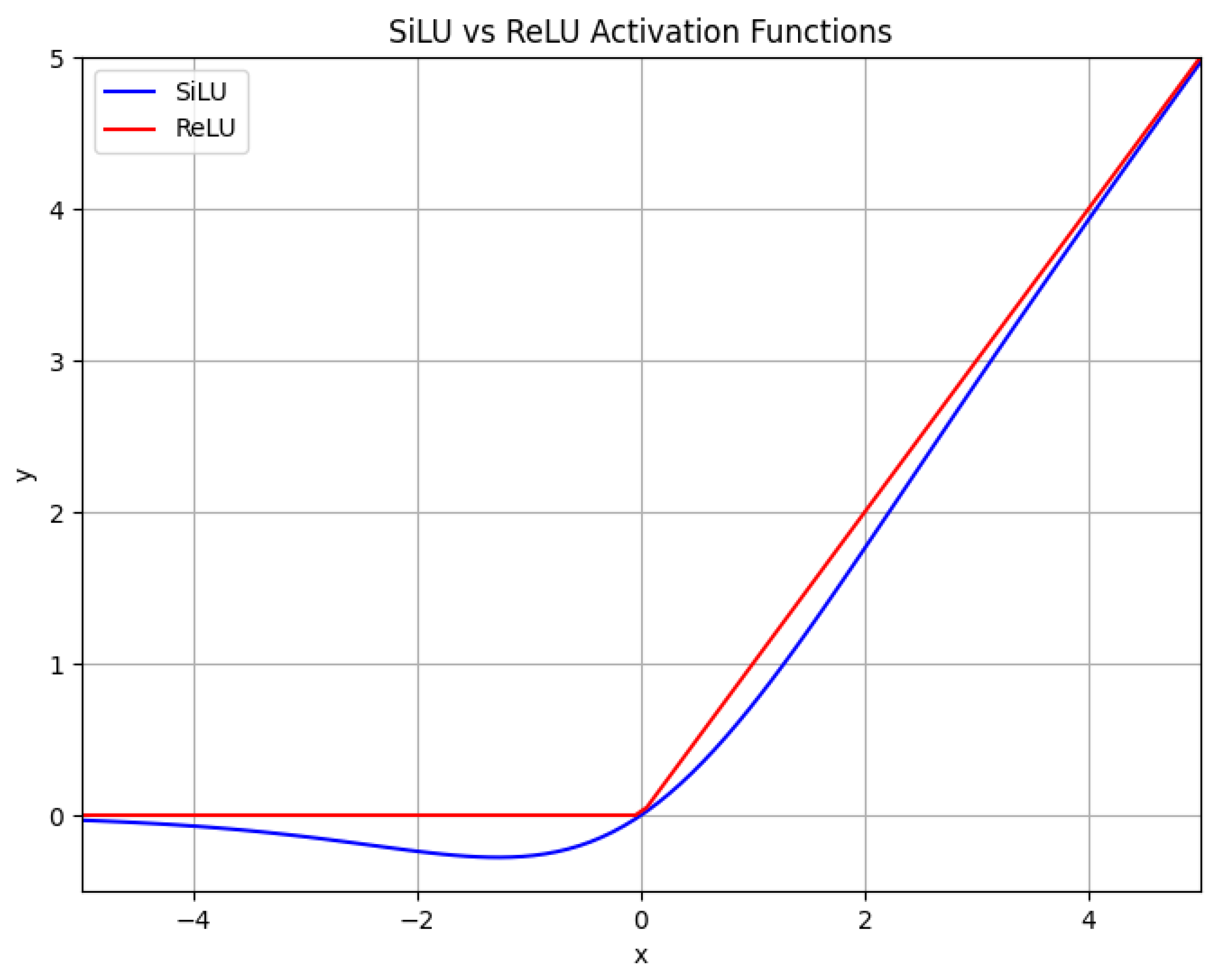
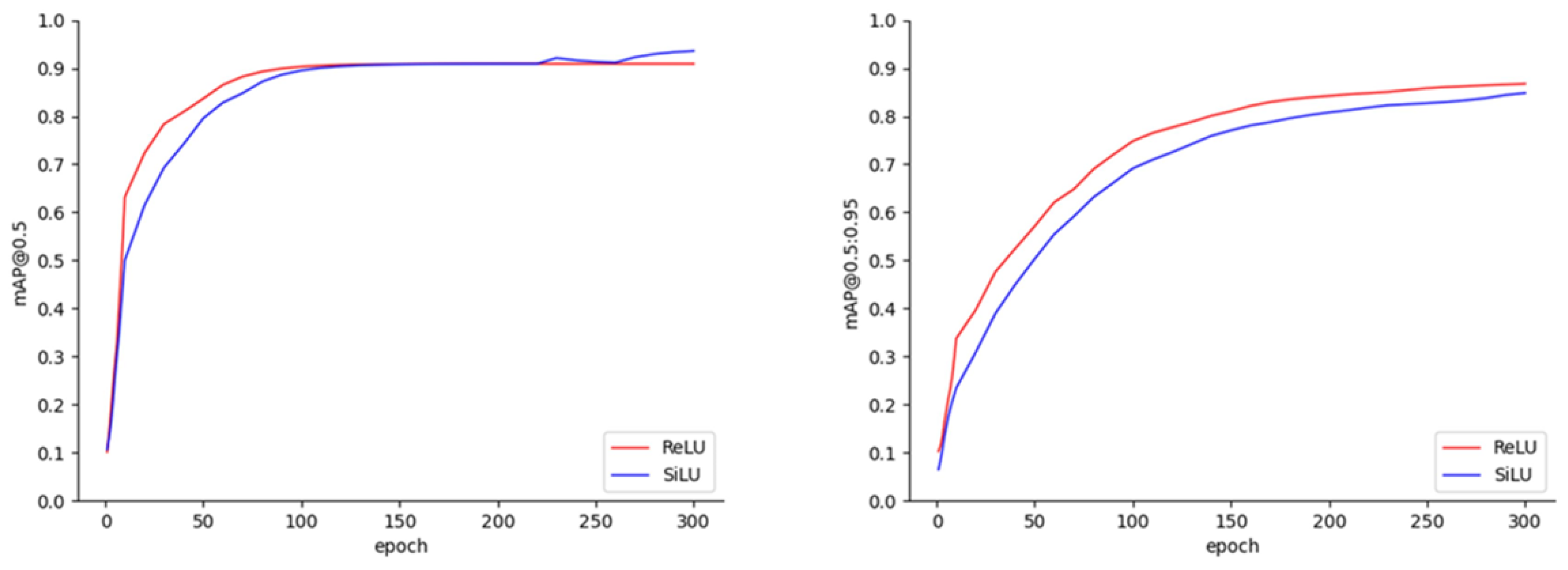
Significant contributions to peanut leaf disease detection tasks have been made by the aforementioned researchers. Considering that their work primarily focused on the algorithm research phase, the present study primarily involved the deployment of object detection networks, thereby providing other researchers with insights into the efficient deployment of such networks. Consequently, YOLOX-Tiny was initially selected for deployment on the Jetson Nano B01 as a case study for peanut leaf disease detection. Subsequently, three efficient deployment optimization methods were analyzed. First, the impact of the ReLU activation function on the inference latency was examined from the perspective of operator fusion. Additionally, optimizations within the TensorRT and TFLite models were studied separately. The former was optimized by inserting EfficientNMS_TRT to accelerate the model’s post-processing section, while the latter involved converting the model’s NCHW format to the NHWC format, which is more suitable for TFLite models. Furthermore, inference tasks on peanut leaf disease images were performed with a batch size of one, and the performance differences in the YOLOX-Tiny network under the TensorRT and TFLite inference frameworks were compared in terms of memory usage, power consumption, and inference latency. Finally, within the TensorRT framework, the more efficient real-time video detection of peanut leaf diseases was achieved through the use of EfficientNMS_TRT and DeepStream.
Several limitations remained in our experiments. Firstly, the YOLOX-Tiny network was initially selected due to its structural simplicity and mature deployment strategies. However, regarding the model’s detection capabilities, the currently employed YOLOX-Tiny network exhibits some challenges in accurately detecting peanut leaf diseases. Since the disease targets on peanut leaves are generally small, there is a need to enhance the model’s ability to detect small objects. Secondly, in terms of inference frameworks, TensorRT and TFLite were utilized to achieve the efficient inference of the object detection network. Nevertheless, this approach introduces certain constraints. For instance, on non-NVIDIA hardware, the implementation cannot be fully replicated, necessitating model adjustments. Additionally, this study was developed using Python, whereas C++ is more suitable for high-performance inference tasks.
Consequently, the pursuit of future work remains highly significant. On one hand, the structure of object detection networks can be optimized by incorporating lightweight modules, such as the CBAM or depthwise separable convolution. These modules enhance the feature extraction capabilities without substantially increasing the model’s complexity; however, specialized optimization is still required during the deployment phase. Furthermore, the adoption of more advanced object detection networks is necessary to address the complexities and challenges inherent in peanut leaf disease detection. Thus, object detection networks can be custom-optimized for edge AI devices, thereby improving the model accuracy and real-time performance and further promoting the widespread application of peanut leaf disease detection technology in agriculture. On the other hand, to overcome the limitations associated with the reliance on specific inference frameworks, future work should explore model compression techniques such as pruning, distillation, and quantization. Pruning removes redundant or insignificant weights and neurons from the model, thereby reducing its size. Distillation transfers knowledge from models with superior recognition capabilities to those requiring optimization, maintaining high recognition accuracy for peanut leaf diseases. In this study, PTQ was employed, which directly quantizes weights and activation values after model training. Conversely, quantization-aware training (QAT) simulates quantization operations during training, achieving higher precision. These techniques can significantly reduce the model complexity and enhance the inference efficiency, facilitating more efficient deployment on edge AI devices. This, in turn, can improve the efficiency and accuracy of agricultural leaf disease detection, further advancing the application and development of deep neural networks in modern agriculture and providing technical support for precision agriculture and sustainable development.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}